Abstract
We investigate a semiparametric generalized partially linear regression model that accommodates missing outcomes, with some covariates modeled parametrically and others nonparametrically. We propose a class of augmented inverse probability weighted (AIPW) kernel–profile estimating equations. The nonparametric component is estimated using AIPW kernel estimating equations, while parametric regression coefficients are estimated using AIPW profile estimating equations. We demonstrate the doubly robust nature of the AIPW estimators for both nonparametric and parametric components. Specifically, these estimators remain consistent if either the assumed model for the probability of missing data or that for the conditional mean of the outcome, given covariates and auxiliary variables, is correctly specified, though not necessarily both simultaneously. Additionally, the AIPW profile estimator for parametric regression coefficients is consistent and asymptotically normal under the semiparametric model defined by the generalized partially linear model on complete data, assuming that the missing data mechanism is missing at random. When both working models are correctly specified, this estimator achieves semiparametric efficiency, with its asymptotic variance reaching the efficiency bound. We validate our approach through simulations to assess the finite sample performance of the proposed estimators and apply the method to a study that investigates risk factors associated with myocardial ischemia.
1. Introduction
Generalized partially linear models,
where is a known monotonic link function (McCullagh and Nelder 1989 [1]), Y is an outcome of interest, is a vector of primary covariates, Z is an additional scalar covariate, is an unknown parameter vector of dimension p, and is an unknown smooth function, have been extensively studied without missing data (Severini and Staniswalis 1994 [2]; Hastie and Tibshirani 1990 [3]; Fan, et al. 1995 [4]; Carroll, et al. 1997 [5]; Lin and Carroll 2001a [6], 2001b [7]; Muller 2001 [8]; Hu and Cui 2010 [9]; Rahman, et al. 2020 [10]). In model (1), summarizes the dependence of the outcome mean on covariates of interest whereas the unknown smooth function allows for model flexibility for the dependence on a secondary covariate Z. Our contribution in this paper is to study the estimation of and and the asymptotics when the outcome Y is missing at random (MAR), i.e., missingness depends on observed data (Little and Rubin 2002 [11]) while some additional auxiliary variables and information exist (Chu and Halloran 2004 [12]).
Our work is motivated by the investigation of risk factors for myocardial ischemia (reduced blood flow due to obstruction in the vessels) from data collected at the radiology clinic of a nuclear imaging group. The standard technique for screening myocardial ischemia at the time of data collection was dual-isotope myocardial perfusion single-photon emission computed tomography (SPECT), whose use was not only expensive but also involved ingestion of radioactive tracing material. Because of this, only a subset of the subjects who attended the radiology clinic were actually referred to have the SPECT test performed. Instead, all subjects attending the clinic were screened with electron beam computed tomography (EBCT). This device is routinely used to measure the degree of calcification in the arteries (Braun, et al. 1996 [13]). Doctors decided whether or not to refer a subject to the SPECT test based on the information available, including the results of the EBCT test. In our investigation, we wish to make inferences about the parameter in the logistic partially linear regression model (1), i.e., with , when Y is a binary indicator of a positive SPECT test, Z is age, and variables include gender, smoking status, blood pressure status (high/low), cholesterol status (high/low), and the presence of chest pain, under the assumption that whether to refer a patient to the SPECT test depends only on the recorded covariates and the EBCT test. Consequently, the missingness of the outcome Y is MAR in this study.
The literature is vast on inference on regression coefficients in parametric generalized linear models of the form when outcomes are missing at random. Both likelihood-based approaches (Little 1982 [14], 1995 [15]; Little and Rubin 2002 [11]) and estimating equation-based approaches (Robins and Rotnitzky 1995 [16]; Robins et al. 1995 [17]) have been extensively studied. Inference on the nonparametric function in generalized nonparametric models with outcomes missing at random has also been studied in the literature (e.g., Wang et al. 1998 [18]; Chen et al. 2006 [19]; Wang et al. 2010 [20]; and Kennedy et al. 2017 [21]). Our primary interest in this paper lies in estimating the finite dimensional parameter vector while treating the infinite dimensional parameter as a nuisance parameter under semiparametric model (1) in the presence of missing outcomes. Liang et al. (2004) [22], Liang (2008) [23], and Wang (2009) [24] considered semiparametric models in the presence of missing covariates. Wang et al. (2004) [25] and Wang and Sun (2007) [26] considered imputation and weighted estimators in partially linear models for Gaussian outcomes when outcomes are missing at random. Liang et al. (2007) [27] also extended the work to a scenario when covariates are measured with error. Chen and Keilegom (2013) [28] proposed an imputation method for semiparametric models, and Kennedy et al. (2017) [21] proposed a kernel-smoothing method for estimating continuous treatment effects, but all these authors do not allow for auxiliary covariates. To the best of our knowledge, there is no existing literature on the semiparametric efficiency bound and semiparametric efficient estimators in generalized semiparametric regression models (1) for both continuous and discrete outcomes when outcomes are missing at random in the presence of auxiliary covariates. This paper aims to fill this gap.
Specifically, this paper makes the following three major contributions and provides a comprehensive investigation of inference in the generalized semiparametric regression model (1) when outcomes are missing at random: (i) Unlike previous authors, we allow for the possibility that some auxiliary covariate(s) are available. For example, in the analysis of myocardial ischemia data, is the EBCT test result. The auxiliary covariates are not of primary interest in the sense that we are concerned with the estimation of rather than . They allow for a weaker modeling assumption that the missingness is assumed to be independent of outcomes, conditional on the auxiliary covariates. They can also help improve the efficiency in estimation of both and . (ii) We derive the explicit form of a semiparametric efficiency score and efficiency bound in generalized partially linear models in the presence of auxiliary covariates when outcomes are missing at random. (iii) We propose a locally semiparametric efficient estimator of in model (1) that reaches the semiparametric efficiency bound when Y is missing at random. Specifically, we propose augmented inverse probability weighted (AIPW) kernel–profile estimating equations where for a given , the nonparametric function is estimated using the AIPW kernel estimating equation and the parametric regression coefficient is estimated using the AIPW profile estimating equation of given in Equation (6). The joint estimation of and proceeds by iteratively solving the two sets of equations. Construction of the proposed estimators requires the specification of a parametric model for the missing data mechanism and a parametric model for . Yet, consistency of the proposed estimators of and requires that one of these models is correctly specified but not necessarily both, that is, the proposed estimators of both and are doubly robust (Robins and Rotnitzky, 1995 [16]; Robins et al. 1994 [29], 1995 [17]; Rotnitzky et al. 1998 [30]; and Bang and Robins 2005 [31]). In addition, the proposed estimator of achieves the semiparametric efficiency bound when both models are correctly specified.
