
Mass Conservative Time-Series GAN for Synthetic Extreme Flood-Event Generation: Impact on Probabilistic Forecasting Models

Abstract
1. Introduction
2. Materials and Methods
2.1. Case Study
2.2. Methods
2.2.1. Methodological Approach
- Data Collection and Spatial Data Integration
- 2.
- MC-TSGAN Training
- 3.
- Data Augmentation
- 4.
- Flood forecast model training
- 5.
- Evaluation
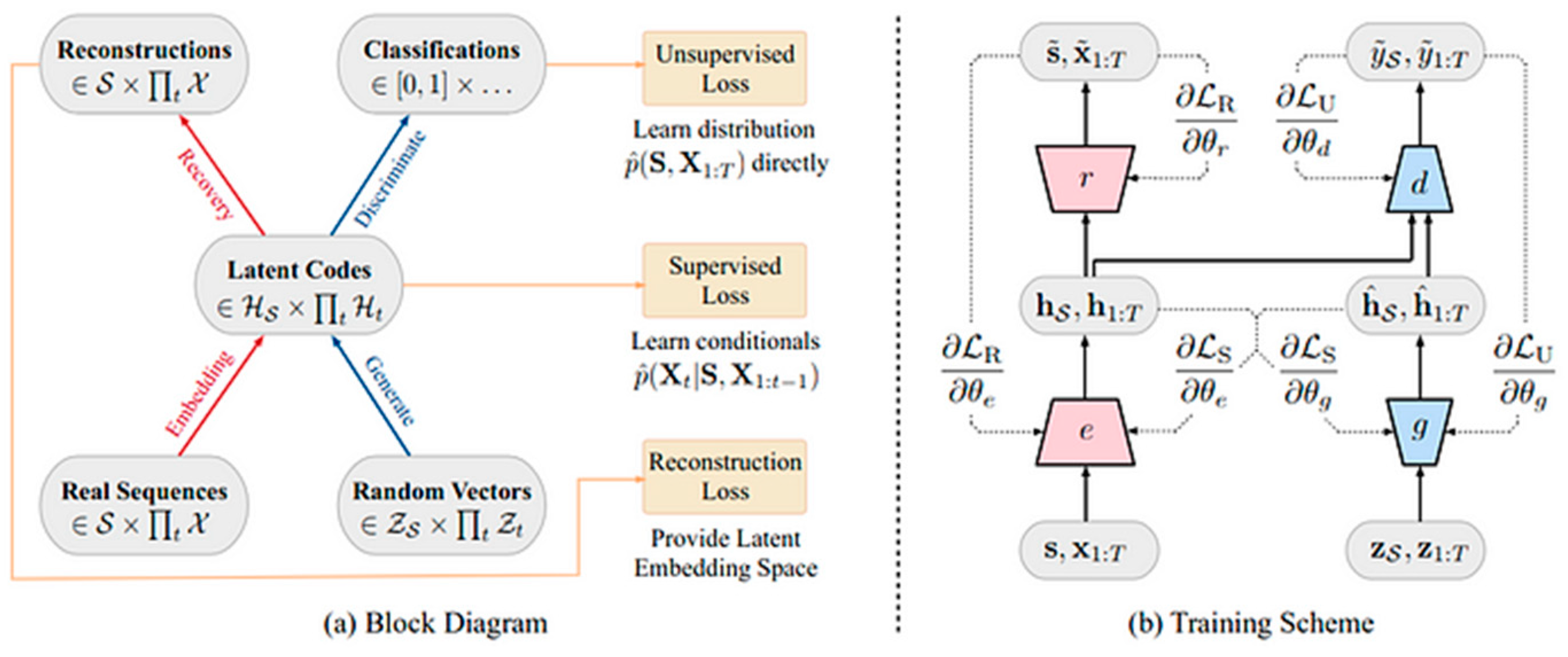
2.2.2. Structure and Training of the MC-TSGAN
2.2.3. Probabilistic Flood-Forecasting Model
- Input data: The model integrates a diverse range of input data, including historical flood events, rainfall measurements, soil moisture levels, catchment characteristics, and future rainfall forecasts. This comprehensive dataset enables the model to capture the complex interactions and dynamics influencing flood events.
