Abstract
This paper presents an artificial neural network (ANN) approach to the estimation of the Vickers hardness parameter at the weld zone of laser-welded sintered duplex stainless steel. The sintered welded stainless-steel hardness is primarily determined by the sintering conditions and laser welding processing parameters. In the current investigation, the process parameters for both the sintering and welding processes were trained by ANNs machine learning (ML) model using a TensorFlow framework for the microhardness predictions of laser-welded sintered duplex stainless steel (DSS 2507 grade). A neural network is trained using a thorough dataset. The mean absolute error (MAE), mean square error (MSE), root mean square error (RMSE), and R2 for the train and test data were calculated. The predicted values were in good agreement with the measured hardness values. Based on the results obtained, the ANN method can be effectively used to predict the mechanical properties of materials.
1. Introduction
The past few decades have witnessed an increase in dual-phase stainless steel steels (DSS). DSS has found applications in oil, gas, chemical industries, and pressure vessels, where a combination of outstanding corrosion resistance and high mechanical strength are major requirements [1]. Powder metallurgy (PM) can effectively control the microstructure of bulk samples, or metallic alloys [2]. In addition, the PM manufacturing doubles as the most cost-effective method, compared to other manufacturing processes, such as casting and forging, in terms of producing complex profile geometries. Meanwhile, it is necessary to join PM parts to other materials produced by other manufacturing processes [3]. Therefore, it is required to understand joining or welding PM parts together [4]. Looking through the different PM manufacturing processes, spark plasma sintering (SPS) has been outstanding; it produces a material with fine microstructures and uniform dispersion of reinforcing particles. Additionally, improved hardness and strength can be achieved, among other amazing attributes. Reducing the sintering time that results in low energy consumption [5,6,7,8].
In the material processing industry, it is pertinent for materials to undergo precise and consistent output to meet the required quality standard set. Therefore, a neural network has recently been employed as a technique developed for processing the elements, named neurons, that have connections with each other [9]. Given adequate data and algorithms, machine learning, with the help of a computer, can determine all known physical laws without the involvement of humans. Therefore, the machine learning method learns the rules that govern datasets by working with part of the data and automatically creates a model to provide a prediction.
An artificial neural network (ANN) is fashioned against the brain’s mode of operation. There are usually three layers in the ANN algorithm: input, hidden, and output. The hidden layer neuron receives signals from other neurons, integrates the imputs and compute final results [10]. A neural network that has one hidden layer (or ≤ 2 hidden layers) is usually known as a multi-layer perceptron or shallow neural network (SNN), usually trained by a back-propagation (BP) algorithm. It has, however, seen diverse applications in materials science, such as predicting materials properties [11,12,13,14,15,16,17,18,19,20,21].
Dehabadi et al. [22] studied the application of ANN to predict the micro-hardness of friction-welded AA6061 sheets. The study showed that the value for mean absolute percentage error (MAPE) in training activity for both ANNs was less than 4.83%. Eventually, the results of their work showed acceptable deviance for the actual microhardness. Balasubramanian et al. [9] also evaluated the ability of neural networks in predicting and analyzing the effect of input parameters, viz., welding speed, beam power, and beam angle on the depth of penetration and bead width, which comprises the output parameters for a laser beam-welded stainless steel. In the end, their work showed the proper abilities of neural networks to predict the parameters for butt laser welding. The mechanical properties of welded steel X70 pipeline were predicted using the neural network modeling by Adel et al. [23]. The input parameter for the predictions was based on the chemical compositions of the alloy. Absolution fraction variance and relative error were used as the metrics to determine the prediction performance of the developed ANN model. The study found that the predicted values agreed with the experimental data.
To the best of the authors knowledge, the use of ANN to predict microhardness obtained from the weld zone (WZ) of sintered 2507 DSS alloy has never been mentioned in any previous research.
In this regard, ANN, implemented in the TensorFlow google framework for machine learning, is used to predict and analyze the effects of input parameters. The input parameters are sintering time, sintering temperature, welding speed, welding power on the output parameters and Vickers hardness of the laser-welded duplex stainless steel. The algorithms tested were (rectified linear unit) RELU, Sigmoid, and Tanh, while the RMSprop, stochastic gradient descent (SGD), and ADAM (or adaptive moments) optimization algorithms were tested for the optimizer; all these packages are available in Keras, RMS prop training algorithm, and RELU. However, more accurate algorithms were found in this study using RELU with an RMSprop optimizer. The following researchers corroborated this training algorithm and RMSprop [24,25], which was also reviewed in the introduction above. The test and training datasets were examined for each training algorithm, and the hidden layers were varied from 2 to 3 in order to evaluate their performance. MSE, MAE, R2, and RMSE were used as performance functions. The present study aims to develop an artificial neural networks model to predict the effect of spark plasma sintering processing parameters and Nd:YAG laser welding parameters on the hardness of the weld zone (WZ) of 2507DSS alloy.
