
A New Weighted Lindley Model with Applications to Extreme Historical Insurance Claims

 , ,
, ,  ,
,  ,
,  ,
, 
Abstract
1. Introduction
2. The Model
- The development and application of the NWLi model represents a novel advancement in statistical modeling techniques tailored specifically for extreme insurance claims. Therefore, this article contributes to the ongoing evolution of statistical methods in risk assessment and management.
- This paper addresses a significant knowledge gap in the analysis of sudden large losses within insurance companies. The results and methodologies presented offer valuable insights into modeling extreme claim severity, which is essential for developing effective risk management strategies.
- This work can directly benefit insurance companies by providing practical tools and methodologies to assess and mitigate sudden large losses. By showcasing the relevance and impact of the NWLi model in addressing real challenges, the paper serves as a valuable resource for industry practitioners.
- Insurance companies rely on scientific evidence and rigorous methodologies to make informed decisions about risk exposure and financial resilience. The NWLi model can support evidence-based decision-making in insurance practices.
- It encourages innovative approaches that can enhance the resilience and competitiveness of insurance companies in addressing sudden large and extreme losses.
3. Properties
3.1. Asymptotic Properties
3.2. Moments
4. Estimation Methods
4.1. Maximum Likelihood
4.2. Least Squares
4.3. Weighted Least Squares
4.4. Cramér-Von Mises
4.5. Anderson–Darling
5. Simulations
6. Applications
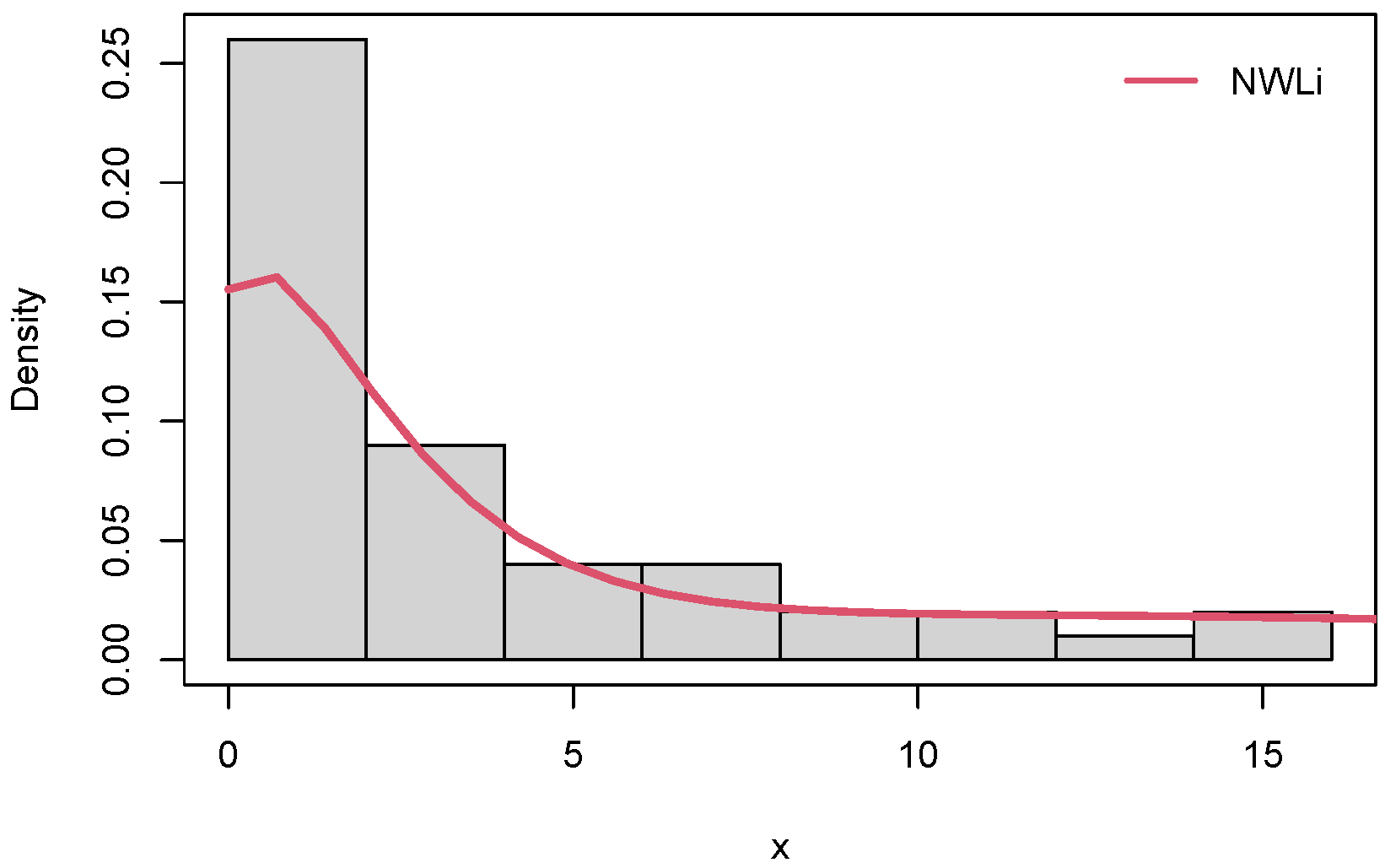
6.1. Failure Times
6.2. Survival Data
7. Risk Indicators
7.1. The Mean of Order P and Optimal Order of P
7.2. The PORT-VaR Estimator
- 1.
- Gather the historical claims data, say , where each represents a claim amount.
- 2.
- Choose a threshold U based on the desired risk level or severity of extreme events. This threshold should typically be higher than the majority of the claim amounts in the dataset.
- 3.
- Determine all claim amounts that exceed the threshold U. Let be the ordered exceedances, where k is the number of exceedances.
- 4.
- Compute the VaR at a specified confidence level using the estimated parameters of and . The VaR at confidence level represents the threshold beyond which the risk of extreme events (exceedances) is considered.
