1. Introduction
The Tobit model was introduced by James Tobin [
1] in his seminal work on consumer behavior, specifically analyzing expenditures on durable goods while accounting for the fact that such expenditures cannot fall below zero. This gave rise to the concept of limited dependent variable models, where the dependent variable is subject to censoring or truncation. The term Tobit model—coined by Goldberger [
2]—has since become a cornerstone in econometrics, particularly for modeling situations in which the outcome variable has a restricted domain.
In the classical Tobit model (Type I), the latent variable follows a normal distribution, and observed values are censored at a certain threshold—typically zero. Amemiya [
3] categorized several variations of the Tobit model, including Types II to V, which handle selection bias, multiple equations, and other data complications.
Tobit models have been extensively used not only in economics but also in other fields such as biometrics, engineering, and environmental sciences. In biometrics, for instance, they help model survival times with censoring; in engineering, they apply to reliability analysis.
However, a key limitation of the standard Tobit framework lies in its reliance on the normality assumption for the error terms. In practice, this assumption is often violated. Several studies have extended the Tobit model to incorporate non-normal error distributions, including symmetric alternatives (e.g., Student’s t, logistic) and asymmetric distributions (e.g., skew-normal, generalized lambda). Works by Powell (1986) [
4], Arabmazar and Schmidt (1981) [
5], and others have explored semi-parametric and non-parametric Tobit models to improve robustness when the distribution of errors is unknown or misspecified. Robust estimation approaches, such as the Student t-based M-estimator proposed by Lucas [
6], have been developed to address sensitivity to outliers and heavy-tailed distributions.
More recently, efforts have been made to adapt Tobit-type models to accommodate log-symmetric and asymmetric distributions, particularly in the presence of censored data. Vanegas and Paula [
7,
8,
9,
10,
11] have developed a comprehensive statistical framework for log-symmetric regression models, addressing their properties [
7], applications to censored data with non-informative censoring [
10], and implementation through a recent R package for semi-parametric estimation [
11]. Saulo et al. [
12,
13] extended this work to asymmetric models and further applied them in censored settings. These approaches offer improved flexibility and robustness when classical normality-based assumptions are not valid. Medeiros and Ferrari [
14] further contributed to this line by offering inference techniques for symmetric and log-symmetric linear regression models, suitable for contexts involving multiplicative and non-normal error structures.
In this paper, we contribute to this line of research by exploring detection methods for the Tobit model under parameter uncertainty. While prior studies have focused on the case where model parameters are known [
15], we extend this analysis to more realistic situations in which these parameters must be estimated. The goal is to assess how uncertainty in parameter estimation influences the reliability of Tobit model detection.
The remainder of this paper is structured as follows.
Section 1 discusses parametric estimation techniques for the Tobit model, including least squares and maximum likelihood estimators.
Section 2 addresses statistical procedures for detecting the presence of a Tobit structure in the data. In
Section 3, we use Monte Carlo simulations to evaluate the performance of these procedures under various conditions. The final section provides conclusions and suggestions for future research.
2. Parametric Estimation
In this section, we present the parametric estimators associated with the Type 1 Tobit model, namely the least squares estimator and the maximum likelihood estimator.
Definition 1. The simple Tobit model (Type 1) is defined as follows:wherewith denoting the observable variable corresponding to the latent variable , representing the vector of observable variables, being the vector of unknown parameters, and are the independent and identically distributed errors terms, assumed to follow a normal distribution . 2.1. Example
Let be the number of purchases of durable goods. If a person’s salary is greater than a certain threshold C, the amount spent is proportional to the salary. If the person’s salary is below this threshold, there are no purchases of durable goods.
Remark 1. In the case of the previous example, the model is written as follows:To find the model (2.1), we translate the variable by an amount . 2.2. Least Squares Estimator
2.2.1. First Case: The Exogenous Variables Are Deterministic
The LS estimator, applied to all N pairs of observations
, is defined as follows:
Even though it is easy and extremely prevalent, the LS estimator is inconsistent in the context of censored models such as the Tobit model [
7]. This inconsistency stems from its failure to account for the censoring mechanism, typically at zero. This omission leads to an asymptotic and systematic downward bias in the estimated regression coefficients. Specifically, as shown by Amemiya [
3] and Greene [
16] the bias arises because OLS underestimates the effect of the explanatory variables in absolute terms, especially when a large proportion of observations are censored. While in very simple settings (e.g., univariate models with normal errors and known thresholds), a closed-form expression of this asymptotic bias can be derived [
17] (see Maddala1983, Chapter 9), in general, the expression becomes analytically intractable due to the dependency on the joint distribution of the latent dependent variable and the covariates. In light of this, Proposition 2 in our paper formally establishes the asymptotic inconsistency of the LS estimator in the censored framework. We clarify that the “bias” we refer to throughout this section is indeed asymptotic in nature.
