1. Introduction
Sentiment analysis (SA) of text aims to extract and analyze knowledge from the personal information posted on the internet. Due to its wide range of industrial and academic applications, as well as the increasing growth of social networks, SA has become a hot topic in the field of natural language processing (NLP) in recent years [
1]. Thus, different tools and techniques have been proposed to identify the polarity of documents. Polarity detection is a binary categorization task that plays a significant role in most SA applications [
2]. Most of the previous approaches for SA have trained shallow techniques on carefully developed efficient features for obtaining satisfactory polarity categorization performances [
3]. These models occasionally apply traditional classification approaches involving Naïve Bayes, support vector machines (SVM), and latent Dirichlet allocation (LDA) to linguistic properties, such as lexical features, part-of-speech (POS) tags, and n-grams. However, these approaches have two major drawbacks: (1) the feature distance on which the model must be trained is highly dimensional and scattered and thus affects the model performance; (2) the feature engineering operation is time intensive and an uphill task.
Several current works have suggested learning word embedding [
4,
5,
6] to tackle the above limitations. Word embedding is a dense real-valued vector generated by a neural language model that considers various lexical associations [
4,
5]. Thus, this makes the employment of word embedding as the input of deep neural networks (DNN) highly common in existing NLP works [
4]. In recent years, DNNs have gained increasing attention from many researchers in varied domains, such as medical informatics [
6], finance [
7], computer vision [
8], and multimedia sentiment analysis [
9].
DNNs have been suggested for analyzing text data that primarily focus on the performance of machine learning tasks or learning word embedding, such as categorization and clustering. Among the wide range of deep networks, recurrent neural networks (RNNs) and convolutional neural networks (CNNs) are more popular in research related to text processing [
10]. The cause of this popularity is due to the fact that the CNN models can learn the local patterns, while the power of RNNs is demonstrated in sequential modelling. Although RNNs are used in several text processing applications, they cannot handle vanishing and exploding gradients, especially if the input data have long dependencies [
4]. These dependencies are highly popular in most NLP approaches, especially in the domain of SA.
To deal with the above problem, long short-term memory (LSTM) was introduced [
11], which has the ability to capture long dependencies. Due to the potential of LSTM to address the problems of RNNs, it has attracted the attention of many researchers in the field of NLP [
12]. Considering both the previous and subsequent contexts, the bidirectional LSTM (Bi-LSTM) model was proposed to combine the forward hidden layers and backward hidden layers. This model can cope with the sequential modelling issue. Bi-LSTM is widely employed in many NLP applications. However, there are two major drawbacks to this model: (1) the high-dimensional input distance popular in the applications of text processing makes the model more complex and thus difficult to improve; (2) the model cannot focus on the significant parts of the context information of the text. To tackle these problems, many studies in the literature have been suggested. For instance, CNNs have been employed to extract meaningful patterns from text and reduce the dimensional feature distance [
12]. The attention mechanism assigns various weights for focusing on the significant parts of context [
4].
The current deep learning models for SA occasionally handle a few issues and disregard others. For instance, Chatterjee et al. [
13] used LSTM and two pre-trained word embeddings for extracting both semantics and sentiments for feeling recognition, but did not address the differences between the importance of various parts of sentences. A study by Liu et al. [
14] combined Bi-LSTM with CNN and the benefited attention mechanism, but this study did not consider the co-occurrence of long and short dependencies. Rezaeinia et al. [
15] used CNNs and improved pre-trained word embeddings, but they did not take account of the different importance values of words and long dependencies.
The Google machine translation team presented a new concept of multi-head attention mechanism MHAT in 2017 to capture related information in various sub-distances via multiple distributed computations [
16]. In our study, we employed the attention mechanism to select the most important contextual information, considered both forward and backward context dependencies, and assigned approximate attention to various words in comments.
