

Unveiling Wildfire Dynamics: A Bayesian County-Specific Analysis in California

 ,
,
Abstract
1. Introduction
2. Exploratory Data Analysis
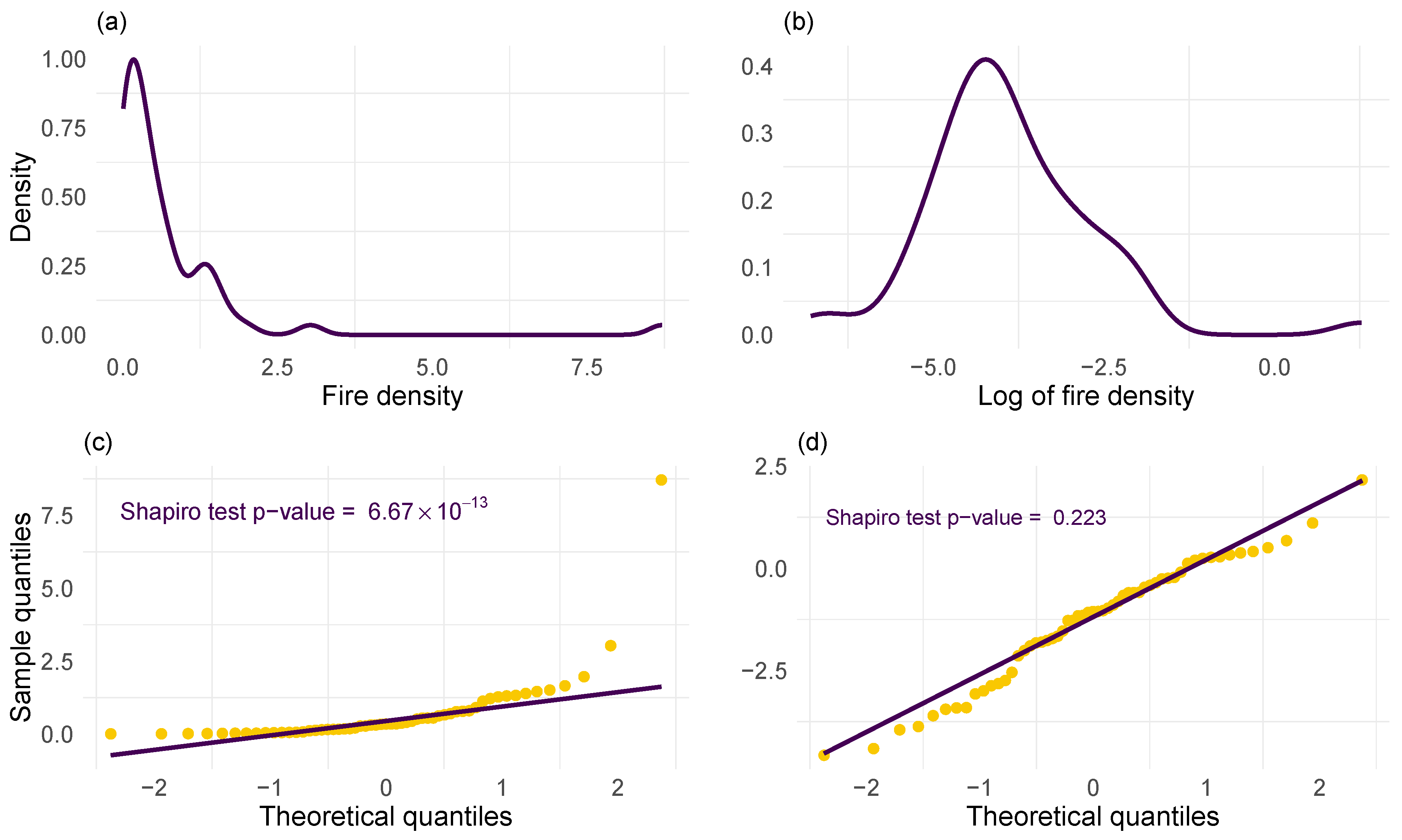
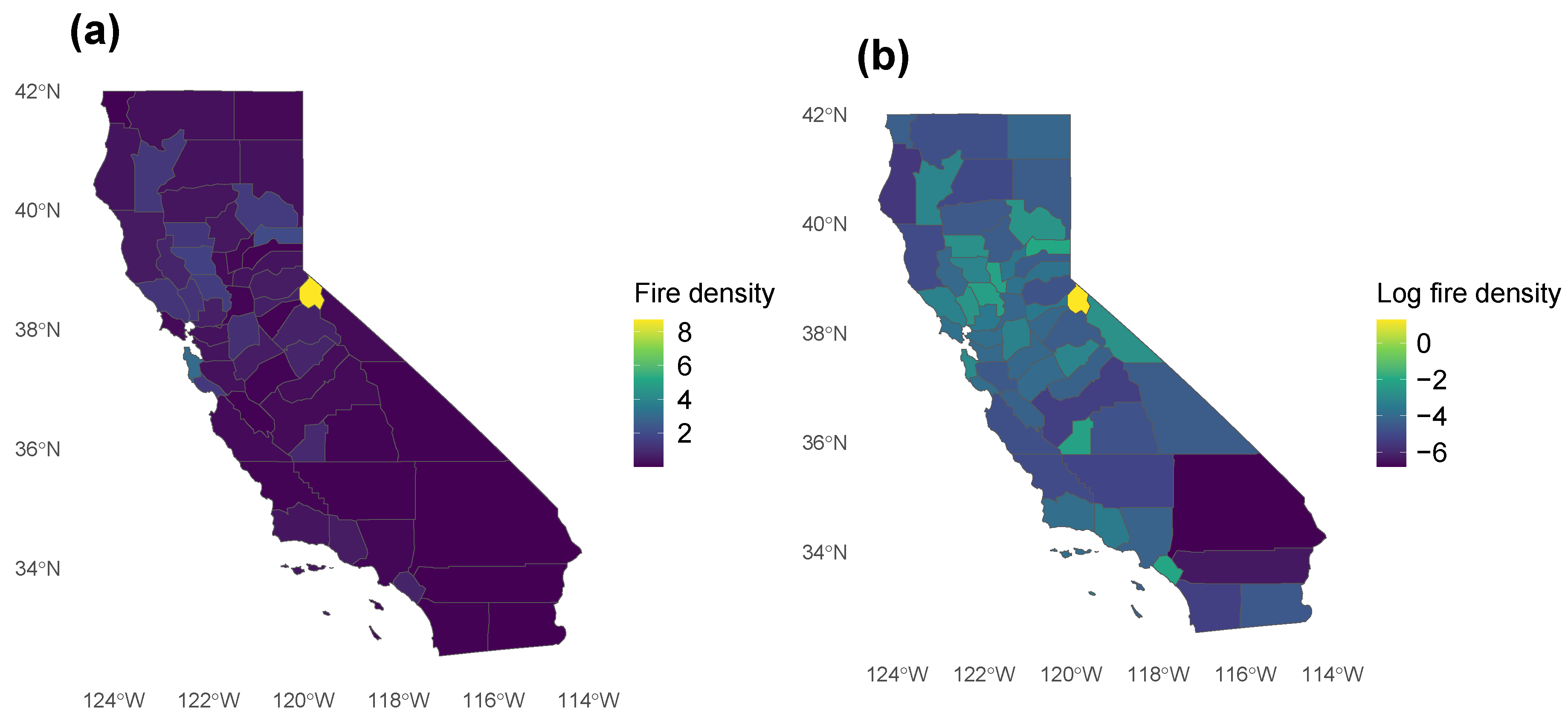
2.1. CAL FIRE Dataset
2.2. NOAA Data
