

Data-Driven PM2.5 Exposure Prediction in Wildfire-Prone Regions and Respiratory Disease Mortality Risk Assessment



Abstract
1. Introduction
2. Methods and Materials
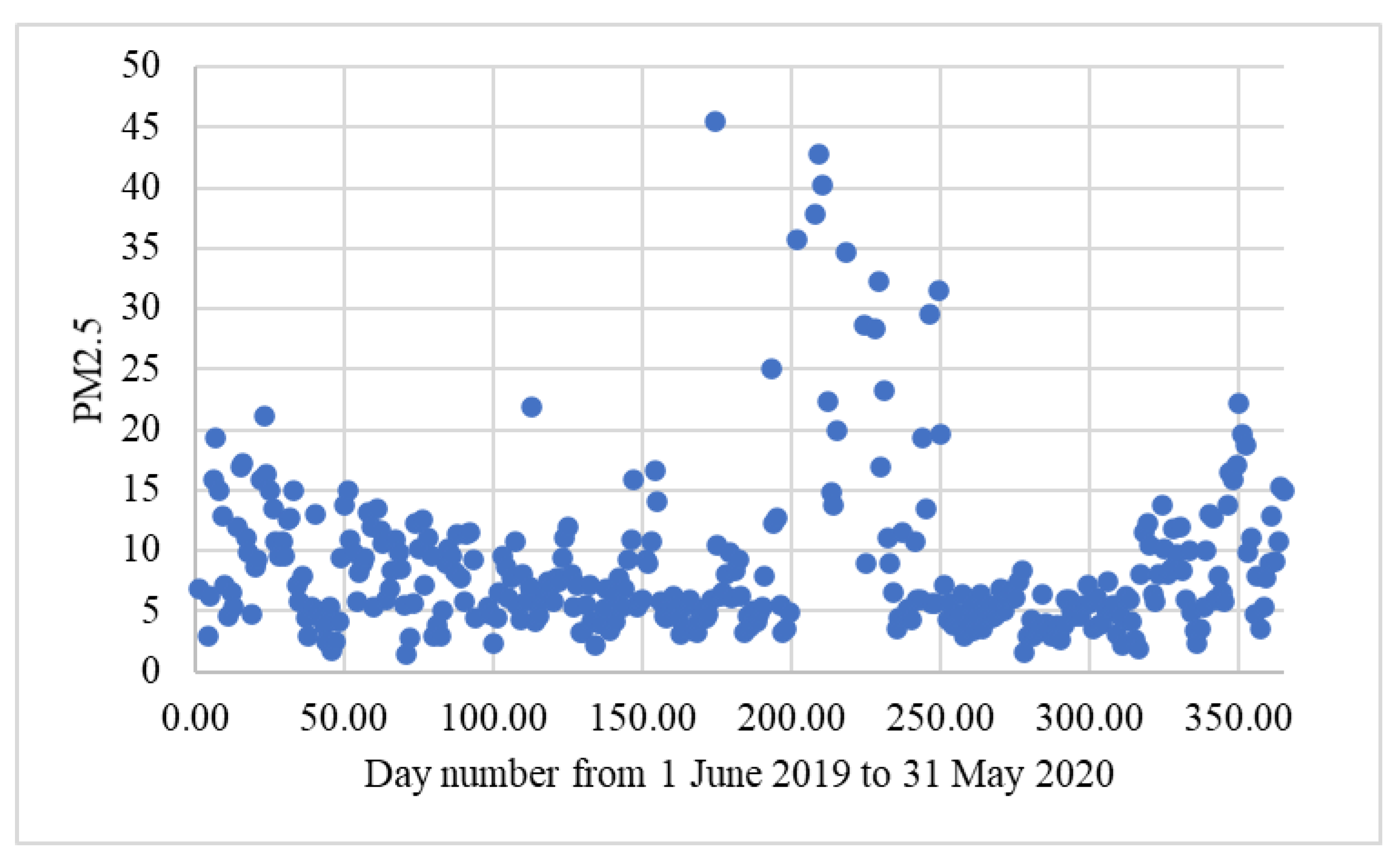
2.1. Dataset Description
2.2. Data-Driven Models
2.3. Removing Outliers
2.4. Model Evaluation and Interpretation
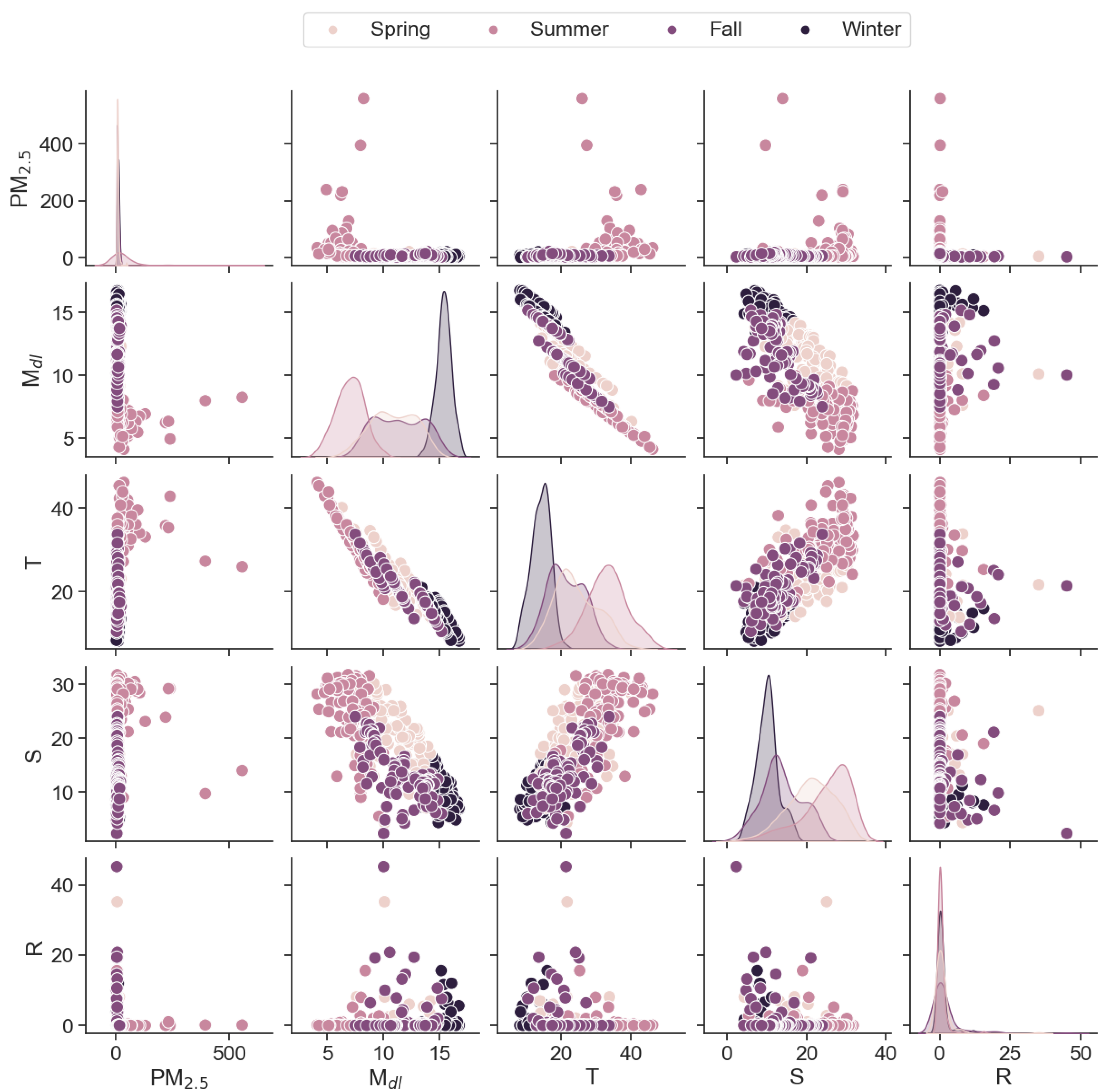
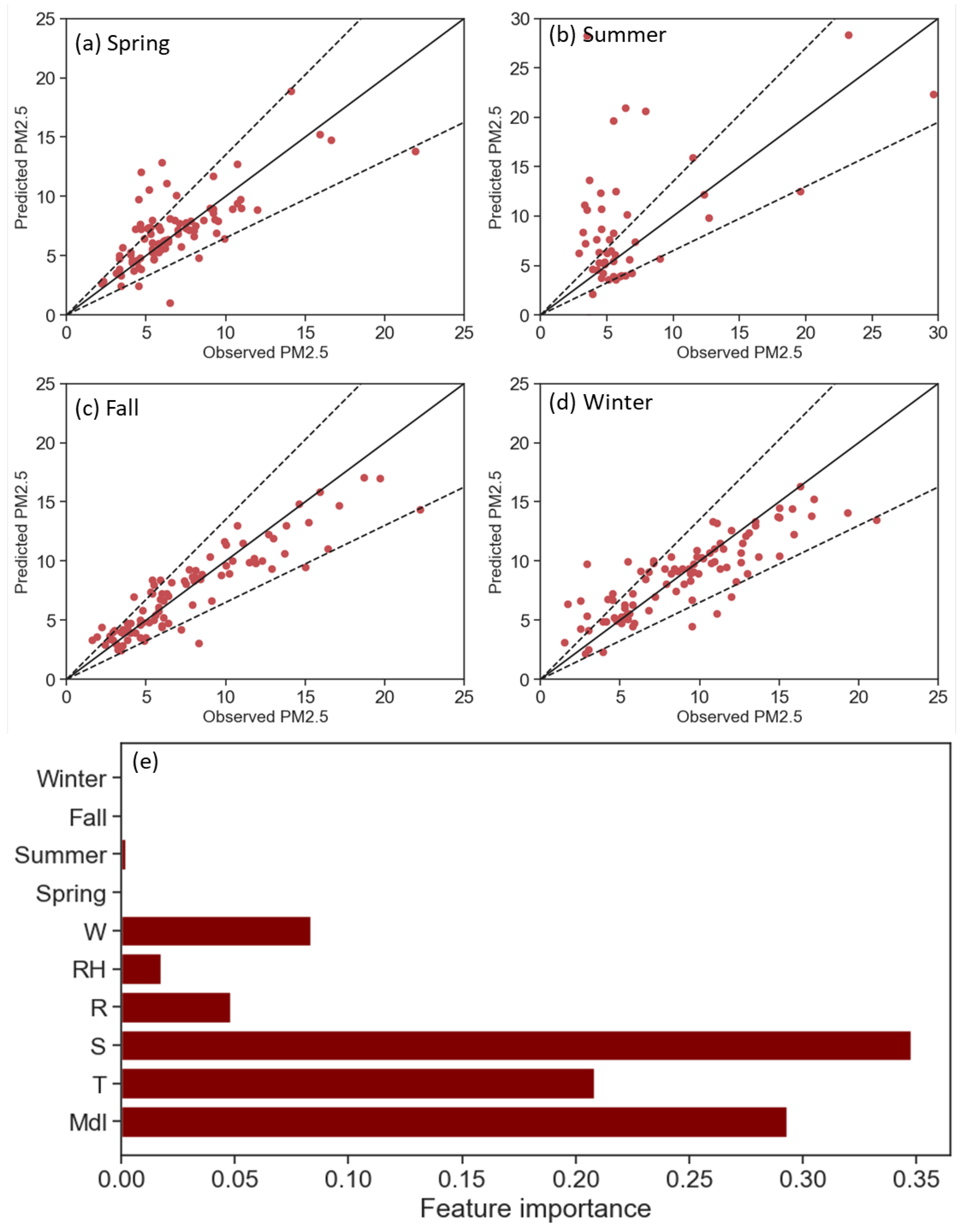
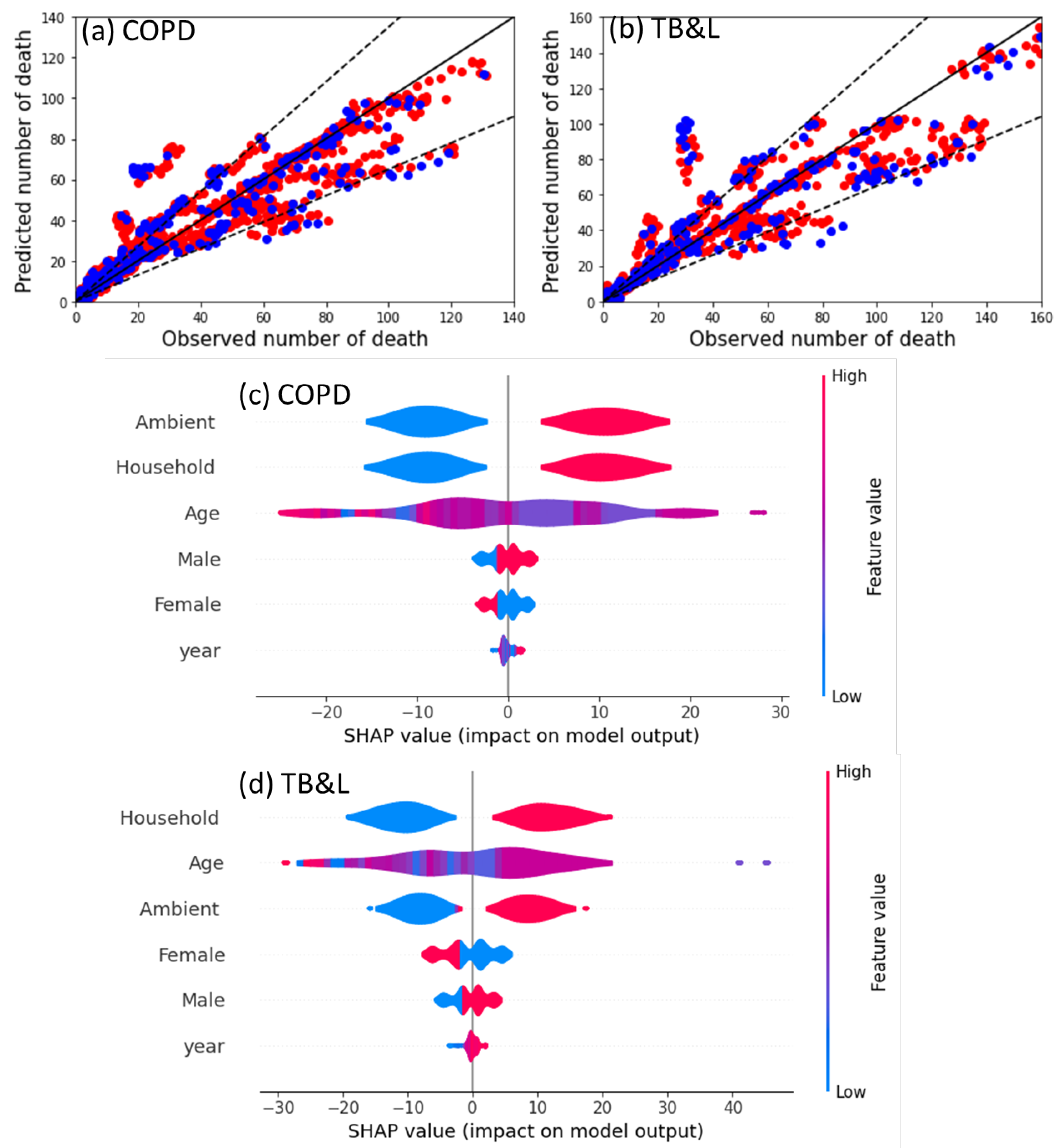
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bhowmik, R.T.; Jung, Y.S.; Aguilera, J.A.; Prunicki, M.; Nadeau, K. A multi-modal wildfire prediction and early-warning system based on a novel machine learning framework. J. Environ. Manag. 2023, 341, 117908. [Google Scholar] [CrossRef] [PubMed]
- Rodrigues, M.; Cunill Camprubí, À.; Balaguer-Romano, R.; Coco Megía, C.J.; Castañares, F.; Ruffault, J.; Fernandes, P.M.; Resco de Dios, V. Drivers and implications of the extreme 2022 wildfire season in Southwest Europe. Sci. Total Environ. 2023, 859, 160320. [Google Scholar] [CrossRef] [PubMed]
- Cong, J.; Gao, C.; Han, D.; Li, Y.; Wang, G. Stability of the permafrost peatlands carbon pool under climate change and wildfires during the last 150 years in the northern Great Khingan Mountains, China. Sci. Total Environ. 2020, 712, 136476. [Google Scholar] [CrossRef] [PubMed]
- Mansoor, S.; Farooq, I.; Kachroo, M.M.; Mahmoud, A.E.D.; Fawzy, M.; Popescu, S.M.; Alyemeni, M.N.; Sonne, C.; Rinklebe, J.; Ahmad, P. Elevation in wildfire frequencies with respect to the climate change. J. Environ. Manag. 2022, 301, 113769. [Google Scholar] [CrossRef] [PubMed]
- Miezïte, L.E.; Ameztegui, A.; De Cáceres, M.; Coll, L.; Morán-Ordóñez, A.; Vega-García, C.; Rodrigues, M. Trajectories of wildfire behavior under climate change. Can forest management mitigate the increasing hazard? J. Environ. Manag. 2022, 322, 116134. [Google Scholar] [CrossRef] [PubMed]
- Kasel, S.; Fairman, T.A.; Nitschke, C.R. Short-Interval, High-Severity Wildfire Depletes Diversity of Both Extant Vegetation and Soil Seed Banks in Fire-Tolerant Eucalypt Forests. Fire 2024, 7, 148. [Google Scholar] [CrossRef]
