
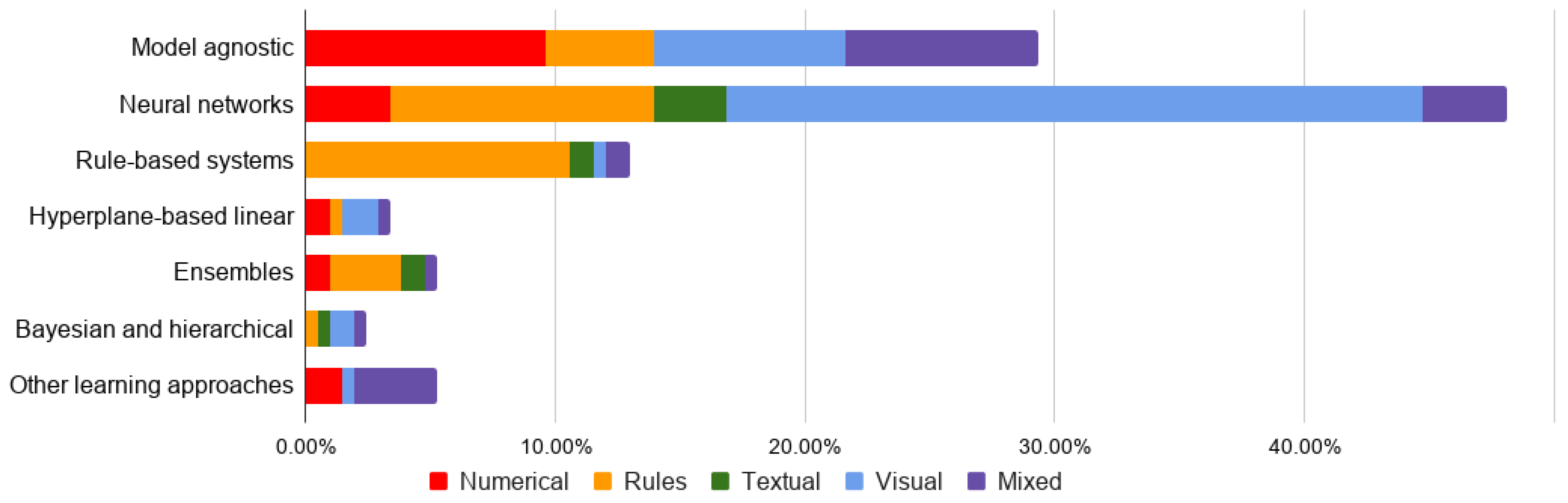
Classification of Explainable Artificial Intelligence Methods through Their Output Formats



Abstract
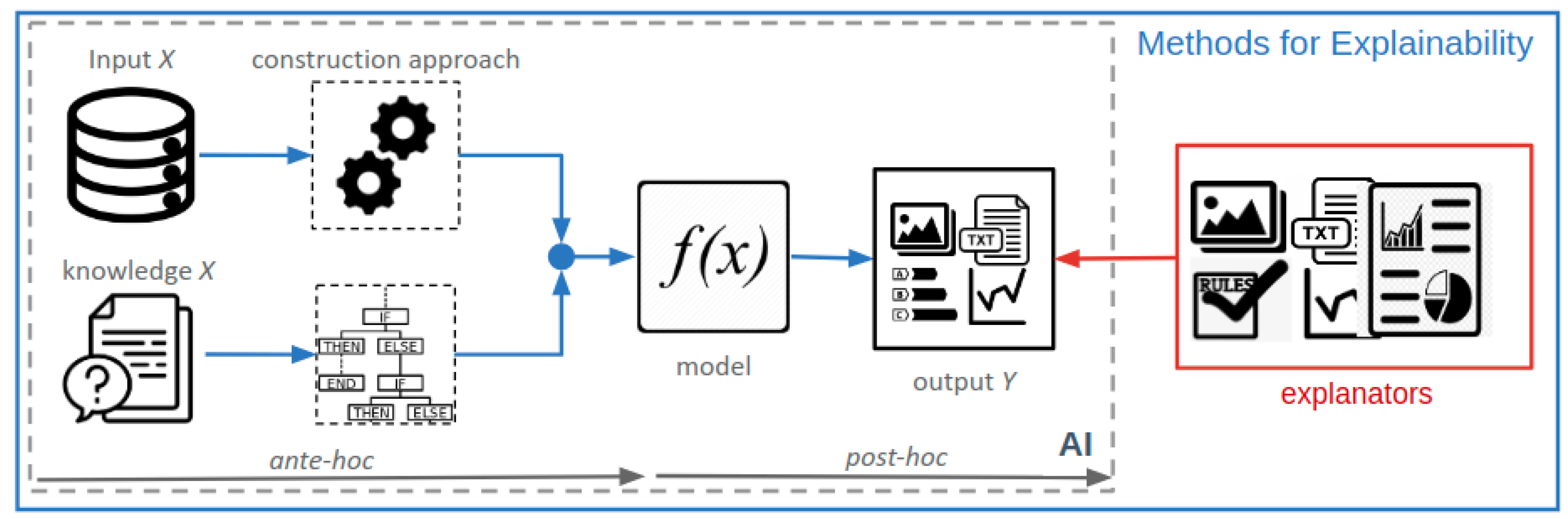
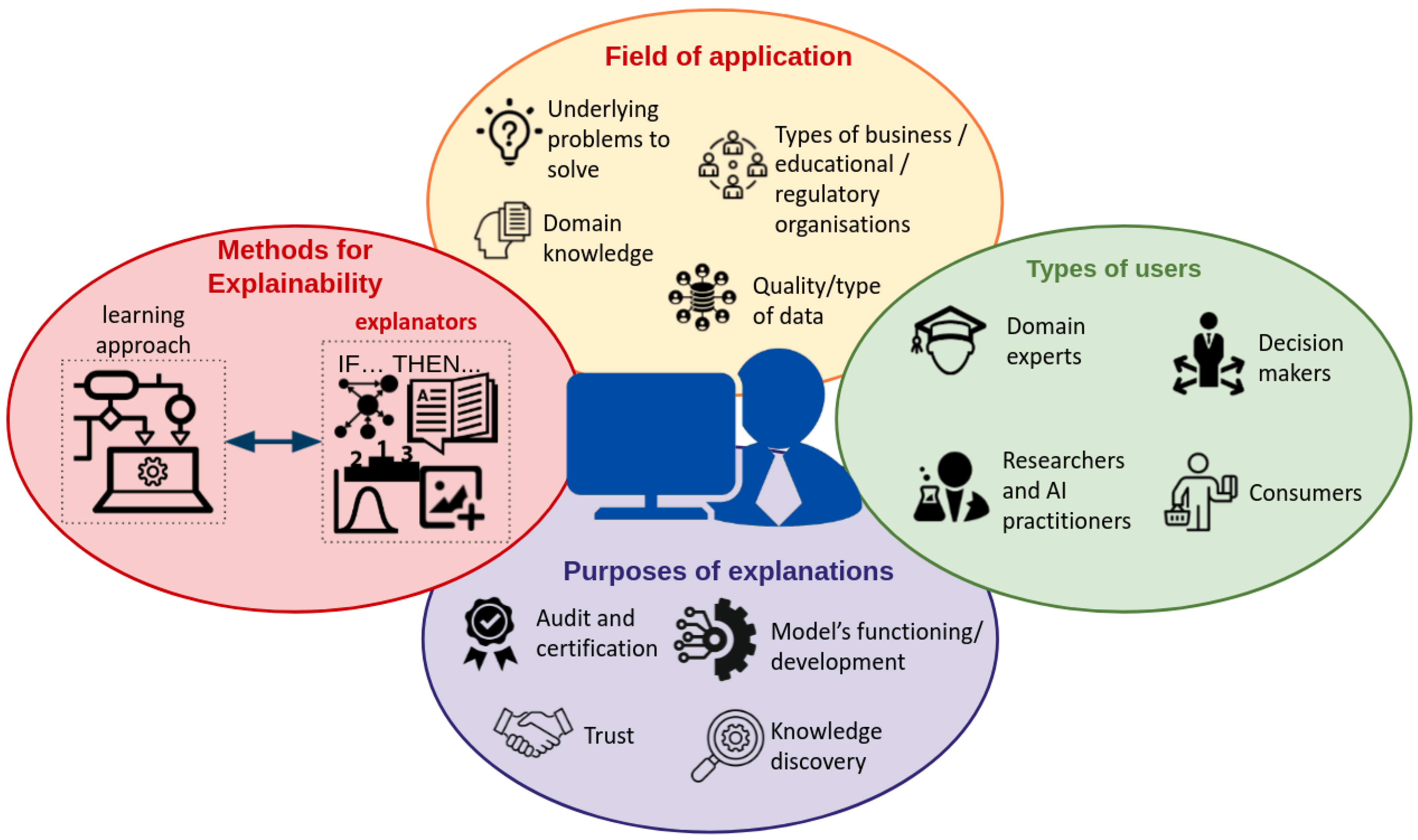
:1. Introduction
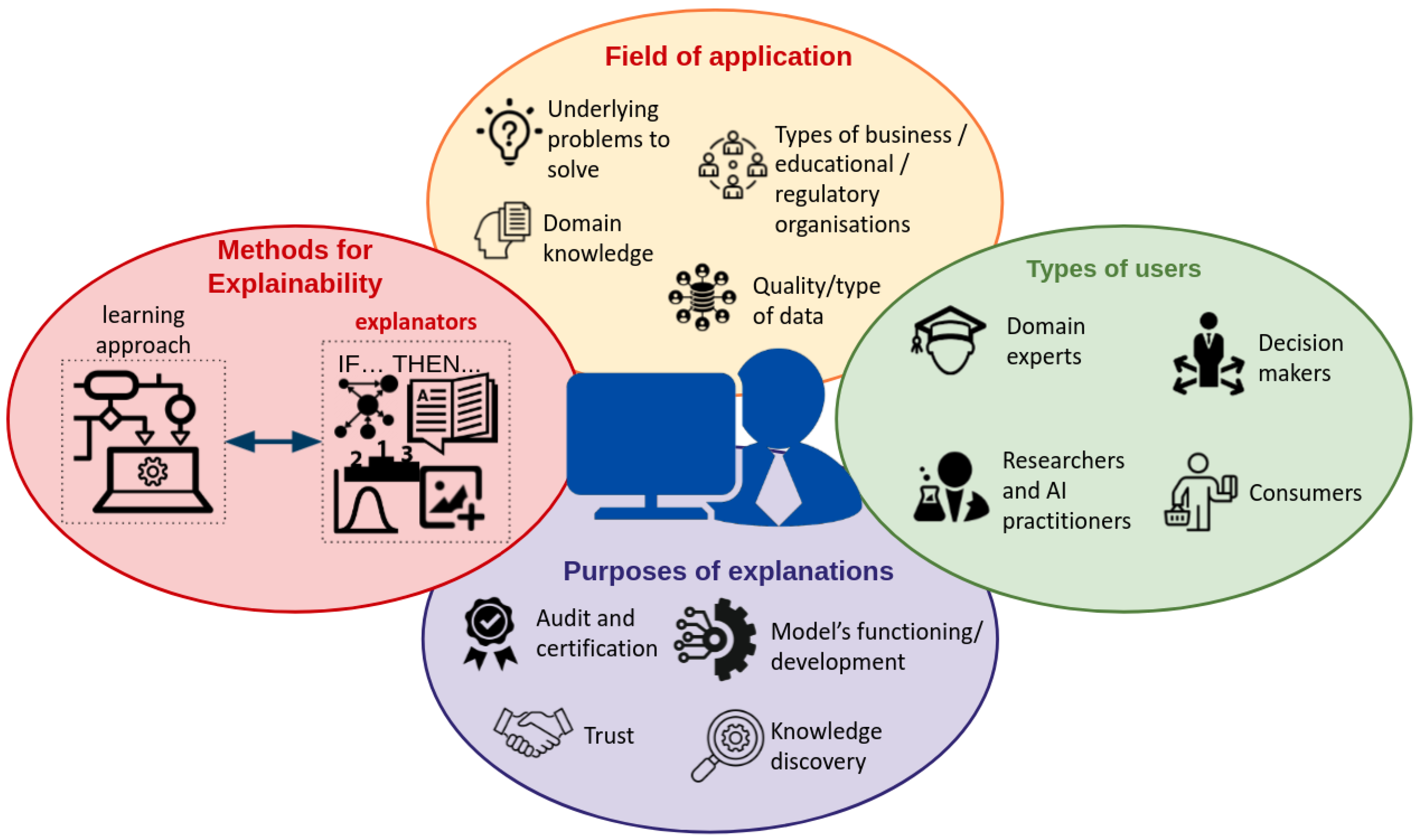
2. Research Methods
- Articles or technical reports that have not been peer reviewed;
- Scientific studies that applied existing XAI methods to specific problems, such as interpreting the forecasts made by DL models on images of cancers, and do not expand the XAI as a field. This exclusion was also necessary to drastically reduce the number of articles to something more manageable. Similarly, articles related to tutorials on XAI were discarded [10,11,12,13];
- Methods that could be employed for enhancing the explainability of AI techniques but that were not specifically designed for this purposes. For example, a considerable number of articles were devoted to methods designed for improving data visualisation or feature selection. These methods can indeed help researchers gain deeper insights into computational models, but they were not specifically designed for producing explanations.
- Google Scholar was queried to find articles discussing the explainability by using the following terms: “explainable artificial intelligence"; “explainable machine learning"; and “interpretable machine learning". The search returned several thousands of results, but only the first ten pages contained relevant articles. Altogether, these searches provided a basis of around 170 peer-reviewed publications;
- The bibliographic section of these articles was thoroughly reviewed. This led to the selection of further 50 articles whose bibliographic section was recursively analysed. This process was iterated until it converged and no more articles were found.
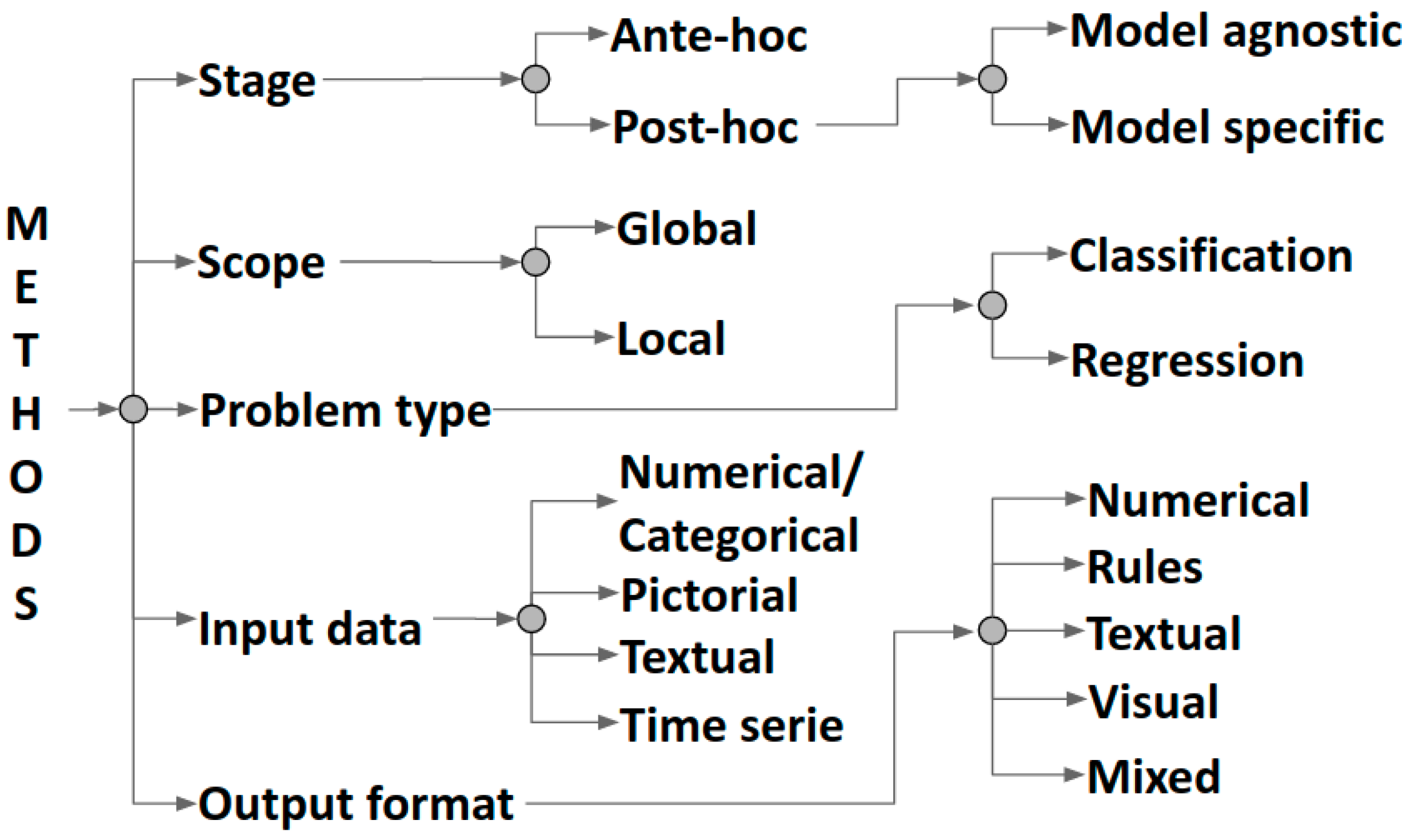
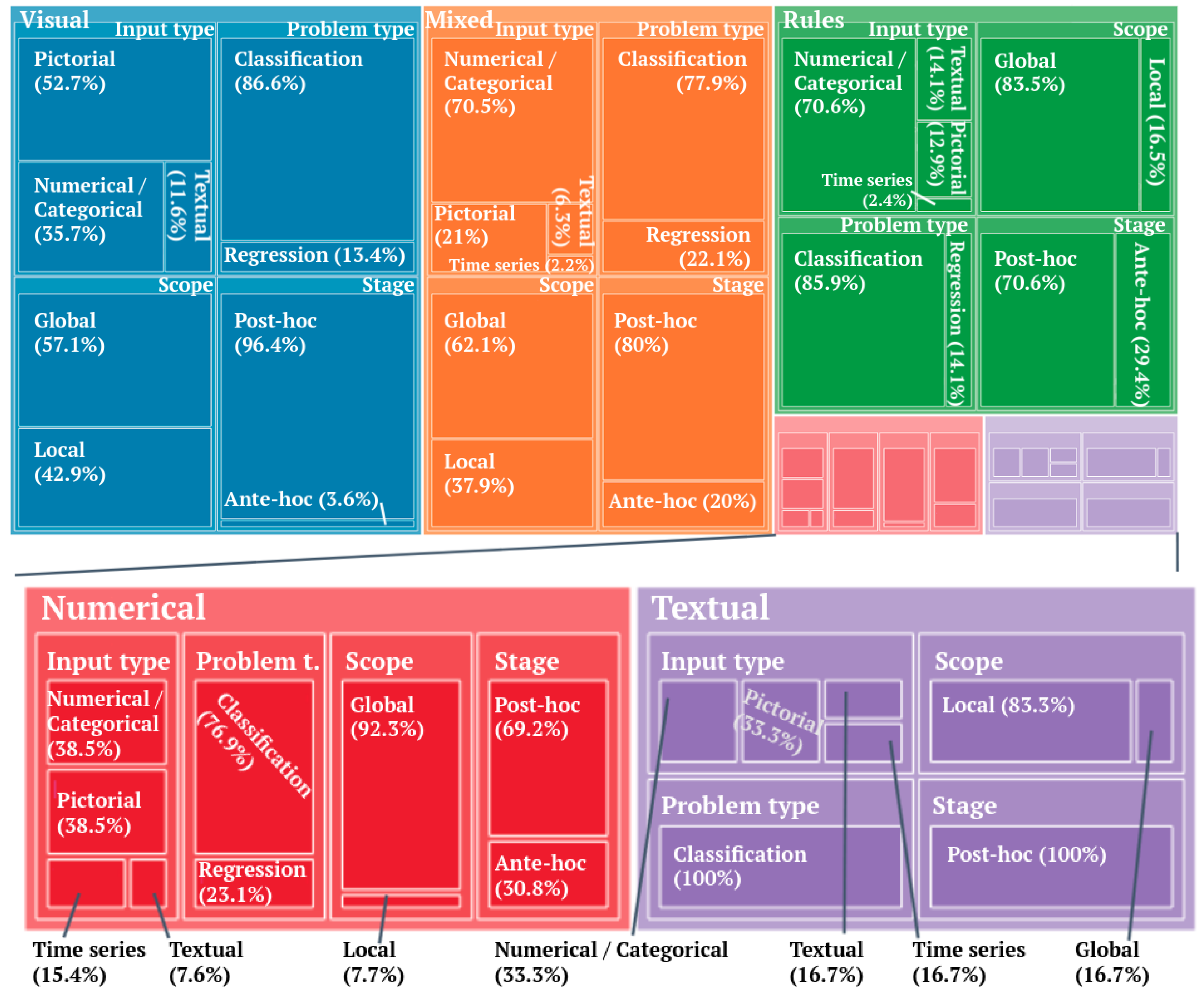
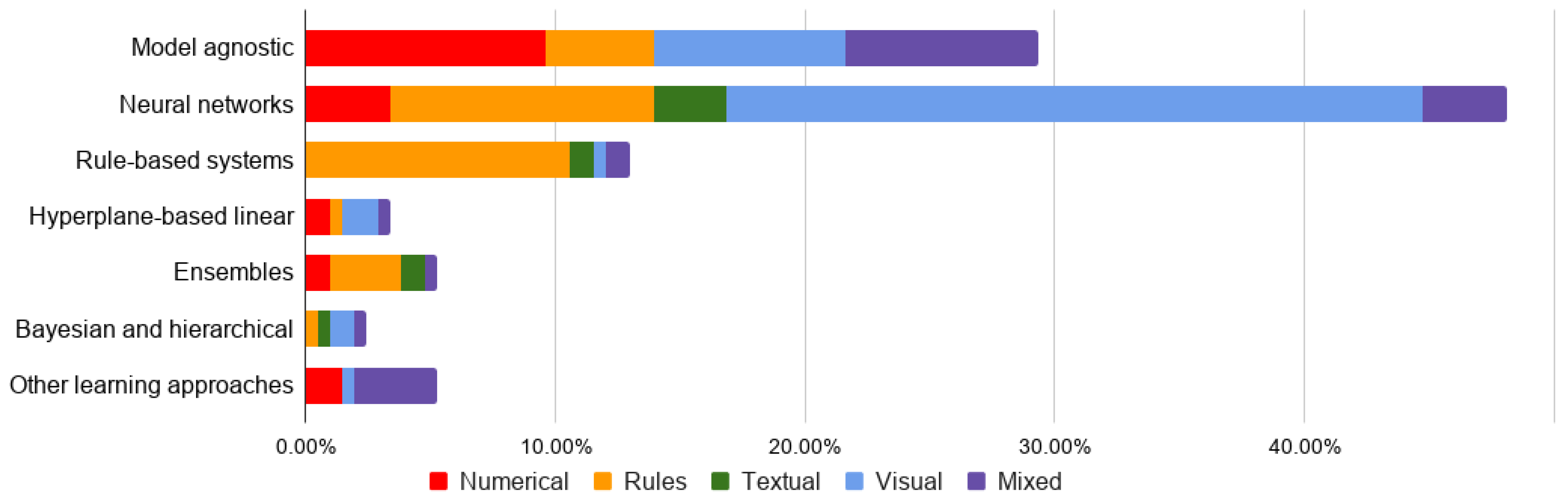
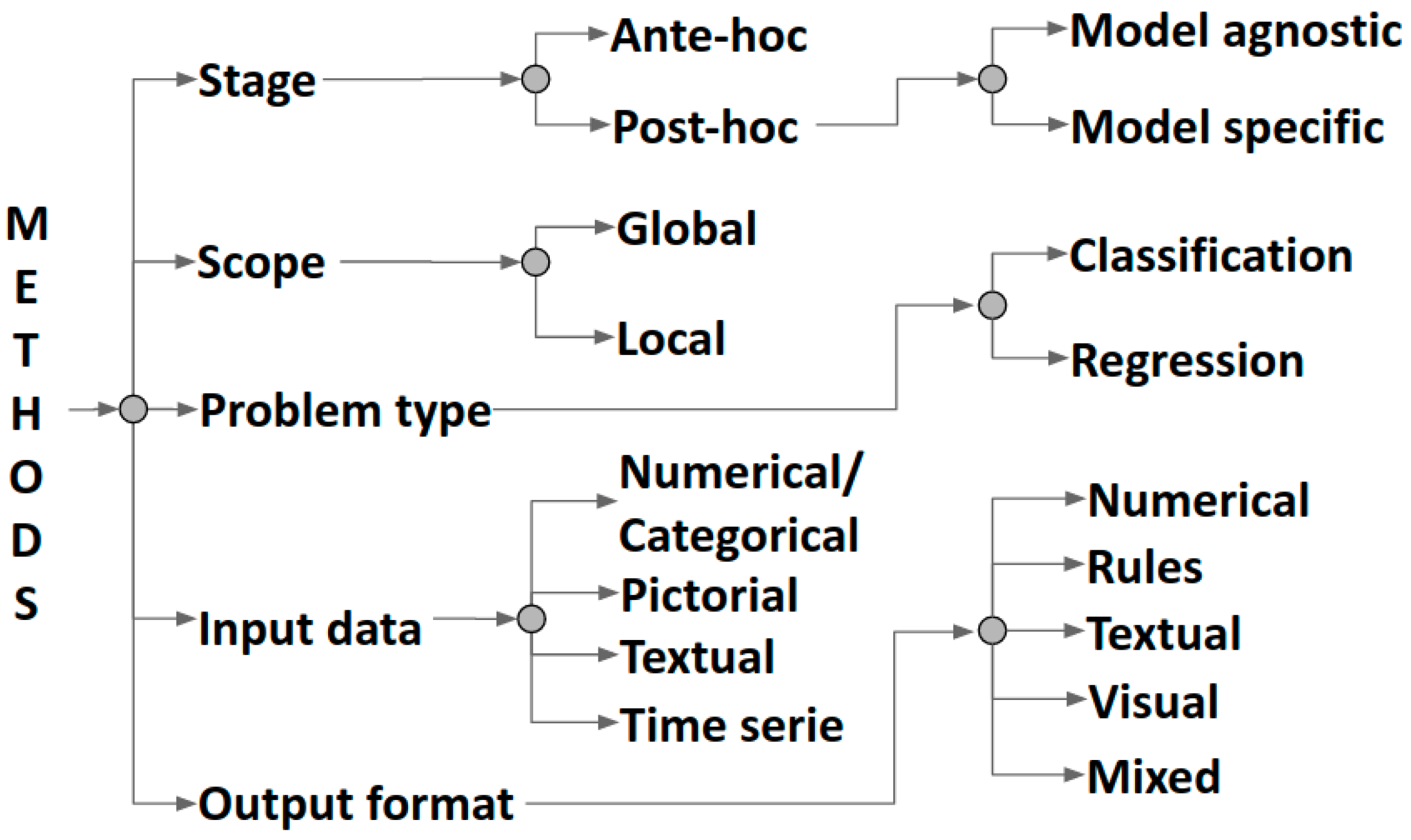
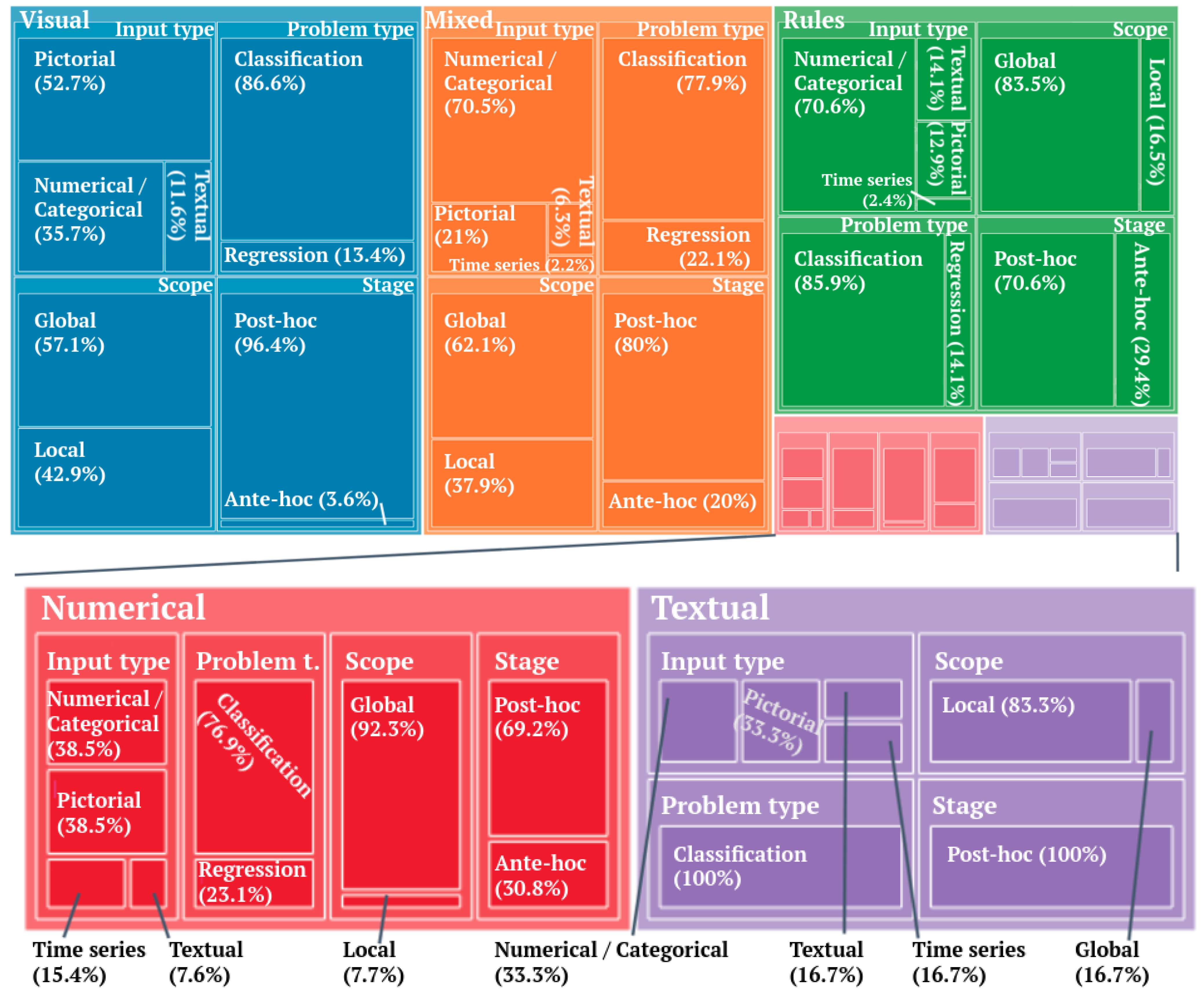
2.1. Classification of XAI Methods by Output Formats
3. Numeric Explanations
3.1. Model Agnostic XAI Methods
3.2. Model-Specific XAI Methods Based on Neural Networks
3.3. Other Model-Specific XAI Methods
3.3.1. Ensembles
3.3.2. Support Vector Machines
3.4. Self-Explainable and Interpretable Methods
4. Rule-Based Explanations
4.1. Model Agnostic XAI Methods
4.2. Model-Specific XAI Methods Based on Neural Networks
4.3. Model-Specific XAI Methods Related to Rule-Based Systems
4.4. Other Model-Specific XAI Methods
4.4.1. Ensembles
4.4.2. Support Vector Machines
4.4.3. Bayesian and Hierarchical Networks
5. Textual Explanations
5.1. Model-Specific XAI Methods Based on Neural Networks
5.2. Other Model-Specific XAI Methods
5.2.1. Rule-Based Systems
5.2.2. Ensembles
5.2.3. Bayesian and Hierarchical Networks
6. Visual Explanations
6.1. Model Agnostic XAI Methods
6.2. Model-Specific XAI Methods Based on Neural Networks
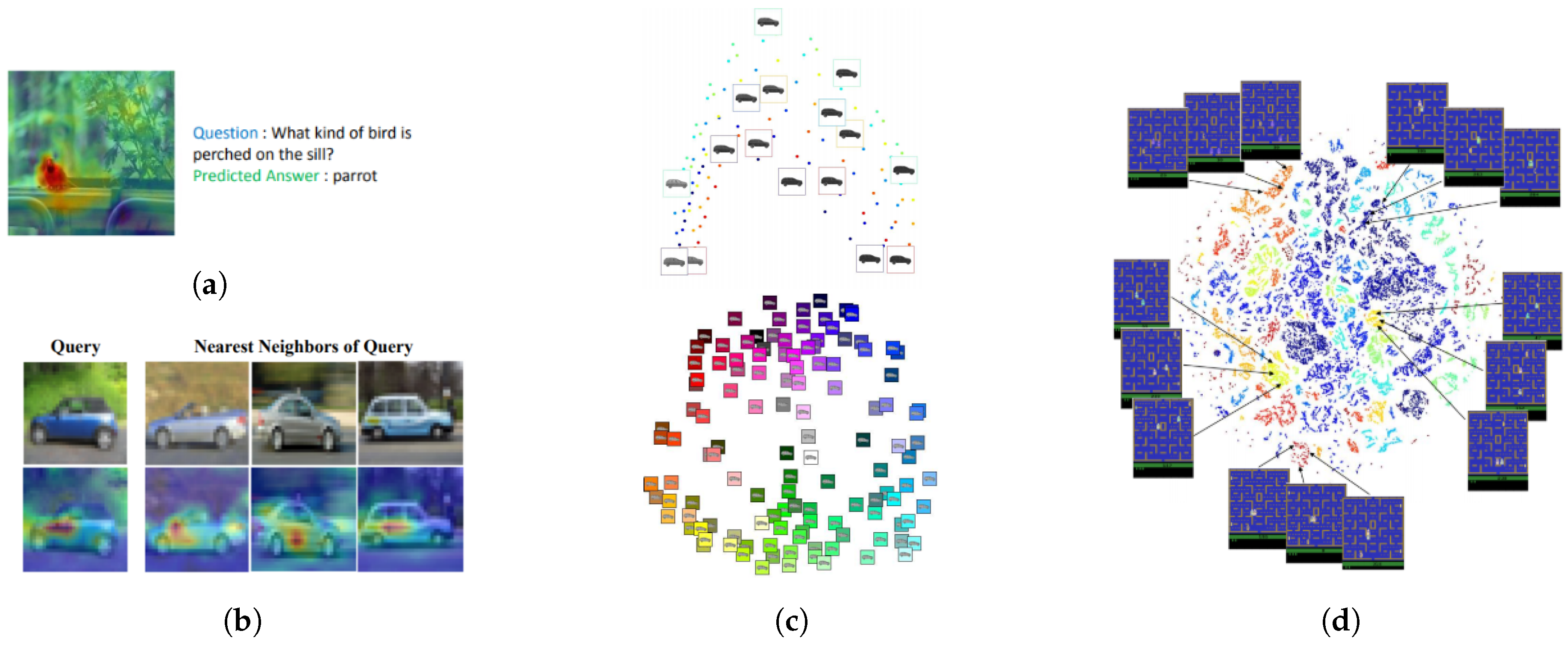
6.2.1. Visual Explanations as Salient Masks
6.2.2. Visual Explanations as Scatter-Plots
6.2.3. Visual Explanations—Miscellaneous
6.3. Other Model-Specific XAI Methods
6.3.1. Rule-Based Systems
6.3.2. Support Vector Machines and Naïve Bayesian-Driven Models
6.3.3. Bayesian and Hierarchical Networks
6.4. Self-Explainable and Interpretable Methods
7. Mixed Explanations
7.1. Model Agnostic XAI Methods
7.2. Model-Specific XAI Methods Based on Neural Networks
7.3. Other Model-Specific XAI Methods
7.3.1. Rule-Based System
7.3.2. Ensembles
7.3.3. Support Vector Machines
7.3.4. Bayesian and Hierarchical Networks
7.4. Self-Explainable and Interpretable Methods
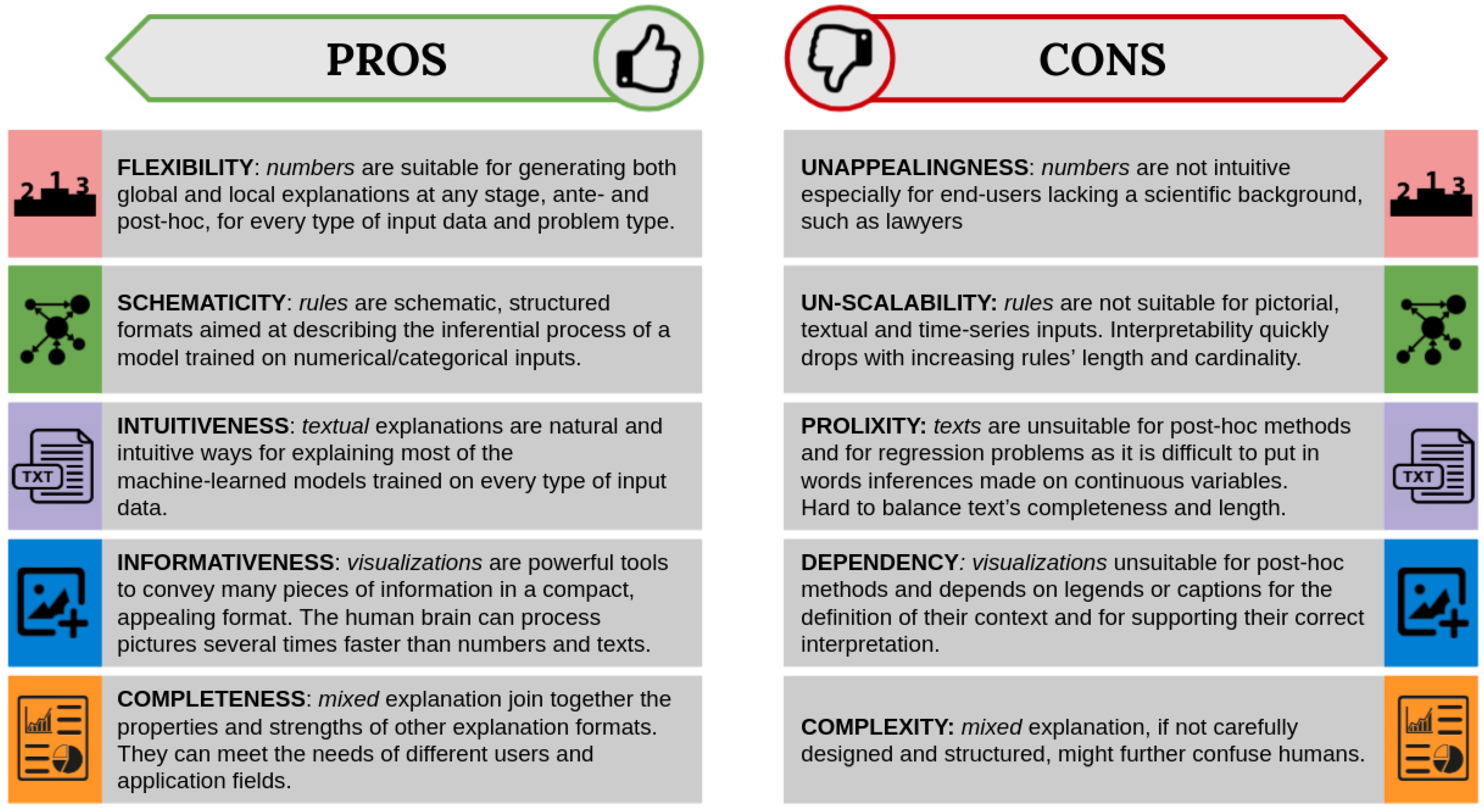
8. Final Remarks and Recommendations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Adadi, A.; Berrada, M. Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI). Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Kim, J.; Rohrbach, A.; Darrell, T.; Canny, J.; Akata, Z. Textual Explanations for Self-Driving Vehicles; ECCV: Munich, Germany, 2018; pp. 563–578. [Google Scholar]
- Lapuschkin, S.; Wäldchen, S.; Binder, A.; Montavon, G.; Samek, W.; Müller, K.R. Unmasking Clever Hans predictors and assessing what machines really learn. Nat. Commun. 2019, 10, 1096. [Google Scholar] [CrossRef] [Green Version]
- Fox, M.; Long, D.; Magazzeni, D. Explainable planning. In IJCAI Workshop on Explainable Artificial Intelligence (XAI); International Joint Conferences on Artificial Intelligence, Inc.: Melbourne, Australia, 2017; pp. 24–30. [Google Scholar]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A survey of methods for explaining black box models. Comput. Surv. (CSUR) 2018, 51, 93:1–93:42. [Google Scholar] [CrossRef] [Green Version]
- de Graaf, M.; Malle, B.F. How People Explain Action (and Autonomous Intelligent Systems Should Too). In Fall Symposium on Artificial Intelligence for Human-Robot Interaction; AAAI Press: Arlington, VA, USA, 2017; pp. 19–26. [Google Scholar]
- Harbers, M.; van den Bosch, K.; Meyer, J.J.C. A study into preferred explanations of virtual agent behavior. In International Workshop on Intelligent Virtual Agents; Springer: Amsterdam, The Netherlands, 2009; pp. 132–145. [Google Scholar] [CrossRef]
- Vilone, G.; Longo, L. Notions of explainability and evaluation approaches for explainable artificial intelligence. Inf. Fusion 2021, 76, 89–106. [Google Scholar] [CrossRef]
- Wick, M.R.; Thompson, W.B. Reconstructive Explanation: Explanation as Complex Problem Solving. In Proceedings of the 11th International Joint Conference on Artificial Intelligence, Detroit, MI, USA, 20–25 August 1989; pp. 135–140. [Google Scholar]
- Alonso, J.M. Teaching Explainable Artificial Intelligence to High School Students. Int. J. Comput. Intell. Syst. 2020, 13, 974–987. [Google Scholar] [CrossRef]
- Bunn, J. Working in contexts for which transparency is important: A recordkeeping view of Explainable Artificial Intelligence (XAI). Rec. Manag. J. 2020, 30, 143–153. [Google Scholar] [CrossRef]
- Gade, K.; Geyik, S.C.; Kenthapadi, K.; Mithal, V.; Taly, A. Explainable AI in industry: Practical challenges and lessons learned: Implications tutorial. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, Barcelona, Spain, 27–30 January 2020; p. 699. [Google Scholar]
- Miller, T.; Weber, R.; Magazzeni, D. Report on the 2019 International Joint Conferences on Artificial Intelligence Explainable Artificial Intelligence Workshop. AI Mag. 2020, 41, 103–105. [Google Scholar]
- Dam, H.K.; Tran, T.; Ghose, A. Explainable software analytics. In Proceedings of the 40th International Conference on Software Engineering: New Ideas and Emerging Results, Gothenburg, Sweden, 27 May–3 June 2018; pp. 53–56. [Google Scholar] [CrossRef] [Green Version]
- Lipton, Z.C. The mythos of model interpretability. Commun. ACM 2018, 61, 36–43. [Google Scholar] [CrossRef]
- Došilović, F.K.; Brčić, M.; Hlupić, N. Explainable artificial intelligence: A survey. In Proceedings of the 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 21–25 May 2018; pp. 0210–0215. [Google Scholar] [CrossRef]
- Lou, Y.; Caruana, R.; Gehrke, J. Intelligible models for classification and regression. In Proceedings of the 18th SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 150–158. [Google Scholar] [CrossRef] [Green Version]
- Lou, Y.; Caruana, R.; Gehrke, J.; Hooker, G. Accurate intelligible models with pairwise interactions. In Proceedings of the 19th SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 623–631. [Google Scholar] [CrossRef] [Green Version]
- Montavon, G.; Samek, W.; Müller, K.R. Methods for interpreting and understanding deep neural networks. Digit. Signal Process. 2017, 73, 1–15. [Google Scholar] [CrossRef]
- Páez, A. The Pragmatic Turn in Explainable Artificial Intelligence (XAI). Minds Mach. 2019, 29, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Vilone, G.; Longo, L. Explainable artificial intelligence: A systematic review. arXiv 2020, arXiv:2006.00093. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Why should I trust you?: Explaining the predictions of any classifier. In Proceedings of the 22nd IGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Strobelt, H.; Gehrmann, S.; Pfister, H.; Rush, A.M. Lstmvis: A tool for visual analysis of hidden state dynamics in recurrent neural networks. Trans. Vis. Comput. Graph. 2018, 24, 667–676. [Google Scholar] [CrossRef] [Green Version]
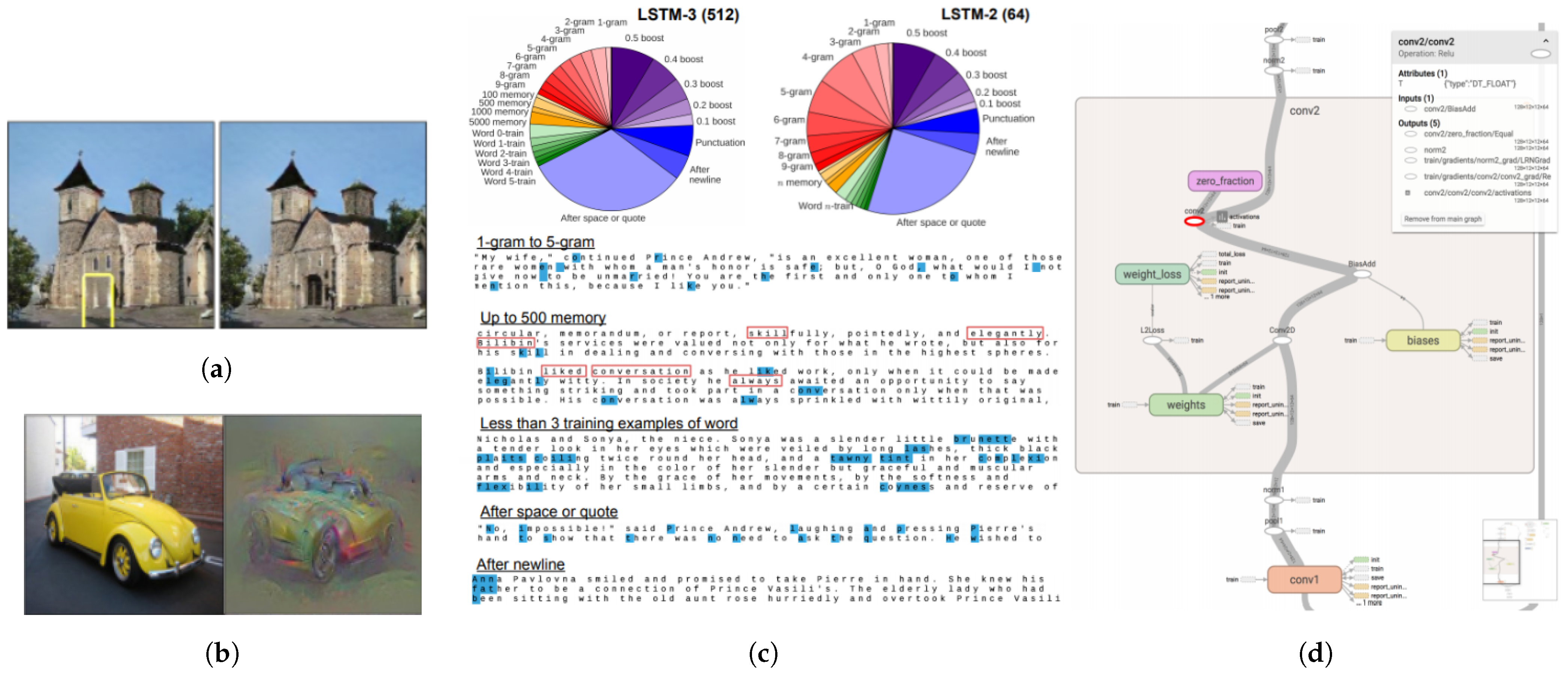
- Wongsuphasawat, K.; Smilkov, D.; Wexler, J.; Wilson, J.; Mané, D.; Fritz, D.; Krishnan, D.; Viégas, F.B.; Wattenberg, M. Visualizing dataflow graphs of deep learning models in TensorFlow. Trans. Vis. Comput. Graph. 2018, 24, 1–12. [Google Scholar] [CrossRef]
- Hendricks, L.A.; Hu, R.; Darrell, T.; Akata, Z. Grounding visual explanations. In Computer Vision—ECCV—15th European Conference, Proceedings, Part II; Springer: Munich, Germany, 2018; pp. 269–286. [Google Scholar] [CrossRef] [Green Version]
- Fung, G.; Sandilya, S.; Rao, R.B. Rule extraction from linear support vector machines. In Proceedings of the 11th SIGKDD International Conference on Knowledge Discovery in Data Mining, Chicago, IL, USA, 21–24 August 2005; pp. 32–40. [Google Scholar] [CrossRef] [Green Version]
- Bologna, G.; Hayashi, Y. Characterization of symbolic rules embedded in deep DIMLP networks: A challenge to transparency of deep learning. J. Artif. Intell. Soft Comput. Res. 2017, 7, 265–286. [Google Scholar] [CrossRef] [Green Version]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Anchors: High-precision model-agnostic explanations. In Proceedings of the 32nd Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 1527–1535. [Google Scholar]
