1. Introduction
The mean, median, and mode are the three most commonly used measures of central tendency of data. When data contain outliers that cause heavy tails or are potentially skewed, the mode is a more sensible representation of the central location of data than the mean or median. The timely review on mode estimation and its application by Chacón [
1] and references therein provide many examples in various fields of research where the mode serves as a more informative representative value of data. Most existing methods developed to draw inference for the mode are semi-/non-parametric in nature, starting from early works on direct estimation in the 1960s [
2,
3,
4] to more recent works based on kernel density estimation [
5] and quantile-based methods [
6,
7]. Two main factors contribute to the enduring preference for semi-/non-parametric methods for mode estimation, despite the typically less straightforward implementation and lower efficiency compared to parametric counterparts. First, parametric models often impose strict constraints on the relationship between the mode and other location parameters, which may not hold in certain applications. Second, very few existing named distribution families that allow the inclusion of both symmetric and asymmetric distributions in the same family can be parameterized so that it is indexed by the mode as the location parameter along with other parameters, such as shape or scale parameters. In this study, we alleviate concerns raised by both reasons that discourage the use of parametric methods for mode estimation by formulating a flexible distribution indexed via the (unique) mode and parameters controlling the shape and scale.
When it comes to modeling heavy-tailed data, the Gumbel distribution [
8] is arguably one of the most widely used models in many disciplines. Indeed, as a case of the generalized extreme value distribution [
9], the Gumbel distribution for the maximum (or minimum) is well-suited for modeling extremely large (or small) events that produce heavy-tailed data. For example, it is often used in hydrology to predict extreme rainfall and flood frequency [
10,
11,
12]. In econometrics, Gumbel distribution plays an important role in modeling extreme movements of stock prices and large changes in interest rates [
13,
14]. The Gumbel distribution is indexed by the mode and a scale parameter, and thus is convenient for mode estimation. However, the Gumbel distribution for the maximum (or minimum) is right-skewed (or left-skewed) with the skewness fixed at around
(or
), and the kurtosis fixed at 5.4 across the entire distribution family. Thus, it may be too rigid for scenarios where the direction and extremeness of outliers presented in data are initially unclear, or when the direction and level of skewness are unknown beforehand. Constructions of more flexible distributions that overcome these limitations have been proposed. In particular, Cooray [
15] applied a logarithmic transformation on a random variable following the odd Weibull distribution to obtain the so-called generalized Gumbel distribution that includes the Gumbel distribution as a subfamily. But the mode of the generalized Gumbel distribution is not indexed by a location parameter, or an explicit function of other model parameters. Shin et al. [
16] considered mixture distributions with one of the components being the Gumbel distribution and the other component(s) being Gumbel of the same skewness direction or a different distribution, such as the gamma distribution. Besides the same drawback pointed out for the generalized Gumbel distribution, it is difficult to formulate a unimodal distribution following their construction of mixtures, and thus their proposed models are unsuitable when unimodality is a feature required to make inferring the mode meaningful, such as in a regression setting, as in modal regression [
5,
17,
18].
With heavy-tailed data in mind and the mode as the location parameter of interest, we construct a new unimodal distribution that does not impose stringent constraints on how the mode relates to other central tendency measures, while allowing a range of kurtosis wide enough to capture heavy tails at either direction, as well as different degrees and directions of skewness. This new distribution, called the flexible Gumbel (FG) distribution, is presented in
Section 2, where we study properties of the distribution and discuss the identifiability of the model. We present a frequentist method and a Bayesian method for estimating parameters in the FG distribution in
Section 3. The finite sample performance of these methods is inspected in a simulation study in
Section 4, followed by an application of the FG distribution in hydrology in
Section 5.
Section 6 demonstrates fitting a modal regression model based on the FG distribution to data from a criminology study.
Section 7 highlights the contributions of our study and outlines future research directions.
2. The Flexible Gumbel Distribution
The probability density function (pdf) of the Gumbel distribution for the maximum is given by
where
is the mode and
is a scale parameter. The pdf of the Gumbel distribution for the minimum with mode
and a scale parameter
is given by
We define a unimodal distribution for a random variable
Y via a mixture of the two Gumbel distributions specified by (
1) and (
2) that share the same mode
while allowing different scale parameters,
and
, in the two components. We call the resultant distribution the flexible Gumbel distribution FG for short with the pdf given by
where
is the mixing proportion parameter. Henceforth, we state that
if
Y follows the distribution specified by the pdf in (
3).
