
Deep Self-Organizing Map of Convolutional Layers for Clustering and Visualizing Image Data


Abstract
:1. Introduction
- (1)
- A generic deep convolutional architecture that extends far beyond the trivial three hidden layer limit of shallow networks.
- (2)
- An inherent flexibility to embed existing deep convolutional models and to facilitate transfer learning from pre-trained CNNs, these can be used either as fixed feature extractors (yielding CNN codes) or as initial weight/parameter values for the subsequent backpropagation stages.
- (3)
- An end-to-end unsupervised learning algorithm that does not necessitate the targets/labels of the training samples at any stage, and is specifically tailored to meet the requirements of the architecture’s complexity, depth, and parameter size.
- (4)
- A complementary neural map visualization technique that offers insight and interpretation of the SOCOM clusters, or equivalently, a projection and quantization of the achieved higher-level representations onto the array of output neurons; this is also achieved without using any type of label information throughout the respective processes.
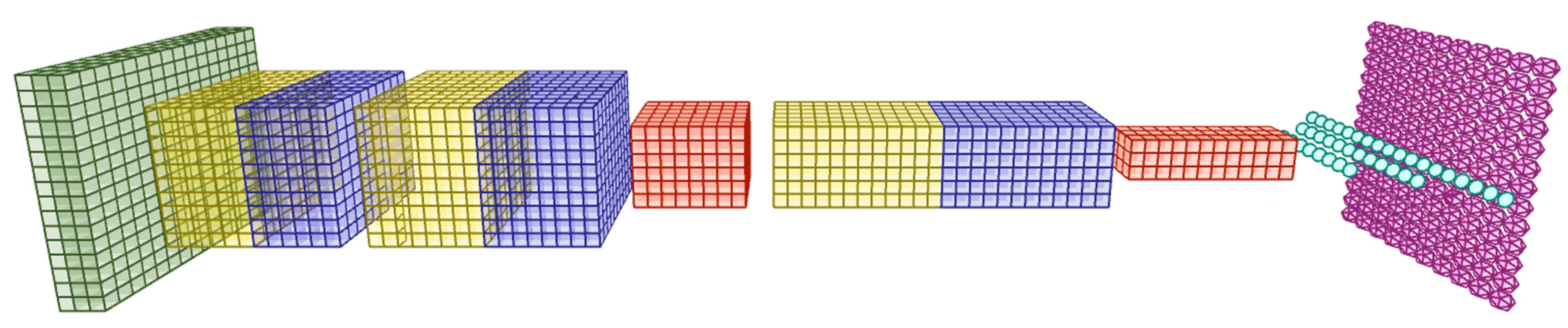
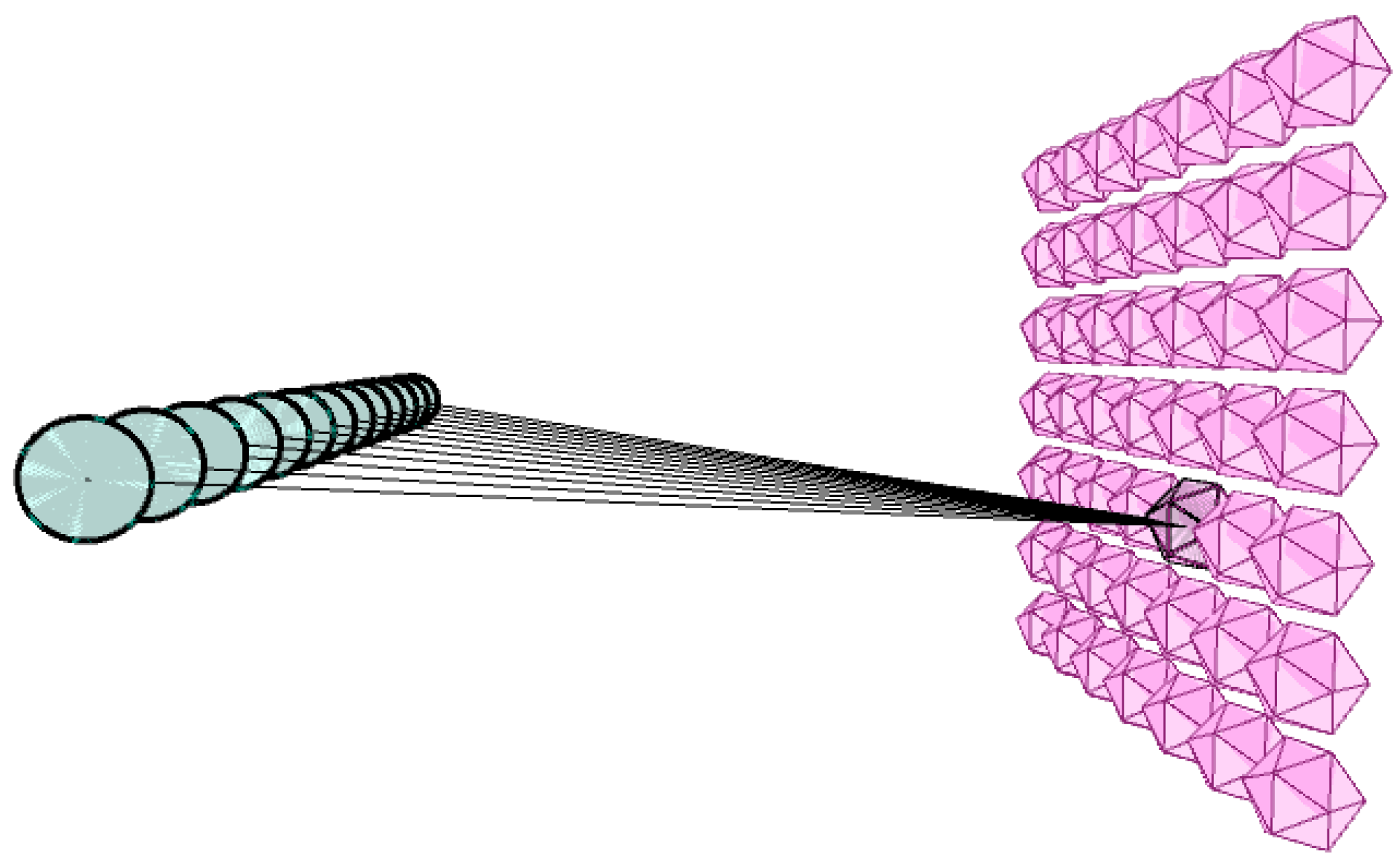
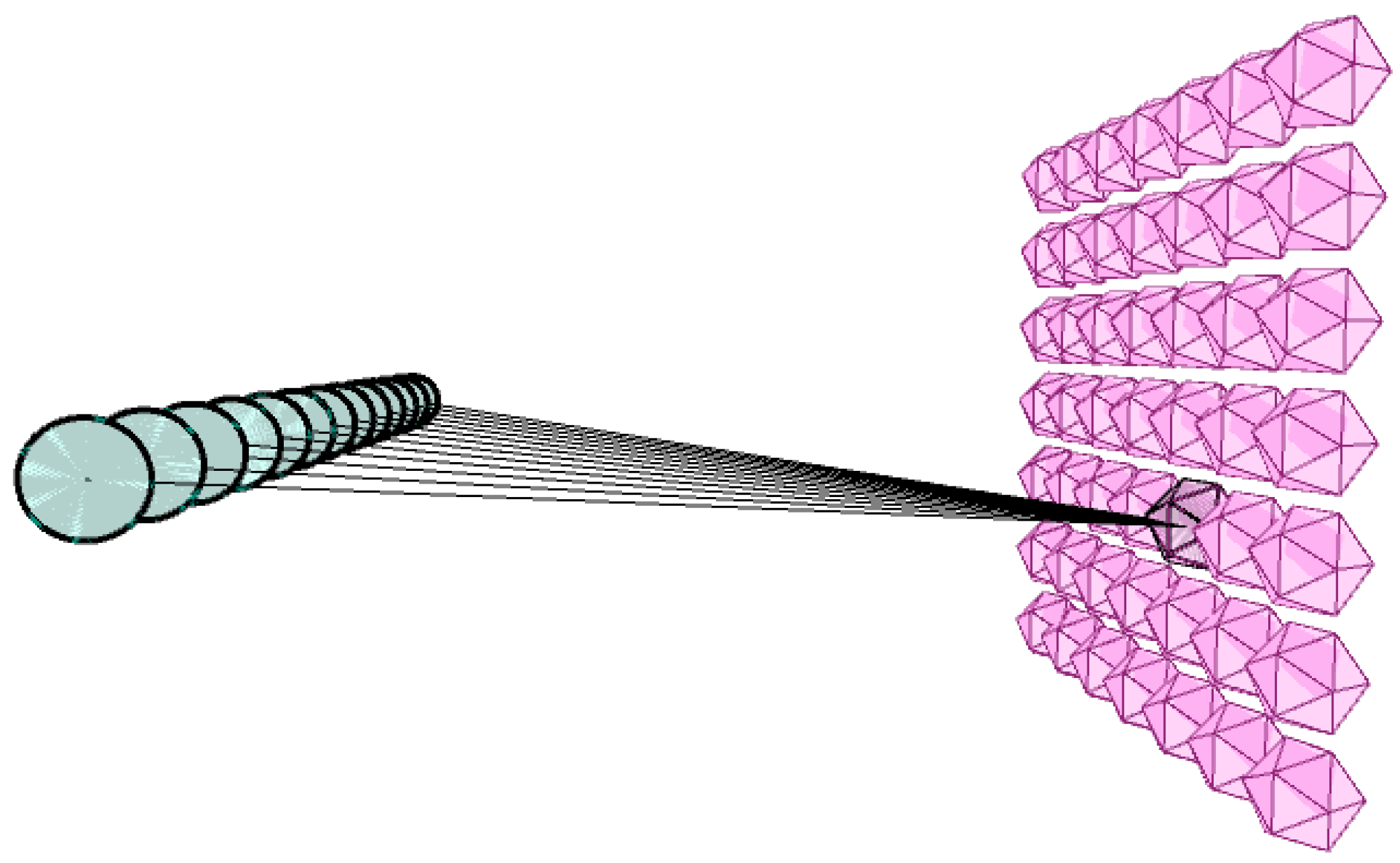
2. SOCOM Prototype
2.1. SOM Review
- (1)
- Decoding of that neuron that has the best match with the input data pattern (the so-called winner);
- (2)
- Adaptive improvement of the match in the neighborhood of neurons centered around the winner.
