
Raw Material Flow Rate Measurement on Belt Conveyor System Using Visual Data

 ,
,  , , and
, , and
Abstract
1. Introduction
2. Dataset
2.1. Industrial Process
2.1.1. Limestone
2.1.2. Coke
2.1.3. Experiment Setup
2.2. Data Acquisition
3. Methodology
3.1. Extracting Region of Interest
3.2. Pre-Processing
3.3. Coke and Limestone Segmentation
3.4. Feature Extraction
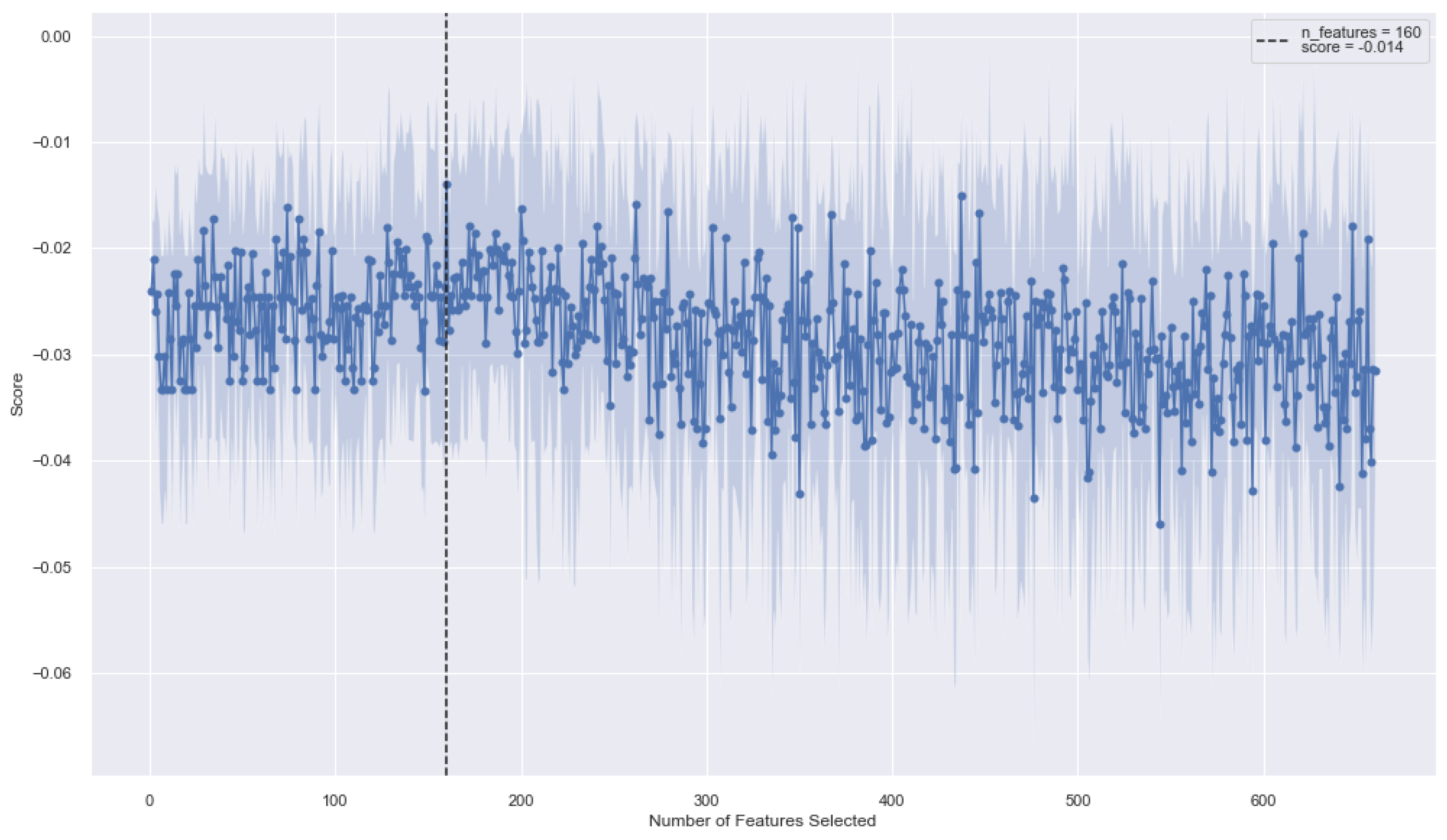
3.5. Feature Selection
3.6. Machine Learning Algorithms
- Decision TreeAs evident from the name, decision trees form a tree-like structure for performing regression. The decision tree was proposed by Quinlan [56] in 1986. In such an algorithm, the dataset is iteratively broken down into smaller chunks while simultaneously building a tree. It contains a root node representing the complete sample and is further broken down to form further nodes. The inner nodes form data features, and branches represent decision rules. Each data point is passed into the nodes one by one, giving binary answers, which are finally used to give the final prediction.