For each component distribution of FG, the mean and median are both some simple shift of the mode, with each shift solely determined by the scale parameter. Because the two components in (
3) share a common mode
, the mode of
Y is also
, and thus the FG distribution is convenient to use when one aims to infer the mode as a central tendency measure, or to formulate parametric modal regression models [
19,
20,
21]. One can easily show that the mean of
Y is
, where
is the Euler–Mascheroni constant. Thus, the discrepancy between the mode and the mean of FG depends on three other parameters that control the scale and shape of the distribution. The median of
Y, denoted by
m, is the solution to the following equation,
Even though this equation cannot be solved for m explicitly to reveal the median in closed form, it is clear that also depends on all three other parameters of FG. In conclusion, the relationships between the three central tendency measures of FG are more versatile than those under a Gumbel distribution for the maximum or a Gumbel distribution for the minimum.
The variance of
Y is
, which does not depend on the mode parameter
. Obviously, by setting
or 1,
reduces to one of the Gumbel components. Unlike a Gumbel distribution that only has one direction of skewness at a fixed level (of
, an FG distribution can be left-skewed, or right-skewed, or symmetric. More specifically, with the mode fixed at zero when studying the skewness and kurtosis of FG, one can show (as outlined in
Appendix A) that the third central moment of
Y is given by
where
, and
is Apéry’s constant. Although the direction of skewness is not immediately clear from (
4), one may consider a special case with
where (
4) reduces to
. Now one can see that
is symmetric if and only if
, and it is left-skewed (or right-skewed) when
is less (or greater) than
. The kurtosis of
Y can also be derived straightforwardly, with a more lengthy expression than (
4) that we omit here, which may not shed much light on its magnitude except that it varies as the scale parameters and the mixing proportion vary, instead of fixing at 5.4 as for a Gumbel distribution. An R Shiny app depicting the pdf of
with user-specified parameter values is available here:
https://qingyang.shinyapps.io/gumbel_mixture/ (accessed on 6 March 2024), created and maintained by the first author. Along with the density function curve, the Shiny app provides skewness and kurtosis of the depicted FG density. From there, one can see that the skewness can be much lower than
or higher than
, and the kurtosis can be much higher than 5.4, suggesting that inference based on FG can be more robust to outliers than when a Gumbel distribution is assumed for data at hand, without imposing stringent assumptions on the skewness of the underlying distribution.
The flexibility of a mixture distribution usually comes with concerns relating to identifiability [
22,
23,
24]. In particular, there is the notorious issue of label switching when fitting a finite mixture model [
25]. Take the family of two-component normal mixture (NM) distributions as an example, defined by
. When fitting a dataset assuming a normal mixture distribution, one cannot distinguish between, for instance,
and
, since the likelihood of the data is identical under these two mixture distributions. As another example, for data from a normal distribution, a two-component normal mixture with two identical normal components and an arbitrary mixing proportion
leads to the same likelihood, and thus
w cannot be identified. Teicher [
23] showed that imposing a lexicographical order for the normal components resolves the issue of non-identifiability, which also excludes mixtures with two identical components in the above normal mixture family. Unlike normal mixtures of which all components are in the same family of normal distributions, the FG distribution results from mixing two components from different families, i.e., a Gumbel distribution for the maximum and a Gumbel distribution for the minimum, with weight
w on the former component. By construction, FG does not have the label-switching issue. And we show in
Appendix B by invoking Theorem 1 in Teicher [
23] that the so-constructed mixture distribution is always identifiable even when the true distribution is a (one-component) Gumbel distribution.
4. Simulation Study
Large-sample properties of MLEs and likelihood-based Bayesian inference under a correct model for data have been well studied. To assess finite-sample performance of the frequentist method and Bayesian method proposed in
Section 3, we carried out a simulation study with two specific aims: first, to compare inference results from the two methods; second, to compare goodness of fit for data from distributions outside of the FG family when one assumes an FG distribution and when one assumes a two-component normal mixture distribution for the data.
