
A Survey of Machine Learning-Based Solutions for Phishing Website Detection


Abstract
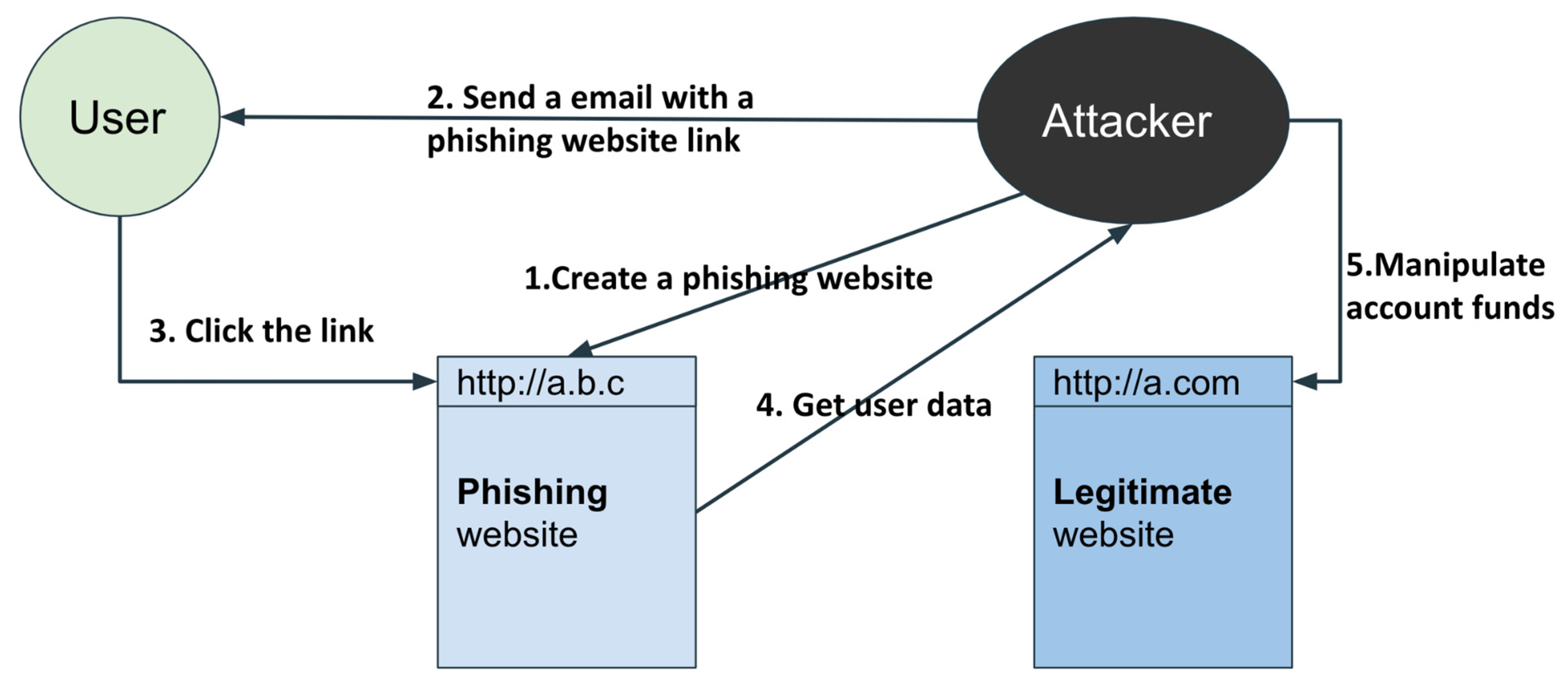
1. Introduction
- A phishing life cycle to clearly capture the phishing problem;
- A survey of major datasets and data sources for phishing detection websites;
- A state-of-the-art survey of machine learning-based solutions for detecting phishing websites.
