
RT-DETR-Smoke: A Real-Time Transformer for Forest Smoke Detection

Abstract
1. Introduction
- (1)
- Proposal of RT-DETR-Smoke: We extended RT-DETR to create a dedicated smoke-detection framework by introducing a hybrid encoder and integrating a coordinate attention mechanism specifically tailored for smoke-edge recognition.
- (2)
- Introduction of WShapeIoU Loss Function: We designed a specialized bounding-box regression loss function to expedite model convergence and improve detection stability in dynamic fire scenes.
- (3)
- Creation of a Custom Smoke-Detection Dataset: To comprehensively evaluate our method, we constructed a challenging smoke dataset containing diverse scene variations drawn from real-world surveillance videos and meticulously annotated.
2. Related Works
2.1. One-Stage Algorithms
2.2. Two-Stage Algorithms
2.3. DETR
2.4. Task-Specific Method
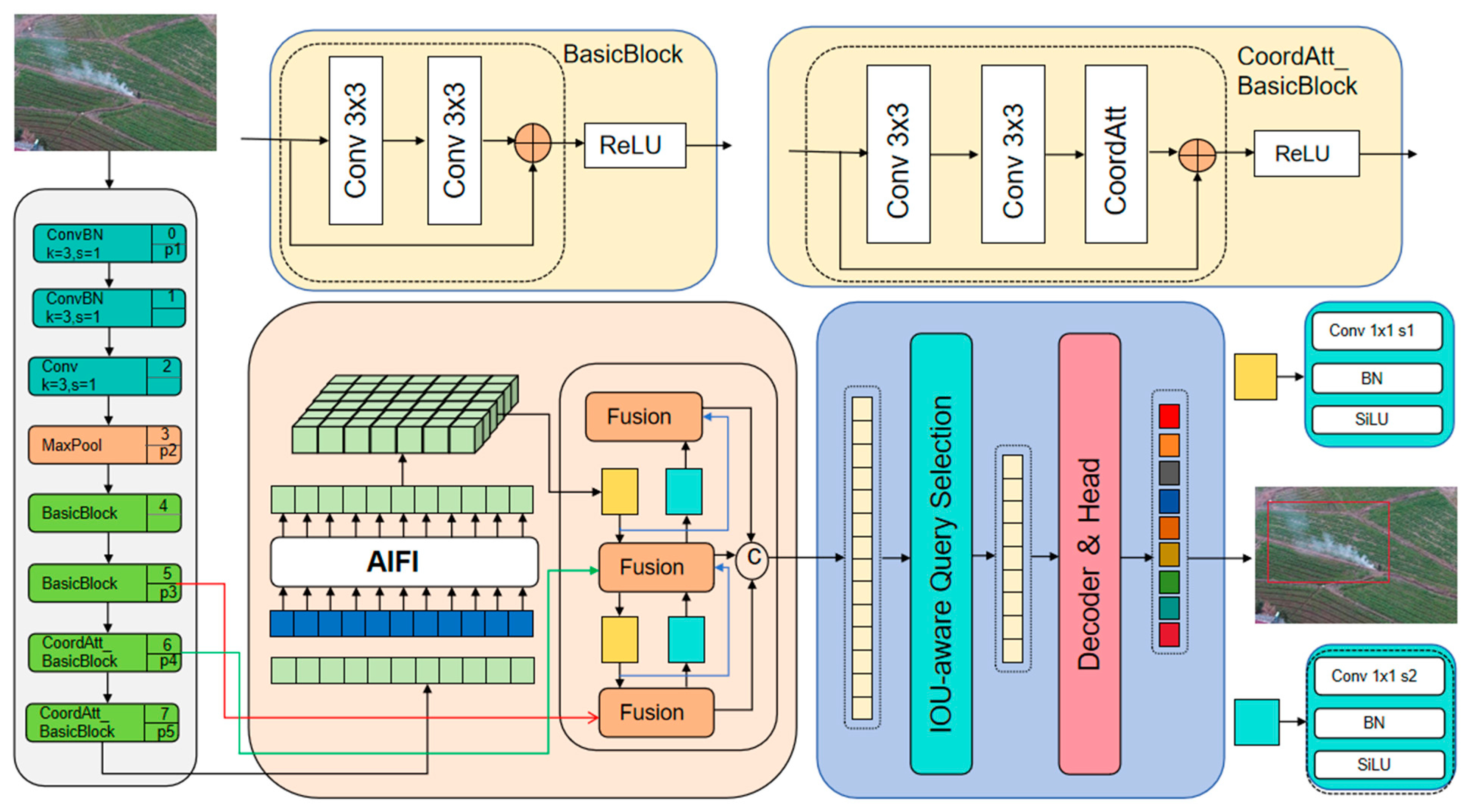
3. Research Method
- A backbone network integrated with Coordinate Attention (CoordAtt) for precise spatial-feature encoding.
- A hybrid encoder that fuses multiscale features via an Attention-based Intra-Feature Interaction (AIFI) and a CNN-based Cross-Scale Feature Fusion (CCFF) module.
- A Transformer decoder leveraging an uncertainty-minimization strategy for query selection and iterative auxiliary heads for bounding-box refinement.
- A novel WShapeIoU loss function that enhances bounding-box regression performance by adapting to smoke’s fluid morphology.
