




Automatic Genre Identification for Robust Enrichment of Massive Text Collections: Investigation of Classification Methods in the Era of Large Language Models

Abstract
:1. Introduction
- To improve the generalization abilities of classifiers, we create a new genre dataset by merging three manually annotated genre datasets based on a new joint schema. We show that training models on multiple diverse datasets can improve their performance.
- We compare fine-tuned BERT-like Transformer-based models to baseline models that were commonly used for this task in previous research, such as support vector machines (SVMs) and the linear fastText [6] model. We show that Transformer-based language models are state-of-the-art in this task and that earlier machine learning models have poor capabilities in terms of generalization to new datasets.
- We investigate a promising new approach: classifying texts using recent large instruction-tuned GPT Transformer-based language models in a zero-shot setting. As the results reveal it to be a promising approach, we deliberate on the benefits and drawbacks of using BERT-like and GPT-like large language models for text classification tasks.
- In addition, we publish a freely available multilingual BERT-like Transformer-based genre classifier that outperforms other models.
- To promote further research, we introduce a publicly available benchmark with a manually annotated English test dataset: the AGILE (Automatic Genre Identification Benchmark), which can be accessed at https://github.com/TajaKuzman/AGILE-Automatic-Genre-Identification-Benchmark (accessed on 6 August 2023).
2. Background
2.1. Impact of Automatic Genre Identification
2.2. Challenges in Automatic Genre Identification
2.3. Machine Learning Methods for Automatic Genre Identification
3. Materials and Methods
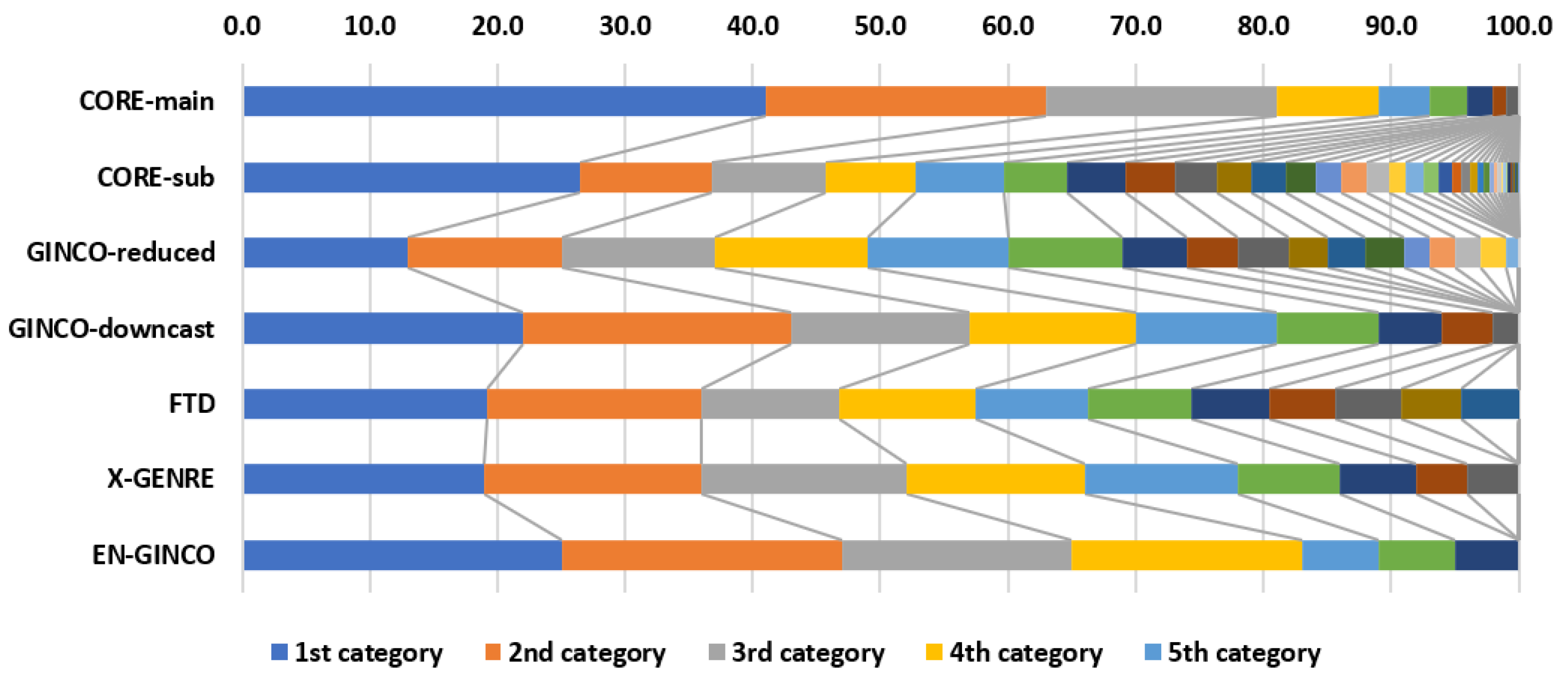
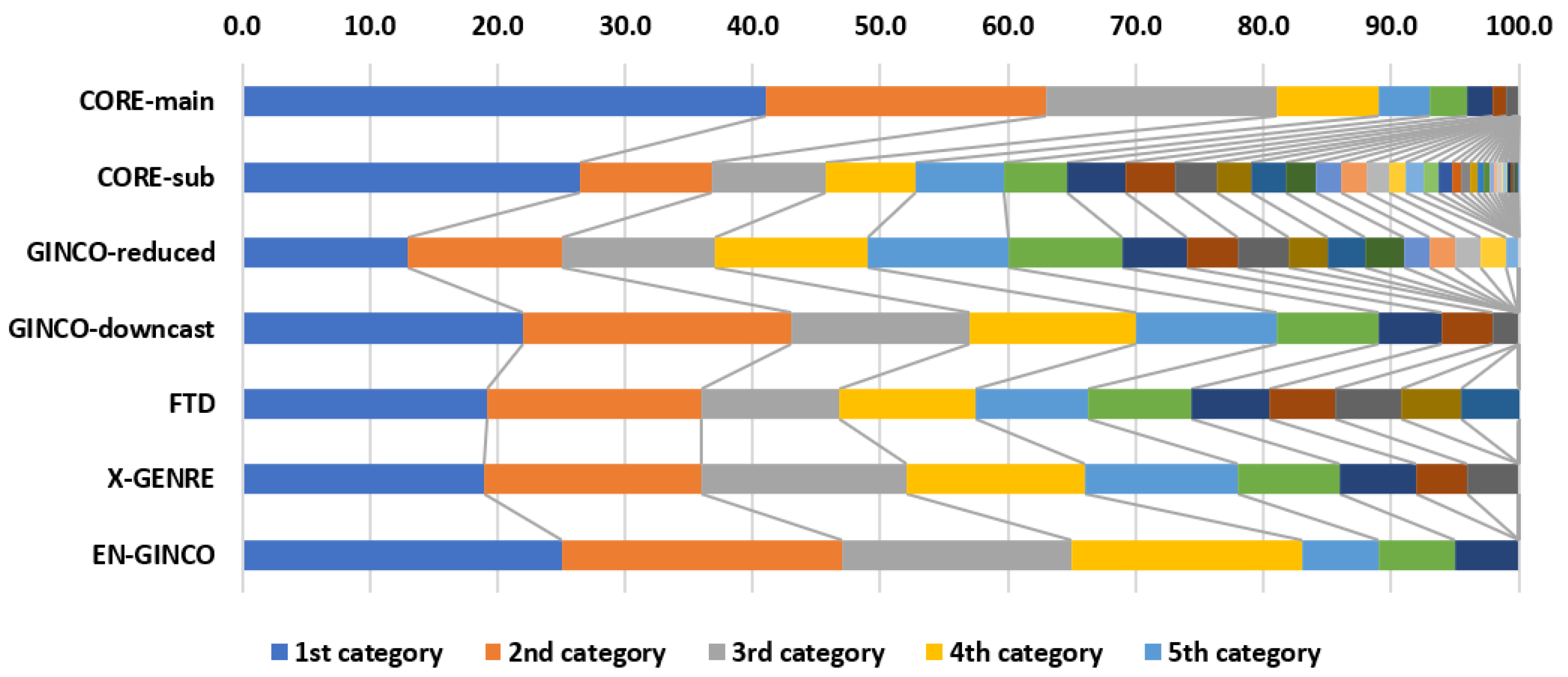
3.1. Genre Datasets
- The English and Slovenian X-GENRE dataset, which consists of samples from the FTD, CORE, and GINCO datasets, and introduces the X-GENRE schema that merges the schemata from previous datasets into one single schema;
- The English EN-GINCO test set, which was manually annotated with the X-GENRE schema.