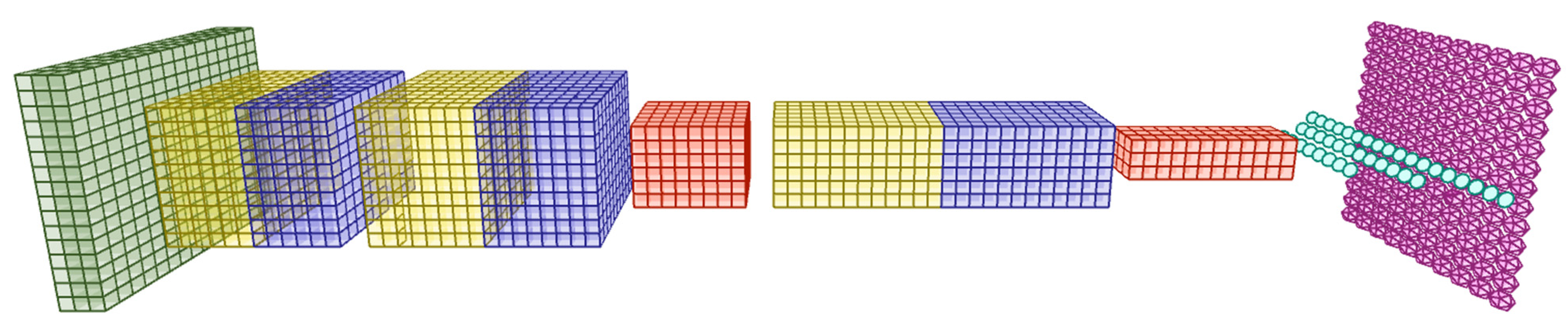
2.2. Forward Propagation
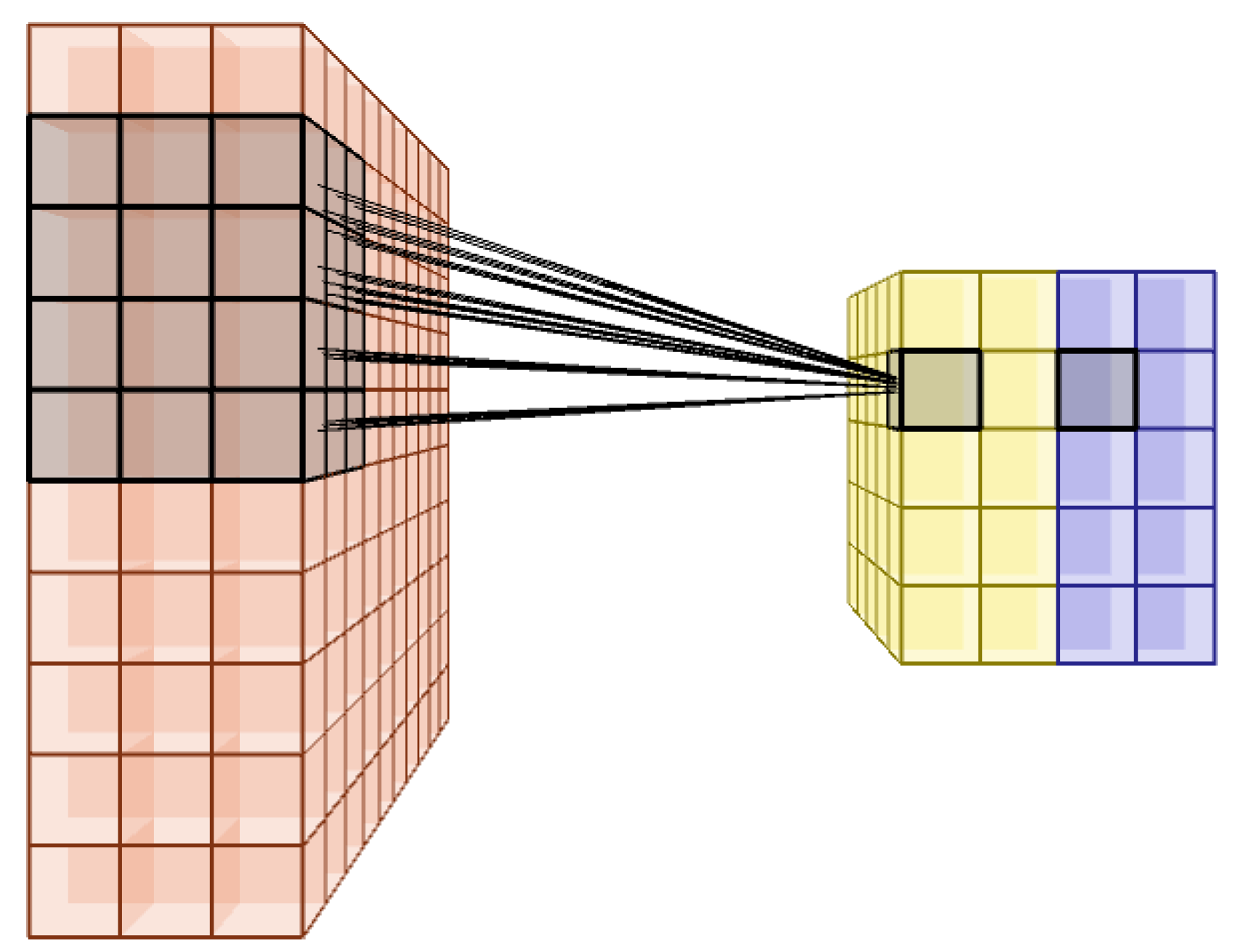
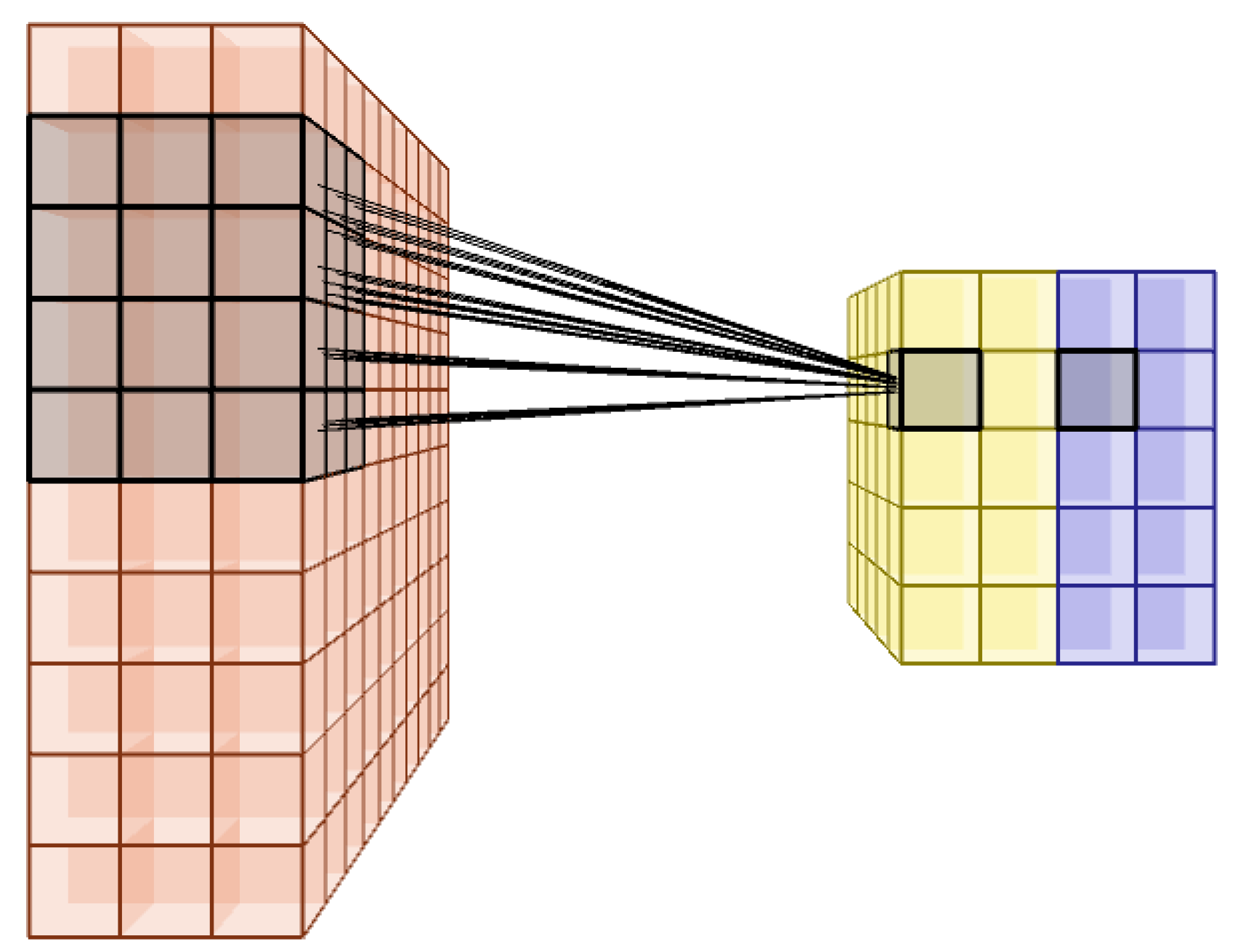
2.2.1. Convolutional Layer
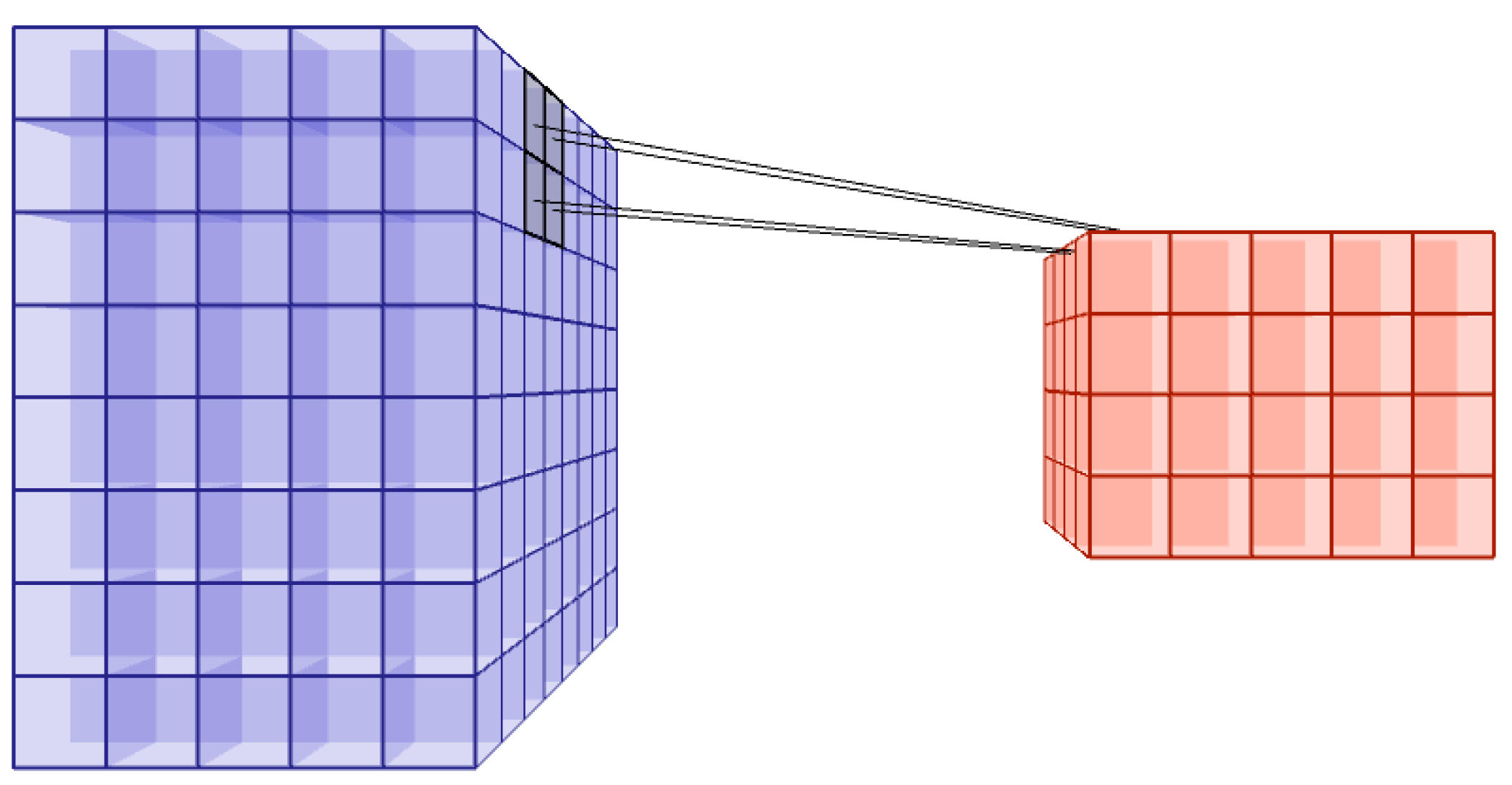
2.2.2. Pooling Layer
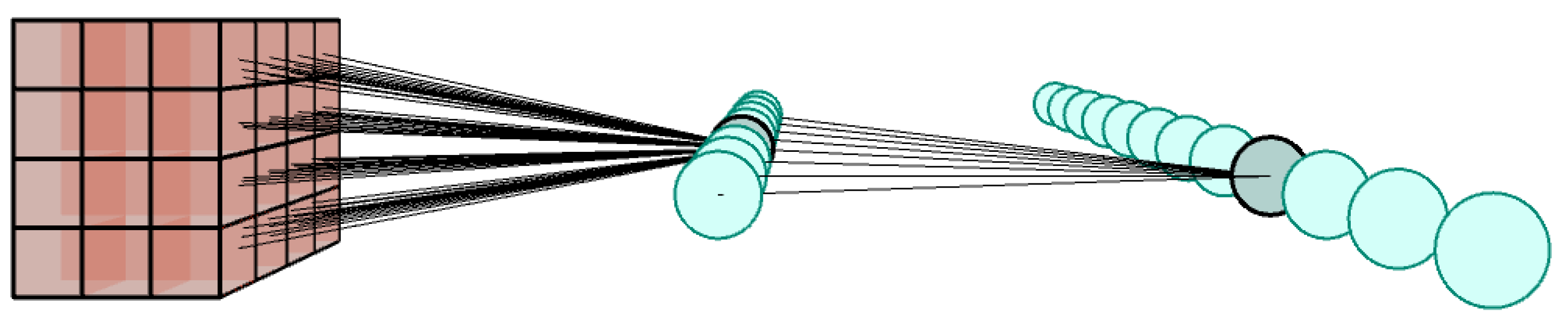
2.2.3. Fully Connected Layer
2.2.4. Output Layer
2.3. Backpropagation
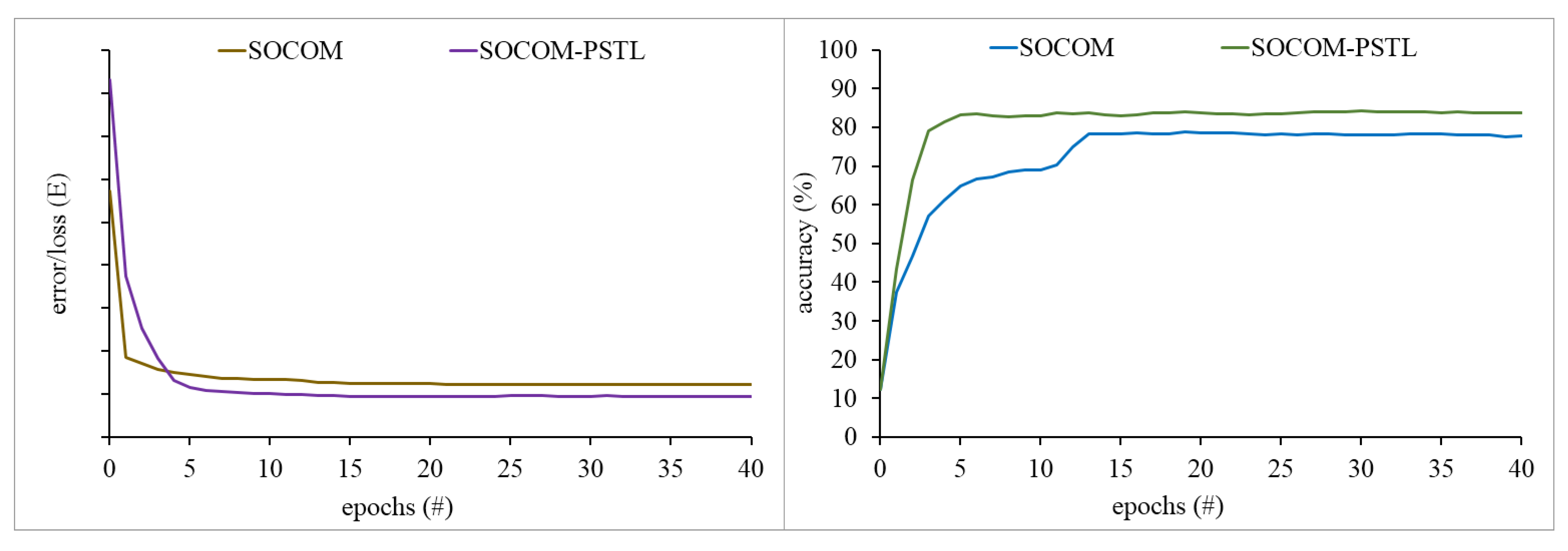
3. Experiments
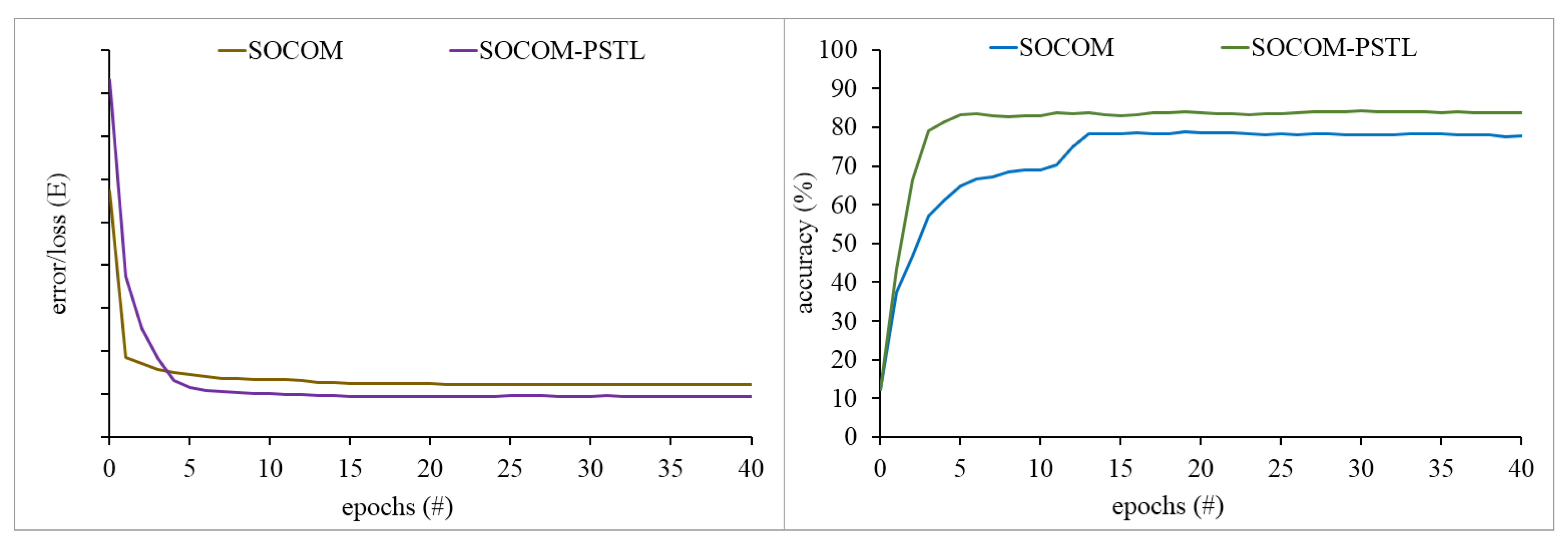
3.1. Neural Output Visualization

3.2. Quantitative Analysis
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [Green Version]
- Northcutt, C.G.; Athalye, A.; Mueller, J. Pervasive label errors in test sets destabilize machine learning benchmarks. arXiv 2021, arXiv:2103.14749. [Google Scholar]
- Malondkar, A.; Corizzo, R.; Kiringa, I.; Ceci, M.; Japkowicz, N. Spark-GHSOM: Growing hierarchical self-organizing map for large scale mixed attribute datasets. Inf. Sci. 2019, 496, 572–591. [Google Scholar] [CrossRef]
- Forti, A.; Foresti, G.L. Growing Hierarchical Tree SOM: An unsupervised neural network with dynamic topology. Neural Netw. 2006, 19, 1568–1580. [Google Scholar] [CrossRef]
- Jin, H.; Shum, W.-H.; Leung, K.-S.; Wong, M.-L. Expanding self-organizing map for data visualization and cluster analysis. Inf. Sci. 2004, 163, 157–173. [Google Scholar] [CrossRef]
- Hsu, A.L.; Tang, S.-L.; Halgamuge, S.K. An unsupervised hierarchical dynamic self-organizing approach to cancer class discovery and marker gene identification in microarray data. Bioinformatics 2003, 19, 2131–2140. [Google Scholar] [CrossRef] [Green Version]
- Lawrence, S.; Giles, C.L.; Tsoi, A.C.; Back, A.D. Face recognition: A convolutional neural-network approach. IEEE Trans. Neural Netw. 1997, 8, 98–113. [Google Scholar] [CrossRef] [Green Version]
- Liu, N.; Wang, J.; Gong, Y. Deep self-organizing map for visual classification. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015. [Google Scholar]
- Hankins, R.; Peng, Y.; Yin, H. Towards complex features: Competitive receptive fields in unsupervised deep networks. In Proceedings of the International Conference on Intelligent Data Engineering and Automated Learning, Madrid, Spain, 21–23 November 2018. [Google Scholar]
- Wickramasinghe, C.S.; Amarasinghe, K.; Manic, M. Deep self-organizing maps for unsupervised image classification. IEEE Trans. Ind. Inform. 2019, 15, 5837–5845. [Google Scholar] [CrossRef]
