
Explaining Deep Q-Learning Experience Replay with SHapley Additive exPlanations


Abstract
:1. Introduction
2. Related Works
2.1. Classic Reinforcement Learning
2.2. Deep Q-Learning
2.3. Experience Replay
2.4. Explainable Reinforcement Learning
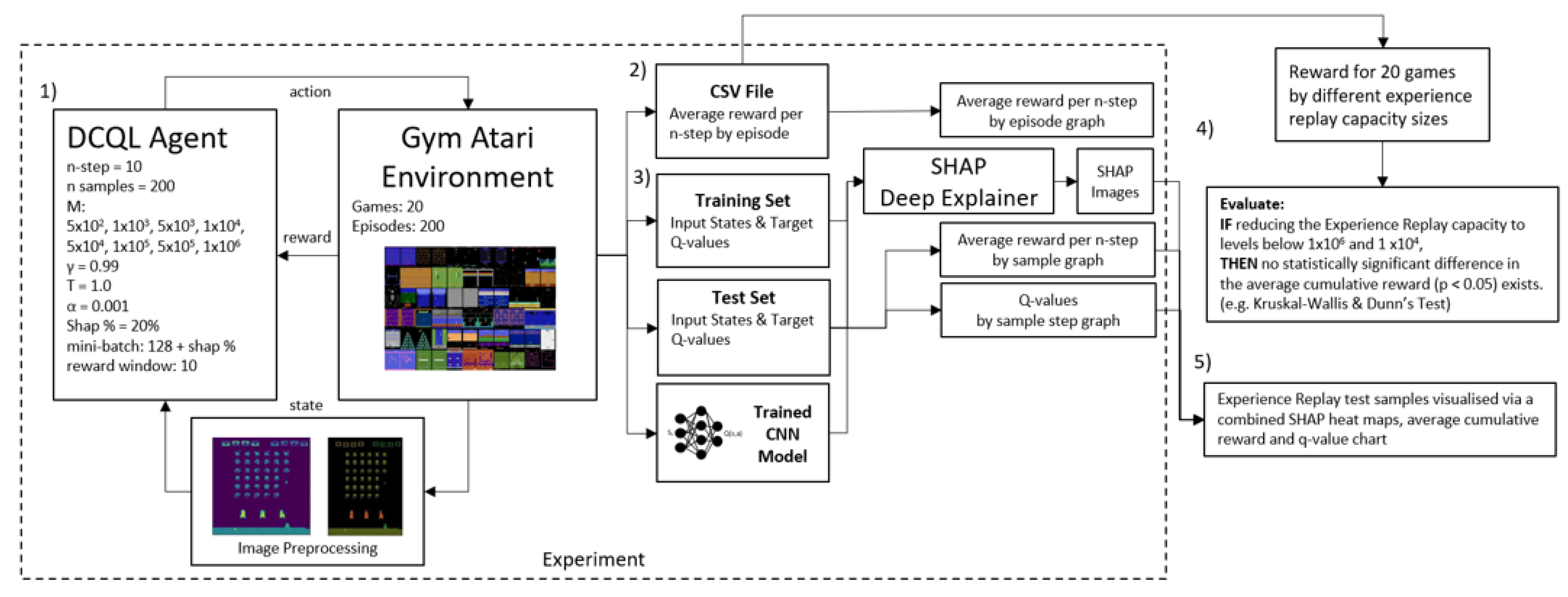
3. Design
3.1. Data Understanding
3.2. Data Preparation
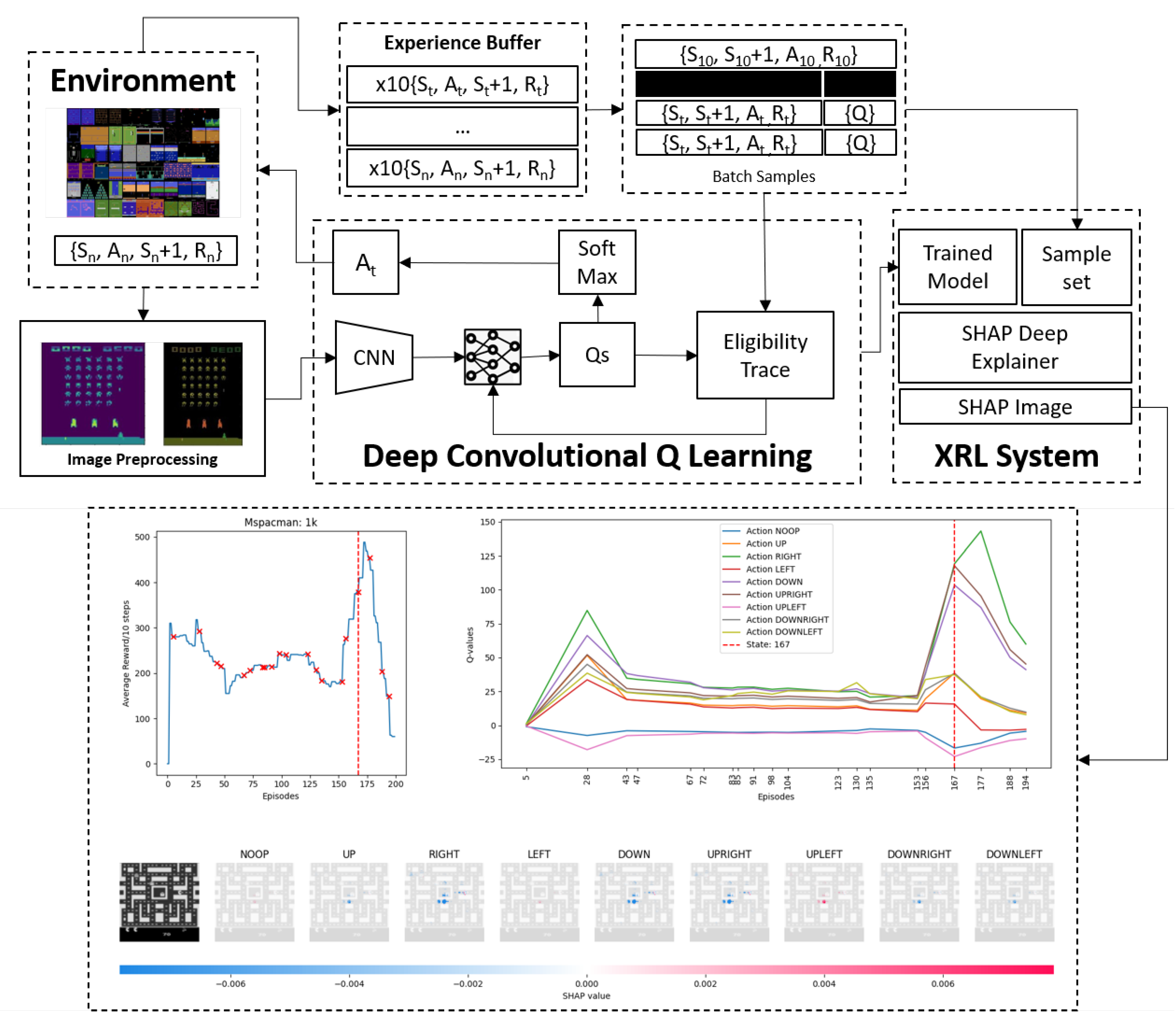
- Image States: Images provided to the Agent without prepossessing, cause training time to be long with no performance increase. Each image is reduced from its default size, similar to the original implementation by [11] (e.g., Atari SpaceInvaders: 210 px, 160 px, 3 color channels) to a greyscale image (i.e., 80 px, 80 px, 1 color). To ascertain motion and direction, images are collected and batched first then passed to the deep convolutional Q-learning model as discussed earlier in Section 2.2. Batching images is set to 10, meaning 10 steps are taken through time occurs then 10 images are grouped and stored in a history buffer to be later used. Ref. [11] used n-step = 4, Ref. [12] used n-step = 1, Ref. [14] experimented with n-step = 2 to n-step = 7.
- Discrete Actions: If the actions allowed are move-left, move-right, move-up or move-down then the Agent’s discrete actions would be accepted as 4 by the environment. Each simulated environment has its own predefined number of actions. Some games in Atari can have up to 14 discrete actions.
- Data Sampling: 154 random samples are taken from the Agent’s Experience Replay buffer as mini-batch samples. 128 are used as training data for the agent while the extra 20% is set aside as test data to later train a SHAP Deep Explainer.
3.3. Modelling
- The first layer takes a single 80 × 80 pixel image as an input feature and outputs 32 feature maps 5 × 5 pixels in size.
- The second layer takes 32 feature map images and outputs feature maps as 3 × 3 pixels in size.
- The final convolutional layer takes 32 feature maps and outputs 64 feature maps 2 × 2 in size.
- The Results of convolutions are passed into a fully connected neural network layer where the number of input neurons used is dynamically determined. This determination is first done by creating a blank fake black and white image (80 px × 80 px), max pooling the resulting layer through the 3 convolutional layers with a stride of 2 and flattening the layer into a one-dimensional layer. This results in the quantity of input neurons needed.
