A Study on the Relationship between the Intelligibility and Quality of Algorithmically-Modified Speech for Normal Hearing Listeners


Abstract
:1. Introduction
2. Speech Modification Algorithms
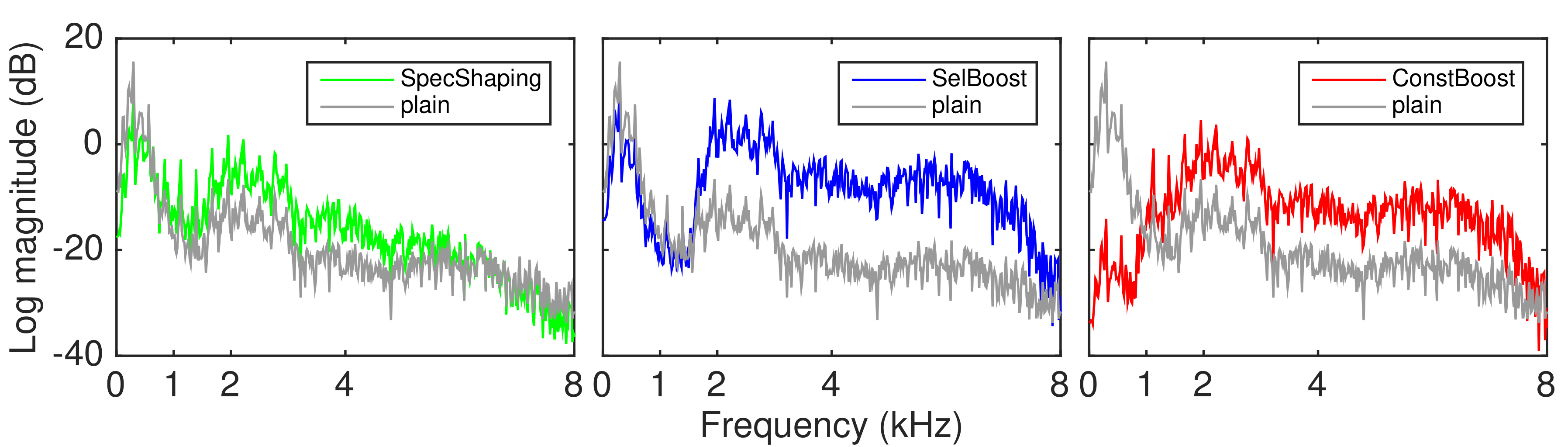
- SpecShaping+DRC consists of two separate stages: spectral shaping in the frequency domain followed by dynamic range compression (DRC) in the time domain [14]. Spectral shaping adaptively enhances the formant information and applies a pre-emphasis filter to the voicing segments. A non-adaptive process is then implemented to avoid loss of high frequency components of the speech signal due to low-pass operations at the stage of signal reconstruction. The DRC stage subsequently applies a time-varying gain to the output of the spectral shaper, in order to increase the perceptual loudness of the output signal (e.g., [22,23]). The DRC used in [14] looks up the gain for each temporal window of 6.7 ms from an input/output envelope characteristic curve. The DRC has a release time of 2 ms and an almost instantaneous attack time for an initial dynamic stage. Its peak threshold is then set to be 30% of the max input speech envelope during the further static stage. Finally, the intensity of the output from the compressor is re-adjusted to that of the original unmodified speech signal. The combination of the two components led to a remarkable performance—SpecShaping+DRC outperformed the other modifications in most of the conditions in the Hurricane Challenge I [17]. Online, modification of this system requires no noise information.In this study, this modification is treated as two separate systems: SpecShaping only and the original SpecShaping+DRC. The aim is to examine the impact of DRC, as a temporal modification, to speech intelligibility and quality, as well as the combination effect with spectral modifications. Previous objective evaluation using PESQ suggested that temporal modifications appear to negatively affect quality more than spectral modifications [10]. Consequently, the DRC will be imposed on the following two modifications to further form another two modifications.
