1. Introduction
Social Networking Sites (SNS) have been established as an important aspect of people’s lives in modern society, seeping into many aspects of our everyday life, both private and public. The number of worldwide social media users as of February 2019 is equal to
billion people, which is about 45% of the total world population, representing an increase of 280 million between January 2018 and February 2019 [
1]. Only in the UK, approximately 45 million people use some kind of social media platform, and this equates to a staggering 67% of the total UK population. In the United States and Canada, these numbers climb even higher at 70% [
2].
The revolution of WEB 2.0, transformed the web content from static into dynamic, which enables users to generate online content. This evolution essentially gave a voice to almost everyone capable of being a part of an online community, thus enabling the expression of opinions. However, as SNS represent the everyday social interactions, the online expression of opinions came along with some side effects, one of the most important being hate speech. Hate speech is often the expression of xenophobia also known as anti-immigration speech, which are quite broad terms. According to Cambridge dictionary [
3], hate speech is defined as public speech that expresses hate or encourages violence towards a person or group based on something such as race, religion, sex, or sexual orientation. For the purpose of this paper, we will refer to anti-immigration speech as extreme dislike or fear of foreigners, their customs and their religions. The presence of anti-immigration sentiments both in private and public can be motivated by several reasons with terrorist attacks being one of the extreme examples, however often having profound influence on rising anti-immigration sentiments [
4]. Politics is another influencing factor, which not only can spark debates about immigration, but also openly display anti-immigration attitudes. Such examples include the 2012 UK Home Office hostile environment policy [
5] and the BREXIT campaign [
6]. However, it appears that not only political issues can be associated with anti-immigration discourse. The recent outbreak of Coronavirus in China has led to many cases of xenophobic attacks both in real-world and online, where often discourse crossed the thin border between being concerned about own safety and anti-Chinese sentiment [
7].
A common theme among such events is that they trigger an intense public debate, which in modern times often takes place in cyberspace, usually through social networks. This leads to privacy concerns, as harvesting user-generated data has become almost effortless, especially concerning public social networks, such as Twitter, which, on one hand, distributes its data freely via Application Programming Interfaces (APIs), and on the other hand seems to treat private data as a valuable asset, by providing paid premium access to its APIs that can enhance data mining capabilities. The availability of user data in combination with provocative events, motivated several academic studies. For example, hate speech on Twitter was examined during and after the most recent US election campaign, using a significant corpus of Tweets originating from US users [
8], along with 50 million Facebook accounts [
9]. Williams & Burnap [
10] analyzed hate speech on Twitter in the aftermath of a terrorist attack in London, focusing on the propagation of hate, showing changing presence of hateful messages over time, as well as depicting event-related Twitter traffic per geo-location. Basile et al. [
11] examined both English and Spanish Tweets for anti-immigration rhetoric without focusing on any specific country. UK-based xenophobia has also been researched previously focusing on the Polish minority; however, the data were collected via interviews with individuals rather than online discourse [
12]. Another study, analyzed real public Twitter data, limited to anti-Islamic hashtag-related rhetoric [
13].
Our work differentiates from previous approaches, as it leverages the bespoke data mining capabilities to investigate the expression of online users’ opinions, by crawling and analyzing a dataset of publicly available Tweets with a focus on anti-immigration/xenophobic opinions. In comparison to previous approaches, we gain a broader view of the problem by leveraging the geo-location feature to obtain data from three English speaking countries (UK, USA, and Canada), which had a rise to anti-immigration rhetoric, to create a diverse dataset of immigration-related Tweets. The dataset was manually annotated to capture anti-immigration sentiment. Finally, three classifiers were trained and evaluated to perform hate-speech detection based on two representation methods: word and character n-grams with the TF-IDF approach. Naïve Bayes, Support Vector Machines (SVM) and Logistic Regression were used for classification and performance comparison between encoding/representation methods, i.e., character n-grams vs word n-grams. Additionally, the labeled data were analyzed for the presence of unique lexical characteristics that could be used to distinguish between neutral and anti-immigration rhetoric. Furthermore, hyperlinks embedded in gathered Tweets were also assessed with relation to the publicly available list of malicious domains, to explore whether xenophobic discourse can be associated with the spread of malicious links. Through the aforementioned empirical study, a wider problem of users’ privacy on social media was brought to attention i.e., users’ discourse can be gathered and extensively analyzed without requiring their consent.
The contributions of our work can be summarized, as follows:
We created a new, manually labeled, immigration-related dataset of publicly available Tweets from three English speaking countries.
We explore whether text classification using machine learning is feasible when dealing with a combination of UK, USA, and Canadian English language and different immigration-related topics by practically testing our dataset while using three different machine learning (ML) algorithms.
Finally, we measure the impact of different language features on the classification performance, we discuss the implication for hate-speech detection, and provide directions for future studies.
The remaining of the paper is organised, as follows:
Section 2 discusses the related work on social media data analysis by considering the related ML techniques.
Section 3 introduces our methodology, while
Section 4 presents the our results. Finally,
Section 6 draws the conclusions and provides avenues for future work.
3. Methodology
In this section, we first provide a brief description of the data collection and dataset creation methodology. Subsequently, we outline the challenges of creating an appropriate dataset for hate speech detection (
Section 3.1). Secondly, we describe our approach to text representation, including the initial pre-processing steps, such as stop-word removal and feature extraction (
Section 3.2). Finally, we present our classification models for anti-immigration rhetoric detection in Tweets (
Section 3.3).
3.1. Dataset Creation
To create our dataset, we used the Twitter public API, which offers free access to all Twitter data that are generated by users. Recently, Twitter has made a small step towards protecting the privacy of its users by requiring a developer Twitter account in order to obtain the aforementioned information. However, the application process did not create a significant barrier as it is quite simple and straightforward to obtain access.
The data was collected from 1 January to 31 January 2020, and included English Tweets with a specific focus on three countries, namely: UK, USA and Canada. The reasoning for selecting these countries was the substantial amount of immigration debate taking place in those countries during the past few years, often inspired by political events, which may have escalated from day to day lives into social media providing valuable data for analysis. In the UK, Brexit appeared to be predominantly motivated by anti-immigration sentiments [
54]. In the USA, the election of Donald Trump gave rise to more heated debates around immigration. Despite the fact that Canada did not go through the same changes involving right-wing politics, it appears that anti-immigration sentiment is rising [
55], which again can lead to interesting discourses taking place in Social Networks, with Twitter being one of them.