- XGBoostThe XGboost Algorithm, given by Chen et al. [57], refers to Extreme Gradient Boosting, which is an effective and efficient version of the gradient boosting algorithm. It can be used for predictive regression modeling. It originates from the decision trees and belongs to the class of ensemble algorithms; in the boosting category, to be precise. This boosting technique creates decision trees in sequential form and adjusts variable weights to increase the model’s accuracy produced through predecessors.
- Random ForestAnother ensemble learning technique, proposed by Breiman [58], comes under the bootstrapping type. The dataset is sampled randomly over a defined number of iterations and variables in bootstrapping. The results of these splits are then averaged out for a better result. It represents a combination of ensemble techniques with a decision tree to attain varied decisions from data. Then these results are averaged out to compute a new result that defines strong results.
- Bagging RegressorAn ensemble meta-estimator, also proposed by Breiman [59]. Bagging Regressor fits the fundamental estimator on randomly taken subsets of data, k times, and then combines their predictions through aggregation to attain the final prediction. It indicates that it generates multiple versions of the predictor and utilizes these to get accumulated predictors. These multiple versions are defined by making replicas of the learning set and turning them into new sets for learning. The bagging technique is considered useful because the trees all fit on different data to some extent, which induces differences between them, leading to different predictions. Moreover, its effectiveness is also evident from the fact that it has a low correlation between predictions and prediction errors. We have utilized the DecisionTreeRegressor as the base estimator for our model.
- Gradient BoostingThe Gradient Boosting regressor, given by Friedman [60], is another tree-based technique that generates an additive model in a stage-wise manner which in turn allows optimization of random differentiable functions of loss. It uses Mean Squared Error (MSE) as a cost function when used as a regressor. At every stage, fitting of a regression tree is done on the negative gradient of the loss function being used. The technique is used to find a non-linear relationship between the model target and features. Besides, it is good at dealing with outliers, missing values, and high cardinality, regardless of any special treatment.
- Gamma RegressorGamma regressor proposed by Nelder et al. [61] is a generalized linear model coupled with gamma distribution. These models allow error distribution other than the available normal distribution and help build a linear relationship between predictors and response. Gamma regressors are used for the estimation and prediction of the conditional expectation of some target variable. This model is recommended in case the dependent variable has a positive value.
- Bayesian RidgeBayesian is a good choice when it comes to situations where data is not properly distributed or is insufficient because it uses probability distributions to formulate linear regressions instead of point estimates. The prediction is not attained as a single value but is estimated through a probability distribution. The implementation used is based on the algorithm described by Tipping [62].
- RANSACRANdom SAmple Consensus (RANSAC), intrdocued by Fischler et al. [63] is a linear model that handles outliers well, so instead of a complete dataset, it uses a subset of inliers iteratively to estimate the parameters of the model. Furthermore, the outliers are excluded from the training process, thus, eliminating their impact on the learned parameters and coefficients. In terms of implementation, RANSAC uses median absolute deviation to distinguish between outliers and handlers. Moreover, it requires a base estimator to be set for estimations.
- Theil-Sen RegressorHenri Theil [64] and Pranab K. Sen [65] introduced Theil-Sen regressor in 1950 and 1968, respectively which is devised to cater to the outliers. In some instances, the Theil-Sen regressor outperforms RANSAC, a linear regression model. Theil-Sen regressor uses a generalized form of the median in varied dimensions, making it robust to multi-variation outliers. However, this robustness is inversely proportional to dimensionality. Theil-Sen regressor’s performance is comparable to the Ordinary Least Squares for the asymptotic efficiency as an unbiased estimator.