2. Significance of the Research
The importance of the WZ on the overall mechanical and chemical integrity of welded metallic alloy cannot be underestimated. Hu et al. [26] studied the mechanical and microstructure analysis of DSS welded using underwater hyperbaric FCA-welding process. From the study, it was noted that the WZ exhibited the highest microhardness with an estimated average value of 262 HV, compared to the other welded zones, such as the base metal (BM) and heat-affected zone (HAZ) [26]. Similar observations were seen in this research. Hence in the present study, the neural network algorithm was applied at the WZ for the microhardness prediction.
Therefore, the hardness at the WZ of a welded duplex stainless steel is a sophisticated task, necessitating an in-depth knowledge of all the processing parameters, including sintering and Nd: YAG welding parameters. Thus, the AI tool was used to estimate the hardness at the WZ. To this end, machine learning techniques, such as ANN and other algorithms, can be used to predict metallic alloy mechanical properties, such as Vickers hardness [22,27].
3. Experimental Process
3.1. Materials
Gas atomized and spherical (SAF2507) DSS powder of high purity of 91.5%, with an average particle size of 22 μm, was used as the starting material, obtained from Sandvik Osprey Ltd. (Neath, UK). The composition of the material is shown in Table 1.

Table 1.
Chemical composition of DSS powder.
3.2. Spark Plasma Sintering Process
The SPS experiment was carried out with SPS equipment (model HHPD-25, FCT system GmbH, Frankenblick, Germany, situated at Tshwane University of Technology Pretoria, South Africa). However, before the sintering process, the gas atomized 2507 DSS powder was first pressed in 20 mm graphite die and punches, while a tungsten foil was used to separate the samples from the graphite tools. The samples were then sintered at the following temperatures 900 °C, 1000 °C, and 1100 °C at a pressure of 50 MPa under vacuum. A heating rate of 100 °C/m was considered for the sintering process, which lasted between 5–10 min. The SPS diagram is shown in Figure 1.
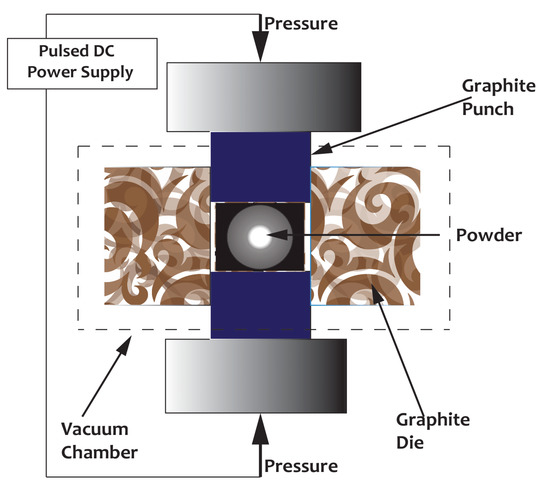
Figure 1.
Spark plasma sintering diagram in 2D.
3.3. Laser Welding Process
Two specimens from the sintered 2507 DSS were sectioned using wire cutting (size: 12 mm × 12 mm × 3 mm), and later prepared in butt joint configuration. The laser welding equipment deployed was a JK 600 pulsed Nd:YAG laser welding machine at the Council for Scientific and Industrial Research (CSIR), South Africa. The laser process is shown in Figure 2. Welding parameters were selected based on the optimized parameters from the literature. The laser power and welding speed adopted in this study for samples A, B, and C were laser powers of 1500, 1700, and 2000 W, while the welding speed employed were 3, 3, and 2 m/min, respectively. Figure 3 shows the three distinct components of laser-welded metallic alloy, showing the base metal (BM), heat affected zone (HAZ), and weld zone (WZ). The processing parameters were fixed based on experimental trials and existing literature on Nd:YAG laser welding of duplex stainless steel.
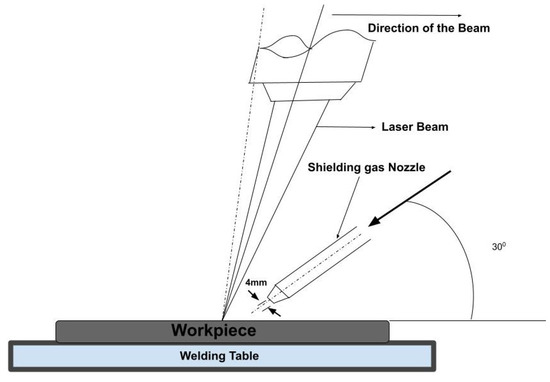
Figure 2.
Schematic diagram showing laser welding process.