3.1. Overall Architecture
- (1)
- Coordinate Attention in the Backbone
- Long-range correlations along horizontal and vertical dimensions; these are crucial for capturing the elongated or diffuse shapes of smoke.
- Relevant local patterns; these are highlighted by suppressing background noise and reinforcing smoke-boundary details.
- (2)
- Hybrid Encoder with Multi-Scale Feature Fusion
- Attention-based Intra-Feature Interaction (AIFI) refines features within each scale, allowing the network to better capture the subtle variations in texture or transparency that characterize smoke.
- CNN-based Cross-Scale Feature Fusion (CCFF) merges the refined features from multiple scales, enabling robust detection of small, medium, and large smoke plumes in various environments.
- (3)
- Uncertainty Minimization in Query Selection
- (4)
- Auxiliary Prediction Heads
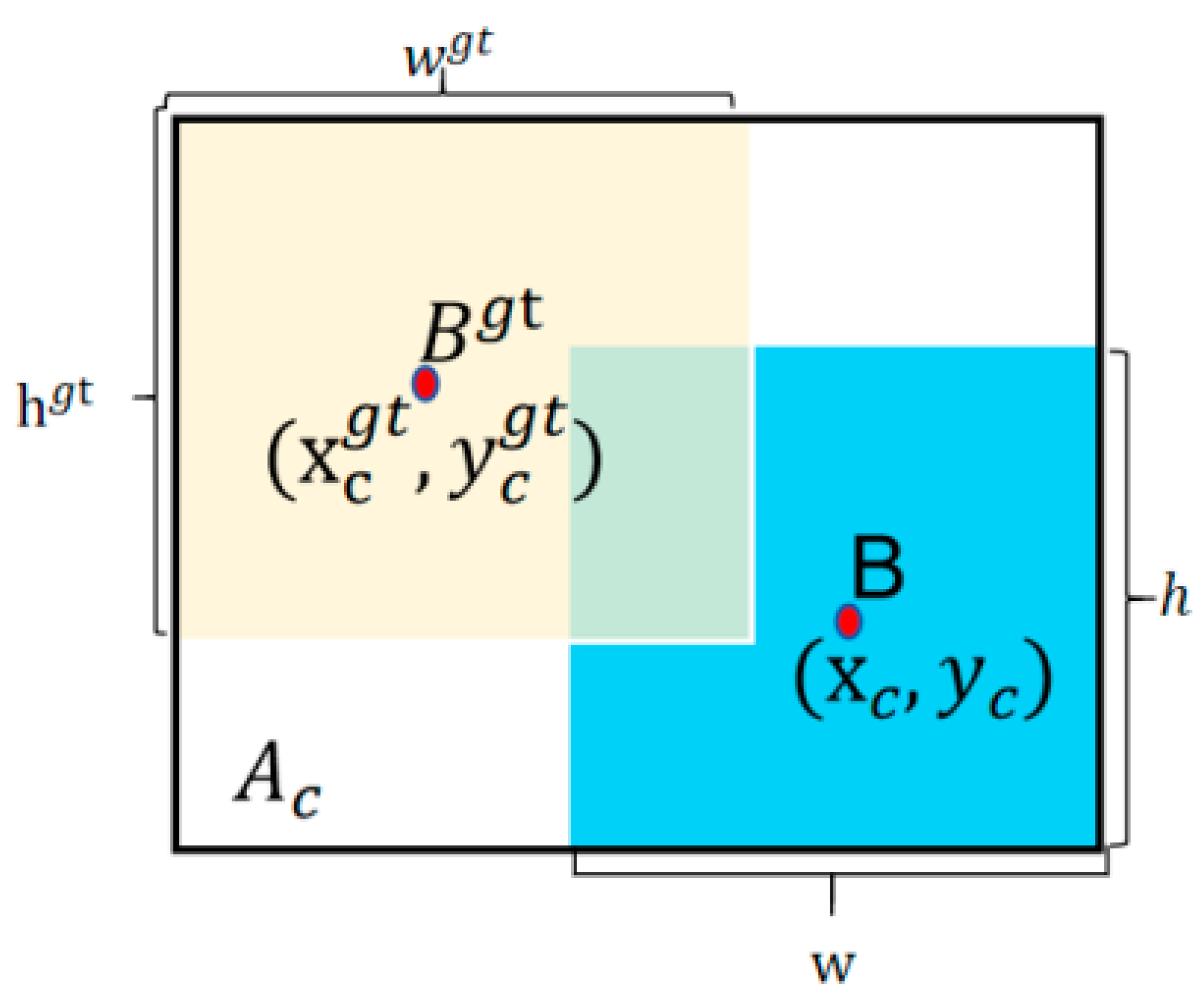
3.2. WShapeIoU Loss Function
3.2.1. Limitations of Existing IoU-Based Losses
- (1)
- Aspect Ratio Mismatch: Smoke can exhibit extremely elongated or irregular forms, making bounding-box regression sensitive to slight inaccuracies. Traditional IoU measures may fail to guide the model effectively when aspect ratios diverge significantly from those of typical rectangular objects.
- (2)
- Displacement Sensitivity: Generalized IoU partially addresses edge cases by introducing the concept of the convex hull but can still yield high similarity scores for boxes that share comparable areas yet are spatially displaced.