- 5.
- Finally, the PORT-VaR is estimated as the expected value of the exceedances above the threshold U based on the fitted WLi parameter.
8. Historical Claims Analysis
8.1. The MOOP(P) Assessments and Optimal Order of P
- 1.
- The true mean value provides a baseline reference point for comparison with the estimated MOOP.
- 2.
- The MOOP values decrease with increasing P, reflecting the increasing complexity and variability captured by higher-order moments. The corresponding MSE values show a slight improvement with higher P, thus indicating reduced error in estimation as more moments are considered.
- 3.
- The bias decreases when P increases, thus suggesting more accurate estimation of the true mean with higher-order moments. The bias values converge towards the true mean when P increases.
- 4.
- The results suggest that considering higher-order moments (increasing P) leads to a better estimation accuracy (lower MSE and bias) but with diminishing improvements beyond a certain point. This analysis highlights the trade-off between model complexity (capturing more variability) and estimation accuracy, emphasizing the importance of selecting an optimal order P based on the specific objectives and requirements of the analysis.
- 1.
- The true mean value provides a reference point for evaluating the performance of MOOP.
- 2.
- Higher-order moments (larger P) captured more variability and detail in the dataset, as evidenced by the increasing values of MOOP.
- 3.
- Both the MSE and bias decrease with increasing P, thus indicating improved accuracy and closer approximation to the true mean as more moments are considered.
- 4.
- This analysis highlights the importance of selecting an optimal order P based on the trade-off between complexity (capturing more details) and accuracy (minimizing bias and MSE). In this case, appears to provide a good balance between model complexity and estimation accuracy.
- 5.
- The results demonstrate the impact of different moment orders on estimating the true mean value, with higher-order moments leading to improved accuracy but potentially increasing model complexity. The choice of P should be carefully considered based on the specific objectives and requirements of the analysis.
- 1.