2.2.2. Second Case: Are Random Variables
In the case where the exogenous variables
are random, Goldberger [
18] analyzed this case by introducing a constant term to the regression equation. The Tobit model can therefore be expressed as follows:
with
where
is a vector of random normal distribution
with
being a positive definite
matrix. The unknown parameters are as follows:
This structure recognizes the stochastic nature of explanatory variables in empirical economic data and is a major advance over deterministic models. Goldberger’s work paved the way for a more nuanced understanding of censored data models and established the basis for more robust estimation methods that are aware of the underlying data-generating process.
Fundamental assumption (FH)
We assume that the variables
follow a multivariate normal distribution:
with the additional condition that
Proposition 1 (Greene [
16])
. Under the assumption (FH), the least squares (LS) estimator is computed using all observations , which satisfies , in probability, when , where . Moreover, under the assumption (FH), the estimator defined by where is the number of observations for which , is a consistent estimator of β: . 2.3. Maximum Likelihood Estimator
For several decades, simpler estimation procedures—such as Heckman’s two-step method [
19]—were used because they were less computationally intensive. These processes had workable solutions when computational capacity was not as great.
However, with the advent of computers that can efficiently solve complex optimization problems, the Maximum Likelihood Estimator (MLE) has found extensive application. The MLE approach uses the whole probabilistic model structure and tends to yield estimators with good asymptotic properties.
Through the use of the reparametrization constructed by Olsen [
20], the log-likelihood function of the Tobit model can be written as:
where
is the number of observations for which
. The LM estimator
of
is the solution to the following problem:
Amemiya [
3] proved that the maximum likelihood estimator
and
are strongly consistent and asymptotically normal.
3. Detection of Tobit Model
3.1. Reminder on Tobit Model Detection (When Parameters Are Known)
3.1.1. Problem Setup
In this section, we give statistical tools for the detection of a Tobit model to from observations of a sample.
Let
be a sample of points
for
. The objective is to determine if there exists a latent variable
satisfying:
where:
with known
are the explanatory variables,
is the parameter vector,
is a constant,
are errors that are independent and identically distributed (i.i.d.) following a normal distribution ,
is observed as (the variable is censored at zero).
3.1.2. Note
Without loss of generality, Proposition 2 remains valid if we replace with , where k is a given constant.
Proposition 2 (Conditions for the detection of the Tobit model [
15])
. The problem admits a solution if the following conditions are satisfied:- 1.
Condition 1 (For ): For all such that , the error is calculated as follows: This means that for observations where is strictly positive, the error is simply the difference between the observed and the predicted value .
- 2.
Condition 2 (For ): For each such that , there exists an error such that the latent variable is negative, i.e., .
- 3.
Condition 3 (Distribution of Errors): The latent variable follows a standard normal distribution, i.e., for all . This implies that the errors are normally distributed with variance .
3.1.3. Summary of the Approach
The underlying idea of the Tobit model is that each observation is associated with a latent (unobserved) variable
that follows a linear model:
However, the observed outcome
is left-censored at c:
For observations where (uncensored), we have
, and the residual can be directly estimated as follows:
For observations where (censored), the latent value
is unobserved and satisfies the following:
In this case,
is not point-identifiable but lies in the truncated interval
. To approximate the latent value
and the residual, we proceed as follows (see
Section 3.2):
- –
We use the Tobit estimates
and
to compute the predicted value:
- –
We simulate
and construct:
accepting only those simulations where
. This guarantees consistency with the censoring.
- –
The residual is then approximated as follows:
This procedure enables consistent residual estimation for both censored and uncensored observations, despite the unobservability of in the former case.