- (3)
- Slow Convergence on Hard Examples: Focal mechanisms have been shown to improve classification by prioritizing difficult samples. However, existing IoU-based regression losses seldom incorporate similar strategies to address poorly localized bounding boxes.
3.2.2. ShapeIoU as a Baseline
3.2.3. Proposed WShapeIoU
- (1)
- Prioritization of Difficult Bounding Boxes: The focal factor compels the model to learn from ambiguous smoke regions where bounding-box overlap remains low or uncertain.
- (2)
- Adaptation to Fluid Shapes: The distance and shape terms ensure that bounding boxes can adjust to irregular boundaries and aspect ratios.
- (3)
- Stable Convergence: dynamically scales the loss, accelerating optimization on harder boxes while maintaining robust updates on easier ones.
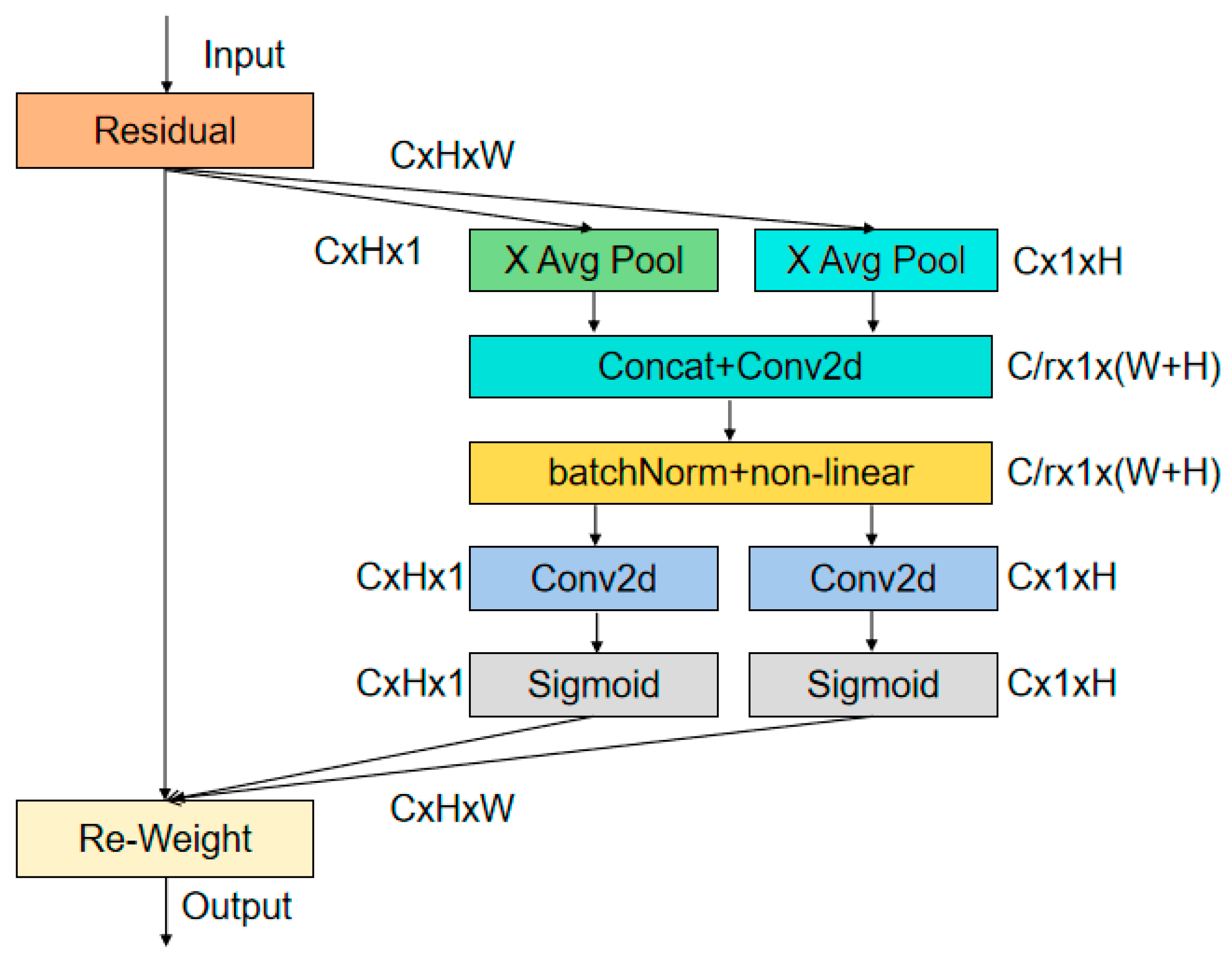
3.3. CoordAtt Attention Mechanism
- (1)
- Preserve finer-scale details from earlier layers, ensuring smaller or thinner smoke structures are not lost during downsampling;
- (2)
- Aggregate more global context from deeper layers, a step beneficial for large smoke clusters or multidirectional drifting of smoke plumes.
- (1)
- Enhanced Spatial Encoding: By splitting pooling into vertical and horizontal directions, CoordAtt better captures elongated or curved smoke shapes than conventional 2D pooling mechanisms do.
- (2)
- Low Overhead: The additional computational cost remains modest compared to the performance gains, preserving the real-time capacity of RT-DETR-Smoke.