- Khanmohammadi, S.; Arashpour, M.; Golafshani, E.M.; Cruz, M.G.; Rajabifard, A. An artificial intelligence framework for predicting fire spread sustainability in semiarid shrublands. Int. J. Wildland Fire 2023, 32, 636–649. [Google Scholar] [CrossRef]
- Johnston, F.H.; Borchers-Arriagada, N.; Morgan, G.G.; Jalaludin, B.; Palmer, A.J.; Williamson, G.J.; Bowman, D.M.J.S. Unprecedented health costs of smoke-related PM2.5 from the 2019–2020 Australian megafires. Nat. Sustain. 2021, 4, 42–47. [Google Scholar] [CrossRef]
- Ryan, R.G.; Silver, J.D.; Schofield, R. Air quality and health impact of 2019–2020 Black Summer megafires and COVID-19 lockdown in Melbourne and Sydney, Australia. Environ. Pollut. 2021, 274, 116498. [Google Scholar] [CrossRef] [PubMed]
- He, J.; Huang, C.-H.; Yuan, N.; Austin, E.; Seto, E.; Novosselov, I. Network of low-cost air quality sensors for monitoring indoor, outdoor, and personal PM2.5 exposure in Seattle during the 2020 wildfire season. Atmos. Environ. 2022, 285, 119244. [Google Scholar] [CrossRef]
- Schweizer, D.; Preisler, H.; Entwistle, M.; Gharibi, H.; Cisneros, R. Using a Statistical Model to Estimate the Effect of Wildland Fire Smoke on Ground Level PM2. 5 and Asthma in California, USA. Fire 2023, 6, 159. [Google Scholar] [CrossRef]
- Zhao, L.; Liu, J.; Peters, S.; Li, J.; Mueller, N.; Oliver, S. Learning class-specific spectral patterns to improve deep learning-based scene-level fire smoke detection from multi-spectral satellite imagery. Remote Sens. Appl. Soc. Environ. 2024, 34, 101152. [Google Scholar] [CrossRef]
- Chetoui, M.; Akhloufi, M.A. Fire and Smoke Detection Using Fine-Tuned YOLOv8 and YOLOv7 Deep Models. Fire 2024, 7, 135. [Google Scholar] [CrossRef]
- Ghali, R.; Akhloufi, M.A. Deep learning approaches for wildland fires using satellite remote sensing data: Detection, mapping, and prediction. Fire 2023, 6, 192. [Google Scholar] [CrossRef]
- Jonnalagadda, A.V.; Hashim, H.A. SegNet: A segmented deep learning based Convolutional Neural Network approach for drones wildfire detection. Remote Sens. Appl. Soc. Environ. 2024, 34, 101181. [Google Scholar] [CrossRef]