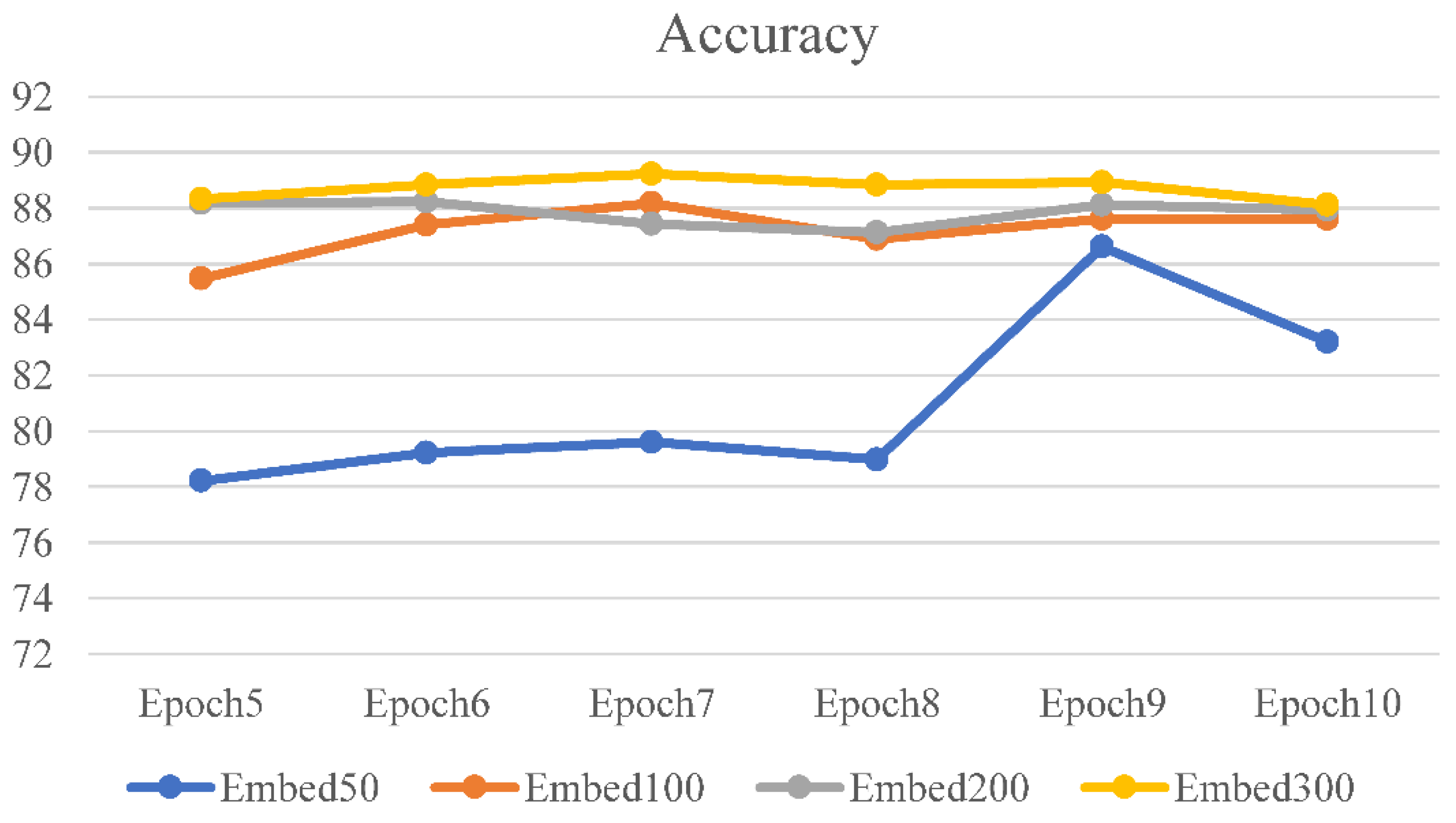
In this work, we propose a new deep learning model that combines a deep neural network with a multi-head attention mechanism (DNN–MHAT) for classifying textual sentiment. We first applied a global vector for word representation (GloVe) [
5] to create word vectors automatically as the weights in the embedding layer. We also designed an improved deep neural network to capture the text’s actual context and extract the local features of position invariants by combining recurrent Bi-LSTM memory units with a CNN. Then, we devised a multi-head attention mechanism to capture the words in the text that are significantly related to long space and encoding dependencies, which adds effective weights to the different contextual features. Finally, the global average pooling layer was applied to obtain a multi-level pattern representation of the text sequences. A Softmax classifier was applied for classifying the processed context information. The DNN–MHAT model was tested on four reviews and two Twitter datasets. The results of the experiments illustrate the effectiveness of the DNN–MHAT model, which achieved excellent performance compared to the state-of-the-art baseline methods based on short tweets and long reviews. The experiments compared the DNN–MHAT model with five state-of-the-art DNN baseline methods based on SA and text classification datasets. DNN–MHAT outperformed the other five methods in terms of popular performance standards in NLP and the domains of SA. Our contributions are summarized as follows:
We propose a new deep learning model, namely, DNN–MHAT, for text classification and SA tasks. First, we design an improved deep neural network to capture the text’s actual context and extract the local features of position invariants using Bi-LSTM and CNN. Then, we present a multi-head attention mechanism to capture the words in the text that are significantly related to long space and encoding dependencies, assigning weighted importance to different information, efficiently enhancing the sentiment polarity of words and detecting the significant information in the text.
We investigate the effectiveness of the DNN–MHAT model on two types of datasets: long reviews and short tweets on social media. Compared to five existing deep structures, the DNN–MHAT achieved better performance on two types of datasets.
The rest of this paper is structured as follows:
Section 2 contains the Literature Review.
Section 3 contains the Materials and Methods.
Section 4 contains Experiments and Results. Finally,
Section 5 contains the Conclusions and Future Work.