- (3)
- Robust to Background Noise: CoordAtt’s selective emphasis on crucial spatial regions aids in suppressing unrelated textures (e.g., foliage, clouds, or urban structures) that can confound detection.
4. Experiments
4.1. Dataset and Experimental Setup
4.2. Dataset Description
- (1)
- Scene Distribution
- (2)
- Smoke Size and Shape Distribution
4.3. Experimental Results
4.3.1. Comparison of Loss Functions
4.3.2. Comparison of Attention Mechanisms
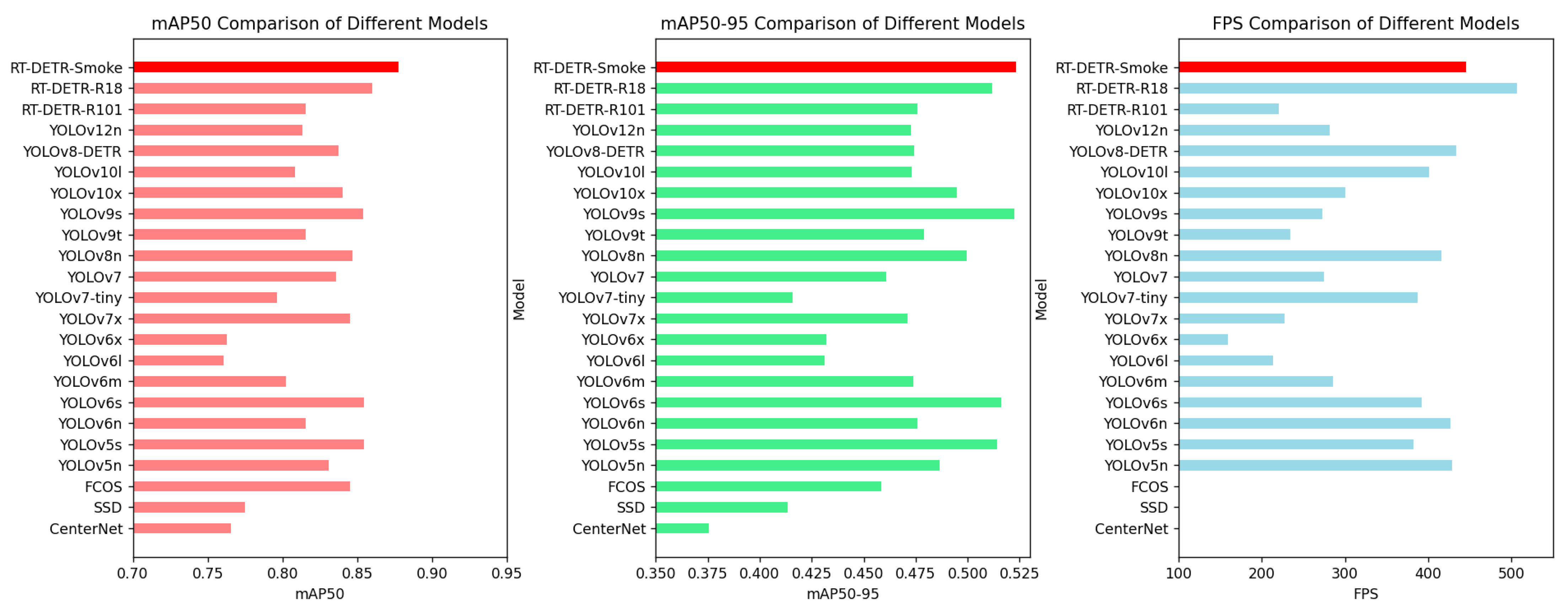
4.3.3. Model-Comparison Experiments
4.3.4. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
| Algorithm A1: The pseudocode of the WShapeIoU loss calculation |
| Algorithm Wise-ShapeIoU_Loss(pred, target, scale, L_IoU): Convert pred and target from (x, y, w, h) to (x1, y1, x2, y2) Compute w1, h1 from predicted box; w2, h2 from ground truth box Compute: ww = 2 * (w2^scale)/((w2^scale) + (h2^scale)) hh = 2 * (h2^scale)/((w2^scale) + (h2^scale)) Calculate convex box dimensions: cw = max(b1_x2, b2_x2) − min(b1_x1, b2_x1) ch = max(b1_y2, b2_y2) − min(b1_y1, b2_y1) c2 = cw^2 + ch^2 + epsilon Compute center distances: Δx2 = ((b2_x1 + b2_x2 − b1_x1 − b1_x2)^2)/4 Δy2 = ((b2_y1 + b2_y2 − b1_y1 − b1_y2)^2)/4 D = (hh * Δx2 + ww * Δy2)/c2 Compute shape differences: ω_w = hh * |w1 − w2|/max(w1, w2) ω_h = ww * |h1 − h2|/max(h1, h2) C_shape = (1 − exp(-ω_w))^4 + (1 − exp(-ω_h))^4 Final Loss: L_WShapeIoU = L_IoU + D + 0.5 * C_shape Return L_WShapeIoU |
| Algorithm A2: The pseudocode of Coordinate Attention |
| Algorithm CoordAtt(x, reduction): Input: x with dimensions (N, C, H, W) Compute x_h = AdaptiveAvgPool(x) along width -> shape: (N, C, H, 1) Compute x_w = AdaptiveAvgPool(x) along height -> shape: (N, C, 1, W) Transpose x_w to shape (N, C, W, 1) Concatenate x_h and x_w along spatial dimension -> y with shape (N, C, (H + W), 1) Apply conv1: y′ = h_swish(BN(Conv1(y))) Split y′ into y′_h (first H rows) and y′_w (remaining W rows) Transpose y′_w back to shape (N, C, 1, W) Compute attention maps: a_h = sigmoid(Conv_h(y′_h)) --> shape: (N, C, H, 1) a_w = sigmoid(Conv_w(y′_w)) --> shape: (N, C, 1, W) Element-wise: out = x * a_h * a_w Return out |
References
- Hirsch, E.; Koren, I. Record-breaking aerosol levels explained by smoke injection into the stratosphere. Science 2021, 371, 1269–1274. [Google Scholar] [CrossRef] [PubMed]
- Song, H.; Chen, Y. Video smoke detection method based on cell root–branch structure. Signal Image Video Process. 2024, 18, 4851–4859. [Google Scholar] [CrossRef]
- Chen, S.; Cao, Y.; Feng, X.; Lu, X. Global2Salient: Self-adaptive feature aggregation for remote sensing smoke detection. Neurocomputing 2021, 466, 202–220. [Google Scholar] [CrossRef]
- Jang, H.-Y.; Hwang, C.-H. Revision of the input parameters for the prediction models of smoke detectors based on the FDS. Fire Sci. Eng. 2017, 31, 44–51. [Google Scholar] [CrossRef]
- Jang, H.-Y.; Hwang, C.-H. Obscuration threshold database construction of smoke detectors for various combustibles. Sensors 2020, 20, 6272. [Google Scholar] [CrossRef]
