
Human Action Recognition-Based IoT Services for Emergency Response Management


Abstract
1. Introduction
- A real-time emergency response management-focused IoT services architecture based on human action recognition is presented. The architecture can automatically identify emergencies, summon the nearest emergency medical services, and report the location of the emergency.
- An emergency incident detection model, that exploits a Convolutional Neural Network (CNN) and Support Vector Machine (SVM) hybrid model to classify human actions, whether in an emergency incident or other daily activities, is proposed.
- Using a prototype implementation, experiments, and the UR fall detection dataset (which comprises 70 sequences of emergency and other daily activities), the proposed emergency incident detection model is validated.
2. Literature Review
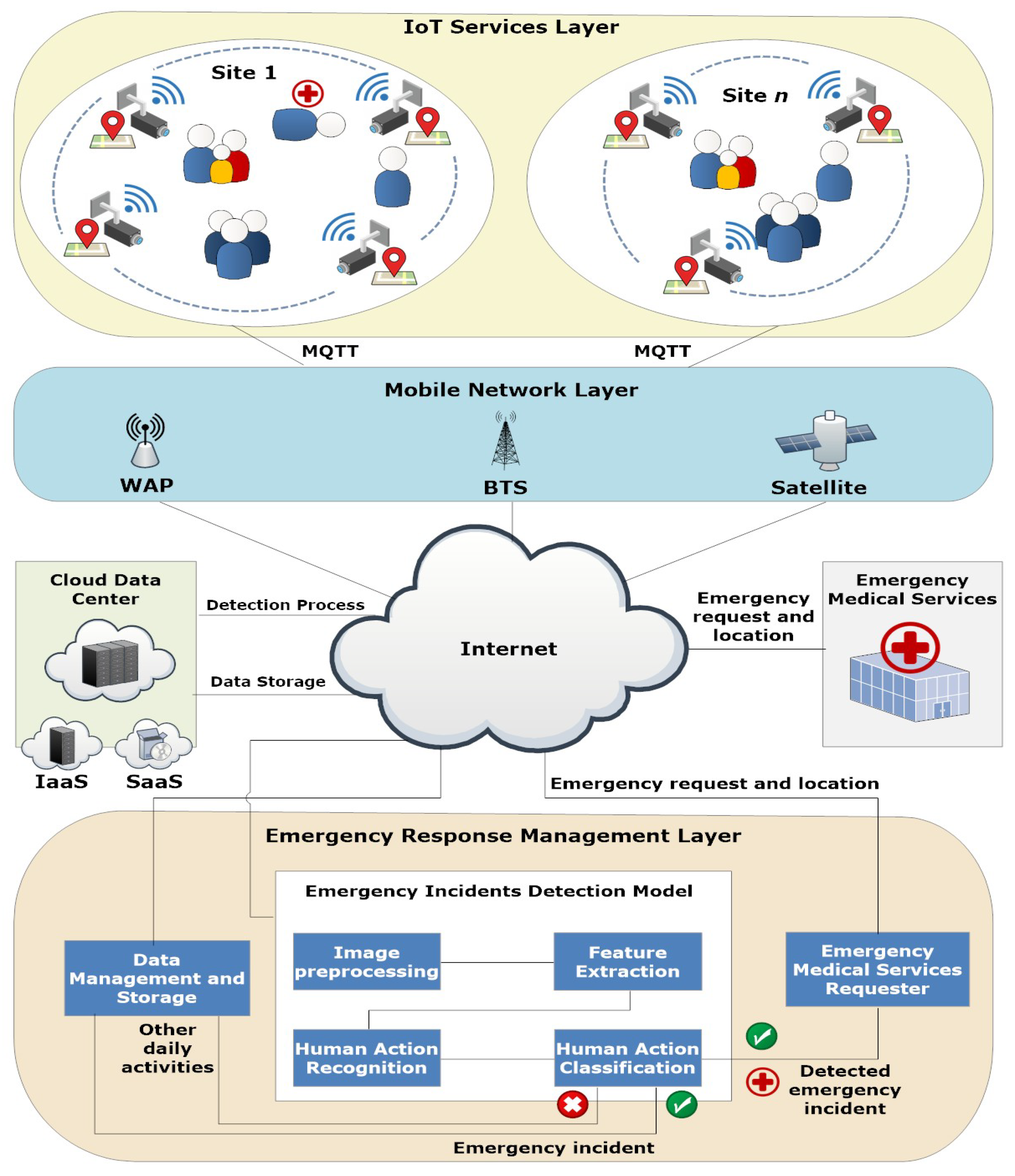
3. IoT Services Architecture for Emergency Response Management
- The IoT Services Layer. This layer encompasses a number of sites n, each of which contains a group of people. Actions, such as routine everyday activities and emergency incidents, are recorded on video by widely accessible surveillance cameras that cover each site for monitoring purposes. Each camera has a Global Positioning System (GPS) module and an Arduino UNO WiFi REV2 module for IoT data transmission. Wireless connection between the nodes and the middleware, which applies a publish–subscribe messaging pattern on top of the Transmission Control Protocol/Internet Protocol (TCP/IP), is made possible by the IoT module using Message Queue Telemetry Transport (MQTT). The IoT devices data is a collection of the camera activity history records, represented by a tuple , where is the camera’s ID, is the video recorded by the camera, is the location of the camera (i.e., the coordinates that are captured from the attached GPS module), and is the timestamps when the camera recorded the video. The data from the IoT Services Layer is then transmitted via the Mobile Network Layer.
- The Mobile Network Layer. This layer serves as the link between the Emergency Response Management Layer and the IoT Services Layer. To facilitate communication, it consists explicitly of several Base Transceiver Stations (BTSs), satellites, and Wireless Access Points (WAPs). The communicated information contains the camera’s ID, the video it has captured and the timestamps at which it did so, and its location.
