1. Introduction
In real-life series applications, it is commonly seen that the current observation in a counting process is influenced by the previous-lagged observation of another related series. Likewise, a popular example in the literature is the tick by tick data from the New York Stock Exchange (NYSE) market that concerns the trading intensity of stocks from different competing firms. Specifically, Pedeli and Karlis [
1] referred to the intraday bid and ask quotes of AT&T stock on the NYSE market where these researchers remarked that the fluctuation in the investment level of intraday bid quotes of AT&T at a specified time point was affected by the transaction level of the ask quotes of AT&T at the previous time point. Similar scenarios of this nature can be encountered in different real-life socio-economic instances such as in time series related to day and night accidents over a same area or the number of thefts or larceny cases and unemployed people in a populated region. The analysis of such series of data poses a number of challenges. Firstly, both series are commonly influenced by some dynamic time-variant factors that lead to time-changing moments and correlations. Secondly, the series are often subject to different levels of over-, under-, or mixed-dispersion. From the papers published in this field of research [
1,
2,
3,
4,
5,
6], there is yet no bivariate time series process that accommodates for the mixed-dispersion of a wider range under non-stationary conditions based on the cross-correlation design specified above.
However, under a simpler cross-correlation design, Jowaheer et al. [
7] have most recently proposed a bivariate integer-valued autoregressive process of order 1 (BINAR(1)M1) with COM-Poisson innovations featured under time-dependent moments that were induced through dynamic explanatory variables. The COM-Poisson is a discrete distribution re-introduced by Shmueli et al. [
8] that can model a wider range of over- and under-dispersion and has shown its capability in different univariate areas of application (see Lord et al. [
9,
10], Sellers and Shmueli [
11], Nadarajah [
12], Zhu [
13], Guikema and Coffelt [
14], Borle [
15,
16,
17]). This BINAR(1)M1 was a simple extension of the classical INAR(1)-based binomial thinning process of McKenzie [
18]. Jowaheer et al. [
7] extended by assuming two INAR(1) series with COM-Poisson innovations where the cross-correlation was simply sourced from the correlated COM-Poisson innovations similar to the bivariate design proposed initially by Pedeli and Karlis [
19,
20], Karlis and Pedeli [
21], and later by Mamode Khan et al. [
22]. For this non-stationary BINAR(1)M1 process, Jowaheer et al. [
7] showed, through Monte Carlo experiments, that the model can be effectively used to simulate and represent real-life experiments where different quantities of over-or under-dispersed or mixed-dispersed series of data are collected. However, as remarked, the local inter-relationship between cross-related observations of same and previous lags as depicted in the stock example above is ignored.
In the literature, another class of BINAR(1) models (BINAR(1)M2) has been developed to cater for the possible relationship between current counting series observation with previous-lagged other series observations. Pedeli and Karlis [
1] proposed such a BINAR(1)M2 with correlated Poisson innovations where the source of inter-relationship was induced by the cross-related observations and the bivariate Poisson innovations [
23]. In this model construction, the counting series was marginally found to follow a Hermite distribution and hence this model was appropriate for series exhibiting mutually mild over-dispersion of different quantum. However, these two sources of cross-correlation increase the number of parameters to be estimated and complicate the specification of the conditional likelihood. Another less complicated version of BINAR(1)M2 (BINAR(1)M3) was proposed by Ristic et al. [
2] and Nastic et al. [
3] where these authors assumed that the cross-correlation could be simply induced by relating the current series observation with the previous-lagged observation of the other series with the pair of innovations held independently. Ristic et al. [
2] and Nastic et al. [
3] developed the BINAR(1)M3 with geometric marginal based on the Negative Binomial (NB) thinning mechanism, which indicates that BINAR(1)M3 was only suited for modeling a series of restricted levels of over-dispersion. Interestingly, Nastic et al. [
3] showed that this BINAR(1)M3 provides better Akaike information criterion (AICs) and root mean square error (RMSE) than the BINAR(1)M1 with NB innovations by Karlis and Pedeli [
21] and BINAR(1)M2 with Poisson innovations by Pedeli and Karlis [
1]. Overall, BINAR(1)M2 and BINAR(1)M3 were developed under stationary conditions only and lack the flexibility to model situations of varied levels of dispersion under set-ups comprising time-independent and time-dependent covariates. This paper aims at developing a versatile non-stationary BINAR(1) model of similar structure as BINAR(1)M3 with COM-Poisson innovations but under binomial thinning that could accommodate the different scenarios of dispersion, as well as the influence of the current series-counting observation by the previous-lagged observation of another series.