In the first experiment, denoted as (E1) hereafter, we considered two FG distributions as true data-generating mechanisms,
and FG
. This design creates two FG distributions with the second one more skewed and variable than the first. Based on a random sample of size
from the first FG distribution, we estimated
by applying the ECM algorithm and the Metropolis-within-Gibbs algorithm. Similarly, based on a random sample of size
, we implemented the two algorithms to estimate
. The former algorithm produced the MLE of
, and we used the median of the posterior distribution of
at convergence of the latter algorithm as another point estimate of
.
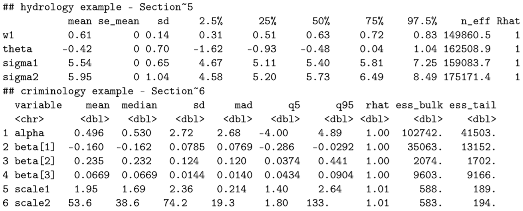
Table 1 presents summary statistics of these estimates of
and estimates of the corresponding standard deviation across 1000 Monte Carlo replicates under each simulation setting specified by the design of an FG distribution and the level of
n.
According to
Table 1, all parameter estimates in
are reasonably close to the true values. When the sample size is as small as 50, estimates for
resulting from the frequentist method are still similar to those from the Bayesian inference method, although estimates for the standard deviations of these point estimators can be fairly different. We do not find such discrepancy surprising because, for the frequentist method where we use the sandwich variance estimator to infer the uncertainty of an MLE for
, the asymptotic properties associated with MLEs that support the use of a sandwich variance estimator may not take effect yet at the current sample size; and, for the Bayesian method, the quantification of standard deviation can be sensitive to the choice of priors when
n is small. These are confirmed by the diminishing discrepancy between the two sets of standard deviation estimates when
, 200. A closer inspection of the reported empirical mean of estimates for
along with their empirical standard error suggests that, when
, the Bayesian method may slightly underestimate
, the larger of the two scale parameters of FG. We believe that this is due to the inverse gamma prior imposed on the scale parameters that is sharply peaked near zero, and thus the posterior median of the larger scale parameter tends to be pulled downwards when the sample size is not large. As the sample size increases to 200, this trend of underestimation appears to diminish. The empirical means of the standard deviation estimates from both methods are close to the corresponding empirical standard deviations, which indicate that the variability of a point estimator is accurately estimated when
n is not small, whether it is based on the sandwich variance estimator in the frequentist framework, or based on the posterior sampling in the Bayesian framework. In summary, the methods proposed in
Section 3 under both frameworks provide reliable inference for
along with accurate uncertainty assessment of the point estimators when data arise from an FG distribution.
Among all existing mixture distributions, normal mixtures probably have the longest history and are most referenced in the literature. In another experiment, we compared the model fitting of normal mixture with that of FG when data arise from three heavy-tailed distributions: (E2) Laplace with the location parameter equal to zero and the scale parameter equal to 2; (E3) a mixture of two Gumbel distributions for the maximum, with a common mode at zero, scale parameters in the two components equal to 2 and 6, respectively, and the mixing proportion equal to 0.5; (E4) a Student-
t distribution with degrees of freedom equal to 5. From each of the three distributions in (E2)–(E4), we generated a random sample of size
, following which we fit a two-component normal mixture model via the EM algorithm implemented using the R package
mixtools (version: 2.0.0), and also fit an FG model via the two algorithms described in
Section 3. This model fitting exercise was repeated for 1000 Monte Carlo replicates under each of (E2)–(E4).
We used an empirical version of the Kullback–Leibler divergence as the metric to assess the quality of modeling fitting. We denote the true density function as
, and let
be a generic estimated density resulting from one of the three considered model fitting strategies. Under each setting in (E2)–(E4), a random sample of size 50,000,
, was generated from the true distribution, and an empirical version of the Kullback–Leibler divergence from
to
is given by
.
