2. Materials and Methods
An effective measurement error model for operator and inspector data must account for variation within and between groups, where a group is, for example, a calibration period, inspection period, item, or laboratory. In this paper, a group is an inspection period. A typical model that assumes additive errors for the inspector (
I) (and similarly for the operator
O) is
where for item
k (from 1 to
n) in group
j (from 1 to
g),
is the inspector’s measured value of the true but unknown value
,
is a random error, and
is a short-term systematic error that arises due to metrology changes, most important of which is recalibration between inspection periods [
1,
2,
3,
14]. For a fixed value of
the total variance of the inspector measurement is
=
.
The measurement error model in Equation (1) sets the stage for applying ANOVA with random effects [
2,
15,
16,
17,
18,
19,
20]. Neither
nor
are observable. If the errors tend to scale with the true value, then a typical model for multiplicative errors (with relative standard deviations (RSD)
and
is
where
,
. As explained below, for a technical reason, the data model in Equation (2) is slightly modified from normal distributions to truncated normal distributions in the IAEA application. Let
and
. For a fixed value of
the total variance of the inspector measurement is
=
. Let
and
. Subsequently, the assumed model for the relative difference between operator and inspector is
for the operators declared value of item
from group
is the net random error and
is the net short-term systematic error. In practice, while assuming no data falsification by the operator, Equation (3) can be calculated using the relative differences,
where
is used in the denominator to estimate
, because typically
, with
always being very small, 0.02 or less, in the IAEA application. Formally, a ratio of normal random variables has infinite variance [
3,
21]. To define a ratio that has finite variance, a truncated normal can be used as the data model in Equation (2) for
in
which is equal in distribution to
, which involves a ratio
of the independent normal random variables
and
(for the case of one measurement per group; multiple measurements per group is treated similarly). Note that the unknown true value
cancels in
, and then specifically, replace
with, for example, the conditional normal random variable
. The value −0.5 is an arbitrary but reasonable truncation value that is at least 25 standard deviations from the mean, and so such truncation would only take effect for a random realized value that is 25 or more standard deviations
from the mean (an event that occurs with almost zero probability). The modified ratio then has finite moments of all orders, because the numerator has a normal distribution and the denominator is an independent truncated normal that is no smaller than 0.5 (so the mean of the ratio cannot exceed twice the mean of the numerator, and similarly for other moments). Therefore, because
and
(typically), the distribution of the values
is guaranteed to have finite moments when the data model for
is a truncated normal, such as just described. In addition, provided
and
the distribution of the truncated version of the ratio
is extremely close to a normal distribution (see
Supplementary 1, and also see
Section 5 and
Section 6 for cases in which the distribution of
does not appear to be approximately normal). Additionally, the expression for the approximate variance
of
arising from using linear error variance propagation is accurate for quite large
, up to approximately
= 0.20, where.
(as confirmed by simulations in R [
20], and see [
3,
21]). In addition, the simulation-based tolerance intervals in
Section 4,
Section 5 and
Section 6 are constructed by simulating the ratio of a normal to a truncated normal, so all of the simulation results are accurate for
(with a truncated data model for the denominator, as described above) to within very small simulation error arising from performing a finite but large number of simulations. To summarize this issue regarding a ratio of normal random variables, the parametric option using simulation assumes, as discussed, that the truncated ratio
, involves a normal distribution for the numerator and a truncated normal for the denominator; and, in many real data sets, this assumption is reasonable on the basis of normality checks. However, because
might not always appear to be approximately normally distributed, this paper also considers the semi-parametric and non-parametric alternatives to calculating alarm thresholds for the truncated version of
in
Section 5 and
Section 6, respectively.
In some applications, all four error variance components must be estimated [
1,
2,
3,
17,
18,
19], but in this application, only the aggregate variances
and
need to be estimated. This paper’s focus is on the total relative variance,
, because
(approximately, due to using
rather than
). The estimated variances
and
are used to compute
, so that
can be used to set an alarm threshold for future
value. Specifically, in future values of the operator-inspector difference statistic
, if
(in two-sided testing), then the
i-th item selected for verification leads to an alarm, where
(with
the total RSD,
the between-period short-term systematic error RSD, and
the within-period reproducibility) and
k = 3 is a common current choice that corresponds to a small
of approximately 0.003 if
=
.Therefore, the focus of this paper is a one-way random effects ANOVA [
16]. Regarding jargon, note that the short-term systematic errors are fixed within an inspection period, but they are random across periods, so this is called a random effects ANOVA model [
15]. Due to the estimation error in
, the actual FAP can be considerably larger than 0.05, as shown in
Section 4.
The usual ANOVA decomposition is
where
for additive models and
for multiplicative models as assumed from now on (to avoid cluttering the notation, the “rel” subscript in
is omitted). In Equation (4), SSW is the within group sum of squares, and SSB is the between group sum of squares. For simplicity, Equation (4) assumes that each group has the same number of measurements
n. As usual in one-way (one grouping variable) random effects ANOVA,
and
, so
and
.