3.4. Evaluation
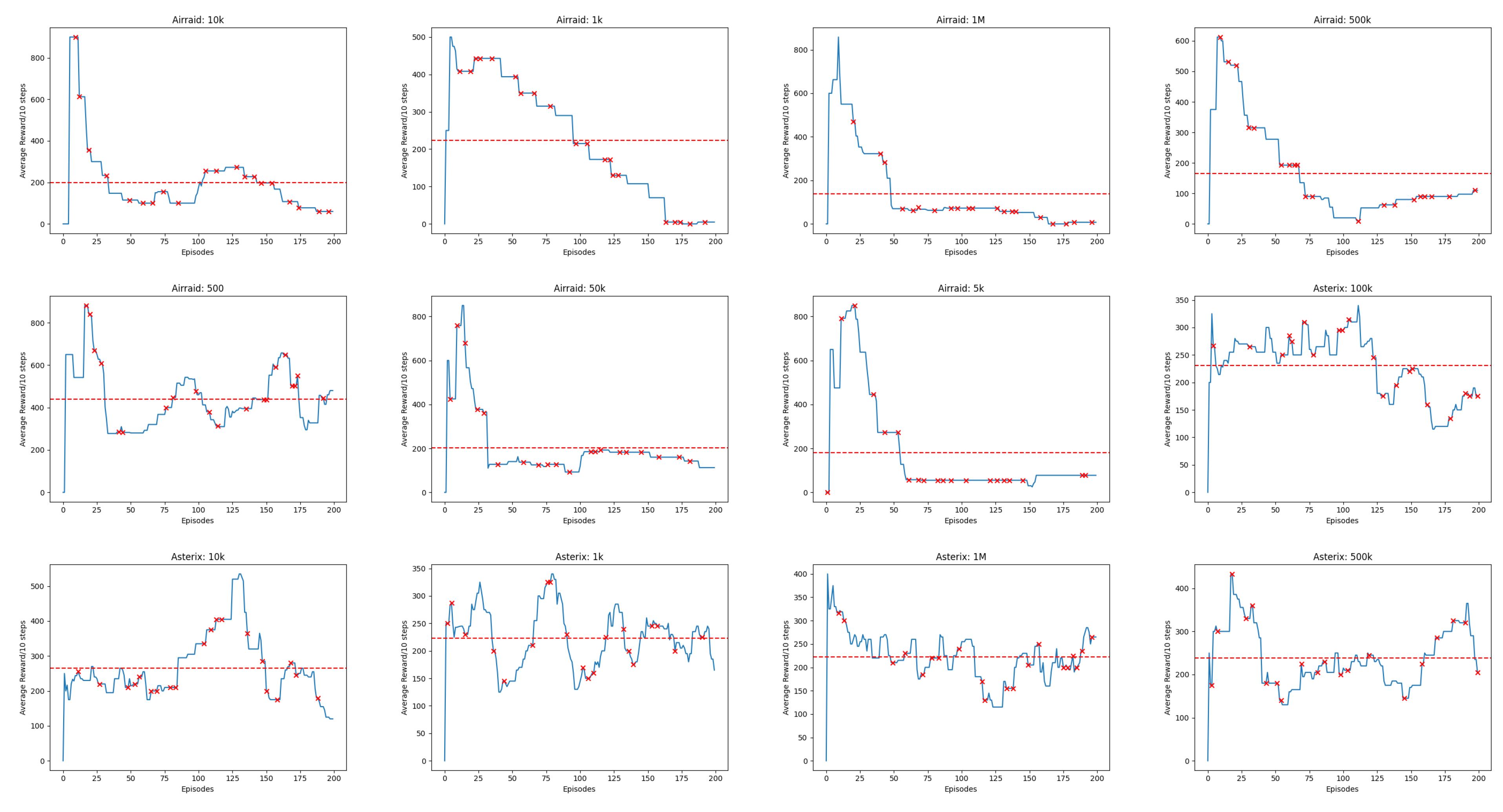
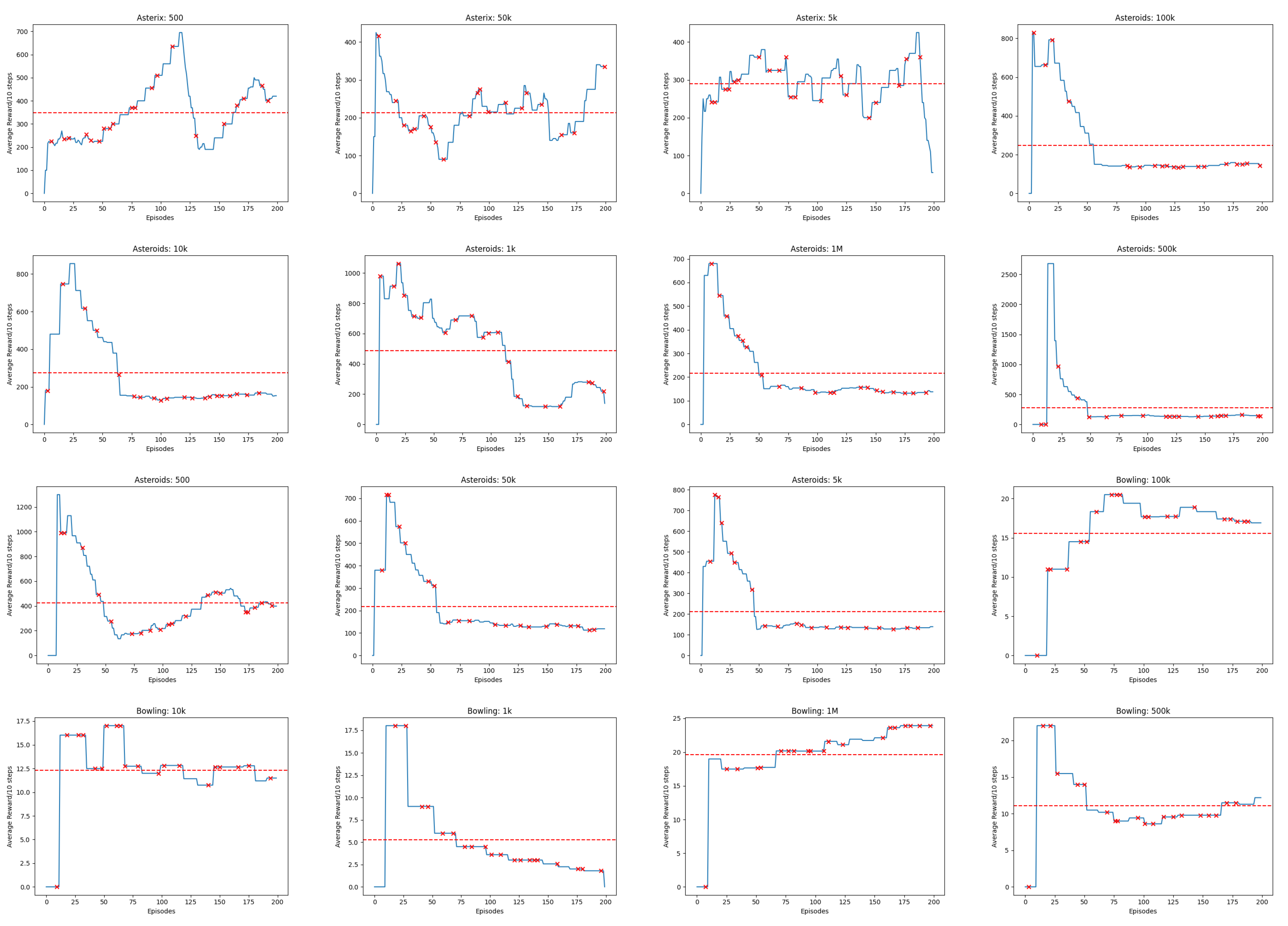
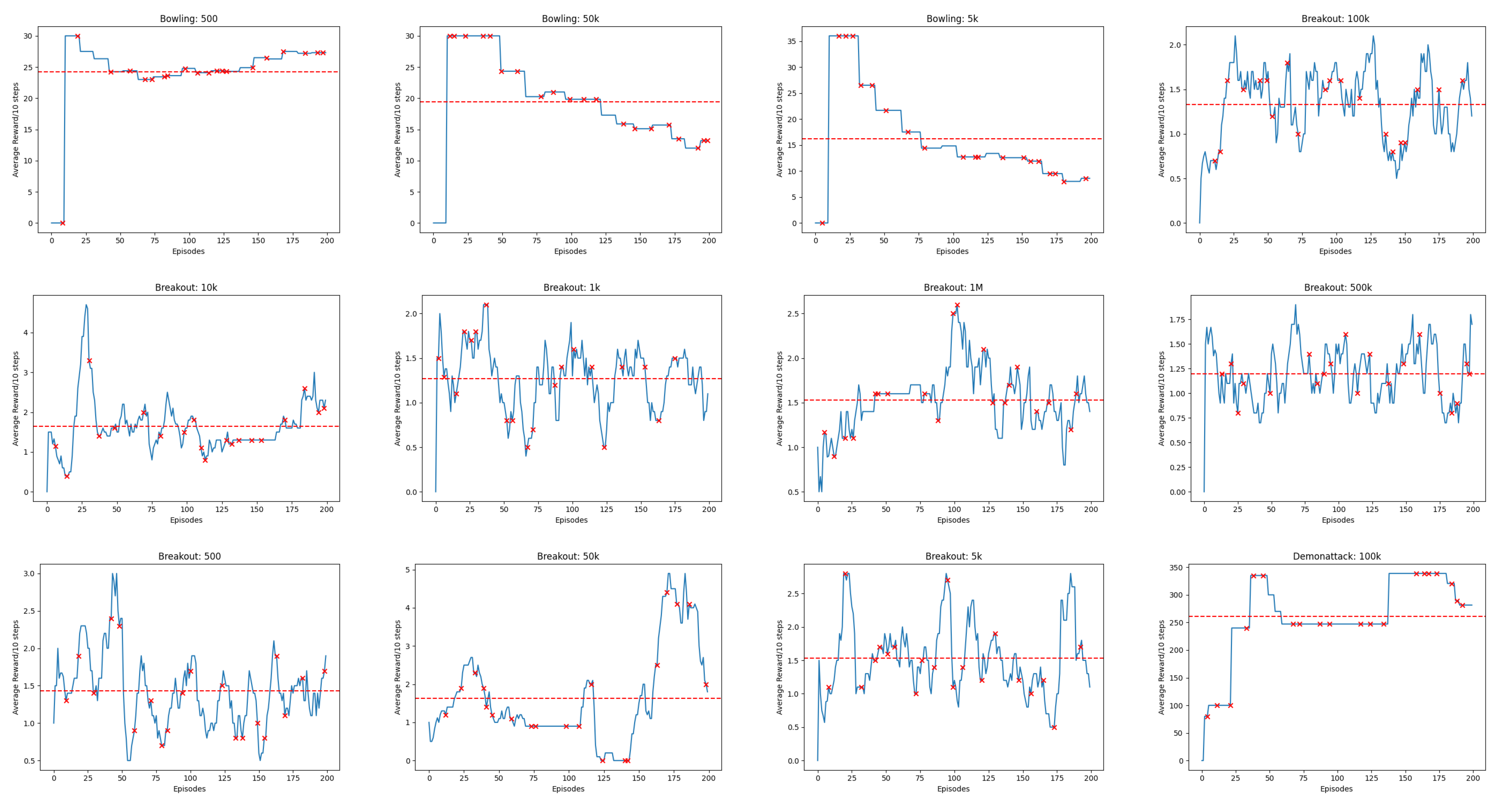
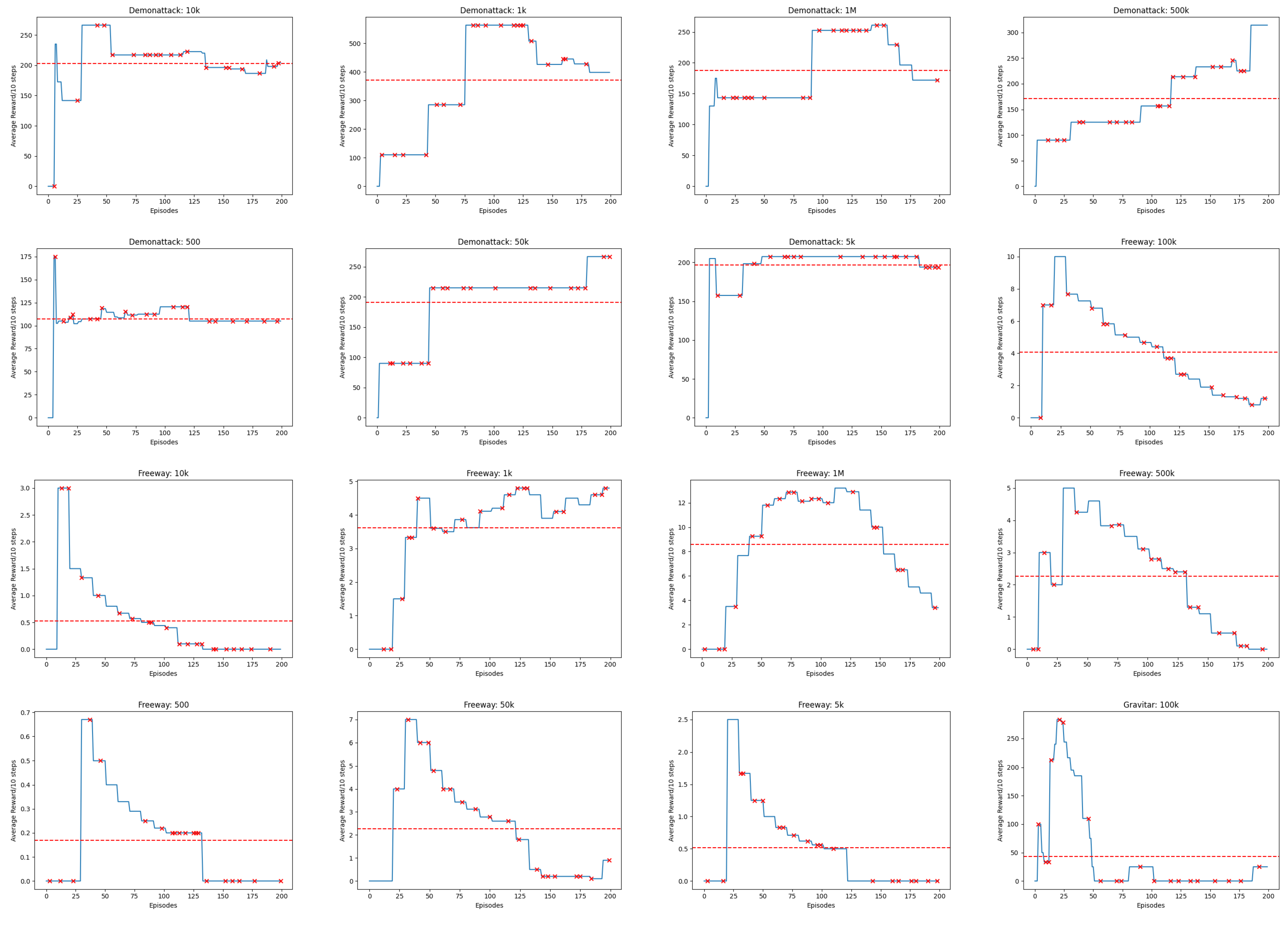
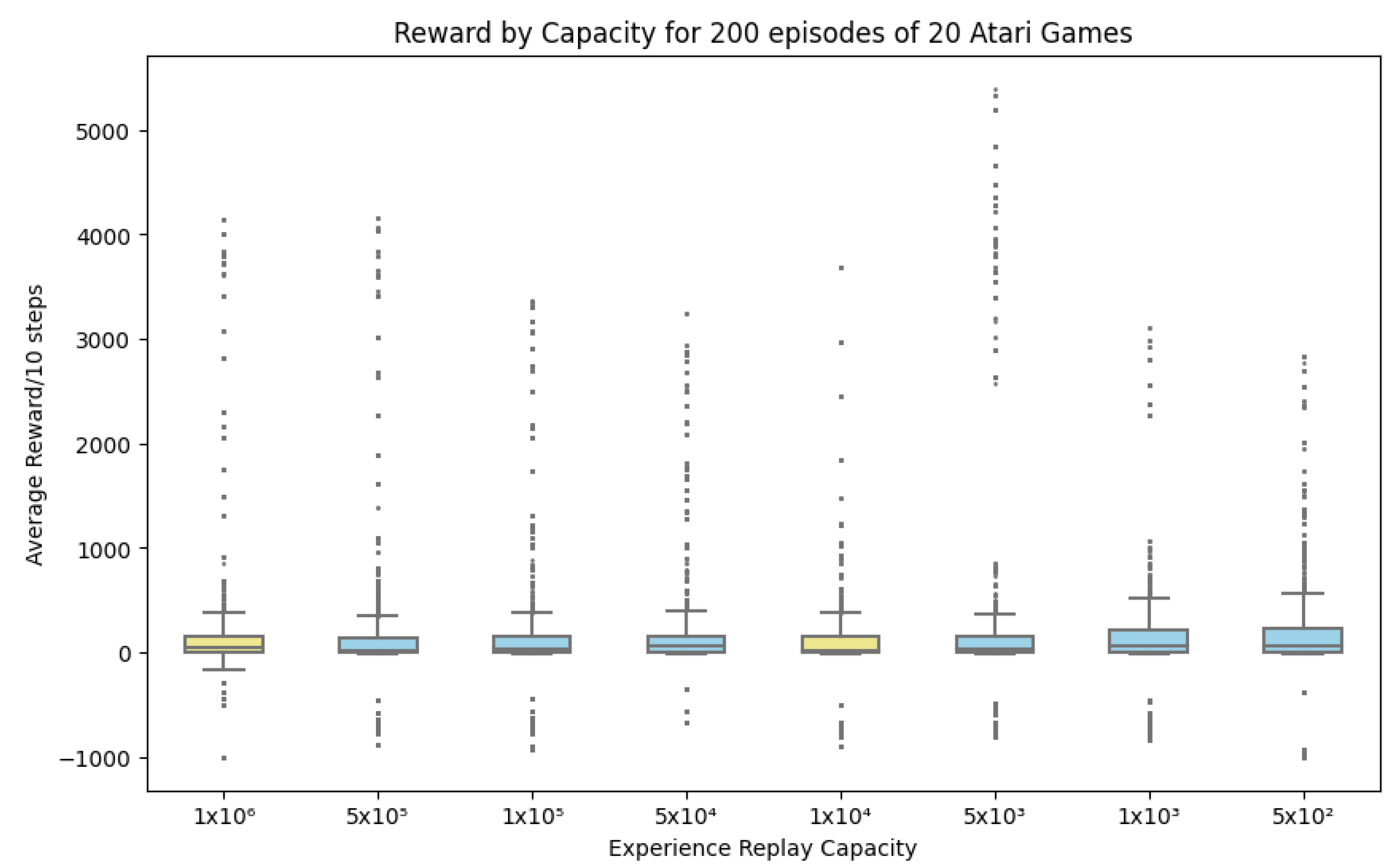
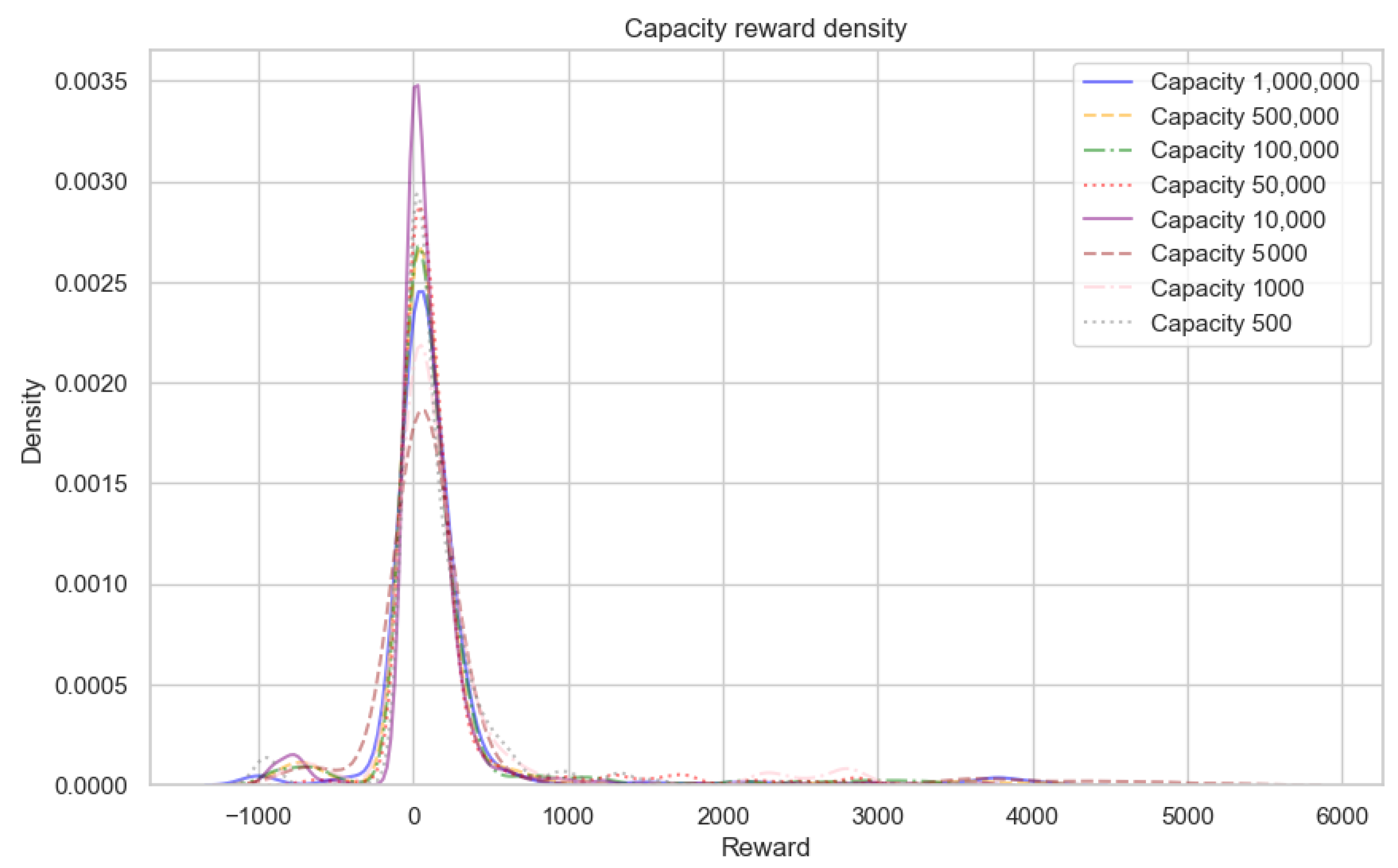
IF the Experience Replay capacity hyperparameter M is reduced below or below the , threshold investigated in [12,13,14], THEN we hypothesize that there exists a specific configuration of M resulting in maximal reward scores while minimizing M, and this configuration demonstrates no statistically significant difference in average cumulative reward compared to the baseline M values of or , with a significance level of . This outcome would imply that the Experience Replay capacity hyperparameter M can be decreased without causing a significant drop in performance.
- One-Way Analysis of Variance (ANOVA): This test is used to tell whether there are any statistically significant differences between the means of the independent (unrelated) groups of reward scores where experience replay capacity is set to and reduced to , , , , , , and transitions respectfully
- Shapiro-Wilk Test: This test is used to confirm if ANOVA and Tukey or Kruskal-Wallis test and Dunn’s post hoc test can be used by checking if the reward data is in fact normally distributed, a prerequisite for ANOVA [44].
- Kruskal-Wallis Test: This is based on the ranks of the data rather than the actual values. It ranks the combined data from all groups and calculates the test statistic, which similar to ANOVA, can measure the differences between the ranked group medians. The test statistic follows a chi-squared distribution with (k − 1) degrees of freedom, where k is the number of groups being compared. The null hypothesis of the Kruskal-Wallis test is that there are no differences in medians among Experience Replay size groups. The alternative hypothesis suggests that at least one group differs from the others [45].
- Tukey Test: This test is used after an ANOVA test. Since, ANOVA can identify if there are significant differences among group means, a Tukey test can identify which specific pairs of group means are significantly different from each other.
- Dunn’s Test: This test is similar to Tukey but used after a Kruskal-Wallis test and determines which Experience Replay groups have significantly different sizes.
