
Knowledge Graph Extraction of Business Interactions from News Text for Business Networking Analysis


Abstract
1. Introduction
2. Related Work
2.1. Building a Knowledge Graph from Text
2.2. Business Network Knowledge Graph Construction and Analysis
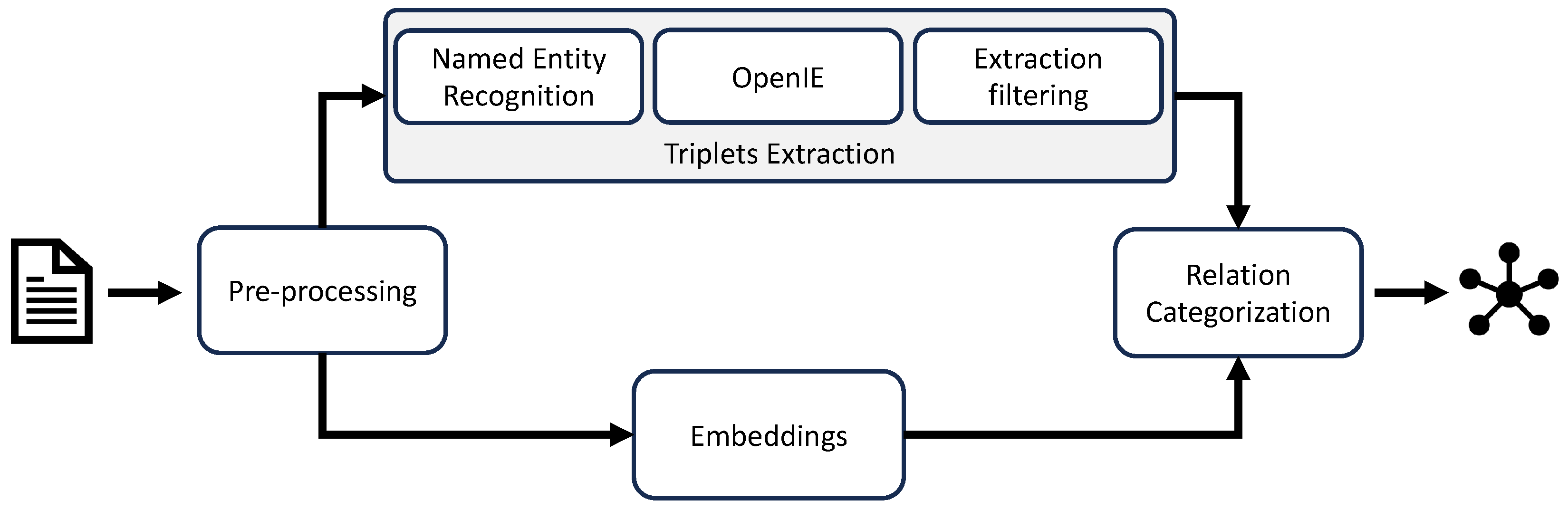
3. Materials and Methods
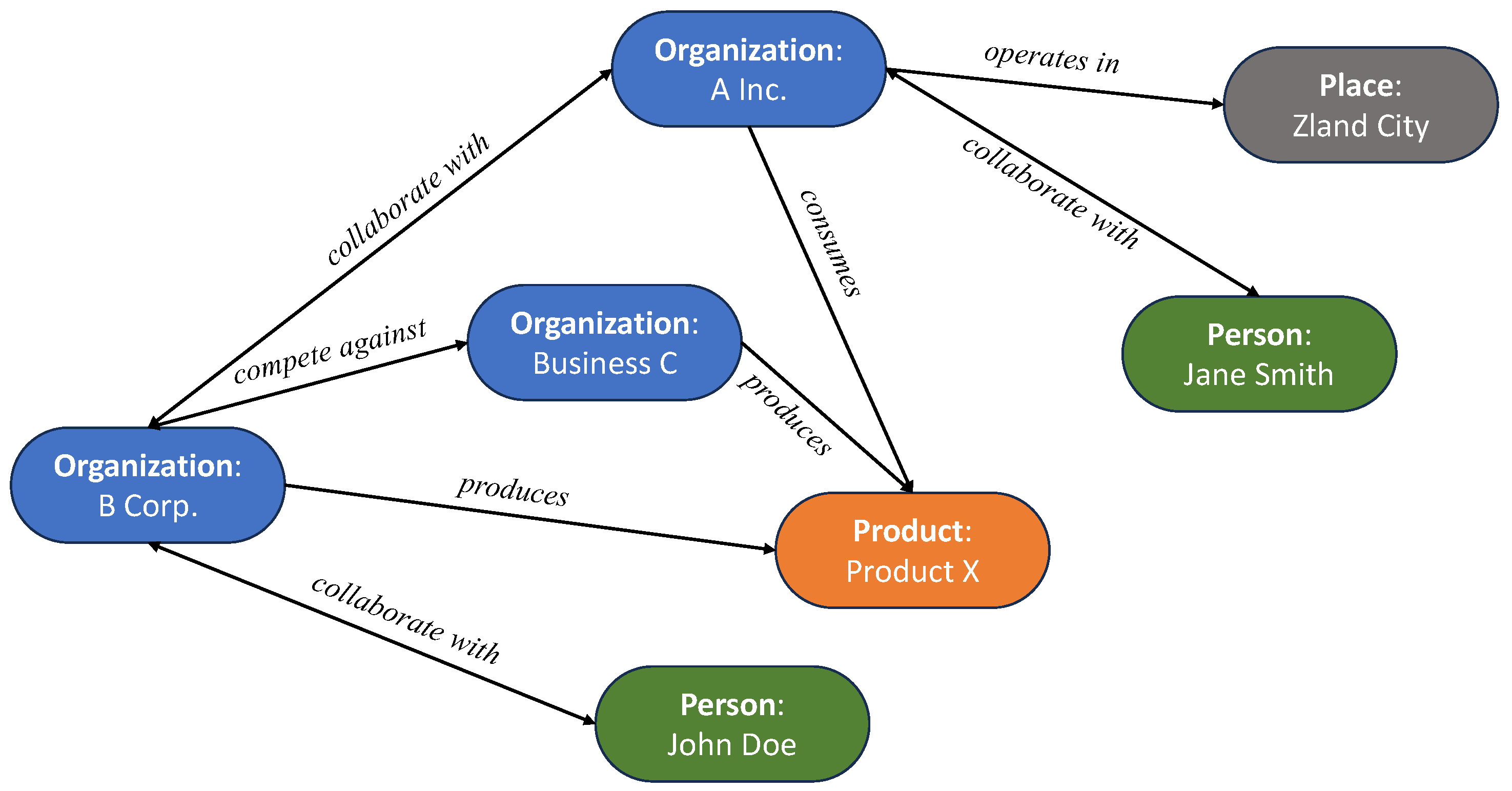
3.1. Ontology
- What is the nature of the relationship between Company A and Company B?
- Who produces Product X?
- What organizations operate in City Y?
- Who are the people working with Company C?
- Who buys Product Y?
3.2. Preprocessing
3.3. Word Embedding
3.4. Triplet Extraction
| Algorithm 1 Triplet Filtering |
| Require: the set of sentences in the dataset Require: the set of named entity types of interest /* Set of filtered triples */ for all do ExtractTriples(s) for all do FindNamedEntity() FindNamedEntity() if ∃ type() and ∃ type() then end if end for end for |
3.5. Reducing Duplicates
3.6. Relation Categorization
3.7. Implementation Details
4. Results
4.1. Dataset
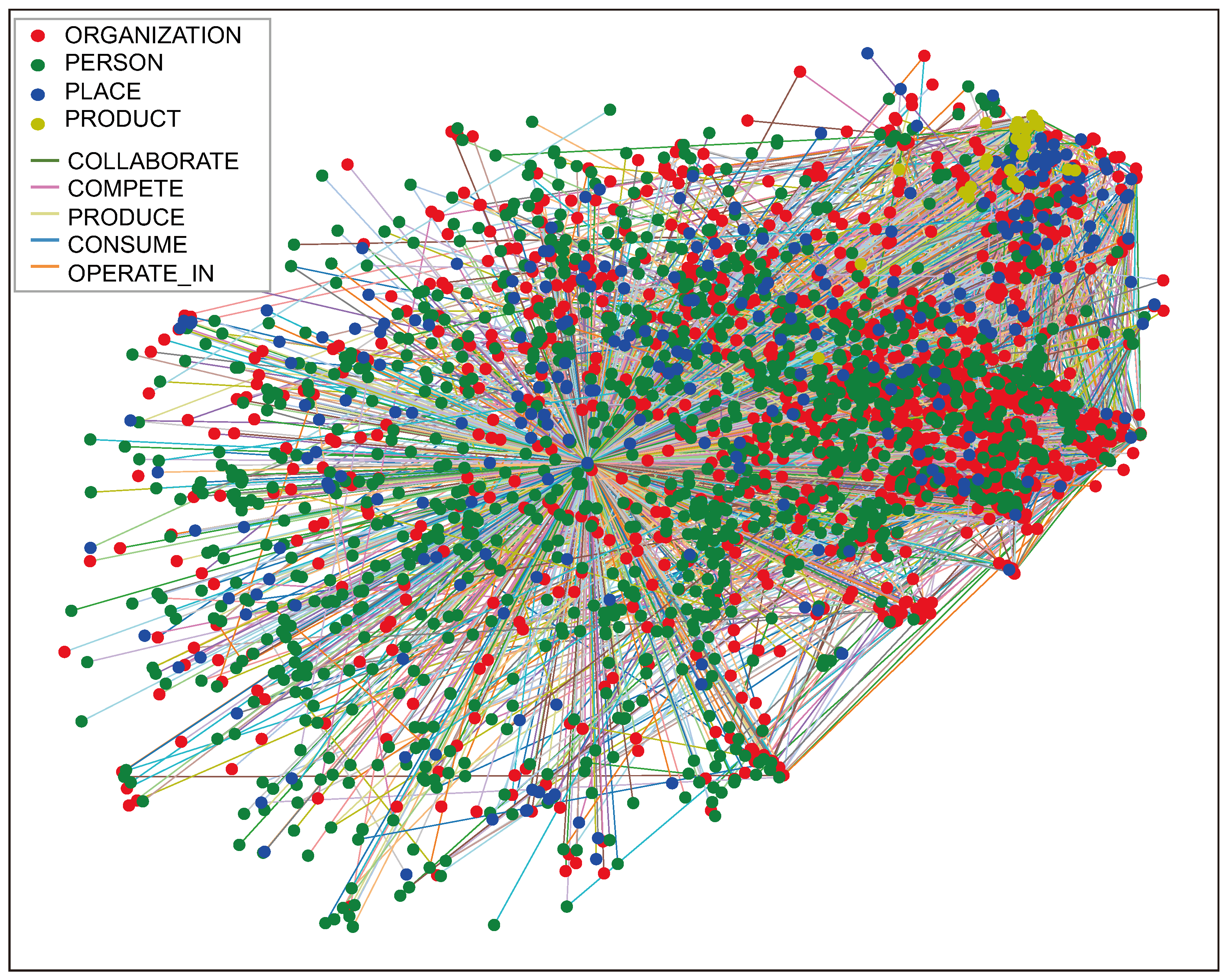
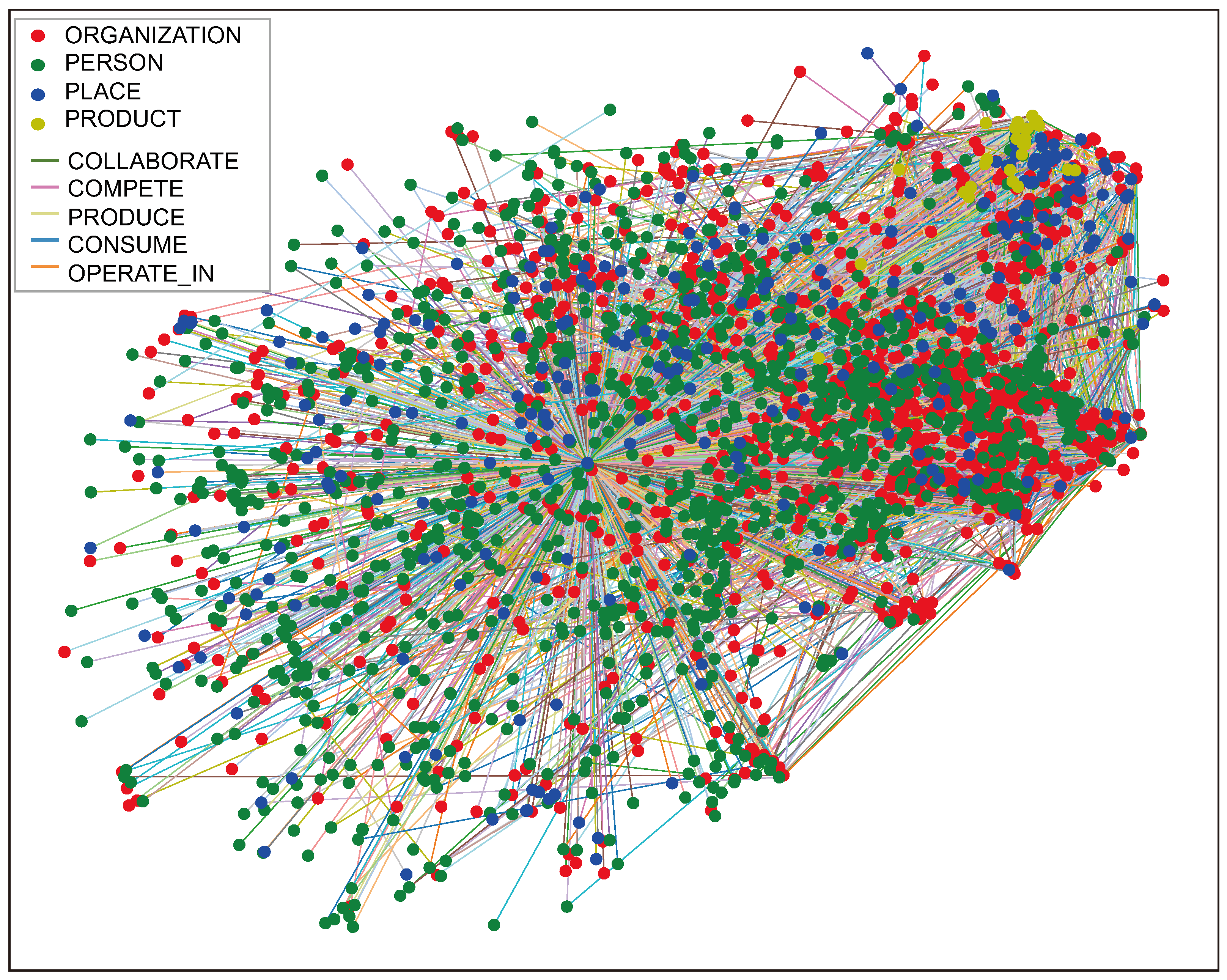
4.2. Graph Extraction
5. Discussion
5.1. Use Cases
5.2. Current Limitations
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| OpenIE | Open information extraction |
| NLP | Natural language processing |
Appendix A
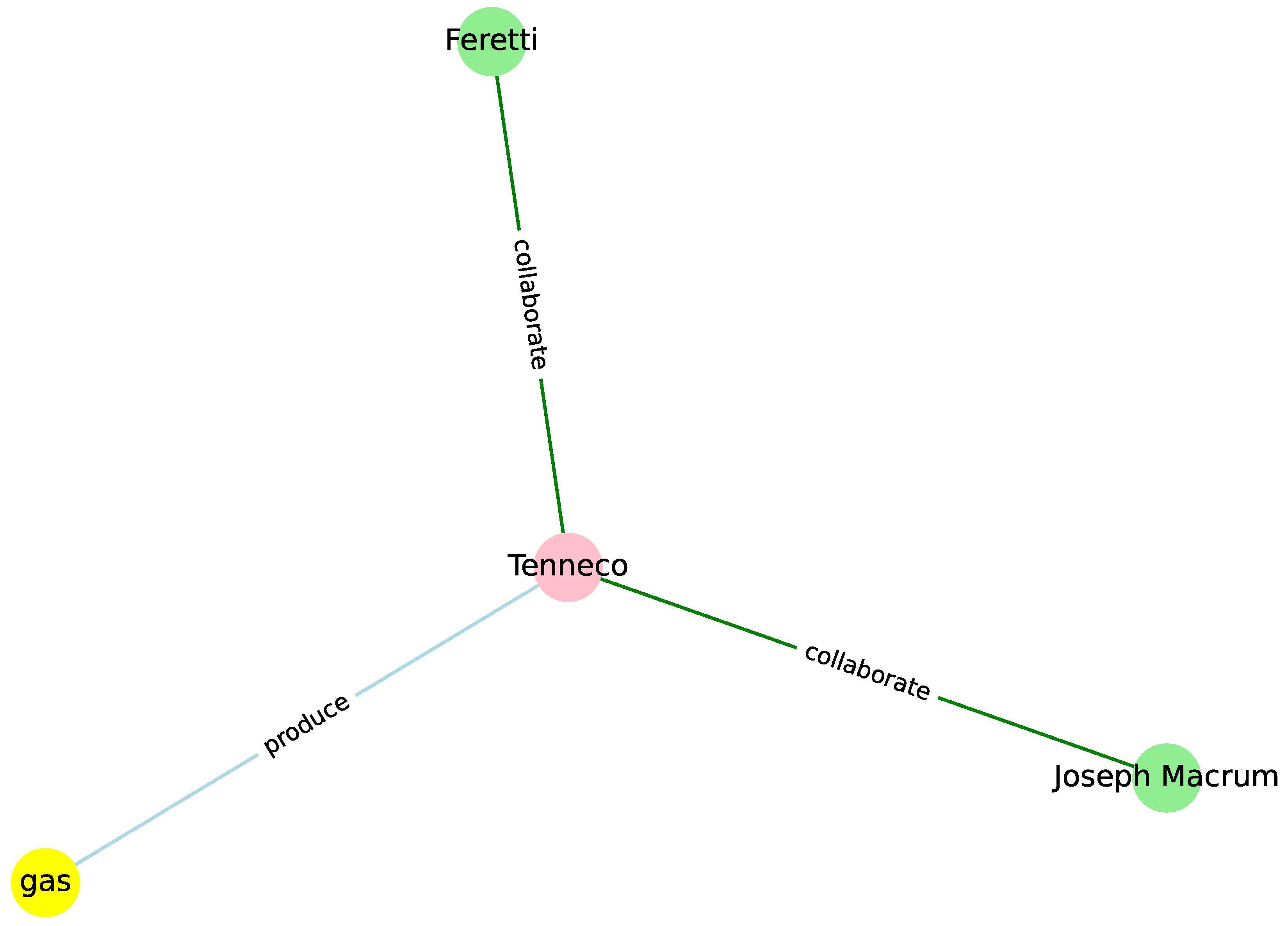
Tenneco Inc., a company that has long been rumored to be a takeover candidate, rose sharply today when speculation surfaced that investor T. Boone Pickens may be targeting the company for an acquisition, traders and analysts said. Tenneco spokesman Joseph Macrum said “we have no comment to make whatsoever.” Pickens was not available for comment. Traders noted that activity in the stock