The rest of this paper is organized as follows. Section 2 formalizes the inferential problem. Section 3 delineates our proposed method for constructing estimators for both and . In Section 4, we delve into the study of asymptotic efficiency concerning the estimation of , presenting the derived semiparametric efficient score and efficiency bound. Section 5 examines the asymptotic properties of the proposed estimators for both and , emphasizing the local semiparametric efficiency of our proposed estimator for . Subsequently, Section 6 conducts a simulation study to evaluate the finite sample performance of the proposed methods, while Section 7 applies these methods to analyze data stemming from the myocardial ischemia study. Finally, we offer concluding remarks in Section 8.
2. A Formalization of the Inferential Problem
Suppose we would ideally like to measure variables on a random sample of n subjects from a population of interest, where the variables follow model (1) with a known monotonic link function that has a continuous first derivative, , an open set in , and an unknown smooth function . For example, in the myocardial ischemia study, we include age as a nonparametric predictor due to the potential nonlinear effect of aging on the risk of myocardial ischemia, and we model all other covariates parametrically to avoid the curse of dimensionality. In this paper, we discuss the estimation of and in settings where Y is only observed on a subsample, but and additional auxiliary variables are always observed under the assumption that Y is missing at random (Little and Rubin 2002 [11]), i.e.,
where if Y is observed and otherwise. Under assumption (2), missingness of the outcome Y may depend on , Z, and but is independent of Y given (, Z, ). In the myocardial ischemia study described in the Introduction, assumption (2) would hold if the variables and the EBCT test result were the only correlates of the SPECT test result that were used by doctors to decide the SPECT test referral status.
In our context, it is worth noting that the variables are not our primary focus; that is, our concern lies in estimating rather than . However, these auxiliary variables may be necessary to ensure that the missingness is conditionally independent of the outcome Y. For instance, in the myocardial ischemia study, our primary interest does not lie in the relationship between EBCT and SPECT test results but rather in understanding the risk of a positive SPECT test result, indicative of myocardial ischemia, in relation to Z and —factors like age, gender, smoking, and other health indicators. Nevertheless, if the referral to the SPECT exam within the strata of and Z were influenced by the EBCT test values, then (2) would fail if were omitted from both sides of the equation, because the EBCT and SPECT test results exhibit correlation within the strata defined by .
We consider the estimation of and when Y is either missing by happenstance, where , which is sometimes abbreviated as when no confusion exists, is an unknown function of consequently, as in the case of the myocardial ischemia study, or missing by design, where is a known function as it is the case in a designed two-stage study (Pepe, 1992 [32]; Reilly and Pepe, 1995 [33]). In the latter case, are measured across the entire sample in the initial stage, followed by the selection of a subsample in the subsequent stage, with selection probabilities contingent on the data from the first stage, and Y is measured within this subsample.
3. The Estimation Procedure
3.1. The AIPW Kernel–Profile Estimating Equations
Our estimating procedure is based on augmented inverse probability weighted (AIPW) kernel–profile estimating equations, where is estimated using AIPW kernel estimating equations (Wang et al. 2010 [20]) and is estimated using profile-type AIPW estimating equations. An AIPW kernel- or profile-type estimating function is constructed as the sum of an inverse probability weighted (IPW) estimating function, corresponding to a kernel- or profile-type, and a specific augmentation term, with weights equal to either the inverse of if is known, as in designed two-stage studies, or the inverse of if is unknown, as when Y is missing by happenstance, where is the maximum likelihood estimator of under a postulated parametric model,
and is a known smooth function subject to . For example, , where and expit. A special case when there are no augmentation terms is referred to as the IPW kernel–profile estimating equations, which are similar to those described in Carroll et al. (1997) [5] and Wang et al. (2005) [34], based on units with Y observed but with each contributing unit weighted by the inverse of its selection probability, if known, or an estimate of it otherwise. The IPW estimators are easier to compute than the AIPW estimator. However, as we shall see, the IPW estimators are generally not efficient nor doubly robust.
To construct an AIPW kernel–profile estimator , we initially input a user-specified function and postulate a working model
for the conditional variance of
with , and as the true values of and as a known smooth function, and as an unknown finite dimensional parameter vector.
For conciseness, here we describe AIPW local linear kernel–profile estimating equations. Extensions to weighted local polynomial estimating equations are straightforward. In what follows, , where is a mean-zero density function, , and for any scalar u we let . We describe the algorithm for the case in which is unknown. For the case where is known, the algorithm differs only in that all instances of are replaced by .
We start the algorithm with an initial estimator , satisfying . Such an initial estimator can be obtained by modifying the estimators described in Carroll et al. (1997) [5] based on the completed units (those with Y observed) weighted by the inverse of their selection probability, if known, or an estimate of it otherwise, with replaced by for any user-specified fixed constant . To compute , we calculate where , . The estimator is obtained by nonlinear least squares regression of on under the model . Then we iterate the following two steps until convergence:
1. For the fixed and any given z, we calculate using an AIPW kernel estimating equation similar to Wang et al. (2010) [20]. Specifically, is defined as , the first component of the vector , solving the following AIPW kernel estimating equations in ,
where, to simplify notation, , is the first derivative of with respect to r when r is evaluated at and , with defined above.
2. We compute by solving the following AIPW profile estimating equation in ,
where , is the first derivative of with respect to r when r is evaluated at .
At convergence, we obtain and . When the link function is the identity and s are constants, both and have a closed form and are linear functions of Y.
