
Portfolio Management of Copula-Dependent Assets Based on P(Y < X) Reliability Models: Revisiting Frank Copula and Dagum Distributions

 ,
,  and
and 
Abstract
:1. Introduction
2. Reliability
3. Copulas and Reliability Measures
4. Revisiting Frank Copula
5. Reliability Calculations
6. Numerical Calculations
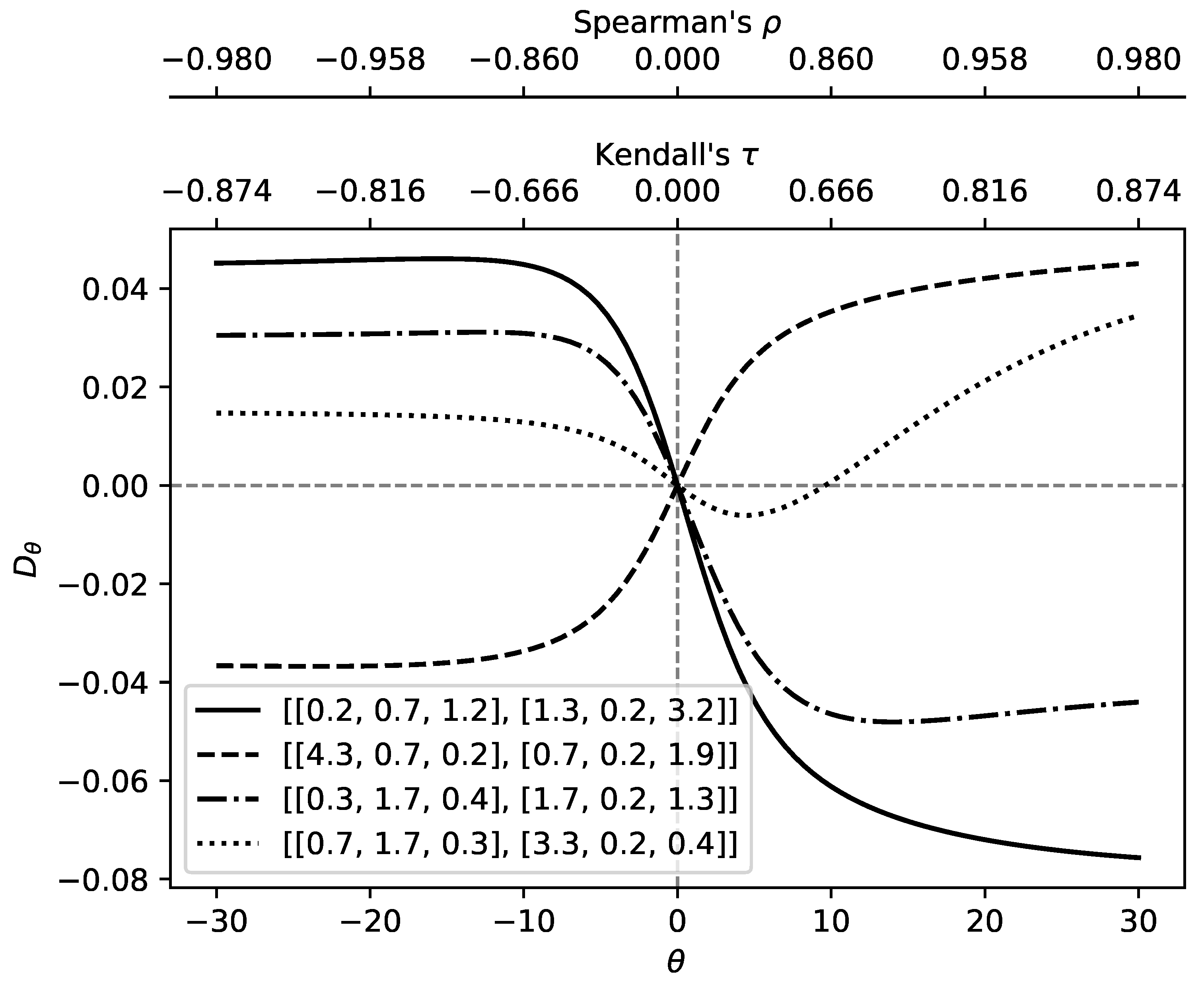
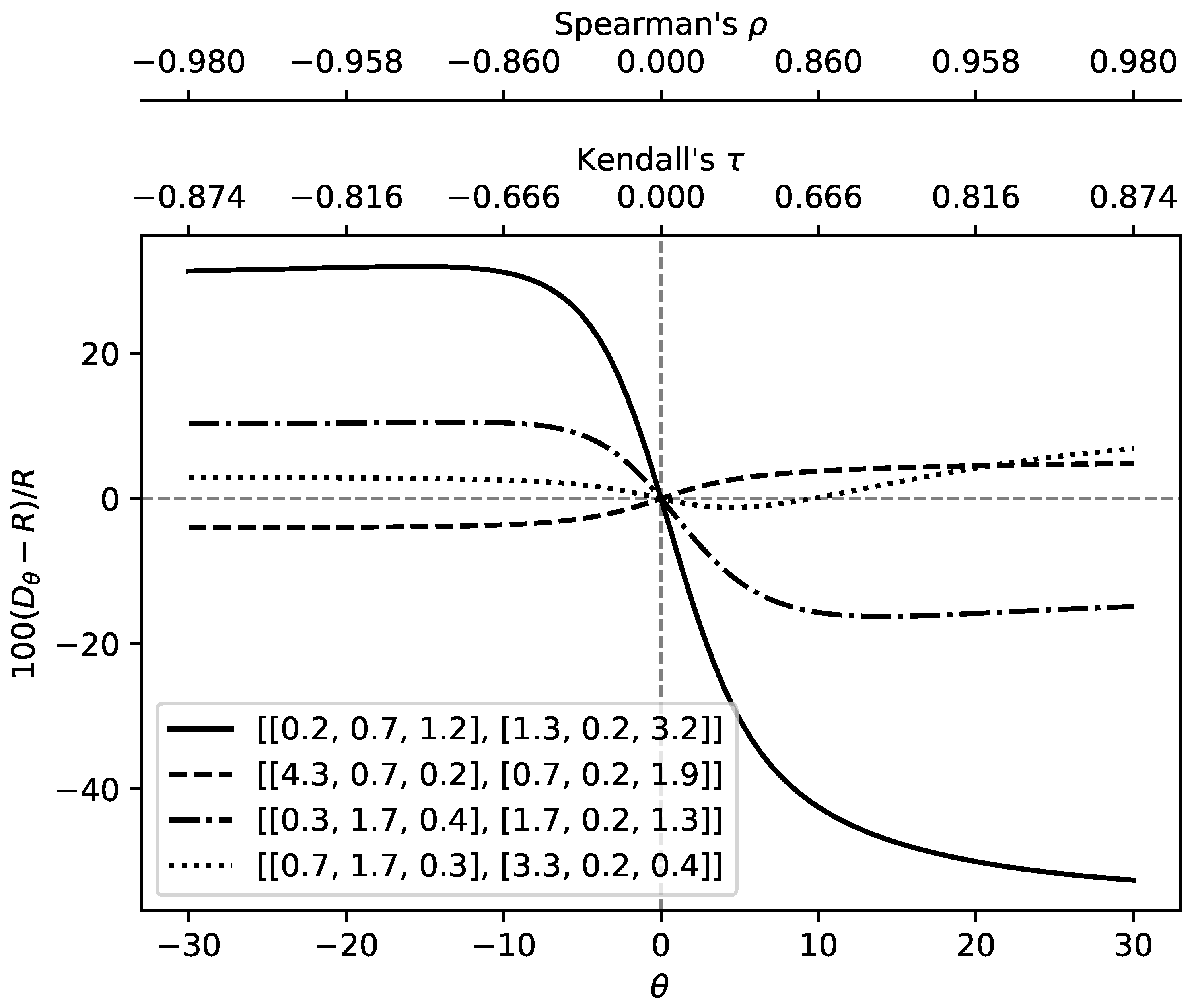
6.1. Parametric Study
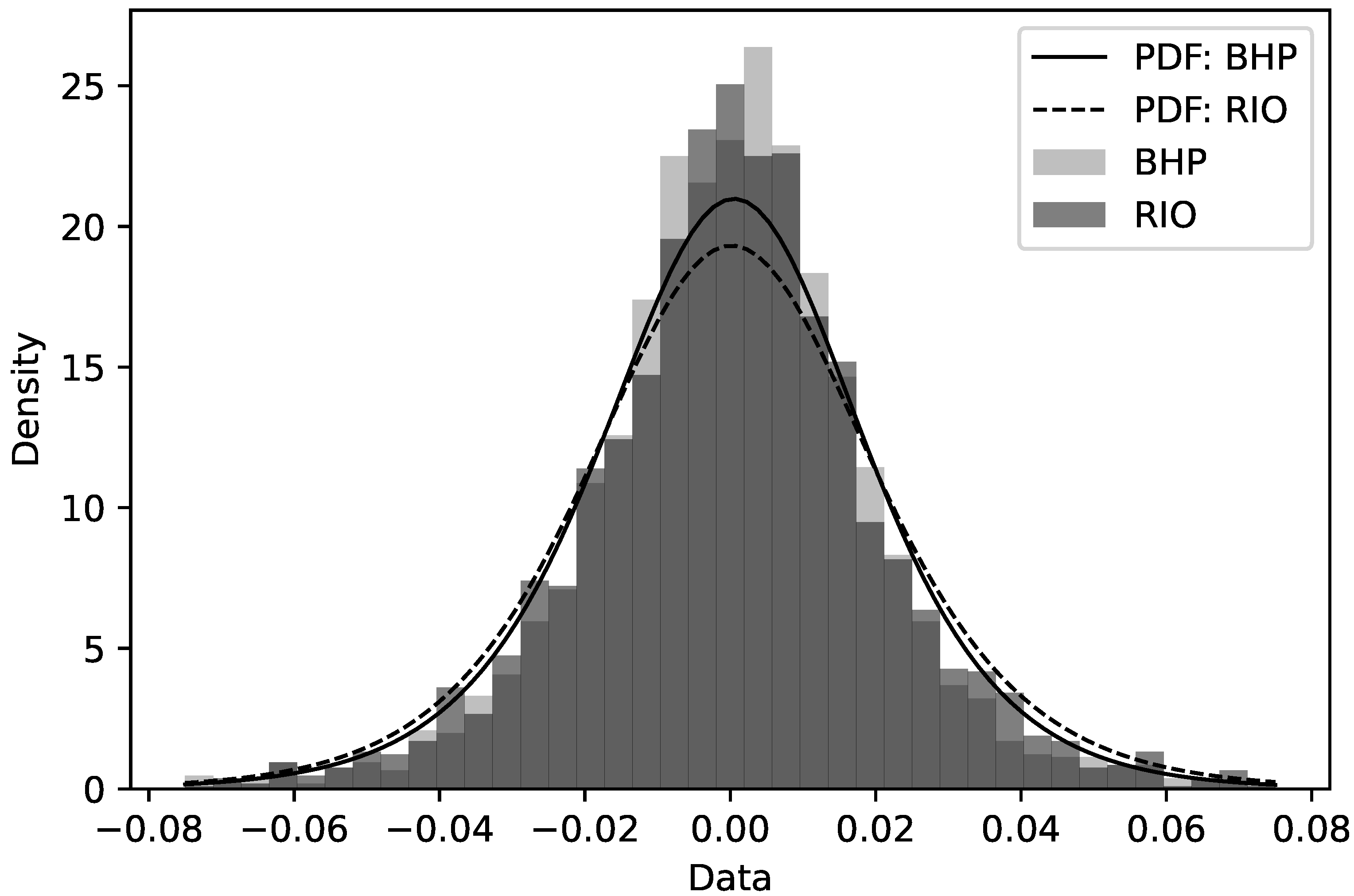
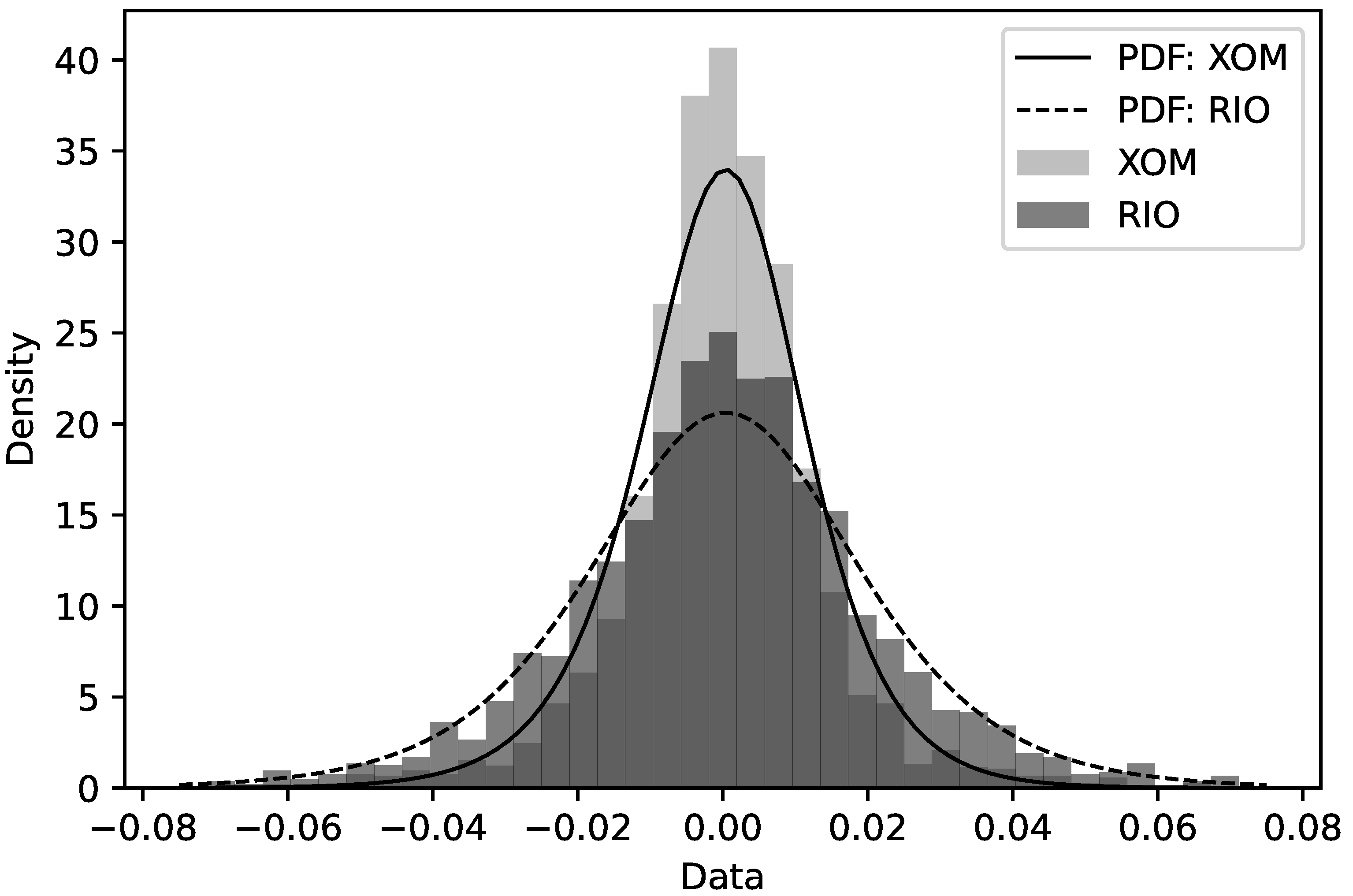
6.2. Applications to Real Stock Data
- Collect the real stock return data samples from 1 January 2010 to 31 December 2020 using the Yfinance Python package for the random variables X and Y;
- Let l be the length of the collected data. Moreover, let and , , denote the elements of the real samples of the real variables X and Y, respectively. Consider the indicator function , where , and , otherwise. The value of can be estimated as and is simply ;
- Generate random samples with elements each for the random variables X and Y;
- Let and , , denote the elements of the random samples of the random variables X and Y, respectively. Consider the indicator function , where , and , otherwise. The value of can be estimated as . Thus, is simply ;
- Repeat the above process 1000 times and then take the mean value of the s generated as the estimated value of . We also compute the standard deviation of such results to check the suitability of the mean estimate.
6.2.1. Modelling Stock Return Data as Log–Dagum Random Variables
6.2.2. Reliability Analyses
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. H-Function
Appendix A.2. Codes
- fullflexible
- from scipy import integrate
- import numpy as np
- from scipy.special import gamma
- from scipy.special import binom
- from scipy.stats import mielke
- from scipy.stats import kendalltau
- from scipy.stats import spearmanr
- import pandas as pd
- import matplotlib.pyplot as plt
- import yfinance as yf
- from scipy.optimize import fsolve
- from scipy.stats import genlogistic
- def RI_Emp (px,py):
- u1,u2,u3=px
- v1,v2,v3=py
- rvals = []
- for n in range(1000):
