
Effective Comparison of Thermo-Mechanical Characteristics of Self-Compacting Concretes Through Machine Learning-Based Predictions †



Abstract
1. Introduction
2. Materials and Methods
2.1. ANN Models
- Bayesian Regularization is an optimal method for addressing the issue of overfitting, particularly when the available data is limited and highly noisy.
- The Levenberg–Marquardt method is renowned for its rapid convergence, rendering it an optimal choice for small to moderate datasets.
- Scaled Conjugate Gradient (SCG) is an optimized variant of gradient methods, designed to ensure stable convergence even in the presence of complex parametric spaces.
- Resilient Backpropagation (RProp) is a method that focuses on the independent updating of weights, thereby ensuring robustness against gradient-scaling problems.
2.1.1. Bayesian Regression Model
2.1.2. Levenberg–Marquardt Model
2.1.3. Scaled Conjugate Gradient (SCG) Model
2.1.4. Resilient Backpropagation (RProp) Model
2.2. Support Vector Regression (SVR) Model
2.3. Random Forest Model
3. Training Database e Data Analysis
- (I)
- Description of the experimental test.
- (II)
- Repeatability of the test.
- (III)
- Presentation of the measurements made and the data obtained.
- (IV)
- Correspondence of the data provided with the quantities needed for the analysis.
- (V)
- Comparison of data from different sources and evaluation of their dispersion.
- (VI)
- The dataset thus created consisted of almost 150 points (θ; σ), which were used for training the starting group of neural networks.
3.1. Statistical Data Analysis
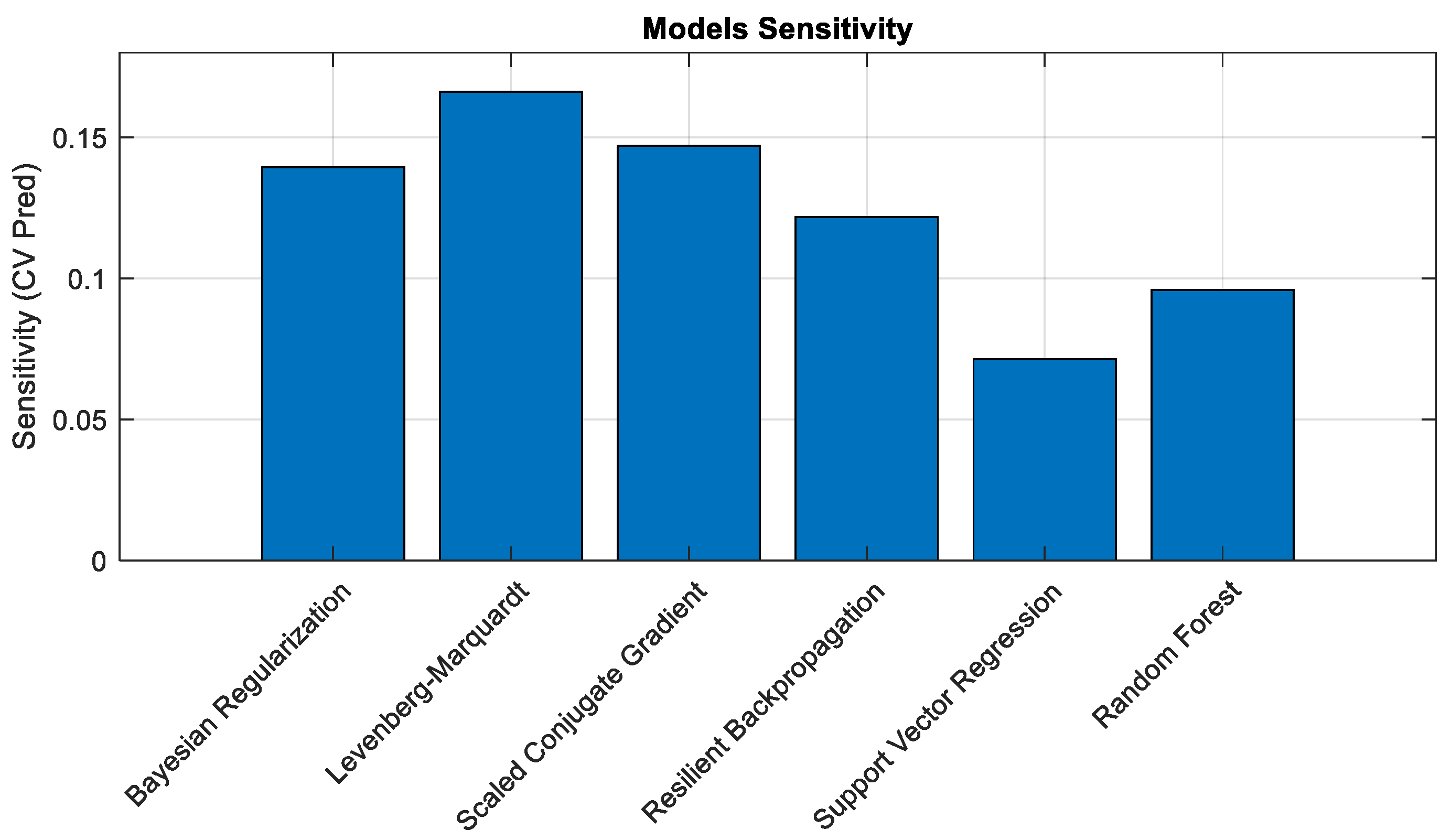
3.2. Algorithm Selection Rationale
4. Machine Learning Network Implementation
