The Number of Topics Optimization: Clustering Approach


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- : The parameter of the prior Dirichlet distribution for “documents-topics”;
- : Parameter of the prior Dirichlet distribution for “topics-words”;
- : The number of topics;
- b: The number of discarded initial iterations according to Gibbs sampling;
- n: The number of samples;
- : Sampling interval.
- It cannot evaluate the quality of deletion of stop words and non-topic words;
- It cannot compare rarefying methods for dictionary;
- It cannot compare uni-gram and n-gram models.
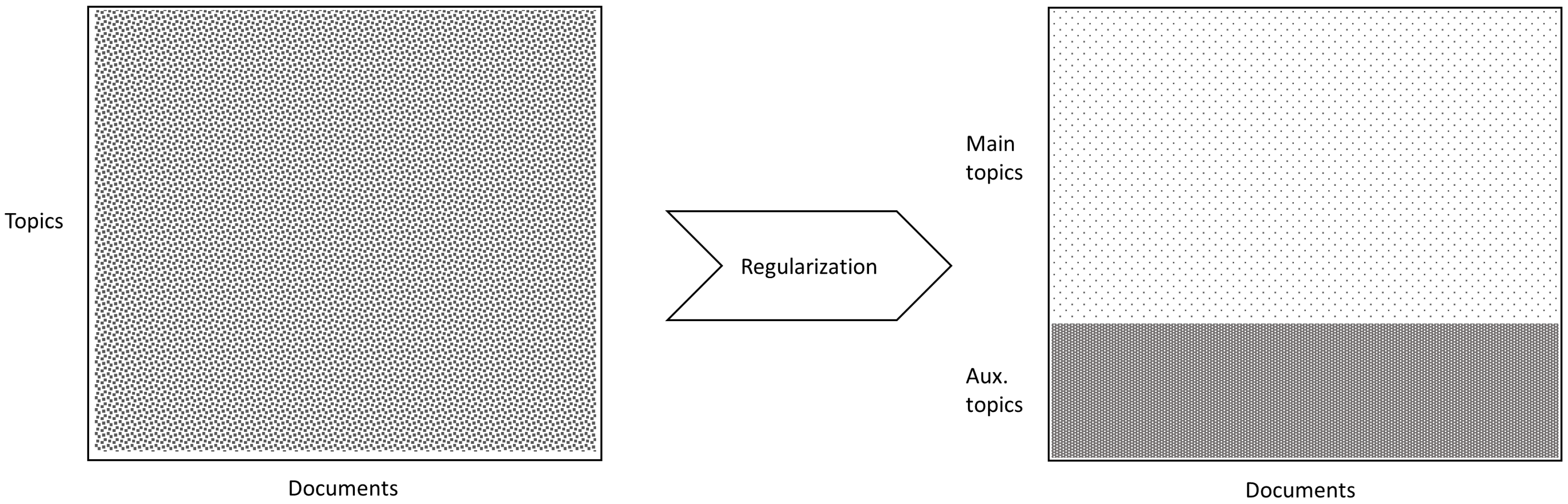
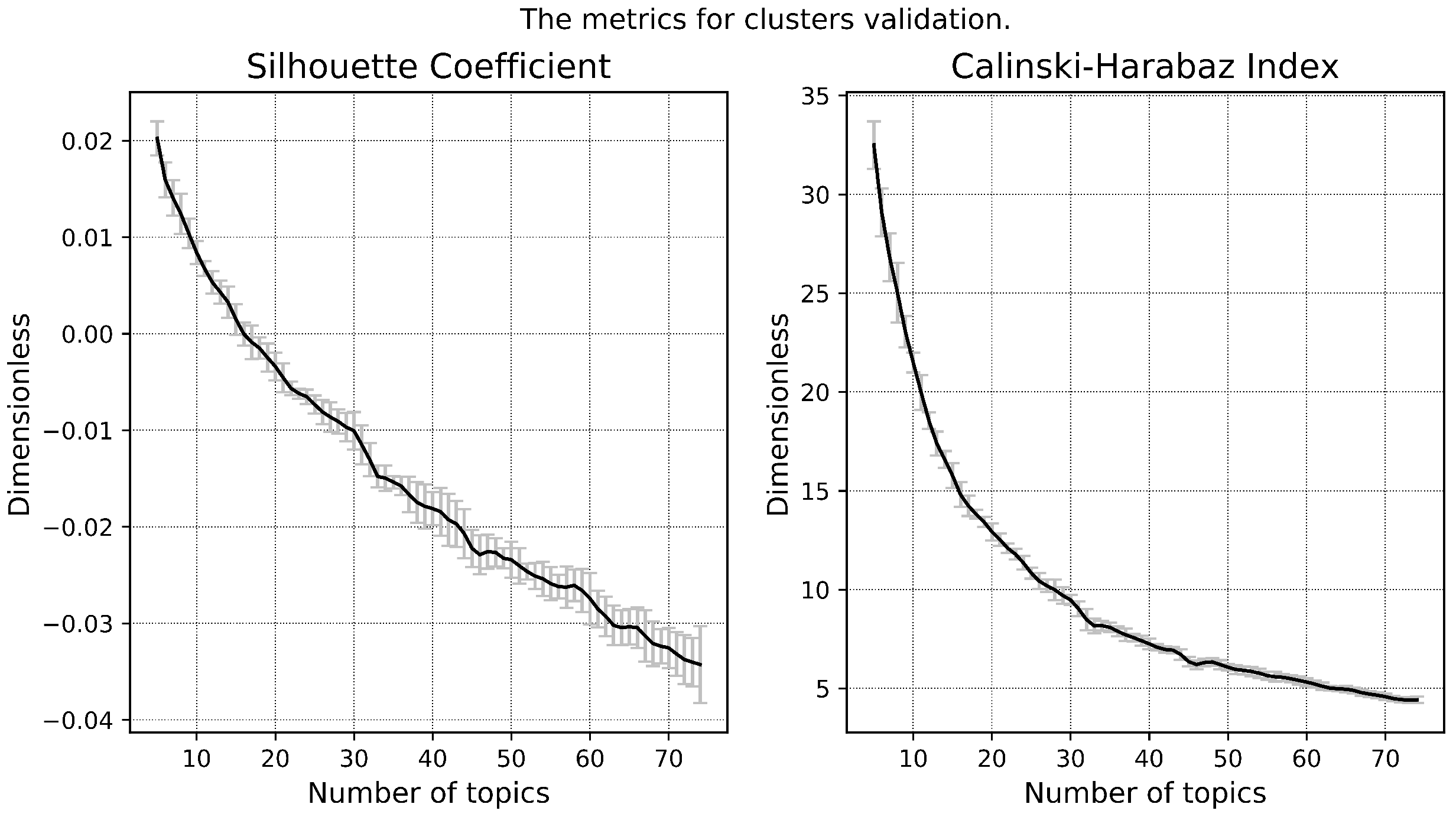
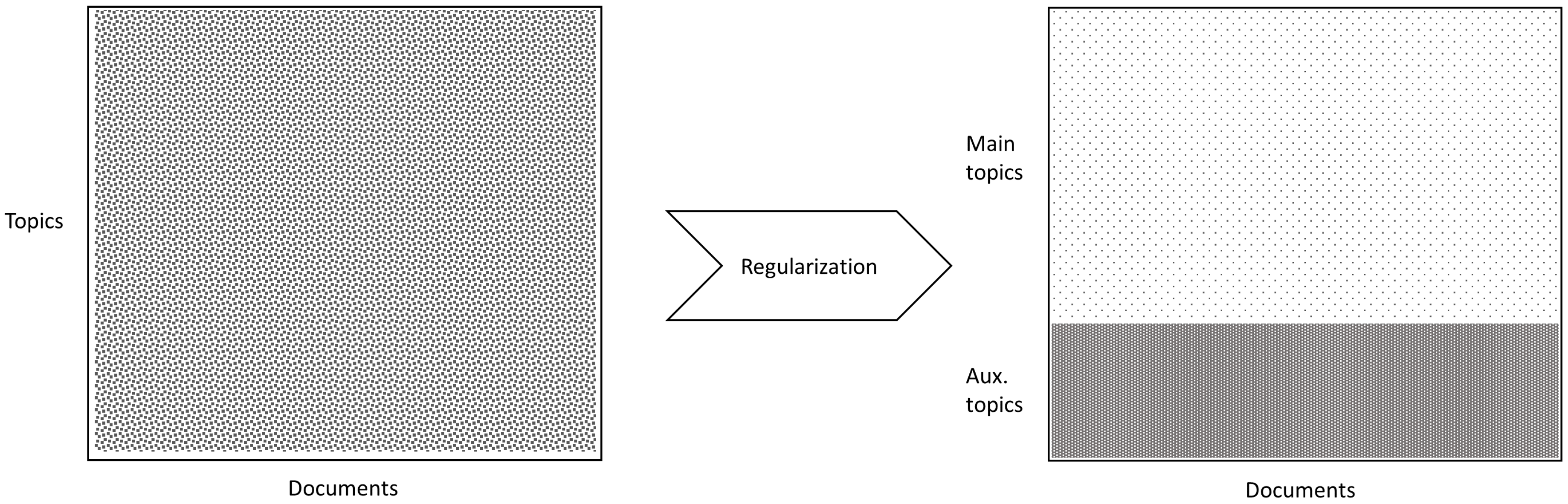
2. Research Methodology
- ○
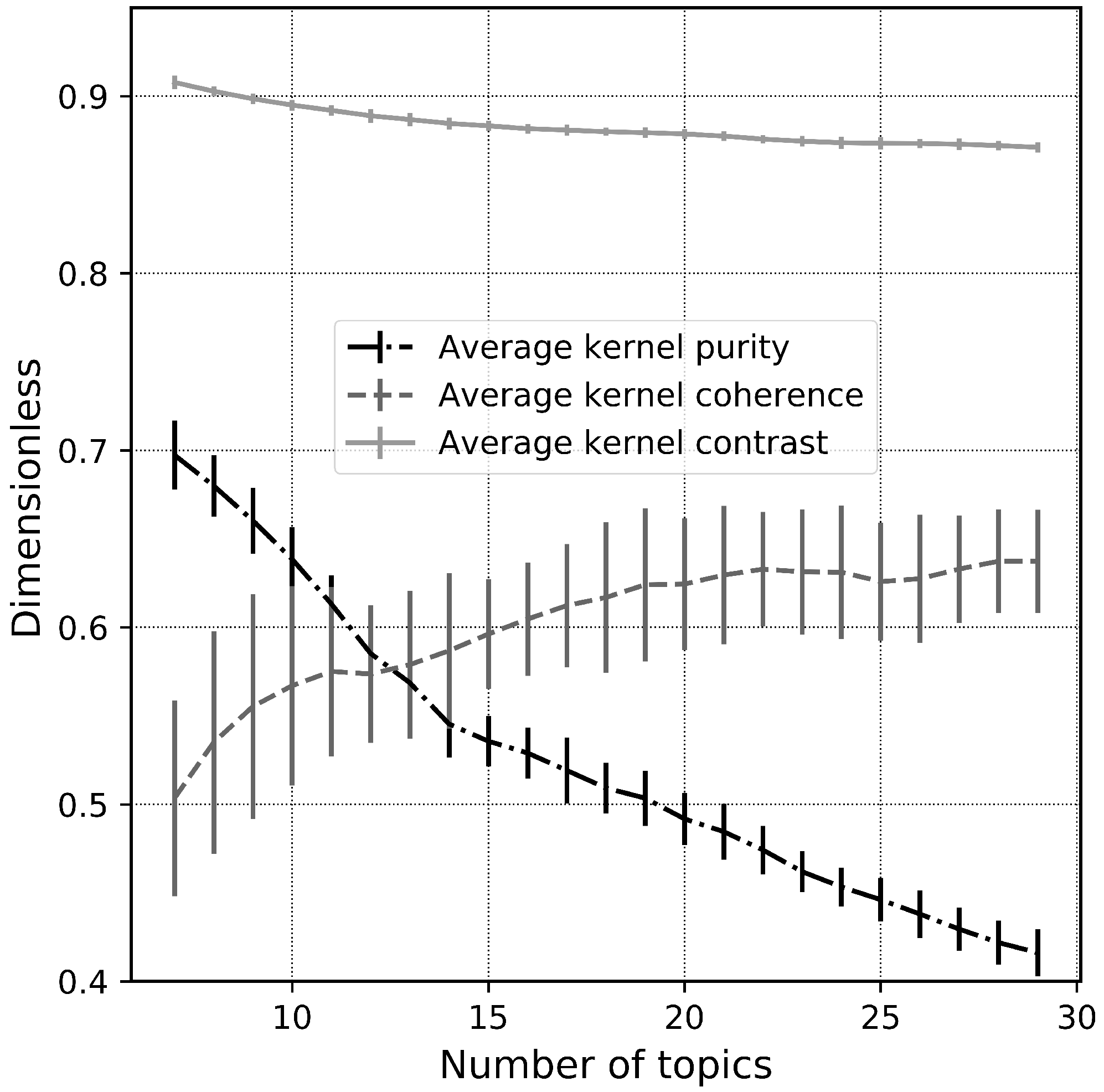
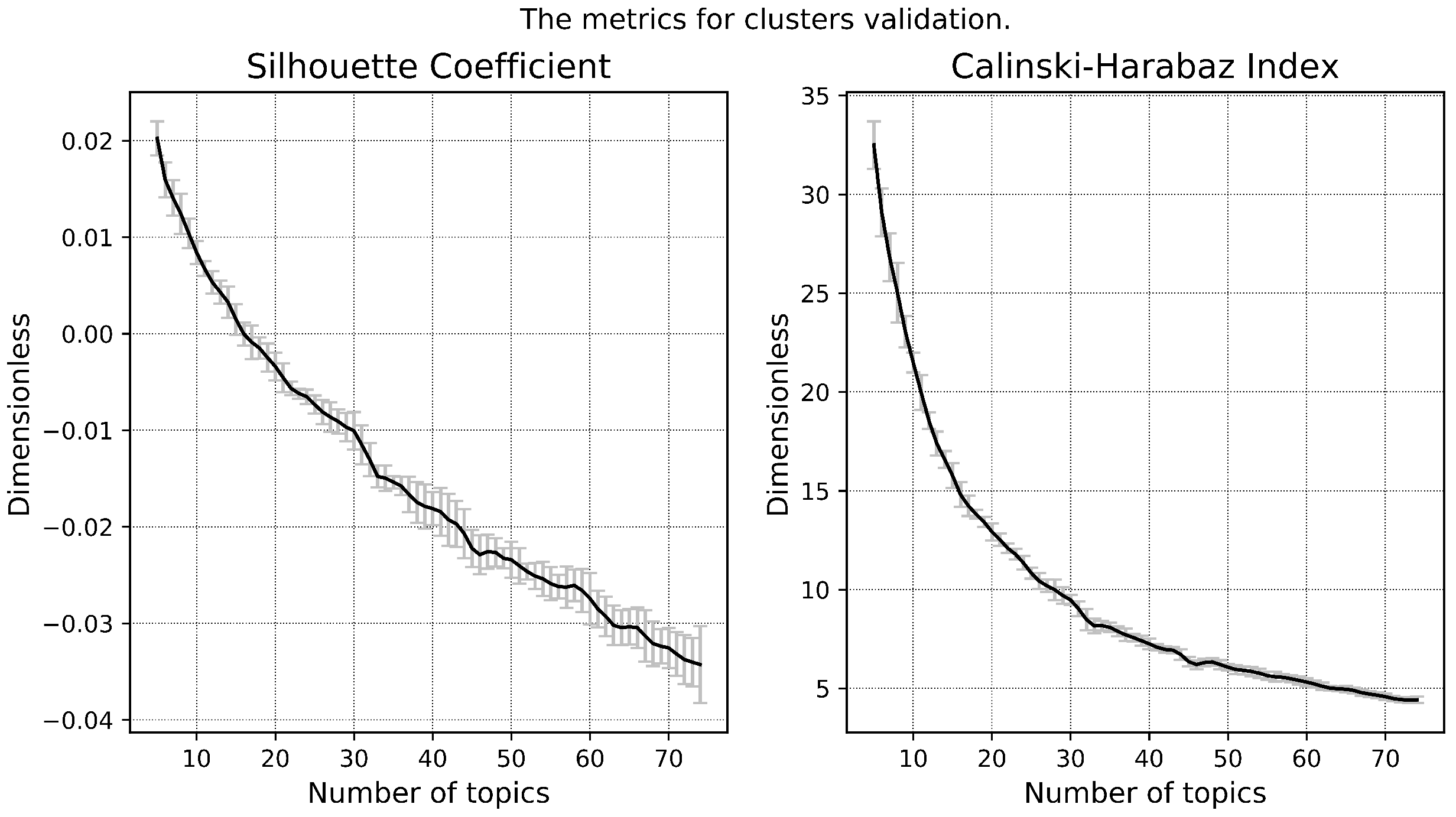
