
Skew Class-Balanced Re-Weighting for Unbiased Scene Graph Generation

Abstract
1. Introduction
- Contributions of our SCR learning scheme to unbiased SGG models:
- Leveraged by the skewness of biased predicate predictions, the Skew Class-Balanced Re-Weighting (SCR) loss function is firstly proposed for the unbiased scene graph generation (SGG) models.
- The SCR is applied to the current state-of-the-art SGG models to show its effectiveness, leading to more generalized performances: the SCR outperforms the prior reweighted methods on both mean recall and recall measurements in the multiple SGG tasks.
2. Related Works
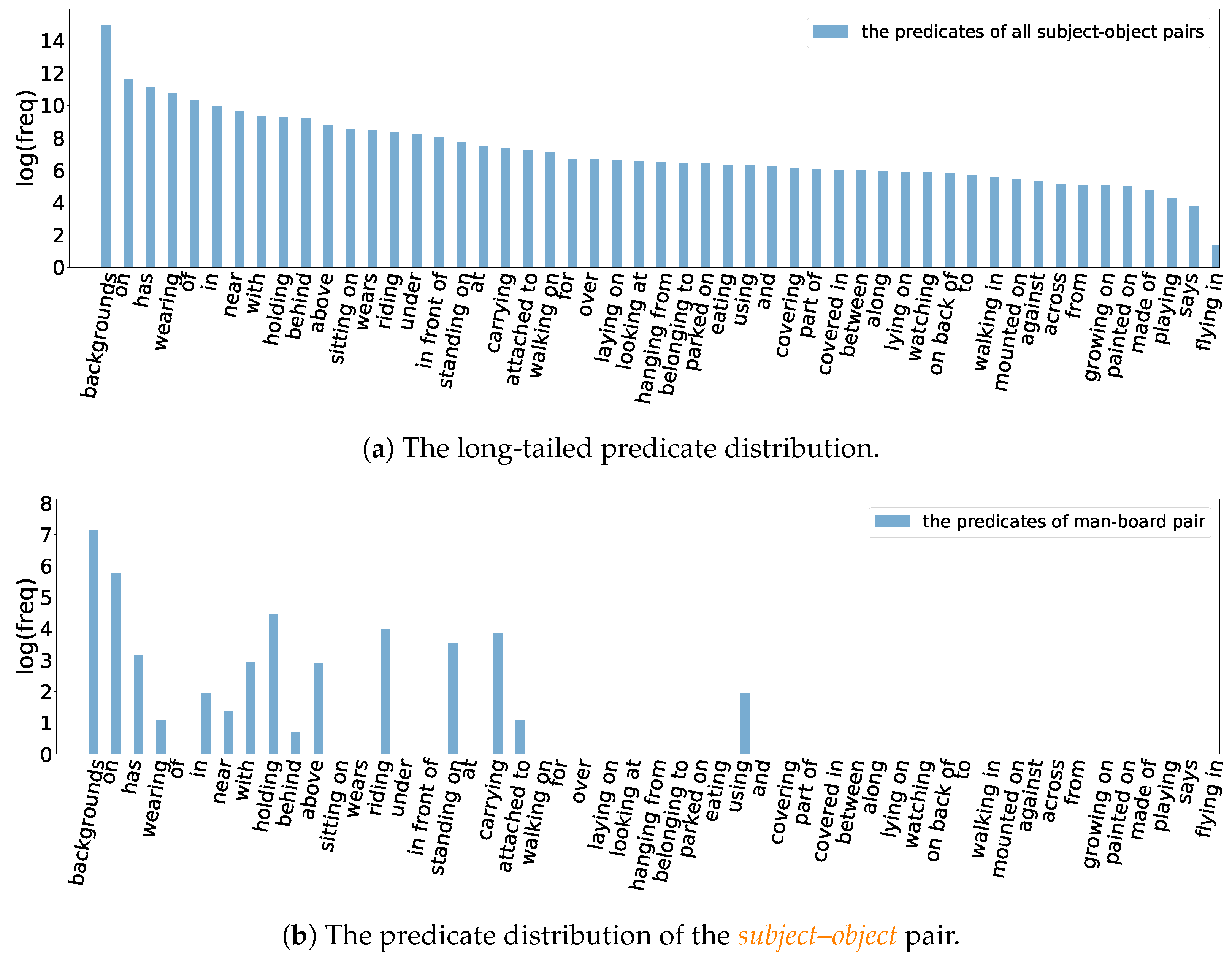
3. Unbiased Scene Graph Generation
3.1. Scene Graph Generations
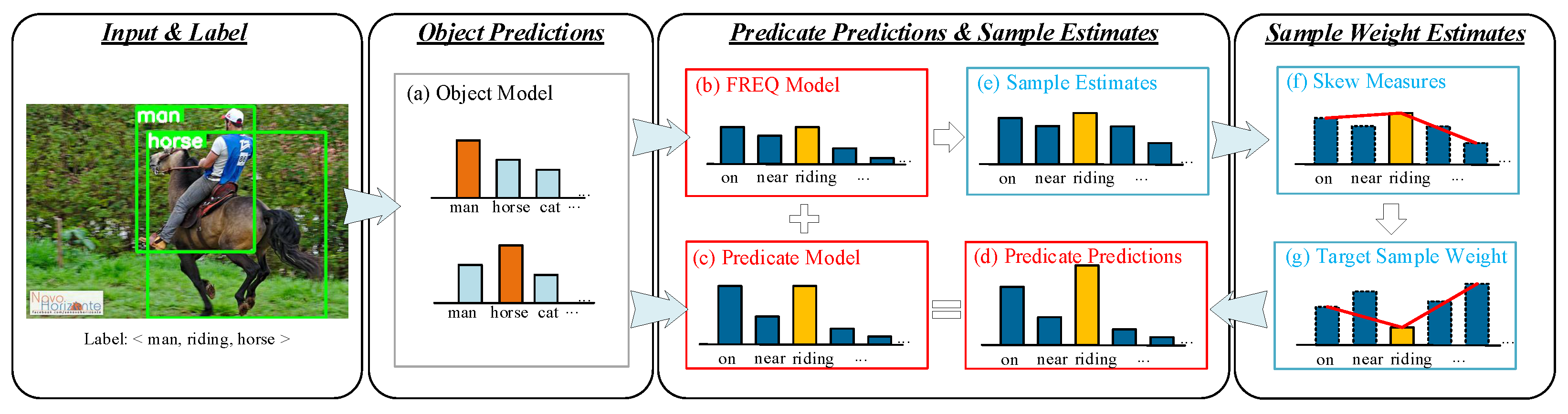
3.1.1. Object Predictions
3.1.2. Predicate Predictions
3.2. Sample Estimates
- SCR of EMB: ;
- SCR of FREQ: ;
- SCR of FREQ+EMB: .
