1. Introduction
Currently, social platforms are prevalent in most people’s lives, as they allow them to express and comment on their views. Moreover, most people spend a long time on these platforms and use them to communicate. Online platforms allow users to share their comments, blogs, images, and videos publicly for viewing. While there are many benefits to this communication, it can also have harmful aspects, such as cyberbullying, which has increased as people spend more time on social platforms. Cyberbullying is a behavior that results in social attacks, and it is a high source of risk, which is generated through these social platforms. In addition, with the massive increase in users on online platforms, the volume of data has also surged. In 2018, Twitter alone had around 330 million active users, generating 550 million tweets daily. While these tweets offer diverse research opportunities, they can also contain offensive content, criminal activities, and instances of bullying [
1].
According to the authors in [
2], one reason for the increase in cyberbullying is that people spend much time on online platforms, which leads them to hurt each other when reaching out through these platforms. In addition, the authors emphasized that not all the content that is posted and viewed is appropriate for all people, so they reply with tweets that contain hurtful words because of their conflicting viewpoints or even only to simply engage in the act of bullying. Thus, using machine learning (ML) to detect cyberbullying on online platforms has become necessary to avoid these unwanted behaviors. However, the detection of cyberbullying faces challenges such as the massive amount of data, and some data need to be detected using binary classification, while others need to be detected using multi-classification, depending on the number of target classes. Additionally, data categories are subject to change, implying that each type of data should be paired with a suitable model to yield effective detection performance. For instance, if the data are categorized into binary labels, binary models optimized for such data are essential. The same principle applies to data classified into multiple categories [
3]. Moreover, the authors in [
4] mentioned that the complexity of detection increases when dealing with datasets containing multiple categories, as the classification process tends to be time-consuming. Also, they stated that most existing experiments on detecting cyberbullying are specific, such as models classifying tweets as bullying or non-bullying. Types of cyberbullying have been allocated into many categories, such as age, religion, race, gender, and ethnicity. Thus, multi-classification techniques are expected to improve the detection of these types of cyberbullying.
The authors in [
5] indicated that cyberbullying has become prevalent, and the detection of cyberbullying has become complex. This is because there are many tweets that contain various kinds of cyberbullying depending on the context of these tweets, which may indicate gender, religion, age, ethnicity, or other types of cyberbullying. Training models to detect specific types of cyberbullying require a different approach than training models to categorize tweets as either free of cyberbullying (0) or containing cyberbullying (1) based on certain words, making it challenging to identify the specific types of cyberbullying.
In addition, some of the challenges that have been discussed when using multiple classes to analyze text data are related to our work in this paper as we are dealing with tweets. The representation of text is different depending on the field in which the text is expressed. This means that, in the preprocessing stage, the feature extraction will be various, so the bag of words feature may achieve optimal performance when analyzing text related to customer reviews or other types of text; however, this feature may not be beneficial when preprocessing cyberbullying text. Thus, when training models to detect multiclass datasets, they need to test several feature extractions to find suitable features that work with the concept of text [
6].
Another challenge that needs to be mentioned when dealing with multiclass datasets is finding a need for the correction of tweets that were written. Extracting the context of tweets or text is complex and requires a high level of training. The authors in [
7] suggested using manual effort to deal with text from experts in this field, which involves understanding the meaning of the writers and training models to understand upcoming tweets with the same concept.
Cyberbullying is difficult and complex to detect manually by humans; thus, an automatic system can help detect text that contains offensive phrases through ML algorithms. Building systems to detect cyberbullying is not a new experiment or field of study, as many frameworks and methodologies have been suggested to solve this issue. However, the increase in the amount of data and cyberbullying that have appeared in recent years has inspired collaboration to improve the performance of models that can detect cyberbullying. As mentioned earlier, there are multiple types of cyberbullying datasets labeled as multiclass cyberbullying, which is more challenging to detect compared to datasets labeled as binary.