3.1.1. Genre Datasets from Previous Works
- CORE-main: a sample of the CORE dataset, consisting of 17,094 texts. For labels, we use the 9 CORE main categories.
- CORE-sub: a sample of the CORE dataset, comprising 15,895 texts, annotated with CORE subcategories. We only use labels that are represented by more than 10 instances, resulting in the final label set of 37 categories.
- GINCO-reduced: only labels, represented with more than 10 instances, are used. This intervention amounts to 37 discarded texts. The final dataset has 17 labels and 965 texts.
- GINCO-downcast: the original GINCO labels are merged into 9 broader categories, and no texts are discarded.
3.1.2. Newly Introduced Genre Datasets
- As it consists of multiple datasets, it provides a greater variety of instances, consequently enhancing the generalization capabilities of models trained on the dataset.
- It consists of two languages and allows the analysis of the multilingual performance of genre classifiers.
- Its English component outweighs the Slovenian component, representing two-thirds of the instances. This is an additional advantage of the dataset, as it allows us to examine the performance of models when confronted with a high-coverage language (English) in contrast to an under-resourced language—a language that is less represented in the data (Slovenian).
3.2. Models
- Dummy classifier;
- Naive Bayes classifier;
- Support Vector Machine (SVM);
- fastText shallow neural model;
- Multilingual Transformer-based base-sized XLM-RoBERTa model;
- Autoregressive instruction-tuned GPT-3.5 and GPT-4 models.
3.2.1. Baseline Models
- Dummy Classifier: The model serves as a simple baseline to reveal what the model’s performance would be without being trained on the labeled texts. The classifier uses the stratified strategy, which means that the predictions are based on the information on the label distribution in the training data.
- Naive Bayes Classifier: This probabilistic machine learning algorithm learns the statistical relationships between the words present in the documents, also taking into account their frequency and the corresponding genre categories. We use the complement Naive Bayes implementation, which is particularly suited to imbalanced multi-class datasets [69].
- Logistic Regression Classifier: This algorithm models the relationship between the features (words) and the probability of belonging to a category using a logistic function. The cross-entropy loss is used to determine the most probable class. We use the implementation based on the limited-memory BFGS (L-BFGS) solver [70], which is suitable for addressing the complexities of multi-class classification.
- Support Vector Machine (SVM): The SVM model is a linear classifier that determines the boundaries between classes in the form of a separating hyperplane. Its efficacy is particularly notable in high-dimensional spaces, making it highly applicable in the context of text categorization tasks, where the feature set can encompass the entire dataset vocabulary. SVMs have successfully been applied in multiple automatic genre identification studies [27,36,38,39], achieving a micro-F1 of up to 0.75 on the subset of the CORE dataset [38]. In this study, we employ the SVC implementation with the linear kernel, which supports multi-class categorization.
3.2.2. Fine-Tuned XLM-RoBERTa Models
3.2.3. Instruction-Tuned GPT Models
4. Results
4.1. In-Domain Performance
4.2. Out-of-Domain Performance
4.3. Zero-Shot Performance of GPT Models
5. Discussion
- It conducted a controlled comparison of different machine learning approaches for automatic genre identification in both in-domain and out-of-domain scenarios.
- It analyzed the performance of the models on a high-resource language (English) and a low-resource language (Slovenian).
- It provided a freely accessible XLM-RoBERTa-based genre classifier, which enables automatic genre identification in numerous languages (available at https://huggingface.co/classla/xlm-roberta-base-multilingual-text-genre-classifier (accessed on 6 August 2023)).
- It explored the zero-shot capabilities of recent large GPT Transformer models for automatic genre identification.
- It proposed a unified genre schema, which facilitates the merging of diverse genre datasets, and introduced a new multilingual genre dataset, demonstrating that combining multiple datasets can enhance the model’s performance in this task.
- It established a benchmark (available at https://github.com/TajaKuzman/AGILE-Automatic-Genre-Identification-Benchmark (accessed on 6 August 2023)) for evaluating the out-of-domain performance of genre classifiers. The benchmark includes the results of our comparison of the models and provides access to the EN-GINCO dataset upon request for any researchers who wish to participate in the benchmarking process.
Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| SVMs | Support Vector Machines |
| NLP | Natural Language Processing |
| PLM | Pre-Trained Language Model |
| FTD | Functional Text Dimensions |
| CORE | Corpus of Online Registers of English |
| GINCO | Genre Identification Corpus |
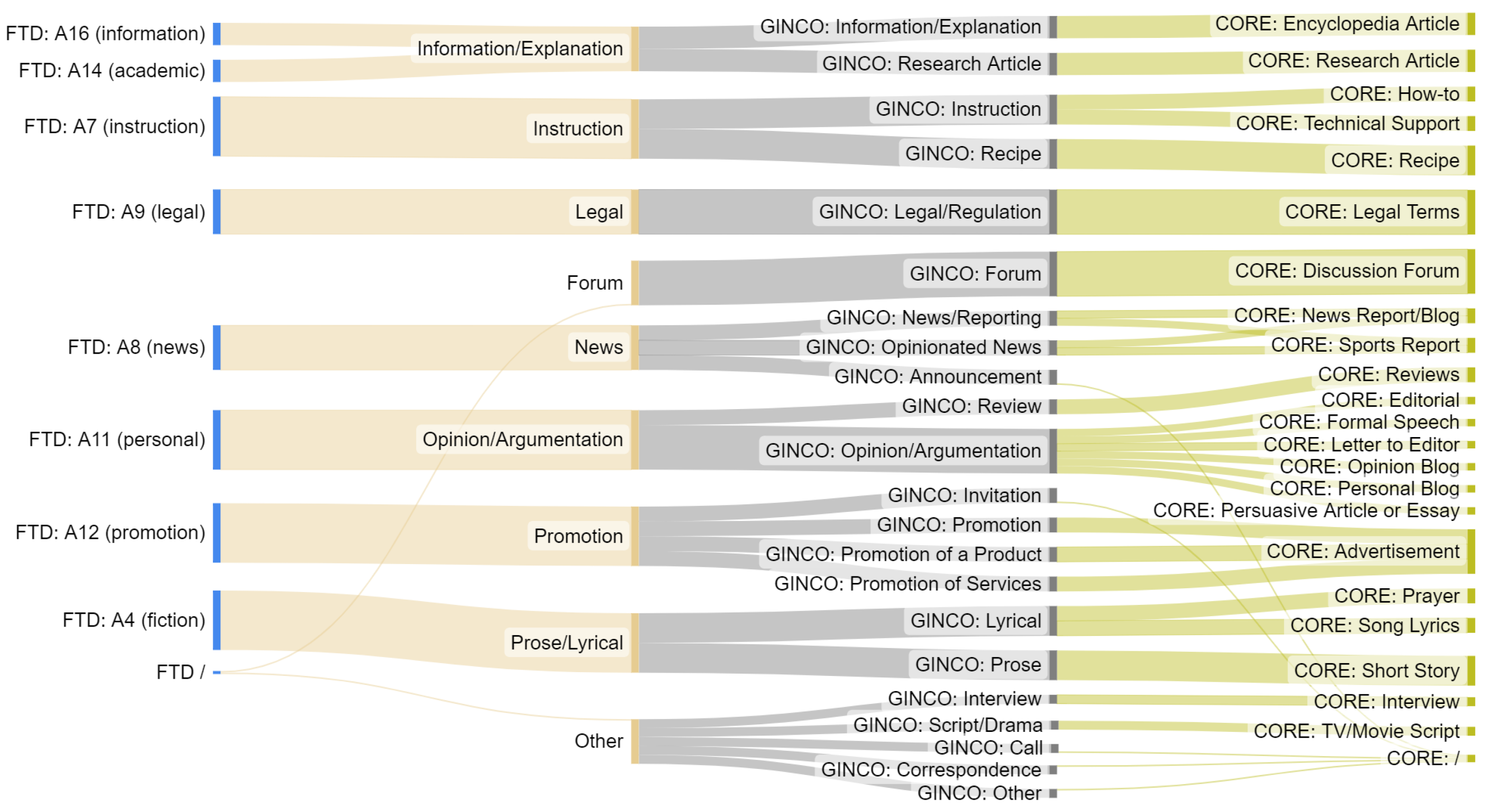
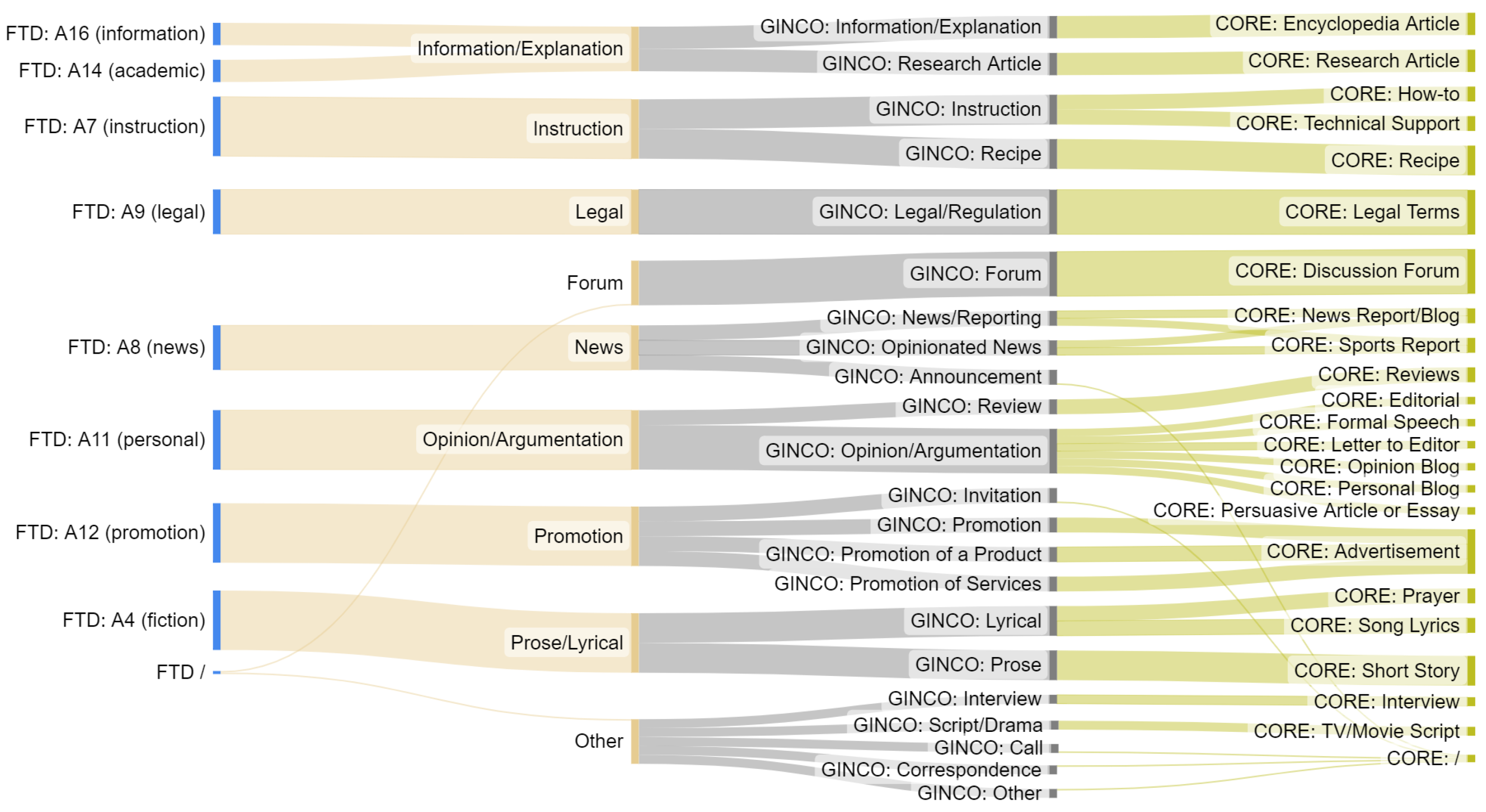
Appendix A. More Details on Genre Datasets
Appendix A.1. Collection and Annotation Procedure of Existing Datasets
Appendix A.2. X-GENRE Labels

{kind=link}
{kind=link}
{kind=link}
| Label | Description | Examples |
|---|---|---|
| Information/Explanation | An objective text that describes or presents an event, a person, a thing, a concept, etc. Its main purpose is to inform the reader about something. | research article, encyclopedia article, product specification, course materials, biographical story/history |
| Instruction | An objective text that instructs the readers on how to do something. | how-to texts, recipes, technical support |
| Legal | An objective formal text that contains legal terms and is clearly structured. | small print, software license, terms and conditions, contracts, law, copyright notices |
| News | An objective or subjective text that reports on an event, recent at the time of writing or coming in the near future. | news report, sports report, police report, announcement |
| Opinion/Argumentation | A subjective text in which the authors convey their opinion or narrate their experiences. It includes the promotion of an ideology and other non-commercial causes. | review, blog, editorial, letter to editor, persuasive article or essay, political propaganda |
| Promotion | A subjective text intended to sell or promote an event, product, or service. It addresses the readers, often trying to convince them to participate in something or buy something. | advertisement, e-shops, promotion of an accommodation, promotion of a company’s services, an invitation to an event |
| Prose/Lyrical | A literary text that consists of paragraphs or verses. A literary text is deemed to have no other practical purpose than to provide pleasure to the reader. Often the author pays attention to the aesthetic appearance of the text. It can be considered as art. | lyrics, poem, prayer, joke, novel, short story |
| Forum | A text in which people discuss a certain topic in the form of comments. | discussion forum, reader/viewer responses, QA forum |
| Other | A text that does not fall under any other genre category. |
Appendix A.3. Label Distribution in X-GENRE and EN-GINCO
| Label | EN-GINCO | X-GENRE |
|---|---|---|
| Information/Explanation | 25% | 17% |
| Promotion | 22% | 16% |
| Opinion/Argumentation | 18% | 14% |
| News | 18% | 19% |
| Other | 6% | 4% |
| Forum | 6% | 8% |
| Instruction | 5% | 12% |
| Legal | 0% | 4% |
| Prose/Lyrical | 0% | 6% |
Appendix B. Model Hyperparameters
- Dummy Classifier: stratified strategy.
- Naive Bayes: ComplementNB model with the default hyperparameters.
- Logistic Regression: Penalty set to None, as preliminary experiments showed that disabling regularization improved the results in our case.
- SVM: SVC model with the linear kernel and the regularization parameter C set to 2.
- fastText: The number of epochs was set to 350 and word unigrams were used (wordNgrams set to 1).
- XLM-RoBERTa: We used a learning rate of 1 × and a maximum sequence length of 512 for all fine-tuned models, as described in Section 3.2.2. However, the models differed in the optimum number of epochs, which was determined based on a hyperparameter tuning, tested on the evaluation split. The optimum number of epochs varied based on the training dataset used. The hyperparameter search determined the following numbers of epochs to be optimal for the specific genre dataset: CORE-main—4 epochs; CORE-sub—6 epochs; FTD—10 epochs; GINCO-downcast and X-GENRE—15 epochs; GINCO-reduced—20 epochs.