- X = mielke.rvs(u1*u3, u3, 0, np.power(u2,1/u3), size=3000)
- Y = mielke.rvs(v1*v3, v3, 0, np.power(v2,1/v3), size=3000)
- rvals.append(sum(1 for i in Y-X if i < 0)/3000)
- return [np.mean(rvals),np.var(rvals)]
- def H2222(z,p1,p2,p3):
- gprod = lambda s: np.power(z,-s)*gamma(p3+s)*gamma(1+p2*s)*gamma(-s)*gamma(1-p1-p2*s)
- c = np.max([-p3,-1/p2])/2
- return integrate.quad(lambda w: np.real(gprod(c+1j*w))/(2*np.pi),-np.infty,np.infty)[0]
- def RI(px,py):
- u1,u2,u3=px
- v1,v2,v3=py
- return H2222(np.power(u2,v3/u3)/v2,1-u1,v3/u3,v1)/(gamma(u1)*gamma(v1))
- def R_FC_Dagum_Emp(theta,size,px,py):
- u1,u2,u3=px
- v1,v2,v3=py
- rvals = []
- for n in range(1000):
- un1 = np.random.random(size)
- vn2 = np.random.random(size)
- un2 = -np.power(theta,-1)*np.log(1+(vn2*(1-np.exp(-theta)))/(vn2*(np.exp(-theta*un1)-1)-np.exp(-theta*un1)))
- rvx = np.power((np.power(un1,-1/u1)-1)/u2,-1/u3)
- rvy = np.power((np.power(un2,-1/v1)-1)/v2,-1/v3)
- rvals.append(sum(1 for i in rvy-rvx if i < 0)/size)
- return [np.mean(rvals),np.var(rvals)]
- def I_ab(px,py,a,b):
- u1,u2,u3=px
- v1,v2,v3=py
- return H2222(np.power(u2,v3/u3)/v2,1-(a+1)*u1,v3/u3,b*v1)/((a+1)*gamma((a+1)*u1)*gamma(b*v1))
- def R_Series_Dagum(theta,px,py,lgt1,lgt2):
- u1,u2,u3=px
- v1,v2,v3=py
- return sum([binom(n,k)*binom(n+1,r)*binom(l,m)*((-theta)**(l))*((-1)**(k+r))*((k+1)**(l-m))*((r)**(m))*I_ab(px,py,l-m,m)/(((1-np.exp(-theta))**(n+1))*gamma(l+1)) for n in range(lgt1) for k in range(n+1) for r in range(n+2) for l in range(lgt2) for m in range(l+1)])
- def R_Num_App(theta,px,py,m1):
- u1,u2,u3=px
- v1,v2,v3=py
- t=np.exp(-theta)
- return (1/m1)*(1/2+sum((t**(w/m1))*(1-t**(np.power(1+v2*np.power((np.power(w/m1,-1/u1)-1)/u2,v3/u3),-v1)))/((1-t)-(1-t**(w/m1))*(1-t**(np.power(1+v2*np.power((np.power(w/m1,-1/u1)-1)/u2,v3/u3),-v1)))) for w in range(1,m1)))
- def R_Exact(theta,px,py):
- u1,u2,u3=px
- v1,v2,v3=py
- t=np.exp(-theta)
- return integrate.quad(lambda w: (t**(w))*(1-t**(np.power(1+v2*np.power((np.power(w,-1/u1)-1)/u2,v3/u3),-v1)))/((1-t)-(1-t**(w))*(1-t**(np.power(1+v2*np.power((np.power(w,-1/u1)-1)/u2,v3/u3),-v1)))),0,1)[0]
- def Debye(k,x):