As for the inferential procedures, Conditional Maximum Likelihood Estimation (CMLE) and Least Squares (LS) techniques have been mostly used to estimate the unknown model parameters in the existing stationary BINAR(1)M1, BINAR(1)M2, and BINAR(1)M3 models [
1,
2,
3,
19,
20]. Nastic et al. [
3] demonstrated that CMLE and LS asymptotically yield estimates of almost the same level of efficiency, but LS is less computationally intensive. The computational cumbersomeness of CMLE was also discussed by Pedeli and Karlis [
24] where the authors noticed that under bivariate time series modeling, the implementation of CMLE is not quite feasible due to the intensive Hessian entries. As for the non-stationary BINAR(1)M1 developed by Mamode Khan et al. [
22] with Poisson innovations, it was seen that the specification of the conditional likelihood function was rather tedious, and alternatively, they developed a novel Generalized Quasi-Likelihood (GQL) estimator that depends only on the correct specification of the mean scores. The other components of GQL are the derivatives and auto-covariance structure. As for the auto-covariance specification, this was computed in its exact form using the auto-regressive structure but with the correlation parameters estimated by the method of moments. Mamode Khan et al. [
22] prove that both GQL and CMLE yield estimates with an asymptotic level of efficiency (see also Sutradhar et al. [