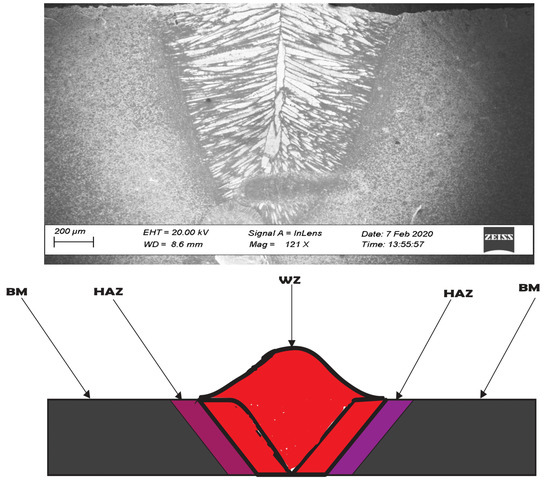
Figure 3.
Schematic diagram showing the welding zones.
3.4. Microhardness Test
Microhardness was carried out to measure the hardness of the welded samples. Vickers microhardness (HV) test was carried out using a Vickers microhardness (EM-700, Future Tech, Tokyo, Japan) tester, applying a load of 300 gf, with a dwell time of 10 s at room temperature. This research targeted the Vickers microhardness test at the welded zone (WZ). As the literature indicates, the chemical composition of the WZ is significant for the mechanical integrity of welded metallic alloy. The microstructure of the WZ differs from the base metal (BM) because of the variations in the chemical composition, as well as the thermal history of the WZ [28]. Therefore, the importance of the WZ to the welded joint overall mechanical integrity led to the consideration of using predictive tools to estimate the hardness of the WZ. An average of three spot hardness values were used and utilized in the neural network.
4. ANN Algorithm
In the material processing industry, it is pertinent for materials to undergo precise and consistent output, to meet the required quality standard set. The neural network has recently been used as a technique developed for processing elements, named neurons, that have connections with each other [9]. Given adequate data and algorithms, machine learning, with the help of a computer, can determine all known physical laws.
4.1. ANN Architecture
The last decade has witnessed a massive application of artificial neural networks (ANN) in many optimizations and prediction applications. ANN is classified as a highly nonlinear function and can capture very complicated patterns in data. Becoming the leading technique in machine learning and helped with complex engineering problems, including the prediction of the mechanical properties of materials. It can be represented by the following function, as indicated in Equation (1), where x is the input vector and is the prediction [29]. Figure 4 shows the steps followed for the implementation of the use case.
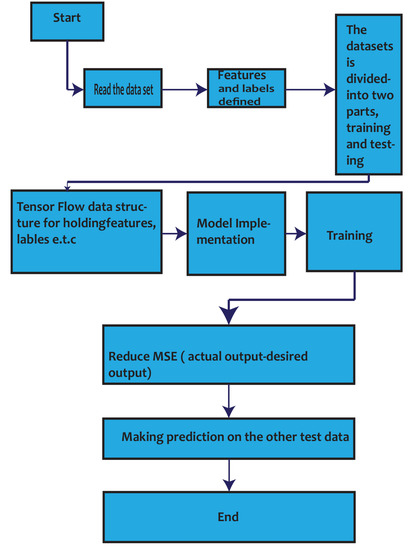
Figure 4.
Flow diagram for the implementation of the use case.
The first layer is the input layer. It transfers information from the outside entity to the network, while the intermediate layers are the hidden layers. It also acts as the connecting link between the input and output layers by performing computation and transferring of information between the input and output layers. The last layer is the output layer, which is mainly responsible for the computations and relaying information outside the world. Therefore, these layers are made of neurons, which can be thought of as a simple computational unit that takes a weighted sum of input variables, sends the sum through an activation function, and finally, the output is the predictions. For the gradient descent equation, we have a linear transformation applied to an input by each neuron in the layers, as described by Equation (2), while Figure 5 presents the flow chart.
where is a tensor, is called the weights, and the vector is the biases. The nonlinear transformation applied by each neuron is called the activation function.
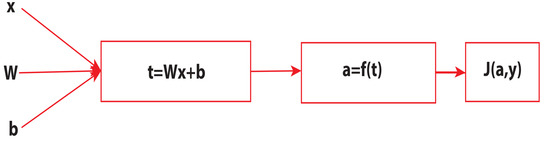
Figure 5.
Flow chart for the linear transformation.
4.2. Activation Function
The literature has many activation functions, such as the sigmoid, hyperbolic tangent, and rectified linear unit or ReLU. Meanwhile, the sigmoid and hyperbolic tangent is subjected to the so-called gradient vanishing.
ReLU activation has enjoyed wide application within neural networks, especially deep neural networks. At its inception, researchers were stimulated to use ReLU because of its biological resemblance. Meanwhile, the ReLU function later showed an improvement in the speed of neural network training, which eventually translated to good results. Its top-notch accurate predictive can be owed to its simplicity and function derivative. The derivative can be computed easily and does not have a vanishing gradient problem [25].