- return (k/(x**k))*integrate.quad(lambda w:(w**k)/(np.exp(w)-1),0,x)[0]
- def KendallTau(theta):
- return 1-4*(1/theta)*(1-Debye(1,theta))
- def SpearmanRho(theta):
- return 1-12*(1/theta)*(Debye(2,-theta)-Debye(1,-theta))
- def flatten_l(l):
- return [item for sublist in l for item in sublist]
- def theta_effect(p):
- tval=np.linspace(-30.0000001,30.0000001, num=100)
- colmn=[r’$\theta$’]
- colmn.append(p)
- lst=[]
- for pvs in p:
- px,py = pvs
- ri=RI(px,py)
- lstq=R_Num_App(tval,px,py,300)-ri
- lst.append(pd.DataFrame({
- r’$\theta$’:tval,
- str(pvs):lstq
- },columns=[r’$\theta$’,str(pvs)]).set_index(r’$\theta$’))
- lf=pd.concat(lst,sort=False,axis=1)
- ax=lf.plot(color=’k’,style = ["-","--","-.",":"])
- ax.set_ylabel(r’$D_{\theta}$’)
- ax.axhline(linewidth=1, color=’k’,ls=’--’,alpha=0.5)
- ax.axvline(linewidth=1, color=’k’,ls=’--’,alpha=0.5)
- axXs = ax.get_xticks()
- ax2Xs = []
- for X in axXs:
- ax2Xs.append("%.3f" %KendallTau(X+0.00001))
- ax2 = ax.twiny()
- ax2.set_xlabel(r"Kendall’s $\tau$")
- ax2.set_xticks(axXs)
- ax2.set_xbound(ax.get_xbound())
- ax2.set_xticklabels(ax2Xs)
- ax3 = ax.twiny()
- ax3Xs = []
- for X in axXs:
- ax3Xs.append("%.3f" %SpearmanRho(X+0.00001))
- ax3.xaxis.set_ticks_position("top")
- ax3.xaxis.set_label_position("top")
- ax3.spines["top"].set_position(("axes", 1.20))
- ax3.set_frame_on(True)
- ax3.patch.set_visible(False)
- for sp in ax3.spines.values():
- sp.set_visible(False)
- ax3.spines["top"].set_visible(True)
- ax3.set_xlabel(r"Spearman’s $\rho$")
- ax3.set_xticks(axXs)
- ax3.set_xbound(ax.get_xbound())
- ax3.set_xticklabels(ax3Xs)
- ax3.figure.savefig(’full_figure.pdf’,bbox_inches="tight")
- return ax3
- def theta_effect_p(p):
- tval=np.linspace(-30.0000001,30.0000001, num=100)
- colmn=[r’$\theta$’]
- colmn.append(p)
- lst=[]
- for pvs in p:
- px,py = pvs
- ri=RI(px,py)
- lstq=100*(R_Num_App(tval,px,py,300)-ri)/ri
- lst.append(pd.DataFrame({
- r’$\theta$’:tval,
- str(pvs):lstq
- },columns=[r’$\theta$’,str(pvs)]).set_index(r’$\theta$’))
- lf=pd.concat(lst,sort=False,axis=1)
- ax=lf.plot(color=’k’,style = ["-","--","-.",":"])
- ax.set_ylabel(r’$100(D_{\theta}-R)/R$’)
- ax.axhline(linewidth=1, color=’k’,ls=’--’,alpha=0.5)