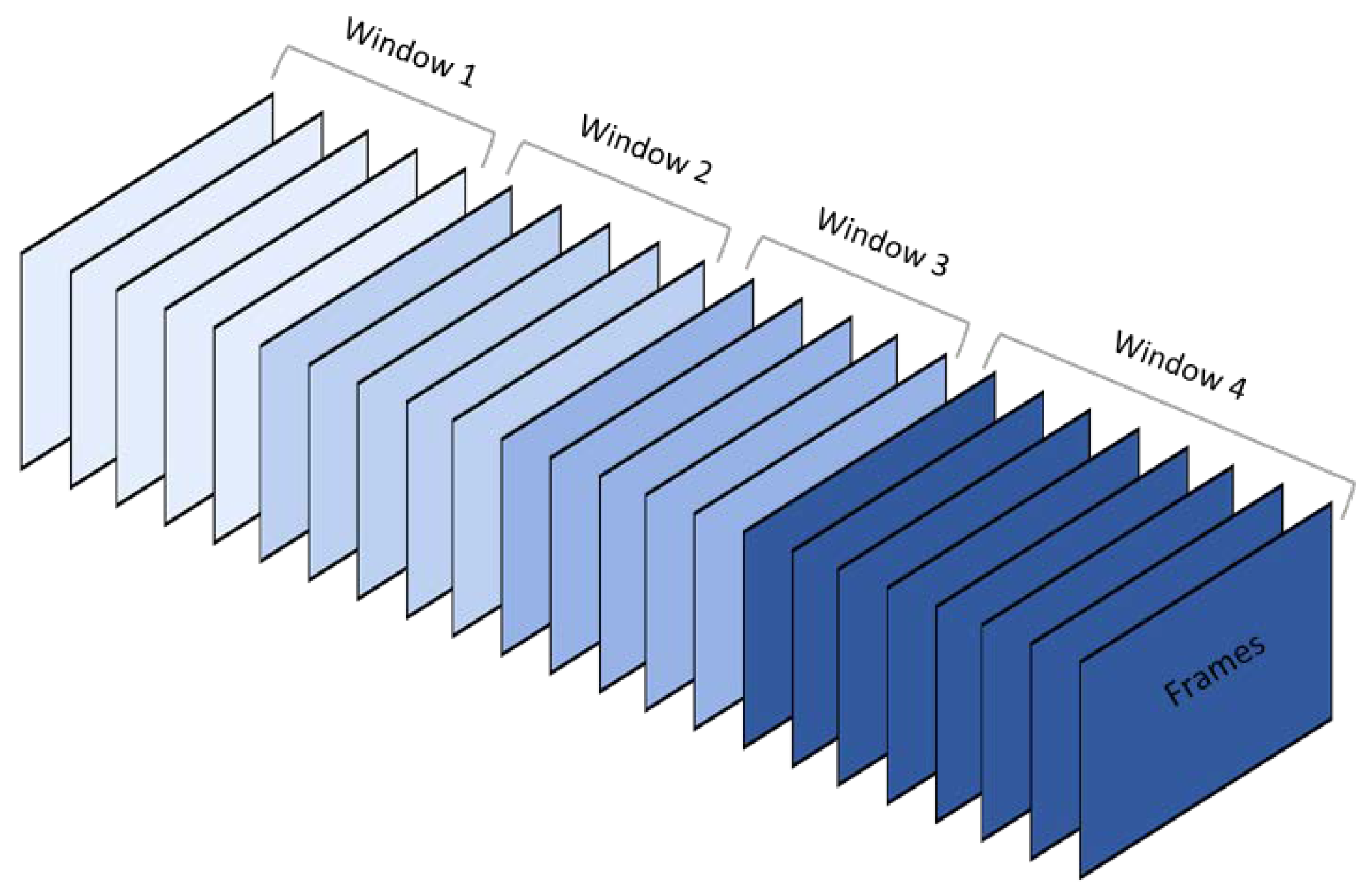
3.7. Window Function
4. Experimental Evaluations
4.1. Evaluation Metrics
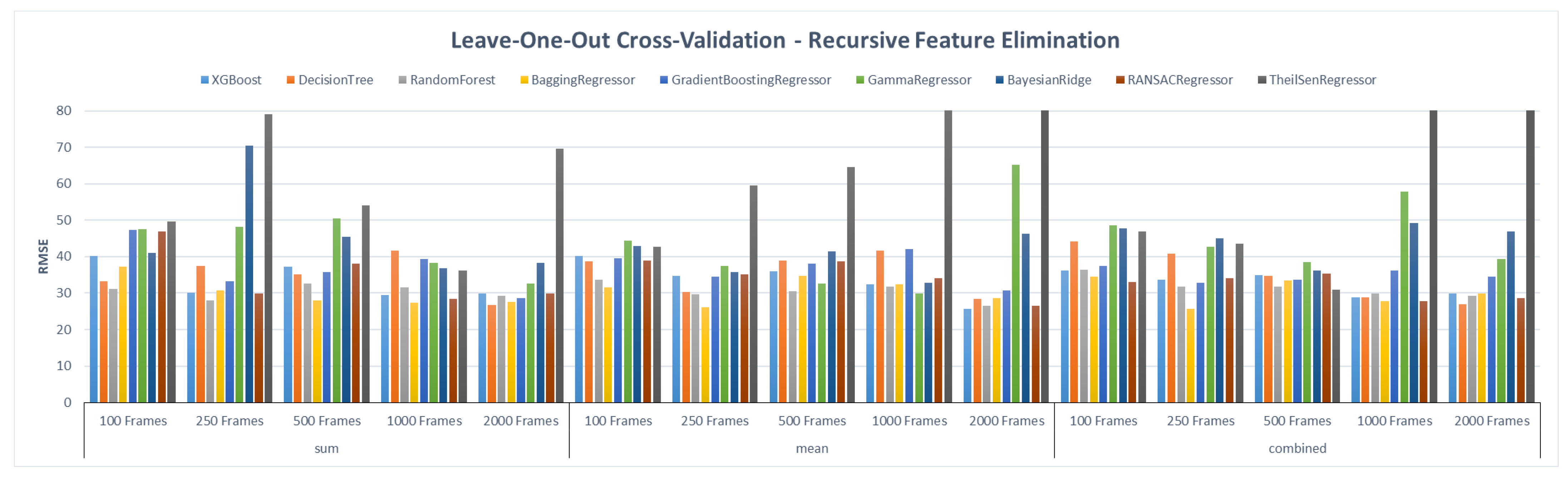
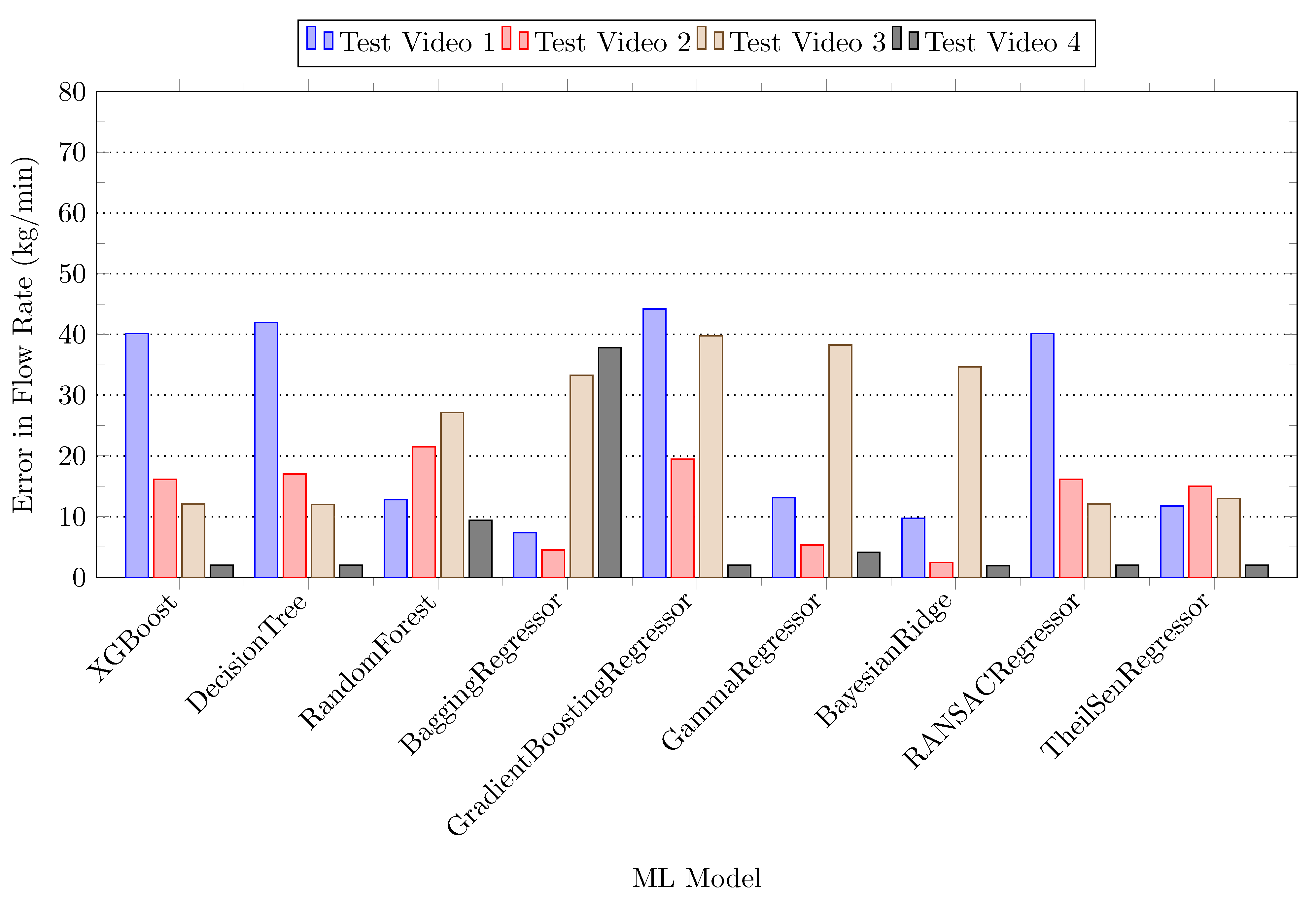
4.2. Results & Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Li, Y.; Zhang, Y. Application Research of Computer Vision Technology in Automation. In Proceedings of the 2020 International Conference on Computer Information and Big Data Applications (CIBDA), Guiyang, China, 17–19 April 2020; pp. 374–377. [Google Scholar] [CrossRef]
- Rao, D.S. The Belt Conveyor: A Concise Basic Course; CRC Press: Boca Raton, FL, USA, 2020. [Google Scholar]
- Simmons, C.W. Manufacture of Soda (Hou, Te-Pan). J. Chem. Educ. 1934, 11, 192. [Google Scholar] [CrossRef][Green Version]
- Zhang, M.; Chauhan, V.; Zhou, M. A machine vision based smart conveyor system. In Proceedings of the Thirteenth International Conference on Machine Vision, Rome, Italy, 2–6 November 2020; Osten, W., Nikolaev, D.P., Zhou, J., Eds.; International Society for Optics and Photonics, SPIE: Bellingham, WA, USA, 2021; Volume 11605, pp. 84–92. [Google Scholar] [CrossRef]
- Zeng, F.; Wu, Q.; Chu, X.; Yue, Z. Measurement of bulk material flow based on laser scanning technology for the energy efficiency improvement of belt conveyors. Measurement 2015, 75, 230–243. [Google Scholar] [CrossRef]