- SelBoost modifies the speech signal by injecting energy to some time-frequency (T-F) regions between the frequency bands 1800 and 7500 Hz, parts of which are known to be important to speech intelligibility in noise. The spare energy may come from places where the local SNR is sufficiently high or is less important to speech intelligibility. Two separate optimisation processes were performed in [10], in order to select the T-F regions which are to be boosted. The results of the first optimisation decides the frequency range (1800–7500 Hz) and the boosting amount of 20 dB. The second optimisation, jointly maximising both objective intelligibility and quality, determines the T-F regions within which the local SNR range should be allocated extra energy. It suggests that boosting those regions where local SNR is under or barely above the threshold of audibility (i.e., less than 5 dB) is the effective strategy. As the local SNR of T-F regions needs to be computed as the criterion for boosting, SelBoost requires access to the noise power spectral density. Along with SpecShaping+DRC, SelBoost also demonstrated above-average performance in the stationary masker in the Hurricane Challenge [17].
- ConstBoost is inspired by the optimal spectral weightings found by maximising objective intelligibility metrics [11,21]. In [11], the spectral weightings were derived using a genetic algorithm with the glimpse proportion [24] as the objective function for a range of noise maskers/SNR conditions. It was found that, regardless of the masker type, the suggested weightings always tend to sparsely boost some of the frequencies above 1000 Hz by approximately 10 dB, although the patterns vary in details across maskers. Another attempt was made using a different optimisation algorithm and objective metric in [21]. A similar boosting pattern was