- Di Virgilio, G.; Hart, M.A.; Maharaj, A.M.; Jiang, N. Air quality impacts of the 2019–2020 Black Summer wildfires on Australian schools. Atmos. Environ. 2021, 261, 118450. [Google Scholar] [CrossRef]
- Xu, Y.; Ho, H.C.; Wong, M.S.; Deng, C.; Shi, Y.; Chan, T.-C.; Knudby, A. Evaluation of machine learning techniques with multiple remote sensing datasets in estimating monthly concentrations of ground-level PM2.5. Environ. Pollut. 2018, 242, 1417–1426. [Google Scholar] [CrossRef] [PubMed]
- Solomon, S. Chlorine activation and enhanced ozone depletion induced by wildfire aerosol. Nature 2023, 615, 259–264. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.C.; Pereira, G.; Uhl, S.A.; Bravo, M.A.; Bell, M.L. A systematic review of the physical health impacts from non-occupational exposure to wildfire smoke. Environ. Res. 2015, 136, 120–132. [Google Scholar] [CrossRef]
- Vedal, S.; Dutton, S.J. Wildfire air pollution and daily mortality in a large urban area. Environ. Res. 2006, 102, 29–35. [Google Scholar] [CrossRef] [PubMed]
- Coker, E.S.; Buralli, R.; Manrique, A.F.; Kanai, C.M.; Amegah, A.K.; Gouveia, N. Association between PM2.5 and respiratory hospitalization in Rio Branco, Brazil: Demonstrating the potential of low-cost air quality sensor for epidemiologic research. Environ. Res. 2022, 214, 113738. [Google Scholar] [CrossRef] [PubMed]
- Reid, C.E.; Jerrett, M.; Tager, I.B.; Petersen, M.L.; Mann, J.K.; Balmes, J.R. Differential respiratory health effects from the 2008 northern California wildfires: A spatiotemporal approach. Environ. Res. 2016, 150, 227–235. [Google Scholar] [CrossRef] [PubMed]
- Navarro, K.M.; Kleinman, M.T.; Mackay, C.E.; Reinhardt, T.E.; Balmes, J.R.; Broyles, G.A.; Ottmar, R.D.; Naher, L.P.; Domitrovich, J.W. Wildland firefighter smoke exposure and risk of lung cancer and cardiovascular disease mortality. Environ. Res. 2019, 173, 462–468. [Google Scholar] [CrossRef] [PubMed]
- Yu, P.; Xu, R.; Li, S.; Yue, X.; Chen, G.; Ye, T.; Coêlho, M.S.Z.S.; Saldiva, P.H.N.; Sim, M.R.; Abramson, M.J. Exposure to wildfire-related PM2. 5 and site-specific cancer mortality in Brazil from 2010 to 2016: A retrospective study. PLoS Med. 2022, 19, e1004103. [Google Scholar] [CrossRef]