For data sets in which
appears to have approximately a normal distribution, key properties (such as the variances, see
Supplementary 1) of the estimators
and
are approximately known [
15,
16]. However, biased estimators can have smaller mean squared error (MSE), so other estimators should be considered. Additionally, again assuming normally distributed
R and
S values, an exact confidence interval (CI) can be constructed for
using the
distribution, but there are only approximate methods to construct CIs for
, because the distribution of
is a difference of two independent
random variables. Kraemer [
11] proposes a modified CI construction method for
and investigates impacts of non-normality.
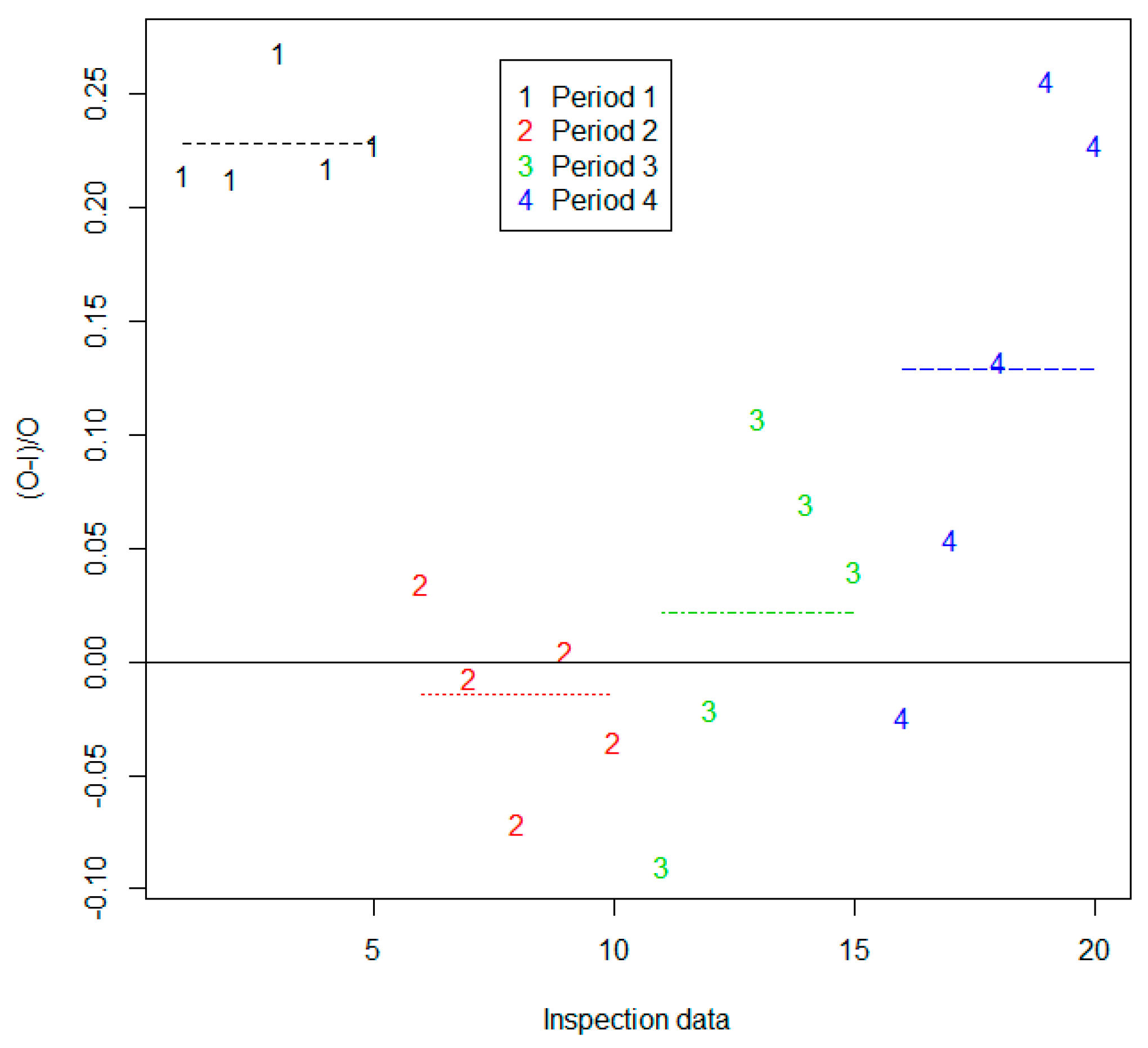
Figure 1 plots 10 realistic simulated
values in each of the three groups of paired (
O,
I) data. All of the simulations and analyses are done in R [
20]. The alarm limit on the right side of the plot in
Figure 1 is estimated on the basis of the
g = 3 sets of
n = 10 values of
d. Burr et al. [
3] evaluates impacts on alarm probabilities of using estimates of
and
instead of the true quantities. As in
Figure 1, in some data sets, the between-group variation is noticeable when compared to the within-group variation.