increased today after a published report linked Pickens to Tenneco. Tenneco rose two points to 48-3/4. Paul Feretti, an analyst with New Orleans-based Howard, Weil, Labouisse, Friedrichs, Inc., said he was not surprised at market rumors that Tenneco might be the target of a takeover attempt. “It’s pure market speculation that Boone Pickens and their group may be interested,” Feretti said. “However, Tenneco would be a challenge to run because of its sheer size and diversity. Mr. Pickens is a man who likes a challenge[…]”

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subject | Relation | Object |
|---|---|---|
| Joseph Macrum | be spokesman of | Tenneco |
| Tenneco | hold | gas reserve |
| Feretti | estimate | Tenneco’s breakup value |
| Feretti | conservatively estimate | Tenneco’s breakup value |
| Source Entity | Destination Entity | Relationship Category |
|---|---|---|
| PERSON:Joseph Macrum | ORGANIZATION:Tenneco | collaborates |
| ORGANIZATION:Tenneco | PRODUCT:gas | produces |
| PERSON:Feretti | ORGANIZATION:Tenneco | collaborates |
| PERSON:Feretti | ORGANIZATION:Tenneco | collaborates |
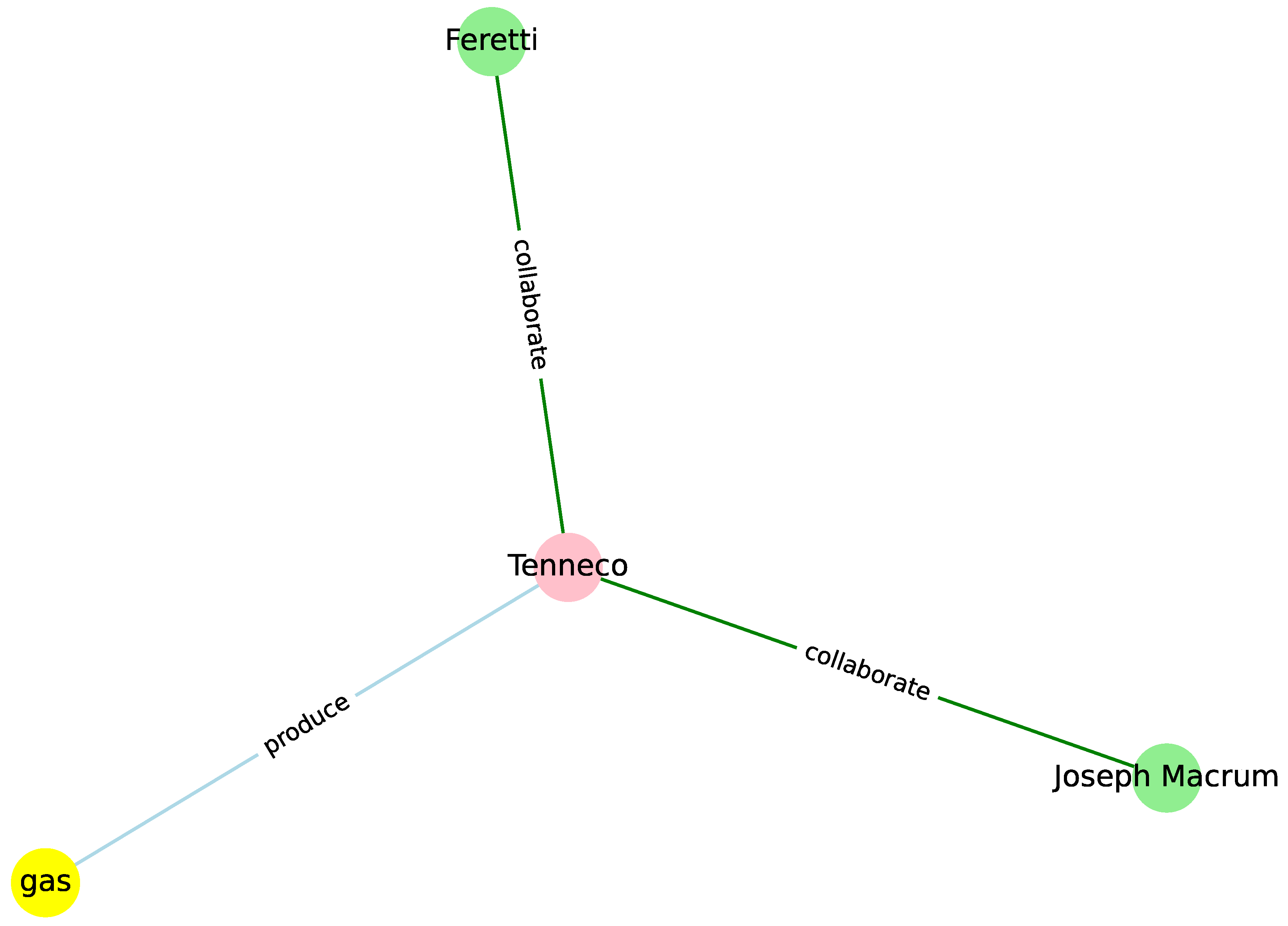
Appendix B
Example 1
Sales of previously owned homes dropped 14.5 pct in January to a seasonally adjusted annual rate of 3.47 mln units, the National Association of Realtors (NAR) said.
Example 2
Kevlar was invented by Du Pont in the late 1960s and is five times stronger than steel and 10 times stronger than aluminum on an equal wieght basis, and is used to replace metals in a variety of products, according to the company.
Appendix C
| Configurations | Entities | Relationships |
|---|---|---|
| TraCER (complete) | 6761 | 9161 |
| TraCER (no coref) | 6756 | 9831 |
| TraCER (no link) | 8082 | 13,842 |