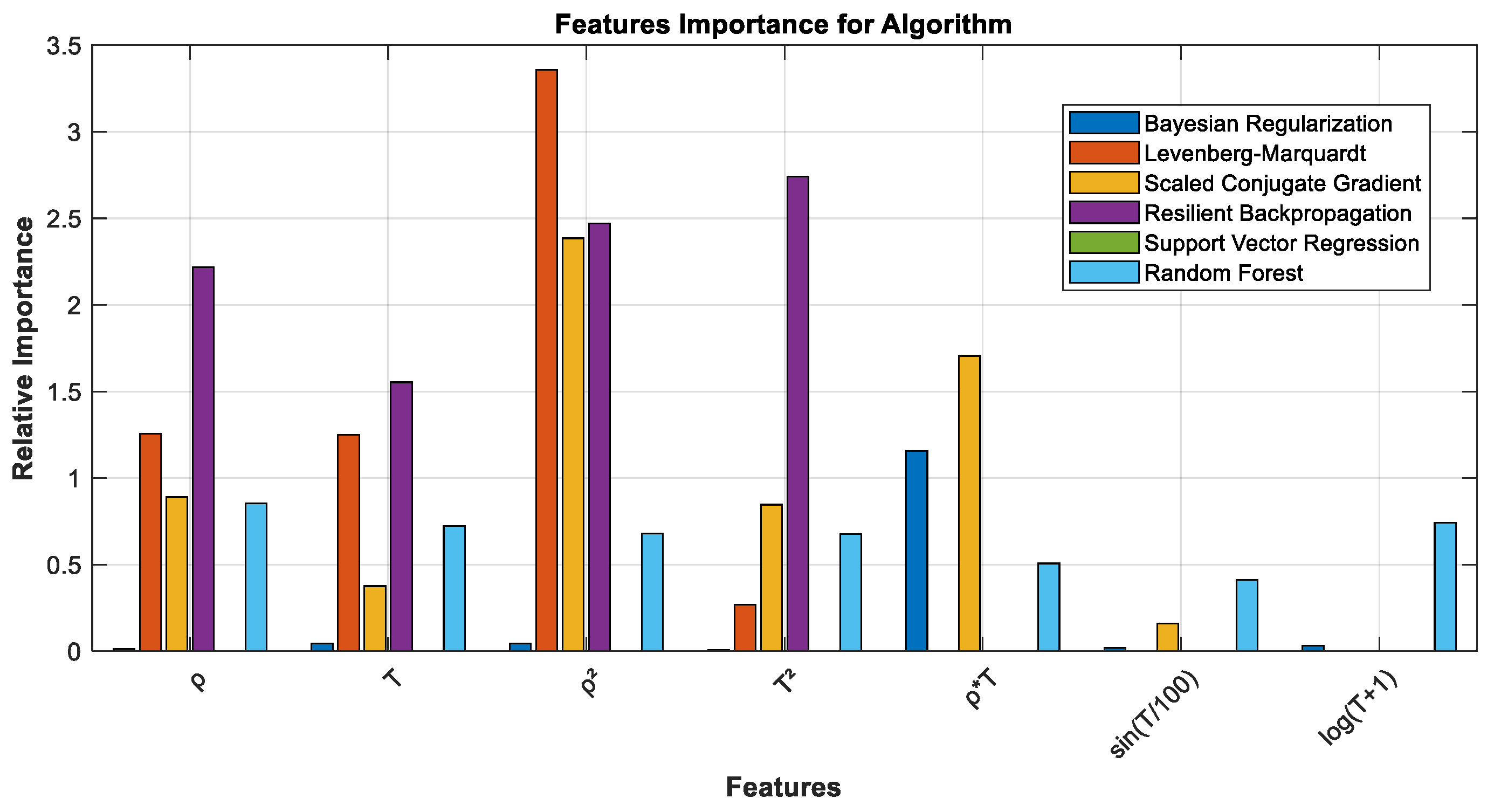
4.1. Preprocessing and Feature Engineering
4.2. Neural Network Architecture
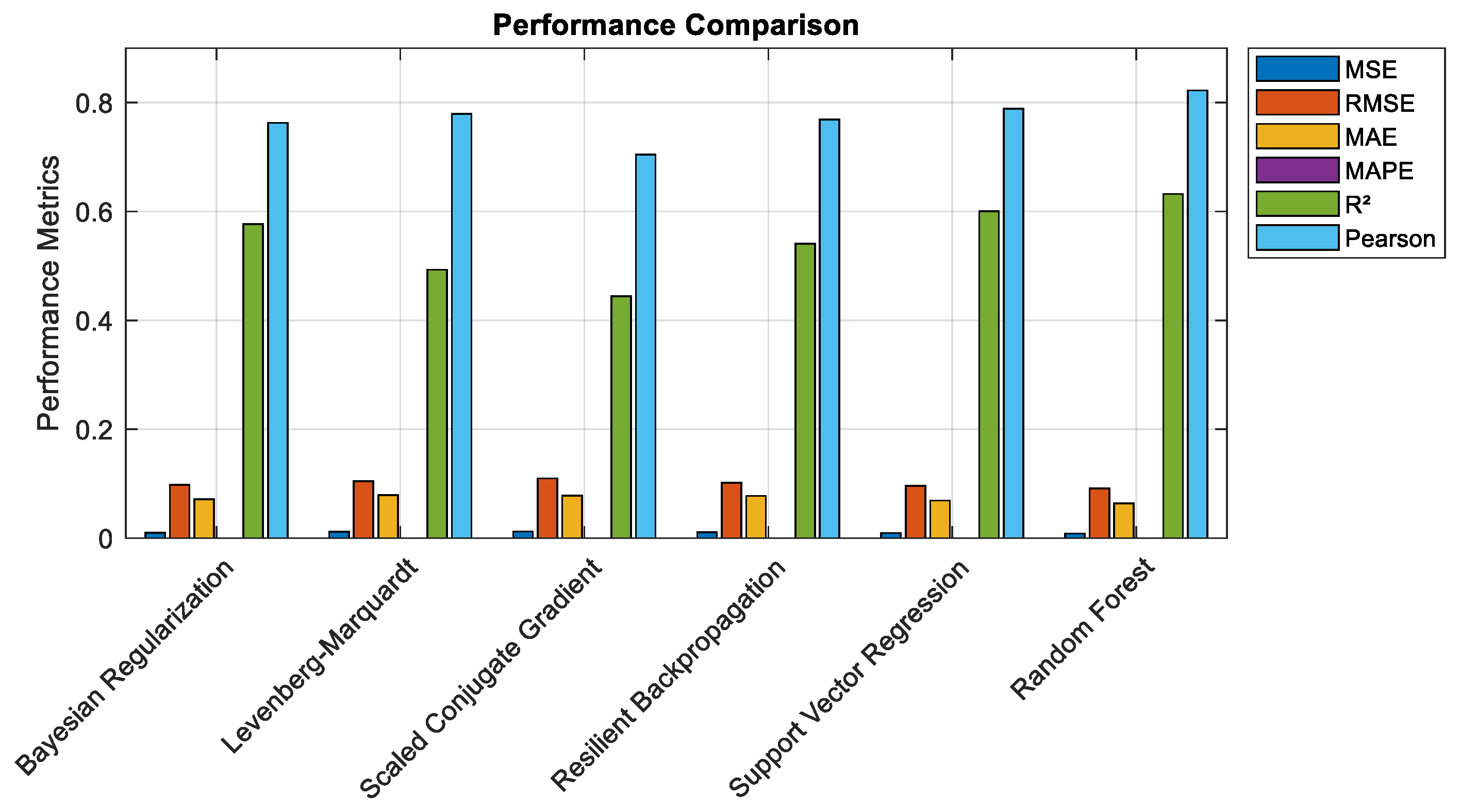
4.3. Evaluation Metrics
5. Laboratory Tests and Validation
6. Discussion
6.1. Performance Analysis
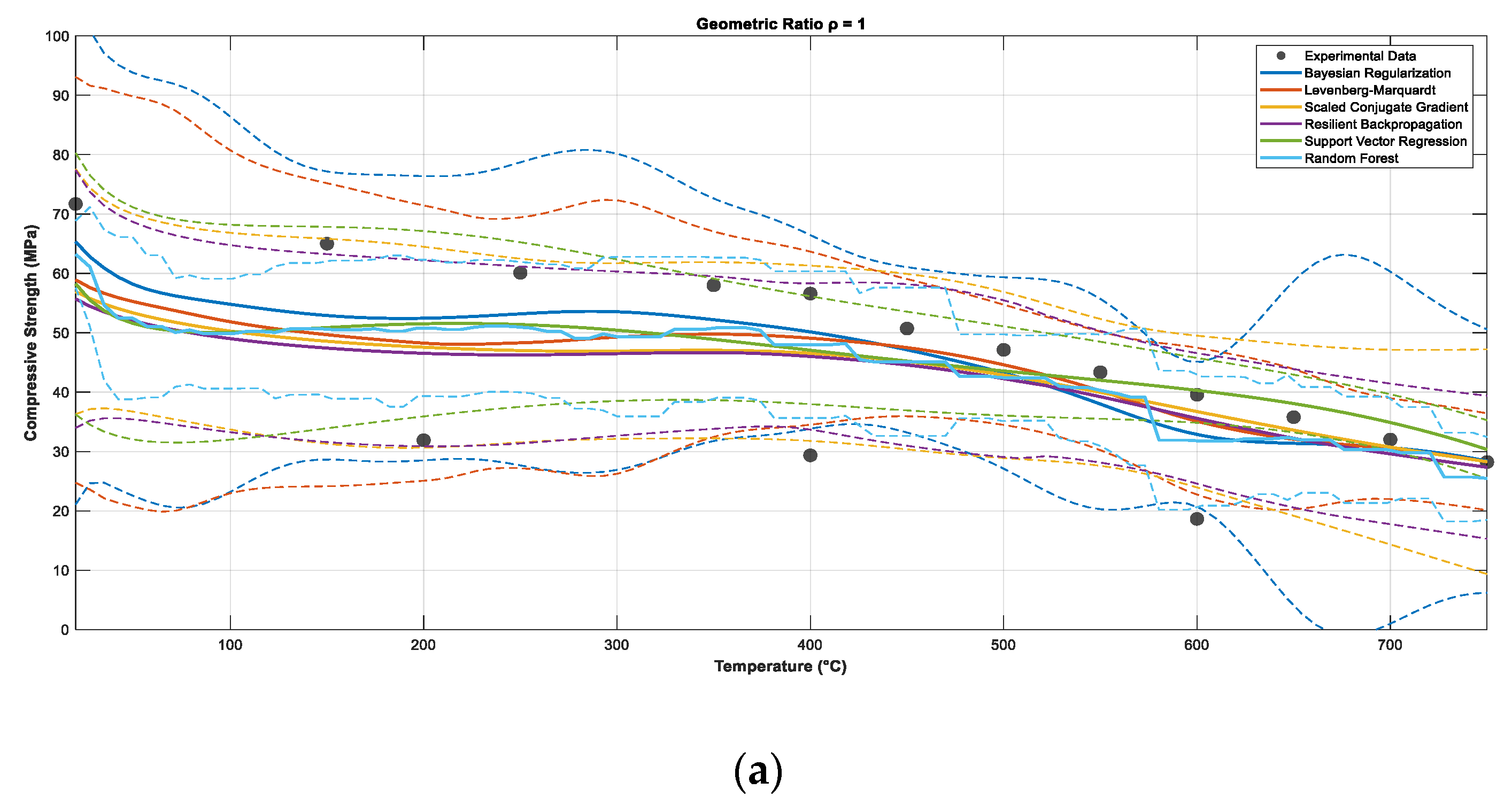
6.2. Prediction Results and Response Surfaces
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- United Nation Office for Disaster Risk Reduction (UNDRR) Fires in Europe Fuelled by Urbanisation and Climate Change. Available online: https://www.undrr.org/news/fires-europe-fuelled-urbanisation-and-climate-change (accessed on 10 April 2025).
- European Innovation Council. The European Prize for Humanitarian Innovation. Available online: https://eic.ec.europa.eu/eic-prizes/european-prize-humanitarian-innovation_en (accessed on 15 June 2024).