- Guillaume, S. Designing fuzzy inference systems from data: An interpretability-oriented review. Trans. Fuzzy Syst. 2001, 9, 426–443. [Google Scholar] [CrossRef] [Green Version]
- Palade, V.; Neagu, D.C.; Patton, R.J. Interpretation of trained neural networks by rule extraction. In Proceedings of the International Conference on Computational Intelligence, Dortmund, Germany, 1–3 October 2001; pp. 152–161. [Google Scholar] [CrossRef]
- Rizzo, L.; Longo, L. Inferential models of mental workload with defeasible argumentation and non-monotonic fuzzy reasoning: A comparative study. In Proceedings of the 2nd Workshop on Advances in Argumentation in Artificial Intelligence, Trento, Italy, 20–23 November 2018; pp. 11–26. [Google Scholar]
- Rizzo, L.; Longo, L. A Qualitative Investigation of the Explainability of Defeasible Argumentation and Non-Monotonic Fuzzy Reasoning. In Proceedings of the 26th AIAI Irish Conference on Artificial Intelligence and Cognitive Science Trinity College Dublin, Dublin, Ireland, 6–7 December 2018; pp. 138–149. [Google Scholar]
- Alain, G.; Bengio, Y. Understanding intermediate layers using linear classifier probes. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 23–26 April 2017; p. 68. [Google Scholar]
- Kim, B.; Wattenberg, M.; Gilmer, J.; Cai, C.; Wexler, J.; Viegas, F.; Sayres, R. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav). In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 2673–2682. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Courville, A.; Salakhutdinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. Int. Conf. Mach. Learn. 2015, 2048, 2057–2088. [Google Scholar]
- Tolomei, G.; Silvestri, F.; Haines, A.; Lalmas, M. Interpretable predictions of tree-based ensembles via actionable feature tweaking. In Proceedings of the 23rd SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 465–474. [Google Scholar] [CrossRef] [Green Version]
- Tan, S.; Caruana, R.; Hooker, G.; Lou, Y. Distill-and-Compare: Auditing Black-Box Models Using Transparent Model Distillation. In Proceedings of the Conference on AI, Ethics, and Society, New Orleans, LA, USA, 2–3 February 2018; pp. 303–310. [Google Scholar] [CrossRef] [Green Version]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: Long Beach, CA, USA, 4–9 December 2017; pp. 4765–4774. [Google Scholar]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.I. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 2522–5839. [Google Scholar] [CrossRef] [PubMed]
- Janzing, D.; Minorics, L.; Blöbaum, P. Feature relevance quantification in explainable AI: A causal problem. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Palermo, Italy, 3–5 June 2020; pp. 2907–2916. [Google Scholar]
- Giudici, P.; Raffinetti, E. Shapley-Lorenz eXplainable artificial intelligence. Expert Syst. Appl. 2020, 167, 114104. [Google Scholar] [CrossRef]
- Robnik-Šikonja, M.; Kononenko, I. Explaining classifications for individual instances. Trans. Knowl. Data Eng. 2008, 20, 589–600. [Google Scholar] [CrossRef] [Green Version]
- Robnik-Šikonja, M. Explanation of Prediction Models with Explain Prediction. Informatica 2018, 42, 13–22. [Google Scholar]
- Cortez, P.; Embrechts, M.J. Opening black box data mining models using sensitivity analysis. In Proceedings of the Symposium on Computational Intelligence and Data Mining (CIDM), Paris, France, 11–15 April 2011; pp. 341–348. [Google Scholar] [CrossRef] [Green Version]
- Cortez, P.; Embrechts, M.J. Using sensitivity analysis and visualization techniques to open black box data mining models. Inf. Sci. 2013, 225, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Strumbelj, E.; Kononenko, I. An Efficient Explanation of Individual Classifications Using Game Theory. J. Mach. Learn. Res. 2010, 11, 1–18. [Google Scholar]
- Kononenko, I.; Štrumbelj, E.; Bosnić, Z.; Pevec, D.; Kukar, M.; Robnik-Šikonja, M. Explanation and reliability of individual predictions. Informatica 2013, 37, 41–48. [Google Scholar]
- Štrumbelj, E.; Kononenko, I.; Šikonja, M.R. Explaining instance classifications with interactions of subsets of feature values. Data Knowl. Eng. 2009, 68, 886–904. [Google Scholar] [CrossRef]
- Štrumbelj, E.; Kononenko, I. Towards a model independent method for explaining classification for individual instances. In Proceedings of the International Conference on Data Warehousing and Knowledge Discovery, Turin, Italy, 1–5 September 2008; pp. 273–282. [Google Scholar] [CrossRef]
- Štrumbelj, E.; Bosnić, Z.; Kononenko, I.; Zakotnik, B.; Kuhar, C.G. Explanation and reliability of prediction models: The case of breast cancer recurrence. Knowl. Inf. Syst. 2010, 24, 305–324. [Google Scholar] [CrossRef]
- Datta, A.; Sen, S.; Zick, Y. Algorithmic transparency via quantitative input influence: Theory and experiments with learning systems. In Proceedings of the Symposium on Security and Privacy (SP), San Jose, CA, USA, 23–25 May 2016; pp. 598–617. [Google Scholar] [CrossRef]
- Adler, P.; Falk, C.; Friedler, S.A.; Nix, T.; Rybeck, G.; Scheidegger, C.; Smith, B.; Venkatasubramanian, S. Auditing black-box models for indirect influence. Knowl. Inf. Syst. 2018, 54, 95–122. [Google Scholar] [CrossRef] [Green Version]
- Koh, P.W.; Liang, P. Understanding black-box predictions via influence functions. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 1885–1894. [Google Scholar]
- Sliwinski, J.; Strobel, M.; Zick, Y. A Characterization of Monotone Influence Measures for Data Classification. In Proceedings of the Workshop on Explainable AI (XAI); International Joint Conferences on Artificial Intelligence (IJCAI), Melbourne, Australia, 19–25 August 2017; pp. 48–52. [Google Scholar]
- Henelius, A.; Puolamäki, K.; Boström, H.; Asker, L.; Papapetrou, P. A peek into the black box: Exploring classifiers by randomization. Data Min. Knowl. Discov. 2014, 28, 1503–1529. [Google Scholar] [CrossRef]
- Štrumbelj, E.; Kononenko, I. Explaining prediction models and individual predictions with feature contributions. Knowl. Inf. Syst. 2014, 41, 647–665. [Google Scholar] [CrossRef]
- Raghu, M.; Gilmer, J.; Yosinski, J.; Sohl-Dickstein, J. Svcca: Singular vector canonical correlation analysis for deep learning dynamics and interpretability. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6076–6085. [Google Scholar]
- Féraud, R.; Clérot, F. A methodology to explain neural network classification. Neural Netw. 2002, 15, 237–246. [Google Scholar] [CrossRef]
- Främling, K. Explaining results of neural networks by contextual importance and utility. In Rule Extraction from Trained Artificial Neural Networks Workshop; Citeseer: Brighton, UK, 1996; pp. 43–56. [Google Scholar]
- Hsieh, T.Y.; Wang, S.; Sun, Y.; Honavar, V. Explainable Multivariate Time Series Classification: A Deep Neural Network Which Learns to Attend to Important Variables as Well as Time Intervals. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, Jerusalem, Israel, 8–12 March 2021; pp. 607–615. [Google Scholar] [CrossRef]
- Clos, J.; Wiratunga, N.; Massie, S. Towards Explainable Text Classification by Jointly Learning Lexicon and Modifier Terms. In Proceedings of the Workshop on Explainable AI (XAI); International Joint Conferences on Artificial Intelligence (IJCAI), Melbourne, Australia, 19–25 August 2017; pp. 19–23. [Google Scholar]
- Petkovic, D.; Alavi, A.; Cai, D.; Wong, M. Random Forest Model and Sample Explainer for Non-experts in Machine Learning—Two Case Studies. Pattern Recognition. In Proceedings of the ICPR International Workshops and Challenges, Online, 10–15 January 2021; Part III. pp. 62–75. [Google Scholar] [CrossRef]
- Barbella, D.; Benzaid, S.; Christensen, J.M.; Jackson, B.; Qin, X.V.; Musicant, D.R. Understanding Support Vector Machine Classifications via a Recommender System-Like Approach; DMIN; CSREA Press: Las Vegas, NV, USA, 2009; pp. 305–311. [Google Scholar]
- Caragea, D.; Cook, D.; Honavar, V. Towards simple, easy-to-understand, yet accurate classifiers. In Proceedings of the 3rd International Conference on Data Mining, San Francisco, CA, USA, 19–22 November 2003; pp. 497–500. [Google Scholar] [CrossRef]
- Caywood, M.S.; Roberts, D.M.; Colombe, J.B.; Greenwald, H.S.; Weiland, M.Z. Gaussian process regression for predictive but interpretable machine learning models: An example of predicting mental workload across tasks. Front. Hum. Neurosci. 2017, 10, 647–665. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, J.; Fujimaki, R.; Motohashi, Y. Trading interpretability for accuracy: Oblique treed sparse additive models. In Proceedings of the 21th SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 1245–1254. [Google Scholar] [CrossRef]
- Ustun, B.; Traca, S.; Rudin, C. Supersparse Linear Integer Models for Interpretable Classification. Stat 2014, 1050, 11–47. [Google Scholar]
- Bride, H.; Dong, J.; Dong, J.S.; Hóu, Z. Towards Dependable and Explainable Machine Learning Using Automated Reasoning. In Proceedings of the International Conference on Formal Engineering Methods, Gold Coast, Australia, 12–16 November 2018; pp. 412–416. [Google Scholar] [CrossRef]
- Johansson, U.; Niklasson, L.; König, R. Accuracy vs. comprehensibility in data mining models. In Proceedings of the 7th International Conference on Information Fusion, Stockholm, Sweden, 28 June–1 July 2004; Volume 1, pp. 295–300. [Google Scholar]
- Johansson, U.; König, R.; Niklasson, L. The Truth is In There-Rule Extraction from Opaque Models Using Genetic Programming. In Proceedings of the FLAIRS Conference, Miami Beach, FL, USA, 12–14 May 2004; pp. 658–663. [Google Scholar]