- ax.axvline(linewidth=1, color=’k’,ls=’--’,alpha=0.5)
- axXs = ax.get_xticks()
- ax2Xs = []
- for X in axXs:
- ax2Xs.append("%.3f" %KendallTau(X+0.00001))
- ax2 = ax.twiny()
- ax2.set_xlabel(r"Kendall’s $\tau$")
- ax2.set_xticks(axXs)
- ax2.set_xbound(ax.get_xbound())
- ax2.set_xticklabels(ax2Xs)
- ax3 = ax.twiny()
- ax3Xs = []
- for X in axXs:
- ax3Xs.append("%.3f" %SpearmanRho(X+0.00001))
- ax3.xaxis.set_ticks_position("top")
- ax3.xaxis.set_label_position("top")
- ax3.spines["top"].set_position(("axes", 1.20))
- ax3.set_frame_on(True)
- ax3.patch.set_visible(False)
- for sp in ax3.spines.values():
- sp.set_visible(False)
- ax3.spines["top"].set_visible(True)
- ax3.set_xlabel(r"Spearman’s $\rho$")
- ax3.set_xticks(axXs)
- ax3.set_xbound(ax.get_xbound())
- ax3.set_xticklabels(ax3Xs)
- ax3.figure.savefig(’full_figure_p.pdf’,bbox_inches="tight")
- return ax3
- def DagumPDF(x,gamma1,gamma2,gamma3):
- return mielke.pdf(x, gamma1*gamma3, gamma3, 0, np.power(gamma2,1/gamma3))
- def Fit_Dagum(data):
- k,s,mu,sigma = mielke.fit(data,floc=0)
- return [k/s,sigma**s,s]
- def Theta_from_Tau(Tau):
- if Tau==1:
- return 100
- else:
- def f_solv(x):
- return KendallTau(x)-Tau
- return fsolve(f_solv,0.3)[0]
- def Emp_R(data1,data2):
- return sum(1 for i in data1-data2 if i < 0)/len(data1)
- def Fit_LogDagum(data):
- c,mu,sigma = genlogistic.fit(data)
- return [c,np.exp(mu/sigma),1/sigma]
- def LogDagumPDF(x,gamma1,gamma2,gamma3):
- return genlogistic.pdf(x, gamma1, np.log(gamma2)/gamma3,1/gamma3)
References
- Milhomem, D.A.; Dantas, M.J.P. Analysis of new approaches used in portfolio optimization: A systematic literature review. Production 2020, 30. [Google Scholar] [CrossRef]
- Markowitz, H. Portfolio Selection. J. Financ. 1952, 7, 77–91. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, X.; Guo, S. Portfolio selection problems with Markowitz’s mean–variance framework: A review of literature. Fuzzy Optim. Decis. Mak. 2017, 17, 125–158. [Google Scholar] [CrossRef]