- Luo, B.; Kou, Z.; Han, C.; Wu, J.; Liu, S. A Faster and Lighter Detection Method for Foreign Objects in Coal Mine Belt Conveyors. Sensors 2023, 23, 6276. [Google Scholar] [CrossRef]
- Karaca, H.N.; Akınlar, C. A Multi-camera Vision System for Real-Time Tracking of Parcels Moving on a Conveyor Belt. In Proceedings of the Computer and Information Sciences-ISCIS 2005, Istanbul, Turkey, 26–28 October 2005; Yolum, P., Güngör, T., Gürgen, F., Özturan, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 708–717. [Google Scholar]
- Liu, J.; Qiao, H.; Yang, L.; Guo, J. Improved Lightweight YOLOv4 Foreign Object Detection Method for Conveyor Belts Combined with CBAM. Appl. Sci. 2023, 13, 8465. [Google Scholar] [CrossRef]
- Hu, K.; Jiang, H.; Zhu, Q.; Qian, W.; Yang, J. Magnetic Levitation Belt Conveyor Control System Based on Multi-Sensor Fusion. Appl. Sci. 2023, 13, 7513. [Google Scholar] [CrossRef]
- Ji, J.; Miao, C.; Li, X.; Liu, Y. Speed regulation strategy and algorithm for the variable-belt-speed energy-saving control of a belt conveyor based on the material flow rate. PLoS ONE 2021, 16, e0247279. [Google Scholar] [CrossRef]
- Zonta, T.; da Costa, C.A.; da Rosa Righi, R.; de Lima, M.J.; da Trindade, E.S.; Li, G.P. Predictive maintenance in the Industry 4.0: A systematic literature review. Comput. Ind. Eng. 2020, 150, 106889. [Google Scholar] [CrossRef]