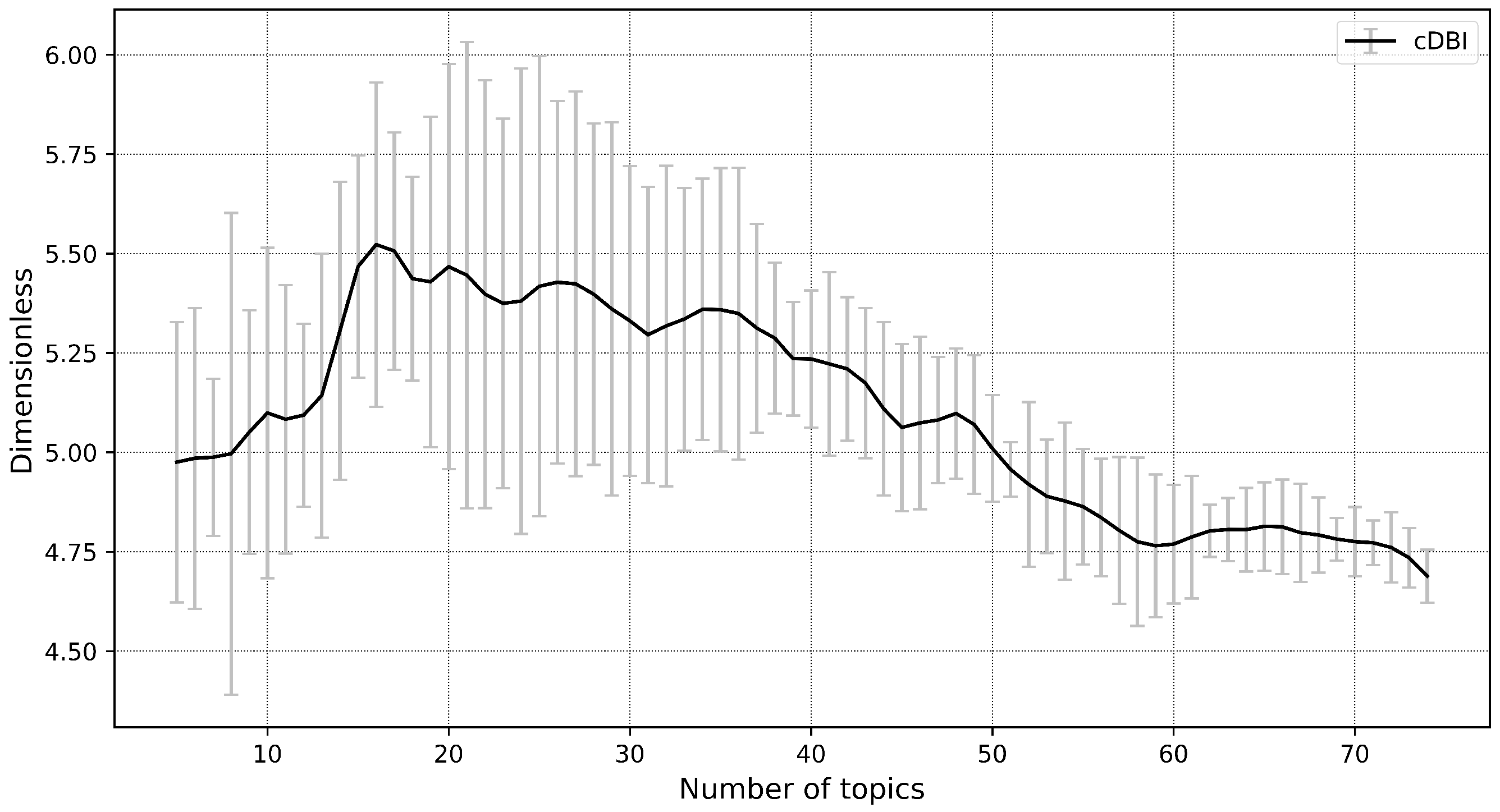
- Purity of the topics:
- ○
- Size of the topic kernel:
- ○
- Contrast of the topics:
- ○
- Coherence of the topics: , where is the interval in which the combined use of words is calculated, point-wise mutual information , —the number of documents in which words and appear in interval at least once. —the number of documents in which the word appear at least once, and is the number of words in the dictionary.
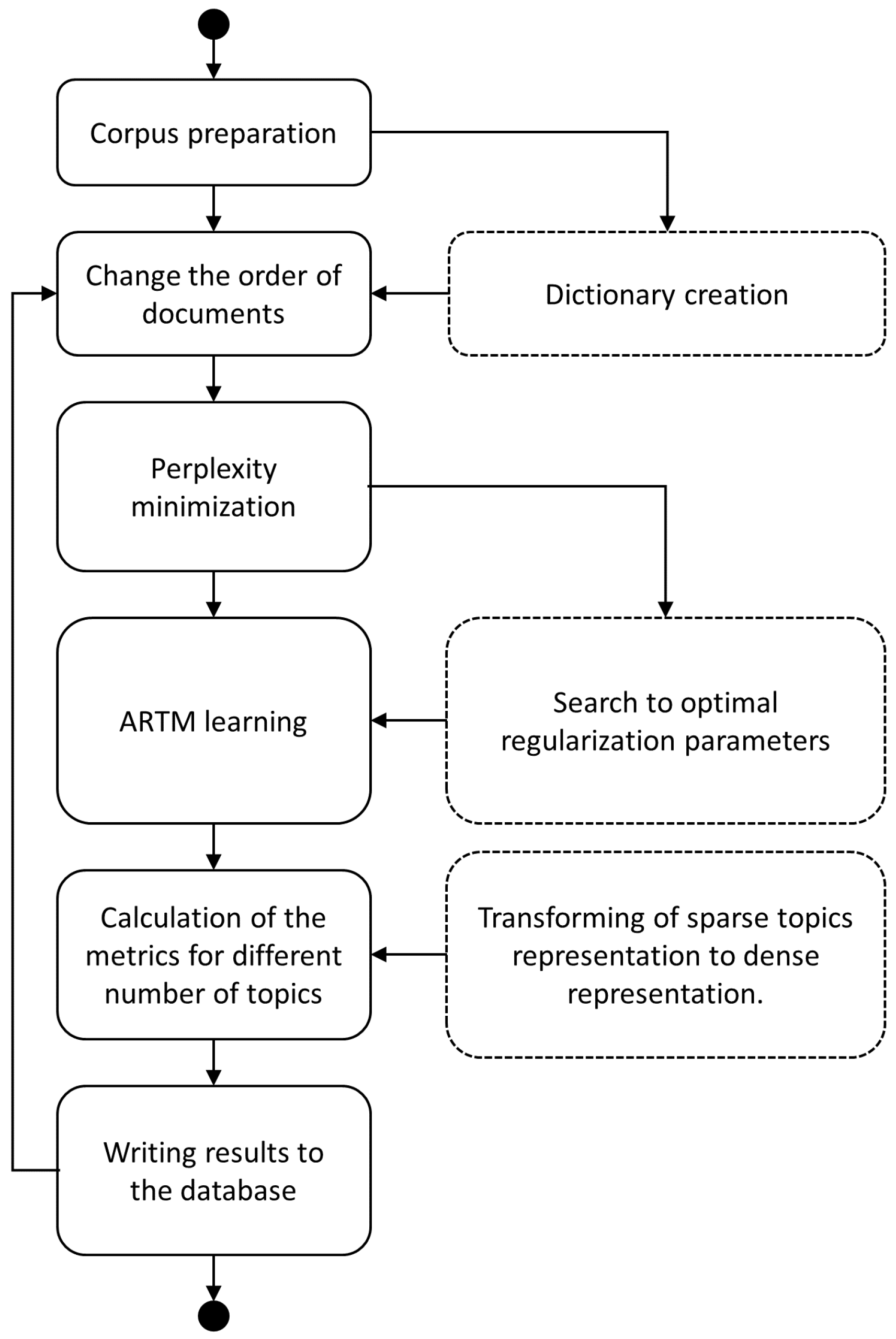
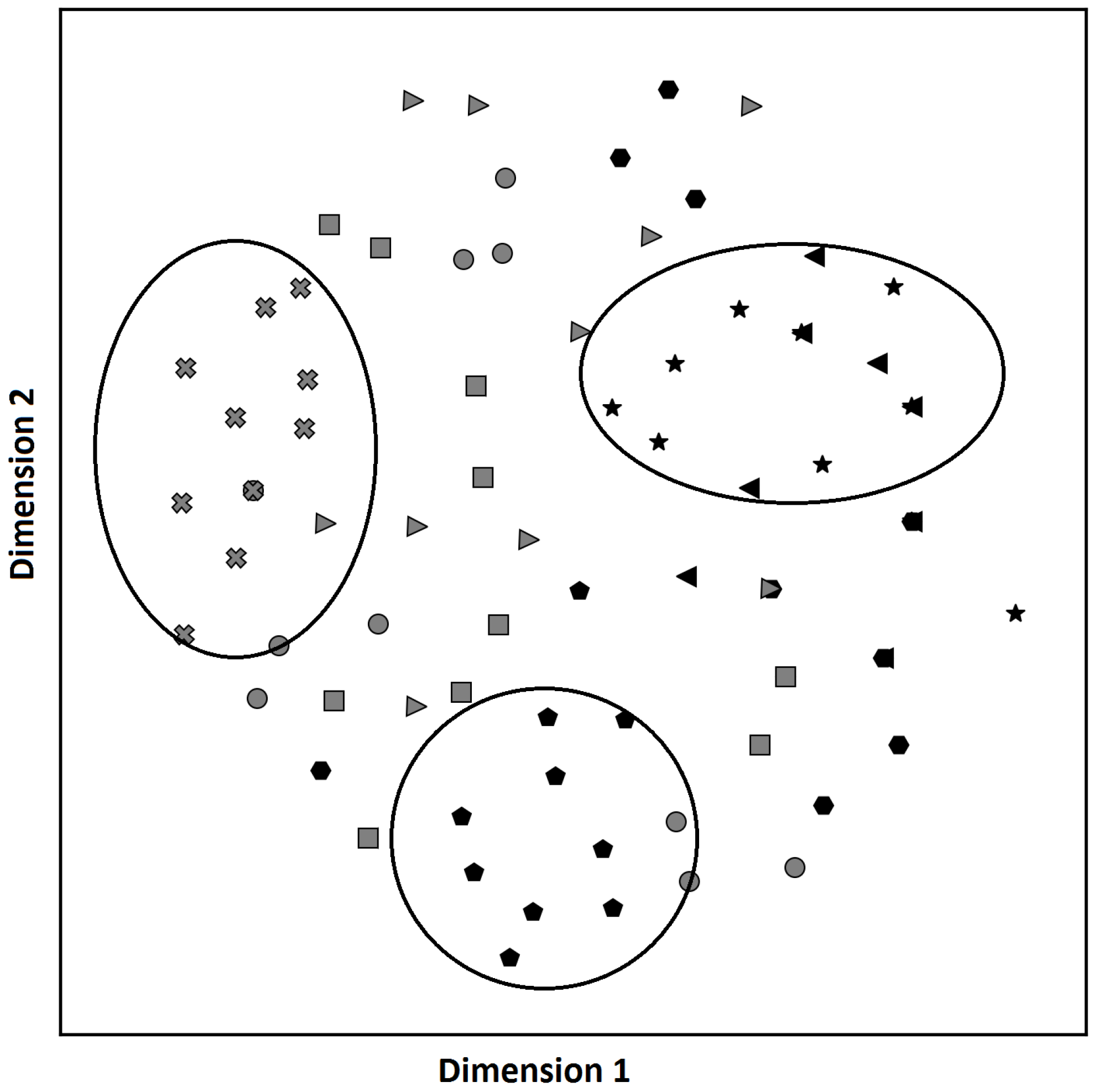
