Abstract
In real-world fire scenarios, complex lighting conditions and smoke interference significantly challenge the accuracy and robustness of traditional fire detection systems. Fusion of complementary modalities, such as visible light (RGB) and infrared (IR), is essential to enhance detection robustness. However, spatial shifts and geometric distortions occur in multi-modal image pairs collected by multi-source sensors due to installation deviations and inconsistent intrinsic parameters. Existing multi-modal fire detection frameworks typically depend on pre-registered data, which struggles to handle modal misalignment in practical deployment. To overcome this limitation, we propose an end-to-end multi-modal Fire Salient Object Detection framework capable of dynamically fusing cross-modal features without pre-registration. Specifically, the Channel Cross-enhancement Module (CCM) facilitates semantic interaction across modalities in salient regions, suppressing noise from spatial misalignment. The Deformable Alignment Module (DAM) achieves adaptive correction of geometric deviations through cascaded deformation compensation and dynamic offset learning. For validation, we constructed an unregistered indoor fire dataset (Indoor-Fire) covering common fire scenarios. Generalizability was further evaluated on an outdoor dataset (RGB-T Wildfire). To fully validate the effectiveness of the method in complex building fire scenarios, we conducted experiments using the Fire in historic buildings (Fire in historic buildings) dataset. Experimental results demonstrate that the F1-score reaches 83% on both datasets, with the IoU maintained above 70%. Notably, while maintaining high accuracy, the number of parameters (91.91 M) is only 28.1% of the second-best SACNet (327 M). This method provides a robust solution for unaligned or weakly aligned modal fusion caused by sensor differences and is highly suitable for deployment in intelligent firefighting systems.
1. Introduction
Wildfires are becoming increasingly frequent with global warming and rapid socioeconomic development. Once ignited, they spread rapidly and are extremely difficult to control. Considerable research has therefore focused on real-time wildfire monitoring systems.
In contrast, indoor fires pose distinct challenges. The high occupant density of buildings impedes evacuation, concentrated combustible materials accelerate propagation, and complex layouts exacerbate hazards. These factors often result in severe casualties and economic losses. However, compared with wildfire research, significantly fewer studies have been devoted to indoor fire detection and early warning. Real-time indoor fire monitoring systems remain urgently needed to support firefighters and relevant authorities in emergency response.
Real-time indoor fire monitoring systems, both historically and at present, predominantly rely on single sensors or combinations of multiple sensors such as temperature sensors, smoke detectors, and gas sensors for early warning. However, these approaches consistently suffer from delayed alerts, which compromises early fire detection efficacy. Recently, computer vision-based fire recognition systems have advanced significantly, offering enhanced real-time performance and accuracy [1]. Traditional fire image recognition methods typically employ manually extracted features such as color, brightness, and texture [2]. Nevertheless, such handcrafted features exhibit inherent errors and demonstrate limited robustness across diverse scenes. The rapid development of deep learning has enabled Convolutional Neural Networks (CNNs) to achieve outstanding performance in early fire recognition tasks through powerful feature extraction capabilities. Transformers have further revolutionized fire detection with superior global feature modeling; notably, Reference [3] proposed an adaptive lightweight backbone network integrating CNN and Transformer architectures, incorporating deformable convolutions to dynamically adapt to irregular flame and smoke morphologies.
However, fire recognition still confronts significant challenges, particularly under complex indoor lighting conditions and in occlusion scenarios with substantial interference. Single-spectrum detection methods (RGB or TIR) demonstrate poor adaptability in such environments, as illustrated in Figure 1. To address the insufficient representational capacity of unimodal data for fire features, researchers are increasingly adopting multimodal fusion for real-time fire monitoring. Reference [4] proposed a novel wildfire recognition framework capable of adaptively learning modality-specific and shared features, utilizing dual parallel encoders to extract multi-scale RGB and TIR features. These features are integrated into a fusion layer, with each modality-specific decoder and a shared decoder supervised by three independent loss functions, achieving state-of-the-art performance across multiple tasks. Complementing this, Reference [5] introduced the FLAME aerial multispectral dataset, containing forest fire imagery with synchronized RGB and thermal data, benchmarked using deep learning techniques including transfer learning and feature fusion for fire or smoke frame detection.

Figure 1.
Examples of complex environments with wildland and indoor scenario fires.
However, existing RGB-TIR datasets are typically pre-aligned to ensure modality-specific data registration. Considering that most surveillance systems employ visible-light cameras and economic constraints, the prevalent practice involves deploying standalone infrared cameras. Due to divergent imaging principles, sensor parameters, and internal calibration methods between visible and infrared cameras, real-time acquisition of multimodal data frequently exhibits perspective deviations and spatial misalignment, as illustrated in Figure 2.

Figure 2.
Sample fire data for RGB-IR indoor scenes without alignment.
This misalignment directly compromises the accuracy of subsequent multimodal feature fusion and fire detection. The current multimodal detection workflow is schematically represented in Figure 3. Presently, fire detection research primarily focuses on developing effective RGB-TIR fusion methodologies, while comparatively limited attention has been devoted to addressing data misalignment issues in real-world acquisitions. This knowledge gap poses significant challenges for practical fire monitoring applications.
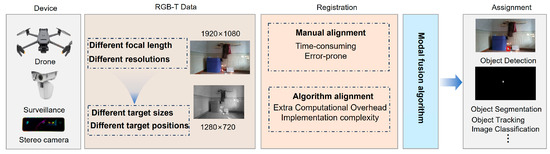
Figure 3.
Current basic flow of tasks based on multimodal data fusion.
Therefore, to address these challenges, the principal contributions of this work are summarized as follows:
- (1)
- We introduce an unaligned RGB-IR fire dataset for indoor environments, encompassing diverse common scenes and fire scenarios under variable illumination conditions. The dataset specifically includes challenging cases such as small-target fires and occlusion interference, providing essential data support for multimodal fire fusion research under spatial misalignment conditions.
- (2)
- We propose a fire saliency detection framework for processing spatially unaligned RGB-IR data, integrating a multimodal feature enhancement module and an improved inter-modal alignment fusion module. These components resolve spatial discrepancies between modalities including RGB and thermal infrared through feature-level correspondence learning and fusion strategies, significantly enhancing detection accuracy compromised by spatial misalignment.
- (3)
- To validate method efficacy, we conduct extensive experiments using the proposed misaligned multimodal fire dataset across indoor and cross-environmental scenarios. The results demonstrate superior performance over state-of-the-art RGB-T multimodal saliency detection models, confirming our method’s capability for accurate fire saliency detection with unregistered RGB and TIR inputs.