References
- Xia, F.; Sun, K.; Yu, S.; Aziz, A.; Wan, L.; Pan, S.; Liu, H. Graph learning: A survey. IEEE Trans. Artif. Intell. 2021, 2, 109–127. [Google Scholar] [CrossRef]
- Hogan, A.; Blomqvist, E.; Cochez, M.; d’Amato, C.; Melo, G.d.; Gutierrez, C.; Kirrane, S.; Gayo, J.E.L.; Navigli, R.; Neumaier, S.; et al. Knowledge graphs. ACM Comput. Surv. CSUR 2021, 54, 1–37. [Google Scholar]
- Bronstein, M.M.; Bruna, J.; Cohen, T.; Veličković, P. Geometric deep learning: Grids, groups, graphs, geodesics, and gauges. arXiv 2021, arXiv:2104.13478. [Google Scholar]
- Jumper, J.; Evans, R.; Pritzel, A.; Green, T.; Figurnov, M.; Ronneberger, O.; Tunyasuvunakool, K.; Bates, R.; Žídek, A.; Potapenko, A.; et al. Highly accurate protein structure prediction with AlphaFold. Nature 2021, 596, 583–589. [Google Scholar] [CrossRef] [PubMed]
- Chunaev, P. Community detection in node-attributed social networks: A survey. Comput. Sci. Rev. 2020, 37, 100286. [Google Scholar] [CrossRef]
- Li, Z.; Chen, X.; Song, J.; Gao, J. Adaptive label propagation for group anomaly detection in large-scale networks. IEEE Trans. Knowl. Data Eng. 2022, 35, 12053–12067. [Google Scholar] [CrossRef]
- Guo, Q.; Zhuang, F.; Qin, C.; Zhu, H.; Xie, X.; Xiong, H.; He, Q. A survey on knowledge graph-based recommender systems. IEEE Trans. Knowl. Data Eng. 2020, 34, 3549–3568. [Google Scholar] [CrossRef]
- Chen, X.; Jia, S.; Xiang, Y. A review: Knowledge reasoning over knowledge graph. Expert Syst. Appl. 2020, 141, 112948. [Google Scholar] [CrossRef]
- Hu, W.; Fey, M.; Zitnik, M.; Dong, Y.; Ren, H.; Liu, B.; Catasta, M.; Leskovec, J. Open graph benchmark: Datasets for machine learning on graphs. Adv. Neural Inf. Process. Syst. 2020, 33, 22118–22133. [Google Scholar]