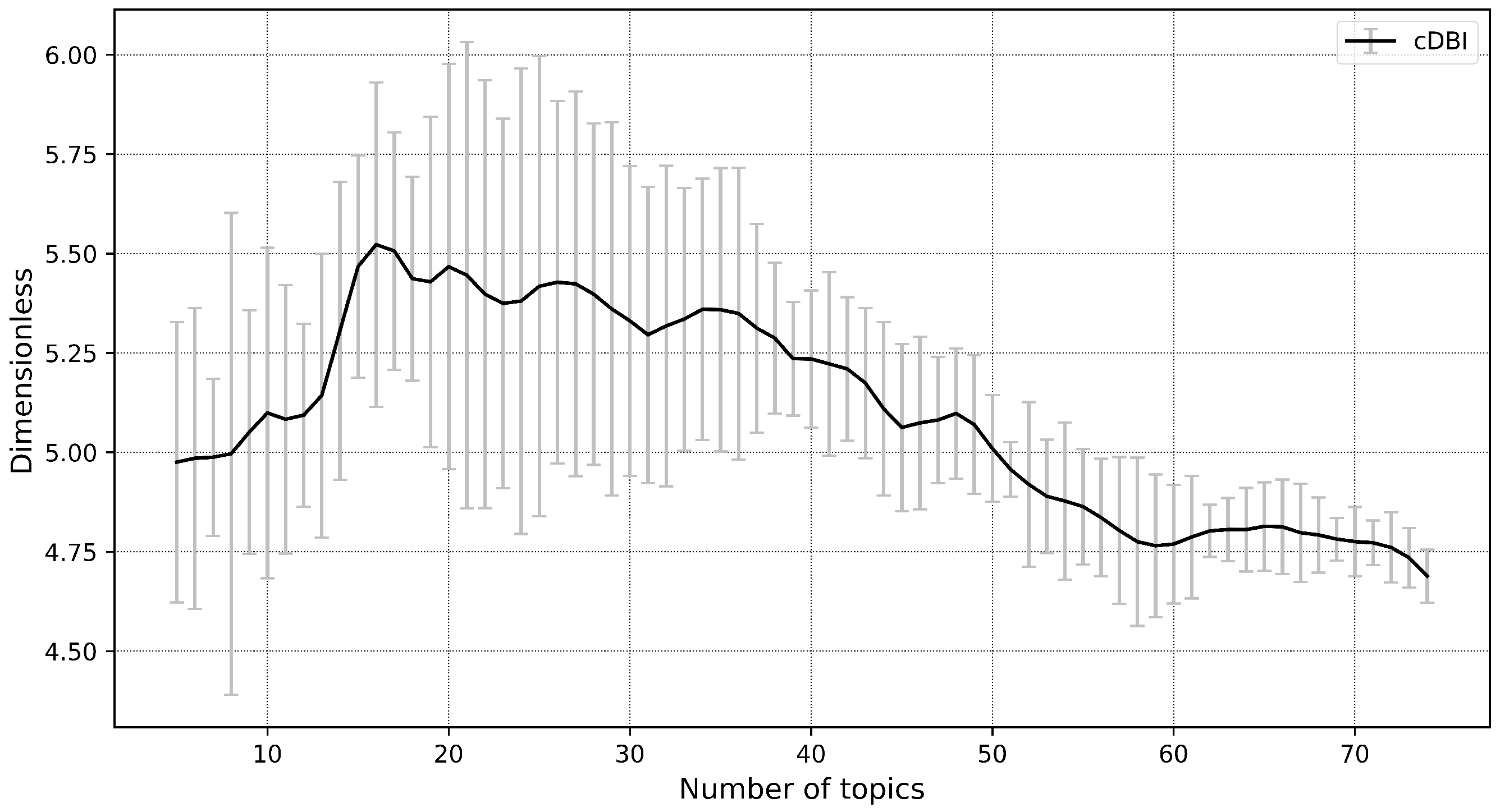
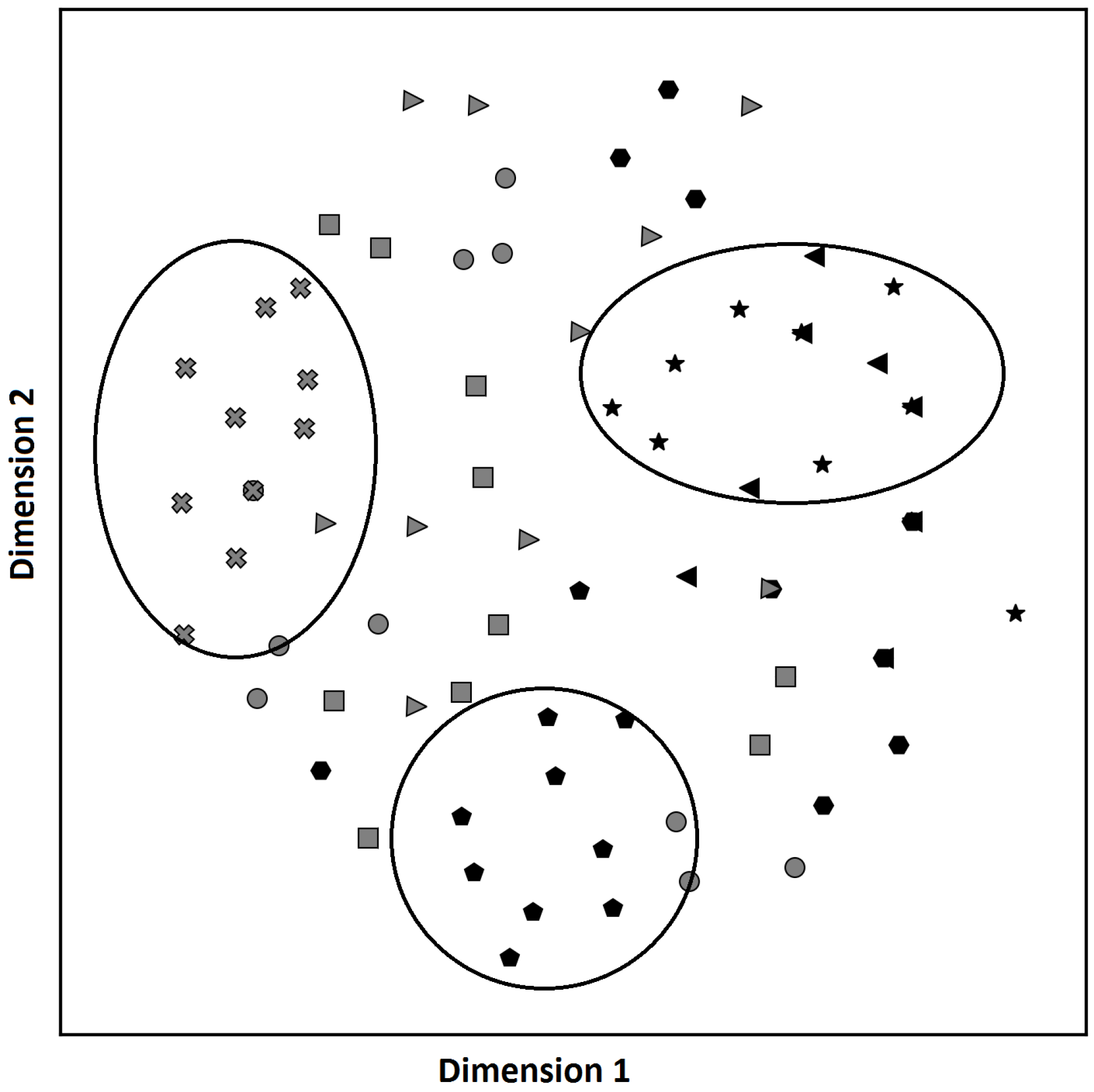
3. Experiment
| Algorithm 1: Calculation of Metrics. |
 |
4. Conclusions
- A small collection of documents;
- English language documents (monolingual text corpus);
- Thematic uniformity.
