
Data-Driven Health Status Assessment of Fire Protection IoT Devices in Converter Stations


Abstract
1. Introduction
2. Methods
2.1. Comprehensive Quality Assessment Model for IoT Data
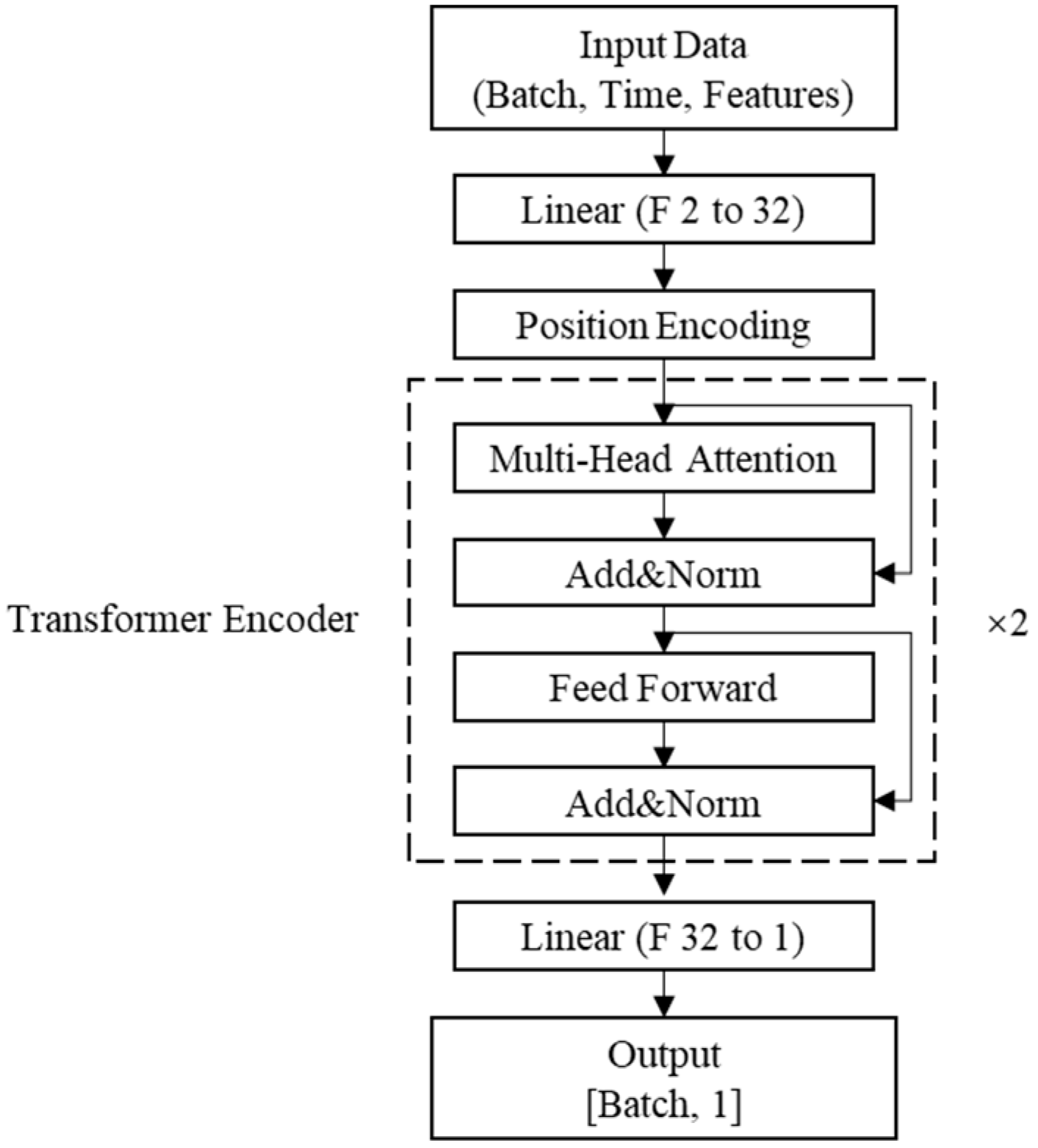
2.1.1. Data Validity Assessment
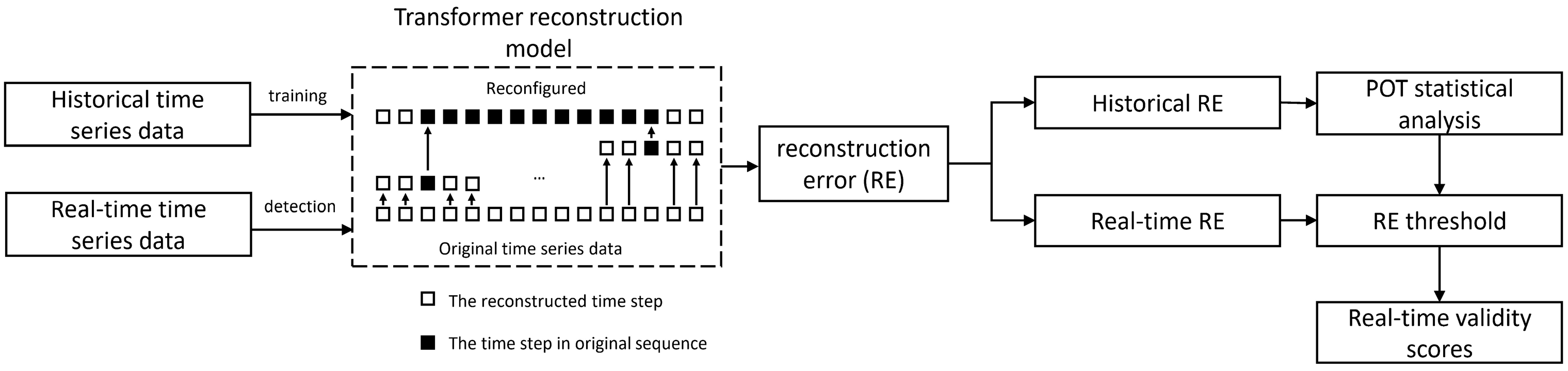
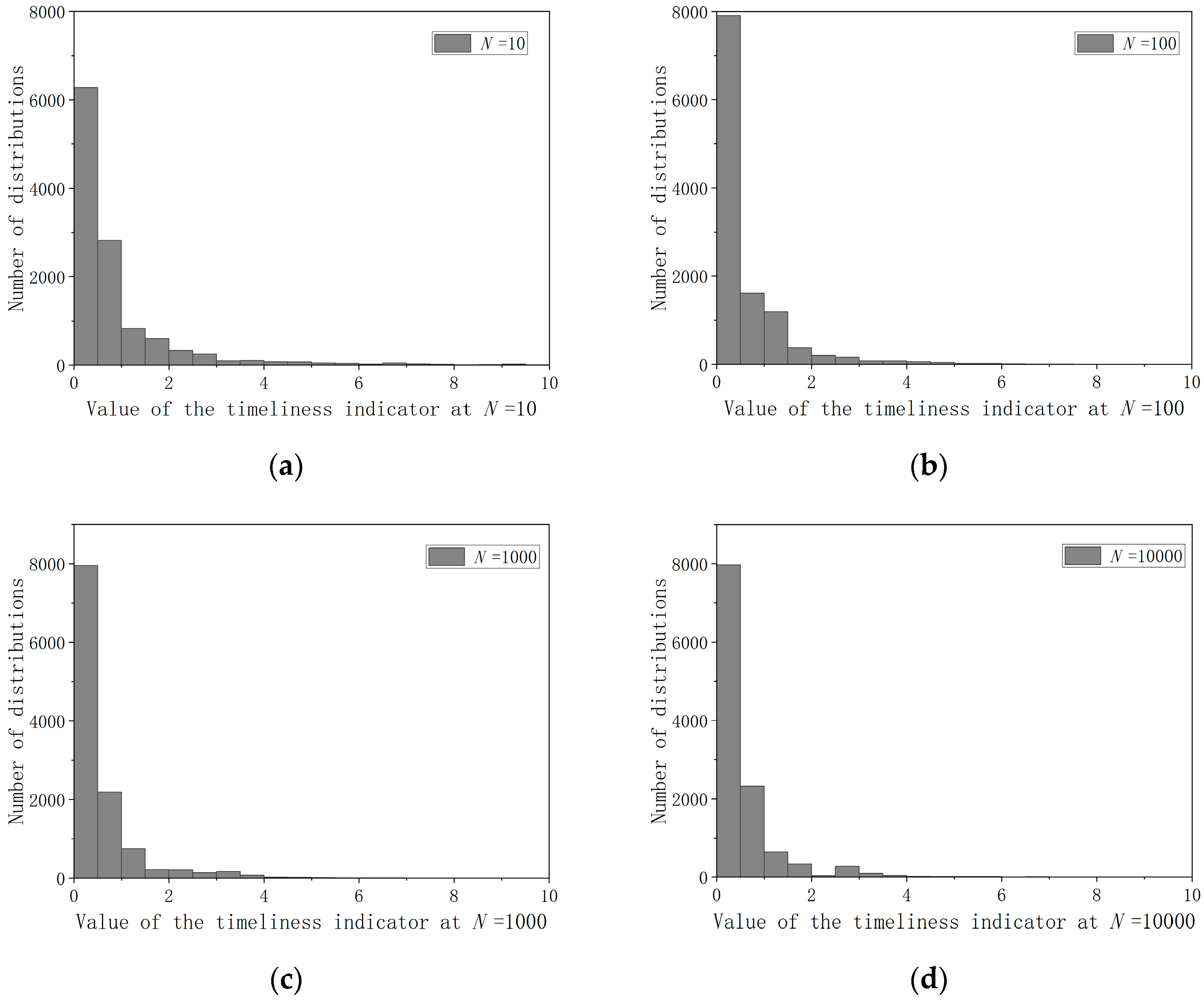
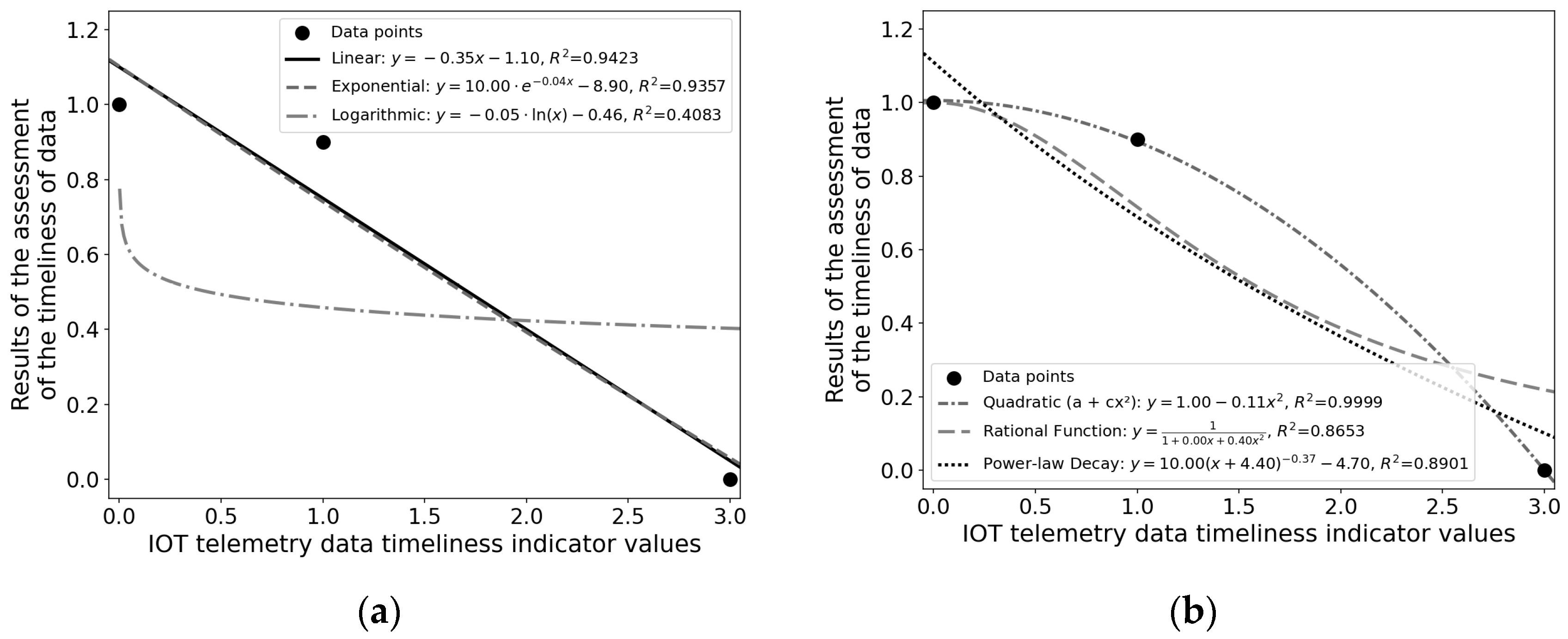
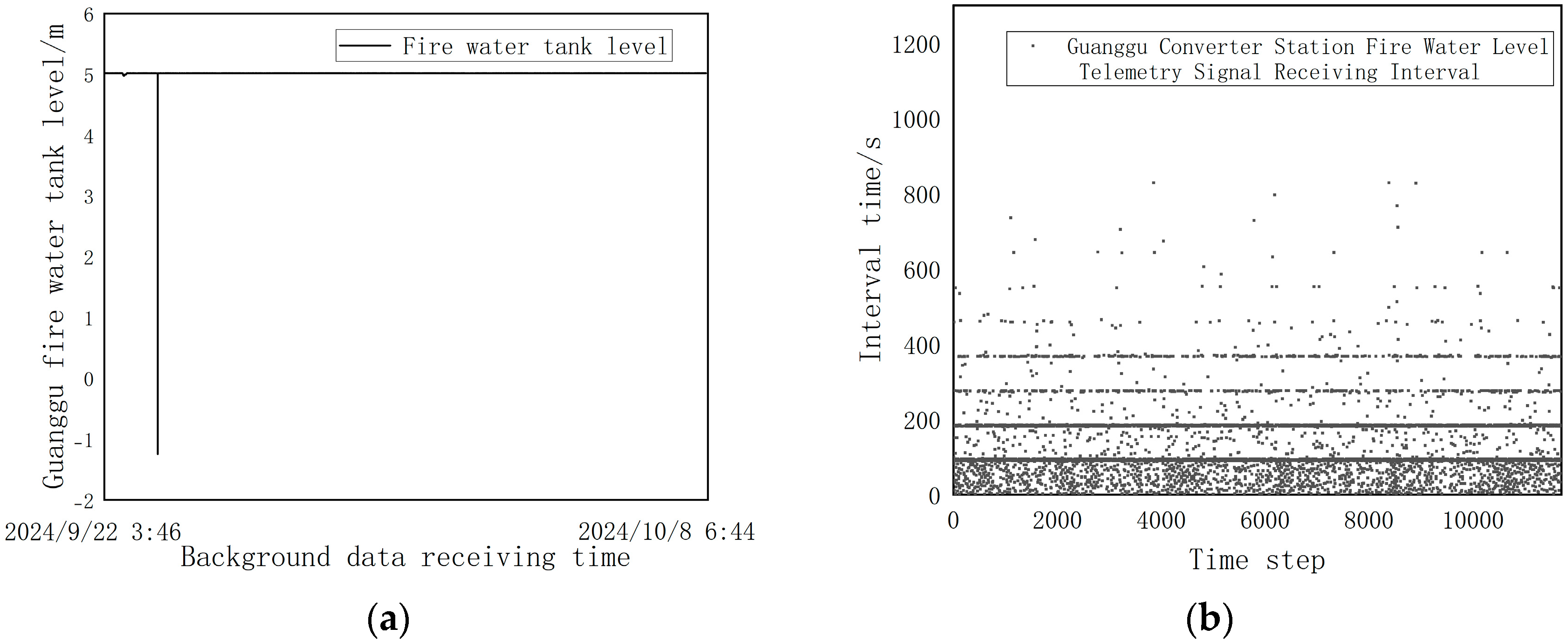