- Aly, S.; Almotairi, S. Deep convolutional self-organizing map network for robust handwritten digit recognition. IEEE Access 2020, 8, 107035–107045. [Google Scholar] [CrossRef]
- Friedlander, D. Pattern Analysis with Layered Self-Organizing Maps. arXiv 2018, arXiv:1803.08996. [Google Scholar]
- Pesteie, M.; Abolmaesumi, P.; Rohling, R. Deep neural maps. arXiv 2018, arXiv:1810.07291. [Google Scholar]
- Stuhr, B.; Brauer, J. Csnns: Unsupervised, backpropagation-free convolutional neural networks for representation learning. In Proceedings of the 2019 18th IEEE International Conference On Machine Learning And Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019. [Google Scholar]
- Part, J.L.; Lemon, O. Incremental on-line learning of object classes using a combination of self-organizing incremental neural networks and deep convolutional neural networks. In Proceedings of the Workshop on Bio-Inspired Social Robot Learning in Home Scenarios (IROS), Daejeon, Korea, 9–14 October 2016. [Google Scholar]
- Wang, M.; Zhou, W.; Tian, Q.; Pu, J.; Li, H. Deep supervised quantization by self-organizing map. In Proceedings of the 25th ACM international conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017. [Google Scholar]
- Kohonen, T. Self-Organizing Maps; Springer: Berlin/Heidelberg, Germany; New York, NY, USA, 1995. [Google Scholar]
- Heskes, T. Energy functions for self-organizing maps. In Kohonen Maps; Elsevier: Amsterdam, The Netherlands, 1999; pp. 303–315. [Google Scholar]
- Ferles, C.; Stafylopatis, A. Self-organizing hidden markov model map (SOHMMM). Neural Netw. 2013, 48, 133–147. [Google Scholar] [CrossRef] [PubMed]
- Ferles, C.; Papanikolaou, Y.; Naidoo, K.J. Denoising autoencoder self-organizing map (DASOM). Neural Netw. 2018, 105, 112–131. [Google Scholar] [CrossRef]
- Ultsch, A. Maps for the visualization of high-dimensional data spaces. In Proceedings of the Workshop on Self Organizing Maps, Hibikono, Japan, 11–14 September 2003. [Google Scholar]
- Ultsch, A. Clustering with SOM: U^* C. In Proceedings of the Workshop on Self-Organizing Maps, Paris, France, 5–8 September 2005. [Google Scholar]
- Ferles, C.; Beaufort, W.-S.; Ferle, V. Self-Organizing Hidden Markov Model Map (SOHMMM): Biological sequence clustering and cluster visualization. In Hidden Markov Models; Springer: Berlin/Heidelberg, Germany, 2017; pp. 83–101. [Google Scholar]
