Review on Learning and Extracting Graph Features for Link Prediction


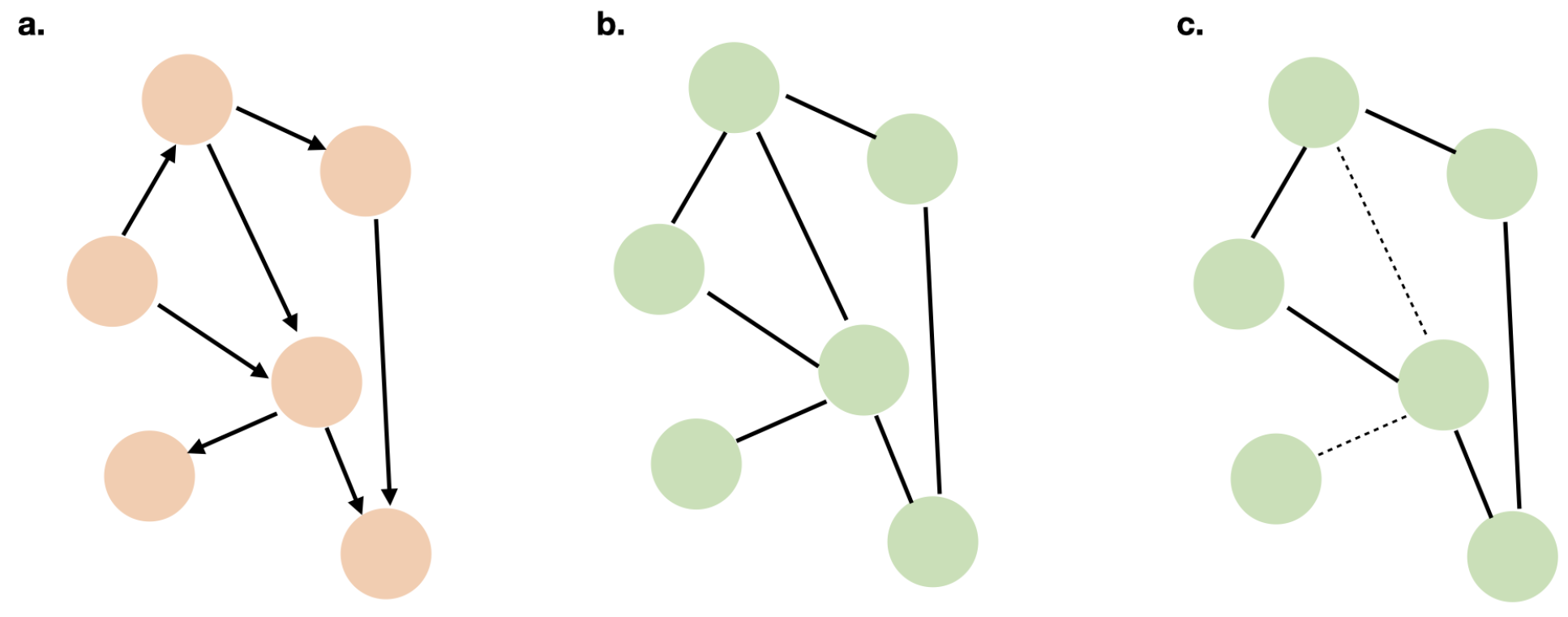{kind=link}
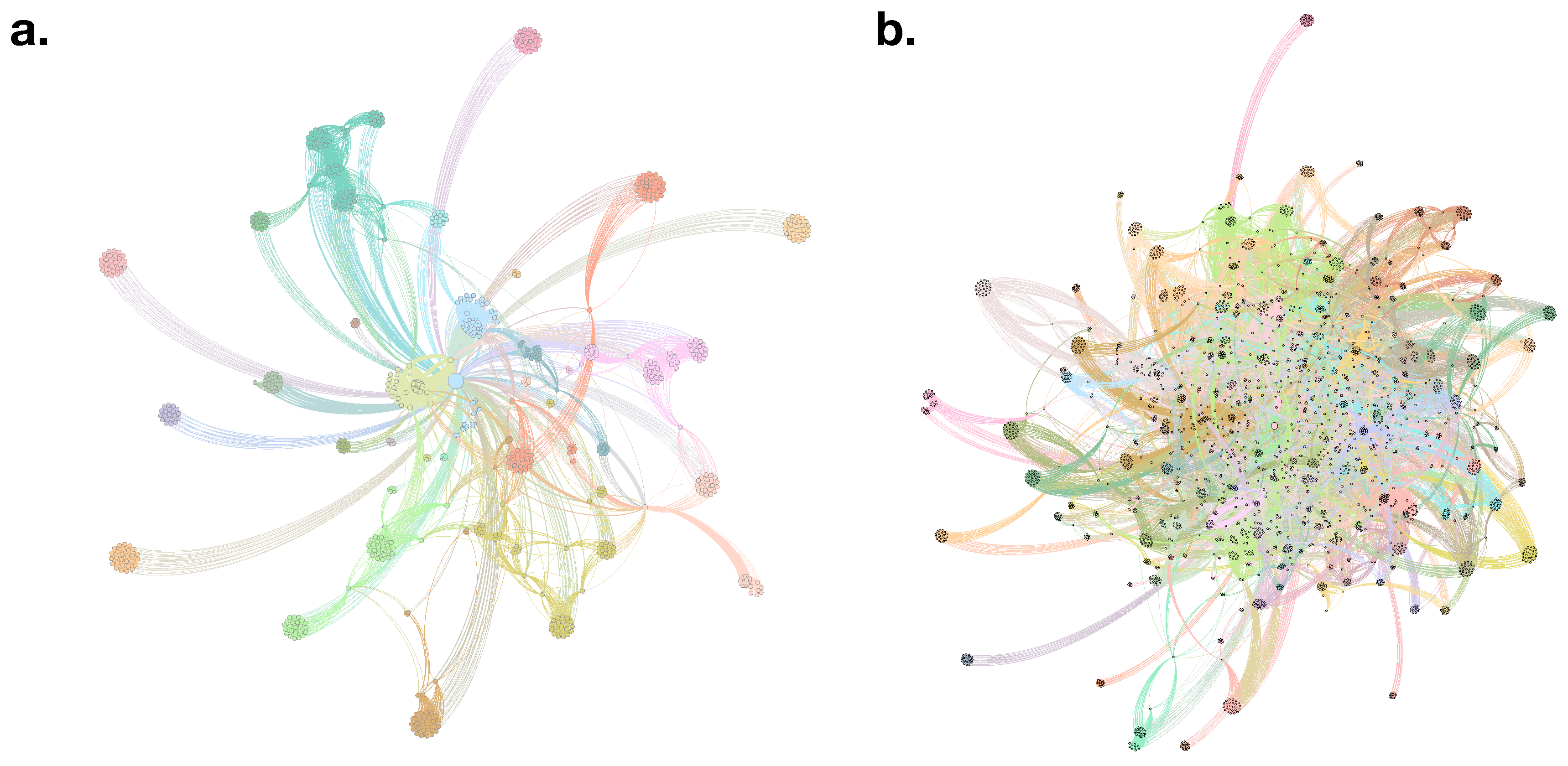{kind=link}
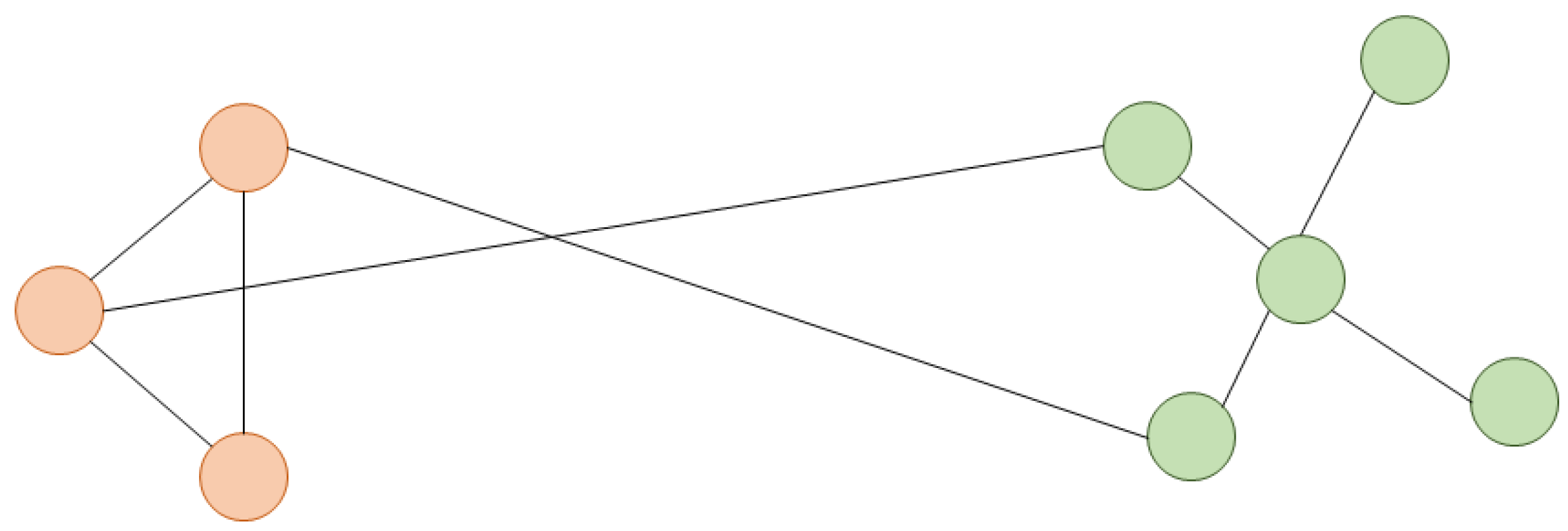{kind=link}
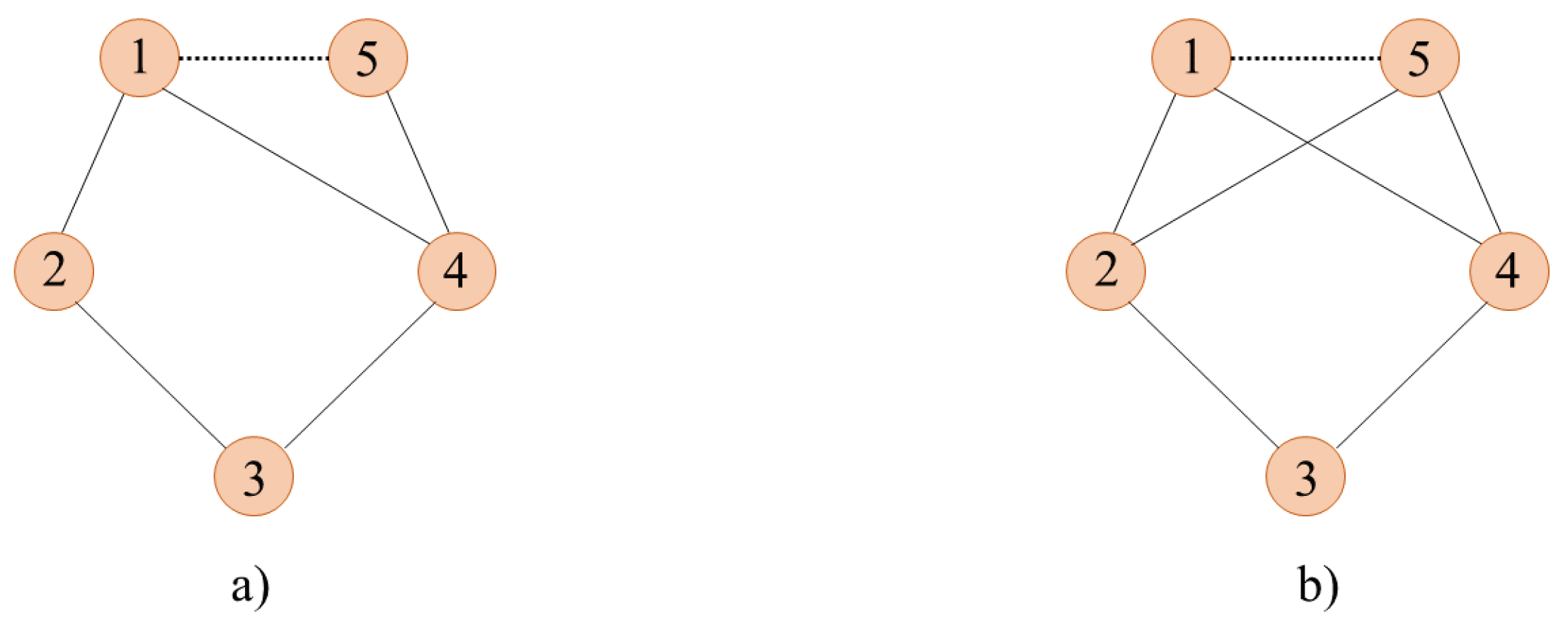{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- (i)
- exploit the similarity metrics as the input features,
- (ii)
- embed the nodes into a low dimensional vector space while preserving the topological structure of the graph, or
- (iii)
- combine the information that is derived from the two aforementioned points, with the node attributes available from the data set.
2. Background
3. Similarity Based Methods
3.1. Local Similarity-Based Approaches
3.1.1. Common Neighbors (CN)
3.1.2. Jaccard Index (JC)
3.1.3. Salton Index (SL)
3.1.4. Sørensen Index (SI)
3.1.5. Preferential Attachment Index (PA)
3.1.6. Adamic-Adar Index (AA)
3.1.7. Resource Allocation Index (RA)
3.1.8. Hub Promoted Index (HP)
3.1.9. Hub Depressed Index (HD)
3.1.10. Leicht-Holme-Newman Index (LHN)
3.1.11. Parameter Dependent Index (PD)
3.1.12. Local Affinity Structure Index (LAS)
3.1.13. CAR-Based Index (CAR)
3.1.14. The Individual Attraction Index (IA)
3.1.15. The Mutual Information Index (MI)
3.1.16. Functional Similarity Weight (FSW)
