1. Introduction
The rapid growth of the population and the accelerating pace of urbanization have led to a significant increase in urban fire incidents, posing a serious societal challenge [
1]. These fires predominantly occur in densely populated urban and suburban areas, threatening lives, property, and public safety. According to the International Association of Fire and Rescue Services (CTIF) [
2], a 2022 survey covering 55 countries reported 64 million fire alarm calls, resulting in 3.7 million fires, approximately 19,000 fatalities, and 55,000 injuries, equivalent to an average of 0.5 deaths and 1.5 injuries per 100 fires. In China, data from the Ministry of Emergency Management [
3] indicate that in the first half of 2023, national fire rescue teams responded to 550,000 fire incidents, resulting in 959 fatalities, 1311 injuries, and direct property losses totaling CNY 3.94 billion. Compared to the same period in the previous year, fire occurrences increased by 19.9%, while the number of injuries rose by 9.3%. The implementation of effective fire prediction methods is essential for optimizing firefighting resource allocation, strategically deploying fire equipment and rescue personnel, and ultimately mitigating both the frequency and impact of urban fires.
Current research on urban fire spatiotemporal prediction primarily focuses on developing risk-based fire inspection systems [
4,
5]. To advance this field, scholars have explored various perspectives, leading to diverse definitions and theoretical frameworks for fire risk. Špatenková et al. [
6] conceptualized fire risk as a function of both the probability of fire occurrence and its potential consequences. Similarly, Xin et al. [
7] quantified fire risk as the product of fire occurrence probability and anticipated outcomes, including material losses and psychological distress. Alternatively, Chuvieco et al. [
8,
9] defined fire risk in terms of the likelihood of fire occurrence in the presence of hazard-inducing factors. A synthesis of these perspectives reveals that the fundamental components of fire risk include fire occurrence probability, contributing hazard factors, and resultant consequences such as property damage, psychological impact, and economic losses. Despite extensive research efforts, a universally applicable fire risk framework that integrates these various theoretical perspectives and methodological approaches remains absent. This study defines fire risk as the probability of a fire occurring at a given location under specific spatiotemporal conditions without engaging in a detailed examination of fire hazard factors or consequences.
With the increasing demand for objective and real-time risk assessments in industrial sectors, machine learning algorithms have gained significant traction in related research within academia [
10,
11]. The ability of machine learning to automatically analyze data, accurately extract patterns, and leverage these patterns for predictive purposes has revitalized research across various domains [
12]. In the field of urban fire risk prediction [
13,
14], numerous studies have explored the application of machine learning algorithms. For instance, some researchers [
15,
16] have employed the K-means clustering algorithm to classify urban fire risks, effectively identifying high-risk areas. Gigovi et al. [
17] applied the random forest algorithm to predict urban fire risks, demonstrating the substantial potential of data-driven methods in fire risk analysis. Dang [
18] integrated artificial neural networks with decision trees for an in-depth analysis of weather data, successfully predicting fire events in South Korea. Additionally, Zhang et al. [
19] proposed a fire risk prediction model based on the ARIMA algorithm, achieving accurate estimations of monthly fire frequency in urban settings. Despite these advancements, several critical limitations persist. First, most existing studies primarily focus on monthly fire predictions at the citywide level [
20,
21], lacking granularity in spatiotemporal analysis. This broad prediction approach reduces the practical effectiveness of fire response strategies, limiting the ability to provide precise regional risk warnings and optimize resource allocation. Second, while these models capture certain spatiotemporal characteristics of fire risks [
22], they often fail to systematically model spatiotemporal interactions, constraining their applicability in real-world scenarios.
This study focuses on Langfang City’s Anci and Guangyang Districts as case studies to develop a more efficient and accurate urban fire spatiotemporal prediction model. The key contributions of this research are as follows. First, the model integrates multi-source data, incorporating fire records, meteorological data, population distribution, and point of interest (POI) information. This comprehensive data fusion facilitates a more robust and informative modeling framework. Second, this study enhances spatiotemporal resolution. In terms of spatial granularity, the study area is divided into 1 km × 1 km grids, significantly improving spatial accuracy. In terms of temporal resolution, daily time intervals are adopted, refining the precision of time-series predictions. Finally, extensive empirical evaluations of real-world datasets demonstrate that the proposed UFSTP model outperforms state-of-the-art spatiotemporal prediction methods. These findings provide more reliable fire risk assessments for urban fire prevention and offer valuable insights for fire department decision-making, ultimately enhancing the efficiency and effectiveness of urban fire prevention strategies.
The remainder of this paper is structured as follows.
Section 2 provides a detailed analysis of the factors influencing urban fire risks.
Section 3 outlines the development of the proposed model.
Section 4 describes the experimental setup and presents the results.
Section 5 discusses the model’s practical applications in urban fire prevention. Finally,
Section 6 concludes this study and highlights directions for future research.
2. Dataset and Data Analysis
2.1. Dataset
This study aimed to develop a spatiotemporal fire prediction model for Anci and Guangyang Districts in Langfang City, China. Four real-world datasets covering the period from January 2020 to September 2024 were collected, as detailed below:
Fire Records: Fire incident data for Anci and Guangyang Districts were obtained from the Fire and Rescue Department of Langfang City. In total, there were 11,420 fire incidents in these districts during the study period. This dataset included the time and geographic coordinates (latitude and longitude) of fire occurrences. For spatial analysis, the districts were divided into grid cells, resulting in a total of 1213 grids. Among these, more than 46% (over 550 grids) recorded no fire incidents per month. On average, fire events occurred in only 4.7 months per grid over the 57-month period.
Population Data: Population estimates were sourced from WorldPop [
23], based on the 2020 census. The total population of the study area (Anci and Guangyang Districts) was 964,500. The dataset, provided in GeoTIFF format with a resolution of 3 arc-s (approximately 100 m), employed the WGS84 latitude–longitude coordinate system and represented population density in terms of people per pixel. For this study, the data were reprocessed to align with the
grid structure.
POI Data: POI data for Anci and Guangyang Districts were obtained from AutoNavi Map [
24]. This dataset categorized and geolocated various types of POIs, including residential areas, commercial zones, and road networks, facilitating the analysis of correlations between fire occurrences and the spatial distribution of public facilities.
Climate Data: To examine the influence of climatic factors on fire risk, climate data from January 2020 to September 2024 were retrieved from Weather China [
25]. This dataset included daily temperature, humidity, and precipitation records, and the average temperature and humidity for each month were computed to support the analysis.
Among the four datasets used in this study, the fire records were obtained from the Fire and Rescue Department of Langfang City through an official collaboration. Due to institutional confidentiality agreements, this dataset is not publicly available. However, the other three datasets—population data from WorldPop [
23], POI data from AutoNavi Map [
24], and climate data from Weather China [
25]—are publicly accessible through the links provided in the corresponding references.
2.2. Data Analysis
The frequency of fire incidents is influenced by multiple factors, primarily categorized into temporal and spatial effects. This section examines both aspects in detail.
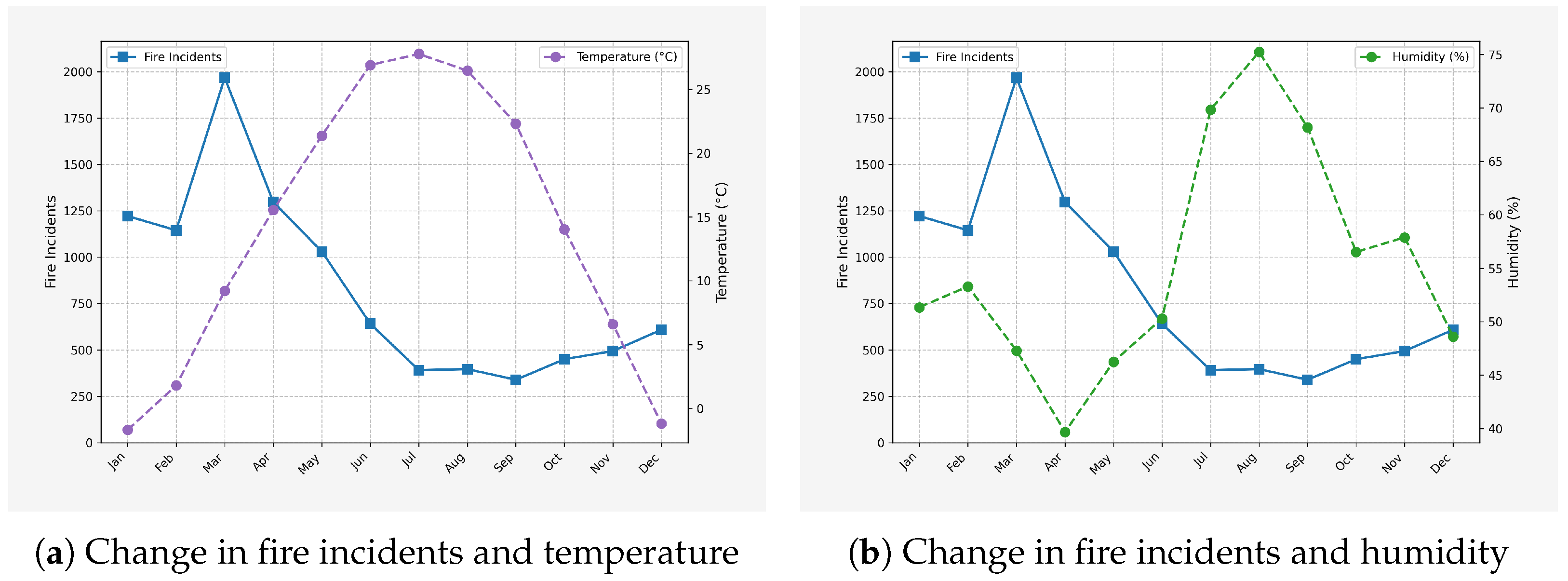
Time Effects: The influence of temporal factors on fire risk was examined through the correlations between temperature, humidity, and fire incident frequency, as shown in
Figure 1.