- Wang, Y.; Piao, Y.; Wang, H.; Zhang, H.; Li, B. An Improved Forest Smoke Detection Model Based on YOLOv8. Forests 2024, 15, 409. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, X.; Zhang, C. A lightweight smoke detection network incorporated with the edge cue. Expert Syst. Appl. 2024, 241, 122583. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1483–1498. [Google Scholar] [CrossRef]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C. Sparse r-cnn: End-to-end object detection with learnable proposals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14454–14463. [Google Scholar]
- Zhao, L.; Zhi, L.; Zhao, C.; Zheng, W. Fire-YOLO: A small target object detection method for fire inspection. Sustainability 2022, 14, 4930. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Computer Vision—ECCV 2016, Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14, 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Cheng, G.; Chen, X.; Wang, C.; Li, X.; Xian, B.; Yu, H. Visual fire detection using deep learning: A survey. Neurocomputing 2024, 596, 127975. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Computer Vision—ECCV 2020, Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Roh, B.; Shin, J.; Shin, W.; Kim, S. Sparse detr: Efficient end-to-end object detection with learnable sparsity. arXiv 2021, arXiv:2111.14330. [Google Scholar]
- Li, F.; Zeng, A.; Liu, S.; Zhang, H.; Li, H.; Zhang, L.; Ni, L.M. Lite detr: An interleaved multi-scale encoder for efficient detr. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 18558–18567. [Google Scholar]
- Zheng, D.; Dong, W.; Hu, H.; Chen, X.; Wang, Y. Less is more: Focus attention for efficient detr. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 6674–6683. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Wu, S.; Zhang, L. Using popular object detection methods for real time forest fire detection. In Proceedings of the 2018 11th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 8–9 December 2018; pp. 280–284. [Google Scholar]
- Guo, H.; Bai, H.; Zhou, Y.; Li, W. DF-SSD: A deep convolutional neural network-based embedded lightweight object detection framework for remote sensing imagery. J. Appl. Remote Sens. 2020, 14, 014521. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. Yolov9: Learning what you want to learn using programmable gradient information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Abdusalomov, A.; Baratov, N.; Kutlimuratov, A.; Whangbo, T.K. An improvement of the fire detection and classification method using YOLOv3 for surveillance systems. Sensors 2021, 21, 6519. [Google Scholar] [CrossRef]
- Zheng, X.; Chen, F.; Lou, L.; Cheng, P.; Huang, Y. Real-time detection of full-scale forest fire smoke based on deep convolution neural network. Remote Sens. 2022, 14, 536. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, X.; Jing, K.; Zhang, C. Learning precise feature via self-attention and self-cooperation YOLOX for smoke detection. Expert Syst. Appl. 2023, 228, 120330. [Google Scholar] [CrossRef]
- Al-Smadi, Y.; Alauthman, M.; Al-Qerem, A.; Aldweesh, A.; Quaddoura, R.; Aburub, F.; Mansour, K.; Alhmiedat, T. Early wildfire smoke detection using different yolo models. Machines 2023, 11, 246. [Google Scholar] [CrossRef]