- Time-series handling: The model is capable of handling the time-series data of varying timescales, allowing it to analyze historical trends, short-term fluctuations, and long-term patterns in the input variables. By considering data from different time intervals, the model can provide accurate and comprehensive flood forecasts.
- Probabilistic forecasting based on tensorflow_probability [19]: The model is modified with a probabilistic head that utilizes negative likelihood loss for training. This probabilistic approach enables the model to generate probabilistic forecasts, providing not only point estimates but also uncertainty quantification in the predictions. This is essential for assessing the reliability and confidence of the forecasted outcomes.
- LSTM or GRU architecture: The model structure incorporates Long Short-Term Memory (LSTM) or Gated Recurrent Unit (GRU) networks, which are specialized recurrent neural network architectures well-suited for processing sequential data like time series. These architectures enable the model to capture temporal dependencies, learn from past observations, and make predictions based on sequential patterns in the input data.
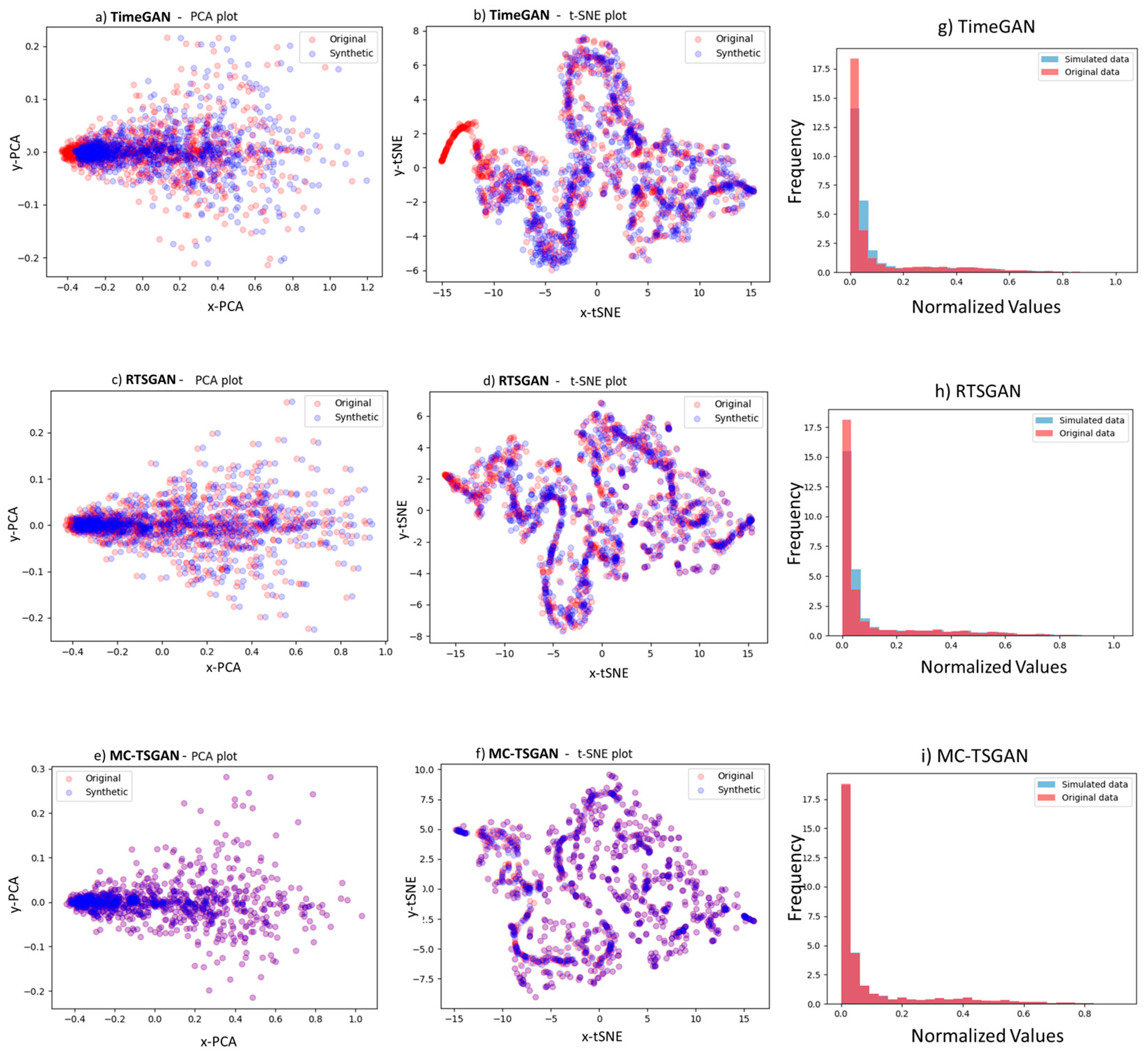
2.2.4. Evaluations of MC-TSGAN Based on PCA and t-SNE
2.2.5. Evaluation of MC-TSGAN Based on t-Statistics
2.2.6. Evaluation of the Flood-Forecasting Model
2.3. Experimental Setup and Simulation
3. Results
4. Discussion
5. Conclusions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dottori, F.; Salamon, P.; Kalas, M.; Bianchi, A.; Alfieri, L.; Feyen, L. Benchmarking machine learning models for the large-scale simulation of flood hazard. Environ. Model. Softw. 2018, 104, 92–104. [Google Scholar]
- Singh, V.P. Calibration and Validation of Hydrological Models. In Handbook of Applied Hydrology; McGraw-Hill Education: New York, NY, USA, 2018; pp. 3-1–3-24. [Google Scholar]
- Yoon, J.; Jordon, J.; van de Lindt, J.; Emani, S. Time series generative adversarial networks. Adv. Neural Inf. Process. Syst. 2019, 32, 10759–10769. [Google Scholar]
- Xie, J.; Lu, Y.; Lin, L.; Wang, Y.; Song, M. SINGAN: Spatio-temporal Interactive Generative Adversarial Networks for Synthetic Weather Radar Data Generation. In Proceedings of the 33rd Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Cao, J.; Wang, S.; Li, J. Time Series Generative Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Data Mining, New Orleans, LA, USA, 18–21 November 2017. [Google Scholar]
- Garg, N.; Singh, V.; Srinivas, V.V. FloodGAN: Synthetic Generation of High-Resolution Radar Rainfall Data using Generative Adversarial Networks. J. Hydrol. 2020, 590, 125413. [Google Scholar] [CrossRef]