- Ruíz, M.A.; Mack-Vergara, Y.L. Resilient and Sustainable Housing Models against Climate Change: A Review. Sustainability 2023, 15, 13544. [Google Scholar] [CrossRef]
- Peng, T.; Lemay, L.; Cody, B. Concrete Building Systems: Disaster Resilient Solutions for Safer Communities. In Proceedings of the 1st Residential Building Design & Construction Conference, Bethlehem, PA, USA, 20–21 February 2013; pp. 46–55. [Google Scholar]
- Uysal, M.; Tanyildizi, H. Estimation of Compressive Strength of Self Compacting Concrete Containing Polypropylene Fiber and Mineral Additives Exposed to High Temperature Using Artificial Neural Network. Constr. Build. Mater. 2012, 27, 404–414. [Google Scholar] [CrossRef]
- Ealiyas Mathews, M.; Kiran, T.; Anand, N.; Lubloy, E.; Naser, M.Z.; Prince Arulraj, G. Effect of Protective Coating on Axial Resistance and Residual Capacity of Self-Compacting Concrete Columns Exposed to Standard Fire. Eng. Struct. 2022, 264, 114444. [Google Scholar] [CrossRef]
- La Scala, A.; Loprieno, P.; Ivorra, S.; Foti, D.; La Scala, M. Modal Analysis of a Fire-Damaged Masonry Vault. Fire 2024, 7, 194. [Google Scholar] [CrossRef]
- Mathews, M.E.; Andrushia, A.D.; Kiran, T.; Yadav, B.S.K.; Kanagaraj, B.; Anand, N. Structural Response of Self-Compacting Concrete Beams under Elevated Temperature. In Proceedings of the Materials Today: Proceedings; Elsevier Ltd.: Amsterdam, The Netherlands, 2021; Volume 49, pp. 1246–1254. [Google Scholar]
- Khaliq, W.; Kodur, V. Thermal and Mechanical Properties of Fiber Reinforced High Performance Self-Consolidating Concrete at Elevated Temperatures. Cem. Concr. Res. 2011, 41, 1112–1122. [Google Scholar] [CrossRef]
- Mansoor, J.; Shah, S.A.R.; Khan, M.M.; Sadiq, A.N.; Anwar, M.K.; Siddiq, M.U.; Ahmad, H. Analysis of Mechanical Properties of Self Compacted Concrete by Partial Replacement of Cement with Industrial Wastes under Elevated Temperature. Appl. Sci. 2018, 8, 364. [Google Scholar] [CrossRef]
- Scala, M.L.; Trovato, M.; Torelli, F.; La Scala, M.; Trovato, M.; Torelli, F. A Neural Network-Based Method for Voltage Security Monitoring. IEEE Trans. Power Syst. 1996, 11, 1332–1341. [Google Scholar] [CrossRef]
- Carnimeo, L.; Foti, D.; Potenza, F. On Protecting and Managing Slender Buildings from Risk Events via a Multitask Monitoring Network. In Proceedings of the SHMII 2015—7th International Conference on Structural Health Monitoring of Intelligent Infrastructure, Torino, Italy, 1–3 July 2015. [Google Scholar]
- Carnimeo, L.; Foti, D.; Ivorra, S. On Modeling an Innovative Monitoring Network for Protecting and Managing Cultural Heritage from Risk Events. Key Eng. Mater. 2015, 628, 243–249. [Google Scholar] [CrossRef]
- Rizzo, F.; Caracoglia, L.; Piccardo, G. Examining Wind-Induced Floor Accelerations in an Unconventionally Shaped, High-Rise Building for the Design of “Smart” Screen Walls. J. Build. Eng. 2021, 43, 103115. [Google Scholar] [CrossRef]
- Rizzo, F.; Barbato, M.; Sepe, V. Shape Dependence of Wind Pressure Peak Factor Statistics in Hyperbolic Paraboloid Roofs. J. Build. Eng. 2021, 44, 103203. [Google Scholar] [CrossRef]
- Rizzo, F. Investigation of the Time Dependence of Wind-Induced Aeroelastic Response on a Scale Model of a High-Rise Building. Appl. Sci. 2021, 11, 3315. [Google Scholar] [CrossRef]
- Rizzo, F.; Sadhu, A.; Abasi, A.; Pistol, A.; Flaga, Ł.; Venanzi, I.; Ubertini, F. Construction and Dynamic Identification of Aeroelastic Test Models for Flexible Roofs. Arch. Civ. Mech. Eng. 2022, 23, 16. [Google Scholar] [CrossRef]
- Scala, A.L.; Rizzo, F.; Carnimeo, L.; Chorro, S.I.; Foti, D. A Proposal of a Neural Predictor of Residual Compressive Strength in an SCC Exposed to High Temperatures for Resilient Housing. In Proceedings of the 2024 IEEE International Humanitarian Technologies Conference (IHTC), Bari, Italy, 27–30 November 2024; pp. 1–6. [Google Scholar]
- Ivorra, S.; Brotóns, V.; Foti, D.; Diaferio, M. A Preliminary Approach of Dynamic Identification of Slender Buildings by Neuronal Networks. Int. J. Non Linear Mech. 2016, 80, 183–189. [Google Scholar] [CrossRef]
- Decreto Ministeriale 14 Ottobre 2021—Approvazione di Norme Tecniche di Prevenzione incendi per gli Edifici Sottoposti a Tutela ai Sensi del Decreto Legislativo 22 Gennaio 2004, n. 42, Aperti al Pubblico, Contenenti una o più Attività ri-Comprese nell’all. Italy: Ministero dell’Interno. 2021. Available online: https://www.tuttoprevenzioneincendi.it/images/Norme/DM_14_10_2021.pdf (accessed on 24 April 2025).