Author Contributions
Funding
Conflicts of Interest
References
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Vorontsov, K.; Potapenko, A.; Plavin, A. Additive Regularization of Topic Models for Topic Selection and Sparse Factorization. In Statistical Learning and Data Sciences; Springer International Publishing: Cham, Switzerland, 2015; pp. 193–202. [Google Scholar] [CrossRef]
- Koltsov, S.; Pashakhin, S.; Dokuka, S. A Full-Cycle Methodology for News Topic Modeling and User Feedback Research. Social Informatics; Staab, S., Koltsova, O., Ignatov, D.I., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 308–321. [Google Scholar] [CrossRef]
- Seroussi, Y.; Bohnert, F.; Zukerman, I. Authorship Attribution with Author-aware Topic Models. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Short Papers, Jeju Island, Korea, 8–14 July 2012; Association for Computational Linguistics: Stroudsburg, PA, USA, 2012; Volume 2, pp. 264–269. [Google Scholar]
- Fang, D.; Yang, H.; Gao, B.; Li, X. Discovering research topics from library electronic references using latent Dirichlet allocation. Libr. Hi Tech 2018, 36, 400–410. [Google Scholar] [CrossRef]
- Binkley, D.; Heinz, D.; Lawrie, D.; Overfelt, J. Understanding LDA in Source Code Analysis. In Proceedings of the 22nd International Conference on Program Comprehension (ICPC 2014), Hyderabad, India, 31 May–7 June 2014; ACM: New York, NY, USA, 2014; pp. 26–36. [Google Scholar] [CrossRef]
- Agrawal, A.; Fu, W.; Menzies, T. What is wrong with topic modeling? And how to fix it using search-based software engineering. Inf. Softw. Technol. 2018, 98, 74–88. [Google Scholar] [CrossRef] [Green Version]
- Storn, R.; Price, K. Differential Evolution—A Simple and Efficient Heuristic for Global Optimization over Continuous Spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Asuncion, A.; Welling, M.; Smyth, P.; Teh, Y.W. On Smoothing and Inference for Topic Models. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, 18–21 June 2009; AUAI Press: Arlington, VA, USA, 2009; pp. 27–34. [Google Scholar]
- Wallach, H.M.; Murray, I.; Salakhutdinov, R.; Mimno, D. Evaluation Methods for Topic Models. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; ACM: New York, NY, USA, 2009; pp. 1105–1112. [Google Scholar] [CrossRef]
- Chang, J.; Boyd-Graber, J.; Gerrish, S.; Wang, C.; Blei, D.M. Reading Tea Leaves: How Humans Interpret Topic Models. In Proceedings of the 22nd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; Curran Associates Inc.: Red Hook, NY, USA, 2009; pp. 288–296. [Google Scholar]
- Koltcov, S.; Koltsova, O.; Nikolenko, S. Latent Dirichlet Allocation: Stability and Applications to Studies of User-generated Content. In Proceedings of the 2014 ACM Conference on Web Science, Bloomington, IN, USA, 23–26 June 2014; ACM: New York, NY, USA, 2014; pp. 161–165. [Google Scholar] [CrossRef]
- Mimno, D.; Blei, D. Bayesian Checking for Topic Models. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 227–237. [Google Scholar]
- Teh, Y.W.; Jordan, M.I.; Beal, M.J.; Blei, D.M. Sharing Clusters Among Related Groups: Hierarchical Dirichlet Processes. In Proceedings of the 17th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 2004; MIT Press: Cambridge, MA, USA, 2004; pp. 1385–1392. [Google Scholar]
- Blei, D.M.; Griffiths, T.L.; Jordan, M.I. The Nested Chinese Restaurant Process and Bayesian Nonparametric Inference of Topic Hierarchies. J. ACM 2010, 57, 7:1–7:30. [Google Scholar] [CrossRef]
- Blei, D.M.; Jordan, M.I.; Griffiths, T.L.; Tenenbaum, J.B. Hierarchical Topic Models and the Nested Chinese Restaurant Process. In Proceedings of the 16th International Conference on Neural Information Processing Systems, Whistler, BC, Canada, 9–11 December 2003; MIT Press: Cambridge, MA, USA, 2003; pp. 17–24. [Google Scholar]
- Bryant, M.; Sudderth, E.B. Truly Nonparametric Online Variational Inference for Hierarchical Dirichlet Processes. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Curran Associates Inc.: Red Hook, NY, USA, 2012; Volume 2, pp. 2699–2707. [Google Scholar]
- Rossetti, M.; Stella, F.; Zanker, M. Towards Explaining Latent Factors with Topic Models in Collaborative Recommender Systems. In Proceedings of the 2013 24th International Workshop on Database and Expert Systems Applications, Prague, Czech Republic, 26–29 August 2013. [Google Scholar] [CrossRef]
- Newman, D.; Lau, J.H.; Grieser, K.; Baldwin, T. Automatic Evaluation of Topic Coherence. In Proceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Los Angeles, CA, USA, 2–4 June 2010; Association for Computational Linguistics: Stroudsburg, PA, USA, 2010; pp. 100–108. [Google Scholar]
- Koltcov, S. Application of Rényi and Tsallis entropies to topic modeling optimization. Phys. A Stat. Mech. Its Appl. 2018, 512, 1192–1204. [Google Scholar] [CrossRef]
- Bing, X.; Bunea, F.; Wegkamp, M.H. A fast algorithm with minimax optimal guarantees for topic models with an unknown number of topics. arXiv, 2018; arXiv:1805.06837. [Google Scholar]
- Lipton, Z.C. The Mythos of Model Interpretability. Queue 2018, 16, 30:31–30:57. [Google Scholar] [CrossRef]
- El-Assady, M.; Sevastjanova, R.; Sperrle, F.; Keim, D.; Collins, C. Progressive Learning of Topic Modeling Parameters: A Visual Analytics Framework. IEEE Trans. Vis. Comput. Graph. 2018, 24, 382–391. [Google Scholar] [CrossRef]
