


FFYOLO: A Lightweight Forest Fire Detection Model Based on YOLOv8


Abstract
1. Introduction
- Through data analysis, an attention module with asymmetric dilated convolutions is designed, which allows the convolutional kernels to closely adhere to the target for feature extraction. And, detection head is improved to achieve a balance between accuracy and speed.
- The MPDIoU loss function, which utilizing the geometric properties of bounding box regression, is introduced to enhance the model’s convergence speed and detection accuracy.
- The lightweight GSConv is used to replace standard convolution, alleviating the parameters increase caused by the attention module and make model more lightweight.
- Knowledge distillation strategy is adopted in the training stage, so that FFYOLO can learn more intrinsic connections between features, thereby improving the model’s generalization ability and detection accuracy.
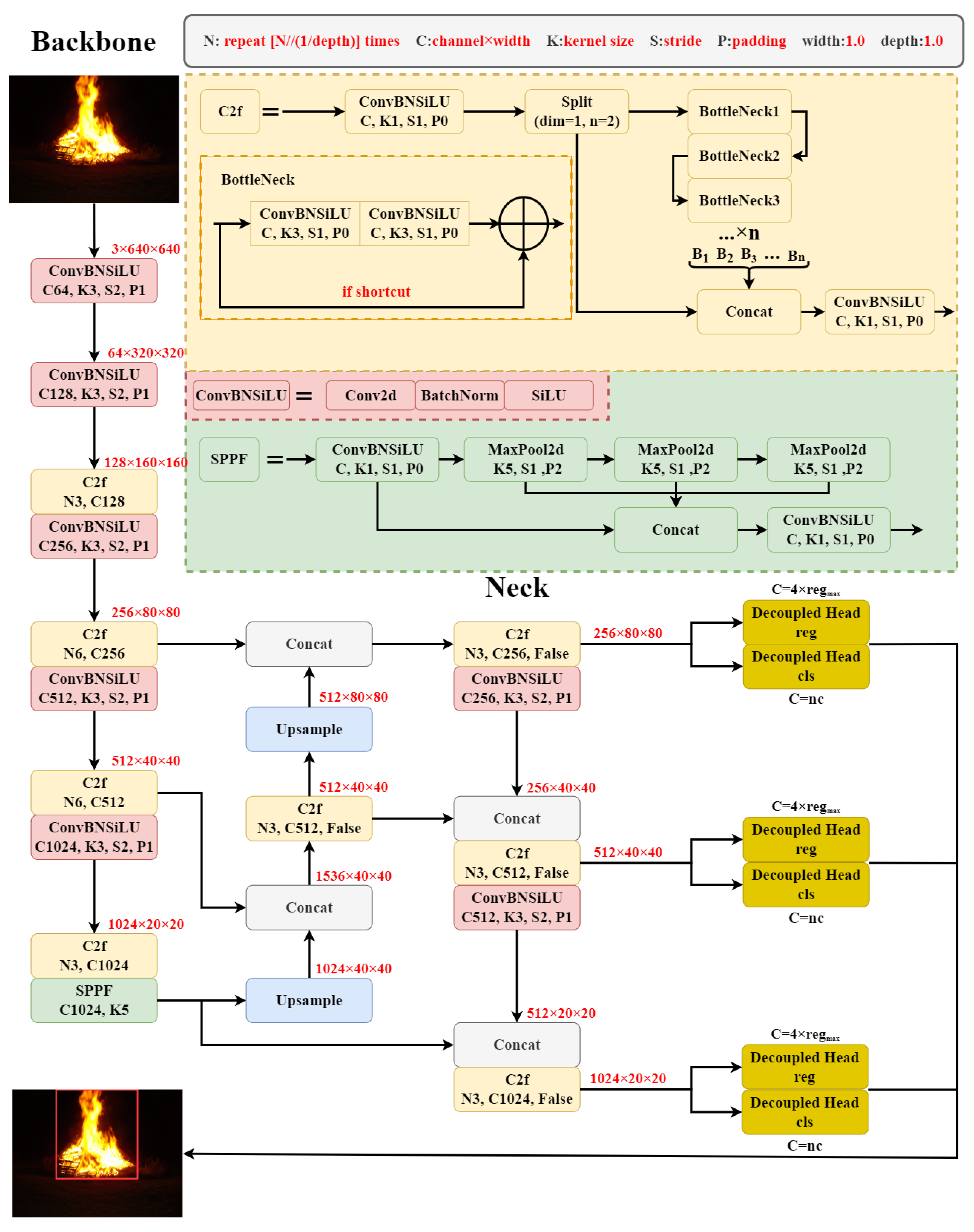
2. Methods
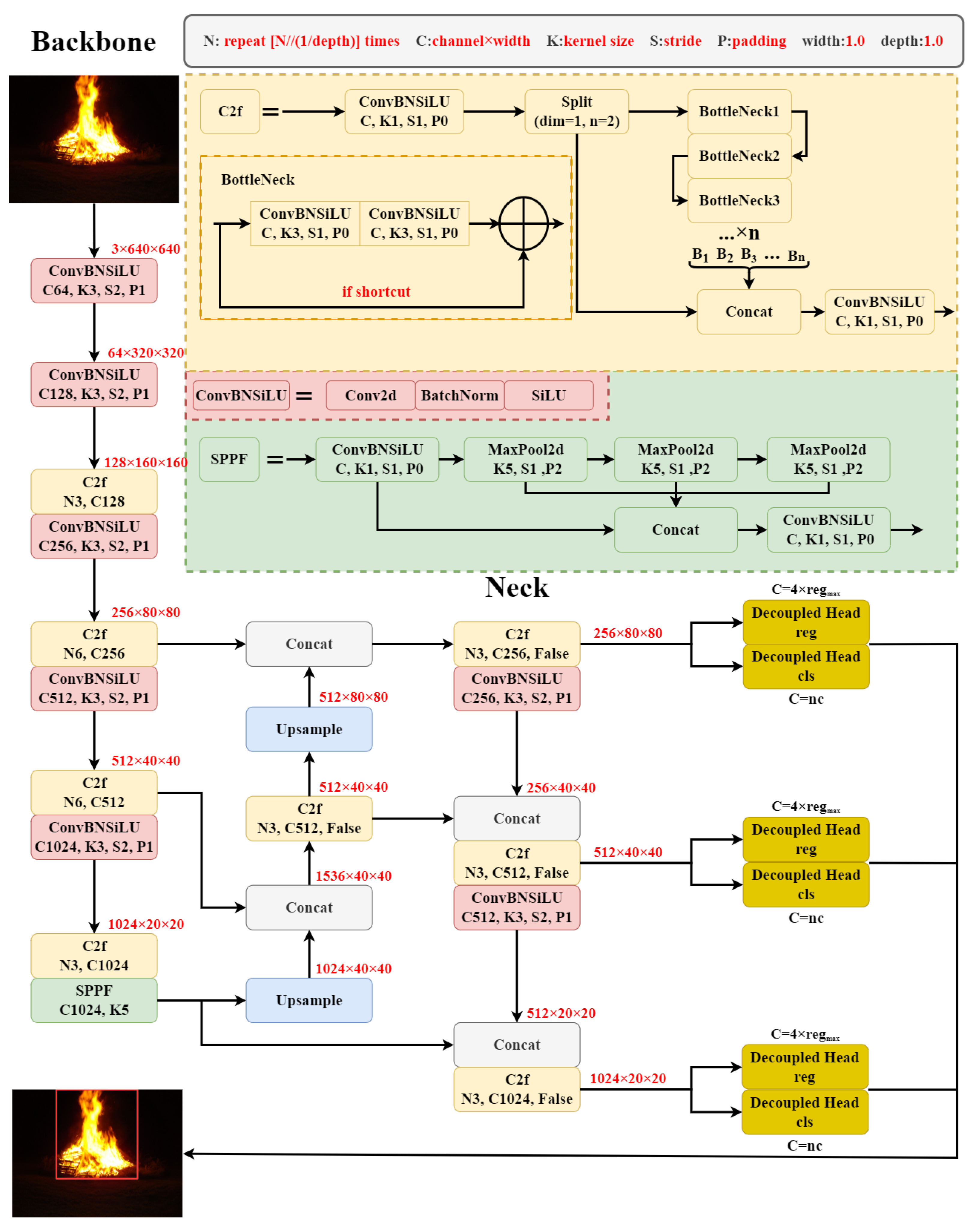
2.1. YOLOv8
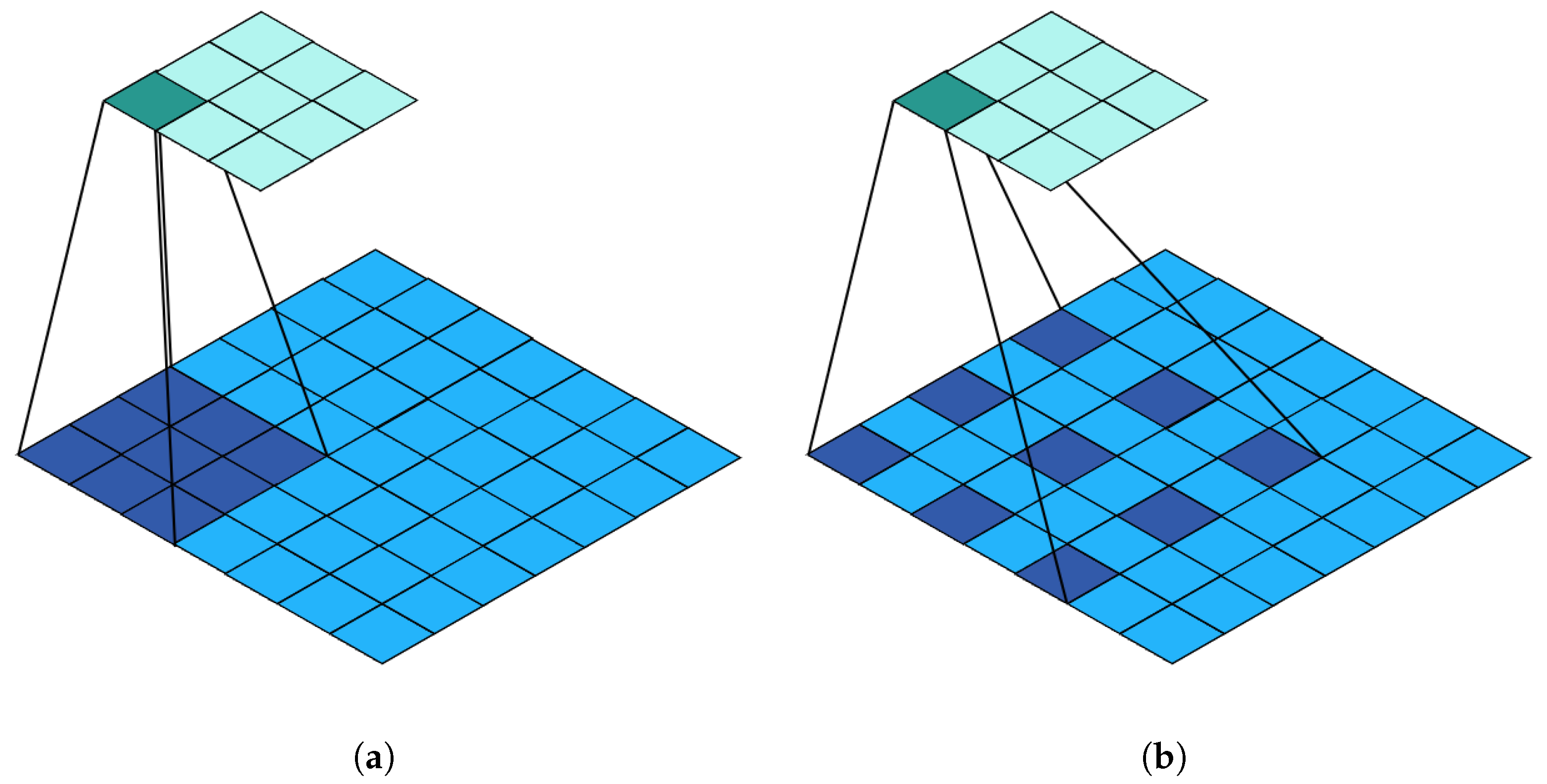
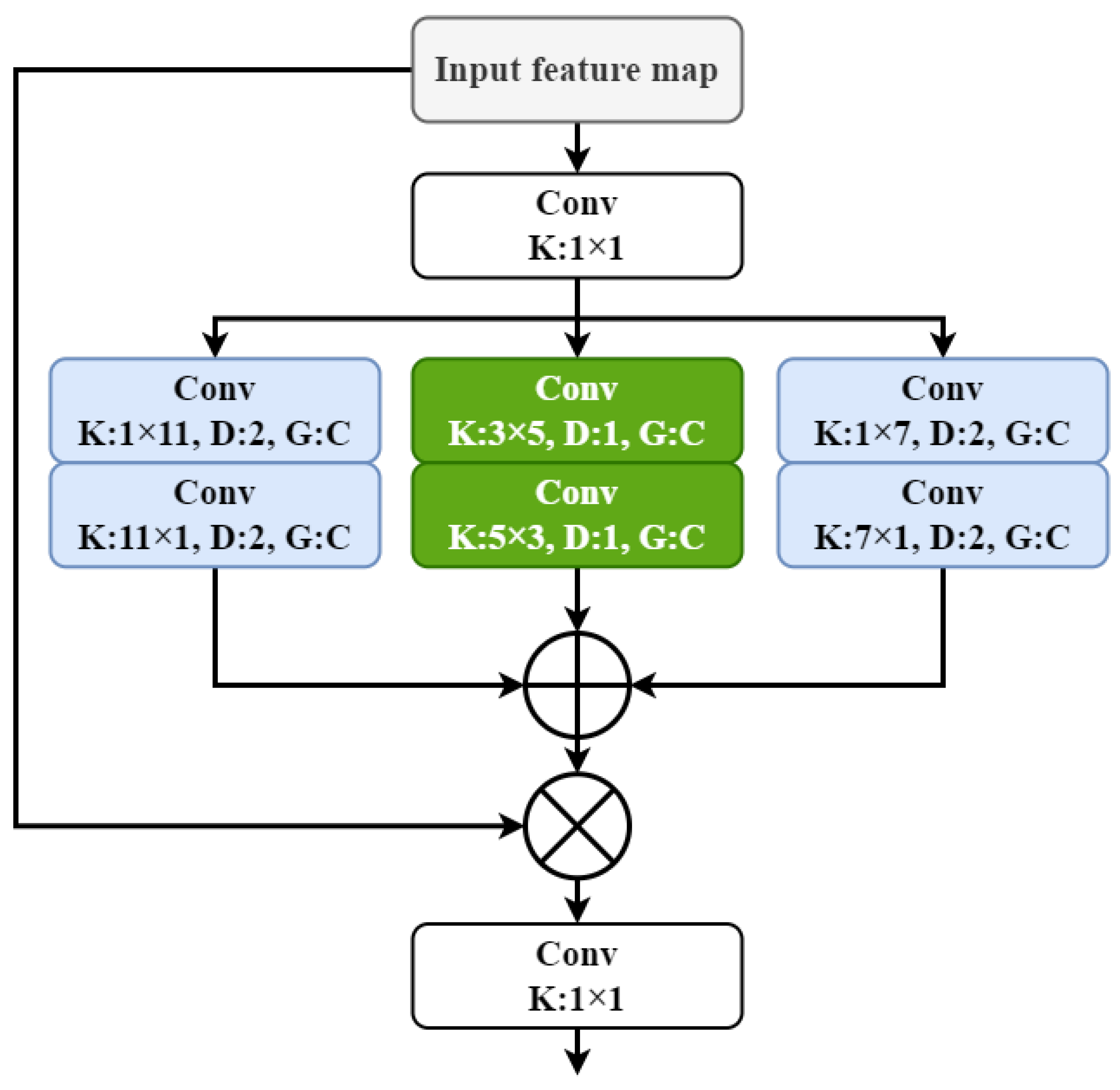
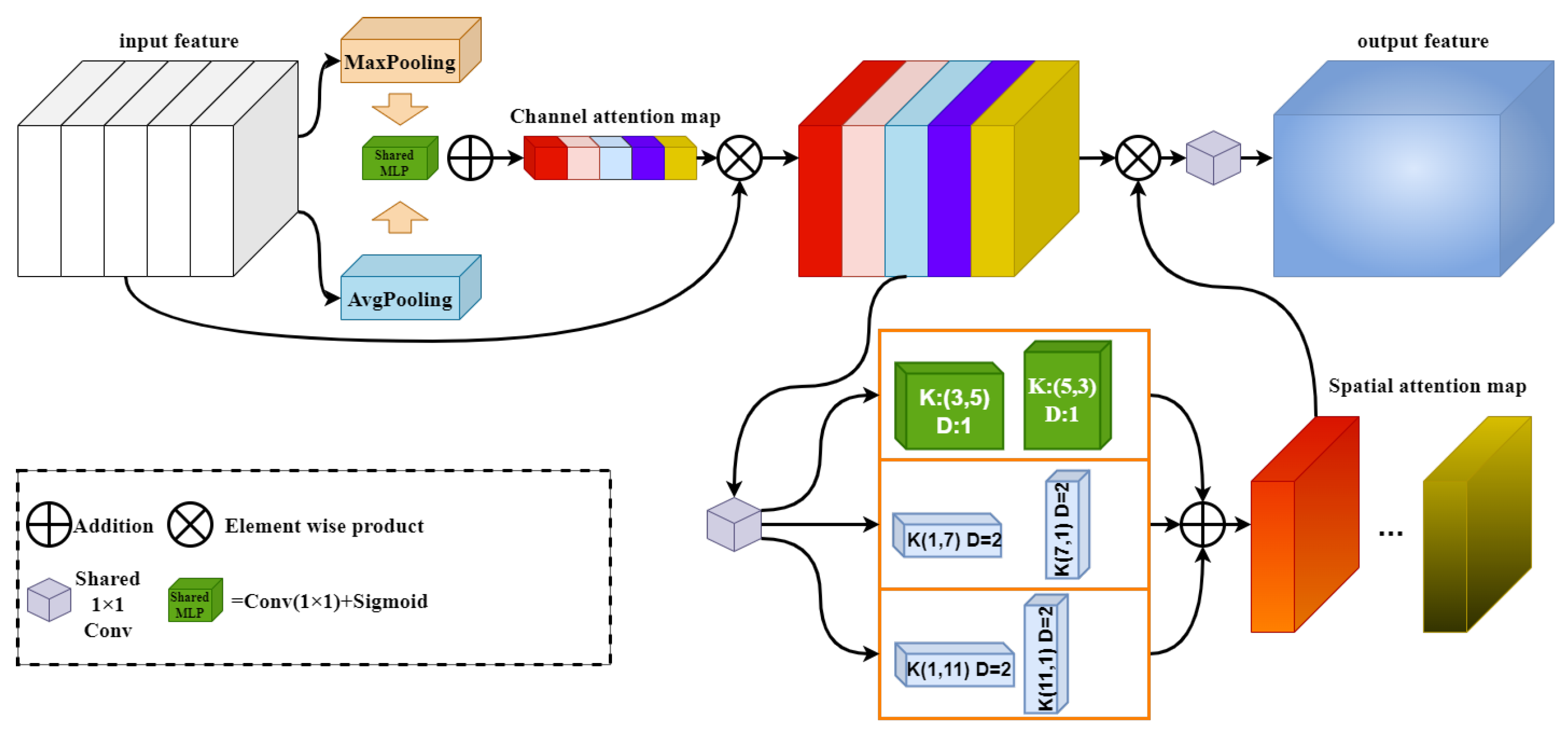
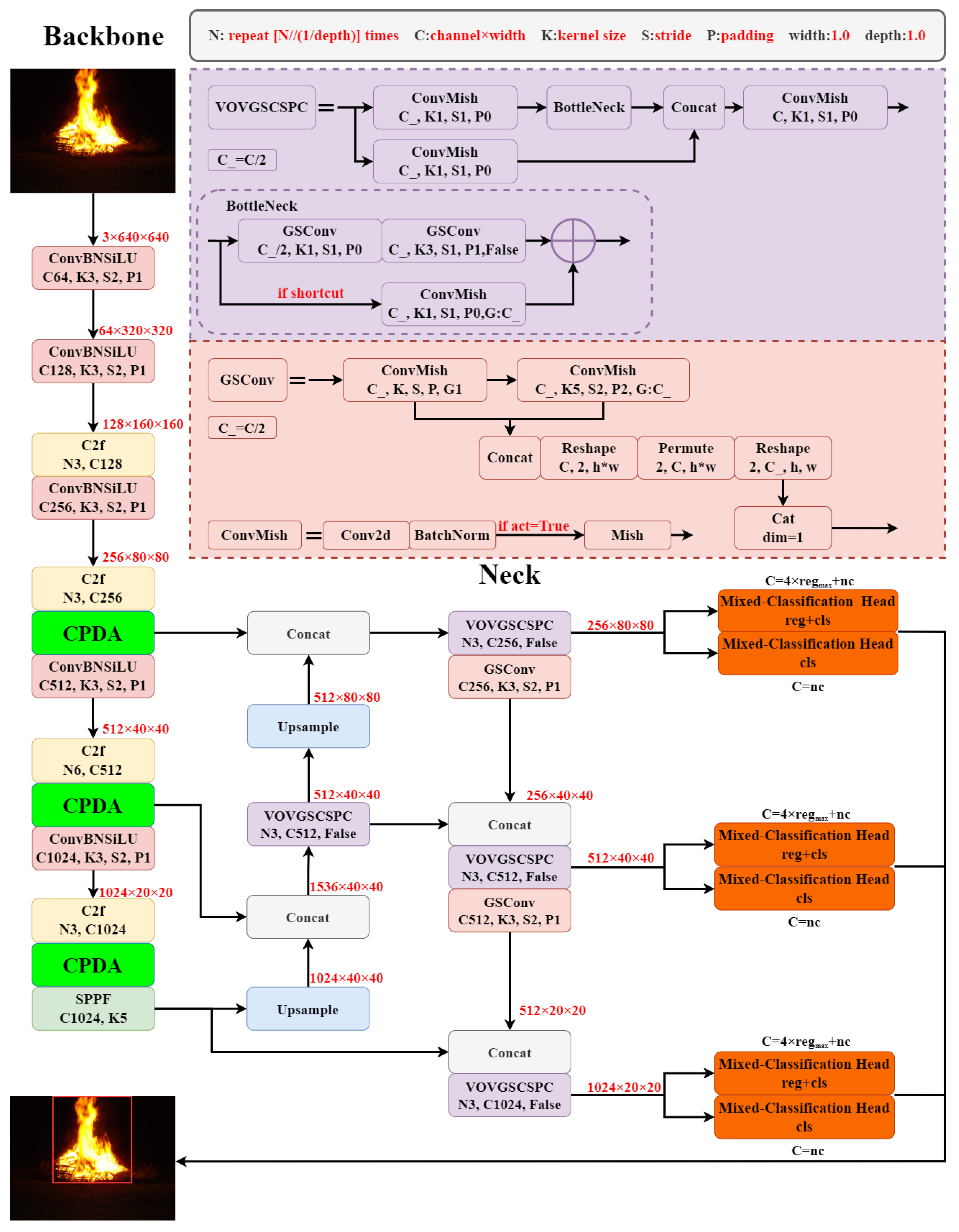
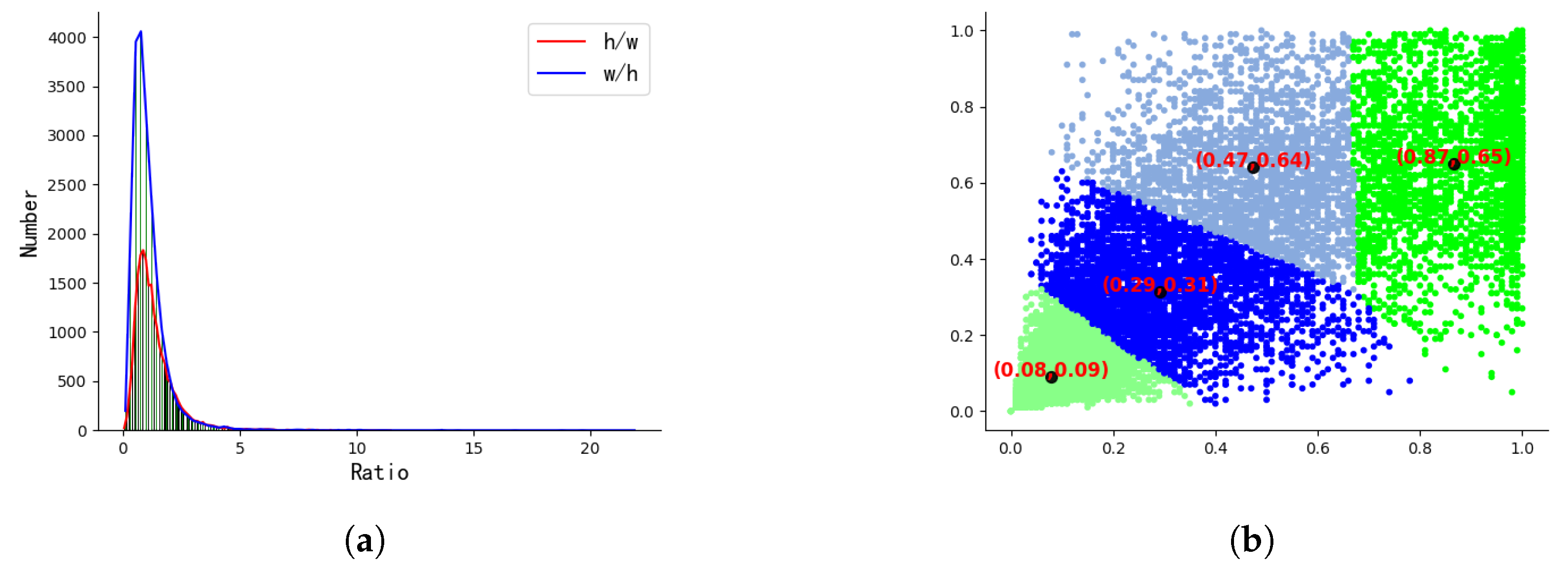
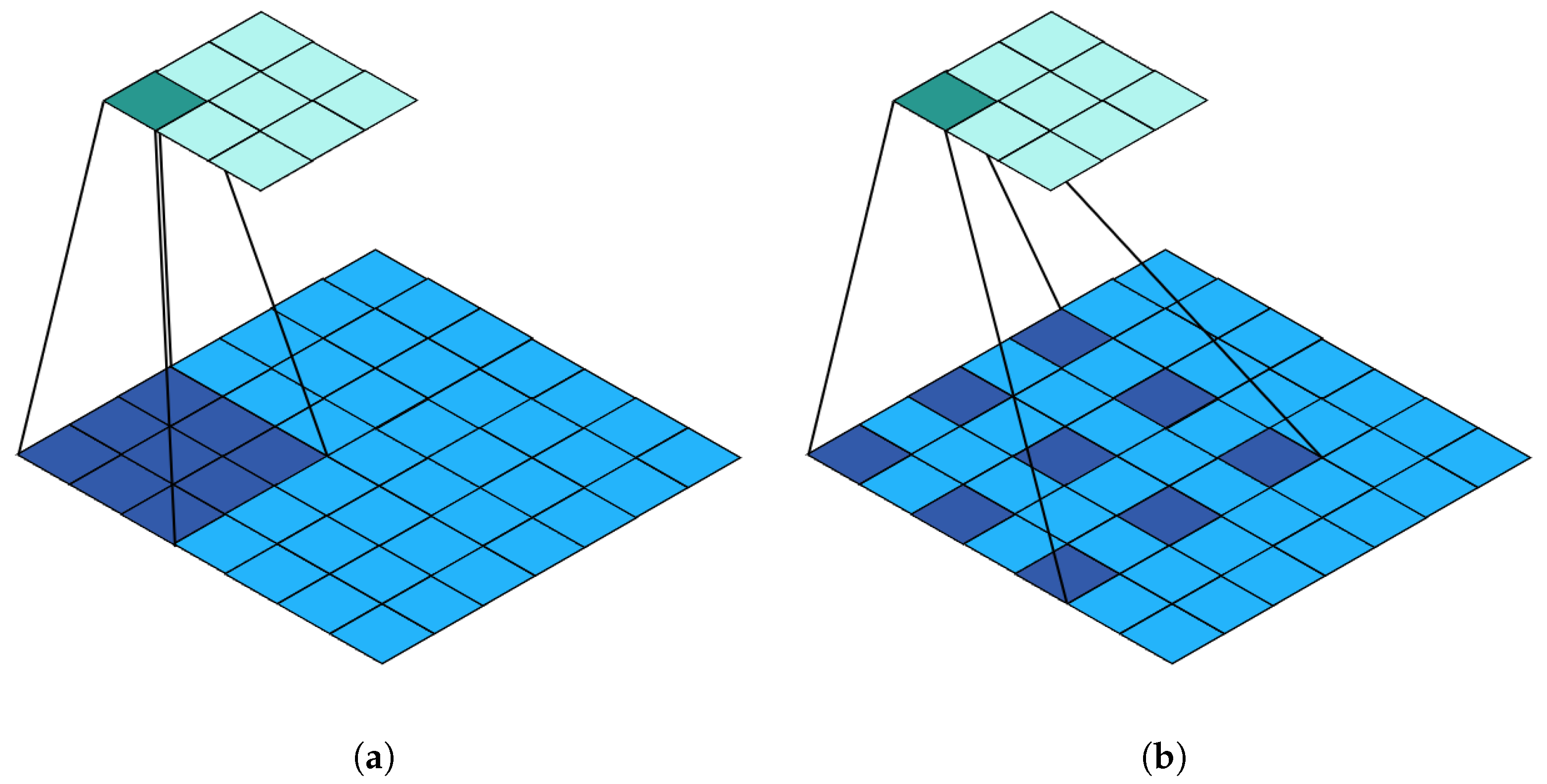
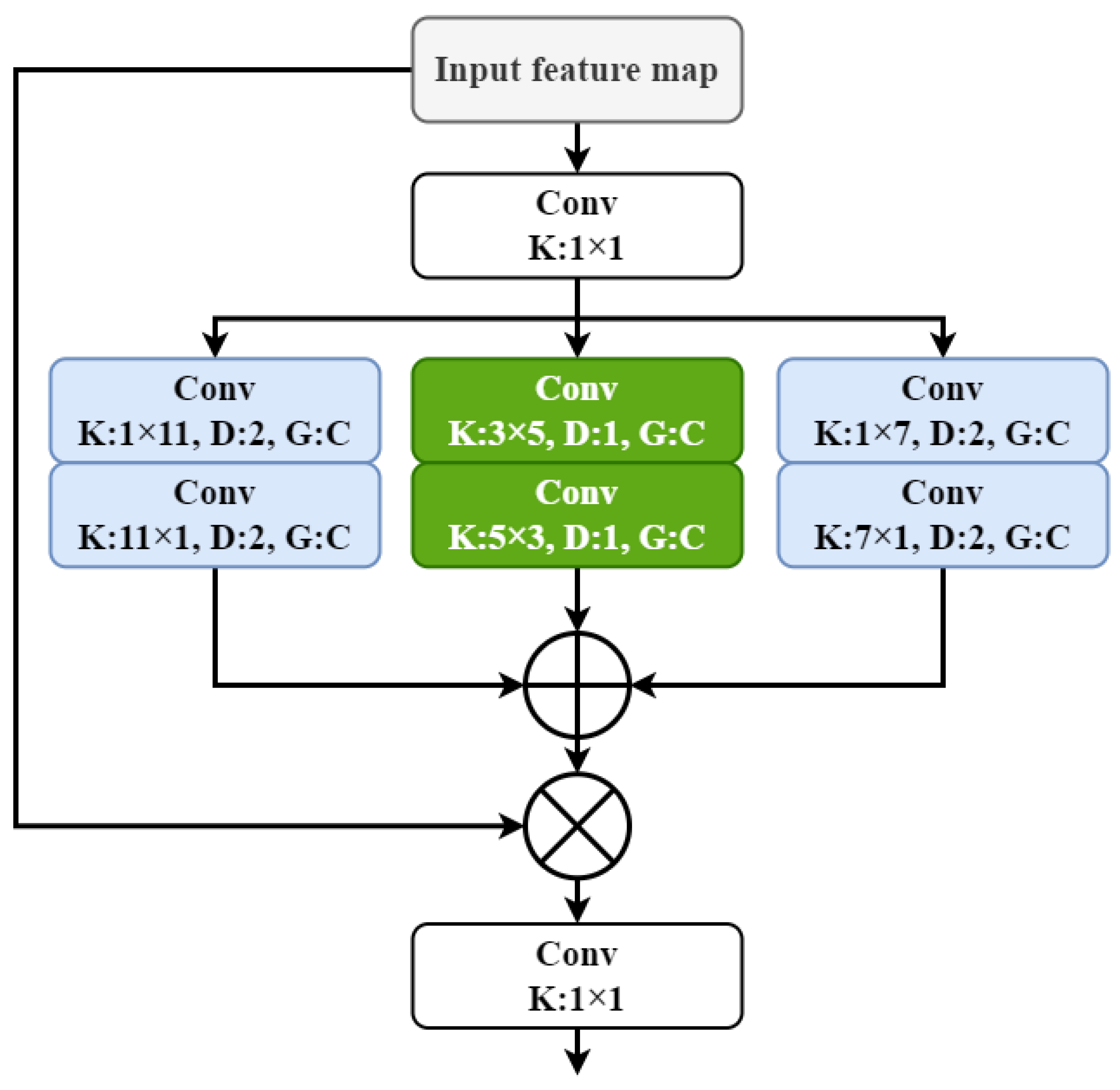
