
CN2VF-Net: A Hybrid Convolutional Neural Network and Vision Transformer Framework for Multi-Scale Fire Detection in Complex Environments



Abstract
1. Introduction
The Key Contribution of This Study
- CN2VF-Net Architecture
- 2.
- Dynamic Multi-Scale Attention Mechanism
2. Related Works
2.1. Deep Learning-Based Fire Detection Techniques
2.2. Smart, Lightweight, and Real-Time Fire Detection Systems
3. Methodology
3.1. CN2VF-Net Architecture
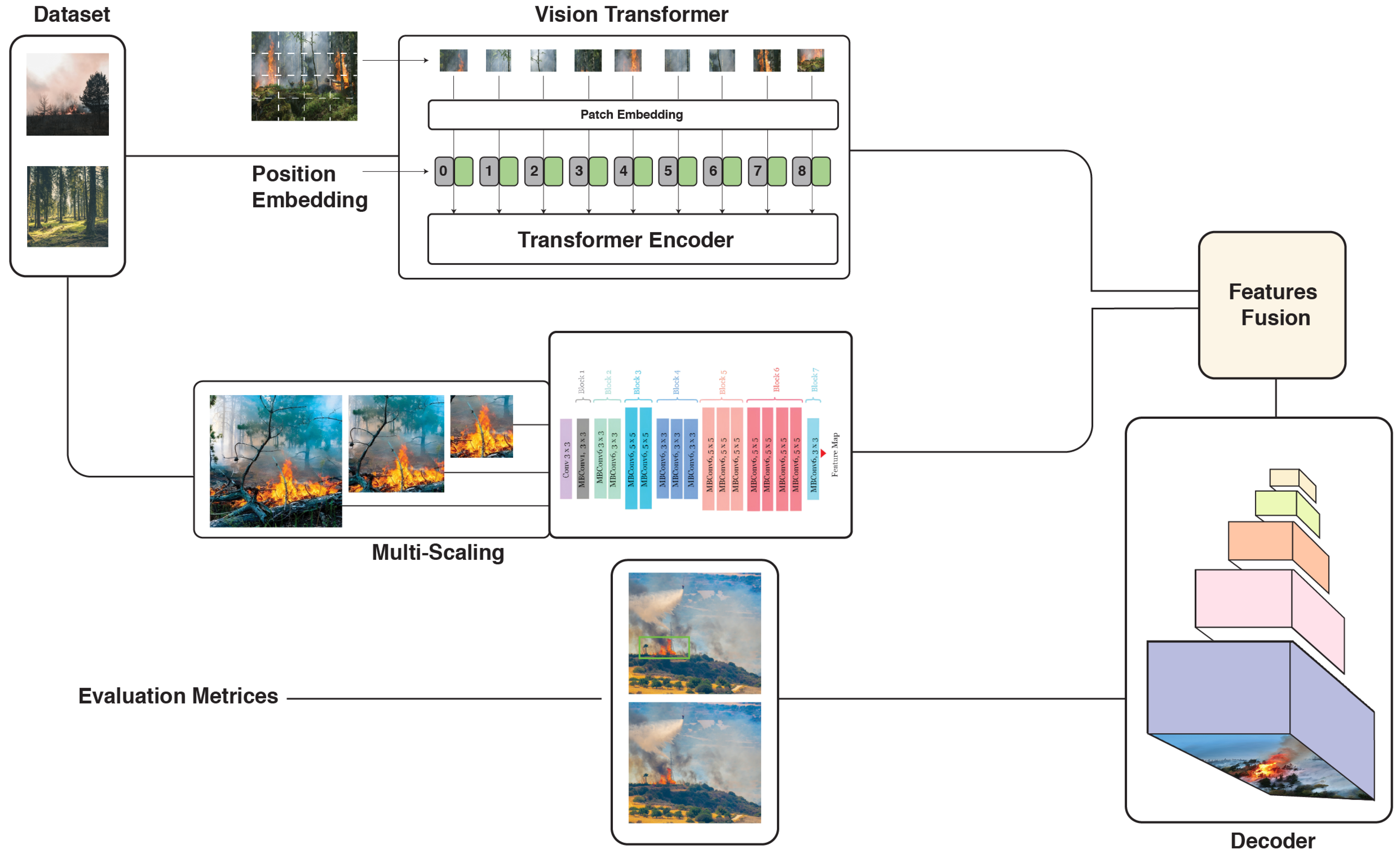
3.1.1. Patch Embedding
3.1.2. Transformer Encoder
3.1.3. CNN Backbone (EfficientNetB0)
3.1.4. Feature Fusion Module
3.1.5. Multi-Scale Attention
3.1.6. Decoder
4. Experimental Setup
4.1. Dataset Collection
4.2. Dataset Preprocessing
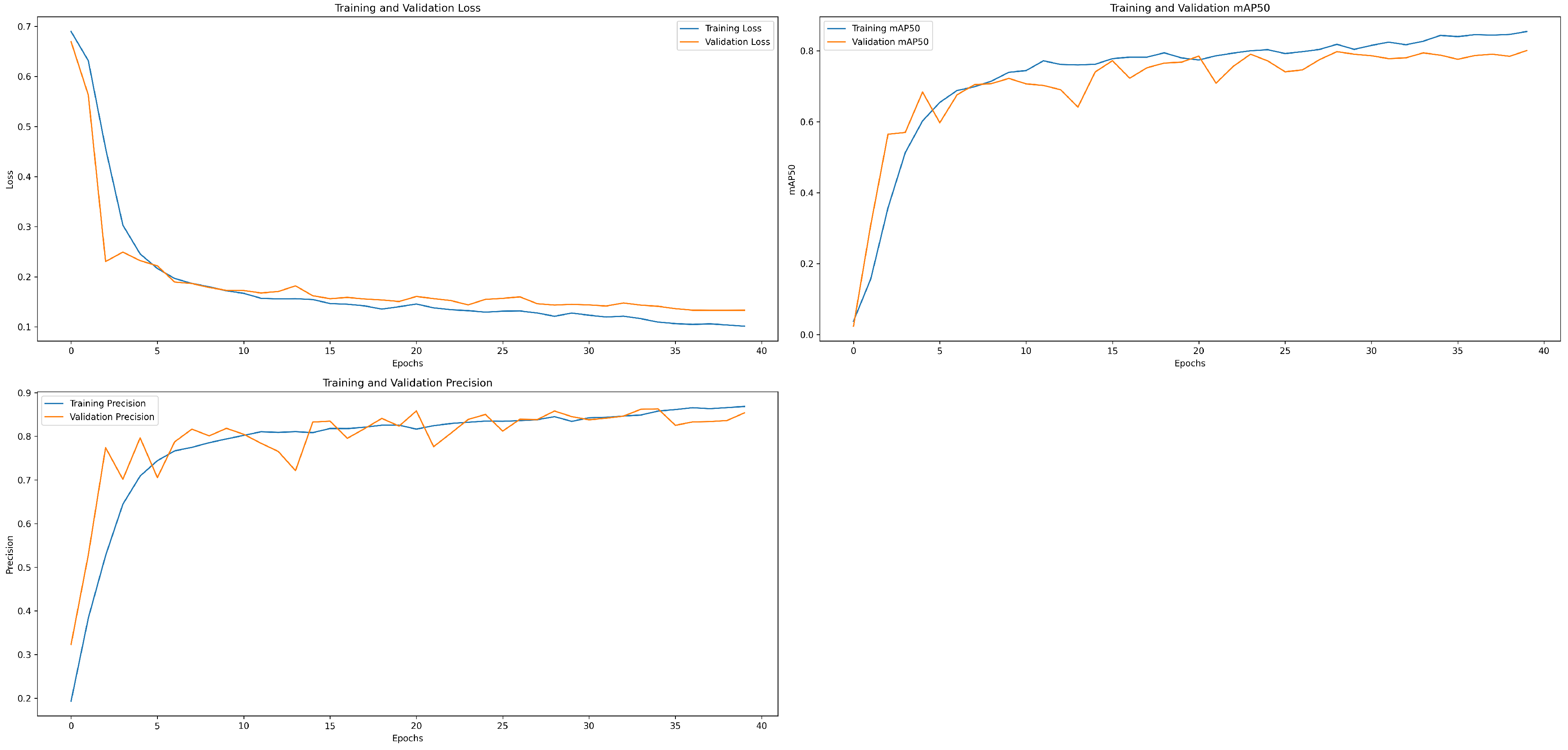
4.3. Model Training and Configuration
4.4. Evaluation Metrics
4.5. Precision
4.6. Recall
4.7. F1-Score
4.8. Mean Average Precision at IoU Threshold 0.5 (mAP50)
4.9. mIoU50–95
4.10. Computational Environment
5. Results and Discussions
6. Ablation Study
7. Conclusions and Future Direction
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Suhardono, S.; Fitria, L.; Suryawan, I.W.K.; Septiariva, I.Y.; Mulyana, R.; Sari, M.M.; Ulhasanah, N.; Prayogo, W. Human Activities and Forest Fires in Indonesia: An Analysis of the Bromo Incident and Implications for Conservation Tourism. Trees For. People 2024, 15, 100509. [Google Scholar] [CrossRef]
- Yuan, C.; Liu, Z.; Zhang, Y. UAV-Based Forest Fire Detection and Tracking Using Image Processing Techniques. In Proceedings of the International Conference on Unmanned Aircraft Systems (ICUAS), Denver, CO, USA, 9–12 June 2015; pp. 639–643. [Google Scholar]
- Gao, Y.; Cao, H.; Cai, W.; Zhou, G. Pixel-Level Road Crack Detection in UAV Remote Sensing Images Based on ARD-Unet. Measurement 2023, 219, 113252. [Google Scholar] [CrossRef]
- Zhan, J.; Hu, Y.; Zhou, G.; Wang, Y.; Cai, W.; Li, L. A High-Precision Forest Fire Smoke Detection Approach Based on ARGNet. Comput. Electron. Agric. 2022, 196, 106874. [Google Scholar] [CrossRef]