observed, but with a boosting amount of 30 dB. Based on these findings, ConstBoost independently imposes a 30 dB gain to all frequency bands above 1000 Hz on the speech, as if applying a high-pass filter to the speech signal. In this way, ConstBoost no longer requires any noise information to operate. After energy renormalisation, the speech energy is effectively transferred to the boosted regions from elsewhere. Further evaluation confirmed that ConstBoost can be as or almost as effective as the noise- and level-dependent spectral weighting in the tested conditions [21].
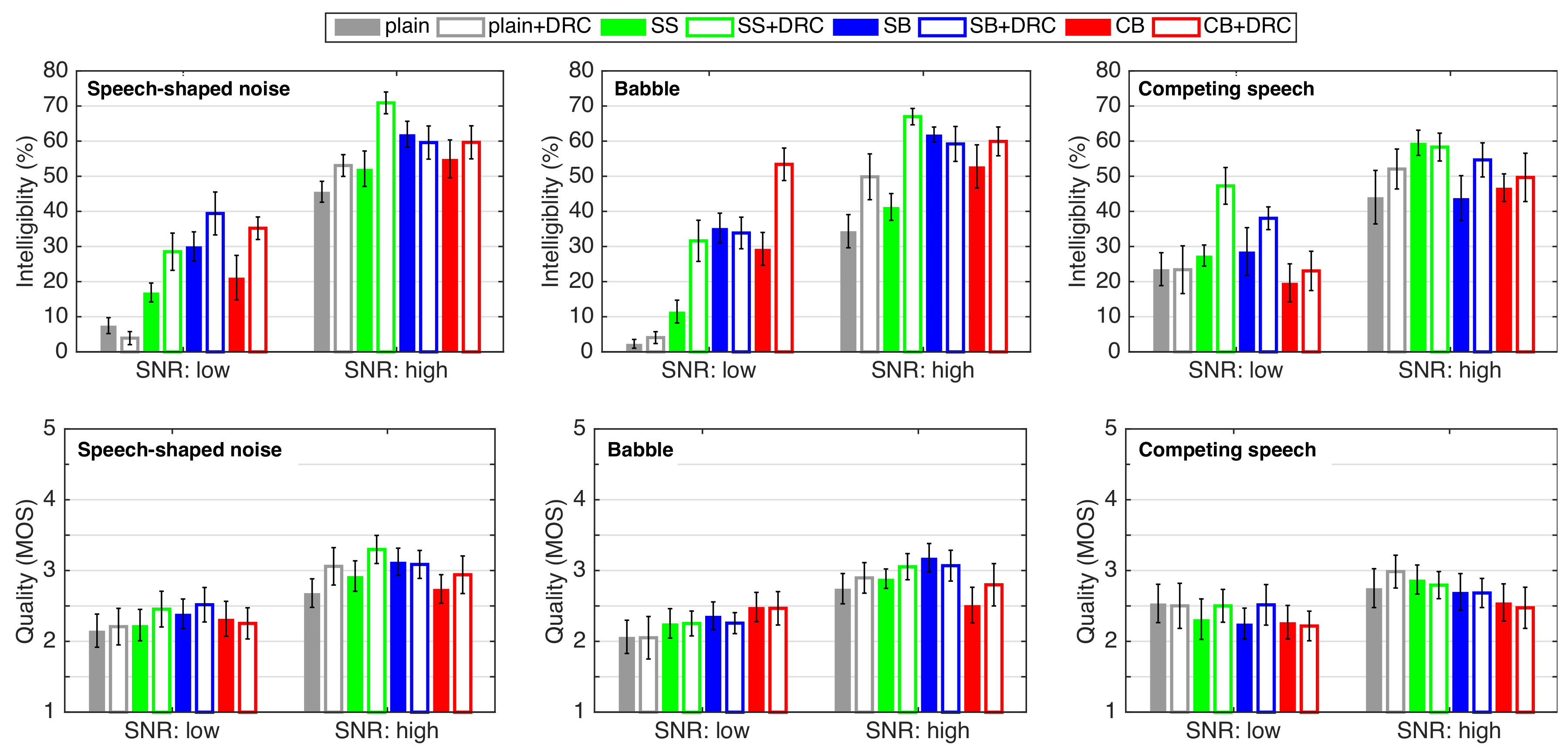
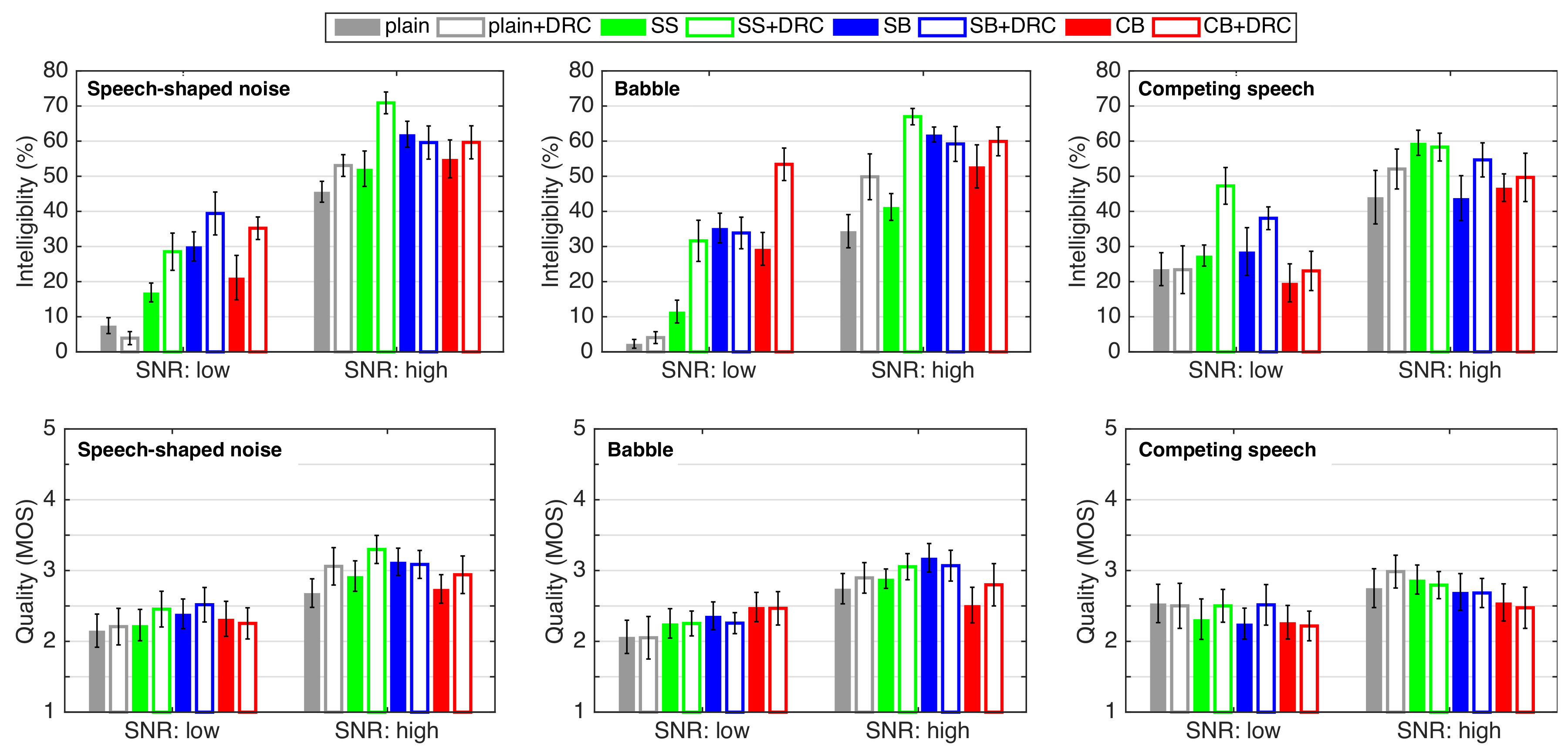
3. Speech Intelligibility and Quality in Noise
3.1. Experiment Design and Procedure
3.2. Results
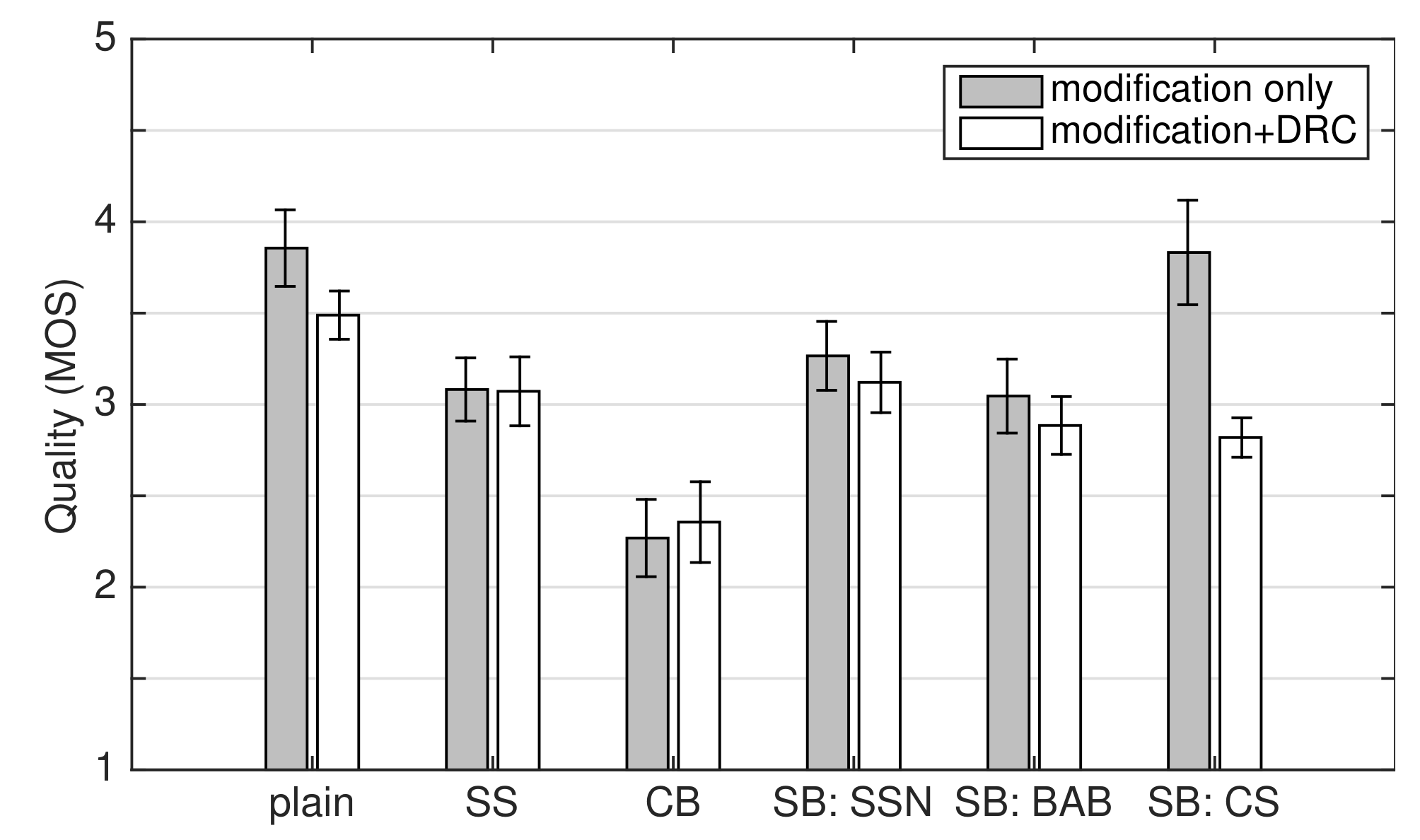
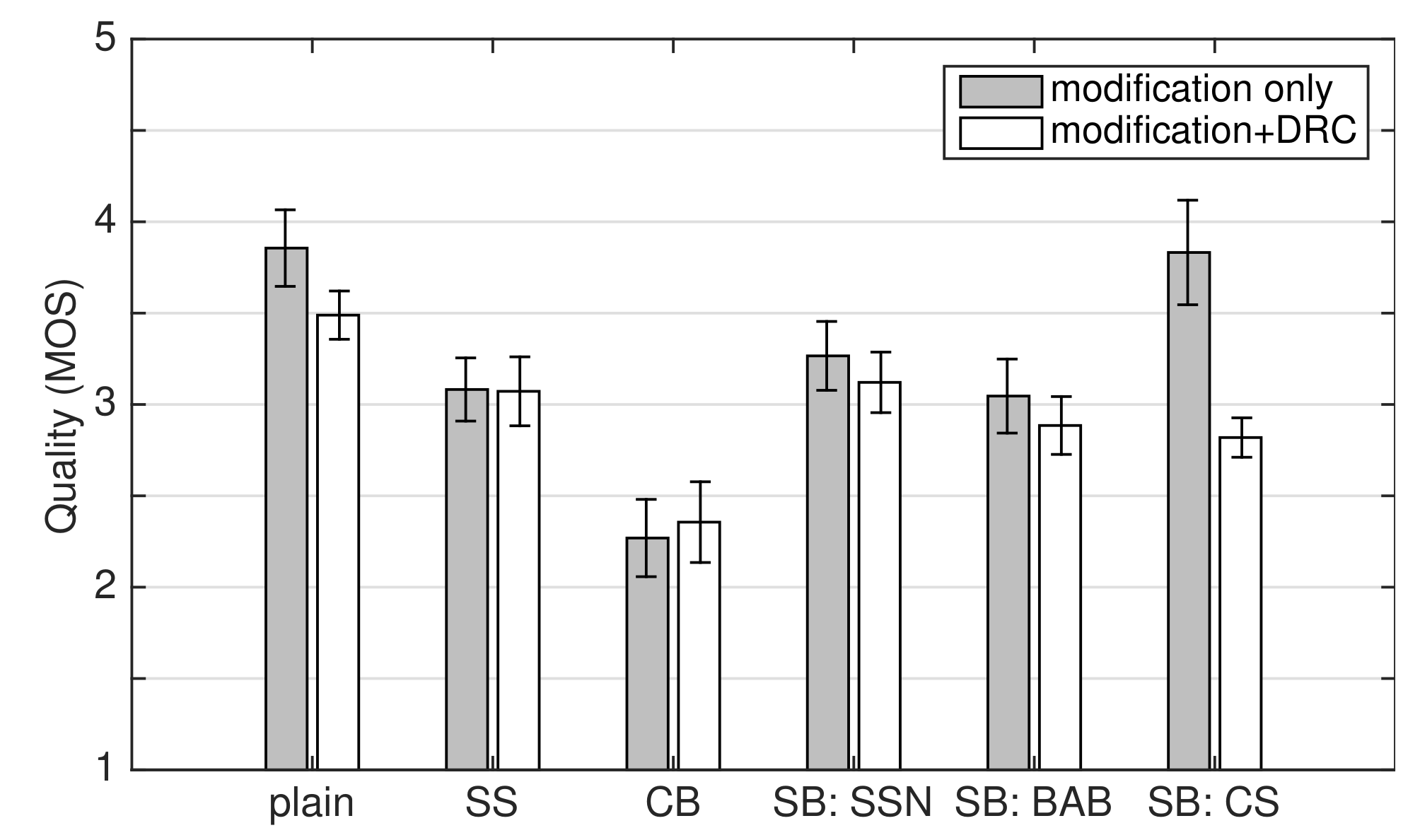
4. Speech Quality in Quiet
4.1. Experiment Design and Procedure
4.2. Results
5. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Nørholm, S.M.; Jensen, J.R.; Christensen, M.G. Enhancement of non-stationary speech using harmonic chirp filters. In Proceedings of the Interspeech, 16th Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015; pp. 1755–1759. [Google Scholar]
- Mohammadiha, N.; Smaragdis, P.; Leijon, A. Supervised and unsupervised speech enhancement using nonnegative matrix factorization. IEEE Trans. Audio Speech Lang. Process. 2013, 21, 2140–2151. [Google Scholar] [CrossRef]
- Paliwal, K.; Wójcicki, K.; Schwerin, B. Single-channel speech enhancement using spectral subtraction in the short-time modulation domain. Speech Commun. 2010, 52, 450–475. [Google Scholar] [CrossRef]
- Martin, R. Speech Enhancement Based on Minimum Mean-Square Error Estimation and Supergaussian Priors. IEEE Trans. Speech Audio Process. 2005, 13, 845–856. [Google Scholar] [CrossRef]