- Tasdemir, K.; Merényi, E. Exploiting data topology in visualization and clustering of self-organizing maps. IEEE Trans. Neural Netw. 2009, 20, 549–562. [Google Scholar] [CrossRef] [PubMed]
- Brugger, D.; Bogdan, M.; Rosenstiel, W. Automatic cluster detection in Kohonen’s SOM. IEEE Trans. Neural Netw. 2008, 19, 442–459. [Google Scholar] [CrossRef] [PubMed]
- Pölzlbauer, G.; Dittenbach, M.; Rauber, A. Advanced visualization of self-organizing maps with vector fields. Neural Netw. 2006, 19, 911–922. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yin, H. ViSOM-a novel method for multivariate data projection and structure visualization. IEEE Trans. Neural Netw. 2002, 13, 237–243. [Google Scholar]
- Pampalk, E.; Rauber, A.; Merkl, D. Using smoothed data histograms for cluster visualization in self-organizing maps. In Proceedings of the International Conference on Artificial Neural Networks, Madrid, Spain, 28–30 August 2002. [Google Scholar]
- Vesanto, J. SOM-based data visualization methods. Intell. Data Anal. 1999, 3, 111–126. [Google Scholar] [CrossRef]
- Erhan, D.; Bengio, Y.; Courville, A.; Vincent, P. Visualizing higher-layer features of a deep network. Univ. Montr. 2009, 1341, 1. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv 2013, arXiv:1312.6034. [Google Scholar]
- Nguyen, A.; Yosinski, J.; Clune, J. Multifaceted feature visualization: Uncovering the different types of features learned by each neuron in deep neural networks. arXiv 2016, arXiv:1602.03616. [Google Scholar]
- Yosinski, J.; Clune, J.; Nguyen, A.; Fuchs, T.; Lipson, H. Understanding neural networks through deep visualization. arXiv 2015, arXiv:1506.06579. [Google Scholar]
- Mahendran, A.; Vedaldi, A. Understanding deep image representations by inverting them. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Olah, C.; Mordvintsev, A.; Schubert, L. Feature visualization. Distill 2017, 2, e7. [Google Scholar] [CrossRef]
- Olah, C.; Satyanarayan, A.; Johnson, I.; Carter, S.; Schubert, L.; Ye, K.; Mordvintsev, A. The building blocks of interpretability. Distill 2018, 3, e10. [Google Scholar] [CrossRef]