We can similarly define the simpler-to-compute nonaugmented inverse probability weighted (IPW) estimators and of and , which are the output of the iterative two-step procedure described above with Equations (5) and (6) replaced by
and
with obtained by regressing on and , , under a model for .
Choosing an appropriate bandwidth parameter h is important when estimating . We generalize the empirical bias bandwidth selection (EBBS) method of Ruppert (1997) [35] to derive a data-driven bandwidth selection approach in practice; for details, refer to Section 4.3 in Wang et al. 2010 [20]. In Section 5, we derive the asymptotic properties of both and .
3.2. Doubly Robust, Locally Efficient Estimation
If is unknown, the consistency of the estimators and requires model (3) for the selection probabilities to be correctly specified. This can be relaxed by a slight modification to the preceding algorithm. Specifically, consider new estimators and obtained by replacing with , where is the possibly weighted least squares estimator of under the model
In Section 5, we show that under regularity conditions, and are consistent for and provided either model (3) or model (9) is correctly specified but not necessarily both. This property is often referred to as double-robustness.
In addition to more protection against model misspecification, the estimators and have attractive asymptotic efficiency properties. Specifically, if model (3) and model (9) are both correctly specified, then has asymptotic variance that is equal to the smallest possible asymptotic variance of , as ranges over all possible functions. In addition, is locally semiparametric efficient under the semiparametric model defined by the restrictions (1)–(3) of the submodel defined by the additional restrictions (4) and (9). That is, under regularity conditions, is consistent and asymptotically normal for when the selection probability satisfies (3); if in addition, the true data generating process satisfies the working models (4) and (9), then its limiting distribution has variance equal to the semiparametric variance bound for regular estimators of in the semiparametric model defined by restrictions (1)–(3). We explicitly demonstrate these properties in Section 4 and Section 5.
4. Semiparametric Efficiency Theory for Estimation of
The semiparametric variance bound for estimators of a finite-dimensional parameter within an arbitrary semiparametric model serves as the counterpart to the Cramer–Rao bound in parametric models. This bound is defined as the supremum of the Cramer–Rao bounds for across all regular parametric submodels (Begun et al., 1983 [36]; Newey, 1990 [37]; Bickel et al., 1993 [38]). Analogous to its parametric counterpart, this bound offers a benchmark against which the efficiency of estimators of that are consistent and asymptotically normal—more precisely, regular and asymptotically linear (RAL) under the semiparametric model— can be assessed. Notably, the semiparametric bound emerges as the reciprocal of the variance of the semiparametric efficient score for .
In this section, we elucidate the semiparametric efficient score and semiparametric variance bound for within the semiparametric model , governing the law of the observed data defined by restriction (1) on the full data and the MAR restriction (2) on the missing data mechanism. To achieve this, we draw upon the general theory established by Ibragimov and Hasminskii (1981) [39], Robins and Rotnitzky (1992) [40], Robins et al. (1994) [29], and Rotnitzky and Robins (1997) [41], and discussed in van der Laan and Robins (2003) [42] and Tsiatis (2006) [43], among others. The derivation requires the characterization of the orthocomplement of the nuisance tangent space, i.e., of the closed linear span of nuisance scores under model , in the Hilbert space of mean-zero, finite variance scalar functions with covariance inner product. We characterize by , the orthocomplement to the nuisance tangent space for under the semiparametric model for the law of the full data defined by restriction (1) in the Hilbert space . This is so since, as shown in Robins and Rotnitzky (1992) [40],
In Supplementary Materials S1, we show that is composed of all finite variance functions of the form , where is defined in Section 3.1, with satisfying
where is the first derivative of . Robins et al. (1994) [29] derived for , Bickel et al. (Sec 4.3, 1993) [38] (Sec 4.3, 1993) for , and Robins and Rotnitzky (2001) [44] for .
According to Bickel et al. 1993 [38], the semiparametric efficient score for in model at is a vector whose elements belong to . Consequently, in view of (10), must be equal to for some function , whose elements satisfy (11), and with
In S1, we show that , where and
It then follows that the semiparametric variance bound for in the observed data model is equal to
In fact, the semiparametric efficient score and efficiency bound given above are also the ones corresponding to a model which additionally imposes model (3) on the selection probabilities. This is so because under MAR, the likelihood factorizes into a part that depends on the selection probabilities and another part that depends on and .
5. Asymptotic Properties
In this section, we investigate the asymptotic properties of the AIPW and IPW profile–kernel estimators. For conciseness, we only present our asymptotic results for the local linear kernel–profile estimators. The results can be extended to local polynomial regression. Here and throughout, we make the following assumptions: (I) , , and ; (II) z is in the interior of the support of Z; (III) for some constant c, with probability 1 in a neighborhood of ; and (IV) the regularity conditions stated at the beginning of the Supplementary Materials hold.
Under the aforementioned assumptions and MAR, both the IPW and AIPW kernel estimators are consistent for provided that the estimating equations use either the true selection probabilities or consistent estimates under a correctly specified model (3). Furthermore, the AIPW estimator of that uses , as defined before, remains consistent if model (9) for the conditional mean of Y given , Z, and is correctly specified even if model (3) for the selection probability is misspecified. These are similar to the findings in Wang et al. (2010) [20], but given that this paper’s model is different with additionally compared to theirs, some of the expressions are slightly different. So we summarize the asymptotic distributions of and briefly in the following Theorems 1 and 2.
Theorem 1.
Suppose that Equation (5) uses (a) that is computed under model (3) or is replaced by fixed probabilities , and (b) a fixed function or , where is a consistent estimator of η under model (9). Suppose the MAR assumption (2) and assumptions (I)–(IV) above hold and further that either of the following hold: (i) model (3) is correct or, if is used, for all i, or (ii) or if is used, model (9) is correctly specified. Then:
(1) There exists a sequence of solutions of (5) such that
where
is the second derivative of , , denotes the density function of Z, , , , denotes if is used or the probability limit of if is used, and denotes if is used or the probability limit of if is used.
