Mission Reliability Assessment for the Multi-Phase Data in Operational Testing


Abstract
1. Introduction
- Traditional RBD are static and function-oriented, while the phased RBD is dynamically constructed based on the mission profile.
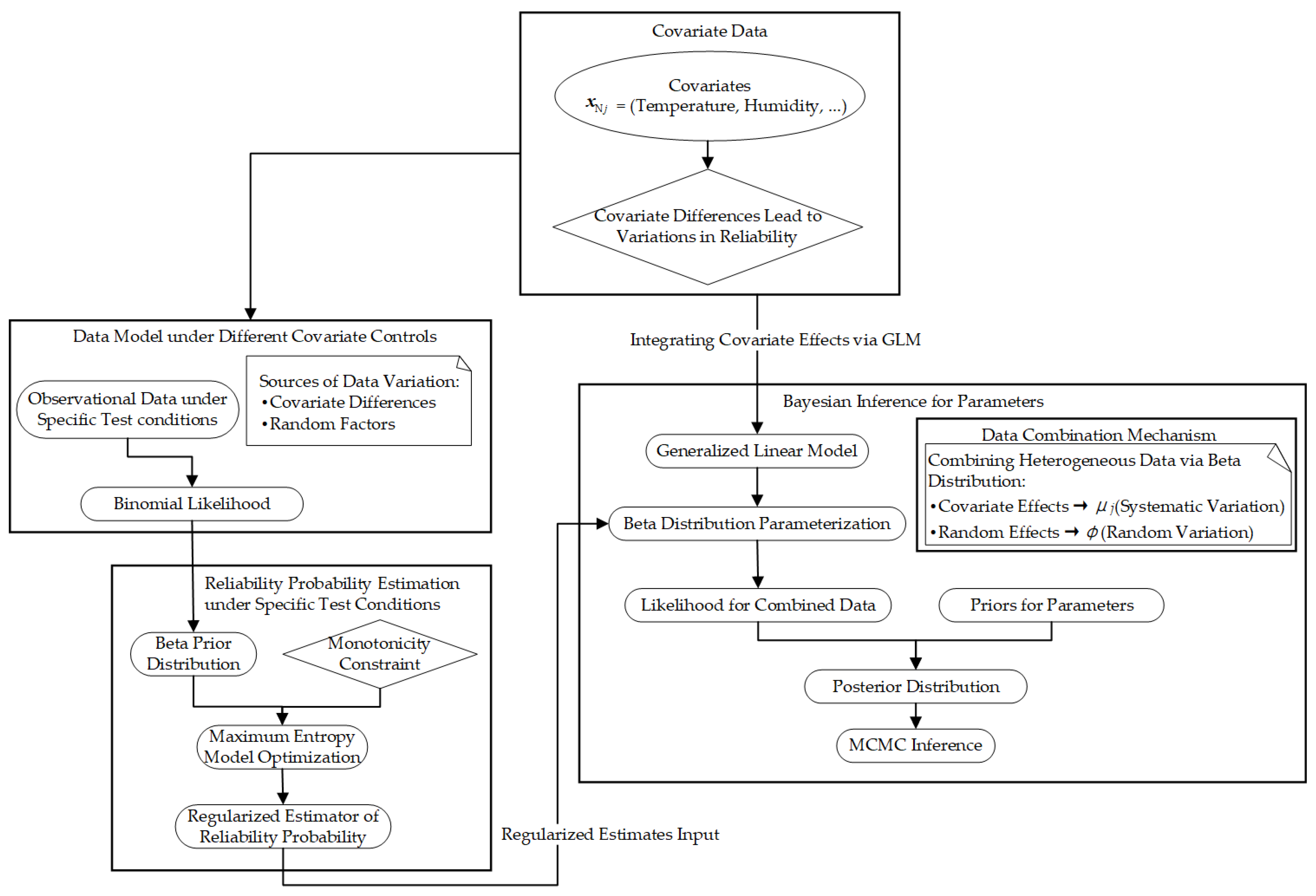
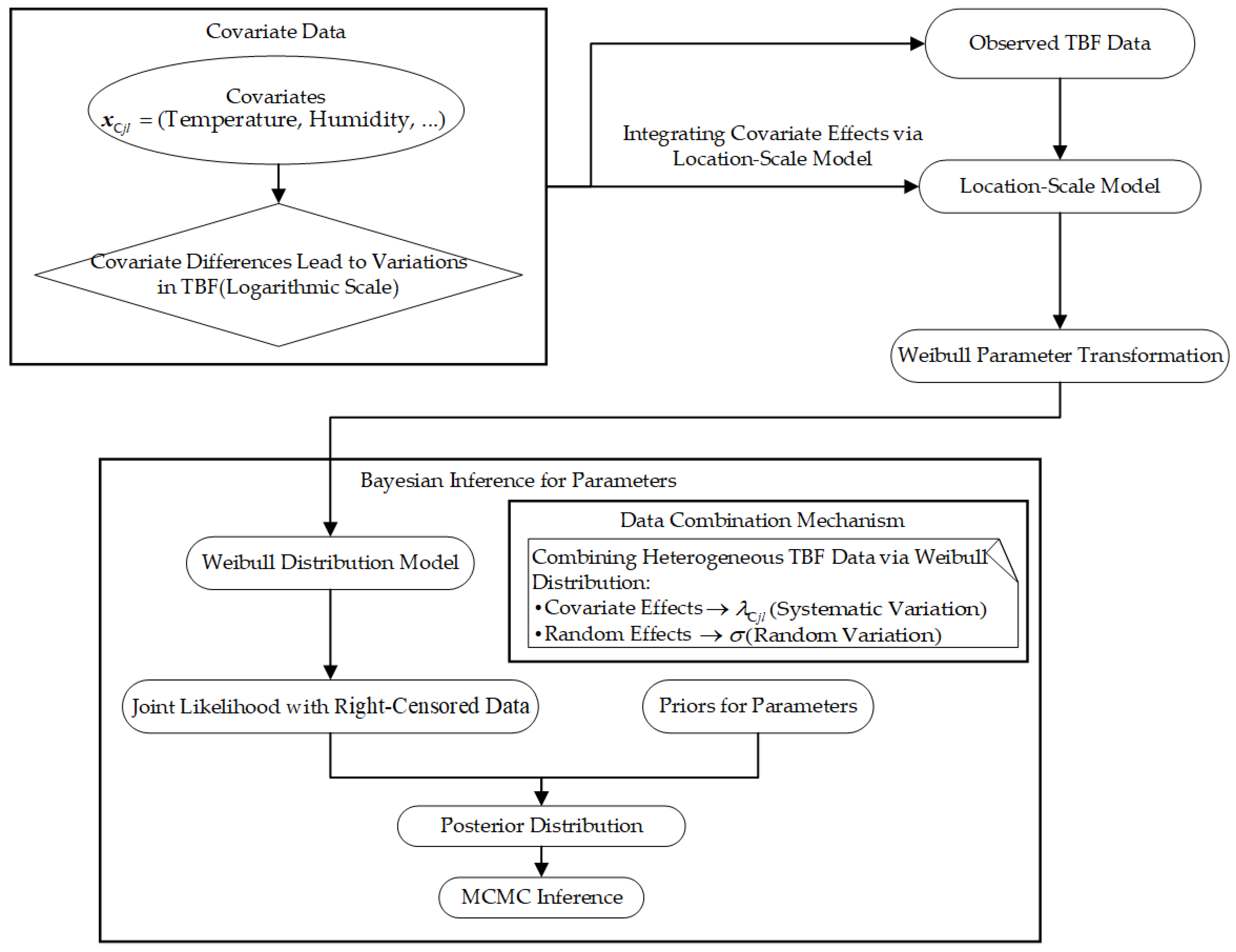
- Traditional Bayesian frameworks enable multi-source data combination through prior distribution; they rarely consider quantifying the intrinsic sources of heterogeneity. This work extends the Bayesian framework by embedding covariates via generalized linear model (GLM) and the location-scale regression model, quantitatively characterizing environmental impacts.