- Zhang, M.; Zhou, M.; Shi, H. A Computer Vision-Based Real-Time Load Perception Method for Belt Conveyors. Math. Probl. Eng. 2020, 2020, 8816388. [Google Scholar] [CrossRef]
- Gröger, T.; Katterfeld, A. Application of the discrete element method in materials handling: Basics and calibration. Bulk Solid Handl. 2007, 27, 17–23. [Google Scholar]
- Hastie, D.; Wypych, P. Experimental validation of particle flow through conveyor transfer hoods via continuum and discrete element methods. Mech. Mater. 2010, 42, 383–394. [Google Scholar] [CrossRef]
- Lucas, B.D.; Kanade, T. An iterative image registration technique with an application to stereo vision. In Proceedings of the IJCAI’81: 7th International Joint Conference on Artificial Intelligence, Vancouver, BC, Canada, 24–28 August 1981; Volume 2, pp. 674–679. [Google Scholar]
- Tomasi, C.; Kanade, T. Detection and Tracking of Point Features; Shape and Motion from Image Streams; School of Computer Science, Carnegie Mellon University: Pittsburgh, PA, USA, 1991. [Google Scholar]
- Kontny, M. Machine vision methods for estimation of size distribution of aggregate transported on conveyor belts. Vibroeng. Procedia 2017, 13. [Google Scholar] [CrossRef]
- Qiao, W.; Lan, Y.; Dong, H.; Xiong, X.; Qiao, T. Dual-field measurement system for real-time material flow on conveyor belt. Flow Meas. Instrum. 2022, 83, 102082. [Google Scholar] [CrossRef]