Part (1) of Theorem 1 formally states the important double-robustness property of . It stipulates that is asymptotically unbiased as when if either the model (3) for the selection probability or the model (9) for is correctly specified but not necessarily both. Part (1) of Theorem 1 also states that converges to at the rate , and it provides the general form of its asymptotic variance, which does not depend on the working variance . Thus, misspecification of the working model for does not impact the asymptotic efficiency of . When model (3) for is misspecified but model (9) for is correctly specified, the asymptotic variance of that uses and simplifies to
Part (2) of this Theorem gives the asymptotic variance of when is computed under a correctly specified model or for all i. The result shows that in such cases, the most efficient AIPW kernel estimator is obtained when is used for or when , a model (9) for is correctly specified.
In contrast to the AIPW approach, inference based on the IPW estimator is valid only when the selection probabilities are correctly specified, as summarized in the following theorem.
Theorem 2.
In the following, we primarily focus on the properties of the AIPW profile estimator in Section 5.1 and compare with those of in Section 5.2. Lemma 1 and Theorem 3 establish that the AIPW profile estimator of is consistent and asymptotically normal when either model (9) for the conditional mean of Y given , Z, and is correctly specified or model (3) for the missing data mechanism is correctly specified. This property is commonly referred to as double robustness. In contrast, the IPW profile estimator is inconsistent for if model (3) for the selection probabilities is misspecified, as shown in Theorem 4. Theorem 3 also establishes that when model (3) for the selection probabilities is correctly specified, then among the class of AIPW profile estimators of computed under the same working model for , the one that uses with computed under a correctly specified model for has the smallest asymptotic variance. This asymptotic variance aligns with the semiparametric variance bound derived in Section 4 for in the model defined by restriction (1) on the full data and restriction (2) on the missing data mechanism.
5.1. Asymptotic Results of the AIPW Profile Estimator
In this subsection, our focus lies on the asymptotic properties of the AIPW profile estimators of , demonstrating that the optimal estimator among this class has an asymptotic variance equivalent to the semiparametric variance bound derived in Section 4. We define . Lemma 1 (proved in Supplementary Materials S2) establishes that converges in probability to defined in (4) when is a correctly specified model for , where is defined in (12). This result, along with the subsequent theorem, is used to argue below that is locally semiparametric efficient.
Let denote the probability limit of and V denote the probability limit of , as . Let be evaluated at and let . Then we have the following Lemma 1.
Lemma 1.
Under regularity conditions, we have
In particular, if is a correctly specified model for , then
Note that is affected by the choice of function used in the AIPW equations only through the working variance model. If or and is calculated under a correctly specified model (9), a direct result from Lemma 1 is that the limit of the AIPW profile estimating function is proportional to the semiparametric efficient score of derived in Section 4.
The next theorem establishes the asymptotic distribution of . Throughout, we use the subscript to emphasize the dependence of and the asymptotic variance of on the choice of function used in the AIPW equations. Let , and be the probability limits of , and . Let be the estimating function for and be the estimating function for . Denote , where . For any , , , and , define as . In what follows, for any symmetric matrices A and B, stands for “ is semipositive definite”.
Theorem 3.
Theorem 3 establishes that is consistent and asymptotically normal so long as either model (3) is correct or model (9) is correct but not necessarily both. This is the so-called double-robustness property, which is desirable in practice against model misspecifications.
When model (3) is correctly specified for the selection probability, , where is the score function of , , , , and . Therefore, reduces to . Then we have the following two corollaries.
Corollary 1.
Part (ii) of Corollary 1 holds since and when the true selection probabilities are used in (6). Notice that in (i), is the residual from the population least squares of on , and residual variances are always less than or equal to the variance of the outcomes in a regression; therefore, whenever model (3) is correct. Thus, Corollary 1 implies that using consistent estimates of the selection probabilities even when these are known yields efficiency gains for estimating . This property has also been observed for parametric regression estimation by Robins et al. (1994) [29]. The asymptotic variance of varies with different choices of and working model V. The following corollary implies that for a fixed working model V, has the smallest variance when is used in the augmentation term. Furthermore, if we correctly specify the working model V as , the asymptotic variance of is minimized and the semiparametric variance bound derived in Section 4 is achieved.
Corollary 2.
Part (i) of Corollary 2 shows that when is employed as the function, then estimating the selection probabilities does not yield efficiency gains for estimating compared to using the true selection probabilities when they are known. As indicated by part (ii) of Corollary 2, among all functions, is the optimal one to achieve the smallest asymptotic variance of . In part (iii), because and by Lemma 1 when it follows that is equal to the semiparametric variance bound (13) for RAL estimators of . We therefore conclude from Theorem 3 and Corollary 2 that the profile AIPW estimator is locally semiparametric efficient in the semiparametric model defined by restriction (1) on the full data and restrictions (2) and (3) on the selection probabilities, at the models (4) and (9). That is, it is consistent and asymptotically normal if (1), (2), and (3) hold regardless of whether (4) and (9) hold, and it has asymptotic variance equal to the semiparametric variance bound if, in addition, models (4) and (9) hold.
Corollary 1 and Corollary 2 present the properties of when model (3) is correctly specified for the selection probability or the true selection probabilities are used. Otherwise, if one can achieve a valid specification for model (9), is still consistent and asymptotically normal due to its double-robustness property, established in Theorem 3. In this situation, , and that leads to the following Corollary 3.
Following Theorem 3, we can estimate the variance of AIPW profile estimator using a sandwich formula after invoking a uniform law of large numbers. Specifically, let , , where is as defined in the first paragraph of Section 5.2, , and . can be estimated consistently when either model (3) is correct or model (9) is correct, as where
and
with
5.2. Asymptotic Results of the IPW Profile Estimator
In comparison, we present the asymptotic properties of the IPW profile estimator in this subsection. The results stated in the next lemma and theorem imply that is generally not efficient. This is not surprising after noticing that actually solves the AIPW equation that uses a fixed function ; however, this specific function is not the optimal one among the AIPW class and also makes the IPW profile estimator lose the double-robustness property. In order for to be consistent and asymptotically normal, model (3) for the selection probability needs to be correctly specified.
Lemma 2.
Let be the partial derivative of the final IPW kernel estimator of θ with respect to β, and let be the probability limit of as . Then
If is correctly specified for , where , then
Theorem 4 on the asymptotic distribution of follows directly from Lemma 2, Theorem 3, and Corollaries 1 and 2 with .