- Rolls, E. Land of grass: The loss of Australia’s Grasslands. Aust. Geogr. Stud. 1999, 37, 197–213. [Google Scholar] [CrossRef]
- Hayes, R.C.; Li, G.D.; Hackney, B.F. Perennial pasture species for the mixed farming zone of southern NSW-We don’t have many options. In Driving Your Landscape to Success-Managing a Grazing Business for Profit in the Agricultural Landscape. Proceedings of the 27th Annual Conference of the Grassland Society of NSW Inc., 24–26 July 2012, Wagga Wagga, NSW, Australia; Harris, C., Lodge, G., Waters, C., Eds.; The Grassland Society of NSW Inc.: Wagga Wagga, NSW, Australia, 2012; pp. 92–100. [Google Scholar]
- Cheney, P.; Sullivan, A. Grassfires: Fuel, Weather and Fire Behaviour; CSIRO Publishing: Clayton, VIC, Australia, 2008. [Google Scholar]
- Akdemir, E.A.; Battye, W.H.; Myers, C.B.; Aneja, V.P. Estimating NH 3 and PM 2.5 emissions from the Australia mega wildfires and the impact of plume transport on air quality in Australia and New Zealand. Environ. Sci. Atmos. 2022, 2, 634–646. [Google Scholar] [CrossRef]
- Volkova, L.; Meyer, C.P.; Haverd, V.; Weston, C.J. A data—Model fusion methodology for mapping bushfire fuels for smoke emissions forecasting in forested landscapes of south-eastern Australia. J. Environ. Manag. 2018, 222, 21–29. [Google Scholar] [CrossRef] [PubMed]
- Collins, L.; Trouvé, R.; Baker, P.J.; Cirulus, B.; Nitschke, C.R.; Nolan, R.H.; Smith, L.; Penman, T.D. Fuel reduction burning reduces wildfire severity during extreme fire events in south-eastern Australia. J. Environ. Manag. 2023, 343, 118171. [Google Scholar] [CrossRef] [PubMed]
- Khanmohammadi, S.; Arashpour, M.; Golafshani, E.M.; Cruz, M.G.; Rajabifard, A.; Bai, Y. Prediction of wildfire rate of spread in grasslands using machine learning methods. Environ. Model. Softw. 2022, 156, 105507. [Google Scholar] [CrossRef]
- Cheney, N.; Gould, J.; Catchpole, W.R. Prediction of fire spread in grasslands. Int. J. Wildland Fire 1998, 8, 1–13. [Google Scholar] [CrossRef]
- Jin, H.; Zhong, R.; Liu, M.; Ye, C.; Chen, X. Spatiotemporal distribution characteristics of PM2.5 concentration in China from 2000 to 2018 and its impact on population. J. Environ. Manag. 2022, 323, 116273. [Google Scholar] [CrossRef] [PubMed]