2. Background and Related Work
2.1. Anti-Phishing
2.1.1. Web Scraping
2.1.2. Spam Filter
2.1.3. Detecting Fake Websites
2.1.4. Second Authorization Verification
2.2. Related Work
3. Methodologies of Phishing Website Detection
3.1. List-Based Approaches
3.2. Heuristic Strategies
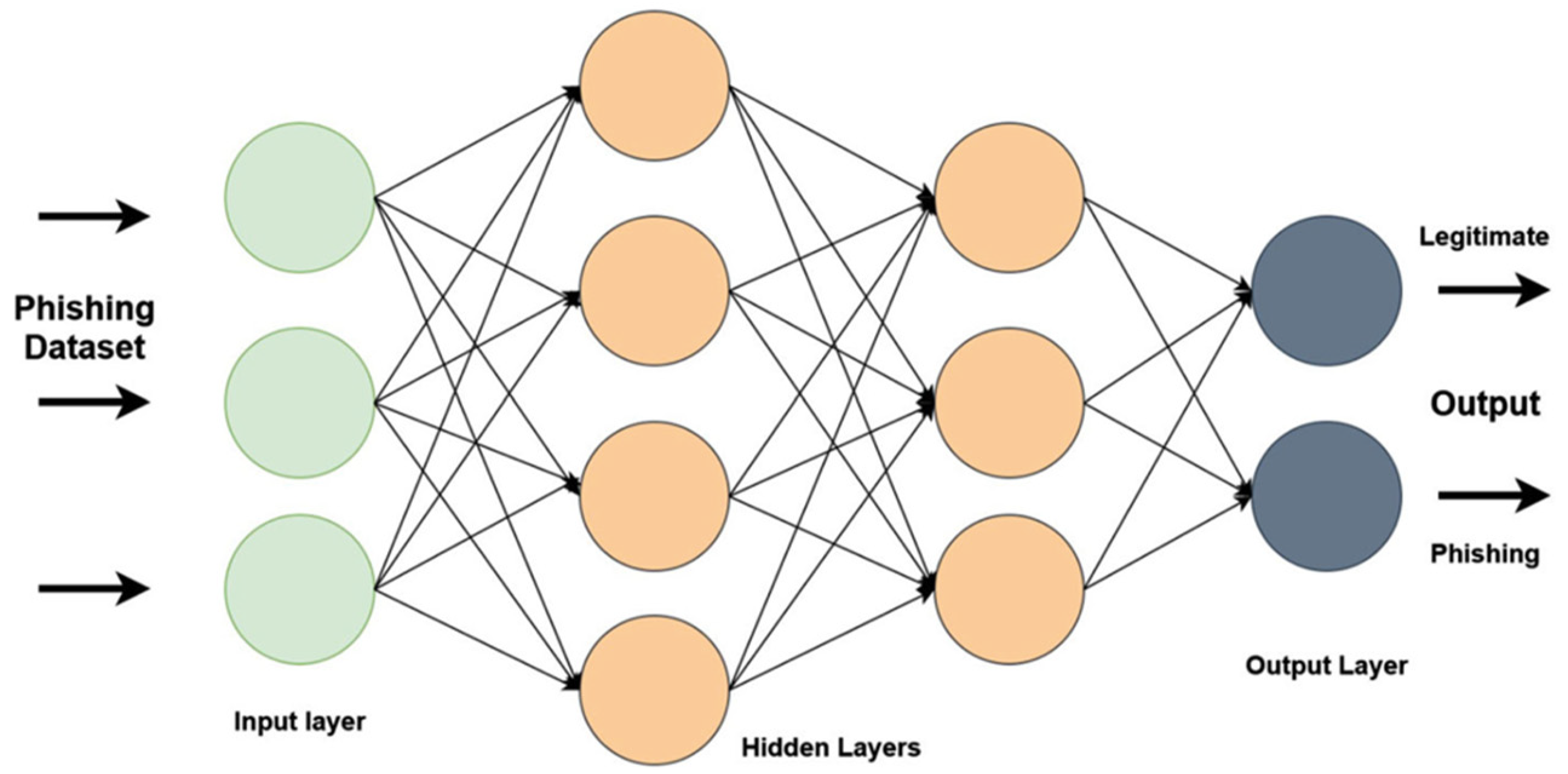
3.3. Machine Learning-Based Methods
3.3.1. Data Collection and Feature Extraction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Source | Type | Remarks |
|---|---|---|
| UCI [22] | Published dataset | 11,055 instances with 30 features |
| Mendeley [23] | Published dataset | 10,000 instances with 48 features |
| ISCX-URL-2016 [25] | Published dataset | 35,000 legitimate URLs |
| 10,000 phishing URLs | ||
| https://phishtank.com (accessed on 18 July 2021) [18] | Website | Valid phishing URLs |
| https://openphish.com (accessed on 18 July 2021) | Website | Valid phishing URLs |
| https://commoncrawl.org/ (accessed on 18 July 2021) | Website | Legitimate URLs |
| https://www.alexa.com/ (accessed on 18 July 2021) [20] | Website | Legitimate URLs |
3.3.2. Feature Selection
3.3.3. Modeling
3.3.4. Performance Evaluation
4. Frameworks of Phishing Website Detection Systems
4.1. Anti-Phishing Web Browser
4.2. Web Browser Extensions
4.3. Mobile Applications
5. State-of-the-Art Machine Learning-Based Solutions
5.1. Single Classifier
5.2. Hybrid Methods
5.3. Deep Learning
6. Opportunities and Challenges
6.1. High-Quality Dataset
6.2. Efficient Features Extraction and Selection
