Abstract
In recent years, agricultural landscapes have increasingly suffered from severe fire incidents, posing significant threats to crop production, economic stability, and environmental sustainability. Timely and precise detection of fires, especially at their incipient stages, remains crucial to mitigate damage and prevent ecological degradation. However, conventional detection methods frequently fall short in accurately identifying small-scale fire outbreaks due to limitations in sensitivity and response speed. Addressing these challenges, this research proposes an advanced fire detection model based on a modified Detection Transformer (DETR) architecture. The proposed framework incorporates an optimized ConvNeXt backbone combined with a novel Feature Enhancement Block (FEB), specifically designed to refine spatial and contextual feature representation for improved detection performance. Extensive evaluations conducted on a carefully curated agricultural fire dataset demonstrate the effectiveness of the proposed model, achieving precision, recall, mean Average Precision (mAP), and F1-score of 89.67%, 86.74%, 85.13%, and 92.43%, respectively, thereby surpassing existing state-of-the-art detection frameworks. These results validate the proposed architecture’s capability for reliable, real-time identification, offering substantial potential for enhancing agricultural resilience and sustainability through improved preventive strategies.
1. Introduction
In recent years, agricultural environments have increasingly become vulnerable to devastating fire incidents, primarily triggered by natural phenomena such as wildfires and anthropogenic activities [1]. These incidents pose severe threats not only to agricultural productivity but also to economic stability and environmental sustainability [2]. Early and accurate detection of fire and smoke in crop fields is imperative, as it significantly mitigates potential large-scale damage and minimizes economic losses and ecological degradation [3]. Traditional fire detection systems, such as infrared (IR) sensors, thermal imaging devices, and threshold-based color segmentation algorithms, often rely on simplistic features and fixed rule sets. These methods typically fail to detect early-stage fires due to limited sensitivity to low-intensity thermal or visual cues, high susceptibility to environmental noise, and a lack of contextual awareness. Studies [4,5] have reported detection failure rates of up to 30% in real-world agricultural scenarios, especially under non-ideal lighting and weather conditions.
In response to these limitations, recent advancements in artificial intelligence, particularly in computer vision and deep learning [6], have opened new avenues for enhancing early-stage fire detection [7]. Deep learning-based object detection frameworks have shown exceptional capabilities in accurately identifying and localizing objects within complex visual scenarios [8]. Among these, the Detection Transformer (DETR) [9] stands out for its innovative use of transformer architectures [10], introducing a fully end-to-end model [11] that eliminates traditional reliance on handcrafted features and heuristics such as anchor boxes and region proposals [12]. Despite its SOTA design, DETR’s original implementation encounters challenges [13] including slower convergence rates and reduced sensitivity [14] to small-scale visual elements, which are crucial for effective early-stage fire detection [15]. To overcome these limitations, we propose a novel architectural enhancement to the DETR framework, integrating a refined convolutional backbone and a feature enrichment strategy to improve small-scale fire detection. ConvNeXt integrates several modern design principles inspired by vision transformers, resulting in improved performance over traditional convolutional networks, as demonstrated in recent benchmarks. Its enhanced capacity for capturing spatial and contextual features through hierarchical stages and depthwise convolutions makes it uniquely suitable for addressing the fine-grained detection tasks encountered in fire identification. To further improve feature representation, we incorporate an FEB, which is designed to enhance the spatial and contextual quality of the features extracted by the backbone.
In this research, we rigorously evaluate the proposed model on a carefully curated dataset comprising diverse agricultural fire scenarios. Our experimental results affirm that integrating a modified ConvNeXt backbone and FEB within the DETR architecture significantly improves detection performance across key metrics, including precision, recall, mean Average Precision (mAP), and F1-score, outperforming state-of-the-art models. These improvements underscore the practical applicability of our model in real-world agricultural settings, offering a robust and reliable solution for timely fire detection, ultimately aiding in preventive strategies and enhancing agricultural resilience.
2. Related Works
Early detection of fire and smoke has attracted considerable research attention due to its critical implications for agricultural management, environmental protection, and public safety [16]. Numerous methods have been developed over the years, evolving from conventional sensor-based approaches to sophisticated computer vision algorithms leveraging advanced deep learning architectures. In earlier studies, conventional methods predominantly relied upon sensor-based solutions employing heat and smoke detectors or infrared sensors [5]. These approaches, although straightforward, frequently exhibited limitations, including delayed detection times, susceptibility to environmental interference, and reduced accuracy in outdoor agricultural environments characterized by variable atmospheric conditions and expansive spatial scales [17]. As a result, these systems struggled to identify incipient fire outbreaks effectively, thereby limiting their utility in large-scale agricultural surveillance. The advent of computer vision technologies marked a significant shift towards visual-based detection methods [18]. Traditional image processing techniques initially employed color segmentation [19], motion detection [20], and thresholding-based algorithms for fire detection tasks [21]. However, these methods frequently encountered challenges related to false positives arising from variations in illumination, smoke interference, and environmental complexities inherent in agricultural settings.
Recent advancements in deep learning have dramatically improved the accuracy and robustness of fire and smoke detection systems [22]. Convolutional Neural Networks (CNNs), in particular, have become dominant due to their superior capability in extracting hierarchical visual features automatically [23]. Prominent CNN-based models such as YOLO (You Only Look Once) [24] and SSD (Single Shot MultiBox Detector) [25] have demonstrated high performance in various object detection tasks. YOLO models, including YOLOv5 [26], YOLOv6, YOLOv7, YOLOv8 [27], and the recently proposed YOLOv9 [28], provide remarkable real-time detection capabilities with high precision and recall, making them particularly suitable for scenarios requiring immediate response, such as fire detection in agriculture. However, these CNN-based architectures typically rely on anchor boxes and non-maximum suppression (NMS) procedures, which often introduce complexity and redundant predictions, resulting in slower inference speeds and decreased performance on small object detection. To overcome these limitations, the Detection Transformer (DETR) [9], proposed by Carion et al., introduced a novel transformer-based object detection framework, eliminating the need for anchor boxes and NMS by formulating detection as a set prediction task using transformers and bipartite matching. DETR demonstrated impressive detection accuracy but faced notable challenges [29], including slow convergence during training and difficulty detecting smaller objects [30], characteristics particularly detrimental for early-stage fire detection applications [11]. To address these shortcomings, subsequent variants of DETR emerged, enhancing the architecture’s capabilities and training efficiency. Zhu et al. proposed Deformable DETR [31], introducing deformable attention mechanisms that significantly improved detection accuracy and convergence speed, especially on smaller-scale objects. Similarly, Conditional DETR [32], developed by Meng et al., leveraged conditional spatial queries to better model spatial contexts, further enhancing small-object detection capabilities and reducing training duration. Another significant direction has been the adoption of hybrid models, integrating CNN backbones with transformer architectures [33]. Liu et al. introduced ConvNeXt [34], a CNN architecture inspired by transformer design principles, achieving state-of-the-art performance by adopting large kernel convolutions, depthwise separable convolutions, and hierarchical stage-wise structures. ConvNeXt significantly narrowed the performance gap between convolutional models and vision transformers [35], demonstrating enhanced feature extraction efficiency and improved generalization capabilities [36]. Due to its architectural strength, ConvNeXt has increasingly been adopted as an effective backbone within various detection frameworks, enabling superior representational capacity in complex detection scenarios [37]. Motivated by these advancements, our work builds upon the DETR framework, integrating an optimized ConvNeXt backbone enhanced with a Feature Enhancement Block (FEB). This combination seeks to harness the robust feature extraction capabilities of ConvNeXt with the powerful detection paradigm offered by transformers. Our approach specifically addresses existing limitations in detecting small-scale fire and smoke instances during early-stage outbreaks in agricultural environments, contributing to improved detection performance, faster convergence, and greater overall reliability, thereby advancing the state-of-the-art in agricultural fire detection.