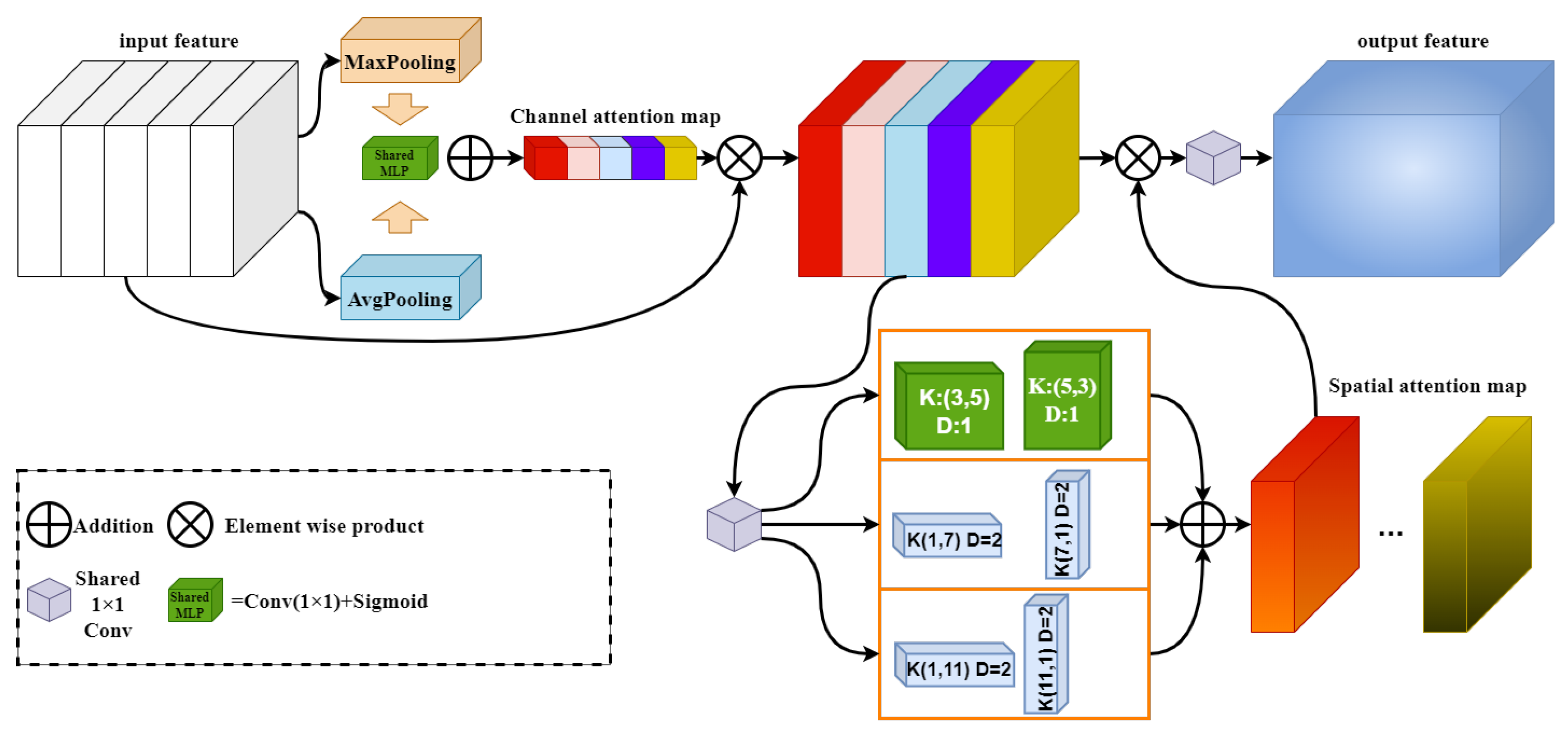
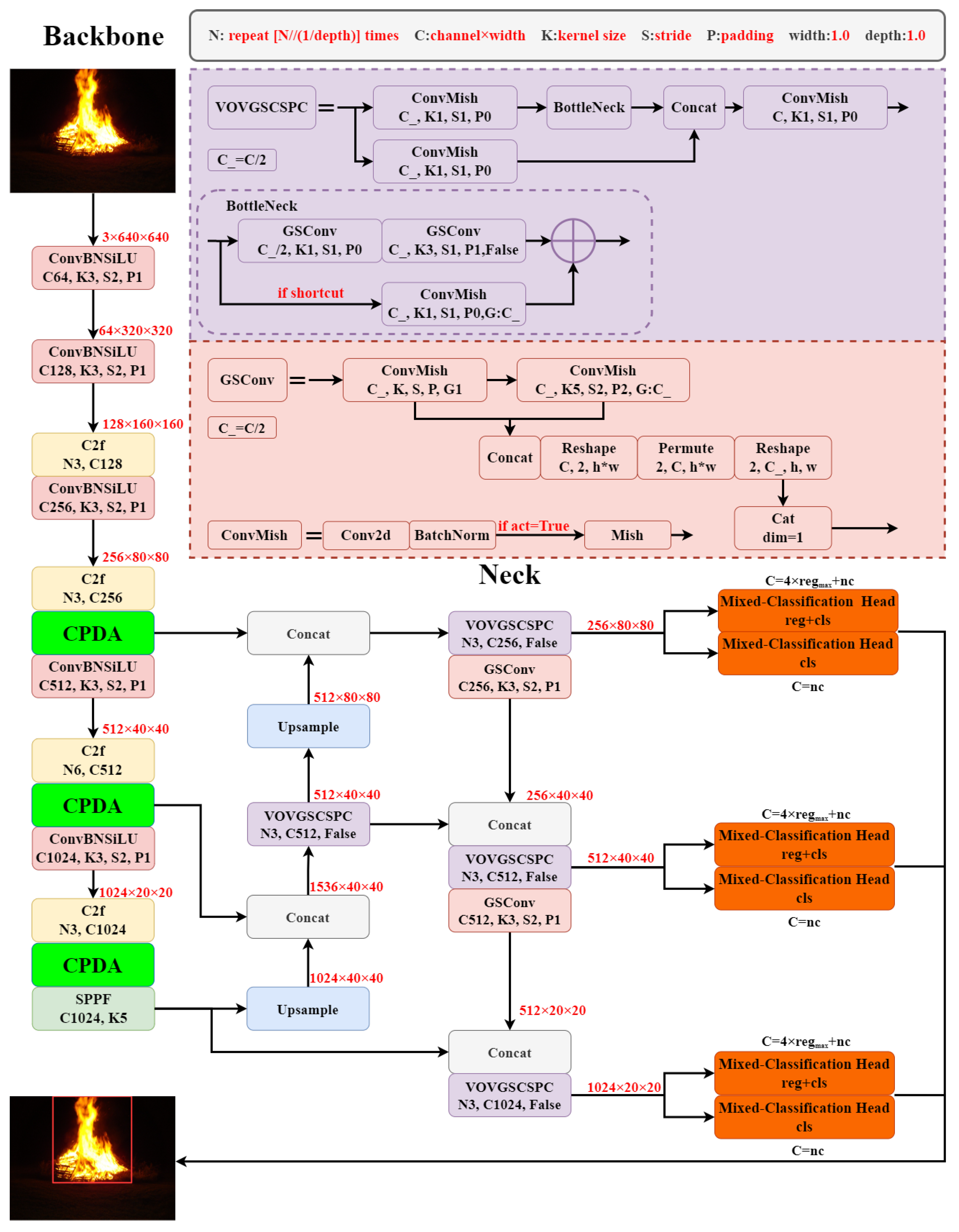
2.2. Channel Prior Dilatation Attention
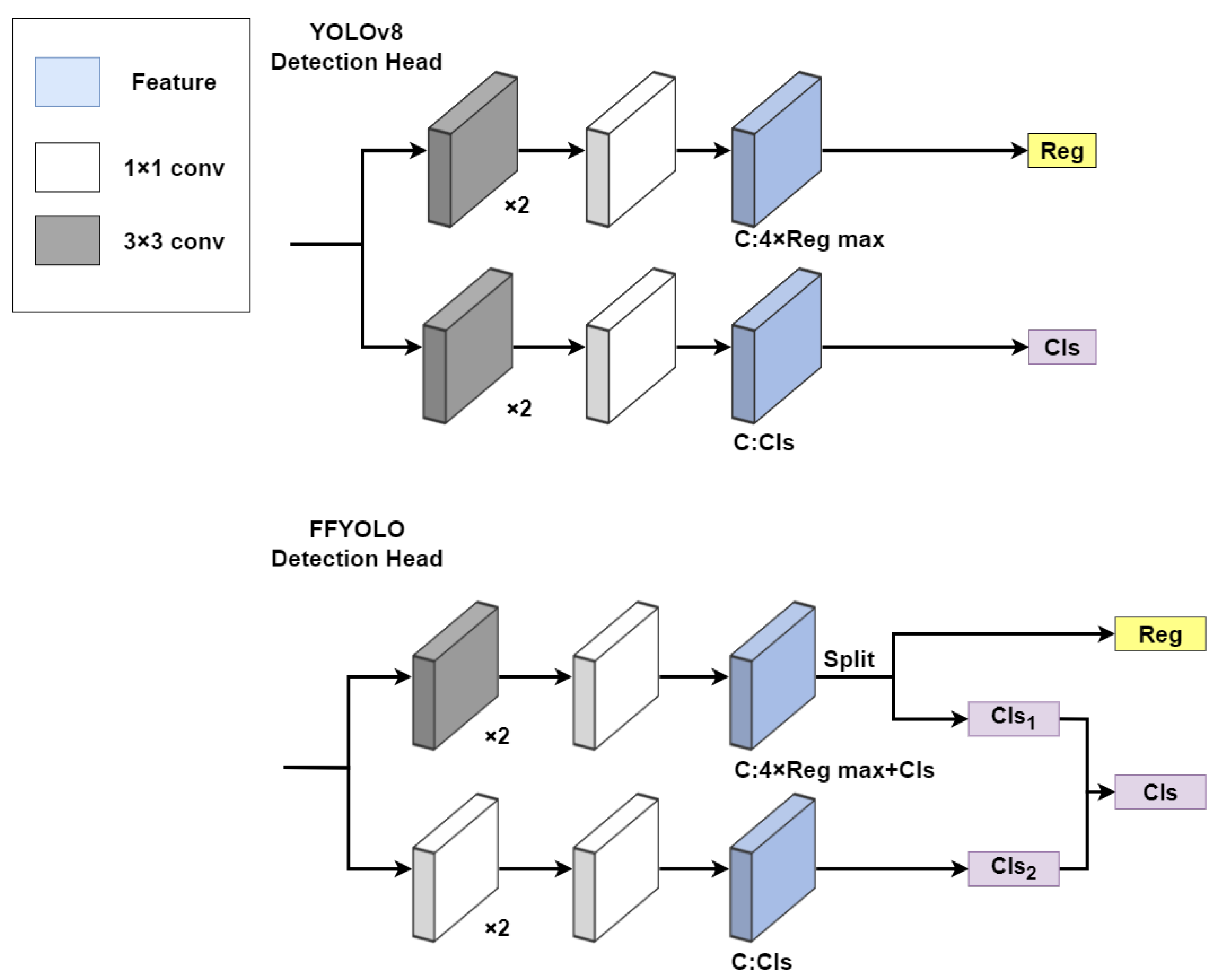
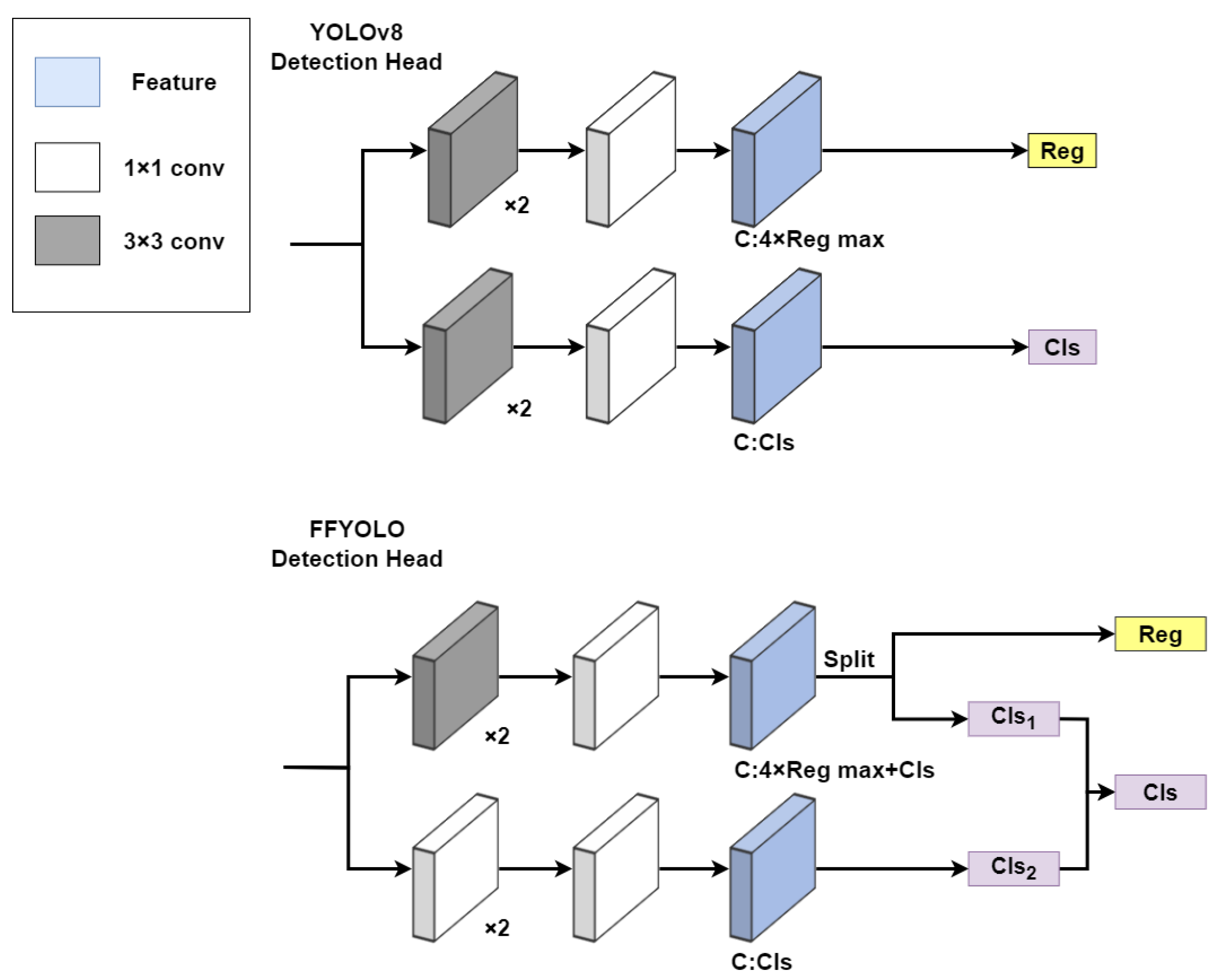
2.3. Mixed-Classification Detection Head
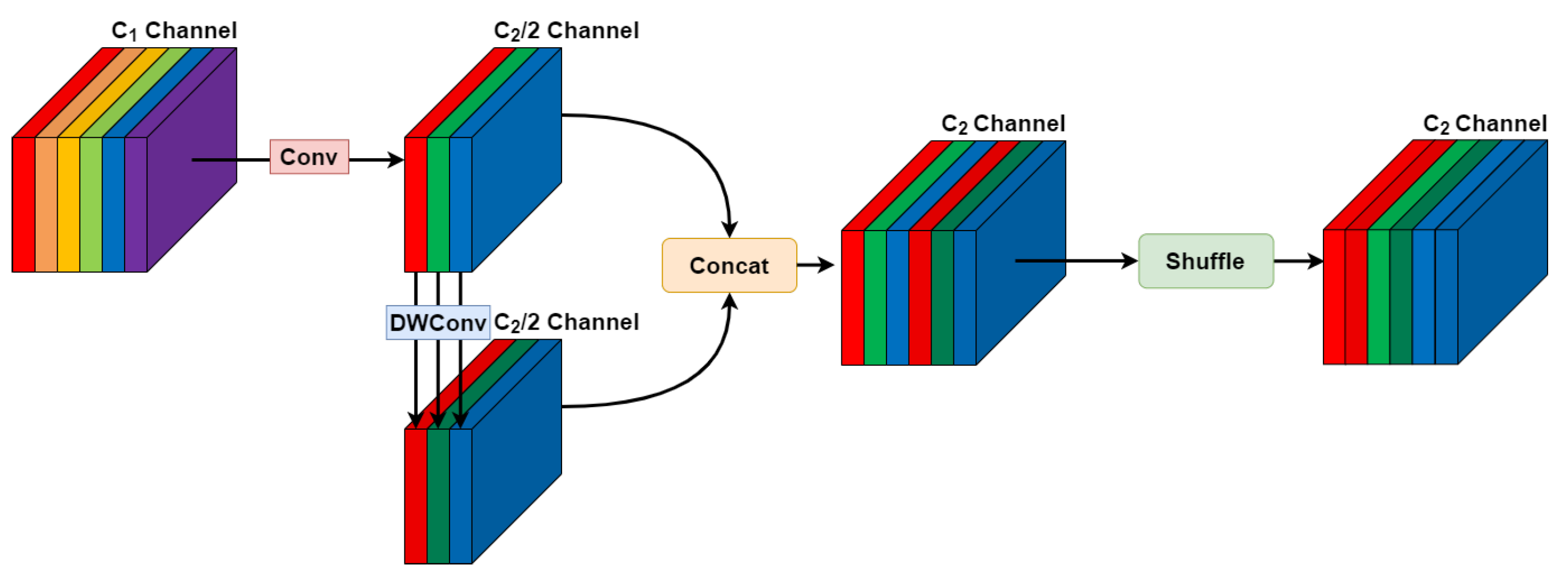
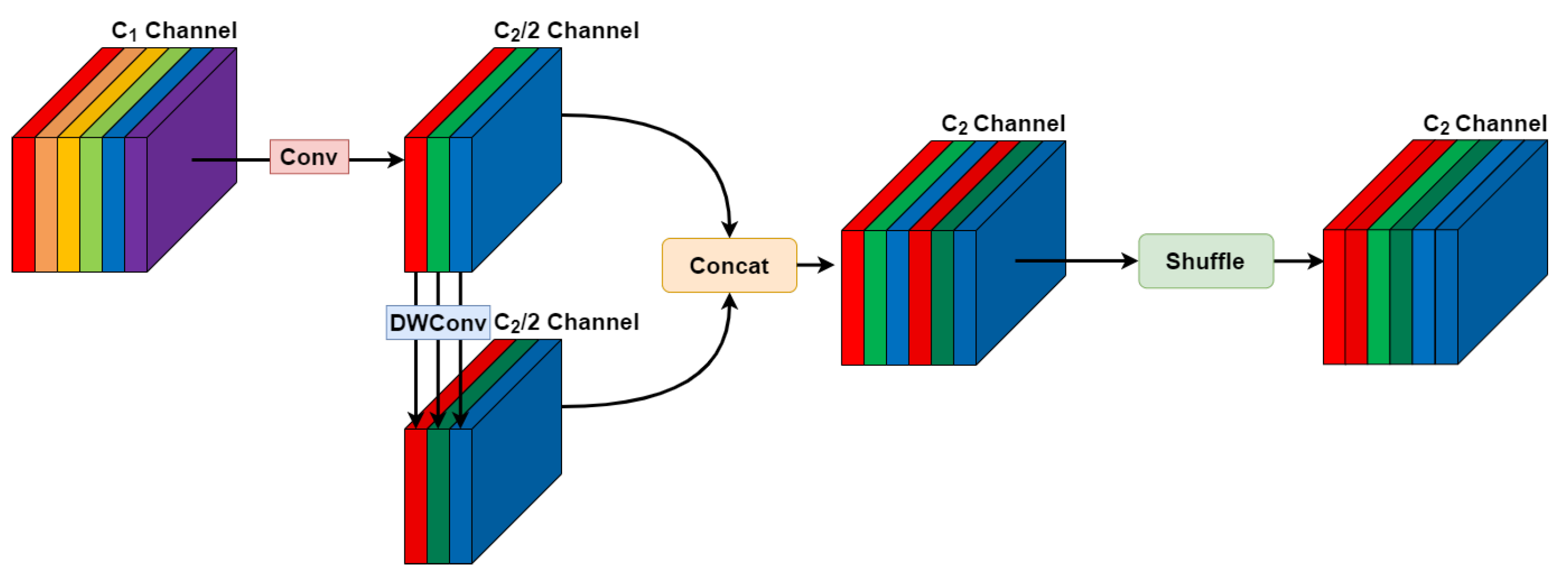
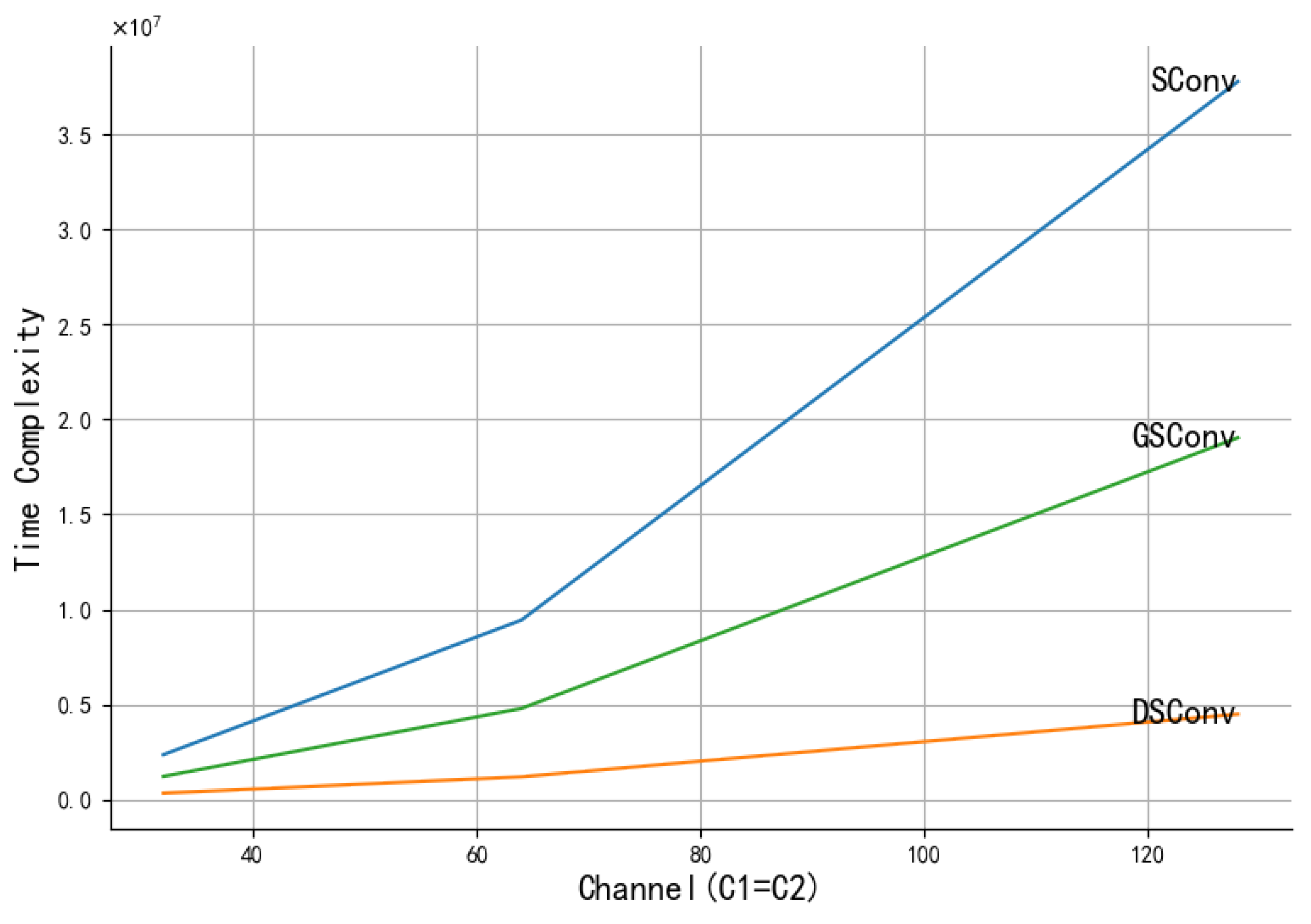
2.4. Lightweight GSConv
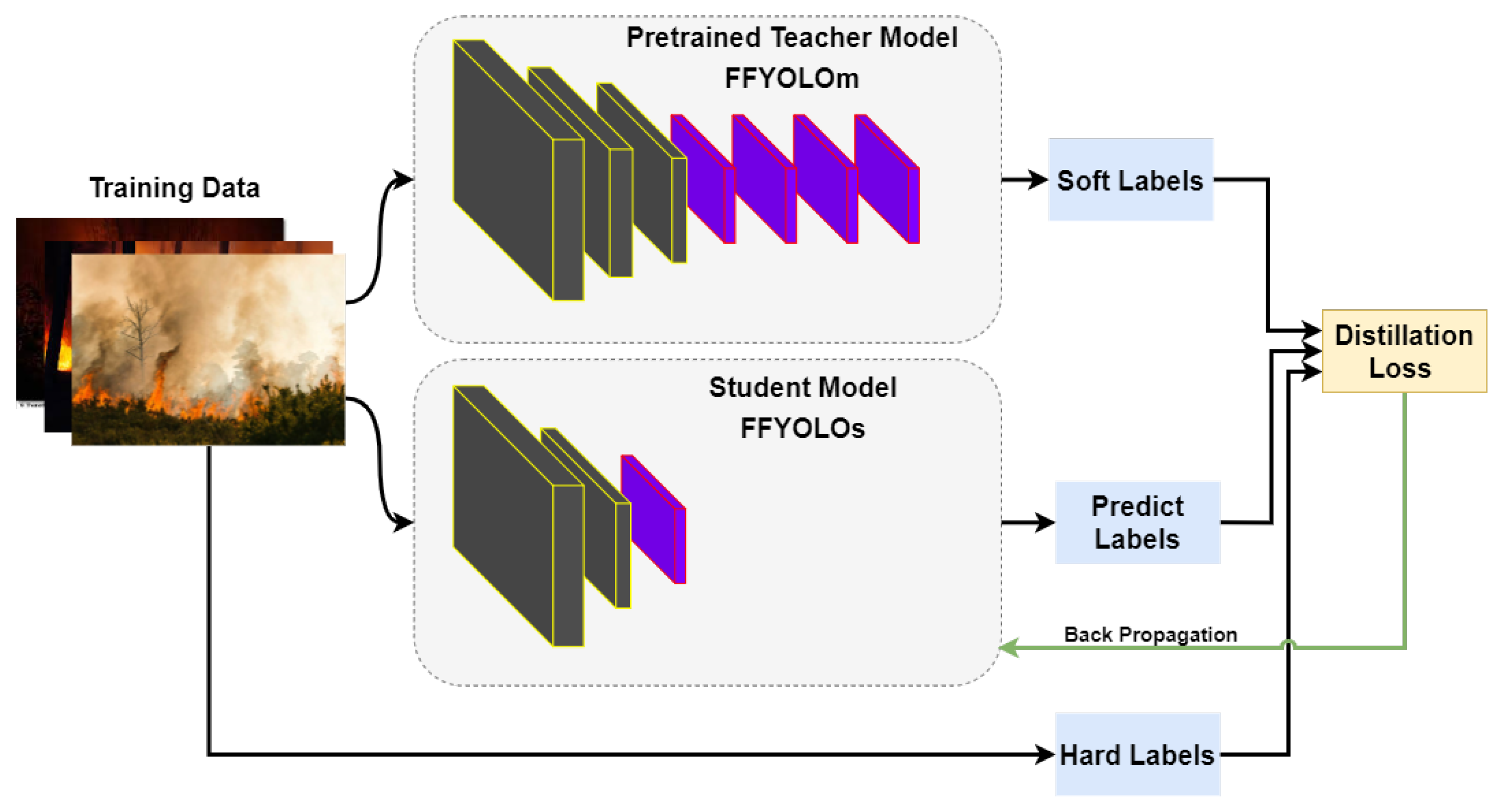
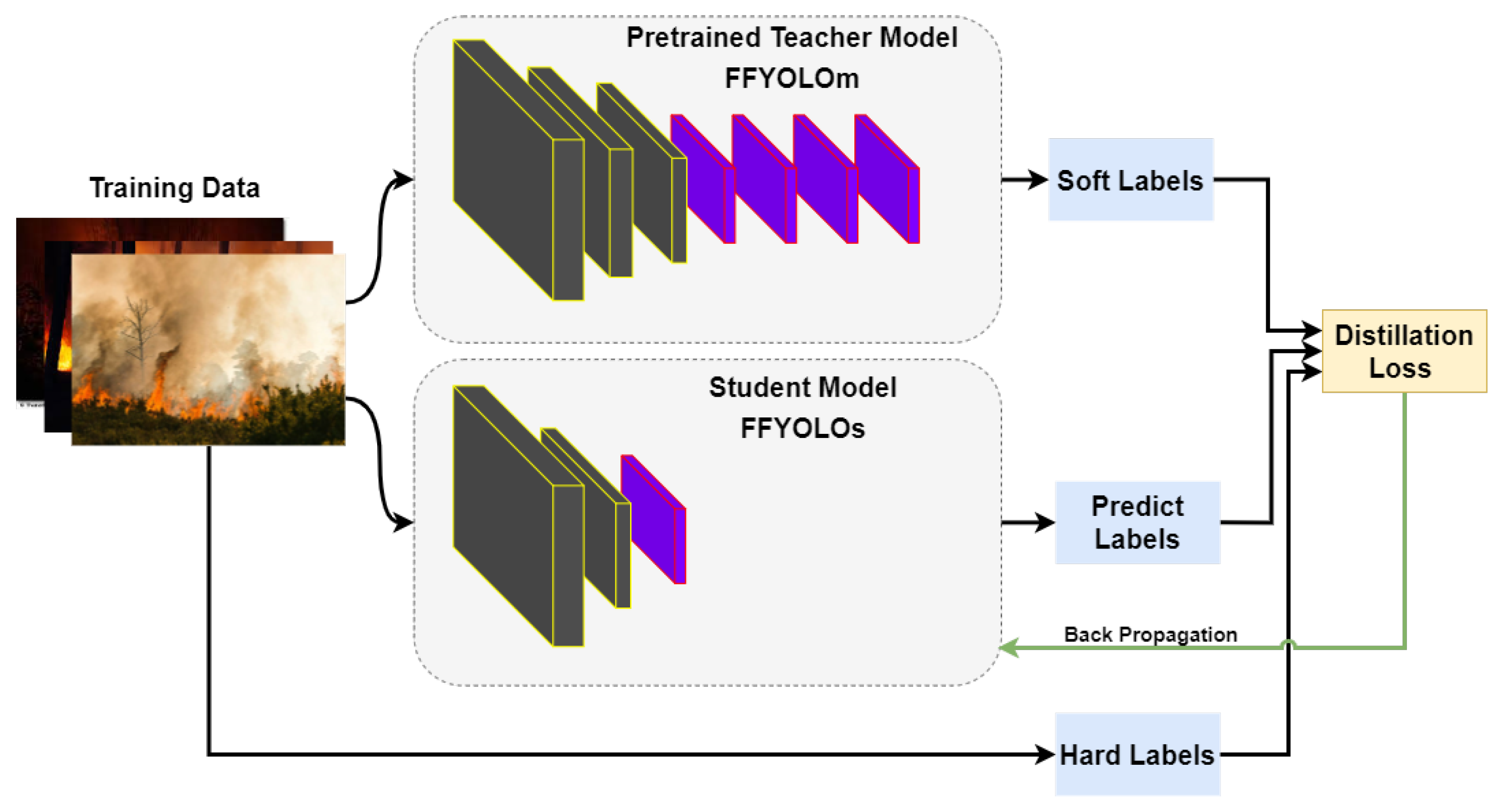
2.5. Soft Label Strategy Based on Knowledge Distillation
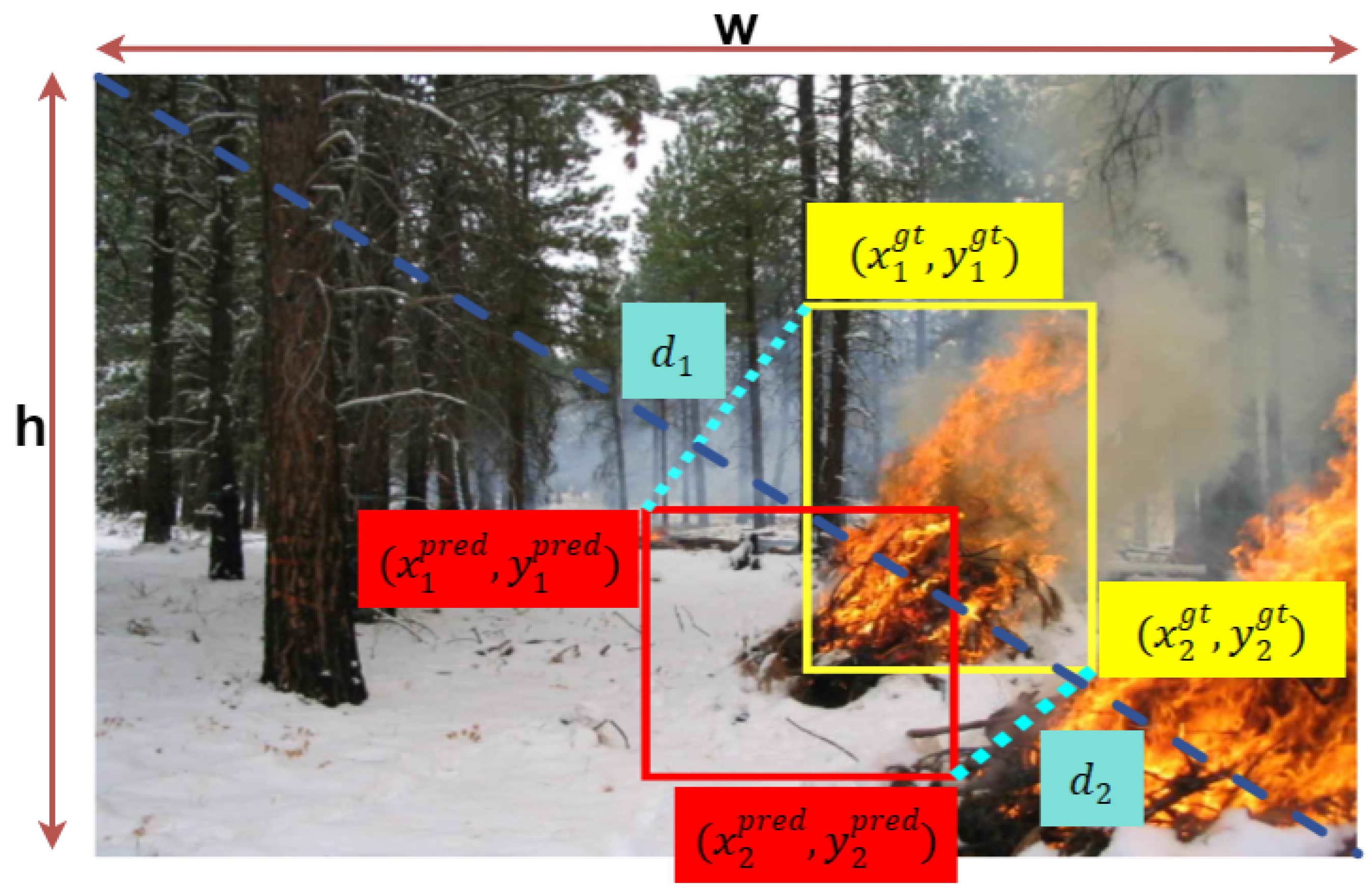
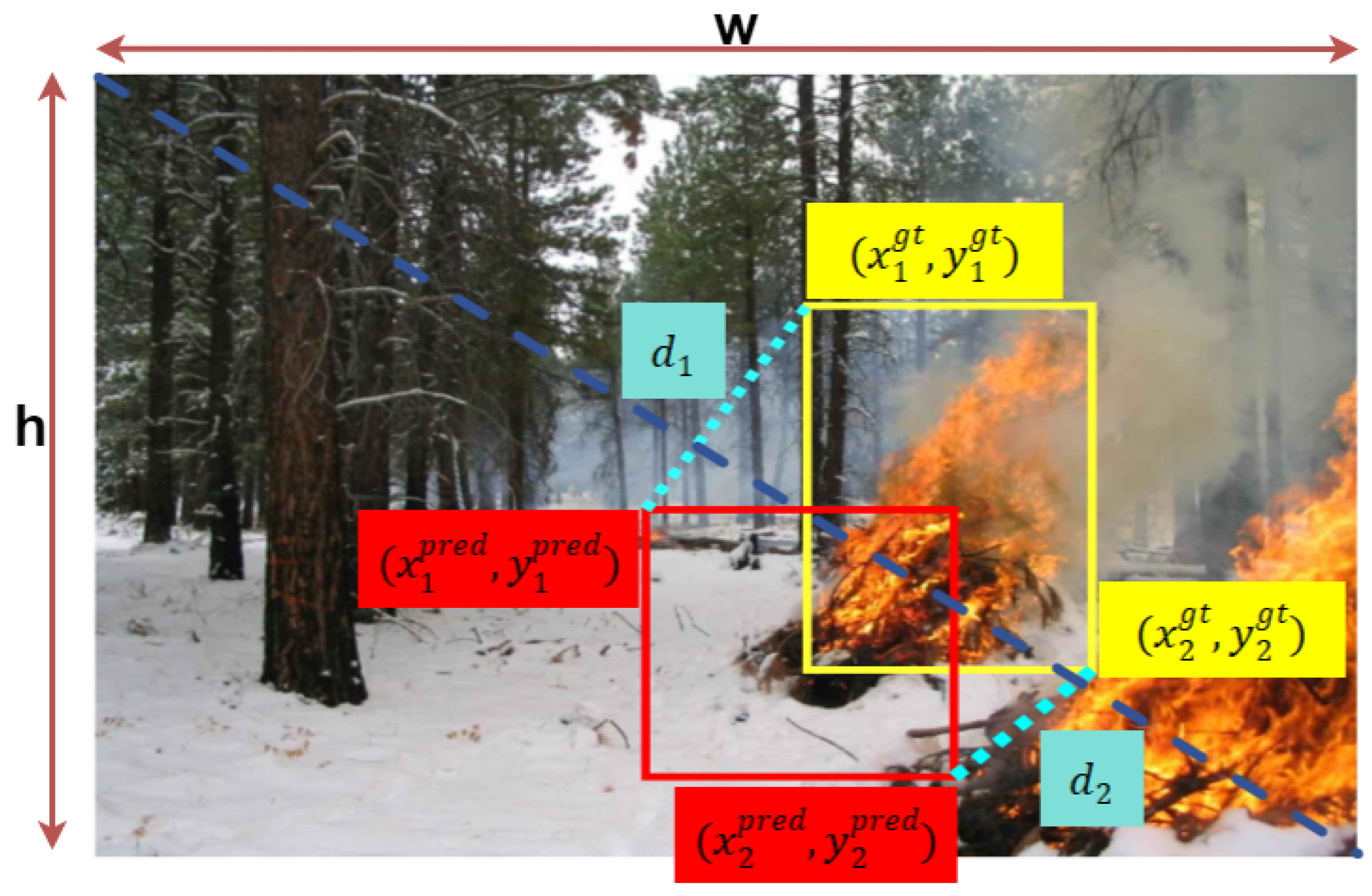
2.6. MPD-IoU Loss
2.7. FFYOLO
3. Experiments and Analysis
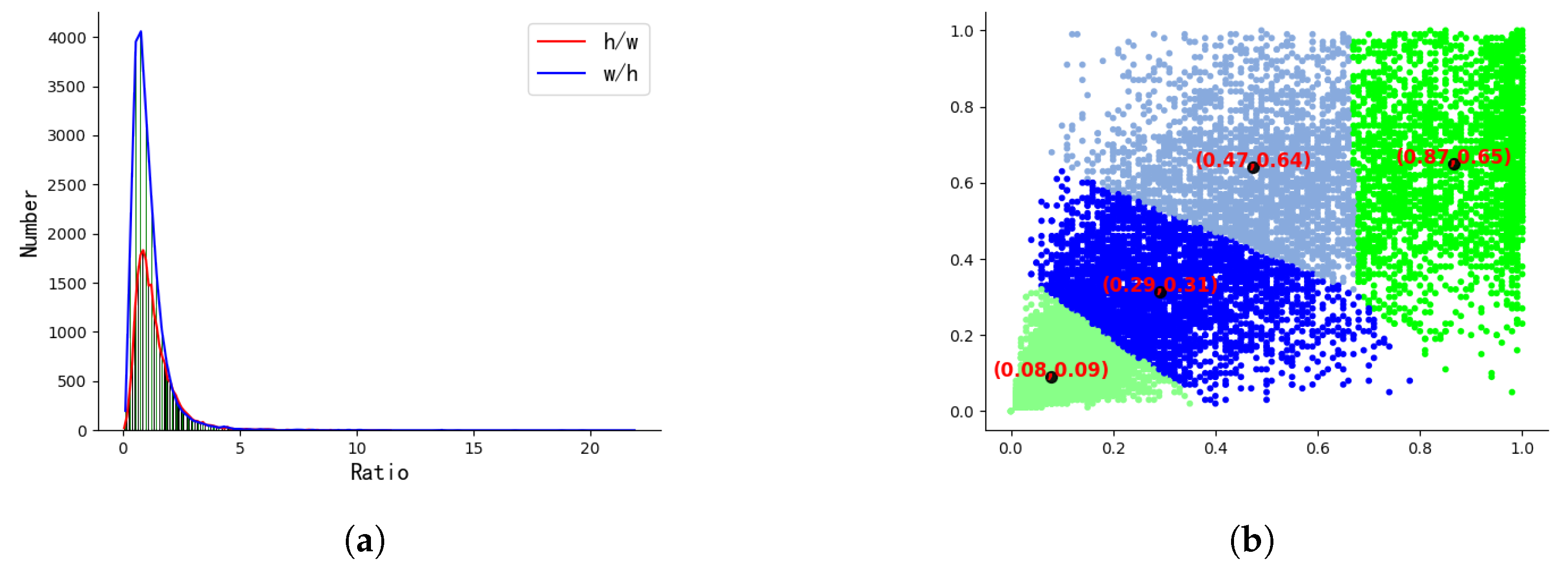
3.1. Dataset
3.2. Experimental Environment
3.3. Model Evaluation
3.4. Detect Performance and Analysis
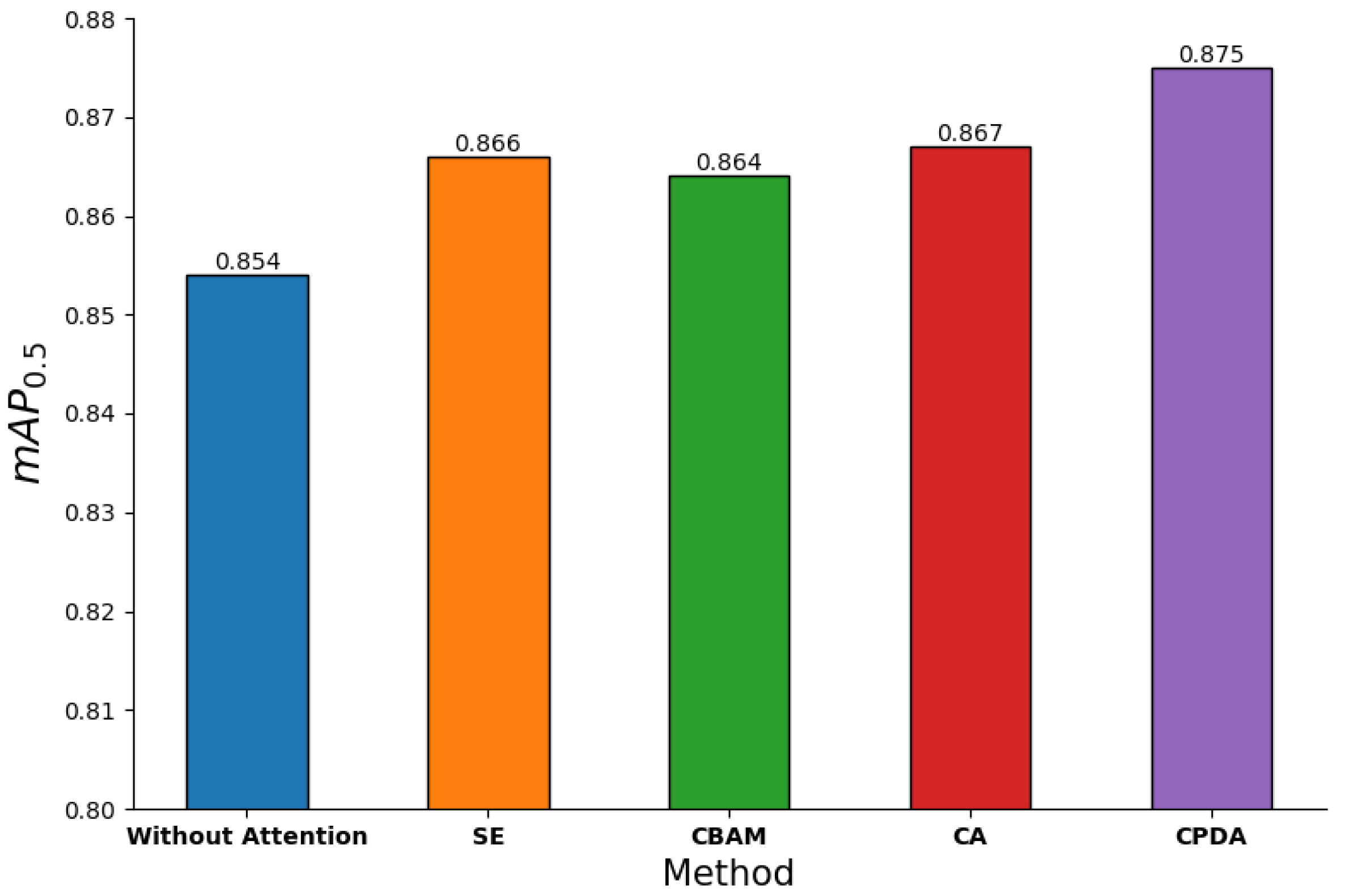
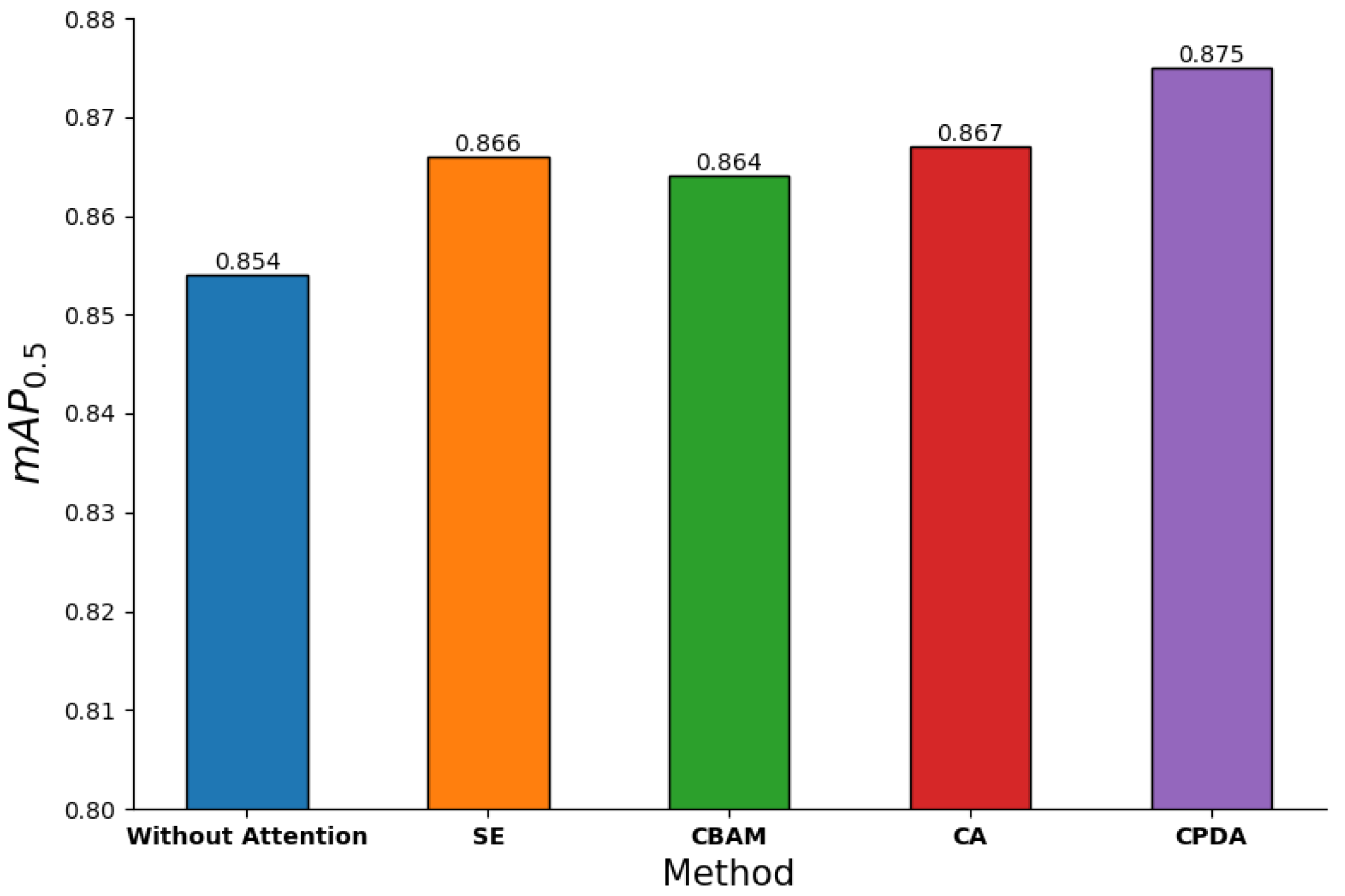
3.4.1. Effectiveness of CPDA
3.4.2. Effectiveness of MCDH
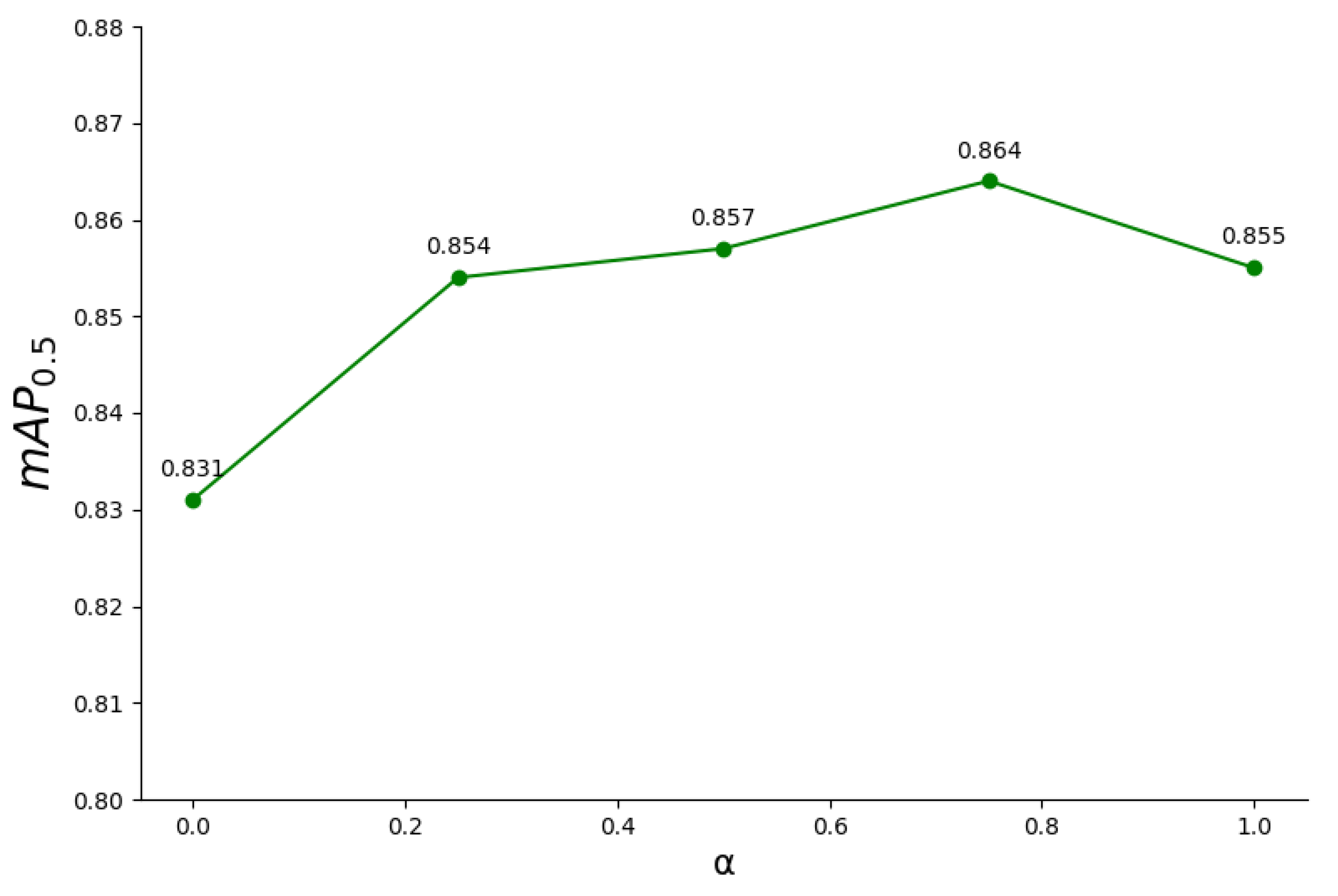
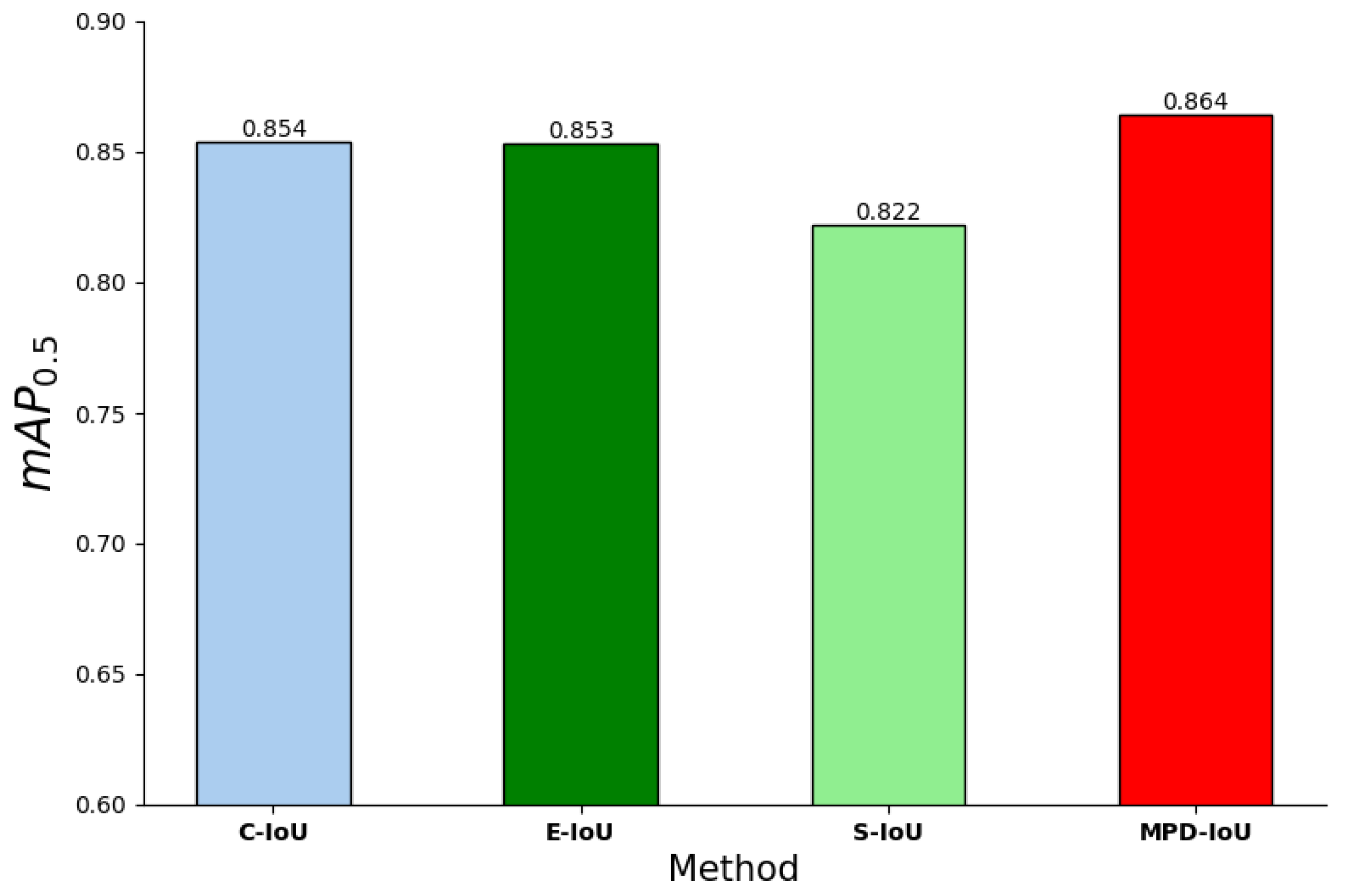
3.4.3. Effectiveness of MPD-IoU
3.4.4. Ablation Experiments
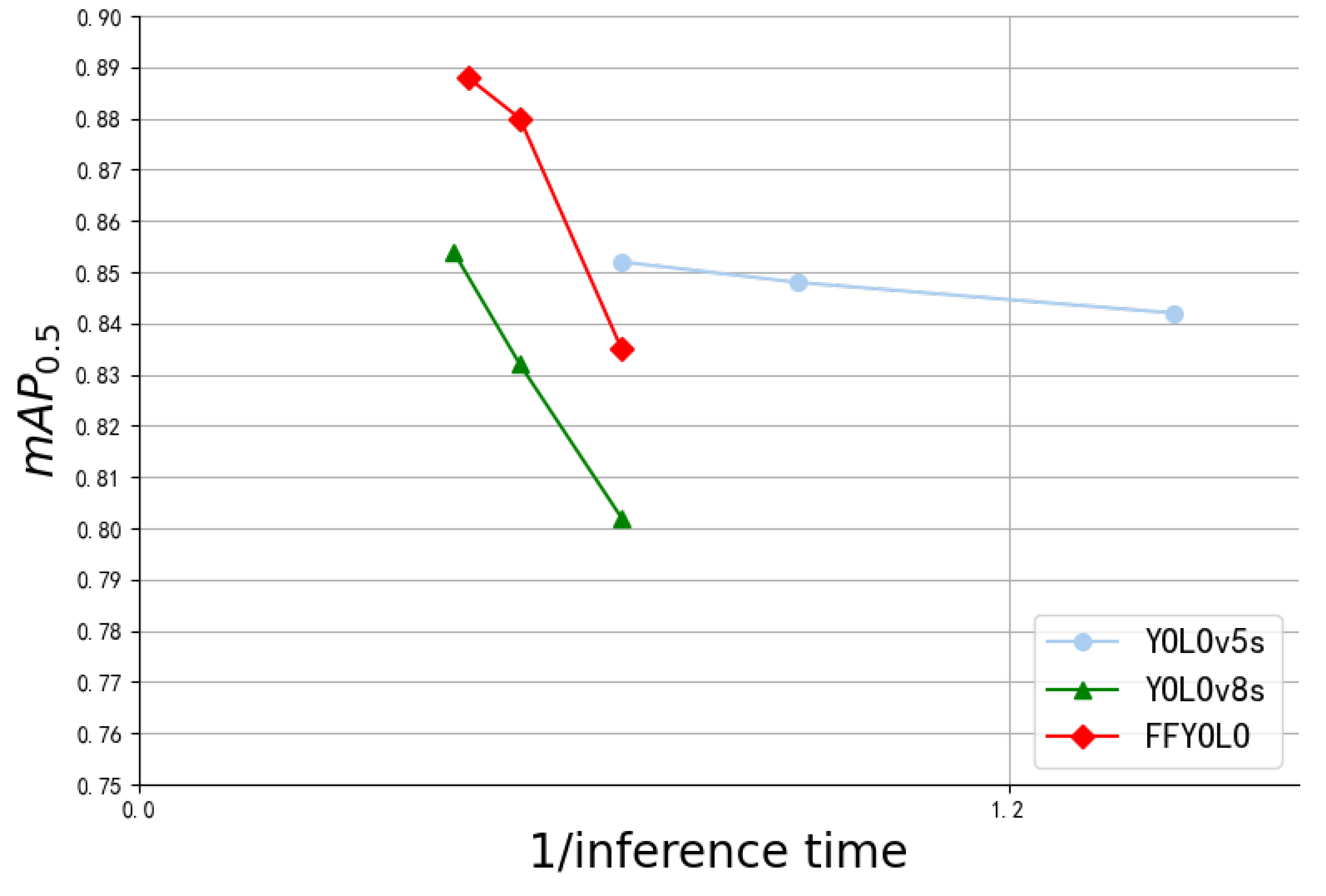
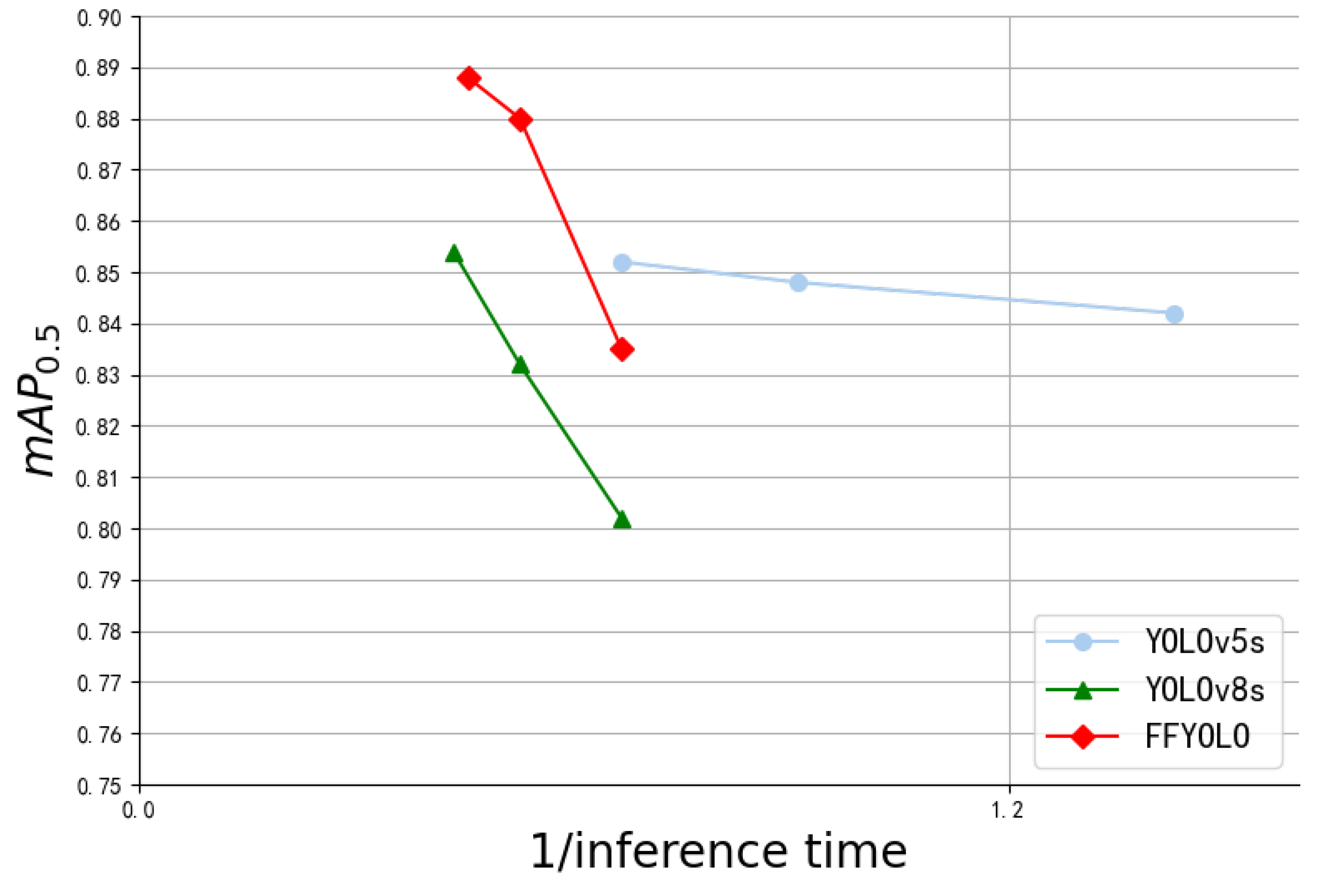
3.4.5. Model Comparison and Visualization