- Uryasev, S. Conditional value-at-risk: Optimization algorithms and applications. In Proceedings of the IEEE/IAFE/INFORMS 2000 Conference on Computational Intelligence for Financial Engineering (CIFEr) (Cat. No.00TH8520), New York, NY, USA, 28–28 March 2000; pp. 49–57. [Google Scholar] [CrossRef]
- Fabozzi, F.J.; Kolm, P.N.; Pachamanova, D.A.; Focardi, S.M. Robust Portfolio Optimization. J. Portf. Manag. 2007, 33, 40–48. [Google Scholar] [CrossRef]
- Hu, Y.; Liu, K.; Zhang, X.; Su, L.; Ngai, E.; Liu, M. Application of evolutionary computation for rule discovery in stock algorithmic trading: A literature review. Appl. Soft Comput. 2015, 36, 534–551. [Google Scholar] [CrossRef]
- Ertenlice, O.; Kalayci, C.B. A survey of swarm intelligence for portfolio optimization: Algorithms and applications. Swarm Evol. Comput. 2018, 39, 36–52. [Google Scholar] [CrossRef]
- Mansini, R.; Ogryczak, W.; Speranza, M.G. Twenty years of linear programming based portfolio optimization. Eur. J. Oper. Res. 2014, 234, 518–535. [Google Scholar] [CrossRef]
- Black, F.; Litterman, R. Global Portfolio Optimization. Financ. Anal. J. 1992, 48, 28–43. [Google Scholar] [CrossRef]
- Lindberg, C. Portfolio optimization when expected stock returns are determined by exposure to risk. Bernoulli 2009, 15, 464–474. [Google Scholar] [CrossRef]
- Ross, S.A. The arbitrage theory of capital asset pricing. J. Econ. Theory 1976, 13, 341–360. [Google Scholar] [CrossRef]
- Boubaker, H.; Sghaier, N. Portfolio optimization in the presence of dependent financial returns with long memory: A copula based approach. J. Bank. Financ. 2013, 37, 361–377. [Google Scholar] [CrossRef]
- Ang, A.; Chen, J. Asymmetric correlations of equity portfolios. J. Financ. Econ. 2002, 63, 443–494. [Google Scholar] [CrossRef]
- Longin, F.; Solnik, B. Extreme Correlation of International Equity Markets. J. Financ. 2001, 56, 649–676. [Google Scholar] [CrossRef]
- Hartmann, P.; Straetmans, S.; Vries, C.G.d. Asset Market Linkages in Crisis Periods. Rev. Econ. Stat. 2004, 86, 313–326. [Google Scholar] [CrossRef] [Green Version]
- Beine, M.; Cosma, A.; Vermeulen, R. The dark side of global integration: Increasing tail dependence. J. Bank. Financ. 2010, 34, 184–192. [Google Scholar] [CrossRef]