- Merz, E.; Saberski, E.; Gilarranz, L.J.; Isles, P.D.F.; Sugihara, G.; Berger, C.; Pomati, F. Disruption of ecological networks in lakes by climate change and nutrient fluctuations. Nat. Clim. Change 2023, 13, 389–396. [Google Scholar] [CrossRef] [PubMed]
- Gourevitch, J.D.; Kousky, C.; Liao, Y.; Nolte, C.; Pollack, A.B.; Porter, J.R.; Weill, J.A. Unpriced climate risk and the potential consequences of overvaluation in US housing markets. Nat. Clim. Change 2023, 13, 250–257. [Google Scholar] [CrossRef]
- Mattiuzzi, C.; Lippi, G. Worldwide asthma epidemiology: Insights from the Global Health Data Exchange database. In International Forum of Allergy & Rhinology; Wiley Online Library: Hoboken, NJ, USA, 2020; Volume 10, pp. 75–80. [Google Scholar]
- Su, X.; An, J.; Zhang, Y.; Zhu, P.; Zhu, B. Prediction of ozone hourly concentrations by support vector machine and kernel extreme learning machine using wavelet transformation and partial least squares methods. Atmos. Pollut. Res. 2020, 11, 51–60. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, Z.; Zhu, L.; Zhang, F.; Sekerinski, E.; Han, J.-C.; Zhou, Y. Real-time prediction of river chloride concentration using ensemble learning. Environ. Pollut. 2021, 291, 118116. [Google Scholar] [CrossRef] [PubMed]
- Tien Bui, D.; Hoang, N.-D.; Martínez-Álvarez, F.; Ngo, P.-T.T.; Hoa, P.V.; Pham, T.D.; Samui, P.; Costache, R. A novel deep learning neural network approach for predicting flash flood susceptibility: A case study at a high frequency tropical storm area. Sci. Total Environ. 2020, 701, 134413. [Google Scholar] [CrossRef] [PubMed]
- Park, J.; Lee, W.H.; Kim, K.T.; Park, C.Y.; Lee, S.; Heo, T.-Y. Interpretation of ensemble learning to predict water quality using explainable artificial intelligence. Sci. Total Environ. 2022, 832, 155070. [Google Scholar] [CrossRef] [PubMed]
- Bannigan, P.; Bao, Z.; Hickman, R.J.; Aldeghi, M.; Häse, F.; Aspuru-Guzik, A.; Allen, C. Machine learning models to accelerate the design of polymeric long-acting injectables. Nat. Commun. 2023, 14, 35. [Google Scholar] [CrossRef] [PubMed]