- Nikolenko, S.I.; Koltcov, S.; Koltsova, O. Topic modelling for qualitative studies. J. Inf. Sci. 2016, 43, 88–102. [Google Scholar] [CrossRef]
- Batmanghelich, K.; Saeedi, A.; Narasimhan, K.; Gershman, S. Nonparametric Spherical Topic Modeling with Word Embeddings. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Berlin, Germany, 7–12 August 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016. [Google Scholar] [CrossRef]
- Law, J.; Zhuo, H.H.; He, J.; Rong, E. LTSG: Latent Topical Skip-Gram for Mutually Improving Topic Model and Vector Representations. In Pattern Recognition and Computer Vision; Springer International Publishing: Cham, Switzerland, 2018; pp. 375–387. [Google Scholar] [CrossRef]
- Das, R.; Zaheer, M.; Dyer, C. Gaussian LDA for Topic Models with Word Embeddings. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, Beijing, China, 26–31 July 2015; pp. 795–804. [Google Scholar] [CrossRef]
- Nguyen, D.Q.; Billingsley, R.; Du, L.; Johnson, M. Improving Topic Models with Latent Feature Word Representations. Trans. Assoc. Comput. Linguist. 2015, 3, 299–313. [Google Scholar] [CrossRef]
- Mantyla, M.V.; Claes, M.; Farooq, U. Measuring LDA Topic Stability from Clusters of Replicated Runs. In Proceedings of the 12th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, Oulu, Finland, 11–12 October 2018; ACM: New York, NY, USA, 2018; pp. 49:1–49:4. [Google Scholar] [CrossRef]
- Mehta, V.; Caceres, R.S.; Carter, K.M. Evaluating topic quality using model clustering. In Proceedings of the 2014 IEEE Symposium on Computational Intelligence and Data Mining (CIDM), Orlando, FL, USA, 9–12 December 2014; pp. 178–185. [Google Scholar] [CrossRef]
- Bezdek, J.C. Cluster Validity with Fuzzy Sets. J. Cybern. 1973, 3, 58–73. [Google Scholar] [CrossRef]
- Dunn, J.C. Well-Separated Clusters and Optimal Fuzzy Partitions. J. Cybern. 1974, 4, 95–104. [Google Scholar] [CrossRef]
- Davies, D.L.; Bouldin, D.W. A Cluster Separation Measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, 1, 224–227. [Google Scholar] [CrossRef]
- Halkidi, M.; Batistakis, Y.; Vazirgiannis, M. Clustering Validity Checking Methods: Part II. SIGMOD Rec. 2002, 31, 19–27. [Google Scholar] [CrossRef]
- Xie, X.L.; Beni, G. A Validity Measure for Fuzzy Clustering. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 841–847. [Google Scholar] [CrossRef]
- Rousseeuw, P. Silhouettes: A Graphical Aid to the Interpretation and Validation of Cluster Analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 1532–1543. [Google Scholar] [CrossRef]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Wu, L.Y.; Fisch, A.; Chopra, S.; Adams, K.; Bordes, A.; Weston, J. StarSpace: Embed All The Things! AAAI: Menlo Park, CA, USA, 2018. [Google Scholar]
- Bicalho, P.V.; de Oliveira Cunha, T.; Mourao, F.H.J.; Pappa, G.L.; Meira, W. Generating Cohesive Semantic Topics from Latent Factors. In Proceedings of the 2014 Brazilian Conference on Intelligent Systems, Sao Paulo, Brazil, 18–22 October 2014; pp. 271–276. [Google Scholar] [CrossRef]
- Kuhn, A.; Ducasse, S.; Gîrba, T. Semantic clustering: Identifying topics in source code. Inf. Softw. Technol. 2007, 49, 230–243. [Google Scholar] [CrossRef]
- Chuang, J.; Roberts, M.E.; Stewart, B.M.; Weiss, R.; Tingley, D.; Grimmer, J.; Heer, J. TopicCheck: Interactive Alignment for Assessing Topic Model Stability. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, Denver, CO, USA, 31 May–5 June 2015; pp. 175–184. [Google Scholar] [CrossRef]
- Greene, D.; O’Callaghan, D.; Cunningham, P. How Many Topics? Stability Analysis for Topic Models. In Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2014; pp. 498–513. [Google Scholar] [CrossRef]
- Koltcov, S.; Nikolenko, S.I.; Koltsova, O.; Filippov, V.; Bodrunova, S. Stable Topic Modeling with Local Density Regularization. In Internet Science; Springer International Publishing: Cham, Switzerland, 2016; pp. 176–188. [Google Scholar] [CrossRef]
- Krasnov, F.; Ushmaev, O. Exploration of Hidden Research Directions in Oil and Gas Industry via Full Text Analysis of OnePetro Digital Library. Int. J. Open Inf. Technol. 2018, 6, 7–14. [Google Scholar]
- Borg, I.; Groenen, P. Modern Multidimensional Scaling: Theory and Applications. J. Educ. Meas. 2003, 40, 277–280. [Google Scholar] [CrossRef]
- Calinski, T.; Harabasz, J. A dendrite method for cluster analysis. Commun. Stat. 1974, 3, 1–27. [Google Scholar] [CrossRef]


© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Krasnov, F.; Sen, A. The Number of Topics Optimization: Clustering Approach. Mach. Learn. Knowl. Extr. 2019, 1, 416-426. https://doi.org/10.3390/make1010025
Krasnov F, Sen A. The Number of Topics Optimization: Clustering Approach. Machine Learning and Knowledge Extraction. 2019; 1(1):416-426. https://doi.org/10.3390/make1010025
Chicago/Turabian StyleKrasnov, Fedor, and Anastasiia Sen. 2019. "The Number of Topics Optimization: Clustering Approach" Machine Learning and Knowledge Extraction 1, no. 1: 416-426. https://doi.org/10.3390/make1010025
APA StyleKrasnov, F., & Sen, A. (2019). The Number of Topics Optimization: Clustering Approach. Machine Learning and Knowledge Extraction, 1(1), 416-426. https://doi.org/10.3390/make1010025