3.2. Tobit Model Detection (When Parameters Are Unknown)
We extend the detection framework for the Tobit model from the case where parameters are known to the more realistic scenario in which the parameters must be estimated. In this context, it is important to highlight the fundamental properties of the maximum likelihood estimator (MLE), which justify its use for such an extension. Specifically, the MLE is consistent—meaning it converges to the true parameter values as the sample size increases—and asymptotically normal, implying that its sampling distribution approaches a normal distribution centered on the true parameters, with an estimable variance, for large sample sizes.
These properties of the MLE provide a solid foundation for constructing a robust framework for estimation and model detection under parameter uncertainty. The theoretical Proposition 2 used in the known-parameter case remains applicable; the key difference is that the detection procedure now relies on estimated parameter values rather than known ones, under the same model assumptions.
3.2.1. Note
To determine whether a Tobit model is suitable for a given dataset, two complementary approaches can be employed:
3.2.2. Method Based on the Application of Proposition 2
This approach [
15] involves evaluating whether the data satisfy the fundamental assumptions that justify the use of a Tobit model. Specifically, it examines:
The presence of censoring (typically left-censoring at zero or another threshold),
A linear relationship between the (latent) dependent variable and the explanatory variables,
The nature of the error distribution and its compatibility with Tobit assumptions.
These checks serve as a preliminary validation step before estimation, helping to confirm whether the Tobit model is conceptually appropriate for the context.
3.2.3. Based on Fitting the Data with the Tobit Model
The second approach involves estimating the Tobit model using maximum likelihood methods implemented in statistical software (e.g., Stata, R-4.5.1, Python 3.12). Once the parameters are estimated, model adequacy is evaluated based on:
The statistical significance of estimated coefficients,
Goodness-of-fit metrics such as the log-likelihood or pseudo-,
Diagnostic tools, including residual analysis and graphical comparisons of observed versus predicted values.
This empirical method not only assesses model fit but also helps determine whether the Tobit specification captures the key features of the data.
By combining these two approaches—theoretical validation and empirical assessment— researchers can more confidently determine whether the Tobit model is appropriate for their specific application. These detection methods are particularly relevant in fields such as labor economics, consumer behavior analysis, healthcare utilization studies, and environmental modeling, where censored outcomes frequently arise.
4. Application
Let a sample
of points
, with:
Using R software, we obtained the estimated values of the parameters for the Tobit model.
We then generated the observed values
, subject to the left-censoring condition:
This implies that if
, the observation is uncensored and
. If
, the observation is censored, and we simulate the latent variable
using:
where
, and
. We accept only those simulated values such that
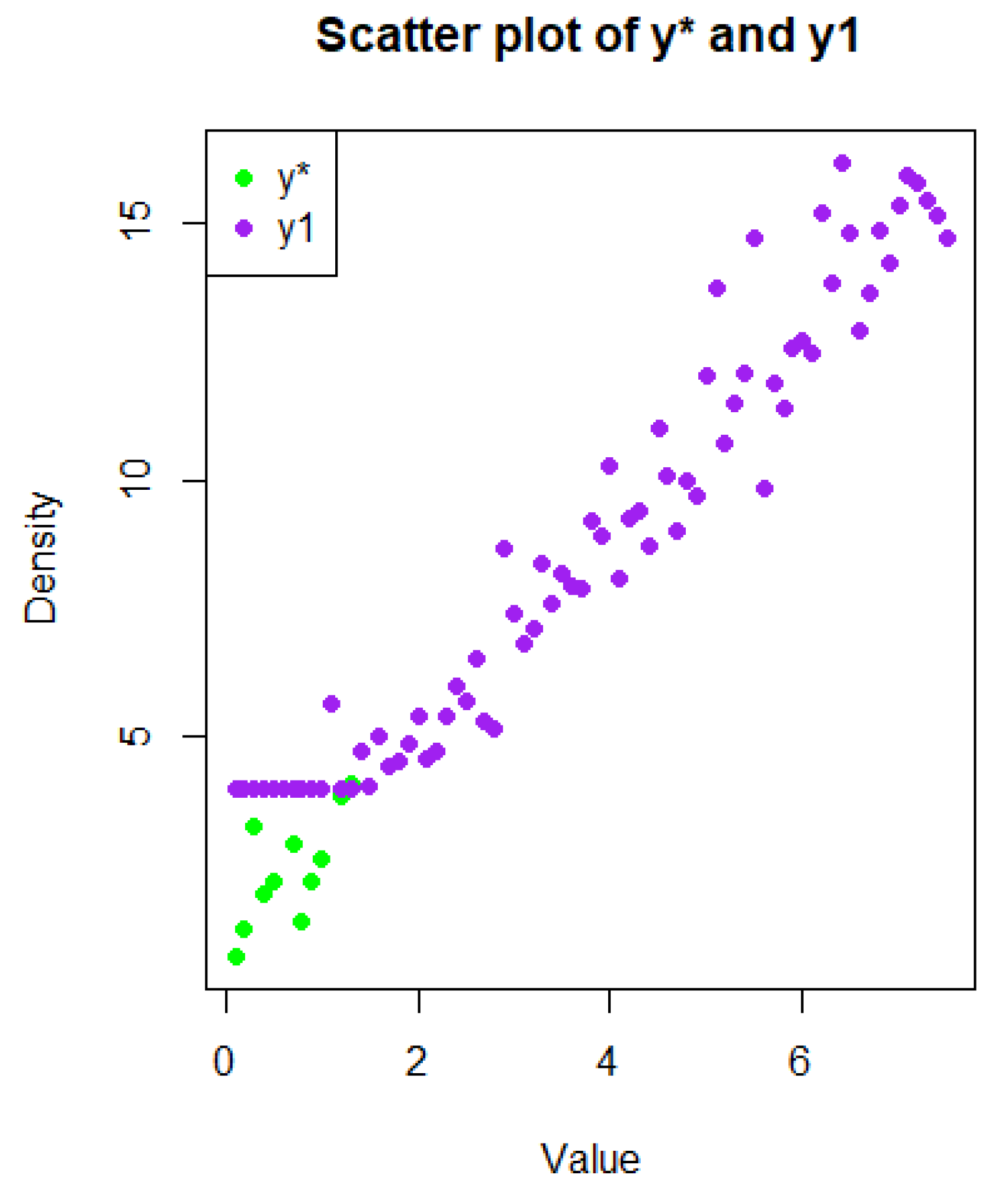
, in accordance with the censoring rule. This process is repeated until the condition is satisfied. The accuracy of this approach is verified using a scatter plot.
To simulate data consistent with a Tobit model, we define the latent variable as:
where
and
is generated using
rnorm(75, 0, 1) in
R. The observed variable is then computed as
.
This construction corresponds to a Tobit model with left-censoring at 4. The true parameter values used for simulation are , , and . These values were intentionally chosen to produce realistic yet controlled data, allowing us to assess the consistency and correctness of the estimation procedure.
To reconstruct the latent variable set , we apply the following logic:
If , then (observation is uncensored).
If , then , accepting only those simulations where (observation is censored). This process is repeated if necessary.
The final set thus consists of:
We then compute the residuals:
to evaluate whether their empirical distribution approximates the standard normal distribution
, as required by the theoretical assumptions of the Tobit model.
The estimation output gives the following parameter values:
Thus, we can obtain all the values of
belonging to a set E’, where:
All that remains is to verify the conditions of Proposition 2. We define
. Thus, the first condition is satisfied (because if
, then
, and we have
The second condition is satisfied by the construction of .
It remains to verify the third condition, which is that
follows a standard normal distribution (mean zero and variance one). To achieve this, we perform a Kolmogorov–Smirnov test (see
Appendix B) for the test code using the R software (version 4.2.1)). The output of the code provides the following results:
In this case: The
p-value is
p = 0.3816986, which is greater than 0.05. Therefore, we fail to reject the null hypothesis. The residuals e can be considered as following a normal distribution. However, it is important to note that failing to reject the null hypothesis does not prove normality; it only suggests that the normality assumption is plausible given the data. For additional insight, a graphical inspection (e.g., Q-Q plot or histogram) may also be considered. The output of the code (
Appendix B) shows: Mean of residuals: −0.06540354 −0.06540354 and Standard deviation of residuals: 1.014941 1.014941.
Conclusion: The three conditions of Proposition 2 are satisfied, hence the existence of such that for all .
5. Visualization
The
Figure 1 below represents the visualization:
6. Project Objective
This mini-project (
Appendix B) aims to illustrate the
detection and validation of a Tobit model in a simulated context. The goal is to demonstrate, using an artificially generated dataset with censored values, how to identify the relevance of a Tobit model, estimate its parameters, and analyze its performance.