2.3. ARB Emissions Data
2.4. CSAC Population Data
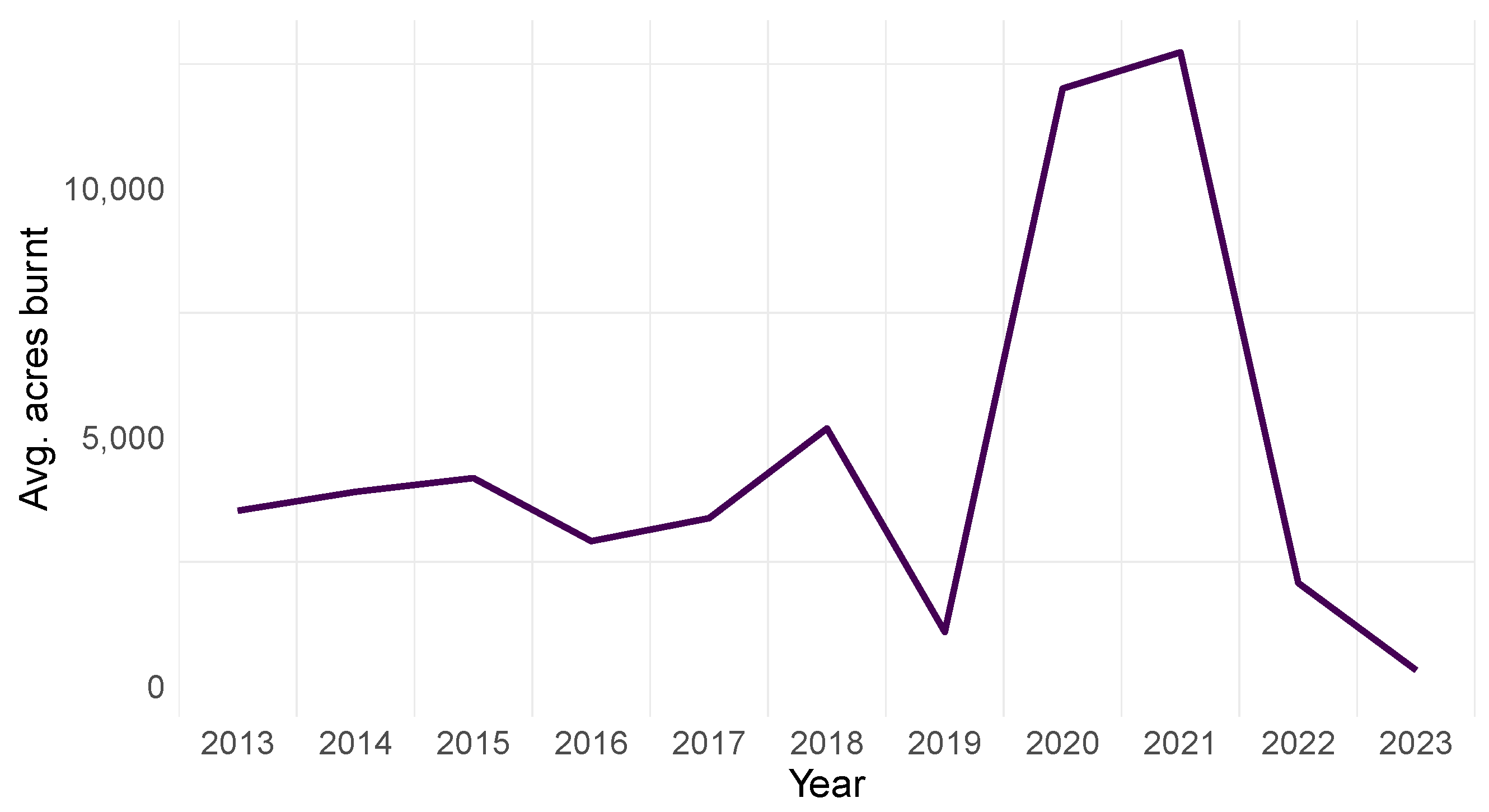
2.5. Analysis of Average Acres Burned
3. Methodology
3.1. Analysis of Variance
3.2. Bayesian Regression
3.3. Software
4. Results
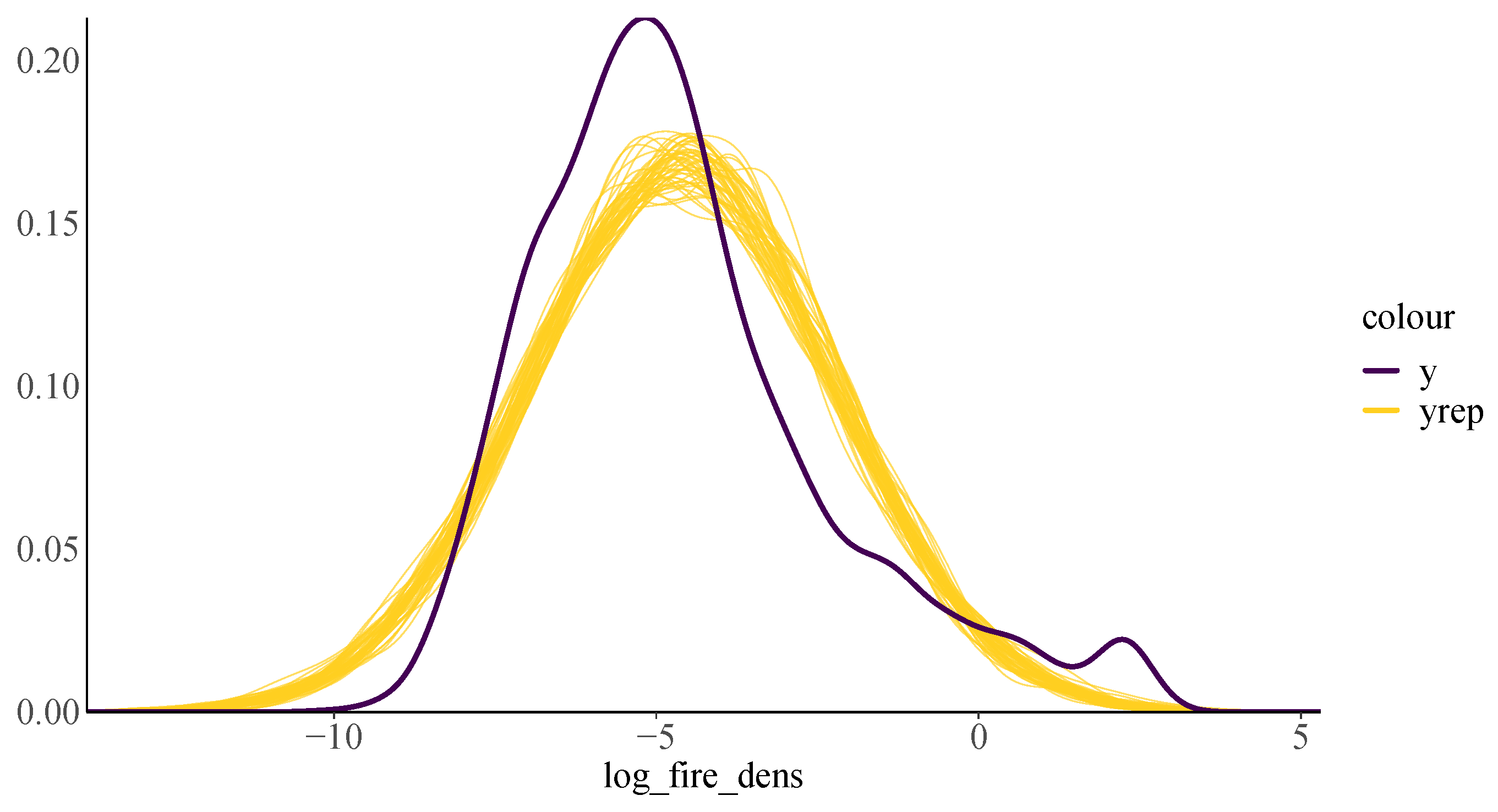
4.1. Bayesian ANOVA Results
4.2. Bayesian Regression Results
5. Discussion
6. Conclusions and Future Work
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gusner, P. Natural Disaster Facts And Statistics 2023. Forbes Advis. Available online: https://www.forbes.com/advisor/homeowners-insurance/natural-disaster-statistics/#:~:text=Jefferson%20Parish%2C%20Louisiana.-,How%20Many%20Natural%20Disasters%20Occur%20Each%20Year%3F,dollar%20climate%20disasters%20per%20year (accessed on 13 August 2024).