4. Skew Class-Balanced Re-Weighting (SCR)
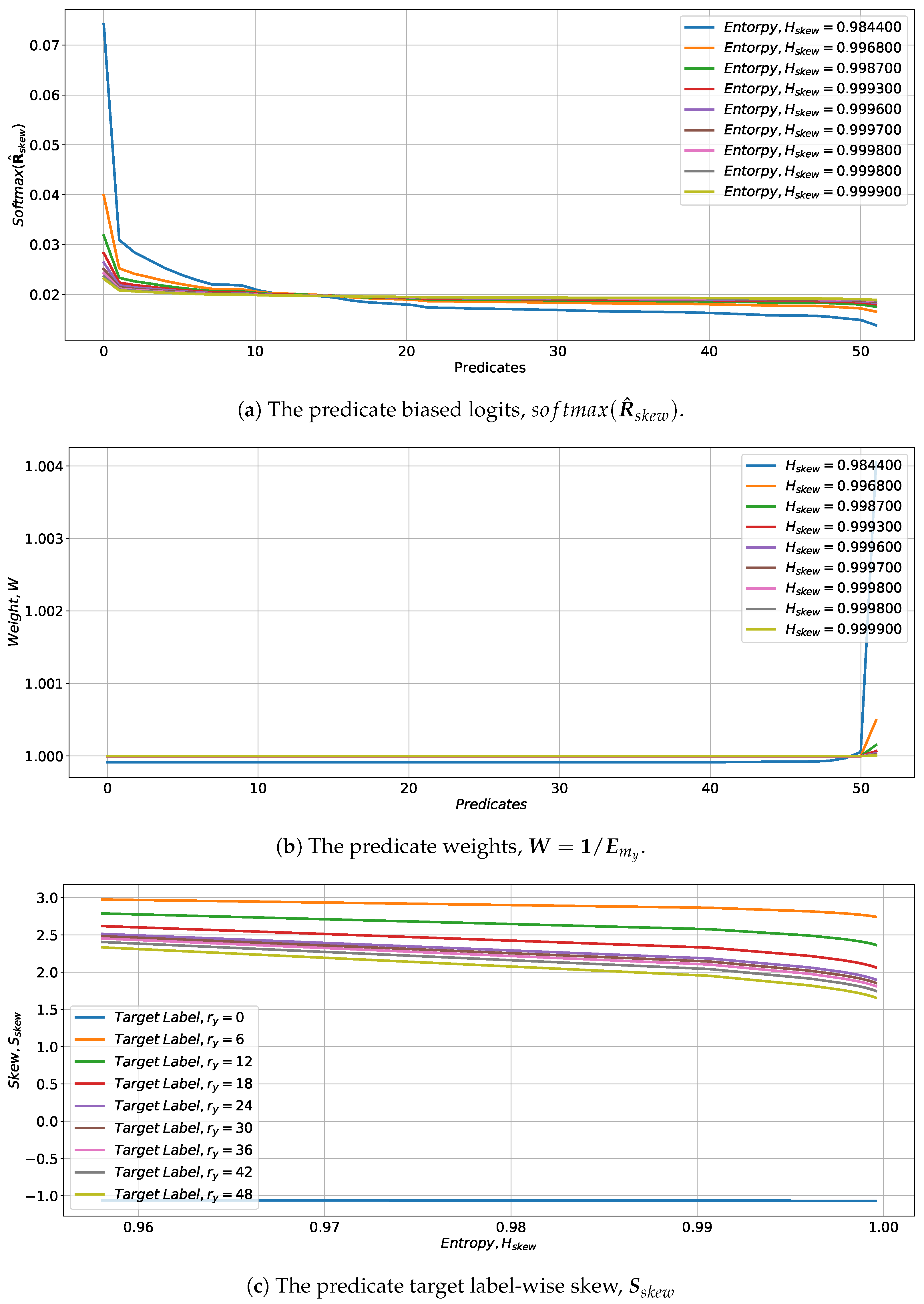
4.1. Skew Class-Balanced Effective Number
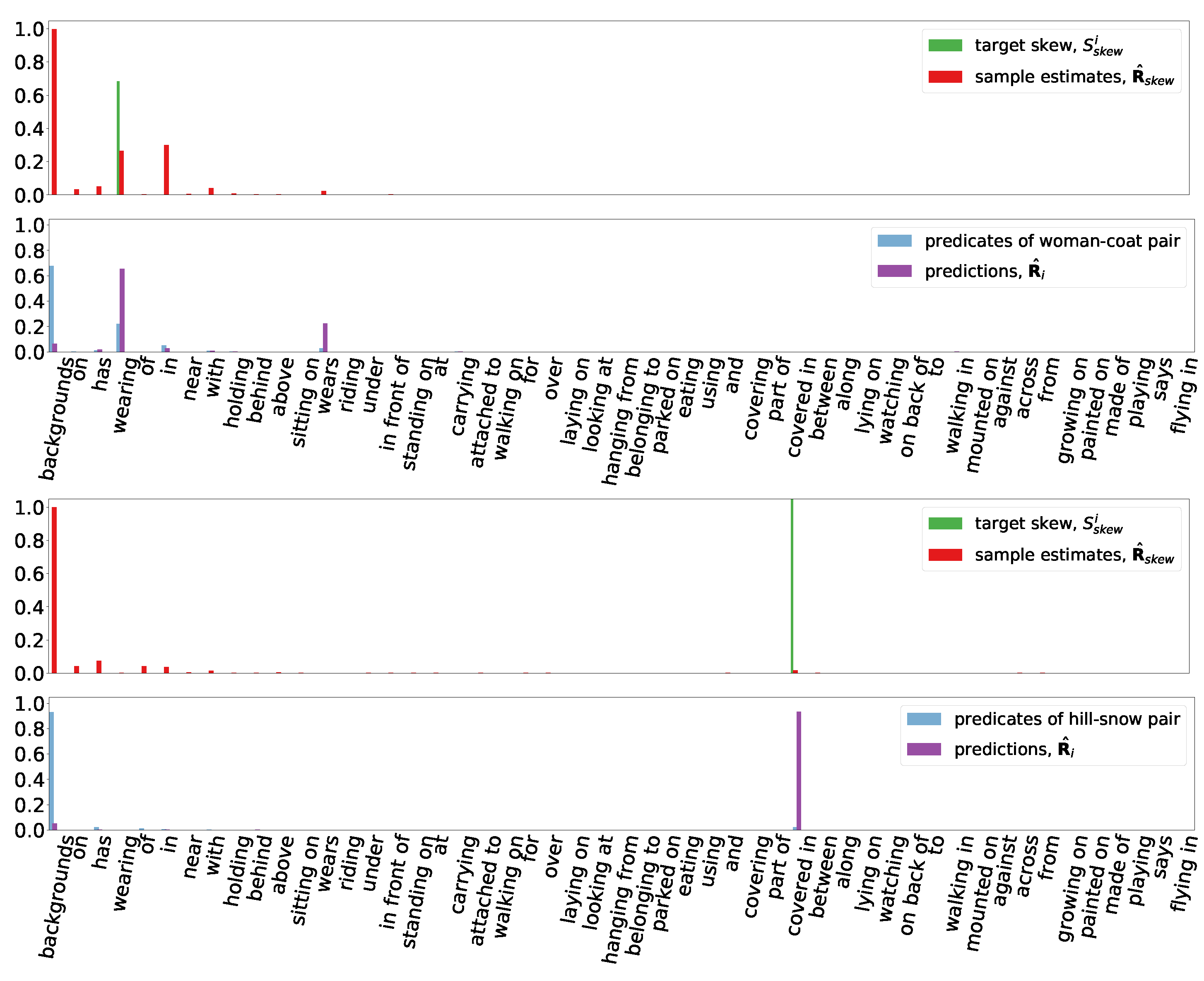
4.2. Skew Measures
| Algorithm 1 Skew Class-Balanced Effective Number. |
4.3. Target Sample Weights
4.4. Learning with SCR
5. Experiments
5.1. Visual Genome
5.2. Open Images
5.3. Experiments Configurations
5.4. Evaluations
5.5. Quantitative Results
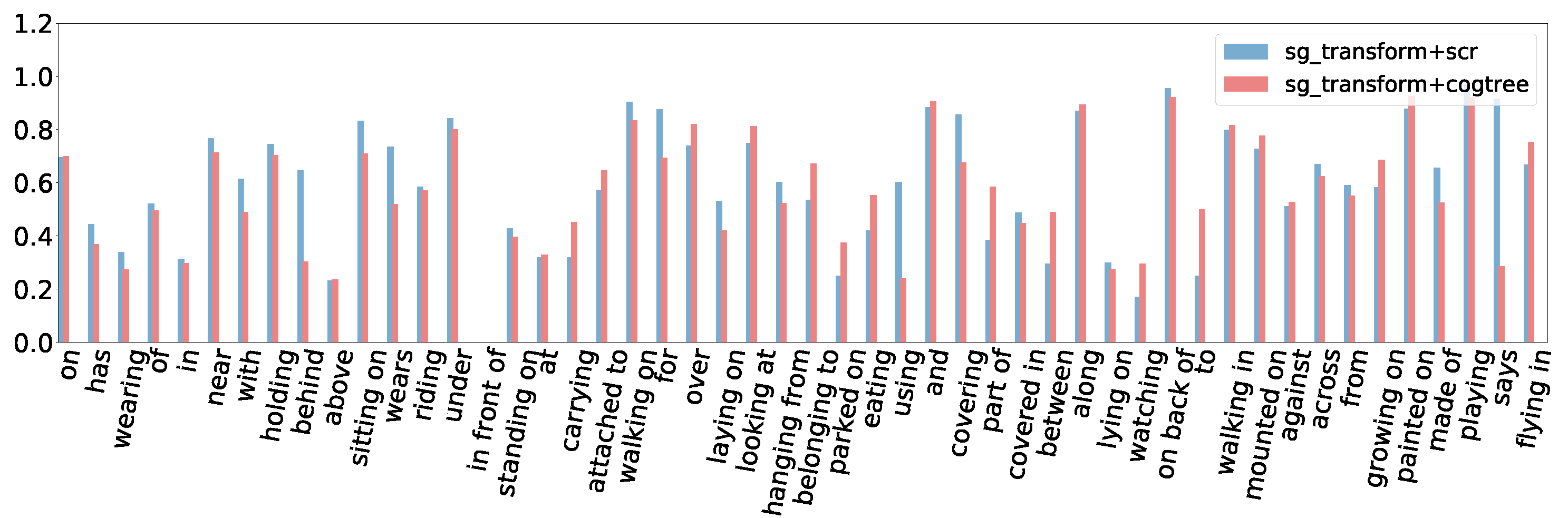
5.6. Ablation Study
5.7. Qualitative Examples
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jarvis, R.A. A perspective on range finding techniques for computer vision. IEEE Trans. Pattern Anal. Mach. Intell. 1983, PAMI-5, 122–139. [Google Scholar] [CrossRef] [PubMed]
- Forsyth, D.A.; Ponce, J. Computer Vision: A Modern Approach; Prentice Hall Professional Technical Reference: Hoboken, NJ, USA, 2002. [Google Scholar]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef] [PubMed]
- Kang, J.-S.; Kang, J.; Kim, J.J.; Jeon, K.W.; Chung, H.J.; Park, B.H. Neural Architecture Search Survey: A Computer Vision Perspective. Sensors 2023, 23, 1713. [Google Scholar] [CrossRef] [PubMed]
- Høye, T.T.; Ärje, J.; Bjerge, K.; Hansen, O.L.; Iosifidis, A.; Leese, F.; Mann, H.M.; Meissner, K.; Melvad, C.; Raitoharju, J. Deep learning and computer vision will transform entomology. Proc. Natl. Acad. Sci. USA 2021, 118, e2002545117. [Google Scholar] [CrossRef] [PubMed]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Sethian, J.A. Level Set Methods and Fast Marching Methods: Evolving Interfaces in Computational Geometry, Fluid Mechanics, Computer Vision, and Materials Science; Cambridge University Press: Cambridge, UK, 1999; Volume 3. [Google Scholar]
- Scheuerman, M.K.; Hanna, A.; Denton, E. Do datasets have politics? Disciplinary values in computer vision dataset development. Proc. Acm Hum. Comput. Interact. 2021, 5, 1–37. [Google Scholar] [CrossRef]
- Verma, T.; De, A.; Agrawal, Y.; Vinay, V.; Chakrabarti, S. Varscene: A deep generative model for realistic scene graph synthesis. In Proceedings of the International Conference on Machine Learning, Guangzhou, China, 18–21 February 2022; PMLR; pp. 22168–22183. [Google Scholar]
- Esteva, A.; Chou, K.; Yeung, S.; Naik, N.; Madani, A.; Mottaghi, A.; Liu, Y.; Topol, E.; Dean, J.; Socher, R. Deep learning-enabled medical computer vision. NPJ Digit. Med. 2021, 4, 5. [Google Scholar] [CrossRef]
- Andriyanov, N.A.; Dementiev, V.E.; Tashlinskiy, A. Detection of objects in the images: From likelihood relationships towards scalable and efficient neural networks. Comput. Opt. 2022, 46, 139–159. [Google Scholar] [CrossRef]
- Dutordoir, V.; van der Wilk, M.; Artemev, A.; Hensman, J. Bayesian Image Classification with Deep Convolutional Gaussian Processes. In Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, Online, 26–28 August 2020; pp. 1529–1539. [Google Scholar]
- Papakostas, G.; Diamantaras, K.; Papadimitriou, T. Parallel pattern classification utilizing GPU-based kernelized Slackmin algorithm. J. Parallel Distrib. Comput. 2017, 99, 90–99. [Google Scholar] [CrossRef]