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kanwal, R.; Rafaqat, W.; Iqbal, M.; Song, W. Data-Driven Approaches for Wildfire Mapping and Prediction Assessment Using a Convolutional Neural Network (CNN). Remote Sens. 2023, 15, 5099. [Google Scholar] [CrossRef]
- Kinaneva, D.; Hristov, G.; Raychev, J.; Zahariev, P. Application of artificial intelligence in UAV platforms for early forest fire detection. In Proceedings of the 2019 27th National Conference with International Participation (TELECOM), Sofia, Bulgaria, 30–31 October 2019; pp. 50–53. [Google Scholar]
- Xu, R.; Yu, P.; Abramson, M.J.; Johnston, F.H.; Samet, J.M.; Bell, M.L.; Haines, A.; Ebi, K.L.; Li, S.; Guo, Y. Wildfires, global climate change, and human health. N. Engl. J. Med. 2020, 383, 2173–2181. [Google Scholar] [CrossRef] [PubMed]
- Johnston, L.M.; Wang, X.; Erni, S.; Taylor, S.W.; McFayden, C.B.; Oliver, J.A.; Stockdale, C.; Christianson, A.; Boulanger, Y.; Gauthier, S.; et al. Wildland fire risk research in Canada. Environ. Rev. 2020, 28, 164–186. [Google Scholar] [CrossRef]
- Yang, X.; Tang, L.; Wang, H.; He, X. Early detection of forest fire based on unmaned aerial vehicle platform. In Proceedings of the 2019 IEEE International Conference on Signal, Information and Data Processing (ICSIDP), Chongqing, China, 11–13 December 2019; pp. 1–4. [Google Scholar]
