1. Introduction
Climate change has led to a sharp increase in the frequency and intensity of natural disasters such as wildfires, landslides, and floods, posing serious challenges for Search and Rescue operations [
1,
2] managed by civil authorities. Rapid localization of people in life-threatening conditions is critical to saving lives, particularly when individuals are trapped, injured, or isolated in inaccessible areas due to environmental disasters or health issues. Aerial platforms such as helicopters and unmanned aerial vehicles (UAVs) have become central tools in Search and Rescue missions, enabling fast coverage of vast territories and high-resolution data acquisition [
3,
4,
5].
Despite these advantages, manually analyzing aerial imagery remains slow, error-prone, and cognitively demanding for human operators; moreover, it requires a complex training that is quite difficult to ensure in the case of people who should carry out several tasks in an organization. Fatigue, attentional drift, and the overwhelming number of uninformative frames can compromise mission effectiveness. These limitations highlight the need for intelligent vision systems to detect people from aerial images in real time. In recent years, deep learning-based object detectors, particularly the YOLO (You Only Look Once) family, have shown promising performance in this context [
6].
Unmanned aerial vehicles (UAVs), or drones, are increasingly employed in Search and Rescue missions in the civil field because of their ability to survey large and complex areas rapidly. In both wilderness and urban scenarios, their effectiveness hinges on the capacity to detect small, sparsely located human figures from aerial imagery; a task that remains highly challenging due to occlusions, scale variation, cluttered backgrounds, and limited onboard computational resources. Recent surveys such as Zhang et al. [
7] provide a comprehensive review of aerial person detection (APD), identifying key challenges related to target size, sparsity, and background complexity. Their introduction of the VTSaR dataset, which includes multimodal data (visible/IR), reinforces the growing need for robust and efficient models tailored to drone-based applications. In this direction, PS-YOLO [
8] demonstrates how lightweight and efficient designs can maintain accuracy while remaining deployable on resource-constrained UAVs. Also, from an economical point of view, which is important for civil applications, the hardware resources needed are more than affordable.
Further advances include Yeom (2024) [
9], who integrates YOLOv5 with Kalman filters for multi-target tracking in thermal imagery, revealing both the potential and limitations of thermal-based Search and Rescue, particularly concerning resolution loss and scene complexity. Similarly, Kucukayan and Karacan (2024) [
10] improve indoor human detection by embedding attention mechanisms into YOLO-based models (YOLO-IHD), highlighting the need for context-specific architectural adaptation. Outside of vision, Calabrò and Marchetti (2024) [
11] introduce Transponder, a Wi-Fi-based localization system that integrates with UAVs for non-GSM areas, exemplifying how multimodal systems can enhance Search and Rescue capabilities.
Nevertheless, the gap between academic performance and field validation remains significant. Manzini and Murphy (2023) [
12] report in a real Search and Rescue that models like EfficientDet, despite strong performance on benchmarks, failed in deployment due to high false positives and unreliable predictions.
One of the root causes of these limitations is the lack of well-suited datasets. Generic datasets such as COCO [
13] or ImageNet [
14] are inadequate for aerial person detection. VisDrone [
15] provides partial support but lacks domain specificity. Newer datasets, like Heridal [
16], offer high-resolution UAV footage focused on Search and Rescue use cases, helping to address issues such as small-object sparsity, high-class imbalance, and large-scale background clutter. Nonetheless, further methodological improvements are needed.
Detecting small and sparse targets in cluttered aerial scenes presents specific architectural challenges. The spatial resolution of deeper convolutional layers is often too low to capture tiny objects effectively. Models must, therefore, integrate multi-scale feature fusion techniques such as FPN [
17], BiFPN [
18], or PB-FPN [
19] and benefit from attention mechanisms like CBAM [
20] and RFCBAM [
21], which allow the network to focus on informative regions. Data augmentation strategies, such as rotation, mosaic, and copy–paste, also play a critical role in expanding the diversity and frequency of positive examples [
22,
23]. Other optimizations, such as anchor box tuning, oversampling, and the use of transformer modules [
24], further contribute to performance gains in low-data or small-object contexts.