Here, we opted for the ReLU, mainly because it is piecewise and highly nonlinear. It provides better results than the sigmoid and hyperbolic tangents. Therefore, for this reason, it will be highly delightful to investigate how a ReLU function helps the networks to approximate functions.
The ReLU activation function is defined as:
could be any activation function, depending on the problem at hand.
Figure 6 illustrates the ReLU activation function, while Table 2 shows the parameters used in the ANN.
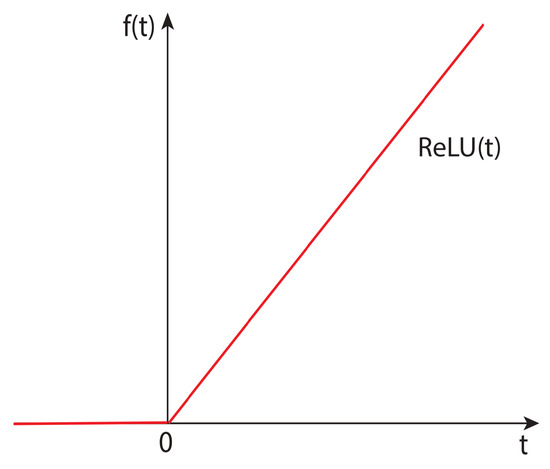
Figure 6.
The ReLU activation function.
Table 2.
ANN parameters.
4.3. The Cost Function
Defining a loss or cost function is fundamental to any machine learning problem. During the training process, the interest is in the weight that minimizes the discrepancies between the estimated hardness values of the weld zone, in contrast to their actual training data values. This increases the accuracy of the network in predicting the new hardness value that is not from the training set. There are many cost functions, but the most widely used for regression problems is the mean square error. In introducing the mean square error cost function, a dataset was assumed:
With the given pairs, i.e., features and corresponding target value , the vector of the targets is denoted as , such that . is a target for object . Similarly, denotes predictions for the objects:
for objects . The MSE loss function is as follows:
The goal of the learning algorithm would be to minimize the loss function. In the context of the deep neural network (DNN), this cost function will be written as follows:
This is called the loss function of the DNN. The parameter theta () stands for the weights and biases that need to be optimized to minimize the loss function, and this is achieved through back-propagation.
4.4. Back-Propagation
Back-propagation can be described as a supervised learning algorithm for training multi-layer ANN. In this research work, back-propagation was used to compute the gradient of the loss function, as indicated by Equation (8).
In addition, the choice of the network parameter does not affect the training data; back-propagation consists of finding the gradient of the network. Once the gradient is computed, gradient descent, or any related algorithm, could be used iteratively to minimize the loss function.
where is called the learning rate, and its value must be set meticulously for convergence reasons. Therefore, through the gradient, the errors are propagated in reverse in the network to adjust the parameter until the loss function reaches its minimum [30].
4.5. Optimizer
Recently, diverse methods have been initiated to effectively minimize the loss function by tracking the gradient and the second moment of the gradient. These methods include AdaGrad, AdaDelta, ADAM, and root mean square propagation (RMS prop). All these are available optimizers in Keras. In the RMS prop, to keep the running average of the first moment of the gradient, the second moment can be tracked or monitored through a moving average. Therefore, the update rule for the RMS prop is given by:
where β dictates the averaging time of the second moment and is usually taken to be about β = 0.9, is a learning rate typically chosen to be and is a small regularization constant to prevent divergences. It can be inferred, from the Equation (10) above, that the learning rate is reduced in directions where the norm of the gradient is persistently large. The Convergence speeds up by enabling the use of a larger learning rate for flat directions [31].
4.6. Model Implementation and Learning
The ANN model was implemented in an open-source, Python-based, deep learning library called Keras with a google machine learning application. The TensorFlow framework was used as the back-end engine. ANN, with a back-propagation algorithm, was implemented with four input parameters, namely welding speed (w-speed), welding temperature (w-temp), sintering time (s-time), and sintering power (s-power). All these processing parameters influence the Vickers hardness of the welded sintered DSS alloy [32,33]. The authors have already published the data used for this analysis in Mendeley data [34]. These parameters, along with their ranges, are summarized in Table 3.
Table 3.
Parameters and their range used in the artificial neural network.
The data obtained from the WZ of each sample was split into training and testing data, which was later used in the final evaluation of the model. The ANNS presented in this study utilizes one to two hidden layers, which are appropriate for the number of unique data, and has small data points; the ANN model was tweaked for different activation functions and training algorithms. Meanwhile, 80% of the data was selected as training data, while the rest was selected for testing. Before training and testing the network, the training datasets were normalized to avoid convergence of the model, thereby making the training more difficult, as well as, eventually, making the resultant model depend on the unit’s choice used in the input. ANN has no restriction on its training data, even with the fact that the magnitude of the measured data varies considerably. To achieve a more excellent training accuracy, it is better to put the training data source in the same order before proceeding with the analysis. Putting the training data in the same order before the training process is necessary. Therefore, the input and output variables were normalized to the range (0,1) by the following equation
where is the original value, is the normalized value, and and are the maximum and minimum of , respectively.