- Sah, S.; Prakash, S.; Meena, S. Forest Fire Detection using Convolutional Neural Network Model. In Proceedings of the 2023 IEEE 8th International Conference for Convergence in Technology (I2CT), Tumkur, Karnataka, India, 7–9 April 2023; pp. 1–5. [Google Scholar]
- Chen, T.H.; Wu, P.H.; Chiou, Y.C. An early fire-detection method based on image processing. In Proceedings of the 2004 International Conference on Image Processing, ICIP’04, Singapore, 24–27 October 2004; Volume 3, pp. 1707–1710. [Google Scholar]
- Ding, X.; Gao, J. A new intelligent fire color space approach for forest fire detection. J. Intell. Fuzzy Syst. 2022, 42, 5265–5281. [Google Scholar] [CrossRef]
- Celik, T.; Demirel, H. Fire detection in video sequences using a generic color model. Fire Saf. J. 2009, 44, 147–158. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Proceedings, Part I 14, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Barmpoutis, P.; Dimitropoulos, K.; Kaza, K.; Grammalidis, N. Fire detection from images using faster R-CNN and multidimensional texture analysis. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8301–8305. [Google Scholar]
- Li, P.; Zhao, W. Image fire detection algorithms based on convolutional neural networks. Case Stud. Therm. Eng. 2020, 19, 100625. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Liu, H.; Hu, H.; Zhou, F.; Yuan, H. Forest flame detection in unmanned aerial vehicle imagery based on YOLOv5. Fire 2023, 6, 279. [Google Scholar] [CrossRef]