3.1.17. Local Neighbors Link Index (LNL)
3.2. Global Similarity-Based Approaches
3.2.1. Katz Index (KI)
3.2.2. Global Leicht-Holme-Newman Index (GLHN)
3.2.3. SimRank (SR)
3.2.4. Pseudo-Inverse of the Laplacian Matrix (PLM)
3.2.5. Hitting Time (HT) and Average Commute Time (ACT)
3.2.6. Rooted PageRank (RPR)
3.2.7. Escape Probability (EP)
3.2.8. Random Walk with Restart (RWR)
3.2.9. Maximal Entropy Random Walk (MERW)
3.2.10. The Blondel Index (BI)
3.3. Quasi-Local Similarity-Based Approaches
3.3.1. The Local Path Index (LPI)
3.3.2. Local (LRW) and Superposed Random Walks (SRW)
3.3.3. Third-Order Resource Allocation Based on Common Neighbor Interactions (RACN)
3.3.4. FriendLink Index (FL)
3.3.5. PropFlow Predictor Index (PFP)
4. Probabilistic Methods
4.1. Hierarchical Structure Model
4.2. Stochastic Blockmodel
4.3. Network Evolution Model
4.4. Local Probabilistic Model
4.5. Probabilistic Model of Generalized Clustering Coefficient
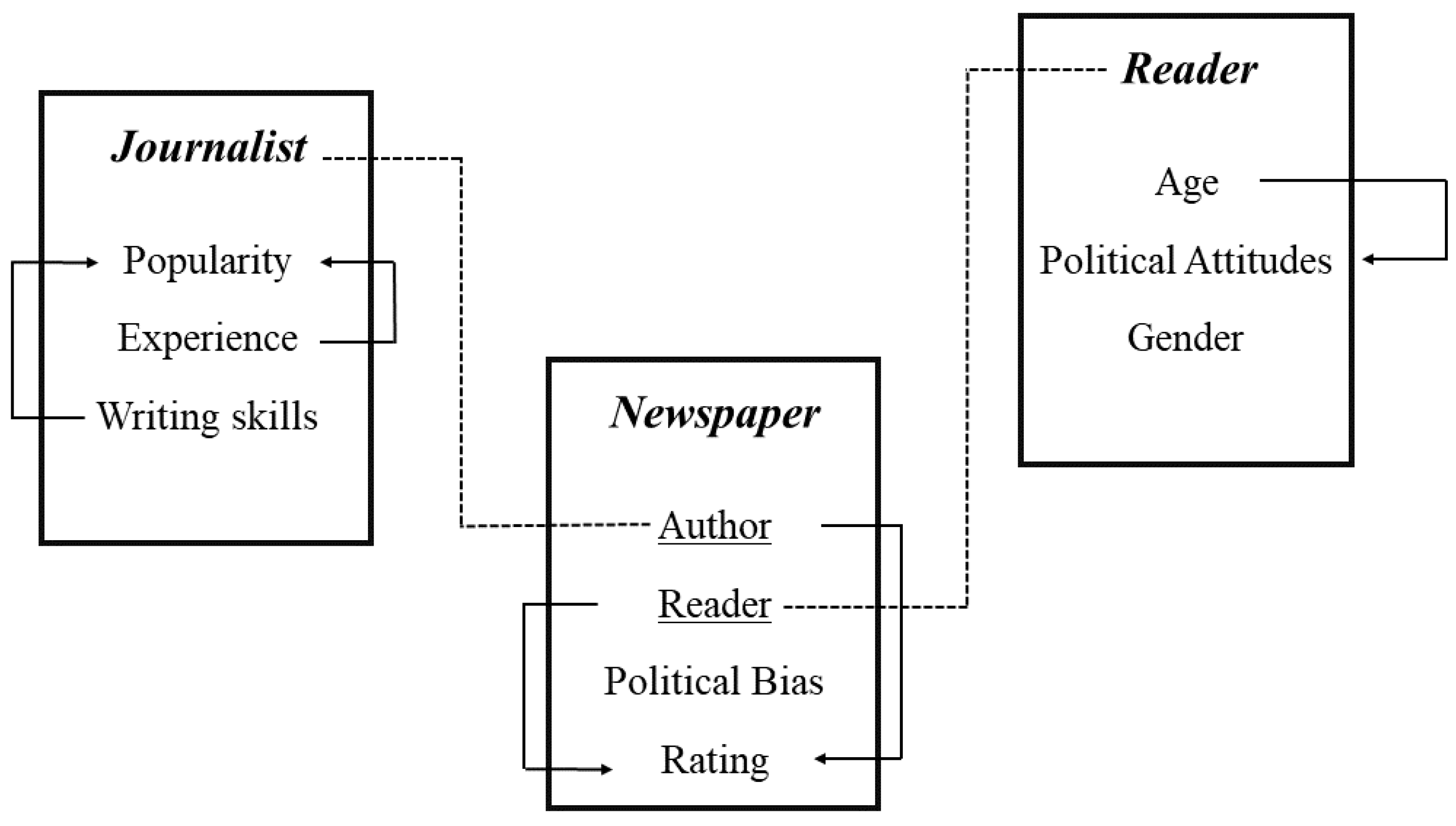
5. Relational Models
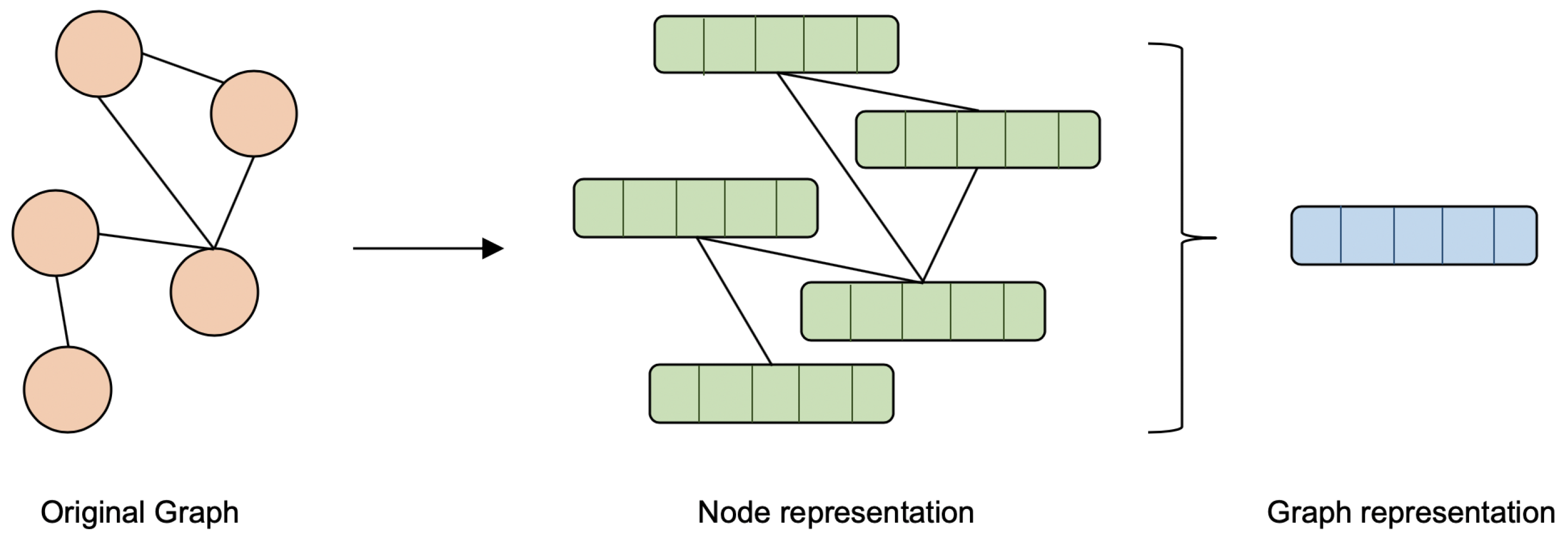
6. Learning-Based Methods
- (i)
- Matrix Factorization-Based Models,
- (ii)
- Path and Walk-Based Models, and
- (iii)
- Deep Neural Network-Based Methods.
6.1. Matrix Factorization-Based Methods
6.2. Path and Walk-Based Methods
6.3. Neural Network-Based Methods
7. Network Data Sets
- SNAP [139]: a collection of more than 90 network data sets by Stanford Network Analysis Platform. With biggest data set consisting of 96 million nodes.
- BioSNAP [140]: more than 30 Bio networks data sets by Stanford Network Analysis Platform
- KONECT [141]: this collection contains more than 250 network data sets of various types, including social networks, authorship networks, interaction networks, etc.
- PAJEK [142]: this collection contains more than 40 data sets of various types.
- Network Repository [143]: a huge collection of more than 5000 network data sets of various types, including social networks.
- Uri ALON [144]: a collection of complex networks data sets by Uri Alon Lab.
- NetWiki [145]: more than 30 network data sets collection of various types.
- WOSN 2009 Data Sets [146]: a collection of Facebook data provided by social computing group.
- Citation Network Data set [147]: a collection of citation network dat aset extracted from DBLP, ACM, and other sources.
- Grouplens Research [148]: a movie rating network data set.
- ASU social computing data repository [149]: a collection of 19 network data sets of various types: cheminformatics, economic networks, etc.
- Nexus network repository [150]: a repository collection of network data sets by iGraph.