- Posterior inference employed the no-U-turn sampler (NUTS), an adaptive Hamiltonian Monte Carlo (HMC) variant within the MCMC framework. It automates tuning of leapfrog steps via recursive tree doubling, eliminating inefficient random-walk behavior inherent in traditional MCMC. This achieves faster convergence to target distribution.
- (1)
- A multi-type data-driven phased assessment modeling method. By partitioning mission phases according to subsystem type characteristics, this approach establishes a granular mapping between data types and evaluation models, laying a foundation for high-resolution mission reliability analysis.
- (2)
- A dynamic optimization model with physical constraints for time-varying reliability parameters. Integrating the maximum entropy criterion with the monotonic reliability degradation principle during hyperparameter estimation, this innovation effectively mitigates parameter distortion under non-stationary data conditions.
- (3)
- A covariate-embedded data fusion evaluation methodology. By embedding covariates into Bayesian models for historical data combination, this innovation effectively addresses the practical engineering challenges of heterogeneous test data fusion while quantifying environmental influences.
2. Materials and Methods
2.1. Construction of Phased RBD
- Continuous operation systems: Include subsystems C, N, and H. These subsystems operate persistently throughout a phase, accumulating operational exposure metrics and generating time-dependent failure data. Aircraft engines (during flight), conveyor belts, data center servers, and analogous systems also fall within this category. Critical faults in C and H can be immediately detected, while subsystem N requires scheduled inspections. Consequently, the data generated by subsystem N differs from that of C and H: the former produces success/failure data with varying success rates, whereas the latter generates TBF data.
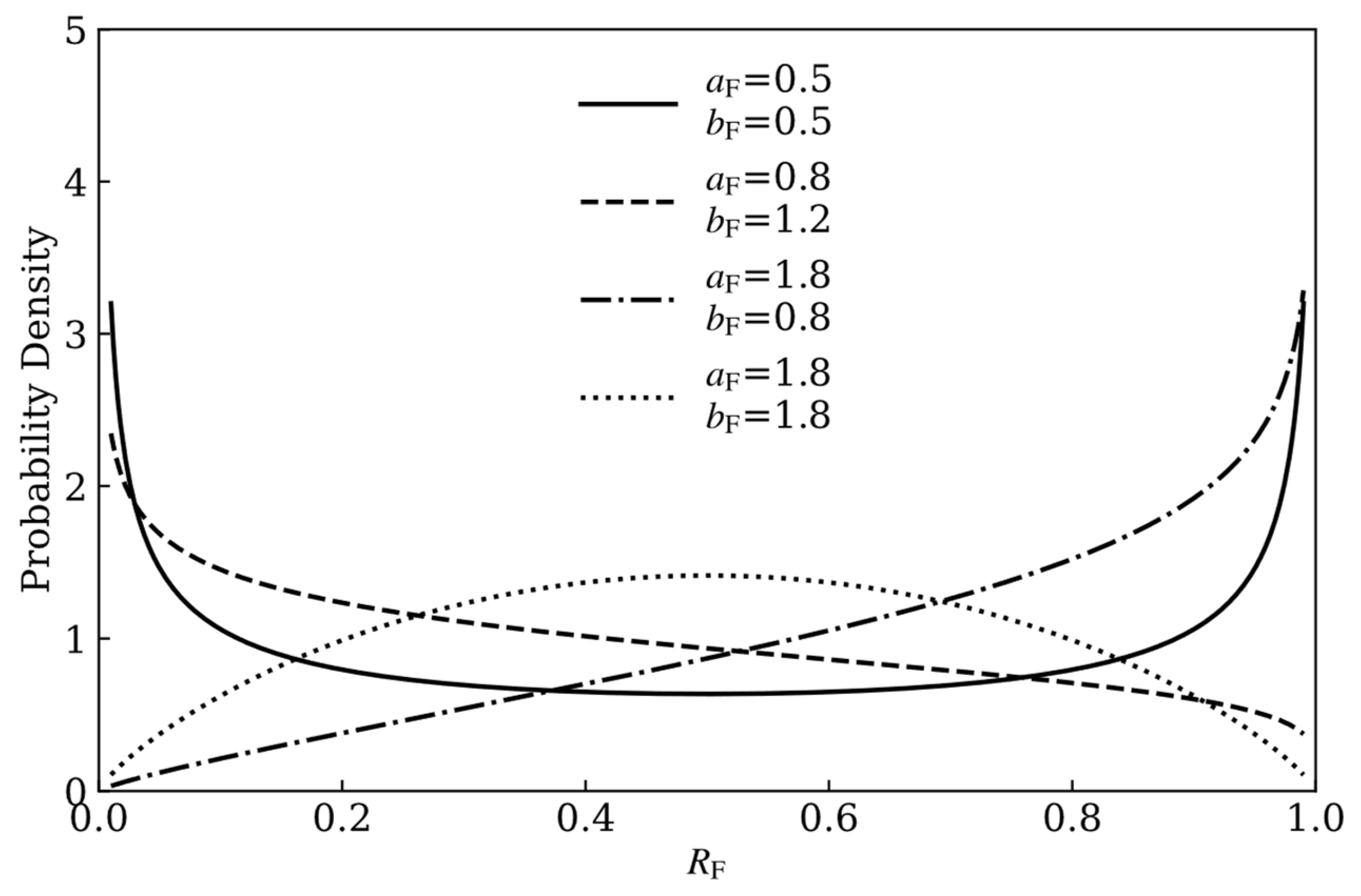
- Demand-operated systems: Include subsystem F. Maintaining quiescent operation (standby/dormant mode) during extended periods with transition to active state only upon defined triggering events, such systems exhibit characteristically transient functional execution phases and consequently undergo reliability assessment via binary success/failure data without operational time monitoring or feasible recording. Fire alarm units, automotive starter motors, and pilot ejection systems are likewise classified within this paradigm.