- Qian, J.; Lin, J.; Bai, D.; Xu, R.; Lin, H. Omni-Dimensional Dynamic Convolution Meets Bottleneck Transformer: A Novel Improved High Accuracy Forest Fire Smoke Detection Model. Forests 2023, 14, 838. [Google Scholar] [CrossRef]
- Li, J.; Xu, R.; Liu, Y. An Improved Forest Fire and Smoke Detection Model Based on YOLOv5. Forests 2023, 14, 833. [Google Scholar] [CrossRef]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. Tood: Task-aligned one-stage object detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 3490–3499. [Google Scholar]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Adv. Neural Inf. Process. Syst. 2020, 33, 21002–21012. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Xiao, Z.; Wan, F.; Lei, G.; Xiong, Y.; Xu, L.; Ye, Z.; Liu, W.; Zhou, W.; Xu, C. FL-YOLOv7: A Lightweight Small Object Detection Algorithm in Forest Fire Detection. Forests 2023, 14, 1812. [Google Scholar] [CrossRef]
- Tang, Y.; Han, K.; Guo, J.; Xu, C.; Xu, C.; Wang, Y. GhostNetv2: Enhance cheap operation with long-range attention. arXiv 2022, arXiv:2211.12905. [Google Scholar]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles. arXiv 2022, arXiv:2206.02424. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Müller, R.; Kornblith, S.; Hinton, G.E. When does label smoothing help? In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 4694–4703. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Siliang, M.; Yong, X. MPDIoU: A loss for efficient and accurate bounding box regression. arXiv 2023, arXiv:2307.07662. [Google Scholar]
- Lee, Y.; Hwang, J.W.; Lee, S.; Bae, Y.; Park, J. An energy and GPU-computation efficient backbone network for real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 752–760. [Google Scholar]
- de Venancio, P.V.A.; Lisboa, A.C.; Barbosa, A.V. An automatic fire detection system based on deep convolutional neural networks for low-power, resource-constrained devices. Neural Comput. Appl. 2022, 34, 15349–15368. [Google Scholar] [CrossRef]
- Varotsos, C.A.; Krapivin, V.F.; Mkrtchyan, F.A. A new passive microwave tool for operational forest fires detection: A case study of Siberia in 2019. Remote Sens. 2020, 12, 835. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Neck with GSconv (FFYOLO) | Original Neck (YOLOv8) | ||||
|---|---|---|---|---|---|
| Layer Name | In/Out Channel | Params | Layer Name | In/Out Channel | Params |
| VoVGSCSPC(L15) | 768/256 | 307,296 | C2f(L12) | 768/256 | 591,360 |
| VoVGSCSPC(L18) | 384/128 | 77,872 | C2f(L15) | 384/128 | 148,224 |
| GSConv(L19) | 128/128 | 75,584 | Conv(L16) | 128/128 | 147,712 |