- SocioPatterns [151]: a collection of 10 network data sets that were collected by SocioPatterns interdisciplinary research collaboration.
- Mark Newman [152]: a collection of Network data sets by Mark Newman.
- Graphviz [143]: an interactive visual graph mining and analysis.
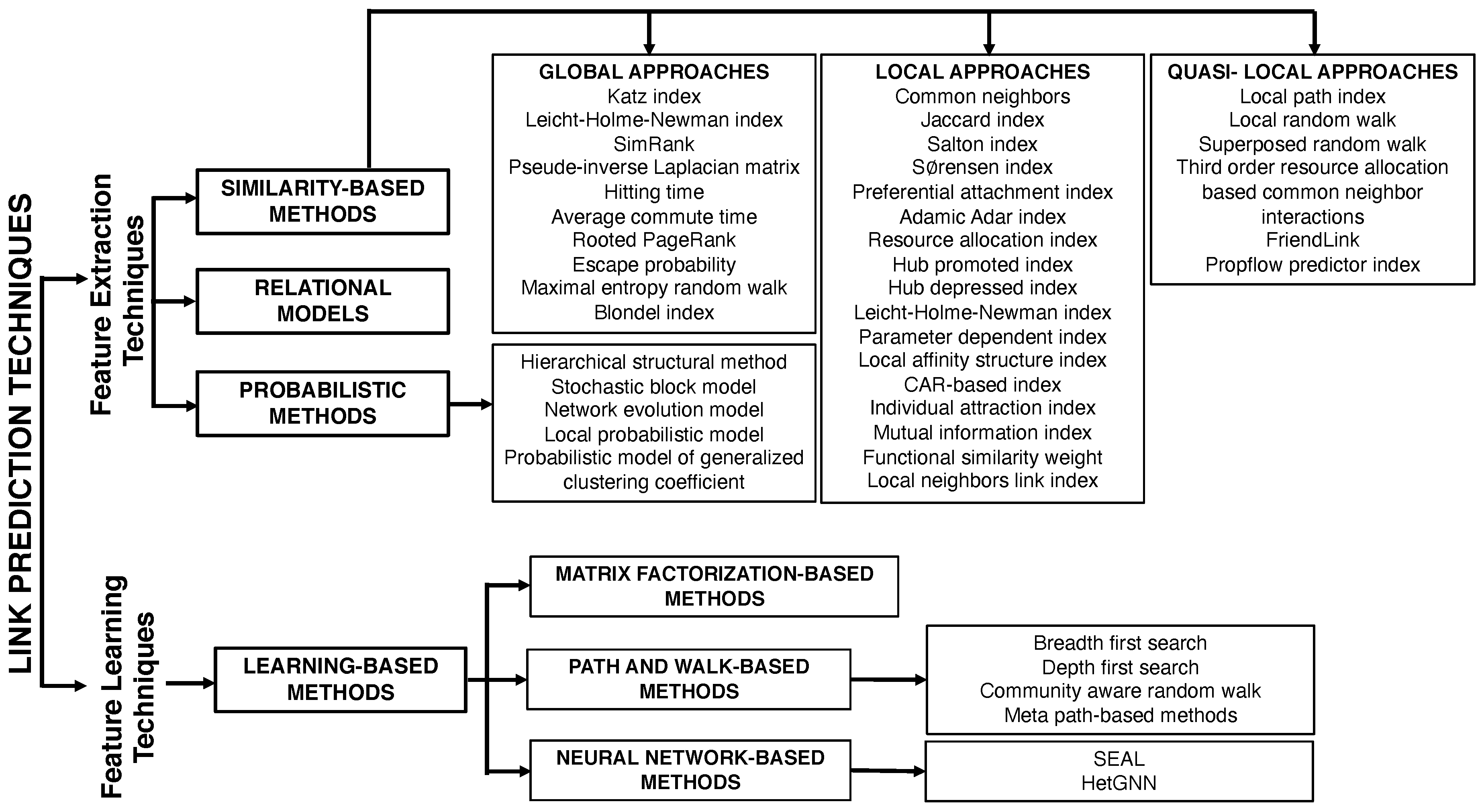
8. Taxonomy
9. Discussion
Funding
Conflicts of Interest
References
- Ahuja, R.; Singhal, V.; Banga, A. Using hierarchies in online social networks to determine link prediction. In Soft Computing and Signal Processing; Springer: Berlin/Heidelberg, Germany, 2019; pp. 67–76. [Google Scholar]
- Sulaimany, S.; Khansari, M.; Masoudi-Nejad, A. Link prediction potentials for biological networks. Int. J. Data Min. Bioinform. 2018, 20, 161–184. [Google Scholar] [CrossRef]
- Wang, Q.; Mao, Z.; Wang, B.; Guo, L. Knowledge graph embedding: A survey of approaches and applications. IEEE Trans. Knowl. Data Eng. 2017, 29, 2724–2743. [Google Scholar] [CrossRef]
- Zhou, W.; Gu, J.; Jia, Y. h-Index-based link prediction methods in citation network. Scientometrics 2018, 117, 381–390. [Google Scholar] [CrossRef]
- Ebrahimi, F.; Golpayegani, S.A.H. Personalized recommender system based on social relations. In Proceedings of the 2016 24th Iranian Conference on Electrical Engineering (ICEE), Shiraz, Iran, 10–12 May 2016; pp. 218–223. [Google Scholar]
- Martínez, V.; Berzal, F.; Cubero, J.C. A survey of link prediction in complex networks. ACM Comput. Surv. (CSUR) 2017, 49, 69. [Google Scholar] [CrossRef]
- Song, H.H.; Cho, T.W.; Dave, V.; Zhang, Y.; Qiu, L. Scalable proximity estimation and link prediction in online social networks. In Proceedings of the 9th ACM SIGCOMM Conference on Internet Measurement, Chicago, IL, USA, 4–6 November 2009; ACM: New York, NY, USA, 2009; pp. 322–335. [Google Scholar]
- Hristova, D.; Noulas, A.; Brown, C.; Musolesi, M.; Mascolo, C. A multilayer approach to multiplexity and link prediction in online geo-social networks. EPJ Data Sci. 2016, 5, 24. [Google Scholar] [CrossRef] [PubMed]
- Jalili, M.; Orouskhani, Y.; Asgari, M.; Alipourfard, N.; Perc, M. Link prediction in multiplex online social networks. R. Soc. Open Sci. 2017, 4, 160863. [Google Scholar] [CrossRef] [PubMed]
- Lei, C.; Ruan, J. A novel link prediction algorithm for reconstructing protein–protein interaction networks by topological similarity. Bioinformatics 2013, 29, 355–364. [Google Scholar] [CrossRef] [PubMed]
- Iakovidou, N.; Symeonidis, P.; Manolopoulos, Y. Multiway spectral clustering link prediction in protein-protein interaction networks. In Proceedings of the 10th IEEE International Conference on Information Technology and Applications in Biomedicine, Corfu, Greece, 3–5 November 2010; pp. 1–4. [Google Scholar]
- Airoldi, E.M.; Blei, D.M.; Fienberg, S.E.; Xing, E.P.; Jaakkola, T. Mixed membership stochastic block models for relational data with application to protein-protein interactions. In Proceedings of the International Biometrics Society Annual Meeting, Hong Kong, China, 5–7 January 2006; Volume 15. [Google Scholar]
- Zhang, M.; Cui, Z.; Jiang, S.; Chen, Y. Beyond link prediction: Predicting hyperlinks in adjacency space. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Ma, Y.; Liang, X.; Huang, J.; Cheng, G. Intercity transportation construction based on link prediction. In Proceedings of the 2017 IEEE 29th International Conference on Tools with Artificial Intelligence (ICTAI), Boston, MA, USA, 6–8 November 2017; pp. 1135–1138. [Google Scholar]
- Desmarais, B.A.; Cranmer, S.J. Forecasting the locational dynamics of transnational terrorism: A network analytic approach. Secur. Inform. 2013, 2, 8. [Google Scholar] [CrossRef][Green Version]
- Heidari, M.; Jones, J.H.J. Using BERT to Extract Topic-Independent Sentiment Features for Social Media Bot Detection. In Proceedings of the IEEE 2020 11th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference, UEMCON 2020, New York, NY, USA, 28–31 October 2020. [Google Scholar]
- Xiao, H.; Huang, M.; Zhu, X. From one point to a manifold: Knowledge graph embedding for precise link prediction. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 1315–1321. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Zhao, Z.; Papalexakis, E.; Ma, X. Learning Physical Common Sense as Knowledge Graph Completion via BERT Data Augmentation and Constrained Tucker Factorization. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November, 2020; pp. 3293–3298. [Google Scholar]
- Heckerman, D.; Geiger, D.; Chickering, D.M. Learning Bayesian networks: The combination of knowledge and statistical data. Mach. Learn. 1995, 20, 197–243. [Google Scholar] [CrossRef]
- Friedman, N.; Getoor, L.; Koller, D.; Pfeffer, A. Learning probabilistic relational models. In Proceedings of the IJCAI, Stockholm, Sweden, 31 July–6 August 1999; Volume 99, pp. 1300–1309. [Google Scholar]
- Getoor, L.; Friedman, N.; Koller, D.; Pfeffer, A.; Taskar, B. Probabilistic relational models. In Introduction to Statistical Relational Learning; The MIT Press: Cambridge, MA, USA, 2007; Volume 8, pp. 128–174. [Google Scholar]
- Getoor, L.; Friedman, N.; Koller, D.; Taskar, B. Learning probabilistic models of link structure. J. Mach. Learn. Res. 2002, 3, 679–707. [Google Scholar]
- Al Hasan, M.; Zaki, M.J. A survey of link prediction in social networks. In Social Network Data Analytics; Springer: Berlin/Heidelberg, Germany, 2011; pp. 243–275. [Google Scholar]
- Zhang, M.; Chen, Y. Link Prediction Based on Graph Neural Networks. arXiv 2018, arXiv:1802.09691. [Google Scholar]
- Kumar, A.; Singh, S.S.; Singh, K.; Biswas, B. Link prediction techniques, applications, and performance: A survey. Phys. A Stat. Mech. Appl. 2020, 553, 124289. [Google Scholar] [CrossRef]
- Nickel, M.; Murphy, K.; Tresp, V.; Gabrilovich, E. A review of relational machine learning for knowledge graphs. Proc. IEEE 2015, 104, 11–33. [Google Scholar] [CrossRef]
- Lü, L.; Zhou, T. Link prediction in complex networks: A survey. Phys. A Stat. Mech. Appl. 2011, 390, 1150–1170. [Google Scholar] [CrossRef]
- Wasserman, S.; Faust, K. Social Network Analysis: Methods and Applications; Cambridge University Press: Cambridge, UK, 1994; Volume 8. [Google Scholar]
- Wang, X.W.; Chen, Y.; Liu, Y.Y. Link Prediction through Deep Learning. bioRxiv 2018, 247577. [Google Scholar] [CrossRef]
