
Improved YOLOv5: Efficient Object Detection for Fire Images

Abstract
1. Introduction
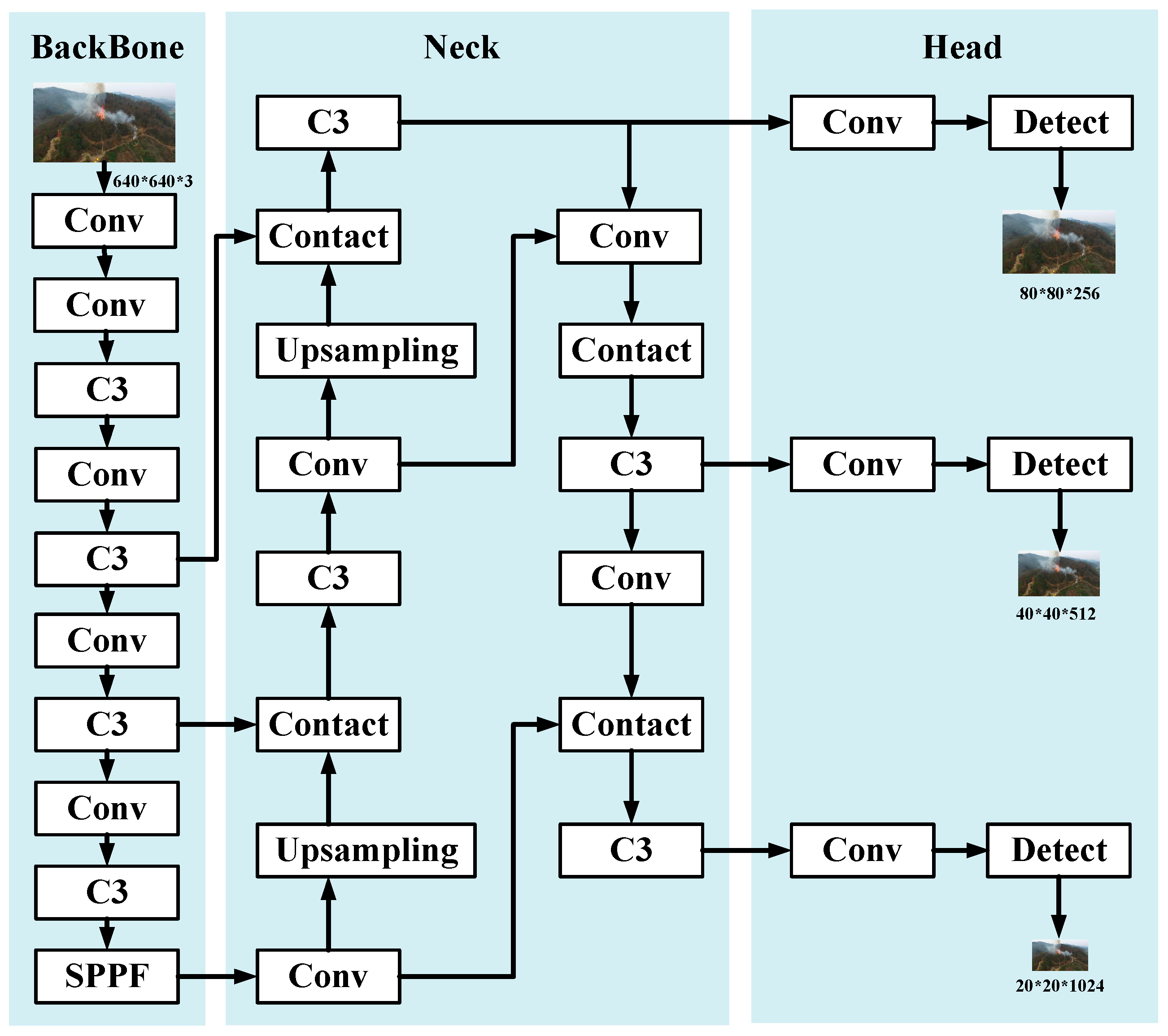
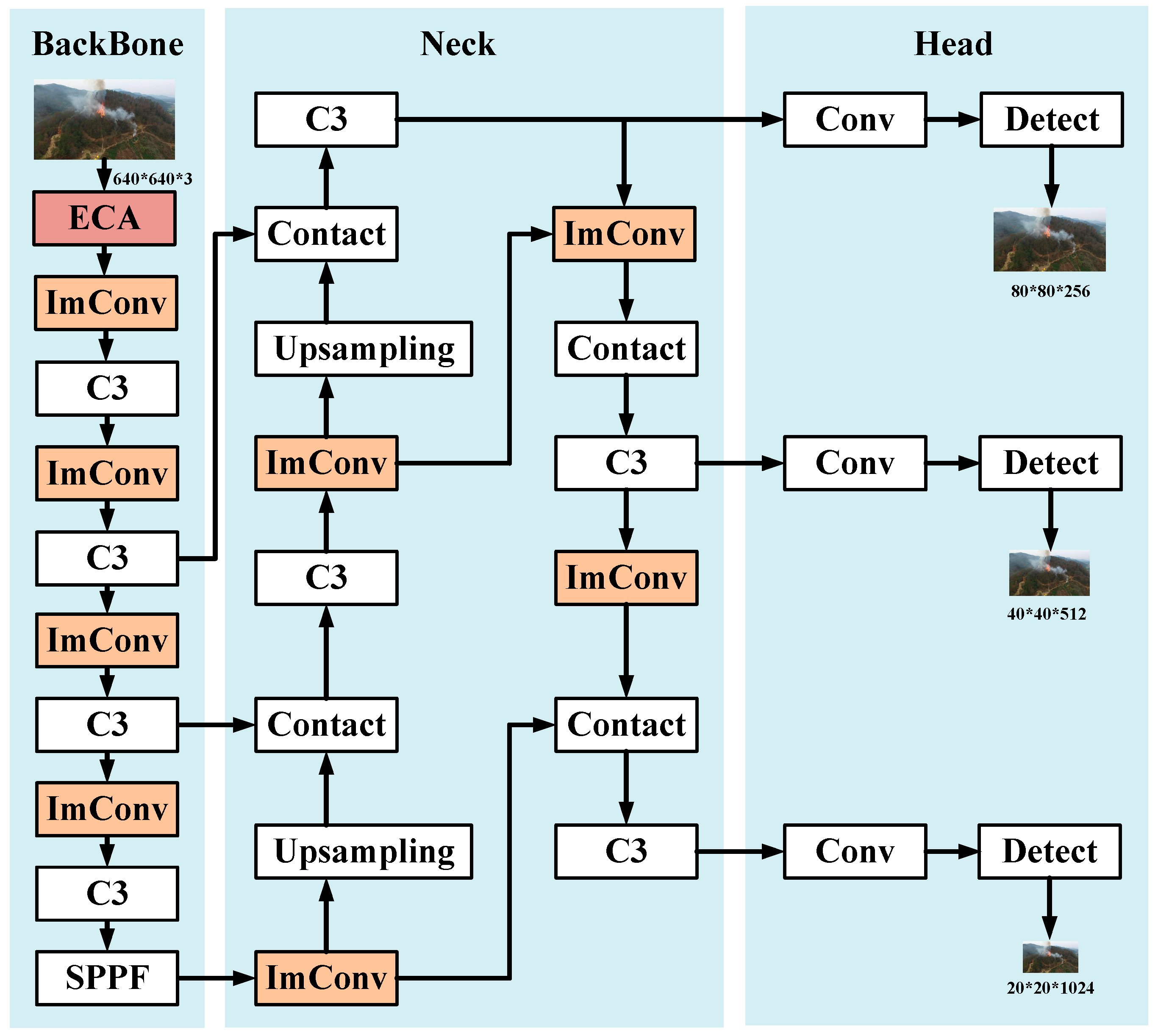
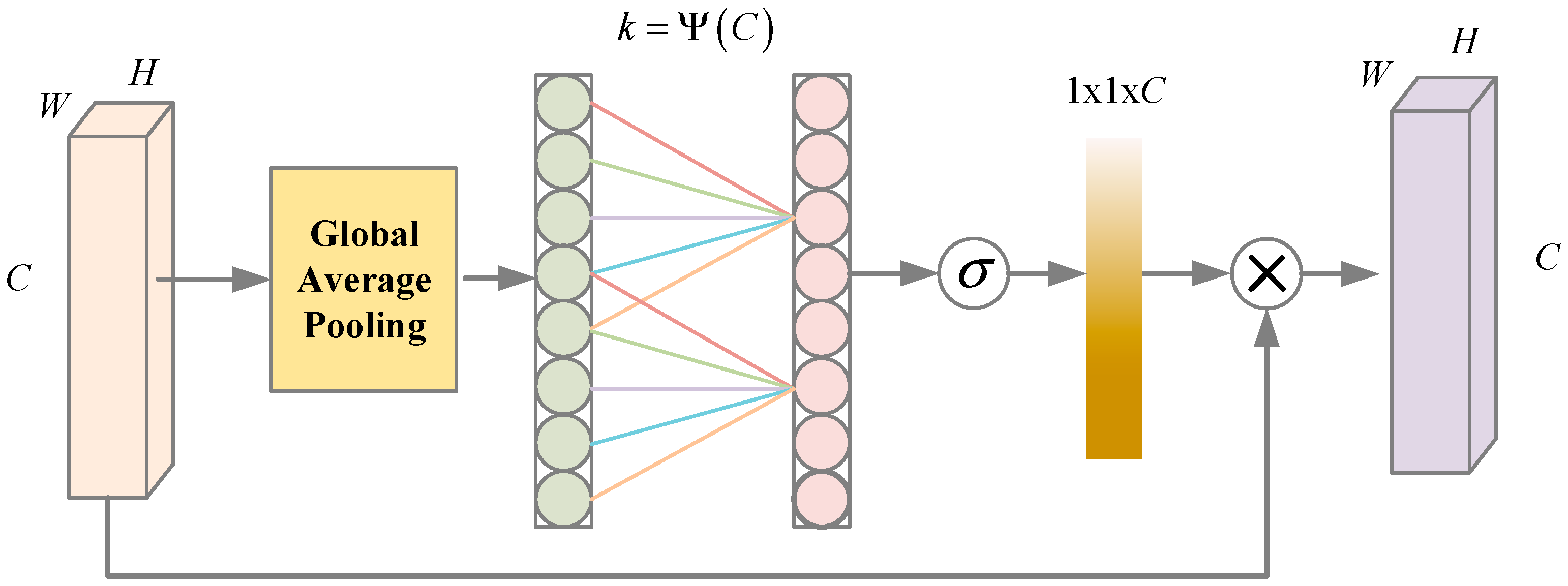
2. Materials and Methods
3. Results
3.1. Experimental Equipment
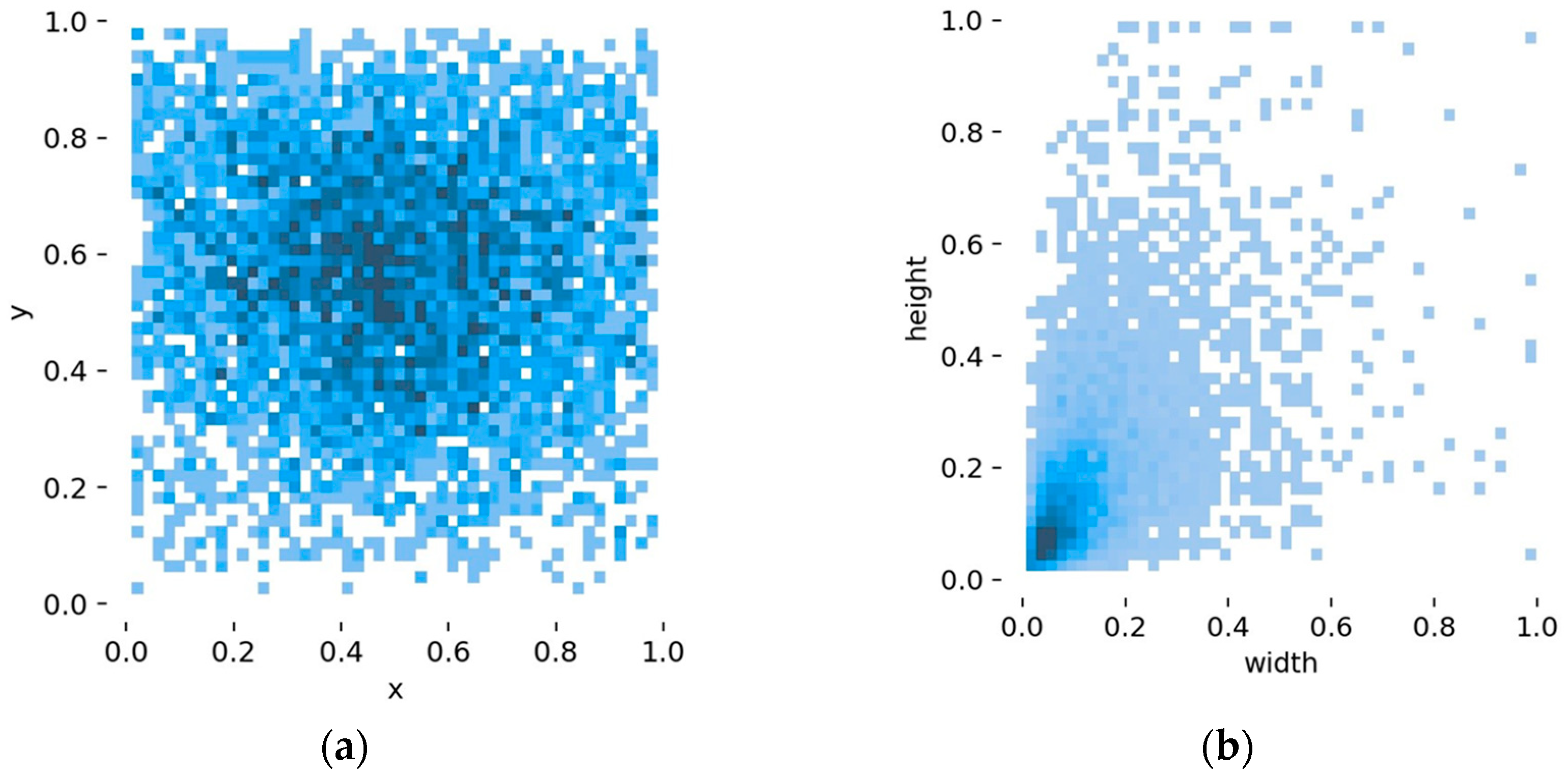
3.2. Fire Dataset
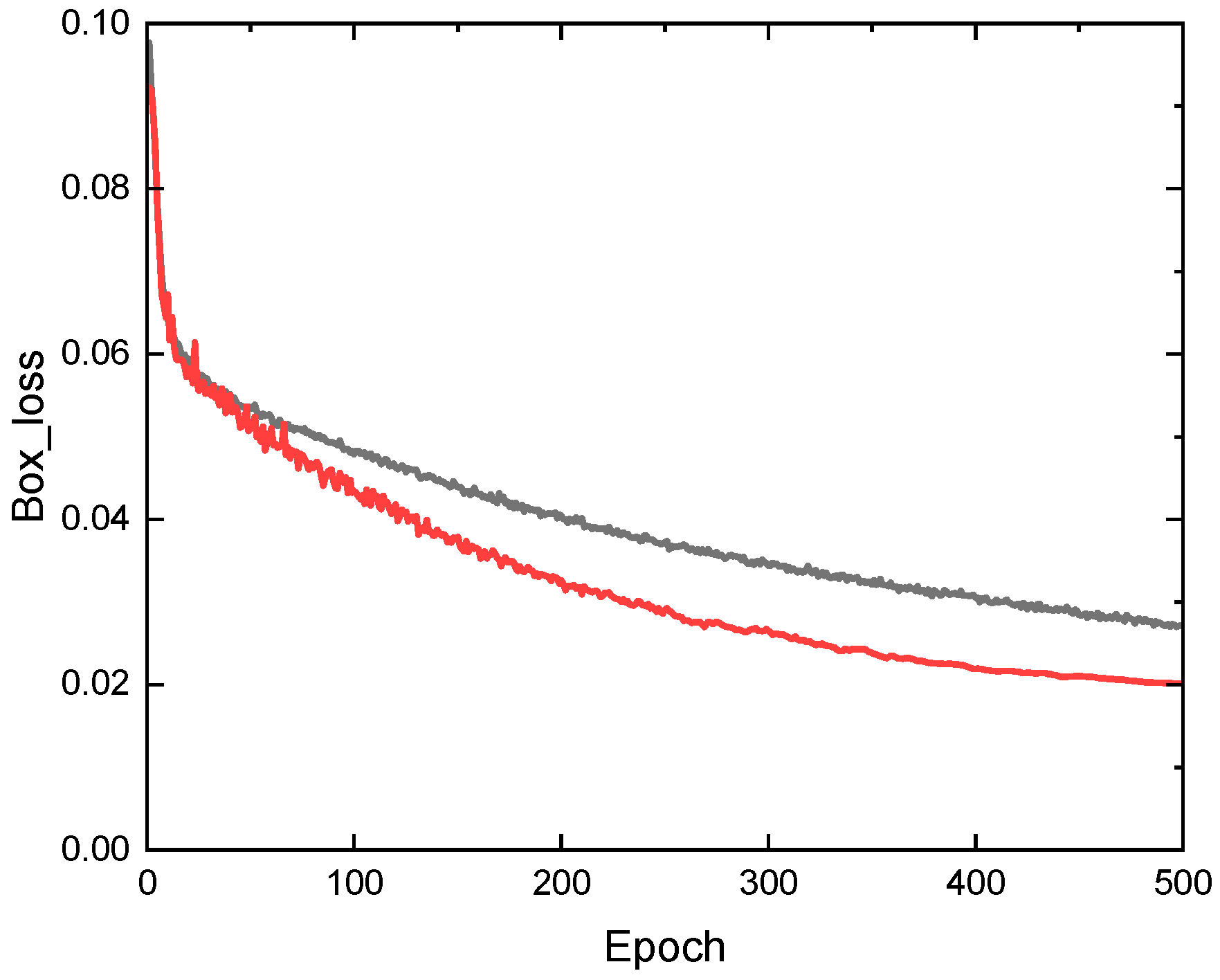
3.3. Training and Analysis
3.4. Ablation Experiment
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Verstockt, S.; Beji, T.; De Potter, P.; Van Hoecke, S.; Sette, B.; Merci, B.; Van de Walle, R. Video driven fire spread forecasting (f) using multi-modal LWIR and visual flame and smoke data. Pattern Recognit. Lett. 2013, 34, 62–69. [Google Scholar] [CrossRef]
- Ren, W.K.; Jin, Z.J. Phase space visibility graph. Chaos Solitons Fract. 2023, 176, 114170. [Google Scholar] [CrossRef]
- Battistoni, P.; Cantone, A.A.; Martino, G.; Passamano, V.; Romano, M.; Sebillo, M.; Vitiello, G. A cyber-physical system for wildfire detection and firefighting. Future Internet 2023, 15, 237. [Google Scholar] [CrossRef]
