1. Introduction
Generalizations and modifications of standard statistical distributions, such as chi-square and Student distributions, play a useful role because of their numerous possible applications in different areas of statistics. However, the modifications introduced here, chi-square and Student bridge distributions, are only considered from the subsequent application.
If the normalized chi-square distributed random variable from the denominator of the common ratio representation of a Student distributed random variable is replaced with a mixture of independent normalized chi-square distributed variables, then the resulting ratio follows a distribution that is called here a Student bridge distribution. The possibly most prominent example of this type of random variables is the Behrens–Fisher statistic. The mixing coefficient in the corresponding representation of this statistic depends on the variances of the underlying two Gaussian sample distributions only through their ratio. The variance ratio thus plays the role of a nuisance parameter when deriving the distribution of the Behrens–Fisher statistic. As described in [
1], it may happen that the variance ratio is known although the individual variances are not when two instruments of equal precision average different numbers of replicates arriving at a response. Another situation where one of the two variances is known and the other one is not is dealt with in [
2].
The well known Behrens–Fisher statistic was introduced already in [
3,
4]. Several authors provided approximations of its distribution. To mention only some of the earlier contributions, first of all we refer to the well known approximation in [
5]. The approximative distribution whose percentage points are dealt with in [
6] is often called the Behrens–Fisher distribution. Convolutions of weighted chi-squares are used for an evaluation of the Welch approximation to the distribution of the Behrens–Fisher statistic in [
7]. In [
8], the exact distribution of the Behrens–Fisher statistic is derived for the case of two unknown variances, and depends on two unknown parameters, which brings with it the need for additional approximations for statistical applications.
The exact distribution of a modified Behrens–Fisher statistic considered in [
9] is very closely related to the distribution derived in [
8]. Authors of [
9] emphasize that there are (at that time) not many computer programs for computing the special functions that appear as components of the exact distributions and replace these functions mostly with suitable elementary ones.
The alternative aim of the present brief report is to take up again and continue earlier structural considerations on weighted chi-square distributions and their convolutions and on accordingly generalized Student distributions. Knowing the symmetry properties of the generalized Student densities considered here, numerical results obtained in [
9] can be taken over to dealing with asymmetric statistical problems in a common way. To be more specific, we prove that the distribution derived in [
8] actually depends on the unknown variances only through their ratio, thus allowing to perform exact statistical decisions in case of known variance ratios without additional approximations. Our proof follows a different line than that presented in [
8]. In particular, we make more visible the influence the mixture coefficient of the chi-square distributed variables from the denominator of the Behrens–Fisher statistic has on the resulting distribution of the Behrens–Fisher statistic itself. Although the densities of this statistic are visually quite close to each other with varying variance ratios, for many choices of the two sample sizes there are more or less exceptional situations of smaller closeness not mentioned in [
8]. From a general structural point of view, our consideration makes the particularly high precision of known approximations to the exact distribution of the Behrens–Fisher statistic more understandable, but it also confirms their limitations, as pointed out in [
9] for selected cases from a numerical point of view.
The more general problem of finding an optimal expectation test in the Gaussian two-sample scheme is called the Behrens–Fisher problem. It is dealt with in [
10] as a problem in the presence of three nuisance parameters. Reviews on numerous papers dealing with the Behrens–Fisher problem and the distribution of the Behrens–Fisher statistic can be found, e.g., in [
11] and in [
12]. The connections between the different classical approaches to statistics and the Behrens–Fisher problem are emphasized in [
11], while in [
12] there is an emphasis on three procedures that are in a certain suitably defined sense exact solutions to the Behrens–Fisher problem. The multivariate Behrens–Fisher distribution is considered, e.g., in [
13,
14]; for the nonparametric approach to the Behrens–Fisher problem see [
15] and the references given there.
The present paper does not deal with the general Behrens–Fisher problem but is devoted to the study of the probability density function of the Behrens–Fisher statistic with a focus on a function of the mixing parameter as a nuisance parameter. We explicitly describe the influence the single nuisance parameter has on the Student bridge distribution.
