1. Introduction
Offensive language is usually defined as hurtful, derogatory, or obscene comments made by one person to another. These kinds of remarks are not uncommon in social media. Cyberbullying is a serious social problem. How to quickly and accurately automatically detect offensive language in social media has become one of the hot research issues in the field of natural language processing. The rapid identification of offensive language on the Internet and prevention of its viral spread has important practical significance for reducing cyberbullying and self-harm behavior.
Offensive-language detection tasks are usually regarded as supervised text-classification tasks. Offensive-language remarks are intrinsically closely related to the relationships between groups and very much depend on the nuance of language. In many cases, despite the manual methods being used to distinguish whether a sentence constitutes offensive language, the consensus level is very low [
1]. In recent years, offensive-language remarks have become more harmful. Therefore, the issue has attracted more and more attention from researchers, and many related datasets and related algorithms have emerged. However, most of the datasets are small in size and low in quality. The algorithms only use artificial features and simple fine-tuning pre-trained models.
Zampie et al. [
2] constructed the Offensive Language Identification Dataset (OLID). A sentence in OLID is annotated by multiple annotators. When annotating conflicts, a majority vote is also required. However, this requires a significant amount of labor and material resources; so, OLID only has 14,100 sentences. The GermEval 2018 [
3] shared task focused on offensive-language recognition in German tweets. Its dataset only contains 8500 sentences.
In recent years, traditional deep-learning methods have also been widely used in offensive-language detection. The deep-learning methods are based on the word-embedding representation obtained from large-scale expected training and use a neural network structure to extract and merge semantic features. Gambäck and Sikdar [
4] used a convolutional neural network (CNN) to detect offensive language. In addition to the CNN method, Badjatiya et al. [
5] also used a Long Short-Term Memory (LSTM) network and FastText [
6] methods to detect offensive language. These methods’ performance is better than the traditional machine-learning methods. However, traditional deep learning uses static word embedding, which cannot solve the polysemy problem. It generates a significant reduction in the performance of the classifier.
Recently, self-supervised learning to obtain pre-trained models unrelated to specific tasks from large-scale data has been a great success in the field of natural language processing. A pre-trained language model can be defined as a black box that has prior knowledge of natural language and can be applied and fine-tuned to solve various NLP problems. The pre-trained models of Generative Pre-Training (GPT) [
7] and Bidirectional Encoder Representations from Transformers (BERT) [
8] have achieved the best performance in many natural-language-processing tasks. Although the contextualized word embedding of the pre-trained models solves the word-ambiguity problem, it ignores character-level features, which reduces the performance of offensive-speech detection models.
To solve the above problems, we proposed a multi-semantic fusion network based on data augmentation (MSF) (code is available at
https://github.com/RoversCode/OffensiveDetectionMSF, accessed on 2 January 2022). Our work is based on intuition: (1) The same semantics can be expressed in different ways, and the corresponding sentence structure may also be different. (2) Pre-trained language models such as BERT can obtain dynamic word vectors and have a stronger ability to represent offensive language sentences. In addition, character-level features are a significant linguistic feature of offensive language. Based on the above two points, we adopted back translation to achieve data augmentation and proposed the MSF model. The proposed model captures features by BERT and combines with CNN to build the information of n-grams character features. Then, we used an interactive fusion mechanism to fuse two kinds of information in the task of offensive-language detection.
To summarize, our contributions are as follows:
(1) For small-scale offensive-language detection tasks, we adopted the back-translation method to enhance the data so that the model can obtain richer semantic information.
(2) We proposed the character-capture module to capture the n-grams character features and to combine deep semantic features. Then, we utilized an interactive fusion mechanism to combine them. The experimental results show that it is useful for offensive-language detection.
(3) The experimental results on the two public datasets demonstrate that our method achieved state-of-the-art performance compared with strong baselines.
The rest of our article is structured as follows.
Section 2 discusses related work on datasets, data augmentation, and offensive-language detection methods.
Section 3 gives a detailed description of our MSF model for offensive-language detection.
Section 4 shows the extensive experiments to evaluate the effectiveness of our model, and
Section 5 summarizes the work and outlines the future direction.
2. Related Work
In this section, we review related works on datasets, data augmentation, deep-learning-based methods, and pre-trained models for offensive-language detection.
