
Machine Learning for Predicting Field Soil Moisture Using Soil, Crop, and Nearby Weather Station Data in the Red River Valley of the North

Abstract
:1. Introduction
2. Methods
2.1. Study Site and Weather Station
2.2. Soil Moisture Measurement
2.3. Crop Types in Study Area
2.4. Residue Cover, Soil Texture, and Saturated Hydraulic Conductivity
2.5. Rainfall and Potential Evapotranspiration
2.6. Machine Learning Algorithms
2.6.1. Classification and Regression Trees (CART)
2.6.2. Random Forest Regression (RFR)
2.6.3. Boosted Regression Trees (BRT)
2.6.4. Multiple Linear Regression (MLR)
2.6.5. Support Vector Regression (SVR)
2.6.6. Artificial Neural Network (ANN)
2.7. Machine Learning Procedures
2.8. Statistical Analysis
2.8.1. Model Performance
2.8.2. Variable Importance
2.8.3. Effect of Predictor Variables
3. Results and Discussion
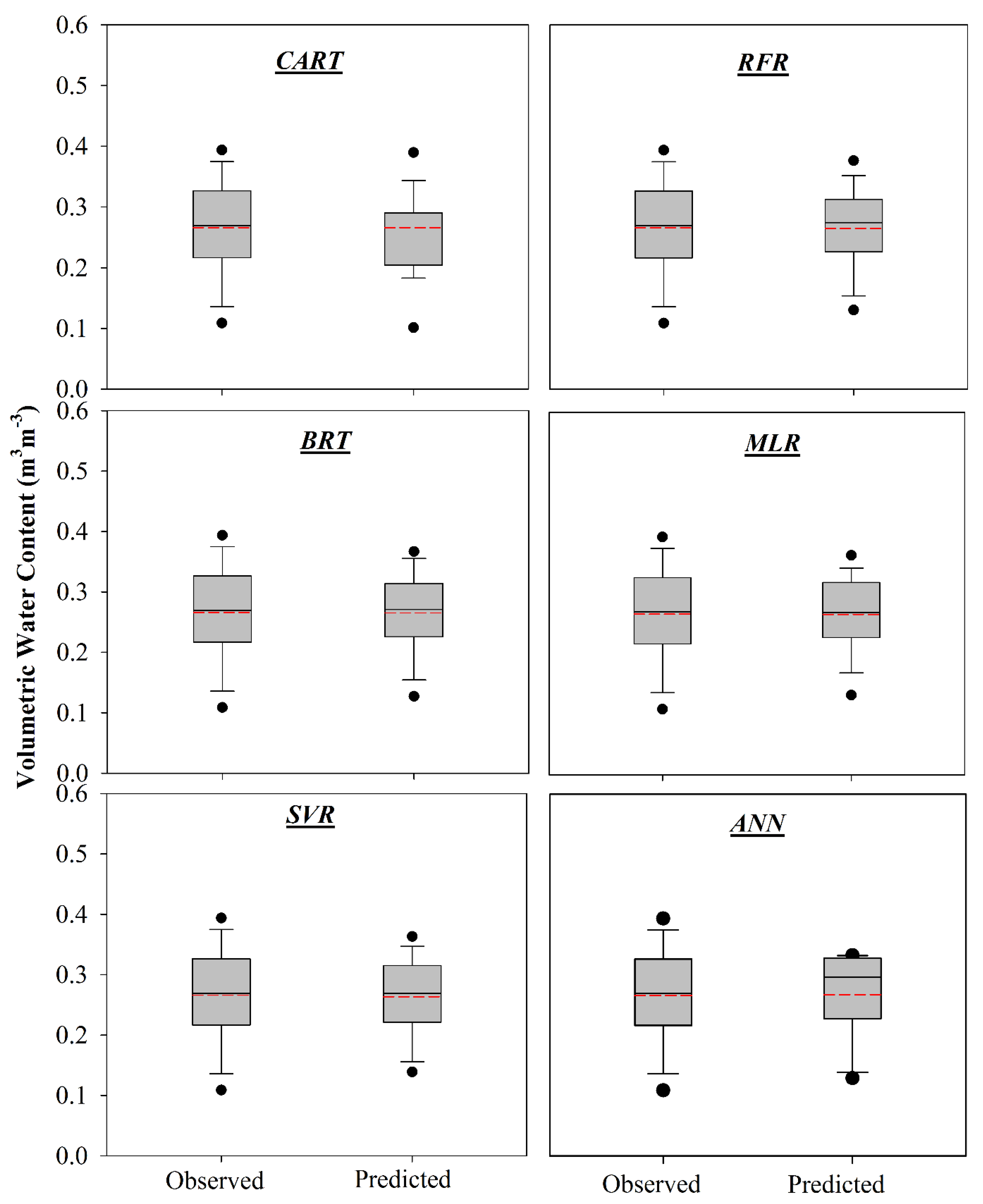
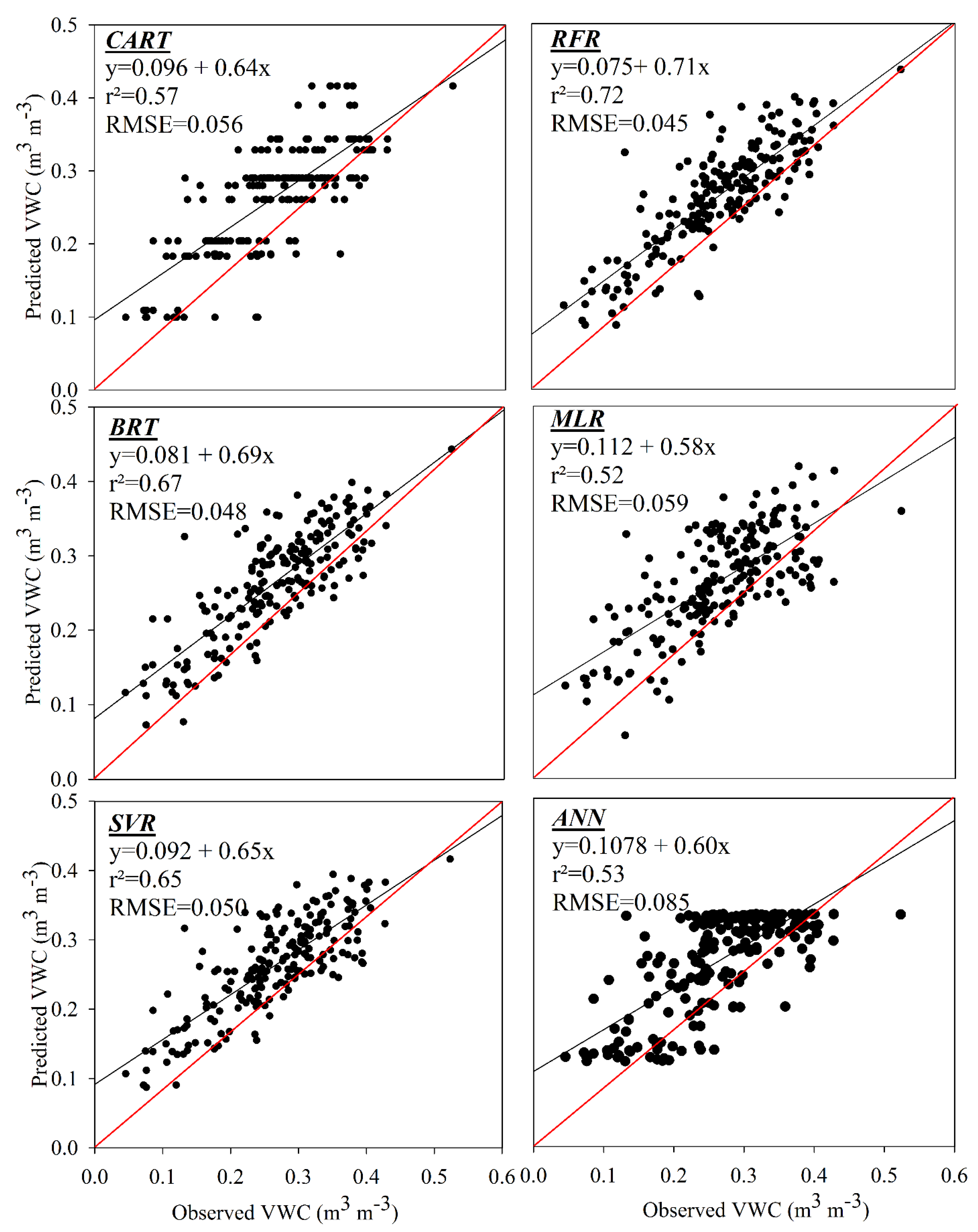
3.1. Model Performance
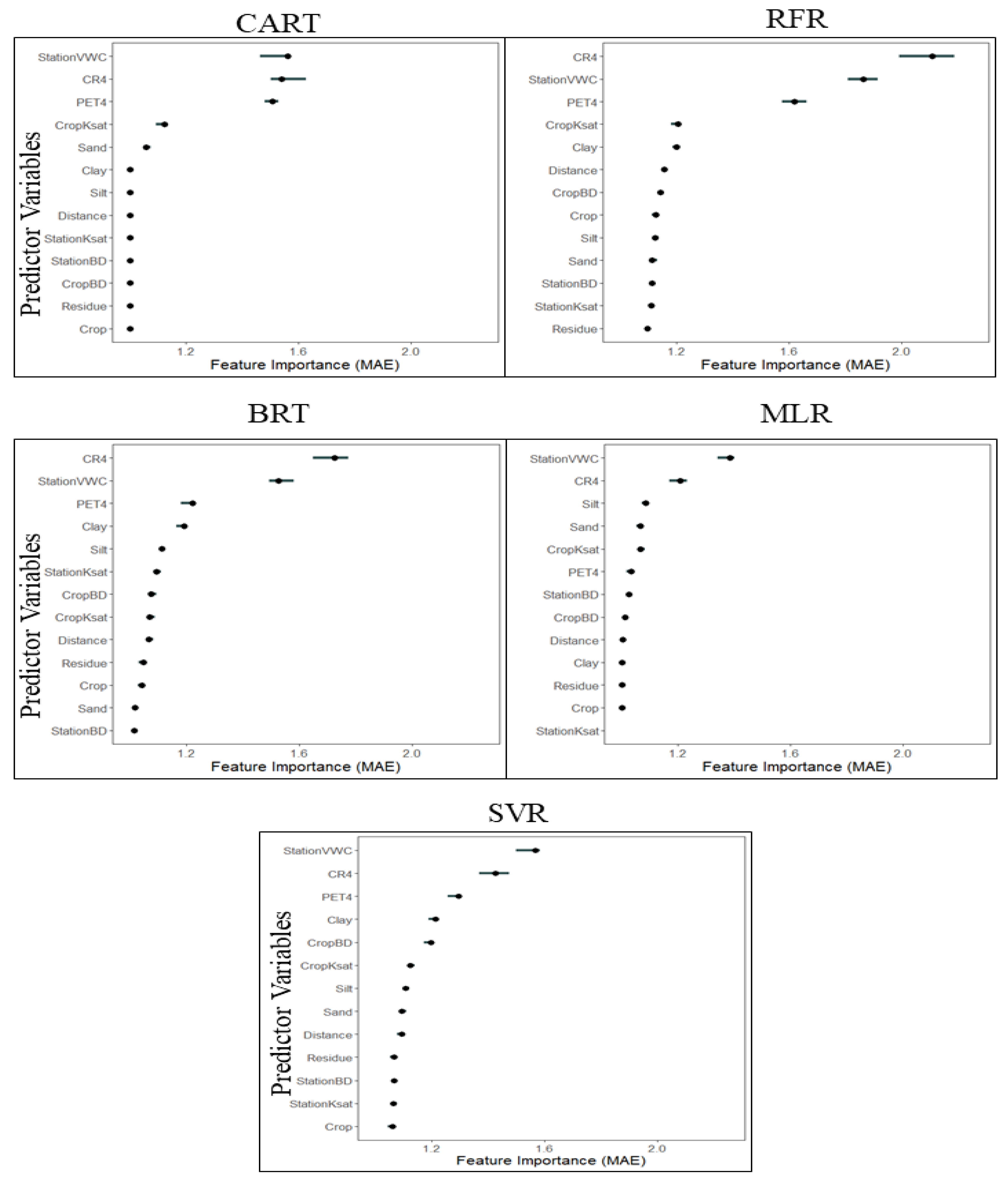
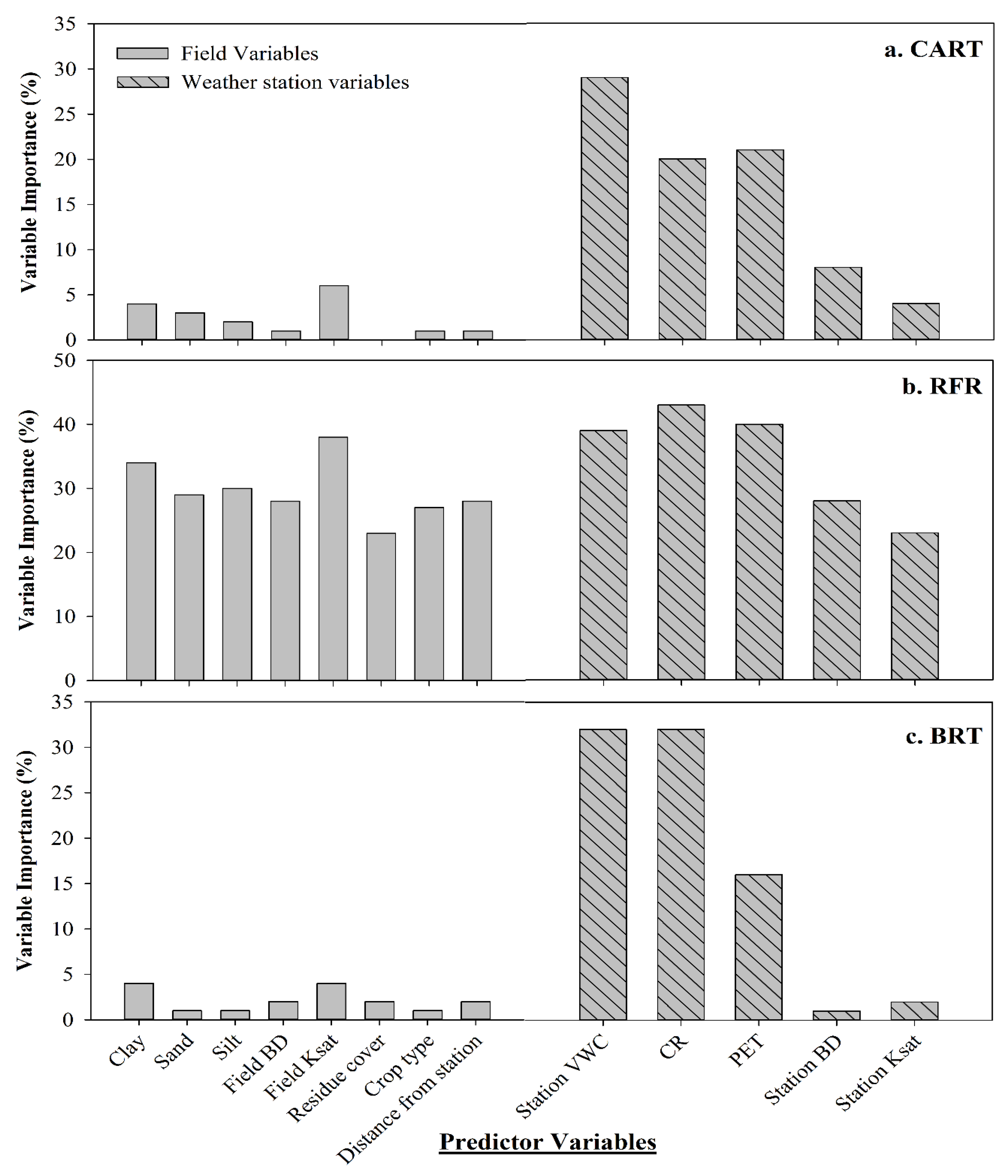