3. Materials and Methods
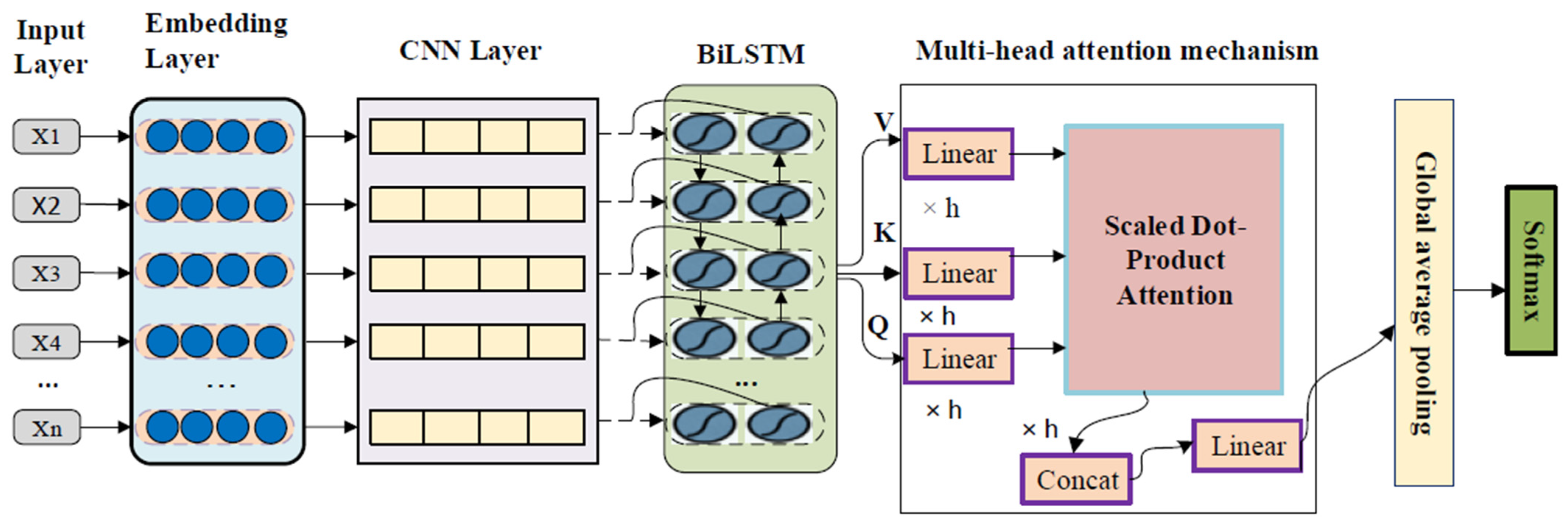
This section describes the overall structure of the DNN–MHAT model, which comprises six fundamental components: the input layer, convolutional neural network, long short-term memory, global average pooling layer, multi-head attention mechanism, and Softmax layer. The overall structure of the DNN–MHAT model is shown in
Figure 1. The key goal of the DNN–MHAT model is to detect the polarity of sentiment for the given sentences.
In our method, first, we preprocessed the input data by tokenizing the input text, removing stop words, and dealing with the capitalization of words. Then, the tokenized texts were fed into the word embedding module. After that, the obtained word embedding vectors were fed into a CNN layer. The output of the CNN layer was fed into a Bi-LSTM layer. The output of the Bi-LSTM layer was fed into a multi-head attention module. After that, a global average pooling was applied to obtain the final representation. Finally, the final representation was fed into the Softmax classifier layer.
Figure 2 shows the flowchart of the DNN–MHAT model.
3.1. Input Layer
A pre-trained GloVe embedding matrix was utilized to create the input comment matrix
where
and
refer to the embedding dimension and the total number of words, respectively. For embedding a comment vector,
represents the maximum number of words
or the padding length,
deemed in the comment as shown below:
3.2. Convolutional Neural Network
CNNs contain many convolution layers employed in the applications of NLP for extracting local features. In CNNs, linear filters are used to perform the convolution process on the features of the input data. Initially, an embedding vector of size
is generated to apply the CNN to a sentence
containing a set of
words. Then, the filter
of the size
is frequently used in sub-matrices as the input feature matrix. The results in a feature map
are shown below:
where
and
represent a sub-matrix of
from row
i to
. The sub-sampling layer or pooling layer is a popular practice in which feature maps are fed to reduce dimensions. Max-pooling is a common pooling strategy that determines the essential feature
of the feature map, as shown in the following equation:
The outputs of the pooling layer are used as the input to the fully connected layer, where these outputs are a pooled feature vector or concatenated (see
Figure 1).