- The decreasing trend in MSE and bias when P increases indicates that higher-order moments captured more of the dataset’s variability, leading to more accurate estimations of the true mean value.
- 2.
- The results suggest that using moments of higher orders (P) improves estimation accuracy, with diminishing improvements when P increases. In this case, provides a good balance between capturing variability and minimizing bias and MSE.
- 3.
- These findings emphasize the importance of considering higher-order moments in statistical analyses, especially for capturing complex patterns and variability in datasets. Selecting the appropriate order of moments depends on the specific characteristics and goals of the analysis, balancing model complexity with the need for accurate estimation.
- 1.
- The extremely small values of MOOP, MSE, and bias suggest that the higher-order moments (P) captured minute variations and details in the dataset, leading to very accurate estimations of the true mean value.
- 2.
- In this case, the diminishing improvements in MSE and bias when P increased suggest that, even with very high-order moments, the estimates were already very close to the true mean. This indicates that capturing higher-order variability may not significantly enhance the estimation in this specific context.
- 3.
- These results demonstrate the high level of precision and accuracy achieved in estimating the true mean value using moments of varying orders. The findings underscore the importance of understanding the sensitivity of moment-based estimators to different levels of data complexity and variability.
- 1.
- The decreasing trend in MSE and bias as P increases suggests that higher-order moments (P) captured more of the variability and complexity in the dataset, leading to improved estimations of the true mean value.
- 2.
- In this case, the diminishing MSE and bias with increasing P suggest that using higher-order moments () provides a good balance between capturing sufficient variability and minimizing estimation error.
- 3.
- These results demonstrate the importance of considering higher-order moments in statistical analyses to capture complex patterns and variability in datasets. The findings highlight the trade-off between model complexity (higher P) and accuracy in estimating statistical parameters like the mean.
8.2. PORT-VaR Estimator for Extreme Claims
- 1.
- The MOOP values showed a decreasing trend as the order of P increased from 1 to 5. This trend suggests that higher-order moments (larger values of P) captured less variability and complexity in the dataset compared to lower-order moments.
- 2.
- The significant drop in MOOP from to 2 indicates that the addition of a second moment () reduced the mean substantially, thus suggesting that the second moment captured important aspects of the data distribution.
- 3.
- If P increases more than 2, the reduction in MOOP becomes less pronounced, thus indicating diminishing returns in terms of capturing additional variability or complexity with higher-order moments.
- 4.
- The choice of the optimal P depends on balancing model complexity with the need to capture essential characteristics of the data distribution. In this case, the significant drop in MOOP from to 2 suggests that a model with may provide a good compromise between simplicity and capturing variability.
- 1.
- For a 50% confidence level, there were 14 extreme claims that exceeded the threshold. This indicates relatively common extreme claims occurrences within this confidence interval.
- 2.
- If the confidence level increased, the number of extreme claims (PORT) also increased, ranging from 19 at a 70% confidence level to 27 at a 99% confidence level. This suggests a higher frequency of extreme claims events as we move towards higher confidence levels, highlighting the tail risk in the claims data.
- 3.
- The minimum (Min) value of the extreme claims increased as the confidence level decreased. This implies that lower confidence levels captured less severe but more frequent extreme claims.
- 4.
- The 1st quartile (25% percentile) of the extreme claims also increased with decreasing confidence levels, reflecting the distribution of less severe events.
- 5.
- The median of the extreme claims (50% percentile) generally increased with decreasing confidence levels, representing the central tendency of extreme claim values at each level of risk.
- 6.
- The mean of the extreme claims (ExV) showed a similar trend, thus increasing with decreasing confidence levels.
- 7.
- The 3rd quartile (75% percentile) and maximum values of the extreme claims also followed a pattern of increasing values with decreasing confidence levels.
- 8.