- GPT-3.5 and GPT-4: We used the GPT-3.5 Turbo model for the GPT-3.5 model and the GPT-4 model. The models were used through the chat completion endpoint. We set the temperature to 0, which ensured that the model was more deterministic and that it output the prediction with the highest probability. To facilitate the parsing of the model’s output, we limited the number of tokens in the output (maxtokens) to 2 and defined a line break to be the point where the model stops its completion (the stop hyperparameter).
Appendix C. Instance of a Prompt for the GPT Models
References
- Zu Eissen, S.M.; Stein, B. Genre classification of web pages. In Proceedings of the 27th Annual German Conference in AI, KI 2004, Ulm, Germany, 20–24 September 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 256–269. [Google Scholar]
- Vidulin, V.; Luštrek, M.; Gams, M. Using genres to improve search engines. In Proceedings of the 1st International Workshop: Towards Genre-Enabled Search Engines: The Impact of Natural Language Processing, Borovets, Bulgaria, 30 September 2007; pp. 45–51. [Google Scholar]
- Penedo, G.; Malartic, Q.; Hesslow, D.; Cojocaru, R.; Cappelli, A.; Alobeidli, H.; Pannier, B.; Almazrouei, E.; Launay, J. The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only. arXiv 2023, arXiv:2306.01116. [Google Scholar]
- Kuzman, T.; Rupnik, P.; Ljubešić, N. Get to Know Your Parallel Data: Performing English Variety and Genre Classification over MaCoCu Corpora. In Proceedings of the Tenth Workshop on NLP for Similar Languages, Varieties and Dialects (VarDial 2023), Dubrovnik, Croatia, 5–6 May 2023; pp. 91–103. [Google Scholar]
- Orlikowski, W.J.; Yates, J. Genre repertoire: The structuring of communicative practices in organizations. Adm. Sci. Q. 1994, 39, 541–574. [Google Scholar] [CrossRef]
- Joulin, A.; Grave, É.; Bojanowski, P.; Mikolov, T. Bag of Tricks for Efficient Text Classification. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; pp. 427–431. [Google Scholar]
- Stubbe, A.; Ringlstetter, C. Recognizing genres. In Proceedings of the Towards a Reference Corpus of Web Genres, Birmingham, UK, 27 July 2007. [Google Scholar]
- Finn, A.; Kushmerick, N. Learning to classify documents according to genre. J. Am. Soc. Inf. Sci. Technol. 2006, 57, 1506–1518. [Google Scholar] [CrossRef]
- Roussinov, D.; Crowston, K.; Nilan, M.; Kwasnik, B.; Cai, J.; Liu, X. Genre based navigation on the web. In Proceedings of the 34th Annual Hawaii International Conference on System Sciences, Maui, HI, USA, 6 January 2001. [Google Scholar]
- Priyatam, P.N.; Iyengar, S.; Perumal, K.; Varma, V. Don’t Use a Lot When Little Will Do: Genre Identification Using URLs. Res. Comput. Sci. 2013, 70, 233–243. [Google Scholar] [CrossRef]
- Boese, E.S. Stereotyping the Web: Genre Classification of Web Documents. Ph.D. Thesis, Colorado State University, Fort Collins, CO, USA, 2005. [Google Scholar]
- Stein, B.; Eissen, S.M.Z.; Lipka, N. Web genre analysis: Use cases, retrieval models, and implementation issues. In Genres on the Web; Springer: Berlin/Heidelberg, Germany, 2010; pp. 167–189. [Google Scholar]
- Crowston, K.; Kwaśnik, B.; Rubleske, J. Problems in the use-centered development of a taxonomy of web genres. In Genres on the Web; Springer: Berlin/Heidelberg, Germany, 2010; pp. 69–84. [Google Scholar]
- Bañón, M.; Esplà-Gomis, M.; Forcada, M.L.; García-Romero, C.; Kuzman, T.; Ljubešić, N.; van Noord, R.; Sempere, L.P.; Ramírez-Sánchez, G.; Rupnik, P.; et al. MaCoCu: Massive collection and curation of monolingual and bilingual data: Focus on under-resourced languages. In Proceedings of the 23rd Annual Conference of the European Association for Machine Translation, Ghent, Belgium, 1–3 June 2022; pp. 301–302. [Google Scholar]
- Baroni, M.; Bernardini, S.; Ferraresi, A.; Zanchetta, E. The WaCky wide web: A collection of very large linguistically processed web-crawled corpora. Lang. Resour. Eval. 2009, 43, 209–226. [Google Scholar] [CrossRef]