Recent developments in UAV-based Search and Rescue have increasingly leveraged lightweight object detection frameworks within realistic operational contexts. Notably, Dumenčić et al. (2025) [
25] present an experimental validation of a YOLO-powered UAV detection system deployed in a wilderness environment, demonstrating how the integration of ergodic search strategies with onboard inference can robustly detect human targets under real-world conditions. Similarly, Fu et al. (2024) [
26] introduce DLSW-YOLOv8n, a customized small-object detection model optimized for maritime SAR imagery captured by UAVs; the work illustrates that careful architectural design (e.g., deformable large kernel and SPD-Conv layers) can significantly enhance detection accuracy in challenging maritime environments. Complementing this, Weng et al. (2025) [
27] propose YOLO-SRMX, a lightweight real-time detector tailored to infrared UAV imagery, showcasing effective small-object detection while preserving onboard efficiency. These studies collectively underscore the practical importance of balancing accuracy, model size, and deployment feasibility in SAR applications, reinforcing the relevance of our architectural modifications and performance evaluations.
This work presents a comprehensive methodology to adapt and optimize the YOLOv5 object detection model for real-time aerial Search and Rescue missions in the civil domain. We propose architectural modifications such as enhanced multi-scale feature fusion and lightweight detection heads to improve small-object sensitivity while preserving computational efficiency. By fine-tuning the model through transfer learning on the VisDrone and Heridal datasets, we substantially boost mAP over the YOLOv5 baseline. The generalizability of our approach is further demonstrated by successfully porting the methodology to YOLOv8, showcasing its scalability and robustness across architectures and mission profiles.
The main contributions of this work are as follows:
The design of a lightweight and accurate object detection model for small-object recognition in aerial Search and Rescue imagery based on YOLOv5s;
The integration of advanced architectural modules (e.g., feature fusion and attention mechanisms) to enhance detection performance;
A comprehensive evaluation of benchmark UAV datasets, including VisDrone and Heridal, demonstrating superior accuracy and real-time suitability;