6.3. Tiny URL Detection
6.4. Response Time for Real-Time Systems
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Johnson, J. Global Digital Population 2020. Statista. Available online: https://www.statista.com/statistics/617136/digital-population-worldwide/#:~:text=How%20many%20people%20use%20the (accessed on 24 July 2020).
- 2020 Internet Crime Report. Federal Bureau of Investigation. Available online: https://www.ic3.gov/Media/PDF/AnnualReport/2020_IC3Report.pdf (accessed on 21 March 2021).
- APWG. Phishing Activity Trends Report for Q4 2020. Available online: https://docs.apwg.org/reports/apwg_trends_report_q4_2020.pdf (accessed on 9 February 2021).
- Alsariera, Y.A.; Adeyemo, V.E.; Balogun, A.O.; Alazzawi, A.K. AI Meta-Learners and Extra-Trees Algorithm for the Detection of Phishing Websites. IEEE Access 2020, 8, 142532–142542. [Google Scholar] [CrossRef]
- Jerry, F.; Chris, H. System Security: A Hacker’s Perspective. In Proceedings of the 1987 North American conference of Hewlett-Packard business computer users, Las Vegas, NV, USA, 20–25 September 1987. [Google Scholar]
- Kumaran, N. Spam Does Not Bring Us Joy—Ridding Gmail of 100 Million More Spam Messages with TensorFlow. Google Cloud Blog. Available online: https://cloud.google.com/blog/products/g-suite/ridding-gmail-of-100-million-more-spam-messages-with-tensorflow (accessed on 6 February 2019).
- Google Safe Browsing. Google.com. 2014. Available online: https://safebrowsing.google.com/ (accessed on 18 July 2021).