4. Results and Discussion
4.1. Finding Minimum Experience Replay Allowed
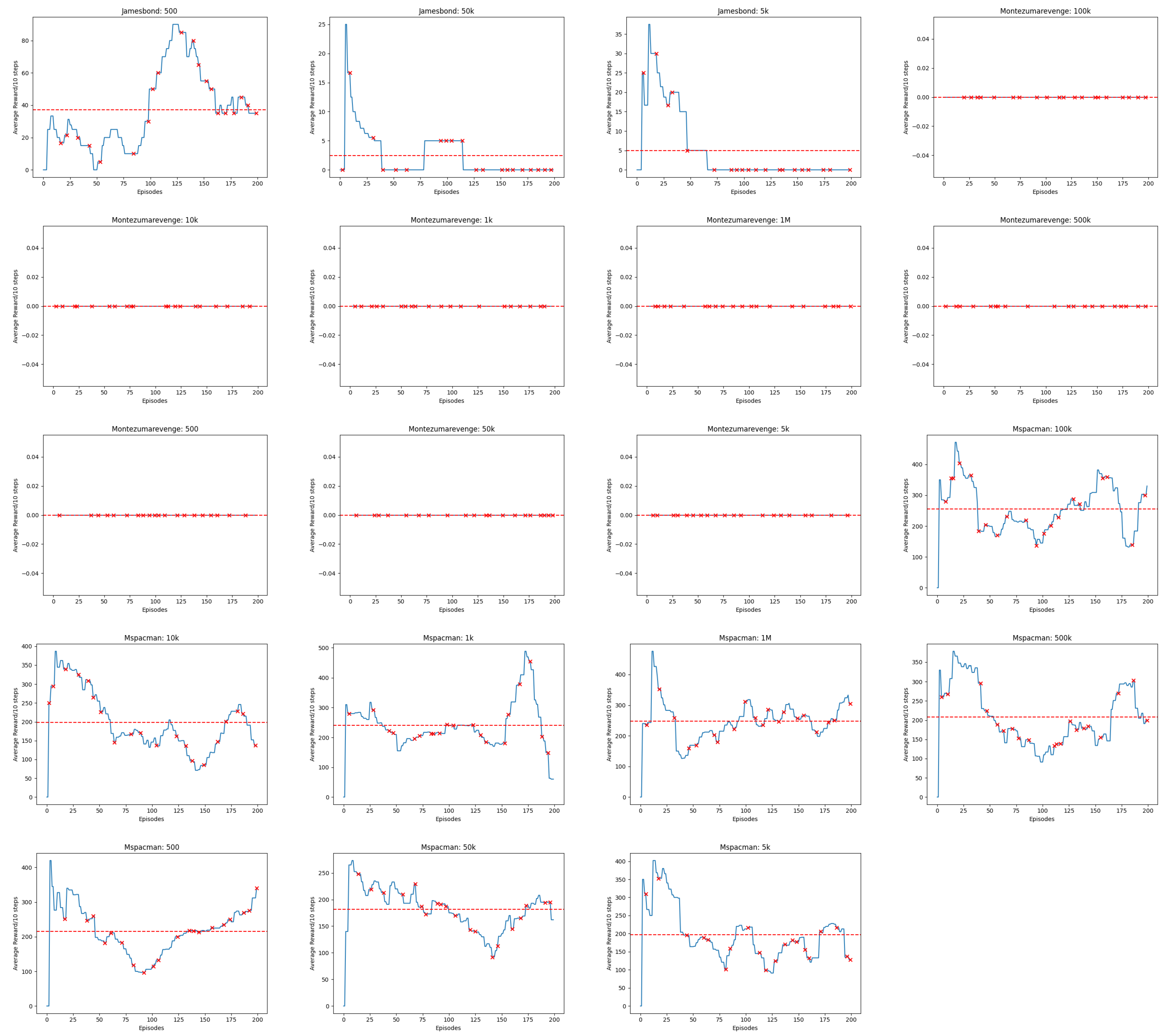
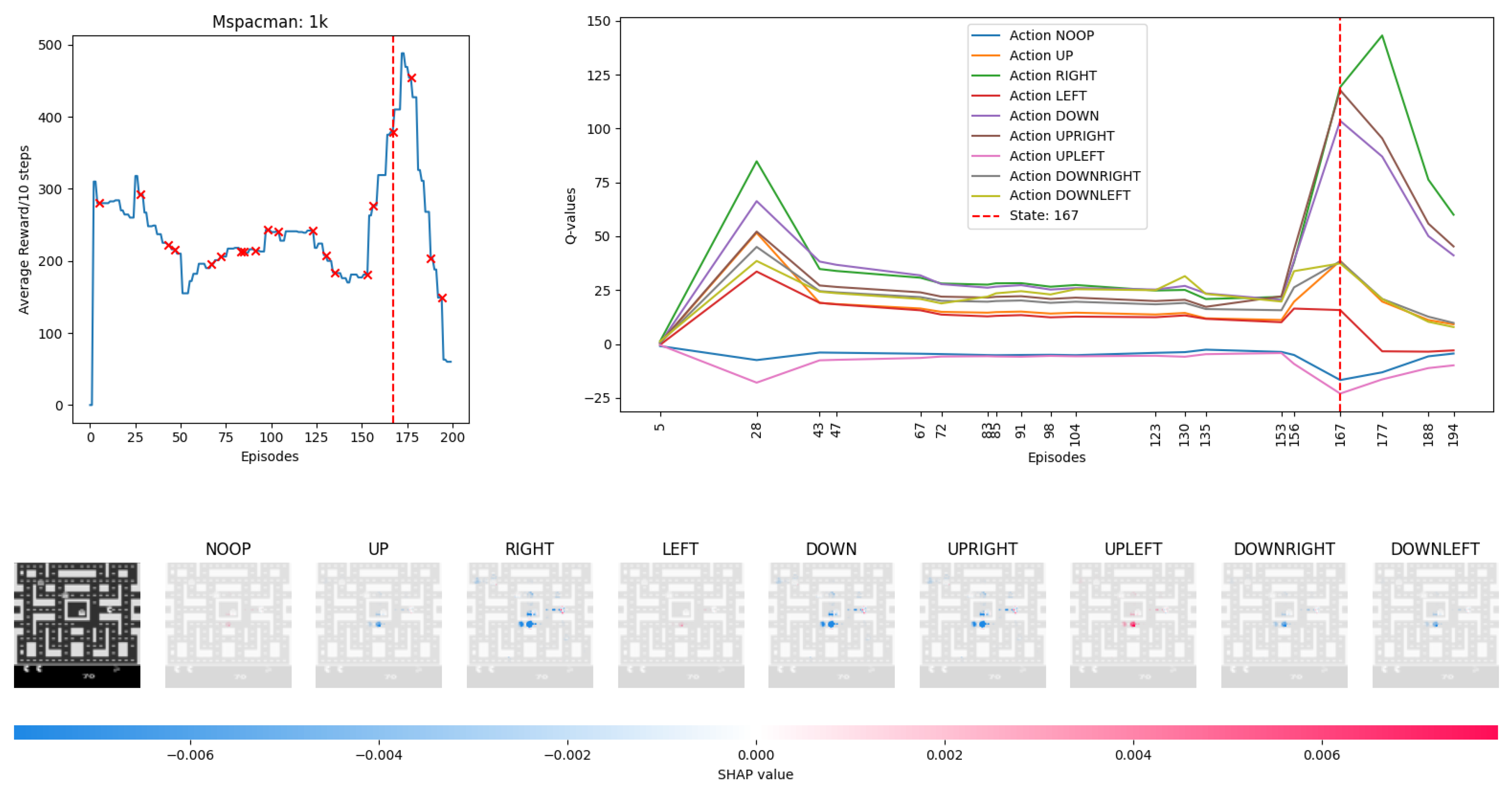
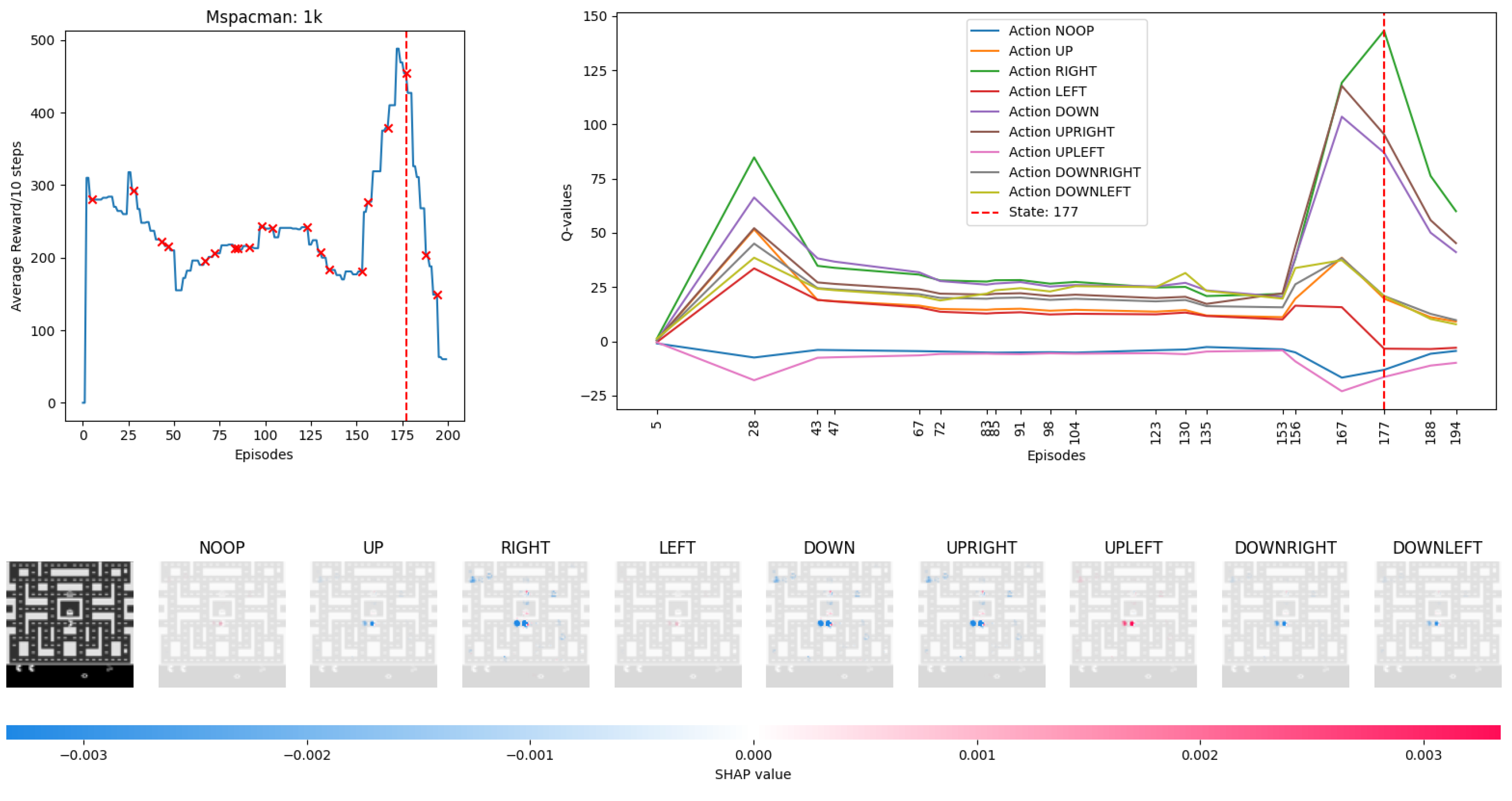
4.2. Visualising Experience from MsPacman