The validation of the proposed methodology on YOLOv8, confirming its generalizability across architectures.
A discussion of practical deployment aspects, including real-world constraints, dataset handling, and embedded implementation for UAV-based Search and Rescue platforms, focusing attention on civil applications, where cost should be kept as low as possible and the usability for operators must be considered.
2. Materials and Methods
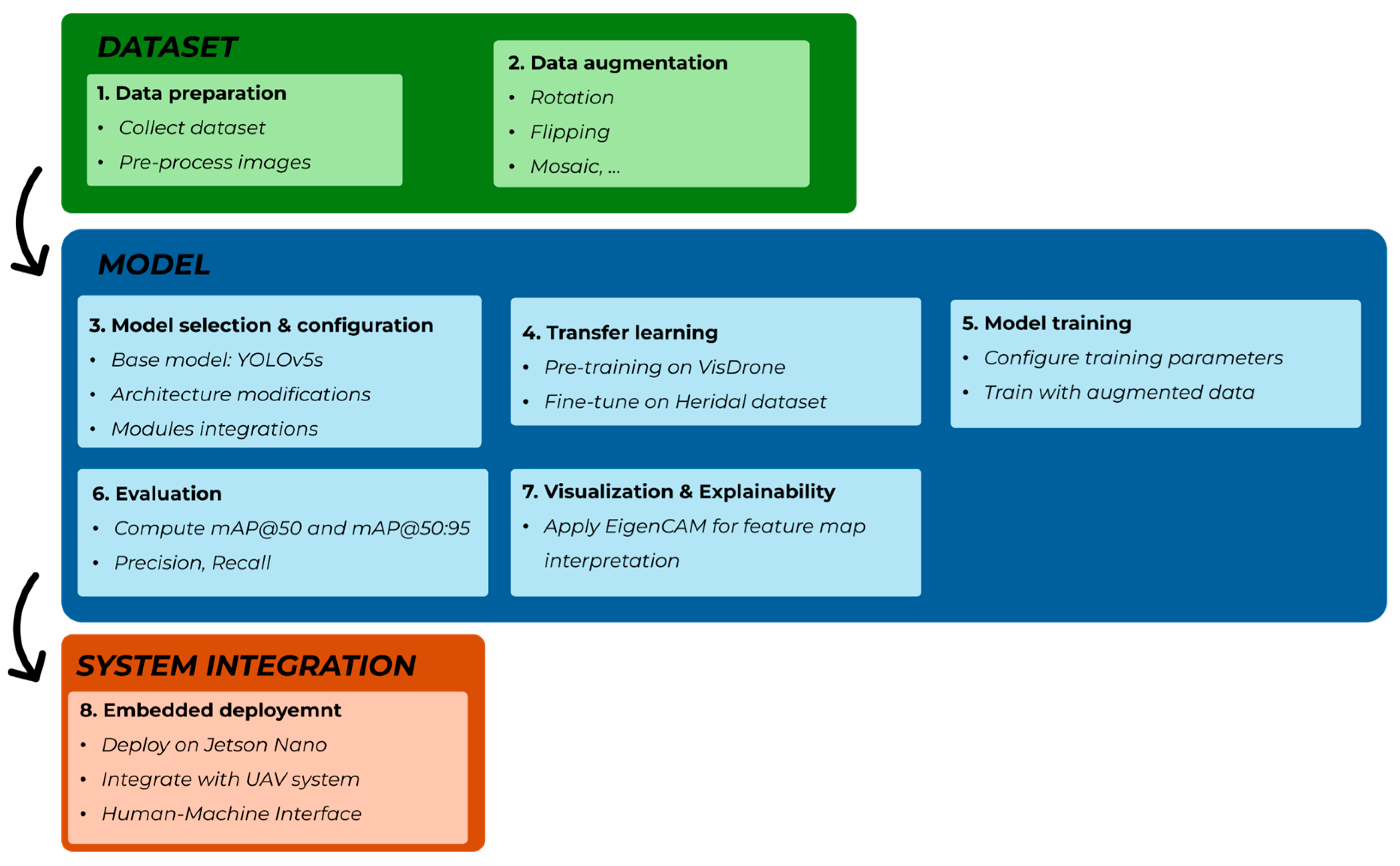
To address the specific challenges of Search and Rescue operations and enable practical deployment of object detection systems on embedded aerial platforms, we developed a comprehensive methodology focused on the algorithmic optimization and hardware implementation of YOLO-based models. Our approach begins with selecting and adapting YOLOv5 and YOLOv8 architectures, targeting the detection of small, sparsely distributed human figures in complex aerial scenes.
The methodology involved three tightly integrated components (
Figure 1):
Dataset selection and preparation, applying pre-processing steps such as resizing, bounding box selection, and splitting the dataset into train, validation, and test sets and applying data augmentation techniques like rotation, flipping, mosaic, copy-paste of small objects;
Architectural customization of the base model, including the integration of enhanced feature fusion layers, additional detection heads, and attention modules to improve small-object sensitivity without significantly increasing computational complexity;
transfer learning and dataset selection using aerial-specific datasets such as Heridal and VisDrone to ensure the model is exposed to realistic Search and Rescue-like conditions during training and validation;
Embedded deployment optimization, involving evaluating and adapting the trained models for execution on constrained hardware platforms (NVIDIA Jetson Nano), with particular attention to inference time, memory usage, and energy efficiency.
The architectural changes were systematically tested across multiple configurations, including variations in input resolution, depth, and width multipliers, to assess the trade-off between performance (in terms of precision and recall) and computational load. Additionally, the pipeline incorporates pre- and post-processing steps suitable for onboard execution, such as image resizing strategies, lightweight data augmentation, and non-maximum suppression tuning.