There are relatively few datasets in the field of offensive-language detection. Labeling methods can be divided into manual labeling and semi-supervised automatic labeling. Sigurbergsson et al. [
9] created the offensive-language dataset DKHATE in Danish with only 3600 sentences. Pitenis et al. [
10] constructed the Offensive Greek Tweet Dataset (OGTD), which contains 10,287 sentences. Compared with other languages, the scale of the offensive-language datasets for English is larger, such as OLID [
2] with 13,240 sentences and the Davidson dataset [
11] containing more than 20,000 sentences. Rosenthal et al. [
12] annotated data in a semi-supervised manner and constructed the SOLID dataset. Although SOLID has 9 million pieces of data, the dataset is much noisier, and the quality is lower. In summary, the manually labeled datasets are small in size and cannot meet the needs of models, and the automatically labeled datasets are large in scale, but the quality cannot be guaranteed.
Data augmentation is a technique for automatically expanding training data. The great success of deep learning is supported by a large amount of data. Wei et al. [
13] replaced some words in the sentence with their synonyms to make the augmented data fit the original semantics as much as possible. Luque et al. [
14] and Zhang et al. [
15] transformed the original document into text in other languages through translation and then translated it back to get the new text in the original language to achieve the purpose of data expansion. In addition to the above methods, there is also word vector-based replacement [
16], simple pattern-matching changes at the word level, and so on [
17]. Previous studies have shown that data augmentation can effectively improve the performance and robustness of the models. Our intuition is that introducing data-augmentation methods into offensive-language-detection tasks can effectively improve model performance.
Traditional deep-learning methods filter and extract the semantic information of sentences by constructing different neural-network structures to obtain features with strong representation and use them for offensive-language-detection tasks. Zhang et al. [
18] proposed a hybrid CNN-LSTM method for offensive-language-detection tasks. The experimental results show that the performance of this method is not much better than when using static word vectors. Gambäck and Sikdar [
4] used CNN to extract four-gram character-level features for offensive-language detection, and character-level features can effectively improve the performance of offensive-language detection. Shen et al. [
19] used maximum pooling and average pooling to fuse features of different dimensions after the word-embedding layer. It was found that the fusion strategy is significantly better than the single pooling strategy. In conclusion, the static word vector is not conducive to detecting offensive language and the combination of multiple pooling helps to improve the performance of models. More importantly, the character-level features can effectively improve the performance of offensive-language-detection tasks.
The transformer-based pre-training model has achieved good performance in natural-language-understanding tasks. Representative models include ELMO [
20], GPT, and BERT. Alatawi et al. [
21] fine-tuned BERT to detect offensive language. Sohn and Lee [
22] proposed multi-channel BERT, and each BERT channel corresponds to a pre-trained BERT in different languages. Sohn believes that offensive language expressed in different languages has a similar semantic representation and syntactic structure; so, he translated the dataset into multiple languages and used multi-channel BERT to extract features. Lou et al. [
23] used a hybrid BERT-GCN method to recognize offensive language. Compared with static word vectors, the performance of pre-trained language models is better, but they often ignore character-level features, and they are likely to play an important role in offensive language.
A comparison of the above method and MSF shows
Table 1.
3. Methodology
In this section, we introduce our proposed MSF model in detail.