- Guidotti, R.; Monreale, A.; Giannotti, F.; Pedreschi, D.; Ruggieri, S.; Turini, F. Factual and counterfactual explanations for black box decision making. IEEE Intell. Syst. 2019, 34, 14–23. [Google Scholar] [CrossRef]
- Setzu, M.; Guidotti, R.; Monreale, A.; Turini, F.; Pedreschi, D.; Giannotti, F. GLocalX-From Local to Global Explanations of Black Box AI Models. Artif. Intell. 2021, 294, 103457. [Google Scholar] [CrossRef]
- Bastani, O.; Kim, C.; Bastani, H. Interpretability via model extraction. In Proceedings of the Fairness, Accountability, and Transparency in Machine Learning Workshop, Halifax, NS, Canada, 14 August 2017; pp. 57–61. [Google Scholar]
- Krishnan, S.; Wu, E. Palm: Machine learning explanations for iterative debugging. In Proceedings of the 2nd Workshop on Human-In-the-Loop Data Analytics, Chicago, IL, USA, 14–19 May 2017; p. 4. [Google Scholar] [CrossRef]
- Asano, K.; Chun, J. Post-hoc Explanation using a Mimic Rule for Numerical Data. In Proceedings of the 13th International Conference on Agents and Artificial Intelligence—Volume 2: ICAART, Setubal, Portugal, 4–6 February 2021; pp. 768–774. [Google Scholar] [CrossRef]
- Hailesilassie, T. Rule extraction algorithm for deep neural networks: A review. Int. J. Comput. Sci. Inf. Secur. 2016, 14, 376–381. [Google Scholar]
- Bologna, G.; Hayashi, Y. A comparison study on rule extraction from neural network ensembles, boosted shallow trees, and SVMs. Appl. Comput. Intell. Soft Comput. 2018, 2018, 4084850. [Google Scholar] [CrossRef]
- Setiono, R.; Liu, H. Understanding neural networks via rule extraction. In Proceedings of the International Joint Conferences on Artificial Intelligence, Montréal, QC, Canada, 20–25 August 1995; Volume 1, pp. 480–485. [Google Scholar] [CrossRef]
- Bondarenko, A.; Aleksejeva, L.; Jumutc, V.; Borisov, A. Classification Tree Extraction from Trained Artificial Neural Networks. Procedia Comput. Sci. 2017, 104, 556–563. [Google Scholar] [CrossRef]
- Thrun, S. Extracting rules from artificial neural networks with distributed representations. In Advances in Neural Information Processing Systems; MIT Press: Denver, CO, USA, 1995; pp. 505–512. [Google Scholar]
- Bologna, G. Symbolic rule extraction from the DIMLP neural network. In Proceedings of the International Workshop on Hybrid Neural Systems, Denver, CO, USA, 3–6 December 1998; pp. 240–254. [Google Scholar] [CrossRef]
- Bologna, G. A Rule Extraction Study Based on a Convolutional Neural Network. In Proceedings of the International Cross-Domain Conference for Machine Learning and Knowledge Extraction, Hamburg, Germany, 27–30 August 2018; pp. 304–313. [Google Scholar] [CrossRef]
- Augasta, M.G.; Kathirvalavakumar, T. Reverse engineering the neural networks for rule extraction in classification problems. Neural Process. Lett. 2012, 35, 131–150. [Google Scholar] [CrossRef]
- Biswas, S.K.; Chakraborty, M.; Purkayastha, B.; Roy, P.; Thounaojam, D.M. Rule extraction from training data using neural network. Int. J. Artif. Intell. Tools 2017, 26, 1750006. [Google Scholar] [CrossRef]
- Garcez, A.d.; Broda, K.; Gabbay, D.M. Symbolic knowledge extraction from trained neural networks: A sound approach. Artif. Intell. 2001, 125, 155–207. [Google Scholar] [CrossRef] [Green Version]
- Frosst, N.; Hinton, G. Distilling a neural network into a soft decision tree. In Proceedings of the 16th International Conference of the Italian Association of Artificial Intelligence. Workshop on Comprehensibility and Explanation in AI and ML, Bari, Italy, 16–17 November 2017; pp. 1–8. [Google Scholar]
- Zhang, Q.; Yang, Y.; Ma, H.; Wu, Y.N. Interpreting cnns via decision trees. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 6261–6270. [Google Scholar]
- Zhou, Z.H.; Jiang, Y.; Chen, S.F. Extracting symbolic rules from trained neural network ensembles. AI Commun. 2003, 16, 3–15. [Google Scholar]
- Zhou, Z.H.; Jiang, Y. Medical diagnosis with C4. 5 rule preceded by artificial neural network ensemble. Trans. Inf. Technol. Biomed. 2003, 7, 37–42. [Google Scholar] [CrossRef] [PubMed]
- Boz, O. Extracting decision trees from trained neural networks. In Proceedings of the 8th SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AL, Canada, 23–26 July 2002; pp. 456–461. [Google Scholar] [CrossRef] [Green Version]
- Craven, M.W.; Shavlik, J.W. Using sampling and queries to extract rules from trained neural networks. In Machine Learning Proceedings; Elsevier: New Brunswick, NJ, USA, 1994; pp. 37–45. [Google Scholar] [CrossRef]
- Craven, M.; Shavlik, J.W. Extracting tree-structured representations of trained networks. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 2–5 December 1996; pp. 24–30. [Google Scholar]
- Wu, M.; Hughes, M.C.; Parbhoo, S.; Zazzi, M.; Roth, V.; Doshi-Velez, F. Beyond sparsity: Tree regularization of deep models for interpretability. In Proceedings of the 32nd Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 1670–1678. [Google Scholar]
- Murdoch, W.J.; Szlam, A. Automatic rule extraction from long short term memory networks. In Proceedings of the 5th International Conference on Learning Representations, Conference Track Proceedings, Toulon, France, 23–26 April 2017. [Google Scholar]
- Hu, Z.; Ma, X.; Liu, Z.; Hovy, E.; Xing, E. Harnessing deep neural networks with logic rules. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 1, pp. 2410–2420. [Google Scholar] [CrossRef] [Green Version]
- Tran, S.N. Unsupervised Neural-Symbolic Integration. In Proceedings of the International Joint Conferences on Artificial Intelligence (IJCAI), Melbourne, Australia, 19–25 August 2017; pp. 58–62. [Google Scholar]
- Otero, F.E.; Freitas, A.A. Improving the interpretability of classification rules discovered by an ant colony algorithm: Extended results. Evol. Comput. 2016, 24, 385–409. [Google Scholar] [CrossRef] [PubMed]
- Verbeke, W.; Martens, D.; Mues, C.; Baesens, B. Building comprehensible customer churn prediction models with advanced rule induction techniques. Expert Syst. Appl. 2011, 38, 2354–2364. [Google Scholar] [CrossRef]
- Lakkaraju, H.; Bach, S.H.; Leskovec, J. Interpretable decision sets: A joint framework for description and prediction. In Proceedings of the 22nd SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1675–1684. [Google Scholar] [CrossRef] [Green Version]
- Letham, B.; Rudin, C.; McCormick, T.H.; Madigan, D. Building interpretable classifiers with rules using Bayesian analysis. Dep. Stat. Tech. Rep. Tr609, Univ. Wash. 2012, 9, 1350–1371. [Google Scholar]
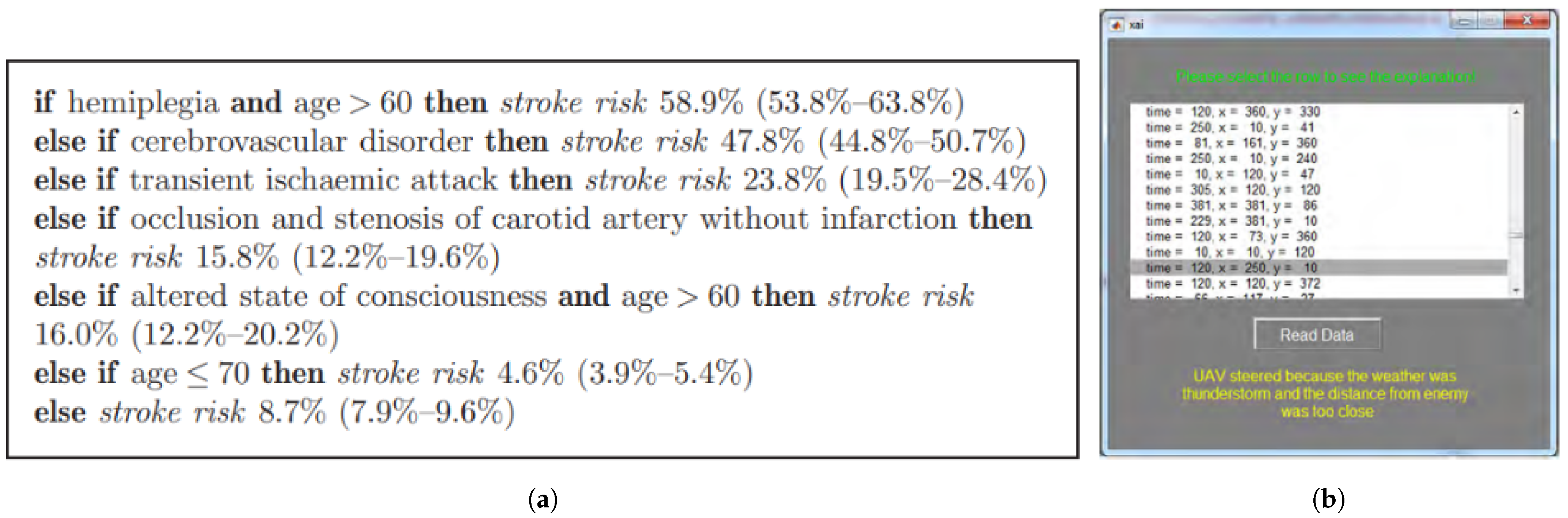
- Letham, B.; Rudin, C.; McCormick, T.H.; Madigan, D. An Interpretable Stroke Prediction Model Using Rules and Bayesian Analysis. In Proceedings of the 17th Conference on Late-Breaking Developments in the Field of Artificial Intelligence, Palo Alto, CA, USA, 1 January 2013; pp. 65–67. [Google Scholar]
- Letham, B.; Rudin, C.; McCormick, T.H.; Madigan, D. Interpretable classifiers using rules and bayesian analysis: Building a better stroke prediction model. Ann. Appl. Stat. 2015, 9, 1350–1371. [Google Scholar] [CrossRef]
- Wang, T.; Rudin, C.; Velez-Doshi, F.; Liu, Y.; Klampfl, E.; MacNeille, P. Bayesian rule sets for interpretable classification. In Proceedings of the 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–16 December 2016; pp. 1269–1274. [Google Scholar] [CrossRef]
- Wang, T.; Rudin, C.; Doshi-Velez, F.; Liu, Y.; Klampfl, E.; MacNeille, P. A bayesian framework for learning rule sets for interpretable classification. J. Mach. Learn. Res. 2017, 18, 2357–2393. [Google Scholar]
- Pazzani, M. Comprehensible knowledge discovery: Gaining insight from data. In Proceedings of the First Federal Data Mining Conference and Exposition, London, UK, 14–17 August 1997; pp. 73–82. [Google Scholar]
- Zeng, Z.; Miao, C.; Leung, C.; Chin, J.J. Building More Explainable Artificial Intelligence With Argumentation. In Proceedings of the 32nd Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 8044–8046. [Google Scholar]
- Ishibuchi, H.; Nojima, Y. Analysis of interpretability-accuracy tradeoff of fuzzy systems by multiobjective fuzzy genetics-based machine learning. Int. J. Approx. Reason. 2007, 44, 4–31. [Google Scholar] [CrossRef] [Green Version]
- Jin, Y. Fuzzy modeling of high-dimensional systems: Complexity reduction and interpretability improvement. Trans. Fuzzy Syst. 2000, 8, 212–221. [Google Scholar] [CrossRef] [Green Version]
- Pierrard, R.; Poli, J.P.; Hudelot, C. Learning Fuzzy Relations and Properties for Explainable Artificial Intelligence. In Proceedings of the International Conference on Fuzzy Systems (FUZZ-IEEE), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Palade, V. Building interpretable fuzzy models for high dimensional data analysis in cancer diagnosis. BMC Genom. 2011, 12, S5:1–S5:11. [Google Scholar] [CrossRef] [Green Version]
- Cano, A.; Zafra, A.; Ventura, S. An interpretable classification rule mining algorithm. Inf. Sci. 2013, 240, 1–20. [Google Scholar] [CrossRef]
- Malioutov, D.M.; Varshney, K.R.; Emad, A.; Dash, S. Learning interpretable classification rules with boolean compressed sensing. In Transparent Data Mining for Big and Small Data; Springer: Cham, Switzerland, 2017; pp. 95–121. [Google Scholar] [CrossRef]
- Su, G.; Wei, D.; Varshney, K.R.; Malioutov, D.M. Interpretable two-level Boolean rule learning for classification. In Proceedings of the ICML Workshop Human Interpretability in Machine Learning, New York, NY, USA, 23 June 2016; pp. 66–70. [Google Scholar]