- Rangachari, S.; Loizou, P.C. A noise-estimation algorithm for highly non-stationary environments. Speech Commun. 2005, 48, 220–231. [Google Scholar] [CrossRef]
- Brouckxon, H.; Verhelst, W.; Schuymer, B.D. Time and frequency dependent amplification for speech intelligibility enhancement in noisy environments. In Proceedings of the 9th Annual Conference of the International Speech Communication Association, Brisbane, Australia, 22–26 September 2008; pp. 557–560. [Google Scholar]
- Villegas, J.; Cooke, M. Maximising objective speech intelligibility by local f0 modulation. In Proceedings of the 13th Annual Conference of the International Speech Communication Association, Portland, OR, USA, 9–13 September 2012; pp. 1704–1707. [Google Scholar]
- Godoy, E.; Koutsogiannaki, M.; Stylianou, Y. Assessing the Intelligibility Impact of Vowel Space Expansion via Clear Speech-Inspired Frequency Warping. In Proceedings of the 14th Annual Conference of the International Speech Communication Association, Lyon, France, 25–29 August 2013; pp. 1169–1173. [Google Scholar]
- Sauert, B.; Vary, P. Recursive closed-form optimization of spectral audio power allocation for near end listening enhancement. In Proceedings of the ITG-Fachtagung Sprachkommunikation, Bochum, Deutschland, 6–8 October 2010; pp. 955–958. [Google Scholar]
- Tang, Y.; Cooke, M. Energy reallocation strategies for speech enhancement in known noise conditions. In Proceedings of the 11th Annual Conference of the International Speech Communication Association, Makuhari, Chiba, Japan, 26–30 September 2010; pp. 1636–1639. [Google Scholar]
- Tang, Y.; Cooke, M. Optimised spectral weightings for noise-dependent speech intelligibility enhancement. In Proceedings of the 13th Annual Conference of the International Speech Communication Association, Portland, OR, USA, 9–13 September 2012; pp. 955–958. [Google Scholar]