- Wang, K.; Zhang, Y.; Jinjun, W.; Zhang, Q.; Bing, C.; Dongcai, L. Fire Detection in Infrared Video Surveillance Based on Convolutional Neural Network and SVM. In Proceedings of the IEEE 3rd International Conference on Signal and Image Processing (ICSIP), Shenzhen, China, 13–15 July 2018; pp. 162–167. [Google Scholar]
- Deng, L.; Chen, Q.; He, Y.; Sui, X.; Liu, Q.; Hu, L. Fire Detection with Infrared Images using Cascaded Neural Network. J. Algorithms Comput. Technol. 2019, 13, 1748302619895433. [Google Scholar] [CrossRef]
- Alkhatib, R.; Sahwan, W.; Alkhatieb, A.; Schütt, B. A Brief Review of Machine Learning Algorithms in Forest Fires Science. Appl. Sci. 2023, 13, 8275. [Google Scholar] [CrossRef]
- Peruzzi, G.; Pozzebon, A.; Van Der Meer, M. Fight Fire with Fire: Detecting Forest Fires with Embedded Machine Learning Models Dealing with Audio and Images on Low Power IoT Devices. Sensors 2023, 23, 783. [Google Scholar] [CrossRef]
- Guria, R.; Mishra, M.; da Silva, R.M.; Mishra, M.; Santos, C.A.G. Predicting Forest Fire Probability in Similipal Biosphere Reserve (India) Using Sentinel-2 MSI Data and Machine Learning. Remote Sens. Appl. 2024, 36, 101311. [Google Scholar] [CrossRef]
- Sobha, P.; Latifi, S. A Survey of the Machine Learning Models for Forest Fire Prediction and Detection. Int. J. Commun. Netw. Syst. Sci. 2023, 16, 131–150. [Google Scholar] [CrossRef]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Chitram, S.; Kumar, S.; Thenmalar, S. Enhancing Fire and Smoke Detection Using Deep Learning Techniques. Eng. Proc. 2024, 62, 7. [Google Scholar]
- Ye, M.; Luo, Y. A deep convolution neural network fusing of color feature and spatio-temporal feature for smoke detection. Multimed. Tools Appl. 2024, 83, 22173–22187. [Google Scholar] [CrossRef]
- Abdikan, S.; Bayik, C.; Sekertekin, A.; Bektas Balcik, F.; Karimzadeh, S.; Matsuoka, M.; Balik Sanli, F. Burned Area Detection Using Multi-Sensor SAR, Optical, and Thermal Data in Mediterranean Pine Forest. Forests 2022, 13, 347. [Google Scholar] [CrossRef]