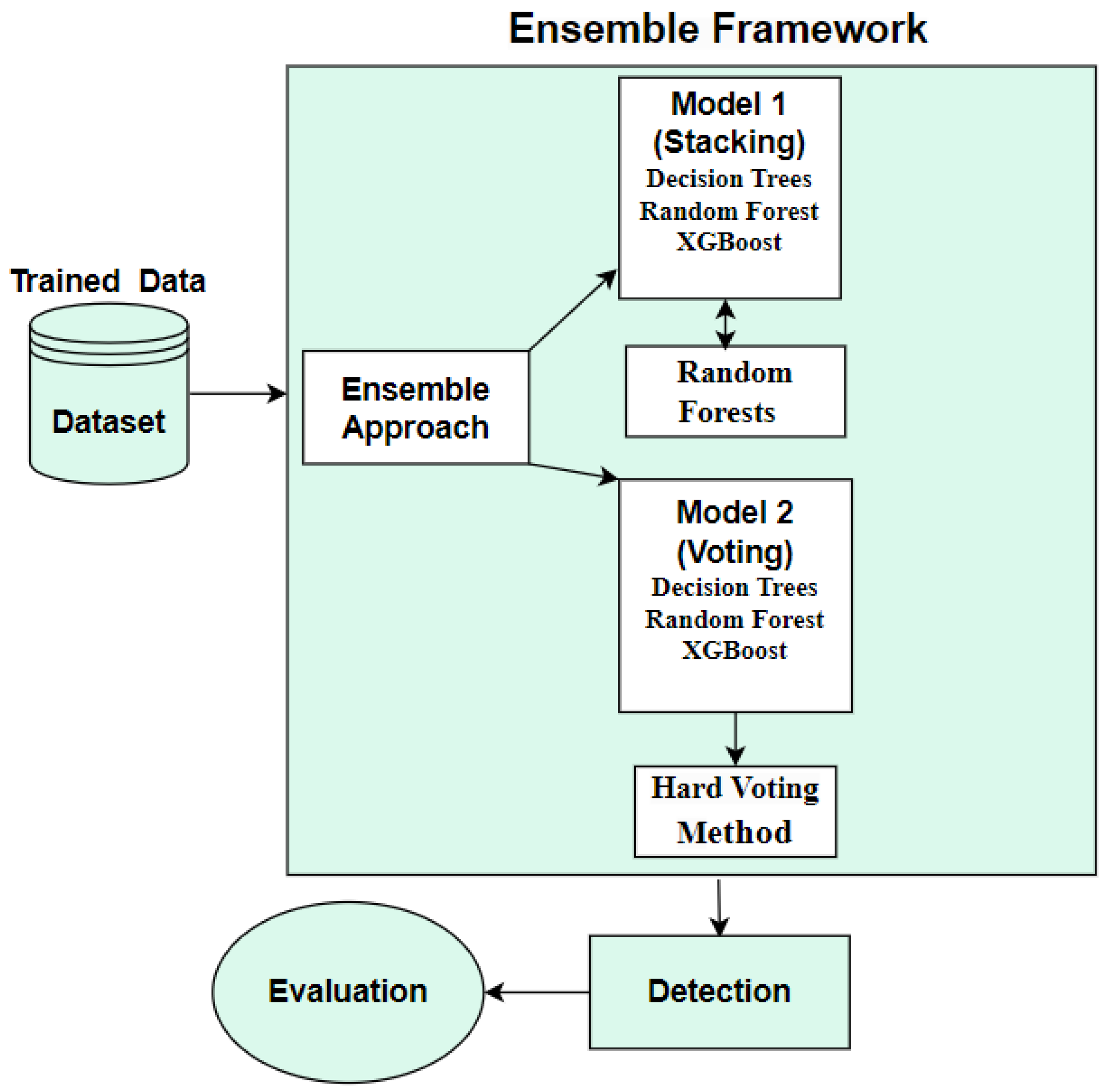
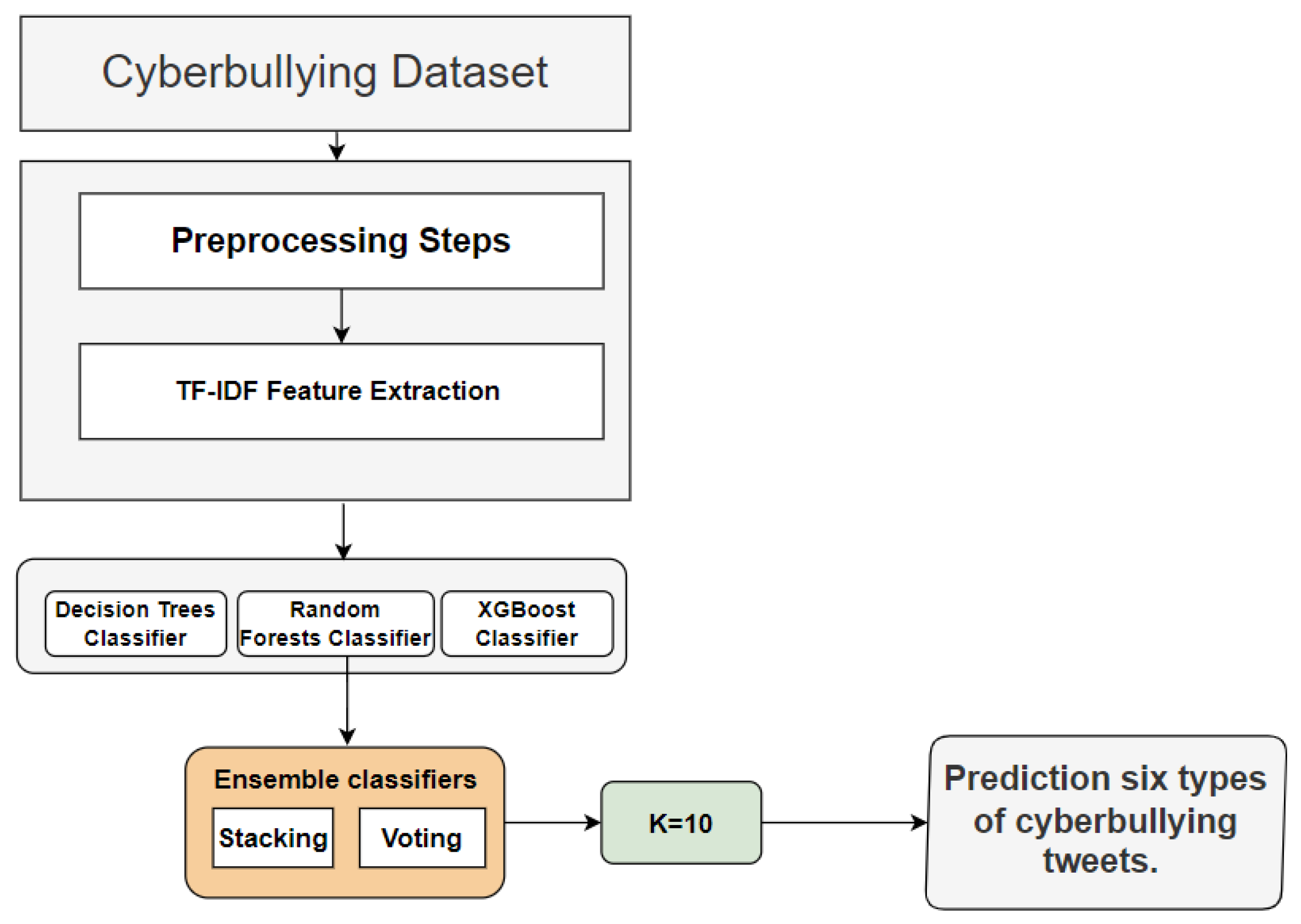
In this paper, we contribute to the development of ensemble models by employing three multi-classification models to detect multiclass cyberbullying in a dataset. Firstly, we tested three multi-classification models—RF, DT, and XGBoost—utilizing the TF-IDF feature-extraction method, and combined these models into two ensemble techniques. Secondly, we aimed to explore and investigate the most-suitable ML techniques for dealing with multiclass cyberbullying datasets compared to traditional ML models. Thirdly, we employed N-gram feature engineering with TF-IDF, achieving state-of-the-art results, particularly with bigrams. Fourthly, our proposed model achieved better performance compared to prior experiments that utilized the same dataset. Based on our investigation, this new framework combines multi-classification models to detect multiclass cyberbullying in a dataset and demonstrates satisfactory performance.
2. Literature Review
Many experiments have contributed to this field using various methodologies and frameworks. This section will summarize some previous research work closely related to cyberbullying detection on online platforms. The authors in [
8] developed bagging ensemble models that achieved satisfactory accuracy while classifying binary cyberbullying datasets. The highest accuracy achieved in their experiment was 96% by using TF-IDF, which is one of the feature-extraction techniques that uses words in documents. They used this feature with unigrams, which deal with each word in the document as one token. The authors emphasized that their aim in this paper was to develop a voting model that involves double and single ensemble-based to detect the content of text and classify it as either ‘offensive’ or ‘non-offensive’. They mentioned in their paper that the dataset classified in their experiment was collected from the Twitter platform and contains 9093 tweets. They completed many preprocessing steps to make it easy for the models to classify the architecture of the model, which uses an ensemble model that combines seven classifiers in different methods, namely a single-level ensemble model that involves all seven classifiers in one novel model. In addition, the double-level ensemble model involves four ML algorithms in one novel model, and the other three models are combined in a second novel model; finally, these two novel models are integrated into one novel model.