- Taal, C.; Hendriks, R.C.; Heusdens, R. Speech energy redistribution for intelligibility improvement in noise based on a perceptual distortion measure. Comput. Speech Lang. 2014, 28, 858–872. [Google Scholar] [CrossRef]
- Aubanel, V.; Cooke, M. Information-preserving temporal reallocation of speech in the presence of fluctuating maskers. In Proceedings of the 14th Annual Conference of the International Speech Communication Association, Lyon, France, 25–29 August 2013; pp. 3592–3596. [Google Scholar]
- Zorila, T.C.; Kandia, V.; Stylianou, Y. Speech-in-noise intelligibility improvement based on spectral shaping and dynamic range compression. In Proceedings of the 13th Annual Conference of the International Speech Communication Association, Portland, OR, USA, 9–13 September 2012; pp. 635–638. [Google Scholar]
- Godoy, E.; Stylianou, Y. Increasing speech intelligibility via spectral shaping with frequency warping and dynamic range compression plus transient enhancement. In Proceedings of the 14th Annual Conference of the International Speech Communication Association, Lyon, France, 25–29 August 2013; pp. 3572–3576. [Google Scholar]
- Schepker, H.; Rennies, J.; Doclo, S. Speech-in-noise enhancement using amplification and dynamic range compression controlled by the speech intelligibility index. J. Acoust. Soc. Am. 2015, 138, 2692–2706. [Google Scholar] [CrossRef] [PubMed]
- Cooke, M.; Mayo, C.; Valentini-Botinhao, C.; Stylianou, Y.; Sauert, B.; Tang, Y. Evaluating the intelligibility benefit of speech modifications in known noise conditions. Speech Commun. 2013, 55, 572–585. [Google Scholar] [CrossRef]
- Cooke, M.; Mayo, C.; Valentini-Botinhao, C. Intelligibility-enhancing speech modifications: The Hurricane Challenge. In Proceedings of the 14th Annual Conference of the International Speech Communication Association, Lyon, France, 25–29 August 2013; pp. 3552–3556. [Google Scholar]