- Qarallah, B.; Othman, Y.A.; Al-Ajlouni, M.; Alheyari, H.A.; Qoqazeh, B.A. Assessment of Small-Extent Forest Fires in Semi-Arid Environment in Jordan Using Sentinel-2 and Landsat Sensors Data. Forests 2022, 14, 41. [Google Scholar] [CrossRef]
- Shin, J.; Seo, W.; Kim, T.; Park, J.; Woo, C. Using UAV Multispectral Images for Classification of Forest Burn Severity—A Case Study of the 2019 Gangneung Forest Fire. Forests 2019, 10, 1025. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Xie, Y.; Zhu, J.; Cao, Y.; Zhang, Y.; Feng, D.; Zhang, Y.; Chen, M. Efficient Video Fire Detection Exploiting Motion-Flicker-Based Dynamic Features and Deep Static Features. IEEE Access 2020, 8, 81904–81917. [Google Scholar] [CrossRef]
- Feng, H.; Qiu, J.; Wen, L.; Zhang, J.; Yang, J.; Lyu, Z.; Liu, T.; Fang, K. U3UNet: An Accurate and Reliable Segmentation Model for Forest Fire Monitoring Based on UAV Vision. Neural Netw. 2025, 185, 107207. [Google Scholar] [CrossRef]
- Wang, G.; Bai, D.; Lin, H.; Zhou, H.; Qian, J. FireViTNet: A Hybrid Model Integrating ViT and CNNs for Forest Fire Segmentation. Comput. Electron. Agric. 2024, 218, 108722. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, F.; Xu, Y.; Wang, J.; Lu, H.; Wei, W.; Zhu, J. Tfnet: Transformer-based multi-scale feature fusion forest fire image detection network. Fire 2025, 8, 59. [Google Scholar] [CrossRef]
- Yu, P.; Wei, W.; Li, J.; Du, Q.; Wang, F.; Zhang, L.; Li, H.; Yang, K.; Yang, X.; Zhang, N.; et al. Fire-PPYOLOE: An Efficient Forest Fire Detector for Real-Time Wild Forest Fire Monitoring. J. Sens. 2024, 2024, 2831905. [Google Scholar] [CrossRef]
- Zhao, C.; Zhao, L.; Zhang, K.; Ren, Y.; Chen, H.; Sheng, Y. Smoke and Fire-You Only Look Once: A Lightweight Deep Learning Model for Video Smoke and Flame Detection in Natural Scenes. Fire 2025, 8, 104. [Google Scholar] [CrossRef]