- Harvey, C.R.; Siddique, A. Autoregressive Conditional Skewness. J. Financ. Quant. Anal. 1999, 34, 465–487. [Google Scholar] [CrossRef]
- Jondeau, E.; Rockinger, M. Conditional volatility, skewness, and kurtosis: Existence, persistence, and comovements. J. Econ. Dyn. Control 2003, 27, 1699–1737. [Google Scholar] [CrossRef] [Green Version]
- Brooks, C.; Burke, P.; Heravi, S.; Persand, G. Autoregressive Conditional Kurtosis. J. Financ. Econom. 2005, 3, 399–421. [Google Scholar] [CrossRef] [Green Version]
- Kotz, S.; Lumelskii, Y.; Pensky, M. The Stress-Strength Model and Its Generalizations; World Scientific Publishing Co. Pte Ltd.: Singapore, 2003. [Google Scholar]
- Domma, F.; Giordano, S. A copula-based approach to account for dependence in stress-strength models. Stat. Pap. 2013, 54, 807–826. [Google Scholar] [CrossRef]
- Rezaei, S.; Tahmasbi, R.; Mahmoodi, M. Estimation of P(Y<X) for generalized Pareto distribution. J. Stat. Plan. Inference 2010, 140, 480–494. [Google Scholar] [CrossRef]
- Wong, A. Interval estimation of P(Y<X) for generalized Pareto distribution. J. Stat. Plan. Inference 2012, 142, 601–607. [Google Scholar] [CrossRef]
- Baklizi, A. Estimation of Pr(X<Y) Using Record Values in the One and Two Parameter Exponential Distributions. Commun.-Stat.-Theory Methods 2008, 37, 692–698. [Google Scholar] [CrossRef]
- Sengupta, S. Unbiased estimation of P(X>Y) for two-parameter exponential populations using order statistics. Statistics 2011, 45, 179–188. [Google Scholar] [CrossRef]
- Ozelim, L.C.S.M.; Otiniano, C.E.G.; Rathie, P.N. On The Linear Combination of N Logistic Random Variables and Reliability Analysis. South East Asian J. Math. Math. Sci. 2016, 12, 19–34. [Google Scholar]
- Ozelim, L.C.S.M.; Rathie, P.N. Linear Combination and Reliability of Generalized Logistic Random Variables. Eur. J. Pure Appl. Math. 2019, 12, 722–733. [Google Scholar] [CrossRef]
- Rathie, P.N.; Ozelim, L.C.S.M. Exact and approximate expressions for the reliability of stable Lévy random variables with applications to stock market modelling. J. Comput. Appl. Math. 2017, 321, 314–322. [Google Scholar] [CrossRef]