- Tang, Y.; Cooke, M. Subjective and objective evaluation of speech intelligibility enhancement under constant energy and duration constraints. In Proceedings of the 12th Annual Conference of the International Speech Communication Association, Florence, Italy, 27–31 August 2011; pp. 345–348. [Google Scholar]
- Rix, A.; Hollier, M.; Hekstra, A.; Beerends, J. Perceptual evaluation of speech quality (PESQ): The new ITU standard for end-to-end speech quality assessment. Part I. Time-delay compensation. J. Audio Eng. Soc. 2002, 50, 755–764. [Google Scholar]
- Tang, Y.; Cooke, M. Learning static spectral weightings for speech intelligibility enhancement in noise. Comput. Speech Lang. 2017. [Google Scholar] [CrossRef]
- Blesser, B.A. Audio dynamic range compression for minimum perceived distortion. IEEE Trans. Audio Electroacoust. 1969, 17, 22–32. [Google Scholar] [CrossRef]
- Schmidt, J.C.; Rutledge, J.C. Multichannel dynamic range compression for music signals. In Proceedings of the 1996 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Atlanta, GA, USA, 9 May 1996; pp. 1013–1016. [Google Scholar]
- Cooke, M. A glimpsing model of speech perception in noise. J. Acoust. Soc. Am. 2006, 119, 1562–1573. [Google Scholar] [CrossRef] [PubMed]
- Rothauser, E.H.; Chapman, W.D.; Guttman, N.; Silbiger, H.R.; Hecker, M.H.L.; Urbanek, G.E.; Nordby, K.S.; Weinstock, M. IEEE Recommended practice for speech quality measurements. IEEE Trans. Audio Electroacoust. 1969, 17, 225–246. [Google Scholar]
- Gabrielsson, A.; Schenkman, B.N.; Hagerman, B. The effects of different frequency responses on sound quality judgments and speech intelligibility. J. Speech Lang. Hear. Res. 1988, 31, 166–177. [Google Scholar] [CrossRef]