2. Related Works
2.1. Single-Modal-Based Fire Identification
Visible light cameras have become widely adopted for fire recognition due to their low cost and rich color-texture information. Numerous studies have been conducted in this domain. Initially, researchers relied on manually extracted features such as color, luminance, chroma, and fire motion characteristics. For instance, Reference [2] proposed a rule-based generic color model for flame pixel classification using the YCbCr color space, which separates luminance from chroma more effectively than RGB-based color spaces. Their method achieved a fire detection rate of up to 99%. However, the reliance on manually extracted features limits its applicability in complex environments. With advancements in computer vision, deep learning models such as Convolutional Neural Networks (CNNs) and Transformers have been extensively used for feature extraction and fire recognition. For example, Reference [6] introduced a lightweight network for smoke segmentation. To enhance feature encoding capabilities, they proposed an Attention Encoding Module (AEM), a Spatial Enhancement Module (SEM) to improve spatial detail representation, and a Channel Attention Module (CAM) to model inter-channel dependencies explicitly. Reference [7] developed an innovative model featuring dual information encoding and decoding paths for real-time wildfire and smoke detection in UAV-captured imagery. This model incorporates nested decoders with pre-activated residual blocks and attention gating mechanisms, significantly improving segmentation accuracy. Reference [8] focused on fire boundary detection using thermal infrared (TIR) imaging, which offers advantages under smoke-obscured and low-visibility conditions, highlighting the effectiveness of TIR in fire monitoring. Reference [9] proposed a real-time forest fire segmentation method based on an enhanced DeepLabv3+ architecture. The encoder network integrates Deep Convolutional Neural Networks (DCNNs) with Atrous Spatial Pyramid Pooling (ASPP) to extract semantic features at multiple scales, thereby improving segmentation accuracy. Reference [10] introduced a hybrid framework combining CNNs and Vision Transformers, named CN2VF-Net, which addresses the challenges of multi-scale object detection, complex backgrounds, and real-time performance in traditional fire detection systems.
2.2. Multi-Modal-Based Fire Identification
However, when fire environments involve challenges such as lighting variation, smoke occlusion, and background interference—particularly in indoor settings where combustibles are concentrated and environmental disturbances are frequent—RGB images often become ambiguous. Methods relying solely on the RGB modality exhibit high false alarm and miss rates in practical fire recognition tasks. To address the limitations of visible light imagery, infrared (IR) imaging has been considered for fire detection. IR sensors can effectively monitor fires in nighttime or low-light conditions by detecting thermal radiation emitted by flames. However, IR imaging is also susceptible to false detections in industrial environments due to the presence of high-temperature devices or flame-like ambient lighting. Moreover, IR images typically offer lower resolution and lack the rich texture details present in RGB images, making precise detection difficult in complex scenes. To leverage the complementary strengths of these two modalities, numerous studies have explored multimodal fusion approaches. For example, Reference [11] proposed a flame detection method combining visible and thermal IR images, utilizing a targeted single-modality detection model and a decision-level fusion strategy to integrate the texture features of visible light with the thermal distribution information from infrared imagery. Reference [12] introduced a forest fire monitoring approach using UAV-based visible and IR image fusion. Building upon the VIF-Net architecture, the authors proposed Fire Fusion-Net, which incorporates an attention mechanism and an optimized loss function to enhance fusion quality. Reference [13] developed a fire segmentation method based on optimized weighted image fusion. By dynamically adjusting the weights of visible images and integrating multimodal features, the method achieved high-precision segmentation on the Corsican dataset. Reference [14] employed transfer learning with the Xception model by modifying its fully connected layers and introducing dropout to reduce overfitting. Leveraging the depthwise separable convolutional structure, the approach efficiently extracts cross-modal composite features, improving both the accuracy and real-time performance of fire detection in complex maritime environments. References [15,16]. Addressing insufficient subject saliency and redundant background interference in IR-RGB fusion for fire scenes, the IAFusion framework was proposed based on an inverse progressive feature pyramid. It enhances flame saliency while retaining background textures through subject-background separation and attention-guided feature reconstruction. Reference [16] built a dataset comprising 2752 synchronized image pairs and enhanced image alignment and fusion techniques. The proposed FFDM-F model, based on YOLOv5s, improves small-fire detection accuracy by over 10% compared with conventional methods by incorporating a small-target detection layer, a decoupled head, and an ECA attention module. Reference [17] designed a network model that segments wild flames using RGB and thermal image data. The architecture features dual encoders for modality-specific feature extraction, a SkipInception module for enhanced representation, and skip connections for fusion, achieving higher accuracy than existing models. Reference [18] presented a multimodal UAV video dataset comprising RGB and thermal IR footage and implemented a simple yet effective fusion strategy, significantly improving the accuracy of fire and smoke detection compared to single-channel video approaches.
2.3. Unaligned Multimodal Data Fusion Study
However, the aforementioned studies that combine visible and infrared data for fire detection generally assume that the input data are well-aligned beforehand. In inter-modal tasks such as RGB-TIR or RGB-Depth, pixel-level spatial misalignment often arises due to inconsistencies in sensor parameters and variations in internal calibration methods across modalities. Currently, most inter-modal fusion approaches require either manual alignment or additional algorithmic correction prior to fusion. Manual alignment is prone to significant errors, while algorithmic alignment increases computational complexity. A representative image alignment technique is the Scale-Invariant Feature Transform (SIFT) [19], which achieves alignment through scale-space extrema detection, keypoint localization, orientation assignment, and feature descriptor generation. To improve alignment efficiency, Reference [20] proposed AffineNet, which learns affine transformation parameters to globally align multimodal images. These parameters are then used to generate a deformation field to complete the alignment. AffineNet reformulates the alignment task as an image similarity optimization problem within the same domain, thus mitigating the impact of modality differences. However, it incurs high computational cost, is susceptible to error accumulation, and directly affects subsequent fusion and downstream tasks. To address these challenges, feature-level alignment methods have been proposed. These approaches do not operate directly in the image space but instead learn cross-modal correspondences in the feature space. For example, Reference [21] introduced the Cross-Modal Alignment Detector (CMA-Det), which leverages deformable field alignment, an object localization refinement module, and a Bi-directional Feature Correction Fusion Module (BFCFM) to address misalignment caused by viewpoint differences. Experimental results show that CMA-Det outperforms existing methods on both the DVTOD and public datasets, achieving a mean average precision (mAP) of 85.0%, significantly enhancing detection robustness in complex environments. Similarly, Reference [22] proposed a Semantically-Guided Asymmetric Association Network (SACNet) for salient object detection in unaligned RGB-TIR pairs. SACNet integrates an Asymmetric Window Association Module (ACM) to model cross-modal semantic interaction, along with a Cascaded Deformable Convolutional Sampling Module (AFSM) to enable dynamic alignment. Validated on the UVT2000 dataset, SACNet achieves an mAP of 85.0% across both aligned and unaligned datasets, demonstrating significant reduction in manual alignment cost and enhanced fusion robustness. To address modal misalignment in RGB-T tracking, Reference [23] proposed the AMNet framework, which consists of an Interaction Space Alignment Module (MSA) and an Information Matching and Fusion Module (IMF). MSA models local cross-modal dependencies and predicts deformable offsets using a Transformer-based strategy for dynamic feature-level alignment. IMF employs a region-aware partitioning strategy to adaptively fuse multimodal features based on spatial consistency, thereby alleviating misalignment interference and optimizing cross-modal complementarity. The framework demonstrates competitive performance on datasets including GTOT, RGBT234, and LasHeR. Adversarial learning has also proven effective in mitigating modal misalignment by introducing mechanisms to reduce inter-modal heterogeneity and enhance alignment. For instance, Reference [24] proposed the CMLA method, which generates adversarial samples by regularizing intra- and inter-modal similarity, promoting alignment. In a similar vein, Reference [25] introduced the AFA method, utilizing contrastive learning to optimize feature-space alignment and reduce misclassification due to modality inconsistencies. Finally, Reference [26] addressed weak image alignment in multimodal fire perception systems for firefighting robots. They proposed a flame detection model based on projection and attention guidance. The model first estimates the flame’s position in the thermal image via 3D-to-2D projection and enhances feature fusion by integrating a Neighborhood Sampling Module (NSM) and an Attention Guidance Module (AGM). This significantly improves flame detection accuracy and reduces false alarm rates. However, AGM requires precise alignment and orientation of the multimodal cameras, and its performance deteriorates under large misalignment or when unpaired inputs are present.