When considering the fact that a single Twitter API request can return only a maximum of 100 Tweets per searched term, it was important to utilize a variety of keywords instead of a single Immigration term. To achieve this task, a combination of keywords and hashtags were selected that were found to be associated with the topic. Keywords included terms such as migrants, refugees, immigration, and multiculturalism. Hashtags were mostly associated with negative rhetoric towards foreigners and included: #refuggesnotwelcome, #Antiimmigration, #DeportThemALL, #defendeurope. However, neutral hashtags were also utilized in order to make the data more diversified, e.g., #immigration, #refugees. The geolocation feature of the Twitter Search API allowed for obtaining Tweets from several locations in the aforementioned countries. To prevent us from gathering duplicate data, reTweets were excluded from the search and any possible duplicates found later were also removed. This was possible, as each Tweet has a unique identification number and any reoccurring IDs were filtered out. This resulted in obtaining a dataset of 47,976 Tweets.
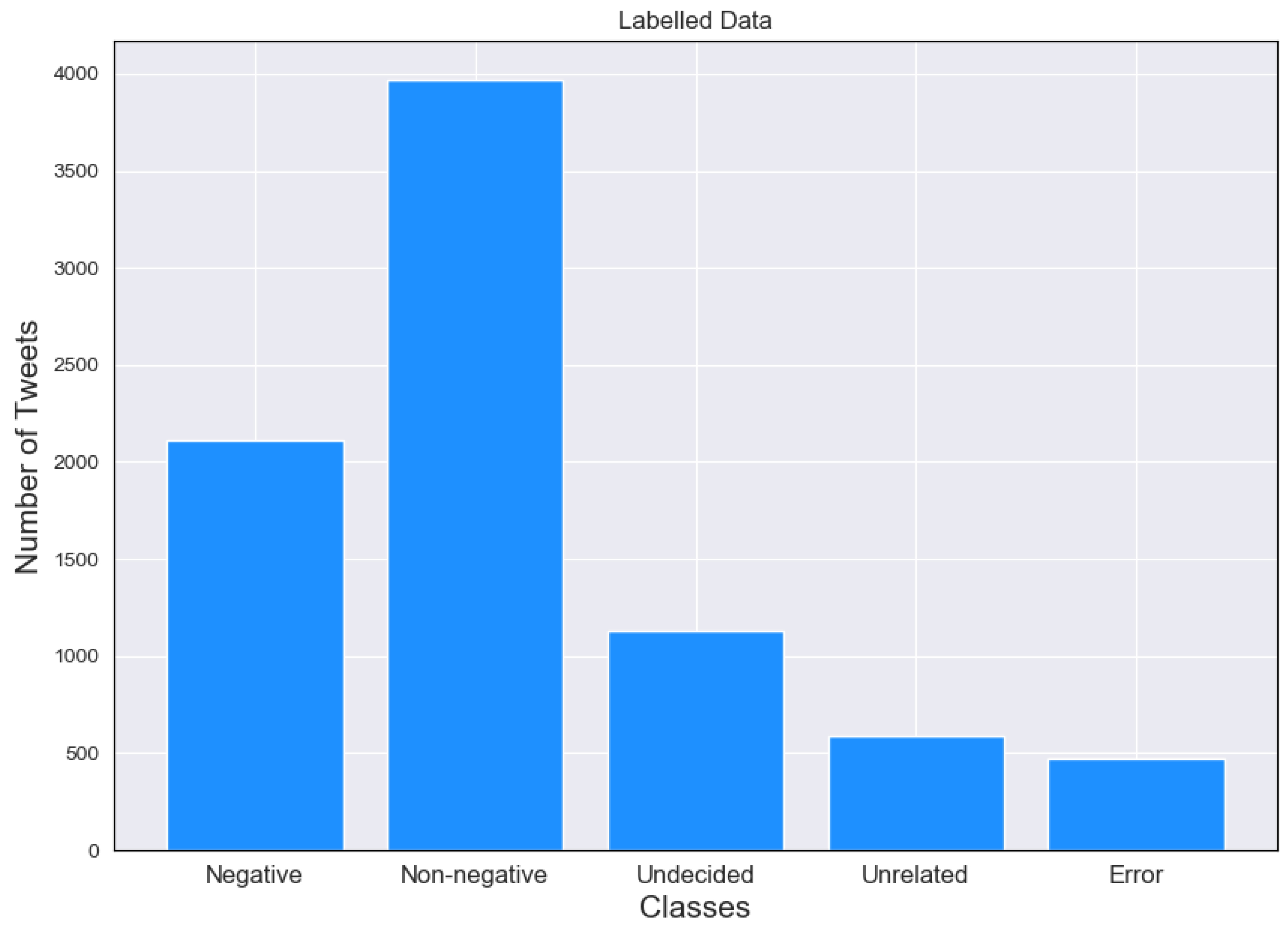
For the purpose of our work, the data were manually annotated for xenophobic/anti-immigration rhetoric into the following five different labels: (i) Negative, which refers to Tweets containing anti-immigration rhetoric, (ii) Non-Negative in the opposite occasion, (iii) Undecided, where it was not possible to determine the person’s view, (iv) Unrelated in case any Tweet happens to be approximately the same as any of the previous ones, despite removing duplicates previously. This occurred as some Tweets were copies of others with some additional different user mentions or URLs, thus reproducing the same content with minor differences only. The last label we used was (v) Error, which was used in cases that we were not able to process the Tweet content, e.g., in Tweets containing special characters. It is worth clarifying that these Tweets were a minority.
To annotate the dataset we followed principles from Waseem et al. [
44]. As such, a Tweet is labelled as xenophobic if it:
uses xenophobic slurs;
attacks criticizes or strives to discredit an individual or a group that is part of immigrant minority;
defends Xenophobia; and,
propagates xenophobic hashtags, such as #Antiimmigration, #DeportThemALL.
As a result, a total of 8270 Tweets were annotated, where 2114 were labeled as Negative towards foreigners and 3971 as Non-Negative.
Figure 1 summarizes the results of our labeling exercise. To validate the annotations and to ensure that the dataset is reliable, a second annotator labelled a subset of the Tweets (fifty random Tweets) and Cohen’s kappa was used to calculate the inter-annotator agreement (
).