- Hafter, E.; Schlauch, R. Noise-Induced Hearing Loss; Chapter Cognitive Factors and Selection of Auditory Listening Bands; Mosby-Year Book: St. Louis, MO, USA, 1992. [Google Scholar]
- Studebaker, G.A. A ‘rationalized’ arcsine transform. J. Speech Hear. Res. 1985, 28, 455–462. [Google Scholar] [CrossRef] [PubMed]
- Preminger, J.E.; Tasell, D.J.V. Quantifying the relation between speech quality and speech intelligibility. J. Speech Hear. Res. 1995, 38, 714–725. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SSN | BAB | CS | |
|---|---|---|---|
| SNR: high | 3.0 () | 2.9 () | 2.7 () |
| SNR: low | 2.3 () | 2.3 () | 2.4 () |
| SSN | BAB | CS | |
|---|---|---|---|
| SNR: high | 0.42 | 0.46 | 0.40 |
| SNR: low | 0.41 | 0.39 | 0.40 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, Y.; Arnold, C.; Cox, T.J. A Study on the Relationship between the Intelligibility and Quality of Algorithmically-Modified Speech for Normal Hearing Listeners. J. Otorhinolaryngol. Hear. Balance Med. 2018, 1, 5. https://doi.org/10.3390/ohbm1010005
Tang Y, Arnold C, Cox TJ. A Study on the Relationship between the Intelligibility and Quality of Algorithmically-Modified Speech for Normal Hearing Listeners. Journal of Otorhinolaryngology, Hearing and Balance Medicine. 2018; 1(1):5. https://doi.org/10.3390/ohbm1010005
Chicago/Turabian StyleTang, Yan, Christopher Arnold, and Trevor J. Cox. 2018. "A Study on the Relationship between the Intelligibility and Quality of Algorithmically-Modified Speech for Normal Hearing Listeners" Journal of Otorhinolaryngology, Hearing and Balance Medicine 1, no. 1: 5. https://doi.org/10.3390/ohbm1010005
APA StyleTang, Y., Arnold, C., & Cox, T. J. (2018). A Study on the Relationship between the Intelligibility and Quality of Algorithmically-Modified Speech for Normal Hearing Listeners. Journal of Otorhinolaryngology, Hearing and Balance Medicine, 1(1), 5. https://doi.org/10.3390/ohbm1010005