The two-sample
t-test with a known ratio of variances where the pooled empirical variance is used instead of individual sample variances is dealt with in [
1,
2]. What these papers have in common is that, unlike here, Student distributions with estimated d.f. are used for performing statistical tests. A test statistic conditional on the value of the variance ratio is studied in [
16].
We derive here exact representations of the pdf of the Behrens–Fisher statistic allowing heteroscedasticity and unbalancedness, i.e., different variances and sample sizes, respectively. These representations can be considered as heteroscedasticity-unbalancedness generalizations of Student’s density.
The paper is organized as follows. The chi-square bridge distribution is introduced and its moments are described in
Section 2.
Section 3 deals with the Student bridge distribution and
Section 4 with its application to the Behrens–Fisher statistic. A discussion including a three pillar bridges explanation for the choice of degrees of freedom in the Welch approximation to the exact distribution of the Behrens–Fisher statistic is presented in
Section 5. Figures were drawn using Matlab.
2. Chi-Square Bridge Distribution
Let
and
be independent random variables, where
is chi-square distributed with
d d.f.,
, and
. For
we consider the mixture of normalized chi-squares or
weighted
sum of
Chi-
squares
The first and second order moments of
W are
respectively. Minimal variance with respect to the mixing coefficient is attained for
, where
Let indicate that the random variable X follows the probability distribution h. If and , then holds for and statistic follows in this case a chi-square distribution with d.f., . Moreover, and . That is why we say that the distribution of WSCS has a three pillar bridges property.
In what follows we assume that
. The density of
W can immediately be derived then from its convolution integral representation
and allows according to commutativity of summands the following two representations:
and
where
denotes the hypergeometric function of order (1,1), see, e.g., Formula 13.2.1 in [
17] and Formula 9.210 in [
18]. The Beta function can be expressed in terms of the Gamma function
as
. In the case that
, we have that
and
. Choosing
in (
2) avoids unboundedness of
in the integrand of
and might motivate favoring Formula (
2) over Formula (
3), in this case.
Definition 1. The probability distribution having density (2) (or (3)) will be called chi-square bridge distribution with d.f. and mixing parameter γ, or -chi-square distribution , for short.
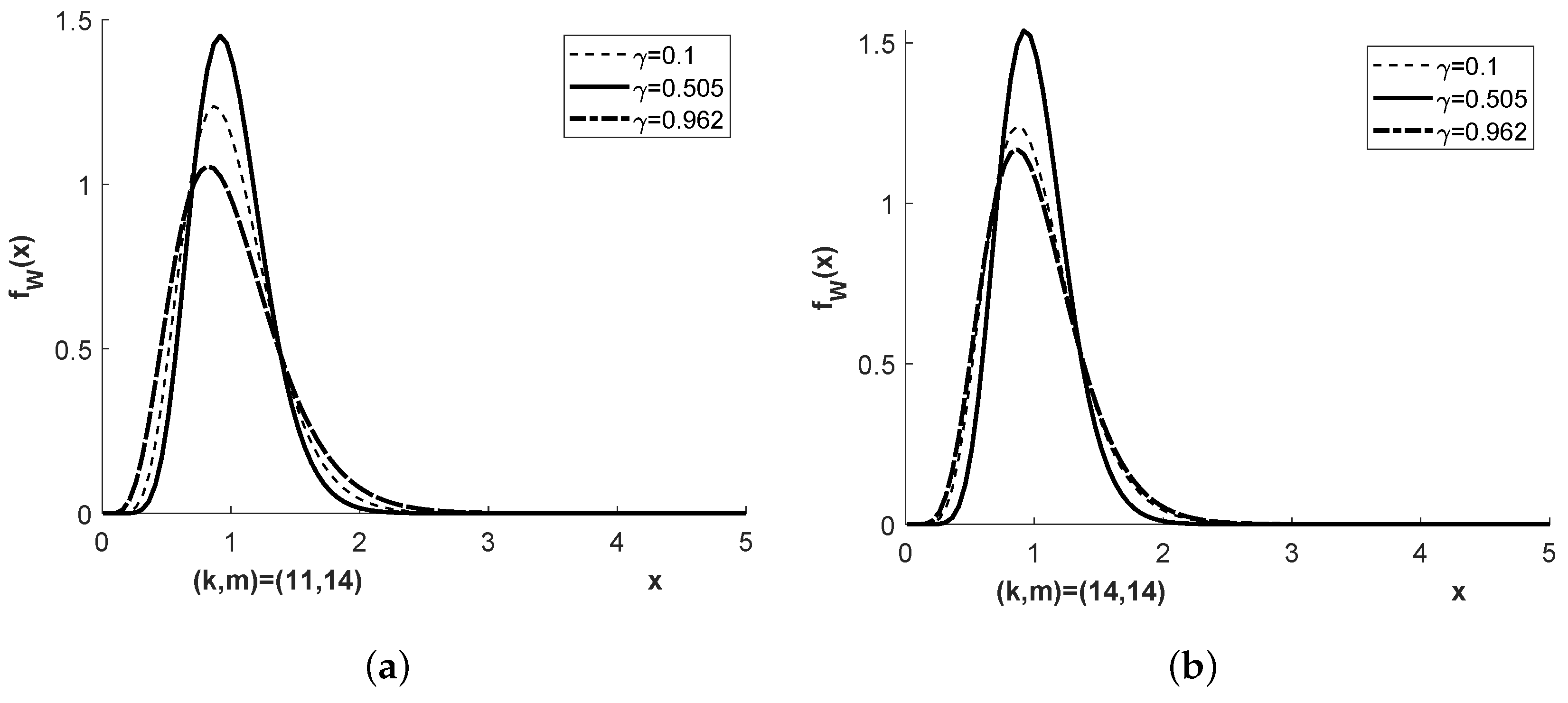
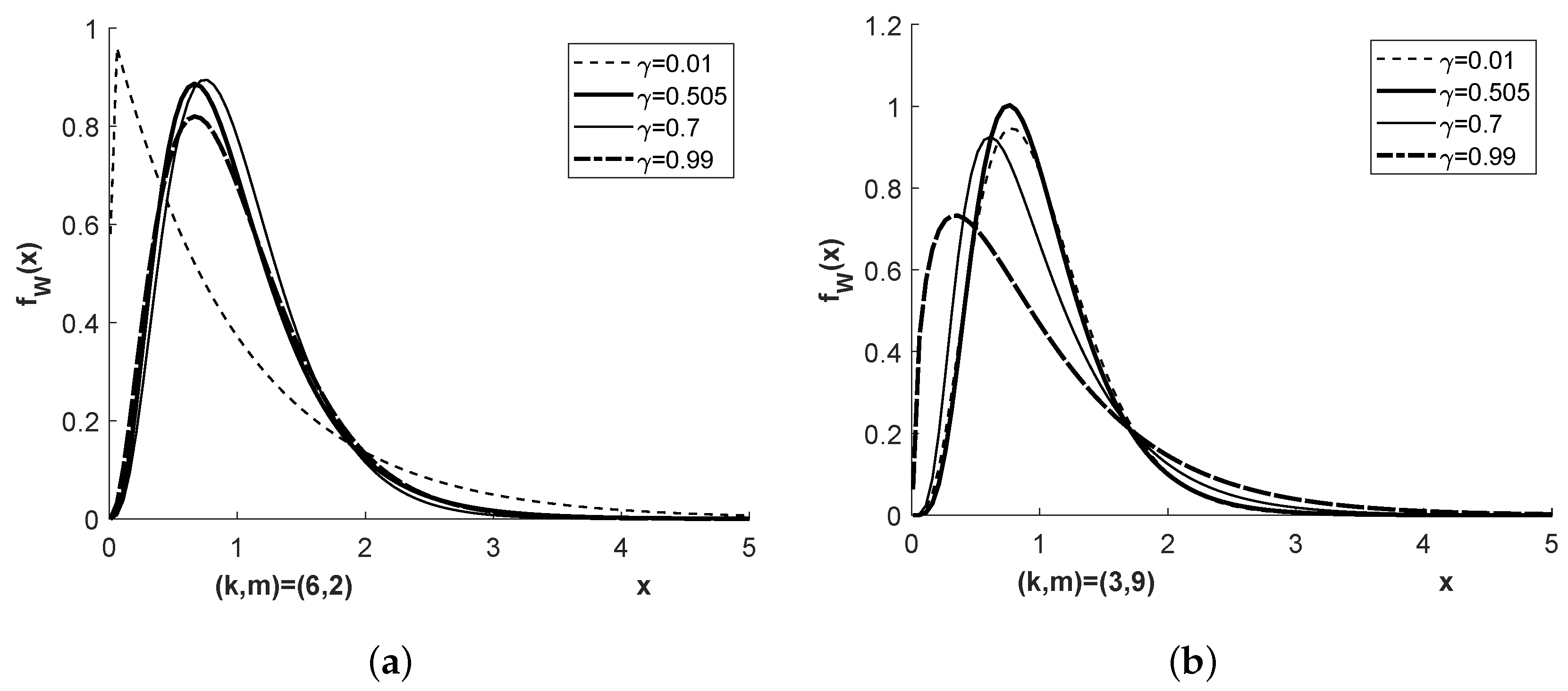
Figure 1 and
Figure 2 show the density
of the distribution
for four different pairs
, and
or
, respectively.