25]) but remarkably, GQL yields considerably fewer non-convergent simulations. In similar lines, Sunecher et al. [
26] compared LS with GQL for bivariate integer-valued moving-average of order 1 (BINMA(1)) process. wherein GQL provides more superior efficient estimates than LS with fewer non-convergent failures. Thus, in this paper, we consider formulating a new GQL method since the bivariate auto-correlation structure is different from the BINMA(1) process.
The organization of the paper is as follows: In
Section 2, the new BINAR(1) model with COM-Poisson innovations is constructed and its properties are derived. Prior to this, we outline the basics of the COM-Poisson model. In
Section 3, the GQL algorithm is implemented to estimate the regression, dispersion, and serial- and cross-dependence parameters. In
Section 4, we present some numerical experiments to illustrate the different scenarios of over, under, and mixed dispersion under various combinations of the serial- and cross-correlation parameters. In
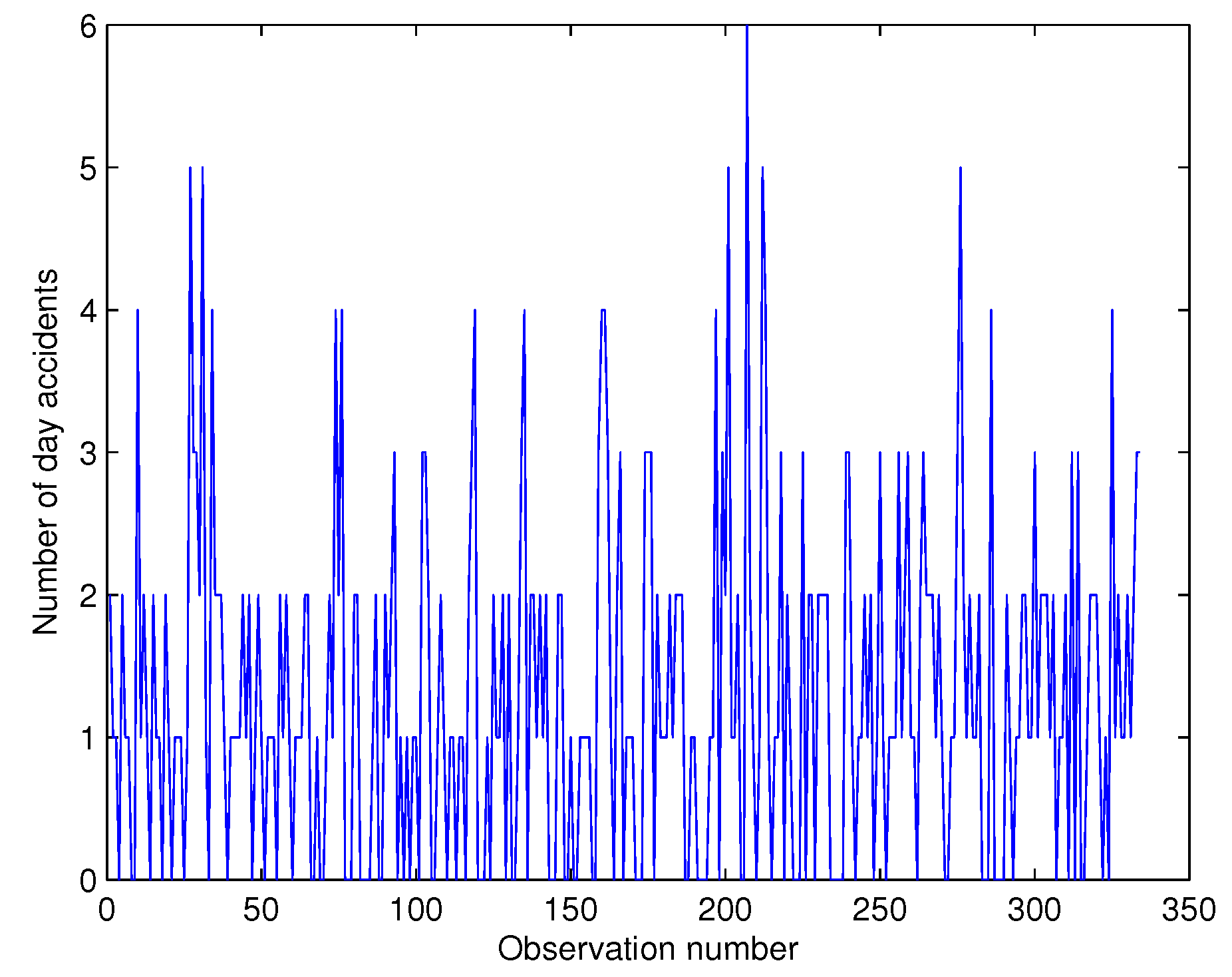
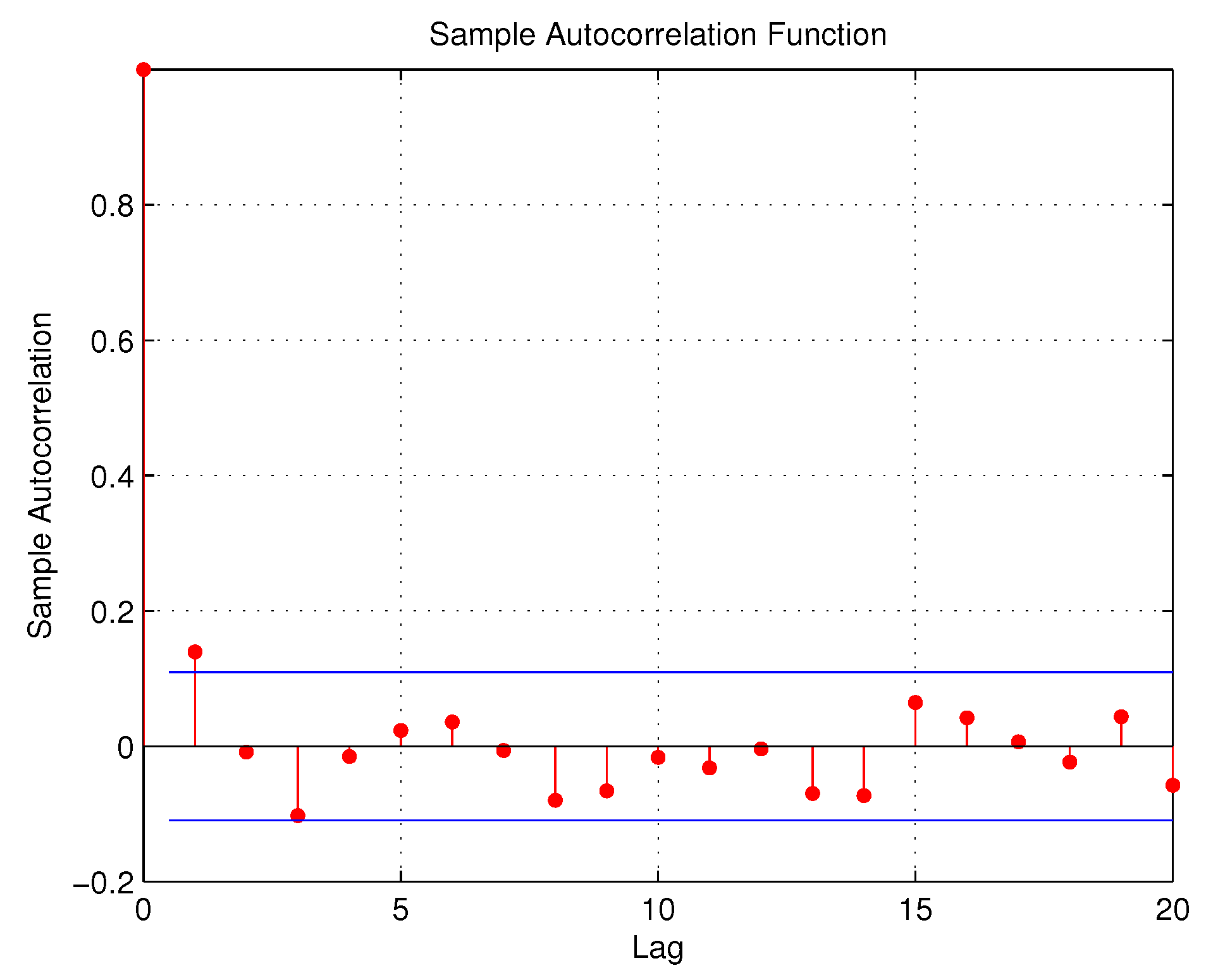
Section 5, the model is applied to three real-life time series data in Mauritius: Firstly, the model is employed in analyzing series of daily day and night accidents on the motorway from the International Airport in Mauritius to the northern zone Grand Bay from 1 February to 30 November 2015. In the second instance, it is applied to the time series of intra-day transactions of two competing banks operating on the Stock Exchange of Mauritius (SEM) from 3 August 2015 to 12 October 2015. The third application consists of analyzing a socio-economic problem of the daily day and night frequently occurring thefts in the Capital City of Port Louis from 1 January to 30 November 2015. This paper ends with some concluding remarks in
Section 6.
2. Model Development
Suppose that the BINAR(1) model
is of the form
where ‘∘’ indicates the binomial thinning operator [
27], wherein
, for
and the so-called counting
is a sequence of independent and identically distributed Bernoulli random variable with P
, for
.
and
are the corresponding innovation terms for
and
, respectively, and
,
is marginally COM-Poisson with probability function
2.1. Properties of the COM-Poisson Model
In the above, . The COM-Poisson model (3) generalizes several discrete distributions. Likewise, under and , the geometric distribution becomes a special case of the COM-Poisson. Under , it generalizes the Poisson distribution with mean parameter and becomes Bernoulli when with the probability of success given by . Under any parametrization of and , the COM-Poisson is shown to be a member of the exponential family with link predictor function for and . Furthermore, is regarded as the dispersion parameter such that represents under-dispersion and over-dispersion.