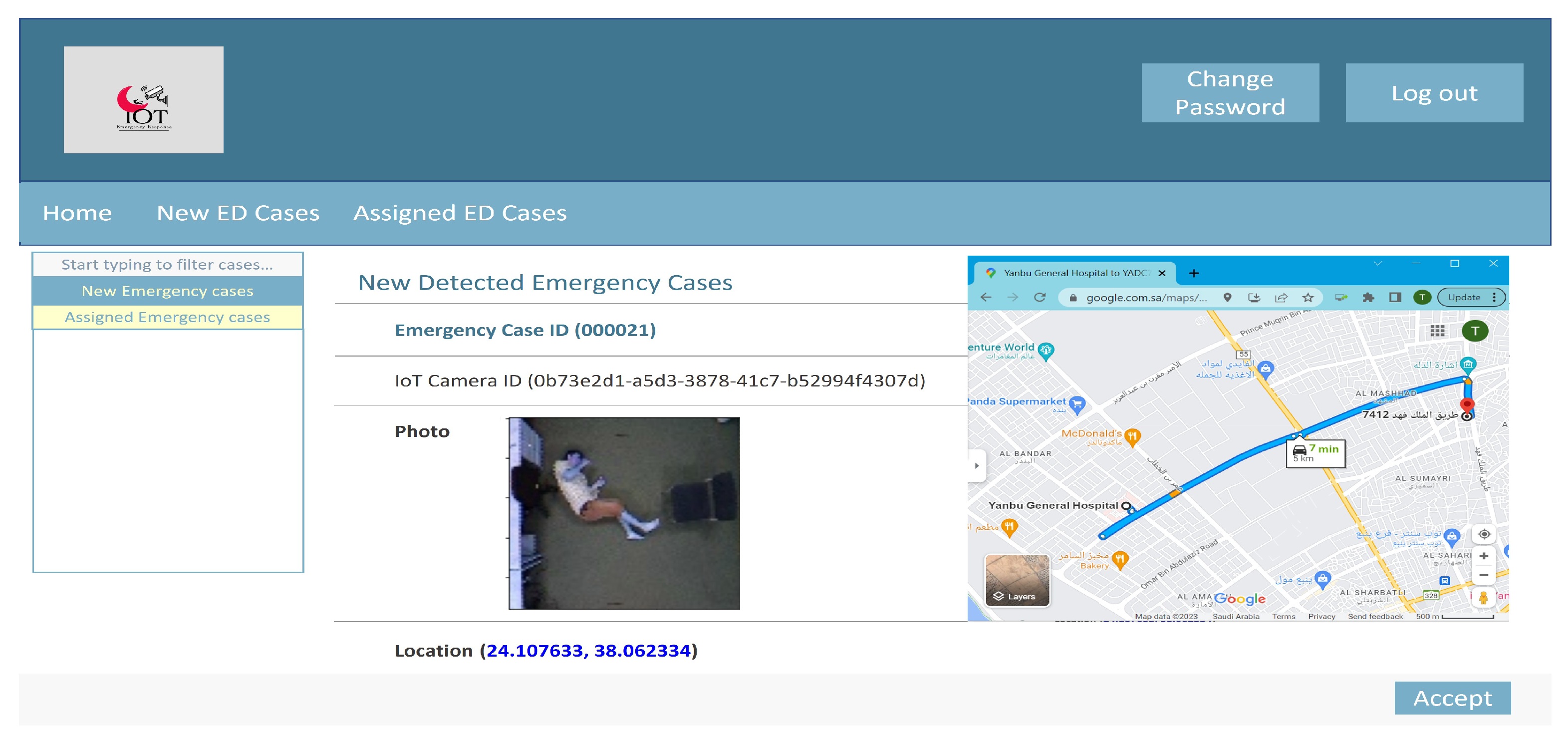
- The Emergency Response Management Layer. This layer consists of three different components: (i) Emergency Medical Services Requester, which is responsible for requesting emergency medical services if an emergency incident is detected by the Emergency Incident Detection Model. The emergency medical services request consists of the request ID, picture of the incident, its location, and the timestamps; (ii) Data Management and Storage component, which is in control of keeping the camera activity history records, providing access to the data using Infrastructure as a Service (IaaS) cloud service as storage in the cloud data center; (iii) Emergency Incident Detection Model, which is responsible for emergency incident detection. The model itself consists of four modules: (a) Image Preprocessing, which is responsible for background subtraction, (b) Feature Extraction, which is responsible for object identification and tracking, (c) Human Action Recognition, which is responsible for action identification; and (d) Human Action Classification, which is responsible for classifying the human activity as either an emergency incident or regular daily activity. More details on emergency incident detection can be found in Section 4), where, if an emergency incident is detected, a copy of the information is sent to the Emergency Medical Services Requester, and another copy to the Data Management and Storage component (i.e., as a record for the future), while a copy of other regular daily activities are also sent to the Data Management and Storage component for learning purposes.
4. Emergency Incidents Detection Model
4.1. Preprocessing
- Background SubtractionThe background subtraction technique is frequently used to identify unexpected movements in a scene. The purpose of using the subtraction technique is to build a model against the scene background by comparing each new image frame with the preceding one. Additionally, the Gaussian Mixture Model (GMM) is used for background subtraction, since it can