- Basit, A.; Zafar, M.; Liu, X.; Javed, A.R.; Jalil, Z.; Kifayat, K. A comprehensive survey of AI-enabled phishing attacks detection techniques. Telecommun. Syst. 2020, 76, 139–154. [Google Scholar] [CrossRef] [PubMed]
- Singh, C. Phishing Website Detection Based on Machine Learning: A Survey. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020. [CrossRef]
- Vijayalakshmi, M.; Shalinie, S.M.; Yang, M.H. Web phishing detection techniques: A survey on the state-of-the-art, taxonomy and future directions. IET Netw. 2020, 9, 235–246. [Google Scholar] [CrossRef]
- Kalaharsha, P.; Mehtre, B.M. Detecting Phishing Sites—An Overview. arXiv 2021, arXiv:2103.12739. [Google Scholar]
- Jain, A.K.; Gupta, B.B. A survey of phishing attack techniques, defence mechanisms and open research challenges. Enterp. Inf. Syst. 2021, 1–39. [Google Scholar] [CrossRef]
- Zabihimayvan, M.; Doran, D. Fuzzy Rough Set Feature Selection to Enhance Phishing Attack Detection. In Proceedings of the 2019 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), New Orleans, LA, USA, 23–26 June 2019. [Google Scholar] [CrossRef]
- Jain, A.K.; Gupta, B.B. A novel approach to protect against phishing attacks at client side using auto-updated white-list. EURASIP J. Inf. Secur. 2016. [Google Scholar] [CrossRef]
- Tan, C.L.; Chiew, K.L.; Wong, K.; Sze, S.N. PhishWHO: Phishing webpage detection via identity keywords extraction and target domain name finder. Decis. Support Syst. 2016, 88, 18–27. [Google Scholar] [CrossRef]
- Chiew, K.L.; Chang, E.H.; Sze, S.N.; Tiong, W.K. Utilisation of website logo for phishing detection. Comput. Secur. 2015, 54, 16–26. [Google Scholar] [CrossRef]
- Mohammad, R.M.; Thabtah, F.; McCluskey, L. An Assessment of Features Related to Phishing Websites Using an Automated Technique. In Proceedings of the 2012 International Conference for Internet Technology and Secured Transactions, London, UK, 10–12 December 2012. [Google Scholar]
- PhishTank|Join the Fight against Phishing. Available online: https://www.phishtank.com/index.php (accessed on 18 July 2021).
- WHOIS Search, Domain Name, Website, and IP Tools—Who.is. Available online: https://who.is/ (accessed on 18 July 2021).
- Keyword Research, Competitive Analysis, & Website Ranking|Alexa. Available online: https://www.alexa.com/ (accessed on 18 July 2021).
- Mohammad, R.M.; Thabtah, F.; McCluskey, L. Predicting phishing websites based on self-structuring neural network. Neural Comput. Appl. 2013, 25, 443–458. [Google Scholar] [CrossRef]
- Mohammad, R.M.A.; McCluskey, L.; Thabtah, F. UCI Machine Learning Repository: Phishing Websites Data Set. Available online: https://archive.ics.uci.edu/mL/datasets/Phishing+Websites (accessed on 26 March 2015).
- Tan, C.L. Phishing Dataset for Machine Learning: Feature Evaluation. Mendeley 2018. [Google Scholar] [CrossRef]
- Aljofey, A.; Jiang, Q.; Qu, Q.; Huang, M.; Niyigena, J.-P. An Effective Phishing Detection Model Based on Character Level Convolutional Neural Network from URL. Electronics 2020, 9, 1514. [Google Scholar] [CrossRef]
- URL 2016|Datasets|Research|Canadian Institute for Cybersecurity|UNB. Available online: https://www.unb.ca/cic/datasets/url-2016.html (accessed on 18 July 2021).