3.3. Long Short-Term Memory
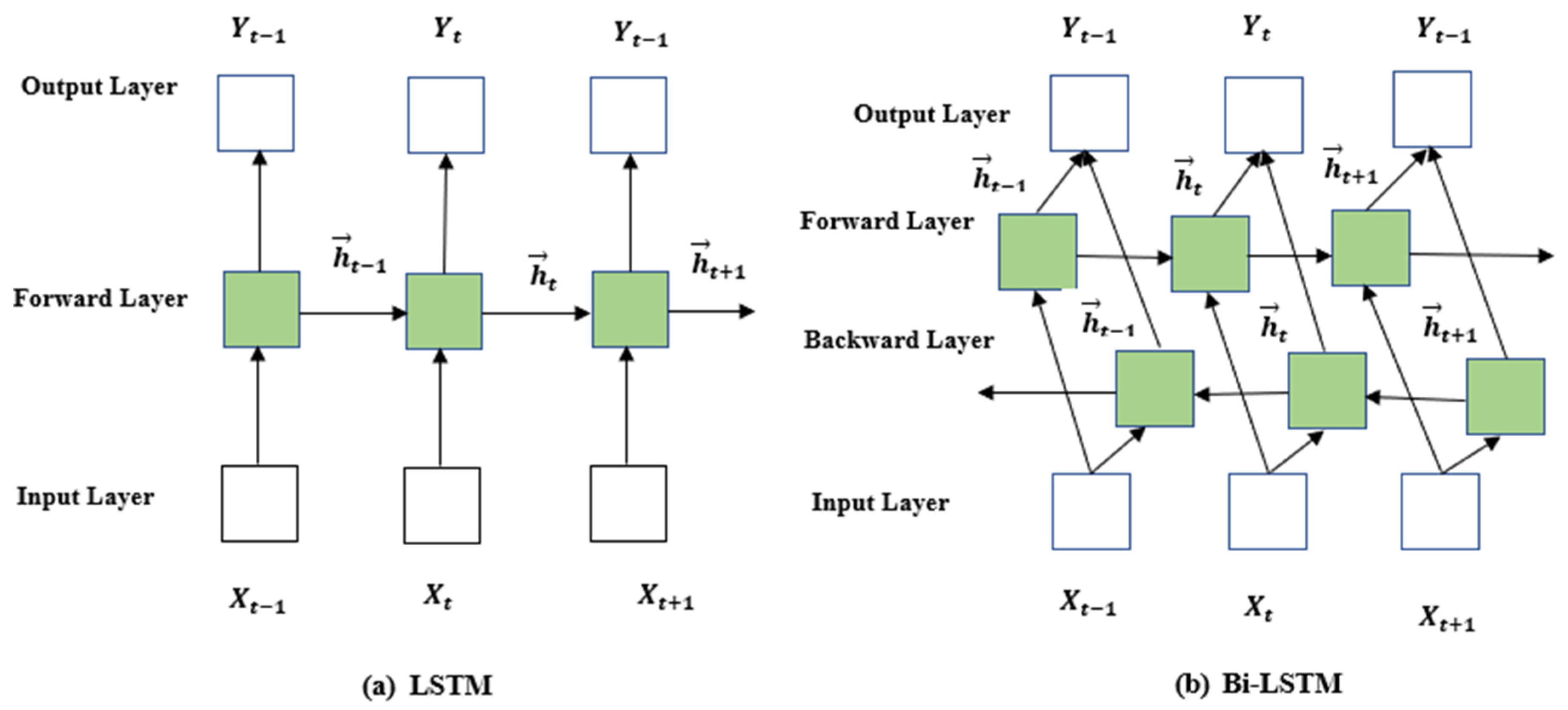
RNNs are a type of feed-forward neural network. RNNs possess a recurrent hidden state activated by using the previous states and can deal with the variable-length sequences and automatically model the contextual information. LSTM is an improved type of RNN (see
Figure 3a) designed to solve the exploding/vanishing issues faced by RNNs. The LSTM model contains a chain of recurrent memory units, and each of these chains implicates three “gates” with various functions. An LSTM unit contains three gates: input gate
, forget gate
, and output gate
and memory cell
to maintain its state over random time intervals. These gates have been generated to organize the flow of data entering and leaving the memory cell. Suppose tanh (.), σ(.), and ⊙ are the hyperbolic tangent function, the sigmoid function and product, respectively.
is the hidden state vector at time
, and
is the input vector at time
.
and
illustrate cells for input
or the weight matrices of gates. The hidden state
and
indicate the bias vectors. In the forget gate
, it defines what information to ignore from the cell state, as indicated by the following equation [
41]:
The input gate
defines what must be stored by calculating
and combining them based on the following equations [
41]:
The output gate
defines what information is outputted according to the state of the cell state based on the following equations [
41]:
The LSTM model is based on serial information, but it is not beneficial, especially if you can reach the following information based on the previous model. Therefore, this is highly useful for sequencing tasks.
The Bi-LSTM model comprises a forward
and a backward
LSTM layer (see
Figure 3b). The core goal of the Bi-LSTM structure is that the forward layer
captures the previous sequential information, and the backward
captures the subsequent sequential information; both layers are connected to the same output layer. The most important feature of the BiLSTM architecture is that sequence contextual information is considered. Suppose that the input of time
is the word embedding
, at time
, the output of the forward layer is
and the output of the forward hidden layer and the backward hidden layer is
,
, respectively. The output of the backward and the hidden layer at time t is listed below [
46]:
where
indicates the hidden layer process of the LSTM hidden layer. The forward
and backward output vector
are
, and they must be combined to obtain the text feature, where
indicates the number of hidden layer cells:
3.4. Multi-Head Attention Mechanism
Attention is a key component of the MHAT mechanism, but there is a fundamental difference in that the MAHT model can perform multiple distributed computations that handle complex information.