3. Materials and Methods
In this study, we propose a novel approach for the early detection of fire and smoke in agricultural and crop field environments. Timely identification of such hazards is crucial for mitigating potential large-scale damage, including crop destruction, economic losses, and environmental degradation. Given the increasing frequency of fire incidents often triggered by wildfires or human impact, early-stage fire prediction has become a critical priority. As a baseline, we employ the DETR object detection framework, enhancing its performance by replacing the original backbone with a modified ConvNeXt architecture, specifically tailored for improved classification accuracy.
3.1. DETR
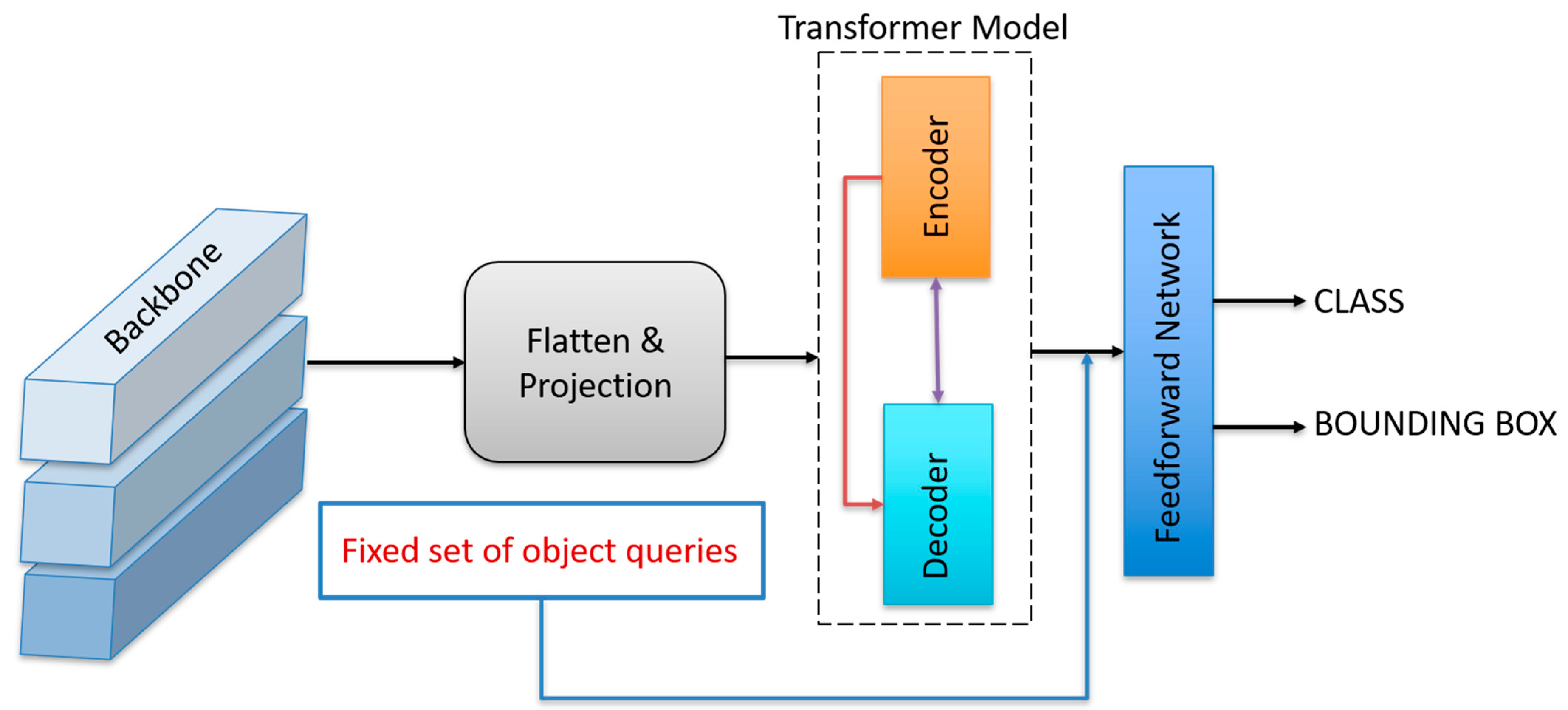
DETR represents a paradigm shift in object detection, introducing a transformer-based end-to-end framework that eliminates the need for traditional hand-crafted components such as region proposal networks, non-maximum suppression (NMS), and anchor generation. Developed by Facebook AI Research, DETR formulates object detection as a direct set prediction problem, enabling a simplified pipeline while achieving competitive performance on standard benchmarks Figure 1. The core architecture of DETR consists of three primary components: a CNN-based backbone, a transformer encoder-decoder architecture, and a feedforward network for final prediction. Backbone, the initial stage of DETR, utilizes a convolutional neural network, typically a ResNet-50 or ResNet-101, to extract dense feature representations from input images.
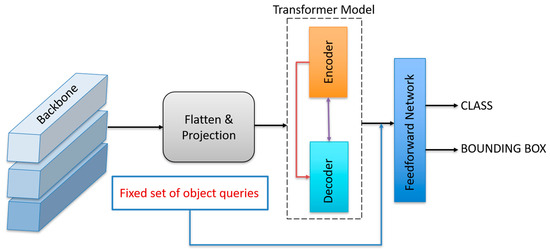
Figure 1.
Architecture of the DETR Framework.
The output feature map is flattened and projected to a fixed dimensional space to serve as input for the transformer module. Transformer module DETR leverages a standard encoder-decoder transformer architecture inspired by models in natural language processing, such as the original Transformer used in machine translation.
- Encoder: The encoder processes the spatially flattened image features, enriching them through multi-head self-attention and feedforward layers. Positional encodings are added to retain spatial information, compensating for the permutation-invariant nature of the transformers,
- Decoder: The decoder consists of a fixed set of learnable object queries that interact with the encoder outputs via cross-attention mechanisms. Each query is designed to attend to different spatial regions of the image and predict one object instance.
Prediction heads: The output from each decoder token is passed through a shared feedforward network that performs classification and bounding box regression. The bounding boxes are predicted in a normalized (cx, cy, w, h) format, representing the center coordinates, width, and height of the detected objects, respectively. A key innovation in DETR is the use of bipartite matching loss, particularly the Hungarian loss, which aligns predicted objects with ground truth targets uniquely, encouraging one-to-one prediction and eliminating redundancy. This design choice ensures that DETR can be trained in a fully end-to-end manner without requiring complex post-processing. Despite its conceptual elegance, DETR exhibits relatively slow convergence during training and struggles with detecting small objects. However, subsequent variants such as Deformable DETR and Conditional DETR have been proposed to address these limitations, improving efficiency and accuracy.
3.2. ConvNeXt
ConvNeXt is an advanced convolutional neural network architecture designed to reimagine conventional CNN approaches by integrating contemporary deep learning strategies inspired by transformer-based models. Developed by Liu et al., ConvNeXt seeks to reconcile the superior performance characteristics of vision transformers with the computational efficiency and inherent inductive biases unique to convolutional networks. The architecture itself resembles a ResNet-like backbone but significantly innovates by embedding principles derived from recent neural design paradigms and sophisticated training practices. Structurally, ConvNeXt employs a hierarchical, stage-wise organization similar to classical CNN frameworks and vision transformer architectures, progressively reducing spatial resolutions while increasing feature complexity.