Dataset Creation Challenges
The challenge with automatic identification of xenophobic discourse on Twitter and, in any other similar source of opinions, is that xenophobia is a very broad term, as already mentioned, referring to dislike towards foreigners. Consequently, a foreigner can be a person from any country in the world meaning that they can be referred to by many names derived from the country of origin e.g., Pole, German, and other ethnic slurs. Additionally, religion is often used to “assign people” to a certain group of foreigners, e.g., Muslims. Previous studies have either focused on narrower groups of people, such as sexual minorities, racial groups or even disabled people, or concentrated on groups with regard to religion/ethnicity [
40,
44]. Foreigners, as a group, includes several subgroups making the classification task challenging. Therefore, to collect the training data, we focused on more broad terms, such as migrant, immigration, or even refugees, to include as many groups as possible in the set.
Another challenge of our dataset creation activities was grasping the dislike sentiment, which covers a certain scope of language. This ranged from discrete forms of negative opinions to the most obvious ones and the use of swear words. Sarcasm and humor pose another classification challenge, as the classifier would need to be specifically trained on this type of language to yield valid results. As our results suggest, the use of hashtags discloses the true meaning of the Tweets, therefore preserving them in the data pre-processing, while providing additional features for the algorithm.
3.2. Feature Extraction and Text Representation
Tweets and many other user-generated social media messages, include significant amount of noise, i.e., they contain a substantial number of unwanted data that can lead to misclassifications. This include data, such as hashtags, user mentions, or URLs, thus the use of several pre-processing steps is necessary. All of the Tweets were stripped off of any mentions of users, as well as links embedded in the text, by filtering words beginning with @ for user mentions and http for links. Subsequently, all newline characters were replaced with spaces, hash characters were removed from hashtags and all punctuation characters were replaced with spaces.
Next, NLP techniques were applied to create word tokens and remove any stop words, such as and, to, etc. using the Natural Language Toolkit (NLTK) to ensure that the classifier focuses on the relevant features. Tokens were lower-cased and filtered for any non-alphanumeric characters. Finally, the tokens were lemmatized to their root form to limit the number of words representing the same meaning e.g., invaders, invading, invaded have the same root form invade. This way words with similar base meanings can be considered as a single feature by the classifier.
We employed a more sophisticated approach compared to the standard Bag of Words, where single word frequencies are used as predictive features for the classifier. This was achieved by splitting the word tokens created previously into word and character n-grams. In our setup, word n-grams of length one to three and character n-grams of length one to four were chosen, spaces included. The purpose of this model was to evaluate whether character n-grams would outperform word n-grams in detecting anti-immigration rhetoric.
Consequently, the greater the number of documents containing a certain word, the less important that word is to the document it appears in. TF-IDF is appropriate for this type of classification because the data was retrieved through keyword searches, such as immigration, thus making highly probable that these would be omnipresent throughout the corpus, both in the Negative and the Non-Negative classes. Therefore, it was necessary to weigh down frequent terms so that more discrete terms could have been highlighted, as these are more indicative of the class they belong to. The training and testing of the supervised classifier were performed using the 10-fold cross-validation approach, which has been used for similar tasks in related literature [
44].
Lexical characteristics can be thought of as certain unique features in text-based data, which can be used to distinguish each class of the set i.e., Negative Tweets from Non-Negative. Drawing information from previous literature [
38,
44,
56], we evaluated several lexical characteristics of the same previously labeled dataset. One of our motivations was to discover whether a combination of USA, UK, and Canadian English language, which differs considerably, can have predictable lexical characteristics in Negative and Non-Negative class. This covered a wide range of tests, which are described below. Before running the tests, the data was pre-processed as described previously, where user mentions were not removed, and hashtags were not stripped of the hash character, as this was used to locate them in the dataset. Additionally, words were not lemmatized, in order to retain all different variations and the dataset was not balanced to include all labeled Tweets from both classes. Apart from the aforementioned changes, data preparation was the same.
3.3. Classification Models
Although Deep Learning approaches have been successful in text classification, they require vast amounts of data, which are often unavailable, expensive, and labor-intensive to obtain. Taking this under consideration, it was necessary to work with traditional ML algorithms that have been used in related tasks in the past. Consequently, three popular supervised ML algorithms were chosen that are used in literature for text classification: Support Vector Machines (SVM), Naïve–Bayes (NB), and Logistic Regression (LR) (regularized logistic regression, with L2 regularization (
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html)). These approaches have been used for abusive speech detection in previous work. Specifically, SVMs has been previously used for hateful Tweet classification [
40], while NB combined with SVM performed very well in abusive language detection [
43]. LR was previously utilized for the detection of racist and sexist content in Tweets [
44]. Because the dataset was imbalanced, under-sampling was used to keep all Tweets from the smaller class Negative and to randomly choose the same amount from the larger class Non-Negative.