- Domma, F.; Giordano, S. A stress–strength model with dependent variables to measure household financial fragility. Stat. Methods Appl. 2012, 21, 375–389. [Google Scholar] [CrossRef]
- Embrechts, P.; Kluppelberg, C.; Mikosch, T. Modelling Extremal Events: For Insurance and Finance (Stochastic Modelling and Applied Probability); Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Gupta, R.C.; Subramanian, S. Estimation of reliability in a bivariate normal distribution with equal coefficients of variation. Commun. Stat.-Simul. Comput. 1998, 27, 675–698. [Google Scholar] [CrossRef]
- Hanagal, D.D. Note on estimation of reliability under bivariate pareto stress-strength model. Stat. Pap. 1997, 38, 453–459. [Google Scholar] [CrossRef]
- Nadarajah, S.; Kotz, S. Reliability for some bivariate exponential distributions. Math. Probl. Eng. 2006, 2006, 041652. [Google Scholar] [CrossRef] [Green Version]
- Nadarajah, S. Reliability for some bivariate gamma distributions. Math. Probl. Eng. 2005, 2005, 924843. [Google Scholar] [CrossRef] [Green Version]
- Gupta, R.C.; Ghitany, M.E.; Al-Mutairi, D.K. Estimation of reliability from a bivariate log-normal data. J. Stat. Comput. Simul. 2013, 83, 1068–1081. [Google Scholar] [CrossRef]
- Dagum, C. Inequality measures between income distributions with applications. Econometrica 1980, 28, 1791–1803. [Google Scholar] [CrossRef]
- Nelsen, R.B. An Introduction to Copulas, 2nd ed.; Springer Series in Statistics; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Joe, H. Multivariate Models and Multivariate Dependence Concepts (Chapman & Hall CRC Monographs on Statistics & Applied Probability), 1st ed.; Chapman and Hall/CRC: London, UK, 1997. [Google Scholar]
- Ruschendorf, L. Construction of multivariate distributions with given marginals. Ann. Inst. Stat. Math. 1985, 37, 225–233. [Google Scholar] [CrossRef]
- Luke, Y.L. The Special Functions and Their Approximations; Mathematics in Science and Engineering 53-1; Academic Press: Cambridge, MA, USA, 1969; Volume 1. [Google Scholar]
- Comtet, L. Advanced Combinatorics: The Art of Finite and Infinite Expansions; D. Reidel Pub. Co.: Dordrecht, The Netherlands, 1974. [Google Scholar]
