
Do We Need a Specific Corpus and Multiple High-Performance GPUs for Training the BERT Model? An Experiment on COVID-19 Dataset


Abstract
:1. Introduction
1.1. Related Works
1.1.1. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding
1.1.2. Zero-Shot Learning (ZSL)
1.1.3. Natural Language Inference (NLI)
- We tried to improve the SciBERT model by increasing the model vocabulary.
- In this paper, we propose a new method of using the pre-trained BERT model for zero-shot classification of COVID-19 literature that requires only one Tesla V100.
- We demonstrated how our model executes faster and uses fewer computation resources than the comparators.
- Additionally, we demonstrated how all models perform with different GPUs.
- Finally, we demonstrated the performance of all models.
2. Materials and Methods
2.1. Data Collection
2.1.1. Stanford Natural Language Inference (SNLI) Corpus
2.1.2. Multi-Genre Natural Language Inference (MultiNLI) Corpus
2.1.3. MedNLI—A Natural Language Inference Dataset for the Clinical Domain
2.2. Data Processing
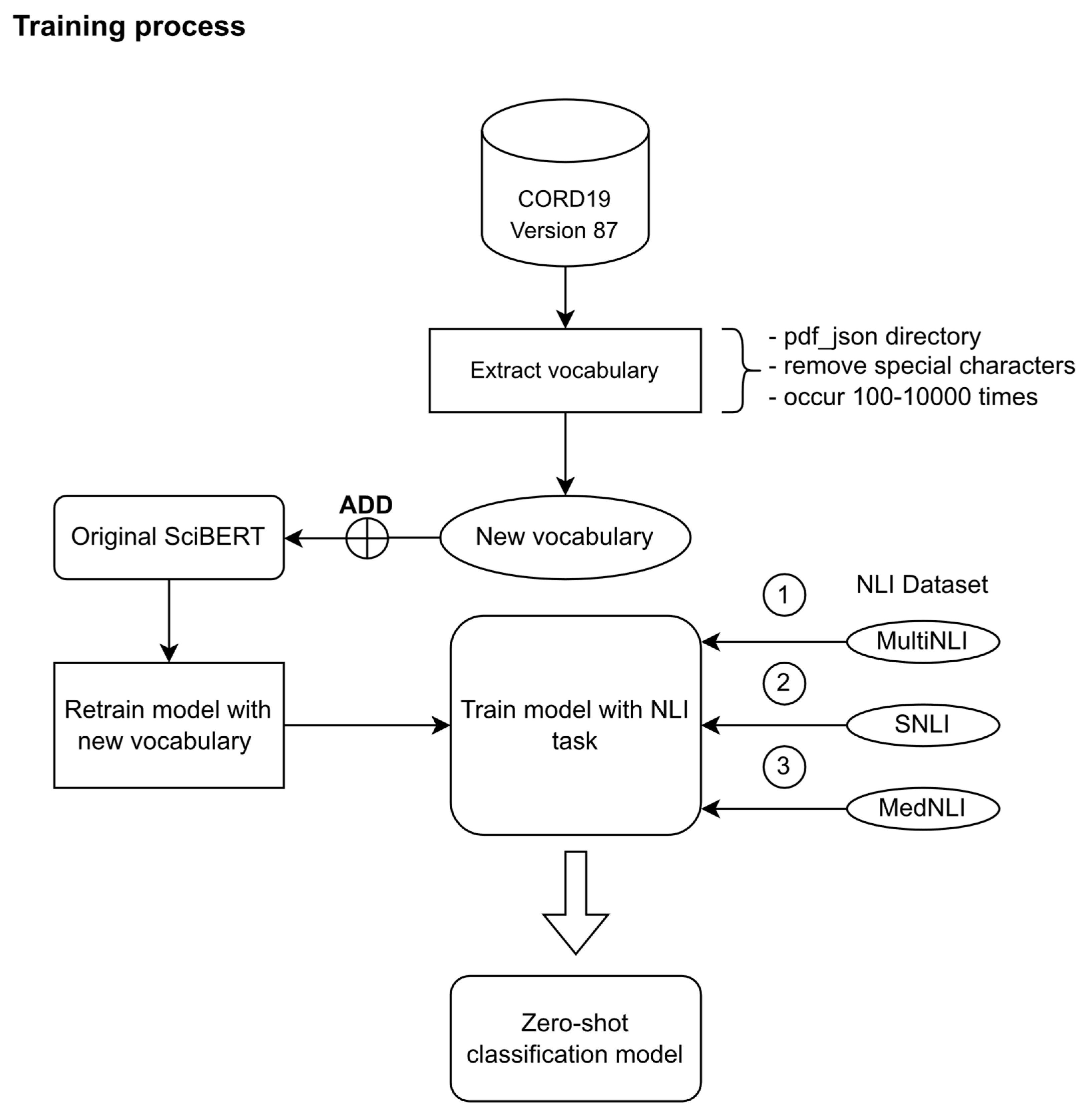
2.2.1. Vocabulary Preparation
- The CORD-19 dataset contains raw data from each article with two directories: pdf_json and pmc_json. The pmc_json directory is a directory which has only xml files and does not have an abstract section; as we intended to classify the abstract, we excluded this directory in this process. The pdf_json directory has