- Pulse-operated systems: Include subsystems M1–M3. Such systems undergo exceptionally high peak loads or stresses within vanishingly brief durations (millisecond to second scale), subsequently persisting in low-load or standby states for extended periods. This operational paradigm is characterized by extreme instantaneous power/stress density juxtaposed with markedly diminished average power/stress levels. Electromagnetic railguns, pyrotechnic airbag inflators, and surge protective devices are also classified within this domain. Missiles further fall into the category of non-repairable systems that produce binary outcome data structurally equivalent to that of subsystem F.
2.2. Model Description
2.2.1. Reliability Assessment Model for Mission Subsystems
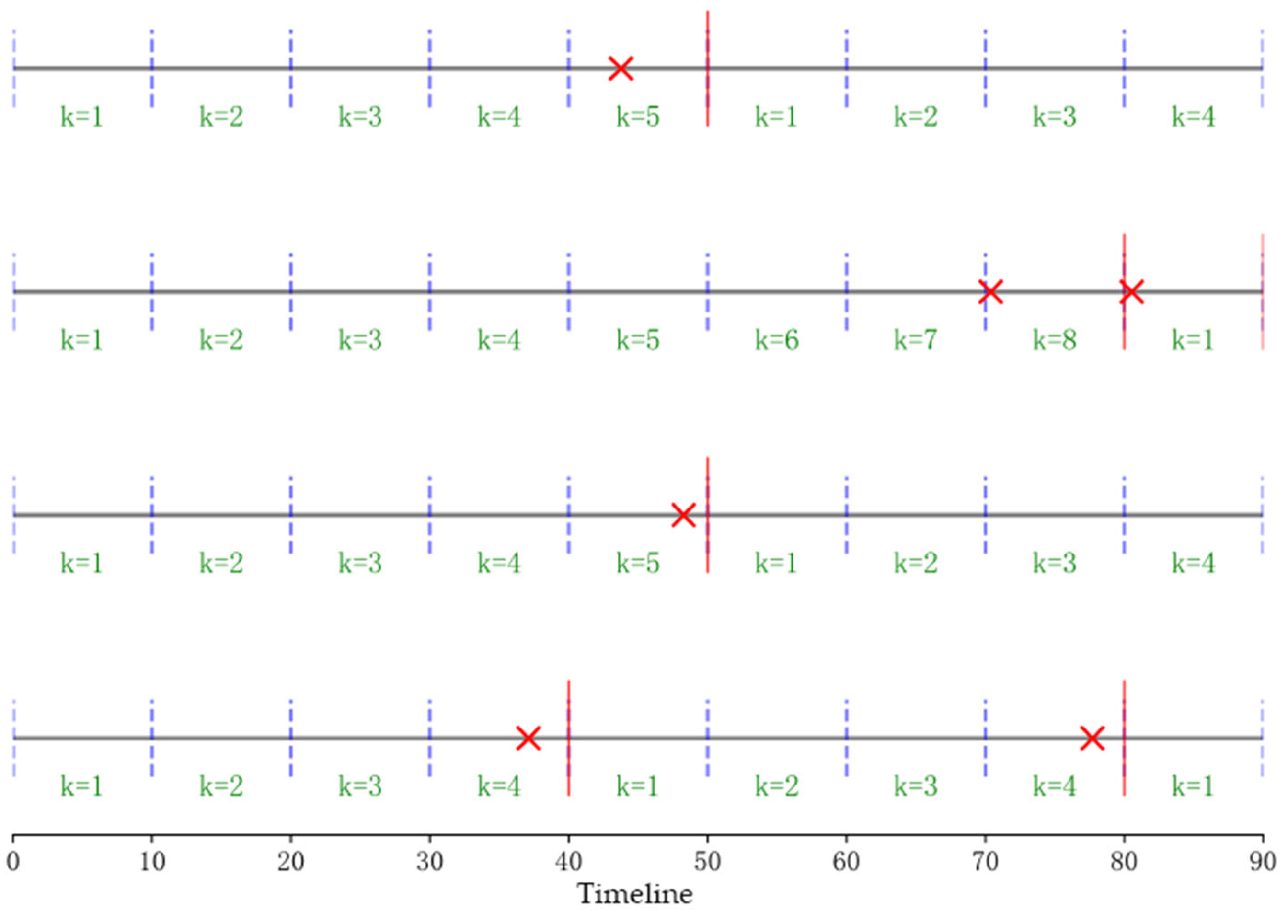
- Four horizontal solid lines representing timelines;
- Vertical dashed lines indicating failure inspection points;
- “×” symbols marking fault occurrences;
- Vertical red solid lines denoting failure restoration points.
- (1)
- Physical violation. Due to the stochastic nature of failure occurrences, estimated values might contradict physical feasibility. For instance, as shown in Figure 2, the reliability estimates for k = 5 and k = 6 yield implausible values of 0.33 and 1, respectively.
- (2)
- Non-continuity. The reliability function of the series system is not a time-dependent continuous function.
- (1)
- Both historical and current test data are sparse due to either the inherent high reliability of these subsystems or cost constraints in testing, resulting in extremely scarce failure incidents.
- (2)
- Failures are predominantly triggered by transient events such as electromagnetic pulse interference or mechanical shocks, rather than cumulative effects of covariates.
- (3)
- Only binary outcomes (success/failure) are recorded, which prevents the acquisition of precise stress profile data over time.
2.2.2. MCMC-Based Posterior Inference and Model Validation
- Half-step momentum update: ;
- Full-step position update: ;
- Half-step momentum completion: .