2.1.2. Data Timeliness Assessment
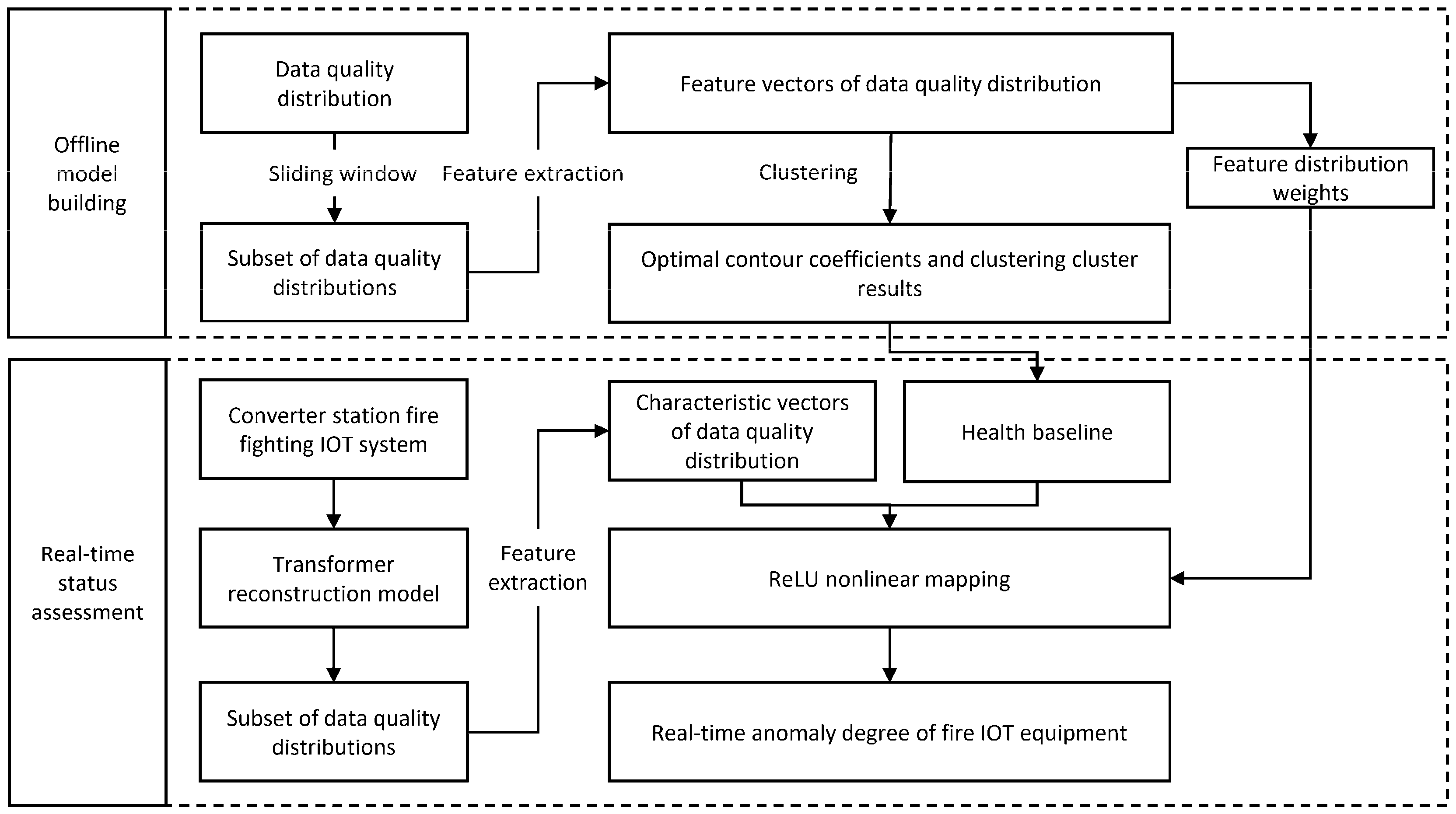
2.2. Device Health State Assessment Based on Integrated Data Quality
2.2.1. Feature Extraction Based on Sliding Time Window
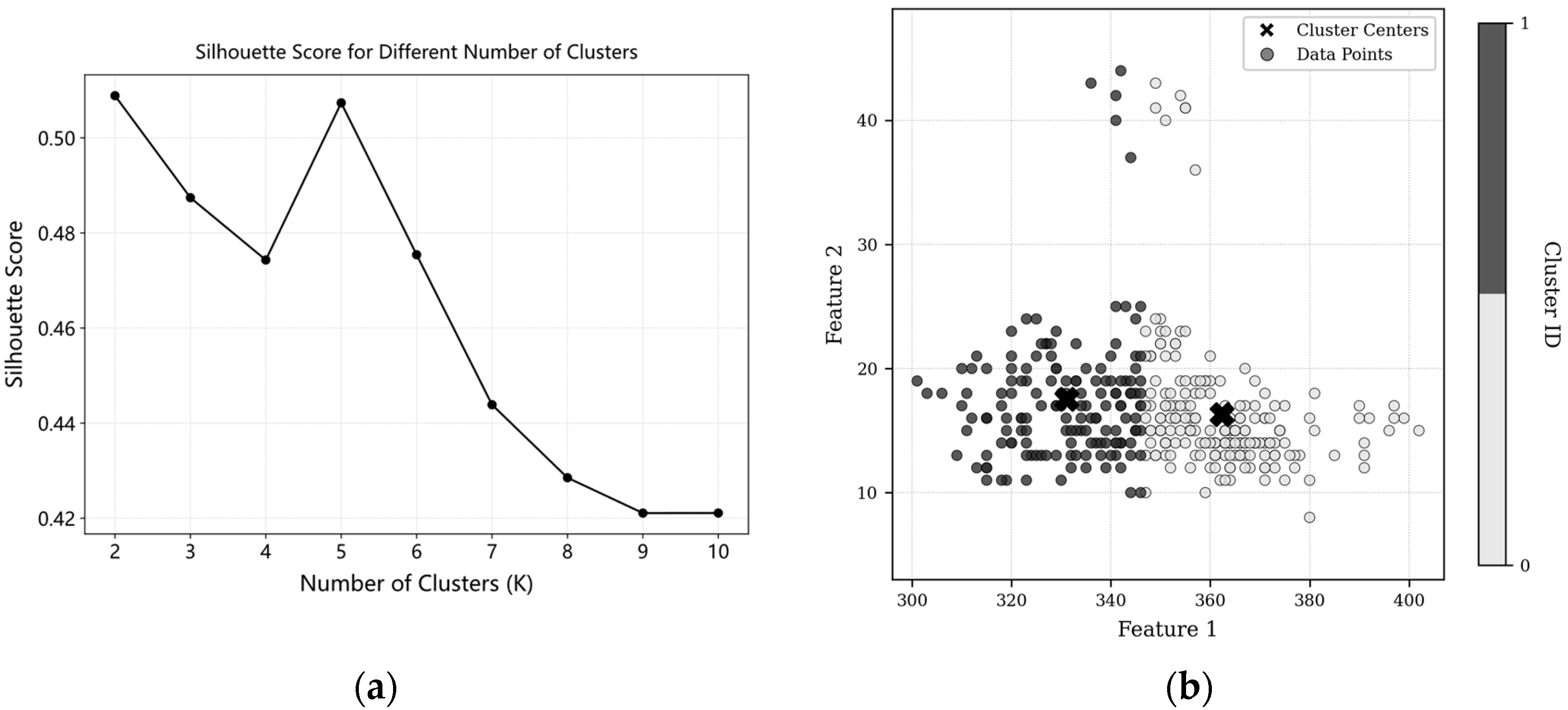
2.2.2. K-Means++ Clustering with Silhouette Coefficient
- Cohesion: the average distance between a data point and other points in the same cluster;
- Separation: the average distance between the data point and points in the nearest neighboring clusters.