3.4.1. Scaled Dot-Product Attention
Scaled dot-product attention is a set of key-value pairs to an output and mapping a query. There are four steps for computing the attention as follows [
46]:
- -
Each key and query weight are computed by considering similarity. The proposed model is used as the dot product to determine the similarity.
- -
The scaling operation is the next step to calculate the attention, where the factor is used as a moderator so that the dot-product is not too big.
- -
The Softmax function is used to normalize the obtained weights.
- -
The weighted sum is equal to the sum of the corresponding principal value and similarity.
According to the steps mentioned above, we obtained the following formula:
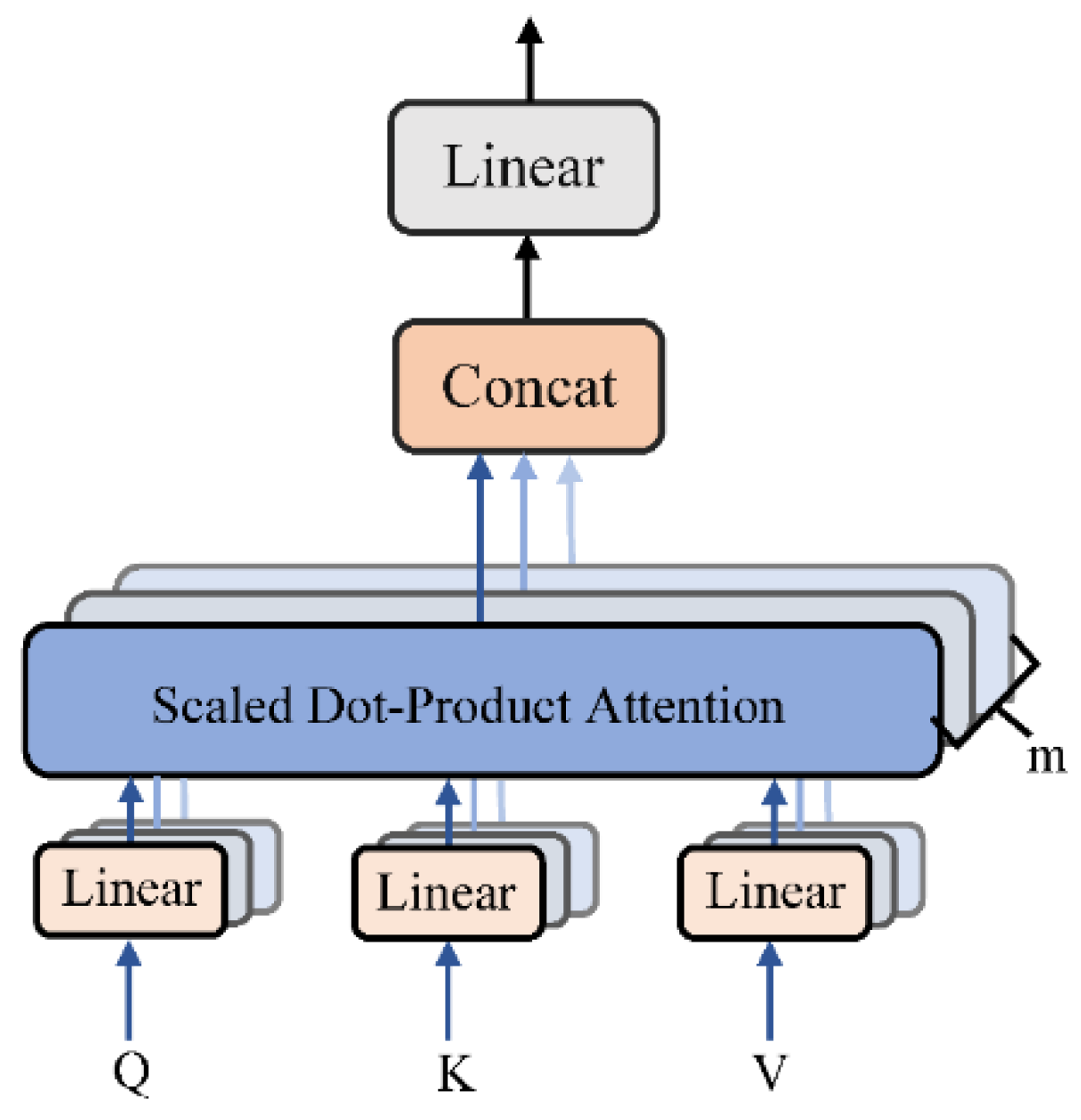
3.4.2. Multi-Head Attention
MHAT is the improvement of the traditional attention mechanism, and it has excellent performance.
Figure 4 shows the architecture of the MHAT mechanism. Initially, by a linear transformation,
are the input of the scaled dot-product attention. Therefore, this operation computes one head at a time. Thus, it should be carried out
, which is called multi-head. The parameters
for each linear transformation of
are different. Each scaled dot-product attention output of
time is concatenated, and the value obtained through a linear transformation is utilized as the output of the MHAT [
47]. The formula can be expressed as shown below:
3.4.3. Self-Attention
In this approach, we employed a self-attention for extracting the inner relations of sentences in
[
48]. For instance, every word that has been entered should carry out the attention computation with each other word of the sentence. Thus, the MHAT mechanism produces a weight matrix α and a feature representation
.