- Li, Y.; Liu, Q.; Zheng, L. TimeGAN: A time series generative adversarial network. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Available online: http://proceedings.mlr.press/v80/yoon18a.html (accessed on 2 May 2024).
- Wang, P.; Tian, Y.; Liu, Y.; Zheng, Y. Time-series generative adversarial networks for flood forecasting. J. Hydrol. 2023, 622, 129702. [Google Scholar] [CrossRef]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein GANs. In Proceedings of the NIPS’17: Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5767–5777. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, Y.; Xu, B. Enhancing flood forecasting models using TimeGAN-generated synthetic data: A case study in the Yangtze River Basin, China. J. Hydrol. 2021, 597, 125818. [Google Scholar] [CrossRef]
- Li, X.; Zhang, T.; Ma, D.; Liu, H.; Wang, W.H. A multi-step ahead photovoltaic power forecasting model based on TimeGAN, Soft DTW-based K-medoids clustering, and a CNN-GRU hybrid neural network. Energy Rep. 2022, 8, 10346–10362. [Google Scholar] [CrossRef]
- Peng, Y.; Wang, Z.; Cui, Y.; Su, Y.; Tang, Y.; Luo, S.; Liu, L.; Zhou, Y.; Dong, J.; Wang, W.; et al. Prediction of drought/flood intensities based on a 500-year time series in three different climate provinces of China. Reg. Environ. Chang. 2022, 22, 80. [Google Scholar] [CrossRef]
- Wang, S.; Gao, Y.; Zhou, Y.; Pan, B.; Xu, X.; Li, T. Reducing the statistical error of generative adversarial networks using space-filling sampling. Stat 2024, 13, e655. [Google Scholar] [CrossRef]
- Karniadakis, G.E.; Kevrekidis, I.G.; Lu, L.; Perdikaris, P.; Wang, S.; Yang, L. Physics-informed machine learning. Nat. Rev. Phys. 2021, 3, 422–440. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, W.; Ma, Z.; Zhao, M.; Li, W.; Hou, X.; Li, J.; Ye, F.; Ma, W. A Deep Learning Approach Based on Physical Constraints for Predicting Soil Moisture in Unsaturated Zones. Water Resour. Res. 2023, 59, e2023WR035194. [Google Scholar] [CrossRef]
- Wi, S.; Steinschneider, S. Assessing the Physical Realism of Deep Learning Hydrologic Model Projections Under Climate Change. Water Resour. Res. 2022, 58, e2022WR032123. [Google Scholar] [CrossRef]
- Wi, S.; Steinschneider, S. On the need for physical constraints in deep learning rainfall–runoff projections under climate change: A sensitivity analysis to warming and shifts in potential evapotranspiration. Hydrol. Earth Syst. Sci. 2024, 28, 479–503. [Google Scholar] [CrossRef]