- Muhammad, K.; Ahmad, J.; Mehmood, I.; Rho, S.; Baik, S.W. Convolutional neural networks based fire detection in surveillance videos. IEEE Access 2018, 6, 18174–18183. [Google Scholar] [CrossRef]
- Mao, W.; Wang, W.; Dou, Z.; Li, Y. Fire recognition based on multi-channel convolutional neural network. Fire Technol. 2018, 54, 531–554. [Google Scholar] [CrossRef]
- Bu, F.; Gharajeh, M.S. Intelligent and vision-based fire detection systems: A survey. Image Vis. Comput. 2019, 91, 103803. [Google Scholar] [CrossRef]
- Yin, H.; Chen, M.; Lin, Y.; Luo, S.; Chen, Y.; Yang, S.; Gao, L. A real-time detection model for smoke in grain bins with edge devices. Heliyon 2023, 9, e18606. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object detection with deep learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Li, P.; Zhao, W. Image fire detection algorithms based on convolutional neural networks. Case Stud. Therm. Eng. 2020, 19, 100625. [Google Scholar] [CrossRef]
- Zhang, J.; Zhu, H.; Wang, P.; Ling, X. ATT squeeze U-Net: A lightweight network for forest fire detection and recognition. IEEE Access 2021, 9, 10858–10870. [Google Scholar] [CrossRef]
- Xu, R.; Lin, H.; Lu, K.; Cao, L.; Liu, Y. A forest fire detection system based on ensemble learning. Forests 2021, 12, 217. [Google Scholar] [CrossRef]