- Carter, S.; Armstrong, Z.; Schubert, L.; Johnson, I.; Olah, C. Activation atlas. Distill 2019, 4, e15. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zürich, Switzerland; 2014. [Google Scholar]
- Zintgraf, L.M.; Cohen, T.S.; Welling, M. A new method to visualize deep neural networks. arXiv 2016, arXiv:1603.02518. [Google Scholar]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.-R.; Samek, W. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nguyen, A.; Yosinski, J.; Clune, J. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 12 2015. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Braga, P.H.; Medeiros, H.R.; Bassani, H.F. Deep Categorization with Semi-Supervised Self-Organizing Maps. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020. [Google Scholar]
- Ferles, C.; Papanikolaou, Y.; Savaidis, S.P.; Mitilineos, S.A. Deep learning self-organizing map of convolutional layers. In Proceedings of the 2nd International Conference on Artificial Intelligence and Big Data (AIBD 2021), Vienna, Austria, 20–21 March 2021; pp. 25–32. [Google Scholar]
- Coates, A.; Ng, A.; Lee, H. An analysis of single-layer networks in unsupervised feature learning. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011. JMLR Workshop and Conference Proceedings. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Yu, W.; Yang, K.; Bai, Y.; Xiao, T.; Yao, H.; Rui, Y. Visualizing and comparing AlexNet and VGG using deconvolutional layers. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Nam, W.-J.; Choi, J.; Lee, S.-W. Interpreting Deep Neural Networks with Relative Sectional Propagation by Analyzing Comparative Gradients and Hostile Activations. arXiv 2020, arXiv:2012.03434. [Google Scholar]
- Sharif Razavian, A.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN features off-the-shelf: An astounding baseline for recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 28 June 2014; pp. 806–813. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? arXiv 2014, arXiv:1411.1792. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010. JMLR Workshop and Conference Proceedings. [Google Scholar]
- Smith, L.N. Cyclical learning rates for training neural networks. In Proceedings of the 2017 IEEE winter conference on applications of computer vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017. [Google Scholar]