Moreover, while discussing prior research work related to detecting cyberbullying, the authors in [
9] experimented with seven ML algorithms to detect cyberbullying tweets in a Twitter dataset containing 37,373 unique tweets. Based on their experiment, the highest accuracy achieved was around 90.57%, which resulted from linear regression. Also, they applied two feature extractions addressed in their experiment, TF-IDF and Word2Vec, to enhance the classifier’s performance. The model approaches in their experiment start by importing the dataset and executing the preprocessing phase, including removing stop words, punctuation, special characters, and stemming. After the preprocessing steps, they split the dataset into training and testing sets and applied TF-IDF for the training set and Word2Vec for the testing set. The last step was running the models to test the prediction and evolution of the model. The reason for using two different feature extractions was to examine which feature performed well in their classification. They stated that TF-IDF is preferable with large data while Word2Vec can excel with small data, as, in general, testing sets mainly involve small data. They specified a limitation in their study, which is real-time detection, while they were able to investigate an appropriate feature-extraction method that performed well in classification.
Many techniques have been experimented with to detect cyberbullying in online platforms. Ahamed et al. [
10] developed an automatic system that detects cyberbullying tweets using a voting ensemble model that combines three classifier networks, the well-known RoBERTa, XLNet, and GPT2, to detect multiclass datasets. The authors emphasized that using an ensemble model was the best choice in their experiment. The ensemble approaches used in their experiment are called hard voting, which is voting based on similarity, and soft voting, which is voting based on averaging. They used two different datasets related to cyberbullying on the Twitter platform and tested their model on these datasets separately. The first dataset was unbalanced, and the second one was balanced to evaluate their model. The result achieved on the first dataset by the ensemble model was 85.81% for detecting six classes related to cyberbullying, and the accuracy of the second dataset was 87.48% for detecting three classes.
In another research paper that used the same dataset we used, the authors in [
11] developed a deep analysis approach to detect six types of cyberbullying. They utilized a variety of five machine learning algorithms using text-based feature extraction. Based on their experimental results, LightGBM demonstrated the best performance in a range between 84.49% and 85.5% for the accuracy, precision, recall, and F-1 score. This study aligns with our experiment in utilizing machine learning algorithms, as we did, and including all classes of the dataset, mirroring our approach. The feature extractions are reasonable for improving the performance of the model. The authors in [
12] tried various types of feature extractions to achieve the best accuracy when testing models that detect cyberbullying texts in their experiment. The first feature is applying the TF-IDF feature to make the texts as suitably represented data when feeding the model, which is a practical feature for converting text into numerical data. The second feature uses the sentiment analysis method to extract the polarity of the text or sentences, and the last feature is N-grams, which are sequences of words that will be added as one token depending on the value of n. TF-IDF’s primary concept is to convert the text to numerical data and determine the relative importance of individual words within a given passage. Also, they applied the sentiment analysis technique to determine the polarity of the sentences, which they then included as a feature alongside TF-IDF’s existing characteristics. To determine whether a sentence should be labeled as positive or negative, they used a polarity function with the Textblob library, which is a pre-trained model for extracting the polarity in textual data. In addition, they used TF-IDF to obtain the features and sentiment polarity. They emphasized their proposed approach of using N-grams to look at the different ways words can be put together when evaluating the model. The result achieved in their experiment by Support Vector Machine (SVM) when using 4-grams was 90.3% and by using a Neural Network (NN) when using 3-grams, it was 92.8%.