- RILEM Technical Committee 200-HTC. Recommendation of RILEM TC 200-HTC: Mechanical concrete properties at high tem-peratures—Modelling and applications. Mater. Struct. 2007, 40, 841–853. [Google Scholar] [CrossRef]
- Lazarevska, M.; Knezevic, M.; Cvetkovska, M.; Trombeva-Gavriloska, A. Application of Artificial Neural Networks in Civil Engineering. Teh. Vjesn. 2014, 21, 1353–1359. [Google Scholar]
- Chojaczyk, A.A.; Teixeira, A.P.; Neves, L.C.; Cardoso, J.B.; Guedes Soares, C. Review and Application of Artificial Neural Networks Models in Reliability Analysis of Steel Structures. Struct. Saf. 2015, 52, 78–89. [Google Scholar] [CrossRef]
- Yuen, K.-V. Bayesian Methods for Structural Dynamics and Civil Engineering; John Wiley & Sons: Singapore, 2010; ISBN 978-0-470-82454-2. [Google Scholar]
- Lopez Peña, F.; Díaz Casás, V.; Gosset, A.; Duro, R.J. A Surrogate Method Based on the Enhancement of Low Fidelity Computational Fluid Dynamics Approximations by Artificial Neural Networks. Comput. Fluids 2012, 58, 112–119. [Google Scholar] [CrossRef]
- Kocabaş, F.; Ünal, S.; Ünal, B. A Neural Network Approach for Prediction of Critical Submergence of an Intake in Still Water and Open Channel Flow for Permeable and Impermeable Bottom. Comput. Fluids 2008, 37, 1040–1046. [Google Scholar] [CrossRef]
- Mata, J. Interpretation of Concrete Dam Behaviour with Artificial Neural Network and Multiple Linear Regression Models. Eng. Struct. 2011, 33, 903–910. [Google Scholar] [CrossRef]
- Nourani, V.; Komasi, M.; Mano, A. A Multivariate ANN-Wavelet Approach for Rainfall-Runoff Modeling. Water Resour. Manag. 2009, 23, 2877–2894. [Google Scholar] [CrossRef]
- Shahin, M.A.; Jaksa, M.B.; Maier, H.R. Artificial Neural Network Applications in Geotechnical Engineering. Aust. Geomech. J. 2001, 36, 49–62. [Google Scholar]
- Gomes, H.M.; Awruch, A.M.; Lopes, P.A.M. Reliability Based Optimization of Laminated Composite Structures Using Genetic Algorithms and Artificial Neural Networks. Struct. Saf. 2011, 33, 186–195. [Google Scholar] [CrossRef]
- Le, V.; Caracoglia, L. A Neural Network Surrogate Model for the Performance Assessment of a Vertical Structure Subjected to Non-Stationary, Tornadic Wind Loads. Comput. Struct. 2020, 231, 106208. [Google Scholar] [CrossRef]
- Seo, D.W.; Caracoglia, L. Estimation of Torsional-Flutter Probability in Flexible Bridges Considering Randomness in Flutter Derivatives. Eng. Struct. 2011, 33, 2284–2296. [Google Scholar] [CrossRef]
- Rizzo, F.; Caracoglia, L. Artificial Neural Network Model to Predict the Flutter Velocity of Suspension Bridges. Comput. Struct. 2020, 233, 106236. [Google Scholar] [CrossRef]
- Rizzo, F.; Caracoglia, L. Examination of Artificial Neural Networks to Predict Wind-Induced Displacements of Cable Net Roofs. Eng. Struct. 2021, 245, 112956. [Google Scholar] [CrossRef]
- Bakhary, N.; Hao, H.; Deeks, A.J. Damage Detection Using Artificial Neural Network with Consideration of Uncertainties. Eng. Struct. 2007, 29, 2806–2815. [Google Scholar] [CrossRef]
- Deng, J.; Gu, D.; Li, X.; Yue, Z.Q. Structural Reliability Analysis for Implicit Performance Functions Using Artificial Neural Network. Struct. Saf. 2005, 27, 25–48. [Google Scholar] [CrossRef]
- Pathirage, C.S.N.; Li, J.; Li, L.; Hao, H.; Liu, W.; Ni, P. Structural Damage Identification Based on Autoencoder Neural Networks and Deep Learning. Eng. Struct. 2018, 172, 13–28. [Google Scholar] [CrossRef]
- Möller, O.; Foschi, R.O.; Quiroz, L.M.; Rubinstein, M. Structural Optimization for Performance-Based Design in Earthquake Engineering: Applications of Neural Networks. Struct. Saf. 2009, 31, 490–499. [Google Scholar] [CrossRef]
- Asteris, P.G.; Nikoo, M. Artificial Bee Colony-Based Neural Network for the Prediction of the Fundamental Period of Infilled Frame Structures. Neural Comput. Appl. 2019, 31, 4837–4847. [Google Scholar] [CrossRef]
- Papadrakakis, M.; Lagaros, N.D. Reliability-Based Structural Optimization Using Neural Networks and Monte Carlo Simulation. Comput. Methods Appl. Mech. Eng. 2002, 191, 3491–3507. [Google Scholar] [CrossRef]
- Chen, S.Z.; Zhang, S.Y.; Han, W.S.; Wu, G. Ensemble Learning Based Approach for FRP-Concrete Bond Strength Prediction. Constr. Build. Mater. 2021, 302, 124230. [Google Scholar] [CrossRef]
- Güçlüer, K.; Özbeyaz, A.; Göymen, S.; Günaydın, O. A Comparative Investigation Using Machine Learning Methods for Concrete Compressive Strength Estimation. Mater. Today Commun. 2021, 27, 102278. [Google Scholar] [CrossRef]
- Chou, J.S.; Pham, A.D. Enhanced Artificial Intelligence for Ensemble Approach to Predicting High Performance Concrete Compressive Strength. Constr. Build. Mater. 2013, 49, 554–563. [Google Scholar] [CrossRef]
- Chen, B.T.; Chang, T.P.; Shih, J.Y.; Wang, J.J. Estimation of Exposed Temperature for Fire-Damaged Concrete Using Support Vector Machine. Comput. Mater. Sci. 2009, 44, 913–920. [Google Scholar] [CrossRef]