A distinct seasonal pattern was identified (
Figure 1a,b), with winter (December–February) and spring (March–May) emerging as high-risk periods for fire incidents. During the winter months, dry air causes an increase in static electricity, which can lead to electrical malfunctions and sparking fires. Also, for negligence-caused house fires, people tend to use more heating equipment during the winter months, and the dry conditions make surrounding flammable materials like curtains and sofas more susceptible to catching fire in the presence of a heat source or sparks.The significant increase in fire incidents in January and February was consistent with this trend.
Fire risk increased in spring, mainly due to dry weather conditions, strong winds and increased human activity. In the case of urban fires, dryness and strong winds can quickly spread any initial source of fire. In addition, increased human activities, including agricultural activities such as the open burning of straw on the outskirts of cities, further exacerbate fire risk. If not managed properly, sparks from straw burning can be carried by the wind into urban areas, potentially igniting combustible materials in residential or industrial areas and leading to an increased potential for large-scale fires.
Conversely, summer and autumn presented relatively lower fire risks. In summer, despite higher temperatures, elevated humidity levels and frequent rainfall mitigate the dryness of combustible materials. For urban fire types such as combustible gas and electrical fires, the moisture in the air reduces flammability and static build-up. Autumn features mild climatic conditions with balanced humidity, the absence of strong winds, and no winter-like dryness. This combination minimizes the risk factors for various urban fire types, resulting in a decreased likelihood of fire incidents.
Spatial Effects: Spatial factors influencing fire risk were categorized into local attributes and global dependencies.
Local Spatial Effects: Local spatial attributes, such as points of interest (POIs), significantly impact fire risk by influencing human activity and power consumption. Increased human presence and energy usage in specific areas elevate fire hazards.
To assess the relationship between fire incidents and POI diversity, the number of POI categories was analyzed across different grid areas.
Figure 2a presents the data showing an overall positive correlation between the number of POI categories and the frequency of fire accidents. This trend was likely due to increased human activity in these grids, which raised the probability of fire incidents. However, in the data analysis, there existed a peak in the correlation between the two variables. After this peak, as the number of POI categories continued to increase, the number of fire incidents showed an overall decline compared to the previous levels. This deviation from the initial positive trend indicated that other factors were at play in influencing the relationship between POI diversity and fire risk.
Furthermore, the correlation between various POI categories and fire incidents was quantified (
Figure 2b). The five POI categories exhibiting the strongest correlation with fire occurrences were shopping, food and beverages, transportation, enterprises, and automobile repair.
Global Spatial Effects: Global spatial attributes were analyzed to determine the distribution patterns of both the population and fire incidents.
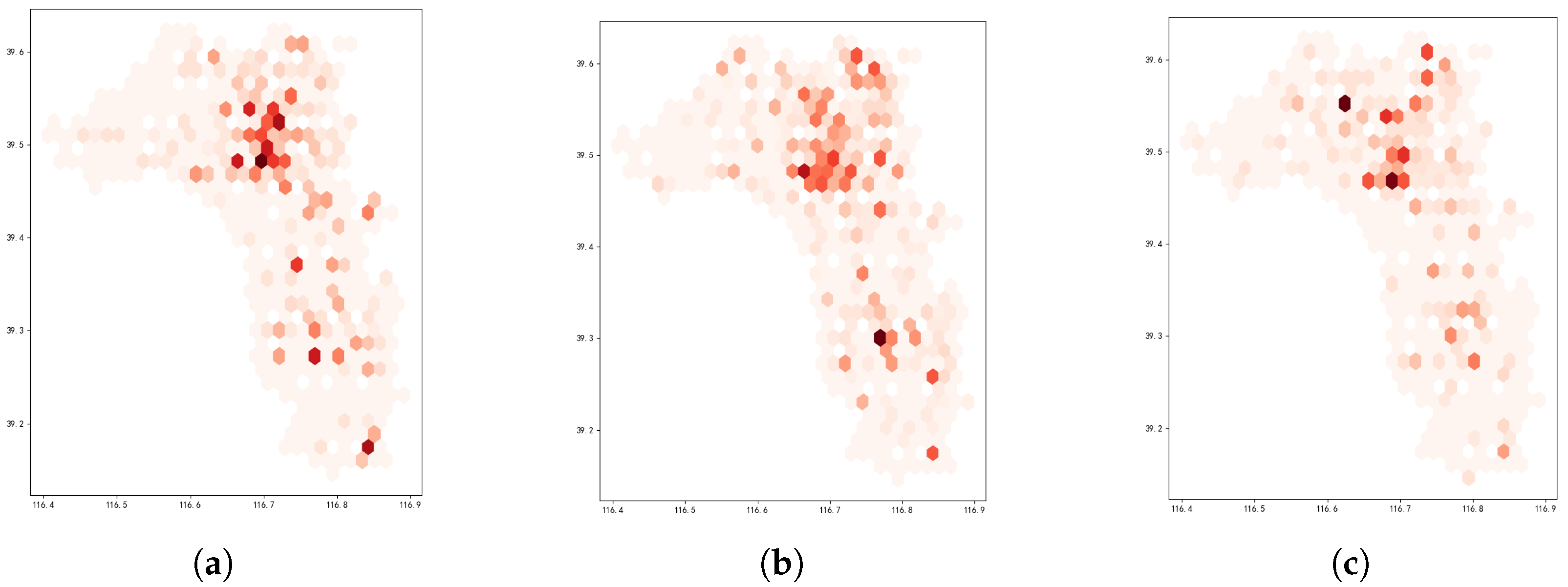
The spatial distributions of these two factors in the city exhibited significant global correlations, which remained relatively stable over time. As illustrated in
Figure 3, the spatial distribution of the population in the Anci and Guangyang Districts of Langfang City is depicted.
Figure 4 presents the distribution of fire incidents over three consecutive months. Notably, the central areas exhibited both the highest population density and a consistently elevated fire risk. In contrast, fire incidents in peripheral regions occurred with lower frequency.
The analysis confirmed that the fire incidents were influenced by both temporal and spatial factors. Even under conditions theoretically associated with reduced fire risk—such as low temperatures and high humidity—fires continued to occur in certain grid areas. This was particularly evident in regions with a high concentration of POIs or a dense population. Accurately capturing and simultaneously representing these complex interdependencies posed a significant challenge. Therefore, temporal effects needed to be integrated to model the dynamic evolution of fire risk over time. Simultaneously, spatial correlations needed to be thoroughly considered to gain a comprehensive understanding of fire risk distribution at each time point.
3. Problem Definition
This study focused on the problem of urban fire spatial–temporal prediction. An urban fire event can be represented as a four-element tuple:
where
r designates the affected region of the fire event, precisely identified by geographical coordinates. For detailed analysis, the region can be further divided into grids or sub-regions. The variable
t represents the exact time of fire occurrence, recorded with high precision to capture temporal patterns. The parameter
is the interarrival time, defined as the time interval between the occurrence of the current fire event and the most recent previous event. Finally,
s is a textual description that provides information about the type of building or area affected (e.g., residential buildings, commercial complexes, industrial facilities), potential causes (e.g., electrical malfunction, arson, cooking accidents), and other relevant details that offer insights into the fire’s nature.
The dataset used in this study consisted of four main components. The fire records dataset contained comprehensive historical fire incident data, including the quadruple representation for each event. The POI dataset provided the locations and classifications of various points of interest within the urban area, which were essential for understanding spatial contexts and identifying potential fire risk factors. The meteorological dataset included key weather parameters such as temperature and humidity, which were recorded continuously over time, as these factors significantly influence fire occurrence and propagation. Additionally, the population dataset provided information on population size, density, and spatial distribution, which were critical in assessing fire risk, as densely populated areas may exhibit a higher probability of fire incidents. This dataset served as a fundamental component for integrating social factors into fire risk prediction models.