- Abdusalomov, A.; Whangbo, T.K. Detection and removal of moving object shadows using geometry and color information for indoor video streams. Appl. Sci. 2019, 9, 5165. [Google Scholar] [CrossRef]
- Abdusalomov, A.; Mukhiddinov, M.; Djuraev, O.; Khamdamov, U.; Whangbo, T.K. Automatic salient object extraction based on locally adaptive thresholding to generate tactile graphics. Appl. Sci. 2020, 10, 3350. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the Computer Vision-ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 630–645. [Google Scholar]
- Su, H.; Sun, H.; Zhao, Y. Efficient Pruning of Detection Transformer in Remote Sensing Using Ant Colony Evolutionary Pruning. Appl. Sci. 2025, 15, 200. [Google Scholar] [CrossRef]
- Shiao, Y.; Gadde, P.; Liu, C.-Y. Wavelet-Based Analysis of Motor Current Signals for Detecting Obstacles in Train Doors. Appl. Sci. 2025, 15, 25. [Google Scholar] [CrossRef]
- Wang, Y.; Deng, Y.; Zheng, Y.; Chattopadhyay, P.; Wang, L. Vision Transformers for Image Classification: A Comparative Survey. Technologies 2025, 13, 32. [Google Scholar] [CrossRef]
- Bochkov, V.S.; Kataeva, L.Y. wUUNet: Advanced Fully Convolutional Neural Network for Multiclass Fire Segmentation. Symmetry 2021, 13, 98. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Chen, C.; Lu, J.; Zhou, M.; Yi, J.; Liao, M.; Gao, Z. A YOLOv3-based computer vision system for identification of tea buds and the picking point. Comput. Electron. Agric. 2022, 198, 107116. [Google Scholar] [CrossRef]
- Ren, W.K.; Jin, N.D.; OuYang, L. Phase Space Graph Convolutional Network for Chaotic Time Series Learning. IEEE Trans. Ind. Inform. 2024, 20, 7576–7584. [Google Scholar] [CrossRef]
- Ren, W.K.; Jin, N.D.; Wang, T.Y. An Interdigital Conductance Sensor for Measuring Liquid Film Thickness in Inclined Gas-Liquid Two-Phase Flow. IEEE Trans. Instrum. Meas. 2024, 73, 9505809. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, C.; Zhong, X.; Shi, G.; Zhang, H.; Yang, D.; Wang, J. A Lightweight Method for Peanut Kernel Quality Detection Based on SEA-YOLOv5. Agriculture 2024, 14, 2273. [Google Scholar] [CrossRef]
- Yan, W.; Wang, X.; Tan, S. YOLO-DFAN: Effective High-Altitude Safety Belt Detection Network. Future Internet 2022, 14, 349. [Google Scholar] [CrossRef]