3.4. Testbed Environment
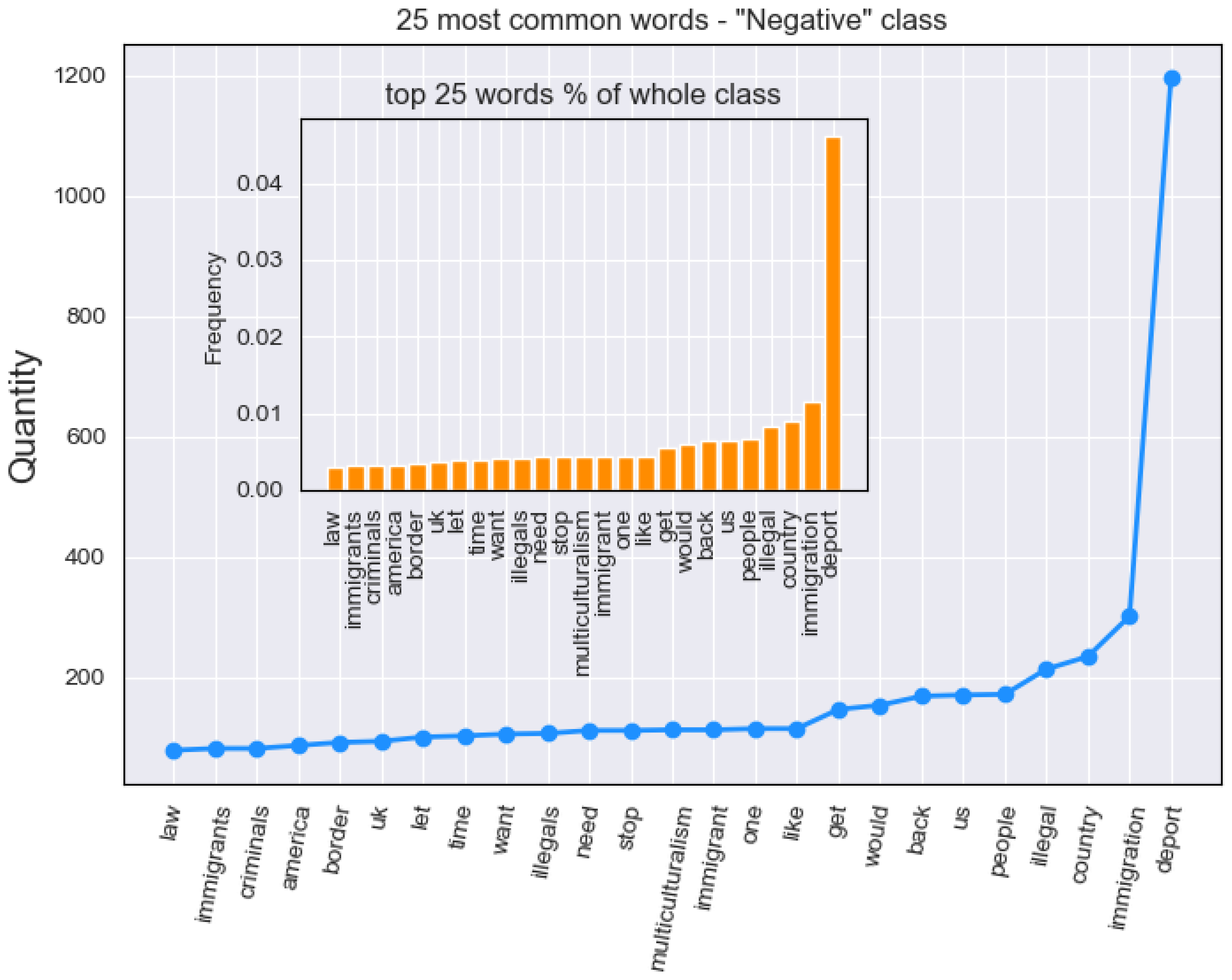
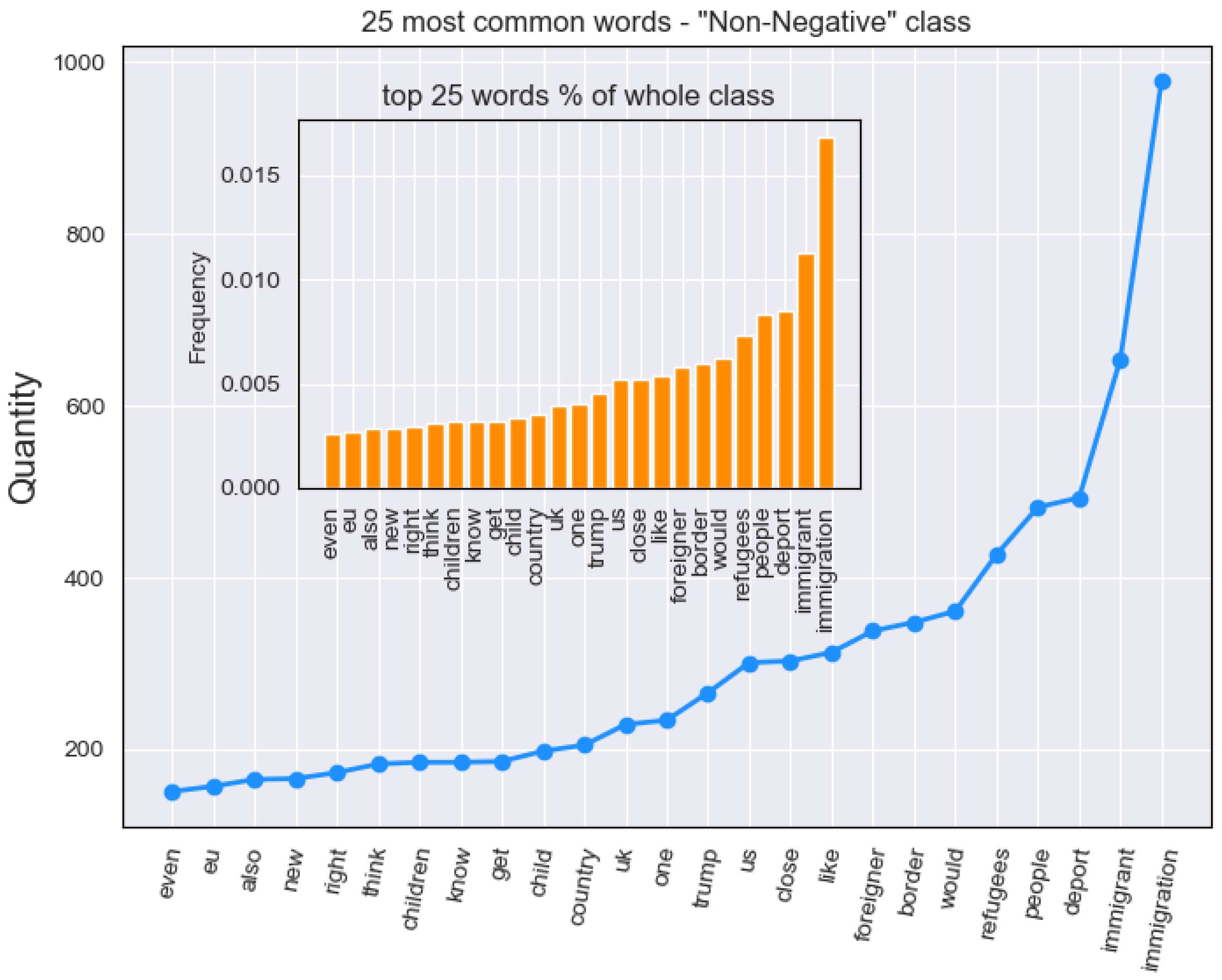
We initially analyzed (
Section 4.1) the standard word frequency (illustrated in
Figure 2 and
Figure 3). The goal was to establish differences in wording between the classes, by selecting 25 most frequent words per class. This threshold was selected, as it was empirically found that the largest variation in word frequency occurs in the top 25 words. The rest of the words in the set appeared to be less indicative of the class that they belong to.