- Tessier, J.; Duchesne, C.; Bartolacci, G. A machine vision approach to on-line estimation of run-of-mine ore composition on conveyor belts. Miner. Eng. 2007, 20, 1129–1144. [Google Scholar] [CrossRef]
- Gao, Y.; Qiao, T.; Zhang, H.; Yang, Y.; Pang, Y.; Wei, H. A contactless measuring speed system of belt conveyor based on machine vision and machine learning. Measurement 2019, 139, 127–133. [Google Scholar] [CrossRef]
- Wang, J.; Liu, Q.; Dai, M. Belt vision localization algorithm based on machine vision and belt conveyor deviation detection. In Proceedings of the 2019 34rd Youth Academic Annual Conference of Chinese Association of Automation (YAC), Jinzhou, China, 6–8 June 2019; pp. 269–273. [Google Scholar] [CrossRef]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Duda, R.O.; Hart, P.E. Use of the Hough Transformation to Detect Lines and Curves in Pictures. Commun. ACM 1972, 15, 11–15. [Google Scholar] [CrossRef]
- Hough, P.V. Method and Means for Recognizing Complex Patterns. US Patent 3,069,654, 18 December 1962. [Google Scholar]
- Thurley, M.J. Automated Image Segmentation and Analysis of Rock Piles in an Open-Pit Mine. In Proceedings of the 2013 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Hobart, Australia, 26–28 November 2013; pp. 1–8. [Google Scholar] [CrossRef]
- Wikipedia Contributors. Solvay Process—Wikipedia, The Free Encyclopedia. Available online: https://en.wikipedia.org/wiki/Solvay_process (accessed on 23 December 2022).