- Mangalathu, S.; Hwang, S.H.; Jeon, J.S. Failure Mode and Effects Analysis of RC Members Based on Machine-Learning-Based SHapley Additive ExPlanations (SHAP) Approach. Eng. Struct. 2020, 219, 110927. [Google Scholar] [CrossRef]
- Amini, K.; Jalalpour, M.; Delatte, N. Advancing Concrete Strength Prediction Using Non-Destructive Testing: Development and Verification of a Generalizable Model. Constr. Build. Mater. 2016, 102, 762–768. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Tran, D.H.; Nguyen, N.M.; Vuong, H.T.; Chien-Cheng, C.; Cao, M.T. Accurately Predicting the Mechanical Behavior of Deteriorated Reinforced Concrete Components Using Natural Intelligence-Integrated Machine Learners. Constr. Build. Mater. 2023, 408, 133753. [Google Scholar] [CrossRef]
- Ushizima, D.; Xu, K.; Monteiro, P.J.M. Materials Data Science for Microstructural Characterization of Archaeological Concrete. MRS Adv. 2020, 5, 305–318. [Google Scholar] [CrossRef]
- Mishra, M. Machine Learning Techniques for Structural Health Monitoring of Heritage Buildings: A State-of-the-Art Review and Case Studies. J. Cult. Herit. 2021, 47, 227–245. [Google Scholar] [CrossRef]
- Dietterich, T.G.; Kolen, J.F.; Pollack, J.B. Ensemble Methods in Machine Learning BT—Multiple Classifier Systems. In Proceedings of the Complex Systems; Springer: Berlin/Heidelberg, Germany, 2000; Volume 4, pp. 1–15. [Google Scholar]
- Zhou, Z.-H. Ensemble Methods: Foundations and Algorithms, 1st ed.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2012. [Google Scholar]
- Hansen, L.K.; Salamon, P. Neural Network Ensembles. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 993–1001. [Google Scholar] [CrossRef]
- Polikar, R. Ensemble Learning. In Ensemble Machine Learning: Methods and Applications; Zhang, C., Ma, Y., Eds.; Springer: New York, NY, USA, 2012; pp. 1–34. ISBN 978-1-4419-9326-7. [Google Scholar]
- Alharthy, S.E.; Mostafa, M.A. Mechanical and Thermal Charactristics of Self-Compacting Concrete Produced with Blast Furnace Slag and Fly Ash. HBRC J. 2020, 16, 283–298. [Google Scholar] [CrossRef]
- Bamonte, P.; Gambarova, P.G. A Study on the Mechanical Properties of Self-Compacting Concrete at High Temperature and after Cooling. Mater. Struct. 2012, 45, 1375–1387. [Google Scholar] [CrossRef]
- Persson, B. A Comparison between Mechanical Properties of Self-Compacting Concrete and the Corresponding Properties of Normal Concrete. Cem. Concr. Res. 2001, 31, 193–198. [Google Scholar] [CrossRef]
- Farhad, A.; Junbo, S.; Guanqi, H. Mechanical Behavior of Fiber-Reinforced Self-Compacting Rubberized Concrete Exposed to Elevated Temperatures. J. Mater. Civ. Eng. 2019, 31, 4019302. [Google Scholar] [CrossRef]
- Mňahončáková, E.; Pavlíková, M.; Grzeszczyk, S.; Rovnanı´ková, P.; Černý, R. Hydric, Thermal and Mechanical Properties of Self-Compacting Concrete Containing Different Fillers. Constr. Build. Mater. 2008, 22, 1594–1600. [Google Scholar] [CrossRef]
- Jiao, P.; Roy, M.; Barri, K.; Zhu, R.; Ray, I.; Alavi, A.H.; Hu, X.; Li, B.; Mo, Y.; Alselwi, O.; et al. Machine Learning Prediction Models to Evaluate the Strength of Recycled Aggregate Concrete. Materials 2022, 15, 3605. [Google Scholar] [CrossRef]
- Shahrokhishahraki, M.; Malekpour, M.; Mirvalad, S.; Faraone, G.; Liu, K.-H.; Xie, T.-Y.; Cai, Z.-K.; Chen, G.-M.; Zhao, X.-Y.; Nguyen, T.-H.; et al. A Comparative Study of Random Forest and Genetic Engineering Programming for the Prediction of Compressive Strength of High Strength Concrete (HSC). J. Build. Eng. 2024, 10, 108160. [Google Scholar] [CrossRef]
- Mai, H.V.T.; Nguyen, M.H.; Ly, H.B. Development of Machine Learning Methods to Predict the Compressive Strength of Fiber-Reinforced Self-Compacting Concrete and Sensitivity Analysis. Constr. Build. Mater. 2023, 367, 130339. [Google Scholar] [CrossRef]
- Liu, Y.; Cao, Y.; Wang, L.; Chen, Z.S.; Qin, Y. Prediction of the Durability of High-Performance Concrete Using an Integrated RF-LSSVM Model. Constr. Build. Mater. 2022, 356, 129232. [Google Scholar] [CrossRef]
- Rajakarunakaran, S.A.; Lourdu, A.R.; Muthusamy, S.; Panchal, H.; Jawad Alrubaie, A.; Musa Jaber, M.; Ali, M.H.; Tlili, I.; Maseleno, A.; Majdi, A.; et al. Prediction of Strength and Analysis in Self-Compacting Concrete Using Machine Learning Based Regression Techniques. Adv. Eng. Softw. 2022, 173, 103267. [Google Scholar] [CrossRef]
- de-Prado-Gil, J.; Palencia, C.; Silva-Monteiro, N.; Martínez-García, R. To Predict the Compressive Strength of Self Compacting Concrete with Recycled Aggregates Utilizing Ensemble Machine Learning Models. Case Stud. Constr. Mater. 2022, 16, e01046. [Google Scholar] [CrossRef]
- Malami, S.I.; Anwar, F.H.; Abdulrahman, S.; Haruna, S.I.; Ali, S.I.A.; Abba, S.I. Implementation of Hybrid Neuro-Fuzzy and Self-Turning Predictive Model for the Prediction of Concrete Carbonation Depth: A Soft Computing Technique. Results Eng. 2021, 10, 100228. [Google Scholar] [CrossRef]
- Arbaoui, A. Wavelet-Based Multiresolution Analysis Coupled with Deep Learning to Efficiently Monitor Cracks in Concrete. Frat. Ed. Integrità Strutt. 2021, 15, 33–47. [Google Scholar] [CrossRef]