- Brauer, C.J.; Sandoval-Castillo, J.; Gates, K.; Hammer, M.P.; Unmack, P.J.; Bernatchez, L.; Beheregaray, L.B. Natural hybridization reduces vulnerability to climate change. Nat. Clim. Change 2023, 13, 282–289. [Google Scholar] [CrossRef]
- Ban, Z.; Hu, X.; Li, J. Tipping points of marine phytoplankton to multiple environmental stressors. Nat. Clim. Change 2022, 12, 1045–1051. [Google Scholar] [CrossRef]
- Khanmohammadi, S.; Cruz, M.G.; Mohammadi Golafshani, E.; Bai, Y.; Arashpour, M. Application of artificial intelligence methods to model the effect of grass curing level on spread rate of fires. Environ. Model. Softw. 2024, 173, 105930. [Google Scholar] [CrossRef]
- Li, Y.; Li, G.; Wang, K.; Wang, Z.; Chen, Y. Forest Fire Risk Prediction Based on Stacking Ensemble Learning for Yunnan Province of China. Fire 2023, 7, 13. [Google Scholar] [CrossRef]
- Susantoro, T.M.; Wikantika, K.; Suliantara, S.; Setiawan, H.L.; Harto, A.B.; Sakti, A.D. Applying random forest to oil and gas exploration in Central Sumatra basin Indonesia based on surface and subsurface data. Remote Sens. Appl. Soc. Environ. 2023, 32, 101039. [Google Scholar] [CrossRef]
- Satpathy, P.; Boopathy, R.; Gogoi, M.M.; Suresh Babu, S.; Das, T. Machine learning techniques to predict atmospheric black carbon in a tropical coastal environment. Remote Sens. Appl. Soc. Environ. 2024, 34, 101154. [Google Scholar] [CrossRef]
- Islam, M.D.; Islam, K.S.; Ahasan, R.; Mia, M.R.; Haque, M.E. A data-driven machine learning-based approach for urban land cover change modeling: A case of Khulna City Corporation area. Remote Sens. Appl. Soc. Environ. 2021, 24, 100634. [Google Scholar] [CrossRef]
- Patton, A.; Datta, A.; Zamora, M.L.; Buehler, C.; Xiong, F.; Gentner, D.R.; Koehler, K. Non-linear probabilistic calibration of low-cost environmental air pollution sensor networks for neighborhood level spatiotemporal exposure assessment. J. Expo Sci. Environ. Epidemiol. 2022, 32, 908–916. [Google Scholar] [CrossRef] [PubMed]
- Callaghan, M.; Schleussner, C.-F.; Nath, S.; Lejeune, Q.; Knutson, T.R.; Reichstein, M.; Hansen, G.; Theokritoff, E.; Andrijevic, M.; Brecha, R.J.; et al. Machine-learning-based evidence and attribution mapping of 100,000 climate impact studies. Nat. Clim. Change 2021, 11, 966–972. [Google Scholar] [CrossRef]