- Johns, R.J. Solvay processes. J. Chem. Educ. 1963, 40, A535. [Google Scholar] [CrossRef]
- Dabek, P.; Szrek, J.; Zimroz, R.; Wodecki, J. An Automatic Procedure for Overheated Idler Detection in Belt Conveyors Using Fusion of Infrared and RGB Images Acquired during UGV Robot Inspection. Energies 2022, 15, 601. [Google Scholar] [CrossRef]
- Sun, R.; Lei, T.; Chen, Q.; Wang, Z.; Du, X.; Zhao, W.; Nandi, A.K. Survey of Image Edge Detection. Front. Signal Process. 2022, 2. [Google Scholar] [CrossRef]
- Schumacher, D.A. II.1—Image Smoothing and Sharpening by Discrete Convolution. In Graphics Gems II; ARVO, J., Ed.; Morgan Kaufmann: San Diego, CA, USA, 1991; pp. 50–56. [Google Scholar] [CrossRef]
- Fan, L.; Zhang, F.; Fan, H.; Zhang, C. Brief review of image denoising techniques. Vis. Comput. Ind. Biomed. Art 2019, 2, 7. [Google Scholar] [CrossRef]
- O’Shea, K.; Nash, R. An Introduction to Convolutional Neural Networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Deng, G.; Cahill, L. An adaptive Gaussian filter for noise reduction and edge detection. In Proceedings of the 1993 IEEE Conference Record Nuclear Science Symposium and Medical Imaging Conference, San Francisco, CA, USA, 31 October–6 November 1993; Volume 3, pp. 1615–1619. [Google Scholar] [CrossRef]
- Tomasi, C.; Manduchi, R. Bilateral filtering for gray and color images. In Proceedings of the Sixth International Conference on Computer Vision (IEEE Cat. No.98CH36271), Bombay, India, 7 January 1998; pp. 839–846. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3523–3542. [Google Scholar] [CrossRef] [PubMed]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Kanezaki, A. Unsupervised Image Segmentation by Backpropagation. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 1543–1547. [Google Scholar] [CrossRef]
- Lin, D.; Dai, J.; Jia, J.; He, K.; Sun, J. ScribbleSup: Scribble-Supervised Convolutional Networks for Semantic Segmentation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3159–3167. [Google Scholar] [CrossRef]
- Beucher, S.; Lantuéjoul, C. Use of Watersheds in Contour Detection. In Proceedings of the International Workshop on Image Processing: Real-Time Edge and Motion Detection/Estimation, Rennes, France, 17–21 September 1979; Volume 132, pp. 1–22. [Google Scholar]
- Mohan, A.S.; Resmi, R. Video image processing for moving object detection and segmentation using background subtraction. In Proceedings of the 2014 First International Conference on Computational Systems and Communications (ICCSC), Trivandrum, India, 17–18 December 2014; pp. 288–292. [Google Scholar] [CrossRef]
- Garcia-Garcia, B.; Bouwmans, T.; Rosales Silva, A.J. Background subtraction in real applications: Challenges, current models and future directions. Comput. Sci. Rev. 2020, 35, 100204. [Google Scholar] [CrossRef]
- Singla, N. Motion detection based on frame difference method. Int. J. Inf. Comput. Technol. 2014, 4, 1559–1565. [Google Scholar]
- Mubasher, M.M.; Farid, M.S.; Khaliq, A.; Yousaf, M.M. A parallel algorithm for change detection. In Proceedings of the 2012 15th International Multitopic Conference (INMIC), Islamabad, Pakistan, 13–15 December 2012; pp. 201–208. [Google Scholar] [CrossRef]
- Zeevi, S. BackgroundSubtractorCNT: A Fast Background Subtraction Algorithm. 2016. Available online: https://zenodo.org/record/4267853 (accessed on 3 October 2022).
- Haralick, R.M.; Sternberg, S.R.; Zhuang, X. Image Analysis Using Mathematical Morphology. IEEE Trans. Pattern Anal. Mach. Intell. 1987, 9, 532–550. [Google Scholar] [CrossRef]
- Jamil, N.; Sembok, T.M.T.; Bakar, Z.A. Noise removal and enhancement of binary images using morphological operations. In Proceedings of the 2008 International Symposium on Information Technology, Kuala Lumpur, Malaysia, 26–28 August 2008; Volume 4, pp. 1–6. [Google Scholar] [CrossRef]
- Raid, A.; Khedr, W.; El-Dosuky, M.; Aoud, M. Image restoration based on morphological operations. Int. J. Comput. Sci. Eng. Inf. Technol. (IJCSEIT) 2014, 4, 9–21. [Google Scholar] [CrossRef]
- Zhang, D. Extended Closing Operation in Morphology and Its Application in Image Processing. In Proceedings of the 2009 International Conference on Information Technology and Computer Science, Kiev, Ukraine, 25–26 July 2009; Volume 1, pp. 83–87. [Google Scholar] [CrossRef]
- Wikipedia contributors. Image Moment—Wikipedia, The Free Encyclopedia. Available online: https://en.wikipedia.org/wiki/Image_moment (accessed on 23 December 2022).