Given the POI data, meteorological data, population data, and a sequence of previous fire events,
where
This study focused on forecasting the next fire event by predicting its expected region and arrival time . The ability to anticipate these factors can provide valuable insights for urban fire prevention and emergency response, enabling authorities to allocate resources efficiently, conduct targeted inspections, and implement proactive measures to mitigate potential losses caused by urban fires.
4. Fire Prediction Model
To achieve the accurate prediction of the time and location of urban fire incidents, this study integrated various spatiotemporal factors to construct a high-precision prediction model. By combining multi-source data, extracting key features, and utilizing an optimized neural network architecture, the model effectively captured the underlying relationships between historical fire incidents, meteorological conditions, population distribution, urban functions, and future fires. This approach can enable precise fire risk prediction, facilitate proactive prevention measures, and optimize resource allocation.
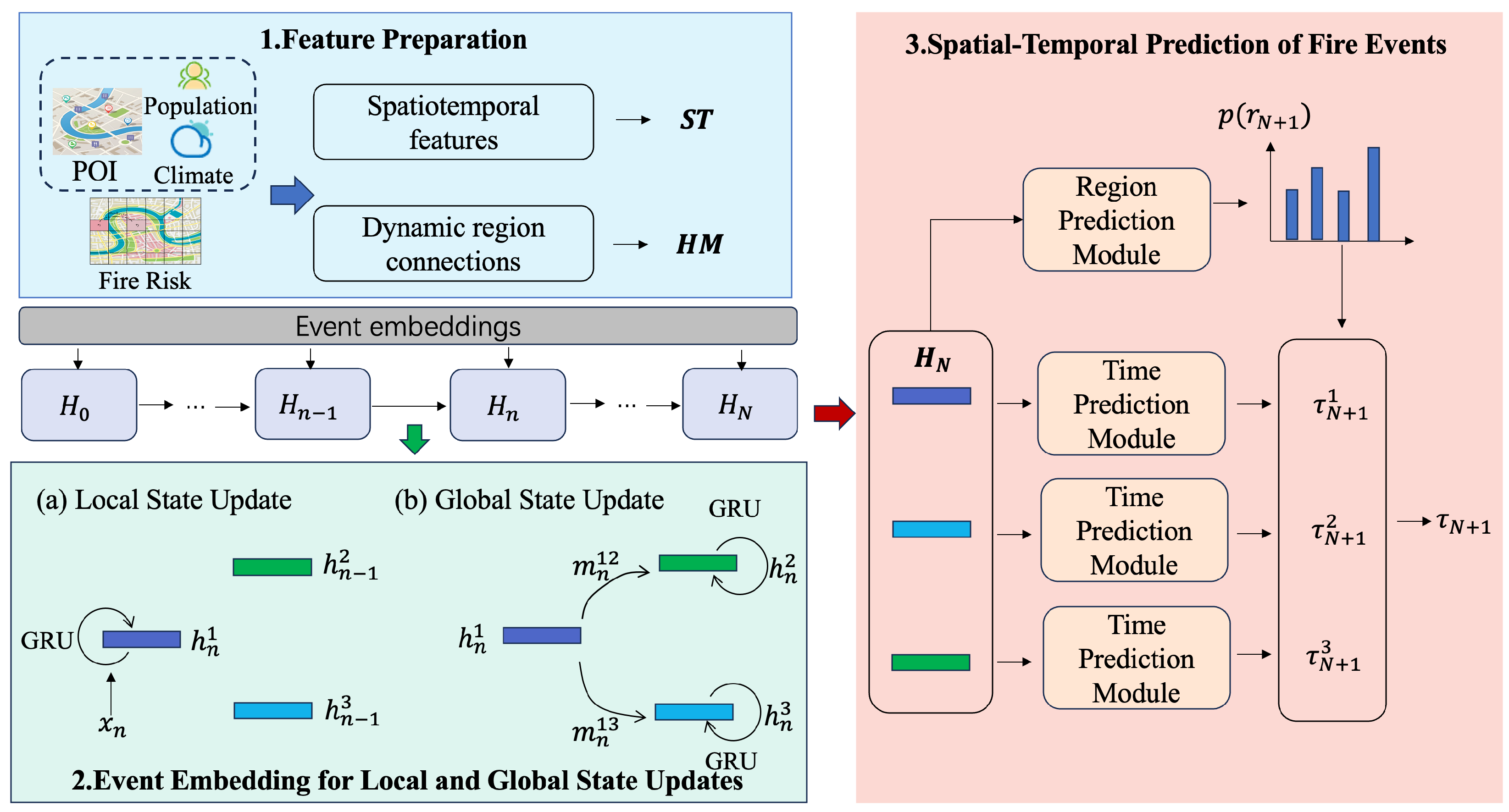
This paper presents the Urban Fire Spatial–Temporal Prediction framework, denoted as UFSTP, whose architecture is illustrated in
Figure 5. The framework comprises three key components. First, key features are constructed by integrating points of interest (POIs), meteorological conditions, population data, and historical fire records. Second, an event embedding mechanism is employed to update both local and global state information, enabling the model to extract insights from past fire incidents. Finally, by utilizing the trained regional states and current environmental conditions, the model predicts the time and location of the next fire occurrence.
4.1. Feature Preparation
Raw features were constructed to capture the spatiotemporal context and interregional dependencies for urban fire prediction, incorporating environmental information and dynamic regional relationships. These features were based on static regional attributes like POI classifications, humidity, temperature, and population density, as well as dynamic factors such as historical fire indices.
Consider an urban area divided into m regions. For each region, environmental features were constructed to capture critical fire risk factors. Real-time humidity and temperature data were incorporated, as these variables significantly influence fire ignition and propagation. The historical fire index reflected the long-term fire propensity of a given region, while POI classifications and population density provided insights into potential fire sources and human-related risk factors.
In addition, relationship features were developed to characterize interactions between regions in terms of fire risk. These features comprehensively integrated both static and dynamic factors, allowing the model to simulate the spatial propagation of fires and assess interregional risk dependencies.
4.1.1. Spatiotemporal Features
Feature extraction at the regional level served as the foundation for subsequent analysis. Each region within the urban area was treated as an independent unit for feature extraction.
POI Features: POIs were classified into various categories, including commercial, residential, industrial, and recreational. For each POI type
j in region
r, with
denoting the number of POIs of that type and
denoting the area of the region, the density of POI type
j in region
r, denoted as
, was calculated as
where
represents the total number of POI types. This formulation ensured that the density information of all POI categories was incorporated, enabling a comprehensive representation of the functional characteristics of each region.
These density values provided insights into the potential fire risk associated with different functional zones. For example, a high density of industrial POIs could indicate the presence of flammable materials and complex machinery, increasing the likelihood of fire incidents.
Climate Feature: Climatic conditions significantly influence fire occurrence and propagation. For each region
r at time
t, key climate variables, including temperature and humidity, were collected and aggregated into a single climate feature vector.
Elevated temperatures contribute to the drying of vegetation and building materials, while low humidity levels create favorable conditions for fire ignition. The combined feature effectively encapsulates the climatic propensity for fire outbreaks in each region.
Population Density Feature: Population density serves as an indicator of human activity intensity, which is strongly correlated with fire risks. With
denoting the total population in the region and
denoting the area of the region, the population density feature
was defined as
Areas with higher population densities typically exhibited increased fire risk due to the greater number of buildings, extensive use of electrical appliances, and higher human activity levels. These regional features—including POI density, climatic conditions, and population density—collectively established the initial fire risk profile of each region.
The spatiotemporal feature vector for region r on a given day was expressed as follows:
4.1.2. Region Relation Features
To account for spatial dependencies between regions, fire risk indices were utilized to quantify interregional relationships. The fire risk index, derived from historical fire data, indicated the probability of fire occurrence in a given region. This approach enabled the modeling of fire risk propagation across regions, rather than relying solely on local features. For two regions
and
, fire risk propagation was defined as
where
- -
and represent the fire risk indices of regions and at time t, derived from historical fire data;
- -
is a scaling factor that controls the sensitivity of propagation to differences in fire risk indices;
- -
measures the fire risk difference between the two regions and at time t. A smaller difference signifies a stronger interregional relationship.
The matrix Risk represents the fire risk propagation relationship between regions, reflecting the dependence of fire risks in different regions.
Fire Risk Propagation Matrix Between Regions: The fire risk propagation relationships among regions were encoded in a matrix, denoted as
. Each element
quantified the directed dependency from region
i to region
j at timestamp
t:
where
captures the interregional dependencies based on fire risk indices, enhancing the predictive accuracy of fire risk assessment for individual regions. By integrating fire risk propagation relationships with localized features, a more comprehensive fire risk prediction model was established.
4.2. Event Embedding for Local and Global State Updates
The influence of historical fire data varied across different regions, primarily due to differences in each region’s internal state and the interdependencies between regions. To address this, this study maintained a neural state for each region to extract all historical fire data, updating the region’s state with each fire event. The initial state for all regions was defined as . After the i-th fire event, the region’s state was defined as , incorporating information from the event and all previous historical fire data.