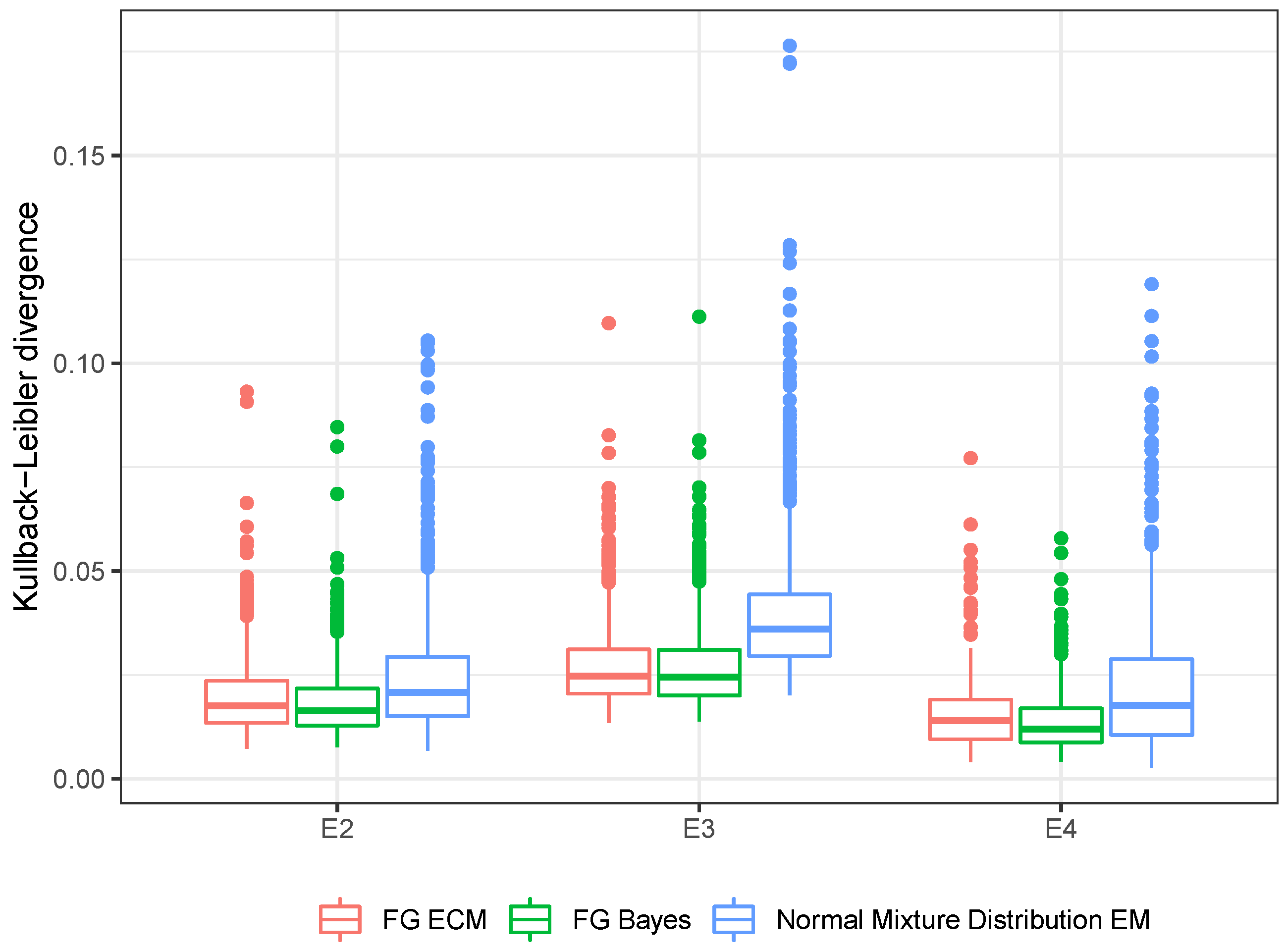
Figure 1 shows the boxplots of
across 1000 Monte Carlo replicates corresponding to each model fitting scheme under (E2)–(E4).
Judging from
Figure 1, the FG distribution clearly outperforms the normal mixture when fitting data from any of the three heavy-tailed distributions in (E2)–(E4), and results from the frequentist method are comparable with those from the Bayesian method for fitting an FG model. When implementing the ECM algorithm for fitting the FG model and the EM algorithm for fitting the normal mixture, we set a maximum number of iterations at 1000. Our ECM algorithm always converged in the simulation, i.e., converged to a stationary point within 1000 iterations. However, the EM algorithm for fitting a normal mixture often had trouble achieving that, with more difficulty when data come from a heavier-tailed distribution. More specifically, under (E4), which has the highest kurtosis (equal to 9) among the three settings, the EM algorithm failed to converge in 59.9% of all Monte Carlo replicates; under (E2), which has the second highest kurtosis (equal to 6), it failed to converge in 6.7% of the replicates. Results associated with the normal mixture from these failing replicates were not included when producing the boxplots in
Figure 1. In conclusion, the FG distribution is more suitable for symmetric or asymmetric heavy-tailed data than the normal mixture distribution.