- D’Alterio, P.; Garibaldi, J.M.; John, R.I. Constrained interval type-2 fuzzy classification systems for explainable AI (XAI). In Proceedings of the International Conference on Fuzzy Systems, Scotland, UK, 19–24 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Fahner, G. Developing Transparent Credit Risk Scorecards More Effectively: An Explainable Artificial Intelligence Approach. In Proceedings of the 7th International Conference on Data Analytics, Athens, Greece, 18–22 November 2018; pp. 17–24. [Google Scholar]
- Liang, Y.; Van den Broeck, G. Towards Compact Interpretable Models: Shrinking of Learned Probabilistic Sentential Decision Diagrams. In Proceedings of the Workshop on Explainable AI (XAI); International Joint Conferences on Artificial Intelligence (IJCAI), Melbourne, Australia, 19–25 August 2017; pp. 31–35. [Google Scholar]
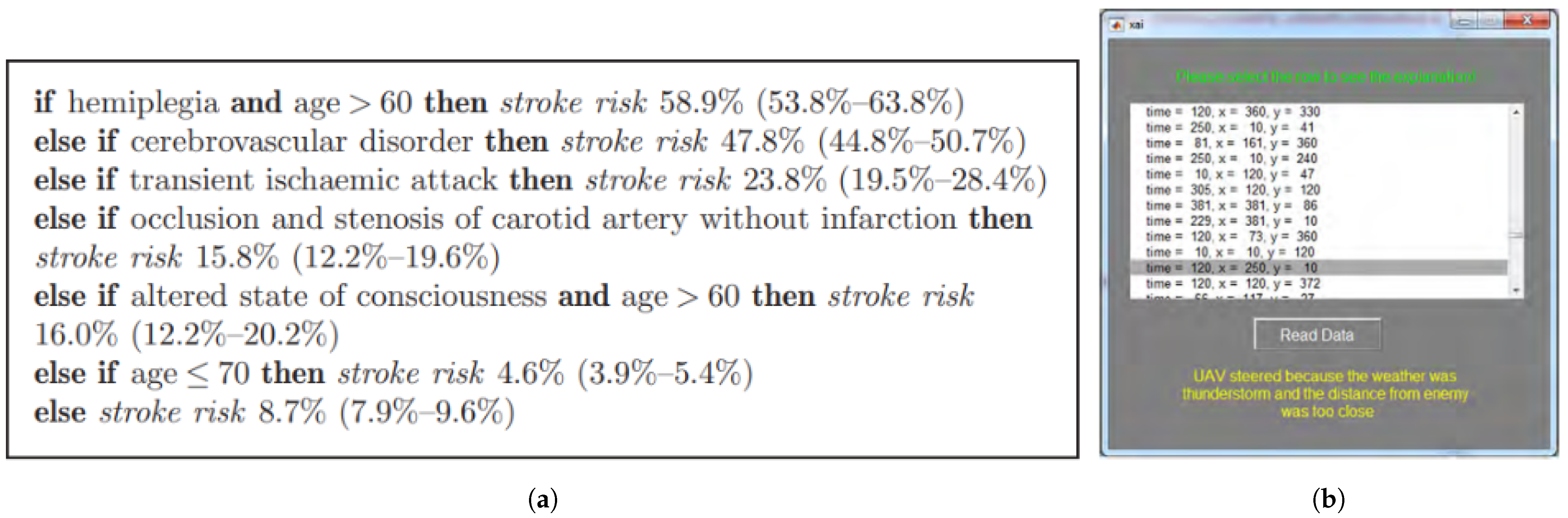
- Keneni, B.M.; Kaur, D.; Al Bataineh, A.; Devabhaktuni, V.K.; Javaid, A.Y.; Zaientz, J.D.; Marinier, R.P. Evolving Rule-Based Explainable Artificial Intelligence for Unmanned Aerial Vehicles. Access 2019, 7, 17001–17016. [Google Scholar] [CrossRef]
- Andrzejak, A.; Langner, F.; Zabala, S. Interpretable models from distributed data via merging of decision trees. In Proceedings of the Symposium on Computational Intelligence and Data Mining (CIDM), Singapore, 16–19 April 2013; pp. 1–9. [Google Scholar] [CrossRef]
- Deng, H. Interpreting tree ensembles with intrees. Int. J. Data Sci. Anal. 2018, 7, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Ferri, C.; Hernández-Orallo, J.; Ramírez-Quintana, M.J. From ensemble methods to comprehensible models. In Proceedings of the International Conference on Discovery Science, Lübeck, Germany, 24–26 November 2002; pp. 165–177. [Google Scholar] [CrossRef]
- Sagi, O.; Rokach, L. Explainable Decision Forest: Transforming a decision forest into an interpretable tree. Inf. Fusion 2020, 61, 124–138. [Google Scholar] [CrossRef]
- Van Assche, A.; Blockeel, H. Seeing the forest through the trees: Learning a comprehensible model from an ensemble. In Proceedings of the European Conference on Machine Learning, Warsaw, Poland, 17–21 September 2007; pp. 418–429. [Google Scholar] [CrossRef] [Green Version]
- Hara, S.; Hayashi, K. Making Tree Ensembles Interpretable: A Bayesian Model Selection Approach. In Proceedings of the International Conference on Artificial Intelligence and Statistics, AISTATS, Canary Islands, Spain, 9–11 April 2018; pp. 77–85. [Google Scholar]
- Yap, G.E.; Tan, A.H.; Pang, H.H. Explaining inferences in Bayesian networks. Appl. Intell. 2008, 29, 263–278. [Google Scholar] [CrossRef]
- Barratt, S. Interpnet: Neural introspection for interpretable deep learning. In Proceedings of the Symposium on Interpretable Machine Learning, Long Beach, CA, USA, 7 December 2017; pp. 47–53. [Google Scholar]
- García-Magariño, I.; Muttukrishnan, R.; Lloret, J. Human-Centric AI for Trustworthy IoT Systems With Explainable Multilayer Perceptrons. Access 2019, 7, 125562–125574. [Google Scholar] [CrossRef]
- Bennetot, A.; Laurent, J.L.; Chatila, R.; Díaz-Rodríguez, N. Towards explainable neural-symbolic visual reasoning. In Proceedings of the NeSy Workshop; International Joint Conferences on Artificial Intelligence (IJCAI), Macao, China, 10–16 August 2019; pp. 71–75. [Google Scholar]
- Lei, T.; Barzilay, R.; Jaakkola, T. Rationalizing neural predictions. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 107–117. [Google Scholar]
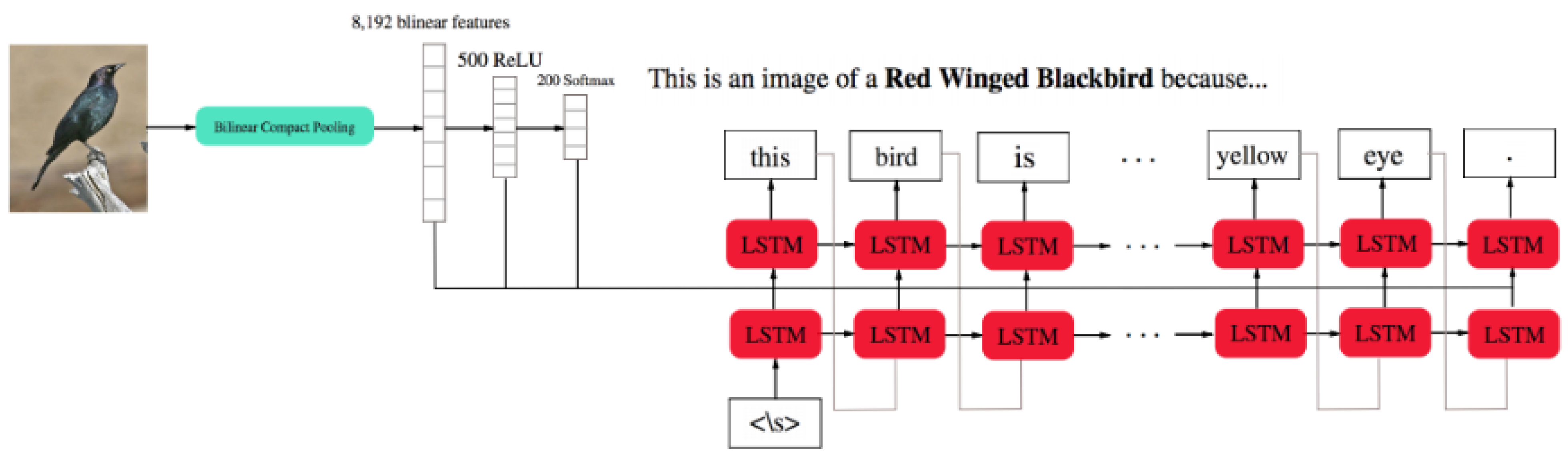
- Hendricks, L.A.; Akata, Z.; Rohrbach, M.; Donahue, J.; Schiele, B.; Darrell, T. Generating visual explanations. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 3–19. [Google Scholar] [CrossRef] [Green Version]
- Shortliffe, E.H.; Davis, R.; Axline, S.G.; Buchanan, B.G.; Green, C.C.; Cohen, S.N. Computer-based consultations in clinical therapeutics: Explanation and rule acquisition capabilities of the MYCIN system. Comput. Biomed. Res. 1975, 8, 303–320. [Google Scholar] [CrossRef]
- Alonso, J.M.; Ramos-Soto, A.; Castiello, C.; Mencar, C. Explainable AI Beer Style Classifier. In Proceedings of the SICSA Workshop on Reasoning, Learning and Explainability, Scotland, UK, 27 June 2018; pp. 1–5. [Google Scholar]
- Gao, J.; Liu, N.; Lawley, M.; Hu, X. An interpretable classification framework for information extraction from online healthcare forums. J. Healthc. Eng. 2017, 2017, 798–809. [Google Scholar] [CrossRef] [Green Version]
- Vlek, C.S.; Prakken, H.; Renooij, S.; Verheij, B. A method for explaining Bayesian networks for legal evidence with scenarios. Artif. Intell. Law 2016, 24, 285–324. [Google Scholar] [CrossRef] [Green Version]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef] [Green Version]
- Apicella, A.; Giugliano, S.; Isgrò, F.; Prevete, R. A general approach to compute the relevance of middle-level input features. In Proceedings of the Pattern Recognition. ICPR International Workshops and Challenges, Online, 10–15 January 2021; Part III. pp. 189–203. [Google Scholar] [CrossRef]
- Fong, R.C.; Vedaldi, A. Interpretable explanations of black boxes by meaningful perturbation. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3429–3437. [Google Scholar] [CrossRef] [Green Version]
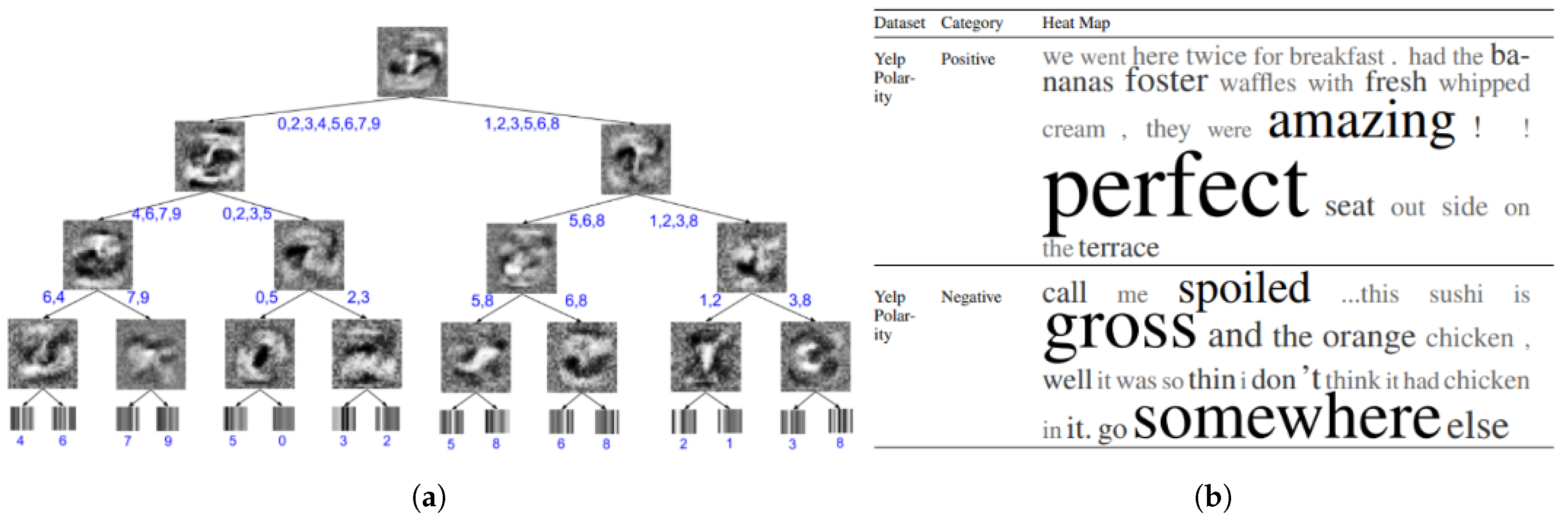
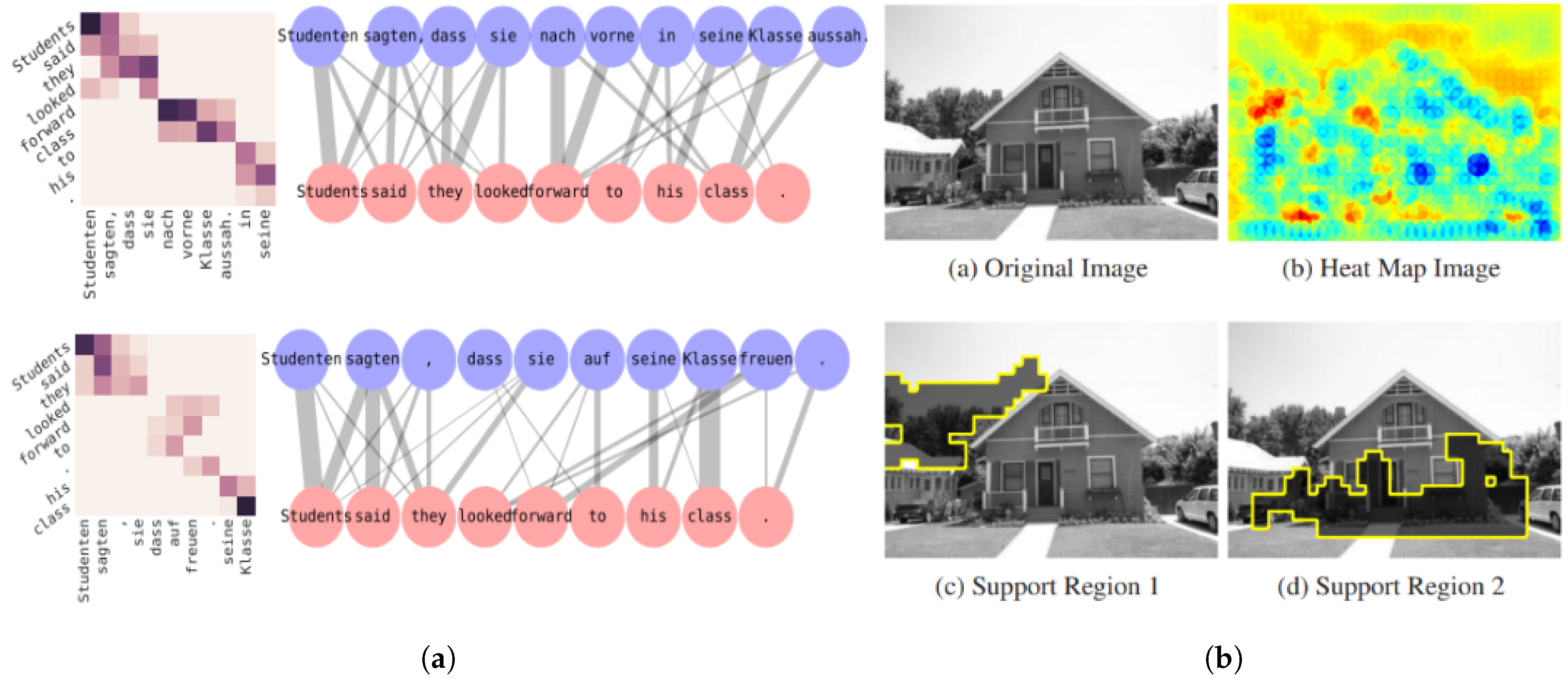
- Liu, L.; Wang, L. What has my classifier learned? Visualizing the classification rules of bag-of-feature model by support region detection. In Proceedings of the 2012 Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3586–3593. [Google Scholar] [CrossRef]
- Choo, J.; Lee, H.; Kihm, J.; Park, H. iVisClassifier: An interactive visual analytics system for classification based on supervised dimension reduction. In Proceedings of the Symposium on Visual Analytics Science and Technology, Salt Lake City, UT, USA, 25–26 October 2010; pp. 27–34. [Google Scholar] [CrossRef]
- Dabkowski, P.; Gal, Y. Real time image saliency for black box classifiers. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6967–6976. [Google Scholar]
- Baehrens, D.; Schroeter, T.; Harmeling, S.; Kawanabe, M.; Hansen, K.; Mãžller, K.R. How to explain individual classification decisions. J. Mach. Learn. Res. 2010, 11, 1803–1831. [Google Scholar]
- Goldstein, A.; Kapelner, A.; Bleich, J.; Pitkin, E. Peeking inside the black box: Visualizing statistical learning with plots of individual conditional expectation. J. Comput. Graph. Stat. 2015, 24, 44–65. [Google Scholar] [CrossRef]
- Casalicchio, G.; Molnar, C.; Bischl, B. Visualizing the feature importance for black box models. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Dublin, Ireland, 10–14 September 2018; pp. 655–670. [Google Scholar] [CrossRef] [Green Version]
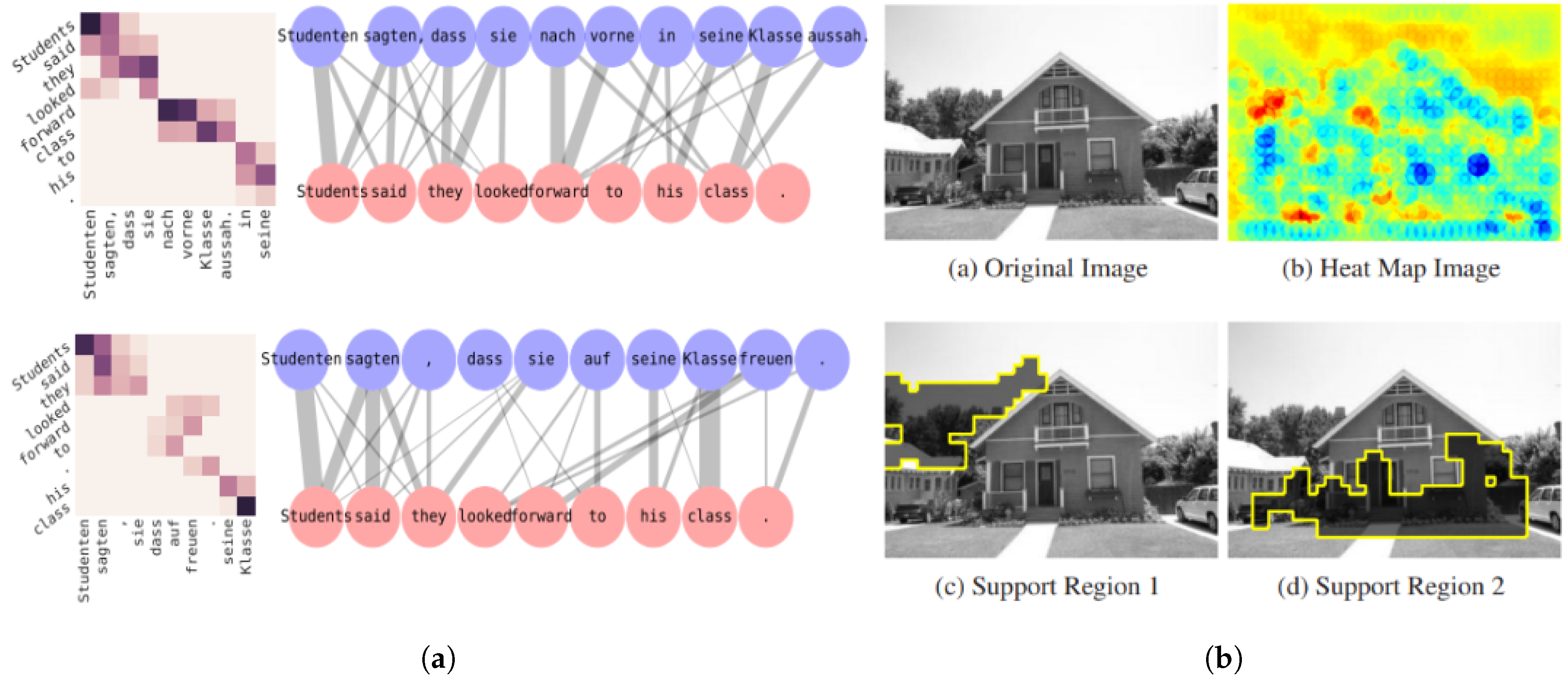
- Alvarez-Melis, D.; Jaakkola, T.S. A causal framework for explaining the predictions of black-box sequence-to-sequence models. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 412–421. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Krause, J.; Perer, A.; Bertini, E. Using visual analytics to interpret predictive machine learning models. In Proceedings of the ICML Workshop on Human Interpretability in Machine Learning, New York, NY, USA, 23 June 2016; pp. 106–110. [Google Scholar]
- Poulin, B.; Eisner, R.; Szafron, D.; Lu, P.; Greiner, R.; Wishart, D.S.; Fyshe, A.; Pearcy, B.; MacDonell, C.; Anvik, J. Visual explanation of evidence with additive classifiers. In Proceedings of the The National Conference On Artificial Intelligence, Boston, MA, USA, 16–20 July 2006; Volume 21, pp. 1822–1829. [Google Scholar]
- Zhang, J.; Wang, Y.; Molino, P.; Li, L.; Ebert, D.S. Manifold: A Model-Agnostic Framework for Interpretation and Diagnosis of Machine Learning Models. Trans. Vis. Comput. Graph. 2019, 25, 364–373. [Google Scholar] [CrossRef] [Green Version]
- Kahng, M.; Fang, D.; Chau, D.H.P. Visual exploration of machine learning results using data cube analysis. In Proceedings of the Workshop on Human-In-the-Loop Data Analytics, San Francisco, CA, USA, 26 June 2016; p. 1. [Google Scholar] [CrossRef] [Green Version]
- Kumar, D.; Wong, A.; Taylor, G.W. Explaining the unexplained: A class-enhanced attentive response (clear) approach to understanding deep neural networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 36–44. [Google Scholar] [CrossRef] [Green Version]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef] [Green Version]
- Liu, G.; Gifford, D. Visualizing Feature Maps in Deep Neural Networks using DeepResolve. A Genomics Case Study. In Proceedings of the International Conference on Machine Learning—Workshop on Visualization for Deep Learning, Sydney, Australia, 10 August 2017; pp. 32–41. [Google Scholar]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic attribution for deep networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 3319–3328. [Google Scholar]
- Smilkov, D.; Thorat, N.; Kim, B.; Viégas, F.; Wattenberg, M. Smoothgrad: Removing noise by adding noise. In Proceedings of the International Conference on Machine Learning—Workshop on Visualization for Deep Learning, Sydney, Australia, 10 August 2017; pp. 15–24. [Google Scholar]
- Jung, H.; Oh, Y.; Park, J.; Kim, M.S. Jointly Optimize Positive and Negative Saliencies for Black Box Classifiers. Pattern Recognition. In Proceedings of the ICPR International Workshops and Challenges, Online, 10–15 January 2021; Part III. pp. 76–89. [Google Scholar] [CrossRef]
- Mogrovejo, O.; Antonio, J.; Wang, K.; Tuytelaars, T. Visual Explanation by Interpretation: Improving Visual Feedback Capabilities of Deep Neural Networks. In Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Rajani, N.F.; Mooney, R.J. Using explanations to improve ensembling of visual question answering systems. Training 2017, 82, 248–349. [Google Scholar]