- Hartonen, T.; Jermy, B.; Sõnajalg, H.; Vartiainen, P.; Krebs, K.; Vabalas, A.; Metspalu, A.; Esko, T.; Nelis, M.; Hudjashov, G.; et al. Nationwide health, socio-economic and genetic predictors of COVID-19 vaccination status in Finland. Nat. Hum. Behav. 2023, 7, 1069–1083. [Google Scholar] [CrossRef] [PubMed]
- Wright, D.P.; Thyer, M.; Westra, S.; Renard, B.; McInerney, D. A generalised approach for identifying influential data in hydrological modelling. Environ. Model. Softw. 2019, 111, 231–247. [Google Scholar] [CrossRef]
- Davis, K.L.; Colefax, A.P.; Tucker, J.P.; Kelaher, B.P.; Santos, I.R. Global coral reef ecosystems exhibit declining calcification and increasing primary productivity. Commun. Earth Environ. 2021, 2, 105. [Google Scholar] [CrossRef]
- Basheer, M.; Nechifor, V.; Calzadilla, A.; Gebrechorkos, S.; Pritchard, D.; Forsythe, N.; Gonzalez, J.M.; Sheffield, J.; Fowler, H.J.; Harou, J.J. Cooperative adaptive management of the Nile River with climate and socio-economic uncertainties. Nat. Clim. Change 2023, 13, 48–57. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.-I. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef] [PubMed]
- Romero, G.Q.; Gonçalves-Souza, T.; Kratina, P.; Marino, N.A.C.; Petry, W.K.; Sobral-Souza, T.; Roslin, T. Global predation pressure redistribution under future climate change. Nat. Clim. Change 2018, 8, 1087–1091. [Google Scholar] [CrossRef]
- Algavi, Y.M.; Borenstein, E. A data-driven approach for predicting the impact of drugs on the human microbiome. Nat. Commun. 2023, 14, 3614. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Ogawa, S. Effects of Meteorological Conditions on PM2.5 Concentrations in Nagasaki, Japan. Int J Environ. Res Public Health 2015, 12, 9089–9101. [Google Scholar] [CrossRef] [PubMed]
- Arashpour, M. AI explainability framework for environmental management research. J. Environ. Manag. 2023, 342, 118149. [Google Scholar] [CrossRef] [PubMed]
- Chalian, H.; Khoshpouri, P.; Assari, S. Patients’ age and discussion with doctors about lung cancer screening: Diminished returns of Blacks. Aging Med. 2019, 2, 35–41. [Google Scholar] [CrossRef] [PubMed]