only json files, which have a metadata section containing an abstract for each file. Eventually we created a pandas dataframe from the json files in the pdf_json directory, then we saved it as a comma-separated values (csv) file. The resulting csv file size was 9.77 GB from 191,569 articles.
- Articles that did not have an abstract and other sections, except an abstract from the file in the previous step, were discarded. The remaining abstracts were converted to lowercase and all special characters were removed (including a newline or \n character). There were 124,979 remaining abstracts.
- Infrequent or too frequent vocabulary, over 10,000 and less than 100 times, were removed. The remaining vocabulary words to add were 12,825.
- Finally, we added the new vocabulary to the SciBERT model, resulting in a total of 33,993 vocabularies in the improved model.
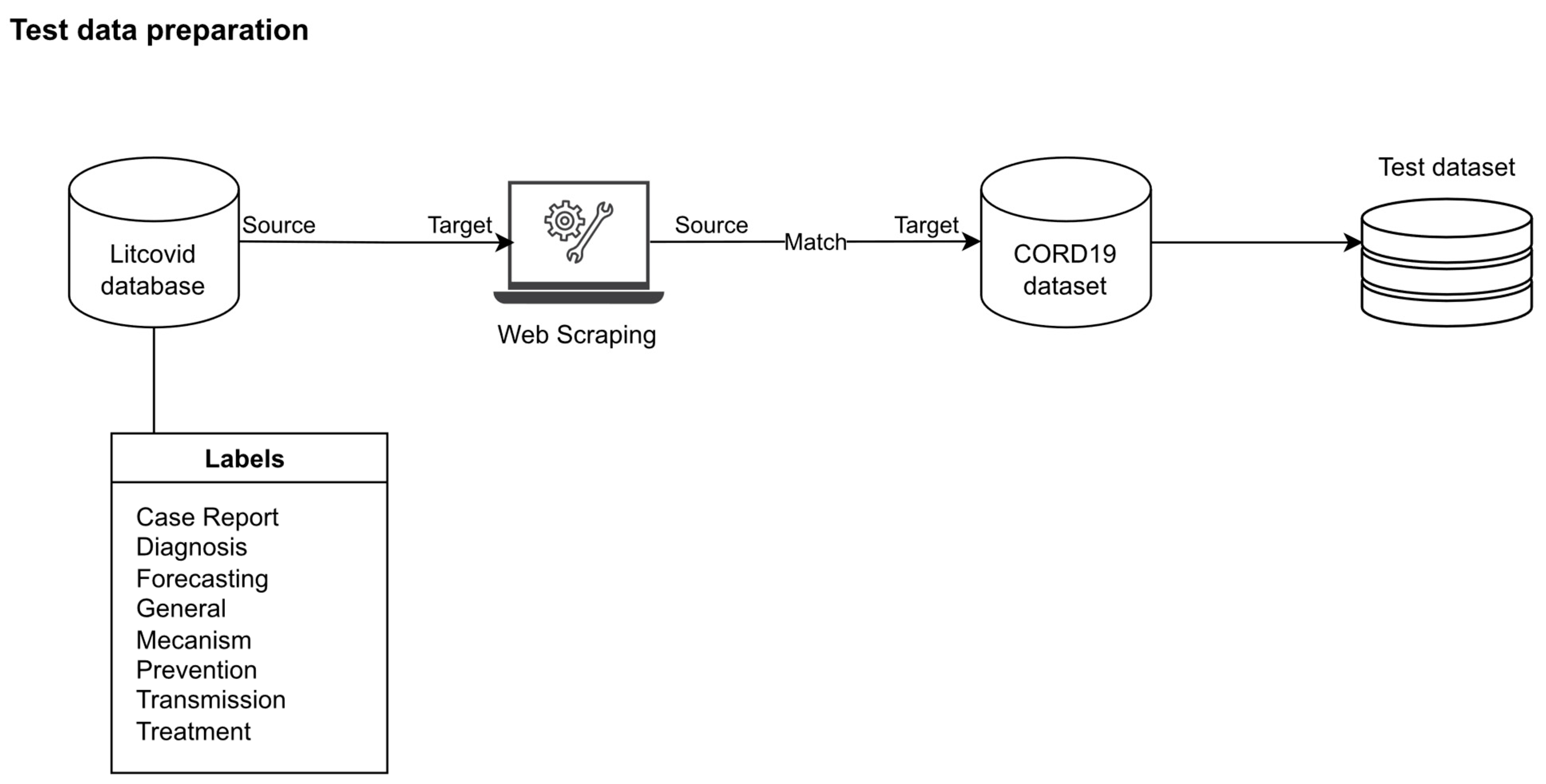
2.2.2. CORD-19 Dataset Preparation
2.2.3. Test Dataset Preparation
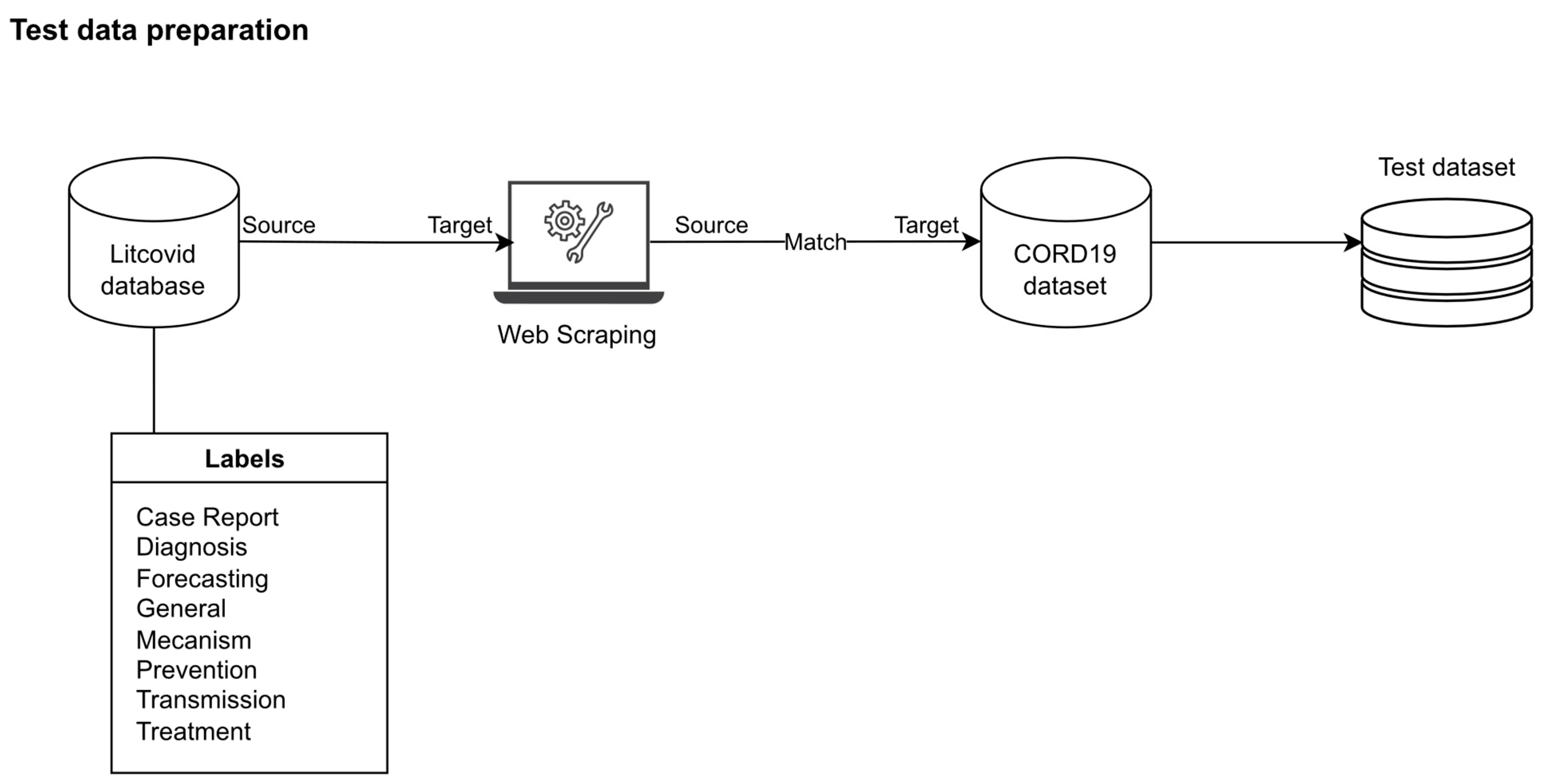
2.2.4. NLI Datasets Preparation
- SNLI and MultiNLI Datasets
- MedNLI Dataset
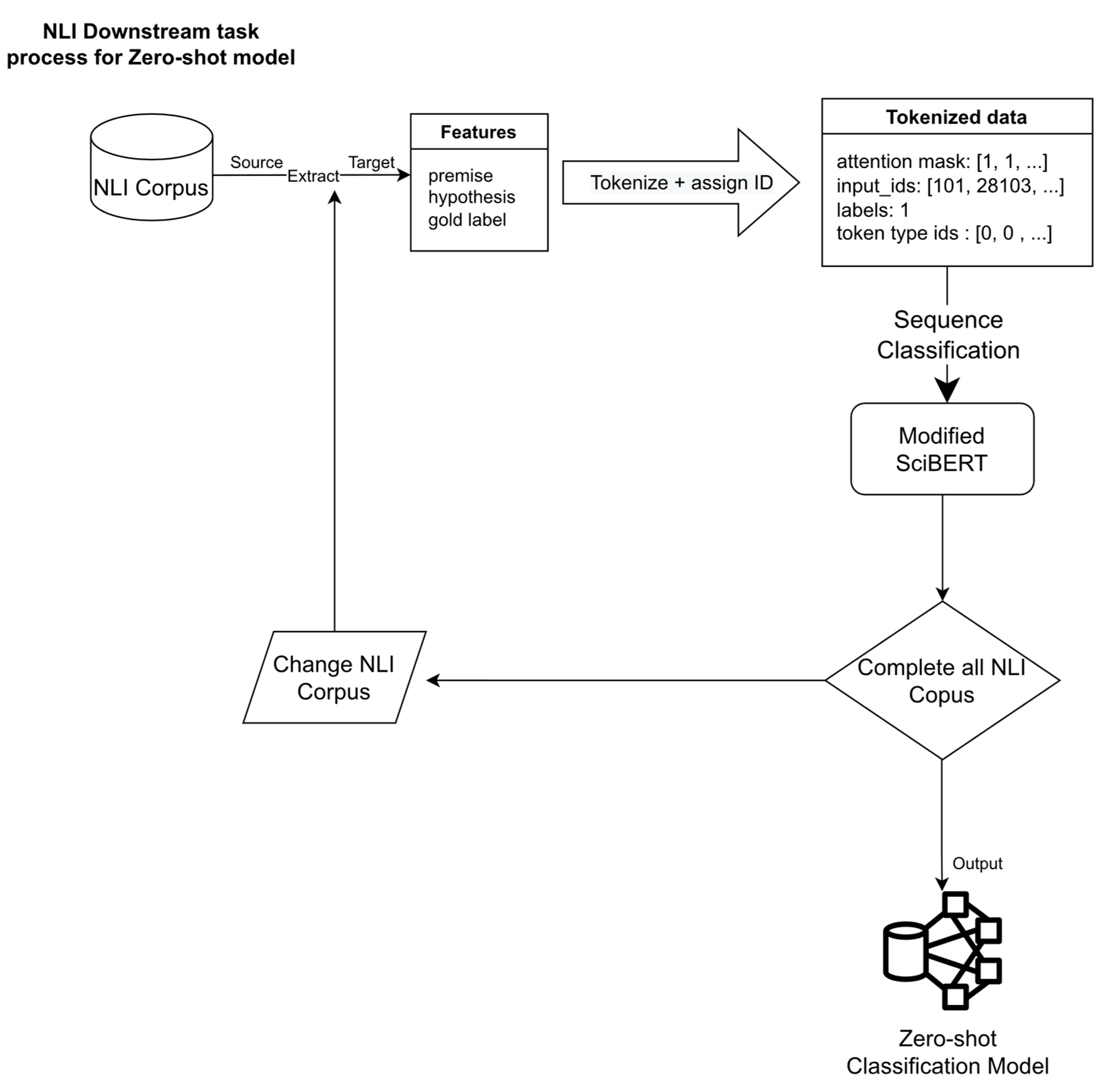
2.3. Training New Downstream Task for SciBERT Model

- Training parameters
- Training NLI downstream task process
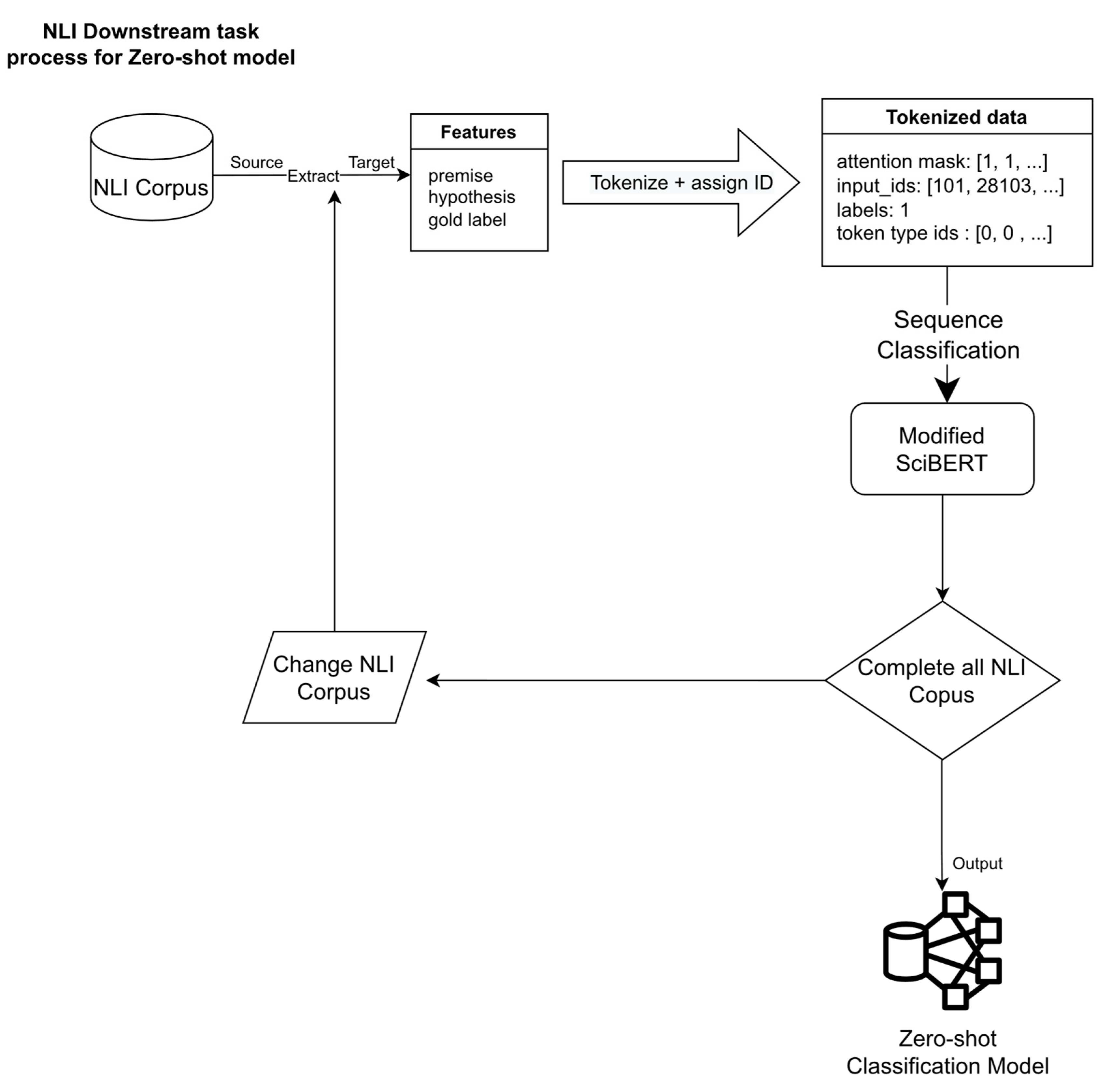
3. Results
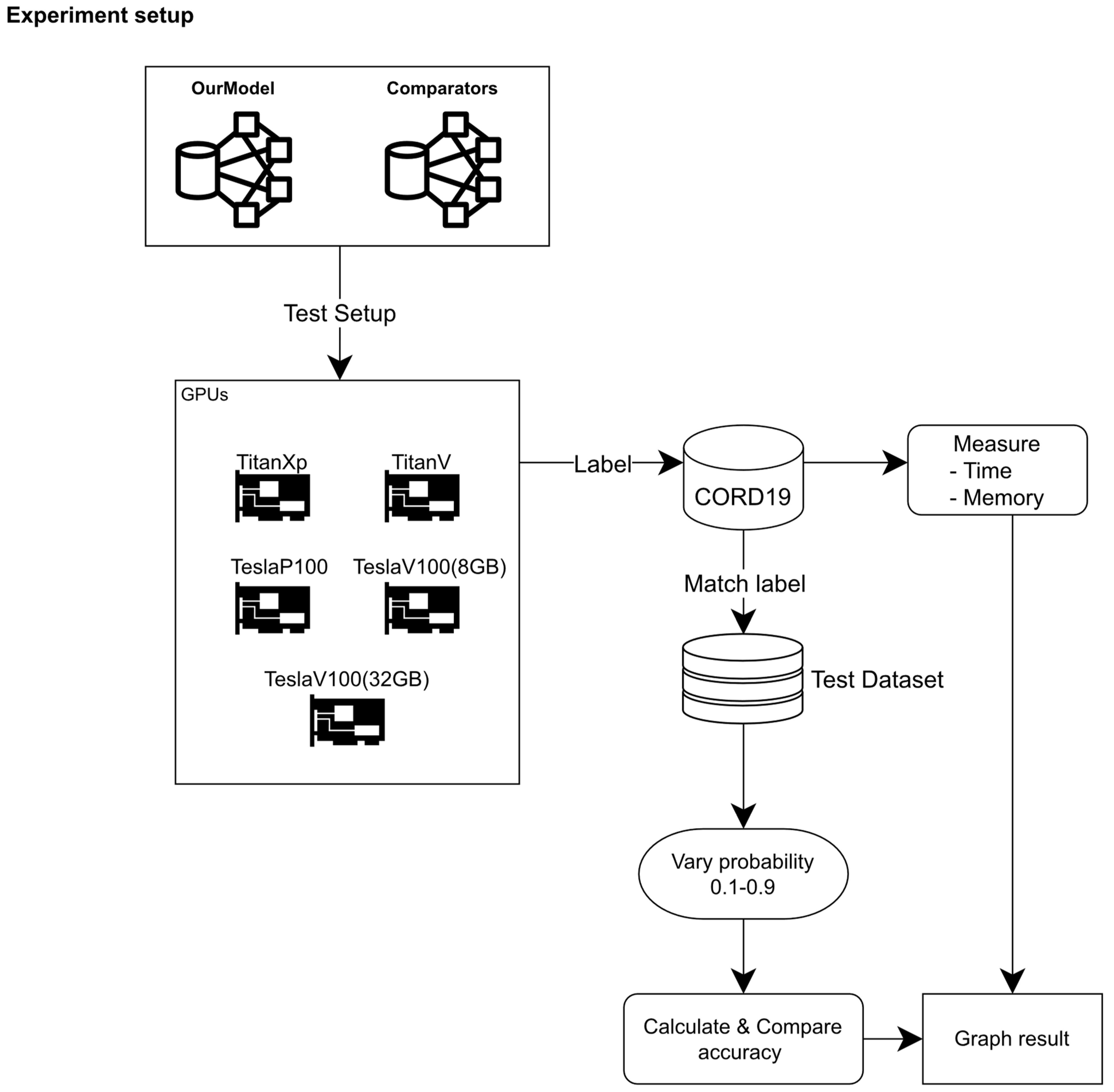
3.1. Model and Metric Comparators
3.2. Model Training Time
3.3. Model Size
3.4. Token Volume