- Zamir, A.; Khan, H.U.; Iqbal, T.; Yousaf, N.; Aslam, F.; Anjum, A.; Hamdani, M. Phishing web site detection using diverse machine learning algorithms. Electron. Libr. 2020, 38, 65–80. [Google Scholar] [CrossRef]
- Song, F.; Guo, Z.; Mei, D. Feature Selection Using Principal Component Analysis. IEEE Xplore 2010. [Google Scholar] [CrossRef]
- Shabudin, S.; Samsiah, N.; Akram, K.; Aliff, M. Feature Selection for Phishing Website Classification. Int. J. Adv. Comput. Sci. Appl. 2020, 11. [Google Scholar] [CrossRef]
- El-Rashidy, M.A. A Smart Model for Web Phishing Detection Based on New Proposed Feature Selection Technique. Menoufia J. Electron. Eng. Res. 2021, 30, 97–104. [Google Scholar] [CrossRef]
- Subasi, A.; Molah, E.; Almkallawi, F.; Chaudhery, T.J. Intelligent phishing website detection using random forest classifier. In Proceedings of the 2017 International Conference on Electrical and Computing Technologies and Applications (ICECTA), Ras Al Khaimah, United Arab Emirates, 21–23 November 2017. [Google Scholar] [CrossRef]
- Vrbančič, G.; Fister, I.; Podgorelec, V. Swarm Intelligence Approaches for Parameter Setting of Deep Learning Neural Network. In Proceedings of the 8th International Conference on Web Intelligence, Mining and Semantics—WIMS’18, Novi Sad, Serbia, 25–27 June 2018. [Google Scholar] [CrossRef]
- HR, M.G.; Adithya, M.V.; Vinay, S. Development of anti-phishing browser based on random forest and rule of extraction framework. Cybersecurity 2020, 3, 20. [Google Scholar] [CrossRef]
- Armano, G.; Marchal, S.; Asokan, N. Real-Time Client-Side Phishing Prevention Add-On. In Proceedings of the 2016 IEEE 36th International Conference on Distributed Computing Systems (ICDCS), Nara, Japan, 27–30 June 2016. [Google Scholar] [CrossRef]
- Marchal, S.; Saari, K.; Singh, N.; Asokan, N. Know Your Phish: Novel Techniques for Detecting Phishing Sites and Their Targets. In Proceedings of the 2016 IEEE 36th International Conference on Distributed Computing Systems (ICDCS), Nara, Japan, 27–30 June 2016. [Google Scholar] [CrossRef]
- Kadhim, H.Y.; Al-saedi, K.H.; Al-Hassani, M.D. Mobile Phishing Websites Detection and Prevention Using Data Mining Techniques. Int. J. Interact. Mob. Technol. IJIM 2019, 13, 205–213. [Google Scholar] [CrossRef][Green Version]
- Varjani, M.M.; Yazdian, A. PhishDetector|A True Phishing Detection System. PhishDetector Landing Page. Available online: https://www.moghimi.net/phishdetector (accessed on 15 July 2019).
- Netcraft. Available online: https://www.netcraft.com/ (accessed on 7 December 2020).
- Website Safety Check & Phishing Protection|Web of Trust. Available online: https://www.mywot.com/ (accessed on 26 May 2021).
- Home-Pixm Anti-Phishing. Available online: https://pixm.net/ (accessed on 3 May 2021).
- Bannister, A. Sharkcop: Google Chrome Extension Uses Machine Learning to Detect Phishing URLs. The Daily Swig|Cybersecurity News and Views. Available online: https://portswigger.net/daily-swig/sharkcop-google-chrome-extension-uses-machine-learning-to-detect-phishing-urls (accessed on 5 October 2020).
- PhishFort Protect Anti-Phishing Cryptocurrency Browser Extension. Available online: https://www.phishfort.com/protect (accessed on 27 May 2021).