2.2.3. Multi-Path Mission Reliability Assessment
3. Results and Discussion
3.1. Simulation Scenario Validation
3.2. Field Deployment Case
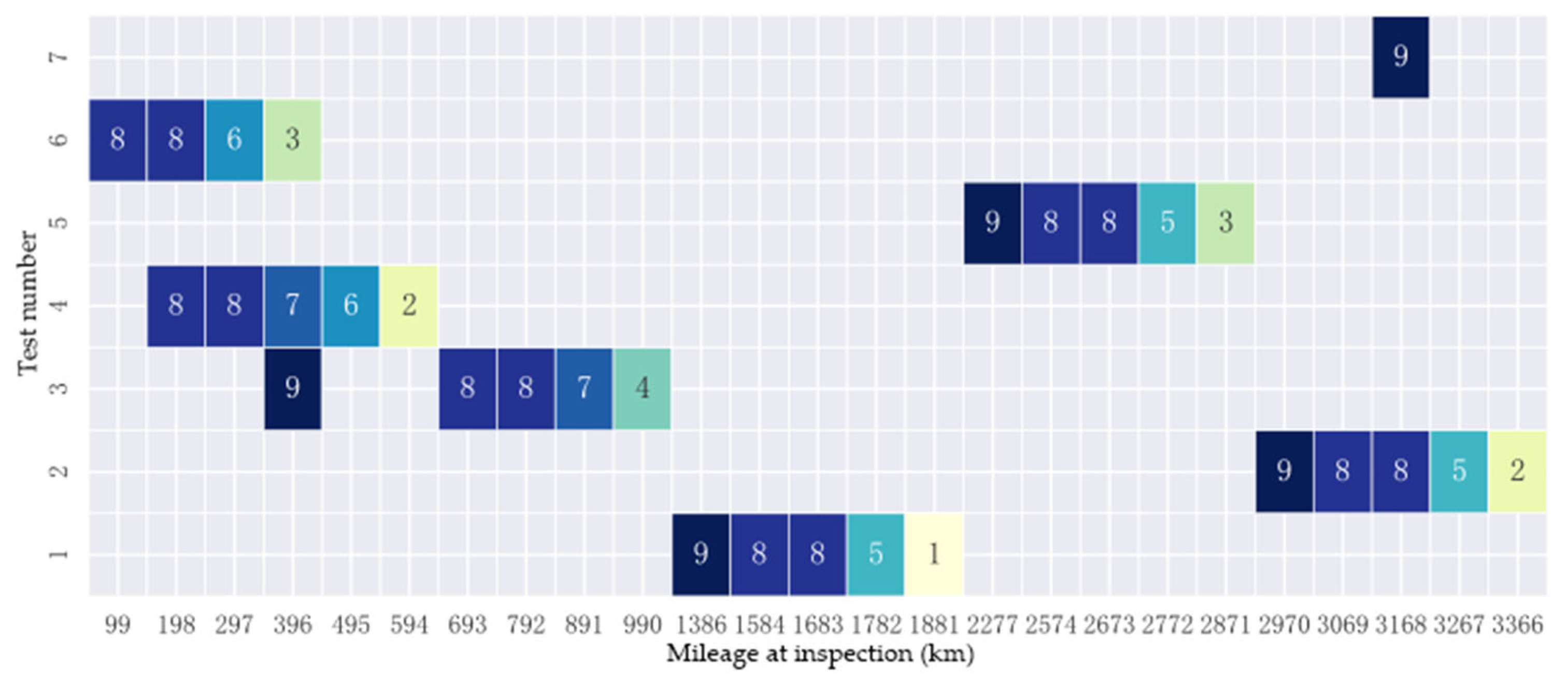
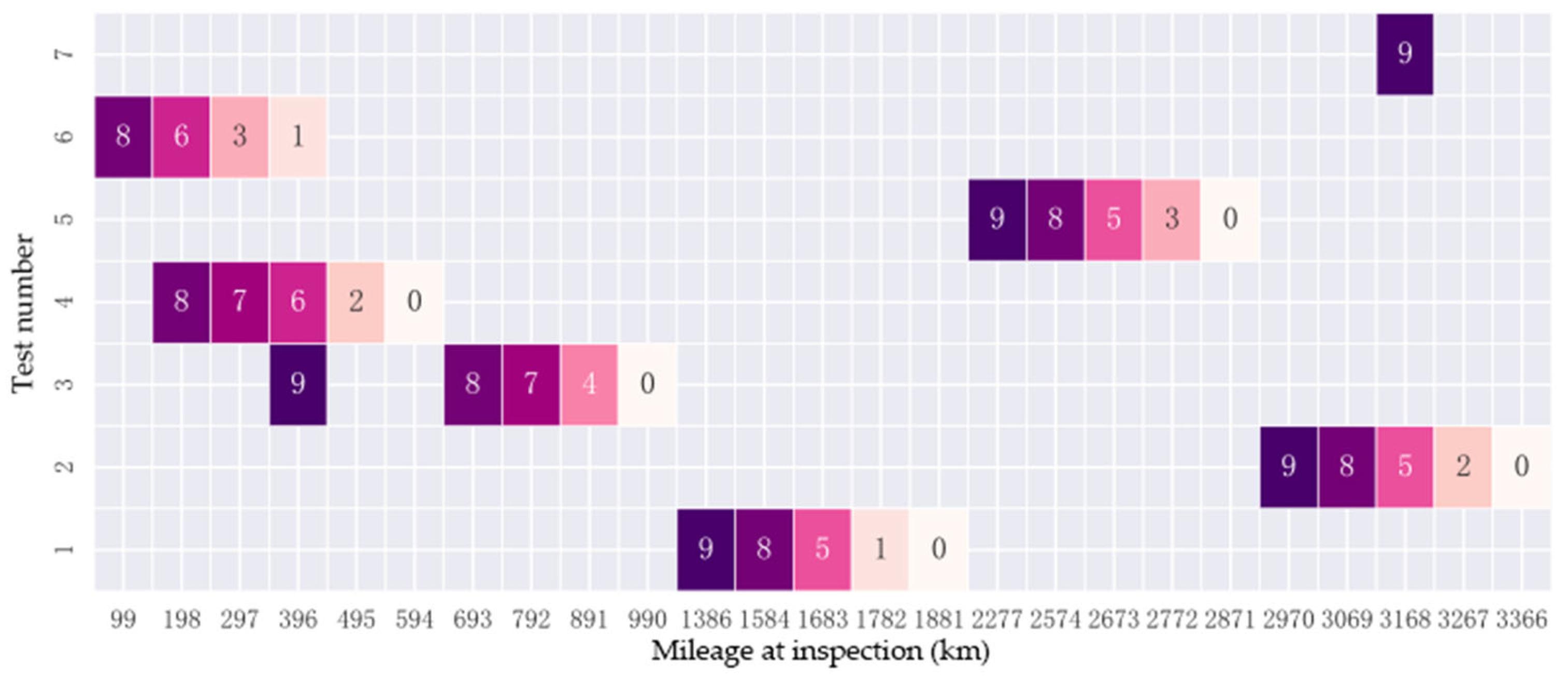
3.2.1. Data Acquisition
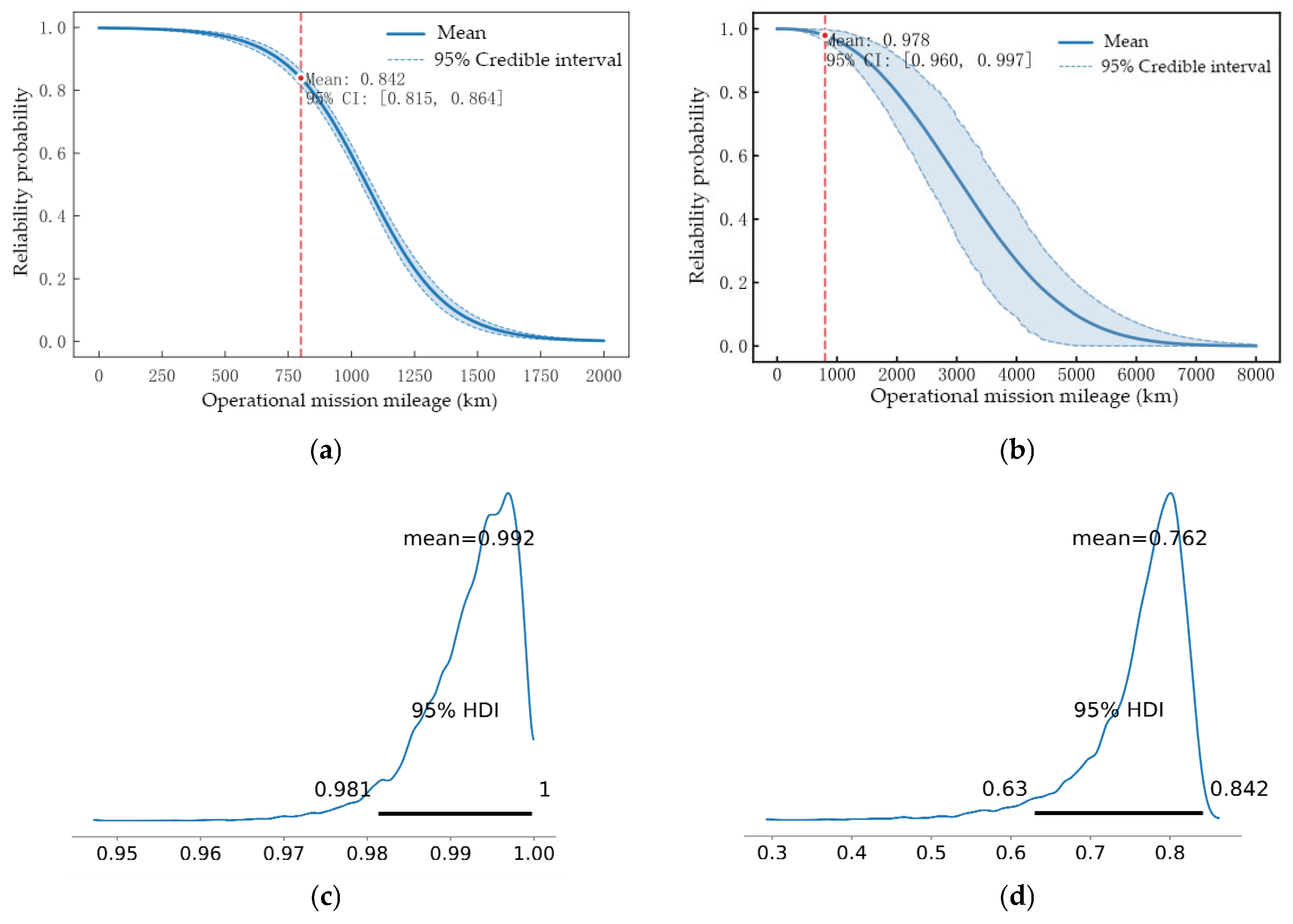
3.2.2. Method Application
- MCSE mean: Monte Carlo standard error of mean estimate
- MCSE SD: Monte Carlo standard error of standard deviation estimate
- ESS bulk: Effective sample size for distribution bulk
- ESS tail: Effective sample size for distribution tails
- R-hat: Gelman–Rubin statistic.
- (1)
- ESS bulk values span 2459~7537 (all substantially surpassing 2000), while ESS tail encompasses 3409~8562 (all well above 3000). These metrics indicate sufficient sampling and high sampling efficiency.
- (2)
- For all parameters, the ratios of MCSE mean and MCSE SD to the standard deviation (SD) in Table 4 are relatively small, with the maximum observed ratios being 0.021 (βN[2]: 0.008/0.386) and 0.019 (σ: 0.001/0.053). This demonstrates highly reliable estimation of both posterior means and dispersions.