- Joseph, K.J.; Khan, S.; Khan, F.S.; Balasubramanian, V.N. Towards open world object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5830–5840. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Zhang, Q.; Wipf, D.; Gan, Q.; Song, L. A Biased Graph Neural Network Sampler with Near-Optimal Regret. arXiv 2021, arXiv:2103.01089. [Google Scholar] [CrossRef]
- Zhang, X.; Bosselut, A.; Yasunaga, M.; Ren, H.; Liang, P.; Manning, C.D.; Leskovec, J. GreaseLM: Graph REASoning Enhanced Language Models. In Proceedings of the International Conference on Learning Representations, Online, 25–29 April 2022. [Google Scholar]
- Wu, Y.X.; Wang, X.; Zhang, A.; He, X.; Chua, T.S. Discovering Invariant Rationales for Graph Neural Networks. In Proceedings of the International Conference on Learning Representations, Online, 25–29 April 2022. [Google Scholar]
- Gao, J.; Ribeiro, B. On the Equivalence Between Temporal and Static Equivariant Graph Representations. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 7052–7076. [Google Scholar]
- Yoon, M.; Wu, Y.; Palowitch, J.; Perozzi, B.; Salakhutdinov, R. Scalable and Privacy-enhanced Graph Generative Model for Graph Neural Networks. arXiv 2022, arXiv:2207.04396. [Google Scholar] [CrossRef]
- Andriyanov, N. Application of Graph Structures in Computer Vision Tasks. Mathematics 2022, 10, 4021. [Google Scholar] [CrossRef]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Chen, S.; Li, B. Multi-Modal Dynamic Graph Transformer for Visual Grounding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 15534–15543. [Google Scholar]
- Ding, Y.; Yu, J.; Liu, Y.; Hu, Y.; Cui, M.; Wu, Q. MuKEA: Multimodal Knowledge Extraction and Accumulation for Knowledge-Based Visual Question Answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5089–5098. [Google Scholar]
- Lou, C.; Han, W.; Lin, Y.; Zheng, Z. Unsupervised Vision-Language Parsing: Seamlessly Bridging Visual Scene Graphs with Language Structures via Dependency Relationships. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 15607–15616. [Google Scholar]
- Walmer, M.; Sikka, K.; Sur, I.; Shrivastava, A.; Jha, S. Dual-Key Multimodal Backdoors for Visual Question Answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 15375–15385. [Google Scholar]
- Koh, J.Y.; Salakhutdinov, R.; Fried, D. Grounding Language Models to Images for Multimodal Generation. arXiv 2023, arXiv:2301.13823. [Google Scholar] [CrossRef]
- Iwamura, K.; Kasahara, J.L.; Moro, A.; Yamashita, A.; Asama, H. Image Captioning Using Motion-CNN with Object Detection. Sensors 2021, 21, 1270. [Google Scholar] [CrossRef]
- Liu, H.; Yan, N.; Mortazavi, M.; Bhanu, B. Fully convolutional scene graph generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11546–11556. [Google Scholar]
- Cong, Y.; Yang, M.Y.; Rosenhahn, B. RelTR: Relation Transformer for Scene Graph Generation. arXiv 2022, arXiv:2201.11460. [Google Scholar] [CrossRef]
- Xu, D.; Zhu, Y.; Choy, C.B.; Li, F.-F. Scene graph generation by iterative message passing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5410–5419. [Google Scholar]
- Dai, B.; Zhang, Y.; Lin, D. Detecting visual relationships with deep relational networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3076–3086. [Google Scholar]