4. Behrens–Fisher Statistic
Let
and
be jointly independent Gaussian samples with expectations
and variances
We consider the statistic
where
and
are common sample means and unbiased sample variances, respectively. By
we mean that two random variables
Z and
U have the same probability distribution.
Lemma 1. The Behrens–Fisher statistic allows the representationwithand where is a standard Gaussian distributed random vector taking values in ,andare independent. Proof. Let us further denote the orthogonal projection onto the linear space
by
and let the matrix
P be defined such that
;
then
where
is a
-matrix. Here and below, missing off-diagonal matrix elements are zero. If
is the subspace of
being orthogonally to
then
. The statistic
can be written as:
where the functional
is defined for all
and
as:
We note that
and
, and put
The random vector
takes its values in
and follows a singular Gaussian distribution of rank
n,
As a consequence, the nominator and denominator of the ratio statistic
are stochastically independent. Let
be orthogonal
and
matrices, respectively. The random vector
with
follows a centered Gaussian distribution with the covariance matrix
The vector
allows almost surely the representation
where the random variables
are independent and centered normally distributed with variances
and
for
and
, respectively. Let
The Kronecker product matrix
describes then a mapping from
to
and, a.s.,
where the norm
is defined in
. The variance of the nominator of the Behrens–Fisher statistic is
Hence,
may be represented as
where the standard Gaussian distributed random variable
is independent of
. □
The constants and from Lemma 1 depend on and only through the variance ratio , which itself plays the role of a nuisance parameter.
If
where
is the sample size ratio then the constants
and
may be expressed in terms of the parameter triple
. The constants
and
depend on the variance ratio
, but in a different way for the different sample size ratio
. For
given, the inverse mapping
is defined by:
Other parameter triples could be introduced, e.g.,
, being closely related to but nevertheless different from the parameter triple in [
6].
The first and second order moments of
are
Finally, it turns out that under the hypothesis
the statistic
allows the representation
where the independent random variables
N and
are as in
Section 2,
, and the mixing coefficient is
Thus, the Behrens–Fisher statistic follows the Student bridge distribution with d.f.
and mixing coefficient
, or
-Student bridge distribution, for short,
In case of a known variance ratio, standard statistical significance testing and confidence estimation methods are based therefore upon the
-Student bridge distribution in the common way. Here, assumption
from
Section 2 means that
Without going here into technical details, the unrestricted distribution of is a non-central Student bridge distribution in a suitably defined sense.
5. Discussion
5.1. Reflection of the Three Pillar Bridges Property
We now consider four examples from [
8] for demonstrating the role the three pillar bridges property discussed in this paper may play in practical statistical work. In each example, we chose a pair of sample sizes
from the set
, and a variance ratio
from the positive real line that we assume to be known. In any case, we then determine the mixture coefficient
by a one-to-one calculation from
. This way,
Examples 1–4 are described (with some redundancy) as:
,
,
and
.