Although previous studies on fusing visible and infrared data for fire detection or segmentation have demonstrated the effectiveness of multimodal fusion, they predominantly rely on pre-aligned data. In real-world fire scenarios, however, differences in sensor installation positions, internal parameters, and resolution inconsistencies often result in weak or even complete misalignment between modalities. Directly fusing such unaligned data tends to cause feature space mismatches, thereby reducing detection accuracy. Therefore, it is essential to overcome the reliance of current multimodal fusion methods on strict alignment and develop a framework capable of adapting to unaligned multimodal inputs for robust fire detection.
3. Materials and Methods
3.1. Proposed Methods
In summary, in real-world fire scenarios, visible, infrared (IR), and other modalities are often unaligned or weakly aligned, making direct multimodal fusion infeasible. Unlike previous multimodal fusion approaches, such as the front-end pixel-level alignment used in the wildfire dataset of Reference [4], fire detection data in practical settings requires a different processing strategy. In this paper, we propose a cross-modal fusion-based fire saliency detection method that incorporates dynamic feature-level alignment. By achieving implicit alignment of fire targets in the feature space, the proposed method avoids the error accumulation and computational overhead associated with traditional image-level alignment techniques. The core components of the proposed fire saliency detection method are divided into two main parts: the modal interaction enhancement module and the modal alignment fusion module. The modal interaction enhancement module is designed to mine complementary saliency features of fire regions across both modalities. Meanwhile, the modal alignment fusion module aligns the RGB and IR modalities at the feature level to improve fusion consistency. This chapter elaborates on four key components of the proposed model: the overall architecture, the CCM module, the DAM module, and the loss function.
3.1.1. Model
The overall structure of the proposed model is illustrated in Figure 4. The model consists of two parallel branches that simultaneously extract features from RGB and IR modalities. In saliency detection, the quality of feature extraction directly affects the model’s ability to accurately identify salient regions within an image. Deeper networks typically provide better feature representations than shallower ones. For instance, Swin Transformers [27] have been adopted as dual-branch feature extractors in models such as [15,20,21,28]. However, these architectures generally rely on large-scale datasets for pretraining to achieve optimal performance, and they incur high computational costs due to their dependence on high-dimensional matrix operations. Given the relatively limited amount of training data and the distinctiveness of fire-related visual cues, deep architectures such as Swin Transformers may struggle to learn sufficiently representative features in this context. Therefore, we adopt the pre-trained Res2Net-50 [29] as the backbone network for both branches. Compared to deeper transformer-based models, Res2Net-50 offers significant advantages in computational efficiency, lightweight deployment, and performance under small-sample learning conditions. The Res2Net-50 backbone is configured to output features from four stages, excluding the lowest-level features. This configuration is designed to accommodate the subsequent cross-channel attention computation and feature alignment fusion modules, while maintaining architectural compatibility when conducting ablation studies with alternative backbone networks. We represent the output features using , and denote the features corresponding to the RGB and IR modalities. The CCM module is designed to enhance feature interaction exclusively at the channel level, thereby avoiding interaction noise caused by spatial misalignment. The enhanced RGB and IR features from each layer are then fused and aligned using the DAM module, which performs dynamic alignment through a cascaded structure. This design enables progressive multimodal fusion and alignment from coarse to fine. Finally, through the UpsampleBlock module, the fused features are progressively aggregated across layers to generate the final fire saliency detection map.
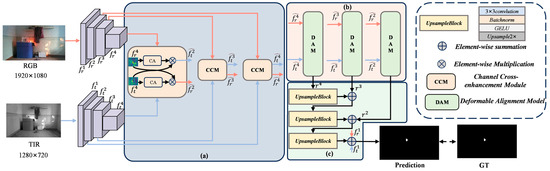
Figure 4.
Overall architecture of the proposed method for fire detection with multimodal fusion under unalignment: (a) Channel Cross-Enhancement Module (CCM); (b) Deformable Alignment Module (DAM); (c) UpsampleBlock module.
3.1.2. Channel Cross Enhancement Module(CCM)
Current multimodal fusion approaches can generally be categorized into pre-fusion, intermediate fusion, and post-fusion strategies. Among them, intermediate fusion architectures are the most widely adopted, as they allow for staged feature interaction and dynamic weight adjustment, achieving a desirable balance between flexibility and robustness in multimodal tasks. In this paper, we employ an intermediate fusion strategy to integrate RGB and IR features across four hierarchical layers. To address the spatial misalignment [30] between the two modalities, we restrict feature interaction to the channel level, thereby avoiding the assumption of precise spatial alignment. This design significantly reduces computational complexity compared to Reference [21], which performs multi-step cross-attention for spatial feature interaction across modalities. Interaction in the spatial domain requires processing high-resolution feature maps, resulting in elevated computational cost—particularly with high-resolution inputs or deeper feature layers. Effective cross-modal fusion depends on mining semantic complementarity between modalities [31]. Since channel dimensions typically encode high-level semantic information, channel attention mechanisms can effectively capture inter-modal semantic associations by modeling relationships between channels, without requiring explicit spatial transformation. The corresponding computational process is described as follows:
where . The Channel Attention (CA) module implements a channel-wise feature refinement mechanism. This architecture first applies dual spatial aggregation operations: global average pooling and global maximum pooling across spatial dimensions to generate channel descriptors. These descriptors are processed through a shared MLP to produce two attention vectors. Subsequent element-wise summation of these vectors followed by sigmoid normalization yields channel attention weights. The final output features are computed via element-wise multiplication ⊗ between the attention weights and the original feature map. The Channel Cross-Enhancement Module structure is illustrated in Figure 5.