- Flusser, J.; Zitova, B.; Suk, T. Moments and Moment Invariants in Pattern Recognition; Wiley Publishing: New York, NY, USA, 2009. [Google Scholar]
- Gong, X.Y.; Su, H.; Xu, D.; Zhang, Z.; Shen, F.; Yang, H.B. An Overview of Contour Detection Approaches. Int. J. Autom. Comput. 2018, 15, 1–17. [Google Scholar] [CrossRef]
- Dhanachandra, N.; Manglem, K.; Chanu, Y.J. Image Segmentation Using K -means Clustering Algorithm and Subtractive Clustering Algorithm. Procedia Comput. Sci. 2015, 54, 764–771. [Google Scholar] [CrossRef]
- Ververidis, D.; Kotropoulos, C. Sequential forward feature selection with low computational cost. In Proceedings of the 2005 13th European Signal Processing Conference, Antalya, Turkey, 4–8 September 2005; pp. 1–4. [Google Scholar]
- Abe, S. Modified backward feature selection by cross validation. In Proceedings of the 13th European Symposium on Artificial Neural Networks, ESANN, Bruges, Belgium, 27–29 April 2005; pp. 163–168. [Google Scholar]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene Selection for Cancer Classification using Support Vector Machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the KDD ’16: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Nelder, J.A.; Wedderburn, R.W.M. Generalized Linear Models. J. R. Stat. Soc. Ser. A (Gen.) 1972, 135, 370–384. [Google Scholar] [CrossRef]
- Tipping, M. Sparse Bayesian Learning and the Relevance Vector Machine. J. Mach. Learn. Res. 2001, 1, 211–244. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Theil, H. A rank-invariant method of linear and polynomial regression analysis. Indag. Math. 1950, 12, 173. [Google Scholar]
- Sen, P.K. Estimates of the Regression Coefficient Based on Kendall’s Tau. J. Am. Stat. Assoc. 1968, 63, 1379–1389. [Google Scholar] [CrossRef]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Property | Value |
|---|---|
| Motor Power | 40 HP |
| Speed | 1465 RPM |
| Length | 1460 feet |
| Small rollers | 510 units |
| Return rollers | 90 units |
| Main rollers | 10 units |
| Operator | Frame Difference | Background Subtraction CNT | ||
|---|---|---|---|---|
| SE | IT | SE | IT | |
| Open | 1 | 1 | ||
| Dilation | 5 | 5 | ||
| Close | 8 | 10 | ||
| Model | MAE | MSE | MAPE | RMSE |
|---|---|---|---|---|
| XGBoost | 16.938 | 443.814 | 0.011 | 21.067 |
| Decision Tree | 19.750 | 535.750 | 0.012 | 23.146 |
| Random Forest | 19.753 | 535.976 | 0.012 | 23.151 |
| Bagging Regressor | 16.160 | 274.602 | 0.010 | 16.571 |
| Gradient Boosting | 26.247 | 1112.44 | 0.016 | 33.353 |
| Gamma Regressor | 14.290 | 415.210 | 0.009 | 20.377 |
| Bayesian Ridge | 12.148 | 322.544 | 0.007 | 17.960 |
| RANSAC | 16.938 | 443.814 | 0.011 | 21.067 |
| Theil-Sen | 12.131 | 322.424 | 0.007 | 17.956 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sabih, M.; Farid, M.S.; Ejaz, M.; Husam, M.; Khan, M.H.; Farooq, U. Raw Material Flow Rate Measurement on Belt Conveyor System Using Visual Data. Appl. Syst. Innov. 2023, 6, 88. https://doi.org/10.3390/asi6050088
Sabih M, Farid MS, Ejaz M, Husam M, Khan MH, Farooq U. Raw Material Flow Rate Measurement on Belt Conveyor System Using Visual Data. Applied System Innovation. 2023; 6(5):88. https://doi.org/10.3390/asi6050088
Chicago/Turabian StyleSabih, Muhammad, Muhammad Shahid Farid, Mahnoor Ejaz, Muhammad Husam, Muhammad Hassan Khan, and Umar Farooq. 2023. "Raw Material Flow Rate Measurement on Belt Conveyor System Using Visual Data" Applied System Innovation 6, no. 5: 88. https://doi.org/10.3390/asi6050088
APA StyleSabih, M., Farid, M. S., Ejaz, M., Husam, M., Khan, M. H., & Farooq, U. (2023). Raw Material Flow Rate Measurement on Belt Conveyor System Using Visual Data. Applied System Innovation, 6(5), 88. https://doi.org/10.3390/asi6050088