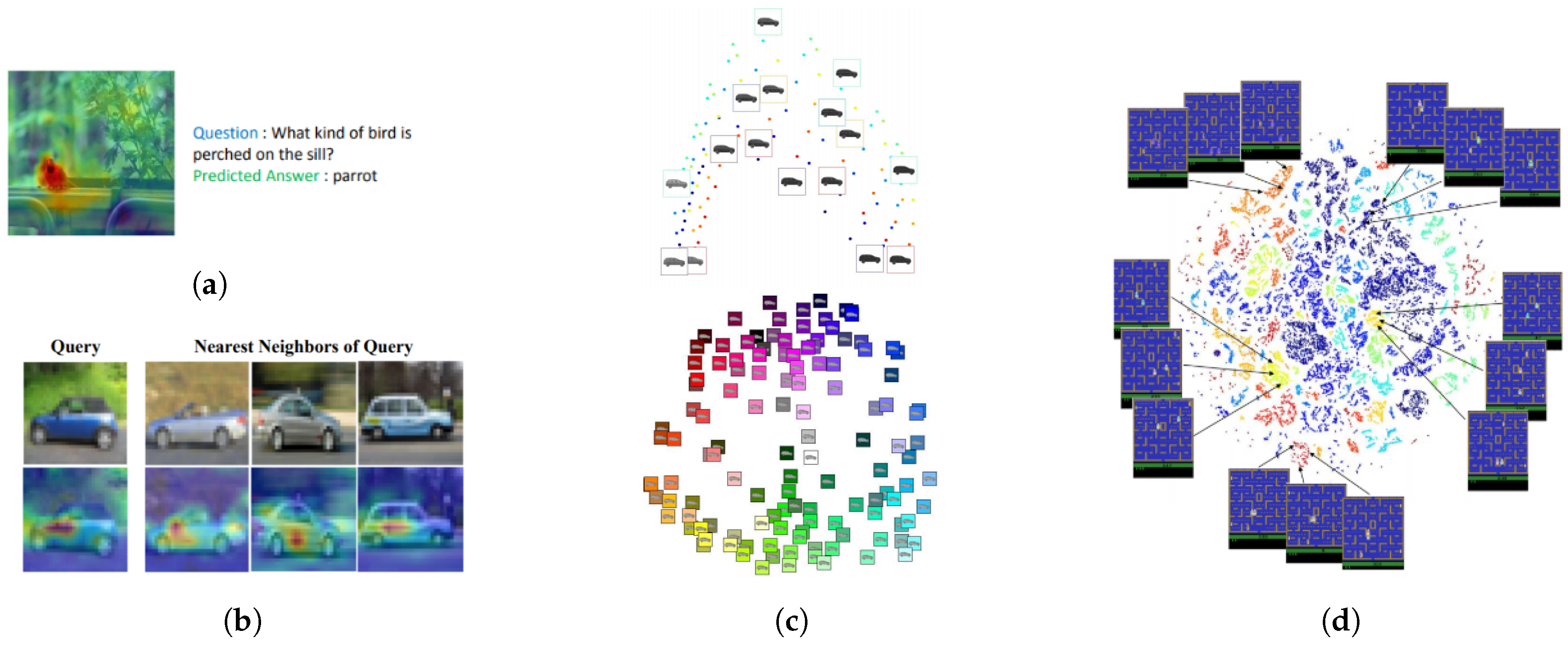
- Goyal, Y.; Mohapatra, A.; Parikh, D.; Batra, D. Towards transparent ai systems: Interpreting visual question answering models. In Proceedings of the ICML Workshop on Visualization for Deep Learning, New York, NY, USA, 23 June 2016. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European conference on computer vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Fong, R.; Vedaldi, A. Net2vec: Quantifying and explaining how concepts are encoded by filters in deep neural networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8730–8738. [Google Scholar] [CrossRef] [Green Version]
- Ghorbani, A.; Wexler, J.; Zou, J.Y.; Kim, B. Towards automatic concept-based explanations. In Advances in Neural Information Processing Systems; Morgan Kaufmann Publishers Inc.: Vancouver, BC, Canada, 8–14 December 2019; pp. 9273–9282. [Google Scholar]
- Mahendran, A.; Vedaldi, A. Understanding deep image representations by inverting them. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5188–5196. [Google Scholar] [CrossRef] [Green Version]
- Du, M.; Liu, N.; Song, Q.; Hu, X. Towards Explanation of DNN-based Prediction with Guided Feature Inversion. In Proceedings of the 24th SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1358–1367. [Google Scholar] [CrossRef] [Green Version]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning important features through propagating activation differences. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 3145–3153. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. In ICLR Workshop; ICLR: Banff, AB, Canada, 2014. [Google Scholar]
- Montavon, G.; Lapuschkin, S.; Binder, A.; Samek, W.; Müller, K.R. Explaining nonlinear classification decisions with deep Taylor decomposition. Pattern Recognit. 2017, 65, 211–222. [Google Scholar] [CrossRef]
- He, S.; Pugeault, N. Deep saliency: What is learnt by a deep network about saliency? In Proceedings of the International Conference on Machine Learning—Workshop on Visualization for Deep Learning, Sydney, Australia, 10 August 2017; pp. 1–5. [Google Scholar]
- Zhang, Q.; Wu, Y.N.; Zhu, S.C. Interpretable convolutional neural networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8827–8836. [Google Scholar] [CrossRef] [Green Version]
- Zintgraf, L.M.; Cohen, T.S.; Adel, T.; Welling, M. Visualizing deep neural network decisions: Prediction difference analysis. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 23–26 April 2017. [Google Scholar]
- Kindermans, P.J.; Schütt, K.T.; Alber, M.; Müller, K.R.; Erhan, D.; Kim, B.; Dähne, S. Learning how to explain neural networks: PatternNet and PatternAttribution. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Davis, B.; Bhatt, U.; Bhardwaj, K.; Marculescu, R.; Moura, J.M. On network science and mutual information for explaining deep neural networks. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing ICASSP, Barcelona, Spain, 4–8 May 2020; pp. 8399–8403. [Google Scholar] [CrossRef]
- Kenny, E.M.; Keane, M.T. Twin-systems to explain artificial neural networks using case-based reasoning: Comparative tests of feature-weighting methods in ANN-CBR twins for XAI. In Proceedings of the 28th International Joint Conferences on Artifical Intelligence, Macao, China, 10–16 August 2019; pp. 2708–2715. [Google Scholar] [CrossRef] [Green Version]
- Kenny, E.M.; Delaney, E.D.; Greene, D.; Keane, M.T. Post-Hoc Explanation Options for XAI in Deep Learning: The Insight Centre for Data Analytics Perspective. In Proceedings of the Pattern Recognition. ICPR International Workshops and Challenges, Online, 10–15 January 2021; Part III. pp. 20–34. [Google Scholar] [CrossRef]
- Chu, L.; Hu, X.; Hu, J.; Wang, L.; Pei, J. Exact and consistent interpretation for piecewise linear neural networks: A closed form solution. In Proceedings of the 24th SIGKDD International Conference on Knowledge Discovery and Data Mining, London, UK, 19–23 August 2018; pp. 1244–1253. [Google Scholar] [CrossRef]
- Arras, L.; Montavon, G.; Müller, K.R.; Samek, W. Explaining recurrent neural network predictions in sentiment analysis. In Proceedings of the 8th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Association for Computational Linguistics, Copenhagen, Denmark, September 2017; pp. 159–168. [Google Scholar] [CrossRef]
- Binder, A.; Montavon, G.; Lapuschkin, S.; Müller, K.R.; Samek, W. Layer-wise relevance propagation for neural networks with local renormalization layers. In Proceedings of the International Conference on Artificial Neural Networks, Barcelona, Spain, 6–9 September 2016; pp. 63–71. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Chen, X.; Hovy, E.; Jurafsky, D. Visualizing and understanding neural models in NLP. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 681–691. [Google Scholar] [CrossRef] [Green Version]
- Aubry, M.; Russell, B.C. Understanding deep features with computer-generated imagery. In Proceedings of the International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2875–2883. [Google Scholar] [CrossRef] [Green Version]
- Zahavy, T.; Ben-Zrihem, N.; Mannor, S. Graying the black box: Understanding DQNs. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1899–1908. [Google Scholar]
- Liu, X.; Wang, X.; Matwin, S. Interpretable deep convolutional neural networks via meta-learning. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- Rauber, P.E.; Fadel, S.G.; Falcao, A.X.; Telea, A.C. Visualizing the hidden activity of artificial neural networks. Trans. Vis. Comput. Graph. 2017, 23, 101–110. [Google Scholar] [CrossRef] [PubMed]
- Thiagarajan, J.J.; Kailkhura, B.; Sattigeri, P.; Ramamurthy, K.N. TreeView: Peeking into deep neural networks via feature-space partitioning. In Proceedings of the Interpretability Workshop, Barcelona, Spain, 9 December 2016. [Google Scholar]
- Bau, D.; Zhu, J.Y.; Strobelt, H.; Bolei, Z.; Tenenbaum, J.B.; Freeman, W.T.; Torralba, A. GAN Dissection: Visualizing and Understanding Generative Adversarial Networks. In Proceedings of the International Conference on Learning Representation, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- López-Cifuentes, A.; Escudero-Viñolo, M.; Gajić, A.; Bescós, J. Visualizing the Effect of Semantic Classes in the Attribution of Scene Recognition Models. In Proceedings of the Pattern Recognition. ICPR International Workshops and Challenges, Online, 10–15 January 2021; Part III. pp. 115–129. [Google Scholar] [CrossRef]
- Gorokhovatskyi, O.; Peredrii, O. Recursive Division of Image for Explanation of Shallow CNN Models. In Proceedings of the Pattern Recognition. ICPR International Workshops and Challenges, Online, 10–15 January 2021; Part III. pp. 274–286. [Google Scholar] [CrossRef]
- Lengerich, B.J.; Konam, S.; Xing, E.P.; Rosenthal, S.; Veloso, M. Towards visual explanations for convolutional neural networks via input resampling. In Proceedings of the International Conference on Machine Learning—Workshop on Visualization for Deep Learning, Sydney, Australia, 10 August 2017; pp. 25–31. [Google Scholar]
- Erhan, D.; Courville, A.; Bengio, Y. Understanding representations learned in deep architectures. Tech. Rep. 2010, 1355. [Google Scholar]
- Nguyen, A.; Yosinski, J.; Clune, J. Multifaceted feature visualization: Uncovering the different types of features learned by each neuron in deep neural networks. In Proceedings of the Visualization for Deep Learning workshop. International Conference on Machine Learning, New York, NY, USA, 23 June 2016. [Google Scholar]
- Nguyen, A.; Dosovitskiy, A.; Yosinski, J.; Brox, T.; Clune, J. Synthesizing the preferred inputs for neurons in neural networks via deep generator networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 3387–3395. [Google Scholar]
- Hamidi-Haines, M.; Qi, Z.; Fern, A.; Li, F.; Tadepalli, P. Interactive Naming for Explaining Deep Neural Networks: A Formative Study. In Proceedings of the Workshops Co-Located with the 24th Conference on Intelligent User Interfaces, Los Angeles, CA, USA, 16–20 March 2019; Volume 2327. [Google Scholar]
- Zhu, P.; Zhu, R.; Mishra, S.; Saligrama, V. Low Dimensional Visual Attributes: An Interpretable Image Encoding. In Proceedings of the Pattern Recognition. ICPR International Workshops and Challenges, Online, 10–15 January 2021; Part III. pp. 90–102. [Google Scholar] [CrossRef]
- Stano, M.; Benesova, W.; Martak, L.S. Explainable 3D convolutional neural network using GMM encoding. In Proceedings of the 12th International Conference on Machine Vision (ICMV), Amsterdam, The Netherlands, 15–17 February 2020; Volume 11433, p. 114331U. [Google Scholar] [CrossRef]
- Halnaut, A.; Giot, R.; Bourqui, R.; Auber, D. Samples Classification Analysis Across DNN Layers with Fractal Curves. In Proceedings of the ICPR 2020’s Workshop Explainable Deep Learning for AI, Milan, Italy, 11 January 2021; pp. 47–61. [Google Scholar] [CrossRef]
- Zhang, Q.; Cao, R.; Shi, F.; Wu, Y.N.; Zhu, S.C. Interpreting cnn knowledge via an explanatory graph. In Proceedings of the 32nd Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 2124–2132. [Google Scholar]
- Liang, X.; Hu, Z.; Zhang, H.; Lin, L.; Xing, E.P. Symbolic graph reasoning meets convolutions. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 2–8 December 2018; pp. 1853–1863. [Google Scholar]
- Zhang, Q.; Cao, R.; Wu, Y.N.; Zhu, S.C. Growing interpretable part graphs on convnets via multi-shot learning. In Proceedings of the 31st Conference on Artificial Intelligence, San Francisco, CA, USA, 4–10 February 2017; pp. 2898–2906. [Google Scholar]