Capturing the meaning of text poses a significant challenge in detecting cyberbullying. The research study [
13] addressed various challenges in cyberbullying detection, with a particular focus on understanding the meaning of context. They presented a compilation of previous works with a focus on improving contextual understanding, including several models and word representations that have contributed to resolving this issue. Detecting cyberbullying is a complex task that requires capturing context. According to this research study, word embedding proved to be an effective tool in conjunction with deep learning, while TF-IDF demonstrated strong performance when applied in machine learning scenarios. While the above prior works suggested to develop automatic systems by ML or deep learning to show the outputs for detecting cyberbullying, our experiment suggests improvements in the accuracy and uses feature extraction. This study contributes to the review of previous experiments that need to optimize their accuracy and efficiency for detecting bullying tweets, whether multiclass or binary class, using feature-extraction methods that enhance the performance. In addition, this study focused on combining several supervised ML classifiers for multi-classification using features that help to enhance the classification.
Table 1 shows our experiment compared with the others.
Table 1 illustrates the results of our proposed approach compared to the recent approaches in [
10,
11] concerning four evaluation metrics using the same dataset. The table gives a thorough summary of each model’s performance by summarizing their accuracy, precision, recall, and F1-Score. We applied k-fold cross-validation to assess the efficiency of various configurations and ensure the optimal performance of our approach. Specifically, we set k = 10 for the ensemble models, providing a robust evaluation across multiple folds [
14]. Hence, in comparison to the alternative experiments, our proposed models outperformed them consistently in the conducted experiments.
Background Ensemble Models for Detection of Text
Ensemble models have been used in many fields for detection using ML. The authors in [