The moment generating function (mgf) and probability generating function (pgf) are expressed as
while the moments of the COM-Poisson model are derived iteratively using
In particular, the mean and variance are given as follows:
However, these moments can be approximated in closed forms using the asymptotic approximation by Minka et al. [
28]
that yields
or alternatively, from Equation (
8),
can be re-written as
(see Mamode Khan and Jowaheer [
29] and Mamode Khan [
30]). Hence, under this parametrization, (
) is the pair of parameters to describe the COM-Poisson variable
, such that
.
In the context of the above approximated moments, Minka et al. [
28], Shmueli et al. [
8], and Zhu [
13] presented some trial experiments that reveal that these approximations are more accurate for large
. As also commented by Jowaheer et al. [
7], for large
and
, the Var(
) outweighs the E(
), while for large
and
, for the COM-Poisson
, the E(
Var(
) indicates under-dispersion, but in fact for
, Nadarajah [
12] provides an exact expression for the mean and variance based on generalized hypergeometric function. However, the approximation by Minka et al. [
28] is rather more suitable as it explores the full range of
.
Remark 1. From Equation (8), it is deduced that any increase/decrease in causes a similar change in . As for the magnitude of the change from to for , the % change in is given by , while the % change in is . Thus, in the interpretation for the unit change in covariates, it is easier to represent the change in , but we note that for , the corresponding change in is considerably greater than the change in . 2.2. Properties of the BINAR(1) Model
Referring to the BINAR(1) model in Equation (
1),
The innovation terms and are independent, such that Corr() = 0. .
We assume that the counting series has a mean, ; this is yet to be determined.
Some important thinning properties to be used for deriving the marginal moments are given in the following lemma:
Lemma 1. - (a)
, .
- (b)
,
- (c)
Cov), .
Thus, based on Lemma 1 and the above properties, we obtain from Equation (
1)
with
and
As for the covariance between (
), it is given by the following:
Remark 2. Under stationary moment conditions,and solving simultaneously, we obtainwhere
However, for the derivation of lag-
h covariance expressions, we refer to Pedeli and Karlis [
1] and Nastic et al. [
3], where by denoting
these authors proved that
with
. Using this general lag-
h auto-covariance formula, it is easy to derive the different diagonal and off-diagonal covariances with lag-
h as shown in (
21).
3. Estimation Methodology: The GQL Approach
The GQL approach is based on the extension of the classical Wedderburn [
31] QL equation. This estimation approach is more flexible and parsimonious since it relies only on the two main moments and joint covariance expressions [
32]. In fact, the GQL equation depends only on the correct specification of the mean scores, the derivatives, and the auto-covariance structure. After the construction of the GQL equation, it is solved iteratively using the Newton–Raphson technique to obtain updated estimates of the model parameters. Sutradhar et al. [
25] proved that these model estimators are consistent, and under mild regularity conditions, follows an asymptotic normal distribution with mean 0 and covariance matrix
.
Hence, this section presents a GQL estimation approach to estimate the parameters
in the BINAR(1) model specified in
Section 2. Note,
indicates the transpose of [.]. The GQL equation is expressed as
Details of the components of Equation (
22) are given in the following subsections:
3.1. The Derivative Matrix ()
The derivative matrix
is expressed as
, where
with
, where
From Equation (
17),
and
where
with
.
Hence, the derivative entries with respect to
for the
covariate and
are obtained iteratively as follows:
Under similar assumptions, the derivatives with respect to
for
are obtained iteratively as follows:
Similarly, the derivative expressions with respect to
for
are computed iteratively as follows:
3.2. The Auto-Covariance Matrix ()
represents the (
) auto-covariance matrix given by
where
is specified as in (
21). Note that the intial variance and covariance expressions at
is given by Equations (
18)–(
20) and thereon for
, Equations (
14)–(
16) are computed iteratively.
3.3. Score Vector
The score vector with and corresponding with for .