- Olah, C.; Satyanarayan, A.; Johnson, I.; Carter, S.; Schubert, L.; Ye, K.; Mordvintsev, A. The building blocks of interpretability. Distill 2018, 3, e10. [Google Scholar] [CrossRef]
- Kahng, M.; Andrews, P.Y.; Kalro, A.; Chau, D.H.P. Activis: Visual exploration of industry-scale deep neural network models. Trans. Vis. Comput. Graph. 2018, 24, 88–97. [Google Scholar] [CrossRef] [Green Version]
- Yosinski, J.; Clune, J.; Nguyen, A.; Fuchs, T.; Lipson, H. Understanding neural networks through deep visualization. In Proceedings of the ICML Workshop on Deep Learning, Poster Presentation, Lille, France, 15 May 2015. [Google Scholar]
- Zhong, W.; Xie, C.; Zhong, Y.; Wang, Y.; Xu, W.; Cheng, S.; Mueller, K. Evolutionary visual analysis of deep neural networks. In Proceedings of the International Conference on Machine Learning—Workshop on Visualization for Deep Learning, Sydney, Australia, 10 August 2017; pp. 6–14. [Google Scholar]
- Alber, M.; Lapuschkin, S.; Seegerer, P.; Hägele, M.; Schütt, K.T.; Montavon, G.; Samek, W.; Müller, K.; Dähne, S.; Kindermans, P. iNNvestigate neural networks. J. Mach. Learn. Res. 2019, 20, 1–8. [Google Scholar]
- Streeter, M.J.; Ward, M.O.; Alvarez, S.A. Nvis: An interactive visualization tool for neural networks. In Proceedings of the Visual Data Exploration and Analysis VIII, San Jose, CA, USA, 22–23 January 2001; Volume 4302, pp. 234–242. [Google Scholar]
- Karpathy, A.; Johnson, J.; Fei-Fei, L. Visualizing and understanding recurrent networks. In Proceedings of the ICLR Workshops, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Strobelt, H.; Gehrmann, S.; Behrisch, M.; Perer, A.; Pfister, H.; Rush, A.M. Seq2Seq-Vis: A visual debugging tool for sequence-to-sequence models. Trans. Vis. Comput. Graph. 2018, 25, 353–363. [Google Scholar] [CrossRef] [Green Version]
- Pancho, D.P.; Alonso, J.M.; Cordón, O.; Quirin, A.; Magdalena, L. FINGRAMS: Visual representations of fuzzy rule-based inference for expert analysis of comprehensibility. Trans. Fuzzy Syst. 2013, 21, 1133–1149. [Google Scholar] [CrossRef]
- Hamel, L. Visualization of support vector machines with unsupervised learning. In Proceedings of the Symposium on Computational Intelligence and Bioinformatics and Computational Biology, Toronto, ON, Canada, 28–29 September 2006; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Jakulin, A.; Možina, M.; Demšar, J.; Bratko, I.; Zupan, B. Nomograms for visualizing support vector machines. In Proceedings of the 11th SIGKDD International Conference on Knowledge Discovery in Data Mining, Chicago, IL, USA, 21–24 August 2005; pp. 108–117. [Google Scholar] [CrossRef] [Green Version]
- Cho, B.H.; Yu, H.; Lee, J.; Chee, Y.J.; Kim, I.Y.; Kim, S.I. Nonlinear support vector machine visualization for risk factor analysis using nomograms and localized radial basis function kernels. Trans. Inf. Technol. Biomed. 2008, 12, 247–256. [Google Scholar] [CrossRef]
- Možina, M.; Demšar, J.; Kattan, M.; Zupan, B. Nomograms for visualization of naive Bayesian classifier. In Proceedings of the European Conference on Principles of Data Mining and Knowledge Discovery, Pisa, Italy, 20–24 September 2004; pp. 337–348. [Google Scholar] [CrossRef] [Green Version]
- Landecker, W.; Thomure, M.D.; Bettencourt, L.M.A.; Mitchell, M.; Kenyon, G.T.; Brumby, S.P. Interpreting individual classifications of hierarchical networks. In Proceedings of the Symposium on Computational Intelligence and Data Mining (CIDM), Singapore, 16–19 April 2013; Volume 165, pp. 32–38. [Google Scholar] [CrossRef] [Green Version]
- Panchenko, A.; Ruppert, E.; Faralli, S.; Ponzetto, S.P.; Biemann, C. Unsupervised does not mean uninterpretable: The case for word sense induction and disambiguation. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; Volume 1, pp. 86–98. [Google Scholar]
- Hooker, G. Discovering additive structure in black box functions. In Proceedings of the 10th SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 575–580. [Google Scholar] [CrossRef]
- Kuhn, D.R.; Kacker, R.N.; Lei, Y.; Simos, D.E. Combinatorial Methods for Explainable AI. In Proceedings of the International Conference on Software Testing, Verification and Validation Workshops (ICSTW), Porto, Portugal, 24–28 October 2020; pp. 167–170. [Google Scholar] [CrossRef]
- Biran, O.; McKeown, K. Justification narratives for individual classifications. In Proceedings of the AutoML Workshop at ICML, Beijing, China, 26 June 2014; Volume 2014, pp. 1–7. [Google Scholar]
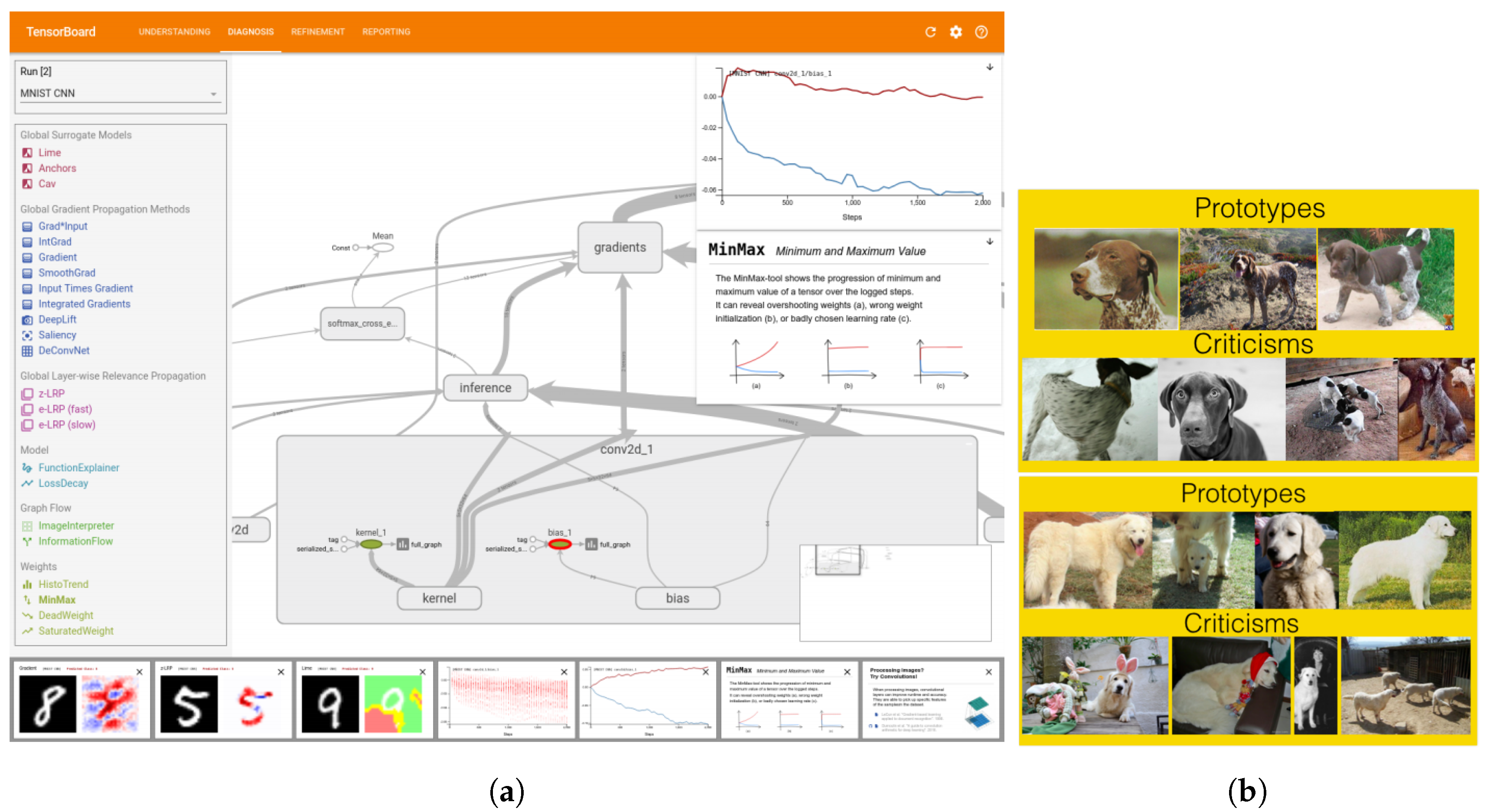
- Spinner, T.; Schlegel, U.; Schäfer, H.; El-Assady, M. explAIner: A visual analytics framework for interactive and explainable machine learning. Trans. Vis. Comput. Graph. 2019, 26, 1064–1074. [Google Scholar] [CrossRef] [Green Version]
- Tamagnini, P.; Krause, J.; Dasgupta, A.; Bertini, E. Interpreting black-box classifiers using instance-level visual explanations. In Proceedings of the 2nd Workshop on Human-In-the-Loop Data Analytics, Chicago, IL, USA, 14–19 May 2017; pp. 6:1–6:6. [Google Scholar] [CrossRef]
- Yang, S.C.H.; Shafto, P. Explainable Artificial Intelligence via Bayesian Teaching. In Proceedings of the Workshop on Teaching Machines, Robots, and Humans, Long Beach, CA, USA, 9 December 2017; pp. 127–137. [Google Scholar]
- Khanna, R.; Kim, B.; Ghosh, J.; Koyejo, S. Interpreting Black Box Predictions using Fisher Kernels. In Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics, Okinawa, Japan, 16–18 April 2019; Volume 89, pp. 3382–3390. [Google Scholar]
- Bien, J.; Tibshirani, R. Prototype selection for interpretable classification. Ann. Appl. Stat. 2011, 5, 2403–2424. [Google Scholar] [CrossRef] [Green Version]
- Caruana, R.; Kangarloo, H.; Dionisio, J.; Sinha, U.; Johnson, D. Case-based explanation of non-case-based learning methods. In Proceedings of the AMIA Symposium, Washington, DC, USA, 6–10 November 1999; p. 212. [Google Scholar]
- Pawelczyk, M.; Broelemann, K.; Kasneci, G. Learning Model-Agnostic Counterfactual Explanations for Tabular Data. In Proceedings of the Web Conference, Taipei, Taiwan, 20–24 April 2020; pp. 3126–3132. [Google Scholar] [CrossRef]
- Mothilal, R.K.; Sharma, A.; Tan, C. Explaining machine learning classifiers through diverse counterfactual explanations. In Proceedings of the Conference on Fairness, Accountability, and Transparency, Barcelona, Spain, 27–30 January 2020; pp. 607–617. [Google Scholar] [CrossRef] [Green Version]
- Liu, N.; Yang, H.; Hu, X. Adversarial detection with model interpretation. In Proceedings of the 24th SIGKDD International Conference on Knowledge Discovery and Data Mining, London, UK, 19–23 August 2018; pp. 1803–1811. [Google Scholar] [CrossRef]
- Kim, B.; Khanna, R.; Koyejo, O.O. Examples are not enough, learn to criticize! criticism for interpretability. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2280–2288. [Google Scholar]
- Dhurandhar, A.; Chen, P.Y.; Luss, R.; Tu, C.C.; Ting, P.; Shanmugam, K.; Das, P. Explanations based on the missing: Towards contrastive explanations with pertinent negatives. In Proceedings of the Advances in Neural Information Processing Systems 31 (NIPS), Montréal, QC, Canada, 2–8 December 2018; pp. 592–603. [Google Scholar]
- Park, D.H.; Hendricks, L.A.; Akata, Z.; Schiele, B.; Darrell, T.; Rohrbach, M. Multimodal explanations: Justifying decisions and pointing to the evidence. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8779–8788. [Google Scholar]
- Mayr, F.; Yovine, S. Regular Inference on Artificial Neural Networks. In Proceedings of the International Cross-Domain Conference for Machine Learning and Knowledge Extraction, Hamburg, Germany, 27–30 August 2018; pp. 350–369. [Google Scholar] [CrossRef]
- Omlin, C.W.; Giles, C.L. Extraction of rules from discrete-time recurrent neural networks. Neural Netw. 1996, 9, 41–52. [Google Scholar] [CrossRef] [Green Version]
- Tamajka, M.; Benesova, W.; Kompanek, M. Transforming Convolutional Neural Network to an Interpretable Classifier. In Proceedings of the International Conference on Systems, Signals and Image Processing (IWSSIP), Osijek, Croatia, 5–7 June 2019; pp. 255–259. [Google Scholar]
- Yeh, C.K.; Kim, J.; Yen, I.E.H.; Ravikumar, P.K. Representer point selection for explaining deep neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 2–8 December 2018; pp. 9291–9301. [Google Scholar]
- Alonso, J.M. Explainable Artificial Intelligence for kids. In Proceedings of the Conference of the International Fuzzy Systems Association and the European Society for Fuzzy Logic and Technology (EUSFLAT), Prague, Czech Republic, 9–13 September 2019. [Google Scholar] [CrossRef] [Green Version]
- Gaines, B.R. Transforming rules and trees into comprehensible knowledge structures. In Advances in Knowledge Discovery and Data Mining; Fayyad, U.M., Piatetsky-Shapiro, G., Smyth, P., Uthurusamy, R., Eds.; American Association for Artificial Intelligence: Menlo Park, CA, USA, 1996; pp. 205–226. [Google Scholar]
- Tan, H.F.; Hooker, G.; Wells, M.T. Tree space prototypes: Another look at making tree ensembles interpretable. In Proceedings of the Interpretability Workshop, Barcelona, Spain, 9 December 2016. [Google Scholar]
- Núñez, H.; Angulo, C.; Català, A. Rule extraction from support vector machines. In Proceedings of the European Symposium on Artificial Neural Networks, Bruges, Belgium, 24–26 April 2002; pp. 107–112. [Google Scholar]
- Timmer, S.T.; Meyer, J.J.C.; Prakken, H.; Renooij, S.; Verheij, B. A two-phase method for extracting explanatory arguments from Bayesian networks. Int. J. Approx. Reason. 2017, 80, 475–494. [Google Scholar] [CrossRef] [Green Version]