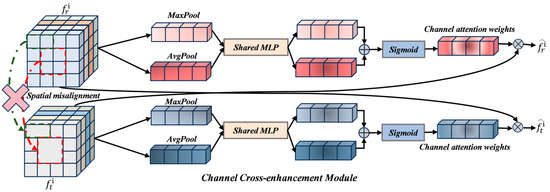
Figure 5.
Structural diagram of the Channel Cross-Enhancement Module.
3.1.3. Deformable Alignment Model (DAM)
After processing through the CCM module, the unaligned RGB and IR modalities interact deeply at the channel level, enabling mutual enhancement of features from both modalities. However, since the modalities remain spatially unaligned, direct feature fusion can result in errors in saliency detection. To address this issue, we incorporate deformable convolution [20] as a key component. Deformable convolution adapts to various geometric deformations by learning additional offsets, allowing the convolutional kernel to sample from irregular regions. This flexibility enables the receptive field to adjust dynamically to targets of different scales, thereby improving the model’s ability to handle multi-scale features. Fire regions often exhibit irregular shapes and non-rigid boundaries. Deformable convolution is particularly effective in capturing such structures by flexibly adjusting the sampling positions to better localize salient targets. To mitigate the fusion challenges caused by modal misalignment in fire saliency detection, we propose a hierarchically guided deformable convolutional alignment module (DAM), which performs alignment progressively from high-level to low-level features. The structure of DAM is illustrated in Figure 6.
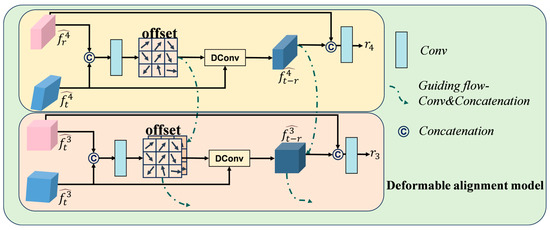
Figure 6.
Detail of the Deformable Alignment Module. The yellow blocks represent the RGB correction and fusion part, while the pink blocks represent the IR correction and fusion part.
In the DAM module, enhanced features and are concatenated to form preliminary fusion features. A subsequent convolution operation then generates the offset, which can be formally described as:
Here, denotes the 9 sampling locations for a standard 3 × 3 convolutional kernel, and represents the offset for each sampling location in the deformable convolution. In this work, we align the IR modality features to the RGB modality features. We utilize and as inputs for the deformable convolution. Therefore, each position of the aligned can be expressed as:
represents the aligned T features, with specific computational details derived from Reference [32], which differs from the methodology presented in Reference [21]. AFSM module cascades four deformable convolutional layers, which consequently increases the parameter count at certain processing stages. Furthermore, deformable convolution is performed independently at each layer. Given that resolution gradually decreases during feature extraction, resulting in higher-level semantic information, the spatial misalignment issue between modalities in higher layers progressively diminishes. Therefore, leveraging high-level correction and offset information to guide lower-level layers can effectively mitigate discontinuity artifacts caused by noise in low-level features. Our DAM module provides dual guidance by propagating both offset and corrected features from high-level to low-level layers.
The guidance for the offset can be expressed as:
where , denotes the process where the offset from the previous layer is upsampled and adjusted through convolution to match the dimensions of the subsequent layer. By summing these adjustments, the global alignment information from the preceding layer guides the local alignment in the current layer. This mechanism prevents abrupt changes in the offset at higher resolutions, which could lead to training instability and hinder the rapid convergence of the model.
The guidance for the rectified features can be expressed as:
To fully integrate multi-scale information and enhance the continuity of cross-modal alignment, we utilize high-level rectified features to guide low-level rectified features. By leveraging the larger receptive field and spatial alignment information learned from high-level features, we augment the low-level rectified features, which helps mitigate information loss and improve the stability of alignment. The computational process is formally described by the equation above, where the aligned features are denoted, denotes upsample and channel-wise convolutional adjustment, and denotes concatenation.
The fused feature for each layer can then be expressed as:
3.1.4. Loss Function and Significance Output
To balance the local and global performance of saliency output, and given that Dice loss is more effective for scenarios with sparse foregrounds, compensating for the shortcomings of BCE in class imbalance, we combine two commonly used loss functions in saliency detection. Through initial training, we observed that a simple summation of these two loss functions to form the final loss function resulted in Dice converging an order of magnitude slower than BCE. Ultimately, our loss function is defined as:
where denotes the loss function, and represent the predicted saliency map and ground truth, respectively. The final saliency map output can be expressed as:
The comprises operations.
3.2. Datasets
The experiment utilizes three datasets. The first is a self-constructed indoor multi-scene RGB-IR fire dataset, named Indoor-Fire, which comprises 1537 pairs of RGB and IR images. The dataset includes multiple combustion experiments, such as burning curtains, common wood, sofas, teddy bears, clothing fabrics, and common plastics, and the data were collected under varying lighting conditions. It covers typical combustible materials found in household environments. Data acquisition was performed using an OAK-D PRO stereo camera. Due to differing perspectives and focal lengths between the RGB and stereo depth cameras, as detailed on the OAK official website, the collected RGB and IR data are spatially misaligned, a common occurrence in real-world scenarios. Notably, the OAK-D PRO stereo camera does not include thermal imaging capabilities; thus, the collected data consist solely of visible light and near-infrared information. The RGB images have a resolution of 1920 × 1080, while the IR images have a resolution of 1080 × 720. To effectively fuse features from both modalities and better correspond to real-world fire incidents, we did not pre-register the dataset but directly fed it into the model for training and inference.
To validate the model’s effectiveness in fire detection in complex building environments, we introduce a multispectral heritage building fire dataset, Fire in historic buildings. This dataset contains multiple unregistered RGB and infrared fire image pairs, covering various complex fire environments, including occlusion scenarios such as smoke and object occlusions, as well as interference scenarios such as lighting disturbances, false fire source interference, and background noise. The dataset is available for request from the National Basic Science Data Center Available online: https://www.nbsdc.cn/ (accessed on 31 July 2025).
To thoroughly validate the model’s multimodal fire saliency detection capabilities in outdoor environments, we employed the RGB-T wildfire dataset proposed in Reference [4]. This dataset is pre-aligned. To further assess the model’s performance on misaligned modalities, we introduced random affine transformations to the RGB-T wildfire data, simulating modality misalignment. Prior to model input, images were uniformly resized to 480 × 480. Data augmentation strategies, including flipping and rotation, were applied during training. A partial visualization of the training dataset is presented in Figure 7.

Figure 7.
Data from indoor scenarios and wildland fire portions of the participating trainings.