A key aspect of ConvNeXt’s architecture involves sequentially organized stages, each containing convolutional blocks that operate at progressively smaller spatial dimensions and increasingly richer feature representations. Transitions between these stages utilize convolutional layers with a stride of two, effectively reducing resolution, analogous to the patch merging strategy commonly employed in transformers. At the heart of ConvNeXt lies a uniquely redesigned convolutional block, departing notably from the conventional ResNet bottleneck design. These blocks incorporate depthwise convolutions featuring large kernels to effectively emulate the long-range dependency modeling characteristic of transformer spatial self-attention mechanisms while maintaining parameter efficiency. Furthermore, ConvNeXt replaces conventional Batch Normalization layers with Layer Normalization, which contributes to improved training stability and generalization performance across diverse datasets. Additionally, the convolutional blocks utilize two pointwise convolution operations surrounding a Gaussian Error Linear Unit (GELU) activation function, introducing necessary non-linear transformations and promoting channel mixing to enrich feature representation. ConvNeXt also adopts an inverted bottleneck structure akin to MobileNetV2, where channel dimensions are initially expanded before compression, enhancing the network’s capability for complex and effective feature transformations without significantly impacting computational demands.
3.3. The Proposed Model
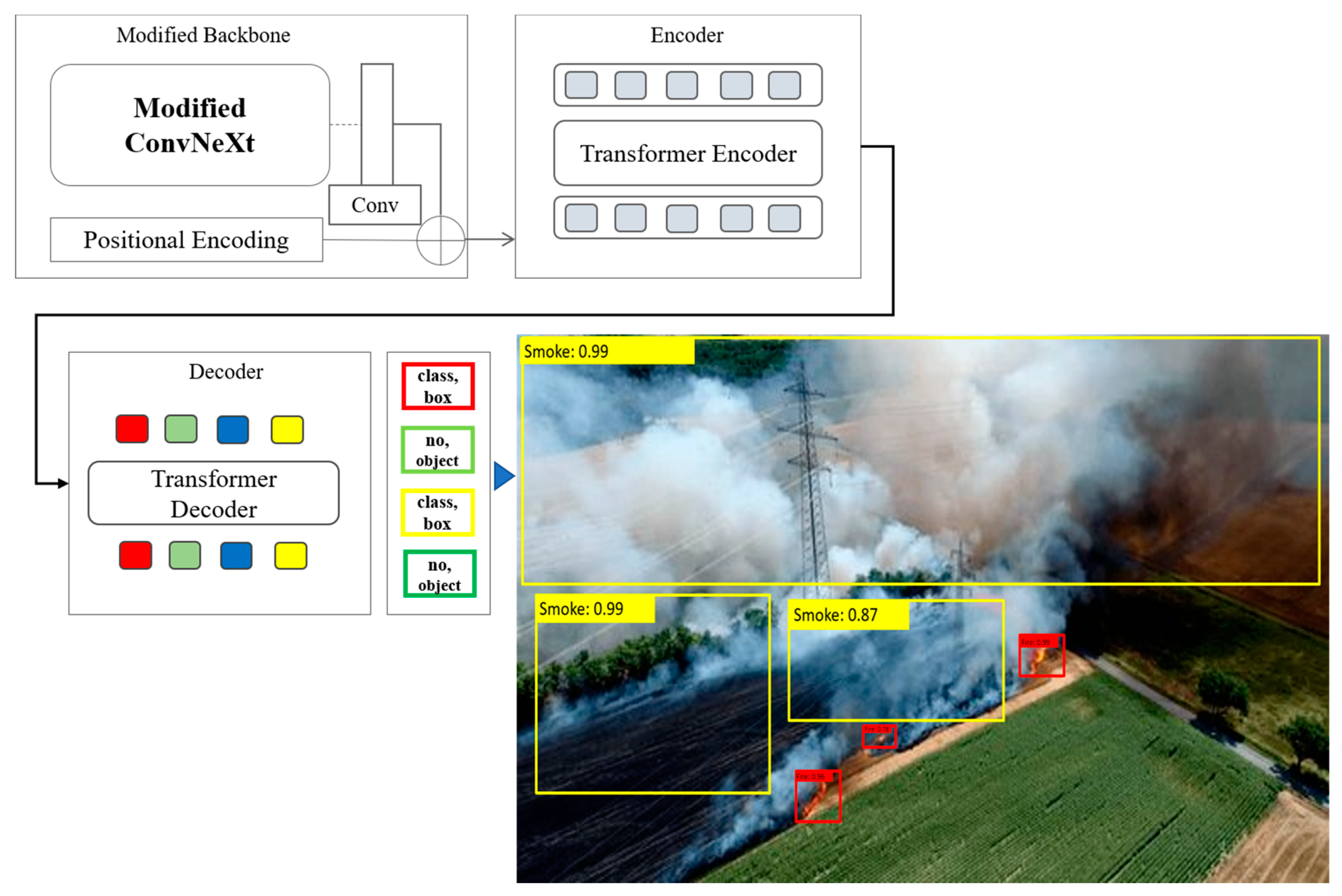
In this section, we describe our modifications to the baseline DETR architecture. As outlined in Section 3.1, DETR comprises three primary components: a convolutional backbone, a transformer module, and a prediction head. Our architectural improvements are focused on the backbone, as illustrated in Figure 2 and Figure 3. Specifically, we replace the original CNN-based backbone with a modified ConvNeXt architecture.
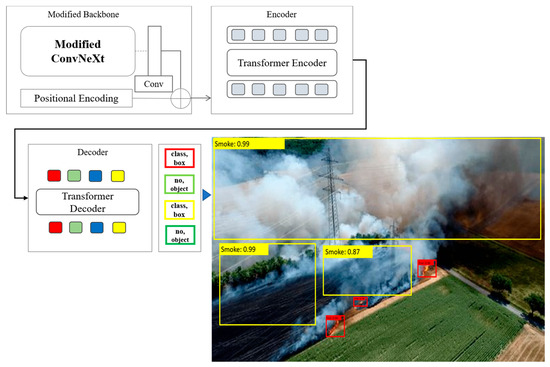
Figure 2.
DETR with modified backbone. The overall system workflow begins with real-time or pre-recorded UAV-based RGB imagery as input. These images undergo preprocessing, including normalization, resizing to 224 × 224, and augmentation. The preprocessed images are then passed through a modified ConvNeXt backbone with a Feature Enhancement Block (FEB), which extracts hierarchical visual features. These enriched features are then forwarded to the DETR transformer module, which predicts bounding boxes and class labels for fire or smoke instances. The final output consists of spatially localized fire/smoke detections, visualized with bounding boxes and classification scores.