- The distribution of extreme claims varied across the different confidence levels, with lower confidence levels capturing more frequent but less severe events, and higher confidence levels focusing on rarer but more severe claims. The analysis emphasizes the importance of understanding tail risk in insurance, as higher confidence levels reveal the occurrence of more severe and less frequent claims that may have significant financial implications. These results can support decision-making processes within insurance companies, helping to assess the frequency and severity of extreme claims events and inform risk management strategies.
- 9.
- The PORT-VaR analysis in Table 4 provides valuable insights into the distribution and characteristics of extreme claims data at different confidence levels. The detailed summary statistics can help quantify tail risk and support informed decision-making in insurance practices, aiding in risk assessment and mitigation strategies.
- 10.
- The distribution of extreme claims across different confidence levels shows that lower confidence levels capture more frequent but less severe events, while higher confidence levels focus on rare but more severe claims. Understanding this tail risk is crucial in insurance, as it reveals severe and less frequent claims that may have substantial financial implications. The insights from this analysis can support decision-making processes within insurance companies, aiding in the assessment of extreme claims frequency and severity to inform risk management strategies.
9. Conclusions
- 1.
- MOOP values decrease with increasing P, thus indicating that higher-order moments capture more variability and complexity within a dataset. This suggests that higher P values lead to more detailed representations of the underlying distribution.
- 2.
- Both mean squared error and bias decrease when P increases. This trend signifies improved accuracy in estimating the true mean value with higher-order moments. The bias converges towards the true mean when P increases, indicating a more accurate estimation.
- 3.
- The results highlight the trade-off between model complexity and estimation accuracy. While higher p values generally lead to improved accuracy (lower MSE and bias), the improvements are reduced beyond a certain point. Selecting an optimal P involves balancing the need to capture dataset variability against increasing model complexity.
- 4.
- The optimal P varies across scenarios based on parameter values and dataset characteristics. For instance, often strikes a balance between capturing sufficient dataset detail and minimizing bias and MSE.
- 5.
- Extremely small values of MOOP, MSE, and bias in certain scenarios suggest that very high-order moments may not significantly enhance estimation accuracy beyond a certain threshold of complexity.
- 6.
- The findings underscore the importance of considering higher-order moments in statistical analyses, particularly for capturing complex patterns and variability in datasets.
- 7.
- The choice of P should be tailored to specific analysis goals and dataset characteristics, ensuring an optimal balance between model complexity and estimation accuracy.
- 8.
- The number of extreme claims exceeding the threshold increases with higher confidence levels, ranging from 14 at a 50% confidence level to 27 at a 99% confidence level. This highlights the higher occurrence of extreme events as the risk level increases.
- 9.
- As confidence levels decrease, the minimum value of extreme claims increases, indicating less severe but more frequent events being captured at lower confidence levels.
- 10.
- The first and third quartiles of extreme claims values increase with decreasing confidence levels, reflecting a shift towards less severe but more frequent events.
- 11.
- The median and mean values of extreme claims also increase with decreasing confidence levels, indicating a shift towards higher values and greater severity at lower confidence levels.
- 12.
- Lower confidence levels capture more frequent but less severe events, while higher confidence levels focus on rarer but more severe claims. Understanding this tail risk is crucial in insurance for assessing potential financial impacts.
- 13.