2.2.3. ReLU Nonlinear Mapping Model
3. Results
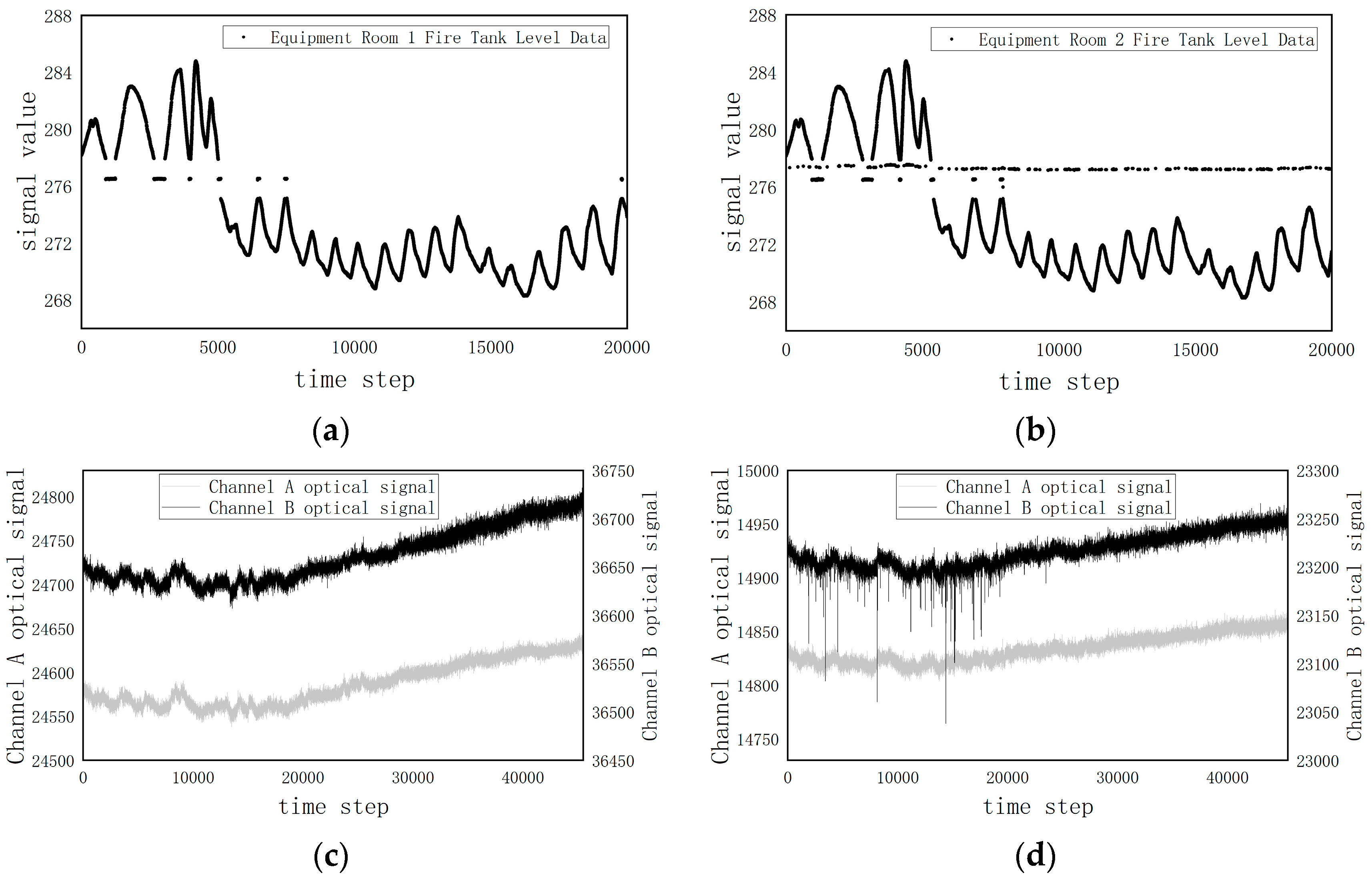
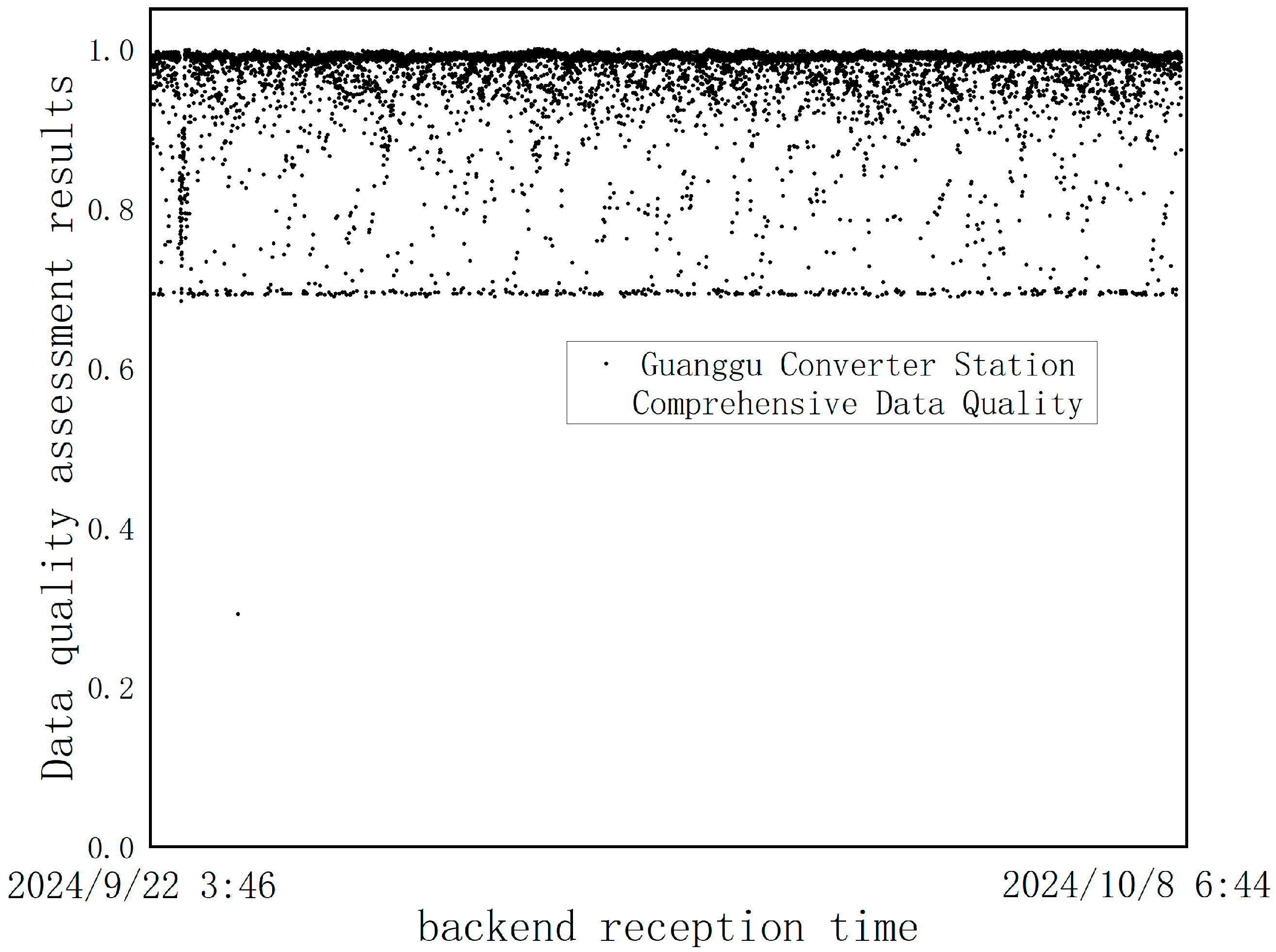
3.1. Results of the Data Validity Assessment
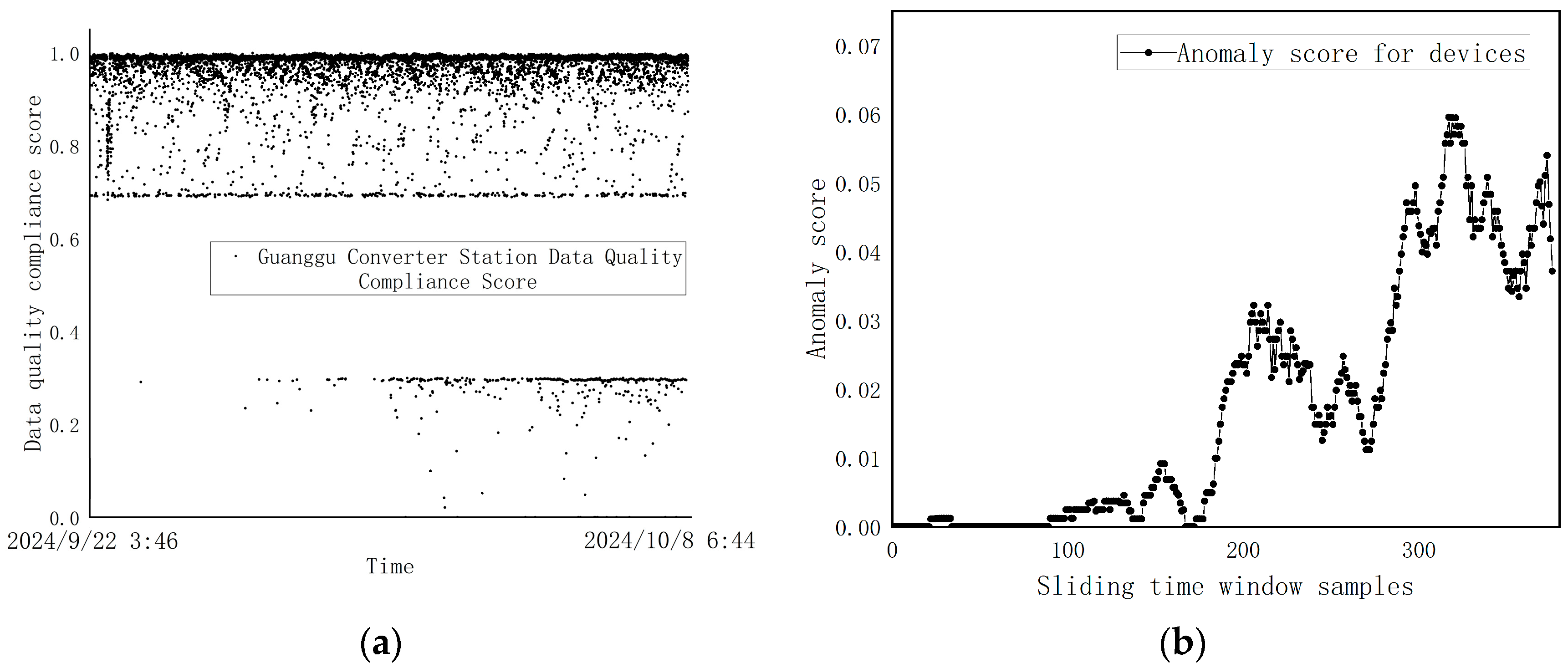
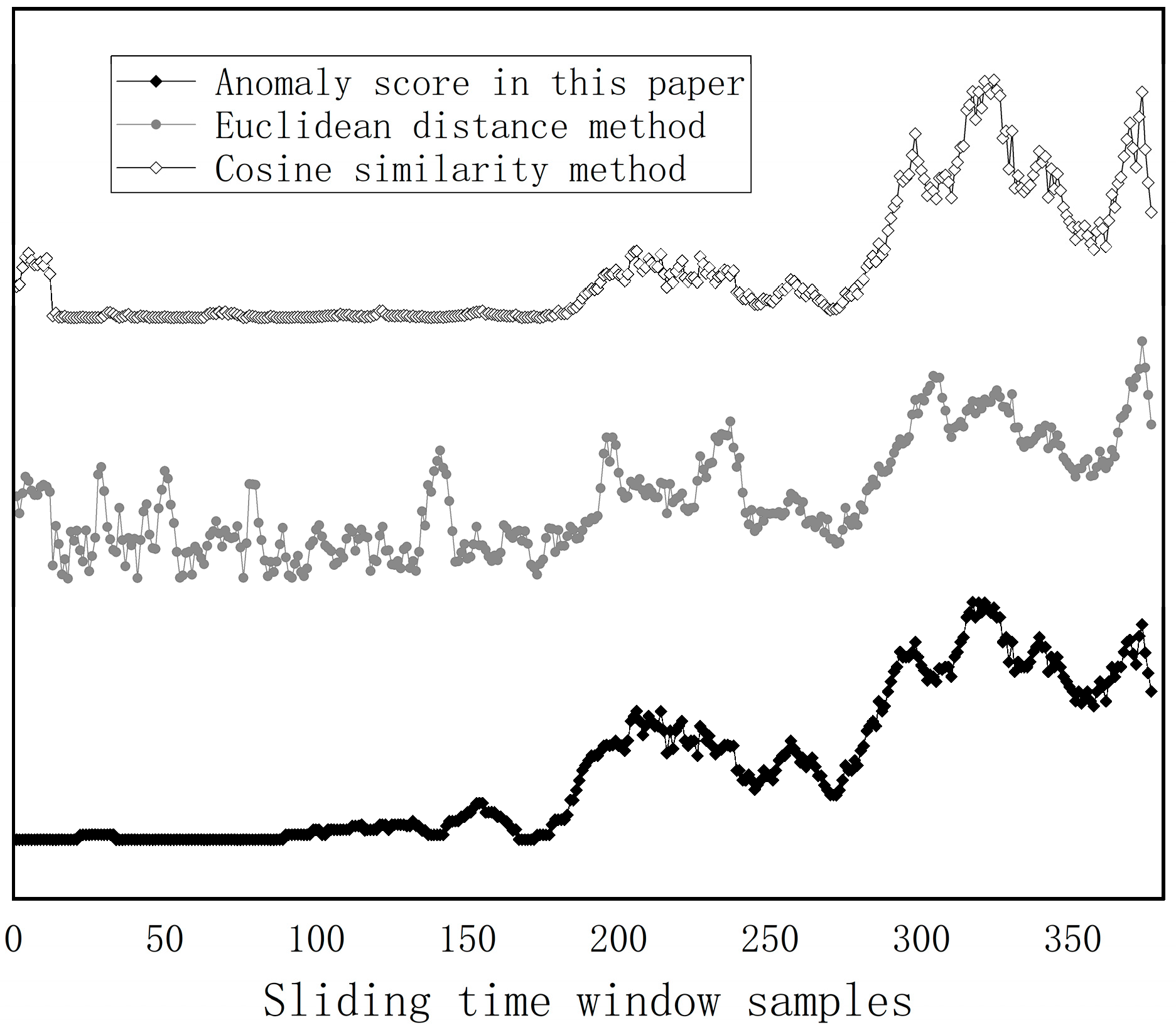
3.2. Results of the Device Health Status
4. Conclusions
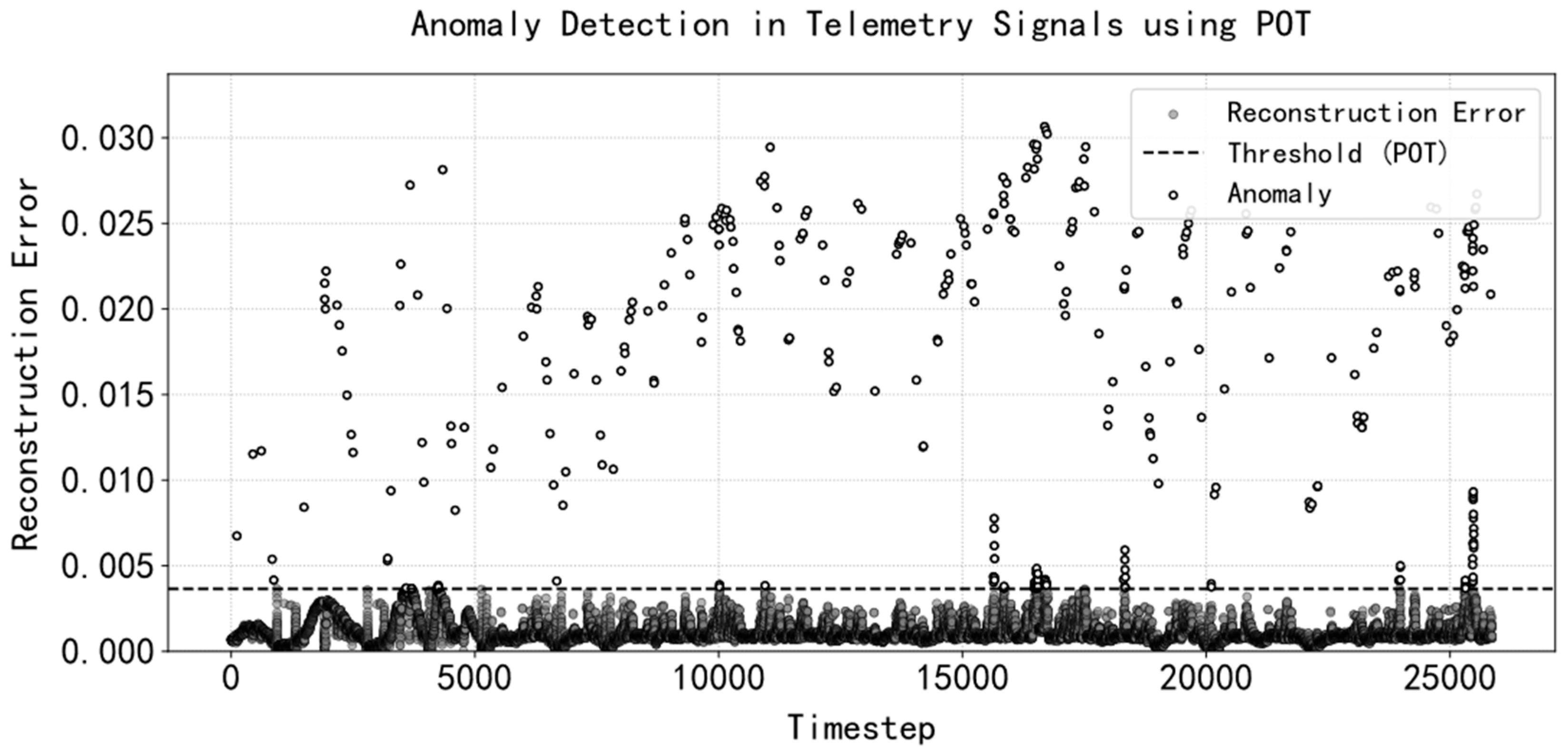
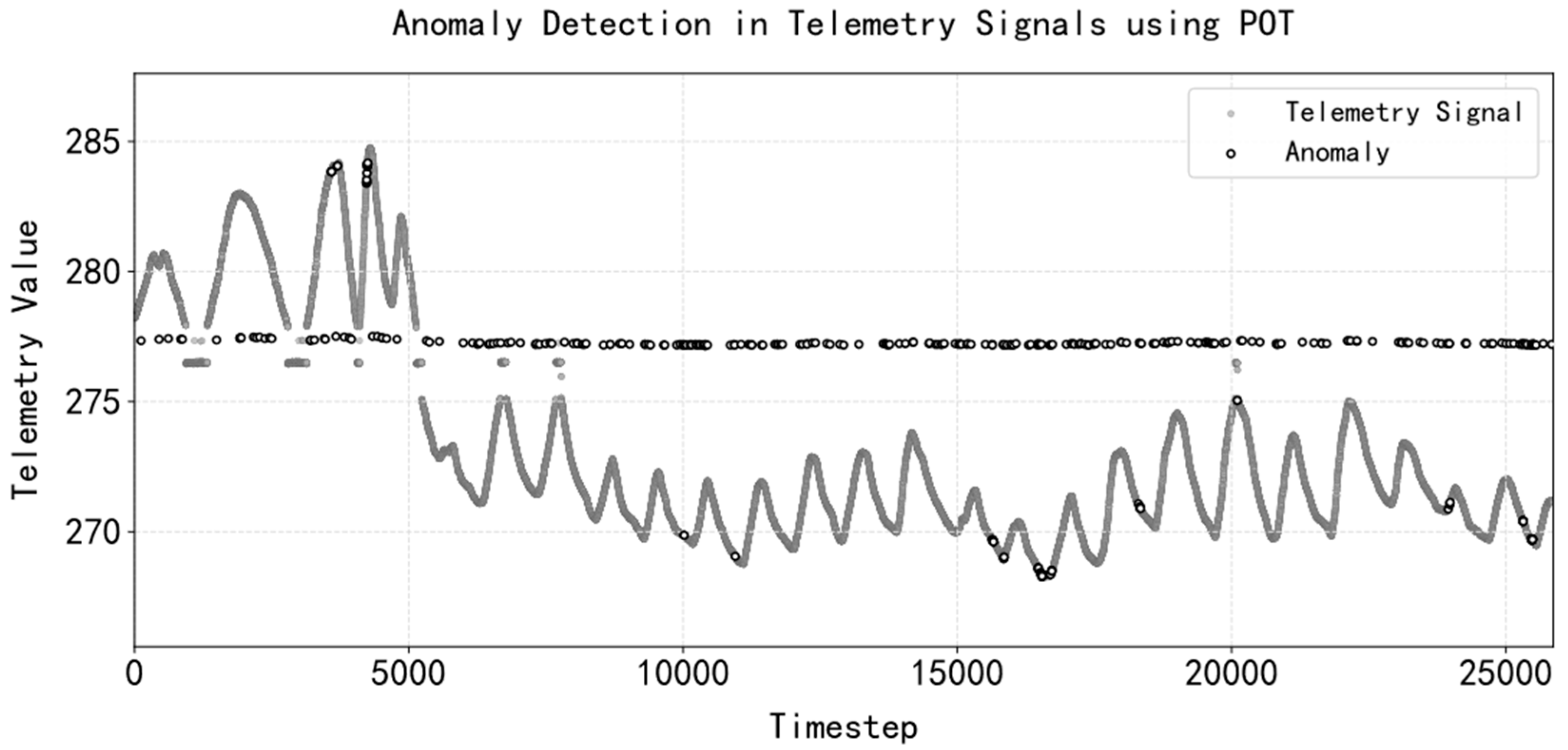