By integrating model-level optimization with hardware-aware constraints, this methodology aims to bridge the gap between high-performing object detectors in controlled environments and their real-world applicability in time-critical Search and Rescue missions conducted by UAVs.
2.1. Dataset
To train a model capable of detecting missing persons in aerial Search and Rescue operations after environmental disasters or emergencies, it is essential to use datasets that reflect the characteristics of real-world scenarios. A typical Search and Rescue civil context involves open-field environments as forests, agricultural fields, or mountainous terrain, where people may appear occluded, lying down, or occupying only a few pixels due to altitude and resolution.
For this purpose, we selected the Heridal dataset, explicitly designed for Search and Rescue missions. It includes various scenes with diverse lighting conditions, heterogeneous terrain types, and multiple human poses. All images were captured from altitudes between 40 and 65 m, resulting in tiny human instances. Each frame included at least one person, making the dataset particularly useful but also highly challenging due to the presence of false positives from natural artifacts and cluttered backgrounds.
We adopted a transfer learning approach to address the scarcity of positive samples and improve generalization. The first training step was conducted using the VisDrone dataset, which contains drone-acquired images and offers many small-object instances. Transfer learning was then applied to Heridal. A further experiment using the Stanford Drone Dataset [
28] as an intermediate fine-tuning step was performed, but its benefits were marginal and did not justify the increased training time. We thus adopted a two-stage training strategy: VisDrone pretraining followed by Heridal fine-tuning.
Figure 2 shows examples of the VisDrone and Heridal datasets in urban and forestal scenarios.
2.2. Model Architecture and Modifications
YOLO is widely recognized as a state-of-the-art object detection framework for real-time applications. Although newer versions like YOLOv9 [
29], YOLOv10 [
30], YOLOv11 [
31], and YOLOv12 [
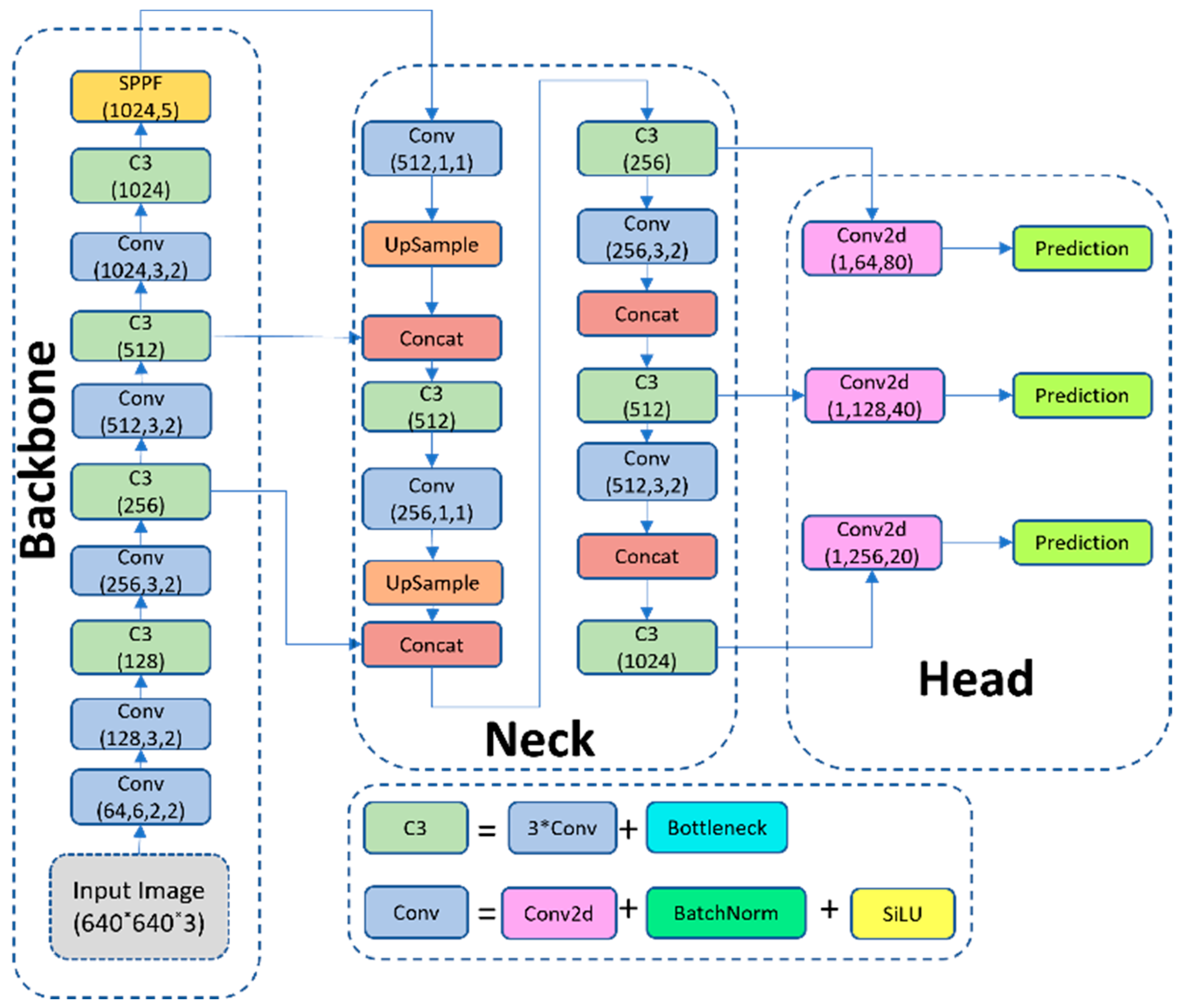