- Sharoff, S. In the Garden and in the Jungle. In Genres on the Web; Springer: Berlin/Heidelberg, Germany, 2010; pp. 149–166. [Google Scholar]
- Egbert, J.; Biber, D.; Davies, M. Developing a bottom-up, user-based method of web register classification. J. Assoc. Inf. Sci. Technol. 2015, 66, 1817–1831. [Google Scholar] [CrossRef]
- Laippala, V.; Kyllönen, R.; Egbert, J.; Biber, D.; Pyysalo, S. Toward multilingual identification of online registers. In Proceedings of the 22nd Nordic Conference on Computational Linguistics, Turku, Finland, 30 September–2 October 2019; pp. 292–297. [Google Scholar]
- Kuzman, T.; Rupnik, P.; Ljubešić, N. The GINCO Training Dataset for Web Genre Identification of Documents Out in the Wild. In Proceedings of the Language Resources and Evaluation Conference, Marseille, France, 20–25 June 2022; pp. 1584–1594. [Google Scholar]
- Giesbrecht, E.; Evert, S. Is part-of-speech tagging a solved task? An evaluation of POS taggers for the German web as corpus. In Proceedings of the Fifth Web as Corpus Workshop, San Sebastián, Spain, 7 September 2009; pp. 27–35. [Google Scholar]
- Müller-Eberstein, M.; van der Goot, R.; Plank, B. Genre as Weak Supervision for Cross-lingual Dependency Parsing. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 4786–4802. [Google Scholar]
- Van der Wees, M.; Bisazza, A.; Monz, C. Evaluation of machine translation performance across multiple genres and languages. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Agrawal, S.; Sanagavarapu, L.M.; Reddy, Y.R. FACT-Fine grained Assessment of web page CredibiliTy. In Proceedings of the TENCON 2019—2019 IEEE Region 10 Conference (TENCON), Kochi, India, 17–20 October 2019; pp. 1088–1097. [Google Scholar]
- Rehm, G.; Santini, M.; Mehler, A.; Braslavski, P.; Gleim, R.; Stubbe, A.; Symonenko, S.; Tavosanis, M.; Vidulin, V. Towards a Reference Corpus of Web Genres for the Evaluation of Genre Identification Systems. In Proceedings of the LREC, Marrakech, Morocco, 26 May–1 June 2008. [Google Scholar]
- Berninger, V.F.; Kim, Y.; Ross, S. Building a document genre corpus: A profile of the KRYS I corpus. In Proceedings of the BCS-IRSG Workshop on Corpus Profiling, London, UK, 18 October 2008; pp. 1–10. [Google Scholar]
- Santini, M. Automatic Identification of Genre in Web Pages. Ph.D. Thesis, University of Brighton, Brighton, UK, 2007. [Google Scholar]
- Sharoff, S.; Wu, Z.; Markert, K. The Web Library of Babel: Evaluating genre collections. In Proceedings of the LREC, Valletta, Malta, 17–23 May 2010. [Google Scholar]
- Sharoff, S. Functional text dimensions for the annotation of web corpora. Corpora 2018, 13, 65–95. [Google Scholar] [CrossRef]
- Asheghi, N.R.; Sharoff, S.; Markert, K. Crowdsourcing for web genre annotation. Lang. Resour. Eval. 2016, 50, 603–641. [Google Scholar] [CrossRef]
- Suchomel, V. Genre Annotation of Web Corpora: Scheme and Issues. In Future Technologies Conference; Springer: Berlin/Heidelberg, Germany, 2020; pp. 738–754. [Google Scholar]
- Sharoff, S. Genre annotation for the web: Text-external and text-internal perspectives. Regist. Stud. 2021, 3, 1–32. [Google Scholar] [CrossRef]
- Kuzman, T.; Ljubešić, N.; Pollak, S. Assessing Comparability of Genre Datasets via Cross-Lingual and Cross-Dataset Experiments. In Jezikovne Tehnologije in Digitalna Humanistika: Zbornik Konference; Fišer, D., Erjavec, T., Eds.; Institute of Contemporary History: München, Germany, 2022; pp. 100–107. [Google Scholar]
- Repo, L.; Skantsi, V.; Rönnqvist, S.; Hellström, S.; Oinonen, M.; Salmela, A.; Biber, D.; Egbert, J.; Pyysalo, S.; Laippala, V. Beyond the English web: Zero-shot cross-lingual and lightweight monolingual classification of registers. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Student Research Workshop, EACL 2021, Online, 19–23 April 2021; Association for Computational Linguistics (ACL): Stroudsburg, PA, USA, 2021; pp. 183–191. Available online: https://aclanthology.org/2021.eacl-srw.24.pdf (accessed on 6 August 2023).