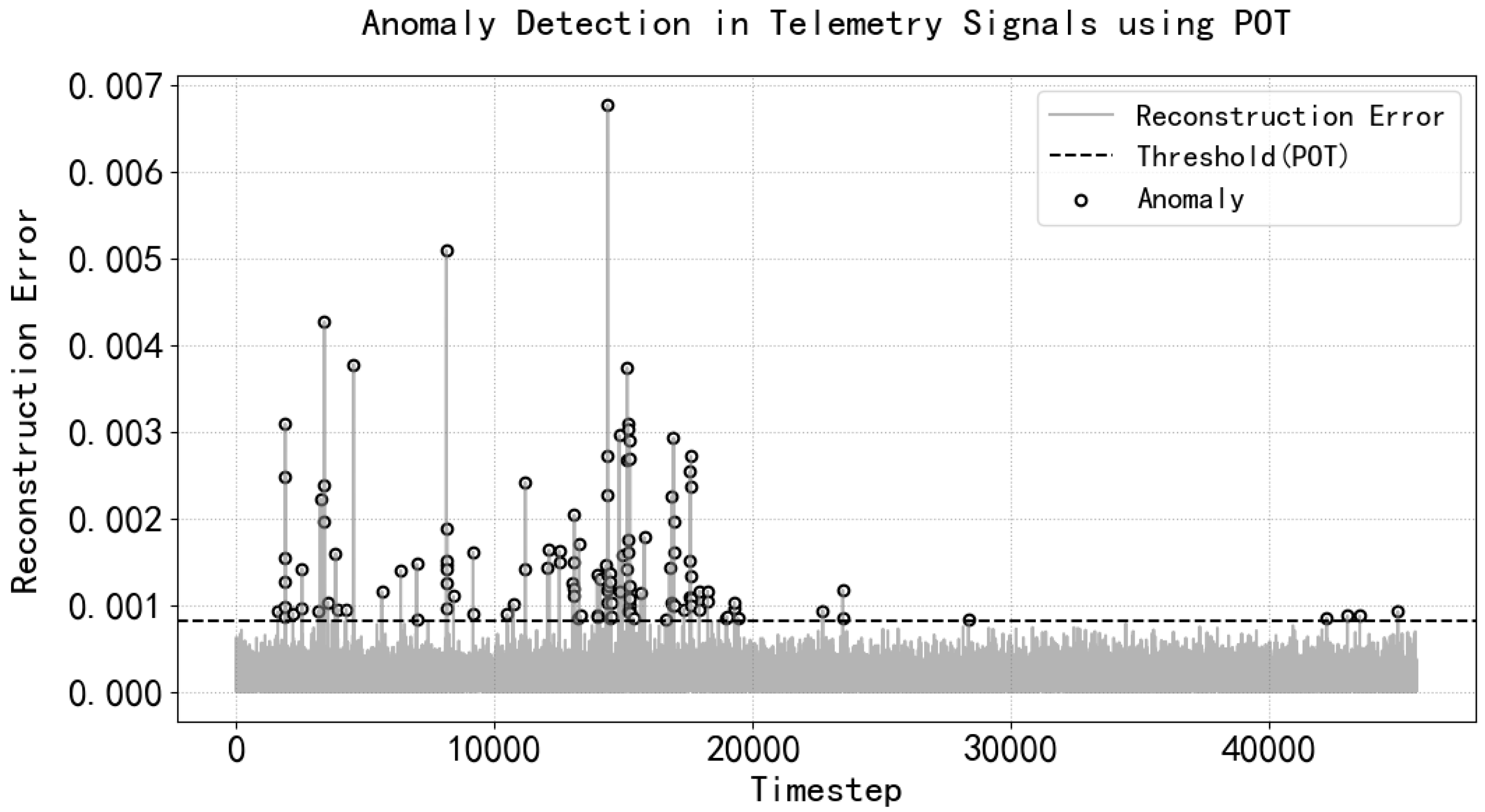
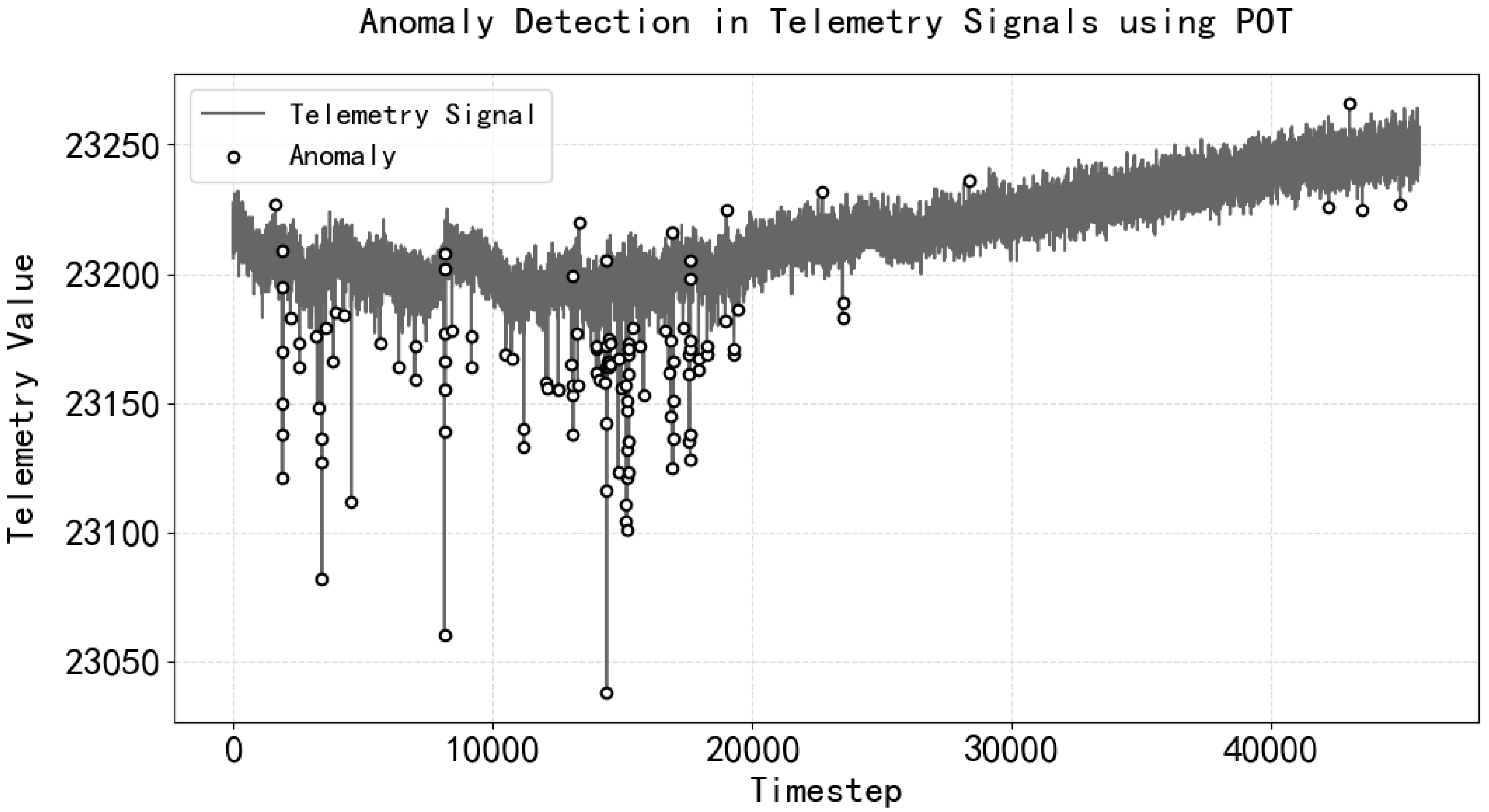
- Validity Assessment with Temporal Reconstruction: A transformer-based sequence reconstruction model integrated with POT (peaks over threshold) anomaly detection was developed to evaluate data credibility. This method effectively identifies tiny jump anomalies through temporal pattern learning and achieves an F1 score of 0.83 on real telemetry data collected at the converter station. Compared with LSTM, TCN, and GRU, the F1 of the transformer model constructed in this case is higher, and other models will have a large amount of normal time-step data that are judged as abnormal by the reconstruction error thresholds, which makes the model’s recall higher and its precision lower;
- Timeliness Quantification Framework: We choose the optimal number of windows and design simple and practical timeliness evaluation functions;
- Interpretable Health Scoring System: Based on the comprehensive quality of the data, a feature extraction method is designed to cluster the extracted features and combine them with an objective evaluation method to measure the degree of deviation between the real-time operating state and the health state of the equipment, so as to derive the degree of abnormality of the equipment.