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Boxplots of Reward
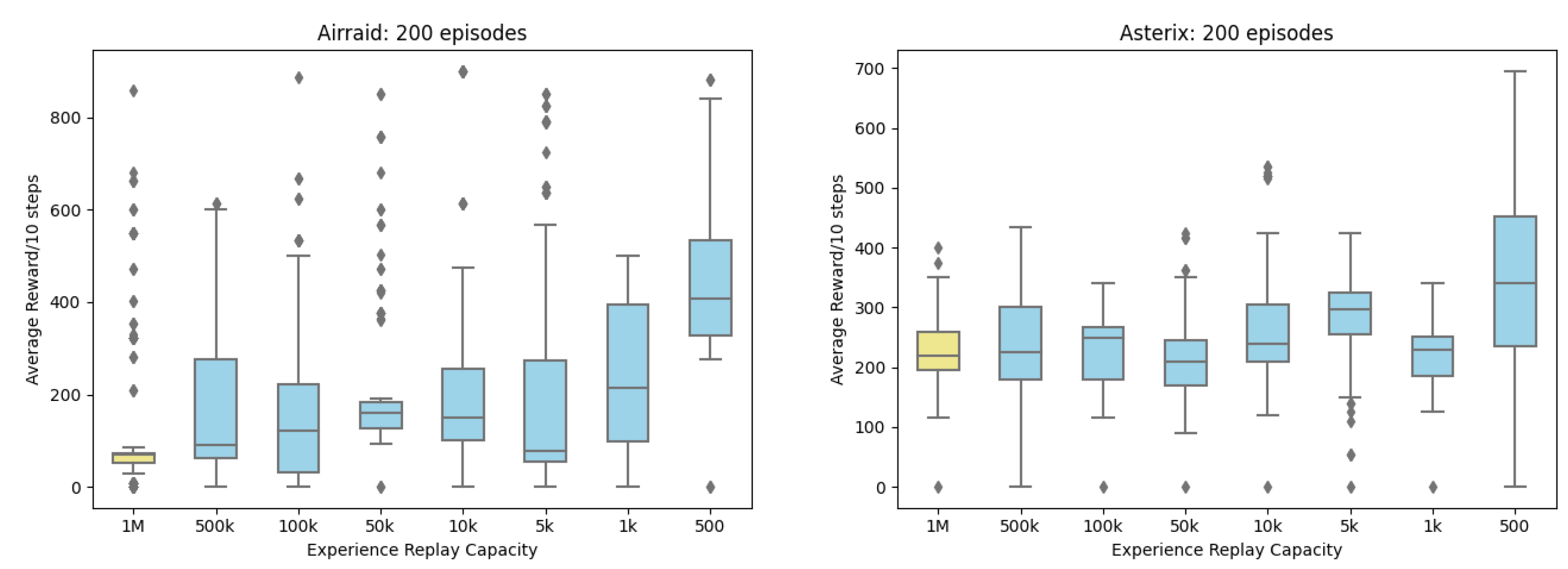
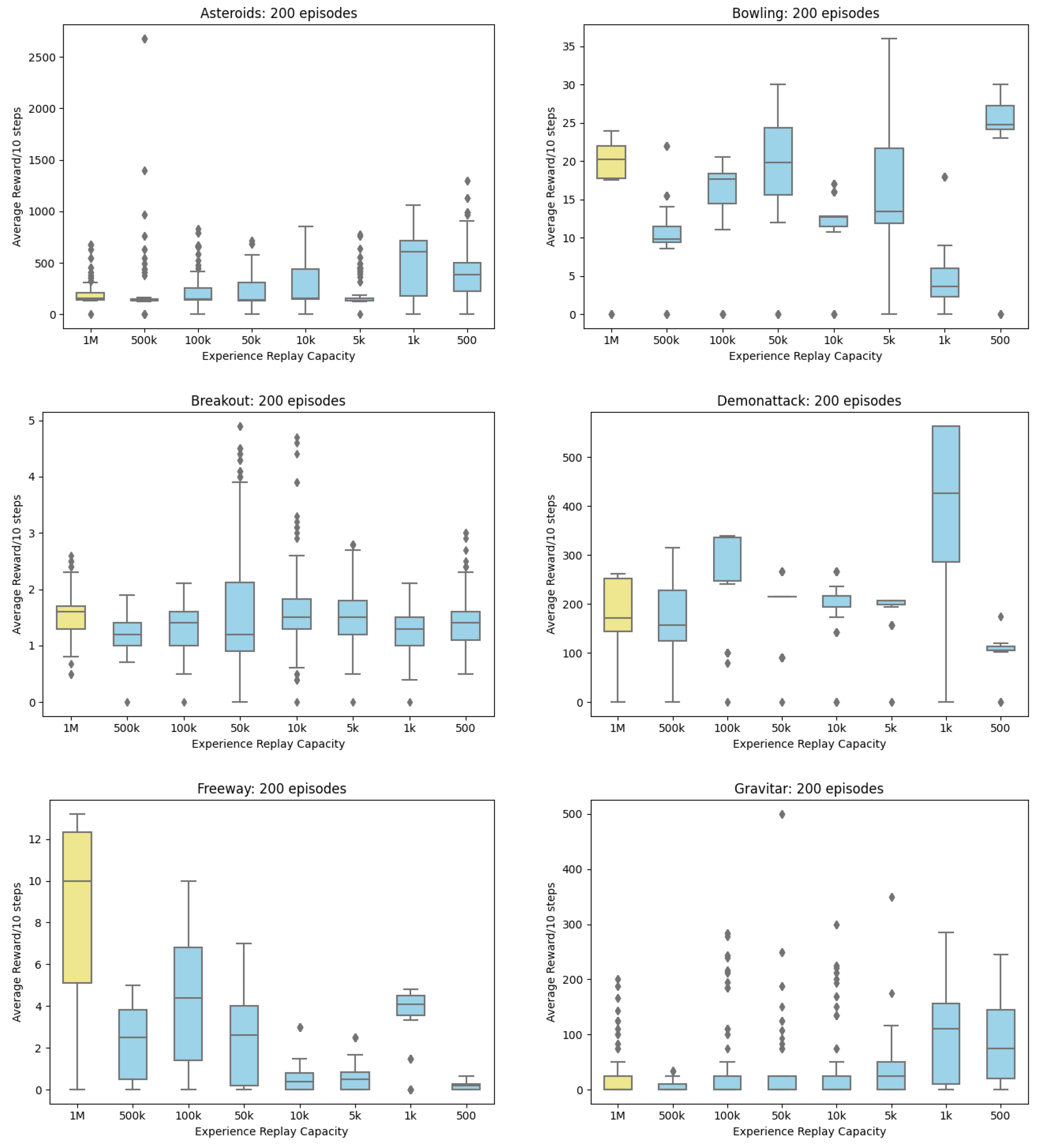
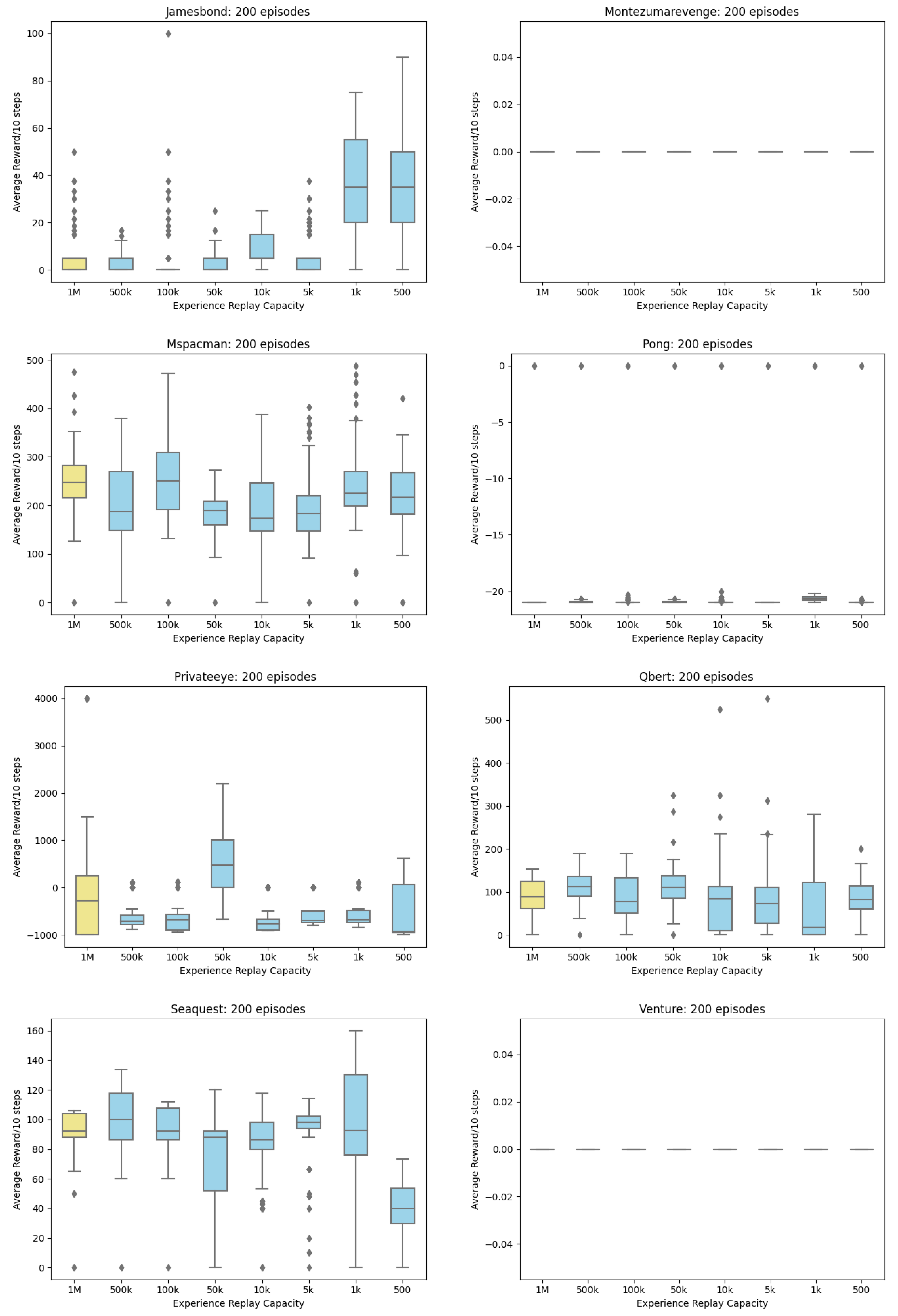