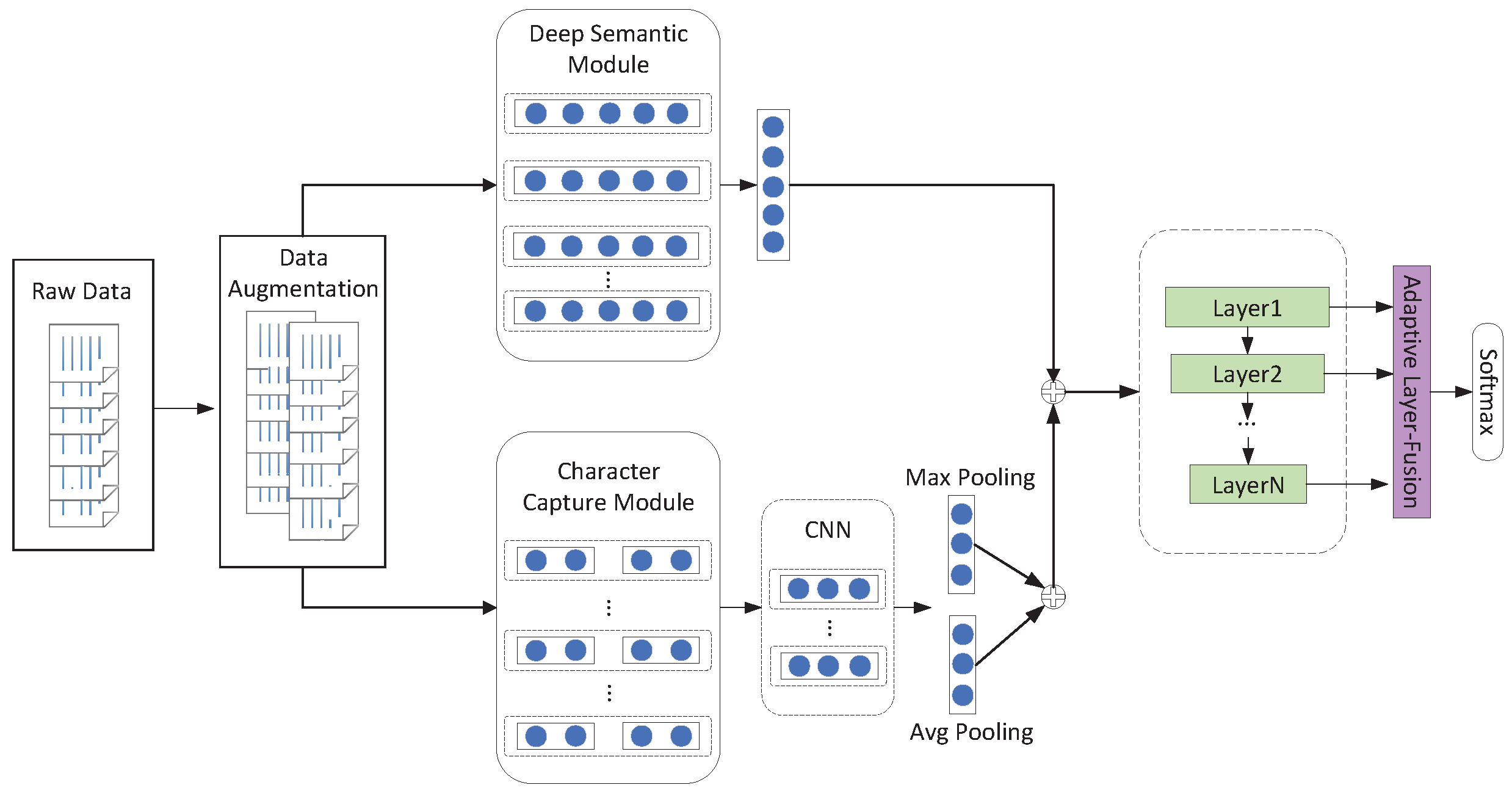
The overall structure of the MSF model is shown in
Figure 1. MSF can be divided into three levels: (1) data augmentation; (2) semantic understanding; and (3) the interaction fusion mechanism. So, we give a detailed summary of each part. In order to expand the dataset, we used back translation to double the size of the dataset. The semantic understanding can be divided into two parts: the deep semantic module and the character-capture module. For the deep semantic part, we directly used BERT. In the character-capture part, we used CNN to extract semantic-information-carrying character features. To better integrate deep semantic features and character-level features, we adopted a features-interaction fusion mechanism. Next, we introduce each part in detail.
3.1. Data Augmentation
We used the back-translation method for data augmentation. Back translation [
14] does not directly replace individual words one by one based on the relationship of synonyms but retells sentences in a generated way to achieve the purpose of data expansion. For example:
exp1 original: Fuckkk I know I seen bitch that’s a slapper lmao.
translation: Shit, I know I’ve seen a bitch. That’s a slut.
exp2 original: fuck no bitch we decided we both was gone steepppp.
translation: No fucking bitch, we decided to leave quickly.