- Gupta, B.B.; Yadav, K.; Razzak, I.; Psannis, K.; Castiglione, A.; Chang, X. A novel approach for phishing URLs detection using lexical based machine learning in a real-time environment. Comput. Commun. 2021, 175, 47–57. [Google Scholar] [CrossRef]
- Ali, W.; Ahmed, A. Hybrid Intelligent Phishing Website Prediction Using Deep Neural Networks with Genetic Algorithm-based Feature Selection and Weighting. IET Inf. Secur. 2019. [Google Scholar] [CrossRef]
- Wang, W.; Zhang, F.; Luo, X.; Zhang, S. PDRCNN: Precise Phishing Detection with Recurrent Convolutional Neural Networks. Secur. Commun. Netw. 2019. [Google Scholar] [CrossRef]
- Gandotra, E.; Gupta, D. Improving Spoofed Website Detection Using Machine Learning. Cybern. Syst. 2020, 52, 169–190. [Google Scholar] [CrossRef]
- Barraclough, P.A.; Fehringer, G.; Woodward, J. Intelligent cyber-phishing detection for online. Comput. Secur. 2021, 104, 102123. [Google Scholar] [CrossRef]
- Sabahno, M.; Safara, F. ISHO: Improved spotted hyena optimization algorithm for phishing website detection. Multimed. Tools Appl. 2021. [Google Scholar] [CrossRef]
- Odeh, A.; Keshta, I. PhiBoost—A novel phishing detection model Using Adaptive Boosting approach. Jordanian J. Comput. Inf. Technol. 2021, 7, 64. [Google Scholar] [CrossRef]
- Adeyemo, V.E.; Balogun, A.O.; Mojeed, H.A.; Akande, N.O.; Adewole, K.S. Ensemble-Based Logistic Model Trees for Website Phishing Detection. Commun. Comput. Inf. Sci. 2021, 627–641. [Google Scholar] [CrossRef]
- Lakshmanarao, A.; Rao, P.; Surya, P.; Krishna, M.M.B. Phishing website detection using novel machine learning fusion approach. IEEE Xplore 2021. [Google Scholar] [CrossRef]
- Harinahalli Lokesh, G.; BoreGowda, G. Phishing website detection based on effective machine learning approach. J. Cyber Secur. Technol. 2020, 1–14. [Google Scholar] [CrossRef]
- Lakshmi, L.; Reddy, M.P.; Santhaiah, C.; Reddy, U.J. Smart Phishing Detection in Web Pages using Supervised Deep Learning Classification and Optimization Technique ADAM. Wirel. Pers. Commun. 2021. [Google Scholar] [CrossRef]
- Yang, L.; Zhang, J.; Wang, X.; Li, Z.; Li, Z.; He, Y. An improved ELM-based and data preprocessing integrated approach for phishing detection considering comprehensive features. Expert Syst. Appl. 2021, 165, 113863. [Google Scholar] [CrossRef]
- Anupam, S.; Kar, A.K. Phishing website detection using support vector machines and nature-inspired optimization algorithms. Telecommun. Syst. 2020, 76, 17–32. [Google Scholar] [CrossRef]
- Deepa, S.T. Phishing Website Detection Using Novel Features and Machine Learning Approach. Turk. J. Comput. Math. Educ. TURCOMAT 2021, 12, 2648–2653. [Google Scholar] [CrossRef]
- Mitsa, T. How Do You Know You Have Enough Training Data? Medium. Available online: https://towardsdatascience.com/how-do-you-know-you-have-enough-training-data-ad9b1fd679ee#:~:text=Computer%20Vision%3A%20For%20image%20classification (accessed on 23 April 2019).