- Li, Y.; Ouyang, W.; Zhou, B.; Wang, K.; Wang, X. Scene graph generation from objects, phrases and region captions. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1261–1270. [Google Scholar]
- Li, Y.; Ouyang, W.; Wang, X. Vip-cnn: A visual phrase reasoning convolutional neural network for visual relationship detection. arXiv 2017, arXiv:1702.07191. [Google Scholar]
- Hwang, S.J.; Ravi, S.N.; Tao, Z.; Kim, H.J.; Collins, M.D.; Singh, V. Tensorize, factorize and regularize: Robust visual relationship learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1014–1023. [Google Scholar]
- Li, Y.; Ouyang, W.; Zhou, B.; Shi, J.; Zhang, C.; Wang, X. Factorizable net: An efficient subgraph-based framework for scene graph generation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 335–351. [Google Scholar]
- Yang, J.; Lu, J.; Lee, S.; Batra, D.; Parikh, D. Graph r-cnn for scene graph generation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 670–685. [Google Scholar]
- Yin, G.; Sheng, L.; Liu, B.; Yu, N.; Wang, X.; Shao, J.; Change Loy, C. Zoom-net: Mining deep feature interactions for visual relationship recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 322–338. [Google Scholar]
- Woo, S.; Kim, D.; Cho, D.; Kweon, I.S. LinkNet: Relational Embedding for Scene Graph. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 558–568. [Google Scholar]
- Wang, W.; Wang, R.; Shan, S.; Chen, X. Exploring Context and Visual Pattern of Relationship for Scene Graph Generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8188–8197. [Google Scholar]
- Tang, K.; Zhang, H.; Wu, B.; Luo, W.; Liu, W. Learning to compose dynamic tree structures for visual contexts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 155–20 June 2019; pp. 6619–6628. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; He, X.; Pu, S.; Chang, S.F. Counterfactual Critic Multi-Agent Training for Scene Graph Generation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4613–4623. [Google Scholar]
- Tang, K.; Niu, Y.; Huang, J.; Shi, J.; Zhang, H. Unbiased scene graph generation from biased training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3716–3725. [Google Scholar]
- Desai, A.; Wu, T.Y.; Tripathi, S.; Vasconcelos, N. Learning of visual relations: The devil is in the tails. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15404–15413. [Google Scholar]
- Suhail, M.; Mittal, A.; Siddiquie, B.; Broaddus, C.; Eledath, J.; Medioni, G.; Sigal, L. Energy-Based Learning for Scene Graph Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13936–13945. [Google Scholar]
- Chen, T.; Yu, W.; Chen, R.; Lin, L. Knowledge-Embedded Routing Network for Scene Graph Generation. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Lin, X.; Ding, C.; Zeng, J.; Tao, D. Gps-net: Graph property sensing network for scene graph generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3746–3753. [Google Scholar]
- Yu, J.; Chai, Y.; Hu, Y.; Wu, Q. CogTree: Cognition Tree Loss for Unbiased Scene Graph Generation. arXiv 2020, arXiv:2009.07526. [Google Scholar]