- The analysis provides valuable insights for insurance decision-making, facilitating risk assessment and mitigation strategies by quantifying the frequency and severity of extreme claims at different confidence levels.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Atikankul, Y.; Thongteeraparp, A.; Bodhisuwan, W. The new Poisson mixed weighted Lindley distribution with applications to insurance claims data. Songklanakarin J. Sci. Technol. 2020, 42, 152–162. [Google Scholar]
- Gel, Y.R.; Gastwirth, J.L. The Lindley distribution and its applications to mixture modeling. J. Data Sci. 2008, 6, 575–590. [Google Scholar]
- Manesh, S.N.; Hamzah, N.A.; Zamani, H. Poisson-weighted Lindley distribution and its application on insurance claim data. AIP Conf. Proc. 2014, 1605, 834–839. [Google Scholar]
- Hogg, R.V.; Klugman, S.A. Loss Distributions; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Klugman, S.A.; Panjer, H.H.; Willmot, G.E. Loss Models: From Data to Decisions; John Wiley & Sons: Hoboken, NJ, USA, 2012; Volume 715. [Google Scholar]
- Alizadeh, M.; Afshari, M.; Contreras-Reyes, J.E.; Mazarei, D.; Yousof, H.M. The Extended Gompertz Model: Applications, Mean of Order P assessment and Statistical Threshold Risk Analysis Based on Extreme Stresses Data. IEEE Trans. Reliab. 2024, in press. [CrossRef]
- Marinho, P.R.D.; Silva, R.B.; Bourguignon, M.; Cordeiro, G.M.; Nadarajah, S. AdequacyModel: An R package for probability distributions and general purpose optimization. PLoS ONE 2019, 14, e0221487. [Google Scholar] [CrossRef] [PubMed]
- Anderson, T.W.; Darling, D.A. Asymptotic theory of certain “goodness of fit” criteria based on stochastic processes. Ann. Math. Stat. 1952, 23, 193–212. [Google Scholar] [CrossRef]
- Alizadeh, M.; Emadi, M.; Doostparast, M. A new two-parameter lifetime distribution: Properties, applications and different methods of estimations. Stat. Optim. Inf. Comput. 2019, 7, 291–310. [Google Scholar] [CrossRef]
- Ghitany, M.E.; Al-Mutairi, D.K.; Balakrishnan, N.; Al-Enezi, L.J. Power Lindley distribution and associated inference. Comput. Stat. Data Anal. 2013, 64, 20–33. [Google Scholar] [CrossRef]
- Ghitany, M.E.; Atieh, B.; Nadarajah, S. Lindley distribution and its application. Math. Comput. Simul. 2008, 78, 493–506. [Google Scholar] [CrossRef]
- Gupta, R.D.; Kundu, D. Theory and Methods: Generalized exponential distributions. Aust. N. Z. J. Stat. 1999, 41, 173–188. [Google Scholar] [CrossRef]
- Nadarajah, S.; Haghighi, F. An extension of the exponential distribution. Statistics 2011, 45, 543–558. [Google Scholar] [CrossRef]
- Murthy, D.P.; Xie, M.; Jiang, R. Weibull Models; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Liu, J.; Hamrouni, A.; Wolowiec, D.; Coiteux, V.; Kuliczkowski, K.; Hetuin, D.; Saudemont, A.; Quesnel, B. Plasma cells from multiple myeloma patients express B7-H1 (PD-L1) and increase expression after stimulation with IFN-γ and TLR ligands via a MyD88-, TRAF6-, and MEK-dependent pathway. Blood J. Am. Soc. Hematol. 2007, 110, 296–304. [Google Scholar] [CrossRef] [PubMed]
- Rice, J.A. Mathematical Statistics and Data Analysis; Thomson/Brooks/Cole: Belmont, CA, USA, 2007; Volume 371. [Google Scholar]