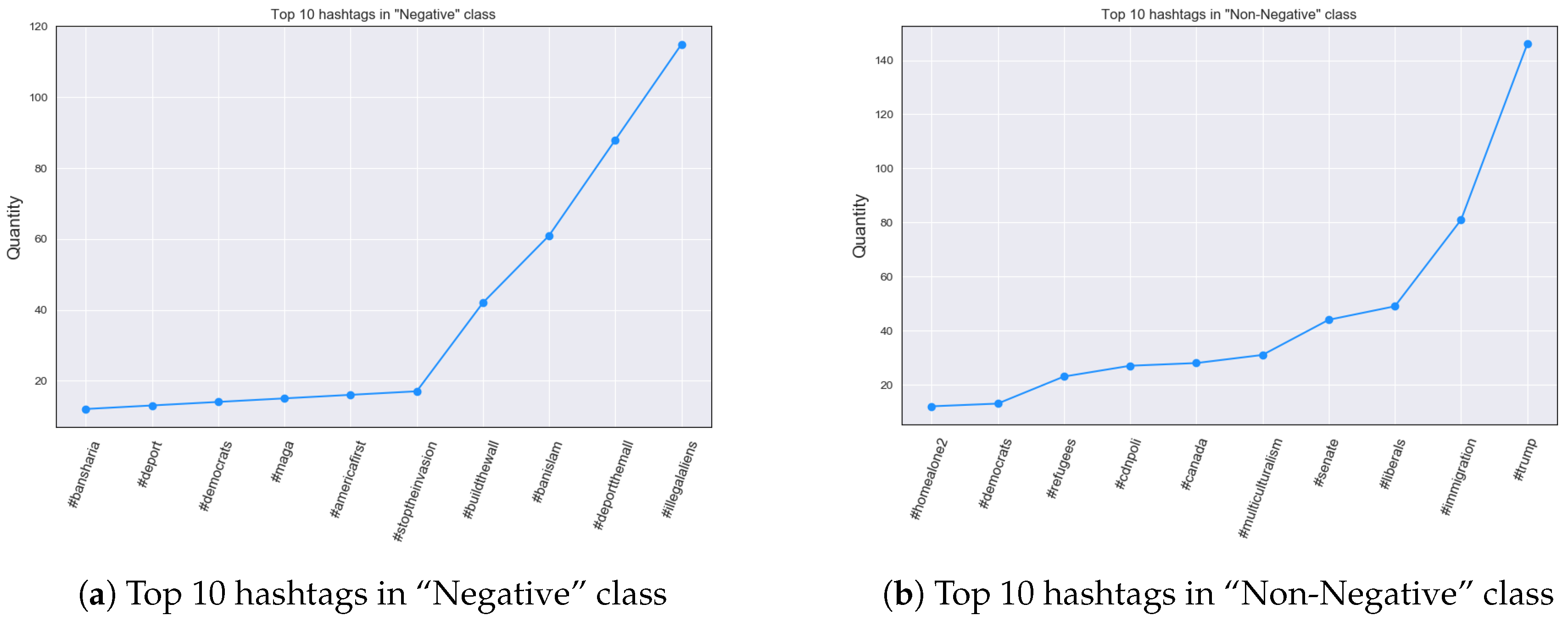
Secondly, we explored the frequency of hashtags present in both classes, as these are very powerful keywords that can convey a substantial amount of information, particularly because they are often used to declare a personal affiliation to certain opinions or groups. Our results suggest that the most interesting and indicative hashtags were present in the top 10 occurrences for both classes; therefore, this was used as a threshold when presenting the findings.
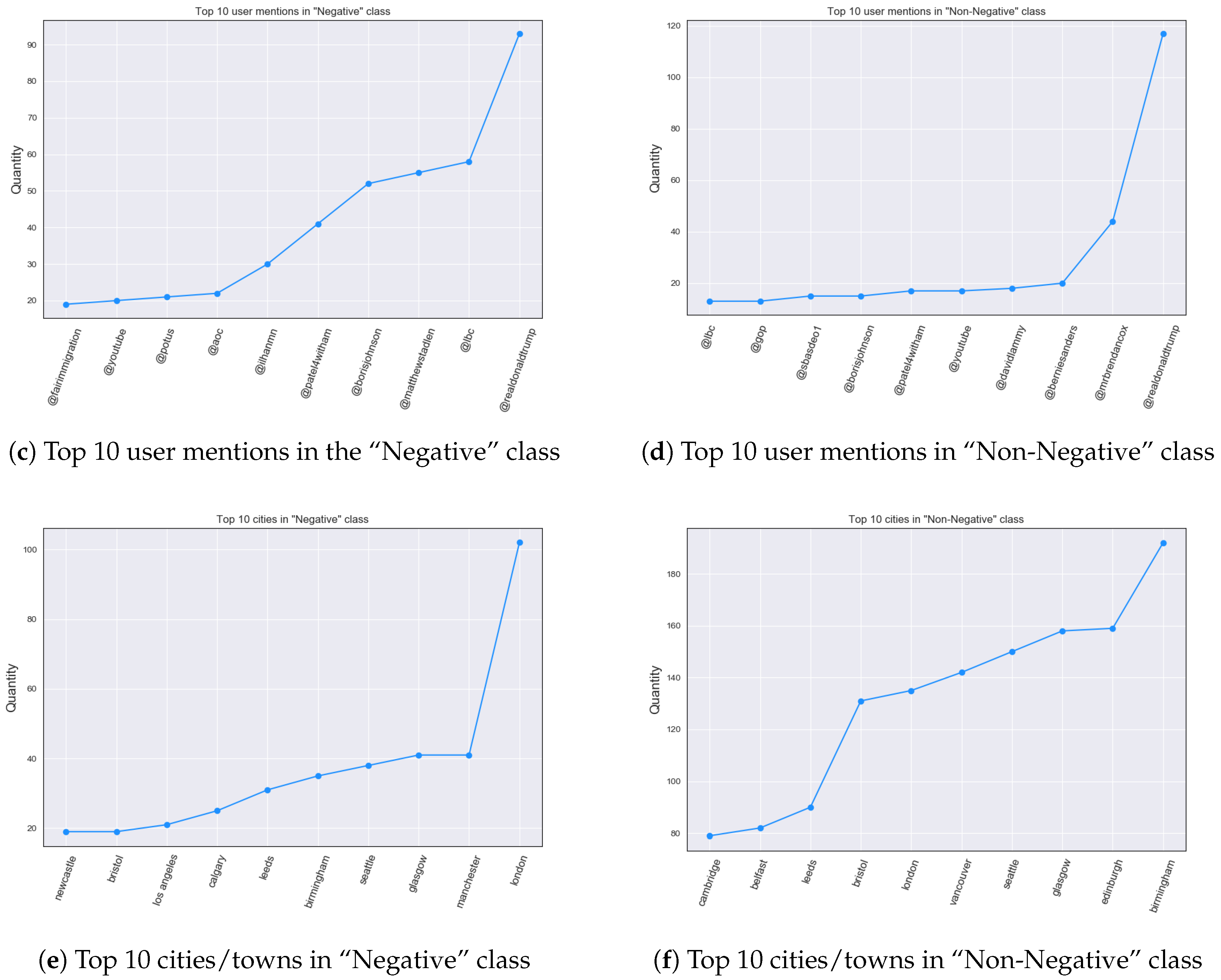
As mentioned previously, different countries can have different causes, often being political, which spark immigration-related debate. Apart from normal words and hashtags, user mentions can also convey some information regarding the topic related to immigration discourse. This phenomenon happens, because political personas can be often brought forward in the conversations through user mentions. Consequently, user mention occurrences needed to be examined. Once again, a threshold of the top 10 was chosen, as this is where the most discrepancies were present, based on our empirical analysis.