- Song, X.; Wei, Z.; Zhang, J.; Gao, E. A Fire Detection Algorithm Based on Adaptive Region Decoupling Distillation. In Proceedings of the 2023 International Annual Conference on Complex Systems and Intelligent Science (CSIS-IAC), Shenzhen, China, 20–22 October 2023; pp. 253–258. [Google Scholar]
- Zhang, T.; Wang, Z.; Zeng, Y.; Wu, X.; Huang, X.; Xiao, F. Building artificial-intelligence digital fire (AID-Fire) system: A real-scale demonstration. J. Build. Eng. 2022, 62, 105363. [Google Scholar] [CrossRef]
- Wang, K.; Zhang, W.; Song, X. A Fire Detection Method for Aircraft Cargo Compartments Utilizing Radio Frequency Identification Technology and an Improved YOLO Model. Electronics 2024, 14, 106. [Google Scholar] [CrossRef]
- De Venâncio, P.V.A.; Rezende, T.M.; Lisboa, A.C.; Barbosa, A.V. Fire detection based on a two-dimensional convolutional neural network and temporal analysis. In Proceedings of the 2021 IEEE Latin American Conference on Computational Intelligence (LA-CCI), Temuco, Chile, 2–4 November 2021; pp. 1–6. [Google Scholar]
- De Venâncio, P.V.A.; Rezende, T.M.; Lisboa, A.C.; Barbosa, A.V. An automatic fire detection system based on deep convolutional neural networks for low-power, resource-constrained devices. Neural Comput. Appl. 2022, 34, 15349–15368. [Google Scholar] [CrossRef]
- Chen, Y.; Li, J.; Sun, K.; Zhang, Y. A lightweight early forest fire and smoke detection method. J. Supercomput. 2024, 80, 9870–9893. [Google Scholar] [CrossRef]
- Peng, R.; Cui, C.; Wu, Y. Real-time fire detection algorithm on low-power endpoint device. J.-Real-Time Image Process. 2025, 22, 29. [Google Scholar] [CrossRef]
- Gragnaniello, D.; Greco, A.; Sansone, C.; Vento, B. FLAME: Fire detection in videos combining a deep neural network with a model-based motion analysis. Neural Comput. Appl. 2025, 2025, 1–17. [Google Scholar] [CrossRef]
- Malebary, S.J. Early fire detection using long short-term memory-based instance segmentation and internet of things for disaster management. Sensors 2023, 23, 9043. [Google Scholar] [CrossRef]