| Algorithm | Training Time Complexity | Interpretability | Training Data Size | Inputs |
|---|---|---|---|---|
| Support Vector Machine (SVM) | Median | Small | Structured data | |
| k-nearest neighbors (k-NN) | k = number of neighbors | Median | Small | Structured data |
| Decision Tree | High | Small | Structured data | |
| Random Forest | k = number of trees | Median | Small | Structured data |
| Naïve Bayes | High | Small | Structured data | |
| Deep Neural Networks | Compute the activation of all neurons | Low | Large | Structured data or text data |
| True Labels | Labels Returned by the Classifier in the Testing Process | |
|---|---|---|
| Positive | Negative | |
| Positive | TP 1 | FN 2 |
| Negative | FP 3 | TN 4 |
| Name | Type | Devices | Techniques | Advantages | Shortcomings | Users |
|---|---|---|---|---|---|---|
| Phish Detector [36] | Web browser extension | Chrome | Rule-based | Zero false-negative alarms | Only for online-banking web sites | 2000+ |
| Netcraft Extension [37] | Web browser extension | Chrome | Blacklist-based | Multiple features, including coronavirus-related cybercrime. | New phishing attacks cannot be prevented | 50,000+ |
| WOT [38] | All | Browser Mobile PC | Blacklist + machine learning algorithms | Multi-platform security service | Charged | 1,000,000+ |
| Pixm Phishing Protection [39] | Web browser extension | Chrome | Deep learning algorithm | Advanced anti-phishing solution (AI) | Charged | 1000+ |
| Sharkcop [40] | Web browser extension | Chrome | SVM algorithm | New attacks can be detected Few features are used | The project is currently on hold Feature extraction relies on third-party services, such as domain age | - |
| PhishFort [41] | Web browser extension | Chrome Firefox | Blacklist-based | Free | New phishing attacks cannot be prevented | 2000+ |
| Model or Algorithm | Type | Dataset | Challenges | Limitations | Accuracy |
|---|---|---|---|---|---|
| Random forest [42] | Single | ISCXURL-2016 | Achieved high accuracy and low response time without relying on third-party services and using limited features extracted from a URL. | Did not use multiple different datasets to train the model, compare the results, or to evaluate the robustness of the model. | 99.57% |
| Random forest [45] | Single | Websites (phishTank, OpenPhish, Alexa, online payment gateway) 5223 instances: 2500 phishing URLs; 2723 legitimate URLs 20 features | The dataset is collected from the original website, 20 features are manually extracted, some features need to be obtained by calling a third-party service, and some features need to parse the website’s HTML source code. | Did not use multiple different datasets to train the model, compare the results, or to evaluate the robustness of the model. The experimental dataset is small. | 99.50% |
| PSL 1 + PART [46] | Hybrid | Websites (phishTank, Relbank) 30,500 original instances: 20,500 phishing URLs; 10,000 legitimate URLs. 3000 experiment data samples 18 features | Extracted 3000 comprehensive features and applied different set of parameters to ML models to compare the experimental results. | The legitimate URLs in the dataset are all related to banks, and some features are limited to e-banking websites. | 99.30% |
| ISHO + SVM [47] | Hybrid | UCI | Improved spotted hyena optimization (ISHO) algorithm to select more efficient features. | The UCI dataset is open source and contains 11,055 instances with normalized features but does not contain the original URL, and the proposed approach did not contain a feature extraction procedure. | 98.64% |
| Adaboost [48] | Single | Websites (phishTank, MillerSmiles, Google Search): size of the dataset not mentioned; each instance has 30 features | The proposed model used Weka 3.6, Python, and MATLAB 2. | Did not use multiple different datasets to train the model, compare the results, and evaluate the robustness of the model. | 98.30% |
| LBET (logistic regression + extra tree) [4] | Hybrid | UCI | Combined meta-learning algorithms and extra trees to achieve high accuracy and low false-positive rate. | Insufficient data sources and lack of a feature extraction process. | 97.57% |
| Bootstrap aggregating + logistic model tree [49] | Hybrid | UCI | The classifiers were trained and tested based on 10-fold cross-validation to reduce bias and variance. | Insufficient data sources and lack of a feature extraction process. | 97.42% |