- Manning, C.D.; Schütze, H.; Raghavan, P. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Hanley, J.A.; McNeil, B.J. The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology 1982, 143, 29–36. [Google Scholar] [CrossRef]
- Chen, H.; Li, X.; Huang, Z. Link prediction approach to collaborative filtering. In Proceedings of the 5th ACM/IEEE-CS Joint Conference on Digital Libraries (JCDL’05), Denver, CO, USA, 7–11 June 2005; pp. 141–142. [Google Scholar]
- Gray, P.M.D. P/FDM. In Encyclopedia of Database Systems; Liu, L., ÖZSU, M.T., Eds.; Springer: Boston, MA, USA, 2009; pp. 2011–2012. [Google Scholar]
- Voorhees, E.M.; Harman, D. Overview of the sixth text retrieval conference (TREC-6). Inf. Process. Manag. 2000, 36, 3–35. [Google Scholar] [CrossRef]
- Zhang, E.; Zhang, Y. Average Precision. In Encyclopedia of Database Systems; Liu, L., Özsu, M.T., Eds.; Springer: Boston, MA, USA, 2009; pp. 192–193. [Google Scholar] [CrossRef]
- Liben-Nowell, D.; Kleinberg, J. The link-prediction problem for social networks. J. Am. Soc. Inf. Sci. Technol. 2007, 58, 1019–1031. [Google Scholar] [CrossRef]
- Newman, M.E. Clustering and preferential attachment in growing networks. Phys. Rev. E 2001, 64, 025102. [Google Scholar] [CrossRef]
- Jaccard, P. Étude comparative de la distribution florale dans une portion des Alpes et des Jura. Bull Soc. Vaudoise Sci. Nat. 1901, 37, 547–579. [Google Scholar]
- Salton, G.; McGill, M.J. Introduction to Modern Information Retrieval; McGraw-Hill, Inc.: New York, NY, USA, 1986. [Google Scholar]
- Wagner, C.S.; Leydesdorff, L. Mapping the network of global science: Comparing international co-authorships from 1990 to 2000. Int. J. Technol. Glob. 2005, 1, 185–208. [Google Scholar] [CrossRef]
- Sørensen, T. A method of establishing groups of equal amplitude in plant sociology based on similarity of species and its application to analyses of the vegetation on Danish commons. Biol. Skr. 1948, 5, 1–34. [Google Scholar]
- McCune, B.; Grace, J.B.; Urban, D.L. Analysis of Ecological Communities; MjM Software Design: Gleneden Beach, OR, USA, 2002; Volume 28. [Google Scholar]
- Barabási, A.L.; Albert, R. Emergence of scaling in random networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef]
- Adamic, L.A.; Adar, E. Friends and neighbors on the web. Soc. Netw. 2003, 25, 211–230. [Google Scholar] [CrossRef]
- Zhou, T.; Lü, L.; Zhang, Y.C. Predicting missing links via local information. Eur. Phys. J. B 2009, 71, 623–630. [Google Scholar] [CrossRef]
- Wang, P.; Xu, B.; Wu, Y.; Zhou, X. Link prediction in social networks: The state-of-the-art. Sci. China Inf. Sci. 2015, 58, 1–38. [Google Scholar] [CrossRef]
- Ravasz, E.; Somera, A.L.; Mongru, D.A.; Oltvai, Z.N.; Barabási, A.L. Hierarchical organization of modularity in metabolic networks. Science 2002, 297, 1551–1555. [Google Scholar] [CrossRef]
- Leicht, E.A.; Holme, P.; Newman, M.E. Vertex similarity in networks. Phys. Rev. E 2006, 73, 026120. [Google Scholar] [CrossRef]
- Zhu, Y.X.; Lü, L.; Zhang, Q.M.; Zhou, T. Uncovering missing links with cold ends. Phys. A Stat. Mech. Appl. 2012, 391, 5769–5778. [Google Scholar] [CrossRef]
- Sun, Q.; Hu, R.; Yang, Z.; Yao, Y.; Yang, F. An improved link prediction algorithm based on degrees and similarities of nodes. In Proceedings of the Computer and Information Science (ICIS), 2017 IEEE/ACIS 16th International Conference, Wuhan, China, 24–26 May 2017; pp. 13–18. [Google Scholar]
- Cannistraci, C.V.; Alanis-Lobato, G.; Ravasi, T. From link-prediction in brain connectomes and protein interactomes to the local-community-paradigm in complex networks. Sci. Rep. 2013, 3, 1613. [Google Scholar] [CrossRef] [PubMed]
- Dong, Y.; Ke, Q.; Wang, B.; Wu, B. Link prediction based on local information. In Proceedings of the Advances in Social Networks Analysis and Mining (ASONAM), 2011 International Conference, Kaohsiung, Taiwan, 25–27 July 2011; pp. 382–386. [Google Scholar]
- Tan, F.; Xia, Y.; Zhu, B. Link prediction in complex networks: A mutual information perspective. PLoS ONE 2014, 9, e107056. [Google Scholar] [CrossRef] [PubMed]
- Chua, H.N.; Sung, W.K.; Wong, L. Exploiting indirect neighbours and topological weight to predict protein function from protein–protein interactions. Bioinformatics 2006, 22, 1623–1630. [Google Scholar] [CrossRef] [PubMed]
- Brun, C.; Chevenet, F.; Martin, D.; Wojcik, J.; Guénoche, A.; Jacq, B. Functional classification of proteins for the prediction of cellular function from a protein-protein interaction network. Genome Biol. 2003, 5, R6. [Google Scholar] [CrossRef]
- Yang, J.; Yang, L.; Zhang, P. A New Link Prediction Algorithm Based on Local Links. In Proceedings of the International Conference on Web-Age Information Management, Qingdao, China, 8–10 June 2015; pp. 16–28. [Google Scholar]
- Katz, L. A new status index derived from sociometric analysis. Psychometrika 1953, 18, 39–43. [Google Scholar] [CrossRef]
- Jeh, G.; Widom, J. SimRank: A measure of structural-context similarity. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–26 July 2002; pp. 538–543. [Google Scholar]
- Liben-Nowell, D. An Algorithmic Approach to Social Networks. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2005. [Google Scholar]
- Spielman, D.A. Spectral graph theory and its applications. In Proceedings of the Foundations of Computer Science, FOCS’07, 48th Annual IEEE Symposium, Providence, RI, USA, 21–23 October 2007; pp. 29–38. [Google Scholar]
- Fouss, F.; Pirotte, A.; Renders, J.M.; Saerens, M. Random-walk computation of similarities between nodes of a graph with application to collaborative recommendation. IEEE Trans. Knowl. Data Eng. 2007, 19, 355–369. [Google Scholar] [CrossRef]
- Pearson, K. The problem of the random walk. Nature 1905, 72, 342. [Google Scholar] [CrossRef]
- Tong, H.; Faloutsos, C.; Faloutsos, C.; Koren, Y. Fast direction-aware proximity for graph mining. In Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Jose, CA, USA, 12–15 August 2007; pp. 747–756. [Google Scholar]
- Lü, L.; Zhou, T. Link prediction in weighted networks: The role of weak ties. EPL Europhys. Lett. 2010, 89, 18001. [Google Scholar] [CrossRef]
- Hetherington, J. Observations on the statistical iteration of matrices. Phys. Rev. A 1984, 30, 2713. [Google Scholar] [CrossRef]
- Duda, J. Extended Maximal Entropy Random Walk. Ph.D. Thesis, Jagiellonian University, Krakow, Poland, 2012. [Google Scholar]