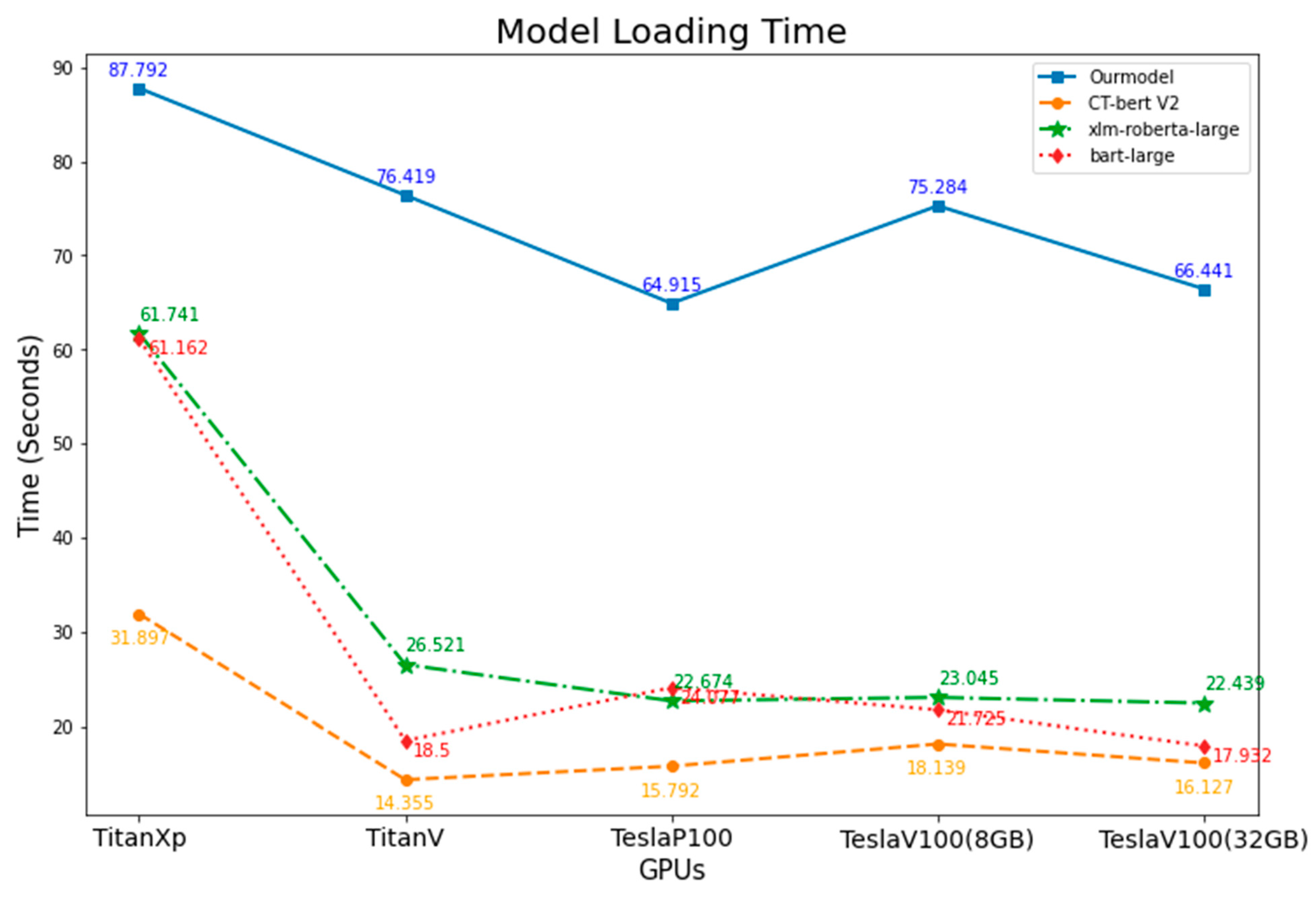
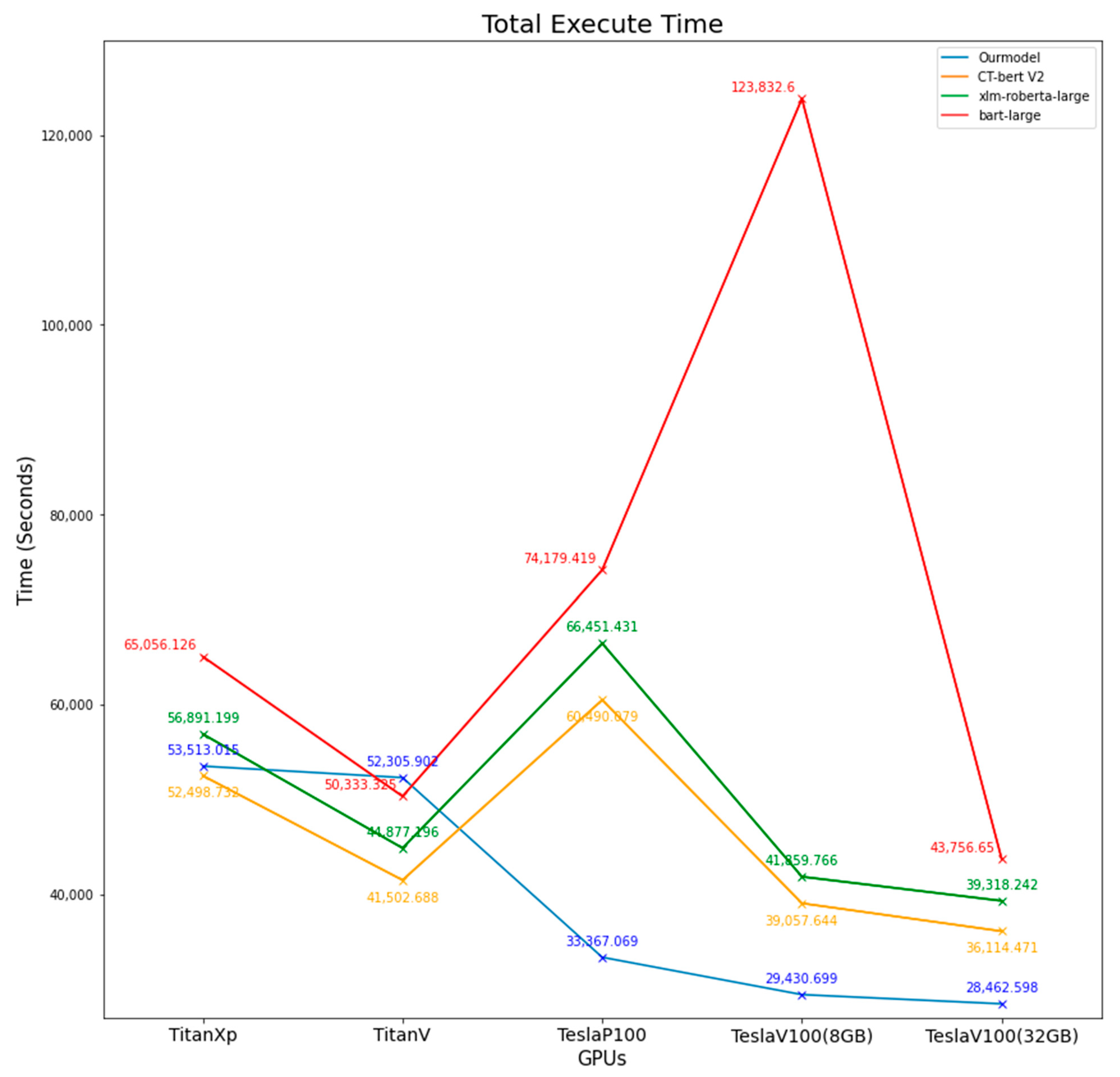
3.5. Time Usage
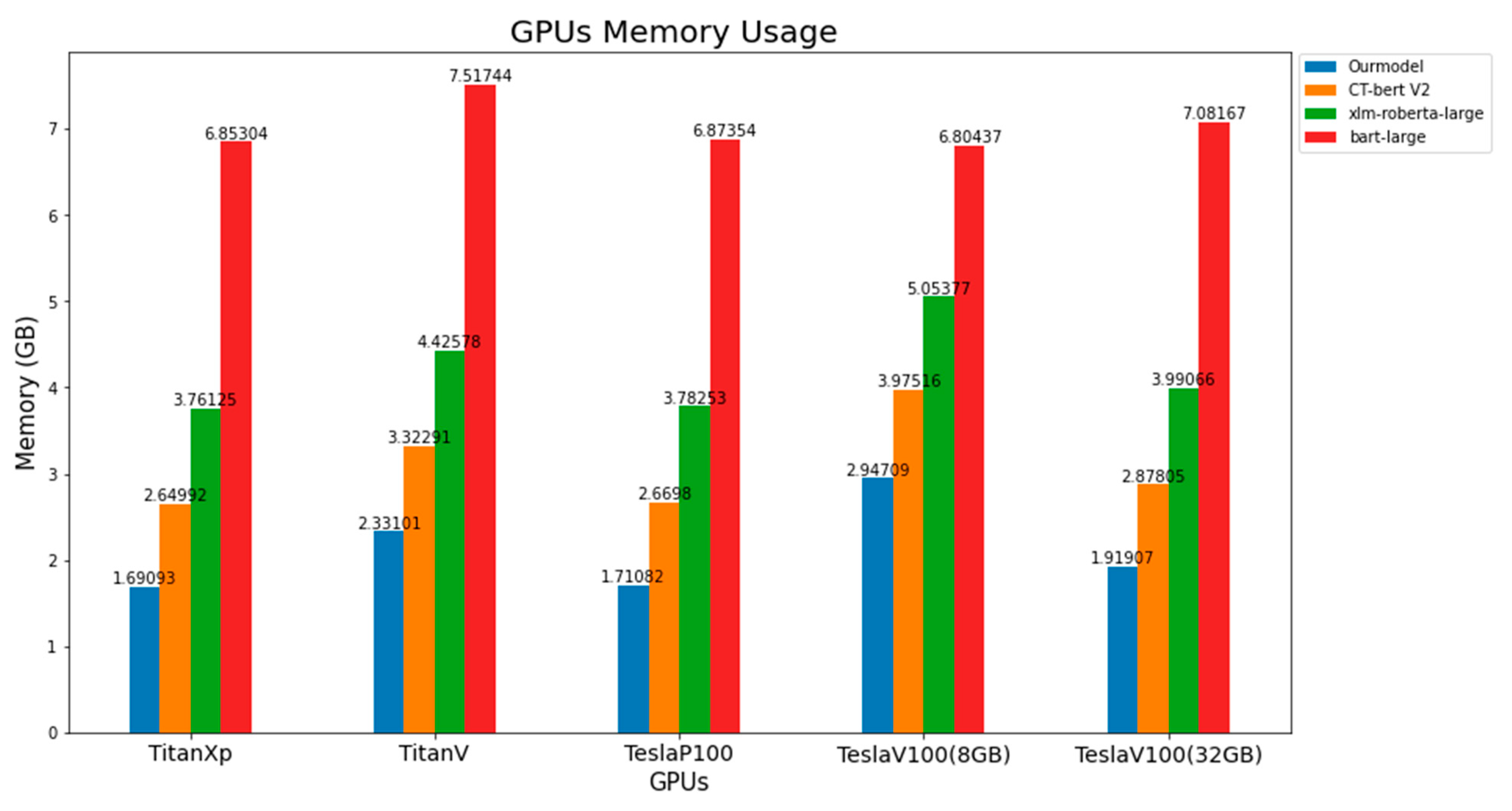
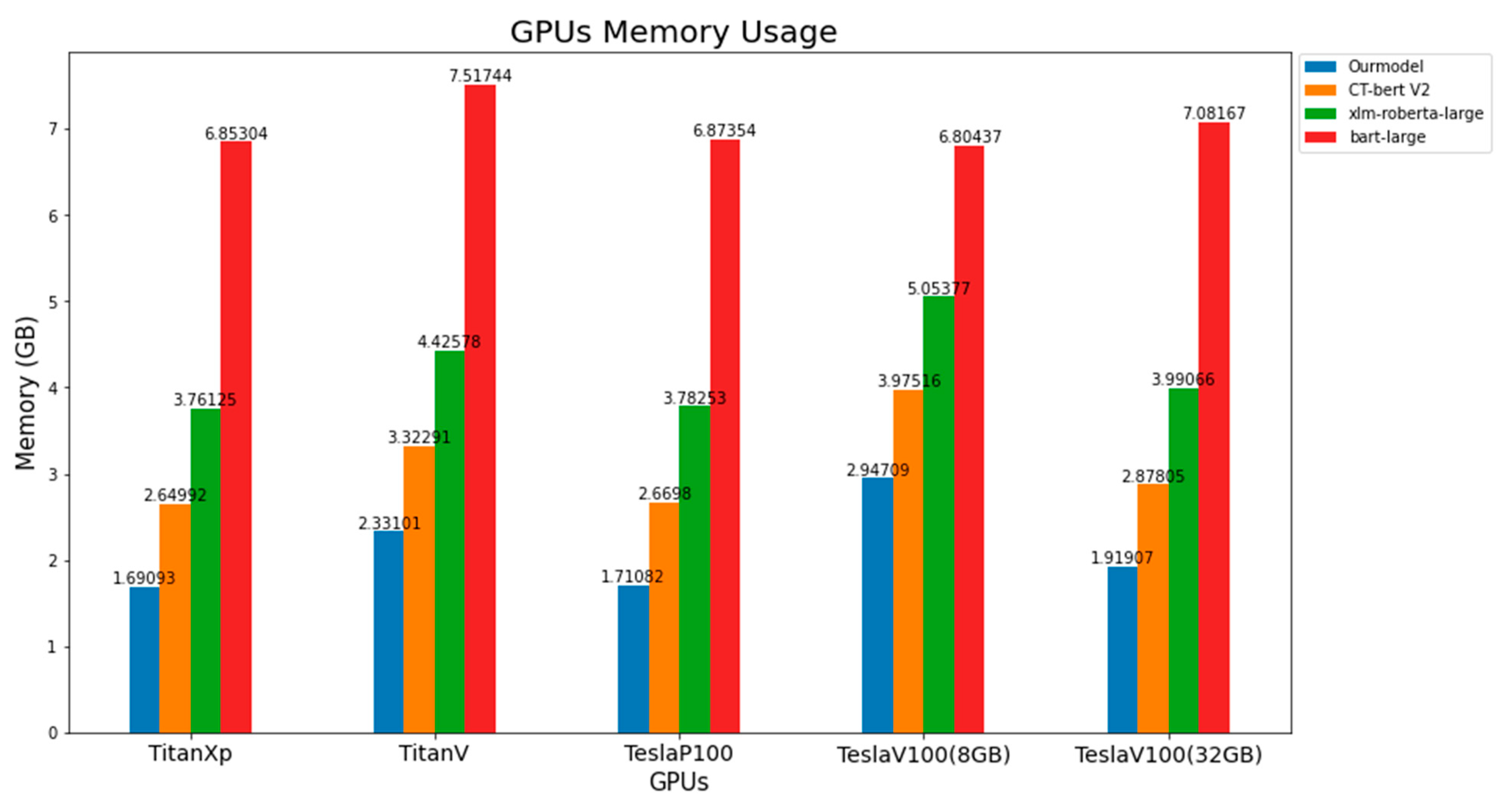
3.6. GPUs Memory Usage
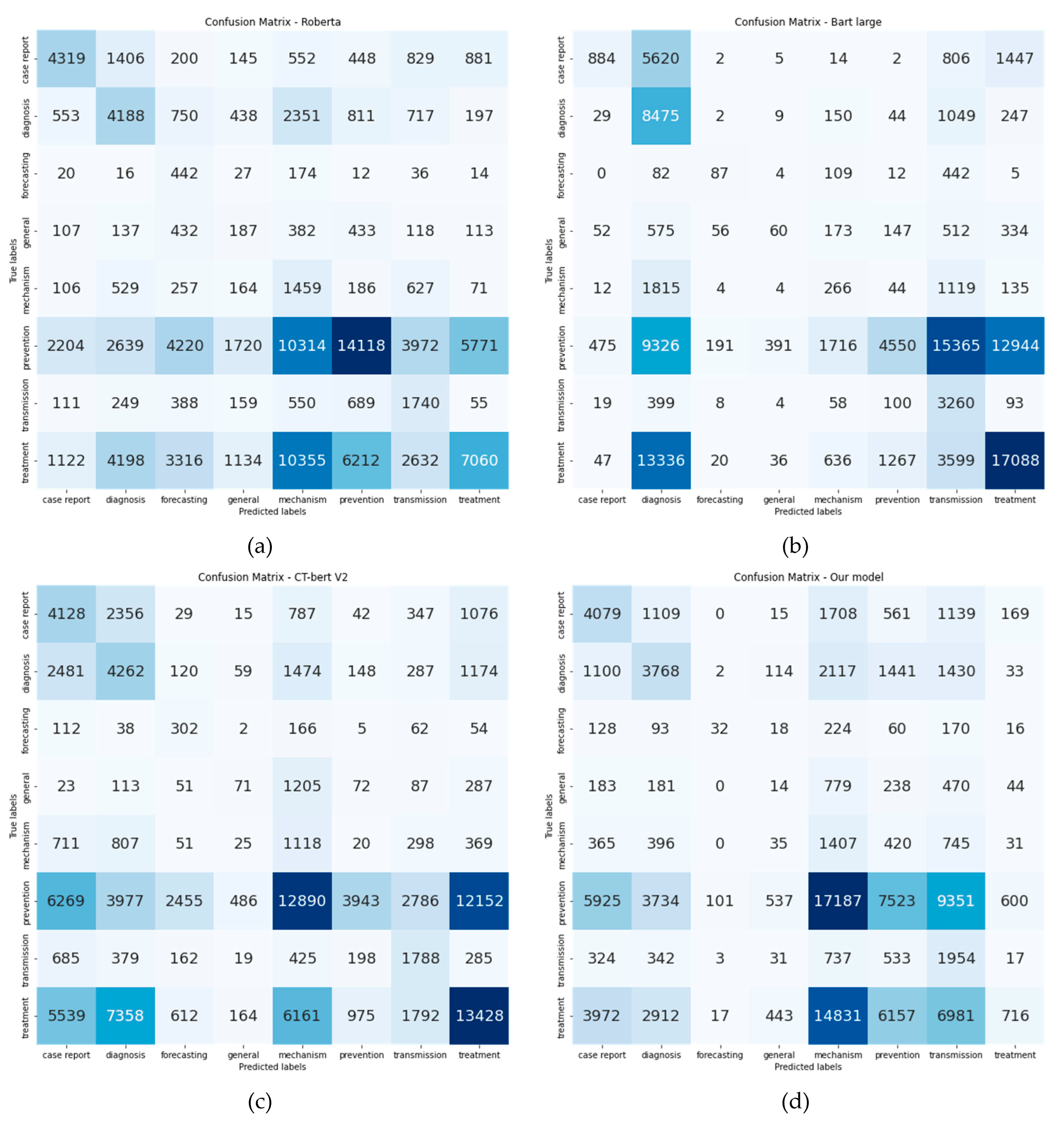
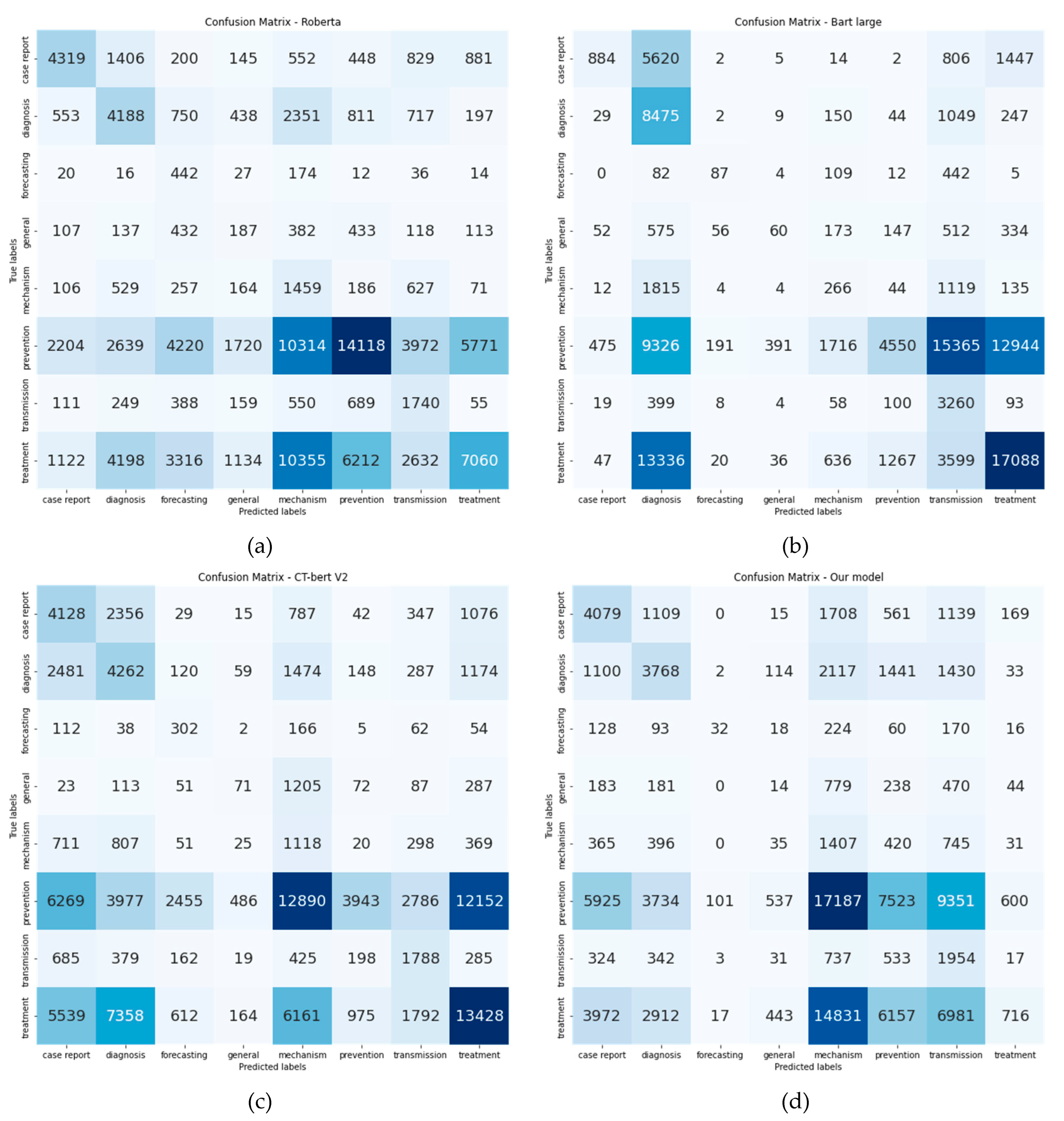
3.7. Precision, Recall and F1-Score
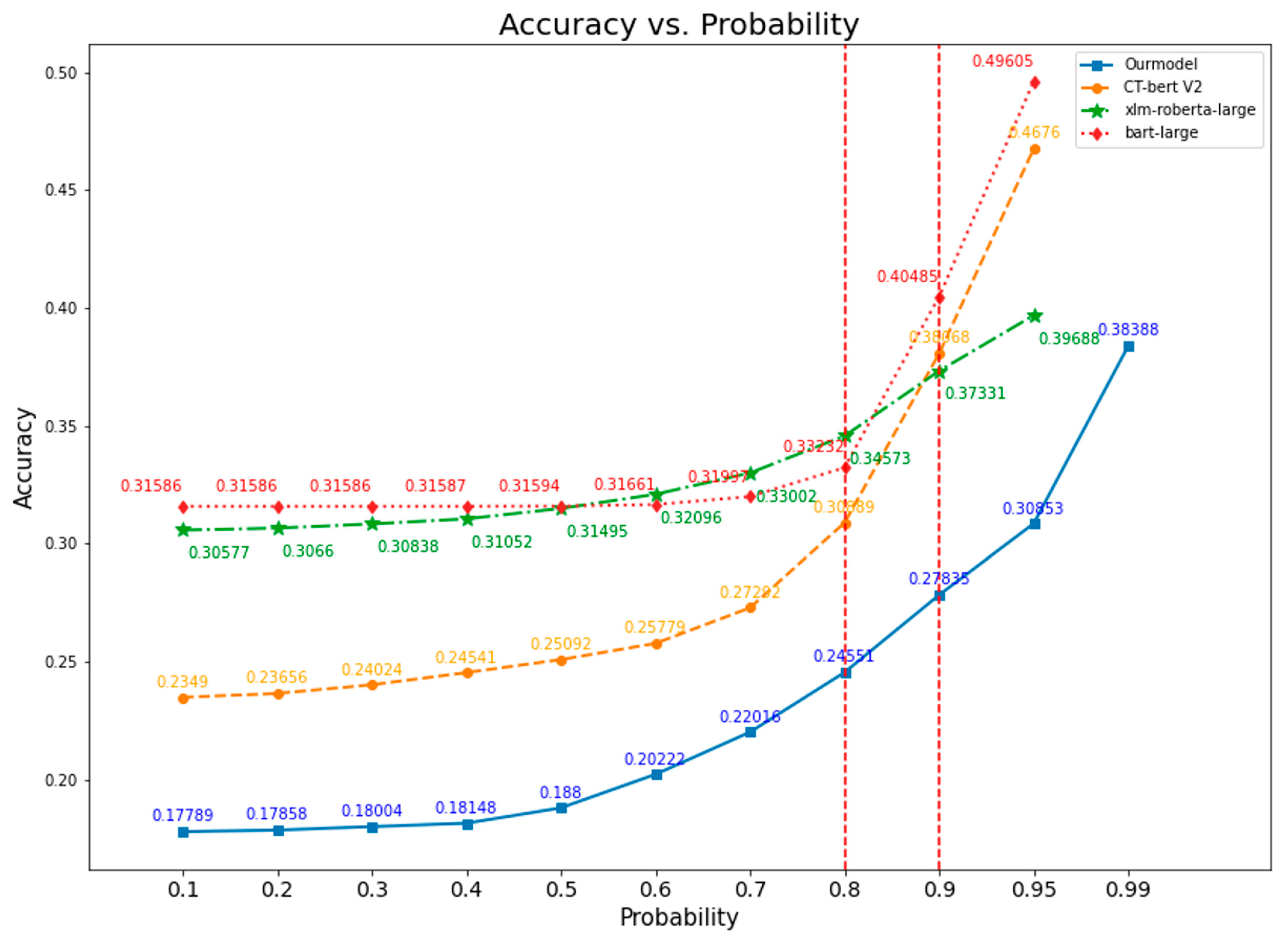
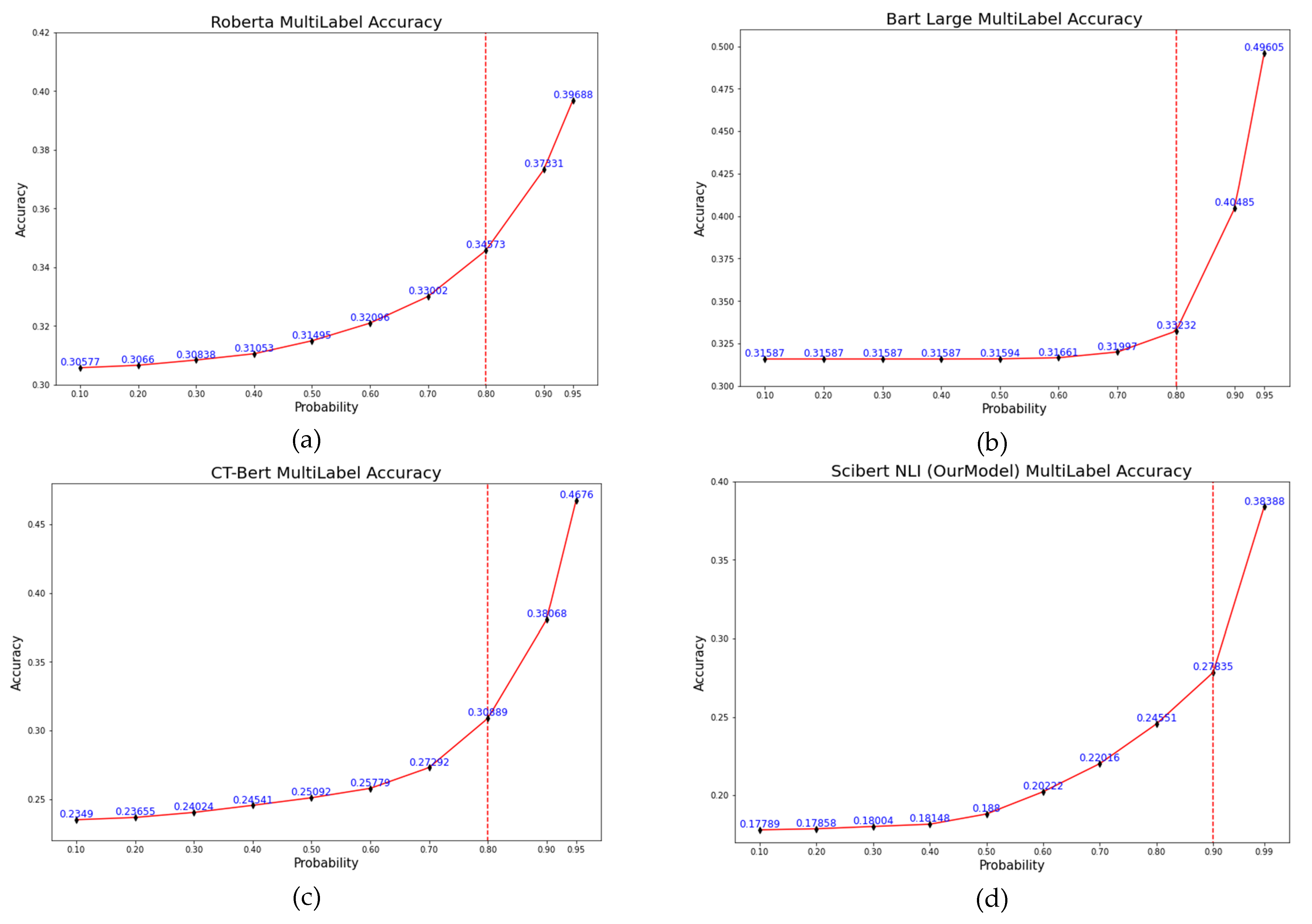
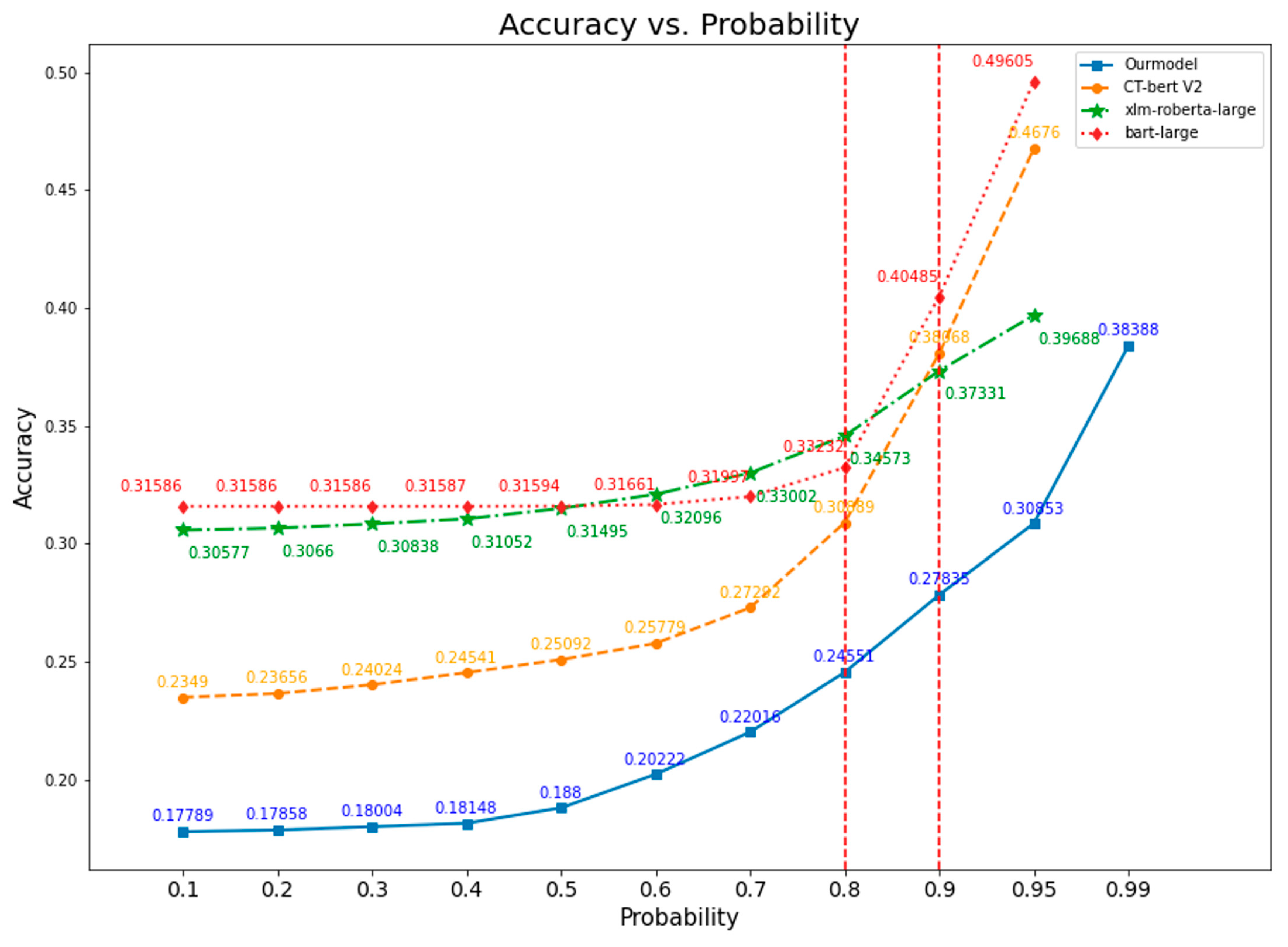
3.8. Accuracy
4. Discussion
Limitations of Our Study
- We used CORD-19 dataset version 87 to add new vocabulary to the SciBERT model. The CORD-19 dataset is updated regularly; now, it is version 105. Therefore, the dataset will now contain more articles than the version used in this paper.