As the data were recorded in video format, a total of 1537 temporally aligned but spatially misaligned RGB-IR data pairs were ultimately extracted from the video streams. The annotation of these misaligned multimodal datasets differs from that of aligned data, as the targets must be fully visible in both modalities. We adopted an annotation strategy in which the RGB modality served as the primary reference and the IR modality as supplementary. By carefully comparing shared target features across the two modalities, we utilized the IR modality to complement the RGB modality in generating pixel-level ground truth annotations.
3.3. Evaluation Metrics
Three widely used evaluation metrics are employed. The F1-score is a commonly used metric that evaluates model performance by balancing precision and recall. It is calculated as the harmonic mean of precision and recall, where a higher F1-score indicates a better trade-off between the two. The F1-score is defined as follows:
where and can be expressed as:
IoU is used to measure the spatial overlap accuracy between the model’s predicted saliency region and the ground truth, reflecting the model’s ability to capture target locations. It can be expressed by the formula:
Mean Absolute Error (MAE) is an evaluation metric employed in SOD tasks, which computes the pixel-wise difference between the saliency map S and the ground truth G, and can be expressed as:
where and denote the height and width of the image, respectively. MAE quantifies the discrepancy between the saliency map and the ground truth map, with values ranging within [0, 1].
3.4. Implementation Details
Our framework is implemented using the Pytorch 2.0.0 framework and trained on an NVIDIA RTX 4090 GPU (NVIDIA Corporation, Santa Clara, CA, USA). All input images are uniformly resized to a resolution of 480 × 480. Res2Net-50, pre-trained on ImageNet, is employed as the backbone network. Its output features are reorganized into four hierarchical levels through dimension reshaping. The model is optimized using the AdamW optimizer, with an initial learning rate of 10−4 and a batch size of 16. The learning rate is reduced by half every 40 epochs, and the training process spans a total of 200 epochs.
4. Results and Discussion
4.1. Quantitative Evaluation of Model Performance
Given that the dataset used in this study comprises unaligned RGB and IR fire data, and that models specifically designed for such unaligned scenarios remain scarce, we selected six state-of-the-art (SOTA) RGB-T models from the past three years for evaluation. Among them, five are designed for pre-aligned data but demonstrate strong performance on their respective benchmarks, while one is explicitly developed for saliency detection in misaligned modalities. To ensure a fair comparison, all models were trained using identical hyperparameter settings. The comparative results across three evaluation metrics are summarized in Table 1.

Table 1.
Benchmarking Recent RGB-T Models: A Performance Evaluation Based on F1, IoU, and MAE Metrics.
Among these, LSNet, CSRNet, MCFNet, TNet, MGAL, and SACNet are models that have demonstrated superior performance in RGB-T SOD tasks over the past three years. Notably, SACNet is specifically designed for handling misaligned data in SOD. Comparative experiments were conducted using the default parameters of these models.
Table 1 presents the evaluation results of our proposed model and state-of-the-art RGB-T methods from the past three years on two datasets: indoor fire and outdoor wildfire scenes. As shown, the first five models, which are designed for pre-aligned images, demonstrate limited performance when handling misaligned data. Since both datasets used in this study are unaligned, the Indoor-Fire dataset, due to sensor differences between visible light and infrared cameras and variations in installation positions, effectively represents real-world scenarios for large-scale multi-modal (RGB and IR) fire early warning systems. The Wildfire dataset undergoes random affine transformations, indicating that data in outdoor scenes may not be perfectly aligned due to severe drone jitter.
This misalignment leads to performance degradation when LSNet, CSRNet, MCFNet, TNet, MGAL, and SACNet perform modal feature fusion, resulting in poorer evaluation outcomes on these fire datasets. In comparison, our method significantly outperforms these models, including SACNet, on both datasets. Specifically, on the Wildfire dataset, our method surpasses the comparative methods in terms of MAE, IoU, and F1 scores. When compared to the optimal RGB-T method under misalignment conditions, our method improves MAE, IoU, and F1 by 1.2%, 11.9%, and 11.3%, respectively, on the Indoor-Fire dataset.
We observed a decrease in performance metrics when testing on the Fire in historic buildings dataset compared to the first two datasets. Specifically, the F1-score decreased by 2.8% and the IoU dropped by 6.5% compared to testing on the Indoor-fire dataset. The MAE increased across all metrics, with the maximum difference reaching 1.1%. Upon analysis, we found that both the RGB and infrared modalities in the Fire in historic buildings dataset suffer from significant interference, including multiple thermal source disturbances. Additionally, texture features are challenging to separate from actual fire signals. Since the interference affects both the visible and infrared modalities simultaneously, the complementary effect between the two modalities is limited. To address this issue, more robust cross-modal fusion strategies could be explored, or the motion characteristics of the fire could be incorporated into the fire detection model.
Furthermore, our method’s evaluation performance on the Indoor-Fire dataset is slightly inferior to SACNet. By analyzing the data with relatively lower evaluation metrics, we found that the SACNet model uses complex multi-head cross-attention [30] computation in its feature interaction module. Additionally, we employed Swin-Transformer as the backbone network for SACNet and observed that its performance yields better evaluation metrics compared to using Res2Net50. This improvement is due to Swin-Transformer’s strong global modeling capability, which excels in feature extraction, particularly for small target flames in the Indoor-Fire dataset. However, Swin-B has nearly four times the number of parameters as Res2Net50. Considering the real-time detection requirements for fire detection, we decided not to use Swin-Transformer as the backbone network. In our ablation studies, we compared MobileViT, a backbone network with fewer parameters, which combines the local feature extraction capabilities of CNNs and the global modeling capabilities of Transformers, to explore the impact of smaller backbone networks on model performance.
4.2. Qualitative Comparison of Methods
Figure 8, Figure 9 and Figure 10 present visual comparisons between our method and other approaches. Specifically, Figure 8 shows a comparison of various models on the Wildfire dataset, categorized by illumination conditions and target scale. It is evident that for prominent targets, such as fire, all models can predict the flame boundaries. However, due to the random affine transformations applied to the dataset, except for our method and SACNet, the remaining predicted saliency maps exhibit deformations or positional deviations. This misalignment affects the performance of the models. Since this paper primarily focuses on saliency detection under misalignment, models designed for pre-aligned data are not extensively compared. As shown in Figure 7, networks designed with misalignment-aware fusion modules outperform those based on alignment-based fusion networks, even if the latter achieve state-of-the-art performance on their respective datasets.
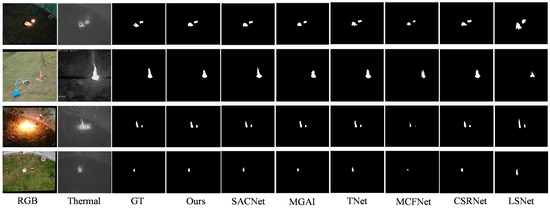
Figure 8.