32] have been released recently, in this study, we selected YOLOv5 for several reasons. First, YOLOv5 provides a mature and stable implementation with extensive documentation and an active developer community, facilitating the integration of custom modules such as additional detection heads, feature fusion layers, and attention mechanisms. Second, YOLOv5 has established compatibility with NVIDIA TensorRT and ONNX export pipelines, which is essential for efficient deployment on embedded systems like the Jetson Nano. Third, preliminary experiments conducted as part of this work demonstrated that applying the same architectural modifications to YOLOv8 yielded comparable detection accuracy (mAP@50 and mAP@50:95) to YOLOv5 on our aerial Search and Rescue dataset while requiring a higher computational burden. YOLOv5 allows for architectural definition, supporting changes in model depth, width, number of classes, and specific modules in the backbone, neck, and head. YOLOv5s, the smallest full-scale version, was selected for its balance between accuracy and efficiency. It employs a CSPDarknet53 backbone, an SPPF (Spatial Pyramid Pooling-Fast) module, a PANet neck, and a YOLOv3 anchor-based detection head.
Figure 3 shows the authors’ representation of YOLOv5 architecture.
Because of the application of the convolutions to the input image, as the number of layers increases, the image’s resolution decreases. If we denote with
the feature level at layer “
i” (
Figure 4), the corresponding resolution will be
of the input image [
18]. Considering an input resolution of 640 × 640, the resolution of the fourth feature level
will be
40 × 40. Even if the deeper layers are rich in semantic features, the shallow layers dominate higher resolutions; in this context, combining the different feature layers (adequately resized) to enhance small-object detection is crucial.
We investigated the impact of different feature fusion strategies on small-object detection by replacing PANet with FPN, BiFPN, and PB-FPN [
19]. FPN and PB-FPN yielded superior results on the Heridal dataset, likely due to their top-down fusion paths, which better preserve high-resolution features from shallow layers. Conversely, BiFPN and PANet, which use bottom-up fusion, underperformed.
Figure 5 shows the schemes of the feature fusion methods used.
Additionally, we experimented with adding extra detection heads to improve sensitivity to small objects and analyzed the integration of Transformer Prediction Heads (TPH) and CBAM (Convolutional Block Attention Module), inspired by TPH-YOLOv5 [
33]. While TPH-YOLOv5 did not significantly improve Heridal, using CBAM and Transformer blocks separately showed more promising results in detecting occluded or tiny targets.