Four neurons were fixed in the input layer corresponding to the input layer, with a hidden layer with variation between two and three layers. One neuron, corresponding to the one output, was fixed in the output layer, as shown in Figure 7a,b. An RMS prop optimizer was used to minimize loss.
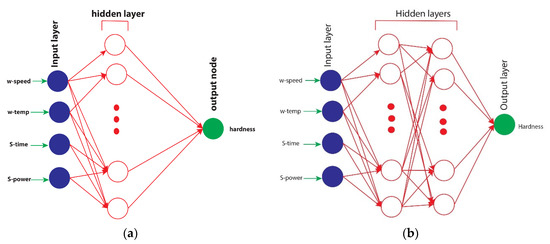
Figure 7.
(a) and (b), graphical representation of a neural network.
The early stopping technique was used to improve the generalization property of the proposed neural network model. Additionally, early stopping was adopted to stop the training after a step of epochs elapses without showing improvement.
In this research, the number of hidden layers that perfectly provide us with the optimized neural network was obtained through trial and error by varying the training algorithm, activation function, and hidden layers.
The model was later compiled for the minimized MSE, RMSE, R2, and MAE loss function, which was used as a metric to evaluate the prediction precision.
The model was later trained for 1000 epochs, and visualization of the training models was achieved using the statistics stored in the history.
5. Results and Discussion
In the model proposed with four input layers, variations between two to three hidden layers with ReLU activation function were used. In the neural networks, the weights and biases were adjusted iteratively by using a training algorithm. Figure 8 shows the numbers of hardness values to be predicted varying from 312 HV to 400 HV. The most important performance metric used in this neural network was MSE [35].
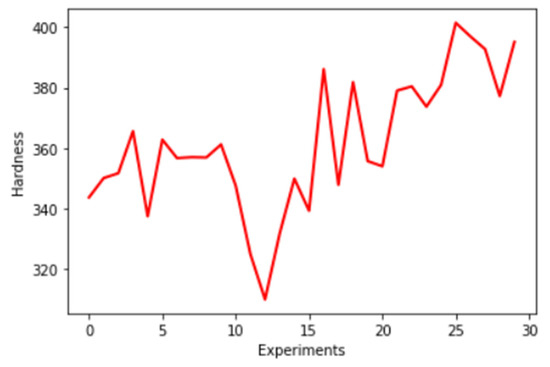
Figure 8.
Actual hardness value against the number of experiments.
The MSE is a common loss function used for regression problems. Therefore, the basic training curve calculated from the training datasets provides an idea of how well the model is learning. The basic validation curve, calculated from a holdout validation dataset, provides an idea of how well the model is generalizing. Figure 9 and Figure 10 show little improvement, or even degradation, in the validation error after approximately 100 epochs.
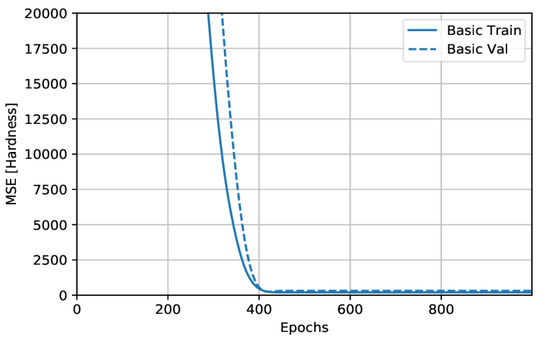
Figure 9.
Plots of MSE against number of epochs.
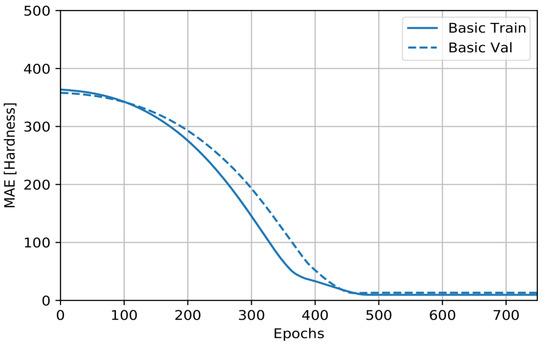
Figure 10.
Plots of MAE against number of epochs.