- Chu, H.H.; Khan, M.A.; Javed, M.; Zafar, A.; Ijaz Khan, M.; Alabduljabbar, H.; Qayyum, S. Sustainable Use of Fly-Ash: Use of Gene-Expression Programming (GEP) and Multi-Expression Programming (MEP) for Forecasting the Compressive Strength Geopolymer Concrete. Ain Shams Eng. J. 2021, 12, 3603–3617. [Google Scholar] [CrossRef]
- Ziolkowski, P.; Niedostatkiewicz, M.; Padmapoorani, P.; Senthilkumar, S.; Mohanraj, R. Machine Learning Techniques in Concrete Mix Design. Materials 2019, 12, 1256. [Google Scholar] [CrossRef]
- Li, Z.; Yoon, J.; Zhang, R.; Rajabipour, F.; Srubar, W.V.; Dabo, I.; Radlińska, A. Machine Learning in Concrete Science: Applications, Challenges, and Best Practices. NPJ Comput. Mater. 2022, 8, 127. [Google Scholar] [CrossRef]
- Kaveh, A.; Khavaninzadeh, N. Efficient Training of Two ANNs Using Four Meta-Heuristic Algorithms for Predicting the FRP Strength. Structures 2023, 52, 256–272. [Google Scholar] [CrossRef]
- Song, H.; Ahmad, A.; Farooq, F.; Ostrowski, K.A.; Maślak, M.; Czarnecki, S.; Aslam, F. Predicting the Compressive Strength of Concrete with Fly Ash Admixture Using Machine Learning Algorithms. Constr. Build. Mater. 2021, 308, 125021. [Google Scholar] [CrossRef]
- Farooq, F.; Ahmed, W.; Akbar, A.; Aslam, F.; Alyousef, R. Predictive Modeling for Sustainable High-Performance Concrete from Industrial Wastes: A Comparison and Optimization of Models Using Ensemble Learners. J. Clean. Prod. 2021, 292, 126032. [Google Scholar] [CrossRef]
- Maherian, M.F.; Baran, S.; Bicakci, S.N.; Toreyin, B.U.; Atahan, H.N. Machine Learning-Based Compressive Strength Estimation in Nano Silica-Modified Concrete. Constr. Build. Mater. 2023, 408, 133684. [Google Scholar] [CrossRef]
- Feng, D.C.; Liu, Z.T.; Wang, X.D.; Chen, Y.; Chang, J.Q.; Wei, D.F.; Jiang, Z.M. Machine Learning-Based Compressive Strength Prediction for Concrete: An Adaptive Boosting Approach. Constr. Build. Mater. 2020, 230, 117000. [Google Scholar] [CrossRef]
- Mohtasham Moein, M.; Saradar, A.; Rahmati, K.; Ghasemzadeh Mousavinejad, S.H.; Bristow, J.; Aramali, V.; Karakouzian, M. Predictive Models for Concrete Properties Using Machine Learning and Deep Learning Approaches: A Review. J. Build. Eng. 2023, 63, 105444. [Google Scholar] [CrossRef]
- Yeh, I.C. Modeling of Strength of High-Performance Concrete Using Artificial Neural Networks. Cem. Concr. Res. 1998, 28, 1797–1808. [Google Scholar] [CrossRef]
- Khademi, F.; Akbari, M.; Jamal, S.M.; Nikoo, M. Multiple Linear Regression, Artificial Neural Network, and Fuzzy Logic Prediction of 28 Days Compressive Strength of Concrete. Front. Struct. Civ. Eng. 2017, 11, 90–99. [Google Scholar] [CrossRef]
- Ashrafian, A.; Taheri Amiri, M.J.; Rezaie-Balf, M.; Ozbakkaloglu, T.; Lotfi-Omran, O. Prediction of Compressive Strength and Ultrasonic Pulse Velocity of Fiber Reinforced Concrete Incorporating Nano Silica Using Heuristic Regression Methods. Constr. Build. Mater. 2018, 190, 479–494. [Google Scholar] [CrossRef]
- Mai, H.-V.T.; Nguyen, T.-A.; Ly, H.-B.; Tran, V.Q. Prediction Compressive Strength of Concrete Containing GGBFS Using Random Forest Model. Adv. Civ. Eng. 2021, 2021, 6671448. [Google Scholar] [CrossRef]
- Li, Y.; Hishamuddin, F.N.S.; Mohammed, A.S.; Armaghani, D.J.; Ulrikh, D.V.; Dehghanbanadaki, A.; Azizi, A. The Effects of Rock Index Tests on Prediction of Tensile Strength of Granitic Samples: A Neuro-Fuzzy Intelligent System. Sustainability 2021, 13, 10541. [Google Scholar] [CrossRef]
- Asteris, P.G.; Lourenço, P.B.; Roussis, P.C.; Elpida Adami, C.; Armaghani, D.J.; Cavaleri, L.; Chalioris, C.E.; Hajihassani, M.; Lemonis, M.E.; Mohammed, A.S.; et al. Revealing the Nature of Metakaolin-Based Concrete Materials Using Artificial Intelligence Techniques. Constr. Build. Mater. 2022, 322, 126500. [Google Scholar] [CrossRef]
- Ali, R.; Muayad, M.; Mohammed, A.S.; Asteris, P.G. Analysis and Prediction of the Effect of Nanosilica on the Compressive Strength of Concrete with Different Mix Proportions and Specimen Sizes Using Various Numerical Approaches. Struct. Concr. 2023, 24, 4161–4184. [Google Scholar] [CrossRef]
- Chen, C.-H.; Wu, J.-C.; Chen, J.-H. Prediction of Flutter Derivatives by Artificial Neural Networks. J. Wind. Eng. Ind. Aerodyn.—J. Wind Eng. Ind. Aerodyn. 2008, 96, 1925–1937. [Google Scholar] [CrossRef]
- MacKay, D.J.C.; Foresee, F.D.; Hagan, M.T. Bayesian Interpolation. Neural Comput. 1992, 4, 415–447. [Google Scholar] [CrossRef]
- Dan Foresee, F.; Hagan, M.T. Gauss-Newton Approximation to Bayesian Learning. In Proceedings of the International Conference on Neural Networks (ICNN’97), Houston, TX, USA, 9–12 June 1997; Volume 3, pp. 1930–1935. [Google Scholar]
- MATLAB Manual. Version: 9.13.0 (R2022b), The MathWorks Inc.: Natick, MA, USA, 2022.
- Riedmiller, M.; Braun, H. RPROP—A Fast Adaptive Learning Algorithm. 1992. Available online: https://api.semanticscholar.org/CorpusID:53929455 (accessed on 1 January 2025).