15] developed an ensemble model to detect cyberbullying in their new dataset with binary classification as their dataset was categorized using binary labels. In the first step, they attempted to improve upon SVM. For their second strategy, they relied on DistilBERT, a more-efficient and -compact rendition of the transformer model BERT. When they combined the first three models, they obtained two more ensemble models. In comparison with the other three models, they found that the ensemble models outperformed the base model on all evaluation metrics except precision. With an ensemble model, they achieved an accuracy of 89.6%, surpassing the SVM model, which yielded an accuracy of 85.53%. The DistilBERT model achieved the highest accuracy of 91.17%. In their experiment, various TF-IDF feature-extraction approaches, including word, character, and N-gram sequencing, were empirically evaluated and compared using an SVM model. In another example of ensemble models for analyzing detection, the authors in [
16] proposed a stacking model to detect short message service (SMS) spam. They identified stacking as a method of ensemble learning used to improve model predictions by aggregating the results of numerous models and passing them through another ML model. They developed an ensemble model with bag of words feature extraction to enhance their model’s performance, naming it AstNB—a new augmentation and stacking approach combined with the transfer learning approach of Naive Bayes (NB). Their goal in this experiment was to detect SMS spam across multiple datasets, achieving the highest accuracy of 98.1% for detecting spam SMS domains.
4. Results
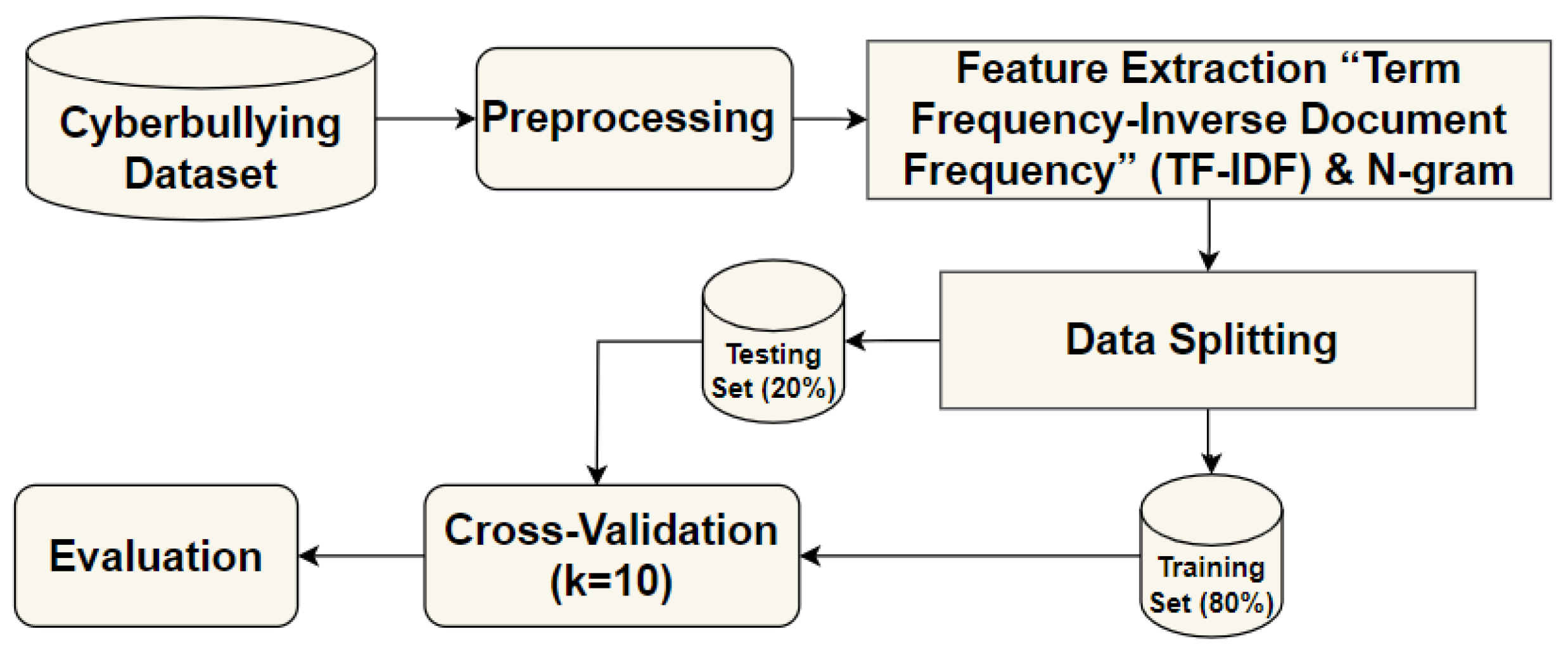
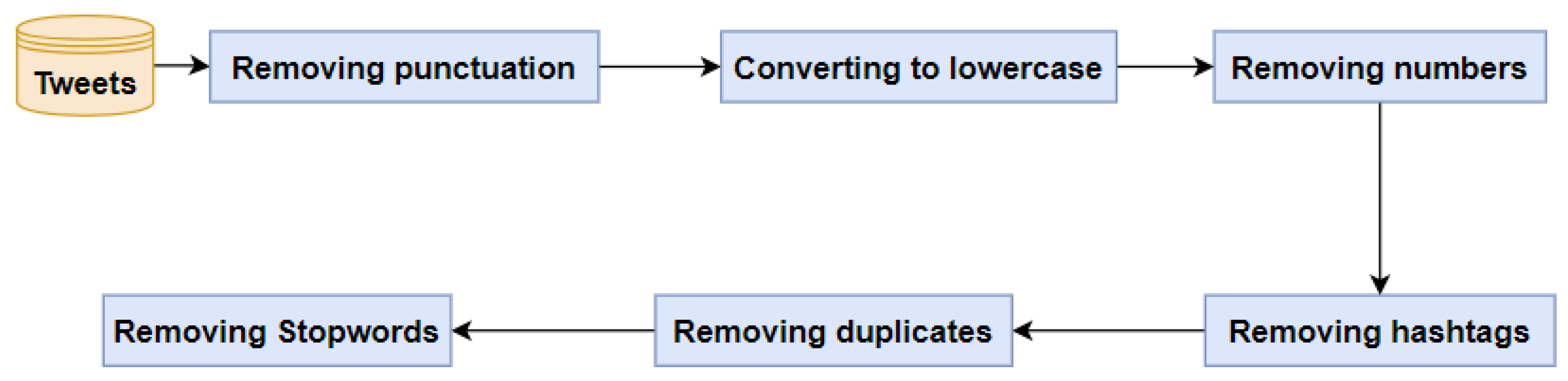
After completing the preprocessing, feature extraction, and data splitting, we built three multi-classification models separately. These models were executed using TF-IDF feature extraction at multiple stages, incorporating N-gram analysis. This means we applied TF-IDF with unigrams across all models, saving the results of this feature. Additionally, we repeated the process with bigrams and trigrams, comparing the results achieved by various multi-classification machine learning algorithms (RF, DT, XGBoost) and two ensemble methods (voting and stacking). The RF model achieved the highest accuracy of 89.0% using TF-IDF with unigrams as a traditional ML classification. For the ensemble methods, specifically voting and stacking, the stacking classifier achieved an accuracy of 90.71%, while voting achieved 90% with unigram words. In addition, stacking outperformed, with an increase of 1% in the accuracy when using 2- and 3-gram features, surpassing the voting classifier. We used three metrics to evaluate the techniques: accuracy, F1-Score, and area under the curve (AUC), as illustrated in
Table 3.