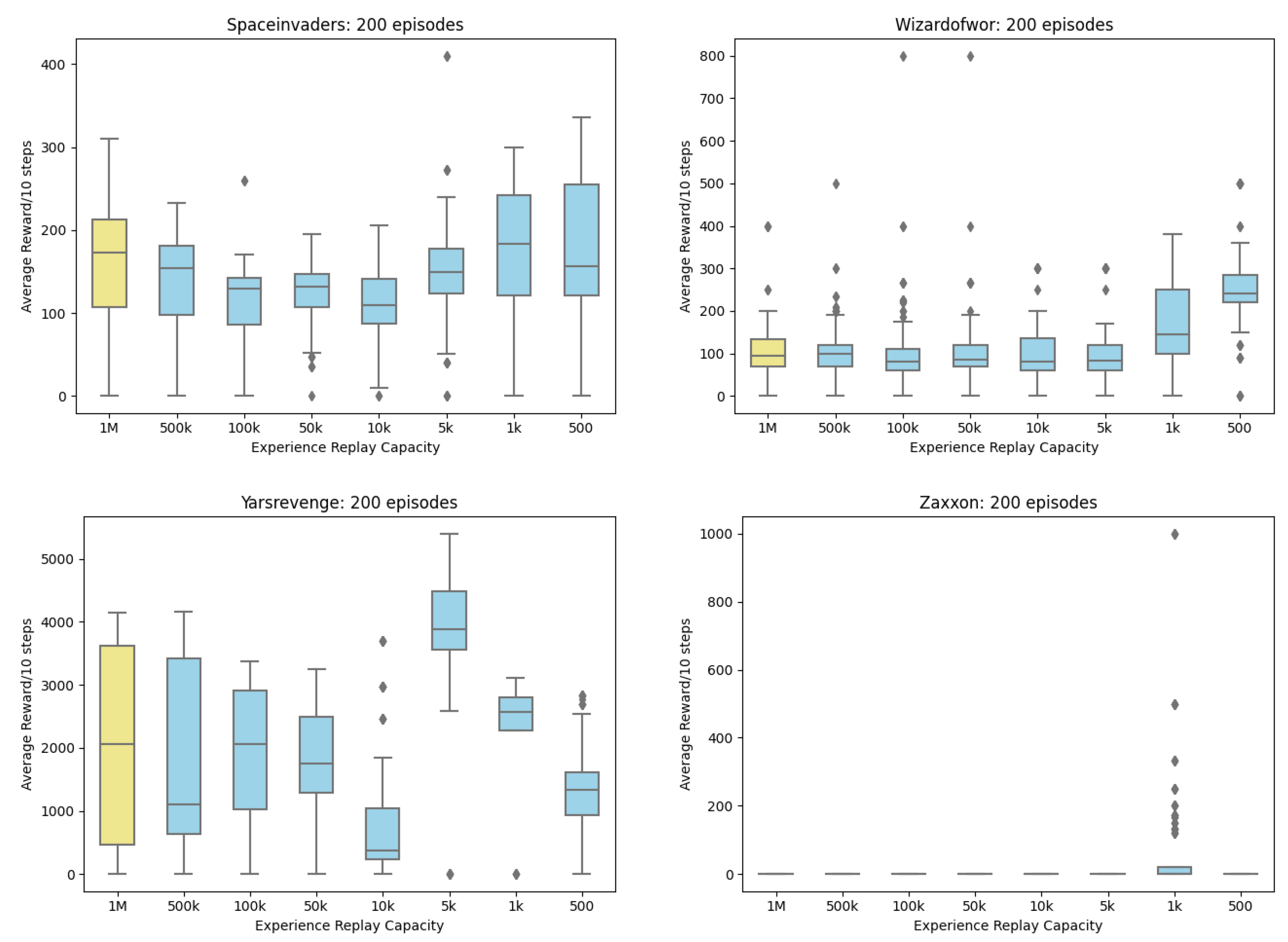
Appendix B. Line Charts of Reward

References
- Li, Y. Reinforcement Learning Applications. CoRR. 2019. Available online: http://xxx.lanl.gov/abs/1908.06973 (accessed on 6 June 2023).