- Chen, Y.; Ye, J.; Wan, X. TF-YOLO: A Transformer–Fusion-Based YOLO Detector for Multimodal Pedestrian Detection in Autonomous Driving Scenes. World Electr. Veh. J. 2023, 14, 352. [Google Scholar] [CrossRef]
- Orgeira-Crespo, P.; Gabín-Sánchez, C.; Aguado-Agelet, F.; Rey-González, G. Novel Algorithm to Detect, Classify, and Count Mussel Larvae in Seawater Samples Using Computer Vision. Appl. Sci. 2024, 14, 5113. [Google Scholar] [CrossRef]
- Matadamas, I.; Zamora, E.; Aquino-Bolaños, T. Detection and Classification of Agave angustifolia Haw Using Deep Learning Models. Agriculture 2024, 14, 2199. [Google Scholar] [CrossRef]
- Yi, S.; Li, J.; Liu, X.; Yuan, X. CCAFFMNet: Dual-spectral semantic segmentation network with channel-coordinate attention feature fusion module. Neurocomputing 2022, 482, 236–251. [Google Scholar] [CrossRef]
- Pandey, A.; Jain, K. A robust deep attention dense convolutional neural network for plant leaf disease identification and classification from smart phone captured real world images. Ecol. Inf. 2022, 70, 101725. [Google Scholar] [CrossRef]