As can be seen from the above two examples, firstly, compared with other data-augmentation methods, back translation can use existing translation tools to generate enhanced data, and it ensures that the sentence is grammatically correct; the semantics are fluent and do not deviate from the original sentence. In this way, the model can learn the correct semantic and grammatical features. Secondly, after the sentence is translated, the structure of some sentences changes slightly, such as exp1; some sentences have large changes in patterns, such as exp2. Although the sentence pattern has changed, its semantics remain unchanged, which enables the model to learn richer semantic features. Lastly, most text on social media is in colloquial form, so the words are more casual. When the users make offensive remarks, they might repeat certain characters or word forms to express the urgency of things or the intensity of emotions. These misspelled words have a high probability of being treated as unregistered words. With augmented data generated by back translation, on the one hand, misspelled words can be corrected, such as Fuckkk in exp1 and steepppp in exp2; on the other hand, some implicit dirty words are made explicit—for example, slapper-slut in exp1.
There is a significant amount of noise in the sentence, which will affect the quality of the back translation; so, we first carried out data preprocessing. In the preprocessing process, we deleted useless symbols, such as url, @, #, and user and converted emoticons into text content. After this processing, we finally used the Google Translate API to achieve data augmentation.
3.2. Semantic Understanding
Due to the language characteristics of offensive language, semantic understanding is divided into the deep semantic module (DSM) and the character capture module (CCM).
3.2.1. Deep Semantics Module
This module is a pre-trained BERT based on the encoder network structure of the transformer [
24]. BERT implements contextualized word embedding, which solves the problem of ambiguity in offensive language. At the same time, BERT continuously extracts the high-level vector representation of the current input through the multi-head attention mechanism and the feedforward network. The formula is as follows:
where the input vector
X is mapped into matrix
by the parameter matrix
.
is the number of dimensions of
K. The final output representation of the multi-head attention mechanism is the concatenation of the output of each attention:
3.2.2. Character-Capture Module
Character-level n-grams are more predictive than word-level features in offensive language [
25]. These misspelled words are often key words in offensive language. To better fine-tune the word-vector representation, we introduced n-grams character features and used a neural network model CNN that can better extract local features to extract sentence information that carries n-grams characters. The character-capture model consists of an embedding layer, a convolutional layer, and a pooling layer. The specific implementation details of each layer are described in detail below.
Embedding Layer. In this layer, words can be expressed as a combination of word vectors and n-grams character vectors. Let the sentence , , and we convert it into , ; is the character of a word. Where d and are the dimensional vectors, and N is the length of the sentence. The n-grams character can be represented as , . The final word can be expressed as , which carries both word semantic and n-grams character features. Taking the word like and as an example, it can be represented . For the character embedding, we randomly initiate.
Convolutional Layer. A convolution strategy can better extract local semantic features. The convolution layer uses a convolution kernel with a window size of
h to extract local features. It is calculated as follows:
where
represents the
to
columns of the input vector
g, with
h as the convolution kernel size.
f is the nonlinear activation function ELU.
w is the parameter matrix, and
b is the bias term.
Pooling Layer. The maximum pooling strategy was used to obtain key information features. Average pooling supplements the semantic information ignored by maximum pooling. We used max pooling and average pooling to extract more comprehensive semantic information:
where
C is the output of the convolutional, layer and ⊕ represents concatenation.
3.3. Interactive Fusion Mechanism
Because the simple fully connected layer connection does not take into account the interaction between potential features, after getting the output of the sentence by DSM and CCM to represent and , we used an interaction mechanism to interact between the two vectors instead of simply connecting them. In detail, this interaction mechanism uses two strategies to learn sentence representation.
Pyramid Layers. He et al. [
26] proposed that the model can use a small number of hidden units as a higher-level model to learn more abstract features. Chen et al. [
27], inspired by this, proposed the pyramid structure. It better integrates features. The pyramid layer is composed of N MLPs where the bottom layer is the widest, and each successive layer has a smaller number of neurons. The output of the MLP of each layer is not only the input of the MLP of the next layer but also the input of the adaptive layer.
In this study, we let the sentence vector
of the
n-th layer be defined as:
where
, and
.
are parameters.
denotes the layer index.
Adaptive Layers Fusion. The output of the MLP of each layer of the pyramid layer is connected in series to be the input of the adaptive layer. The formula is as follows:
where
are parameters.
is a normalized weight learned during training.
3.4. Model Training
We used the cross-entropy loss function to train our model in an end-to-end manner. The objective of learning
is to minimize the loss function as follows:
where
i is the index of sentences;
j is the index of class;
is the
regularization parameter; and
denotes all trainable parameters.