- Oliver-Smith, A. Climate change, disasters, and development in Florida. In Disasters in Paradise: Natural Hazards, Social Vulnerability, and Development Decisions; Rowman & Littlefield: Lanham, MD, USA, 2019; Volume 203. [Google Scholar]
- Bell, J.E.; Herring, S.C.; Jantarasami, L.; Adrianopoli, C.; Benedict, K.; Conlon, K.; Escobar, V.; Hess, J.; Luvall, J.; Garcia-Pando, C.P.; et al. Ch. 4: Impacts of Extreme Events on Human Health. In The Impacts of Climate Change on Human Health in the United States: A Scientific Assessment. III; Technical Report; US Global Change Research Program: Washington, DC, USA, 2016. [Google Scholar]
- Group, C. Mandatory Natural Disaster Evacuations Prove Costly for Homeowners. 2020. Available online: https://www.crcgroup.com/Tools-Intel/post/Mandatory-Natural-Disaster-Evacuations-Prove-Costly-for-Homeowners (accessed on 12 May 2024).
- National Academies of Sciences, Engineering, and Medicine. Implications of the California Wildfires for Health, Communities, and Preparedness: Proceedings of a Workshop; National Academies Press: Washington, DC, USA, 2020. [Google Scholar]
- Calkin, D.; Short, K.; Traci, M. California wildfires. In US Emergency Management in the 21st Century; Routledge: Oxfordshire, UK, 2019; pp. 155–182. [Google Scholar]
- Domínguez, D.; Yeh, C. Social justice disaster relief, counseling, and advocacy: The case of the Northern California wildfires. Couns. Psychol. Q. 2020, 33, 287–311. [Google Scholar] [CrossRef]
- MacDonald, G.; Wall, T.; Enquist, C.A.; LeRoy, S.R.; Bradford, J.B.; Breshears, D.D.; Brown, T.; Cayan, D.; Dong, C.; Falk, D.A.; et al. Drivers of California’s changing wildfires: A state-of-the-knowledge synthesis. Int. J. Wildland Fire 2023, 32, 1039–1058. [Google Scholar] [CrossRef]
- Moser, S.C.; Ekstrom, J.; Franco, G. Our Changing Climate 2012: Vulnerability & Adaptation to the Increasing Risks from Climate Change in California; University of California: Berkeley, CA, USA, 1 July 2012. [Google Scholar]
- Schweizer, D. Fine Particulate Matter and Wildland Fire Smoke: Integrating Air Quality, Fire Management, and Policy in the California Sierra Nevada. Ph.D. Thesis, UC Merced, Merced, CA, USA, 2016. [Google Scholar]
- Goldman, T. Consequences of Sprawl: Threats to California’s Natural Environment and Human Health; University of California Press: Berkeley, CA, USA, 2001. [Google Scholar]
- Pathak, T.B.; Maskey, M.L.; Dahlberg, J.A.; Kearns, F.; Bali, K.M.; Zaccaria, D. Climate change trends and impacts on California agriculture: A detailed review. Agronomy 2018, 8, 25. [Google Scholar] [CrossRef]
- Kolden, C.A.; Weigel, T.J. Fire risk in San Diego County, California: A weighted Bayesian model approach. Calif. Geogr. Soc. 2007, 47, 42–60. [Google Scholar]
- Joseph, M.B.; Rossi, M.W.; Mietkiewicz, N.P.; Mahood, A.L.; Cattau, M.E.; St. Denis, L.A.; Nagy, R.C.; Iglesias, V.; Abatzoglou, J.T.; Balch, J.K. Spatiotemporal prediction of wildfire size extremes with Bayesian finite sample maxima. Ecol. Appl. Online Libr. 2019, 29, e01898. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Banerjee, T. Spatial and temporal pattern of wildfires in California from 2000 to 2019. Sci. Rep. 2021, 11, 8779. [Google Scholar] [CrossRef]
- Keeley, J.E.; Syphard, A.D. Large California wildfires: 2020 fires in historical context. Fire Ecol. 2021, 17, 1–11. [Google Scholar] [CrossRef]
- Nidis, N. Study Finds Climate Change to Blame for Record-Breaking California Wildfires; National Integrated Drought Information System: Boulder, Co, USA, 2023. [Google Scholar]
- Fire, C. Current Emergency Incidents Dataset; State of California, California Department of Forestry and Fore Protection: Sacramento, CA, USA, 2023. [Google Scholar]
- Petras, G.; Thorson, M.; Sullivan, S. Why California wildfires have increased in frequency and size. 2018. Available online: https://www.usatoday.com/pages/interactives/news/california-wildfires-carr-fire-data/ (accessed on 12 May 2024).