6.1. Background and Justification
The Tobit model is used when the dependent variable is censored, meaning it is truncated at a certain threshold. This situation commonly arises in economics, sociology, or engineering. In this project, we simulate a case of left-censoring at a fixed threshold , which justifies the use of a Tobit model.
6.2. Methodology
6.2.2. Detecting the Tobit Model
The relevance of a Tobit model is assessed through:
Observing a stack of values at k,
A shifted distribution after the censoring point,
The failure of a standard linear regression model to properly capture the full data pattern.
6.2.3. Parameter Estimation
We use the tobit() function from the AER package in R:
6.3. Results Analysis
6.3.1. Reconstructing the Latent Variable
ypred <- apred + bpred * x
ystar <- ifelse(y1 == k, ypred, y1)
6.3.3. Graphical Visualization
Scatter plots for , y, and
Histogram of residuals
Q-Q plot to test normality
6.4. Guidelines for Application
Examine the data structure: Check for the presence of censored values (e.g., constant threshold, clustering at the censoring point).
Assess the relevance of the Tobit model:
Identify a clustering of values at the censoring threshold k;
Observe a truncated or distorted distribution beyond this threshold;
Confirm that a standard linear model fails to adequately fit the censored data;
Visualize the data using a scatter plot of to detect any structural break or accumulation near the censoring limit—this is typical of a Tobit model.
Estimate parameters using the tobit() function from the AER package in R.
Reconstruct the latent variable by comparing predictions with censored observations.
Interpret the results: analyze bias, residual variability, and the overall validity of the model.
6.5. Conclusions
This mini-project demonstrates how to detect the Tobit structure in a censored dataset, estimate the model parameters, and evaluate its performance. This approach can be extended to real-world applications in economics, social sciences, or biomedical studies.
7. General Conclusions
In this extension of the study, we addressed the problem of detecting the presence of a Tobit model when the model parameters are unknown. This case is particularly relevant in many real-world situations where the exact model structure is not known a priori; one must then simultaneously specify, estimate, and validate the model.
To tackle this challenge, we relied on appropriate parametric estimation methods, in particular the Maximum Likelihood Estimation (MLE) method. Once the parameters were estimated, we reconstructed the full values of the censored dependent variable . Then, by applying Proposition 2, we were able to verify the validity of the estimated model. This validation step includes, among other things, a check of the normality of residuals, which is a fundamental criterion for confirming the correct specification of the Tobit model.
This approach thus provides a coherent and operational framework for the estimation and validation of Tobit models in empirical contexts. It is particularly useful in fields where censored data are common, such as:
health economics (e.g., healthcare expenditures limited to zero),
labor economics (e.g., number of hours worked, often zero for some observations),
environmental studies (e.g., pollution levels below a detection threshold).
By incorporating parameter estimation uncertainty from the outset, this approach enhances the robustness and relevance of Tobit model applications, making it a versatile tool across a wide range of applied disciplines.
Author Contributions
Conceptualization, E.o.R. and M.B.; methodology, E.o.R.; software, M.B. and E.o.R.; validation, E.o.R. and M.B.; formal analysis, E.o.R.; investigation, E.o.R.; resources, E.o.R.; data curation, M.B. and E.o.R.; writing—original draft preparation, E.o.R.; writing—review and editing, E.o.R. and M.B.; visualization, M.B. and E.o.R.; supervision, E.o.R.; project administration, E.o.R.; funding acquisition, E.o.R. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data is contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
| Listing A1: R code for estimating Tobit model parameters and generating scatter plot. |
![Stats 08 00059 i0a1a]() |
![Stats 08 00059 i0a1b]() |
![Stats 08 00059 i0a1c]() |
| Total | Left-Censored | Uncensored | Right-Censored |
| 75 | 12 | 63 | 0 |
| Estimate | Std. Error | z Value | Pr (>|z|) | |
| (Intercept) | 1.093579 | 0.300237 | 3.642 | 0.00027 *** |
| ×1 | 1.981041 | 0.064305 | 30.807 | <2 × 10−16 *** |
| Log(scale) | −0.004416 | 0.087543 | −0.050 | 0.95977 |
| Significance codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1. Scale: 0.9956. Gaussian distribution. Number of Newton-Raphson Iterations: 8. Log-likelihood: −91.52 on 3 Df. Wald-statistic: 949.1 on 1 Df, p-value: <2.22 × 10 −16. |
Appendix B
| Listing A2: R code for testing the assumption of residuals normality. |
![Stats 08 00059 i0a2a]() |
![Stats 08 00059 i0a2b]() |
Figure A1.