- Li, R.; Zhang, S.; Wan, B.; He, X. Bipartite Graph Network With Adaptive Message Passing for Unbiased Scene Graph Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 11109–11119. [Google Scholar]
- Yan, S.; Shen, C.; Jin, Z.; Huang, J.; Jiang, R.; Chen, Y.; Hua, X.S. Pcpl: Predicate-correlation perception learning for unbiased scene graph generation. In Proceedings of the 28th ACM International Conference on Multimedia, Online, 12–16 October 2020; pp. 265–273. [Google Scholar]
- Chiou, M.J.; Ding, H.; Yan, H.; Wang, C.; Zimmermann, R.; Feng, J. Recovering the unbiased scene graphs from the biased ones. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 1581–1590. [Google Scholar]
- Guo, Y.; Gao, L.; Wang, X.; Hu, Y.; Xu, X.; Lu, X.; Shen, H.T.; Song, J. From general to specific: Informative scene graph generation via balance adjustment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 16383–16392. [Google Scholar]
- Li, W.; Zhang, H.; Bai, Q.; Zhao, G.; Jiang, N.; Yuan, X. PPDL: Predicate Probability Distribution Based Loss for Unbiased Scene Graph Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 19447–19456. [Google Scholar]
- Li, L.; Chen, L.; Huang, Y.; Zhang, Z.; Zhang, S.; Xiao, J. The Devil is in the Labels: Noisy Label Correction for Robust Scene Graph Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18869–18878. [Google Scholar]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.J.; Shamma, D.A.; et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; et al. The open images dataset v4. Int. J. Comput. Vis. 2020, 128, 1956–1981. [Google Scholar] [CrossRef]
- Zhan, Y.; Yu, J.; Yu, T.; Tao, D. On Exploring Undetermined Relationships for Visual Relationship Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5128–5137. [Google Scholar]
- Sadeghi, M.A.; Farhadi, A. Recognition using visual phrases. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1745–1752. [Google Scholar]
- Gu, J.; Zhao, H.; Lin, Z.; Li, S.; Cai, J.; Ling, M. Scene graph generation with external knowledge and image reconstruction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1969–1978. [Google Scholar]
- Yu, R.; Li, A.; Morariu, V.I.; Davis, L.S. Visual relationship detection with internal and external linguistic knowledge distillation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1974–1982. [Google Scholar]
- Yang, G.; Zhang, J.; Zhang, Y.; Wu, B.; Yang, Y. Probabilistic Modeling of Semantic Ambiguity for Scene Graph Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12527–12536. [Google Scholar]
- Lyu, X.; Gao, L.; Guo, Y.; Zhao, Z.; Huang, H.; Shen, H.T.; Song, J. Fine-Grained Predicates Learning for Scene Graph Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 19467–19475. [Google Scholar]
- Dong, X.; Gan, T.; Song, X.; Wu, J.; Cheng, Y.; Nie, L. Stacked Hybrid-Attention and Group Collaborative Learning for Unbiased Scene Graph Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 19427–19436. [Google Scholar]
- Goel, A.; Fernando, B.; Keller, F.; Bilen, H. Not All Relations are Equal: Mining Informative Labels for Scene Graph Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 15596–15606. [Google Scholar]