5. An Application in Hydrology
Daily maximum water elevation changes of a water body, such as ocean, lake, and wetland, are of interest in hydrologic research. These changes may be close to zero on most days but can be extremely large or small under extreme weather. From the National Water Information System (
https://waterdata.usgs.gov/), we downloaded water elevation data for Lake Murray near Columbia, South Carolina, United States, recorded from 18 September 2020 to 18 September 2021. The water elevation change of a given day was calculated by contrasting the maximum elevation and the minimum elevation on that day, returning a positive (negative) value if the maximum record of the day comes after (before) the minimum record on the same day. We fit the FG distribution to the resultant data with
records using the frequentist method and the Bayesian method, with results presented in
Table 2. The two inference methods produced very similar estimates for most parameters, although small differences were observed. For example, one would estimate the mode of daily maximum water elevation change to be
feet based on the frequentist method, but estimate it to be
feet using the Bayesian method. The discrepancy between these two mode estimates is minimal considering that the daily maximum water elevation changes range from
feet to 49.4 feet within this one year. Taking into account the uncertainty in these point estimates, we do not interpret any of these differences as statistically significant because a parameter estimate from one method always falls in the interval estimate for the same parameter from the other method according to
Table 2. Using parameter estimates in
Table 2 in the aforementioned R Shiny app, we obtained an estimated skewness of
and an estimated kurtosis of 6.384 based on the frequentist inference results, whereas the Bayes inference yielded an estimated skewness of 0.058 and an estimated kurtosis of 6.074. Combining these two sets of results, we concluded that the underlying distribution of daily maximum water elevation change may be nearly symmetrical, with outliers on both tails that cause tails heavier than that of a Gumbel distribution.
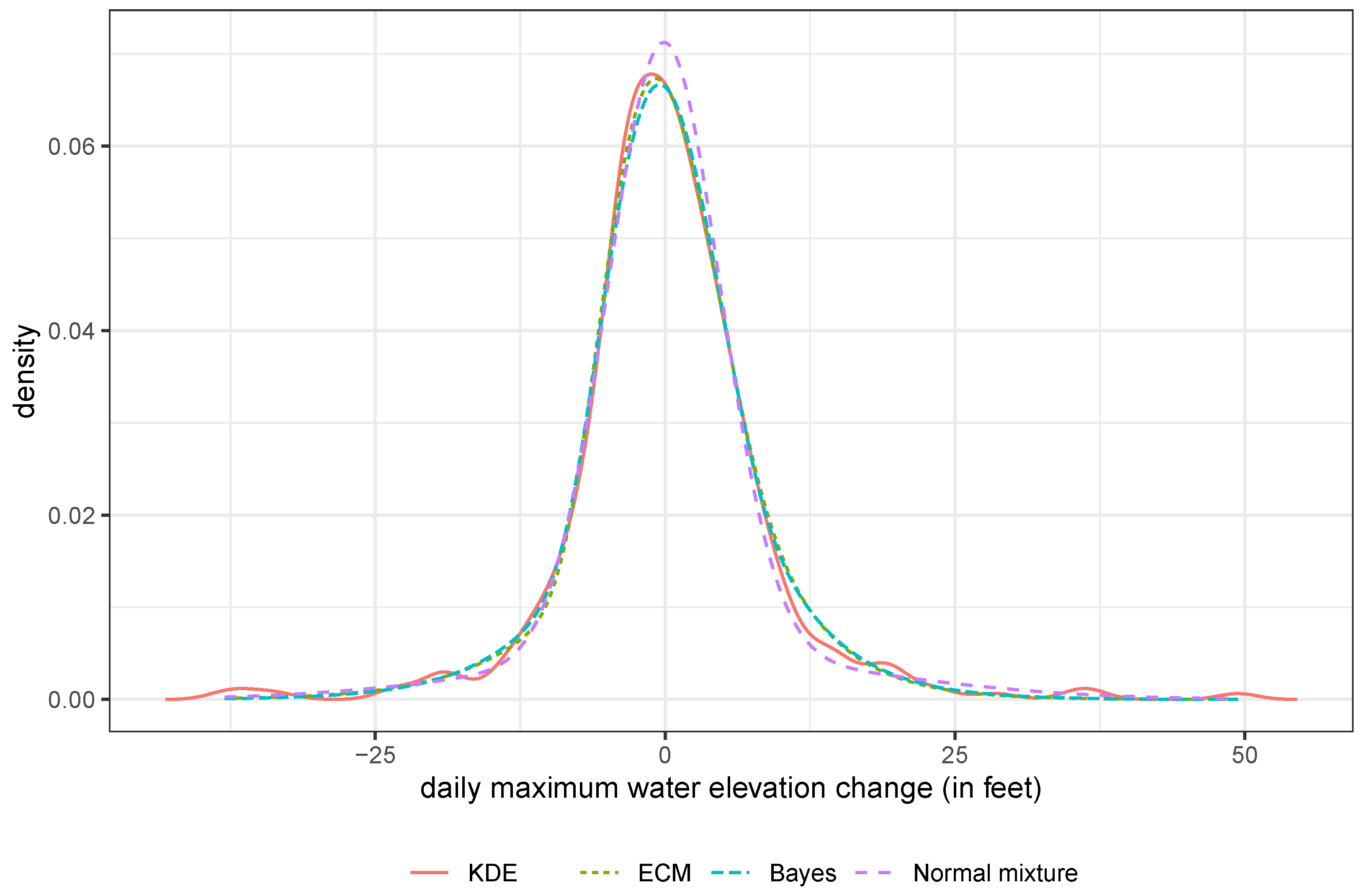
Figure 2 presents the estimated density functions from these two methods, in contrast with the estimated density curve resulting from fitting the data to a two-component normal mixture, and a kernel density estimate using a Gaussian kernel with the bandwidth selected according to the method proposed by Sheather and Jones [
41]. The last estimate is fully nonparametric and served as a benchmark against which the other three density estimates were assessed graphically. The kernel density estimate is more flexible at describing varying tail behaviors, but such flexibility comes at the cost of statistical efficiency and interpretability. With the wiggly tails evident in