3.5. Global Average Pooling Layer
The fully connected network is the main architecture of the classification network, which contains an activation function, Softmax, for performing classification. The fully connected network function represents multiplying the vector, stretching the feature map into a vector, and eventually reducing its dimension. To obtain the corresponding result of every category, this vector is entered into a Softmax layer. The fully connected network has two major drawbacks: (i) the number of parameters is very large and thus reduces the training speed; (ii) it is easy to carry out overfitting. Based on the two problems mentioned above, the global average pooling can avoid the shortcomings to achieve the same effect and thus adds the sequences of input features to the averaging [
49]. After presenting the MHAT mechanism to the sentence, the feature matrix of the corresponding output is
, and the feature vector of every word in the sentence is
. The global average pooling of the input sentence is shown below:
3.6. Softmax Layer
To predict sentiment analysis, we fed the output of vector
immediately into the Softmax layer, as shown in the equation below:
To evaluate the proposed model, the purpose of cross-entropy was presented to reflect the gap among the predicted sentimental categories
and the real sentimental categories
.
where
represents the index number of the sentence.
The Bi-LSTM layer can determine the context to arrange the information of sequences. MHAT can learn information from the representation of sub-distances and various dimensions and fully capture long-space textual features, which can play a critical role in effectively improving the sentimental analysis capability of the model straightway. The pseudo-code of DNN–MHAT is shown in Algorithm 1.
| Algorithm 1 Pseudo-code of DNN–MHAT |
| 1: Build word embedding table using pre-trained word vectors with Equation (1); |
| 2: Use the convolutional layer to obtain the feature sequences, using Equation (3); |
| 3: Use BiLSTM to obtain the preceding contextual features and the succeeding contextual features from the feature sequences, using Equations (10)–(12); |
| 4: Use multi-head attention layers to obtain the future context representation from the preceding and succeeding contextual features, using Equations (16) and (17); |
| 5: Feed the output of multi-head attention into global average pooling, using Equation (18); |
| 6: Feed the comprehensive context representations outputted from global average pooling into the Softmax function to obtain the class labels, using Equation (19); |
| 7: Update parameters of the model using the loss function Equation (20) with the Adam method. |
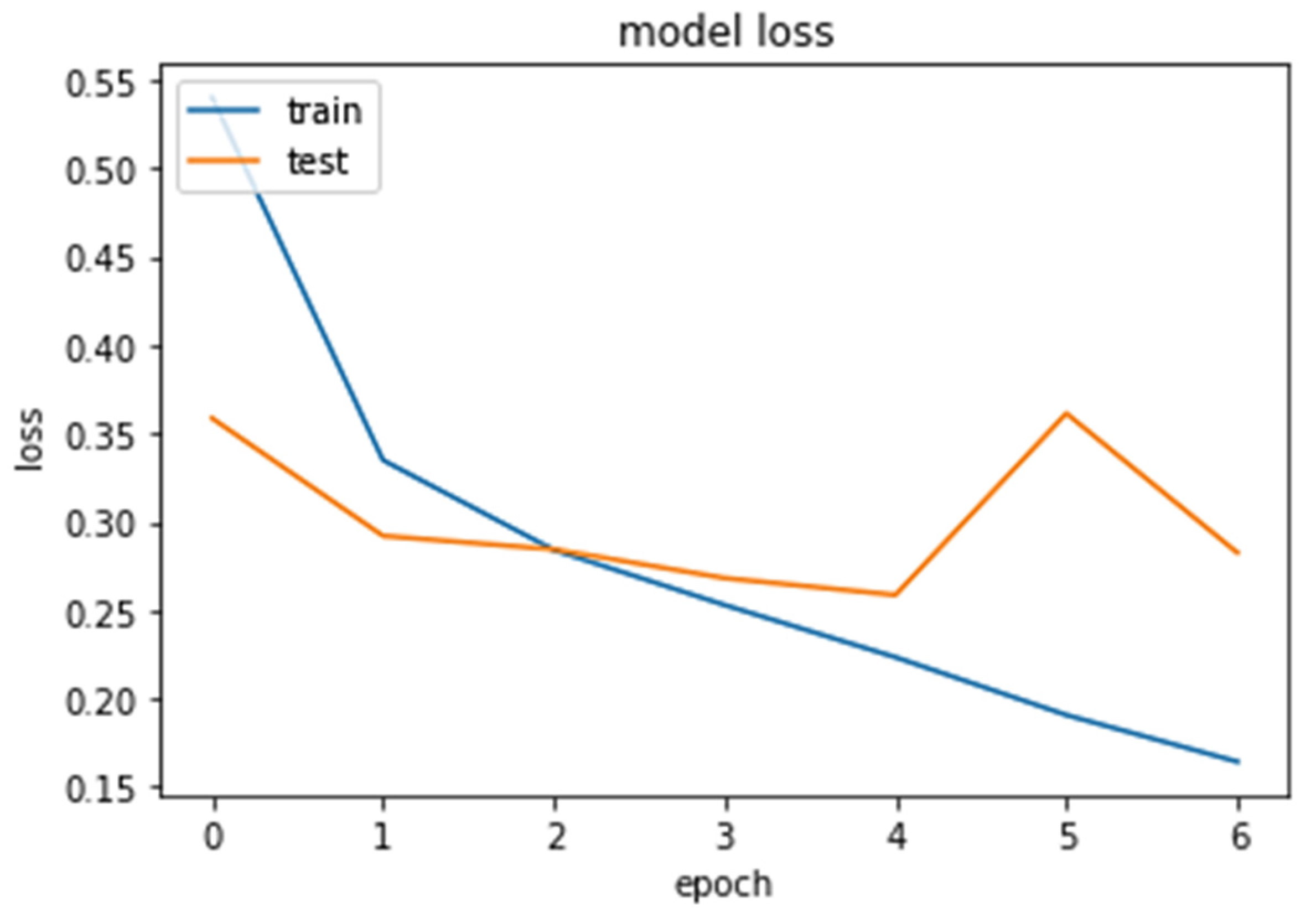
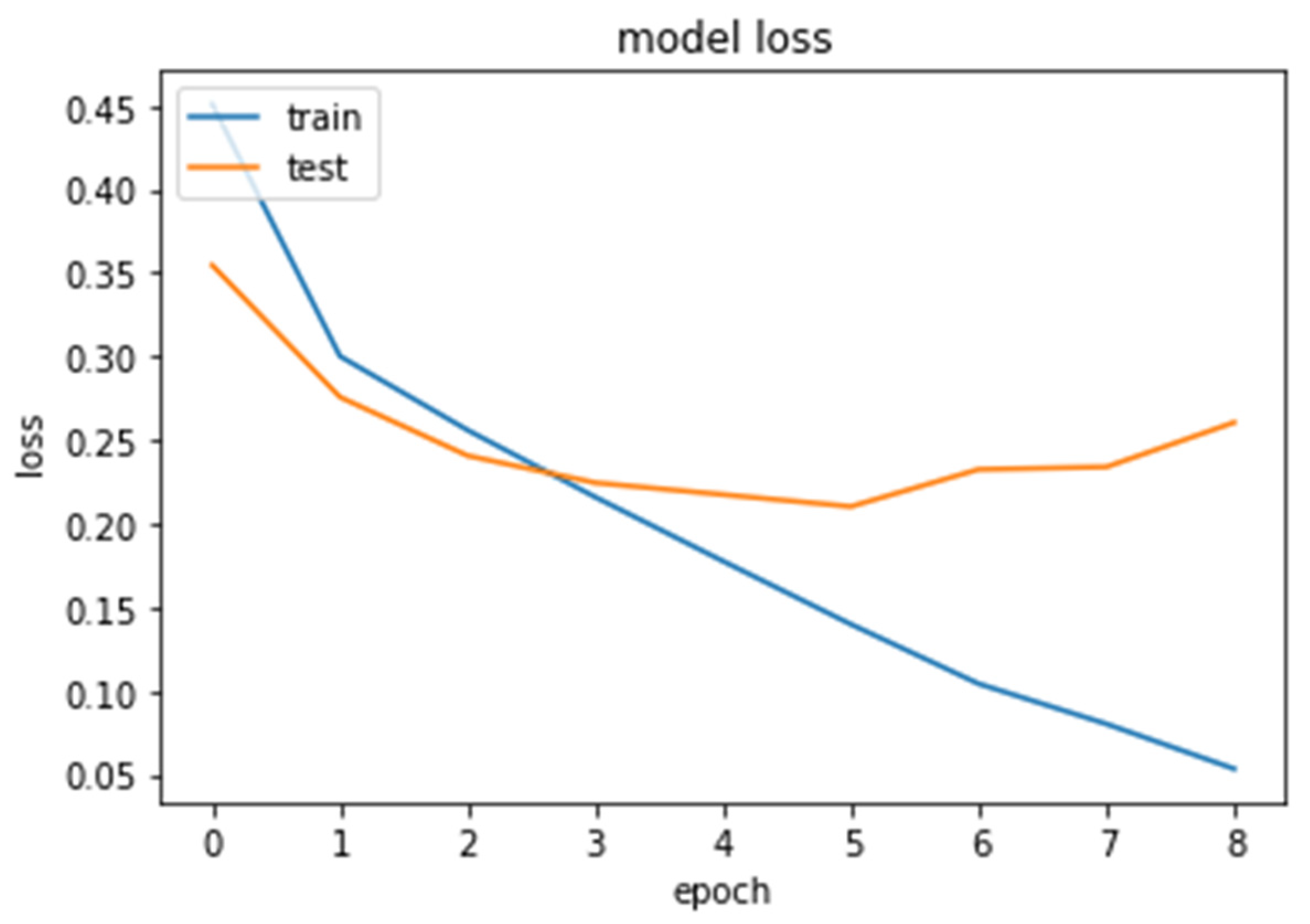
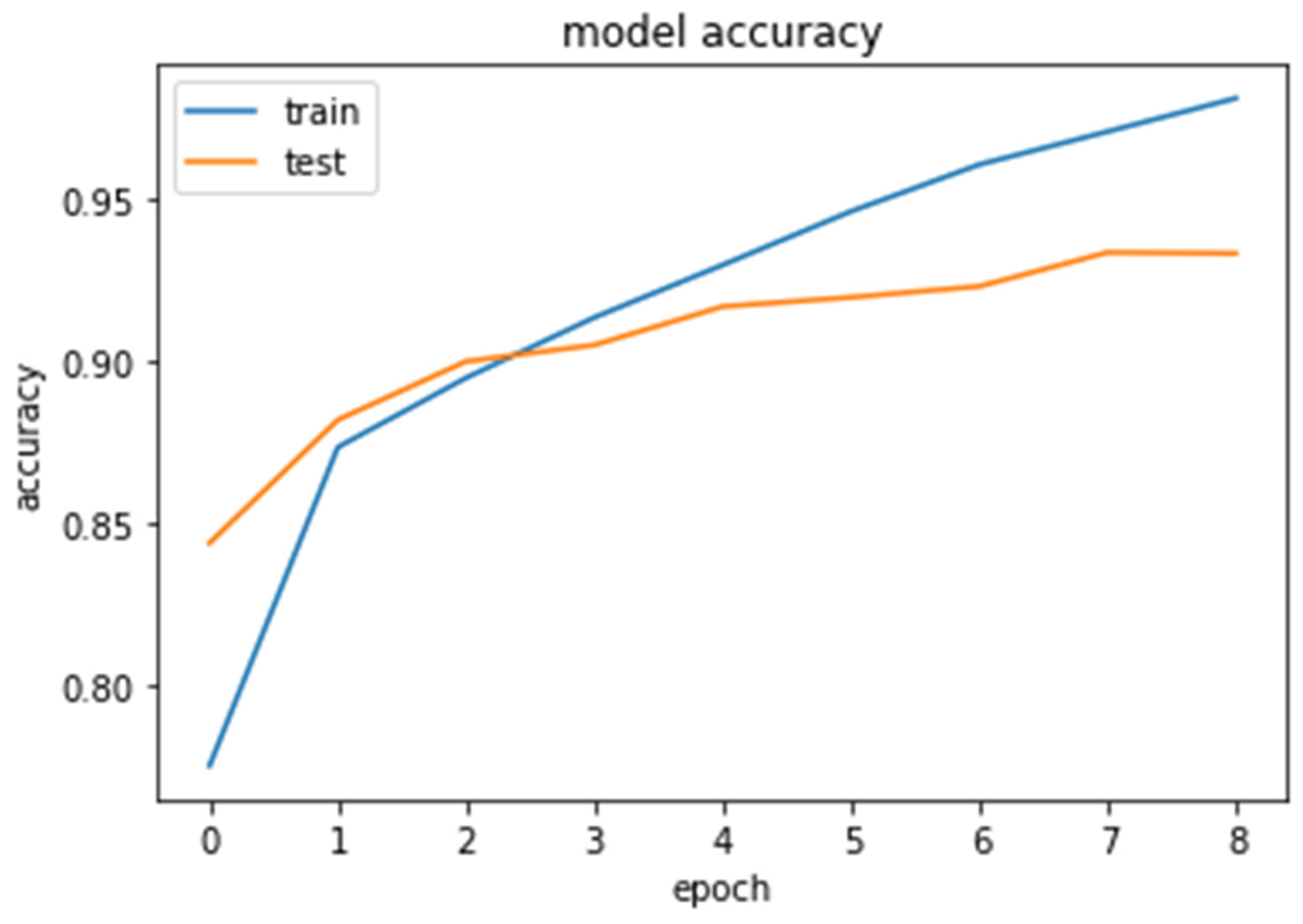
5. Conclusions and Future Work
For sentiment analysis, we propose a hybrid model that combines a deep neural network with a multi-head attention (DNN–MHAT) mechanism to tackle text data sparsity and high dimensionality problems. First, DNN–MHAT exploits pre-trained GloVe word embedding vectors as the primary weights into the embedding layer. Second, the CNN layer was used for extracting the local features of position invariants. Third, a recurrent Bi-LSTM unit was used for capturing the actual context of the text. After that, a multi-head attention mechanism was applied to the outputs of Bi-LSTM to capture the words in a text that are significantly related to long space and encode dependencies. The purpose of this is to add effect weights to the generated text concatenation. The MHAT provides an emphasis on variant words in a comment and hence makes the semantic representations more informative. Finally, a global average pooling with a sigmoid classifier is applied to transform the vector into a high-level sentiment representation while avoiding model overfitting and implementing the sentiment polarity classification of comments.
This study focused on detecting the polarity of sentiment analysis at the document level. In future work, we propose the verification of the effectiveness of our DNN–MHAT model for other levels, such as sentence-level and aspect-level sentiment analysis, and other sentiment analysis tasks, such as helpfulness and rating prediction.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}