To enable the model to learn from historical fire incidents, we represented each historical fire event as
, and the event embedding was represented as
where
denotes the concatenation of three components:
, representing the arrival time of the fire event;
, representing the spatiotemporal feature for region
r at time
t; and
s, representing the description of the fire event.
When embedding the i-th fire event, the update of the regional state was primarily divided into two stages: local state update and global state update.
4.2.1. Local State Update
When embedding historical fire data, the state of the region experiencing the fire event was first adjusted. Here, the fire event directly influenced the region’s state, with the updated state depending exclusively on the previous state of the region and the incoming event information. This temporal adjustment was naturally modeled using a recurrent neural network architecture. In this study, GRU was used to update the local regional state. The specific calculation process was as follows:
The GRU’s gating mechanism enabled the region state to retain long-term dependencies from past fire events, thereby effectively capturing the temporal dynamics of fire propagation.
4.2.2. Global State Update
In the global state update phase, the model focused on how fire event information spread across regions that were not directly affected by the incident. The degree of influence that a fire exerted on neighboring regions was contingent upon the spatial relationships between these regions at a given time. This process was inspired by the concept of message passing in graph neural networks [
26], and we broke it down into two distinct steps. First, a message was generated by combining fire event data with the relationship matrix of regions. Specifically, the matrix
represented the inter-regional relationships at time
t, where each element encapsulates the connection between two regions. Second, the receiving region processed the incoming message and adjusted its state accordingly. The state update followed the mechanism of a GRU network. The update rule for region
, informed by the fire event information
, was as follows:
Here,
and
denote the regional relation feature and the message passed from region
to region
at time
, respectively. The function
represents the message generation mechanism, which was implemented via a multilayer perceptron (MLP). The update in Equation (
5c) mirrored the update process in Equations (
4a)–(
4d).
This dual-stage propagation mechanism—spanning both spatial and temporal dimensions—ensured that historical fire event information was effectively conveyed. On the spatial side, the extent to which fire events influenced different regions was contingent on the dynamic nature of inter-regional relationships, which were influenced by factors like human movement and connectivity. Temporally, the gated recurrent update enabled each region to retain relevant historical fire event information over time. Through successive updates across multiple fire events, each region learned to prioritize and integrate the most significant fire-related information encoded in its state.
4.3. Spatial–Temporal Prediction of Fire Events
The region states were updated sequentially in response to a given time-ordered record of urban fire events , resulting in state sequence . The objective was to forecast the next fire event’s occurrence region and arrival time of the next fire event, conditioned on the preceding state . This prediction process consisted of two steps. The prediction process began by estimating the probability of the next fire event occurring in region r. Subsequently, the conditional distribution was computed for each region, leading to the overall temporal distribution . This formulation simplified the complexity of by separating it into a spatial component and a conditional temporal component .
4.3.1. Spatial Prediction of Fire Occurrences
To predict the next fire event’s occurrence region, a multinomial distribution
was utilized, with probabilities satisfying
and defined as
. These probability values were formulated based on the state of the region and its spatiotemporal context:
Here, represents a numerical scalar and is realized using a multi-layer perceptron (MLP) network.
4.3.2. Temporal Prediction of Fire Occurrences
Utilizing past data embedded in local region states and associated spatiotemporal features, the estimated occurrence time for the upcoming fire event was assumed to be independently distributed across different areas. Thus, individual estimations were performed separately, and the comprehensive probability distribution of
resulted from a weighted summation over all possible regions:
Thus, modeling the conditional distribution
became a critical step in the prediction. As a probabilistic technique adept at representing complex multi-modal distributions, variational autoencoders (VAEs) [
27] have been successfully employed in sequential modeling through recurrent structures [
28,
29]. Leveraging this capability, a variational module was developed for fire event time prediction by incorporating spatiotemporal context.
A VAE characterizes the data generation mechanism through a latent variable
z. Initially,
z is sampled from a predefined prior
, typically assumed to be standard normal. The observable variable
x is then drawn from
, which is parameterized by neural networks and usually follows a Gaussian distribution. However, since
was highly non-linear, directly computing the posterior
was infeasible. To address this, an approximate inference model
was employed, which was also implemented via neural networks. Training the VAE involved maximizing the variational lower bound (ELBO):
In this formulation, quantifies the Kullback–Leibler divergence and the term on the left defines the ELBO, also known as the variational lower bound.
Within this framework, every region and time step was associated with an independent VAE. During prediction, the model sampled latent variables from a prior that followed a normal distribution, parameterized by regional conditions and spatiotemporal features, rather than relying on a fixed standard normal assumption.
To derive the arrival time distribution, the latent variable was processed by a decoder. Since
was non-negative by nature, we modeled
as an exponential distribution
. Unlike traditional VAEs, where the distribution parameters were solely a function of the latent variable
, in this case,
also incorporated information from the previous state
and spatiotemporal attributes
.
The prediction procedure concluded by calculating the arrival time of the subsequent fire event, denoted as
, through the following computational process:
A weighting coefficient
governed the trade-off between spatial prediction loss and temporal prediction loss during model optimization. The reparameterization trick [
27] was applied to handle the first term of
, that is,
was sampled, where
. This allowed for the computation of gradients, which were subsequently minimized using backpropagation.
The above steps elaborate in detail upon the prediction phase of the model. During the model training process, to effectively calculate ELBO and facilitate the training progress of the model, obtaining the posterior distribution
was a crucial step. In mathematical modeling, this posterior distribution
was characterized as a normal distribution, and its distribution characteristics were closely dependent on the input feature vector of the next fire event
:
The ELBO of the time prediction module was computed as
In summary, the proposed UFSTP framework is tailored for urban fire spatiotemporal prediction and overcomes several key limitations in existing methods through three major innovations:
- (1)
A region-specific hidden state mechanism that preserves independent temporal memories for each spatial grid. This design addresses the limitation of global or shared representations in traditional RNN-based models, which often fail to capture location-specific fire patterns and temporal dynamics.
- (2)
A spatiotemporal propagation strategy based on inter-region message passing, which enables the model to simulate dynamic risk interactions between regions. This overcomes the static or oversimplified spatial correlation modeling used in many prior works, allowing UFSTP to adaptively reflect evolving spatial dependencies.
- (3)
A sequential VAE-based co-prediction module that jointly models the time and location of future fire events using a flexible latent-variable framework. This innovation addresses the rigid and often unimodal time modeling assumptions in conventional temporal point process approaches and significantly improves the model’s ability to handle uncertainty and complexity in real-world fire event distributions.
This framework is versatile and can be applied to predict other types of urban events, provided appropriate spatiotemporal features are selected. Although the current application is focused on urban fire event prediction, the methodology can be easily adapted for other urban event prediction tasks.
4.4. Model Training
To effectively predict fire events, the model was trained on a sequence of observations
, optimizing an objective function that balanced both spatial and temporal accuracy. The training and prediction phases are shown in
Figure 6. The loss for region prediction followed a negative log-likelihood approach, while the estimation of event timing relied on the cumulative negative ELBO function.
The Adam optimizer was used to train the model. During training, the model continuously adjusted its parameters to minimize the objective function . Specifically, in each iteration, the loss between the predicted results and the true labels was computed based on the current parameter values and the optimizer updated the parameters according to the gradient information of the loss. For the region prediction component, minimizing the negative log-likelihood ensured that the probability distribution of the predicted fire event occurrence regions aligned as closely as possible with the true distribution. For the time prediction component, minimizing the negative ELBO function improved the accuracy of the predicted fire event arrival times. During training, the hyperparameter played a critical role in balancing the region prediction loss and time prediction loss. It needed to be adjusted appropriately based on the specific dataset and task to achieve optimal prediction performance.
Through this training process, the model learned the spatiotemporal characteristics of fire events and the influence patterns of historical events on future fires, thereby improving its ability to predict urban fire events. In practical applications, multiple experiments may be necessary to determine the optimal settings for hyperparameters and training configurations (such as the number of training epochs) to ensure that the model demonstrates good generalization performance on the test set.
5. Evaluation
5.1. Experiment Settings
This study aimed to construct sequences for model training and testing using the collected fire event data. Considering the temporal characteristics of fire events and the practicality of the data, a 7-day period was selected as the time unit to form fire event sequences. Specifically, all fire events recorded within any 7 consecutive days were combined into a single sequence. After meticulous sorting and screening of the original data, a series of fire event sequence sets that met the required criteria were successfully constructed.