- Lepekhin, M.; Sharoff, S. Estimating Confidence of Predictions of Individual Classifiers and Their Ensembles for the Genre Classification Task. In Proceedings of the Language Resources and Evaluation Conference, Marseille, France, 20–25 June 2022; pp. 5974–5982. [Google Scholar]
- Rezapour Asheghi, N. Human Annotation and Automatic Detection of Web Genres. Ph.D. Thesis, University of Leeds, Leeds, UK, 2015. [Google Scholar]
- Laippala, V.; Luotolahti, J.; Kyröläinen, A.J.; Salakoski, T.; Ginter, F. Creating register sub-corpora for the Finnish Internet Parsebank. In Proceedings of the 21st Nordic Conference on Computational Linguistics, Gothenburg, Sweden, 22–24 May 2017; pp. 152–161. [Google Scholar]
- Petrenz, P.; Webber, B. Stable classification of text genres. Comput. Linguist. 2011, 37, 385–393. [Google Scholar] [CrossRef]
- Laippala, V.; Egbert, J.; Biber, D.; Kyröläinen, A.J. Exploring the role of lexis and grammar for the stable identification of register in an unrestricted corpus of web documents. Lang. Resour. Eval. 2021, 55, 757–788. [Google Scholar] [CrossRef]
- Pritsos, D.; Stamatatos, E. Open set evaluation of web genre identification. Lang. Resour. Eval. 2018, 52, 949–968. [Google Scholar] [CrossRef]
- Feldman, S.; Marin, M.A.; Ostendorf, M.; Gupta, M.R. Part-of-speech histograms for genre classification of text. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 4781–4784. [Google Scholar]
- Biber, D.; Egbert, J. Using grammatical features for automatic register identification in an unrestricted corpus of documents from the open web. J. Res. Des. Stat. Linguist. Commun. Sci. 2015, 2, 3–36. [Google Scholar] [CrossRef]
- Dewdney, N.; Van Ess-Dykema, C.; MacMillan, R. The form is the substance: Classification of genres in text. In Proceedings of the ACL 2001 Workshop on Human Language Technology and Knowledge Management, Toulouse, France, 6–7 July 2001. [Google Scholar]
- Lim, C.S.; Lee, K.J.; Kim, G.C. Multiple sets of features for automatic genre classification of web documents. Inf. Process. Manag. 2005, 41, 1263–1276. [Google Scholar]
- Levering, R.; Cutler, M.; Yu, L. Using visual features for fine-grained genre classification of web pages. In Proceedings of the 41st Annual Hawaii International Conference on System Sciences (HICSS 2008), Waikoloa, HI, USA, 7–10 January 2008; p. 131. [Google Scholar]
- Maeda, A.; Hayashi, Y. Automatic genre classification of Web documents using discriminant analysis for feature selection. In Proceedings of the 2009 Second International Conference on the Applications of Digital Information and Web Technologies, London, UK, 4–6 August 2009; pp. 405–410. [Google Scholar]
- Abramson, M.; Aha, D.W. What’s in a URL? Genre Classification from URLs. In Proceedings of the Workshops at the Twenty-Sixth AAAI Conference on Artificial Intelligence, Toronto, Canada, 22–26 July 2012. [Google Scholar]
- Jebari, C. A pure URL-based genre classification of web pages. In Proceedings of the 2014 25th International Workshop on Database and Expert Systems Applications, Munich, Germany, 1–5 September 2014; pp. 233–237. [Google Scholar]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep Learning Based Text Classification: A Comprehensive Review. arXiv 2020, arXiv:2004.03705. [Google Scholar] [CrossRef]
- Kuzman, T.; Ljubešić, N. Exploring the Impact of Lexical and Grammatical Features on Automatic Genre Identification. In Proceedings of the Odkrivanje Znanja in Podatkovna Skladišča—SiKDD, Ljubljana, Slovenia, 10 October 2022; Mladenić, D., Grobelnik, M., Eds.; Institut “Jožef Stefan”: Ljubljana, Slovenia, 2022. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, California, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf (accessed on 6 August 2023).
- Kenton, J.D.M.W.C.; Toutanova, L.K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 17th Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2019), Minneapolis, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Laippala, V.; Rönnqvist, S.; Oinonen, M.; Kyröläinen, A.J.; Salmela, A.; Biber, D.; Egbert, J.; Pyysalo, S. Register identification from the unrestricted open Web using the Corpus of Online Registers of English. Lang. Resour. Eval. 2022, 57, 1045–1079. [Google Scholar] [CrossRef]
- Rönnqvist, S.; Skantsi, V.; Oinonen, M.; Laippala, V. Multilingual and Zero-Shot is Closing in on Monolingual Web Register Classification. In Proceedings of the 23rd Nordic Conference on Computational Linguistics (NoDaLiDa), Reykjavik, Iceland, 31 May–2 June 2021; pp. 157–165. [Google Scholar]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, É.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised Cross-lingual Representation Learning at Scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 8440–8451. [Google Scholar]
- OpenAI. ChatGPT General FAQ. 2023. Available online: https://help.openai.com/en/articles/6783457-chatgpt-general-faq (accessed on 3 March 2023).
- Christiano, P.F.; Leike, J.; Brown, T.; Martic, M.; Legg, S.; Amodei, D. Deep reinforcement learning from human preferences. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, California, USA, 4–9 December 2017; pp. 4302–4310. [Google Scholar]
- Qin, C.; Zhang, A.; Zhang, Z.; Chen, J.; Yasunaga, M.; Yang, D. Is ChatGPT a General-Purpose Natural Language Processing Task Solver? arXiv 2023, arXiv:2302.06476. [Google Scholar]
- Zhang, B.; Ding, D.; Jing, L. How would Stance Detection Techniques Evolve after the Launch of ChatGPT? arXiv 2022, arXiv:2212.14548. [Google Scholar]
- Huang, F.; Kwak, H.; An, J. Is ChatGPT better than Human Annotators? Potential and Limitations of ChatGPT in Explaining Implicit Hate Speech. arXiv 2023, arXiv:2302.07736. [Google Scholar]
- Hendy, A.; Abdelrehim, M.; Sharaf, A.; Raunak, V.; Gabr, M.; Matsushita, H.; Kim, Y.J.; Afify, M.; Awadalla, H.H. How Good Are GPT Models at Machine Translation? A Comprehensive Evaluation. arXiv 2023, arXiv:2302.09210. [Google Scholar]
- Kuzman, T.; Ljubešić, N.; Mozetič, I. ChatGPT: Beginning of an End of Manual Annotation? Use Case of Automatic Genre Identification. arXiv 2023, arXiv:2303.03953. [Google Scholar]
- OpenAI. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Santini, M. Cross-testing a genre classification model for the web. In Genres on the Web; Springer: Berlin/Heidelberg, Germany, 2010; pp. 87–128. [Google Scholar]
- Laippala, V.; Rönnqvist, S.; Hellström, S.; Luotolahti, J.; Repo, L.; Salmela, A.; Skantsi, V.; Pyysalo, S. From web crawl to clean register-annotated corpora. In Proceedings of the 12th Web as Corpus Workshop, Marseille, France, 11–16 May 2020; pp. 14–22. [Google Scholar]
- Skantsi, V.; Laippala, V. Analyzing the unrestricted web: The Finnish corpus of online registers. Nord. J. Linguist. 2023, 1. Available online: https://www.cambridge.org/core/journals/nordic-journal-of-linguistics/article/analyzing-the-unrestricted-web-the-finnish-corpus-of-online-registers/BDCA0FE03ABD9087CC5652533880C8C0 (accessed on 6 August 2023). [CrossRef]
- Jakubíček, M.; Kilgarriff, A.; Kovář, V.; Rychlỳ, P.; Suchomel, V. The TenTen corpus family. In Proceedings of the 7th International Corpus Linguistics Conference CL, Lancaster, UK, 23–26 July 2013; pp. 125–127. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Rennie, J.D.; Shih, L.; Teevan, J.; Karger, D.R. Tackling the poor assumptions of Naive Bayes text classifiers. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 616–623. [Google Scholar]
- Byrd, R.H.; Lu, P.; Nocedal, J.; Zhu, C. A limited memory algorithm for bound constrained optimization. SIAM J. Sci. Comput. 1995, 16, 1190–1208. [Google Scholar] [CrossRef]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.L.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. arXiv 2022, arXiv:2203.02155. [Google Scholar]
- Kowsari, K.; Jafari Meimandi, K.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text classification algorithms: A survey. Information 2019, 10, 150. [Google Scholar] [CrossRef]
- Asheghi, N.R.; Markert, K.; Sharoff, S. Semi-supervised graph-based genre classification for web pages. In Proceedings of the TextGraphs-9: The Workshop on Graph-Based Methods for Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 39–47. [Google Scholar]
- Santini, S.M. Common criteria for genre classification: Annotation and granularity. In Proceedings of the Workshop on Text-Based Information Retrieval (TIR-06), Riva del Garda, Italy, 29 August 2006; Available online: https://ceur-ws.org/Vol-205/paper9.pdf (accessed on 6 August 2023).