- Our model can understand English only; the dataset may contain articles from different languages, meaning that our model cannot correctly classify them. On the other hand, xlm-roberta-large-xnli can understand languages other than English, including: French, Spanish, German, Greek, Bulgarian, Russian, Turkish, Arabic, Vietnamese, Thai, Chinese, Hindi, Swahili, Urdu, etc. [60].
- The metric that we presented was calculated with one label. However, as mentioned above, some articles were labeled with more than one class, and we did not have the tools to calculate the accuracy of all the labels.
- Due to limited resources, we could only completely execute the experiment on a virtual machine with Tesla V100 (8 GB) once. After that, the experiment on this virtual machine was interrupted before finishing.
- The tokenized abstract, which is longer than 512, was trimmed due to the original BERT’s length restriction.
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, L.L.; Lo, K.; Chandrasekhar, Y.; Reas, R.; Yang, J.; Eide, D.; Funk, K.; Kinney, R.; Liu, Z.; Merrill, W.; et al. CORD-19: The COVID-19 Open Research Dataset. arXiv 2020, arXiv:2004.10706v2. [Google Scholar]
- Pushp, P.K.; Srivastava, M.M. Train Once, Test Anywhere: Zero-Shot Learning for Text Classification. 2017. Available online: http://arxiv.org/abs/1712.05972 (accessed on 10 August 2021).
- COVID-19 Open Research Dataset Challenge (CORD-19)|Kaggle. Available online: https://www.kaggle.com/datasets/allen-institute-for-ai/CORD-19-research-challenge/code?datasetId=551982&searchQuery=zero-shot (accessed on 27 February 2022).
- Chang, M.W.; Ratinov, L.; Roth, D.; Srikumar, V. Importance of semantic representation: Dataless classification. Proc. Natl. Conf. Artif. Intell. 2008, 2, 830–835. [Google Scholar]
- Xian, Y.; Lampert, C.H.; Schiele, B.; Akata, Z. Zero-Shot Learning—A Comprehensive Evaluation of the Good, the Bad and the Ugly. 2017. Available online: http://arxiv.org/abs/1707.00600 (accessed on 10 August 2021).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Processing Syst. 2017, 30, 5998–6008. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized word representations. In Proceedings of the NAACL HLT 2018—2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LO, USA, 1–6 June 2018; Volume 1, pp. 2227–2237. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL HLT 2019—2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. Available online: http://arxiv.org/abs/1810.04805 (accessed on 30 September 2020).
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Gu, Y.; Tinn, R.; Cheng, H.; Lucas, M.; Usuyama, N.; Liu, X.; Naumann, T.; Gao, J.; Poon, H. Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing. ACM Trans. Comput. Healthc. 2022, 3, 1–23. [Google Scholar] [CrossRef]
- Alsentzer, E.; Murphy, J.R.; Boag, W.; Weng, W.H.; Jin, D.; Naumann, T.; McDermott, M. Publicly Available Clinical BERT Embeddings. arXiv 2019, arXiv:1904.03323. [Google Scholar]
- Rasmy, L.; Xiang, Y.; Xie, Z.; Tao, C.; Zhi, D. Med-BERT: Pretrained contextualized embeddings on large-scale structured electronic health records for disease prediction. NPJ Digit. Med. 2021, 4, 86. [Google Scholar] [CrossRef] [PubMed]
- Johnson, A.E.; Pollard, T.J.; Shen, L.; Lehman, L.W.H.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Anthony Celi, L.; Mark, R.G. MIMIC-III, a freely accessible critical care database. Sci. Data 2016, 3, 160035. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2020, 36, 1234–1240. [Google Scholar] [CrossRef] [PubMed]
- Beltagy, I.; Lo, K.; Cohan, A. SciBERT: A Pretrained Language Model for Scientific Text. arXiv 2019, arXiv:1903.10676v3. [Google Scholar]
- Zhu, Y.; Kiros, R.; Zemel, R.; Salakhutdinov, R.; Urtasun, R.; Torralba, A.; Fidler, S. Aligning Books and Movies: Towards Story-like Visual Explanations by Watching Movies and Reading Books. arXiv 2015, arXiv:1506.06724v1. [Google Scholar]
- Barbieri, F.; Camacho-Collados, J.; Neves, L.; Espinosa-Anke, L. TWEETEVAL: Unified benchmark and comparative evaluation for tweet classification. In Findings of the Association for Computational Linguistics Findings of ACL: EMNLP 2020; The Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 1644–1650. Available online: https://doi.org/10.18653/v1/2020.findings-emnlp.148 (accessed on 7 March 2022).
- Romera-Paredes, B.; Torr, P.H.S. An embarrassingly simple approach to zero-shot learning. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 3, pp. 2142–2151. [Google Scholar] [CrossRef]
- Zero-Shot Learning in Modern NLP|Joe Davison Blog. Available online: https://joeddav.github.io/blog/2020/05/29/ZSL.html (accessed on 3 March 2022).
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence embeddings using siamese BERT-networks. In Proceedings of the EMNLP-IJCNLP 2019—2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 3982–3992. [Google Scholar] [CrossRef] [Green Version]
- Cognitive Computation Group. Available online: https://cogcomp.seas.upenn.edu/page/resource_view/89 (accessed on 7 March 2022).
- Yin, W.; Hay, J.; Roth, D. Benchmarking zero-shot text classification: Datasets, evaluation and entailment approach. In Proceedings of the EMNLP-IJCNLP 2019—2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 3914–3923. [Google Scholar] [CrossRef]
- ScienceDirect Search Results—Keywords (Zero Shot Classification). Available online: https://www.sciencedirect.com/search?qs=zero%20shot%20classification&articleTypes=FLA&lastSelectedFacet=articleTypes (accessed on 16 June 2022).
- ScienceDirect Search Results—Keywords (Zero Shot Classification). Available online: https://www.sciencedirect.com/search?qs=zero%20shot%20classification&articleTypes=FLA&lastSelectedFacet=years&years=2022%2C2021%2C2020 (accessed on 16 June 2022).
- Chalkidis, I.; Fergadiotis, M.; Androutsopoulos, I. MultiEURLEX—A multi-lingual and multi-label legal document classification dataset for zero-shot cross-lingual transfer. In Proceedings of the EMNLP 2021—2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 6974–6996. [Google Scholar] [CrossRef]
- Mahapatra, D.; Bozorgtabar, B.; Ge, Z. Medical Image Classification Using Generalized Zero Shot Learning. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; Volume 2021, pp. 3337–3346. [Google Scholar] [CrossRef]
- Huang, S.C.; Shen, L.; Lungren, M.P.; Yeung, S. GLoRIA: A Multimodal Global-Local Representation Learning Framework for Label-efficient Medical Image Recognition. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3922–3931. [Google Scholar] [CrossRef]
- Mahapatra, D.; Ge, Z.; Reyes, M. Self-Supervised Generalized Zero Shot Learning For Medical Image Classification Using Novel Interpretable Saliency Maps. IEEE Trans. Med. Imaging, 2022; online ahead of print. [Google Scholar] [CrossRef]
- Models—Hugging Face. Available online: https://huggingface.co/models?search=bert (accessed on 27 February 2022).
- Models—Hugging Face. Available online: https://huggingface.co/models?pipeline_tag=zero-shot-classification&sort=downloads (accessed on 27 February 2022).
- Lupart, S.; Favre, B.; Nikoulina, V.; Ait-Mokhtar, S. Zero-Shot and Few-Shot Classification of Biomedical Articles in Context of the COVID-19 Pandemic. 2022. Available online: www.aaai.org (accessed on 10 August 2021).
- COVID-19 Open Research Dataset Challenge (CORD-19)|Kaggle. Available online: https://www.kaggle.com/dataset/08dd9ead3afd4f61ef246bfd6aee098765a19d9f6dbf514f0142965748be859b/version/87 (accessed on 1 March 2022).
- Bowman, S.R.; Angeli, G.; Potts, C.; Manning, C.D. A large annotated corpus for learning natural language inference. In Proceedings of the Conference Proceedings—EMNLP 2015: Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 632–642. [Google Scholar] [CrossRef]
- Williams, A.; Nangia, N.; Bowman, S.R. A broad-coverage challenge corpus for sentence understanding through inference. In Proceedings of the NAACL HLT 2018—2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LO, USA, 1–6 June 2018; Volume 1, pp. 1112–1122. [Google Scholar] [CrossRef] [Green Version]
- Romanov, A.; Shivade, C. Lessons from Natural Language Inference in the Clinical Domain. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 1586–1596. [Google Scholar] [CrossRef] [Green Version]
- Chen, Q.; Allot, A.; Lu, Z. LitCovid: An open database of COVID-19 literature. Nucleic Acids Res. 2021, 49, D1534–D1540. [Google Scholar] [CrossRef]
- joeddav/xlm-roberta-large-xnli Hugging Face. Available online: https://huggingface.co/joeddav/xlm-roberta-large-xnli (accessed on 26 March 2022).
- joeddav/bart-large-mnli-yahoo-answers Hugging Face. Available online: https://huggingface.co/joeddav/bart-large-mnli-yahoo-answers (accessed on 26 March 2022).
- digitalepidemiologylab/covid-twitter-bert-v2-mnli Hugging Face. Available online: https://huggingface.co/digitalepidemiologylab/covid-twitter-bert-v2-mnli (accessed on 26 March 2022).
- Tesla P100 Data Center Accelerator|NVIDIA. Available online: https://www.nvidia.com/en-us/data-center/tesla-p100/ (accessed on 5 April 2022).
- Comparison between NVIDIA GeForce and Tesla GPUs. Available online: https://www.microway.com/knowledge-center-articles/comparison-of-nvidia-geforce-gpus-and-nvidia-tesla-gpus/ (accessed on 5 April 2022).
- NVIDIA Tesla P100 16 GB, vs. Titan Xp Comparison. Available online: https://www.gpuzoo.com/Compare/NVIDIA_Tesla_P100_16_GB__vs__NVIDIA_Titan_Xp/ (accessed on 5 April 2022).