- Kim, B.; Rudin, C.; Shah, J.A. The bayesian case model: A generative approach for case-based reasoning and prototype classification. In Proceedings of the Advances in Neural Information Processing Systems. Neural Information Processing Systems Foundation, Montréal, QC, Canada, 8–13 December 2014; pp. 1952–1960. [Google Scholar]
- Caruana, R.; Lou, Y.; Gehrke, J.; Koch, P.; Sturm, M.; Elhadad, N. Intelligible models for healthcare: Predicting pneumonia risk and hospital 30-day readmission. In Proceedings of the 21th SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 1721–1730. [Google Scholar] [CrossRef]
- Howard, D.; Edwards, M.A. Explainable AI: The Promise of Genetic Programming Multi-run Subtree Encapsulation. In Proceedings of the International Conference on Machine Learning and Data Engineering (iCMLDE), Dallas, TX, USA, 3–7 December 2018; pp. 158–159. [Google Scholar] [CrossRef]
- Kim, B.; Shah, J.A.; Doshi-Velez, F. Mind the gap: A generative approach to interpretable feature selection and extraction. In Proceedings of the Advances in Neural Information Processing Systems. Neural Information Processing Systems Foundation, Montréal, QC, Canada, 7–12 December 2015; pp. 2260–2268. [Google Scholar]
- Campagner, A.; Cabitza, F. Back to the Feature: A Neural-Symbolic Perspective on Explainable AI. In Proceedings of the International Cross-Domain Conference for Machine Learning and Knowledge Extraction, Dublin, Ireland, 25–28 August 2020; pp. 39–55. [Google Scholar] [CrossRef]
- Belle, V. Logic meets probability: Towards explainable AI systems for uncertain worlds. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 19–25. [Google Scholar] [CrossRef] [Green Version]

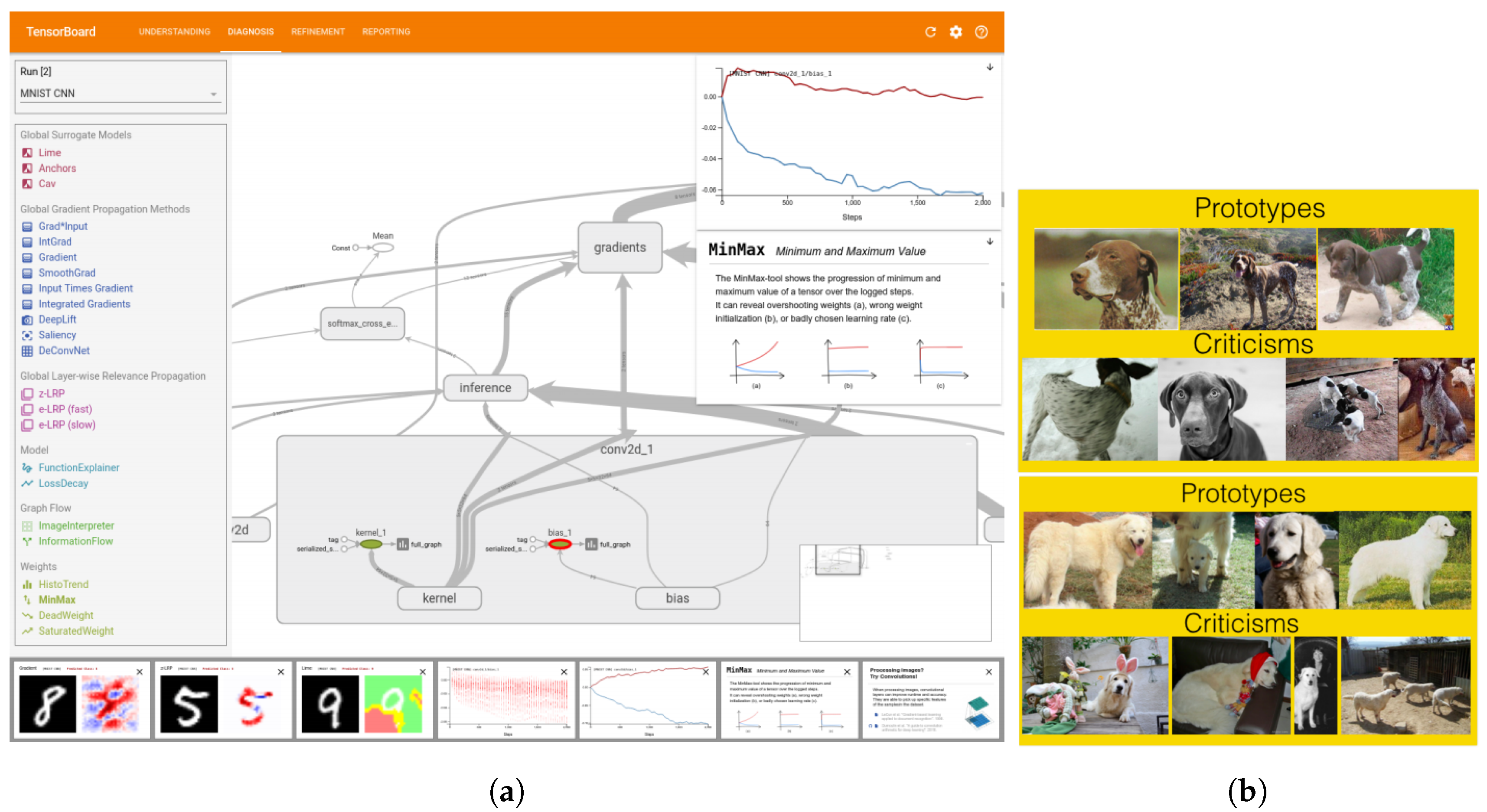


{kind=link}
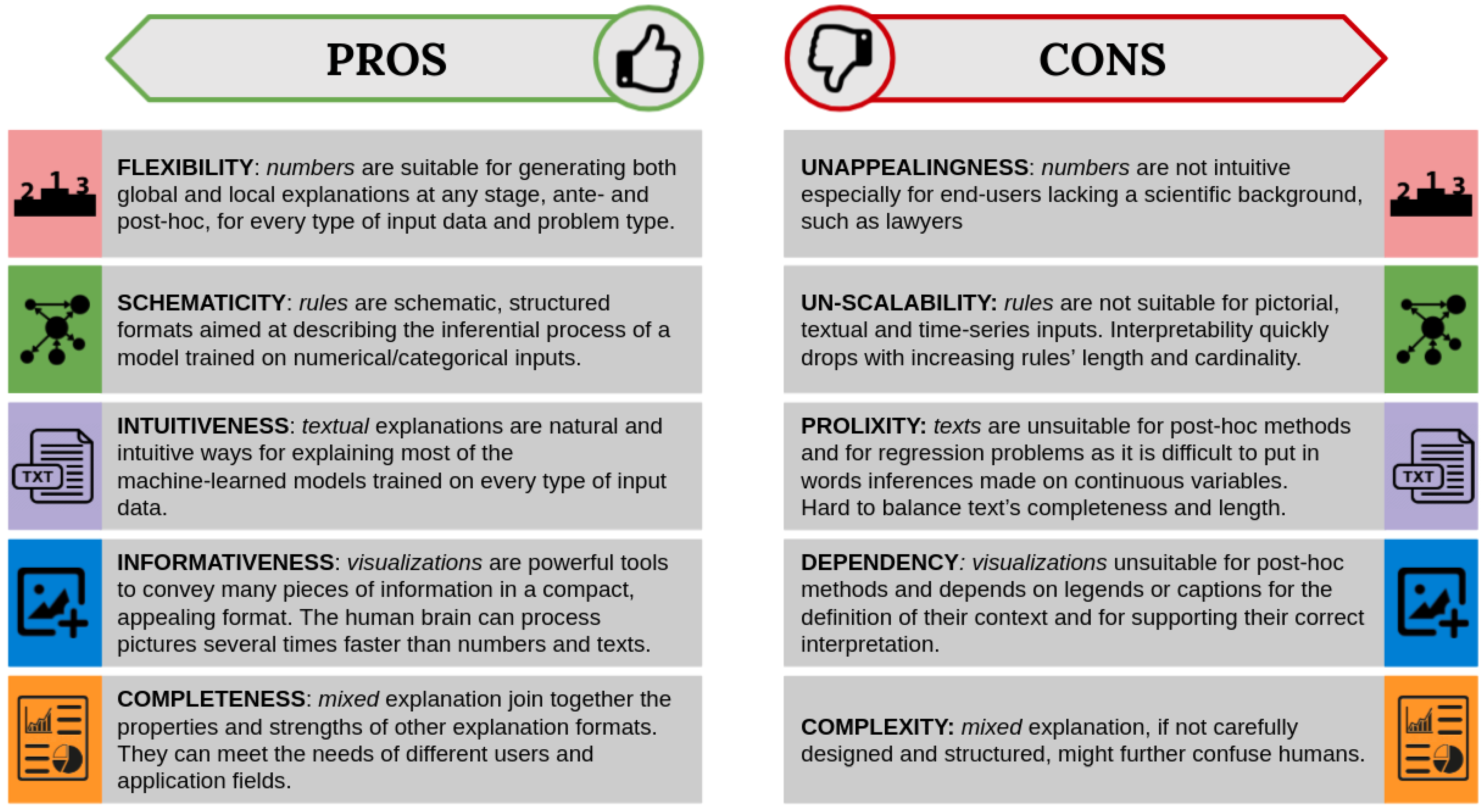
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method for Explainability | Authors | Ref | Year | Scope | Problem | Input |
|---|---|---|---|---|---|---|
| Distill-and-Compare | Tan et al. | [37] | 2018 | G | C/R | NC |
| Explain and Ime | Robnik-Šikonja | [42,43] | 2008, 2018 | L | C | NC |
| Feature Contribution | Kononenko et al., Štrumbelj et al. | [46,47,48] | 2010, 2013, 2009 | L | C/R | NC |
| Feature Contribution | Štrumbelj et al. | [49,50] | 2008, 2010 | G | C/R | NC |
| Feature Importance | Henelius et al. | [55] | 2014 | G | C | NC |
| Feature Perturbation | Štrumbelj and Kononenko | [56] | 2014 | G | C/R | NC |
| GSA | Cortez and Embrechts | [44,45] | 2011, 2013 | G | C/R | NC |
| GFA | Adler et al. | [52] | 2018 | G | C/R | NC |
| Influence Functions | Koh and Liang | [53] | 2017 | G | C | P |
| Monotone Influence Measures | Sliwinski et al. | [54] | 2017 | L | C | P |
| QII functions | Datta et al. | [51] | 2016 | G | C | NC |
| SHAP | Lundberg and Lee, Janzing et al. | [38,40] | 2017, 2020 | G | C | P |
| Shapley–Lorenz–Zonoid Decomposition | Giudici and Raffinetti | [41] | 2020 | G | R | P |
| TreeExplainer | Lundberg et al. | [39] | 2020 | L | C | NC |
| Method for Explainability | Authors | Ref | Year | Stage | Scope | Problem | Input |
|---|---|---|---|---|---|---|---|
| Causal Importance | Féraud and Clérot | [58] | 2002 | PH | G | C | NC |
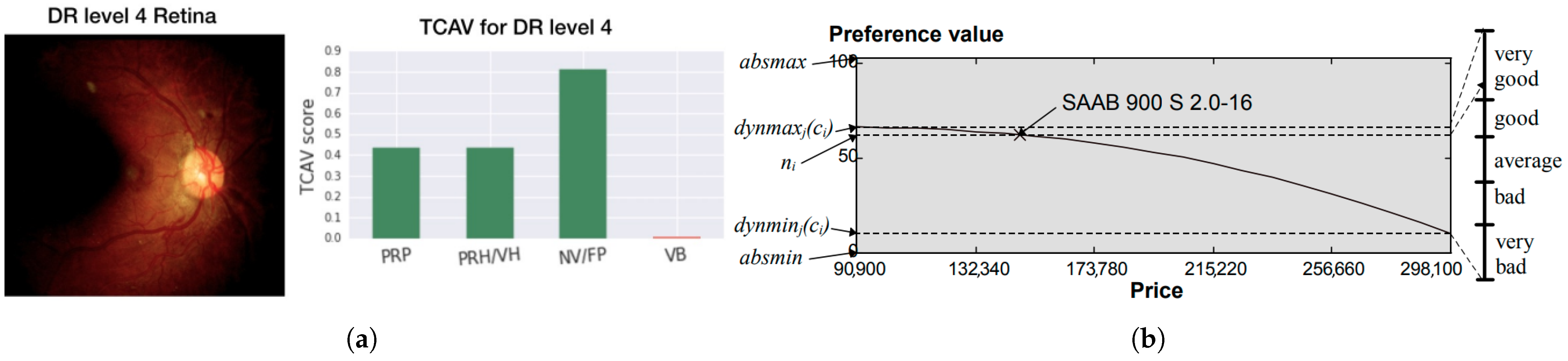
| CAVs | Kim et al. | [34] | 2018 | PH | G | C | P |
| Contextual Importance and Utility | Främling | [59] | 1996 | PH | G/L | C | NC |
| LAXCAT | Hsieh et al. | [60] | 2021 | PH | G | C | TS |
| Probes | Alain and Bengio | [33] | 2017 | PH | G | C | P |
| RELEXNET | Clos et al. | [61] | 2017 | AH | G | C | T |
| SVCCA | Raghu et al. | [57] | 2017 | PH | G | C/R | P |
| Method for Explainability | Authors | Ref | Year | Construction Approach | Stage | Scope | Problem | Input |
|---|---|---|---|---|---|---|---|---|
| Feature Tweaking | Tolomei et al. | [36] | 2017 | Ensembles | PH | L | C | NC |
| Important Support Vectors and Border Classification | Barbella et al. | [63] | 2009 | SVM | PH | L | C | NC |
| RFEX | Petkovic et al. | [62] | 2021 | Ensembles | PH | G | C | NC |
| Weighted Linear Classifier | Caragea et al. | [64] | 2003 | SVM | PH | G | C | NC |
| Method for Explainability | Authors | Ref | Year | Scope | Problem | Input |
|---|---|---|---|---|---|---|
| GPR | Caywood et al. | [65] | 2017 | G | R | TS |
| OT-SpAMs | Wang et al. | [66] | 2015 | G | C | NC |
| RELEXNET | Clos et al. | [61] | 2017 | G | C | T |
| SLIM | Ustun et al. | [67] | 2014 | G | C | NC |
| Method for Explainability | Authors | Ref | Year | Scope | Problem | Input |
|---|---|---|---|---|---|---|
| Anchors | Ribeiro et al. | [28] | 2018 | G/L | C | T |
| Automated Reasoning | Bride et al. | [68] | 2018 | G | C | NC |
| GLocalX | Guidotti et al., Setzu et al. | [71,72] | 2019, 2021 | G/L | C | NC |
| G-REX | Johansson et al. | [69,70] | 2004 | G | C/R | NC |
| Model Extraction | Bastani et al. | [73] | 2017 | G | C/R | NC |
| MRE | Asano and Chun | [75] | 2021 | G | C | NC |
| PALM | Krishnan and Wu | [74] | 2017 | G | C/R | NC |
| Method for Explainability | Authors | Ref | Year | Scope | Problem | Input |
|---|---|---|---|---|---|---|
| C4.5Rule-PANE | Zhou and Jiang | [89] | 2003 | L | C/R | NC |
| DecText | Boz | [90] | 2002 | G | C | NC |
| DIMLP | Bologna and Hayashi | [27,77,81,82] | 2017, 1998, 2018 | G/L | C | P; NC; T |
| Discretising Hidden Unit Activation Values by Clustering | Setiono and Liu | [78] | 1995 | G | C | NC |
| DT Extraction | Frosst and Hinton, Zhang et al. | [86,87] | 2017, 2019 | G | C | P |
| Interval Propagation | Palade et al. | [30] | 2001 | G | C | NC |
| Iterative Rule Knowledge Distillation | Hu et al. | [95] | 2016 | G | C | T |
| NNKX | Bondarenko et al. | [79] | 2017 | G | C | NC |
| REFNE | Zhou et al. | [88] | 2003 | G | C/R | NC |
| RxNCM | Biswas et al. | [84] | 2017 | G | C | NC |
| RxREN | Augasta and Kathirvalavakumar | [83] | 2012 | G | C/R | NC |
| Symbolic Logic Integration | Tran | [96] | 2017 | G | C/R | NC |
| Symbolic Rules | Garcez et al. | [85] | 2001 | G | C/R | NC |
| Tree Regularisation | Wu et al. | [93] | 2018 | G | C | NC |
| TREPAN | Craven and Shavlik | [91,92] | 1994, 1996 | G | C/R | NC |
| VIA | Thrun | [80] | 1995 | G | C/R | TS |
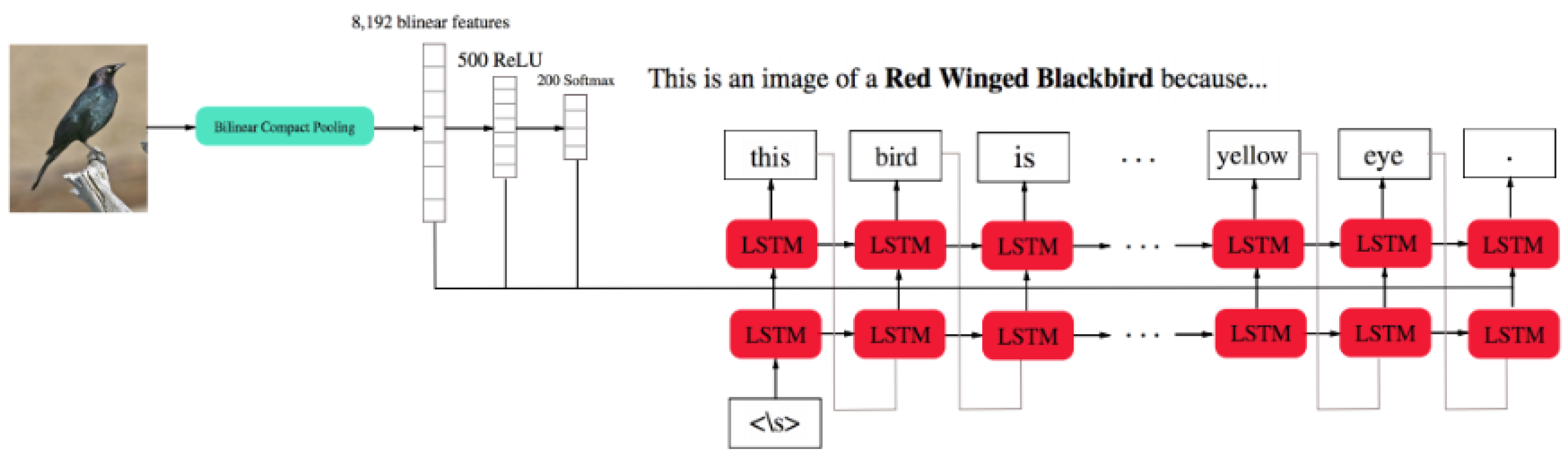
| Word Importance Scores | Murdoch and Szlam | [94] | 2017 | G | C | T |
| Method for Explainability | Authors | Ref | Year | Scope | Problem | Input |
|---|---|---|---|---|---|---|
| ACO | Otero and Freitas | [97] | 2016 | G | C | NC |
| AntMiner+ and ALBA | Verbeke et al. | [98] | 2011 | G | C | NC |
| Argumentation | Rizzo and Longo | [31,32] | 2018 | G | C | NC |
| Argumentation | Zeng et al. | [106] | 2018 | G | C/R | P |
| BRL | Letham et al. | [100,101,102] | 2012, 2013, 2015 | G | C | NC |
| BRS | Wang et al. | [103,104] | 2016, 2017 | G | C | NC |
| CIT2 fuzzy sets | D’Alterio et al. | [114] | 2020 | G | C | NC |
| Interpretable Decision Set | Lakkaraju et al. | [99] | 2016 | G | C | NC |
| FOCL | Pazzani | [105] | 1997 | G | C | NC |
| Fuzzy logic | Pierrard et al. | [109] | 2018 | L | C | NC |
| Fuzzy system | Jin | [108] | 2000 | G | C | NC |
| GBML | Ishibuchi and Nojima | [107] | 2007 | G | C | NC |
| ICRM | Cano et al. | [111] | 2013 | G | C | NC |
| Linear Programming Relaxation | Malioutov et al., Su et al. | [112,113] | 2017, 2016 | G | C | NC |
| MOEAIF | Wang and Palade | [110] | 2011 | G | C | NC |
| PSDD | Liang and Van den Broeck | [116] | 2017 | G | C/R | NC |
| TGAMT | Fahner | [115] | 2018 | G | C | NC |
| Method for Explainability | Authors | Ref | Year | Construction Approach | Scope | Problem | Input |
|---|---|---|---|---|---|---|---|
| DT extraction | Andrzejak et al. | [118] | 2013 | Distributed DTs | G | C/R | NC |
| DT extraction | Ferri et al., Sagi and Rokach, Van Assche and Blockeel | [120,121,122] | 2002, 2020, 2007 | Ensembles | G | C | NC |
| EBI | Yap et al. | [124] | 2008 | Bayesian networks | G | C | NC |
| ExtractRule | Fung et al. | [26] | 2005 | Hyperplane-Based Linear Classifiers | G | C | P; NC |
| FAB inference | Hara and Hayashi | [123] | 2018 | Ensembles | G | C | NC |
| inTrees | Deng | [119] | 2018 | Ensembles | G | C/R | NC |
| Method for Explainability | Authors | Ref | Year | Scope | Problem | Input |
|---|---|---|---|---|---|---|
| InterpNET | Barratt | [125] | 2017 | L | C | P |
| Most-Weighted-Path, Most-Weighted-Combination and Maximum-Frequency-Difference | García-Magarinoet al. | [126] | 2019 | L | C | TS |
| Neural-Symbolic Integration | Bennetot et al. | [127] | 2019 | L | C | P |
| Rationales | Lei et al. | [128] | 2016 | L | C | T |
| Relevance and Discriminative Loss | Hendricks et al. | [25,129] | 2018, 2016 | L | C | P |
| Method for Explainability | Authors | Ref | Year | Construction Approach | Scope | Problem | Input |
|---|---|---|---|---|---|---|---|
| DT Extraction | Alonso et al. | [131] | 2018 | Ensembles | L | C | NC |
| Discriminative Patterns | Gao et al. | [132] | 2017 | Ensembles | G | C | T |
| Fuzzy Inference Systems | Keneni et al. | [117] | 2019 | Rule-Based System | L | C | TS |
| Mycin | Shortliffe et al. | [130] | 1975 | Rule-based system | L | C | NC |
| Scenarios | Vlek et al. | [133] | 2016 | Bayesian networks | L | C | NC |
| Method for Explainability | Authors | Ref | Year | Scope | Problem | Input |
|---|---|---|---|---|---|---|
| Class Signatures | Krause et al. | [145] | 2016 | G | C/R | NC |
| ExplainD | Poulin et al. | [146] | 2006 | G | C | NC |
| Explanation Graph | Alvarez-Melis and Jaakkola | [143] | 2017 | L | C | T |
| Image Perturbation | Fong and Vedaldi | [136] | 2017 | L | C | P |
| ICE plots | Goldstein et al. | [141] | 2015 | G | C/R | NC |
| iVisClassifier | Choo et al. | [138] | 2010 | G | C | NC |
| LRP | Bach et al. | [134] | 2015 | L | C | P |