- Li, Y.; Yang, X.; Xu, C. Dynamic Scene Graph Generation via Anticipatory Pre-Training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13874–13883. [Google Scholar]
- Teng, Y.; Wang, L. Structured sparse r-cnn for direct scene graph generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 19437–19446. [Google Scholar]
- Zhang, A.; Yao, Y.; Chen, Q.; Ji, W.; Liu, Z.; Sun, M.; Chua, T.S. Fine-Grained Scene Graph Generation with Data Transfer. arXiv 2022, arXiv:2203.11654. [Google Scholar]
- Lin, X.; Ding, C.; Zhang, J.; Zhan, Y.; Tao, D. RU-Net: Regularized Unrolling Network for Scene Graph Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 19457–19466. [Google Scholar]
- Yang, J.; Ang, Y.Z.; Guo, Z.; Zhou, K.; Zhang, W.; Liu, Z. Panoptic Scene Graph Generation. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 178–196. [Google Scholar]
- Deng, Y.; Li, Y.; Zhang, Y.; Xiang, X.; Wang, J.; Chen, J.; Ma, J. Hierarchical Memory Learning for Fine-Grained Scene Graph Generation. arXiv 2022, arXiv:2203.06907. [Google Scholar]
- He, T.; Gao, L.; Song, J.; Li, Y.F. Towards open-vocabulary scene graph generation with prompt-based finetuning. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 56–73. [Google Scholar]
- Brown, S. Measures of shape: Skewness and kurtosis. Retrieved August 2011, 20, 2012. [Google Scholar]
- Zhu, Z.; He, X.; Qi, G.; Li, Y.; Cong, B.; Liu, Y. Brain tumor segmentation based on the fusion of deep semantics and edge information in multimodal MRI. Inf. Fusion 2023, 91, 376–387. [Google Scholar] [CrossRef]
- Zellers, R.; Yatskar, M.; Thomson, S.; Choi, Y. Neural motifs: Scene graph parsing with global context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5831–5840. [Google Scholar]
- Cui, Y.; Jia, M.; Lin, T.Y.; Song, Y.; Belongie, S. Class-balanced loss based on effective number of samples. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9268–9277. [Google Scholar]
- Kang, H.; Vu, T.; Yoo, C.D. Learning Imbalanced Datasets With Maximum Margin Loss. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 1269–1273. [Google Scholar]
- Zhang, J.; Shih, K.J.; Elgammal, A.; Tao, A.; Catanzaro, B. Graphical contrastive losses for scene graph parsing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 155–20 June 2019; pp. 11535–11543. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in neural information processing systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Misra, I.; Lawrence Zitnick, C.; Mitchell, M.; Girshick, R. Seeing through the human reporting bias: Visual classifiers from noisy human-centric labels. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2930–2939. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PredCls | SGCls | SGDet | ||||
|---|---|---|---|---|---|---|
| Model | mR@20/50/100 | R@20/50/100 | mR@20/50/100 | R@20/50/100 | mR@20/50/100 | R@20/50/100 |
| IMP+ [31] | -.-/ 9.8/10.5 | 52.7/59.3/61.3 | -.-/ 5.8/ 6.0 | 31.7/34.6/35.4 | -.-/ 3.8/ 4.8 | 14.6/20.7/24.5 |
| FREQ [74] | 8.3/13.0/16.0 | 53.6/60.6/62.2 | 5.1/ 7.2/ 8.5 | 29.3/32.3/32.9 | 4.5/ 6.1/ 7.1 | 20.1/26.2/30.1 |
| KERN [46] | -.-/17.7/19.2 | -.-/65.8/67.6 | -.-/ 9.4/10.0 | -.-/36.7/37.4 | -.-/ 6.4/ 7.3 | -.-/27.1/29.8 |