- Gragnaniello, D.; Greco, A.; Sansone, C.; Vento, B. Onfire 2023 Contest: What did we learn about real time fire detection from cameras? J. Ambient. Intell. Humaniz. Comput. 2025, 16, 253–264. [Google Scholar] [CrossRef]
- Huang, X.; Xie, W.; Zhang, Q.; Lan, Y.; Heng, H.; Xiong, J. A Lightweight Wildfire Detection Method for Transmission Line Perimeters. Electronics 2024, 13, 3170. [Google Scholar] [CrossRef]
- Titu, M.F.S.; Pavel, M.A.; Goh, K.O.M.; Babar, H.; Aman, U.; Khan, R. Real-Time Fire Detection: Integrating Lightweight Deep Learning Models on Drones with Edge Computing. Drones 2024, 8, 483. [Google Scholar] [CrossRef]
- Kumar, A.; Perrusquía, A.; Al-Rubaye, S.; Guo, W. Wildfire and Smoke Early Detection for Drone Applications: A Light-Weight Deep Learning Approach. Eng. Appl. Artif. Intell. 2024, 136, 108977. [Google Scholar] [CrossRef]
- Wu, D.; Qian, Z.; Wu, D.; Wang, J. FSNet: Enhancing Forest-Fire and Smoke Detection with an Advanced UAV-Based Network. Forests 2024, 15, 787. [Google Scholar] [CrossRef]
- de Venâncio, P.V.A.B.; Campos, R.J.; Rezende, T.M.; Lisboa, A.C.; Barbosa, A.V. A hybrid method for fire detection based on spatial and temporal patterns. Neural Comput. Appl. 2023, 35, 9349–9361. [Google Scholar] [CrossRef]
- Kim, S.; Jang, I.-s.; Ko, B.C. Domain-free fire detection using the spatial—Temporal attention transform of the yolo backbone. Pattern Anal. Appl. 2024, 27, 45. [Google Scholar] [CrossRef]
- Abdusalomov, A.; Baratov, N.; Kutlimuratov, A.; Whangbo, T.K. An improvement of the fire detection and classification method using YOLOv3 for surveillance systems. Sensors 2021, 21, 6519. [Google Scholar] [CrossRef]
- Eckle, K.; Schmidt-Hieber, J. A comparison of deep networks with ReLU activation function and linear spline-type methods. Neural Netw. 2019, 110, 232–242. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Available online: https://github.com/gaiasd/DFireDataset (accessed on 7 May 2025).