Table 3 summarizes the results obtained from five classifiers: three multi-classification classifiers and two ensemble classifiers. Upon comparing the performance of multi-classification classifiers, Random Forest (RF) achieved the highest accuracy across all evaluation metrics, consistently maintaining the results while employing feature extraction with three different N-gram words. The Decision Tree (DT) classifier achieved similar performance to RF for most N-gram levels. XGBoost had lower accuracy initially; however, its performance slightly improved with the use of 2- and 3-grams. In terms of ensemble comparison, both classifiers demonstrated similar performance when using unigram words. However, stacking outperformed voting when using 2- and 3-grams. Additionally, employing bigrams with TF-IDF exhibited favorable performance in our experiment, as the results remained consistent across most N-gram tests and other evaluation metrics, ranging from 89% to 91% on the F1-Score and AUC when using bigrams. Stacking outperformed by 1% on the F1-Score, accuracy, and AUC when using unigrams. The voting classifier utilizes a hard voting technique, where the label agreed upon by the majority of algorithms in the classifier is used. This technique proved to be most efficient in our experiment. Considering all factors, our experiment showed that the ensemble models were outperformed, with multi-classification classifiers also surpassing traditional ML classifiers.
4.1. Evaluation Metrics
It is possible to assess the potential of each model using evaluation metrics to determine the classifiers’ ability to classify five classes of cyberbullying in the dataset or the class of not cyberbullying. The efficacy of the models was evaluated by examining their respective evaluation metrics, including the accuracy, precision, recall, AUC, and the F-score from the confusion matrix, which were used to rank the models.
The accuracy of a model represents the fraction of its predictions that are correct out of the total predictions made by the model. The formula below provides an estimate using the accuracy.
where:
TP = True positive.
FP = False positive.
FN = False negative.
TN = True negative.
The precision of a model enables the determination of the proportion of useful information among true positive (TP) and false positive (FP) data to identify a specific class.
One definition of recall is the rate at which true positives are correctly predicted.
F1-score is the harmonic mean of the precision and recall. Additionally, the F1-Score serves as a single measure that combines both the precision and recall.
Another evaluation metric employed in our assessment is the area under the curve (AUC), which is scale-invariant and measures how well predictions are ranked compared to their correct values. The authors in [
36] utilized this metric to evaluate the performance outcomes based on their experiment.
4.2. Comparison of Ensemble Models with Simple Traditional Models
Our aim in this paper was to develop a framework for detecting multiple classes of cyberbullying. This section discusses all the evaluation metrics for our approaches for both the ensemble classifiers that combined three multi-classifications models compared with two simple classifiers. The effectiveness of ensemble learning stems from its capacity to harness complementary learning processes with diverse strengths. In our experiment, we developed an automated system to detect cyberbullying tweets, surpassing the capabilities of traditional systems.
Table 4 illustrates a comparison of the evaluations between our proposed ensemble models and simple traditional models.
5. Discussion
The dataset utilized in our experiment is both recent and widely employed in various studies focused on detecting cyberbullying. Its recentness introduces new idioms associated with cyberbullying. Moreover, certain tweets present challenges in identifying the type of cyberbullying due to the presence of multiple words. Additionally, the dataset poses certain complexities, characterized by six target labels termed multiclass, further complicating the detection process. This section delves into the comparison of our framework with others that have explored the same dataset, demonstrating the enhancement in our performance. As depicted in
Table 1, numerous experiments were conducted on the same dataset, each employing diverse methods for detection and prediction. This experiment [
10] aimed to make a contribution by developing a system using an ensemble of transformer models, proposing a new framework in this field. The dataset comprises six labeled classes, prompting them to train their model in two scenarios: first, within five classes by excluding one labeled class and, second, within all six classes of the dataset. According to the experimental results, the model achieved higher accuracy when trained on five classes compared to six classes, attributed to the reduction in the number of classes and rows in the dataset. They utilized three deep learning models, namely RoBERTa, XLNet, and GPT2, combined into one Max-voting ensemble method. Their approach achieved an evaluation model with 85.25% accuracy, an 85.10% F1-Score, 85.02% precision, 85.25% recall, and an overall performance falling within the range of 85% for the classification of all classes in the dataset. We selected this study for comparison due to its similarity in approaches, involving ensemble techniques and encompassing all labels of the dataset in the second scenario. Consequently, our approach outperformed it, achieving a 90.71% accuracy, 90.63% F1-Score, 90.85% precision, and 90.60% recall.