Visual Comparison Results on the Wildfire Dataset.
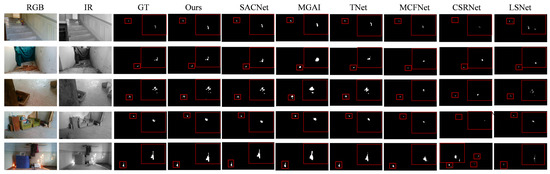
Figure 9.
Visual comparison results on the Indoor-Fire dataset. The red boxes indicate enlarged views of the detected targets.
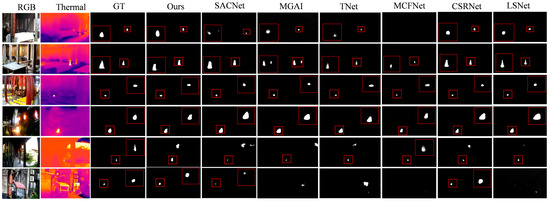
Figure 10.
Visual Comparison Results on the Fire in historic buildings. The red boxes indicate enlarged views of the detected targets.
Figure 9 presents the visual comparison on the Indoor-Fire dataset. Due to the relatively small size of the fire targets, we performed target region magnification, with the red bounding box indicating the magnified target. Five representative results are selected, covering common indoor fire scenes, such as stairwells, corridors, living room sofas, and wooden tables. The first result demonstrates a fire in a stairwell, where the fire target in the IR spectrum is more clearly defined than in the RGB spectrum, showing that our method provides better fire region prediction coverage than other models. A comparison with SACNet reveals that SACNet outperforms our method in some cases. For instance, in the third set of results, our model misjudged the fire region due to the absence of complex spatial cross-calculations. However, this issue does not occur in all data; in the other four sets of results, our predictions are highly consistent with the ground truth.
Figure 10 presents a comparative performance analysis of various models on the Fire in historic buildings dataset. The first and second rows display the results under occlusion conditions, where it is evident that the RGB modality fails to detect the fire source’s location. Although the infrared (IR) modality can indicate the presence of fire, it still suffers from thermal source interference. By comparison, our method successfully detects the precise location of the fire, whereas other methods, while able to detect the fire source, exhibit inaccuracies, mainly in the form of under-detection or misalignment in detection.
The third and fourth rows illustrate scenarios with lighting interference and similar fire source interference. In these cases, all models are able to detect the presence of fire, but the results show that after applying modality misalignment correction, our model’s saliency map coverage and precision outperform those of models trained on pre-registered data. The fifth and sixth rows represent scenarios with significant interference in both modalities. In the fifth row, the fire in both the RGB and IR modalities is difficult to distinguish from the environment. In the sixth row, the heating water tank and the heat-absorbing carport both exhibit thermal information, with the flame in the RGB modality being overlaid with a similar fire source, such as a lantern. These situations lead to inaccurate saliency map predictions, with both missed detections and false positives occurring.
To further evaluate our method on pre-aligned data, we trained our model on the Wildfire dataset [4]. Figure 11 presents the model’s output on the pre-aligned dataset. The results show that the model performs well on both unaligned and pre-aligned data, automatically establishing correlations between misaligned modalities. This indicates that the model can adapt to fusion scenarios involving aligned, weakly aligned, and unaligned modalities, producing salient results.

Figure 11.
Visual demonstration of our model under alignment data.
4.3. Model Parameters and Computational Complexity
The real-time performance of fire saliency detection is a crucial factor when evaluating model effectiveness. To better reflect the complexity of the models, we present the number of parameters (Params) and floating-point operations (FLOPs) for various model types, as shown in Table 2. Multi-modal fusion networks typically employ dual-branch backbone networks for feature extraction, resulting in a higher number of parameters and FLOPs compared to single-branch networks, which is an important consideration for multi-modal architectures. As seen in Table 2, most multi-modal networks have approximately 80 M parameters. Our network utilizes Res2Net-50, with its dual-branch backbone accounting for about 50 M parameters, which constitutes 55% of the total network parameters and is critical for performance.
Table 2.
Comparison of Params and FLOPS Across Various Comparative Models.
Through the quantitative and qualitative analyses above, it can be observed that SACNet’s results on both datasets are comparable to or even outperform our method. However, when considering the overall parameters and FLOPs, SACNet’s parameters are three times greater than ours, and its computational complexity, in terms of FLOPs, is also higher. Under the same computational configuration, the inference speed of SACNet is 30 FPS, while our method achieves 75 FPS. Although our model includes a DAM module, the total number of parameters and FLOPs in our model remains comparable to those of typical multi-modal networks.
To further illustrate the relationship between model complexity and evaluation performance, we present two scatter plots. Figure 12 and Figure 13 depict the relationship between each model’s number of parameters (Params) and its F1 and IoU scores, respectively. As shown, our model achieves high F1 and IoU scores with significantly lower complexity compared to SACNet, while maintaining comparable complexity to the other models.
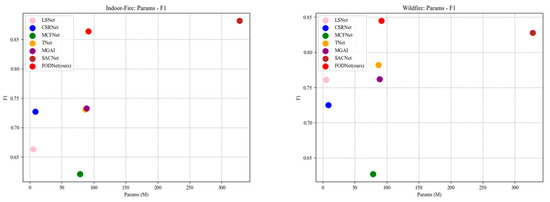
Figure 12.
Scatter Plot of the Relationship Between Params and F1 Across Different Models.
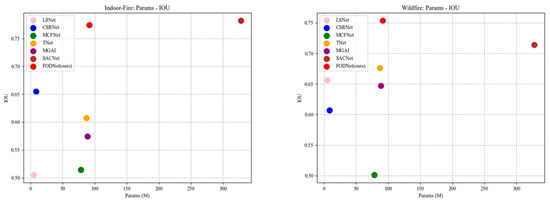
Figure 13.
Scatter Plot of the Relationship Between Params and IoU Across Different Models.
4.4. Ablation Study
To evaluate the effectiveness of the key components in our proposed method, we conducted ablation experiments on the Indoor-Fire dataset. The results are summarized in Table 3. Comparison of Metrics Across Modules in Ablation Experiments. First, we replaced the backbone network, denoted as M1. Specifically, Res2Net-50 was substituted with MobileViT [33], a lightweight backbone that integrates the local inductive bias of CNNs with the global contextual modeling capability of Transformers. Through hierarchical design and parameter optimization, MobileViT significantly reduces the number of parameters and computational complexity while preserving feature representation capability. Second, we ablated the CCM module by removing it and instead performing feature interaction through direct concatenation of RGB and IR features at each layer. This variant is denoted as M2. Third, we evaluated the contribution of the DAM module by removing it during the fusion stage and replacing it with simple element-wise addition of features at each layer, denoted as M3. Finally, we investigated the impact of upsampling depth in the decoding stage. We removed the top two upsampling blocks and retained only the final one. This configuration, denoted as M4, was used to analyze how the number of upsampling blocks influences performance.