3.2. Importance of Predictor Variables
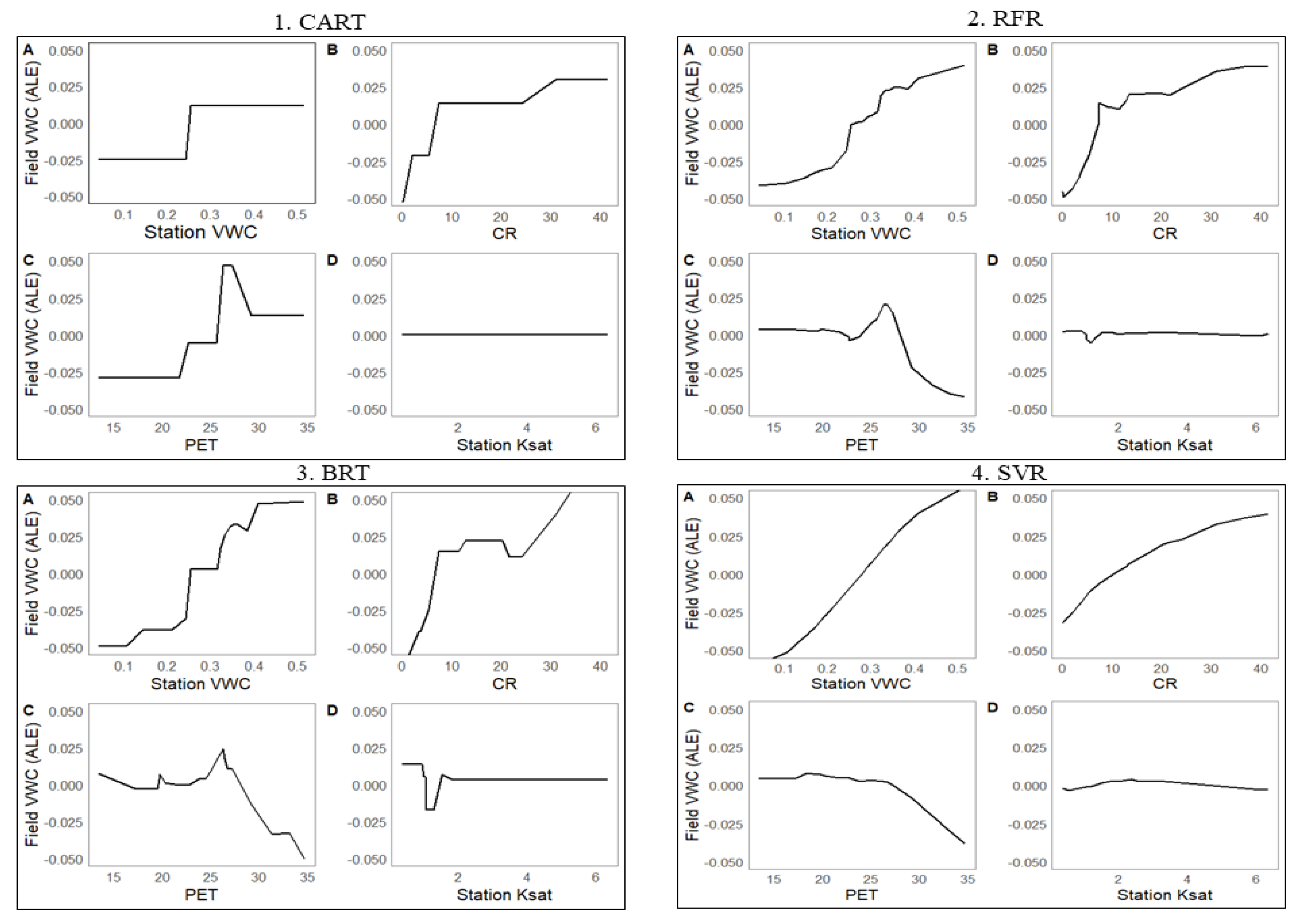
3.3. Accumulated Local Effect of Predictor Variables
4. Conclusions
- RFR, BET, and SVR outperformed other models in soil moisture prediction based on the r2, RMSE, and MAE values.
- RFR showed the highest r2 (0.72), and lowest MAE (0.034 m3 m−3) and RMSE (0.045 m3 m−3).