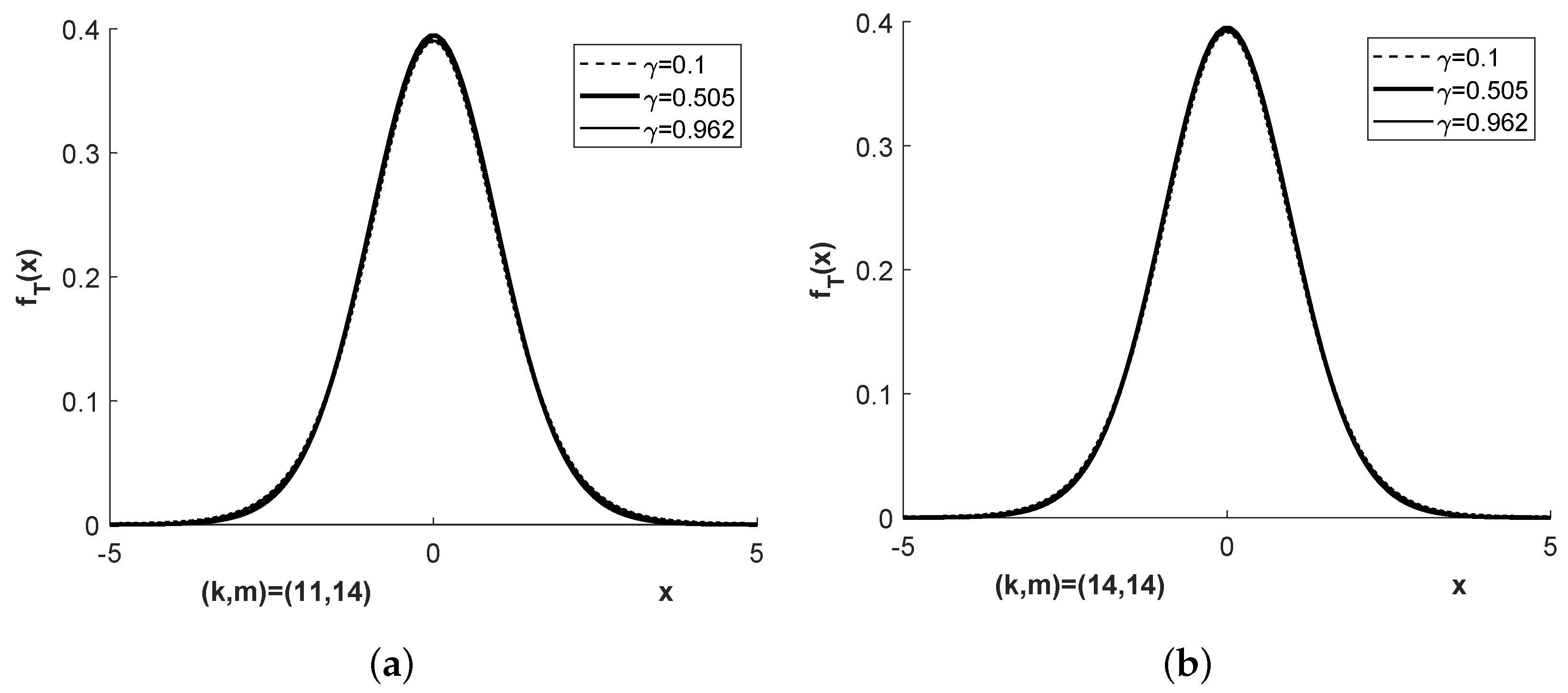
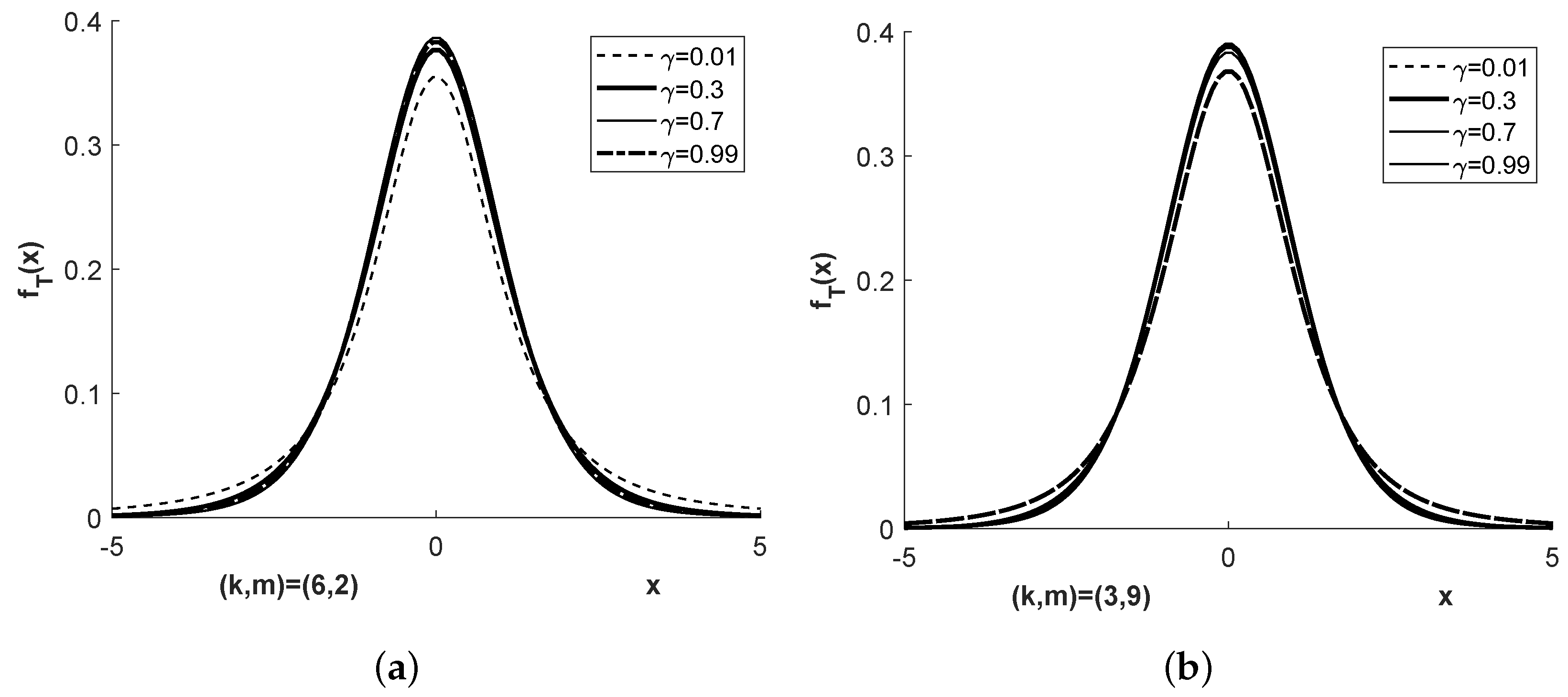
Figure 1,
Figure 2,
Figure 3 and
Figure 4 show the densities
and
for more parameter combinations
than required in Examples E1 to E4.
A value of close to 1 corresponds to a value of close to zero, , meaning that the sample size in the second population compared to that in the first is disproportionately large compared to the corresponding quotient of variances; in other words, the first population is under represented.
A value of close to 0 corresponds to a very large value of , , meaning that the sample size in the first population compared to that in the second is disproportionately large compared to the corresponding quotient of variances; in other words, the second population is under represented.
Unlike these two cases of imbalance, a value of in the order of speaks for an approximately achieved balance. The latter can be observed close to the middle pillar of the three pillar Student bridge distribution and is suitable to explain some effect when choosing the degree of freedom in the Welch approximation to the exact density of T.
The chi-square bridge densities shown in
Figure 1 correspond tho those of the Student bridge densities in
Figure 3. It is shown in [
8] that for such cases the Welch approximation seems to be the best that were found so far. Welch’s approximate degrees of freedom, see Formula (1.2) in [
8] with
and
replaced with
, are
for Example 1 and
for Example 2. This corresponds very well to the three pillar property of the Student bridge distribution.
If , as is approximately the case in Example 1, then the denominator of T can be written as Because the numbers 11 and 14 are of comparable size, a reasonable approximation is finally leading for Example 1 to .
In Example 2, the denominator of T allows the representation , which is reasonably approximated by . Thus, .
Figure 2 shows a broader variability between the densities when the mixing coefficient
is varied compared to
Figure 1. This is reflected in more visible variation of the corresponding Student bridge densities in
Figure 4, both in their distribution centers and their distribution tails. This should be taken into account if applications of the Student bridge distribution are required, in particular in the areas of the distributions just mentioned.