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation. arXiv 2019, arXiv:1910.13461. [Google Scholar]
- BART training time Issue #1525 pytorch/fairseq GitHub. Available online: https://github.com/pytorch/fairseq/issues/1525 (accessed on 7 April 2022).
- Müller, M.; Salathé, M.; Kummervold, P.E. COVID-Twitter-BERT: A Natural Language Processing Model to Analyse COVID-19 Content on Twitter. arXiv 2020, arXiv:2005.07503v1. [Google Scholar]
- You, Y.; Li, J.; Reddi, S.; Hseu, J.; Kumar, S.; Bhojanapalli, S.; Song, X.; Demmel, J.; Keutzer, K.; Hsieh, C.J. Large Batch Optimization for Deep Learning: Training BERT in 76 minutes. arXiv 2019, arXiv:1904.00962v5. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2022, arXiv:1609.08144v2. [Google Scholar]
- Gutiérrez, B.J.; Zeng, J.; Zhang, D.; Zhang, P.; Su, Y. Document Classification for COVID-19 Literature. arXiv 2020, arXiv:2006.13816v2. [Google Scholar]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The Long-Document Transformer. arXiv 2020, arXiv:2004.05150v2. [Google Scholar]
- Wahle, J.P.; Ashok, N.; Ruas, T.; Meuschke, N.; Ghosal, T.; Gipp, B. Testing the Generalization of Neural Language Models for COVID-19 Misinformation Detection. In Proceedings of the Information for a Better World: Shaping the Global Future: 17th International Conference, iConference 2022, Virtual, 28 February – 4 March 2022. [Google Scholar] [CrossRef]
- Mutlu, E.C.; Oghaz, T.; Jasser, J.; Tutunculer, E.; Rajabi, A.; Tayebi, A.; Ozmen, O.; Garibay, I. A stance data set on polarized conversations on Twitter about the efficacy of hydroxychloroquine as a treatment for COVID-19. Data in brief. 2020, 33, 106401. [Google Scholar] [CrossRef] [PubMed]
- Cui, L.; Lee, D. CoAID: COVID-19 Healthcare Misinformation Dataset. arXiv 2020, arXiv:2006.00885v3. [Google Scholar]
- Zhou, X.; Mulay, A.; Ferrara, E.; Zafarani, R. ReCOVery: A Multimodal Repository for COVID-19 News Credibility Research. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management (CIKM ’20). Association for Computing Machinery, Virtual, 19–23 October 2020; pp. 3205–3212. [Google Scholar] [CrossRef]
- Memon, S.A.; Carley, K.M. Characterizing COVID-19 Misinformation Communities Using a Novel Twitter Dataset. arXiv 2020, arXiv:2008.00791v4. [Google Scholar]
- Agarwal, I. COVID19FN. Available online: https://data.mendeley.com/datasets/b96v5hmfv6/2 (accessed on 20 April 2021).
- Eren, M.E.; Solovyev, N.; Raff, E.; Nicholas, C.; Johnson, B. COVID-19 Kaggle Literature Organization. In Proceedings of the ACM Symposium on Document Engineering, DocEng 2020, Virtual, 29 September–1 October 2020. [Google Scholar] [CrossRef]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised Cross-lingual Representation Learning at Scale. arXiv 2019, arXiv:1911.02116. [Google Scholar]



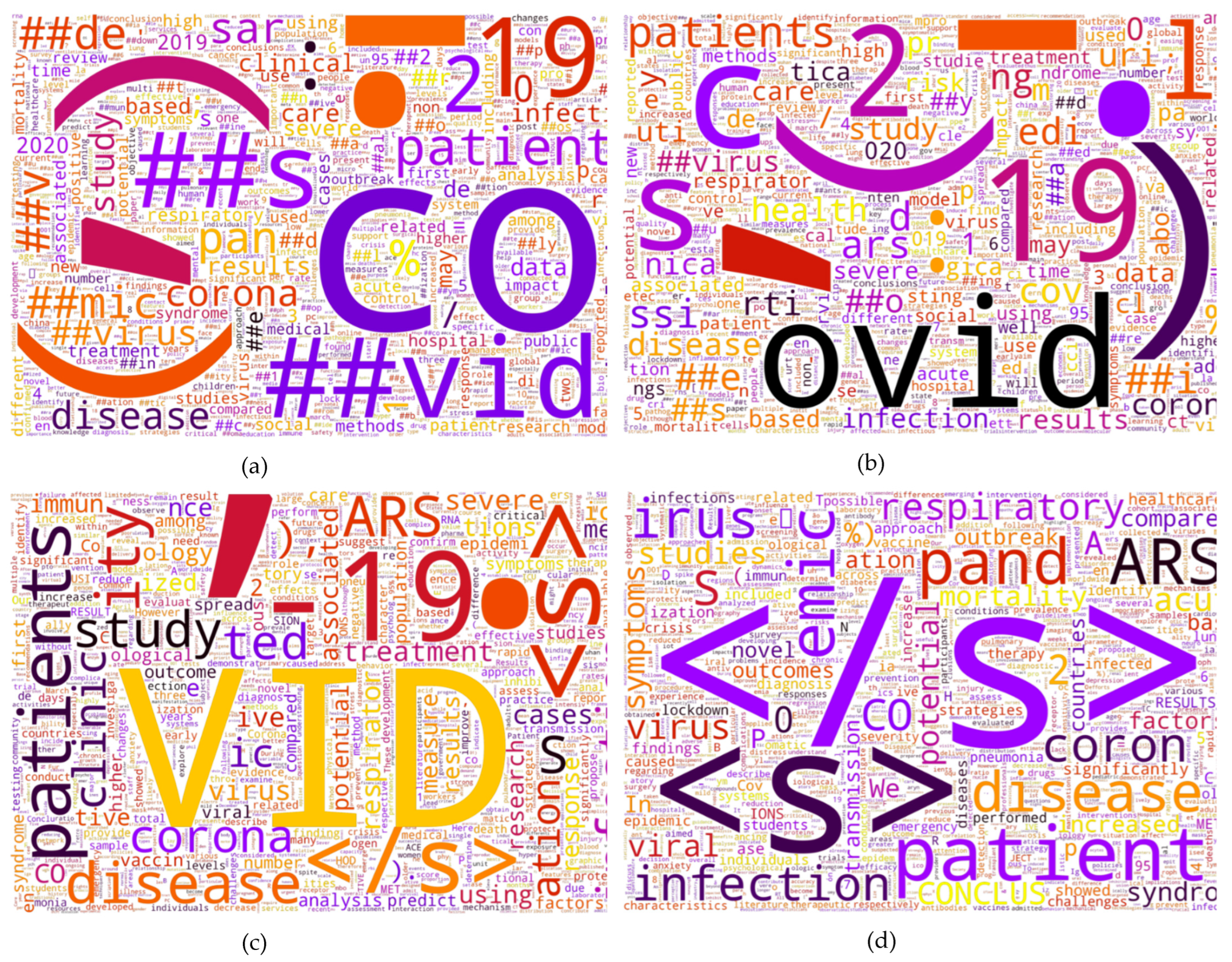

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Full Term | Summary |
|---|---|---|
| BERT-Base BERT-Large | Bidirectional Encoder Representations from Transformers | BERT-Base (L = 12, H = 768, A = 12, Total Parameters = 110M) BERT-Large (L = 24, H = 1024, A = 16, Total Parameters = 340M) L is the number of layers (i.e., Transformer blocks), H is the hidden layer, and A is the number of self-attention heads. |
| ALBERT [10] | A Lite BERT | The ALBERT model has 12 million parameters with 768 hidden layers and 128 embedding layers |
| RoBERTa [11] | Robustly Optimized BERT pre-training Approach |
Uses different pretraining step
|
| DistilBERT [12] | Distillation BERT | Uses the knowledge distillation method to reduce the model size and achieve 97% of the ability of the original BERT |
| Criteria | PubMedBERT [13] | Clinical BERT [14] | Med-BERT [15] | Our Model |
|---|---|---|---|---|
| Type of corpus | Articles from PubMed | Clinical notes | ICD-9 + ICD-10 code for diagnosis | CORD-19 dataset |
| Vocabulary size | Same as original BERT (30 K) | N/A but taken from 2 million clinical notes | 82 K | ~33 K |
| Pretraining data source | Wikipedia, BookCorpus, PubMed articles | MIMIC-III v1.4 [16] | General Electronic Health Record (EHR) | Computer science and broad biomedical papers |
| Data source size | 14 million abstracts, 3.2 billion words (filter from 4 billion words), 21 GB | 26 tables in a relational database, 23.5 GB compressed zip file | 28 million EHRs | 3.4 GB (filter from 38.91 GB raw data) |
| Input data structure | Biomedical vocabulary | Clinical notes, MedNLI | ICD Code + visit + serialization embeddings | COVID-19 article abstract, SNLI, Multi-NLI, MedNLI |
| Pretraining task | From scratch | From scratch, initialized from BioBERT [17] | Masked LM + predict length of stay | Adding new vocabulary and creating an NLI downstream task |
| Evaluation task | NER, PICO, relation extraction, sentence similarity, document classification, question answering | Clinical NLP tasks | Disease predictions | Same as SciBERT [18] + Zero-shot classification |
| Column Name | Description | Data |
|---|---|---|
| cord_uid | String valued field that assigns a unique identifier to each CORD-19 paper | ug7v899j |
| sha | String valued field that is the SHA1 of all PDFs associated with the CORD-19 paper | d1aafb70c066a2068b02 786f8929fd9c900897fb |
| source_x | String valued field that is the names of sources | PMC |
| title | String valued field for the paper title | Heterogeneous nuclear ribonucleoprotein A1 regulates RNA synthesis of a cytoplasmic virus |
| doi | String valued field for the paper DOI | 10.1251/bpo66 |
| pmcid | String valued field for the paper’s ID on PubMed Central | PMC302190 |
| pubmed_id | Integer valued field for the paper’s ID on PubMed | 14702098 |
| license | String valued field with the most permissive license | no-cc |
| abstract | String valued field for the paper’s abstract | The UBA domain is a conserved sequence motif among polyubiquitin binding proteins. For the first tim... |
| publish_time | String valued field for the published date of the paper in yyyy-mm-dd format | 2003-12-12 |
| authors | String valued field for the authors of the paper. Each author name is in Last, First Middle format and semicolon-separated | Pridgeon, Julia W.; Geetha, Thangiah; Wooten, Marie W. |
| journal | String valued field for the paper journal | Biol Proced Online |
| mag_id | Integer valued filed for Microsoft Academic Graph, Deprecated | - |
| who_COVIDence_id | String valued field for the ID assigned by the WHO for that paper | #20061721 |
| arxiv_id | String valued field for the arXiv ID of that paper | 2004.09354 |
| pdf_json_files | String valued field containing paths from the root of the current data dump version to the parses of the paper PDFs into JSON format | document_parses/pdf_ json/4eb6e165ee705e2 ae2a24ed2d4e67da428 31ff4a.json |