In other to improve the network generation, a combination of MSE and the mean square of the weights were minimized. Weights were also considered random variables, with Gaussian distribution. However, the early stopping callback was used to improve the generalization property of the different machine learning models proposed. If the set amount of epoch elapses without improvements, the early stopping callback automatically stops the training, as shown in Figure 11a,b. The plots show that the training process stopped as soon as the error validation set increased, showing the variation of MAE and MSE with varying epochs. In this research, R2 and MAE were the metrics used to evaluate the predicting precision of the proposed models for both the test and training sets, as shown in Table 4 [36].
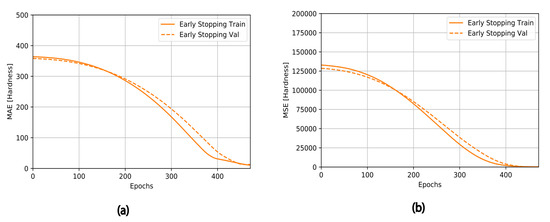
Figure 11.
Early stopping plot of (a) MAE and (b) MSE against epochs.
Table 4.
Calculated values for R2 and MAE for training and testing data.
Meanwhile, the different activation functions and optimizers available under the Keras API were tested, but the ones that could provide the best optimized predicted value were ReLU and RMSProp, respectively, with two and three hidden layers. As shown in Table 4, it is important to note that the model performed better when applied to the test set than when applied to the training set. The reason may be because training datasets have more data points than the test sets. Therefore, the probability of it containing a greater number of abnormal values is high, thereby significantly increasing the MSE that span from 2500 above. The best R2 which is 0.54 and 0..43 respectively for both test and training with hidden layers 2 and R2 values of 0.57 and 0.41 for the test, and training data with 3 hidden layers, explains the low ability of generalization. Meanwhile, The MAE values are lower in the training datasets with 0.43 and 0.41 for 2 hidden compared with 3 hidden layer architecture with MAE value of 15.42.
Table 5 and Table 6 show the test and training predictions vs true values, respectively, showing their errors for the best predicted ANN architecture with two hidden layers. Figure 12 shows the plot of the actual and predicted values.
Table 5.
Training predictions vs true values.
Table 6.
Testing predictions vs true values.
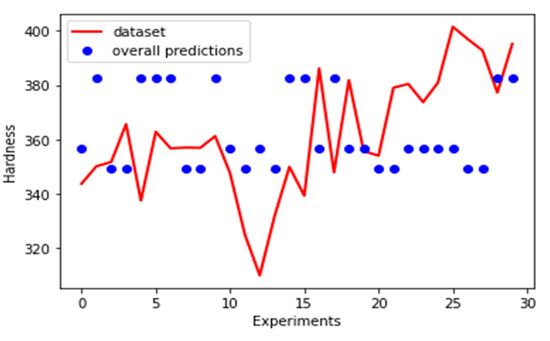
Figure 12.
Actual versus ANN predicted results for hardness.
The minimum and maximum possible error values for the prediction of the hardness value were 0.09% and 9.57%, respectively. Clearly, with such a small dataset, a lack of generalization is expected, which warranted the use of another metric to appreciate how well the model is at prediction. The percentage error was computed on each prediction, according to the Equation (10). is the target value, and is the predicted value.
Figure 12 shows how the variations of actual hardness value versus ANN predicted results for hardness. This shows the disparity between the actual datasets points to the predicted values graphically.
6. Conclusions
This research developed a predictive model, to predict the hardness value. Meanwhile, the predictive model was developed using a neural network with an RMS prop optimizer and ReLU activation, which seems to be the best parameter selected. This is also justified in the cited research [24]. The hidden layers were varied from two to three layers to predict the hardness value. Through the linear regression analysis, it can be inferred that the predicted and real values did not deviate too much. Empirical examinations of the predicted hardness value (by comparisons of predicting measures, such as MSE and MAE) show that the proposed neural network improves the precision of predicting the hardness of the welded metallic alloy.
It can be noticed that the evolution of MSE with the training and test data of the ANN suggested no overfitting of the ANN. However, the study cannot guarantee the top-notch performance of the ANN model, as the R2 achieved in the test data was greater than that of the training data. This may be because there is not much numerical diversity in the input data used. Hence, the anomalous values might be more noticeable in the training sets than the test sets, given their larger dimension, compared to the test sets, which increases the R2 value of the test sets.
Forecasts of the hardness value were acceptable from the technological viewpoint. To enhance the reliability of the model and improve the predictive performance of the ANN model, it is important to use an increased number of data points for the training, testing, and validation process.
Lastly, this research work proposes that the full integration of the analysis and prediction into one framework is possible.
Author Contributions
Conceptualization, A.T.O. and P.M.M.; methodology, A.T.O. and N.B.M.; software, A.T.O. and O.A.O.; validation, A.T.O.; formal analysis, A.T.O. and P.M.M.; data curation, A.T.O.; writing—original draft preparation, A.T.O.; writing—review and editing, A.T.O., O.A.O.; visualization, A.T.O.; supervision, P.M.M. and N.B.M. All authors have read and agreed to the published version of the manuscript.