- Mathai, A.M.; Haubold, H.J. Special Functions for Applied Scientist; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Domma, F.; Perri, P.F. Some developments on the log–Dagum distribution. Stat. Methods Appl. 2009, 18, 205–220. [Google Scholar] [CrossRef]
- Springer, M.D. The Algebra of Random Variables; John Wiley: Hoboken, NJ, USA, 1979. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Random Variable | Company Code | Company Name |
|---|---|---|
| BHP | BHP Group | |
| XOM | Exxon Mobil Corporation | |
| RIO | Rio Tinto Group |
| Random Variables | |
|---|---|
| 12.275 | |
| Random Variables | |
|---|---|
| 4.182 | |
| Index | Real Data | Rnd Data | Equation (46) | Equation (64) w/10 Term | Equation (64) w/100 Terms | Equation (64) w/400 Terms |
|---|---|---|---|---|---|---|
| 0.495303 | 0.494546 | 0.494523 | 0.495982 | 0.494575 | 0.494528 | |
| 0.485549 | 0.487365 | 0.487262 | 0.489479 | 0.487400 | 0.487282 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rathie, P.N.; de Sena Monteiro Ozelim, L.C.; de Andrade, B.B. Portfolio Management of Copula-Dependent Assets Based on P(Y < X) Reliability Models: Revisiting Frank Copula and Dagum Distributions. Stats 2021, 4, 1027-1050. https://doi.org/10.3390/stats4040059
Rathie PN, de Sena Monteiro Ozelim LC, de Andrade BB. Portfolio Management of Copula-Dependent Assets Based on P(Y < X) Reliability Models: Revisiting Frank Copula and Dagum Distributions. Stats. 2021; 4(4):1027-1050. https://doi.org/10.3390/stats4040059
Chicago/Turabian StyleRathie, Pushpa Narayan, Luan Carlos de Sena Monteiro Ozelim, and Bernardo Borba de Andrade. 2021. "Portfolio Management of Copula-Dependent Assets Based on P(Y < X) Reliability Models: Revisiting Frank Copula and Dagum Distributions" Stats 4, no. 4: 1027-1050. https://doi.org/10.3390/stats4040059
APA StyleRathie, P. N., de Sena Monteiro Ozelim, L. C., & de Andrade, B. B. (2021). Portfolio Management of Copula-Dependent Assets Based on P(Y < X) Reliability Models: Revisiting Frank Copula and Dagum Distributions. Stats, 4(4), 1027-1050. https://doi.org/10.3390/stats4040059