Table 3.
Comparison of Metrics Across Modules in Ablation Experiments.
As shown in Table 3, using Res2Net-50 as the backbone network yields superior performance compared to M1. Although the dual-branch configuration of Res2Net-50 results in approximately 50 M parsameters, while MobileViT-S has only about 12 M, MobileViT exhibits weaker capability in capturing fine-grained local features and lacks sufficient multi-scale representation. Its lower feature resolution at each layer leads to suboptimal saliency detection performance. As illustrated in Figure 14. Visualization of Saliency Maps with MobileViT as Backbone., it generates numerous small and fragmented saliency regions, primarily due to insufficient detail extraction. Despite achieving a fourfold reduction in parameters, accurate extraction of the actual fire area is crucial, especially for downstream applications such as real-time fire spread prediction or heat release rate estimation based on flame images.

Figure 14.
Visualization of Saliency Maps with MobileViT as Backbone.The red boxes indicate enlarged views of the detected targets.
A comparison between our model and M2 further confirms the effectiveness of our design. While simple concatenation retains modality-specific features independently, deep-level cross-modal interaction prior to fusion facilitates alignment and complementary feature integration, thereby enhancing saliency detection performance. In contrast to methods such as Reference [14], which employ multi-head attention Reference [34] at each layer for cross-modal modeling—resulting in substantial model complexity—we account for the inherent spatial inconsistencies between modalities and avoid complex spatial-domain operations Reference [35]. Instead, we adopt channel attention to perform lightweight and effective cross-modal feature enhancement.
A comparison with M2 demonstrates that our model achieves superior performance. While simple concatenation preserves modality-specific features independently, deep cross-modal interaction prior to fusion facilitates more effective feature alignment and integration. This is particularly important given the complementarity and heterogeneity of multimodal features, thereby enhancing saliency detection performance. Compared to approaches such as Reference [14], which apply multi-head attention at each layer for cross-modal modeling—resulting in increased model complexity—we account for spatial inconsistencies between modalities and avoid complex spatial-domain operations. Instead, we employ channel attention to achieve efficient cross-modal feature enhancement.
When compared with M3, this module was found to have the most significant impact on overall model performance. As shown in Table 2, M3 led to a decline of 2.1%, 31.3%, and 25.4% in MAE, IoU, and F1 scores, respectively, compared to our full model. M3 employs simple convolutional transformations and direct summation, which fuses spatially inconsistent features without proper alignment. This approach fails to effectively integrate features from misaligned modalities, highlighting the effectiveness of our dual-guided deformable alignment fusion module in addressing spatial inconsistency during fusion.
To explore the depth of upsampling blocks, the results for M4 show a decrease across all three metrics, indicating that a certain depth of upsampling blocks is necessary in the decoding part.
5. Conclusions
This study addresses the critical challenge of multimodal fusion errors arising from sensor misalignment in real-world fire detection scenarios. To tackle this problem, we proposed an end-to-end multimodal saliency detection framework capable of dynamically fusing cross-modal features without explicit pre-registration. The major conclusions are summarized as follows:
- (1)
- We constructed an unregistered RGB-IR dataset for indoor fire scenarios, covering diverse environments and fire conditions. This dataset provides essential support for research on multimodal fusion under spatial misalignment.
- (2)
- The proposed framework integrates a Channel Cross-Enhancement Module (CCM) and a Deformable Alignment Module (DAM), which jointly enhance cross-modal interaction and progressively correct geometric deviations.
- (3)
- Experimental validation demonstrates that our method achieves F1 = 0.864 and IoU = 0.774 on the Indoor-Fire dataset, surpassing SACNet by +11.9% IoU and +11.3% F1. On the Wildfire dataset, our method also outperforms competing approaches with F1 = 0.845 and IoU = 0.754 while maintaining lower parameter complexity (91.9 M, 28.1% of SACNet). In addition, when tested on the complex Fire in historic buildings dataset, our method also demonstrates strong performance, achieving F1 = 0.836 and IoU = 0.709.
- (4)
- The proposed model achieves a favorable balance between accuracy and efficiency, making it suitable for real-world deployment in intelligent firefighting systems.
- (5)
- Limitations remain: (i) the scale and diversity of available datasets still restrict model generalizability; (ii) inference speed requires further optimization for time-sensitive applications. Future work will expand multimodal fire datasets and explore more efficient fusion strategies.
Future work will focus on expanding multimodal fire datasets to cover a broader range of scenarios and explore alternative modality combinations. Additionally, we will investigate more efficient fusion strategies to better balance detection accuracy and real-time performance in life-critical applications.
Author Contributions
Conceptualization, N.S., J.Z. and K.H.; methodology, J.Z. and K.H.; software, J.Z. and C.W.; validation, C.W. and Z.W.; formal analysis, N.S., J.Z. and K.H.; investigation, Z.W. and L.S.; resources, J.Z. and C.W.; data curation, C.W. and Z.W.; writing—original draft preparation, N.S., J.Z. and L.S.; writing—review and editing, N.S. and K.H.; visualization, J.Z. and C.W.; supervision, N.S.; project administration, N.S. and K.H. All authors have read and agreed to the published version of the manuscript.
Funding
The research in this article was supported by the Jiangsu Postgraduate Innovation Project (Nos. SJCX25_0534 and SJCX25_0488).