These sequences were then divided into three subsets according to the standard data partitioning principle, with a focus on time-based division. Given the potential temporal trends and patterns in fire events, time-based division could better capture the dynamic nature of the data. The training set, comprising 70% of the data, was selected from the earlier time periods. This allowed the model to learn various characteristics and patterns of fire events from historical data, such as seasonal trends or long-term changes in fire occurrence. The validation set, accounting for 10%, was chosen from the time periods following the training set data. It played a crucial role in adjusting and optimizing model parameters during the training process, facilitating the selection of the best model configuration. Since it had a different time-frame from the training set but still shared some temporal characteristics, it could effectively evaluate how well the model generalized within a relatively close time range. The remaining 20% was designated as the test set, which was sourced from the most recent time periods. This setup enabled an objective assessment of the model’s performance on unseen data and ensured good generalization ability as it mimicked the real-world scenario for which the model was used to predict future fire events.
During model training, the Adam optimizer was employed to guide the learning process. After conducting multiple experiments and adjusting parameters, a learning rate of 0.0001 was determined to be optimal. This learning rate ensured both adequate convergence speed and the prevention of local optima. Additionally, to improve training efficiency and stability, a batch size of 32 was selected, enabling the model to update parameters with an appropriate sample size at each iteration.
Regarding model architecture, the dimension of the region state was set to 128 after a comprehensive analysis. This configuration effectively captured relevant regional information without incurring excessive computational complexity. The weight of the region prediction loss was set to 1, ensuring a balanced contribution from the region prediction and other loss components. Function implementations for , , and were based on MLP networks. Specifically, and utilized a 2-layer MLP structure with layers of sizes , which efficiently processed input data and produced appropriate outputs. and were designed as 3-layer MLPs with layers of sizes , accommodating more complex input features and task requirements. Both and adopted a 2-layer MLP architecture with layers of sizes , ensuring a balance between computational efficiency and accuracy. To meet specific mathematical requirements, the output layer of used an exponential function, while the RelU function was employed as the activation function for all other layers. The RelU function effectively introduced nonlinearities, enhancing the model’s expressive power.
Two widely used evaluation metrics were employed to evaluate the model’s prediction performance for the arrival time of fire events accurately: the Mean Absolute Error (MAE) and the Root Mean Square Error (RMSE). Their respective calculation formulas were as follows:
In the above formulas, n represents the total number of fire event sequences in the test set, represents the length of the i-th sequence, is the actual arrival time of the j-th fire event in the i-th sequence, and is the corresponding arrival time predicted by the model. The units of and were both hours. In addition, for the evaluation of the prediction effect of the fire event occurrence area, we adopted the top hit rate (HR@k) metric. The meaning of HR@k was, among all the prediction results, the ratio of the actual occurrence area covered by the top k regions with the highest predicted probability, which could intuitively reflect the accuracy and reliability of the model in regional prediction.
Let n be the total number of fire event sequences in the test set and be the length of sequence i. The actual arrival time of the j-th fire event in sequence i was denoted as , while the model’s predicted arrival time was given by , both measured in hours.
For spatial prediction evaluation, we employed the top-k hit rate (HR@k), where . The HR@k metric measured the proportion of fire occurrences correctly predicted within the top k regions ranked by probability, providing a straightforward assessment of prediction accuracy.
5.2. Data Preprocessing
In addition, the data preprocessing stage played a pivotal role in enhancing model performance and uncovering the latent relationships within the datasets.
For point of interest (POI) data, Term Frequency-Inverse Document Frequency (TF-IDF) normalization was applied. This technique not only standardized feature vectors but also quantified the significance of various POI types in the context of fire risk. For instance, industrial areas with high POI density exhibited distinct TF-IDF profiles compared to residential zones. TF-IDF normalization accentuated these disparities, enabling the model to better discern their impact on fire risk.
Regarding fire risk data, normalization using relative frequencies was employed to achieve a more accurate assessment of risk levels across different regions. Given that the absolute number of fire incidents could vary significantly due to regional size or characteristics, focusing on relative risk through normalization provided a more reliable basis for fire prevention strategies and resource allocation.
Population and meteorological data, although not normalized, were integrated into the model while preserving their original integrity. Population data, which directly reflected human activity, aided the model in identifying areas prone to fire due to increased human presence. Meteorological data, with its fixed value ranges, offered stable inputs for the model to learn the influence of environmental conditions on fire risk. This comprehensive data preprocessing approach ensured that the model captured the intricate interactions among multiple factors, thus facilitating more effective urban fire risk prediction.
5.3. Baselines
- -
HA:
- -
Principle: This baseline was relatively simple. The average arrival time of all past fire events in the training set was calculated to predict the arrival time of fire events. By contrast, the region with the highest frequency of fire incidents was selected to predict the occurrence region. This method assumed that future fire events would follow the same temporal and spatial patterns observed in past events without considering more complex correlations.
- -
Model Complexity: Extremely low. The model involved only basic statistical operations, such as computing means and frequencies, with no neural network components or complex parameter estimations.
- -
- -
Principle: Recurrent Marked Temporal Point Processes (RMTPPs) utilized a recurrent neural network. Historical fire event data were first embedded into vectors, which were used to construct a flexible intensity function capable of adapting to different temporal patterns. In this model, the “mark” associated with the process was used to predict the occurrence region of the fire event, leveraging learned temporal features to infer spatial information.
- -
Model Complexity: High. The inclusion of a recurrent neural network entailed the use of backpropagation through time, which required careful gradient handling. Additionally, the construction of the intensity function introduced further complexity.
- -
- -
Principle: The Intensity RNN (IRNN) focused on fully modeling the intensity function of the temporal point process through recurrent neural networks (RNNs). The model employed two Long Short-Term Memory (LSTM) networks. One LSTM embedded the fire event sequence, while the other processes related time-series information. The combined embeddings were used to predict both the arrival time and the occurrence region of the fire event, leveraging the long-term memory capabilities of LSTMs.
- -
Model Complexity: Considerably high. The use of two LSTM models increased the number of parameters to be trained, and the interaction between these models to generate accurate predictions required intricate tuning.
- -
- -
Principle: In the Variational Event Point Process (VEPP), the historical fire event sequence was initially embedded using an RNN. At each time step, the model integrated a variational auto-encoder (VAE), which helped generate the distribution of fire event times and regions by capturing complex latent variable representations underlying the data. This approach was well-suited to handling the uncertainty in fire event occurrences.
- -
Model Complexity: Considerably high. The combination of RNNs and VAEs necessitated the integration of sequential processing, variational inference, and neural network training, all of which contributed to a large number of parameters and complex computational operations.
For the RNN-based baselines (RMTPP, IRNN, and VEPP), the hidden state size was set to 128, and the Adam optimizer was used with a learning rate of 0.0001, consistent with the proposed model. Additionally, during experimentation, environmental features (e.g., nearby weather conditions and population density) were incorporated as supplementary contextual information in the fire event sequences.
5.4. Comparisions with Baselines
A structured experimental analysis was conducted for Guangyang and Anci Districts to assess the effectiveness of the proposed fire event prediction framework relative to selected baseline models. The results are presented in
Table 1 and
Table 2, offering a clear comparison of performance across the different methods.
Time Prediction: The proposed model demonstrated significant superiority in predicting the arrival time of fire events. Assessed using MAE and RMSE, the model consistently achieved lower error values compared to most baselines. For instance, compared to HA, which simply used the historical average and often failed to capture the dynamic nature of fire events, the proposed model reduced the MAE by approximately 69.5% on average. This was because the model not only incorporated historical data but also factored in environmental variables and complex spatial–temporal relationships. Even when compared to more advanced baselines such as VEPP, which utilized variational auto-encoders for distribution modeling, the proposed model maintained a competitive edge, achieving a 10.1% reduction in RMSE.
Region Prediction: The proposed model also outperformed the baselines in predicting the occurrence region of fire events, evaluated using the top-k hit rate (HR@k) metric for k = 1, 5, and 10. For HR@1, the model surpassed IRNN, which performed relatively well among the baselines in region prediction due to its use of LSTM models for information embedding. The model’s HR@1 was, on average, 3.3% higher. This improvement can be attributed to the region-varying historical information retrieval mechanism employed by the model, which more precisely tailored the influence of past events on different regions.
Among the deep learning-based baselines (excluding HA, which was a simplistic method), each had its own strengths. IRNN performed well in region prediction as it captured long-term dependencies using LSTM, while VEPP excelled in time prediction by leveraging VAE-based distribution generation. However, by integrating effective region-based historical information handling with accurate time prediction capabilities, the proposed model delivered a more balanced and higher-performing outcome in predicting urban fire events. In contrast, the traditional HA method lagged behind in overall performance due to its oversimplification of the complex nature of fire events, neglecting the underlying temporal and spatial variabilities. HP, on the other hand, faced challenges in accurately predicting both time and region, primarily due to difficulties in handling high-dimensional spatial data and complex self-exciting relationships across regions.