- Everitt, B.S. The Analysis of Contingency Tables; CRC Press: Boca Raton, FL, USA, 1992. [Google Scholar]
- Dietterich, T.G. Approximate statistical tests for comparing supervised classification learning algorithms. Neural Comput. 1998, 10, 1895–1923. [Google Scholar] [CrossRef]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.H.; Le, Q.V.; Zhou, D. Chain of Thought Prompting Elicits Reasoning in Large Language Models. In Proceedings of the Advances in Neural Information Processing Systems 35, New Orleans, LA, USA, 28 November–9 December 2022; pp. 24824–24837. [Google Scholar]
- Hu, E.J.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. In Proceedings of the International Conference on Learning Representations, Online, 3–7 May 2021; Available online: https://openreview.net/pdf?id=nZeVKeeFYf9 (accessed on 6 August 2023).
- Dettmers, T.; Pagnoni, A.; Holtzman, A.; Zettlemoyer, L. Qlora: Efficient finetuning of quantized llms. arXiv 2023, arXiv:2305.14314. [Google Scholar]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Davies, M.; Fuchs, R. Expanding horizons in the study of World Englishes with the 1.9 billion word Global Web-based English Corpus (GloWbE). Engl. World-Wide 2015, 36, 1–28. [Google Scholar] [CrossRef]
- Erjavec, T.; Ljubešić, N. The slWaC 2.0 corpus of the Slovene web. Jezikovne Tehnol. Zb. 2014, 17, 50–55. Available online: https://nl.ijs.si/isjt14/proceedings/isjt2014_08.pdf (accessed on 6 August 2023).
- Bañón, M.; Esplà-Gomis, M.; Forcada, M.L.; García-Romero, C.; Kuzman, T.; Ljubešić, N.; van Noord, R.; Pla Sempere, L.; Ramírez-Sánchez, G.; Rupnik, P.; et al. Slovene Web Corpus MaCoCu-sl 1.0. 2022. Slovenian Language Resource Repository CLARIN.SI. Available online: http://hdl.handle.net/11356/1517 (accessed on 6 August 2023).
- Forsyth, R.S.; Sharoff, S. Document dissimilarity within and across languages: A benchmarking study. Lit. Linguist. Comput. 2014, 29, 6–22. [Google Scholar] [CrossRef]

| Dataset (Lang) | Labels | Texts (Train-Dev-Test) |
|---|---|---|
| CORE-main (EN) | 9 | 17,094 (10,256-3419-3419) |
| CORE-sub (EN) | 37 | 15,895 (9537-3179-3179) |
| GINCO-reduced (SL) | 17 | 965 (579-193-193) |
| GINCO-downcast (SL) | 9 | 1002 (601-201-200) |
| FTD (EN) | 10 | 1415 (849-283-283) |
| X-GENRE (SL + EN) | 9 | 2956 (1772-592-592) |
| EN-GINCO (EN) | 9 | 272 (test only) |
| Dataset (No. of Labels) | Micro-F1 | Macro-F1 |
|---|---|---|
| X-GENRE (9) | 0.80 | 0.79 |
| FTD (10) | 0.74 | 0.74 |
| GINCO-downcast (9) | 0.73 | 0.72 |
| CORE-main (9) | 0.75 | 0.62 |
| GINCO-reduced (17) | 0.59 | 0.47 |
| CORE-sub (37) | 0.66 | 0.39 |
| Model | Micro-F1 | Macro-F1 | Accuracy |
|---|---|---|---|
| Fine-tuned XLM-RoBERTa | 0.80 | 0.79 | 0.80 |
| Logistic Regression | 0.65 | 0.67 | 0.65 |
| SVM | 0.66 | 0.66 | 0.66 |
| fastText | 0.64 | 0.64 | 0.64 |
| Naive Bayes | 0.56 | 0.52 | 0.56 |
| Dummy Classifier | 0.13 | 0.09 | 0.13 |
| Model | Micro-F1—EN | Micro-F1—SL | Micro-F1 Absolute Difference | Macro-F1—EN | Macro-F1—SL | Macro-F1 Absolute Difference |
|---|---|---|---|---|---|---|