- Unser, M.; Aldroubi, A.; Eden, M. Fast B-spline transforms for continuous image representation and interpolation. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 277–285. [Google Scholar] [CrossRef]
- Braytee, A.; Anaissi, A.; Naji, M. A Comparative Analysis of Loss Functions for Handling Foreground-Background Imbalance in Image Segmentation. In International Conference on Neural Information Processing; Springer International Publishing: Cham, Switzerland, 2022; pp. 3–13. [Google Scholar]
- Mamadaliev, D.; Touko, P.L.M.; Kim, J.A.; Kim, S. Esfd-yolov8n: Early smoke and fire detection method based on an improved yolov8n model. Fire 2024, 7, 303. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, R.; Zhong, H.; Sun, Y. YOLOv8 for Fire and Smoke Recognition Algorithm Integrated with the Convolutional Block Attention Module. Open J. Appl. Sci. 2023, 14, 159–170. [Google Scholar] [CrossRef]
- Xu, F.; Zhang, X.; Deng, T.; Xu, W. An image-based fire monitoring algorithm resistant to fire-like objects. Fire 2023, 7, 3. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref | Precision | Recall | F1-Score | mAP@50 | MeanIoU50–95 |
|---|---|---|---|---|---|
| Liu et al. [22] | 81.6 | 74.8 | 78.1 | 81.2 | - |
| Mamadaliev et al. [47] | 80.1 | 72.7 | - | 79.4 | - |
| Liu et al. [48] | 80.9 | 63.6 | - | 69.0 | - |
| Xu et al. [49] | 81.7 | 82.5 | - | 82.3 | - |
| Segmenter | 80.4 | 79.2 | 77.3 | 75.7 | 74.1 |
| Swin Transformer | 81.9 | 82.2 | 79.5 | 78.6 | 76.5 |
| Proposed | 83.3 | 82.8 | 81.5 | 76.1 | 77.1 |
| Model Type | Precision (%) | Recall (%) | F1-Score (%) | mAP@50 (%) | MeanIoU50–95 (%) |
|---|---|---|---|---|---|
| CNN (EfficientNetB0) | 65.06 | 61.76 | 62.34 | 60.87 | 57.65 |
| Vision Transformer | 71.46 | 73.02 | 74.57 | 75.16 | 71.21 |
| CN2VF-Net Model | 83.30 | 82.80 | 81.50 | 76.10 | 77.10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmad, N.; Akbar, M.; Alkhammash, E.H.; Jamjoom, M.M. CN2VF-Net: A Hybrid Convolutional Neural Network and Vision Transformer Framework for Multi-Scale Fire Detection in Complex Environments. Fire 2025, 8, 211. https://doi.org/10.3390/fire8060211
Ahmad N, Akbar M, Alkhammash EH, Jamjoom MM. CN2VF-Net: A Hybrid Convolutional Neural Network and Vision Transformer Framework for Multi-Scale Fire Detection in Complex Environments. Fire. 2025; 8(6):211. https://doi.org/10.3390/fire8060211
Chicago/Turabian StyleAhmad, Naveed, Mariam Akbar, Eman H. Alkhammash, and Mona M. Jamjoom. 2025. "CN2VF-Net: A Hybrid Convolutional Neural Network and Vision Transformer Framework for Multi-Scale Fire Detection in Complex Environments" Fire 8, no. 6: 211. https://doi.org/10.3390/fire8060211
APA StyleAhmad, N., Akbar, M., Alkhammash, E. H., & Jamjoom, M. M. (2025). CN2VF-Net: A Hybrid Convolutional Neural Network and Vision Transformer Framework for Multi-Scale Fire Detection in Complex Environments. Fire, 8(6), 211. https://doi.org/10.3390/fire8060211