- Li, J.; Sun, A.; Han, J.; Li, C. A Survey on Deep Learning for Named Entity Recognition. IEEE Trans. Knowl. Data Eng. 2022, 34, 50–70. [Google Scholar] [CrossRef]
- Nasar, Z.; Jaffry, S.W.; Malik, M.K. Named Entity Recognition and Relation Extraction: State-of-the-Art. ACM Comput. Surv. 2021, 54, 1–39. [Google Scholar] [CrossRef]
- Zachary, W. An Information Flow Model for Conflict and Fission in Small Groups. J. Anthropol. Res. 1976, 33, 452–473. [Google Scholar] [CrossRef]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. DeepWalk: Online Learning of Social Representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’14, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar] [CrossRef]
- Kipf, T.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017—Conference Track Proceedings, Toulon, France, 24–26 April 2017; pp. 1–14. [Google Scholar]
- Miller, G.A. WordNet: A Lexical Database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Lenat, D.B. CYC: A Large-Scale Investment in Knowledge Infrastructure. Commun. ACM 1995, 38, 33–38. [Google Scholar] [CrossRef]
- Giles, C.; Bollacker, K.; Lawrence, S. CiteSeer: An automatic citation indexing system. In Proceedings of the ACM International Conference on Digital Libraries, ACM, Pittsburgh, PA, USA, 23–26 June 1998; pp. 89–98. [Google Scholar]
- Zhong, L.; Wu, J.; Li, Q.; Peng, H.; Wu, X. A Comprehensive Survey on Automatic Knowledge Graph Construction. arXiv 2023, arXiv:2302.05019. [Google Scholar] [CrossRef]
- Kertkeidkachorn, N.; Ichise, R. An Automatic Knowledge Graph Creation Framework from Natural Language Text. IEICE Trans. Inf. Syst. 2018, E101.D, 90–98. [Google Scholar] [CrossRef]