- RFR, CART, and BRT showed that weather station soil moisture, 4-day cumulative rainfall, and PET had a strong influence compared to soil and crop factors on predicting soil moisture in nearby crop fields.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gill, M.K.; Asefa, T.; Kemblowski, M.W.; McKee, M. Soil moisture prediction using support vector machines. J. Am. Water Resour. Assoc. 2006, 42, 1033–1046. [Google Scholar] [CrossRef]
- Amani, M.; Salehi, B.; Mahdavi, S.; Masjedi, A.; Dehnavi, S. Temperature-Vegetation-soil Moisture Dryness Index (TVMDI). Remote Sens. Environ. 2017, 197, 1–14. [Google Scholar] [CrossRef]
- Hamman, B.; Egil, D.B.; Koning, G. Seed vigor, soilborne pathogens, pre-emergent growth, and soybean seeding emergence. Crop Sci. 2002, 42, 451–457. [Google Scholar] [CrossRef]
- Laguardia, G.; Niemeyer, S. On the comparison between the LISFLOOD modelled and the ERS/SCAT derived soil moisture estimates. Hydrol. Earth Syst. Sci. 2008, 12, 1339–1351. [Google Scholar] [CrossRef] [Green Version]
- Zeng, Y.; Su, Z.; Van der Velde, R.; Wang, L.; Xu, K.; Wang, X.; Wen, J. Blending satellite observed, model simulated, and in situ measured soil moisture over Tibetan Plateau. Remote Sens. 2016, 8, 268. [Google Scholar] [CrossRef] [Green Version]
- Cai, Y.; Zheng, W.; Zhang, X.; Zhangzhong, L.; Xue, X. Research on soil moisture prediction model based on deep learning. PLoS ONE 2019, 14, 0214508. [Google Scholar] [CrossRef]
- Sanuade, O.A.; Hassan, A.M.; Akanji, A.O.; Olaojo, A.A.; Oladunjoye, M.A.; Abdulraheem, A. New empirical equation to estimate the soil moisture content based on thermal properties using machine learning techniques. Arab. J. Geosci. 2020, 13, 377. [Google Scholar] [CrossRef]
- Zhou, L. Study on estimation of soil-water content by using Soil-Water Dynamics Model. Water Sav. Irrig. 2007, 3, 10–13. [Google Scholar]
- Zhang, H.X.; Yang, J.; Fang, X.Y.; Fang, J.; Feng, C. Application of time series analysis in soil moisture forecast. Res. Soil Water Conserv. 2008, 15, 82–84. [Google Scholar]
- Huang, C.; Li, L.; Ren, S.; Zhou, Z. Research of soil moisture content forecast model based on genetic algorithm BP neural network. In Proceedings of the International Conference on Computer and Computing Technologies in Agriculture, Beijing, China, 22–25 October 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 309–316. [Google Scholar]
- Ali, I.; Greifeneder, F.; Stamenkovic, J.; Neumann, M.; Notarnicola, C. Review of machine learning approaches for biomass and soil moisture retrievals from remote sensing data. Remote Sens. 2015, 7, 16398–16421. [Google Scholar] [CrossRef] [Green Version]
- Clapcott, J.; Goodwin, E.; Snelder, T. Predictive Models of Benthic Macro-Invertebrate Metrics; Cawthron Report No. 2301; Cawthron Institute: Nelson, New Zealand, 2013; p. 35. [Google Scholar]
- Olden, J.D.; Lawler, J.J.; Poff, N.L. Machine learning methods without tears: A primer for ecologists. Q. Rev. Biol. 2008, 83, 171–193. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Naghibi, S.A.; Pourghasemi, H.R.; Dixon, B. GIS-based groundwater potential mapping using boosted regression tree, classification and regression tree, and random forest machine learning models in Iran. Environ. Monit. Assess. 2016, 188, 44. [Google Scholar] [CrossRef] [PubMed]
- Liaw, A.; Wiener, M. Classification and regression by RandomForest. R News 2002, 2, 18–22. [Google Scholar]
- Zaman, B.; McKee, M.; Neale, C.M.U. Fusion of remotely sensed data for soil moisture estimation using relevance vector and support vector machines. Int. J. Remote Sens. 2012, 33, 6516–6552. [Google Scholar] [CrossRef]
- Zaman, B.; Mckee, M. Spatio-temporal prediction of root zone soil moisture using multivariate relevance vector machines. Open J. Mod. Hydrol. 2014, 4, 80–90. [Google Scholar] [CrossRef] [Green Version]
- Hassan-Esfahani, L.; Torres-Rua, A.; Jensen, A.; McKee, M. Assessment of surface soil moisture using high-resolution multi-spectral imagery and artificial neural networks. Remote Sens. 2015, 7, 2627–2646. [Google Scholar] [CrossRef] [Green Version]
- Qiao, X.; Yang, F.; Xu, X. The prediction method of soil moisture content based on multiple regression and RBF neural network. In Proceedings of the 15th International Conference on Ground Penetrating Radar (GPR), Brussels, Belgium, 30 June–4 July 2014; pp. 140–143. [Google Scholar]
- Kashif Gill, M.; Kemblowski, M.W.; McKee, M. Soil moisture data assimilation using support vector machines and ensemble Kalman filter. J. Am. Water Resour. Assoc. 2007, 43, 1004–1015. [Google Scholar] [CrossRef]
- Gorthi, S.; Dou, H. Prediction models for the estimation of soil moisture content. In Proceedings of the International Design Engineering Technical Conferences and Computers and Information in Engineering Conference 54808, Washington, DC, USA, 28–31 August 2011; pp. 945–953. [Google Scholar]
- Matei, O.; Rusu, T.; Petrovan, A.; Mihuţ, G. A data mining system for real time soil moisture prediction. Procedia Eng. 2017, 181, 837–844. [Google Scholar] [CrossRef]
- Gumiere, S.J.; Camporese, M.; Botto, A.; Lafond, J.A.; Paniconi, C.; Gallichand, J.; Rousseau, A.N. Machine Learning vs. Physics-Based Modeling for Real-Time Irrigation Management. Front. Water 2020, 2, 8. [Google Scholar] [CrossRef] [Green Version]
- Yoon, H.; Jun, S.C.; Hyun, Y.; Bae, G.O.; Lee, K.K. A comparative study of artificial neural networks and support vector machines for predicting groundwater levels in a coastal aquifer. J. Hydrol. 2011, 396, 128–138. [Google Scholar] [CrossRef]
- Li, B.; Yang, G.; Wan, R.; Dai, X.; Zhang, Y. Comparison of random forests and other statistical methods for the prediction of lake water level: A case study of the Poyang Lake in China. Hydrol. Res. 2016, 47 (Suppl. 1), 69–83. [Google Scholar] [CrossRef] [Green Version]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 2000. [Google Scholar] [CrossRef]
- NOAA/NCEI. National Oceanic and Atmospheric Administration/National Centers for Environmental Information. 2020. Available online: https://www.ncdc.noaa.gov/ (accessed on 15 July 2020).