The GQL in Equation (
22) is solved iteratively using the Newton–Raphson
where
are the estimates at the
iteration and
are the values of the expression at the
iteration. The working of this algorithm is as follows: For an initial
, we calculate the entries of the auto-covariance structure at
and thereon use the iterative equation developed above and ultimately solve Equation (
32) to obtain an updated [
,
]. These updated values are again used to compute the entries of the auto-covariance structure and in turn Equation (
32) is solved to obtain a new set of parameters. This cycle continues until convergence.
:
For true
, lets define
where E
.
By the Central Limit Theorem (CLT), .
Then E[] = 0 and Cov[.
From Lindeberg–Feller CLT [
33],
Further, because
is estimated by Equation (
32), which by first order Taylor series expansion produces
. Then,
and it follows
Remark 3. Note for any change in to at time point t with unchanged, it signifies a % change in the link by which implies a % change in as (Refer to Remark 1) which may not be easier to compute since is of iterative form. Hence, it is more convenient to report the change in . Since the corresponding change in the mean is to be computed at each time point, we conclude that for , the change in the mean is considerably larger than the change in .
Remark 4. Using the converged estimates, we derive the forecasting equations of the unconstrained BINAR(1) model with independent COM-Poisson innovations. The conditional expectation and variance of the one-step ahead forecast given by are expressed as follows:with the following corresponding variances: 4. Numerical Evaluation
Using Equations (17)–(19), we illustrate in this section, for the different values of , , and , the possible scenarios where Var() exceeds or is lower than .
The results in
Table 1,
Table 2,
Table 3 and
Table 4 could only demonstrate that for different parameter inputs, there exists the possibility that the counting series are mutually or mixedly over- and under-dispersed with different quanta of dispersion.
Case A: :
Table 1.
Experimental results under different correlation and dispersion combinations.
Table 1.
Experimental results under different correlation and dispersion combinations.
| | | | | | | | | Var() | | Var() |
|---|
| 0.1 | 0.15 | 0.2 | 0.25 | 0.1 | 0.15 | 0.1 | 0.2 | 5.9 | 1.3 | 5.3 | 2 |
| | | | | | | 0.9 | 0.95 | 6.5 | 5.1 | 6.4 | 5.1 |
| | | | | | | 1.1 | 1.2 | 9.7 | 29.2 | 10.9 | 27.8 |
| | | | | | | 2 | 2.1 | 1978 | 17,186 | 719 | 2184 |
| 0.5 | 0.55 | 0.6 | 0.65 | 0.1 | 0.15 | 0.1 | 0.2 | 16.9 | 12.5 | 19.7 | 16 |
| | | | | | | 0.9 | 0.95 | 18.9 | 20.4 | 23 | 27 |
| | | | | | | 1.1 | 1.2 | 29.1 | 65.2 | 37.4 | 74.8 |
| | | | | | | 2 | 2.1 | 3143 | 17,314 | 2716 | 8567 |
| 0.9 | 0.1 | 0.11 | 0.8 | 0.1 | 0.15 | 0.1 | 0.2 | 131.5 | 233 | 86.5 | 281.8 |
| | | | | | | 0.9 | 0.95 | 147 | 304 | 98 | 368 |
| | | | | | | 1.1 | 1.2 | 227 | 692 | 156 | 755 |
| | | | | | | 2 | 2.1 | 24,450 | 137,849 | 14,165 | 81,309 |
| 0.1 | 0.15 | 0.2 | 0.25 | 0.8 | 0.9 | 0.1 | 0.2 | 0.26 | 0.15 | 0.37 | 0.31 |
| | | | | | | 0.9 | 0.95 | 1.4 | 1.5 | 1.7 | 1.691 |
| | | | | | | 1.1 | 1.2 | 1.8 | 1.9 | 2.17 | 2.19 |
| | | | | | | 2 | 2.1 | 3.45 | 3.94 | 4.03 | 4.08 |
| 0.5 | 0.55 | 0.6 | 0.65 | 0.8 | 0.9 | 0.1 | 0.2 | 0.84 | 0.82 | 1.18 | 1.19 |
| | | | | | | 0.9 | 0.95 | 4.29 | 5.2 | 5.7 | 6.4 |
| | | | | | | 1.1 | 1.2 | 5.4 | 6.6 | 7.3 | 8.2 |
| | | | | | | 2 | 2.1 | 10.5 | 13 | 13.7 | 15.7 |
| 0.9 | 0.1 | 0.11 | 0.8 | 0.8 | 0.9 | 0.1 | 0.2 | 6.5 | 13 | 5 | 16.4 |
| | | | | | | 0.9 | 0.95 | 33.4 | 72.9 | 23.4 | 85.6 |
| | | | | | | 1.1 | 1.2 | 42 | 92 | 30 | 108 |
| | | | | | | 2 | 2.1 | 82 | 180 | 57 | 209 |
Case B: :
Table 2.