Figure 2 for this estimate, we suspected a certain level of overfitting of the kernel density estimate. This often happens to kernel-based estimation of a function around a region where data are scarce, with a bandwidth not large enough for the region. Between the two FG density estimates, the difference is almost negligible. They both track the kernel density estimate closely over a wide range of the support around the mode. The mode of the estimated normal mixture density is close to the other three mode estimates, but the tails are much lighter than those of the other three estimated densities.
Besides comparing the three parametric density estimates pictorially, we also used the Monte-Carlo-based one-sample Kolmogorov–Smirnov test to assess the goodness of fit. The
p-values from this test are 0.223, 0.312, and 0.106 for the frequentist FG density estimate, the Bayesian FG density estimate, and the estimated normal mixture density, respectively. Although none of the
p-values are low enough to indicate a lack of fit (at significance level 0.05, for example), the
p-value associated with the normal mixture is much lower than those for FG. Hence, between the two null hypotheses, with one assuming an FG distribution and the other claiming a normal mixture for this dataset, we find even weaker evidence to reject the former than data evidence against the latter. It is also worth noting that the Kolmogorov–Smirnov test is known to have low power to detect deviations from a posited distribution that occurs in the tails [
42]. This may explain the above-0.05
p-value for the normal mixture fit of the data even though the tail of this posited distribution may be too thin for the current data. Finally, as suggested by a referee, we computed the Akaike information criterion (AIC) and the Bayesian information criterion (BIC) after fitting the FG distribution and the normal mixture distribution to the data. When assuming an FG distribution, we obtained an AIC/BIC of 2506.028/2521.638 from the frequentist method, and 2506.299/2521.909 from the Bayesian method. When assuming a mixture normal, we found the values of AIC and BIC to be 2499.821 and 2519.334, respectively. Even though the fitted normal mixture distribution produces a lower AIC/BIC than the fitted FG distribution, we argue that these metrics focus more on the
overall goodness of fit, and can be more forgiving when it comes to a relatively poor fit for certain feature of a distribution, such as the tail behavior.
We used STAN to implement the Bayesian inference for the Lake Murray data. The code can be found here:
https://github.com/rh8liuqy/flexible_Gumbel/blob/main/FG_MLR.stan, accessed on 6 March 2024), where the JAGS code for fitting the FG distribution is also provided. The posterior output is given in
Appendix C. The output provided there indicates that our MCMC chain has converged (see the
Rhat statistics).