- Sant’Anna, D.T.; Caus, R.O.; dos Santos Ramos, L.; Hochgreb, V.; dos Reis, J.C. Generating Knowledge Graphs from Unstructured Texts: Experiences in the E-commerce Field for Question Answering. In Proceedings of the Joint Proceedings of Workshops AI4LEGAL2020, NLIWOD, PROFILES 2020, QuWeDa 2020 and SEMIFORM2020, Colocated with the 19th International Semantic Web Conference (ISWC 2020), CEUR, Virtual Conference, 1–6 November 2020; pp. 56–71. [Google Scholar]
- Yu, S.; He, T.; Glass, J. AutoKG: Constructing Virtual Knowledge Graphs from Unstructured Documents for Question Answering. arXiv 2021, arXiv:2008.08995. [Google Scholar]
- Saha, S.; Mausam. Open Information Extraction from Conjunctive Sentences. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 21–24 August 2018; pp. 2288–2299. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Zhang, Z.; Han, X.; Liu, Z.; Jiang, X.; Sun, M.; Liu, Q. ERNIE: Enhanced Language Representation with Informative Entities. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1441–1451. [Google Scholar] [CrossRef]
- Cao, E.; Wang, D.; Huang, J.; Hu, W. Open Knowledge Enrichment for Long-Tail Entities. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; Association for Computing Machinery: New York, NY, USA; Springer: Cham, Switzerland, April 2020; pp. 384–394. [Google Scholar]
- Ruan, T.; Xue, L.; Wang, H.; Hu, F.; Zhao, L.; Ding, J. Building and Exploring an Enterprise Knowledge Graph for Investment Analysis. In Proceedings of the Semantic Web—ISWC 2016, Kobe, Japan, 17–21 October 2016; Groth, P., Simperl, E., Gray, A., Sabou, M., Krötzsch, M., Lecue, F., Flöck, F., Gil, Y., Eds.; Springer: Cham, Switzerland, 2016; pp. 418–436. [Google Scholar]
- Dai, L.; Yin, Y.; Qin, C.; Xu, T.; He, X.; Chen, E.; Xiong, H. Enterprise Cooperation and Competition Analysis with a Sign-Oriented Preference Network. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 6–10 July 2020; pp. 774–782. [Google Scholar]