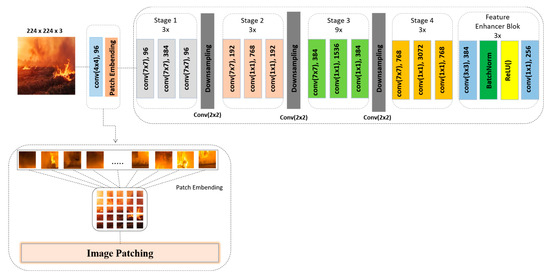
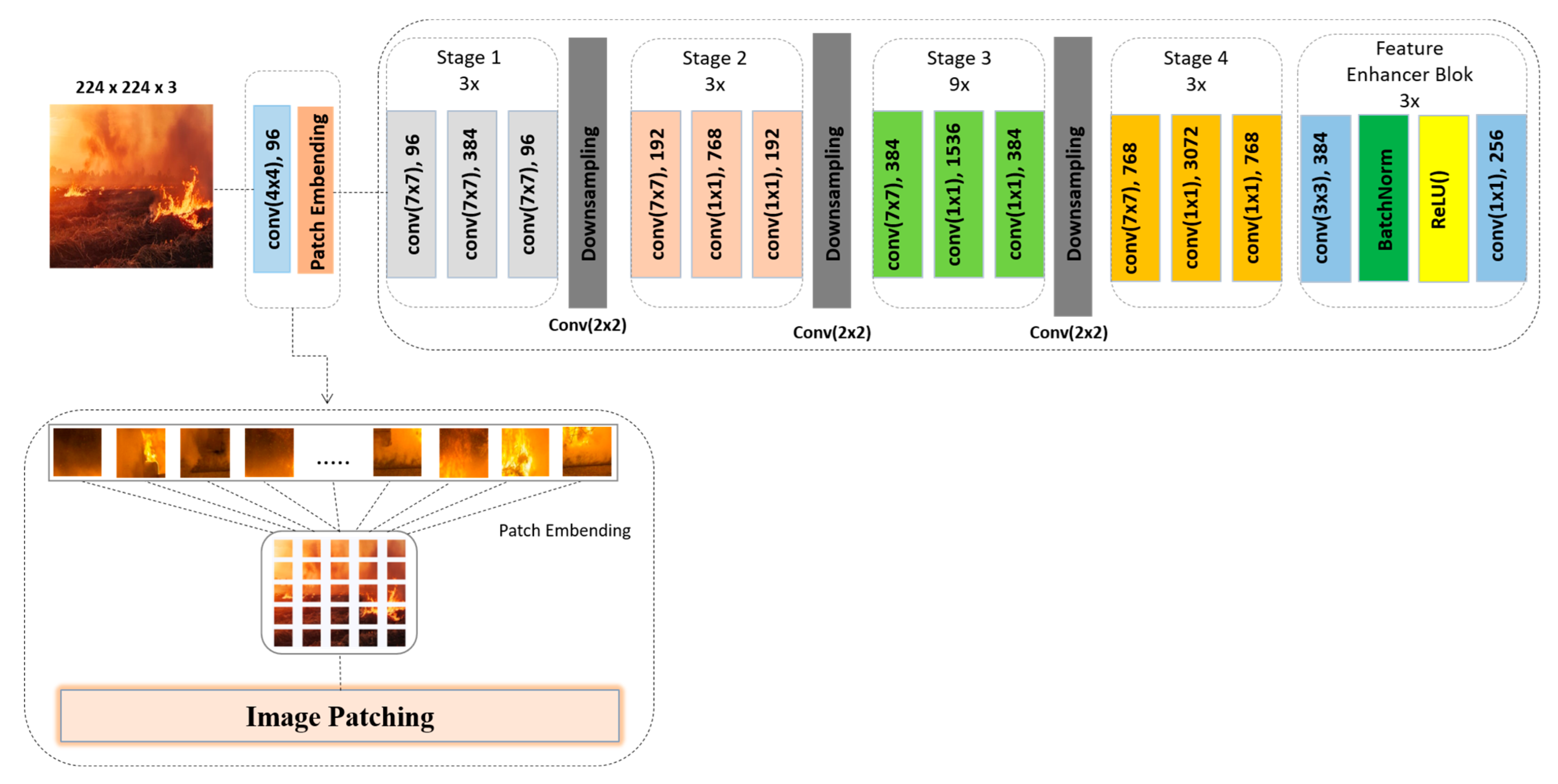
Figure 3.
The architecture of the modified ConvNeXt with Feature Enhancer Block.
To tailor ConvNeXt for feature extraction rather than classification, we remove its prediction head and introduce a Feature Enhancement Block (FEB). The FEB is designed to improve the representational capacity of the extracted features and consists of two sequential convolutional layers with kernel sizes of 3 × 3 and 1 × 1, respectively. These are followed by normalization layers and ReLU activation functions to ensure stable training and non-linearity. This modified backbone is intended to improve the expressiveness of feature maps, which may enhance downstream object detection performance. Where, comes into the modified ConvNeXt, as shown in Equation (1):
The initial layer of the modified backbone performs image patching, wherein a convolutional layer partitions the input image into a grid of patches, typically 56 × 56, using a kernel size and stride of 4 × 4. The 4 × 4 kernel with stride 4 was selected to mirror tokenization strategies used in ConvNeXt and ViT models, ensuring a consistent patch grid while controlling computational complexity. This configuration provides a trade-off between spatial granularity and inference efficiency. These parameters are configurable, allowing for flexibility in patch resolution depending on the input size and task requirements. This patching process functions analogously to tokenization in natural language processing, converting the raw image into a sequence of localized visual tokens. Each patch is then projected into a higher-dimensional embedding space, serving as the foundational representation for subsequent layers in the backbone. This embedding mechanism allows the model to capture localized spatial patterns while preserving the structural integrity of the image:
Stage 1 of the backbone Equation (2) architecture comprises three sequential convolutional layers, each employing a 7 × 7 kernel to capture broad spatial features at the early stages of processing.
This is followed by a downsampling layer that serves as the output of Stage 1, effectively reducing the spatial resolution of the feature maps while increasing their representational depth. This design facilitates the extraction of coarse-grained information and prepares the feature maps for subsequent hierarchical processing in the deeper stages of the network:
Stages 2–4 demonstrate the same number of convolution layers, only with 7 × 7, 1 × 1 kernel sizes, and same downsampling:
As illustrated in Figure 3, our proposed modification to the ConvNeXt backbone is introduced after Stage 4 and is referred to as the FEB. This additional module, defined in Equation (5), is designed to refine and enrich the feature representations prior to their use in classification. The FEB consists of two convolutional layers, such as the first with a 3 × 3 kernel and the second with a 1 × 1 kernel. This combination allows the block to capture both local spatial relationships and channel-wise dependencies, enhancing the discriminative power of the learned features. To ensure stability during training and accelerate convergence, each convolutional layer is followed by a batch normalization layer. Additionally, a ReLU activation function is applied to introduce non-linearity and improve the representational capacity of the model. By integrating this block at the end of the backbone, we aim to extract more semantically rich features that can lead to higher classification accuracy, particularly for complex visual patterns. The architectural flow in Figure 2 shows how the feature maps generated by the four-stage hierarchical ConvNeXt are further processed by the FEB before being passed to the transformer module in DETR. This enhancement ensures that the input to the DETR decoder is both contextually enriched and spatially informative.