5.5. Ablation Studies
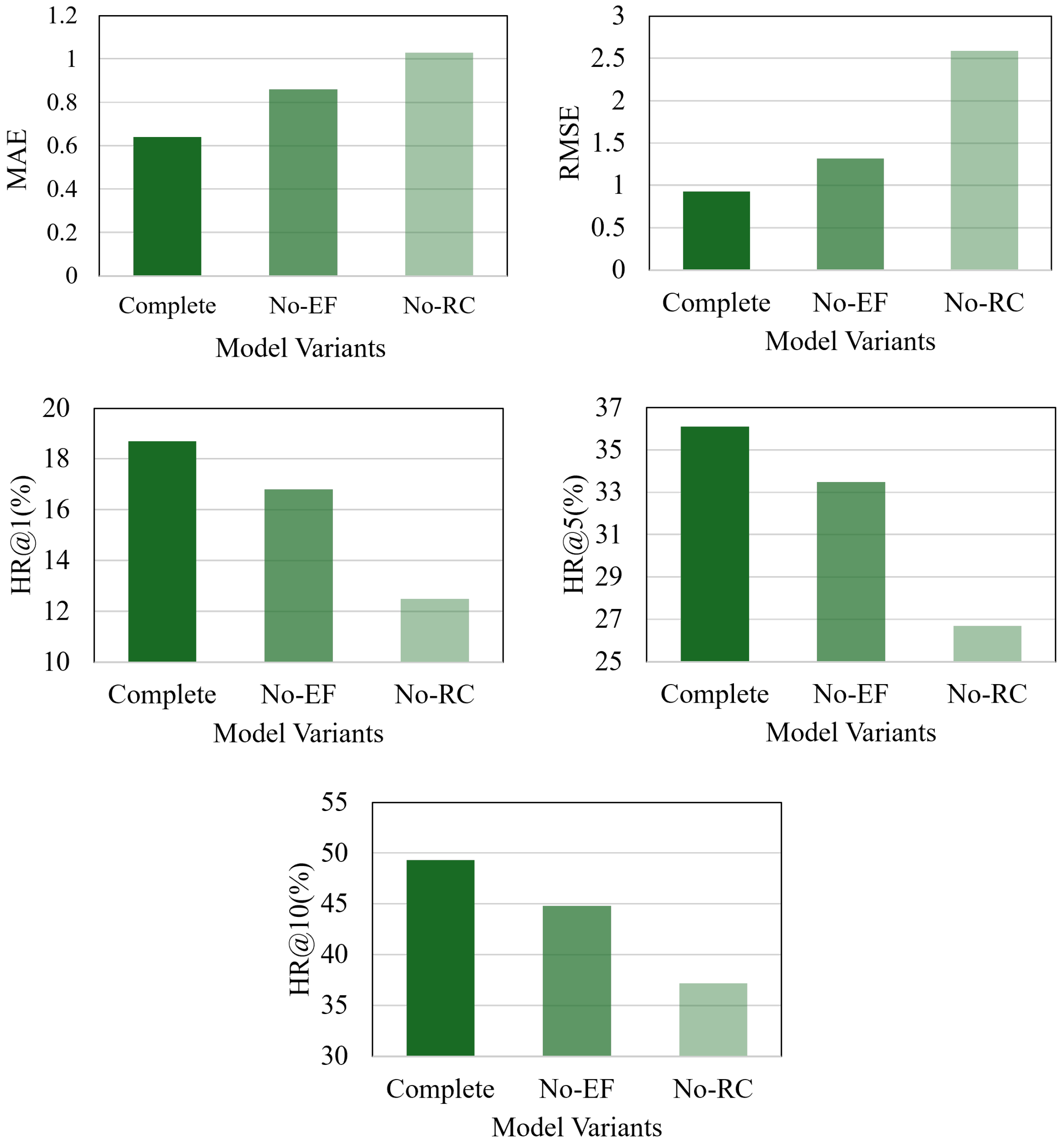
An ablation study was conducted to better understand the contribution of each key component in the proposed fire event prediction model. The results, based on the Anci fire dataset, are presented in
Figure 7. This study systematically removed specific components from the complete model, observing the subsequent effects on performance. The results illustrate the individual functions and relative importance of each component.
- -
Removing Environmental Features (No-EF):
- -
Model Adjustment: In this variant, all environmental features related to fire events, such as weather conditions and population density, were excluded. Without these factors, the model relied solely on historical fire event sequences for prediction. The encoding of regions and time intervals became more basic, losing the rich context provided by environmental data.
- -
Performance Impact: Evaluations of the test set revealed a significant increase in both time prediction metrics (MAE and RMSE). The absence of environmental data hindered the model’s ability to account for external factors influencing the arrival time of fire events. Additionally, region prediction performance, as measured by the top-k hit rates (HR@k for k = 1, 5, 10), declined, indicating that environmental features were essential for narrowing down potential regions of fire occurrence.
- -
Disabling Region Connections (No-RC):
- -
Model Adjustment: In this variant, the mechanism enabling information exchange across regions was disabled. Specifically, the global update process, as described in earlier sections, was removed. Consequently, each region’s state was updated solely based on local events, cutting off the spatial propagation of historical fire event impacts. This modification simplified the model’s architecture and information flow.
- -
Performance Impact: For time prediction, both MAE and RMSE values increased compared to the full model. The inability to share information between regions meant that the model could not leverage correlated events in other regions, which could provide crucial insights into the timing of future fires. In terms of region prediction, the HR@k values decreased significantly as the model was unable to account for spatial relationships between regions, leading to less accurate forecasts of fire occurrence locations.
The results of this ablation study underscore the indispensability of both environmental features and region connections within the model. Incorporating these elements allowed the model to more effectively capture the complex nature of urban fire events, utilizing both spatial and environmental contexts to enhance prediction accuracy.
5.6. Region State Analysis
Region states functioned as memory units within the fire event prediction model, storing historical information in a region-specific manner. An in-depth analysis was conducted for Anci District to obtain deeper insights into how these region states operated and captured the propagation of fire event impacts. The analysis began by collecting the region states corresponding to a series of fire events over a specific time period. These states, which were continuously updated as new fire events occurred, encapsulated the cumulative influence of past incidents on each region. K-means clustering was employed to facilitate visualization of the similarities and differences among the region states. Regions with similar states were grouped into the same cluster, with coordinate icons and numbers representing the locations of fire events and their respective sequences. The results are presented in
Figure 8.
Clustering Examples and Interpretation
- -
Case 1: One example focused on a cluster of fire events that occurred within a relatively small geographical area, as shown in
Figure 8a. After applying k-means clustering to the region states of these events (with k set to 4), distinct groupings emerged. Regions that experienced closely spaced and potentially related fire events tended to fall into the same cluster. These regions exhibited similar values in their region states, suggesting that they were similarly affected by the historical fires. This clustering demonstrated how the region state mechanism could detect and group regions with shared fire event histories, a crucial feature for predicting future occurrences in similar areas.
- -
Case 2: An additional example, shown in
Figure 8b, illustrated that the initial two events occurred within the same region. As a result, the region consolidated information from both events, leading to its classification into a unique group. Meanwhile, the region where the third event took place merged with two neighboring regions, reflecting the spread of impact from the event.
In summary, these cases demonstrate that the regional hidden state mechanism could effectively disseminate event-related information, provide exclusive historical memories for each region, and enhance the model’s ability to handle complex spatial information.