6. An Application in Criminology
With the location parameter
signified in the FG distribution as the mode, it is straightforward to formulate a modal regression model that explores the relationship between the response variable and predictors. To demonstrate the formulation of a modal regression model based on the FG distribution, we analyzed a dataset from Agresti et al. [
43] in the area of criminology. This dataset contains the percentage of college education, poverty percentage, metropolitan rate, and murder rate for the 50 states in the United States and the District of Columbia from the year 2003. The poverty percentage is the percentage of the residents with income below the poverty level; the metropolitan rate is defined as the percentage of the population living in the metropolitan area; and the murder rate is the annual number of murders per 100,000 people in the population.
We fit the following modal regression model to investigate the association between the murder rate (
Y) and the aforementioned demographic variables,
where
includes all regression coefficients. For the prior elicitation in Bayesian inference, we assume that
and use the same priors for
,
, and
w as those in
Section 3.2. As a more conventional regression analysis to compare with our modal regression, we also fit the mean regression model assuming mean-zero normal model error to the data.
Table 3 shows the inference results from the modal regression model, and
Table 4 presents the inference results from the mean regression model. At
significance level, both frequentist and Bayesian modal regression analyses confirm that there exists a
negative association between the percentage of college education and the murder rate, as well as a positive association between the metropolitan rate and the murder rate. In contrast, according to the inferred mean regression model, there is a
positive association between the percentage of college education and the murder rate. Such claimed positive association is intuitively difficult to justify and contradicts many published results in criminology [
44,
45].
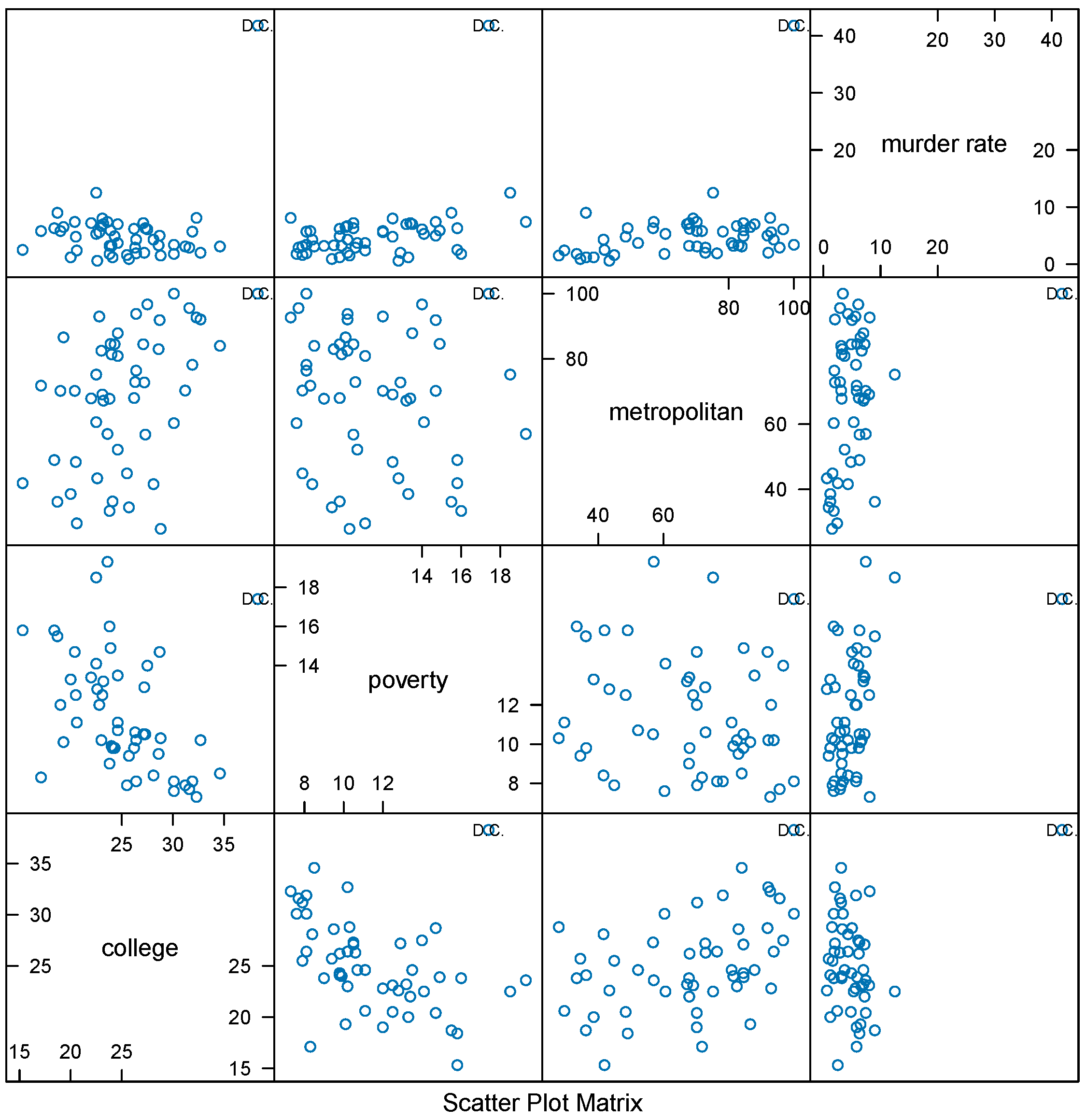
The scatter plot of the data in
Figure 3 can shed some light on why one reaches such a drastically different conclusion on a covariate effect when mean regression is considered in place of modal regression. As shown in
Figure 3, there exists an obvious outlier, the District of Columbia (D.C.), in panels of the first row of the scatter plot matrix, for instance. D.C. not only exhibited the highest murder rate but also the highest percentage of college-educated individuals. These dual characteristics position D.C., as an outlier within the dataset. Mean regression reacts to this one extreme outlier by inflating the covariate effect associated with the percentage of college education in the inferred mean regression function. Thanks to the heavy-tailed feature of the FG distribution, modal regression based on this distribution is robust to outliers; it strives to capture data features suggested by the majority of the data and is not distracted by the extreme outlier when inferring covariate effects in this application.