Because the Twitter data was geo-located, it seemed compelling to investigate more detailed origins of both Negative and Non-Negative Tweets, especially with regard to cities. Although the Twitter API does not necessarily return Tweets with the exact geo-location details, the Location parameter is often present, which can be utilized to unveil Tweet city/town of origin. The issue was that this parameter is user-defined, therefore it can contain valid, incorrect, general locations (e.g., only Alberta, which is a province in Canada), or it can also be omitted. These limitations hindered the obtaining of comprehensive results, as well as our analysis showed that only a relatively small number of users unveil their real location in our dataset. To identify users that provided city name as their location, a list of 19,709 city names from the three countries was utilized. Additionally, some error correction had to be conducted as some city/town names in the list were the same as country or province/state name, e.g., a city named Florida, which is also a state in the USA. Therefore, when looking at the location parameter such as Tampa, Florida the Tweet could be assigned to two different cities both Tampa and Florida. For that reason, the list had to be stripped from country or state/county names. Similarly, based on our empirical analysis the top 10 terms was used as the threshold.
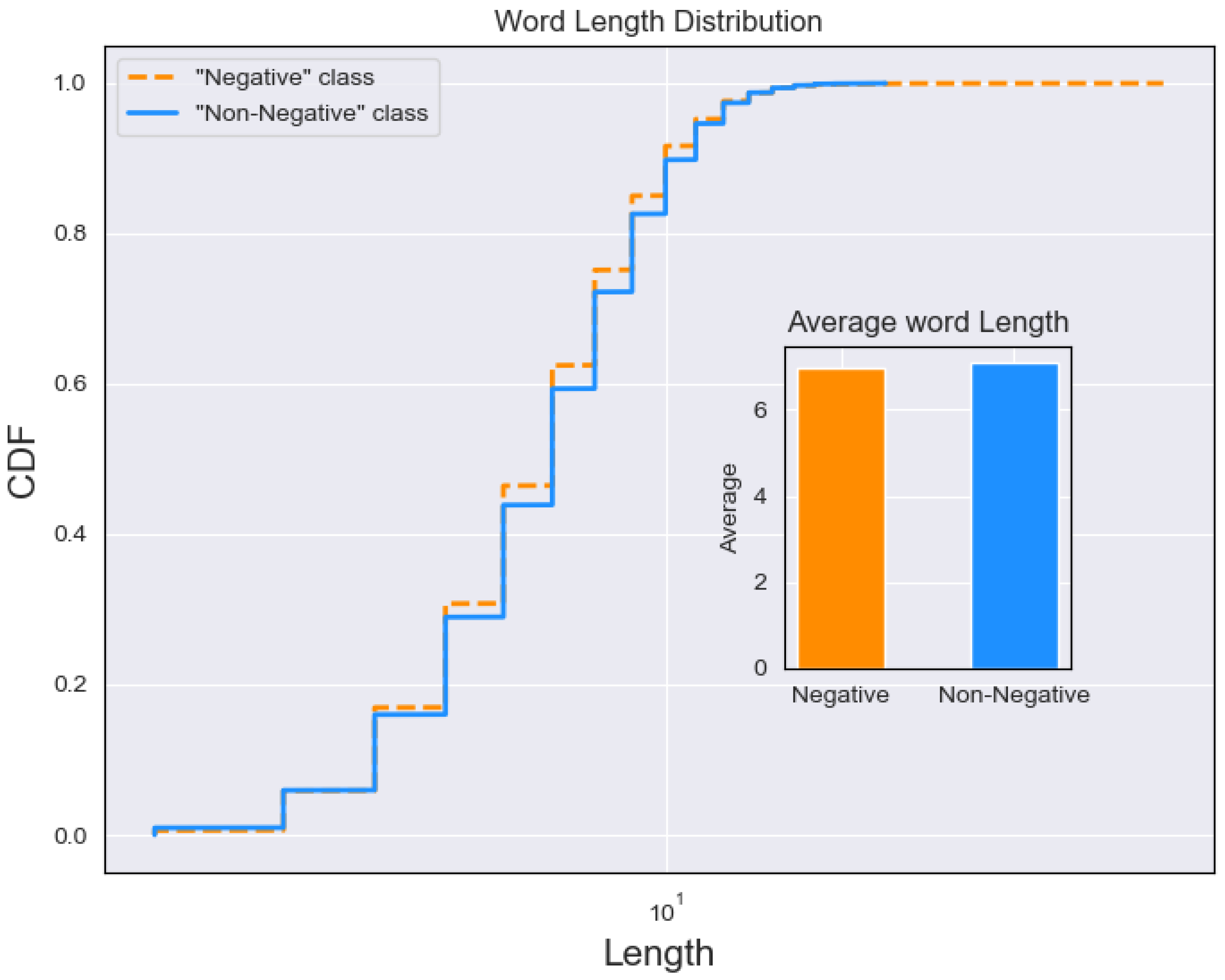
Another feature that we considered was the length of Tweets and words for each class. Although the total length of Tweets was taken under consideration in the past [
44], this could not be used in our work, because the analyzed dataset was imbalanced i.e., number of Tweets per class was different, which would result in biased values. Thus, the length of all Tweets/words for each class were used instead, in order to present differences/similarities between these features through Cumulative Distribution Function (CDF), which has been previously used to represent data in similar tasks [
56].