2.3. Training Strategy and Hyperparameters Tuning
The training process adopted in this study was designed to maximize both generalizations across diverse aerial scenarios and specialization for search and rescue environments after environmental disasters. The approach was centered on a two-step transfer learning strategy, consisting of a pretraining phase on the VisDrone dataset, targeted at general small-object detection from aerial views, followed by fine-tuning on the Heridal dataset, which contains realistic Search and Rescue-specific imagery. This curriculum-based learning approach led to a 7.82% improvement in mAP@50 over models trained directly on Heridal, as demonstrated in
Section 3.
Training was conducted using Stochastic Gradient Descent (SGD) with the following parameters: an initial learning rate (lr0) of 0.01, momentum of 0.937, and weight decay of 0.0005. A OneCycleLR scheduler was employed, with a final learning rate factor (lrf) of 0.1. The initial phase included a 3-epoch warmup, with linearly increasing momentum and bias learning rates (warmup momentum = 0.8, warmup bias_lr = 0.1) to ensure stable convergence.
All experiments were executed at 640 × 640 input resolution, with a batch size of 16 and early stopping after 50 epochs of stagnant validation performance. Training proceeded for a maximum of 300 epochs per configuration. A 70/20/10 train/validation/test split was used across all datasets, with consistent seed initialization to ensure reproducibility.
YOLOv5 supports a wide range of “bag of freebies” options, training improvements that do not increase inference cost [
34]. Several of these techniques were leveraged, including the following:
CutMix [
35] and MixUp [
36] for advanced data augmentation that encourages generalization by blending samples and their labels;
Modified IoU-based loss functions, including GIoU, DIoU, and CIoU [
37,
38], to improve bounding box regression accuracy;
Customization of the configuration files to adjust hyperparameters such as learning rate, batch size, mosaic probability, and anchor box scaling.
Additional augmentation strategies included HSV augmentation (hue: 0.015, saturation: 0.7, value: 0.4), image translation (±10%), scaling (±10%), left–right flipping (50%), and segment-level augmentations such as copy–paste (10%) and mosaic (100%). While techniques like perspective distortion and up–down flipping were disabled (perspective = 0.0, flipud = 0.0) due to limited applicability in aerial imagery, these carefully tuned augmentations reduced overfitting and improved performance in complex cases.
Anchor boxes were re-optimized for the Heridal dataset using the built-in K-means clustering with a genetic algorithm, adapting to the real-world distribution of object sizes and improving localization, particularly for small, partially occluded figures.
Finally, loss weighting was manually calibrated to reflect the detection task’s priorities: box loss = 0.05, objectness = 0.7, and class loss = 0.3, with all positive class/object weights set to 1.0. The training IoU threshold (iou_t) was set to 0.20 to allow the model to consider even loosely overlapping predictions, which is particularly beneficial in low-resolution, cluttered scenes typical of Search and Rescue imagery in scenarios of interest for civil protection.
This comprehensive training pipeline enabled robust convergence, minimized overfitting (as later discussed), and yielded models capable of generalizing well across datasets while remaining computationally efficient for deployment on embedded UAV systems; all the details of the training phase hyperparameters are collected in
Table 1.
2.4. Embedded Deployment Setup
We implemented and tested the entire system on an embedded UAV platform to validate the feasibility of deploying person detection models for real-time Search and Rescue operations. The objective was to enable onboard AI inference for detecting missing persons from aerial imagery and provide real-time communication with a ground station through a Human–Machine Interface (HMI). This section describes in detail the hardware and software setup, the communication infrastructure, and the functionalities integrated into the GUI for field deployment.