- Mooney, H.; Zavaleta, E. Ecosystems of California; University of California Press: Berkeley, CA, USA, 2016. [Google Scholar]
- Li, S.; Dao, V.; Kumar, M.; Nguyen, P.; Banerjee, T. Mapping the wildland-urban interface in California using remote sensing data. Sci. Rep. 2022, 12, 5789. [Google Scholar] [CrossRef]
- Huntsinger, L.; Barry, S. Grazing in California’s Mediterranean Multi-Firescapes. Front. Sustain. Food Syst. 2021, 5, 715366. [Google Scholar] [CrossRef]
- Garfin, G.; Jardine, A.; Merideth, R.; Black, M.; LeRoy, S. Assessment of Climate Change in the Southwest United States: A Report Prepared for the National Climate Assessment; Island Press: Washington, CA, USA, 2013. [Google Scholar]
- Goss, M.; Swain, D.L.; Abatzoglou, J.T.; Sarhadi, A.; Kolden, C.A.; Williams, A.P.; Diffenbaugh, N.S. Climate change is increasing the likelihood of extreme autumn wildfire conditions across California. Environ. Res. Lett. 2020, 15, 094016. [Google Scholar] [CrossRef]
- Minnich, R.A. California fire climate. In Fire in California’s Ecosystems; University of California Press: Berkeley, CA, USA, 2018; pp. 11–25. [Google Scholar]
- Viswanathan, S.; Eria, L.; Diunugala, N.; Johnson, J.; McClean, C. An analysis of effects of San Diego wildfire on ambient air quality. J. Air Waste Manag. Assoc. 2006, 56, 56–67. [Google Scholar] [CrossRef] [PubMed]
- Naqvi, H.R.; Mutreja, G.; Shakeel, A.; Singh, K.; Abbas, K.; Naqvi, D.F.; Chaudhary, A.A.; Siddiqui, M.A.; Gautam, A.S.; Gautam, S.; et al. Wildfire-induced pollution and its short-term impact on COVID-19 cases and mortality in California. Gondwana Res. 2023, 114, 30–39. [Google Scholar] [CrossRef] [PubMed]
- Fasullo, J.T.; Phillips, A.; Deser, C. Evaluation of leading modes of climate variability in the CMIP archives. J. Clim. 2020, 33, 5527–5545. [Google Scholar] [CrossRef]
- Huang, Y.; Wu, S.; Kaplan, J.O. Sensitivity of global wildfire occurrences to various factors in the context of global change. Atmos. Environ. 2015, 121, 86–92. [Google Scholar] [CrossRef]
- Fasullo, J.; Otto-Bliesner, B.; Stevenson, S. ENSO’s changing influence on temperature, precipitation, and wildfire in a warming climate. Geophys. Res. Lett. 2018, 45, 9216–9225. [Google Scholar] [CrossRef]
- Johnson, A.A.; Ott, M.Q.; Dogucu, M. Bayes Rules!: An Introduction to Applied Bayesian Modeling; CRC Press: Boca Raton, FL, USA, 2022. [Google Scholar]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Rubin, D.B. Bayesian Data Analysis; Chapman and Hall/CRC: Boca Raton, FL, USA, 1995. [Google Scholar]
- CAGOV. California Open Data. 2023. Available online: https://data.ca.gov/dataset/cal-fire (accessed on 12 May 2024).
- NOAA. Climate Data Online, National Centers for Environmental Information; National Oceanic and Atmospheric Administration: Washington, DC, USA, 2023.
- ARB. Current California GHG Emission Inventory Data; California Air Resources Board: Riverside, CA, USA, 2023. [Google Scholar]
- EPA. Greenhouse Gas Reporting Program (GHGRP); United States Environmental Protection Agency: Washington, DC, USA, 2023.