4. Experimentation
In this section, we first introduce the datasets, evaluation metrics, and implementation details. Then, we compare our model with several strong baselines. Finally, a detailed analysis is presented.
4.1. Experimental Settings
Data Settings. To prove the validity of the model, we conducted experiments on two public offensive-language datasets. On the two datasets, we only performed data augmentation on the training set. The amount of enhanced data was twice that of the original training set. The details of the datasets are shown in
Table 2.
The Offensive Language Identification Dataset (OLID) released by SemEval-2019 Task 6 has three subtasks. We only focused on subtask A: Offensive-Language Detection. The test set had 820 sentences, and the training set had 13,420 sentences. OLID is an unbalanced dataset, and the ratio of positive samples to negative samples is about 1:2.
The Davidson Dataset (DV) was created by [
11]. The DV dataset contains more than 20,000 sentences, which is relatively large. DV contains three categories, including hate speech, offensive language, and neither. It is also an unbalanced dataset, with the ratio of the three categories of 1:13:3, respectively.
Data imbalance is fairly common in ecology, and it usually reflects an unequal distribution of classes within a dataset. Models built on imbalanced datasets will be constrained by its ability to predict rare and minority points. On the other hand, the predictive capabilities of the model are better by balancing the data compared with imbalanced data [
28]. Therefore, whether to train on a balanced dataset does not affect the experimental results.
Evaluation Metrics. To facilitate comparison with the baseline methods, we used different evaluation metrics. To be consistent with the SemEval competition, we used standard Acc and macro-F1. For the DV dataset, we used the five-fold cross-validation mechanism and used Acc and weighted F1. The formulas are as followings.
where
and
represent positive F1 and negative F1, respectively.
is the total number of positive samples.
is the negative samples.
Implementation Details. In our experiment, we augmented the dataset through the Google Translate API. The input sentence length was 128. For the CCM module, we randomly initialized the n-grams vector, and its dimension was 300. Then, we used the CNN with two layers of convolution kernels: 3 and 5, respectively. For the DSM module, we used BERTbase (, , , and M) where L is the number of transformer blocks; H is the hidden size; and A is the number of heads. The pyramid layer has three layers with 128, 64, and 32 hidden units. The adaptive fusion layer has 128 hidden units. There is a dropout layer after the adaptive fusion layer, and the dropout rate was 0.2. Finally, MSF was optimized by the Nadam optimizer where , , and the initial learning rate was . The models were trained by a mini-batch of 16 instances. To prevent overfitting, we used an early stop in the training process.
4.2. Comparison with Baselines
We used the following baseline methods for comparison to comprehensively evaluate the performance of our method.
SVM. This method uses statistical features and linear support vector machine as a classifier to detect offensive language [
2,
11].
CNN. This method uses a convolutional layer and maximum pooling to detect offensive language [
29].
Bi-GRU. This method uses a bidirectional gated recurrent unit network to extract the semantic features of the text [
29].
Bi-GRU-CNN. This method uses hybrid Bi-GRU-CNN for offensive-language detection [
29].
Bi-LSTM. This method uses the bidirectional long- and short-term memory network to obtain semantic features of the text and to detect offensive language [
29].
Bi-LSTM-Att. In addition to Bi-LSTM, this method adds an attention mechanism to extract text semantic features [
30].
BERT. This model uses a fine-tuning BERTbase for offensive-language detection [
31,
32].
BERT-CNN. This method uses hybrid BERT-CNN for offensive-language detection [
31].
SKS. This method detects offensive language based on emotional knowledge sharing [
33].
MSF. MSF is our proposed model, which detects offensive language based on multi-semantic fusion.
The results of the comparisons are listed in
Table 3. From the results, we observe that:
(1) The performance of traditional machine-learning methods based on the bag-of-words model was not satisfactory. Using only n-grams character features and shallow semantic features cannot well characterize offensive language. The experimental results show that the performance of SVM is quite different from mainstream deep-learning methods, and its generalization ability is weak.
(2) The performance of RNN is better than CNN. After the introduction of the attention mechanism, the performance was further improved, and a deeper hierarchical network structure, such as BiGRU-CNN, can better extract deep semantic features.