- Hillebrand, L.; Deußer, T.; Dilmaghani, T.; Kliem, B.; Loitz, R.; Bauckhage, C.; Sifa, R. Kpi-bert: A joint named entity recognition and relation extraction model for financial reports. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 606–612. [Google Scholar]
- Gohourou, D.; Kuwabara, K. Building a Domain-Specific Knowledge Graph for Business Networking Analysis. In Proceedings of the Intelligent Information and Database Systems: 13th Asian Conference, ACIIDS 2021, Phuket, Thailand, 7–10 April 2021; Proceedings 13. Springer: Cham, Switzerland, 2021; pp. 362–372. [Google Scholar]
- Grüninger, M.; Fox, M. Methodology for the Design and Evaluation of Ontologies. In Proceedings of the Workshop on Basic Ontological Issues in Knowledge Sharing, Montreal, QC, Canada, 13 April 1995. [Google Scholar]
- Noy, N.F.; McGuinness, D.L. Ontology Development 101: A Guide to Creating Your First Ontology; Stanford University: Stanford, CA, USA, 2001. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018; Preprint. Available online: https://paperswithcode.com/paper/improving-language-understanding-by (accessed on 27 December 2023).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. Palm: Scaling language modeling with pathways. arXiv 2022, arXiv:2204.02311. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.S.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Angeli, G.; Premkumar, M.J.; Manning, C.D. Leveraging linguistic structure for open domain information extraction. In ACL-IJCNLP 2015—53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing, Proceedings of the Conference; Association for Computational Linguistics: Beijing, China, 2015; Volume 1, pp. 344–354. [Google Scholar] [CrossRef]