- Szubzda, F.; Chlebus, M. Comparison of Block Maxima and Peaks Over Threshold Value-at-Risk models for market risk in various economic conditions. Cent. Eur. Econ. J. 2019, 6, 70–85. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | MLE | W | A | AIC | BIC |
|---|---|---|---|---|---|
| (SE) | |||||
| NWLi | |||||
| LN | |||||
| NH | |||||
| Ga | |||||
| PL | |||||
| W | |||||
| GE | |||||
| Li | |||||
| NOLL-HL | |||||
| Model | MLE | W | A | AIC | BIC |
|---|---|---|---|---|---|
| (SE) | |||||
| NWLi | |||||
| LN | |||||
| NH | |||||
| Ga | |||||
| PL | |||||
| W | |||||
| GE | |||||
| Li | |||||
| 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
| TMV | 0.1390 | ||||
| MOOP | 5.852 | 0.0002 | 0.0003 | 0.0004 | 0.0005 |
| MSE | 0.0193 | 0.0193 | 0.0193 | 0.0193 | 0.0193 |
| Bias | 0.1390 | 0.1390 | 0.1389 | 0.1389 | 0.1389 |
| TMV | 0.5491 | ||||
| MOOP | 5.852 | 0.0002 | 0.0003 | 0.0004 | 0.0005 |
| MSE | 0.3015 | 0.3013 | 0.3011 | 0.3010 | 0.3009 |
| Bias | 0.5491 | 0.5489 | 0.5488 | 0.5487 | 0.5485 |
| TMV | 0.5194 | ||||
| MOOP | 0.0032 | 0.0128 | 0.0185 | 0.0237 | 0.0298 |
| MSE | 0.2664 | 0.2566 | 0.2508 | 0.2456 | 0.2397 |
| Bias | 0.5162 | 0.5065 | 0.5008 | 0.4956 | 0.4896 |
| TMV | 0.002 | ||||
| MOOP | 2.9699 | 1.2063 | 1.7511 | 2.2556 | 2.8527 |
| MSE | 8.4937 | 8.4884 | 8.4853 | 8.4823 | 8.4789 |
| Bias | 0.0029 | 0.0029 | 0.0029 | 0.0029 | 0.0029 |
| TMV | 0.9988 | ||||
| MOOP | 0.0326 | 0.1304 | 0.1877 | 0.2388 | 0.2949 |
| MSE | 0.9335 | 0.7539 | 0.6577 | 0.5776 | 0.4954 |
| Bias | 0.9661 | 0.8683 | 0.8110 | 0.7600 | 0.7038 |
| CLs | Number of PORT | Min. | 1st Qu. | Median | ExV | 3rd Qu. | Max. |
|---|---|---|---|---|---|---|---|
| 50% | 14 | 2320 | 3559 | 3966 | 4044 | 4340 | 6283 |
| 70% | 19 | 1712 | 2299 | 3702 | 3518 | 4222 | 6283 |
| 75% | 21 | 1320 | 2266 | 3511 | 3318 | 4150 | 6283 |
| 80% | 22 | 1238 | 2084 | 3483 | 3224 | 4113 | 6283 |
| 85% | 23 | 1180 | 1984 | 3455 | 3135 | 4076 | 6283 |
| 90% | 25 | 956 | 1712 | 3215 | 2965 | 4001 | 6283 |
| 95% | 26 | 629 | 1570 | 2768 | 2875 | 3984 | 6283 |
| 99% | 27 | 587 | 1421 | 2320 | 2790 | 3966 | 6283 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alizadeh, M.; Afshari, M.; Cordeiro, G.M.; Ramaki, Z.; Contreras-Reyes, J.E.; Dirnik, F.; Yousof, H.M. A New Weighted Lindley Model with Applications to Extreme Historical Insurance Claims. Stats 2025, 8, 8. https://doi.org/10.3390/stats8010008
Alizadeh M, Afshari M, Cordeiro GM, Ramaki Z, Contreras-Reyes JE, Dirnik F, Yousof HM. A New Weighted Lindley Model with Applications to Extreme Historical Insurance Claims. Stats. 2025; 8(1):8. https://doi.org/10.3390/stats8010008
Chicago/Turabian StyleAlizadeh, Morad, Mahmoud Afshari, Gauss M. Cordeiro, Ziaurrahman Ramaki, Javier E. Contreras-Reyes, Fatemeh Dirnik, and Haitham M. Yousof. 2025. "A New Weighted Lindley Model with Applications to Extreme Historical Insurance Claims" Stats 8, no. 1: 8. https://doi.org/10.3390/stats8010008
APA StyleAlizadeh, M., Afshari, M., Cordeiro, G. M., Ramaki, Z., Contreras-Reyes, J. E., Dirnik, F., & Yousof, H. M. (2025). A New Weighted Lindley Model with Applications to Extreme Historical Insurance Claims. Stats, 8(1), 8. https://doi.org/10.3390/stats8010008