Experimental results under different correlation and dispersion combinations.
Table 2.
Experimental results under different correlation and dispersion combinations.
| | | | | | | | | Var() | | Var() |
|---|
| 0.1 | 0.15 | 0.2 | 0.25 | 1 | 1 | 0.1 | 0.2 | 0.1627 | 0.1633 | 0.31 | 0.296 |
| | | | | | | 0.9 | 0.95 | 1.267 | 1.270 | 1.60 | 1.53 |
| | | | | | | 1.1 | 1.2 | 1.558 | 1.562 | 2.016 | 1.59 |
| | | | | | | 2 | 2.1 | 2.814 | 2.821 | 3.55 | 3.40 |
| 0.5 | 0.55 | 0.6 | 0.65 | 1 | 1 | 0.1 | 0.2 | 0.57 | 0.68 | 0.93 | 1 |
| | | | | | | 0.9 | 0.95 | 3.93 | 4.63 | 5.32 | 5.88 |
| | | | | | | 1.1 | 1.2 | 4.86 | 5.73 | 6.64 | 7.33 |
| | | | | | | 2 | 2.1 | 8.7 | 10.3 | 11.8 | 13 |
| 0.9 | 0.1 | 0.11 | 0.8 | 1 | 1 | 0.1 | 0.2 | 4.4 | 9.8 | 3.4 | 12.4 |
| | | | | | | 0.9 | 0.95 | 30.6 | 66 | 21.6 | 78.4 |
| | | | | | | 1.1 | 1.2 | 37.8 | 81.6 | 26.8 | 97.3 |
| | | | | | | 2 | 2.1 | 67.8 | 146 | 48 | 174 |
Case C: :
Table 3.
Experimental results under different correlation and dispersion combinations.
Table 3.
Experimental results under different correlation and dispersion combinations.
| | | | | | | | | Var() | | Var() |
|---|
| 0.1 | 0.15 | 0.2 | 0.25 | 1.1 | 1.2 | 0.1 | 0.2 | 0.13 | 0.17 | 0.27 | 0.30 |
| | | | | | | 0.9 | 0.95 | 1.21 | 1.17 | 1.49 | 1.34 |
| | | | | | | 1.1 | 1.2 | 1.47 | 1.41 | 1.83 | 1.63 |
| | | | | | | 2 | 2.1 | 2.54 | 2.42 | 3.04 | 2.67 |
| 0.5 | 0.55 | 0.6 | 0.65 | 1.1 | 1.2 | 0.1 | 0.2 | 0.48 | 0.63 | 0.80 | 0.94 |
| | | | | | | 0.9 | 0.95 | 3.72 | 4.31 | 4.97 | 5.37 |
| | | | | | | 1.1 | 1.2 | 4.53 | 5.23 | 6.1 | 6.6 |
| | | | | | | 2 | 2.1 | 7.77 | 8.91 | 10.26 | 10.97 |
| 0.9 | 0.1 | 0.11 | 0.8 | 1.1 | 1.2 | 0.1 | 0.2 | 3.71 | 8.59 | 2.93 | 10.94 |
| | | | | | | 0.9 | 0.95 | 28.9 | 61.8 | 20.3 | 73 |
| | | | | | | 1.1 | 1.2 | 35.2 | 75.3 | 24.8 | 89 |
| | | | | | | 2 | 2.1 | 60 | 128 | 42 | 151 |
| 0.1 | 0.15 | 0.2 | 0.25 | 2 | 2.5 | 0.1 | 0.2 | 0.129 | 0.228 | 0.335 | 0.308 |
| | | | | | | 0.9 | 0.95 | 0.97 | 0.74 | 1.17 | 0.81 |
| | | | | | | 1.1 | 1.2 | 1.11 | 0.83 | 1.33 | 0.91 |
| | | | | | | 2 | 2.1 | 1.6 | 1.12 | 1.82 | 1.20 |
| 0.5 | 0.55 | 0.6 | 0.65 | 2 | 2.5 | 0.1 | 0.2 | 0.511 | 0.752 | 0.947 | 1.03 |
| | | | | | | 0.9 | 0.95 | 2.97 | 3.1 | 3.92 | 3.81 |