- Li, R.H.; Yu, J.X.; Liu, J. Link prediction: The power of maximal entropy random walk. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management, Glasgow, UK, 24–28 October 2011; pp. 1147–1156. [Google Scholar]
- Blondel, V.D.; Gajardo, A.; Heymans, M.; Senellart, P.; Van Dooren, P. A measure of similarity between graph vertices: Applications to synonym extraction and web searching. SIAM Rev. 2004, 46, 647–666. [Google Scholar] [CrossRef]
- Lü, L.; Jin, C.H.; Zhou, T. Similarity index based on local paths for link prediction of complex networks. Phys. Rev. E 2009, 80, 046122. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Lü, L. Link prediction based on local random walk. EPL Europhys. Lett. 2010, 89, 58007. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, Y.; Yang, H.; Yang, J. A link prediction algorithm based on socialized semi-local information. J. Comput. Inf. Syst. 2014, 10, 4459–4466. [Google Scholar]
- Papadimitriou, A.; Symeonidis, P.; Manolopoulos, Y. Fast and accurate link prediction in social networking systems. J. Syst. Softw. 2012, 85, 2119–2132. [Google Scholar] [CrossRef]
- Lichtenwalter, R.N.; Lussier, J.T.; Chawla, N.V. New perspectives and methods in link prediction. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–28 July 2010; pp. 243–252. [Google Scholar]
- Ravasz, E.; Barabási, A.L. Hierarchical organization in complex networks. Phys. Rev. E 2003, 67, 026112. [Google Scholar] [CrossRef]
- Clauset, A.; Moore, C.; Newman, M.E. Hierarchical structure and the prediction of missing links in networks. Nature 2008, 453, 98. [Google Scholar] [CrossRef]
- Goldenberg, A.; Zheng, A.X.; Fienberg, S.E.; Airoldi, E.M. A Survey of Statistical Network Models; Now Publishers Inc.: Delft, The Netherlands, 2010. [Google Scholar]
- Guimerà, R.; Sales-Pardo, M. Missing and spurious interactions and the reconstruction of complex networks. Proc. Natl. Acad. Sci. USA 2009, 106, 22073–22078. [Google Scholar] [CrossRef]
- Peixoto, T.P. Hierarchical block structures and high-resolution model selection in large networks. Phys. Rev. X 2014, 4, 011047. [Google Scholar] [CrossRef]
- Vallès-Català, T.; Peixoto, T.P.; Sales-Pardo, M.; Guimerà, R. Consistencies and inconsistencies between model selection and link prediction in networks. Phys. Rev. E 2018, 97, 062316. [Google Scholar] [CrossRef]
- Guimera, R.; Sales-Pardo, M. A network inference method for large-scale unsupervised identification of novel drug-drug interactions. PLoS Comput. Biol. 2013, 9, e1003374. [Google Scholar] [CrossRef]
- Rovira-Asenjo, N.; Gumí, T.; Sales-Pardo, M.; Guimera, R. Predicting future conflict between team-members with parameter-free models of social networks. Sci. Rep. 2013, 3, 1–6. [Google Scholar] [CrossRef] [PubMed]
- Godoy-Lorite, A.; Guimerà, R.; Moore, C.; Sales-Pardo, M. Accurate and scalable social recommendation using mixed-membership stochastic block models. Proc. Natl. Acad. Sci. USA 2016, 113, 14207–14212. [Google Scholar] [CrossRef] [PubMed]
- Holland, P.W.; Laskey, K.B.; Leinhardt, S. Stochastic blockmodels: First steps. Soc. Netw. 1983, 5, 109–137. [Google Scholar] [CrossRef]
- Bhanot, G. The metropolis algorithm. Rep. Prog. Phys. 1988, 51, 429. [Google Scholar] [CrossRef]
- Kashima, H.; Abe, N. A parameterized probabilistic model of network evolution for supervised link prediction. In Proceedings of the Sixth International Conference on Data Mining (ICDM’06), Hong Kong, China, 18–22 December 2006; pp. 340–349. [Google Scholar]
- Wang, C.; Satuluri, V.; Parthasarathy, S. Local probabilistic models for link prediction. In Proceedings of the Seventh IEEE International Conference on Data Mining (ICDM 2007), Omaha, NE, USA, 28–31 October 2007; pp. 322–331. [Google Scholar]
- Huang, Z. Link prediction based on graph topology: The predictive value of generalized clustering coefficient. SSRN Electron. J. 2010. [Google Scholar] [CrossRef][Green Version]
- Bilgic, M.; Namata, G.M.; Getoor, L. Combining collective classification and link prediction. In Proceedings of the Seventh IEEE International Conference on Data Mining Workshops (ICDMW 2007), Omaha, NE, USA, 28–31 October 2007; pp. 381–386. [Google Scholar]
- Taskar, B.; Abbeel, P.; Koller, D. Discriminative probabilistic models for relational data. arXiv 2012, arXiv:1301.0604. [Google Scholar]
- Taskar, B.; Wong, M.F.; Abbeel, P.; Koller, D. Link prediction in relational data. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2004; pp. 659–666. [Google Scholar]
- Taskar, B.; Abbeel, P.; Wong, M.F.; Koller, D. Relational markov networks. In Introduction to Statistical Relational Learning; The MIT Press: Cambridge, MA, USA, 2007; pp. 175–200. [Google Scholar]
- Heckerman, D.; Meek, C.; Koller, D. Probabilistic entity-relationship models, PRMs, and plate models. In Introduction to Statistical Relational Learning; The MIT Press: Cambridge, MA, USA, 2007; pp. 201–238. [Google Scholar]
- Heckerman, D.; Meek, C.; Koller, D. Probabilistic Models for Relational Data; Technical Report, Technical Report MSR-TR-2004-30; Microsoft Research: Redmond, WA, USA, 2004. [Google Scholar]
- Yu, K.; Chu, W.; Yu, S.; Tresp, V.; Xu, Z. Stochastic relational models for discriminative link prediction. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; The MIT Press: Cambridge, MA, USA, 2007; pp. 1553–1560. [Google Scholar]
- Neville, J.; Jensen, D. Relational dependency networks. J. Mach. Learn. Res. 2007, 8, 653–692. [Google Scholar]
- Heckerman, D.; Chickering, D.M.; Meek, C.; Rounthwaite, R.; Kadie, C. Dependency networks for collaborative filtering and data visualization. arXiv 2013, arXiv:1301.3862. [Google Scholar]
- Xu, Z.; Tresp, V.; Yu, K.; Yu, S.; Kriegel, H.P. Dirichlet enhanced relational learning. In Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; pp. 1004–1011. [Google Scholar]
- Al Hasan, M.; Chaoji, V.; Salem, S.; Zaki, M. Link prediction using supervised learning. In Proceedings of the SDM06: Workshop on Link Analysis, Counter-Terrorism and Security, Bethesda, MD, USA, 22 April 2006. [Google Scholar]
- Duan, L.; Ma, S.; Aggarwal, C.; Ma, T.; Huai, J. An ensemble approach to link prediction. IEEE Trans. Knowl. Data Eng. 2017, 29, 2402–2416. [Google Scholar] [CrossRef]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Representation learning on graphs: Methods and applications. arXiv 2017, arXiv:1709.05584. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 855–864. [Google Scholar]