- CSAC. Population Estimates for Counties and Cities–1970 to 2018 Dataset; California State Association of Counties: Sacramento, CA, USA, 2023. [Google Scholar]
- Faraway, J.J. Linear Models with R; Chapman and Hall/CRC: Riverside, CA, USA, 2004. [Google Scholar]
- Dobson, A.J.; Barnett, A.G. An Introduction to Generalized Linear Models; Chapman and Hall/CRC: Boca Raton, FL, USA, 2018. [Google Scholar]
- Shapiro, S.S.; Wilk, M.B. An analysis of variance test for normality (complete samples). Biometrika 1965, 52, 591–611. [Google Scholar] [CrossRef]
- Stevens-Rumann, C.; Morgan, P. Repeated wildfires alter forest recovery of mixed-conifer ecosystems. Ecol. Appl. 2016, 26, 1842–1853. [Google Scholar] [CrossRef] [PubMed]
- McElreath, R. Statistical Rethinking: A Bayesian Course with Examples in R and Stan; Chapman and Hall/CRC: Boca Raton, FL, USA, 2018. [Google Scholar]
- Dogucu, M.; Johnson, A.; Ott, M. bayesrules: Datasets and Supplemental Functions from Bayes Rules Book; CRC Press: Boca Raton, FL, USA, 2021. [Google Scholar]
- Aryal, R.; Kafley, D.; Beecham, S.; Morawska, L. Air quality in the Sydney metropolitan region during the 2013 Blue Mountains wildfire. Aerosol Air Qual. Res. 2018, 18, 2420–2432. [Google Scholar] [CrossRef]
- Schmidt, A.; Leavell, D.; Punches, J.; Rocha Ibarra, M.A.; Kagan, J.S.; Creutzburg, M.; McCune, M.; Salwasser, J.; Walter, C.; Berger, C. A quantitative wildfire risk assessment using a modular approach of geostatistical clustering and regionally distinct valuations of assets—A case study in Oregon. PLoS ONE 2022, 17, e0264826. [Google Scholar] [CrossRef]
- Halofsky, J.E.; Peterson, D.L.; Harvey, B.J. Changing wildfire, changing forests: The effects of climate change on fire regimes and vegetation in the Pacific Northwest, USA. Fire Ecol. 2020, 16, 4. [Google Scholar] [CrossRef]
- Voulgarakis, A.; Field, R.D. Fire influences on atmospheric composition, air quality and climate. Curr. Pollut. Rep. 2015, 1, 70–81. [Google Scholar] [CrossRef]
- Tiwari, S.; Chate, D.M.; Srivastava, M.K.; Safai, P.; Srivastava, A.; Bisht, D.; Padmanabhamurty, B. Statistical evaluation of PM 10 and distribution of PM 1, PM 2.5, and PM 10 in ambient air due to extreme fireworks episodes (Deepawali festivals) in megacity Delhi. Nat. Hazards 2012, 61, 521–531. [Google Scholar] [CrossRef]
- Spittlehouse, D.L.; Dymond, C.C. Interaction of elevation and climate change on fire weather risk. Can. J. For. Res. 2022, 52, 237–249. [Google Scholar] [CrossRef]
- Parisien, M.A.; Moritz, M.A. Environmental controls on the distribution of wildfire at multiple spatial scales. Ecol. Monogr. 2009, 79, 127–154. [Google Scholar] [CrossRef]
- Gedalof, Z.; Peterson, D.L.; Mantua, N.J. Atmospheric, climatic, and ecological controls on extreme wildfire years in the northwestern United States. Ecol. Appl. 2005, 15, 154–174. [Google Scholar] [CrossRef]