One of the defining characteristics of the baseline model is its use of a set-based global loss function, which fundamentally differs from traditional object detection methods reliant on anchor boxes and post-processing heuristics. The baseline approach formulates object detection explicitly as a direct set prediction task, employing a specialized loss function designed to impose a strict one-to-one correspondence between each predicted object and the ground truth annotations. The proposed model utilizes the same loss function framework established by the baseline. This loss comprises two primary components. First, the Hungarian matching component (set-based assignment) ensures that predictions uniquely align with ground truth objects by solving an optimal bipartite matching problem using the Hungarian algorithm. Through this mechanism, each prediction is matched to precisely one ground truth object based on minimizing the cumulative matching cost across all potential pairs. Following this optimal assignment, the second component—the matching cost and corresponding loss—is computed. Specifically, a composite loss function is calculated over each matched prediction-target pair, aggregating individual terms to quantify prediction accuracy comprehensively. This composite loss enforces the prediction’s quality and ensures consistent performance aligned closely with ground truth data, ultimately facilitating improved detection results without resorting to heuristic-based post-processing techniques:
where is the classification loss, typically computed using cross-entropy between predicted class probabilities and the ground truth label. is the L1 loss between the predicted and ground truth bounding box coordinates. is the Generalized Intersection over Union (GIoU) loss, which provides a more comprehensive measure of overlap and spatial alignment than traditional IoU. ,, and are hyperparameters that weight the contribution of each component to the total loss. The Hungarian loss function incorporates three weighted components: classification loss ( = 1.0), bounding box regression loss ( = 5.0), and generalized IoU loss ( = 2.0). These weights were initially adopted from the original DETR implementation and were validated through pilot experiments, showing stable convergence without the need for extensive tuning in our dataset context.
4. Experiment and Results
4.1. Dataset
As part of this research, we have curated a specialized dataset comprising visual imagery and video sequences that capture agricultural fire incidents at both global and regional levels. This dataset has been further enriched with contextually relevant visual content extracted from publicly available sources such as YouTube, thereby ensuring a broad spectrum of fire-related scenarios is represented (Figure 4). To maintain consistency in preprocessing and to optimize computational performance, all visual inputs were standardized to a uniform resolution. Specifically, each image was resized to 224 × 224 pixels. This resolution standardization plays a pivotal role in preserving uniform quality across the dataset, which is essential for the reliable training and rigorous evaluation of the proposed detection model. The homogeneity in image dimensions minimizes variability introduced by differing source formats and enhances the model’s capacity to generalize across diverse real-world conditions. As a result, the accuracy and robustness of fire and smoke detection are significantly improved, supporting the practical deployment of the model in varied agricultural environments.

Figure 4.
Data preprocessing of the custom dataset. This figure demonstrates various domain-aware image augmentation techniques used to enhance agricultural fire image features for deep learning model training.
To evaluate the proposed model, we constructed a custom dataset specifically designed for agricultural fire detection. The dataset includes visual content extracted from 38 video clips obtained through UAV surveillance and publicly accessible online video sources. From these, a total of 8410 RGB frames were extracted, of which 5763 were manually annotated to indicate visible fire, smoke, or both, using bounding boxes formatted according to the COCO standard. These annotations were produced using the LabelImg tool, with careful quality control to ensure consistency across scenes.
The dataset was divided into training, validation, and test sets, following a 70%/15%/15% split, corresponding to 4034 images for training, 865 for validation, and 864 for testing. All images were resized to a uniform resolution of 224 × 224 pixels to maintain consistency across model inputs and enable efficient batch processing. The preprocessing pipeline included normalization, as well as data augmentation techniques such as random rotations, horizontal flipping, and color adjustments. The dataset reflects a range of scene types, including cultivated fields, orchard zones, and forest-adjacent agricultural land. Captured conditions span various times of day and weather settings, including daylight, dusk, and overcast scenarios. Visual complexity varies from clearly visible flames to partial or smoke-only scenes, with different levels of camera distance (close, medium, and far) and capture angles (overhead versus oblique views), offering a degree of diversity suitable for real-world generalization Table 1. Although the dataset cannot currently be released to the public due to third-party content licensing restrictions, we provide a detailed description here to ensure transparency. A small subset of fully licensable sample frames is available for peer review purposes upon request, and we aim to prepare a cleaned, openly shareable version in the future.

Table 1.
Summary of the Agricultural Fire Detection Dataset Used in This Study.
The preprocessing pipeline employed in this study comprises a structured sequence of operations aimed at optimally preparing the dataset for high-performance model training and evaluation. Initially, all collected visual data, consisting of both static images and extracted video frames, undergo a rigorous normalization procedure. This step standardizes pixel intensity values across the dataset, effectively mitigating discrepancies arising from heterogeneous lighting conditions and diverse sensor configurations inherent in multi-source imagery. Subsequent to normalization, a range of data augmentation techniques is applied to enhance the dataset’s variability, reduce the risk of overfitting, and simulate a more comprehensive array of fire-related scenarios. As depicted in Figure 4, these techniques include random rotations, horizontal and vertical flipping, scaling transformations, and color filtering. Collectively, they introduce controlled randomness into the dataset, thereby increasing its robustness and the generalizability of the model. Additionally, targeted cropping is employed to address issues of inconsistent aspect ratios and framing, ensuring that essential visual features, namely fire and smoke, remain centralized and well-represented within each image. To further ensure uniformity and computational efficiency, all images are ultimately resized to a fixed resolution of 224 × 224 pixels. This final step standardizes input dimensions for the model, streamlining batch processing and reducing computational overhead. Overall, this meticulously designed preprocessing workflow contributes substantially to the development of a diverse, high-quality dataset that is specifically tailored to improve the performance and reliability of fire detection systems in complex agricultural environments.
The dataset comprises visual data primarily obtained from UAV surveillance footage and publicly available aerial videos, capturing various agricultural fire events. No satellite or fixed surveillance tower data were included in this study. All experiments were conducted on a system equipped with an NVIDIA RTX 3090 GPU (24 GB VRAM), 128 GB RAM, and an Intel Core i9 processor. The model was implemented using Python 3.9 and PyTorch 2.0.1 with CUDA 11.7. Training and evaluation scripts were executed on Ubuntu 20.04.
4.2. Results
Table 2 shows that the proposed model demonstrates a significant performance improvement over the DETR baseline after 150 training epochs.
Table 2.
The results of comparison between baseline model and the proposed model after 150 epochs.