| MOTIFS [74] | 10.8/14.0/15.3 | 58.5/65.2/67.1 | 6.3/ 7.7/ 8.2 | 32.9/35.8/36.5 | 4.2/ 5.7/ 6.6 | 21.4/27.2/30.3 |
| VCTree [41] | 14.0/17.9/19.4 | 60.1/66.4/68.1 | 8.2/10.1/10.8 | 35.2/38.1/38.8 | 5.2/ 6.9/ 8.0 | 22.0/27.9/31.3 |
| MSDN [33] | -.-/15.9/17.5 | -.-/64.6/66.6 | -.-/ 9.3/ 9.7 | -.-/38.4/39.8 | -.-/ 6.1/ 7.2 | -.-/31.9/36.6 |
| G-RCNN [37] | -.-/16.4/17.2 | -.-/64.8/66.7 | -.-/ 9.0/ 9.5 | -.-/38.5/37.0 | -.-/ 5.8/ 6.6 | -.-/29.7/32.8 |
| BGNN [49] | -.-/30.4/32.9 | -.-/59.2/61.3 | -.-/14.3/16.5 | -.-/37.4/38.5 | -.-/10.7/12.6 | -.-/31.0/35.8 |
| DT2-ACBS [44] | -.-/35.9/39.7 | -.-/23.3/25.6 | -.-/24.8/27.5 | -.-/16.2/17.6 | -.-/22.0/24.4 | -.-/15.0/16.3 |
| MOTIFS [74] | 11.5/14.6/15.8 | 59.5/66.0/67.9 | 6.5/ 8.0/ 8.5 | 35.8/39.1/39.9 | 4.1/ 5.5/ 6.8 | 25.1/32.1/36.9 |
| + TDE [43] | 18.5/25.5/29.1 | 33.6/46.2/51.4 | 9.8/13.1/14.9 | 21.7/27.7/29.9 | 5.8/ 8.2/ 9.8 | 12.4/16.9/20.3 |
| + PCPL [50] | -.-/24.3/26.1 | -.-/54.7/56.5 | -.-/12.0/12.7 | -.-/35.3/36.1 | -.-/10.7/12.6 | -.-/27.8/31.7 |
| + CogTree [48] | 20.9/26.4/29.0 | 31.1/35.6/36.8 | 12.1/14.9/16.1 | 19.4/21.6/22.2 | 7.9/10.4/11.8 | 15.7/20.0/22.1 |
| + DLFE [51] | 22.1/26.9/28.8 | -.-/52.5/54.2 | 12.8/15.2/15.9 | -.-/32.3/33.1 | 8.6/11.7/13.8 | -.-/25.4/29.4 |
| + BPL-SA [52] | 24.8/29.7/31.7 | -.-/50.7/52.5 | 14.0/16.5/17.5 | -.-/30.1/31.0 | 10.7/13.5/15.6 | -.-/23.0/26.9 |
| + PPDL [53] | -.-/32.2/33.3 | -.-/47.2/47.6 | -.-/17.5/18.2 | -.-/28.4/29.3 | -.-/11.4/13.5 | -.-/21.2/23.9 |
| + NICE [54] | -.-/29.9/32.3 | -.-/55.1/57.2 | -.-/16.6/17.9 | -.-/33.1/34.0 | -.-/12.2/14.4 | -.-/27.8/31.8 |
| + SCR† (ours) | 25.9/31.5/33.6 | 51.0/57.9/60.1 | 14.2/17.1/18.2 | 27.1/31.0/32.3 | 9.6/13.5/15.9 | 18.1/25.1/29.5 |
| VCTree [41] | 11.7/14.9/16.1 | 59.8/66.2/68.1 | 6.2/ 7.5/ 7.9 | 37.0/40.5/41.4 | 4.2/ 5.7/ 6.9 | 24.7/31.5/36.2 |
| + TDE [43] | 18.4/25.4/28.7 | 36.2/47.2/51.6 | 8.9/12.2/14.0 | 19.9/25.4/27.9 | 6.9/ 9.3/11.1 | 14.0/19.4/23.2 |
| + PCPL [50] | -.-/22.8/24.5 | -.-/56.9/58.7 | -.-/15.2/16.1 | -.-/40.6/41.7 | -.-/10.8/12.6 | -.-/26.6/30.3 |
| + CogTree [48] | 22.0/27.6/29.7 | 39.0/44.0/45.4 | 15.4/18.8/19.9 | 27.8/30.9/31.7 | 7.8/10.4/12.1 | 14.0/18.2/20.4 |
| + DLFE [51] | 20.8/25.3/27.1 | -.-/51.8/53.5 | 15.8/18.9/20.0 | -.-/33.5/34.6 | 8.6/11.8/13.8 | -.-/22.7/26.3 |
| + BPL-SA [52] | 26.2/30.6/32.6 | -.-/50.0/51.8 | 17.2/20.1/21.2 | -.-/34.0/35.0 | 10.6/13.5/15.7 | -.-/21.7/25.5 |
| + PPDL [53] | -.-/33.3/33.8 | -.-/47.6/48.0 | -.-/14.3/15.7 | -.-/32.1/33.0 | -.-/11.3/13.3 | -.-/20.1/22.9 |
| + NICE [54] | -.-/30.7/33.0 | -.-/55.0/56.9 | -.-/19.9/21.3 | -.-/37.8/39.0 | -.-/11.9/14.1 | -.-/27.0/30.8 |
| + SCR† (ours) | 27.7/33.5/35.5 | 49.7/56.4/58.3 | 15.4/18.9/20.1 | 26.7/30.6/31.9 | 10.3/13.8/16.3 | 18.1/25.0/29.4 |
| SG-Transformer [48] | 14.8/19.2/20.5 | 58.5/65.0/66.7 | 8.9/11.6/12.6 | 35.6/38.9/39.8 | 5.6/ 7.7/ 9.0 | 24.0/30.3/33.3 |
| + CogTree[48] | 22.9/28.4/31.0 | 34.1/38.4/39.7 | 13.0/15.7/16.7 | 20.8/22.9/23.4 | 7.9/11.1/12.7 | 15.1/19.5/21.7 |
| + SCR† (ours) | 27.0/32.2/34.5 | 45.3/52.7/55.0 | 14.9/17.7/18.7 | 25.1/28.9/30.2 | 10.4 /13.4/15.0 | 17.7/23.2/26.2 |
| Zero-Shot Relationship Retrieval | PredCls | SGCls | SGDet | ||||