- Lu, R.; Yang, X.; Jing, X.; Chen, L.; Fan, J.; Li, W.; Li, D. Infrared small target detection based on local hypergraph dissimilarity measure. IEEE Geosci. Remote Sens. Lett. 2020, 19, 7000405. [Google Scholar] [CrossRef]
- Lu, R.; Yang, X.; Li, W.; Fan, J.; Li, D.; Jing, X. Robust infrared small target detection via multidirectional derivative-based weighted contrast measure. IEEE Geosci. Remote Sens. Lett. 2020, 19, 7000105. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision/% | Recall/% | F1 | mAP@0.5 | FPS |
|---|---|---|---|---|---|
| YOLOv3 | 84.22 | 85.23 | 0.88 | 50.32 | 67 |
| YOLOv4 | 90.66 | 93.63 | 0.91 | 51.95 | 78 |
| YOLOv4-Tiny | 83.57 | 82.51 | 0.83 | 54.04 | 89 |
| SSD | 82.78 | 81.52 | 0.81 | 48.14 | 78 |
| EfficientDet | 89.12 | 92.16 | 0.91 | 52.96 | 72 |
| YOLOv5s | 87.98 | 91.73 | 0.90 | 51.61 | 80 |
| YOLOv8 | 91.87 | 94.11 | 0.95 | 59.12 | 91 |
| Improved YOLOv5s | 91.22 | 93.78 | 0.93 | 60.27 | 91 |
| Model | Precision/% | Recall/% | F1 |
|---|---|---|---|
| YOLOv3 | 90.16 | 89.77 | 0.91 |
| YOLOv4 | 95.25 | 96.73 | 0.95 |
| EfficientDet | 96.31 | 96.93 | 0.97 |
| YOLOv5s | 95.35 | 97.03 | 0.97 |
| YOLOv8 | 96.87 | 97.33 | 0.98 |
| Improved YOLOv5s | 96.46 | 97.12 | 0.98 |