handle the larger class of density models that include numerous additive functions [31]. Let us assume that K is the number of distributions and stands for a pixel in the current frame. To represent each pixel, a K Gaussian mixture can be used as follows:A method of observing the histogram of the dataset, and basing the selection of K on the number of peaks for this histogram, is used to determine the number of K components. Here, the number of components is automatically determined by a constructive algorithm that forces the process of maximizing a likelihood function [31]. The value is the component’s prior probability of the component in Equation (1). It is also known as the weighting function, and it is produced from the mixture’s constituent parts of the component i of the mixture. The value reflects the component’s Gaussian density model (Equation (2)).where the terms and denote, respectively, the component’s mean and covariance. The feature space is also referred to as f. The K components are chosen, and the mean, covariance, and prior probability for each component are estimated using the available dataset. These parameters are calculated using the algorithm [22], and re-estimates and optimizations are based on minimizing the error function E (Equation (3)).In this equation, N is the total number of data points . When a threshold of 0.5 is applied, the background distribution continues to be the dominant one with the lowest variance. For this reason, the foreground is the label applied to all pixels that do not match the components.There are still some isolated areas and noise. A small area near the foreground that does not belong there exists. Therefore, outliers like noise and spurious components are eliminated using morphological processes, like erosion and dilation. A desired picture processing effect is also produced by combining erosion and dilation operations. In this way the foreground regions are found. Additionally, using median filtering, regarding the size of the neighboring window, acquires the foreground items. They are localized using a blob analysis function after the captioned foreground image has been established. Figure 2 shows an illustration based on the outcomes of a background computation with .