- Liu, W.; Zhou, P.; Zhao, Z.; Wang, Z.; Ju, Q.; Deng, H.; Wang, P. K-BERT: Enabling Language Representation with Knowledge Graph; Cornrll University: Ithaca, NY, USA, 2019. [Google Scholar]
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; Van Den Berg, R.; Titov, I.; Welling, M. Modeling relational data with graph convolutional networks. In Proceedings of the European Semantic Web Conference, Heraklion, Greece, 3–7 June 2018; pp. 593–607. [Google Scholar]
- Yao, L.; Mao, C.; Luo, Y. KG-BERT: BERT for knowledge graph completion. arXiv 2019, arXiv:1909.03193. [Google Scholar]
- Khosla, M.; Leonhardt, J.; Nejdl, W.; Anand, A. Node representation learning for directed graphs. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Würzburg, Germany, 16–20 September 2019; pp. 395–411. [Google Scholar]
- Lichtenwalter, R.N.; Chawla, N.V. Vertex collocation profiles: Subgraph counting for link analysis and prediction. In Proceedings of the 21st International Conference on World Wide Web, Lyon, France, 16–20 April 2012; pp. 1019–1028. [Google Scholar]
- Tang, J.; Qu, M.; Wang, M.; Zhang, M.; Yan, J.; Mei, Q. Line: Large-scale information network embedding. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 1067–1077. [Google Scholar]
- Cui, P.; Wang, X.; Pei, J.; Zhu, W. A survey on network embedding. arXiv 2017, arXiv:1711.08752. [Google Scholar] [CrossRef]
- Ou, M.; Cui, P.; Pei, J.; Zhang, Z.; Zhu, W. Asymmetric transitivity preserving graph embedding. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 1105–1114. [Google Scholar]
- Menon, A.K.; Elkan, C. Link prediction via matrix factorization. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Bristol, UK, 23–27 September 2011; pp. 437–452. [Google Scholar]
- Ahmed, A.; Shervashidze, N.; Narayanamurthy, S.; Josifovski, V.; Smola, A.J. Distributed large-scale natural graph factorization. In Proceedings of the 22nd International Conference on World Wide Web, Janeiro, Brazil, 13–17 May 2013; ACM: New York, NY, USA, 2013; pp. 37–48. [Google Scholar]
- Cao, S.; Lu, W.; Xu, Q. Grarep: Learning graph representations with global structural information. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 19–23 October 2015; ACM: New York, NY, USA, 2015; pp. 891–900. [Google Scholar]
- Goyal, P.; Ferrara, E. Graph embedding techniques, applications, and performance: A survey. Knowl.-Based Syst. 2018, 151, 78–94. [Google Scholar] [CrossRef]
- Zhou, J.; Cui, G.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. arXiv 2018, arXiv:1812.08434. [Google Scholar]
- Wang, H.; Wang, J.; Wang, J.; Zhao, M.; Zhang, W.; Zhang, F.; Xie, X.; Guo, M. Graphgan: Graph representation learning with generative adversarial nets. arXiv 2017, arXiv:1711.08267. [Google Scholar]
- Keikha, M.M.; Rahgozar, M.; Asadpour, M. Community aware random walk for network embedding. Knowl.-Based Syst. 2018, 148, 47–54. [Google Scholar] [CrossRef]
- Sun, Y.; Han, J.; Yan, X.; Yu, P.S.; Wu, T. Pathsim: Meta path-based top-k similarity search in heterogeneous information networks. Proc. VLDB Endow. 2011, 4, 992–1003. [Google Scholar] [CrossRef]
- Fu, G.; Ding, Y.; Seal, A.; Chen, B.; Sun, Y.; Bolton, E. Predicting drug target interactions using meta-path-based semantic network analysis. BMC Bioinform. 2016, 17, 160. [Google Scholar] [CrossRef]
- Zhang, C.; Song, D.; Huang, C.; Swami, A.; Chawla, N.V. Heterogeneous graph neural network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 793–803. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Kipf, T.N.; Welling, M. Variational graph auto-encoders. arXiv 2016, arXiv:1611.07308. [Google Scholar]
- Berg, R.v.d.; Kipf, T.N.; Welling, M. Graph convolutional matrix completion. arXiv 2017, arXiv:1706.02263. [Google Scholar]
- Gilmer, J.; Schoenholz, S.S.; Riley, P.F.; Vinyals, O.; Dahl, G.E. Neural message passing for quantum chemistry. arXiv 2017, arXiv:1704.01212. [Google Scholar]
- Cao, S.; Lu, W.; Xu, Q. Deep Neural Networks for Learning Graph Representations. In Proceedings of the AAAI 2016, Phoenix, AZ, USA, 12–17 February 2016; pp. 1145–1152. [Google Scholar]
- Pan, S.; Hu, R.; Long, G.; Jiang, J.; Yao, L.; Zhang, C. Adversarially regularized graph autoencoder for graph embedding. arXiv 2018, arXiv:1802.04407. [Google Scholar]
- Wang, D.; Cui, P.; Zhu, W. Structural deep network embedding. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 1225–1234. [Google Scholar]
- Harada, S.; Akita, H.; Tsubaki, M.; Baba, Y.; Takigawa, I.; Yamanishi, Y.; Kashima, H. Dual Convolutional Neural Network for Graph of Graphs Link Prediction. arXiv 2018, arXiv:1810.02080. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2017; pp. 1024–1034. [Google Scholar]
- Yang, B.; Yih, W.T.; He, X.; Gao, J.; Deng, L. Embedding entities and relations for learning and inference in knowledge bases. arXiv 2014, arXiv:1412.6575. [Google Scholar]
- Zachary, W.W. An information flow model for conflict and fission in small groups. J. Anthropol. Res. 1977, 33, 452–473. [Google Scholar] [CrossRef]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of ‘small-world’networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef]
- Spring, N.; Mahajan, R.; Wetherall, D. Measuring ISP topologies with Rocketfuel. ACM SIGCOMM Comput. Commun. Rev. 2002, 32, 133–145. [Google Scholar] [CrossRef]
- Von Mering, C.; Krause, R.; Snel, B.; Cornell, M.; Oliver, S.G.; Fields, S.; Bork, P. Comparative assessment of large-scale data sets of protein–protein interactions. Nature 2002, 417, 399–403. [Google Scholar] [CrossRef]
- Newman, M.E. Finding community structure in networks using the eigenvectors of matrices. Phys. Rev. E 2006, 74, 036104. [Google Scholar] [CrossRef] [PubMed]
- Lusseau, D.; Schneider, K.; Boisseau, O.J.; Haase, P.; Slooten, E.; Dawson, S.M. The bottlenose dolphin community of Doubtful Sound features a large proportion of long-lasting associations. Behav. Ecol. Sociobiol. 2003, 54, 396–405. [Google Scholar] [CrossRef]
- Markov, N.T.; Ercsey-Ravasz, M.; Ribeiro Gomes, A.; Lamy, C.; Magrou, L.; Vezoli, J.; Misery, P.; Falchier, A.; Quilodran, R.; Gariel, M.; et al. A weighted and directed interareal connectivity matrix for macaque cerebral cortex. Cereb. Cortex 2014, 24, 17–36. [Google Scholar] [CrossRef] [PubMed]
- Leskovec, J.; Krevl, A. SNAP Datasets: Stanford Large Network Dataset Collection. 2014. Available online: http://snap.stanford.edu/data (accessed on 16 December 2020).