- Pointer, I. Programming PyTorch for Deep Learning: Creating and Deploying Deep Learning Applications; O’Reilly Media, Inc.: Newton, MA, USA, 2019. [Google Scholar]
- Hoffer, E.; Hubara, I.; Ailon, N. Deep unsupervised learning through spatial contrasting. arXiv 2016, arXiv:1610.00243. [Google Scholar]
- Sakkari, M.; Zaied, M. A Convolutional Deep Self-Organizing Map Feature extraction for machine learning. Multimed. Tools Appl. 2020, 79, 19451–19470. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Fischer, P.; Springenberg, J.T.; Riedmiller, M.; Brox, T. Discriminative unsupervised feature learning with exemplar convolutional neural networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 1734–1747. [Google Scholar] [CrossRef] [Green Version]
- Dundar, A.; Jin, J.; Culurciello, E. Convolutional clustering for unsupervised learning. arXiv 2015, arXiv:1511.06241. [Google Scholar]
- Paine, T.L.; Khorrami, P.; Han, W.; Huang, T.S. An analysis of unsupervised pre-training in light of recent advances. arXiv 2014, arXiv:1412.6597. [Google Scholar]
- Wang, D.; Tan, X. Unsupervised feature learning with C-SVDDNet. Pattern Recognit. 2016, 60, 473–485. [Google Scholar] [CrossRef] [Green Version]
- Miclut, B. Committees of deep feedforward networks trained with few data. In Proceedings of the German Conference on Pattern Recognition, Münster, Germany, 2–5 September 2014. [Google Scholar]
- Dosovitskiy, A.; Springenberg, J.; Brox, T. Unsupervised feature learning by augmenting single images. arXiv 2014, arXiv:1312.5242. [Google Scholar]
- Bo, L.; Ren, X.; Fox, D. Unsupervised feature learning for RGB-D based object recognition. In Experimental Robotics; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Nakayama, H. Efficient Discriminative Convolution Using Fisher Weight Map. In Proceedings of the BMVC, Bristol, UK, 9–13 September 2013. [Google Scholar]
- Ji, X.; Henriques, J.F.; Vedaldi, A. Invariant information clustering for unsupervised image classification and segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Haeusser, P.; Plapp, J.; Golkov, V.; Aljalbout, E.; Cremers, D. Associative deep clustering: Training a classification network with no labels. In Proceedings of the German Conference on Pattern Recognition, Stuttgart, Germany, 9–12 October 2018. [Google Scholar]