- Yang, Z.; Shao, Y.; Wei, Y.; Li, J. Precision-Boosted Forest Fire Target Detection via Enhanced YOLOv8 Model. Appl. Sci. 2024, 14, 2413. [Google Scholar] [CrossRef]
- Barmpoutis, P.; Dimitropoulos, K.; Kaza, K.; Grammalidis, N. Fire detection from images using faster R-CNN and multidimensional texture analysis. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8301–8305. [Google Scholar]
- Chaoxia, C.; Shang, W.; Zhang, F. Information-guided flame detection based on faster R-CNN. IEEE Access 2020, 8, 58923–58932. [Google Scholar] [CrossRef]
- Duan, K.; Xie, L.; Qi, H.; Bai, S.; Huang, Q.; Tian, Q. Corner proposal network for anchor-free, two-stage object detection. In Computer Vision—ECCV 2020, Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 399–416. [Google Scholar]
- Huang, J.; Zhou, J.; Yang, H.; Liu, Y.; Liu, H. A small-target forest fire smoke detection model based on deformable transformer for end-to-end object detection. Forests 2023, 14, 162. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, W.; Liu, Y.; Jing, R.; Liu, C. An efficient fire and smoke detection algorithm based on an end-to-end structured network. Eng. Appl. Artif. Intell. 2022, 116, 105492. [Google Scholar] [CrossRef]
- Liang, T.; Zeng, G. Fsh-detr: An efficient end-to-end fire smoke and human detection based on a deformable detection transformer (detr). Sensors 2024, 24, 4077. [Google Scholar] [CrossRef]
- Sun, B.; Cheng, X. Smoke Detection Transformer: An Improved Real-Time Detection Transformer Smoke Detection Model for Early Fire Warning. Fire 2024, 7, 488. [Google Scholar] [CrossRef]
- Ren, D.; Wang, Z.; Sun, H.; Liu, L.; Wang, W.; Zhang, J. Salience Feature Guided Decoupling Network for UAV Forests Flame Detection. Expert Syst. Appl. 2025, 270, 126414. [Google Scholar] [CrossRef]
- Zhao, H.; Jin, J.; Liu, Y.; Guo, Y.; Shen, Y. FSDF: A high-performance fire detection framework. Expert Syst. Appl. 2024, 238, 121665. [Google Scholar] [CrossRef]
- Ding, S.; Zhang, H.; Zhang, Y.; Huang, X.; Song, W. Hyper real-time flame detection: Dynamic insights from event cameras and FlaDE dataset. Expert Syst. Appl. 2025, 263, 125746. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, S. Shape-iou: More accurate metric considering bounding box shape and scale. arXiv 2023, arXiv:2312.17663. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding box regression loss with dynamic focusing mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Zhang, H.; Zhang, S. Focaler-IoU: More Focused Intersection over Union Loss. arXiv 2024, arXiv:2401.10525. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. AAAI Conf. Artif. Intell. 2020, 34, 12993–13000. [Google Scholar] [CrossRef]
- Gevorgyan, Z. SIoU loss: More powerful learning for bounding box regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Liu, C.; Wang, K.; Li, Q.; Zhao, F.; Zhao, K.; Ma, H. Powerful-IoU: More straightforward and faster bounding box regression loss with a nonmonotonic focusing mechanism. Neural Netw. 2024, 170, 276–284. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Xu, C.; Zhang, S. Inner-IoU: More effective intersection over union loss with auxiliary bounding box. arXiv 2023, arXiv:2311.02877. [Google Scholar]