- Karimanzira, D.; Ritzau, L.; Emde, K. Catchment Area Multi-Streamflow Multiple Hours Ahead Forecast Based on Deep Learning. Trans. Mach. Learn. Artif. Intell. 2022, 10, 15–29. [Google Scholar] [CrossRef]
- TensorFlow Developers, TensorFlow (v2.17.0-rc0), Zenodo: Honolulu, HI, USA, 2024. [CrossRef]
- Frazier, P. A Tutorial on Bayesian Optimization. arXiv 2018, arXiv:1807.02811. [Google Scholar]
- Ketkar, N. Introduction to Keras. In Deep Learning with Python; Ketkar, N., Ed.; Apress: Berkeley, CA, USA, 2017; pp. 97–111. ISBN 978-1-4842-2766-4. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- PyTorch Documentation—PyTorch 1.13 Documentation. Available online: https://pytorch.org/docs/stable/index.html (accessed on 7 May 2024).
- Cloke, H.L.; Pappenberger, F.; Smith, P.J.; Matgen, P.; Thielen, J.; Ramos, M.H.; Demeritt, D. Improving flood forecasting communication: An experiment in information exchange in the Red River Basin. J. Flood Risk Manag. 2013, 6, 211–225. [Google Scholar]
- Bryant, F.B.; Yarnold, P.R. Principal-components analysis and exploratory and confirmatory factor analysis. In Reading and Understanding Multivariate Statistics; American Psychological Association: Washington, DC, USA, 1995; pp. 99–136. [Google Scholar]
- Maaten, L.v.D.; Hinton, G. Visualizing data using t-sne. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Score | TimeGAN | RTSGAN | MC-TSGAN |
|---|---|---|---|
| Discriminative | 0.102 (0.021) | 0.054 (0.024) | 0.0490 (0.0185) |
| Predictive | 0.088 (0.001) | 0.067 (0.030) | 0.0519 (0.0474) |
| Metric (6th Hour Ahead) | Augmented with MC-TSGAN | Original Data |
|---|---|---|
| CRPS | 0.375(0.023) | 0.576 (0.024) |
| MPIW | 0.43 (0.021) | 0.56 (0.02) |
| PICP | 0.921 | 0.941 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karimanzira, D. Mass Conservative Time-Series GAN for Synthetic Extreme Flood-Event Generation: Impact on Probabilistic Forecasting Models. Stats 2024, 7, 808-826. https://doi.org/10.3390/stats7030049
Karimanzira D. Mass Conservative Time-Series GAN for Synthetic Extreme Flood-Event Generation: Impact on Probabilistic Forecasting Models. Stats. 2024; 7(3):808-826. https://doi.org/10.3390/stats7030049
Chicago/Turabian StyleKarimanzira, Divas. 2024. "Mass Conservative Time-Series GAN for Synthetic Extreme Flood-Event Generation: Impact on Probabilistic Forecasting Models" Stats 7, no. 3: 808-826. https://doi.org/10.3390/stats7030049
APA StyleKarimanzira, D. (2024). Mass Conservative Time-Series GAN for Synthetic Extreme Flood-Event Generation: Impact on Probabilistic Forecasting Models. Stats, 7(3), 808-826. https://doi.org/10.3390/stats7030049