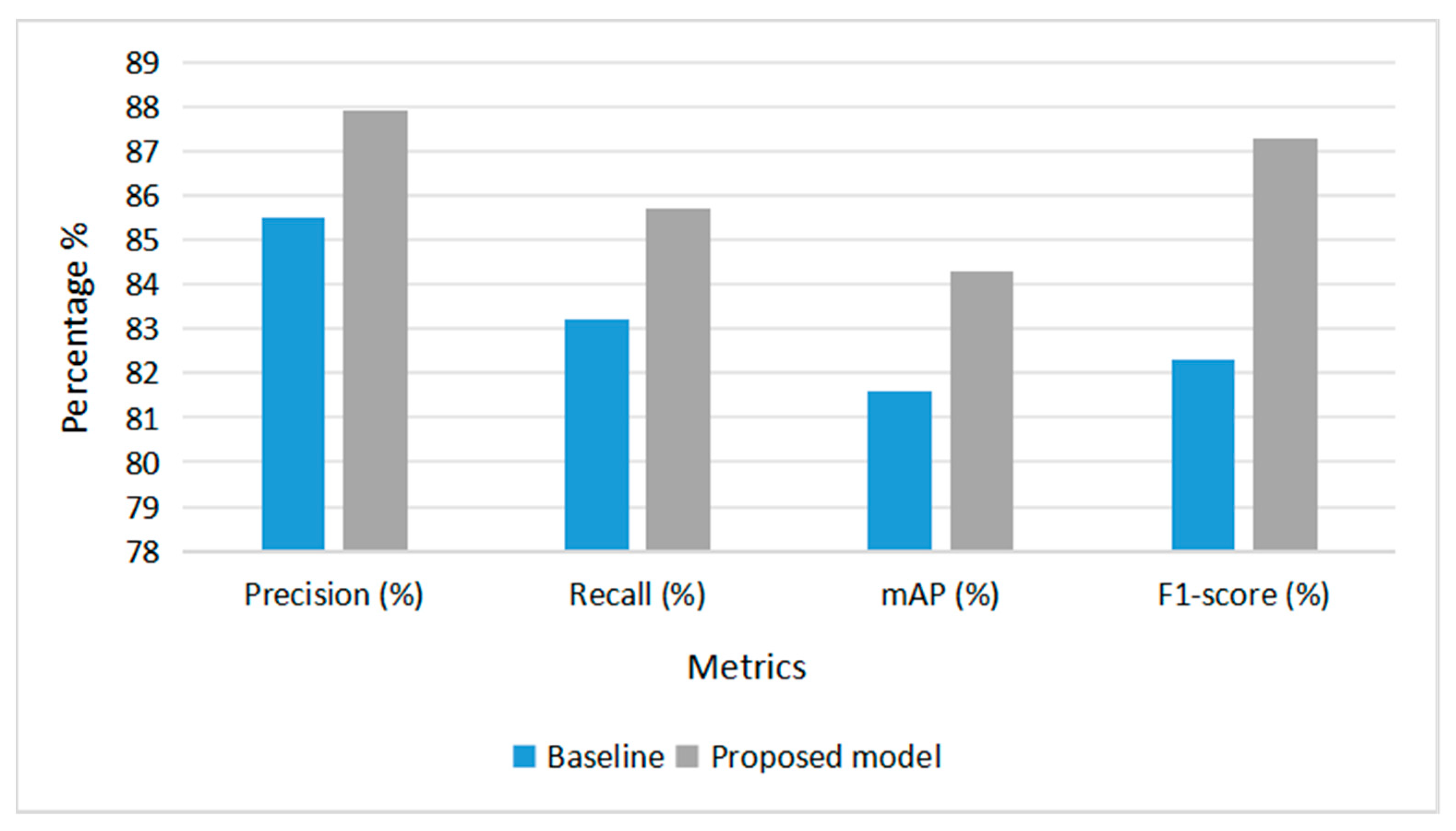
In particular, the precision increased from 85.5% to 87.9%, and recall improves from 83.2% to 85.7%, indicating that the model not only identifies fire-related objects more accurately but also captures a greater number of true positives. Furthermore, mAP, a critical metric for object detection performance, rose from 81.6% to 84.3%, reflecting a notable enhancement in the detection accuracy of the model across all classes in Figure 5.
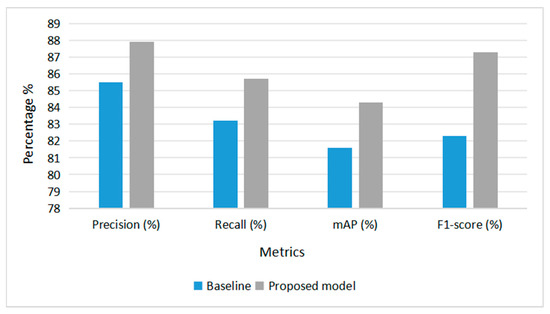
Figure 5.
Performance Comparison Between Baseline DETR and Proposed Model Across Key Evaluation Metrics.
The F1-score, which balances precision and recall, also improved substantially from 82.3% to 87.3%, showcasing the robustness of the proposed architecture. These gains validate the effectiveness of the architectural modifications, particularly the integration of the modified ConvNeXt backbone and the FEB, in improving feature representation and classification reliability (Figure 6).

Figure 6.
The results of the proposed model on custom dataset. The majority of the images, including those shown, capture fires in their smoldering or incipient stages. While some instances were manually selected to ensure clear visibility of subtle fire indicators, all samples represent realistic detection conditions. The observation range, although relatively short, is consistent with UAV-based surveillance setups commonly used in field-level agricultural monitoring.
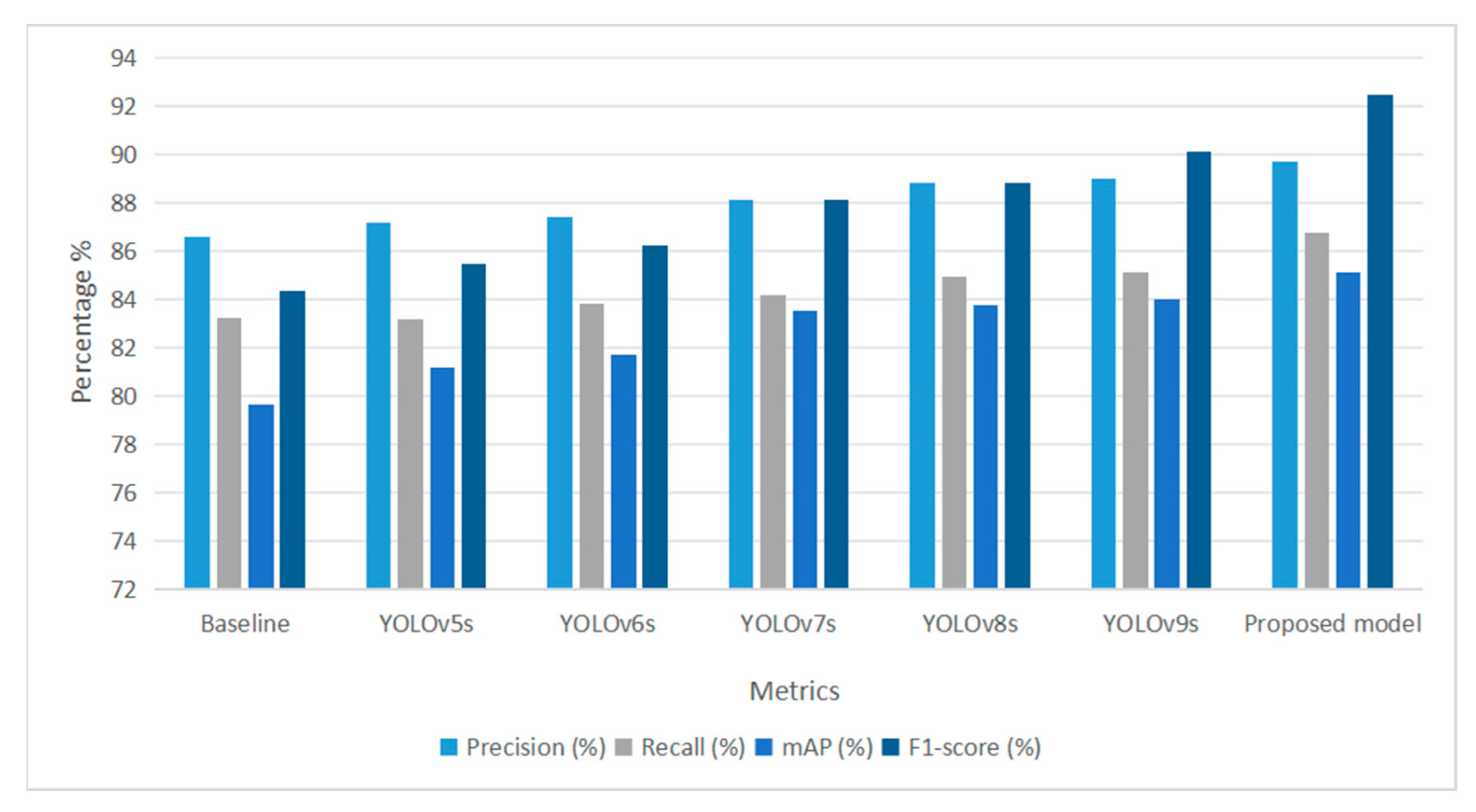
Table 3 provides a comprehensive comparative analysis between the proposed model and several state-of-the-art (SOTA) object detection frameworks, including DETR and various YOLOv-series models ranging from YOLOv5s to YOLOv9s. Table 2 presents a comparative evaluation showing that our proposed model achieves marginally higher performance across all key metrics under the specific experimental setup used. In terms of precision, the proposed model achieves the highest score of 89.67%, outperforming YOLOv9s with 88.96% and YOLOv8s with 88.78%, indicating fewer false positives and a higher degree of confidence in predictions.