- Reynolds, S.G. The gravimetric method of soil moisture determination Part I: A study of equipment, and methodological problems. J. Hydrol. 1970, 11, 258–273. [Google Scholar] [CrossRef]
- USDA. United States Department of Agriculture, International Production Assessment Division. Metadata for Crops at Different Growth Stage. 2020. Available online: https://ipad.fas.usda.gov/cropexplorer/description.aspx?legendid=312 (accessed on 8 May 2020).
- Daigh, A.L.M.; DeJong-Hughes, J.; Gatchell, D.H.; Derby, N.E.; Alghamdi, R.; Leitner, Z.R.; Wick, A.; Acharya, U. Crop and soil responses to on-farm conservation tillage practices in the Upper Midwest. Agric. Environ. Lett. 2019, 4, 190012. [Google Scholar] [CrossRef] [Green Version]
- Gee, G.W.; Bauder, J.W. Particle Size Analysis. In Methods of Soil Analysis, Part A, 2nd ed.; Klute, A., Ed.; American Society of Agronomy: Madison, WI, USA, 1986; Volume 9, pp. 383–411. [Google Scholar]
- Schaap, M.G.; Leij, F.J.; van Genuchten, M.T. Rosetta: A computer program for estimating soil hydraulic parameters with hierarchical pedotransfer functions. J. Hydrol. 2001, 251, 163–176. [Google Scholar] [CrossRef]
- Simunek, J.; Sejna, M.; Saito, H.; Sakai, M.; van Genuchten, M.T. The HYDRUS-1D Software Package for Simulating the One-Dimensional Movement of Water, Heat, and Multiple Solutes in Variably-Saturated Media; Version 4.0.; Department of Environmental Sciences, University of California: Riverside, CA, USA, 2008. [Google Scholar]
- Richards, L.A. Porous plate apparatus for measuring moisture retention and transmission by soil. Soil Sci. 1948, 66, 105–110. [Google Scholar] [CrossRef]
- Penman, H.L. Natural evaporation from open water, bare soil and grass. Proc. R. Soc. Lond. Ser. A Math. Phys. Sci. 1948, 193, 120–145. [Google Scholar]
- Brocca, L.; Moramarco, T.; Melone, F.; Wagner, W. A new method for rainfall estimation through soil moisture observations. Geophys. Res. Lett. 2013, 40, 853–858. [Google Scholar] [CrossRef]
- Stewart, J.R. Applications of Classification and Regression Tree Methods in Roadway Safety Studies. In Transportation Research Record 1542, TRB; National Research Council: Washington, DC, USA, 1996; pp. 1–5. [Google Scholar]
- Samadi, M.; Jabbari, E.; Azamathulla, H.M. Assessment of M5 model tree and classification and regression trees for prediction of scour depth below free overfall spillways. Neural Comput. Appl. 2014, 24, 357–366. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. CART. Classification and Regression Trees; Wadsworth and Brooks/Cole: Monterey, CA, USA, 1984. [Google Scholar]
- Breiman, L. Random Forest. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: New York, NY, USA, 2013. [Google Scholar]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Elith, J.; Leathwick, J.R.; Hastie, T. A working guide to boosted regression trees. J. Anim. Ecol. 2008, 77, 802–813. [Google Scholar] [CrossRef] [PubMed]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobot. 2013, 7, 21. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Zhang, W.; Yuan, S.; Hu, N.; Lou, Y.; Wang, S. Predicting soil fauna effect on plant litter decomposition by using boosted regression trees. Soil Biol. Biochem. 2015, 82, 81–86. [Google Scholar] [CrossRef]
- Moisen, G.G.; Freeman, E.A.; Blackard, J.A.; Frescino, T.S.; Zimmermann, N.E.; Edwards, T.C. Predicting tree species presence and basal area in Utah: A comparison of stochastic gradient boosting, generalized additive models, and tree-based methods. Ecol. Model. 2006, 199, 176–187. [Google Scholar] [CrossRef]
- De’Ath, G. Boosted trees for ecological modeling and prediction. Ecology 2007, 88, 243–251. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V.N. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Drucker, H.; Burges, C.J.; Kaufman, L.; Smola, A.; Vapnik, V. Support vector regression machines. Adv. Neural Inf. Process. Syst. 1997, 9, 155–161. [Google Scholar]
- Yang, H.; Huang, K.; King, I.; Lyu, M.R. Localized support vector regression for time series prediction. Neurocomputing 2009, 72, 2659–2669. [Google Scholar] [CrossRef]
- Priddy, K.L.; Keller, P.E. Artificial Neural Networks: An Introduction; SPIE Press: Bellingham, WA, USA, 2005; Volume 68. [Google Scholar]
- Grimes, D.I.F.; Coppola, E.; Verdecchia, M.; Visconti, G. A neural network approach to real-time rainfall estimation for Africa using satellite data. J. Hydrometeorol. 2003, 4, 1119–1133. [Google Scholar] [CrossRef]
- Twarakavi, N.K.; Misra, D.; Bandopadhyay, S. Prediction of arsenic in bedrock derived stream sediments at a gold mine site under conditions of sparse data. Nat. Resour. Res. 2006, 15, 15–26. [Google Scholar] [CrossRef]
- Ahmad, S.; Simonovic, S.P. An artificial neural network model for generating hydrograph from hydro-meteorological parameters. J. Hydrol. 2005, 315, 236–251. [Google Scholar] [CrossRef]
- R Development Core Team. R: A Language and Environment for Statistical Computing. 2020. Available online: https://www.r-project.org/ (accessed on 1 October 2020).