Lastly, to compare their overall goodness of fit for the current data, we computed AIC and BIC following fitting each regression model. Adopting the frequentist and Bayesian methods, the modal regression analysis yields AIC/BIC equal to 239.394/252.917 and 238.710/252.233, respectively. The mean regression analysis leads to AIC and BIC equal to 303.154 and 312.813, respectively.
Appendix C contains the convergence diagnosis for the Bayesian inferential method applied to this dataset, from which we see no concerns about convergence.
7. Discussion
The mode had been an overlooked location parameter in statistical inference until recently when the statistics community witnessed a revived interest in modal regression among statisticians [
1,
5,
46,
47,
48,
49,
50]. Historically, statistical inference for the mode has been mostly developed under the nonparametric framework for reasons we point out in
Section 1. Existing semiparametric methods for modal regression only introduce parametric ingredients in the regression function, i.e., the conditional mode of the response, with the mode-zero error distribution left in a nonparametric form [
18,
51,
52,
53,
54,
55,
56,
57]. The few recently proposed parametric modal regression models all impose stringent parametric assumptions on the error distribution [
19,
20,
21]. Our proposed flexible Gumbel distribution greatly alleviates concerns contributing to data scientists’ reluctance to adopt a parametric framework when drawing inferences for the mode. This new distribution is a heterogeneous mixture in the sense that the two components in the mixture belong to different Gumbel distribution families, which is a feature that shields it from the non-identifiability issue most traditional mixture distributions face, such as the normal mixtures. The proposed distribution is indexed by the mode along with shape and scale parameters, and thus is convenient to use to draw inferences for the mode while remaining flexible. It is also especially suitable for modeling heavy-tailed data, whether the heaviness in tails is due to extremely large or extremely small observations, or both. These are virtues of FG that cannot be achieved by the popular normal mixture and many other existing mixture distributions.
We develop the numerically efficient and stable ECM algorithm for frequentist inference for the FG distribution, and a reliable Bayesian inference method that can be easily implemented using free software, including STAN, JAGS, and BUGS. Compared with the more widely adopted mean regression framework, the modal regression model based on FG we entertained in
Section 6 shows great potential in revealing meaningful covariate effects potentially masked by extreme outliers. With these advances made in this study, we open up new directions for parametric modal regression and semiparametric modal regression with a fully parametric yet flexible error distribution, and potentially nonparametric ingredients incorporated in the regression function.




{kind=link}
{kind=link}
{kind=link}