5.7. Robustness Evaluation of Performance
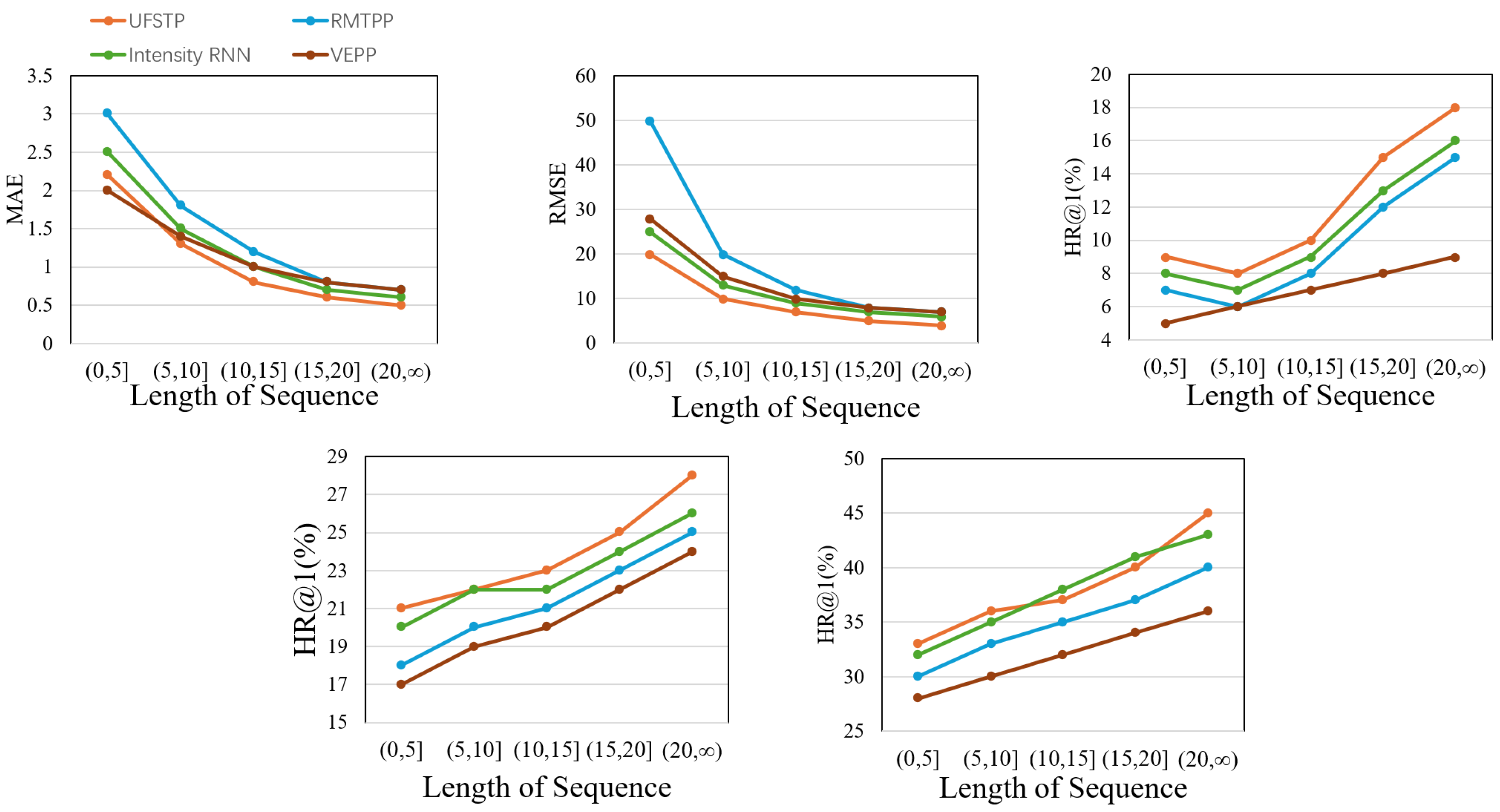
5.7.1. Impact of the Length of Sequences
The length of fire event sequences was a crucial factor in assessing the robustness of the prediction model. Fire events in urban areas were not distributed uniformly over time; periods of high frequency alternated with those of relative scarcity. Consequently, the number of historical fire events available as input to the model could vary significantly, directly influencing the sequence length.
The fire event sequences in the test set were categorized based on their lengths. Specifically, sequences were grouped into several bins: those with lengths of less than 5, between 5 and 10, between 10 and 15, between 15 and 20, and greater than 20. This categorization allowed for an examination of the model’s performance under varying amounts of historical data. The results are presented in
Figure 9.
Upon analyzing the time prediction performance, all models generally demonstrated improved accuracy with longer sequences. This was expected, as more historical events provided additional patterns and correlations for the model to learn from. However, the proposed model consistently outperformed the baseline models across all sequence length categories. Notably, when dealing with short sequences (lengths of less than 5), the difference in prediction errors—measured by MAE and RMSE—between our model and the baselines was substantial. The proposed model maintained a relatively low error rate, even when historical data were limited.
For predicting regions, we primarily focused on the top-1 region prediction accuracy (HR@1). When the sequence length was reduced from 20 to under 5, the HR@1 of the baseline models decreased to varying extents. In contrast, our model’s HR@1 remained largely unaffected. This robustness can be attributed to two fundamental factors. First, the model did not solely depend on historical fire events but also integrated environmental data such as local weather conditions, POIs, and population features. When historical data were limited, these additional factors became even more crucial for guiding region predictions. Second, the region-varying historical information retrieval mechanism in our model enabled the extraction of valuable insights from shorter sequences, leading to more accurate location forecasts.
In summary, the model’s ability to perform effectively with both short and long fire event sequences underscores its robustness, offering a significant advantage over existing methods in addressing the uneven temporal distribution of urban fire events.
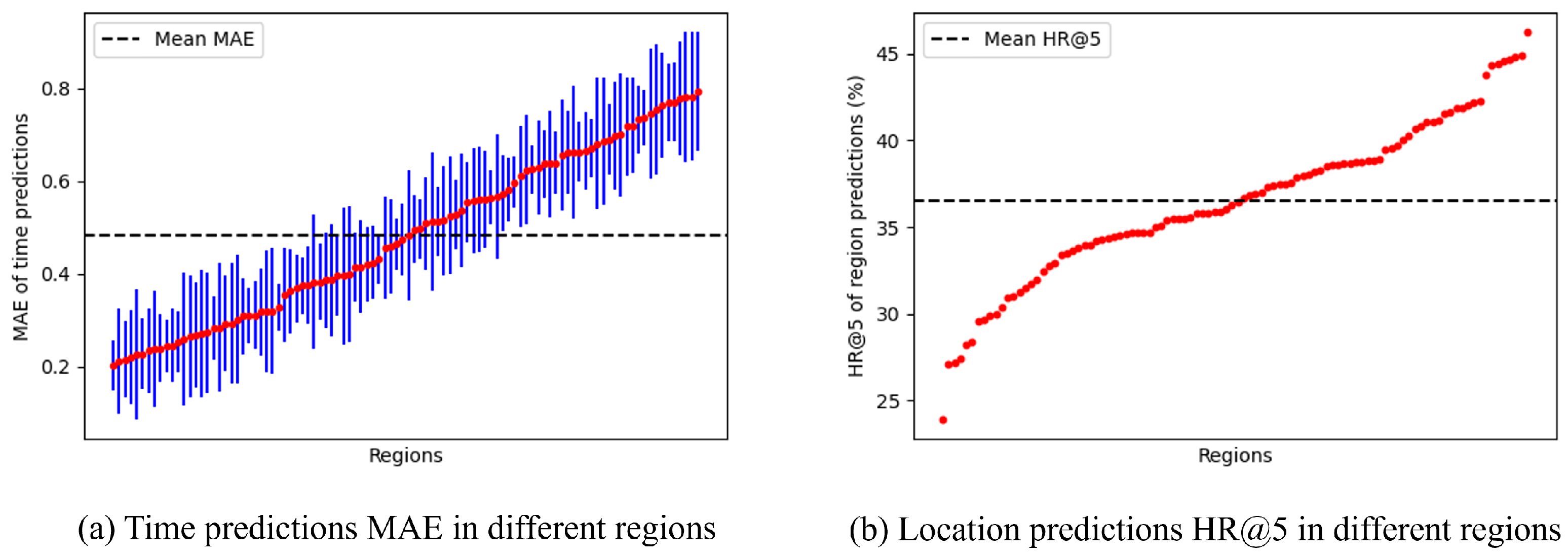
5.7.2. Impact of Locations
The geographical location of a fire event could significantly influence the performance of the prediction model. Different regions within a city exhibited variations in urban layout, population density, and potential fire hazards. The prediction results from the fire event datasets were grouped according to the last observed regions to assess how location factors affected prediction outcomes.
For time prediction, the mean and standard deviation of the MAE were calculated for each region.
As illustrated in
Figure 10a, the MAE values exhibited fluctuations around the overall mean across all regions. Even in the regions with the poorest performance, the average MAE remained only marginally above the global mean. This indicated that despite variations in local conditions, the model maintained a relatively consistent level of accuracy in predicting the arrival time of fire events across different locations. The model appeared to adapt to the unique temporal patterns of each region, whether in densely populated commercial centers or sparsely populated suburban areas.
For region prediction, the focus was on the top-5 hit rates (HR@5). As illustrated in
Figure 10b, after excluding outliers caused by extremely small sample sizes (where the HR@5 was either 0% or 100%), the HR@5 values for different regions clustered closely around the mean HR@5. This finding suggests that the model’s ability to predict the region of fire events was not overly sensitive to geographical location. Whether in areas susceptible to industrial fires or those dominated by residential buildings, the model generated reliable region predictions with comparable accuracy.
Overall, the minimal performance variation across different locations highlights the robustness of the model. It effectively accommodates the diverse characteristics of various urban regions, delivering stable and reliable predictions for fire events regardless of location.