| VoVGSCSPC(L21) | 384/256 | 208,992 | C2f(L18) | 384/256 | 493,056 |
| GSConv(L22) | 256/256 | 298,624 | Conv(L19) | 256/256 | 590,336 |
| VoVGSCSPC(L24) | 768/512 | 827,584 | C2f(L21) | 768/512 | 1,969,152 |
| Dataset | Number of Images | Number of Targets | Number of Smoke | Number of Fires |
|---|---|---|---|---|
| Training | 7069 | 17,082 | 11,941 | 5141 |
| Validation | 2019 | 4835 | 3354 | 1481 |
| Testing | 1011 | 2839 | 1964 | 875 |
| Input Image Size | Epochs | Optimizer | Learning Rate Scheduling | SGD Momentum | Batch Size | Weight Decay |
|---|---|---|---|---|---|---|
| 640 × 640 | 300 | SGD | Linear decay (0.01:0.0001) | 0.937 | 32 | 0.0005 |
| Baseline | IoU | CPDA | MCDH | GSConv | Params (M) | FLOPs (G) | FPS | APsmoke | APfire | mAP0.5 |
|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv5 | CIoU | - | - | - | 7,015,519 | 15.8 | 175 | 86.0% | 84.4% | 85.2% |
| YOLOv8 | CIoU | - | - | - | 11,166,560 | 28.8 | 172 | 88.0% | 82.8% | 85.4% |
| YOLOv8 | MPDIoU | - | - | - | 11,166,560 | 28.8 | 172 | 89.0% | 83.7% | 86.4% |
| YOLOv8 | CIoU | ✓ | - | - | 12,235,750 | 31.2 | 166 | 88.8% | 86.2% | 87.5% |
| YOLOv8 | CIoU | - | ✓ | - | 9,470,310 | 22.1 | 169 | 89.2% | 83.5% | 86.4% |
| YOLOv8 | CIoU | - | - | ✓ | 8,992,470 | 24.6 | 178 | 88.5% | 84.5% | 86.5% |
| YOLOv8 * | CIoU | - | - | - | 11,166,560 | 28.8 | 171 | 88.6% | 84.7% | 86.6% |