- Ma, S.; Xu, Y. MPDIoU: A loss for efficient and accurate bounding box regression. arXiv 2023, arXiv:2307.07662. [Google Scholar]
- Wang, J.; Xu, C.; Yang, W.; Yu, L. A normalized Gaussian Wasserstein distance for tiny object detection. arXiv 2021, arXiv:2110.13389. [Google Scholar]
- Azad, R.; Niggemeier, L.; Hüttemann, M.; Kazerouni, A.; Aghdam, E.K.; Velichko, Y.; Bagci, U.; Merhof, D. Beyond self-attention: Deformable large kernel attention for medical image segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 1287–1297. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Wan, D.; Lu, R.; Shen, S.; Xu, T.; Lang, X.; Ren, Z. Mixed local channel attention for object detection. Eng. Appl. Artif. Intell. 2023, 123, 106442. [Google Scholar] [CrossRef]
- Goyal, A.; Bochkovskiy, A.; Deng, J.; Koltun, V. Non-deep networks. Adv. Neural Inf. Process. Syst. 2022, 35, 6789–6801. [Google Scholar]
- Zhang, Q.-L.; Yang, Y.-B. Sa-net: Shuffle attention for deep convolutional neural networks. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2235–2239. [Google Scholar]
- Liu, H.; Liu, F.; Fan, X.; Huang, D. Polarized self-attention: Towards high-quality pixel-wise regression. arXiv 2021, arXiv:2107.00782. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Huang, H.; Chen, Z.; Zou, Y.; Lu, M.; Chen, C.; Song, Y.; Zhang, H.; Yan, F. Channel prior convolutional attention for medical image segmentation. Comput. Biol. Med. 2024, 178, 108784. [Google Scholar] [CrossRef] [PubMed]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. arXiv 2019, arXiv:1904.01355. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Tian, Y.; Ye, Q.; Doermann, D. Yolov12: Attention-centric real-time object detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environmental Parameter | Value |
|---|---|
| Operating system | Ubuntu20.04 |
| Deep learning framework | Pytorch |
| Programming language | Python3.8.12 |
| CPU | AMD EPYC 7713 64-Core Processor |
| GPU | A100-SXM4-80 GB |
| RAM | 256 GB |
| Hyperparameters | Value |
|---|---|
| Learning Rate | 0.01 |
| Image Size | 640 × 640 |
| Momentum | 0.9 |
| Batch Size | 32 |
| Epoch | 250 |
| Weight Decay | 0.0005 |
| Optimizer | AdamW |
| Loss Function | mAP50 | mAP50-95 |
|---|---|---|
| GIoU [47] | 0.85982 | 0.51181 |
| CIoU [48] | 0.85954 | 0.50841 |
| SIoU [49] | 0.86316 | 0.51389 |
| WIoU [44] | 0.8646 | 0.51174 |
| PIoU2 [50] | 0.86218 | 0.51005 |
| InnerIoU [51] | 0.86691 | 0.51334 |
| ShapeIoU [43] | 0.86379 | 0.50705 |
| MPDIoU [52] | 0.86561 | 0.50603 |
| NWD [53] | 0.86377 | 0.51201 |
| PIoU [50] | 0.86002 | 0.51133 |
| WShapeIoU | 0.87224 | 0.50842 |
| Model | Parameter | GFLOPs | mAP50 | mAP50-95 |
|---|---|---|---|---|
| Deformable_LKA [54] | 30,150,052 | 74.0 | 0.86562 | 0.50457 |
| ECA [55] | 20,083,048 | 58.3 | 0.86548 | 0.50842 |
| MLCA [56] | 20,083,068 | 58.3 | 0.86785 | 0.51757 |
| ParNetAttention [57] | 27,302,740 | 66.7 | 0.86317 | 0.50699 |
| ShuffleAttention [58] | 20,083,604 | 58.3 | 0.86597 | 0.51018 |
| SequentialPolarizedAttention [59] | 21,402,200 | 59.5 | 0.87093 | 0.522 |