Theorem 4.
In general, is not proportional to the efficient score derived in Section 4, and thus, the IPW profile estimator is generally an inefficient estimator.
6. Simulations
In this section, we conduct simulation studies to compare the finite-sample performance of the AIPW and IPW kernel–profile estimators for and , as well as the naive approach which solves unweighted kernel–profile estimating equations based on units with no missing data (complete cases). We generate data according to the spirit of a two-stage study design, where in the first stage we observe the covariates of interest X (e.g., treatment), nuisance covariates Z (e.g., age), and auxiliary variables U for every subject, while in the second stage we only measure the outcome of interest Y on a subset resampled from the first-stage cohort according to some selection probabilities, which depend on the first-stage variables, especially U. For each replication, we generate random samples of , where Z is generated from a distribution, X is generated from , U is generated from a , and the outcome Y is generated from a normal distribution with mean
and variance , where , , , and , a unimodal function. Note that Z is correlated with X, U, and Y, while U is correlated with X, Z, and Y. We generate R, the selection indicator, according to
where is the probability that subject i is selected to the second stage, , , and . Based on this selection mechanism, the Monte Carlo median missing percentage of the outcome Y is around . Since the selection probability depends on U only, the assumption of missing at random holds. Note that
where the true , and true Our primary interest lies in estimating and the nonparametric curve .
We generated 100 replications with sample sizes or in each dataset. For each simulated dataset, we applied the naive approach, which uses the complete cases directly, as well as the IPW and the proposed AIPW kernel–profile methods to estimate the nonparametric function and the semiparametric parameter . We employed the generalized EBBS method to select the optimal local bandwidth.
Figure 1 displays the average estimated nonparametric functions over 100 replications using the naive, IPW, and AIPW approaches. The plot shows the estimates when the weighted kernel–profile estimating equations use the true and . The IPW and AIPW kernel estimates closely matched the true curve , while the naive approach produced an estimate biased away from the true curve.
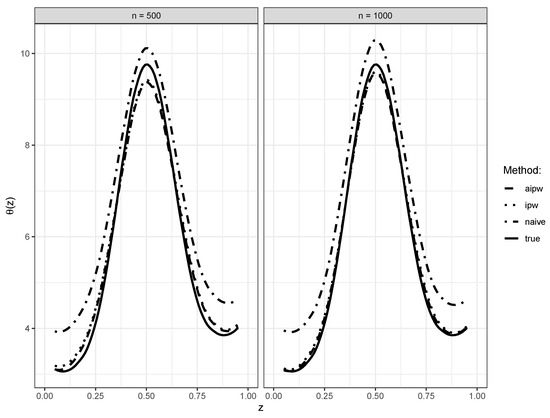
Figure 1.
The true and the estimated nonparametric functions through naive, IPW, and AIPW kernel estimating equations based on 100 replications.
Table 1 summarizes the performance of each kernel estimator using integrated relative bias, integrated empirical standard error (SE), integrated estimated SE, and empirical mean integrated squared error (MISE), over the support of Z. The integrated estimated SEs are close to the integrated empirical SEs. As expected, the naive kernel estimate exhibits a much larger relative bias than the IPW and AIPW kernel estimates. The AIPW kernel estimate using the true and is optimal, having both a smaller SE and a smaller MISE compared to the IPW kernel estimate. The efficiency gain for in terms of MISE is about 40%. Figure 2 illustrates the estimated pointwise variance of and based on 100 replications. It shows that the AIPW approach is more efficient than the IPW approach at each point z in this simulation setup.

Table 1.
Simulation results of the naive, IPW, and AIPW kernel–profile estimates based on 100 replications (sample size n = 500). Note: 1 relative bias is defined as ; 2 EMP S.E. is the empirical S.E., defined as , where is the sampling S.E. of the replicated ; 3 EST S.E. is the estimated S.E., defined as , where is the sampling average of the replicated sandwich estimates ; 4 EMP MISE is the empirical MISE, defined as ; and 5 represents .
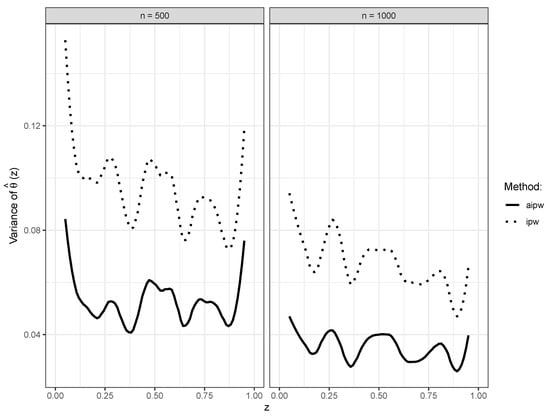
Figure 2.
Empirical pointwise variance of the IPW and AIPW estimated nonparametric functions based on 100 replications.
In Table 1, we also evaluate the performance of each profile estimator using the averaged relative bias, empirical SE, estimated SE, and mean squared error (MSE). For all estimates, the estimated SEs are close to the empirical SEs, demonstrating that the sandwich estimator we proposed for the variance of in Section 5.2 performs well. The bias of was relatively large. When the true or consistent estimates of was used, had very little bias. Otherwise, was biased. By contrast, the simulation results in Table 1 demonstrate the double robustness of the AIPW kernel-profile estimators. We computed and under three scenarios: (i) with an incorrectly specified model of , e.g., on the right side of (18), but with computed from a correctly specified model (17); (ii) with computed from an incorrectly specified model, e.g., in the right side of (17), but with derived from the correctly specified model (18); and (iii) with both and computed from incorrectly specified models respectively. When either the true or the true was used or the consistent estimates were used, as in scenarios (i) and (ii), the AIPW kernel-profile estimates were still close to the true values. However, when both were incorrectly specified, as in scenario (iii), the AIPW estimates were subject to biases. Comparing the IPW estimator using the true and the AIPW estimator using both true and true , the SE and the MSE of the IPW profile estimate are much larger than the AIPW profile estimate. Under the true model and the true model, the efficiency gain of in terms of the MSE is about 47% relative to .