Q—Q plot assessing the normality of residuals.
Figure A1.
Q—Q plot assessing the normality of residuals.
Figure A2.
Histogram of residuals used to verify the normality assumption.
Figure A2.
Histogram of residuals used to verify the normality assumption.
References
- Tobin, J. Estimation of relationships for limited dependent variables. Econometrica 1958, 26, 24–36. [Google Scholar] [CrossRef]
- Goldberger, A.S. Econometric Theory; Wiley: New York, NY, USA, 1964. [Google Scholar]
- Amemiya, T. Tobit models: A survey. J. Econom. 1984, 24, 3–61. [Google Scholar] [CrossRef]
- Powell, J.L. Symmetrically trimmed least squares estimation for Tobit models. Econom. J. Econom. Soc. 1986, 54, 1435–1460. [Google Scholar] [CrossRef]
- Arabmazar, A.; Schmidt, P. Further evidence on the robustness of the Tobit estimator to heteroskedasticity. J. Econom. 1981, 17, 253–258. [Google Scholar] [CrossRef]
- Lucas, A. Robustness of the Student t-based M-estimator. Econom. Theory 1997, 13, 343–353. [Google Scholar] [CrossRef]
- Vanegas, L.H.; Paula, G.A. Log-symmetric distributions: Statistical properties and parameter estimation. Braz. J. Probab. Stat. 2016, 30, 1–20. [Google Scholar] [CrossRef]
- Vanegas, L.H.; Paula, G.A. A semiparametric log-symmetric regression model for positive data. Stat. Pap. 2016, 57, 363–388. [Google Scholar]
- Vanegas, L.H.; Paula, G.A. Log-symmetric regression models for censored data. J. Stat. Comput. Simul. 2017, 87, 102–123. [Google Scholar]
- Vanegas, L.H.; Paula, G.A. Log-symmetric regression models under the presence of non-informative left- or right-censored observations. Stat. Pap. 2017, 58, 293–324. [Google Scholar] [CrossRef]
- Vanegas, L.H.; Paula, G.A. ssym: Fitting Semi-Parametric Log-Symmetric Regression Models. R J. 2023, 15, 45–68. [Google Scholar]
- Saulo, H.; Leiva, V.; Paula, G.A. Log-symmetric regression models for censored data: Diagnostics and applications. Stat. Methods Med. Res. 2021, 30, 741–758. [Google Scholar]
- Saulo, H.; Leiva, V.; Paula, G.A. Asymmetric models in survival analysis under censoring schemes. Commun. Stat. Theory Methods 2021, 50, 1832–1846. [Google Scholar]
- Medeiros, F.M.; Ferrari, S.L.P. Inference in symmetric and log-symmetric linear regression models. J. Stat. Plan. Inference 2017, 185, 1–16. [Google Scholar] [CrossRef]
- Rahmani, E.; Kaaouachi, A. Detection of a Tobit Model. Appl. Math. Sci. 2015, 9, 1911–1917. [Google Scholar] [CrossRef]
- Greene, W.H. On the asymptotic bias of the ordinary least squares estimator of the Tobit model. Econometrica 1981, 49, 505–513. [Google Scholar] [CrossRef]
- Maddala, G.S. Limited-Dependent and Qualitative Variables in Econometrics; Cambridge University Press: Cambridge, UK, 1983. [Google Scholar]
- Goldberger, A.S. Linear regression after selection. J. Econom. 1981, 15, 357–366. [Google Scholar] [CrossRef]
- Heckman, J.J. The common structure of statistical models of truncation, sample selection and limited dependent variables and a simple estimator for such models. Ann. Econ. Soc. Meas. 1976, 5, 475–492. [Google Scholar]
- Olsen, R.J. Note on the uniqueness of the maximum likelihood estimator for the Tobit model. Econometrica 1978, 46, 1211–1215. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).



{kind=link}
{kind=link}
{kind=link}