4.2. Feature Extraction
4.2.1. Global Feature
- Elliptic Fourier descriptorsIn this study, the action silhouettes are obtained using an elliptic Fourier descriptor following the shape curve . The trigonometric representation is made more axiomatic and simpler to use. Elliptic coefficients are determined using Equations (5) and (6).whereWith a value, denotes the fundamental frequency. The value T is a harmonic number and defines the function period. These coefficients, it should be noted, ensure that the yielding curve descriptor is rotation, translation, and scale invariant. Additionally, it is independent of the choice of the contour start point for the object. Readers who want more information might consult [31].
- Zernike MomentsThe orthogonal collection of rotation-invariant Zernike moments that they award can be used to confirm an object’s invariance for a silhouette image. Moment normalization can also be used to achieve translation and scale invariance [9]. The following is a brief discussion of a complicated Zernike moment () of repetition q and order p for the intensity function of a particular image:where, is a normalization factor, p denotes a positive integer, and , . Depending on how the constraint condition is met, q is either a positive or negative integer. The centroid of the silhouette image and a scale parameter a are used to normalize the function f, subject to translation and scale. The value is a redial polynomial. As a result of this, the geometric properties that shape scaling, translation, and rotation with notable similarities to invariant moments are achieved by; = . Experimentally, the feature invariant percentage error is less than 0.5 percent.
4.2.2. Local Feature
- Center of Silhouettes Motion (CM)The use of motion data persuaded us to fuse it with global features to approach the classification of SVM and CNN’s ultimate results. The extracted motion feature estimates the centroid , which forwards the motion centroid point. Furthermore, the feature , which describes the general motion distribution, is specified using Equation (9);According to the total number of moving pixels, are the spatial coordinates of . These characteristics have a significant impact not only on the motion rate and velocity, but also on the type of motion, such as oscillatory or transnational motion. With these characteristics, the model is able to distinguish between an action that occurred in a relatively big area (such as a running action) and an activity that occurred in a smaller area with the motion of a particular body part, such as a waving action with one or two hands.
4.3. Classification
4.3.1. Support Vector Machine (SVM)
4.3.2. Convolutional Neural Network (CNN)
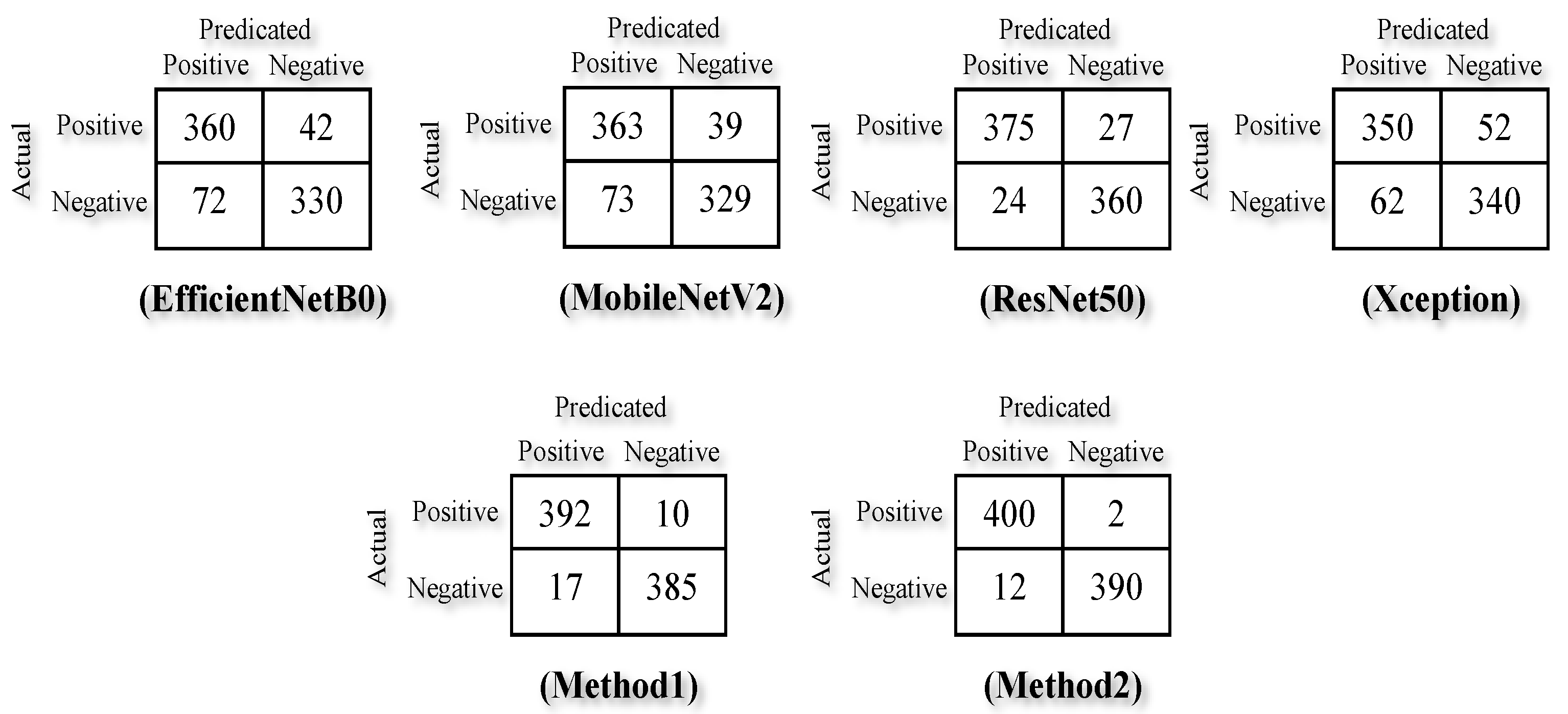
5. Implementation and Experimental Results