- Deep Learning-Enhanced Data Quality Assessment: In the traditional method of measuring the comprehensive quality of data, only the threshold value is used to judge the validity of the data, while the introduction of the deep learning method into the comprehensive quality assessment of data can well discriminate minor anomalies and uncover potential anomalies before the state of health does not deteriorate rapidly;
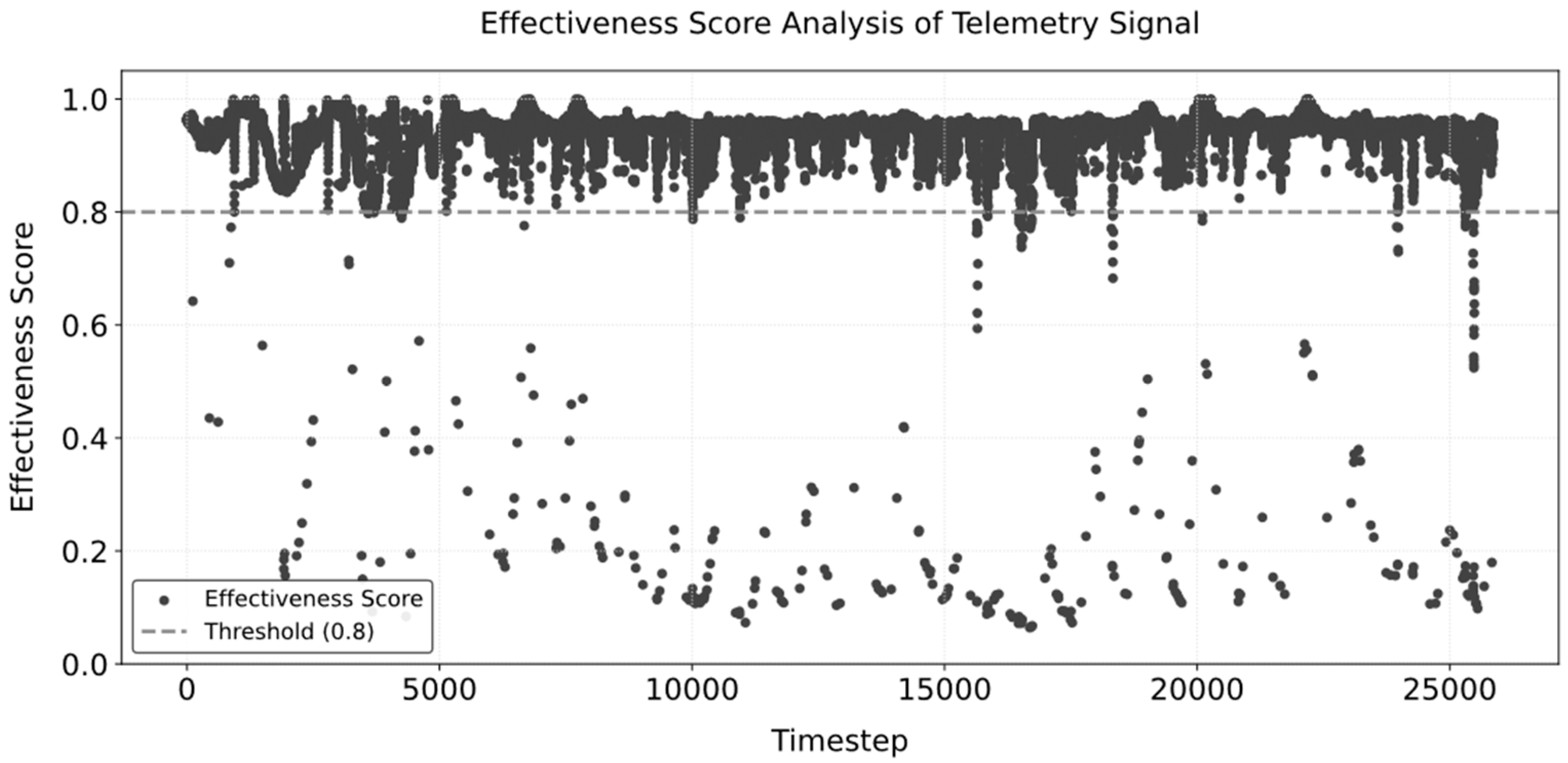
- Highly Interpretable Fire Equipment Health Assessment: The health state assessment starts from the comprehensive quality of each data point, and the final evaluation results are highly interpretable compared with those of gray models, such as machine learning. And the model can also be used to detect whether the equipment is abnormal, as well as to assess the degree of abnormality. We use the ReLU function so that the device has an anomaly score of 0 in the absence of anomalies, which is superior to the commonly used methods for assessing distance;
5. Future Work
- Advanced Utilization of Comprehensive Data Quality Metrics: While this study applied data quality metrics to equipment health assessment, future work will explore novel applications of these metrics as independent time-series inputs. This includes integrating quality scores into potential models, such as predictive analysis and temporal correlation analysis, to improve the stability of the converter station fire protection system;
- -BasedHealth State Taxonomy and Maintenance Framework: In this study, device anomaly scores were proposed to measure the severity of device faults. Currently, a device anomaly score of 0 indicates that the device is healthy, while a non-zero score indicates an anomaly, with higher values indicating greater severity. In future research, more on-site device information will be collected and combined with device anomaly scores to obtain device health status grades, which will be used to construct replacement and maintenance management strategies for fire protection devices.
- Compare the Influence of Different Clustering Algorithms on the Assessment of Health Status: In this study, we used K-means clustering to obtain health status. Currently, we lack quantitative indicators to measure the impact of different clustering algorithms on health status results. In the future, we will accumulate more real anomaly data and develop a quantitative indicator to describe the accuracy of health status identification, similar to describing and verifying forest fire risks, in order to measure the impact of different clustering algorithms on equipment health status assessment and select the most appropriate clustering method.
- Implement actual deployment and address corresponding challenges: In this study, we aim for the health status evaluation model to detect faults originating from the fire-protection IoT device itself, such as transmission delays or faulty data caused by performance degradation. However, in real-world scenarios, external factors such as strong electromagnetic interference or network failures may affect the stability of telemetry signals. This can result in the model failing to detect actual device faults and, in some cases, mistakenly identifying multiple devices as abnormal. Therefore, mitigating the influence of such external interferences—including electromagnetic and network-related disruptions—on the model’s diagnostic capability is an important aspect of our future work. In the future, we plan to deploy the model in real fire-protection IoT environments, testing it on various devices and types of time-series data, while specifically evaluating its response and robustness to network failures, sensor faults, and background interferences.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bianco, A.M.; Martinez, E.J.; Ben, M.G.; Yohai, V.J. Robust Procedures for Regression Models with ARIMA Errors. In COMPSTAT.; Prat, A., Ed.; Physica-Verlag HD: Heidelberg, Germany, 1996; pp. 27–38. [Google Scholar]
- Hernandez-Garcia, M.R.; Masri, S.F. Application of Statistical Monitoring Using Latent-Variable Techniques for Detection of Faults in Sensor Networks. J. Intell. Mater. Syst. Struct. 2014, 25, 121–136. [Google Scholar] [CrossRef]
- Samparthi, V.K.; Verma, H.K. Outlier Detection of Data in Wireless Sensor Networks Using Kernel Density Estimation. Int. J. Comput. Appl. 2010, 5, 28–32. [Google Scholar] [CrossRef]
- Gu, Y.; Deng, H. Fault Analysis of Pipeline System Sensor Based on K-Nearest Neighbor Algorithm. Chin. J. Sens. Actuators 2017, 30, 1076–1082. [Google Scholar]
- Arias, L.A.S.; Oosterlee, C.W.; Cirillo, P. AIDA: Analytic Isolation and Distance-Based Anomaly Detection Algorithm. Pattern Recognit. 2023, 141, 109607. [Google Scholar] [CrossRef]
- Wu, D. Research on deep learning-based anomaly data recognition method for structural health monitoring system. Intell. City 2020, 6, 10–13. [Google Scholar]
- Hooshmand, M.K.; Hosahalli, D. Network Anomaly Detection Using Deep Learning Techniques. CAAI Trans. Intell. Technol. 2022, 7, 228–243. [Google Scholar] [CrossRef]
- Audibert, J.; Michiardi, P.; Guyard, F.; Marti, S.; Zuluaga, M.A. USAD: UnSupervised Anomaly Detection on Multivariate Time Series. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, San Diego, CA, USA, 23–27 August 2020; ACM: New York, NY, USA, 2020; pp. 3395–3404. [Google Scholar]
- Gao, H.; Chen, Z.; Zhou, F.; Li, D.; Yang, K.; Shi, X. Abnormal Identification of Oil Monitoring Data Based on Classification-Driven SAE. In 2022 Global Reliability and Prognostics and Health Management (PHM-Yantai); IEEE: New York, NY, USA, 2022; pp. 1–6. [Google Scholar]
- Darban, Z.Z.; Webb, G.I.; Pan, S.; Aggarwal, C.C.; Salehi, M. CARLA: Self-Supervised Contrastive Representation Learning for Time Series Anomaly Detection. Pattern Recognit. 2025, 157, 110874. [Google Scholar] [CrossRef]
- Zhang, Z.; Cheng, D.; Liu, N.; Yang, H. Research and Implementation of Conformity Testing Method for Military Information System Information Exchange Standards. J. CAEIT 2019, 14, 1242–1248. [Google Scholar]
- Yin, R.; Yao, Z. Research on Data Quality Assessment Framework for Multidisciplinary Standards. Stand. Sci. 2020, 1, 92–95. [Google Scholar]
- Zhu, H.; Gao, A.; Wang, S. Research on Conformance Testing of Data Standard. Stand. Sci. 2019, 7, 53–57. [Google Scholar]
- Yang, J.; Guo, J. Design of Observation Data Quality Assessment Model of CINRAD. Stand. Sci. 2021, 12, 123–127, 144. [Google Scholar]
- Zheng, P. Evaluation index system of compliance test for information business collaboration standards. J. Fuzhou Univ. (Nat. Sci. Ed.) 2021, 49, 747–752. [Google Scholar]