Data Availability Statement
Requests for more data can be addressed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Sharma, A.; Kumar, R.; Kansal, I.; Popli, R.; Khullar, V.; Verma, J.; Kumar, S. Fire detection in urban areas using multimodal data and federated learning. Fire 2024, 7, 104. [Google Scholar] [CrossRef]
- Celik, T.; Demirel, H. Fire detection in video sequences using a generic color model. Fire Saf. J. 2009, 44, 147–158. [Google Scholar] [CrossRef]
- Shen, P.; Sun, N.; Hu, K.; Ye, X.; Wang, P.; Xia, Q.; Wei, C. FireViT: An adaptive lightweight backbone network for fire detection. Forests 2023, 14, 2158. [Google Scholar] [CrossRef]
- Rui, X.; Li, Z.; Zhang, X.; Li, Z.; Song, W. An RGB-thermal based adaptive modality learning network for day–night wildfire identification. Int. J. Appl. Earth Obs. Geoinf. 2023, 125, 103554. [Google Scholar] [CrossRef]
- Chen, X.; Hopkins, B.; Wang, H.; O’Neill, L.; Afghah, F.; Razi, A.; Fulé, P.; Coen, J.; Rowell, E.; Watts, A. Wildland fire detection and monitoring using a drone-collected RGB/IR image dataset. IEEE Access 2022, 10, 121301–121317. [Google Scholar] [CrossRef]
- Yuan, F.; Li, K.; Wang, C.; Fang, Z. A lightweight network for smoke semantic segmentation. Pattern Recognit. 2023, 137, 109289. [Google Scholar] [CrossRef]
- Muksimova, S.; Mardieva, S.; Cho, Y.-I. Deep encoder–decoder network-based wildfire segmentation using drone images in real-time. Remote Sens. 2022, 14, 6302. [Google Scholar] [CrossRef]
- Doshi, J.; Garcia, D.; Massey, C.; Llueca, P.; Borensztein, N.; Baird, M.; Cook, M.; Raj, D. FireNet: Real-time segmentation of fire perimeter from aerial video. arXiv 2019, arXiv:1910.06407. [Google Scholar]
- Li, M.; Zhang, Y.; Mu, L.; Xin, J.; Yu, Z.; Jiao, S.; Liu, H.; Xie, G.; Yingmin, Y. A real-time fire segmentation method based on a deep learning approach. IFAC-PapersOnLine 2022, 55, 145–150. [Google Scholar] [CrossRef]
- Ahmad, N.; Akbar, M.; Alkhammash, E.H.; Jamjoom, M.M. CN2VF-Net: A hybrid convolutional neural network and vision transformer framework for multi-scale fire detection in complex environments. Fire 2025, 8, 211. [Google Scholar] [CrossRef]
- Sun, W.; Liu, Y.; Wang, F.; Hua, L.; Fu, J.; Hu, S. A study on flame detection method combining visible light and thermal infrared multimodal images. Fire Technol. 2024, 61, 2167–2188. [Google Scholar] [CrossRef]
- Liu, Y.; Zheng, C.; Liu, X.; Tian, Y.; Zhang, J.; Cui, W. Forest fire monitoring method based on UAV visual and infrared image fusion. Remote Sens. 2023, 15, 3173. [Google Scholar] [CrossRef]
- Tlig, M.; Bouchouicha, M.; Sayadi, M.; Moreau, E. Fire segmentation with an optimized weighted image fusion method. Electronics 2024, 13, 3175. [Google Scholar] [CrossRef]
- Kim, D.; Ruy, W. CNN-based fire detection method on autonomous ships using composite channels composed of RGB and IR data. Int. J. Nav. Archit. Ocean. Eng. 2022, 14, 100489. [Google Scholar] [CrossRef]
- Guo, Y.; Zhang, Y.; Wang, R. Inverse asymptotic fusion framework for fusion of infrared and visible images of fires. In Proceedings of the 2024 International Conference on Image Processing, Computer Vision and Machine Learning (ICICML), Beijing, China, 22 November 2024; pp. 139–143. [Google Scholar]
- Niu, K.; Wang, C.; Xu, J.; Liang, J.; Zhou, X.; Wen, K.; Lu, M.; Yang, C. Early forest fire detection with UAV image fusion: A novel deep learning method using visible and infrared sensors. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 6617–6629. [Google Scholar] [CrossRef]
- Guo, S.; Hu, B.; Huang, R. Real-time flame segmentation based on RGB-thermal fusion. In Proceedings of the 2021 IEEE International Conference on Robotics and Biomimetics (ROBIO), Sanya, China, 27 December 2021; pp. 1435–1440. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Chen, P.; Chen, Y.; Yang, D.; Wu, F.; Li, Q.; Xia, Q.; Tan, Y. I2UV-HandNet: Image-to-UV prediction network for accurate and high-fidelity 3D hand mesh modeling. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 12929–12938. [Google Scholar] [CrossRef]
- Song, K.; Xue, X.; Wen, H.; Ji, Y.; Yan, Y.; Meng, Q. Misaligned visible-thermal object detection: A drone-based benchmark and baseline. IEEE Trans. Intell. Veh. 2024, 9, 7449–7460. [Google Scholar] [CrossRef]
- Wang, K.; Lin, D.; Li, C.; Tu, Z.; Luo, B. Alignment-free RGBT salient object detection: Semantics-guided asymmetric correlation network and a unified benchmark. IEEE Trans. Multimed. 2024, 26, 10692–10707. [Google Scholar] [CrossRef]
- Zhang, T.; He, X.; Jiao, Q.; Zhang, Q.; Han, J. AMNet: Learning to align multi-modality for RGB-T tracking. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 7386–7400. [Google Scholar] [CrossRef]
- Li, C.; Gao, S.; Deng, C.; Xie, D.; Liu, W. Cross-modal learning with adversarial samples. In Advances in Neural Information Processing Systems (NeurIPS); Curran Associates: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Park, L.H.; Kim, J.; Oh, M.G.; Park, J.; Kwon, T. Adversarial feature alignment: Balancing robustness and accuracy in deep learning via adversarial training. In Proceedings of the 2024 Workshop on Artificial Intelligence and Security (AISec), Copenhagen, Denmark, 6 November 2024; pp. 101–112. [Google Scholar]
- Chaoxia, C.; Shang, W.; Zhang, F.; Cong, S. Weakly aligned multimodal flame detection for fire-fighting robots. IEEE Trans. Ind. Inform. 2022, 19, 2866–2875. [Google Scholar] [CrossRef]
- Wen, X.; Zhao, J.; He, Y.; Yin, H. Three-decoder cross-modal interaction network for unregistered RGB-T salient object detection. IEEE Trans. Instrum. Meas. 2025, 74, 1–13. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar] [CrossRef]
- Peng, H.; Hu, Y.; Yu, B.; Zhang, Z. TCAINet: An RGB-T salient object detection model with cross-modal fusion and adaptive decoding. Sci. Rep. 2025, 15, 14266. [Google Scholar] [CrossRef] [PubMed]
- Gao, S.H.; Cheng, M.M.; Zhao, K.; Zhang, X.Y.; Yang, M.H.; Torr, P. Res2Net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 652–662. [Google Scholar] [CrossRef] [PubMed]
- Hu, K.; Xu, K.; Xia, Q.; Li, M.; Song, Z.; Song, L.; Sun, N. An Overview: Attention Mechanisms in Multi-Agent Reinforcement Learning. Neurocomputing 2024, 598, 128105. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems (NeurIPS); Curran Associates: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar] [CrossRef]
- Mehta, S.; Rastegari, M. MobileViT: Light-weight, general-purpose, and mobile-friendly vision transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Hu, K.; Zhang, Q.; Feng, X.; Liu, Z.; Shao, P.; Xia, M.; Ye, X. An Interpolation and Prediction Algorithm for XCO2 based on Multi-Source Time Series Data. Remote Sens. 2024, 16, 1907. [Google Scholar] [CrossRef]
- Hu, K.; Li, M.; Song, Z.; Xu, K.; Xia, Q.; Sun, N.; Zhou, P.; Xia, M. A Review of Research on Reinforcement Learning Algorithms for Multi-Agent. Neurocomputing 2024, 599, 128068. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).