Funding
No funding was provided for this research.
Data Availability Statement
The data used for this research is available Mendeley data. Link: https://data.mendeley.com/datasets/c49p4g34cc (accessed on 10 June 2020).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ouali, N.; Khenfer, K.; Belkessa, B.; Fajoui, J.; Cheniti, B.; Idir, B.; Branchu, S. Effect of Heat Input on Microstructure, Residual Stress, and Corrosion Resistance of UNS 32101 Lean Duplex Stainless Steel Weld Joints. J. Mater. Eng. Perform. 2019, 28, 4252–4264. [Google Scholar] [CrossRef]
- Degnan, C.; Shipway, P.; Wood, J. Elevated temperature sliding wear behaviour of TiC-reinforced steel matrix composites. Wear 2001, 251, 1444–1451. [Google Scholar] [CrossRef]
- Chandramouli, R.; Kandavel, T.; Karthikeyan, P. Experimental investigations on welding behaviour of sintered and forged Fe–0.3% C–3% Mo low alloy steel. Mater. Des. 2014, 53, 645–650. [Google Scholar] [CrossRef]
- Suresh, M.; Krishna, B.V.; Venugopal, P.; Rao, K.P. Effect of pulse frequency in gas tungsten arc welding of powder metallurgical preforms. Sci. Technol. Weld. Join. 2004, 9, 362–368. [Google Scholar] [CrossRef]
- Cui, G.; Kou, Z. The effect of boron on mechanical behavior and microstructure for Fe–Cr matrix alloy prepared by P/M. J. Alloys Compd. 2014, 586, 699–702. [Google Scholar] [CrossRef]
- Das, A.; Harimkar, S.P. Effect of graphene nanoplate and silicon carbide nanoparticle reinforcement on mechanical and tribological properties of spark plasma sintered magnesium matrix composites. J. Mater. Sci. Technol. 2014, 30, 1059–1070. [Google Scholar] [CrossRef]
- Diouf, S.; Molinari, A. Densification mechanisms in spark plasma sintering: Effect of particle size and pressure. Powder Technol. 2012, 221, 220–227. [Google Scholar] [CrossRef]
- Jain, J.; Kar, A.M.; Upadhyaya, A. Effect of YAG addition on sintering of P/M 316L and 434L stainless steels. Mater. Lett. 2004, 58, 2037–2040. [Google Scholar] [CrossRef]
- Balasubramanian, K.; Buvanashekaran, G.; Sankaranarayanasamy, K. Modeling of laser beam welding of stainless steel sheet butt joint using neural networks. CIRP J. Manuf. Sci. Technol. 2010, 3, 80–84. [Google Scholar] [CrossRef]
- Butler, K.T.; Davies, D.W.; Cartwright, H.; Isayev, O.; Walsh, A. Machine learning for molecular and materials science. Nature 2018, 559, 547–555. [Google Scholar] [CrossRef]
- Dimitriu, R.; Bhadeshia, H.; Fillon, C.; Poloni, C. Strength of ferritic steels: Neural networks and genetic programming. Mater. Manuf. Process. 2008, 24, 10–15. [Google Scholar] [CrossRef]
- Malinov, S.; Sha, W. Application of artificial neural networks for modelling correlations in titanium alloys. Mater. Sci. Eng. A 2004, 365, 202–211. [Google Scholar] [CrossRef]
- Solano-Alvarez, W.; Peet, M.; Pickering, E.; Jaiswal, J.; Bevan, A.; Bhadeshia, H. Synchrotron and neural network analysis of the influence of composition and heat treatment on the rolling contact fatigue of hypereutectoid pearlitic steels. Mater. Sci. Eng. A 2017, 707, 259–269. [Google Scholar] [CrossRef]
- Bhadeshia, H.; MacKay, D.; Svensson, L.-E. Impact toughness of C–Mn steel arc welds–Bayesian neural network analysis. Mater. Sci. Technol. 1995, 11, 1046–1051. [Google Scholar] [CrossRef] [Green Version]
- Allegri, G. Modelling fatigue delamination growth in fibre-reinforced composites: Power-law equations or artificial neural networks? Mater. Des. 2018, 155, 59–70. [Google Scholar] [CrossRef] [Green Version]
- Anjum, Z.; Qayyum, F.; Khushnood, S.; Ahmed, S.; Shah, M. Prediction of non-propagating fretting fatigue cracks in Ti6Al4V sheet tested under pin-in-dovetail configuration: Experimentation and numerical simulation. Mater. Des. 2015, 87, 750–758. [Google Scholar] [CrossRef]
- Guo, L.; Roelofs, H.; Lembke, M.; Bhadeshia, H. Modelling of transition from upper to lower bainite in multi-component system. Mater. Sci. Technol. 2017, 33, 430–437. [Google Scholar] [CrossRef] [Green Version]