(3) BERT uses the transformer encoder structure, which can capture longer-distance dependencies. Therefore, it is more efficient than RNN and CNN, and its performance was generally improved by about 1% on offensive-language-detection tasks. Based on BERT, after adding the CNN layer, the performance of the model was further improved.
(4) Zhou et al. [
33] adopted a multi-task learning method and introduced more sentiment features. Compared with other methods, SKS performance was significantly improved. However, this model needs to use a significant amount of external sentiment resources, and the model structure is complicated.
(5) MSF, our proposed method, achieved the best performance on both datasets. For the DV dataset, MSF improved upon ordinary BERT by 6.2% for weighted F1 and BERT-CNN by 5.2%. Even compared with the strong baseline SKS, the performance of our model was superior by 0.9%. For the OLID dataset, MSF improved upon ordinary BERT by 6.6%. MSF can learn the deep semantics and character features of offensive language, such as semantic information and n-grams features, and apply interaction fusion mechanisms to fuse and adjust the potential feature interactions between them.
4.3. Ablation Experiment
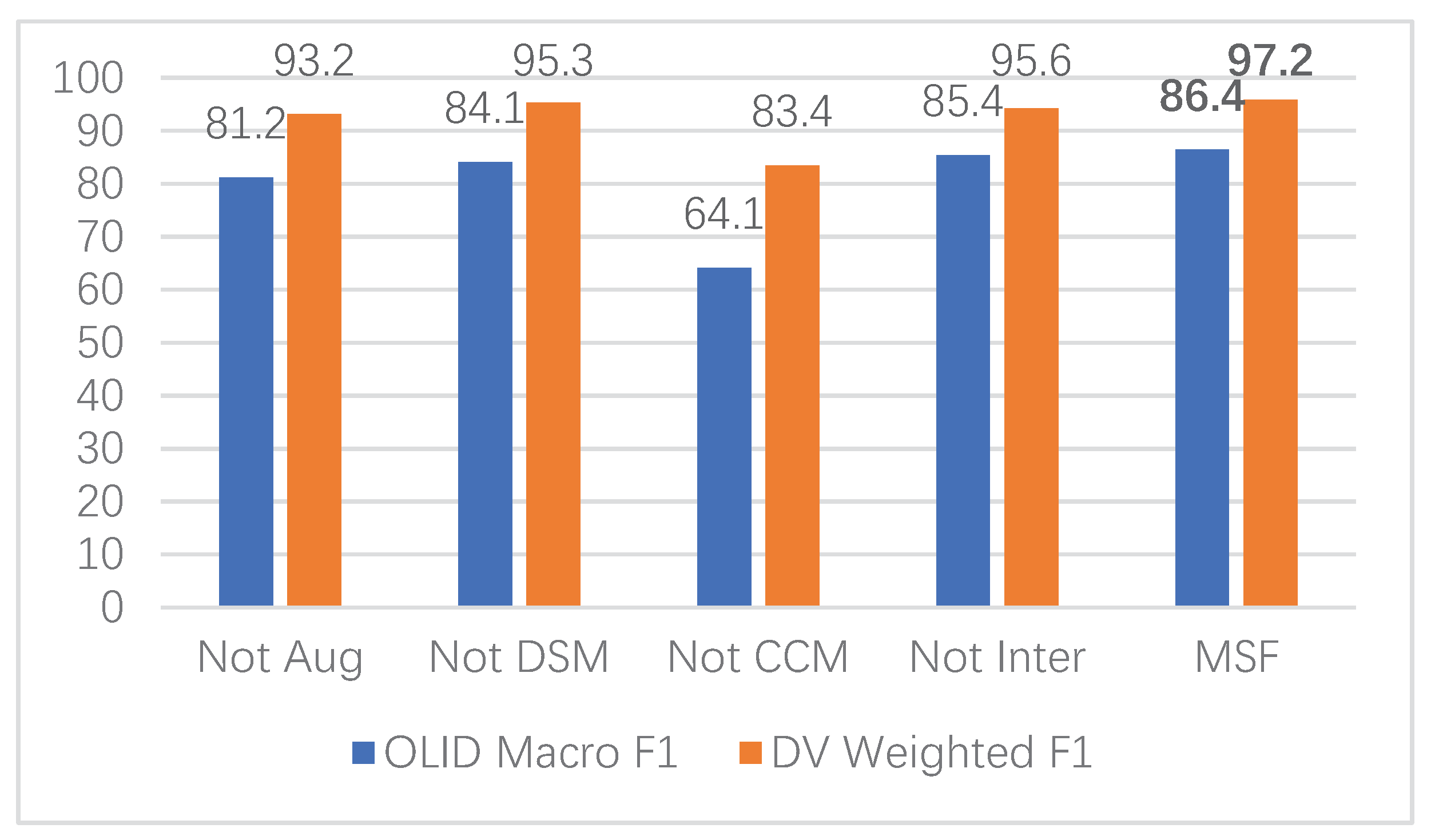
We analyze the impact of different parts in this section. The results are shown in
Figure 2, where “Not Aug” denotes ablation of augmentation. Similarly, “Not DSM” means that a deep semantic module was not used, and “Not CCM” means to cancel the character-capture module; “Not Inter” denotes that there is no interaction fusion mechanism.