- (3)
- All parameters exhibit R-hat values of exactly 1, indicating complete convergence of sampling chains. No systematic divergence emerges among four Markov chains during the iteration process.
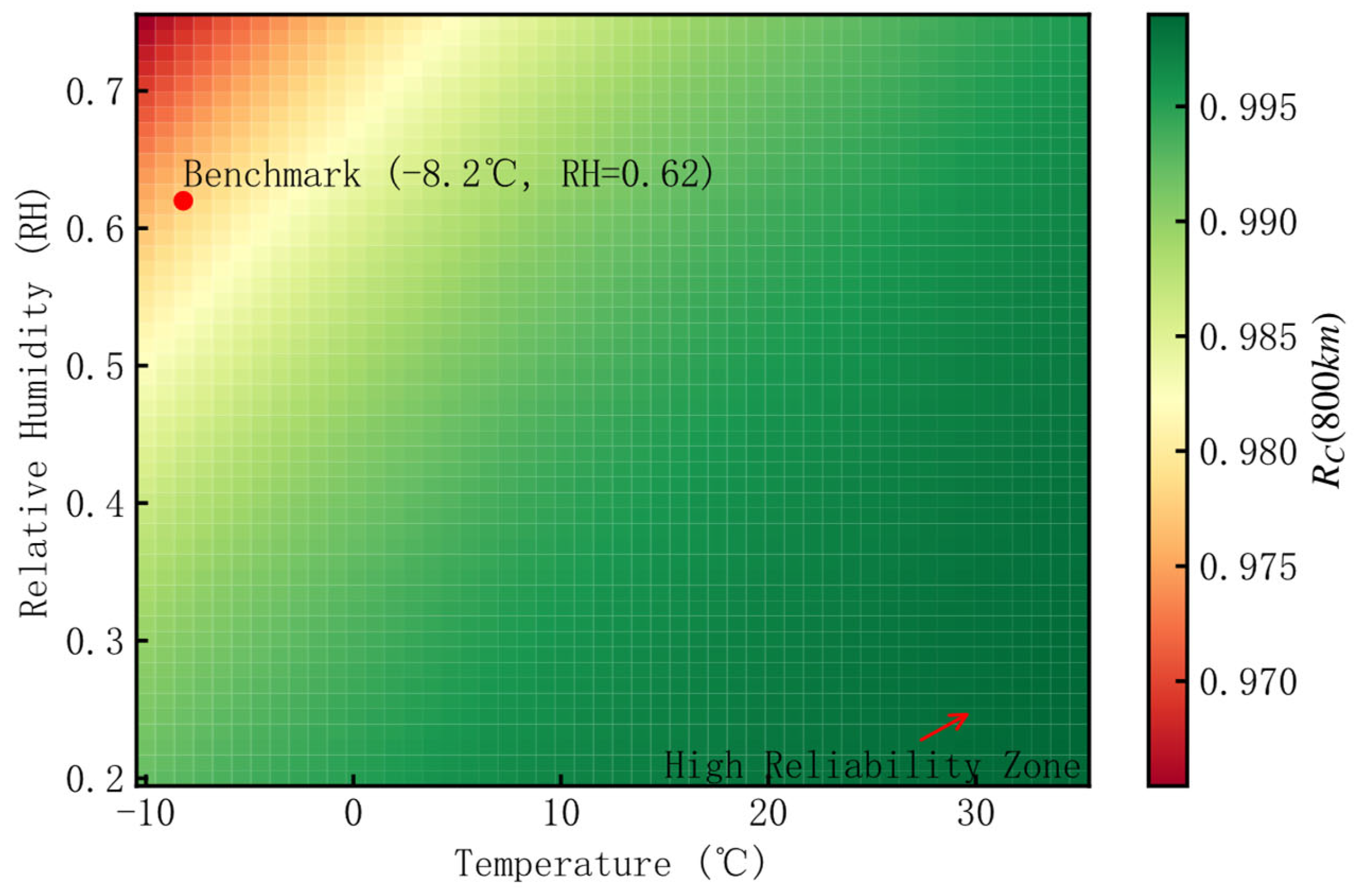
3.2.3. Sensitivity Analysis
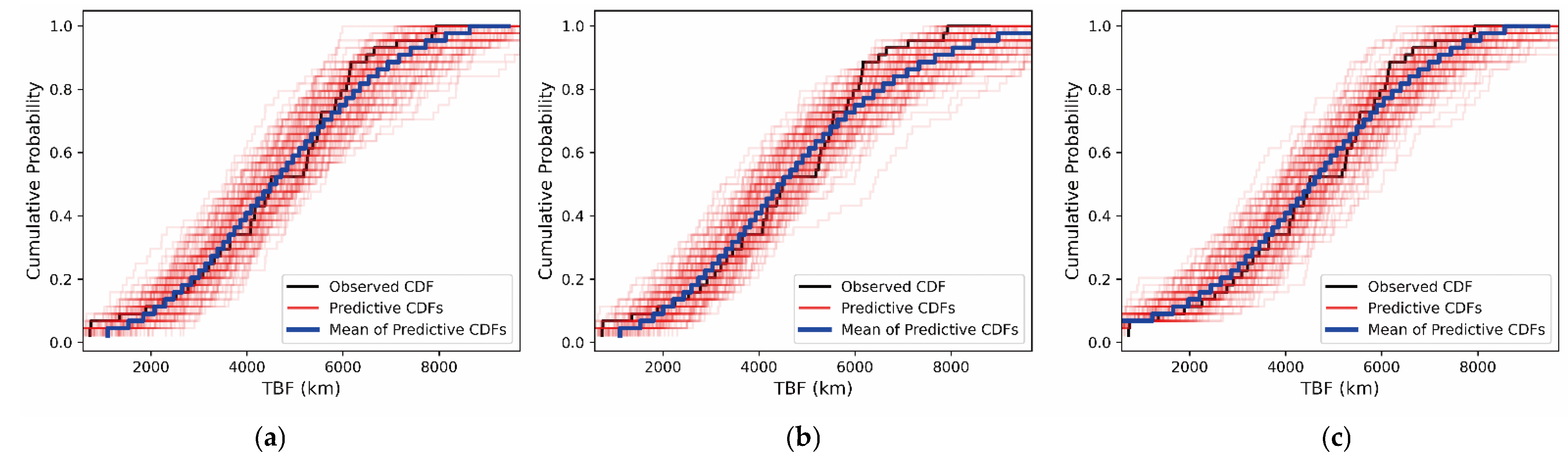
3.2.4. Comparative Validation
- Model 2: It assumes all chassis samples follow a single Weibull distribution and completely ignores the failure heterogeneity induced by covariates. The data model is Weibull (a, b), where a denotes the shape parameter and b represents the scale parameter. There is no covariate or grouping structure, and the failure law is characterized solely by global parameters.
- Model 3: It captures heterogeneity through data grouping. Specifically, historical data and operational test data are divided into two groups. It is assumed that two groups share the shape parameter a’, and the scale parameters follow a proportional relationship (the scale of historical data is ωb’, where b’ represents the scale of operational test data and ω is the proportional coefficient). The forms of the data models are Weibull (a’, b’) and Weibull (a’, ωb’).
4. Conclusions
- (1)
- The construction of the phased RBD achieves a refined decomposition of the mission profile based on distinguishing mission subsystems and their corresponding test data types, laying a foundation for more rational mission reliability assessment.
- (2)
- The optimization model integrating maximum entropy principle with monotonic decreasing reliability constraint effectively reduces parameter estimation bias and suppresses estimation uncertainty.
- (3)
- The covariate-embedded Bayesian assessment model successfully combines heterogeneous historical data and operational testing data, while quantitatively characterizing the system’s adaptability to covariates.