- Waskom, M.L. Seaborn: Statistical data visualization. J. Open Source Softw. 2021, 6, 3021. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RMSE | MAE | MAPE | MBE | |
|---|---|---|---|---|
| ||||
| Support Vector Regression (SVR) | 28.3 | 8.5 | 54% | −6.1 |
| Multi-layer Perceptron (MLP) | 23.7 | 8.6 | 84% | 0.1 |
| Random Forest (RF) | 23.2 | 8.1 | 71% | −1.2 |
| Extreme Gradient Boosting (XGBoost) | 30.1 | 10.6 | 81% | −0.65 |
| Natural Gradient Boosting (NGBoost) | 23.4 | 8.0 | 66% | −1.5 |
| ||||
| Support Vector Regression (SVR) | 24.1 | 14.0 | 155% | −6.8 |
| Multi-layer Perceptron (MLP) | 28.1 | 21.6 | 2824% | −18.67 |
| Random Forest (RF) | 12.42 | 5.3 | 32% | −0.1 |
| Extreme Gradient Boosting (XGBoost) | 11.1 | 5.7 | 47% | −0.4 |
| Natural Gradient Boosting (NGBoost) | 11.2 | 5.6 | 139% | 0.1 |
| ||||
| Support Vector Regression (SVR) | 25.1 | 13.9 | 342% | −5.0 |
| Multi-layer Perceptron (MLP) | 27.3 | 18.3 | 216% | −4.2 |
| Random Forest (RF) | 13.9 | 6.7 | 38% | −0.38 |
| Extreme Gradient Boosting (XGBoost) | 21.4 | 9.5 | 251% | −0.03 |
| Natural Gradient Boosting (NGBoost) | 14.3 | 6.4 | 128% | 0.07 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khanmohammadi, S.; Arashpour, M.; Bazli, M.; Farzanehfar, P. Data-Driven PM2.5 Exposure Prediction in Wildfire-Prone Regions and Respiratory Disease Mortality Risk Assessment. Fire 2024, 7, 277. https://doi.org/10.3390/fire7080277
Khanmohammadi S, Arashpour M, Bazli M, Farzanehfar P. Data-Driven PM2.5 Exposure Prediction in Wildfire-Prone Regions and Respiratory Disease Mortality Risk Assessment. Fire. 2024; 7(8):277. https://doi.org/10.3390/fire7080277
Chicago/Turabian StyleKhanmohammadi, Sadegh, Mehrdad Arashpour, Milad Bazli, and Parisa Farzanehfar. 2024. "Data-Driven PM2.5 Exposure Prediction in Wildfire-Prone Regions and Respiratory Disease Mortality Risk Assessment" Fire 7, no. 8: 277. https://doi.org/10.3390/fire7080277
APA StyleKhanmohammadi, S., Arashpour, M., Bazli, M., & Farzanehfar, P. (2024). Data-Driven PM2.5 Exposure Prediction in Wildfire-Prone Regions and Respiratory Disease Mortality Risk Assessment. Fire, 7(8), 277. https://doi.org/10.3390/fire7080277