- Benjeddou, O.; Katman, H.Y.; Jedidi, M.; Mashaan, N. Experimental Investigation of the High Temperatures Effects on Self-Compacting Concrete Properties. Buildings 2022, 12, 729. [Google Scholar] [CrossRef]
- Rukavina, M.J.; Gabrijel, I.; Grubeša, I.N.; Mladenovič, A. Residual Compressive Behavior of Self-Compacting Concrete after High Temperature Exposure-Influence of Binder Materials. Materials 2022, 15, 2222. [Google Scholar] [CrossRef]
- Bamonte, P.; Gambarova, P.G. High-Temperature Behavior of SCC in Compression: Comparative Study on Recent Experimental Campaigns. J. Mater. Civ. Eng. 2016, 28. [Google Scholar] [CrossRef]
- Khaliq, W.; Kodur, V. Effectiveness of Polypropylene and Steel Fibers in Enhancing Fire Resistance of High-Strength Concrete Columns. J. Struct. Eng. 2018, 144, 4017224. [Google Scholar] [CrossRef]
- Bogas, J.A.; Gomes, A.; Pereira, M.F.C. Self-Compacting Lightweight Concrete Produced with Expanded Clay Aggregate. Constr. Build. Mater. 2012, 35, 1013–1022. [Google Scholar] [CrossRef]
- Al-Martini, S.; Nehdi, M. Effects of Heat and Mixing Time on Self-Compacting Concrete. Proc. Inst. Civ. Eng. Constr. Mater. 2010, 163, 175–182. [Google Scholar] [CrossRef]
- Raif Boğa, A.; Karakurt, C.; Ferdi Şenol, A. The Effect of Elevated Temperature on the Properties of SCC’s Produced with Different Types of Fibers. Constr. Build. Mater. 2022, 340, 127803. [Google Scholar] [CrossRef]
- Surya, T.R.; Prakash, M.; Satyanarayanan, K.S.; Celestine, A.K.; Parthasarathi, N. Compressive Strength of Self Compacting Concrete under Elevated Temperature. In Proceedings of the Materials Today: Proceedings; Elsevier Ltd.: Amsterdam, The Netherlands, 2020; Volume 40, pp. S83–S87. [Google Scholar]
- Tao, J.; Yuan, Y.; Taerwe, L. Compressive Strength of Self-Compacting Concrete during High-Temperature Exposure. J. Mater. Civ. Eng. 2010, 22, 1005–1011. [Google Scholar] [CrossRef]
- Sideris, K.K. Mechanical Characteristics of Self-Consolidating Concretes Exposed to Elevated Temperatures. J. Mater. Civ. Eng. 2007, 19, 648–654. [Google Scholar] [CrossRef]
- Ente Nazionale Italiano di Unificazione. Prova sul Calcestruzzo Autocompattante Fresco—Determinazione del Tempo di Efflusso Dall’imbuto (UNI 11042:2003). 2003. Available online: https://store.uni.com/uni-11042-2003 (accessed on 24 April 2025).
- Ente Nazionale Italiano di Unificazione. Calcestruzzo—Specificazione, Prestazione, Produzione e Conformità (UNI EN 206:2021). 2022. Available online: https://store.uni.com/uni-en-206-2021 (accessed on 24 April 2025).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Temperature | Specimens for Determining Compressive Strength | Specimens for Determining the Modulus of Elasticity |
|---|---|---|
| SCC Samples | SCC Samples | |
| 20 °C | 4 | 2 |
| 150 °C | 2 | |
| 250 °C | 2 | |
| 350 °C | 2 | 2 |
| 400 °C | 2 | |
| 450 °C | 2 | |
| 500 °C | 2 | 2 |
| 550 °C | 2 | |
| 600 °C | 2 | |
| 650 °C | 2 | 2 |
| 700 °C | 2 | |
| 750 °C | 2 | |
| 800 °C | 2 | 2 |
| Total tests | 28 | 10 |
| Test Temperature | Mass [kg] | Force Applied [kN] | Residual Compressive Strength [N/mm2] |
|---|---|---|---|
| 20 °C | 1.517 | 508.4 | 71.7 |
| 150 °C | 1.537 | 461.0 | 65 |
| 250 °C | 1.538 | 426 | 60.1 |
| 350 °C | 1.563 | 411.2 | 58 |
| 400 °C | 1.532 | 401.5 | 56.6 |
| 450 °C | 1.501 | 359.1 | 50.7 |
| 500 °C | - | 0 | 0 |
| Test Temperature | Mass [kg] | Force Applied [kN] | Residual Compressive Strength [N/mm2] | Elastic Modulus [MPa] |
|---|---|---|---|---|
| 20 °C | 3.1 | 472.1 | 66.6 | 39,106.1 |
| 350 °C | 3.0 | 368.4 | 52.0 | 34,548.7 |
| 500 °C | - | 0.0 | 0.0 | - |
| Temperature | Compressive Strength [MPa] | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Experimental | BR | Error (%) | LM | Error (%) | SCG | Error (%) | RProp | Error (%) | SVR | Error (%) | RF | Error (%) | |
| 20 | 71.70 | 69.60 | 2.93 | 71.46 | 0.33 | 56.86 | 20.70 | 61.97 | 13.57 | 61.41 | 14.35 | 63.23 | 11.81 |
| 350 | 58.00 | 51.06 | 11.97 | 49.27 | 15.05 | 46.39 | 20.02 | 48.69 | 16.05 | 48.81 | 15.84 | 50.84 | 12.34 |
| 450 | 50.70 | 46.24 | 8.80 | 38.97 | 23.14 | 49.85 | 1.68 | 46.64 | 8.01 | 45.41 | 10.43 | 45.10 | 11.05 |
| 550 | 43.34 | 39.50 | 8.86 | 33.22 | 23.35 | 49.05 | −13.17 | 41.48 | 4.29 | 42.02 | 3.05 | 40.23 | 7.18 |
| 650 | 35.78 | 32.22 | 9.95 | 27.74 | 22.47 | 41.70 | −16.55 | 33.61 | 6.06 | 37.73 | −5.45 | 31.94 | 10.73 |
| 750 | 28.22 | 25.07 | 11.16 | 27.35 | 3.08 | 36.92 | −30.83 | 27.40 | 2.91 | 30.10 | −6.66 | 25.46 | 9.78 |
| 800 | 24.44 | 21.00 | 14.08 | 27.35 | −11.91 | 34.58 | −41.49 | 22.41 | 8.31 | 24.35 | 0.37 | 23.78 | 2.70 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
La Scala, A.; Carnimeo, L. Effective Comparison of Thermo-Mechanical Characteristics of Self-Compacting Concretes Through Machine Learning-Based Predictions. Fire 2025, 8, 289. https://doi.org/10.3390/fire8080289
La Scala A, Carnimeo L. Effective Comparison of Thermo-Mechanical Characteristics of Self-Compacting Concretes Through Machine Learning-Based Predictions. Fire. 2025; 8(8):289. https://doi.org/10.3390/fire8080289
Chicago/Turabian StyleLa Scala, Armando, and Leonarda Carnimeo. 2025. "Effective Comparison of Thermo-Mechanical Characteristics of Self-Compacting Concretes Through Machine Learning-Based Predictions" Fire 8, no. 8: 289. https://doi.org/10.3390/fire8080289
APA StyleLa Scala, A., & Carnimeo, L. (2025). Effective Comparison of Thermo-Mechanical Characteristics of Self-Compacting Concretes Through Machine Learning-Based Predictions. Fire, 8(8), 289. https://doi.org/10.3390/fire8080289