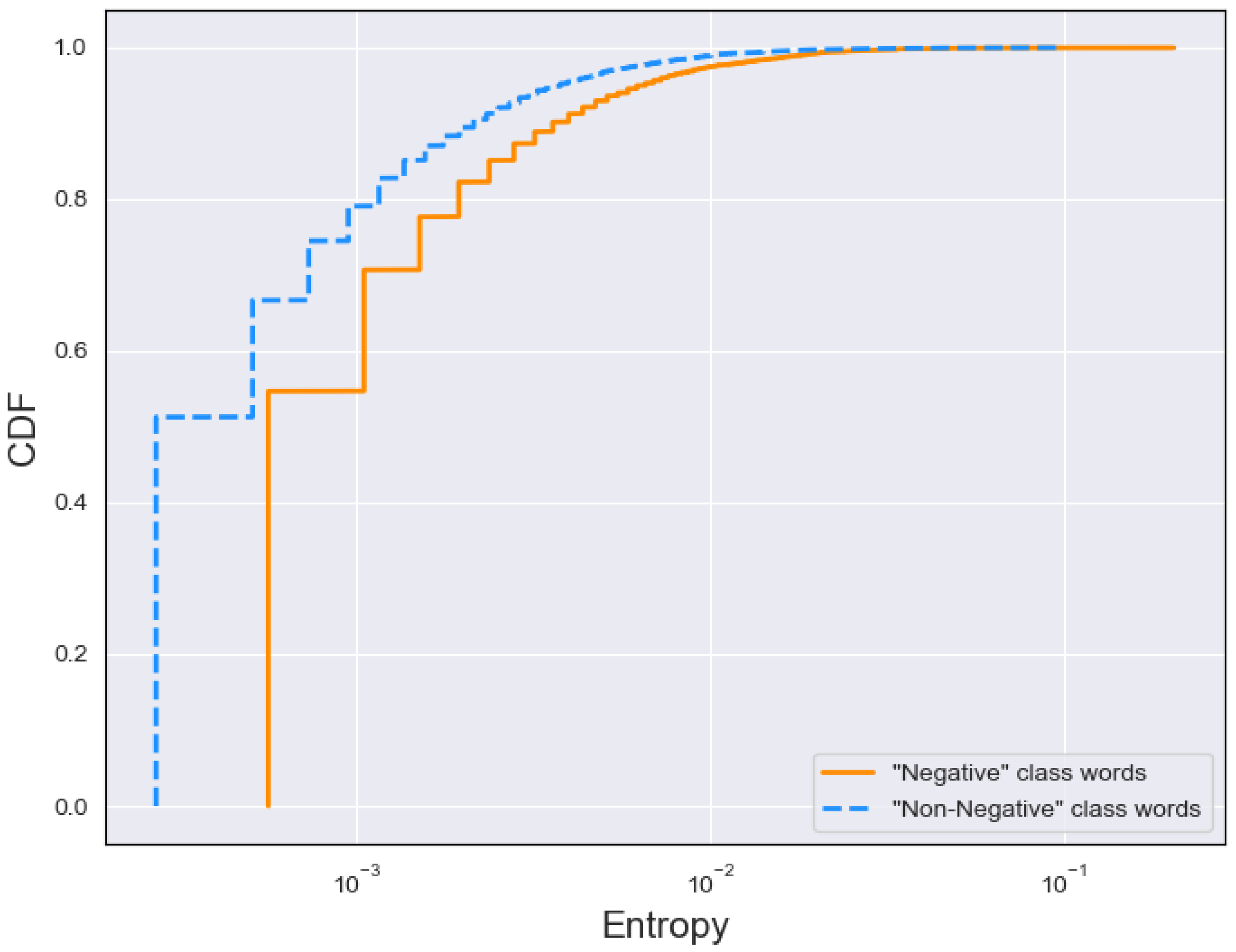
Next, we analyzed the entropy, which refers to a measure of information, sometimes referred to as a measure of uncertainty. Whhen considering word frequency in a text as an example, the highest uncertainty to whether a word will appear is when its frequency is 0.5, which means it has 50% chances of appearing. On the contrary, if the frequency of a word is high or low, there is less uncertainty to whether it will appear (low entropy). Low-frequency word is unlikely to occur; therefore, we are more certain that it will not show up, with the same applied to the high-frequency word, which is more likely to occur. Therefore, entropy is the highest for uniform distributions, e.g., in a text where each word has a similar probability (frequency). In our work the entropy of each word is calculated for both Tweet classes and, as previously, depicted as a CDF. Our objective was to determine which class has lower word entropy, therefore being less random, with our calculations being based on Shannon’s entropy formula.
where H is the entropy of X and p is the probability of word I (frequency). In our work, the entropy is calculated and presented for each word separately (CDF); therefore, the values are not summed up as in the formula.
5. Discussion
The first goal of our work was to successfully classify xenophobic content on social media. Our results suggest that, contrarily to previous studies [
38,
43], in some cases, word n-grams outperformed character n-grams (i.e., having best char f-score of 83 against 84 for word). This suggests that carefully chosen features, such as specific unigrams, can be useful for the classification of abusive text.
The results provide us with some additional insights. We show that discriminative methods, such as SVMs and LR, are better suited for this task and less sensitive to the underlying features (char n-grams vs word n-grams). Although previous works (e.g., by Waseem) have used character n-grams for such models, for our task, the choice of model seems to be more important than the choice of features. However, when considering a generative model, such as NB, which takes into account the sequence of characters, character n-grams perform better. Essentially, these results provide us with insights regarding feature engineering, which is a very important task when using traditional ML (rather than deep learning, where feature engineering is not needed). It is evident from the results that generative models are less sensitive to characters, whereas discriminative models, such as SVMs and LR, can work well with both. If one considers Precision and Recall, there are differences in scores, i.e., some models are more prone to Type I errors (i.e., False Positive Errors) and some are more prone to Type II errors (i.e., False Negative Errors). The classification scores for the models that have been tested suggest that there is no difference with regards to F-Score, which is their harmonic mean of Precision and Recall. However, we consider that one that is deploying a hate-speech detection engine would opt to select the models that scored higher in our tests in the Recall metric. This holds true, as this would mean that the hate-speech detection engine would have less False Negative, i.e., less Tweets with anti-immigration rhetoric which have been misclassified in the “Non-Negative” class. Such misclassifications could be decreased with the creation of more sophisticated features that consider sarcasm and humor, which seem to be the main reason for their existence. While we anticipate that this would increase the accuracy of the hate-speech detection engine, we consider this as out of scope of this work.