- Nabhan, A.; Ghazaly, N.; Samy, A.; Mousa, M.O. Bearing Fault Detection Techniques-a Review. Turk. J. Eng. Sci. Technol. 2015, 3, 1–18. [Google Scholar]
- Helbing, G.; Ritter, M. Deep Learning for Fault Detection in Wind Turbines. Renew. Sustain. Energy Rev. 2018, 98, 189–198. [Google Scholar] [CrossRef]
- Udu, A.G.; Lecchini-Visintini, A.; Dong, H. Feature Selection for Aero-Engine Fault Detection. In Database and Expert Systems Applications; Springer: Cham, Switzerland, 2023; pp. 522–527. [Google Scholar]
- Tayarani-Bathaie, S.S.; Vanini, Z.S.; Khorasani, K. Dynamic Neural Network-Based Fault Diagnosis of Gas Turbine Engines. Neurocomputing 2014, 125, 153–165. [Google Scholar] [CrossRef]
- Cao, X.; Duan, Y.; Zhao, J.; Yang, X.; Zhao, F.; Fan, H. Summary of research on health status assessment of fully mechanized mining equipment. J. Mine Autom. 2023, 49, 23–35, 97. [Google Scholar]
- Hao, X.; Liu, X.; Li, X.; Zhao, X. Research on Online Safety Precaution Technology of a High-Medium Pressure Gas Regulator. J. Therm. Sci. 2017, 26, 229–234. [Google Scholar] [CrossRef]
- Gao, F.; Li, H.; Wu, F. Health Status Monitoring and Fault Diagnosis Based on Spectrum Analysis for Centrifugal Pump. Process Autom. Instrum. 2019, 40, 24–28. [Google Scholar]
- Hu, Y.; Ping, B.; Zeng, D.; Niu, Y.; Gao, Y.; Zhang, D. Research on Fault Diagnosis of Coal Mill System Based on the Simulated Typical Fault Samples. Measurement 2020, 161, 107864. [Google Scholar] [CrossRef]
- Aker, E.; Othman, M.L.; Veerasamy, V.; Aris, I.b.; Wahab, N.I.A.; Hizam, H. Fault Detection and Classification of Shunt Compensated Transmission Line Using Discrete Wavelet Transform and Naive Bayes Classifier. Energies 2020, 13, 243. [Google Scholar] [CrossRef]
- Choudhary, A.; Mian, T.; Fatima, S. Convolutional Neural Network Based Bearing Fault Diagnosis of Rotating Machine Using Thermal Images. Measurement 2021, 176, 109196. [Google Scholar] [CrossRef]
- Zhao, J.H. Research on Anomaly Detection of Mine CO Sensor Based on Variational Autoencoder. Master’s Thesis, Xi’an University of Science and Technology, Xi’an, China, 2024. [Google Scholar]
- Sousa Tomé, E.; Ribeiro, R.P.; Dutra, I.; Rodrigues, A. An Online Anomaly Detection Approach for Fault Detection on Fire Alarm Systems. Sensors 2023, 23, 4902. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Quality Category (Score Range) | Variable in Feature Vector | Meaning of Variable |
|---|---|---|
| General (0.80–1.00) | x1 | Number of data points within the sliding window assessed as general (normal) quality |
| Minor (0.60–0.80) | x2 | Number of data points within the sliding window assessed as minor anomaly |
| Urgent (0.40–0.60) | x3 | Number of data points within the sliding window assessed as urgent anomaly |
| Critical (0.00–0.40) | x4 | Number of data points within the sliding window assessed as critical anomaly |
| Parameter | Value |
|---|---|
| Loss Function | MSE (mean-squared error) |
| Optimizer | Adam |
| Number of Epochs | 100 |
| Batch Size | 256 |
| Learning Rate | 0.001 |
| Number of Attention Heads | 8 |
| Number of Encoder Layers | 2 |
| Input Sequence Length | 20 |
| Feature Dimension | 2 |
| Name | Time Series Length | Number of Anomalies | Percentage of Anomalies/% |
|---|---|---|---|
| Yibin Converter Station Equipment 2 tank water level | 25,865 | 272 | 1.0516 |
| Indoor smoke detector channel B optical signal | 45,694 | 95 | 0.2079 |
| Time Series Data Name | Threshold Selection Method | Metric | Model | |||
|---|---|---|---|---|---|---|
| LSTM | GRU | TCN | Transformer | |||
| Converter Station Tank Water Level | POT | Accuracy | 0.8965 | 0.9390 | 0.9728 | 0.9957 |
| Precision | 0.0923 | 0.1466 | 0.2785 | 0.7238 | ||
| Recall | 1.0000 | 0.9963 | 0.9963 | 0.9632 | ||
| F1 score | 0.1689 | 0.2555 | 0.4353 | 0.8265 | ||
| Accuracy | 0.8353 | 0.8532 | 0.8959 | 0.9539 | ||
| Precision | 0.0600 | 0.0668 | 0.0915 | 0.1845 | ||
| Recall | 1.0000 | 1.0000 | 0.9963 | 0.9890 | ||
| F1 score | 0.1132 | 0.1253 | 0.1676 | 0.3110 | ||
| 95th percentile | Accuracy | 0.6987 | 0.6898 | 0.7183 | 0.9314 | |
| Precision | 0.0337 | 0.0328 | 0.0359 | 0.1326 | ||
| Recall | 1.0000 | 1.0000 | 0.9963 | 0.9963 | ||
| F1 score | 0.0652 | 0.0635 | 0.0692 | 0.2340 | ||
| Smoke Detector Channel B Optical Signal | POT | Accuracy | 0.9968 | 0.9982 | 0.9964 | 0.9988 |
| Precision | 0.3473 | 0.5547 | 0.2697 | 0.6694 | ||
| Recall | 0.6105 | 0.7474 | 0.4316 | 0.8737 | ||
| F1 score | 0.4427 | 0.6368 | 0.3320 | 0.7580 | ||
| Accuracy | 0.9916 | 0.9919 | 0.9900 | 0.9941 | ||
| Precision | 0.1608 | 0.1874 | 0.1154 | 0.2569 | ||
| Recall | 0.7263 | 0.8737 | 0.5684 | 0.9789 | ||
| F1 score | 0.2634 | 0.3086 | 0.1918 | 0.4070 | ||
| 95th percentile | Accuracy | 0.9513 | 0.9517 | 0.9508 | 0.9521 | |
| Precision | 0.0337 | 0.0381 | 0.0289 | 0.0416 | ||
| Recall | 0.8105 | 0.9158 | 0.6947 | 1.0000 | ||
| F1 score | 0.0647 | 0.0731 | 0.0555 | 0.0798 | ||
| Model | ||||
|---|---|---|---|---|
| LSTM | GRU | TCN | Transformer | |
| Average Latency Ms | 0.46 ± 0.07 | 0.44 ± 0.08 | 0.57 ± 0.10 | 0.97 ± 0.15 |
| Cluster | Parameter | x1 | x2 | x3 | x4 |
|---|---|---|---|---|---|
| Cluster 1 | Health Lower Bound | 345.46 | 10.22 | 0 | 0 |
| Health Baseline | 362.37 | 18.81 | 0 | 0 | |
| Health Upper Bound | 397.16 | 48.72 | 0 | 0 | |
| Combined Weight | 0.0657 | 0.1305 | 0.3719 | 0.4319 | |
| Cluster 2 | Health Lower Bound | 301.27 | 10.13 | 0 | 0 |
| Health Baseline | 331.33 | 19.73 | 0 | 0 | |
| Health Upper Bound | 347.47 | 40.93 | 0 | 0 | |
| Combined Weight | 0.0657 | 0.1305 | 0.3719 | 0.4319 |
| Samples | x1 | x2 | x3 | x4 | Anomaly Score |
|---|---|---|---|---|---|
| 1 | 344 | 37 | 0 | 0 | 0 |
| 2 | 357 | 36 | 0 | 0 | 0 |
| … | … | … | … | … | … |
| 374 | 286 | 19 | 0 | 36 | 0.0469 |
| 375 | 293 | 19 | 0 | 33 | 0.0418 |
| 376 | 301 | 18 | 0 | 30 | 0.0372 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Y.; Sun, T.; Cheng, Y.; Zhang, J.; Yang, Z.; Yang, T. Data-Driven Health Status Assessment of Fire Protection IoT Devices in Converter Stations. Fire 2025, 8, 251. https://doi.org/10.3390/fire8070251
Huang Y, Sun T, Cheng Y, Zhang J, Yang Z, Yang T. Data-Driven Health Status Assessment of Fire Protection IoT Devices in Converter Stations. Fire. 2025; 8(7):251. https://doi.org/10.3390/fire8070251
Chicago/Turabian StyleHuang, Yubiao, Tao Sun, Yifeng Cheng, Jiaqing Zhang, Zhibing Yang, and Tan Yang. 2025. "Data-Driven Health Status Assessment of Fire Protection IoT Devices in Converter Stations" Fire 8, no. 7: 251. https://doi.org/10.3390/fire8070251
APA StyleHuang, Y., Sun, T., Cheng, Y., Zhang, J., Yang, Z., & Yang, T. (2025). Data-Driven Health Status Assessment of Fire Protection IoT Devices in Converter Stations. Fire, 8(7), 251. https://doi.org/10.3390/fire8070251