|---|---|---|---|---|---|---|---|
| Model | Method | R@50 | R@100 | R@50 | R@100 | R@50 | R@100 |
| MOTIFS [43] | baseline [43] Reweight [43] TDE [43] CogTree [48] SCR† (ours) | 10.9 0.7 14.4 2.4 18.0 | 14.5 0.9 18.2 4.0 21.1 | 2.2 0.1 3.4 0.9 5.1 | 3.0 0.1 4.5 1.5 5.9 | 0.1 0.0 2.3 0.3 2.4 | 0.2 0.0 2.9 0.6 3.8 |
| VCTree [43] | Baseline [43] TDE [43] CogTree [48] SCR† (ours) | 10.8 14.3 3.3 17.6 | 14.3 17.6 5.0 20.4 | 1.9 3.2 2.1 4.5 | 2.6 4.0 2.6 5.2 | 0.2 2.6 0.4 2.5 | 0.7 3.2 0.6 3.5 |
| SG-Transformer [48] | Baseline CogTree [48] SCR† (ours) | 4.1 5.2 16.4 | 6.3 7.3 19.6 | 1.6 2.3 4.6 | 2.3 3.0 5.3 | 0.2 0.3 2.0 | 0.5 0.5 3.2 |
| BGNN [49] | BGNN CogTree [48] SCR† (ours) | 15.0 13.4 16.3 | 18.0 16.1 19.5 | 4.5 5.0 4.9 | 5.4 5.7 5.9 | 4.5 0.5 1.9 | 5.3 0.8 3.0 |
| Dataset | Models | mR@50 | R@50 | wmAP | score | |
|---|---|---|---|---|---|---|
| rel | phr | |||||
| V4 | RelDN [77] | 70.40 | 75.66 | 36.13 | 39.91 | 45.21 |
| GPS-Net [47] | 69.50 | 74.65 | 35.02 | 39.40 | 44.70 | |
| BGNN [49] | 72.11 | 75.46 | 37.76 | 41.70 | 46.87 | |
| BGNN+SCR† (ours) | 72.20 | 75.48 | 38.64 | 45.01 | 45.01 | |
| V6 | RelDN [77] | 33.98 | 73.08 | 32.16 | 33.39 | 40.84 |
| VCTree [41] | 33.91 | 74.08 | 34.16 | 33.11 | 40.21 | |
| MOTIFS [74] | 32.68 | 71.63 | 29.91 | 31.59 | 38.93 | |
| TDE [43] | 35.47 | 69.30 | 30.74 | 32.80 | 39.27 | |
| GPS-Net [47] | 35.26 | 74.81 | 32.85 | 33.98 | 41.69 | |
| BGNN [49] | 40.45 | 74.98 | 33.51 | 34.15 | 42.06 | |
| BGNN+SCR† (ours) | 42.43 | 75.21 | 33.98 | 35.13 | 42.66 | |
| Relationship Retrieval | PredCls | SGCls | SGDet | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Model | Method | mRR | ZSRR | RR | mRR | ZSRR | RR | mRR | ZSRR | RR |
| VCTree | SCR of FREQ SCR of EMB SCR of FREQ+EMB | 31.6 33.3 33.7 | 22.2 21.1 20.1 | 60.0 60.1 60.0 | 16.9 17.9 18.0 | 6.2 5.9 6.1 | 35.4 35.2 33.3 | 13.3 15.4 14.4 | 3.5 3.5 3.5 | 31.6 30.0 31.9 |
| Relationship Retrieval | PredCls | SGCls | SGDet | |||||
|---|---|---|---|---|---|---|---|---|
| Model | mRR | RR | mRR | RR | mRR | RR | ||
| VCTree +SCR† | 0.03 0.06 0.08 | 0.7 0.7 0.7 | 35.5 33.7 32.8 | 58.3 60.0 60.4 | 20.1 18.0 17.2 | 31.9 33.3 34.2 | 16.3 14.4 13.5 | 29.4 31.9 32.6 |
| 0.06 0.06 0.06 | 0.6 0.7 0.8 | 33.5 33.7 33.3 | 60.6 60.0 59.3 | 17.8 18.0 17.6 | 34.3 33.3 33.0 | 14.2 14.4 14.0 | 32.0 31.9 30.6 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, H.; Yoo, C.D. Skew Class-Balanced Re-Weighting for Unbiased Scene Graph Generation. Mach. Learn. Knowl. Extr. 2023, 5, 287-303. https://doi.org/10.3390/make5010018
Kang H, Yoo CD. Skew Class-Balanced Re-Weighting for Unbiased Scene Graph Generation. Machine Learning and Knowledge Extraction. 2023; 5(1):287-303. https://doi.org/10.3390/make5010018
Chicago/Turabian StyleKang, Haeyong, and Chang D. Yoo. 2023. "Skew Class-Balanced Re-Weighting for Unbiased Scene Graph Generation" Machine Learning and Knowledge Extraction 5, no. 1: 287-303. https://doi.org/10.3390/make5010018
APA StyleKang, H., & Yoo, C. D. (2023). Skew Class-Balanced Re-Weighting for Unbiased Scene Graph Generation. Machine Learning and Knowledge Extraction, 5(1), 287-303. https://doi.org/10.3390/make5010018