- Li, C.; Zheng, P.; Yin, Y.; Wang, B.; Wang, L. Deep reinforcement learning in smart manufacturing: A review and prospects. CIRP J. Manuf. Sci. Technol. 2023, 40, 75–101. [Google Scholar] [CrossRef]
- Wu, X.; Chen, H.; Wang, J.; Troiano, L.; Loia, V.; Fujita, H. Adaptive stock trading strategies with deep reinforcement learning methods. Inf. Sci. 2020, 538, 142–158. [Google Scholar] [CrossRef]
- Yu, C.; Liu, J.; Nemati, S.; Yin, G. Reinforcement Learning in Healthcare: A Survey. ACM Comput. Surv. 2021, 55, 1–36. [Google Scholar] [CrossRef]
- Vouros, G.A. Explainable Deep Reinforcement Learning: State of the Art and Challenges. ACM Comput. Surv. 2022, 55, 1–39. [Google Scholar] [CrossRef]
- Strubell, E.; Ganesh, A.; McCallum, A. Energy and Policy Considerations for Modern Deep Learning Research. Proc. AAAI Conf. Artif. Intell. 2020, 34, 13693–13696. [Google Scholar] [CrossRef]
- Thompson, N.C.; Greenewald, K.; Lee, K.; Manso, G.F. Deep Learning’s Diminishing Returns: The Cost of Improvement is Becoming Unsustainable. IEEE Spectr. 2021, 58, 50–55. [Google Scholar] [CrossRef]
- Heuillet, A.; Couthouis, F.; Díaz-Rodríguez, N. Explainability in deep reinforcement learning. Knowl.-Based Syst. 2021, 214, 106685. [Google Scholar] [CrossRef]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning Important Features through Propagating Activation Differences. In Proceedings of the ICML’17, 34th International Conference on Machine Learning—Volume 70, Sydney, Australia, 6–11 August 2017; pp. 3145–3153. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 4768–4777. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Zhang, S.; Sutton, R.S. A deeper look at experience replay. Deep Reinforcement Learning Symposium. NIPS 2017. [Google Scholar] [CrossRef]
- Bruin, T.D.; Kober, J.; Tuyls, K.; Babuška, R. Experience Selection in Deep Reinforcement Learning for Control. J. Mach. Learn. Res. 2018, 19, 347–402. [Google Scholar]
- Fedus, W.; Ramachandran, P.; Agarwal, R.; Bengio, Y.; Larochelle, H.; Rowland, M.; Dabney, W. Revisiting Fundamentals of Experience Replay. In Proceedings of the ICML’20, 37th International Conference on Machine Learning—Volume 119, Vienna, Austria, 12–18 July 2020; pp. 6–11. [Google Scholar]
- Bilgin, E. Mastering Reinforcement Learning with Python: Build Next-Generation, Self-Learning Models Using Reinforcement Learning Techniques and Best Practices; Packt Publishing: Birmingham, UK, 2020. [Google Scholar]
- De Ponteves, H. AI Crash Course: A Fun and Hands-On Introduction to Reinforcement Learning, Deep Learning, and Artificial Intelligence with Python; Expert Insight, Packt Publishing: Birmingham, UK, 2019. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Van Otterlo, M.; Wiering, M. Reinforcement Learning and Markov Decision Processes. In Reinforcement Learning: State-of-the-Art; Wiering, M., van Otterlo, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 3–42. [Google Scholar] [CrossRef]
- White, D.J. A Survey of Applications of Markov Decision Processes. J. Oper. Res. Soc. 1993, 44, 1073–1096. [Google Scholar] [CrossRef]
- Ghavamzadeh, M.; Mannor, S.; Pineau, J.; Tamar, A. Bayesian Reinforcement Learning: A Survey. Found. Trends Mach. Learn. 2015, 8, 359–483. [Google Scholar] [CrossRef]
- Wu, G.; Fang, W.; Wang, J.; Ge, P.; Cao, J.; Ping, Y.; Gou, P. Dyna-PPO reinforcement learning with Gaussian process for the continuous action decision-making in autonomous driving. Appl. Intell. 2022, 53, 16893–16907. [Google Scholar] [CrossRef]
- Sutton, R.S. Learning to Predict by the Methods of Temporal Differences. Mach. Learn. 1988, 3, 9–44. [Google Scholar] [CrossRef]
- Bellman, R. Dynamic Programming; Dover Publications: Mineola, NY, USA, 1957. [Google Scholar]
- Tokic, M.; Palm, G. Value-Difference Based Exploration: Adaptive Control between Epsilon-Greedy and Softmax. In Proceedings of the KI 2011: Advances in Artificial Intelligence, Berlin, Germany, 4–7 October 2011; Bach, J., Edelkamp, S., Eds.; pp. 335–346. [Google Scholar]
- Lanham, M. Hands-On Reinforcement Learning for Games: Implementing Self-Learning Agents in Games Using Artificial Intelligence Techniques; Packt Publishing: Birmingham, UK, 2020; pp. 109–112. [Google Scholar]
- Bellemare, M.G.; Naddaf, Y.; Veness, J.; Bowling, M. The Arcade Learning Environment: An Evaluation Platform for General Agents. J. Artif. Int. Res. 2013, 47, 253–279. [Google Scholar] [CrossRef]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous Methods for Deep Reinforcement Learning. In Proceedings of the PMLR’16, 33rd International Conference on Machine Learning—Volume 48, New York, NY, USA, 19–24 June 2016; pp. 1928–1937. [Google Scholar]
- Lin, L.J. Self-Improving Reactive Agents Based on Reinforcement Learning, Planning and Teaching. Mach. Learn. 1992, 8, 293–321. [Google Scholar] [CrossRef]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized Experience Replay. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. Conference Track Proceedings; Bengio, Y., LeCun, Y., Eds.; 2016. [Google Scholar]
- Ramicic, M.; Bonarini, A. Attention-Based Experience Replay in Deep Q-Learning; Association for Computing Machinery: New York, NY, USA, 2017; pp. 476–481. [Google Scholar] [CrossRef]
- Sovrano, F.; Raymond, A.; Prorok, A. Explanation-Aware Experience Replay in Rule-Dense Environments. IEEE Robot. Autom. Lett. 2021, 7, 898–905. [Google Scholar] [CrossRef]
- Osei, R.S.; Lopez, D. Experience Replay Optimisation via ATSC and TSC for Performance Stability in Deep RL. Appl. Sci. 2023, 13, 2034. [Google Scholar] [CrossRef]
- Kapturowski, S.; Campos, V.; Jiang, R.; Rakicevic, N.; van Hasselt, H.; Blundell, C.; Badia, A.P. Human-level Atari 200x faster. In Proceedings of the The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Vilone, G.; Longo, L. A Quantitative Evaluation of Global, Rule-Based Explanations of Post-Hoc, Model Agnostic Methods. Front. Artif. Intell. 2021, 4, 160. [Google Scholar] [CrossRef]
- Longo, L.; Goebel, R.; Lécué, F.; Kieseberg, P.; Holzinger, A. Explainable Artificial Intelligence: Concepts, Applications, Research Challenges and Visions. In Proceedings of the Machine Learning and Knowledge Extraction—4th IFIP TC 5, TC 12, WG 8.4, WG 8.9, WG 12.9 International Cross-Domain Conference, CD-MAKE 2020, Dublin, Ireland, 25–28 August 2020; pp. 1–16. [Google Scholar] [CrossRef]
- Vilone, G.; Longo, L. Classification of Explainable Artificial Intelligence Methods through Their Output Formats. Mach. Learn. Knowl. Extr. 2021, 3, 615–661. [Google Scholar] [CrossRef]
- Keramati, M.; Durand, A.; Girardeau, P.; Gutkin, B.; Ahmed, S.H. Cocaine addiction as a homeostatic reinforcement learning disorder. Psychol. Rev. 2017, 124, 130–153. [Google Scholar] [CrossRef] [PubMed]
- Miralles-Pechuán, L.; Jiménez, F.; Ponce, H.; Martinez-Villaseñor, L. A Methodology Based on Deep Q-Learning/Genetic Algorithms for Optimizing COVID-19 Pandemic Government Actions; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1135–1144. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, J.; Xu, P.D.; Gao, T.; Gao, D.W. Explainable AI in Deep Reinforcement Learning Models for Power System Emergency Control. IEEE Trans. Comput. Soc. Syst. 2022, 9, 419–427. [Google Scholar] [CrossRef]
- Thirupathi, A.N.; Alhanai, T.; Ghassemi, M.M. A Machine Learning Approach to Detect Early Signs of Startup Success; Association for Computing Machinery: New York, NY, USA, 2022. [Google Scholar] [CrossRef]
- Ras, G.; Xie, N.; van Gerven, M.; Doran, D. Explainable Deep Learning: A Field Guide for the Uninitiated. J. Artif. Int. Res. 2022, 73, 319–355. [Google Scholar] [CrossRef]
- Kumar, S.; Vishal, M.; Ravi, V. Explainable Reinforcement Learning on Financial Stock Trading Using SHAP. CoRR. 2022. Available online: http://xxx.lanl.gov/abs/2208.08790 (accessed on 6 June 2023).
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Shapiro, S.S.; Wilk, M.B. An Analysis of Variance Test for Normality (Complete Samples). Biometrika 1965, 52, 591–611. [Google Scholar] [CrossRef]
- Kruskal, W.H.; Wallis, W.A. Use of Ranks in One-Criterion Variance Analysis. J. Am. Stat. Assoc. 1952, 47, 583–621. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1.000 | 0.001 | 0.111 | 0.017 | 0.003 | 0.003 | <0.001 | <0.001 | |
| 0.001 | 1.000 | 0.090 | 0.715 | 0.722 | <0.001 | <0.001 | <0.001 | |
| 0.111 | 0.090 | 1.000 | <0.001 | 0.181 | 0.184 | <0.001 | <0.001 | |
| 0.017 | 0.715 | <0.001 | 1.000 | <0.001 | <0.001 | 0.009 | 0.001 | |
| 0.003 | 0.722 | 0.181 | <0.001 | 1.000 | 0.993 | <0.001 | <0.001 | |
| 0.003 | <0.001 | 0.184 | <0.001 | 0.993 | 1.000 | <0.001 | <0.001 | |
| <0.001 | <0.001 | <0.001 | 0.009 | <0.001 | <0.001 | 1.000 | 0.480 | |
| <0.001 | <0.001 | <0.001 | 0.001 | <0.001 | <0.001 | 0.480 | 1.000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sullivan, R.S.; Longo, L. Explaining Deep Q-Learning Experience Replay with SHapley Additive exPlanations. Mach. Learn. Knowl. Extr. 2023, 5, 1433-1455. https://doi.org/10.3390/make5040072
Sullivan RS, Longo L. Explaining Deep Q-Learning Experience Replay with SHapley Additive exPlanations. Machine Learning and Knowledge Extraction. 2023; 5(4):1433-1455. https://doi.org/10.3390/make5040072
Chicago/Turabian StyleSullivan, Robert S., and Luca Longo. 2023. "Explaining Deep Q-Learning Experience Replay with SHapley Additive exPlanations" Machine Learning and Knowledge Extraction 5, no. 4: 1433-1455. https://doi.org/10.3390/make5040072
APA StyleSullivan, R. S., & Longo, L. (2023). Explaining Deep Q-Learning Experience Replay with SHapley Additive exPlanations. Machine Learning and Knowledge Extraction, 5(4), 1433-1455. https://doi.org/10.3390/make5040072