Table 3.
The results of comparison among the proposed and SOTA models.
The recall rate of 86.74% also surpasses all other models, with YOLOv9s being the closest at 85.12%, highlighting the model’s strength in detecting relevant fire and smoke instances with minimal omission. For mAP, the proposed method yields a score of 85.13%, exceeding the best-performing YOLOv9s at 84.01% and significantly outperforming the DETR baseline at 79.66% in Figure 7.
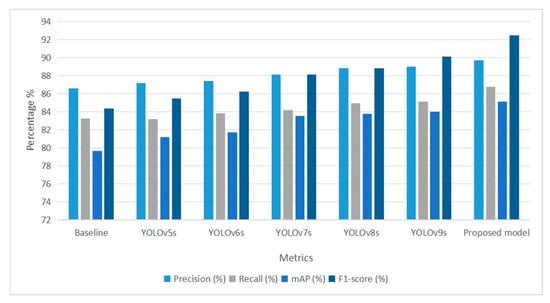
Figure 7.
Evaluation of Detection Performance Across YOLO Variants and the Proposed DETR-Based Model.
This affirms the capability of the model to accurately localize and classify fire-related objects over crop fields. Notably, the F1-score of the proposed model reaches 92.43%, marking a substantial improvement over the top-performing SOTA model, YOLOv9s, at 90.1% and clearly outperforming the DETR baseline at 84.33%. This further emphasizes the balance and reliability of the proposed detection framework. The consistent improvements across all evaluation metrics precision, recall, mAP, and F1-score affirm that the proposed model offers not only a viable alternative to established architectures but also a superior solution for accurate and real-time fire detection in agricultural environments. The integration of a modified ConvNeXt backbone and the FEB proved instrumental in enriching feature extraction, thereby elevating the overall performance of the model. These results suggest the potential applicability of the proposed model in real-world agricultural scenarios that require accurate and timely fire detection.
To further evaluate the individual contribution of the FEB, we conducted an ablation study comparing three configurations: (1) the DETR baseline with a ResNet-50 backbone, (2) a modified DETR with a ConvNeXt backbone but without the FEB, and (3) the full proposed model integrating both ConvNeXt and FEB Table 4. The aim of this comparison is to isolate the performance gain specifically attributable to the FEB. The results, presented in Table Y, show that replacing the original ResNet backbone with ConvNeXt (without FEB) already yields notable performance gains in all four-evaluation metrics. However, the inclusion of FEB further enhances the model’s ability to capture spatial and contextual features, resulting in additional improvements across precision, recall, mAP, and F1-score. These results validate the importance of the FEB in boosting representational power and overall detection reliability.
Table 4.
Ablation Study Evaluating the Impact of ConvNeXt Backbone and FEB.
5. Conclusions
In this study, we presented a modified DETR-based fire detection model tailored for agricultural environments, with a particular focus on the early identification of fire and smoke occurrences. The proposed framework integrates a ConvNeXt-based convolutional backbone and an FEB, aiming to improve feature representation before transformer-based detection.
Experimental evaluations were conducted on a curated UAV-derived dataset representing various fire scenarios, including both visible flames and low-intensity smoldering fires. The model demonstrated improved performance over both the DETR baseline and several YOLO-based architectures across precision, recall, mAP, and F1-score metrics. These improvements suggest that the integration of the ConvNeXt backbone and FEB contributes to more robust detection, particularly in visually complex scenes. In terms of implementation, the model was developed using PyTorch and was tested on a high-performance computing environment with GPU acceleration. The system supports deployment on both edge devices for localized, real-time monitoring and scalable server-based platforms for broader agricultural surveillance operations. While the results are promising, limitations remain. The model’s reliance on RGB imagery may restrict performance under poor lighting or in thermal-variant conditions. Future work will explore multimodal inputs, such as infrared data or multispectral imaging, and extend deployment testing across different geographies and crop types. Moreover, further optimization for resource-constrained edge inference environments remains a key objective. The proposed approach offers a viable and reproducible solution for early-stage fire detection in agricultural settings, contributing to preventive safety strategies and environmental risk mitigation.
Author Contributions
Methodology, A.A., S.U., K.T., J.S., Z.T., B.M., A.B., L.S.U. and C.L.; software, A.A., S.U., B.M. and C.L.; validation, A.B., Z.T., B.M. and L.S.U.; formal analysis, Z.T., B.M., A.B. and L.S.U.; resources, K.T., J.S., Z.T. and B.M.; data curation, S.U., A.B., K.T., J.S. and Z.T.; writing—original draft, A.A., S.U. and C.L.; writing—review and editing, A.A., S.U., K.T., J.S. and C.L.; supervision, S.U. and C.L.; project administration, S.U., K.T., J.S. and C.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Konkuk University in 2024 (2024-A019-0268).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The dataset used in this study consists of publicly accessible video sequences and images depicting agricultural fire scenarios.
Conflicts of Interest
The authors declare no conflicts of interest.
Correction Statement
This article has been republished with a minor correction to the Funding statement. This change does not affect the scientific content of the article.