| pmc_json_files | String valued field corresponding to the full text XML files downloaded from PMC | document_parses/pmc_ json/PMC1481583.xml. json |
| url | String valued field containing all URLs associated with that paper, comma separated | https://www.ncbi.nlm (accessed on 27 April 2022) .nih.gov/pmc/article s/PMC1481583/ |
| s2_id | String valued field containing the Semantic Scholar ID for that paper | 9445722 |
| Premise | Label | Hypothesis |
|---|---|---|
| A man inspects the uniform of a figure in some East Asian country. | contradiction C C C C C | The man is sleeping. |
| An older and younger man smiling. | neutral N N E N N | Two men are smiling and laughing at the cats playing on the floor. |
| A black race car starts up in front of a crowd of people. | contradiction C C C C C | A man is driving down a lonely road. |
| Premise | Label | Hypothesis |
|---|---|---|
| Met my first girlfriend that way. | FACE-TO-FACE contradiction C C N C | I did not meet my first girlfriend until later. |
| 8 million in relief in the form of emergency housing. | GOVERNMENT neutral N N N N | The 8 million dollars for emergency housing was still not enough to solve the problem. |
| Now, as children tend their gardens, they have a new appreciation of their relationship to the land, their cultural heritage, and their community. | LETTERS neutral N N N N | All of the children love working in their gardens. |
| Premise | Hypothesis | Label |
|---|---|---|
| ALT, AST, and lactate were elevated as noted above. | Patient has abnormal LFTs. | entailment |
| Chest x-ray showed mild congestive heart failure. | The patient complains of cough. | neutral |
| Aorta is mildly tortuous and calcified. | The aorta is normal. | contradiction |
| Label | Number of articles |
|---|---|
| Case Report | 8786 |
| Diagnosis | 10,005 |
| Forecasting | 741 |
| General | 1909 |
| Mechanism | 3405 |
| Prevention | 45,005 |
| Transmission | 3943 |
| Treatment | 36,059 |
| Total | 109,853 * |
| Step | Time Usage |
|---|---|
| Retrain SciBERT after adding new vocabulary | 52 min 26 s |
| Train NLI downstream task with dataset | |
| 2 h 26 min 41 s |
| 2 h 56 min |
| 1 h 15 min 20 s |
| Total training time | 7 h 30 min 27 s |
| Model | Size (GB) | Size (Byte) | Vocabulary |
|---|---|---|---|
| SciBERT uncased | 0.41 | 440,457,270 | 31,090 |
| Our Model | 1.25 | 1,348,305,925 | 33,993 |
| CT-bert V2 | 1.24 | 1,341,435,039 | 30,522 |
| xlm-roberta-large | 2.09 | 2,253,900,123 | 250,002 |
| bart-large | 1.51 | 1,630,968,591 | 50,265 |
| Model | Number of Token ID | Total Number of Tokens |
|---|---|---|
| SciBERT uncased | 26,168 | 57,183,423 |
| Ourmodel | 26,783 | 61,326,123 |
| CT-bert V2 | 26,663 | 61,209,919 |
| xlm-roberta-large | 60,535 | 65,282,093 |
| bart-large | 46,242 | 59,891,876 |
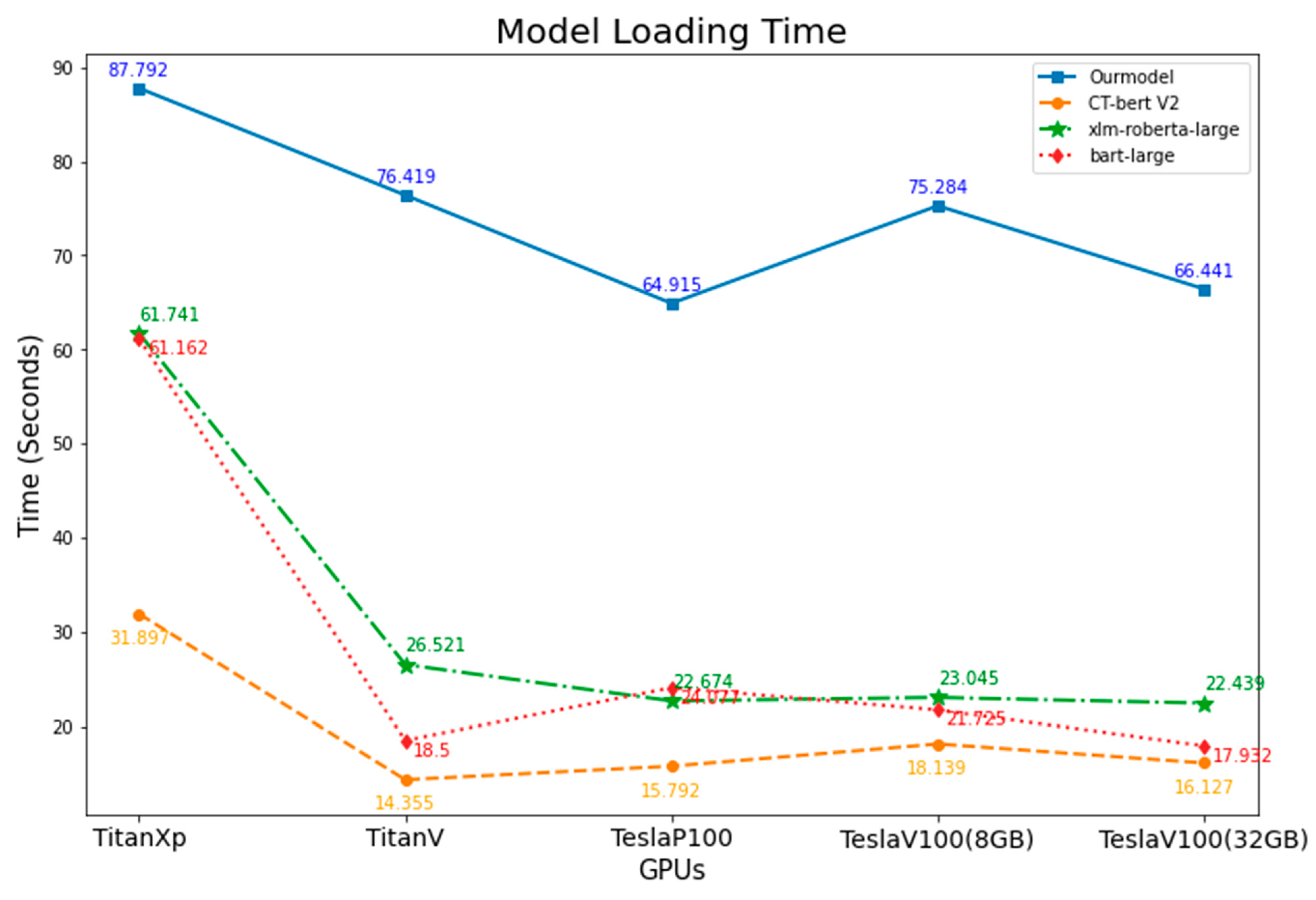
| Loading Time (Seconds) | |||||
| Model | GPUs | ||||
| TitanXp | TitanV | TeslaP100 | TeslaV100 (8 GB) | TeslaV100 (32 GB) | |
| Ourmodel | 87.7915 | 76.41922 | 64.9150097 | 75.2837092 | 66.44118 |
| CT-bert V2 | 31.89718 | 14.35474 | 15.7923569 | 18.1387475 | 16.12749 |
| xlm-roberta-large | 61.74109 | 26.52093 | 22.6739579 | 23.0446838 | 22.43863 |
| bart-large | 61.16165 | 18.49952 | 24.0774501 | 21.7254039 | 17.9323 |
| Total Execute Time (Seconds) | |||||
| Model | GPUs | ||||
| TitanXp | TitanV | TeslaP100 | TeslaV100 (8 GB) | TeslaV100 (32 GB) | |
| Ourmodel | 53,513.01 | 52,305.9 | 33,367.07 | 29,430.7 | 28,462.6 |
| CT-bert V2 | 52,498.73 | 41,502.69 | 60,490.08 | 39,057.64 | 36,114.47 |
| xlm-roberta-large | 56,891.2 | 44,877.2 | 66,451.43 | 41,859.77 | 39,318.24 |
| bart-large | 65,056.13 | 50,333.32 | 74,179.42 | 123,832.6 | 43,756.65 |
| Class | Precision | Recall | f1-Score | Support | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Roberta-large * | Bart-large | CT-Bert V2 | OurModel | Roberta-large * | Bart-large | CT-Bert V2 | OurModel | Roberta-Large * | Bart-large | CT-Bert V2 | OurModel | ||
| Case Report | 0.5056 | 0.5823 | 0.3347 | 0.2537 | 0.4919 | 0.1007 | 0.4319 | 0.4646 | 0.4987 | 0.1717 | 0.3772 | 0.3282 | 8,780 |
| Diagnosis | 0.3134 | 0.2139 | 0.3361 | 0.3006 | 0.4186 | 0.8471 | 0.273 | 0.3766 | 0.3585 | 0.3415 | 0.3013 | 0.3343 | 10,005 |
| Forecasting | 0.0442 | 0.2351 | 0.0884 | 0.2065 | 0.5965 | 0.1174 | 0.3954 | 0.0432 | 0.0823 | 0.1566 | 0.1445 | 0.0714 | 741 |
| General | 0.0471 | 0.117 | 0.0657 | 0.0116 | 0.098 | 0.0314 | 0.0115 | 0.0073 | 0.0636 | 0.0495 | 0.0196 | 0.009 | 1909 |
| Mechanism | 0.0558 | 0.0852 | 0.0453 | 0.0361 | 0.4292 | 0.0783 | 0.6799 | 0.4139 | 0.0988 | 0.0816 | 0.0849 | 0.0664 | 3,399 |
| Prevention | 0.6163 | 0.7379 | 0.7374 | 0.4443 | 0.314 | 0.1012 | 0.0978 | 0.1673 | 0.416 | 0.178 | 0.1727 | 0.2431 | 44,958 |
| Transmission | 0.1631 | 0.1247 | 0.2393 | 0.0879 | 0.4415 | 0.8272 | 0.455 | 0.4958 | 0.2382 | 0.2167 | 0.3137 | 0.1493 | 3,941 |
| Treatment | 0.4985 | 0.5292 | 0.4677 | 0.4403 | 0.196 | 0.4743 | 0.2879 | 0.0199 | 0.2813 | 0.5002 | 0.3564 | 0.038 | 36,029 |
| Word | CT-Bert V2 | Our Model | Xlm-Roberta-Large | Bart-Large |
|---|---|---|---|---|
| COVID-19 | co, ##vid, -, 19 | c, ovid, -, 19 | co, vid, -19 | c, ov, id, -, 19 |
| respiratory | respiratory | respirator, y | respirator, y | res, pir, atory |
| coronavirus | corona, ##virus | corona, ##virus | corona, virus | cor, on, av, irus |
| pandemic | pan, ##de, ##mic | pandemic | pande, mic | p, and, emic |
| wuhan | wu, ##han | wuhan | w, uhan | w, uh, an |
| virus | virus | virus | virus | v, irus |
| lopinavir | lo, ##pina, ##vir | lopinavir | lo, pina, vir | l, op, inav, ir |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nuntachit, N.; Sugunnasil, P. Do We Need a Specific Corpus and Multiple High-Performance GPUs for Training the BERT Model? An Experiment on COVID-19 Dataset. Mach. Learn. Knowl. Extr. 2022, 4, 641-664. https://doi.org/10.3390/make4030030
Nuntachit N, Sugunnasil P. Do We Need a Specific Corpus and Multiple High-Performance GPUs for Training the BERT Model? An Experiment on COVID-19 Dataset. Machine Learning and Knowledge Extraction. 2022; 4(3):641-664. https://doi.org/10.3390/make4030030
Chicago/Turabian StyleNuntachit, Nontakan, and Prompong Sugunnasil. 2022. "Do We Need a Specific Corpus and Multiple High-Performance GPUs for Training the BERT Model? An Experiment on COVID-19 Dataset" Machine Learning and Knowledge Extraction 4, no. 3: 641-664. https://doi.org/10.3390/make4030030
APA StyleNuntachit, N., & Sugunnasil, P. (2022). Do We Need a Specific Corpus and Multiple High-Performance GPUs for Training the BERT Model? An Experiment on COVID-19 Dataset. Machine Learning and Knowledge Extraction, 4(3), 641-664. https://doi.org/10.3390/make4030030