| Model | a | b | F1 | mAP/% |
|---|---|---|---|---|
| 1 | N | N | 0.90 | 91.51 |
| 2 | Y | N | 0.91 | 93.42 |
| 3 | N | Y | 0.92 | 92.88 |
| 4 | Y | Y | 0.93 | 95.57 |
| Model | FLOPs | Parameters | Precision/% |
|---|---|---|---|
| Improved YOLOv5s (α = 1) | 56 M | 0.4 M | 90.12 |
| Improved YOLOv5s (α = 0.5) | 26 M | 0.2 M | 91.22 |
| Improved YOLOv5s (α = 0.25) | 20 M | 0.1 M | 89.08 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, D.; Li, S.; Zhang, Z.; Liu, X.; Ding, W.; Zhao, X. Improved YOLOv5: Efficient Object Detection for Fire Images. Fire 2025, 8, 38. https://doi.org/10.3390/fire8020038
Yu D, Li S, Zhang Z, Liu X, Ding W, Zhao X. Improved YOLOv5: Efficient Object Detection for Fire Images. Fire. 2025; 8(2):38. https://doi.org/10.3390/fire8020038
Chicago/Turabian StyleYu, Dongxing, Shuchao Li, Zhongze Zhang, Xin Liu, Wei Ding, and Xinyi Zhao. 2025. "Improved YOLOv5: Efficient Object Detection for Fire Images" Fire 8, no. 2: 38. https://doi.org/10.3390/fire8020038
APA StyleYu, D., Li, S., Zhang, Z., Liu, X., Ding, W., & Zhao, X. (2025). Improved YOLOv5: Efficient Object Detection for Fire Images. Fire, 8(2), 38. https://doi.org/10.3390/fire8020038