- Vasudevan, M.; Bhaduri, A.; Raj, B.; Rao, K.P. Artificial neural network modelling of solidification mode in austenitic stainless steel welds. Mater. Sci. Technol. 2007, 23, 451–459. [Google Scholar] [CrossRef]
- Cassar, D.R.; de Carvalho, A.C.; Zanotto, E.D. Predicting glass transition temperatures using neural networks. Acta Mater. 2018, 159, 249–256. [Google Scholar] [CrossRef]
- Liu, G.; Jia, L.; Kong, B.; Guan, K.; Zhang, H. Artificial neural network application to study quantitative relationship between silicide and fracture toughness of Nb-Si alloys. Mater. Des. 2017, 129, 210–218. [Google Scholar] [CrossRef]
- Xia, X.; Nie, J.; Davies, C.; Tang, W.; Xu, S.; Birbilis, N. An artificial neural network for predicting corrosion rate and hardness of magnesium alloys. Mater. Des. 2016, 90, 1034–1043. [Google Scholar] [CrossRef]
- Dehabadi, V.M.; Ghorbanpour, S.; Azimi, G. Application of artificial neural network to predict Vickers microhardness of AA6061 friction stir welded sheets. J. Cent. South Univ. 2016, 23, 2146–2155. [Google Scholar] [CrossRef]
- Saoudi, A.; Fellah, M.; Hezil, N.; Lerari, D.; Khamouli, F.; Atoui, L.h.; Bachari, K.; Morozova, J.; Obrosov, A.; Samad, M.A. Prediction of mechanical properties of welded steel X70 pipeline using neural network modelling. Int. J. Press. Vessel. Pip. 2020, 186, 104153. [Google Scholar] [CrossRef]
- Tieleman, T.; Hinton, G. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Hansson, M.; Olsson, C. Feedforward Neural Networks with ReLU Activation Functions Are Linear Splines. Bachelor’s Thesis, Lund University, Lund, Sweden, 2017. [Google Scholar]
- Hu, Y.; Shi, Y.; Sun, K.; Shen, X.; Wang, Z. Microstructure and mechanical properties of underwater hyperbaric FCA-welded duplex stainless steel joints. J. Mater. Processing Technol. 2018, 261, 31–38. [Google Scholar] [CrossRef]
- Pouraliakbar, H.; Khalaj, M.-j.; Nazerfakhari, M.; Khalaj, G. Artificial neural networks for hardness prediction of HAZ with chemical composition and tensile test of X70 pipeline steels. J. Iron Steel Res. Int. 2015, 22, 446–450. [Google Scholar] [CrossRef]
- Gunn, R. Duplex Stainless Steels: Microstructure, Properties and Applications; Elsevier: Amsterdam, The Netherlands, 1997. [Google Scholar]
- Spears, B.K.; Brase, J.; Bremer, P.-T.; Chen, B.; Field, J.; Gaffney, J.; Kruse, M.; Langer, S.; Lewis, K.; Nora, R. Deep learning: A guide for practitioners in the physical sciences. Phys. Plasmas 2018, 25, 080901. [Google Scholar] [CrossRef]
- Rojas, R. The Back-Propagation Algorithm. In Neural Networks; Springer: Berlin/Heidelberg, Germany, 1996; pp. 149–182. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Mohammed, G.R.; Ishak, M.; Aqida, S.N.; Abdulhadi, H.A. Effects of heat input on microstructure, corrosion and mechanical characteristics of welded austenitic and duplex stainless steels: A review. Metals 2017, 7, 39. [Google Scholar] [CrossRef] [Green Version]
- Kumar, P.K.; Sai, N.V.; Krishna, A.G. Influence of sintering conditions on microstructure and mechanical properties of alloy 218 steels by powder metallurgy route. Arab. J. Sci. Eng. 2018, 43, 4659–4674. [Google Scholar] [CrossRef]
- Olanipekun, A.; Mashinini, M.; Maledi, N. Data on sintering, Nd:YAG welding and vickers hard-ness value of 2507 duplex stainless steel (DSS). Mendeley Data 2020, 2. [Google Scholar] [CrossRef]
- Pouraliakbar, H.; Nazari, A.; Fataei, P.; Livary, A.K.; Jandaghi, M. Predicting Charpy impact energy of Al6061/SiCp laminated nanocomposites in crackics divider and crack arrester forms. Ceram. Int. 2013, 39, 6099–6106. [Google Scholar] [CrossRef]
- Pouraliakbar, H.; Monazzah, A.H.; Bagheri, R.; Reihani, S.S.; Khalaj, G.; Nazari, A.; Jandaghi, M. Toughness prediction in functionally graded Al6061/SiCp composites produced by roll-bonding. Ceram. Int. 2014, 40, 8809–8825. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).