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- GMB Union. 35% of Ambulance Workers Witnessed Deaths Due to Delays. 2022. Available online: https://www.gmb.org.uk/news/35-ambulance-workers-witnessed-deaths-due-delays (accessed on 15 November 2022).
- Shepherd, T. More than 30 Deaths Linked to Delays at Victoria’s Overloaded Triple-Zero Service. 2022. Available online: https://www.theguardian.com/australia-news/2022/sep/03/all (accessed on 17 November 2022).
- Noor, T.H. Behavior Analysis-Based IoT Services For Crowd Management. Comput. J. 2022, 65, bxac071. [Google Scholar] [CrossRef]
- Lopez-Fuentes, L.; van de Weijer, J.; González-Hidalgo, M.; Skinnemoen, H.; Bagdanov, A.D. Review on Computer Vision Techniques in Emergency Situations. Multimed. Tools Appl. 2018, 77, 17069–17107. [Google Scholar] [CrossRef]
- Fedele, R.; Merenda, M. An IoT System for Social Distancing and Emergency Management in Smart Cities Using Multi-sensor Data. Algorithms 2020, 13, 254. [Google Scholar] [CrossRef]
- Noor, T.H. A Gesture Recognition System for Gesture Control on Internet of Things Services. J. Theor. Appl. Inf. Technol. 2018, 96, 3886–3895. [Google Scholar]
- Yao, L.; Wang, X.; Sheng, Q.Z.; Dustdar, S.; Zhang, S. Recommendations on the Internet of Things: Requirements, Challenges, and Directions. IEEE Internet Comput. 2019, 23, 46–54. [Google Scholar] [CrossRef]
- Hamad, S.A.; Sheng, Q.Z.; Zhang, W.E.; Nepal, S. Realizing an Internet of Secure Things: A Survey on Issues and Enabling Technologies. IEEE Commun. Surv. Tutor. 2020, 22, 1372–1391. [Google Scholar] [CrossRef]
- Bello, O.; Zeadally, S. Toward Efficient Smartification of the Internet of Things (IoT) Services. Future Gener. Comput. Syst. 2019, 92, 663–673. [Google Scholar] [CrossRef]
- Bosch, M.; Conroy, C.; Ortiz, B.; Bogden, P. Improving Emergency Response During Hurricane Season Using Computer Vision. In Proceedings of the Earth Resources and Environmental Remote Sensing/GIS Applications XI Conference; SPIE: Bellingham, WA, USA, 2020; pp. 72–79. [Google Scholar]
- Han, Y.K.; Choi, Y.B. Detection of Emergency Disaster using Human Action Recognition based on LSTM Model. IEIE Trans. Smart Process. Comput. 2020, 9, 177–184. [Google Scholar] [CrossRef]
- Maguluri, L.P.; Srinivasarao, T.; Syamala, M.; Ragupathy, R.; Nalini, N. Efficient Smart Emergency Response System for Fire Hazards Using IoT. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 314–320. [Google Scholar]
- Ma, X.; Wang, X.; Zhang, K. Fall Detection Method for Embedded Devices. J. Imaging Sci. Technol. 2022, 66, 040407-1–040407-11. [Google Scholar] [CrossRef]
- Zheng, H.; Liu, Y. Lightweight Fall Detection Algorithm based on AlphaPose Optimization Model and ST-GCN. Math. Probl. Eng. 2022, 2022, 9962666. [Google Scholar] [CrossRef]
- Elmezain, M.; Malki, Z.S.; Abdel-Rahman, E.O. Human Action Recognition: An Innovative Approach Using Dynamic Affine-Invariants and Spatio-Temporal Action Features. J. Comput. Theor. Nanosci. 2017, 14, 999–1008. [Google Scholar] [CrossRef]