The Welch approximation is known to perform better when both k and m are sufficiently large. Our Figures show what may happen for small sample sizes.
Because the consideration in [
8] is even for higher dimensions it might be of some interest to extend the present work to this case, too.
5.2. Examples Where the Student Bridge Distribution Should Be Preferred
The aim of this section is to give a complementary structural argumentation confirming the numerical discoveries in [
9] with respect to the question of when Welch’s approximation is not sufficiently precise. To this end, we present, for two cases of sample sizes and variance ratios, the exact Student bridge density and Welch’s approximation to it in a joint figure.
Example 5. Assume that as in
Figure 1,
Figure 2 and
Figure 3 in [
9], sample sizes
are
and
and that the estimated variance ratio is always equal to 0.25. If we assume that the exact variance ratio in (10) is equal to 0.25, then the mixing coefficient
of the Student bridge distribution
is accordingly equal to 0.706, 0.840, 0.750, 0.889, 0.8 and 0.8.
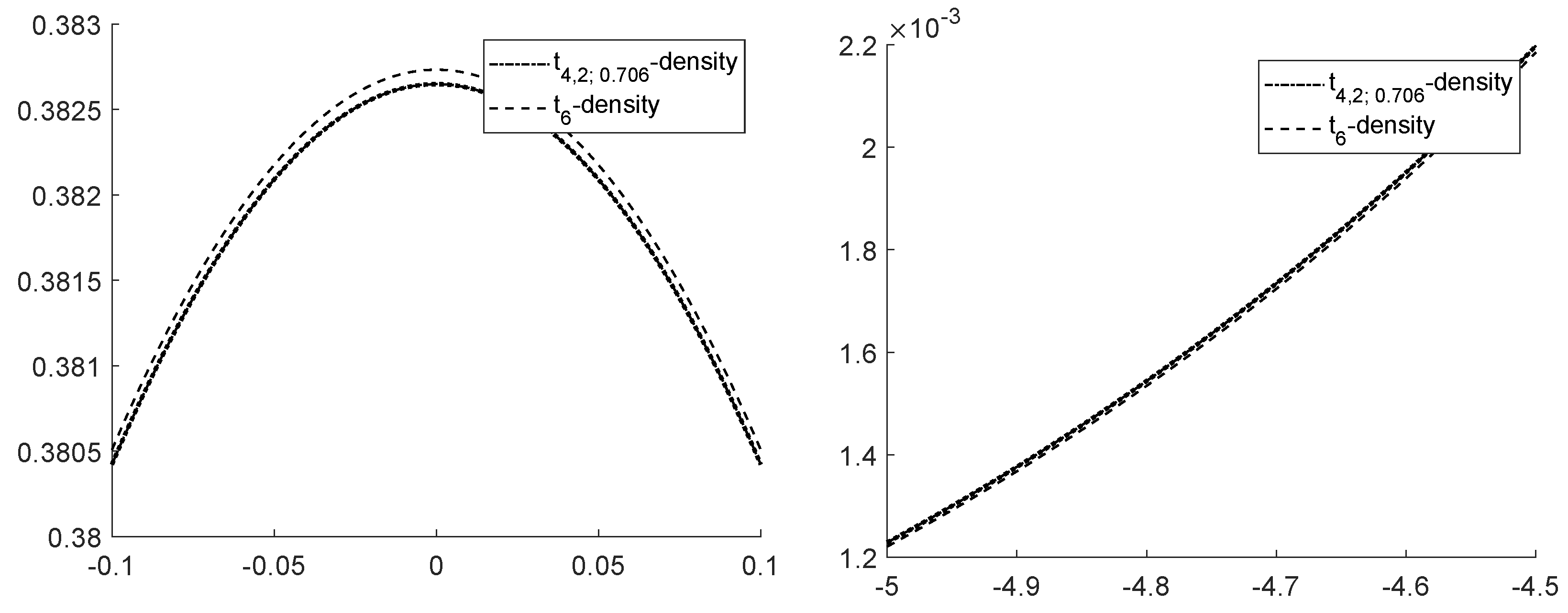
Figure 5 shows the density of
and the density of its Welch approximation
that can hardly be visually distinguished from each other if considered on the whole line, but differ locally.