As mentioned previously, the majority of our dataset was obtained using xenophobic hashtags as keywords for the API. Additionally, the results from our hashtags measurements are omnipresent throughout the Negative class. The presence of such hashtags made the classification of xenophobic Tweets easier, and as a result, improved model performance. On the other hand, the TF-IDF approach should lower the importance of frequent terms occurring throughout the documents, which was not true in our analysis due to the variety of such hashtags. Additionally, our work uncovers terms that strongly indicate anti-immigration sentiment and prevail in the Negative class, such as Deport and Illegal, or get, back, and country. Consequently, it can be deduced that the wording for each class exhibits significant differences in terms of most frequent words, a result that aligns with previous study findings [
44].
Moving to the hashtags measurements, there were at least six hashtags that can be considered related to xenophobia (e.g.,
#deport,
#stoptheinvasion). However, it must be noted that different variations of certain hashtags were considered as a single feature, as they express essentially the same attitude. For example
#Deport and
#deport are treated similarly in the context of our analysis. Additionally, as already discussed, the Tweets were searched using keywords, with xenophobic hashtags being one of them. It was also mentioned that religion can be used to assign people to immigration groups, something that can be observed in the results where hashtags representing negative sentiment towards Muslim communities (
#bansharia, #banislam). However, the other class favors more neutral hashtags, some of which are related to politics (e.g.,
#senate), which proves our original assumption that politics can be a major trigger factor in the immigration debate. Surprisingly, even though Donald Trump is often associated with political incorrectness [
57], his name (
#trump) was the most frequently occurring hashtag in Non-Negative class and did not occur at all in the Negative, despite some of his ideologies being present (such as
#maga, #buildthewall). One possible explanation for this was that he was being brought forward in non-xenophobic discourse to criticize him or his agenda.
Political personas were involved in discourse through user mentions. In this case,
@realdonaldtrump was found at the top in both classes. This indicates that even though this persona is often invoked in the immigration debate, associating his presence on Twitter with either class is not a simple task, as he appears on both sides of the debate, which is in line with findings from a previous study [
8]. On the other hand, British politicians seem to be predominant in Negative Tweets, with
@borisjohnson appearing almost three times as often when compared to the other class along with others such as Priti Patel (
@patel4witham). Another interesting matter brought forward through our analysis, was the ability to associate real Twitter users with content that they publish and drawing conclusions about their suggested policies towards certain topics, such as immigration. Thus, through such simple processing it was possible to profile users, which has been previously identified as a threat to privacy on Twitter [
32].
The geo-location analysis showed that most certainly UK and USA cities dominated the Negative class where only Calgary is a Canadian city. However, the same can be observed in the second class where only Vancouver is a Canadian city and this reflects that Canadian cities prevailed in the Non-Negative class, something that was expected, as Canada was not going through major political events at that period of time. On the other hand, the limitations of this analysis suggest a careful approach to the evidence as our analysis suggests that the use of geographical information as a text classification feature is not feasible, which was previously supported by related literature [
44]. Nonetheless London dominated the xenophobic Tweets, whereas it was ranked 6th in the Non-Negative class. This is quite surprising as cities such as London appear to be multicultural and encouraging immigration. However, the aforementioned observation could be challenged by the fact that the cultural differences could manifest themselves in local communities, which may indicate that what we observe in general does not necessarily apply to local communities. If we take into consideration that social media can give voice to almost anyone, such differences can be expressed online, as it can be seen in the results.
The Tweet lengths were in fact smaller for Negative class in most of the distribution, with averages having similar differences. On the other hand, word lengths do not present significant differences, both in terms of overall distribution and averages (slightly higher for Non-Negative), which also confirms the initial expectations. The results suggest that Tweet lengths could be used as features in text classification as they demonstrate differences between classes. One reason that could have affected previous work is the fact that at that time twitter posts were limited 140 characters, which changed in 2017, as compared to today, where there is more room for variance.
Our entropy results indicate that the Negative class tends to be more uniform, suggesting higher entropy. This further indicates that the top 25 words cannot be used to make assumptions for the entire set, as other potentially less frequent words can also have an impact on entropy. Nonetheless, the entropy difference between classes, although small, seems to be present for the majority of the distribution, suggesting a possible use of this characteristic as a classification feature.
6. Conclusions
The political changes seen throughout modern societies have led to heated debates that, along with the availability of WEB 2.0, have been elevated from private level discussions into public debates. These often take place in social media, resulting in the expression of opinions that can be harvested and analyzed. The controversial topics discussed in these debates have often led to the expression of negative opinions with regards to immigrants [
45,
53] or racial minorities [
13]. Such controversial debates, while being disturbing, provide an opportunity to study and better understand mechanisms behind such discourse, which can then be utilized to improve classification methods. They also can raise awareness regarding the absence of privacy on social media, where disclosing antagonistic opinions can have far-reaching consequences, even in form of imprisonment [
39].
Our work is an attempt to investigate the presence of anti-immigration rhetoric on Twitter, by providing another insight into the broad field of online content analysis. It differs from previous attempts in related literature because it incorporated a combination of text classification of xenophobic content, along with in-depth analysis of lexical characteristics of such discourse. All of these were feasible through the creation of a new, manually labeled, unique dataset of Tweets, constituted of a compelling combination of UK, USA and Canadian English language. Our model proved that besides the existence of certain language differences in every English-speaking country, accurate text classification can still be feasible. We also studied the lexical differences between xenophobic and non-xenophobic discourse, while emphasizing on the importance of privacy on social media.
The next steps for our work would be to first create a larger dataset by employing expert annotators, which will make Deep Learning approaches feasible. We also plan to test our current model on different datasets offered by the community, providing more knowledge regarding the generalizability of our results. We plan to test other models as well as improving the current model’s features by incorporating more sophisticated semantic features, which could further improve model accuracy. This could allow addressing challenges, such as sarcasm and humor, which are one of the biggest challenges in hateful content classification. Finally, our plans include the exploration of privacy-preserving machine learning methods to minimize the threat of information leakage and promote the privacy of the users.

 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}