- Karatzoglou, A.; Smola, A.; Hornik, K.; Zeileis, A. Kernlab: An S4 Package for Kernel Methods in R (version 0.9-25). J. Stat. Softw. 2004, 11, 1–20. Available online: http://www.jstatsoft.org/v11/i09/ (accessed on 1 October 2020). [CrossRef] [Green Version]
- Liaw, A.; Wiener, M. RandomForest: Breiman and Cutler’s Random Forests for Classification and Regression; R Package Version 4; CRAN R package, 2015. pp. 6–10. Available online: https://cran.r-project.org/web/packages/randomForest/randomForest.pdf (accessed on 15 September 2021).
- Gunther, F.; Fritsch, S. Neuralnet: Training of neural networks. R J. 2010, 2, 30–38. [Google Scholar] [CrossRef] [Green Version]
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S (Statistics and Computing); Springer: New York, NY, USA, 2002. [Google Scholar]
- Apley, D.W.; Zhu, J. Visualizing the effects of predictor variables in black box supervised learning models. J. R. Stat. Soc. B. 2020, 82, 1059–1086. [Google Scholar] [CrossRef]
- Greenwell, B.M. An R Package for Constructing Partial Dependence Plots. R J. 2017, 9, 421. [Google Scholar] [CrossRef] [Green Version]
- Molnar, C. Interpretable Machine Learning: A Guide for Making Black Box Models Explainable. 2019. Available online: https://christophm.github.io/interpretable-ml-book/ (accessed on 10 January 2020).
- Caruana, R.; Niculescu-Mizil, A. An empirical comparison of supervised learning algorithms. In Proceedings of the 23rd international conference on Machine learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 161–168. [Google Scholar]
- Hengl, T.; Mendes de Jesus, J.; Heuvelink, G.B.; Ruiperez Gonzalez, M.; Kilibarda, M.; Blagotić, A.; Shangguan, W.; Wright, M.N.; Geng, X.; Bauer-Marschallinger, B.; et al. SoilGrids250m: Global gridded soil information based on machine learning. PLoS ONE 2017, 12, e0169748. [Google Scholar]
- Nussbaum, M.; Spiess, K.; Baltensweiler, A.; Grob, U.; Keller, A.; Greiner, L.; Schaepman, M.E.; Papritz, A. Evaluation of digital soil mapping approaches with large sets of environmental covariates. Soil 2018, 4, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Keskin, H.; Grunwald, S.; Harris, W.G. Digital mapping of soil carbon fractions with machine learning. Geoderma 2019, 339, 40–58. [Google Scholar] [CrossRef]
- Szabo, B.; Szatmári, G.; Takács, K.; Laborczi, A.; Makó, A.; Rajkai, K.; Pásztor, L. Mapping soil hydraulic properties using random-forest-based pedotransfer functions and geostatistics. Hydrol. Earth Syst. Sci. 2019, 23, 2615–2635. [Google Scholar] [CrossRef] [Green Version]
- Araya, S.N.; Fryjoff-Hung, A.; Anderson, A.; Viers, J.H.; Ghezzehei, T.A. Advances in Soil Moisture Retrieval from Multispectral Remote Sensing Using Unmanned Aircraft Systems and Machine Learning Techniques. Hydrol. Earth Syst. Sci. 2020, 1–33. [Google Scholar] [CrossRef]
- Kalra, A.; Ahmad, S. Using oceanic–atmospheric oscillations for long lead time streamflow forecasting. Water Resour. Res. 2009, 45, W03413. [Google Scholar] [CrossRef]
- Dibike, Y.B.; Velickov, S.; Solomatine, D.; Abbott, M.B. Model induction with support vector machines: Introduction and application. J. Comput. Civ. Eng. 2001, 15, 208–216. [Google Scholar] [CrossRef]
- Asefa, T.; Kemblowski, M.; McKee, M.; Khalil, A. Multi-time scale stream flow predictions: The support vector machines approach. J. Hydrol. 2006, 318, 7–16. [Google Scholar] [CrossRef]
- Liong, S.Y.; Sivapragasam, C. Flood stage forecasting with support vector machines 1. J. Am. Water Resour. As. 2002, 38, 173–186. [Google Scholar] [CrossRef]
- Achieng, K.O. Modelling of soil moisture retention curve using machine learning techniques: Artificial and deep neural networks vs. support vector regression models. Comput. Geosci. 2019, 133, 104320. [Google Scholar] [CrossRef]
- Karandish, F.; Simunek, J. A comparison of numerical and machine-learning modeling of soil water content with limited input data. J. Hydrol. 2016, 543, 892–909. [Google Scholar] [CrossRef] [Green Version]
- Bray, M.; Han, D. Identification of support vector machines for runoff modeling. J. Hydrol. 2004, 6, 265–280. [Google Scholar]
- Pal, M.; Mather, P.M. Support Vector Classifiers for Land Cover Classification. Map India 2003, Image processing and interpretation. 2003. Available online: http://www.gisdevelopment.net/technology/rs/pdf/23.pdf (accessed on 1 October 2020).