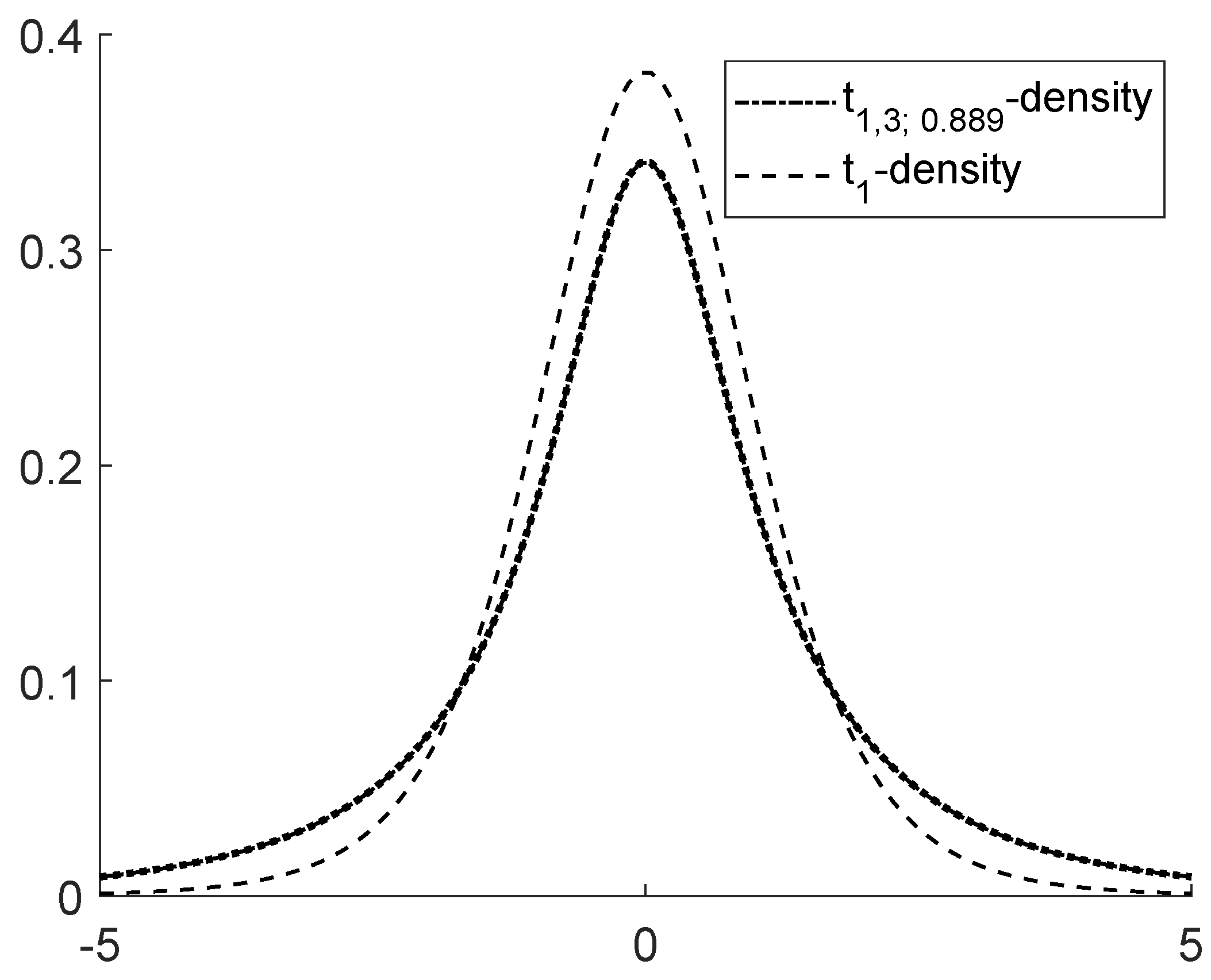
Figure 6 shows the densities of the Student bridge distribution
and Welch’s Student approximation to it,
. In this case, preference for the Student bridge density can even be seen globally.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}