- Elmezain, M.; Abdel-Rahman, E.O. Human Activity Recognition: Discriminative Models Using Statistical Chord-Length and Optical Flow Motion Features. Appl. Math. Inf. Sci. 2015, 9, 3063–3072. [Google Scholar]
- Sun, Z.; Ke, Q.; Rahmani, H.; Bennamoun, M.; Wang, G.; Liu, J. Human Action Recognition from Various Data Modalities: A Review. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2023, 45, 3200–3225. [Google Scholar] [CrossRef] [PubMed]
- Saif, S.; Tehseen, S.; Kausar, S. A Survey of the Techniques for the Identification and Classification of Human Actions from Visual Data. Sensors 2018, 18, 3979. [Google Scholar] [CrossRef]
- Kong, Y.; Fu, Y. Human Action Recognition and Prediction: A Survey. Int. J. Comput. Vis. 2022, 130, 1366–1401. [Google Scholar] [CrossRef]
- Arshad, B.; Ogie, R.; Barthelemy, J.; Pradhan, B.; Verstaevel, N.; Perez, P. Computer Vision and IoT-based Sensors in Flood Monitoring and Mapping: A Systematic Review. Sensors 2019, 19, 5012. [Google Scholar] [CrossRef]
- Deak, G.; Curran, K.; Condell, J.; Asimakopoulou, E.; Bessis, N. IoTs (Internet of Things) and DfPL (Device-free Passive Localisation) in a Disaster Management Scenario. Simul. Model. Pract. Theory 2013, 35, 86–96. [Google Scholar] [CrossRef]
- Zhang, Z.; Conly, C.; Athitsos, V. A Survey on Vision-based Fall Detection. In Proceedings of the 8th ACM International Conference on PErvasive Technologies Related to Assistive Environments, Corfu, Greece, 1–3 July 2015; pp. 1–7. [Google Scholar]
- Nooruddin, S.; Islam, M.; Sharna, F.A.; Alhetari, H.; Kabir, M.N. Sensor-based Fall Detection Systems: A Review. J. Ambient Intell. Humaniz. Comput. 2022, 13, 2735–2751. [Google Scholar] [CrossRef]
- Gutiérrez, J.; Rodríguez, V.; Martin, S. Comprehensive Review of Vision-based Fall Detection Systems. Sensors 2021, 21, 947. [Google Scholar] [CrossRef]
- Usmani, S.; Saboor, A.; Haris, M.; Khan, M.A.; Park, H. Latest Research Trends in Fall Detection and Prevention Using Machine Learning: A Systematic Review. Sensors 2021, 21, 5134. [Google Scholar] [CrossRef] [PubMed]
- Lee, T.; Mihailidis, A. An Intelligent Emergency Response System: Preliminary Development and Testing of Automated Fall Detection. J. Telemed. Telecare 2005, 11, 194–198. [Google Scholar] [CrossRef] [PubMed]
- Jeong, I.W.; Choi, J.; Cho, K.; Seo, Y.H.; Yang, H.S. A Vision-based Emergency Response System with a Paramedic Mobile Robot. IEICE Trans. Inf. Syst. 2010, 93, 1745–1753. [Google Scholar] [CrossRef]
- Zhu, N.; Zhao, G.; Zhang, X.; Jin, Z. Falling Motion Detection Algorithm Based on Deep Learning. IET Image Process. 2022, 16, 2845–2853. [Google Scholar] [CrossRef]
- Chua, J.L.; Chang, Y.C.; Lim, W.K. A Simple Vision-Based Fall Detection Technique for Indoor Video Surveillance. Signal Image Video Process. 2015, 9, 623–633. [Google Scholar] [CrossRef]