7. Application to the SPECT Data
To illustrate the proposed methods, we applied the AIPW kernel–profile estimating equations to analyze the SPECT data described in Section 1. Our primary objective was to investigate the potential risk factors of myocardial ischemia while controlling for patient age. The data analysis indicated that the risk of myocardial ischemia varies nonlinearly with age, prompting us to model the age effect nonparametrically. The data were collected at the Radiology Clinic of the Nuclear Imaging Group at Cedars Sinai Medical Center. Since myocardial ischemia is relatively rare in younger individuals, we focused on 6185 patients aged 45 and older. This two-stage study involved all patients undergoing EBCT in the first stage. Based on the initial results and other health variables, 458 patients with high-risk factors for coronary artery disease were referred by their doctors to undergo SPECT in the second stage.
The SPECT test serves as the gold standard for screening myocardial ischemia. Consequently, we assumed that the 5727 (93%) patients who did not undergo SPECT were unaware of their true myocardial ischemia status, resulting in missing outcomes. We employed model (1) with myocardial ischemia status as the outcome variable. The covariates of interest include patient age, a continuous variable, and patient gender, smoking status, presence of chest pain, high blood pressure status, and cholesterol status, all binary variables. While polynomial regression with terms like or can model nonlinear relationships, it may overlook local variations. Kernel-profile estimating equations offer greater flexibility, capturing nuances in the data that fixed polynomial terms might miss. We use a partially linear logistic regression model to estimate the probability of myocardial ischemia, with patient gender, smoking status, presence of chest pain, high-blood-pressure status, and cholesterol status serving as linear predictors, while the effect of age was modeled nonparametrically. The bandwidth was determined using the generalized EBBS method.
Figure 3 presents the estimated nonparametric curve of the risk of myocardial ischemia in relation to patient age. The curves estimated by the IPW and AIPW methods closely resemble each other, whereas the naive unweighted approach tends to overestimate the risk of myocardial ischemia. Given that primarily high-risk patients underwent the SPECT exam, relying solely on complete cases using the naive approach is likely to lead to bias in estimating the nonparametric relationship between myocardial ischemia risk and age, as well as the relationship on the logistic scale with other covariates. Our analysis utilizing IPW and AIPW kernel–profile estimating equations suggests that the risk of myocardial ischemia nonlinearly increases with age, with a notable change point around age 70.
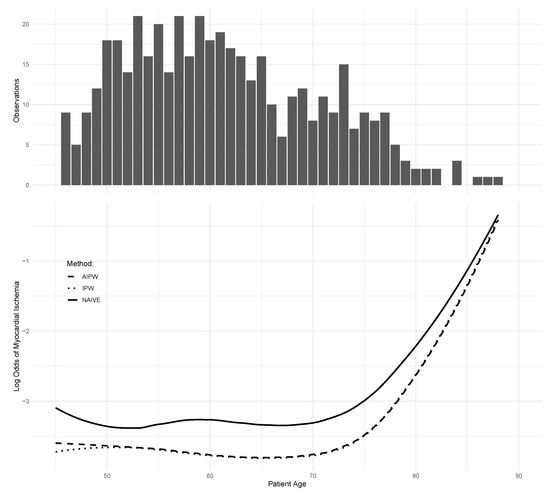
Figure 3.
Estimate of for the risk of myocardial ischemia controlled for other potential risk factors and confounders.
Table 2 displays the estimates of regression coefficients from the model, along with the corresponding p-values. Once more, the IPW and AIPW profile-kernel estimates exhibit similarity and contrast with the naive estimates. Our weighted analysis indicates that women tend to have a lower risk of myocardial ischemia compared to men, while patients who smoke or experience chest pain, high blood pressure, or high cholesterol tend to have a heightened risk of myocardial ischemia. Particularly noteworthy is the statistically significant impact of gender and high blood pressure on myocardial ischemia risk. According to the AIPW analysis, patients experiencing high blood pressure have odds approximately times higher of developing myocardial ischemia. Additionally, men have approximately 5 times higher odds of experiencing myocardial ischemia compared to women.
Table 2.
Estimates of in the semiparametric logistic regression for evaluating the risk factors of myocardial ischemia.
8. Discussion
In this paper, we propose weighted local polynomial kernel-profile estimation methods for generalized semiparametric partially linear regression in cases where outcomes are missing at random while auxiliary variables exist. We demonstrate that the estimators based on the IPW and AIPW kernel-profile estimating equations are consistent and asymptotically normal if the selection probability model is correctly specified. When the model is misspecified, the IPW approach fails to provide consistent estimators. However, the AIPW kernel-profile estimators maintain consistency and asymptotic normality if either the model or the model for is correctly specified. This double-robustness property of the AIPW approach allows investigators two avenues for making valid inferences. Furthermore, the AIPW kernel-profile estimators optimally utilize information in observed data: when both the selection probability model and the model are correctly specified, the corresponding AIPW kernel-profile estimators are the most efficient among its class, with the AIPW profile estimator achieving the semiparametric efficiency bound. User-friendly R code has been uploaded to GitHub, which can be accessed at https://github.com/Team-Wang-Lab/AIPWKPEE.git (accessed on 23 July 2024).
When is not correctly specified, Wang et al. (2010) [20] proposed a modified AIPW kernel estimator for nonparametric regression, which is guaranteed to be more efficient than the IPW kernel estimator and meanwhile also doubly robust. The same idea can be applied to the semiparametric IPW and AIPW kernel-profile estimators proposed in this paper. The IPW and AIPW kernel-profile estimating equations provide consistent estimators when the selection probability model is correctly specified and is bounded away from 0. However, when some ’s are close to 0 with moderate sample sizes, the associated large weights can dramatically inflate a few observations. Therefore, the IPW and AIPW estimators might not perform well and cause unstable results. Special caution is hence needed when applying the proposed methods to studies when the selection probability is very small for some sample units.