- Klein, D.; Smarr, J.; Nguyen, H.; Manning, C.D. Named entity recognition with character-level models. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003, Edmonton, AB, Canada, 31 May 2003; pp. 180–183. [Google Scholar]
- Mikolov, T.; Yih, W.t.; Zweig, G. Linguistic Regularities in Continuous Space Word Representations. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 31 May–1 June 2013; pp. 746–751. [Google Scholar]
- Řehůřek, R.; Sojka, P. Software Framework for Topic Modelling with Large Corpora. In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, Valletta, Malta, 25 July 2010; pp. 45–50. Available online: http://is.muni.cz/publication/884893/en (accessed on 20 November 2023).
- Manning, C.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.; McClosky, D. The Stanford CoreNLP Natural Language Processing Toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 23–24 June 2014; pp. 55–60. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Wu, L.; Petroni, F.; Josifoski, M.; Riedel, S.; Zettlemoyer, L. Scalable Zero-shot Entity Linking with Dense Entity Retrieval. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 6397–6407. [Google Scholar] [CrossRef]
- Soares, L.B.; FitzGerald, N.; Ling, J.; Kwiatkowski, T. Matching the blanks: Distributional similarity for relation learning. arXiv 2019, arXiv:1906.03158. [Google Scholar]


| Source (Subject) | Destination (Object) | Relationship Type |
|---|---|---|
| Organization, | Organization, | collaborates, |
| Person | Person | competes |
| Organization | Product | produces, |
| consumes | ||
| Organization | Place | operates in |
| Entity | Entity Type |
|---|---|
| Youcef Yousfi | Person |
| Sonatrach | Organization |
| Cabot Corp | Organization |
| CBT | Organization |