- Alhimale, L.; Zedan, H.; Al-Bayatti, A. The Implementation of an Intelligent and Video-based Fall Detection System Using a Neural Network. Appl. Soft Comput. 2014, 18, 59–69. [Google Scholar] [CrossRef]
- Elmezain, M. Invariant Color Features-based Foreground Segmentation for Human-computer Interaction. Math. Methods Appl. Sci. 2018, 41, 5770–5779. [Google Scholar] [CrossRef]
- Elmezain, M.; Al-Hamadi, A. Vision-Based Human Activity Recognition Using LDCRFs. Int. Arab J. Inform. Technol. 2018, 15, 389–395. [Google Scholar]
- Hahm, G.J.; Cho, K. Event-based Sport Video Segmentation Using Multimodal Analysis. In Proceedings of the 2016 International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Korea, 19–21 October 2016; pp. 1119–1121. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Cengıl, E.; Çinar, A. Multiple Classification of Flower Images Using Transfer Learning. In Proceedings of the 2019 International Artificial Intelligence and Data Processing Symposium (IDAP), Malatya, Turkey, 21–22 September 2019; pp. 1–6. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Tripathi, K.; Gupta, A.K.; Vyas, R.G. Deep Residual Learning for Image Classification using Cross Validation. Int. J. Innov. Technol. Explor. Eng. (IJITEE) 2020, 9, 1526–1530. [Google Scholar] [CrossRef]
- Cleetus, L.; Sukumar, A.R.; Hemalatha, N. Computational Prediction of Disease Detection and Insect Identification Using Xception Model. bioRxiv 2021, 1–7. [Google Scholar] [CrossRef]
- Kwolek, B.; Kepski, M. Human Fall Detection on Embedded Platform Using Depth Maps and Wireless Accelerometer. Comput. Methods Programs Biomed. 2014, 117, 489–501. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensitivity | Specificity | Precision | Accuracy | |
|---|---|---|---|---|
| EfficientNetB0 | 0.90 | 0.82 | 0.83 | 0.86 |
| MobileNetV2, | 0.90 | 0.82 | 0.83 | 0.86 |
| ResNet50 | 0.93 | 0.90 | 0.90 | 0.91 |
| Xception | 0.87 | 0.87 | 0.87 | 0.87 |
| Method 1 (SVM on extracted features) | 0.98 | 0.96 | 0.96 | 0.97 |
| Method 2 (CNN-SVM) | 0.99 | 0.97 | 0.97 | 0.98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Noor, T.H. Human Action Recognition-Based IoT Services for Emergency Response Management. Mach. Learn. Knowl. Extr. 2023, 5, 330-345. https://doi.org/10.3390/make5010020
Noor TH. Human Action Recognition-Based IoT Services for Emergency Response Management. Machine Learning and Knowledge Extraction. 2023; 5(1):330-345. https://doi.org/10.3390/make5010020
Chicago/Turabian StyleNoor, Talal H. 2023. "Human Action Recognition-Based IoT Services for Emergency Response Management" Machine Learning and Knowledge Extraction 5, no. 1: 330-345. https://doi.org/10.3390/make5010020
APA StyleNoor, T. H. (2023). Human Action Recognition-Based IoT Services for Emergency Response Management. Machine Learning and Knowledge Extraction, 5(1), 330-345. https://doi.org/10.3390/make5010020