- Han, J.; Mao, K.; Xu, T.; Guo, J.; Zuo, Z.; Gao, C. A soil moisture estimation framework based on the CART algorithm and its application in China. J. Hydrol. 2018, 563, 65–75. [Google Scholar] [CrossRef]
- Revermann, R.; Finckh, M.; Stellmes, M.; Strohbach, B.J.; Frantz, D.; Oldeland, J. Linking land surface phenology and vegetation-plot databases to model terrestrial plant α-diversity of the Okavango Basin. Remote Sens. 2016, 8, 370. [Google Scholar] [CrossRef] [Green Version]
- Brocca, L.; Morbidelli, R.; Melone, F.; Moramarco, T. Soil moisture spatial variability in experimental areas of Central Italy. J. Hydrol. 2007, 333, 356–373. [Google Scholar] [CrossRef]
- Cosh, M.H.; Stedinger, J.R.; Brutsaert, W. Variability of surface soil moisture at the watershed scale. Water Resour. Res. 2004, 40, W12513. [Google Scholar] [CrossRef]
- Ziadat, F.M.; Taimeh, A.Y. Effect of rainfall intensity, slope, land use and antecedent soil moisture on soil erosion in an arid Environment. Land Degrad. Dev. 2013, 24, 582–590. [Google Scholar] [CrossRef]
- Zhang, R. Determination of soil sorptivity and hydraulic conductivity from the disk infiltrometer. Soil Sci. Soc. Am. J. 1997, 61, 1024–1030. [Google Scholar] [CrossRef]
- Upchurch, D.R.; Wilding, L.P.; Hatfield, J.L. Methods to evaluate spatial variability. In Reclamation of Surface-Mined Land; CRC Press: Boca Raton, FL, USA, 1988; pp. 201–229. [Google Scholar]
- Li, T.; Hao, X.M.; Kang, S.Z. Spatiotemporal variability of soil moisture as affected by soil properties during irrigation cycles. Soil Sci. Soc. Am. J. 2014, 78, 598–608. [Google Scholar] [CrossRef]
- Manns, H.R.; Berg, A.A.; Bullock, P.R.; McNairn, H. Impact of soil surface characteristics on soil water content variability in agricultural fields. Hydrol. Process. 2014, 28, 4340–4351. [Google Scholar] [CrossRef]
- Kravchenko, A.N.; Wang, A.N.W.; Smucker, A.J.M.; Rivers, M.L. Long-term differences in tillage and land use affect intra-aggregate pore heterogeneity. Soil Sci. Soc. Am. J. 2011, 75, 1658–1666. [Google Scholar] [CrossRef] [Green Version]
- McIsaac, G.F.; David, M.B.; Mitchell, C.A. Miscanthus and switchgrass production in central Illinois: Impacts on hydrology and inorganic nitrogen leaching. J. Environ. Qual. 2010, 39, 1790–1799. [Google Scholar] [CrossRef] [Green Version]
- Entekhabi, D.; Rodriguez-Iturbe, I. Analytical framework for the characterization of the space-time variability of soil moisture. Adv. Water Resour. 1994, 17, 35–45. [Google Scholar] [CrossRef]
- Pan, F.; Peters-Lidard, C.D.; Sale, M.J. An analytical method for predicting surface soil moisture from rainfall observations. Water Resour. Res. 2003, 39, 1–12. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithms | r2 | RMSE | MAE |
|---|---|---|---|
| CART | 0.57 | 0.056 | 0.045 |
| MLR | 0.52 | 0.059 | 0.046 |
| RFR | 0.72 | 0.045 | 0.034 |
| SVR | 0.65 | 0.050 | 0.039 |
| BRT | 0.67 | 0.048 | 0.037 |
| ANN | 0.53 | 0.085 | 0.068 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Acharya, U.; Daigh, A.L.M.; Oduor, P.G. Machine Learning for Predicting Field Soil Moisture Using Soil, Crop, and Nearby Weather Station Data in the Red River Valley of the North. Soil Syst. 2021, 5, 57. https://doi.org/10.3390/soilsystems5040057
Acharya U, Daigh ALM, Oduor PG. Machine Learning for Predicting Field Soil Moisture Using Soil, Crop, and Nearby Weather Station Data in the Red River Valley of the North. Soil Systems. 2021; 5(4):57. https://doi.org/10.3390/soilsystems5040057
Chicago/Turabian StyleAcharya, Umesh, Aaron L. M. Daigh, and Peter G. Oduor. 2021. "Machine Learning for Predicting Field Soil Moisture Using Soil, Crop, and Nearby Weather Station Data in the Red River Valley of the North" Soil Systems 5, no. 4: 57. https://doi.org/10.3390/soilsystems5040057
APA StyleAcharya, U., Daigh, A. L. M., & Oduor, P. G. (2021). Machine Learning for Predicting Field Soil Moisture Using Soil, Crop, and Nearby Weather Station Data in the Red River Valley of the North. Soil Systems, 5(4), 57. https://doi.org/10.3390/soilsystems5040057