References
- Maharani, D.N.; Umami, N.; Yuliyani, U.; Kurniyawan, E.H.; Nur, K.R.M.; Kurniawan, D.E.; Afandi, A.T. Psychosocial Problems among Farmers in Agricultural Areas. Health Technol. J. HTechJ 2025, 3, 120–130. [Google Scholar] [CrossRef]
- Taboada-Hermoza, R.; Martínez, A.G. “No One Is Safe”: Agricultural Burnings, Wildfires and Risk Perception in Two Agropastoral Communities in the Puna of Cusco, Peru. Fire 2025, 8, 60. [Google Scholar] [CrossRef]
- Abdusalomov, A.; Umirzakova, S.; Bakhtiyor Shukhratovich, M.; Mukhiddinov, M.; Kakhorov, A.; Buriboev, A.; Jeon, H.S. Drone-Based Wildfire Detection with Multi-Sensor Integration. Remote Sens. 2024, 16, 4651. [Google Scholar] [CrossRef]
- Morchid, A.; Alblushi, I.G.M.; Khalid, H.M.; El Alami, R.; Said, Z.; Qjidaa, H.; Cuce, E.; Muyeen, S.M.; Jamil, M.O. Fire detection and anti-fire system to enhance food security: A concept of smart agriculture systems-based IoT and embedded systems with machine-to-machine protocol. Sci. Afr. 2025, 27, e02559. [Google Scholar] [CrossRef]
- Krüll, W.; Tobera, R.; Willms, I.; Essen, H.; Von Wahl, N. Early forest fire detection and verification using optical smoke, gas and microwave sensors. Procedia Eng. 2012, 45, 584–594. [Google Scholar] [CrossRef]
- Asbaş, C.; Tuzlukaya, Ş.E. The New Agricultural Revolution: Agriculture 4.0 and Artificial Intelligence Applications in Agriculture, Forestry, and Fishery. In Generating Entrepreneurial Ideas with AI; IGI Global: Hershey, PA, USA, 2024; pp. 265–291. [Google Scholar]
- Gonzáles, H.; Ocaña, C.L.; Cubas, J.A.; Vega-Nieva, D.J.; Ruíz, M.; Santos, A.; Barboza, E. Impact of forest fire severity on soil physical and chemical properties in pine and scrub forests in high Andean zones of Peru. Trees For. People 2024, 18, 100659. [Google Scholar] [CrossRef]
- Abdusalomov, A.; Umirzakova, S.; Tashev, K.; Egamberdiev, N.; Belalova, G.; Meliboev, A.; Atadjanov, I.; Temirov, Z.; Cho, Y.I. AI-Driven UAV Surveillance for Agricultural Fire Safety. Fire 2025, 8, 142. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Dias, F.D.C.P.M. Rural Fire Detection: A Close-Range Approach for Classification and Localisation. Master’s Thesis, Universidade NOVA de Lisboa, Lisboa, Portugal, 2024. [Google Scholar]
- Liu, H.; Zhang, F.; Xu, Y.; Wang, J.; Lu, H.; Wei, W.; Zhu, J. Tfnet: Transformer-based multi-scale feature fusion forest fire image detection network. Fire 2025, 8, 59. [Google Scholar] [CrossRef]
- Yar, H.; Khan, Z.A.; Hussain, T.; Baik, S.W. A modified vision transformer architecture with scratch learning capabilities for effective fire detection. Expert Syst. Appl. 2024, 252, 123935. [Google Scholar] [CrossRef]
- Ai, H.Z.; Han, D.; Wang, X.Z.; Liu, Q.Y.; Wang, Y.; Li, M.Y.; Zhu, P. Early fire detection technology based on improved transformers in aircraft cargo compartments. J. Saf. Sci. Resil. 2024, 5, 194–203. [Google Scholar] [CrossRef]
- Makhmudov, F.; Umirzakova, S.; Kutlimuratov, A.; Abdusalomov, A.; Cho, Y.-I. Advanced Object Detection for Maritime Fire Safety. Fire 2024, 7, 430. [Google Scholar] [CrossRef]
- Sun, B.; Cheng, X. Smoke Detection Transformer: An Improved Real-Time Detection Transformer Smoke Detection Model for Early Fire Warning. Fire 2024, 7, 488. [Google Scholar] [CrossRef]
- Morchid, A.; Oughannou, Z.; El Alami, R.; Qjidaa, H.; Jamil, M.O.; Khalid, H.M. Integrated internet of things (IoT) solutions for early fire detection in smart agriculture. Results Eng. 2024, 24, 103392. [Google Scholar] [CrossRef]
- Maraveas, C.; Loukatos, D.; Bartzanas, T.; Arvanitis, K.G. Applications of artificial intelligence in fire safety of agricultural structures. Appl. Sci. 2021, 11, 7716. [Google Scholar] [CrossRef]
- Vasconcelos, R.N.; Franca Rocha, W.J.; Costa, D.P.; Duverger, S.G.; Santana, M.M.D.; Cambui, E.C.; Ferreira-Ferreira, J.; Oliveira, M.; Barbosa, L.D.S.; Cordeiro, C.L. Fire Detection with Deep Learning: A Comprehensive Review. Land 2024, 13, 1696. [Google Scholar] [CrossRef]
- Lopez-Alanis, A.; De-la-Torre-Gutierrez, H.; Hernández-Aguirre, A.; Orvañanos-Guerrero, M.T. Fuzzy rule-based combination model for the fire pixel segmentation. IEEE Access 2025, 13, 52478–52496. [Google Scholar] [CrossRef]
- Taşpınar, Y.S.; Köklü, M.; Altın, M. Fire detection in images using framework based on image processing, motion detection and convolutional neural network. Int. J. Intell. Syst. Appl. Eng. 2021, 9, 171–177. [Google Scholar] [CrossRef]
- Khatami, A.; Mirghasemi, S.; Khosravi, A.; Lim, C.P.; Nahavandi, S. A new PSO-based approach to fire flame detection using K-Medoids clustering. Expert Syst. Appl. 2017, 68, 69–80. [Google Scholar] [CrossRef]
- Cheng, G.; Chen, X.; Wang, C.; Li, X.; Xian, B.; Yu, H. Visual fire detection using deep learning: A survey. Neurocomputing 2024, 596, 127975. [Google Scholar] [CrossRef]
- Özel, B.; Alam, M.S.; Khan, M.U. Review of Modern Forest Fire Detection Techniques: Innovations in Image Processing and Deep Learning. Information 2024, 15, 538. [Google Scholar] [CrossRef]
- Wang, D.; Qian, Y.; Lu, J.; Wang, P.; Yang, D.; Yan, T. Ea-yolo: Efficient extraction and aggregation mechanism of YOLO for fire detection. Multimed. Syst. 2024, 30, 287. [Google Scholar] [CrossRef]
- Khan, Q. A Vision-Based Approach for Real Time Fire and Smoke Detection Using FASDD. Doctoral Dissertation, College of Electrical & Mechanical Engineering (CEME), NUST, Rawalpindi, Pakistan, 2025. [Google Scholar]
- Sun, Z.; Xu, R.; Zheng, X.; Zhang, L.; Zhang, Y. A forest fire detection method based on improved YOLOv5. Signal Image Video Process. 2025, 19, 136. [Google Scholar] [CrossRef]
- Alkhammash, E.H. A Comparative Analysis of YOLOv9, YOLOv10, YOLOv11 for Smoke and Fire Detection. Fire 2025, 8, 26. [Google Scholar] [CrossRef]
- Geng, X.; Han, X.; Cao, X.; Su, Y.; Shu, D. YOLOV9-CBM: An improved fire detection algorithm based on YOLOV9. IEEE Access 2025, 13, 19612–19623. [Google Scholar] [CrossRef]
- Liu, C.; Wu, F.; Shi, L. FasterGDSF-DETR: A Faster End-to-End Real-Time Fire Detection Model via the Gather-and-Distribute Mechanism. Electronics 2025, 14, 1472. [Google Scholar] [CrossRef]
- Liu, C.; Wu, F.; Shi, L. April. FasterGold-DETR: An Efficient End-to-End Fire Detection Model via Gather-and-Distribute Mechanism. In Proceedings of the ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Hyderabad, India, 6–11 April 2025; IEEE: Piscataway, NJ, USA, 2025; pp. 1–5. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Meng, D.; Chen, X.; Fan, Z.; Zeng, G.; Li, H.; Yuan, Y.; Sun, L.; Wang, J. Conditional detr for fast training convergence. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3651–3660. [Google Scholar]
- Wu, S.; Sheng, B.; Fu, G.; Zhang, D.; Jian, Y. Multiscale fire image detection method based on cnn and transformer. Multimed. Tools Appl. 2024, 83, 49787–49811. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Zahir, S.; Abbas, A.W.; Khan, R.U.; Ullah, M. Vision sensor assisted fire detection in iot environment using convnext. J. Artif. Intell. Syst. 2023, 5, 23–35. [Google Scholar]
- Khan, T.; Khan, Z.A.; Choi, C. Enhancing real-time fire detection: An effective multi-attention network and a fire benchmark. Neural Comput. Appl. 2023, 1–15. [Google Scholar] [CrossRef]
- Xu, Y.; Li, J.; Zhang, L.; Liu, H.; Zhang, F. CNTCB-YOLOv7: An effective forest fire detection model based on ConvNeXtV2 and CBAM. Fire 2024, 7, 54. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).