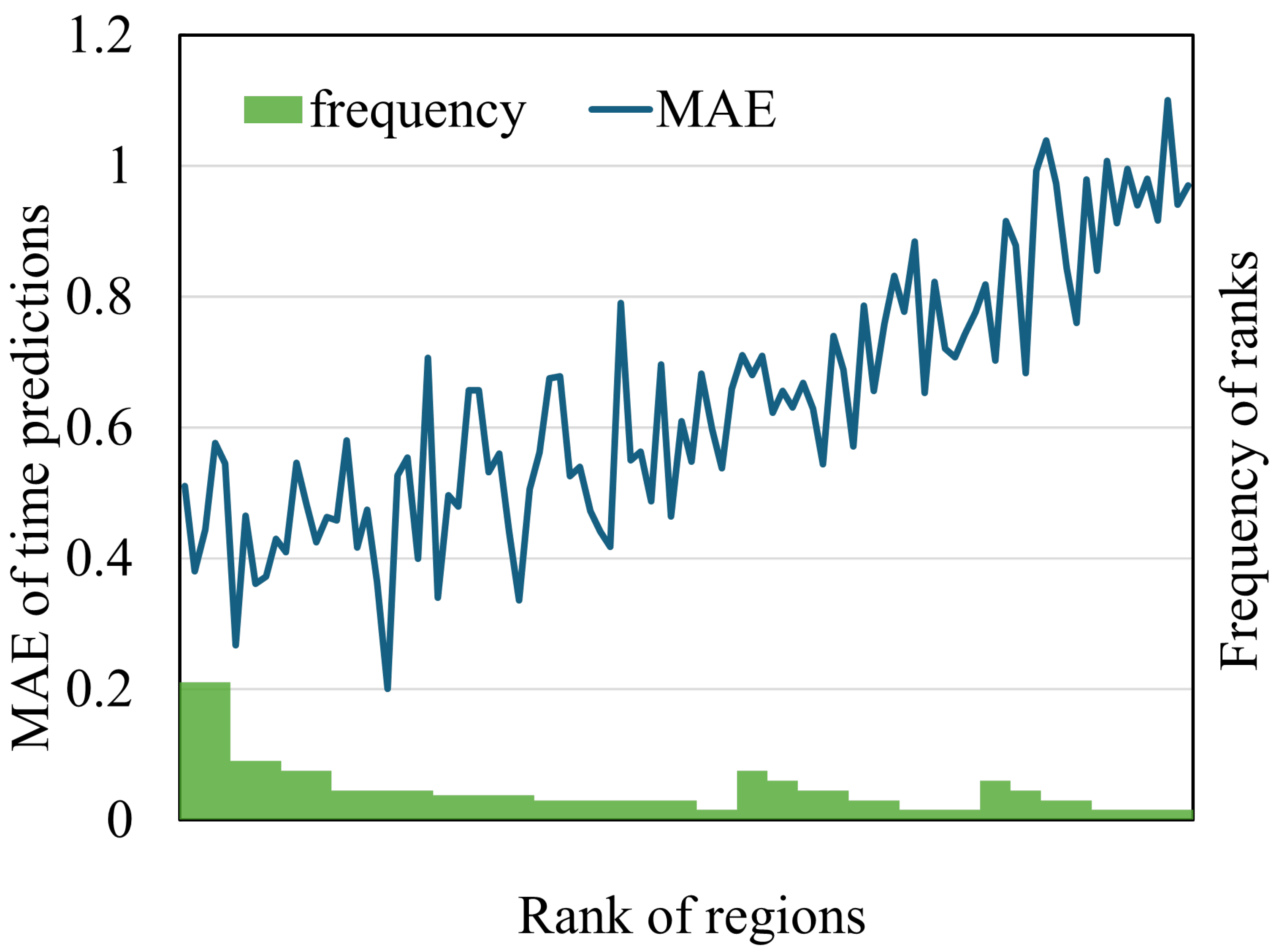
5.7.3. Impact of Location Prediction Accuracy
In the fire event prediction model, location predictions served not only as an end goal but also as a factor that influenced the overall performance in time prediction.
Data from the Anci District fire dataset were used to assess the impact of location predictions on time prediction accuracy. The performance of location prediction was evaluated by ranking the actual fire-affected regions among the predicted regions, where a lower rank indicated a more accurate prediction.
Subsequently, the MAEs of time predictions were calculated for regions grouped by their rank. As shown in
Figure 11, a clear trend emerged: the MAE of time prediction increased as the performance of location prediction worsened. This suggests that the accurate location predictions of fire events improved time prediction accuracy, while inaccurate predictions hindered performance.
Additionally, the frequencies of the ranks for actual fire-affected regions are presented at the bottom of
Figure 11. The results indicated that most location predictions assigned a relatively low rank to the actual fire-affected regions. Overall, the findings suggest that the location predictions of fire events were generally advantageous for time prediction accuracy.
5.8. Computational Efficiency and Scalability
To evaluate the computational feasibility of UFSTP, we conducted training and inference on a workstation equipped with an NVIDIA RTX 3090 GPU (24 GB memory) and an Intel Core i9-10,900K CPU. For the Guangyang District dataset, the model converged in approximately 2.1 h over 100 training epochs, while, for the Anci District dataset, convergence took around 2.9 h due to its slightly larger spatial coverage and higher fire incident density. These durations were acceptable for offline model training and periodic updates. In the inference phase, the model processed each fire event by updating the relevant region’s state and generating its spatiotemporal prediction. The average inference time per event was less than 0.3 s, enabling near-real-time forecasting. This efficiency supports integration into early warning systems or emergency dispatch platforms, where timely predictions are critical.
In addition, UFSTP adopts a modular and adaptable design, in which key components—such as the spatial region resolution, model depth, and message-passing iterations—can be flexibly tuned to accommodate different data densities, urban layouts, and hardware configurations. This structural flexibility ensures that the framework is scalable across cities of varying sizes and complexity. Furthermore, the core modeling principles—region-specific memory, inter-region propagation, and variational time modeling—are not tied to any geographic or administrative boundary. As demonstrated by our experiments on two distinct urban districts (Guangyang and Anci), the model maintains strong predictive performance across different spatial distributions and fire occurrence patterns. These results support the robustness and generalizability of UFSTP when applied to diverse urban environments or data scenarios.
6. Discussion
6.1. Model Insights and Limitations
The proposed UFSTP framework exhibits substantial potential for urban fire risk prediction. It effectively captures the complex spatiotemporal dynamics of fire events by integrating multi-source data and advanced neural network architectures. The inclusion of environmental features and regional connections is particularly crucial, as demonstrated in the ablation study, enhancing the model’s ability to predict both the occurrence time and location of fires.
However, the model does have certain limitations. For instance, the accuracy of predictions can be influenced by the quality and availability of data. In some cases, incomplete or inaccurate data related to POIs, climate, or population density could lead to suboptimal results. Moreover, although the model accounts for historical and environmental factors, it may not fully address rare or extreme events that deviate significantly from established patterns. Future research should explore methods to better handle such outliers.
6.2. Implications for Urban Fire Prevention
The UFSTP framework provides valuable insights for urban fire prevention strategies. The precise prediction of fire risk at specific locations and times enables fire departments to allocate resources more effectively. This facilitates targeted inspections in high-risk areas and during vulnerable periods, potentially reducing response times and minimizing fire damage. For example, areas with a high concentration of industrial POIs and a history of fire incidents could be prioritized for safety audits and preventive measures.
Furthermore, the model’s ability to assess the impact of environmental factors offers a foundation for developing proactive prevention strategies. Understanding the relationship between temperature, humidity, and fire occurrence enables the implementation of appropriate measures during high-risk seasons or weather conditions, such as raising public awareness of fire safety or enhancing fire surveillance in areas with heightened susceptibility.
6.3. Generalizability and Adaptability
While UFSTP was trained and evaluated here on two districts of Langfang City, its core framework is inherently modular and can be transferred to other urban settings. To deploy UFSTP in a different city, one needs to collect analogous local datasets—historical fire events, contextual features (e.g., points of interest, population distribution), and meteorological measurements—and process them into spatial and temporal units that suit the new environment. The model is then trained or fine-tuned on these local inputs, enabling its region-specific hidden states, inter-region propagation, and variational time-prediction modules to learn the city’s unique fire dynamics and predict fire risk. Depending on differences in land use, climate, and fire-behavior patterns, additional feature engineering and hyperparameter adjustments may be required. Moreover, incorporating transfer-learning or domain-adaptation strategies can further facilitate application in data-scarce cities by leveraging models pre-trained on data-rich regions.
6.4. Future Research Directions
Future research could focus on several key areas to further enhance the proposed model. In particular, the incorporation of a broader range of fire-related data sources is essential for improving prediction accuracy, robustness, and real-world applicability. Building upon the current dataset—which included POI, meteorological, population, and fire incident data—future efforts may consider integrating additional factors such as fuel type and distribution, urban infrastructure features (e.g., building materials, road networks, hydrant locations), emergency response records, and socio-economic indicators. These data could be acquired through collaborations with local authorities, open-access platforms, or customized data collection methods.
Second, enhancing the interpretability of the model is critical. While the current model demonstrates strong performance, a deeper understanding of its internal mechanisms and feature contributions would increase its transparency and foster greater trust among practitioners. Techniques such as attention mechanisms or explainable AI could be employed to elucidate how the model generates its predictions.
Third, future work will explore 3D spatial modeling through the integration of building information modeling (BIM) to characterize vertical fire propagation patterns, particularly for high-rise structures.
Finally, the continuous optimization of the model’s architecture and training algorithms is necessary. Exploring advanced neural network architectures or hybrid models that integrate multiple machine learning techniques may further improve accuracy and efficiency, enabling the model to effectively handle the growing complexity of urban environments and the factors contributing to fire risk.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}