- Zitnik, M.; Sosič, R.; Maheshwari, S.; Leskovec, J. BioSNAP Datasets: Stanford Biomedical Network Dataset Collection. 2018. Available online: http://snap.stanford.edu/biodata (accessed on 16 December 2020).
- Kunegis, J. KONECT: The Koblenz Network Collection. In Proceedings of the 22Nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; ACM: New York, NY, USA, 2013; pp. 1343–1350. [Google Scholar]
- Batagelj, V.; Mrvar, A. Pajek Datasets. 2006. Available online: http://http://vlado.fmf.uni-lj.si/pub/networks/data/ (accessed on 16 December 2020).
- Rossi, R.A.; Ahmed, N.K. The Network Data Repository with Interactive Graph Analytics and Visualization. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Lab, U.A. Collection of Complex Networks. 2006. Available online: http://www.weizmann.ac.il (accessed on 16 December 2020).
- Mucha, P.; Porter, M. Netwiki Shared Data. 2013. Available online: http://netwiki.amath.unc.edu (accessed on 16 December 2020).
- Viswanath, B.; Mislove, A.; Cha, M.; Gummadi, K.P. On the Evolution of User Interaction in Facebook. In Proceedings of the 2nd ACM SIGCOMM Workshop on Social Networks (WOSN’09), Barcelona, Spain, 16–21 August 2009. [Google Scholar]
- Tang, J.; Zhang, J.; Yao, L.; Li, J.; Zhang, L.; Su, Z. ArnetMiner: Extraction and Mining of Academic Social Networks. In Proceedings of the KDD’08, Las Vegas, NV, USA, 24–27 August 2008; pp. 990–998. [Google Scholar]
- Grouplens. Movielens Rating Dataset. Available online: https://grouplens.org/datasets/movielens/ (accessed on 16 December 2020).
- Zafarani, R.; Liu, H. Social Computing Data Repository at ASU. 2009. Available online: https://www.re3data.org/repository/r3d100010959 (accessed on 16 December 2020).
- Nexus Network Repository. 2015. Available online: https://igraph.org/r/doc/nexus.html (accessed on 16 December 2020).
- SocioPAttern Research Collaboration. Available online: http://www.sociopatterns.org/datasets/ (accessed on 16 December 2020).
- Newman, M. Mark Newman Network Datasets Collection. 2013. Available online: http://www-personal.umich.edu/~mejn/netdata (accessed on 16 December 2020).
- Mohan, A.; Venkatesan, R.; Pramod, K. A scalable method for link prediction in large real world networks. J. Parallel Distrib. Comput. 2017, 109, 89–101. [Google Scholar] [CrossRef]
- Xiao, Y.; Li, X.; Wang, H.; Xu, M.; Liu, Y. 3-HBP: A three-level hidden Bayesian link prediction model in social networks. IEEE Trans. Comput. Soc. Syst. 2018, 5, 430–443. [Google Scholar] [CrossRef]
- Getoor, L.; Diehl, C.P. Link mining: A survey. Acm Sigkdd Explor. Newsl. 2005, 7, 3–12. [Google Scholar] [CrossRef]
- Kushwah, A.K.S.; Manjhvar, A.K. A review on link prediction in social network. Int. J. Grid Distrib. Comput. 2016, 9, 43–50. [Google Scholar] [CrossRef]
- Wind, D.K.; Mørup, M. Link prediction in weighted networks. In Proceedings of the 2012 IEEE International Workshop on Machine Learning for Signal Processing, Santander, Spain, 23–26 September 2012; pp. 1–6. [Google Scholar]
- Kunegis, J.; De Luca, E.W.; Albayrak, S. The link prediction problem in bipartite networks. In Proceedings of the International Conference on Information Processing and Management of Uncertainty in Knowledge-Based Systems, Dortmund, Germany, 28 June–2 July 2010; pp. 380–389. [Google Scholar]
- Bu, Z.; Wang, Y.; Li, H.J.; Jiang, J.; Wu, Z.; Cao, J. Link prediction in temporal networks: Integrating survival analysis and game theory. Inf. Sci. 2019, 498, 41–61. [Google Scholar] [CrossRef]
- Marjan, M.; Zaki, N.; Mohamed, E.A. Link prediction in dynamic social networks: A literature review. In Proceedings of the 2018 IEEE 5th International Congress on Information Science and Technology (CiSt), Marrakech, Morocco, 21–27 October 2018; pp. 200–207. [Google Scholar]
- Daud, N.N.; Ab Hamid, S.H.; Saadoon, M.; Sahran, F.; Anuar, N.B. Applications of link prediction in social networks: A review. J. Netw. Comput. Appl. 2020, 166, 102716. [Google Scholar] [CrossRef]
- Zhang, P.; Wang, X.; Wang, F.; Zeng, A.; Xiao, J. Measuring the robustness of link prediction algorithms under noisy environment. Sci. Rep. 2016, 6, 1–7. [Google Scholar] [CrossRef]







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mutlu, E.C.; Oghaz, T.; Rajabi, A.; Garibay, I. Review on Learning and Extracting Graph Features for Link Prediction. Mach. Learn. Knowl. Extr. 2020, 2, 672-704. https://doi.org/10.3390/make2040036
Mutlu EC, Oghaz T, Rajabi A, Garibay I. Review on Learning and Extracting Graph Features for Link Prediction. Machine Learning and Knowledge Extraction. 2020; 2(4):672-704. https://doi.org/10.3390/make2040036
Chicago/Turabian StyleMutlu, Ece C., Toktam Oghaz, Amirarsalan Rajabi, and Ivan Garibay. 2020. "Review on Learning and Extracting Graph Features for Link Prediction" Machine Learning and Knowledge Extraction 2, no. 4: 672-704. https://doi.org/10.3390/make2040036
APA StyleMutlu, E. C., Oghaz, T., Rajabi, A., & Garibay, I. (2020). Review on Learning and Extracting Graph Features for Link Prediction. Machine Learning and Knowledge Extraction, 2(4), 672-704. https://doi.org/10.3390/make2040036