Based on the results in
Figure 2, we observed that:
(1) Data augmentation has a significant impact on model performance. When data augmentation was used, the performance was comparable to SKS and better than other baselines. When data augmentation was canceled, the performance of the model decreased significantly by about 5%. The reason for this is that data augmentation increases the diversity of data, and the model can learn richer semantic features without the need to introduce external resources.
(2) DSM has little effect on model performance. When the module was canceled, the model performance only decreased by about 2%. The reason for this is that our proposed model uses two modules to extract the semantic information of sentences. The semantic information extracted by the CCM module can better represent offensive language, and the adaptive fusion layer can better integrate the features extracted by the CCM module.
(3) CCM has a great impact on model performance. To our surprise, when CCM was canceled, the performance for OLID decreased by nearly 20%, and it also decreased by 15% for the DV dataset. The main reasons for this were as follows. First, the semantic features of the character level have a significant impact on the offensive-language detection task, which can effectively improve performance. Second, the features extracted by the deep network are not suitable to be used as the input for the interactive-fusion level alone. In our experiments, this structure decreased model performance significantly.
(4) The interactive-fusion level can fuse the semantic features extracted from the two modules of DSM and CCM, which is a useful supplement to the model.
(5) Our proposed model uses data augmentation, DSM, CCM, and an interactive fusion mechanism to achieve state-of-the-art performance.
4.4. The Influence of the N-Grams
Table 4 shows the influence of the value of n-grams on the performance. When n was small, the performance was relatively poor. As n increased, the performance gradually improved. When
, the model achieved the best performance on both datasets. When n continued to increase, the performance decreased. Therefore, the value of
in our experiment.
4.5. Error Analysis
To better study the problems of the model proposed in this study and in the hope of further improvement in future offensive-language detection tasks, we analyzed the error examples. The following is an example that the model does not recognize correctly:
exp1: Alex this is so fucking beautiful.
exp2: #auspol I don’t know why he is still in his job. Seriously.
Exp 1 is normal speech, but the model recognizes it as offensive language. This is mainly because the word fucking is common in offensive language, but here it is only a means to emphasize the tone. Exp 2 is an offensive sentence, but our model did not classify it correctly. This sentence lacks obvious sentiment words, the expression is more obscure, and its offensive meaning is implicit in the semantics of the text. Similar examples are common in political sentences.
5. Conclusions and Future Work
In this work, we focused on offensive-language detection through data augmentation, n-grams character features, and semantic fusion. For this purpose, we employed back translation to augment the data, used the DSM to extract semantic features, and, to extract n-grams features, we used CCM. Finally, using an interactive fusion mechanism, we fused the features extracted by the two modules. Extensive experiments were conducted on two offensive-language datasets, which showed that back translation significantly improve model performance and that multiple semantic-feature information can complement each other to improve model performance based on the interactive fusion mechanism. Our proposed model outperformed the strong state-of-the-art baselines.
Sentences containing strong negative-sentiment-polarity words are more likely to be offensive-language sentences; so, sentiment features are an important feature for automatic detection of offensive language. How to better dig out the sentiment features of sentences and transfer them is a direction worthy of our attention. In addition, there are many implicit-sentiment-expression sentences in offensive language, and it is difficult to accurately judge whether they contain offensive meaning by simply using monomodal features, such as text features. So, how to introduce multi-modal features is also a direction worthy of further research.




{kind=link}
{kind=link}