| | | | | | | 1.1 | 1.2 | 3.39 | 3.52 | 4.48 | 4.32 |
| | | | | | | 2 | 2.1 | 4.82 | 4.89 | 6.23 | 5.95 |
| 0.9 | 0.1 | 0.11 | 0.8 | 2 | 2.5 | 0.1 | 0.2 | 3.98 | 9.71 | 3.31 | 11.9 |
| | | | | | | 0.9 | 0.95 | 23.1 | 47.1 | 16.1 | 55.5 |
| | | | | | | 1.1 | 1.2 | 26.37 | 53.6 | 18.4 | 63.2 |
| | | | | | | 2 | 2.1 | 37.5 | 75.4 | 25.8 | 88.7 |
Case D: :
Table 4.
Experimental results under different correlation and dispersion combinations.
Table 4.
Experimental results under different correlation and dispersion combinations.
| | | | | | | | | Var() | | Var() |
|---|
| 0.1 | 0.15 | 0.2 | 0.25 | 0.8 | 1.5 | 0.1 | 0.2 | 0.25 | 0.14 | 0.30 | 0.33 |
| | | | | | | 0.9 | 0.95 | 1.35 | 1.44 | 1.42 | 1.21 |
| | | | | | | 1.1 | 1.2 | 1.68 | 1.84 | 1.73 | 1.45 |
| | | | | | | 2 | 2.1 | 3.25 | 3.7 | 2.83 | 2.34 |
| 0.5 | 0.55 | 0.6 | 0.65 | 0.8 | 1.5 | 0.1 | 0.2 | 0.768 | 0.751 | 1.014 | 1.155 |
| | | | | | | 0.9 | 0.95 | 4 | 4.8 | 5 | 5.4 |
| | | | | | | 1.1 | 1.2 | 4.95 | 5.98 | 6.12 | 6.6 |
| | | | | | | 2 | 2.1 | 9.26 | 11.4 | 10.6 | 11.7 |
| 0.9 | 0.1 | 0.11 | 0.8 | 0.8 | 1.5 | 0.1 | 0.2 | 5.98 | 11.94 | 4.16 | 15.37 |
| | | | | | | 0.9 | 0.95 | 31 | 67 | 21 | 76 |
| | | | | | | 1.1 | 1.2 | 39 | 83 | 26 | 94 |
| | | | | | | 2 | 2.1 | 72 | 157 | 47 | 170 |
Some common remarks are as follows:
- (a)
For and , Var() is lesser than for small and .
- (b)
For a high serial-correlation and low pair of cross-correlations, as in , the counting series becomes hugely over-dispersed.
- (c)
For relatively lower serial/cross-correlation values, the counting series are subject to under-dispersion/over-dispersion for both series or to some combination of over- and under-dispersion, but as the correlation increases, both counting series express huge over-dispersion.
- (d)
For mixed dispersion, that is , we note that for low serial/cross-correlation parameters, there is a mixed dispersed series and as serial values increases, the data tend toward over-dispersion under both series.
In general, irrespective of any serial/cross-correlation parameters and values of , as increases, also increases. Hence, the proposed model is suitable for analyzing dispersed series of high and low levels of dispersion.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}