| YOLOv8 | CIoU | ✓ | ✓ | - | 10,569,718 | 24.6 | 158 | 88.6% | 86.6% | 87.6% |
| YOLOv8 | CIoU | - | ✓ | ✓ | 7,326,422 | 18.0 | 178 | 89.1% | 83.3% | 86.2% |
| YOLOv8 | CIoU | ✓ | - | ✓ | 10,091,878 | 27.1 | 164 | 88.9% | 86.5% | 87.7% |
| FFYOLO | MPDIoU | ✓ | ✓ | ✓ | 8,343,638 | 19.5 | 188 | 89.1% | 87.6% | 88.3% |
| FFYOLO * | MPDIoU | ✓ | ✓ | ✓ | 8,343,638 | 19.5 | 188 | 89.5% | 88.1% | 88.8% |
| Model | Detect Results | ||
|---|---|---|---|
| YOLOv5 |  |  |  |
| YOLOv8 |  |  |  |
| FasterRCNN |  |  |  |
| RetinaNet |  |  |  |
| FFYOLO |  |  |  |
| (a) | (b) | (c) | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yun, B.; Zheng, Y.; Lin, Z.; Li, T. FFYOLO: A Lightweight Forest Fire Detection Model Based on YOLOv8. Fire 2024, 7, 93. https://doi.org/10.3390/fire7030093
Yun B, Zheng Y, Lin Z, Li T. FFYOLO: A Lightweight Forest Fire Detection Model Based on YOLOv8. Fire. 2024; 7(3):93. https://doi.org/10.3390/fire7030093
Chicago/Turabian StyleYun, Bensheng, Yanan Zheng, Zhenyu Lin, and Tao Li. 2024. "FFYOLO: A Lightweight Forest Fire Detection Model Based on YOLOv8" Fire 7, no. 3: 93. https://doi.org/10.3390/fire7030093
APA StyleYun, B., Zheng, Y., Lin, Z., & Li, T. (2024). FFYOLO: A Lightweight Forest Fire Detection Model Based on YOLOv8. Fire, 7(3), 93. https://doi.org/10.3390/fire7030093