| SKAttention [60] | 20,739,948 | 58.3 | 0.86484 | 0.51625 |
| CPCA [61] | 21,238,484 | 61.0 | 0.8588 | 0.50086 |
| ParallelPolarizedAttention [59] | 21,402,200 | 59.5 | 0.86706 | 0.51407 |
| DualAttention [62] | 20,694,172 | 58.0 | 0.85564 | 0.49782 |
| CoordAtt [46] | 20,147,684 | 58.3 | 0.8775 | 0.5233 |
| Model | Parameters | GFLOPS | mAP50 | mAP50-95 | FPS | GPU Time |
|---|---|---|---|---|---|---|
| CenterNet [63] | 32,665,432 | 70.2 | 0.76551 | 0.37556 | ||
| SSD [14] | 26,284,974 | 62.7 | 0.77465 | 0.41334 | ||
| FCOS [64] | 32,154,969 | 161.9 | 0.84500 | 0.45854 | ||
| YOLOv5n | 2,503,139 | 7.1 | 0.83077 | 0.4867 | 428.69 | 2.3327 ms |
| YOLOv5s | 9,111,923 | 23.8 | 0.85463 | 0.51421 | 382.29 | 2.6158 ms |
| YOLOv6n [65] | 4,238,243 | 11.9 | 0.81541 | 0.47587 | 426.57 | 2.34427 ms |
| YOLOv6s [65] | 116,297,619 | 44.0 | 0.85422 | 0.51601 | 392.52 | 2.54761 ms |
| YOLOv6m [65] | 51,978,931 | 161.1 | 0.80247 | 0.47384 | 285.50 | 3.50259 ms |
| YOLOv6l [65] | 110,864,083 | 391.2 | 0.76037 | 0.43131 | 213.89 | 4.67555 ms |
| YOLOv6x [65] | 172,983,795 | 610.2 | 0.7628 | 0.43215 | 159.22 | 6.28052 ms |
| YOLOv7x [16] | 70,780,150 | 188.0 | 0.845 | 0.471 | 227.29 | 4.39959 ms |
| YOLOv7-tiny [16] | 6,007,596 | 13.0 | 0.796 | 0.416 | 386.86 | 2.58493 ms |
| YOLOv7 [16] | 36,481,772 | 103.2 | 0.836 | 0.461 | 274.48 | 3.64323 ms |
| YOLOv8n | 3,005,843 | 8.1 | 0.84668 | 0.49937 | 415.49 | 2.40637 ms |
| YOLOv9t [26] | 2,005,603 | 7.8 | 0.8155 | 0.47887 | 234.35 | 4.2671 ms |
| YOLOv9s [26] | 7,287,795 | 27.4 | 0.85396 | 0.52243 | 272.67 | 3.66743 ms |
| YOLOv10x [27] | 31,656,806 | 171.0 | 0.83989 | 0.49463 | 300.50 | 3.32788 ms |
| YOLOv10l [27] | 25,766,870 | 127.2 | 0.80827 | 0.47293 | 401.45 | 2.49099 ms |
| YOLOv8-DETR | 6,091,124 | 11.7 | 0.83722 | 0.47444 | 433.21 | 2.30832 ms |
| YOLOv12n [66] | 2,508,539 | 5.8 | 0.81327 | 0.47284 | 281.31 | 3.55475 ms |
| RT-DETR-R101 [22] | 74,657,603 | 247.1 | 0.81541 | 0.47587 | 220.51 | 4.53381 ms |
| RT-DETR-R18 [22] | 19,873,044 | 56.9 | 0.85982 | 0.51181 | 506.62 | 1.97383 ms |
| RT-DETR-Smoke | 19,937,700 | 56.9 | 0.8775 | 0.5233 | 445.50 | 2.24464 ms |
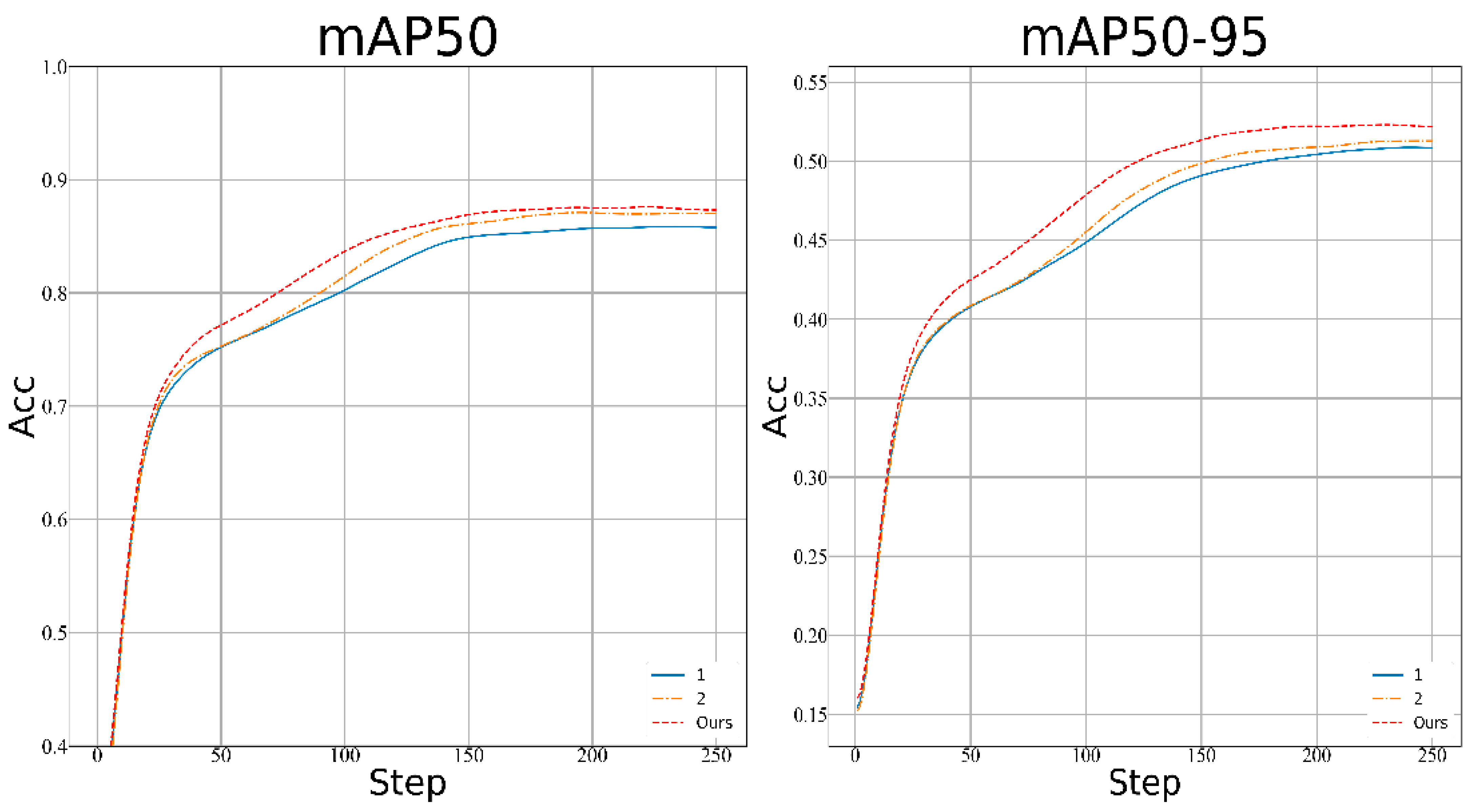
| Model | Baseline | WShapeIoU | CoordAtt | mAP50 | mAP50-95 |
|---|---|---|---|---|---|
| 1 | √ | 0.85954 | 0.50841 | ||
| 2 | √ | √ | 0.87224 | 0.50842 | |
| RT-DETR-Smoke | √ | √ | √ | 0.87750 | 0.5233 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Lei, L.; Li, T.; Zu, X.; Shi, P. RT-DETR-Smoke: A Real-Time Transformer for Forest Smoke Detection. Fire 2025, 8, 170. https://doi.org/10.3390/fire8050170
Wang Z, Lei L, Li T, Zu X, Shi P. RT-DETR-Smoke: A Real-Time Transformer for Forest Smoke Detection. Fire. 2025; 8(5):170. https://doi.org/10.3390/fire8050170
Chicago/Turabian StyleWang, Zhong, Lanfang Lei, Tong Li, Xian Zu, and Peibei Shi. 2025. "RT-DETR-Smoke: A Real-Time Transformer for Forest Smoke Detection" Fire 8, no. 5: 170. https://doi.org/10.3390/fire8050170
APA StyleWang, Z., Lei, L., Li, T., Zu, X., & Shi, P. (2025). RT-DETR-Smoke: A Real-Time Transformer for Forest Smoke Detection. Fire, 8(5), 170. https://doi.org/10.3390/fire8050170