Figure 2 is the same type of plot as
Figure 1, but it is for real data consisting of
n = 5 paired comparisons in each of the four inspection periods (groups). For the 30 simulated
values in
Figure 1, the estimated RSDs are
and the true values used in the simulation are
For the 20
values in
Figure 2, the estimated RSDs are
3. Tolerance Interval Approach to Setting Alarm Thresholds
Many readers are probably more familiar with confidence intervals (CIs) than tolerance intervals (TIs). A CI is defined as an interval that, on average, includes a model parameter, such as a population mean with a stated confidence, often 95%. A TI is very similar to a CI, but it is defined as in interval that bounds a percentage of the population with a stated confidence, often bounding 95% of the population with confidence 99%. In the IAEA application, an alarm threshold is used that is assumed to correspond to a small false alarm probability (FAP), such as 5%, so the TI-based threshold bounds the lower (one-sided testing) or middle (two-sided testing) 95% of the population. Therefore, TIs are needed to control the FAP with high confidence (such as 99%) to be 5% or less.
Historical differences, such as
, are often used to estimate an alarm threshold for future measurements that has a small nominal
, such as
. Accordingly, instead of requiring a CI for the true value
the need is to estimate a threshold denoted
, which is the 0.95 quantile of the probability distribution of
d corresponds to
in one-sided testing. In contrast to a CI, a TI is an interval that bounds a fraction of a probability distribution with a specified confidence (frequentist) or probability (Bayesian approach) [
22,
23,
24].
Section 3 presents the Frequentist and Bayesian TI approaches, for the model
where, in this paper,
as computed with paired (
O,
I) data.
It is helpful to first review inference in a simpler setting without data being grouped by an inspection period. Suppose that data x1, x2, …, xn, xn+1 are collected from a distribution that is approximately normal with unknown mean µ and standard deviation , so . Assume that is test data and that are the training data used to estimate and , while using the usual estimates and , respectively. When constructing intervals of the form , the multiplier k can be chosen in order to have any user-desired confidence that the interval will include the true parameter Specifically, for the commonly-used t-based CI, where is the desired confidence and denotes the quantile of the t distribution with n − 1 degrees of freedom. For example, if n = 10, 20, or 30, then = 2.26, 2.09, or 2.05, respectively. Note that the well-known t-based CI is appropriate for ungrouped data. Or, if is known, then , where is the quantile of the normal distribution (the commonly-used z-based CI).
The previous paragraph adopted a frequentist viewpoint (
and
are unknown constants), so the intervals are referred to as CIs. In repeated applications of training on
n observations of
X, a fraction of approximately
of these CIs for
will include the true value of
(and similarly for
). The Bayesian viewpoint regards
and
as random variables. A prior distribution is assumed for both
and
and the training data are used via Bayes theorem to update the prior to produce a posterior distribution [
24], which is used to produce an interval that includes the true parameter with any user-desired probability (assuming that the data
are approximately normal and the prior distributions for
and
are appropriate). The Bayesian approach is subjective, unless there is some objective means to choose the prior probability [
24].
Moving from inference about
and
this paper reviews methods to use
to calculate a threshold
such that
, where
is the true
threshold of the distribution of
x. The methods are frequentist TIs and Bayesian prediction intervals, which include a specified fraction of at least
of future data, with
being the specified confidence in the frequentist TI approach and
being the posterior probability in a Bayesian approach [
22,
23]. The frequentist TI estimators that are presented have the form
, where
is the coverage factor that depends on the sample size. In any Bayesian approach, probabilities are calculated with respect to the joint posterior distribution
for given
[
22]. In this context, in the Bayesian approach,
and
are random unknown parameters, so
is computed with respect to
and
for given
. The Bayesian approach that was used in the IAEA application generates observations
and
from the posterior probability, which can be used to compute the posterior means
and
(the hat notation is somewhat non-standard in Bayesian literature, but it denotes the respective point estimate), which can then be used to numerically search for a suitable value of
to estimate
. In the frequentist approach,
and
are random, while
and
are fixed unknowns, so
is computed with respect to random samples of size
n. A frequentist TI has an associated confidence, which is the long-run relative frequency that an interval such as (0,
) will include a future observation
X from the same distribution as the training data used to estimate
and
An exact expression for a TI is only available in the one-sided Gaussian case [
4,
23]. However, good approximate expressions for many other cases are available [
4,
5,
6,
7,
8,
9,
10,
11]. Alternatively, TIs can be estimated well by using a simulation to approximate an alarm threshold that is designed to contain at least
percent of future observations with a specified coverage probability
For the case
, in one-sided testing, [
4] the exact upper limit for a 1 −
p TI upper bound is
where
where the noncentrality parameter
, and
denotes the
pth quantile (
p = 0.99 here) of the standard normal (mean 0, variance 1). For example, with
n = 10, 20, or 30,
k = 3.74, 2.81, and 2.52, respectively. Note that these values of
k are larger than the corresponding values in a
CI for
(2.26, 2.09, or 2.05, from above).
Supplementary 1 provides example simulation results that can be compared to these exact results in order to illustrate the simulation approach.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}