Additionally, the authors in [
11] introduced a sophisticated machine learning approach for deep analysis to detect cyberbullying in the dataset that we employed. In this study, they assessed the performance of five diverse machine learning models—LightGBM, XGBoost, Logistic Regression, Random Forest, and AdaBoost—using a textual feature extraction. They included all six classes of dataset, which consisted of over 47,000 tweets. Their analysis revealed that LightGBM outperformed the other models, achieving notable accuracy rates of 85.5%, precision rates of 84%, recall rates of 85%, and an F1-Score of 84.49%. We opted to contrast our study with this particular research due to its resemblance in its approaches, which involved utilizing machine learning techniques and incorporating all labels of the dataset. As a consequence, our methodology demonstrated superior performance, attaining 90.71% accuracy, a 90.63% F1-Score, 90.85% precision, and 90.60% recall. In our experiment, we implemented an ensemble technique that combined three commonly used classifiers, proving to be efficient for multiclass classification. In contrast, they employed traditional machine learning classifiers. Furthermore, we utilized TF-IDF as the word representation method, while they opted for textual features
The goal of this study was to develop a model that enhances system performance. We aimed to compare our model’s approach with recent experiments that utilized the same dataset. Consequently, we selected all classes in the dataset for training the model, covering all types of cyberbullying present in these classes. Our experiment outperformed recent studies, achieving the highest results across all evaluation metrics and classifying entire datasets. We utilized ensemble learning to combine three classifiers previously employed for the individual classification and detection of cyberbullying tweets. These classifiers were integrated into a unified model using two ensemble learning techniques: voting and stacking. The stacking technique resulted in our model achieving 90.71% accuracy, while voting achieved 90% accuracy. For feature extraction, TF-IDF was employed with various N-grams, including unigrams, bigrams, and trigrams, among which unigrams demonstrated the best performance. TF-IDF offers several advantages, such as the ease of implementation, the simplicity in calculating document similarity, and robustness against common words. However, a limitation arose in its ability to capture the nuanced meanings between words. The authors in [
15] achieved the highest accuracy using unigrams, a result consistent with our experiment. However, in [
12], three-grams improved accuracy when employing the NN and SVM models. Therefore, our experiment suggests that considering the content of the text is crucial for accuracy improvement when using N-gram features. Combining multiple words as one token may impact the context of tweets, potentially confusing the model.
6. Conclusions
Cyberbullying is a complex issue, magnified by the widespread use of social media. In light of this, the automation of cyberbullying detection methods on social media platforms has become increasingly crucial. Our experiment contributes to this area by introducing an automated system designed to identify various types of cyberbullying on the Twitter platform. It is worth noting that the dataset was collected before Twitter’s name changed to X. The study focused on exploring the effectiveness of ensemble multi-classification models for detecting diverse cyberbullying tweets. Our findings suggest that both voting and stacking ensemble classifier techniques outperformed recent experiments that aimed to detect cyberbullying using the same dataset. Moreover, our multi-classification classifiers demonstrated superior performance compared to traditional machine learning classifiers, achieving an increase of approximately 5% in accuracy across most models. We introduced three multi-classification models, namely Decision Trees (DTs), Random Forest (RF), and XGBoost, for detecting various classes of cyberbullying. Among these models, Decision Trees exhibited the highest accuracy at 89%, followed by Random Forest at 88%, and XGBoost at 86%. After testing these models, we applied ensemble techniques, which were voting and stacking classifiers, to combine these three models and enhance the performance. The results from both ensemble techniques revealed nearly identical outputs, with stacking exhibiting a marginal 1% improvement, signifying enhanced accuracy. Additionally, we conducted various N-gram experiments to optimize the performance. Among these, bigrams, particularly with TF-IDF feature extraction, demonstrated the most-promising results. We performed a detailed comparison between the two ensemble classifiers implemented in our study and juxtaposed our experimental results with recent studies in the field. This analysis employed well-established evaluation metrics, as detailed in this paper. In summary, our experiment showcased the superiority of ensemble models, with multi-classification classifiers outperforming traditional ML classifiers. Looking ahead, we intend to extend the application of our approach to different languages, such as Arabic, using multiclass datasets. This expansion will ensure the robust performance of our approach across diverse content.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}