- Holden, Z.A.; Swanson, A.; Luce, C.H.; Jolly, W.M.; Maneta, M.; Oyler, J.W.; Warren, D.A.; Parsons, R.; Affleck, D. Decreasing fire season precipitation increased recent western US forest wildfire activity. Proc. Natl. Acad. Sci. USA 2018, 115, E8349–E8357. [Google Scholar] [CrossRef]
- Xystrakis, F.; Kallimanis, A.; Dimopoulos, P.; Halley, J.; Koutsias, N. Precipitation dominates fire occurrence in Greece (1900–2010): Its dual role in fuel build-up and dryness. Nat. Hazards Earth Syst. Sci. 2014, 14, 21–32. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Mean | Std. Dev. | Min | Max |
|---|---|---|---|---|
| Wildfire density (acre) | ||||
| Elevation (m) | 666 | 565 | 30 | 2216 |
| Temperature (°F) | 77 | 109 | ||
| Precipitation (mm) | 33 | |||
| Population | ||||
| PM10 (g/m3) | 284 | |||
| SOX (ppb) |
| Estimate | Std. Error | 80% Credible Interval | |
|---|---|---|---|
| Fixed Effects | |||
| −4.05 | 0.145 | (−4.23, −3.86) | |
| Random Effects | |||
| 0.993 | |||
| 2.11 |
| Term | Estimate | Std. Error | 80% Credible Interval | Neff Ratio | Rhat |
|---|---|---|---|---|---|
| (Intercept) | −3.610 | 3.79 | (−8.42, 1.26) | 0.76 | 1.00 |
| SOX | −0.077 | 0.07 | (−0.18, 0.02) | 0.93 | 0.99 |
| PM10 | −0.035 | 0.03 | (−0.07, 0.01) | 0.86 | 1.00 |
| Population | 0.225 | 0.21 | (−0.05, 0.51) | 0.75 | 0.99 |
| Elevation | 0.010 | 0.00 | (0.005, 0.015) | 0.89 | 1.00 |
| Temperature | 0.013 | 0.03 | (−0.03, 0.06) | 0.77 | 1.00 |
| Precipitation | −0.050 | 0.04 | (−0.10, 0.01) | 0.87 | 0.99 |
| Sigma | 0.960 | 0.15 | (0.80, 1.19) | 0.66 | 1.00 |
| Term | Estimate | Std. Error | 80% Credible Interval | Neff Ratio | Rhat |
|---|---|---|---|---|---|
| (Intercept) | −3.110 | 3.58 | (−7.74, 1.49) | 0.67 | 1.00 |
| SOX | −0.120 | 0.08 | (−0.23, −0.01) | 0.65 | 1.00 |
| PM10 | 0.001 | 0.01 | (−0.00, 0.01) | 0.78 | 1.00 |
| Population | 0.455 | 0.25 | (0.13, 0.78) | 0.62 | 1.00 |
| Elevation | 0.003 | 0.01 | (0.000, 0.008) | 0.82 | 0.99 |
| Temperature | −0.023 | 0.03 | (−0.06, 0.02) | 0.69 | 1.00 |
| Precipitation | 0.006 | 0.02 | (−0.02, 0.03) | 0.77 | 1.00 |
| Sigma | 0.652 | 0.10 | (0.54, 0.80) | 0.61 | 1.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Poudyal, S.; Lindquist, A.; Smullen, N.; York, V.; Lotfi, A.; Greene, J.; Meysami, M. Unveiling Wildfire Dynamics: A Bayesian County-Specific Analysis in California. J 2024, 7, 319-333. https://doi.org/10.3390/j7030018
Poudyal S, Lindquist A, Smullen N, York V, Lotfi A, Greene J, Meysami M. Unveiling Wildfire Dynamics: A Bayesian County-Specific Analysis in California. J. 2024; 7(3):319-333. https://doi.org/10.3390/j7030018
Chicago/Turabian StylePoudyal, Shreejit, Alex Lindquist, Nate Smullen, Victoria York, Ali Lotfi, James Greene, and Mohammad Meysami. 2024. "Unveiling Wildfire Dynamics: A Bayesian County-Specific Analysis in California" J 7, no. 3: 319-333. https://doi.org/10.3390/j7030018
APA StylePoudyal, S., Lindquist, A., Smullen, N., York, V., Lotfi, A., Greene, J., & Meysami, M. (2024). Unveiling Wildfire Dynamics: A Bayesian County-Specific Analysis in California. J, 7(3), 319-333. https://doi.org/10.3390/j7030018