| Frank Spadine | Person |
| Bankers Trust | Organization |
| Shearson | Organization |
| Tulis | Person |
| gas | Product |
| Entity | Linked Entity |
|---|---|
| National Association of Realtors | NAR |
| ChemLawn Corp | CHEM |
| Securities and Exchange Commission | SEC |
| Government Accounting Office | GAO |
| Swiss Mortgage Institute | Schweizerischer Hypothekarinstitute |
| General Petroleum and Mineral Organisation | Petromin |
| Cassa Di Risparmio Delle Provincie Lombarde | CARIPLO |
| Nippon Telegraph and Telephone Corp | NTT |
| Subject | Relation | Object |
|---|---|---|
| Youcef Yousfi | general of | Sonatrach |
| Cabot Corp | be | CBT |
| Frank Spadine | economist with | Bankers Trust |
| Shearson | have | Tulis |
| gas drilling | in decline be | Tulis |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gohourou, D.; Kuwabara, K. Knowledge Graph Extraction of Business Interactions from News Text for Business Networking Analysis. Mach. Learn. Knowl. Extr. 2024, 6, 126-142. https://doi.org/10.3390/make6010007
Gohourou D, Kuwabara K. Knowledge Graph Extraction of Business Interactions from News Text for Business Networking Analysis. Machine Learning and Knowledge Extraction. 2024; 6(1):126-142. https://doi.org/10.3390/make6010007
Chicago/Turabian StyleGohourou, Didier, and Kazuhiro Kuwabara. 2024. "Knowledge Graph Extraction of Business Interactions from News Text for Business Networking Analysis" Machine Learning and Knowledge Extraction 6, no. 1: 126-142. https://doi.org/10.3390/make6010007
APA StyleGohourou, D., & Kuwabara, K. (2024). Knowledge Graph Extraction of Business Interactions from News Text for Business Networking Analysis. Machine Learning and Knowledge Extraction, 6(1), 126-142. https://doi.org/10.3390/make6010007