- (4)
- The multi-path mission reliability assessment demonstrates that other performance metrics of the system also influence its mission reliability level, and its logic is extensible to other multi-phase systems (e.g., unmanned platforms, electronic warfare systems) with phased mission profiles and heterogeneous data sources.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sun, A.; Zhuang, Y.; Wang, B.; Bao, S.H.; Dong, L. Research and Application of Weapons and Equipments Combat Test; National Defense Industry Press: Beijing, China, 2021. [Google Scholar]
- Lu, P. Operational Test and Evaluation of US Marine Crops; National Defense Industry Press: Beijing, China, 2019. [Google Scholar]
- Cui, R.; Sun, J.; Yang, K.; Li, M. Construction method of operational test indicator systems based on UAF. Syst. Eng. Electron. 2025, 47, 1536–1550. [Google Scholar]
- Musallam, M.; Yin, C.; Bailey, C.; Johnson, M. Mission profile-based reliability design and real-time life consumption estimation in power electronics. IEEE Trans. Power Electron. 2014, 30, 2601–2613. [Google Scholar] [CrossRef]
- Lie, C.H.; Kuo, W.; Tillman, F.A.; Hwang, C. Mission effectiveness model for a system with several mission types. IEEE Trans. Reliab. 2009, 33, 346–352. [Google Scholar] [CrossRef]
- Zhang, R.; Mahadevan, S. Integration of computation and testing for reliability estimation. Reliab. Eng. Syst. Saf. 2001, 74, 13–21. [Google Scholar] [CrossRef]
- Li, S.; Wang, K.; Yuan, H.; Zhu, G.; Wang, X. An in-service mission reliability assessment method of complex equipment system. Air Space Def. 2023, 6, 23–28. [Google Scholar]
- Wang, S.; Zhang, S.; Li, Y.; Dong, Y.-S. Research on selective maintenance decision-making method of complex system considering imperfect maintenance. Acta Armamentarii 2018, 39, 1215–1224. [Google Scholar]
- Liu, Z.; Ma, X.; Hong, D.; Zhao, Y. Mission reliability assessment for battle-plane based on flight profile. J. Beijing Univ. Aeronaut. Astronaut. 2012, 38, 59–63. [Google Scholar]
- Lim, J.H.; Kim, S.Y. A Study on the Determination of Optimal Repair Parts Inventory based on Simulation and Analysis of Its Influencing Factors. Ind. Eng. Manag. Syst. 2024, 23, 515–534. [Google Scholar] [CrossRef]
- Guo, J.; Li, Y.; Peng, W.; Huang, H.-Z. Bayesian information fusion method for reliability analysis with failure-time data and degradation data. Qual. Reliab. Eng. Int. 2022, 38, 1944–1956. [Google Scholar] [CrossRef]
- Hu, J.; Huang, H.; Li, Y.; Gao, H. Bayesian prior information fusion for power law process via evidence theory. Commun. Stat.-Theory Methods 2022, 51, 4921–4939. [Google Scholar] [CrossRef]
- Kleyner, A.; Bhagath, S.; Gasparini, M.; Robinson, J. Bayesian techniques to reduce the sample size in automotive electronics attribute testing. Microelectron. Reliab. 1997, 37, 879–883. [Google Scholar] [CrossRef]
- Steiner, S.; Dickinson, R.M.; Freeman, L.J.; Simpson, B.A.; Wilson, A.G. Statistical methods for combining information: Stryker family of vehicles reliability case study. J. Qual. Technol. 2015, 47, 400–415. [Google Scholar] [CrossRef]
- Gilman, J.F.; Fronczyk, K.M.; Wilson, A.G. Bayesian modeling and test planning for multiphase reliability assessment. Qual. Reliab. Eng. Int. 2019, 35, 750–760. [Google Scholar] [CrossRef]
- Dewald, S.L.; Holcomb, R.; Parry, S.; Wilson, A. A Bayesian approach to evaluation of operational testing of land warfare systems. Mil. Oper. Res. 2016, 21, 23–32. [Google Scholar]
- Krolo, A.; Bertsche, B. An approach for the advanced planning of a reliability demonstration test based on a Bayes procedure. In Proceedings of the Annual Reliability and Maintainability Symposium, Tampa, FL, USA, 27–30 January 2003; pp. 288–294. [Google Scholar]
- Tait, N.R.S. Robert Lusser and Lusser’s Law. Saf. Reliab. 1995, 15, 15–18. [Google Scholar] [CrossRef]
- Martz, H.F.; Waller, R.A. 14. Bayesian methods. Methods Exp. Phys. 1994, 28, 403–432. [Google Scholar]
- Flegal, J.M.; Jones, G.L. Implementing MCMC: Estimating with confidence. In Handbook of Markov Chain Monte Carlo; Chapman and Hall/CRC: Boca Raton, FL, USA, 2011; Volume 1, pp. 175–197. [Google Scholar]
- Jerke, G.; Kahng, A.B. Mission profile aware IC design—A case study. In Proceedings of the 2014 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 24–28 March 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1–6. [Google Scholar]
- Franciosi, C.; Polenghi, A.; Lezoche, M.; Voisin, A.; Roda, I.; Macchi, M. Semantic interoperability in industrial maintenance-related applications: Multiple ontologies integration towards a unified BFO-compliant taxonomy. In Proceedings of the 16th IFAC/IFIP International Workshop on Enterprise Integration, Interoperability and Networking, EI2N, Valletta, Malta, 24–26 October 2022; SCITEPRESS-Science and Technology Publications: Setúbal, Portugal, 2022; pp. 218–229. [Google Scholar]
- Xia, X.; Ye, L.; Li, Y.; Chang, Z. Reliability evaluation based on hierarchical bootstrap maximum entropy method. Acta Armamentarii 2016, 37, 1317–1329. [Google Scholar]
- Guo, J.; Wilson, A. Bayesian methods for estimating system reliability using heterogeneous multilevel information. Technometrics 2013, 55, 461–472. [Google Scholar] [CrossRef]
- Zhang, W.; Yang, H.; Zhang, S.H. Reliability assessment for device with only safe-or-failure pattern based on Bayesian hyprid prior approach. Acta Armamentarii 2016, 37, 505–511. [Google Scholar]
- Karras, C.; Karras, A.; Avlonitis, M.; Sioutas, S. An overview of mcmc methods: From theory to applications. Proceedings of the IFIP International Conference on Artificial Intelligence Applications and Innovations, Crete, Greece, 17–20 June 2022, Springer International Publishing: Cham, Switzerland, 2022; 319–332. [Google Scholar]
- Wikle, C.K. Hierarchical Bayesian models for predicting the spread of ecological processes. Ecology 2003, 84, 1382–1394. [Google Scholar] [CrossRef]
- Bian, R.; Zhang, Y.; Pan, Z.; Cheng, Z.; Bai, S. Reliability analysis of phased-mission system of systems for escort formation based on BDD. Acta Armamentarii 2020, 41, 1016–1024. [Google Scholar]
- Chen, J. Survival Analysis and Reliability; Peking University Press: Beijing, China, 2005. [Google Scholar]