| Random forest + neural network + bagging [26] | Hybrid | UCI | No previous research focuses on using a feedforward NN and ensemble learners for detecting phishing websites. | Insufficient data sources and lack of a feature extraction process. | 97.40% |
| priority-based algorithms [50] | Hybrid | UCI | \ | Insufficient data sources and lack of a feature extraction process. | 97.00% |
| Random forest [51] | Single | UCI | \ | Insufficient data sources and lack of a feature extraction process. | 96.87% |
| Adam optimizer + Deep Neural Network (DNN) [52] | Deep learning | UCI | \ | Insufficient data sources and lack of a feature extraction process. | 96.00% |
| Recurrent Neural Network (RNN) + Convolutional Neural Network (CNN) [44] | Deep learning | Websites (phishTank, Alexa) 490,408 instances: 245,385 phishing URLs; 245,023 legitimate URLs features: semantic features (word embedding) | The large-scale dataset is collected from the original website. The first one to use the deep learning model to detect phishing in the context of cybersecurity issues and the first to use hundreds of thousands of phishing URLs and normal website URLs for training and testing. | The maximum length of the URL is 255 characters. Training time was too long. When the phishing website URL itself does not have relevant semantics, PDRCNN will not be able to classify correctly, and PDRCNN does not care whether the website corresponding to the URL is alive or if there is an error. | 95.79% |
| CNN [24] | Deep learning | Websites (Alexa + OpenPhish + spamhaus.org + techhelplist.com + isc.sans.edu + phishTank) 318,642 instances. 157,626 legitimate URLs; 161,016 phishing URLs features: FG2: character embedding level features | The four different large-scale datasets are collected from original websites. The extracted features. Four different groups of features are extracted to compare the results of multiple sets of experiments. | The maximum length of the URL is 200 characters. The training time is rather long. The model is not interested in whether the URL of the website is active or has an error. The model will misclassify short links, sensitive keywords, and phishing URLs that do not imitate other websites. | 95.02% |
| Auto encoder + NIOSELM [53] | Hybrid | Websites (phishTank, Alexa, DMOZ) 60,000 legitimate URLs; 5000 phishing URLs; 56 features | The dataset is imbalanced. | The detection accuracy may not be the best compared with the existing methods. | 94.60% |
| Grey wolf optimizer + SVM [54] | Hybrid | Websites (phishTank, Yahoo) 1353 instances: 805 phishing URLs; 548 legitimate URLs 30 rule-based features | It is proven that in addition to the grid search-optimized RF classifier, nature-inspired optimization algorithms can also optimize the parameters of the Support Vector Machine (SVM) model to obtain high accuracy. | The dataset is small, and there is no comparison of the results of different datasets to the model. | 90.38% |
| Genetic algorithm (GA) + DNN [43] | Deep learning | UCI | Using GAs to select effective features and weights is a new idea. | Insufficient data sources and lack of a feature extraction process. Feature selection and weighting using GAs may require more time. The detection accuracy may be lower compared with the existing methods. | 89.50% |
| Convolutional auto encoder + DNN [55] | Deep learning | Websites (phishTank, clients’ daily requests) 6116 instance rule-based features | Features extracted based on convolutional autoencoder. | The detection accuracy may be lower compared with the existing methods. The dataset is small for deep learning models. | 89.00% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, L.; Mahmoud, Q.H. A Survey of Machine Learning-Based Solutions for Phishing Website Detection. Mach. Learn. Knowl. Extr. 2021, 3, 672-694. https://doi.org/10.3390/make3030034
Tang L, Mahmoud QH. A Survey of Machine Learning-Based Solutions for Phishing Website Detection. Machine Learning and Knowledge Extraction. 2021; 3(3):672-694. https://doi.org/10.3390/make3030034
Chicago/Turabian StyleTang, Lizhen, and Qusay H. Mahmoud. 2021. "A Survey of Machine Learning-Based Solutions for Phishing Website Detection" Machine Learning and Knowledge Extraction 3, no. 3: 672-694. https://doi.org/10.3390/make3030034
APA StyleTang, L., & Mahmoud, Q. H. (2021). A Survey of Machine Learning-Based Solutions for Phishing Website Detection. Machine Learning and Knowledge Extraction, 3(3), 672-694. https://doi.org/10.3390/make3030034