The proposed method can be extended to the situation where multiple covariates need to be modeled nonparametrically, e.g., using additive models. For simplicity, we concentrate on local linear kernel estimators for the nonparametric function, but these methods can be readily extended to higher-order local polynomial kernel regression with similar asymptotic results. Although we adopt a parametric model for the missingness probability in this paper, future research could explore the nonparametric estimation of and its impact on the semiparametric efficiency of both IPW and AIPW profile estimators of . However, fully nonparametric modeling of is challenged by the curse of dimensionality, particularly when depends on a set of covariates.
If some covariates of interest among and Z are missing in addition to Y, the general AIPW profile-kernel theory remains applicable, but the efficient score and efficiency bound may change, and adjustments may be necessary for the corresponding estimating procedure. This topic exceeds the scope of our current paper, and further research is needed on complex scenarios where missingness occurs in both outcomes and covariates. We assume in this paper that the outcome is missing at random (MAR). However, justification for the MAR assumption may be required in observational studies, particularly when the missing data mechanism is not well understood. The literature is substantial on statistical methods for parametric regression in the presence of not missing at random (NMAR) for specific cases. Extending these methods and our proposed methods to fit the semiparametric model (1) under NMAR conditions represents a future research direction.
There are several challenges in the practical implementation. For example, bandwidth selection can be time-consuming in a grid search without any prior knowledge. To reduce the computational burden, one can initially search for the bandwidth on a coarser grid, followed by a finer grid search. Additionally, selecting the appropriate auxiliary variable(s) and specifying the model are crucial factors. Insights from experts would also be beneficial.
Supplementary Materials
The following supporting information can be downloaded at https://www.mdpi.com/article/10.3390/stats7030056/s1. These include detailed regularity conditions; Section S1: derivation of the semiparametric efficient score presented in Section 4; Section S2: proof of Lemmas 1 and 2; Section S3: proof of Theorem 3 and Corollary 2; and Section S4: additional simulation results and a sensitivity analysis for the application.
Author Contributions
Conceptualization, L.W. and X.L.; methodology, L.W. and X.L.; software, L.W. and Z.O.; validation, L.W.; formal analysis, L.W.; data curation, L.W. and Z.O.; writing-original draft preparation, L.W.; writing-review & editing, L.W. and X.L.; visualization, L.W. and Z.O.; supervision, L.W. and X.L.; project administration, L.W. All authors have read and agreed to the published version of the manuscript.
Funding
Wang’s research is partially funded by NIH Grants P50-DA-054039-02, P30-ES-017885-10-A1, and CDC Grant R01-CE-003497-01.
Institutional Review Board Statement
Not applicable. This is a statistical method paper, and does not involve new data collection.
Informed Consent Statement
Not applicable. This is a statistical method paper, and does not involve new data collection.
Data Availability Statement
Available upon request.
Acknowledgments
The authors would like to thank Andrea Rotnitzky for her invaluable guidance, support, and expert advice throughout this research.
Conflicts of Interest
The authors declare no conflict of interest.
References
- McCullagh, P.; Nelder, J. Generalized Linear Models; Chapman & Hall: London, UK, 1989. [Google Scholar]
- Severini, T.A.; Staniswalis, J.G. Quasi-Likelihood Estimation in Semiparametric Models. J. Am. Stat. Assoc. 1994, 89, 501–511. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R. Generalized Additive Models; Chapman & Hall/CRC: Boca Raton, FL, USA, 1990. [Google Scholar]
- Fan, J.; Heckman, N.E.; Wand, M.P. Local Polynomial Kernel Regression for Generalized Linear Models and Quasi-Likelihood Functions. J. Am. Stat. Assoc. 1995, 90, 141–150. [Google Scholar] [CrossRef]
- Carroll, R.J.; Fan, J.; Gijbels, I.; Wand, M.P. Generalized Partially Linear Single-Index Models. J. Am. Stat. Assoc. 1997, 92, 477–489. [Google Scholar] [CrossRef]
- Lin, X.; Carroll, R.J. Semiparametric Regression for Clustered Data Using Generalized Estimating Equations. J. Am. Stat. Assoc. 2001, 96, 1045–1056. [Google Scholar] [CrossRef]
- Lin, X.; Carroll, R.J. Semiparametric Regression for Clustered Data. Biometrika 2001, 88, 1179–1185. [Google Scholar] [CrossRef]
- Muller, M. Estimation and Testing in Generalized Partial Linear Models: A comparative Study. Stat. Comput. 2001, 11, 299–309. [Google Scholar] [CrossRef]
- Hu, T.; Cui, H. Robust estimates in generalised varying-coefficient partially linear models. J. Nonparametr. Stat. 2010, 22, 737–754. [Google Scholar] [CrossRef]
- Rahman, J.; Luo, S.; Fan, Y.; Liu, X. Semiparametric efficient inferences for generalised partially linear models. J. Nonparametr. Stat. 2020, 32, 704–724. [Google Scholar] [CrossRef]
- Little, R.J.A.; Rubin, D.B. Statistical Analysis with Missing Data, 2nd ed.; John Wiley: New York, NY, USA, 2002. [Google Scholar]
- Chu, H.; Halloran, M.E. Estimating vaccine efficacy using auxiliary outcome data and a small validation sample. Stat. Med. 2004, 23, 2697–2711. [Google Scholar] [CrossRef]