| Manifold | Zhang et al. | [147] | 2019 | G | C/R | NC |
| MLFR | Apicella et al. | [135] | 2021 | L | C | P |
| MLCube Explorer | Kahng et al. | [148] | 2016 | G | C | NC |
| PI and ICI plots | Casalicchio et al. | [142] | 2018 | G | C/R | NC |
| RSRS Detection | Liu and Wang | [137] | 2012 | L | C | T |
| Saliency Detection | Dabkowski and Gal | [139] | 2017 | L | C | P |
| Sensitivity Analysis | Baehrens et al. | [140] | 2010 | L | C | P; NC |
| SpRAy | Lapuschkin et al. | [3] | 2019 | G | C | P |
| Worst-Case Perturbations | Goodfellow et al. | [144] | 2015 | L | C | P |
| Method for Explainability | Authors | Ref | Year | Stage | Scope | Problem | Input |
|---|---|---|---|---|---|---|---|
| ACE | Ghorbani et al. | [160] | 2019 | PH | G | C | P |
| Average Activation Values | Mogrovejo et al. | [155] | 2019 | PH | L | C | P |
| CLEAR | Kumar et al. | [149] | 2017 | PH | L | C | NC |
| Compositionality | Li et al. | [176] | 2016 | PH | L | C | T |
| DeepLIFT | Shrikumar et al. | [163] | 2017 | PH | L | C | P; NC |
| Deep-Taylor Decomposition | Montavon et al. | [165] | 2017 | PH | G | C | P |
| DeepResolve | Liu and Gifford | [151] | 2017 | PH | G | C | NC |
| Feature Maps | Zhang et al. | [167] | 2018 | AH | L | C | P |
| GradCam | Selvaraju et al. | [150] | 2017 | PH | L | C | P |
| Guided BackProp and Occlusion | Goyal et al. | [157] | 2016 | PH | L | C | P |
| Guided Feature Inversion | Du et al. | [162] | 2018 | PH | L | C | P |
| Integrated Gradients | Sundararajan et al. | [152] | 2017 | PH | L | C | P |
| Inverting Representations | Mahendran and Vedaldi | [161] | 2015 | PH | L | C | P |
| JMM | Jung et al. | [154] | 2021 | PH | L | C | P |
| LRP w/Relevance Conservation | Arras et al. | [174] | 2017 | PH | L | C | T |
| LRP w/Local Renormalisation Layers | Binder et al. | [175] | 2016 | PH | L | C | P |
| Net2Vec | Fong and Vedaldi | [159] | 2018 | PH | G | C | P |
| NIF | Davis et al. | [170] | 2020 | PH | G | C | NC; P |
| Neural Network AND CBR Twin-Systems | Kenny and Keane, Kenny et al. | [171,172] | 2019, 2021 | PH | L | C | P |
| OcclusionSensitivity | Zeiler and Fergus | [158] | 2014 | PH | G | C | P |
| OpenBox | Chu et al. | [173] | 2018 | PH | G | C | P; NC |
| PatternNet, PatternAttribution | Kindermans et al. | [169] | 2018 | PH | L | C | P |
| Prediction Difference Analysis | Zintgraf et al. | [168] | 2017 | PH | L | C | P |
| Receptive Fields | He and Pugeault | [166] | 2017 | PH | G | C | P |
| Relevant Features Selection | Mogrovejo et al. | [155] | 2019 | PH | L | C | P |
| Saliency Maps | Simonyan et al. | [164] | 2014 | PH | L | C | P |
| SmoothGrad | Smilkov et al. | [153] | 2017 | PH | L | C | P |
| SWAF | Rajani and Mooney | [156] | 2017 | PH | L | C | P |
| Method for Explainability | Authors | Ref | Year | Scope | Problem | Input |
|---|---|---|---|---|---|---|
| Cnn-Inte | Liu et al. | [179] | 2018 | G | C | P |
| Hidden Activity Visualisation | Rauber et al. | [180] | 2017 | G | C | P |
| Principal Component Analysis | Aubry and Russell | [177] | 2015 | G | C | P |
| t-SNE maps | Zahavy et al. | [178] | 2016 | G | C | NC |
| TreeView | Thiagarajan et al. | [181] | 2016 | G | C | P |
| Method for Explainability | Authors | Ref | Year | Stage | Scope | Problem | Input |
|---|---|---|---|---|---|---|---|
| Activation Maps | Hamidi-Haines et al. | [189] | 2019 | PH | L | C | P |
| Activation Maximisation | Erhan et al., Nguyen et al. | [186,187,188] | 2010, 2016 | PH | L | C | P |
| ActiVis | Kahng et al. | [197] | 2018 | PH | G | C/R | NC |
| AOG | Zhang et al. | [195] | 2017 | PH | G | C | P |
| Cell Activation Values | Karpathy et al. | [202] | 2016 | PH | G/L | C | T |
| Data-flow Graphs | Wongsuphasawat et al. | [24] | 2018 | PH | G | C/R | P; NC; T |
| Deep View | Zhong et al. | [199] | 2017 | PH | G | C/R | P |
| Deep Visualisation Toolbox | Yosinski et al. | [198] | 2015 | PH | G | C | P |
| Explanatory Graph | Zhang et al. | [193] | 2018 | PH | G | C | P |
| Fractal View for Deep Learning | Halnaut et al. | [192] | 2021 | PH | G | C | P |
| GMM | Stano et al. | [191] | 2020 | PH | L | C | P |
| GAN Dissection | Bau et al. | [182] | 2019 | PH | L | C | P |
| Important Neurons and Patches | Lengerich et al. | [185] | 2017 | PH | G | C | P |
| iNNvestigate | Alber et al. | [200] | 2019 | PH | L | C | P |
| LSTMVis | Strobelt et al. | [23] | 2018 | PH | G/L | C | T |
| NVIS | Streeter et al. | [201] | 2001 | PH | G | C/R | NC |
| Part Prototypes | Zhu et al. | [190] | 2021 | PH | G | C | P |
| Recursive Division Method | Gorokhovatskyi and Peredrii | [184] | 2021 | PH | L | C | P |
| Saliency Maps | Olah et al. | [196] | 2018 | PH | G/L | C | P |
| Score Deviation Map | López-Cifuentes et al. | [183] | 2021 | PH | L | C | P |
| Seq2seq-Vis | Strobelt et al. | [203] | 2018 | PH | L | C | T |
| SGR | Liang et al. | [194] | 2018 | AH | G | C/R | P |
| Method for Explainability | Authors | Ref | Year | Construction Approach | Scope | Problem | Input |
|---|---|---|---|---|---|---|---|
| Contribution Propagation | Landecker et al. | [209] | 2013 | Hierarchical networks | L | C | P |
| Fingrams | Pancho et al. | [204] | 2013 | Rule-based system | G | C | NC |
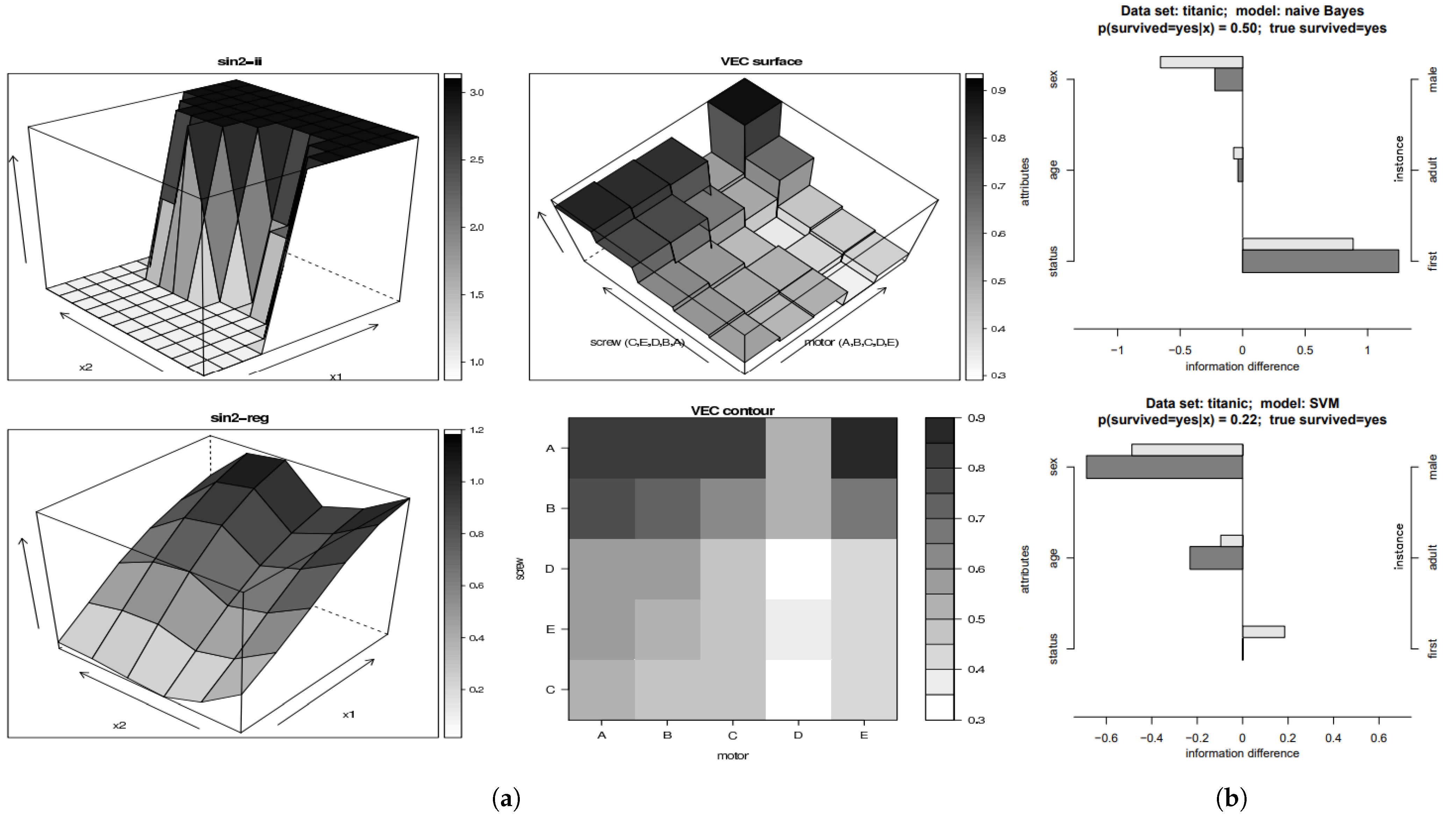
| Nomograms | Jakulin et al. | [206] | 2005 | SVM | G | C | NC |
| Nomograms | Možina et al. | [208] | 2004 | Naïve Bayes | G | C | NC |
| Self-Organising Maps | Hamel | [205] | 2006 | SVM | G | C | NC |
| VRIFA | Cho et al. | [207] | 2008 | SVM | G | C | NC |
| Method for Explainability | Authors | Ref | Year | Scope | Problem | Input |
|---|---|---|---|---|---|---|
| Feature Maps | Zhang et al. | [167] | 2018 | L | C | P |
| SGR | Liang et al. | [194] | 2018 | G | C/R | P |
| Unsupervised Interpretable Word Sense Disambiguation | Panchenko et al. | [210] | 2017 | G | C | T |
| Method for Explainability | Authors | Ref | Year | Scope | Problem | Input |
|---|---|---|---|---|---|---|
| Bayesian Teaching | Yang and Shafto | [216] | 2017 | G | C | NC |
| C-CHVAE | Pawelczyk et al. | [220] | 2020 | L | C | NC |
| Combinatorial Methods | Kuhn et al. | [212] | 2020 | L | C/R | NC |
| DiCE | Mothilal et al. | [221] | 2020 | L | C | NC |
| Evasion-Prone Samples Selection | Liu et al. | [222] | 2018 | G | C | T |
| ExplAIner | Spinner et al. | [214] | 2019 | G | C/R | P; NC; TS |
| Functional ANOVA Decomposition and Variable Interaction Network Graph | Hooker | [211] | 2004 | G | C/R | NC |
| Justification Narratives | Biran and McKeown | [213] | 2014 | G | C | NC |
| LIME | Ribeiro et al. | [22] | 2016 | L | C | P; T |
| MMD-Critic | Kim et al. | [223] | 2016 | L | C | P |
| Neighbourhood-Based Explanations | Caruana et al. | [219] | 1999 | L | C | NC |
| Pertinent Negatives | Dhurandhar et al. | [224] | 2018 | L | C | P; NC |
| Rivelo | Tamagnini et al. | [215] | 2017 | L | C | T |
| SBQ | Khanna et al. | [217] | 2019 | L | C | P; NC |
| SCO | Bien et al. | [218] | 2011 | L | C | P; NC |
| Method for Explainability | Authors | Ref | Year | Stage | Scope | Problem | Input |
|---|---|---|---|---|---|---|---|
| Activation Values of Hidden Neurons | Tamajka et al. | [228] | 2019 | AH | L | C | P |
| Attention Alignment | Kim et al. | [2] | 2018 | PH | L | C | P |
| Deterministic Finite Automaton | Mayr and Yovine | [226] | 2018 | PH | L | C | NC |
| DFAs | Omlin and Giles | [227] | 1996 | PH | G | C | NC |
| Image Caption Generation w/ Attention Mechanism | Xu et al. | [35] | 2015 | PH | L | C | P |
| PJ-X | Park et al. | [225] | 2018 | AH | L | C | P |
| Representer Points | Yeh et al. | [229] | 2018 | PH | L | C | P |
| Method for Explainability | Authors | Ref | Year | Construction Approach | Stage | Scope | Problem | Input |
|---|---|---|---|---|---|---|---|---|
| EDAGs | Gaines | [231] | 1996 | Rule-based system | AH | G | C | NC |
| ExpliClas | Alonso | [230] | 2019 | Rule-based system | PH | L | C | NC |
| Probabilistically Supported Arguments | Timmer et al. | [234] | 2017 | Bayesian networks | PH | G | C | NC |
| SVM+Prototypes | Núnez et al. | [233] | 2002 | SVM | PH | G | C | NC |
| Tree Space Prototypes | Tan et al. | [232] | 2016 | Ensembles | PH | L | C | NC |
| Method for Explainability | Authors | Ref | Year | Scope | Problem | Input |
|---|---|---|---|---|---|---|
| BCM | Kim et al. | [235] | 2014 | G | C | P; T |
| EDAGs | Gaines | [231] | 1996 | G | C | NC |
| GAMs | Lou et al., Lou et al. | [17,18] | 2012 | G | C/R | NC |
| GAMs | Lou et al., Caruana et al. | [236] | 2015 | G | C/R | NC |
| Hybrid Deep Learning | Campagner and Cabitza | [239] | 2020 | G | C/R | NC |
| MGM | Kim et al. | [238] | 2015 | G | C | P; NC; T |
| Multi-Run Subtree Encapsulation | Howard and Edwards | [237] | 2018 | G | C | NC |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vilone, G.; Longo, L. Classification of Explainable Artificial Intelligence Methods through Their Output Formats. Mach. Learn. Knowl. Extr. 2021, 3, 615-661. https://doi.org/10.3390/make3030032
Vilone G, Longo L. Classification of Explainable Artificial Intelligence Methods through Their Output Formats. Machine Learning and Knowledge Extraction. 2021; 3(3):615-661. https://doi.org/10.3390/make3030032
Chicago/Turabian StyleVilone, Giulia, and Luca Longo. 2021. "Classification of Explainable Artificial Intelligence Methods through Their Output Formats" Machine Learning and Knowledge Extraction 3, no. 3: 615-661. https://doi.org/10.3390/make3030032
APA StyleVilone, G., & Longo, L. (2021). Classification of Explainable Artificial Intelligence Methods through Their Output Formats. Machine Learning and Knowledge Extraction, 3(3), 615-661. https://doi.org/10.3390/make3030032