- Chang, J.; Wang, L.; Meng, G.; Xiang, S.; Pan, C. Deep adaptive image clustering. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Xie, J.; Girshick, R.; Farhadi, A. Unsupervised deep embedding for clustering analysis. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model/Network | Accuracy (%) | End-to-End Unsupervised Learning | Unsupervised Clustering and Classification Operations |
|---|---|---|---|
| SOCOM-PSTL | 84.19 | ● | ● |
| Spatial Contrasting Initialization (Soft-max classifier) [58] | 81.34 | ● | — |
| UDSOM (SVM classifier) [59] | 80.19 | ● | — |
| SOCOM | 78.7 | ● | ● |
| Exemplar CNN (SVM classifier) [60] | 74.2 | ● | — |
| Convolutional k-Means Clustering (Linear classifier) [61] | 74.1 | ● | — |
| Zero-bias CNN ADCU (Soft-max classifier) [62] | 70.2 | ● | — |
| MSRV+C-SVDDNet (SVM and soft-max classifier) [63] | 68.23 | ● | — |
| Committees of Deep Networks (SVM classifier) [64] | 68.0 | ● | — |
| Unsupervised Feature Learning by Augmenting Single Images (SVM classifier) [65] | 67.4 | ● | — |
| Hierarchical Matching Pursuit (SVM classifier) [66] | 64.5 | ● | — |
| Discriminative Convolution with Fisher Weight Map (Logistic regression classifier) [67] | 66.0 | ● | — |
| IIC [68] | 59.8 | ● | ● |
| ADC [69] | 53.0 | ● | ● |
| DAC [70] | 47.0 | ● | ● |
| DEC [71] | 35.9 | ● | ● |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ferles, C.; Papanikolaou, Y.; Savaidis, S.P.; Mitilineos, S.A. Deep Self-Organizing Map of Convolutional Layers for Clustering and Visualizing Image Data. Mach. Learn. Knowl. Extr. 2021, 3, 879-899. https://doi.org/10.3390/make3040044
Ferles C, Papanikolaou Y, Savaidis SP, Mitilineos SA. Deep Self-Organizing Map of Convolutional Layers for Clustering and Visualizing Image Data. Machine Learning and Knowledge Extraction. 2021; 3(4):879-899. https://doi.org/10.3390/make3040044
Chicago/Turabian StyleFerles, Christos, Yannis Papanikolaou, Stylianos P. Savaidis, and Stelios A. Mitilineos. 2021. "Deep Self-Organizing Map of Convolutional Layers for Clustering and Visualizing Image Data" Machine Learning and Knowledge Extraction 3, no. 4: 879-899. https://doi.org/10.3390/make3040044
APA StyleFerles, C., Papanikolaou, Y., Savaidis, S. P., & Mitilineos, S. A. (2021). Deep Self-Organizing Map of Convolutional Layers for Clustering and Visualizing Image Data. Machine Learning and Knowledge Extraction, 3(4), 879-899. https://doi.org/10.3390/make3040044