- Jia, X.; Guo, B. Reliability evaluation for products by fusing expert knowledge and lifetime data. Control Decis. 2022, 37, 2600–2608. [Google Scholar]
- Hoffman, M.D.; Gelman, A. The No-U-Turn sampler: Adaptively setting path lengths in Hamiltonian Monte Carlo. J. Mach. Learn. Res. 2014, 15, 1593–1623. [Google Scholar]
- Turkkan, N.; Pham-Gia, T. Computation of the highest posterior density interval in Bayesian analysis. J. Stat. Comput. Simul. 1993, 44, 243–250. [Google Scholar] [CrossRef]
- Dahl, F.A. On the conservativeness of posterior predictive p-values. Stat. Probab. Lett. 2006, 76, 1170–1174. [Google Scholar] [CrossRef]
- Vehtari, A.; Gelman, A.; Gabry, J. Practical Bayesian model evaluation using leave-one-out cross-validation and WAIC. Stat. Comput. 2017, 27, 1413–1432. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| k | |||
|---|---|---|---|
| 1 | 12 | 10 | 5 |
| 2 | 9 | 8 | 10 |
| 4 | 8 | 8 | 20 |
| 5 | 8 | 7 | 25 |
| 6 | 6 | 5 | 30 |
| 7 | 4 | 3 | 35 |
| 12 | 3 | 3 | 60 |
| 13 | 2 | 0 | 65 |
| T | Δt | True Parameter Values | Parameter Estimation Results | |
|---|---|---|---|---|
| Proposed Method | Existing Method | |||
| 90 | 5 | 1.983 [1.237, 2.763] | 2.585 [1.266, 4.141] | |
| −0.024 [−0.036, −0.013] | −0.018 [−0.048, 0.007] | |||
| 300 | 20 | 1.852 [1.111, 2.595] | 2.188 [0.930, 3.540] | |
| −0.028 [−0.038, −0.017] | −0.033 [−0.059, −0.008] | |||
| 400 | 20 | 3.468 [2.758, 4.270] | 6.476 [3.712, 9.383] | |
| −0.023 [−0.029, −0.017] | −0.043 [−0.065, −0.020] | |||
| 500 | 25 | 3.144 [2.349, 4.037] | 6.494 [2.900, 10.697] | |
| −0.018 [−0.022, −0.003] | −0.023 [−0.041,−0.006] | |||
| Time Period | Evaluation Content | Operational Actions | Test Environment | ||
|---|---|---|---|---|---|
| Terrain | Lighting | Meteorological | |||
| 3 days | command and communication capability (CCC), integrated support capability (ISC), and in-service suitability (ISS) | readiness level transition | urban roads | daytime, nighttime | clear weather |
| 12 days | CCC, maneuver and assault capability (MAC), and OS | maneuver and assembly | urban roads, moderately rolling roads | daytime, nighttime | clear weather, precipitation weather |
| 2 days | reconnaissance and intelligence capability (RIC), CCC, OS, and SoS suitability | combat organization | moderately rolling roads | daytime, nighttime | precipitation weather |
| 2 days | RIC, CCC, MAC, firepower strike capability (FSC), multi-domain defense capability, ISC, OS, SoS suitability, and ISS | combat execution | moderately rolling roads | daytime, nighttime | precipitation weather, fog weather |
| Mission Subsystem | Data Type | Data Distribution | Data Source | Sample Size (Censored) | Covariate Values |
|---|---|---|---|---|---|
| Navigation module | mileage from repair to failure inspection(km), number of success/total inspections | time-varying binomial distribution | operational testing | 2 groups | relative humidity (RH): 0.62 temperature (Temp): −8.2 °C |
| historical data | 107 groups | RH: 0.20~0.75 Temp: −10 °C~35 °C | |||
| Chassis | TBF(km) | Weibull distribution | operational testing | 6 (4) time records | RH: 0.62, Temp: −8.2 °C |
| historical data | 60 (18) time records | RH: 0.20~0.75 Temp: −10 °C~35 °C | |||
| Missile | success/failure | Bernoulli distribution | operational testing | 6 trials | — |
| expert knowledge | 1 judgment | — |
| Parameter | Posterior Mean | Standard Deviation | HPD Interval (95%) |
|---|---|---|---|
| θN | 13.457 | 0.678 | [12.171, 14.683] |
| ηN | −0.006 | 0.0001 | [−0.007, −0.006] |
| βN | (−0.019, 7.465) | (0.029, 0.386) | ([−0.079, 0], [6.744, 8.176]) |
| φ | 12.282 | 1.127 | [10.270, 14.492] |
| θC | 8.640 | 0.071 | [8.502, 8.722] |
| βC | (−0.157, 0.217) | (0.090, 0.088) | ([−0.325, 0.015], [0.088, 0.044]) |
| σ | 0.395 | 0.053 | [0.298, 0.494] |
| Parameter | MCSE Mean | MCSE SD | ESS Bulk | ESS Tail | R-Hat |
|---|---|---|---|---|---|
| θN | 0.014 | 0.009 | 2459 | 3409 | 1.0 |
| ηN | 0 | 0 | 2461 | 3422 | 1.0 |
| βN[1] | 0 | 0 | 6076 | 6117 | 1.0 |
| βN[2] | 0.008 | 0.005 | 2466 | 3544 | 1.0 |
| φ | 0.017 | 0.012 | 4559 | 5185 | 1.0 |
| θC | 0.001 | 0.001 | 7414 | 8099 | 1.0 |
| βC[1] | 0.001 | 0.001 | 6919 | 8562 | 1.0 |
| βC[2] | 0.001 | 0.001 | 7537 | 8182 | 1.0 |
| σ | 0.001 | 0.001 | 7350 | 7408 | 1.0 |
| Temp (°C) | λC (km) | RC (800 km) | Reliability Variation Rate |
|---|---|---|---|
| −10 | 3480.46 | 0.976 | −0.2% |
| −8.2 (benchmark) | 3595.68 | 0.978 | 0 |
| 0 | 4170.78 | 0.984 | 0.6% |
| 15 | 5471.28 | 0.992 | 1.4% |
| 35 | 7856.89 | 0.996 | 1.8% |
| RH | λC (km) | RC (800 km) | Reliability Variation Rate |
|---|---|---|---|
| 0.20 | 5683.07 | 0.993 | 1.5% |
| 0.35 | 4825.94 | 0.990 | 1.2% |
| 0.50 | 4098.10 | 0.985 | 0.7% |
| 0.62 (benchmark) | 3595.68 | 0.978 | 0 |
| 0.75 | 3120.66 | 0.971 | −0.7% |
| Prior SD Perturbation | (800 km) Point Estimate | 95% HPD Interval | Variation Rate of Interval Width |
|---|---|---|---|
| 100 (benchmark) | 0.978 | [0.960, 0.997] | 0 |
| 200 | 0.978 | [0.959, 0.996] | 0 |
| 50 | 0.979 | [0.959, 0.997] | 2.7% |
| 10 | 0.978 | [0.959, 0.997] | 2.7% |
| 5 | 0.979 | [0.960, 0.997] | 0 |
| 0.6 | 0.975 | [0.953, 0.995] | 13.5% |
| 0.5 | 0.969 | [0.942, 0.995] | 43.2% |
| Model | WAIC | ppp | ||||
|---|---|---|---|---|---|---|
| Mean | Median | Lower Quartile | Upper Quartile | |||
| Model 1 | 845.172 | 4.111 | 0.535 | 0.386 | 0.423 | 0.647 |
| Model 2 | 861.601 | 2.018 | 0.739 | 0.375 | 0.375 | 0.739 |
| Model 3 | 865.938 | 2.987 | 0.597 | 0.357 | 0.469 | 0.601 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hao, J.; Pei, M. Mission Reliability Assessment for the Multi-Phase Data in Operational Testing. Stats 2025, 8, 49. https://doi.org/10.3390/stats8030049
Hao J, Pei M. Mission Reliability Assessment for the Multi-Phase Data in Operational Testing. Stats. 2025; 8(3):49. https://doi.org/10.3390/stats8030049
Chicago/Turabian StyleHao, Jianping, and Mochao Pei. 2025. "Mission Reliability Assessment for the Multi-Phase Data in Operational Testing" Stats 8, no. 3: 49. https://doi.org/10.3390/stats8030049
APA StyleHao, J., & Pei, M. (2025). Mission Reliability Assessment for the Multi-Phase Data in Operational Testing. Stats, 8(3), 49. https://doi.org/10.3390/stats8030049