- Braun, J.; Oldendorf, M.; Moshage, W.; Heidler, R.; Zeitler, E.; Luft, F.C. Electron beam computed tomography in the evaluation of cardiac calcifications in chronic dialysis patients. Am. J. Kidney Dis. 1996, 27, 394–401. [Google Scholar] [CrossRef]
- Little, R.J.A. Models for nonresponse in sample surveys. J. Am. Stat. Assoc. 1982, 77, 237–250. [Google Scholar] [CrossRef]
- Little, R.J.A. Modeling the Drop-Out Mechanism in Repeated-Measures Studies. J. Am. Stat. Assoc. 1995, 90, 1112–1121. [Google Scholar] [CrossRef]
- Robins, J.M.; Rotnitzky, A. Semiparametric Efficiency in Multivariate Regresion Models with Missing Data. J. Am. Stat. Assoc. 1995, 90, 122–129. [Google Scholar] [CrossRef]
- Robins, J.M.; Rotnitzky, A.; Zhao, L.P. Analysis of Semiparametric Regression Models for Repeated Outcomes in the Presence of Missing Data. J. Am. Stat. Assoc. 1995, 90, 106–121. [Google Scholar] [CrossRef]
- Wang, C.Y.; Wang, S.; Gutierrez, R.G.; Carroll, R.J. Local Linear Regresion for Generalized Linear Models with Missing Data. Ann. Stat. 1998, 26, 1028. [Google Scholar]
- Chen, J.; Fan, J.; Li, K.H.; Zhou, H. Local quasi-likelihood estimation with data missing at random. Stat. Sin. 2006, 16, 1044–1070. [Google Scholar]
- Wang, L.; Rotnitzky, A.; Lin, X. Nonparametric Regression with Missing Outcomes Using Weighted Kernel Estimating Equations. J. Am. Stat. Assoc. 2010, 105, 1135–1146. [Google Scholar] [CrossRef] [PubMed]
- Kennedy, E.H.; Ma, Z.; McHugh, M.D.; Small, D.S. Non-parametric methods for doubly robust estimation of continuous treatment effects. J. R. Stat. Soc. Ser. B Stat. Methodol. 2017, 79, 1229–1245. [Google Scholar] [CrossRef]
- Liang, H.; Wang, S.; Robins, J.M.; Carroll, R.J. Estimation in partially linear models with missing covariates. J. Am. Stat. Assoc. 2004, 99, 357–367. [Google Scholar] [CrossRef]
- Liang, H. Generalized partially linear models with missing covariates. J. Multivar. Anal. 2008, 99, 880–895. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Wang, Q. Statistical estimation in partial linear models with covariate data missing at random. Ann. Inst. Stat. Math. 2009, 61, 47–84. [Google Scholar] [CrossRef]
- Wang, Q.; Linton, O.; Hardle, W. Semiparametric Regression Analysis With Missing Response at Random. J. Am. Stat. Assoc. 2004, 99, 334–345. [Google Scholar] [CrossRef]
- Wang, Q.; Sun, Z. Estimation in partially linear models with missing responses at random. J. Multivar. Anal. 2007, 98, 1470–1493. [Google Scholar] [CrossRef]
- Liang, H.; Wang, S.; Carroll, R.J. Partially linear models with missing response variables and error-prone covariates. Biometrika 2007, 94, 185–198. [Google Scholar] [CrossRef]
- Chen, S.; Keilegom, I.V. Estimation in semiparatric models with missing data. Ann. Inst. Stat. Math. 2013, 65, 785–805. [Google Scholar] [CrossRef][Green Version]
- Robins, J.M.; Rotnitzky, A.; Zhao, L.P. Estimation of Regression Coefficients When Some Regressors Are Not Always Observed. J. Am. Stat. Assoc. 1994, 89, 846–866. [Google Scholar] [CrossRef]
- Rotnitzky, A.; Robins, J.M.; Scharfstein, D.O. Semiparametric Regression fro Repeated Outcomes with Nonignorable Nonresponse. J. Am. Stat. Assoc. 1998, 93, 1321–1339. [Google Scholar] [CrossRef]
- Bang, H.; Robins, J.M. Doubly Robust Estimation in Missing Data and Causal Inference Models. Biometrics 2005, 61, 962–972. [Google Scholar] [CrossRef]
- Pepe, M.S. Inference Using Surrogate Outcome Data and a Validation Sample. Biometrika 1992, 79, 355–365. [Google Scholar] [CrossRef]
- Reilly, M.; Pepe, M.S. A mean score method for missing and auxiliary covariate data in regression models. Biometrika 1995, 82, 299–314. [Google Scholar] [CrossRef]
- Wang, N.; Carroll, R.J.; Lin, X. Efficient Semiparametric Marginal Estimation for Longitudinal/Clustered Data. J. Am. Stat. Assoc. 2005, 100, 147–157. [Google Scholar] [CrossRef]
- Ruppert, D. Empirical-Bias Bandwidths for Local Polynomial Nonparametric Regression and Density Estimation. J. Am. Stat. Assoc. 1997, 92, 1049. [Google Scholar] [CrossRef]
- Begun, J.M.; Hal, W.J.; Huang, W.M.; Wellner, J.A. Information and Asymptototic Efficiency in Parametric-Nonparametric Models. Ann. Stat. 1983, 11, 432–452. [Google Scholar] [CrossRef]
- Newey, W.K. Semiparametric Efficiency Bounds. J. Appl. Econom. 1990, 5, 99–135. [Google Scholar] [CrossRef]
- Bickel, P.J.; Klaassen, C.A.; Bickel, P.J.; Ritov, Y.; Klaassen, J.; Wellner, J.A.; Ritov, Y. Efficient and Adaptive Estimation for Semiparametric Models; Springer: New York, NY, USA, 1998. [Google Scholar]
- Ibragimov, I.; Hasminskii, R. Statistical Estimation: Asymptotic Theory; Springer: New York, NY, USA, 1981. [Google Scholar]
- Robins, J.M.; Rotnitzky, A. Recovery of information and adjustment for dependent censoring using surrogate markers. In AIDS Epidemiology: Methodological Issues; Jewell, N., Dietz, K., Farewell, V., Eds.; Birkhäuser: Boston, MA, USA, 1992; pp. 297–331. [Google Scholar]
- Rotnitzky, A.; Holcroft, C.; Robins, J.M. Efficiency comparisons in multivariate multiple regression with missing outcomes. J. Multivar. Anal. 1997, 61, 102–128. [Google Scholar] [CrossRef][Green Version]
- van der Laan, M.; Robins, J.M. Unified Methods for Censored Longitudinal Data and Causality; Springer: New York, NY, USA, 2003. [Google Scholar]
- Tsiatis, A.A. Semiparametric Theory and Missing Data; Springer Series in Statistics; Springer: New York, NY, USA, 2006. [Google Scholar]
- Robins, J.M.; Rotnitzky, A. Comment on the Bickel and Kwon article, Inference for semiparametric models: Some questions and an answer. Stat. Sin. 2001, 11, 920–936. [Google Scholar]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).