| Fine-tuned XLM-RoBERTa | 0.82 | 0.75 | 0.07 | 0.83 | 0.76 | 0.07 |
| Logistic Regression | 0.71 | 0.51 | 0.20 | 0.73 | 0.48 | 0.25 |
| SVM | 0.71 | 0.54 | 0.17 | 0.73 | 0.44 | 0.29 |
| fastText | 0.68 | 0.55 | 0.13 | 0.68 | 0.43 | 0.25 |
| Naive Bayes | 0.60 | 0.46 | 0.14 | 0.54 | 0.18 | 0.36 |
| Model | Micro-F1 | Macro-F1 | Accuracy |
|---|---|---|---|
| Fine-tuned XLM-RoBERTa | 0.68 | 0.69 | 0.68 |
| Logistic Regression | 0.49 | 0.47 | 0.49 |
| SVM | 0.49 | 0.51 | 0.49 |
| fastText | 0.45 | 0.41 | 0.45 |
| Naive Bayes | 0.36 | 0.29 | 0.36 |
| Dummy Classifier | 0.14 | 0.10 | 0.14 |
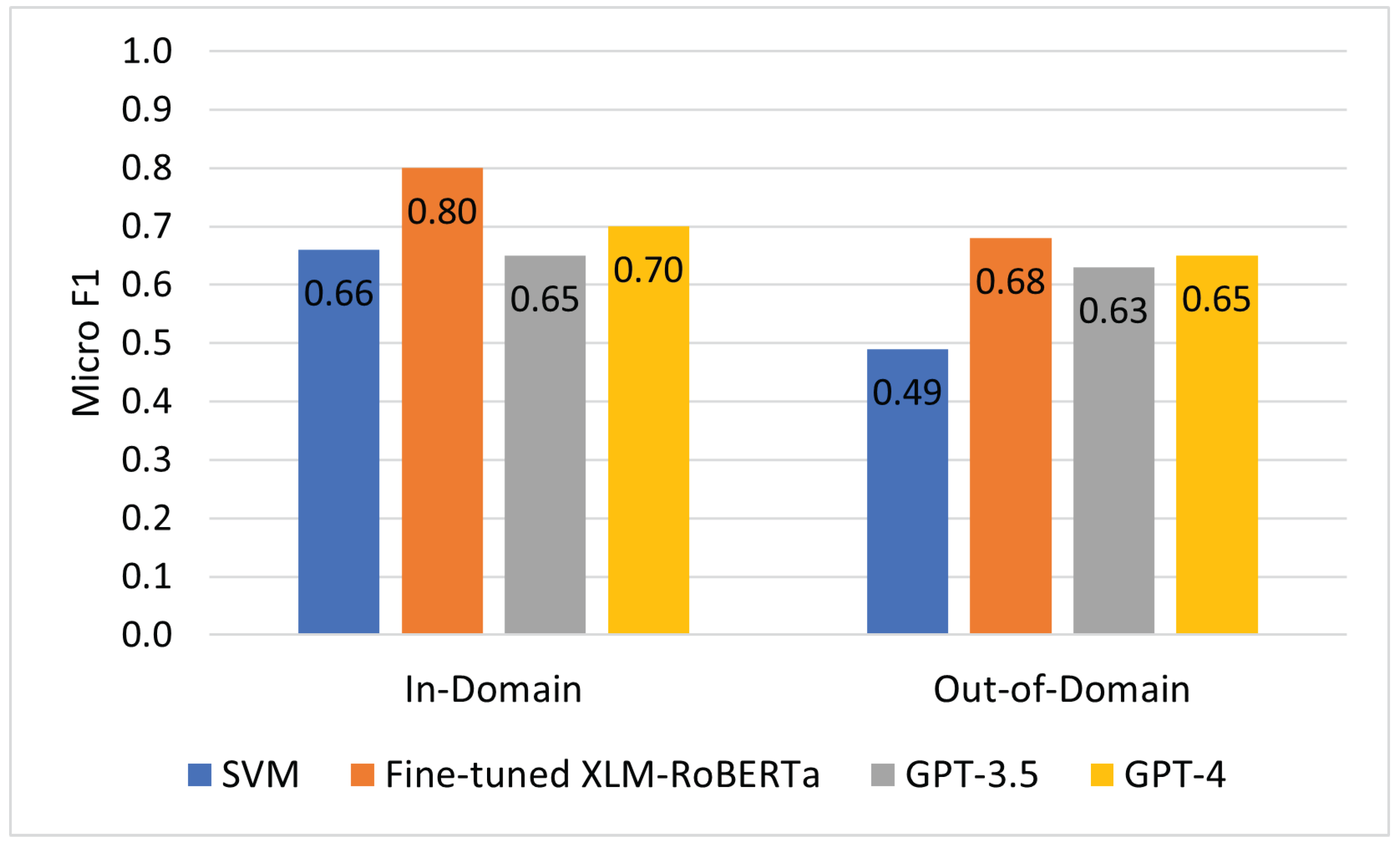
| Model | Test Dataset (Evaluation Scenario) | Micro-F1 | Macro-F1 | Accuracy |
|---|---|---|---|---|
| Fine-tuned XLM-RoBERTa | EN-GINCO (out-of-domain) | 0.68 | 0.69 | 0.68 |
| GPT-4 | EN-GINCO (zero-shot) | 0.65 | 0.55 | 0.65 |
| GPT-3.5 | EN-GINCO (zero-shot) | 0.63 | 0.53 | 0.63 |
| Fine-tuned XLM-RoBERTa | X-GENRE-test (in-domain) | 0.80 | 0.79 | 0.80 |
| GPT-4 | X-GENRE-test (zero-shot) | 0.70 | 0.66 | 0.70 |
| GPT-3.5 | X-GENRE-test (zero-shot) | 0.65 | 0.63 | 0.65 |
| Pair of Models | Test Set | Test Statistic | p-Value |
|---|---|---|---|
| XLM-RoBERTa, GPT-3.5 | EN-GINCO | 2.33 | 0.127 |
| XLM-RoBERTa, GPT-4 | EN-GINCO | 0.71 | 0.399 |
| GPT-3.5, GPT-4 | EN-GINCO | 0.64 | 0.423 |
| XLM-RoBERTa, GPT-3.5 | X-GENRE-test | 49.82 | 0.000 ** |
| XLM-RoBERTa, GPT-4 | X-GENRE-test | 26.47 | 0.000 ** |
| GPT-3.5, GPT-4 | X-GENRE-test | 7.86 | 0.005 * |
| Model | Micro-F1—EN | Micro-F1—SL | Micro-F1 Absolute Difference | Macro-F1—EN | Macro-F1—SL | Macro-F1 Absolute Difference |
|---|---|---|---|---|---|---|
| Fine-tuned XLM-RoBERTa | 0.82 | 0.75 | 0.07 | 0.83 | 0.76 | 0.07 |
| GPT-4 | 0.70 | 0.68 | 0.02 | 0.68 | 0.63 | 0.05 |
| GPT-3.5 | 0.65 | 0.64 | 0.01 | 0.63 | 0.62 | 0.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kuzman, T.; Mozetič, I.; Ljubešić, N. Automatic Genre Identification for Robust Enrichment of Massive Text Collections: Investigation of Classification Methods in the Era of Large Language Models. Mach. Learn. Knowl. Extr. 2023, 5, 1149-1175. https://doi.org/10.3390/make5030059
Kuzman T, Mozetič I, Ljubešić N. Automatic Genre Identification for Robust Enrichment of Massive Text Collections: Investigation of Classification Methods in the Era of Large Language Models. Machine Learning and Knowledge Extraction. 2023; 5(3):1149-1175. https://doi.org/10.3390/make5030059
Chicago/Turabian StyleKuzman, Taja, Igor Mozetič, and Nikola Ljubešić. 2023. "Automatic Genre Identification for Robust Enrichment of Massive Text Collections: Investigation of Classification Methods in the Era of Large Language Models" Machine Learning and Knowledge Extraction 5, no. 3: 1149-1175. https://doi.org/10.3390/make5030059
APA StyleKuzman, T., Mozetič, I., & Ljubešić, N. (2023). Automatic Genre Identification for Robust Enrichment of Massive Text Collections: Investigation of Classification Methods in the Era of Large Language Models. Machine Learning and Knowledge Extraction, 5(3), 1149-1175. https://doi.org/10.3390/make5030059