2.4.1. UAV and Embedded Hardware Setup
The embedded system was integrated into a Holybro X500 V2 quadrotor platform equipped with a Pixhawk 6C flight controller. This drone was selected for its payload capacity, flight stability, and modular design, making it well suited for testing embedded AI systems in Search and Rescue civil scenarios. The Holybro X500 V2 features a carbon-fiber frame with a 500 mm wheelbase, providing a maximum payload capacity of approximately 1.5 kg. The Pixhawk 6C was configured with PX4 firmware (v1.13) to enable MAVLink telemetry and reliable autonomous flight control.
The onboard AI inference was performed by an NVIDIA Jetson Nano (4 GB), selected for its compact form factor, low power consumption, and CUDA-capable 128-core GPU, enabling deep learning inference directly onboard the UAV. The Jetson Nano was powered by a dedicated 5 V power bank battery. The system ran Ubuntu 18.04 with JetPack 4.6 and CUDA 10.2. The Jetson Nano was connected to a USB camera capable of capturing 1080p video at 30 FPS. Video acquisition was implemented using the V4L2 driver and OpenCV (v4.5).
Wireless connectivity was provided by a TP-Link Archer T2U Plus Wi-Fi module configured in Access Point mode, creating a dedicated peer-to-peer Wi-Fi network between the Jetson Nano and the ground station.
The ground station was a laptop running Windows 10, executing a custom Python (v3.9) application capable of receiving the video stream, displaying detection results in real time, and sending commands to the Jetson Nano to start or stop inference, adjust model parameters, or control the data flow.
All components were securely mounted on the UAV in a manner that preserved flight stability and minimized electromagnetic interference. The hardware setup is summarized in
Table 2.
2.4.2. Human–Machine Interface (HMI)
To interact with the onboard AI system, a custom Graphical User Interface (GUI) was developed in Python and deployed on the ground station. The GUI was designed to offer task-specific modules for Search and Rescue, focusing on person detection from aerial video. The GUI was developed to support firefighters or civil protection agencies: the interface prioritizes usability for non-technical operators while supporting advanced AI functionalities such as:
Establishing connections with the drone and Jetson Nano;
Streaming real-time video from the onboard camera;
Sending commands to trigger AI inference;
Receiving and visualizing detection results, including bounding boxes and metadata;
Saving frames or exporting inference outputs for post-mission analysis.
The GUI also integrates a real-time telemetry monitor that displays essential drone parameters such as GPS location, altitude, heading, and battery status.
2.4.3. Communication Architecture
The system employs a hybrid communication framework based on the following protocols:
TCP is used for reliable transmission of control commands (e.g., start video, stop video, send image, shut down) and to request or retrieve inference results from the Jetson Nano;
UDP handles real-time video and telemetry streaming due to its low-latency characteristics, which are crucial for maintaining situational awareness during flight.
This architecture ensures a reliable and responsive communication channel between the Jetson and the GUI, balancing speed and reliability based on the type of data being exchanged.
Figure 6 shows the general architecture of the hardware and communication setup.
2.4.4. Person Detection Workflow
The person detection workflow on the embedded UAV platform was structured to provide a reliable and responsive user experience, even under operational constraints typical of Search and Rescue civil missions. The process begins with the initialization phase, during which the ground station operator launches the GUI and establishes connections with both the UAV via telemetry and the Jetson Nano via TCP/UDP sockets. Once these connections are active, the system displays real-time video from the drone’s onboard camera and relevant telemetry data, such as altitude, heading, and battery status. After initialization, the operator can activate the onboard inference system by directly selecting and launching the person detection model from the GUI. The Jetson Nano then applies the object detection model, identifies any instances of persons in the scene, and generates bounding boxes around detected individuals. The resulting frame, with overlaid detection information, is transmitted back to the ground station, where the GUI immediately displays this output to the operator and logs relevant metadata such as the number of detections, timestamp, and frame index, thereby ensuring traceability and facilitating post-mission review.
An optional feature allows the operator to save selected frames locally on the ground station. When enabled, this functionality stores inference results for subsequent analysis or reporting, enhancing the system’s documentation and mission debriefing usability.
2.4.5. Performance and Optimization
The embedded system was optimized for reliable performance under resource constraints to meet the real-time requirements of aerial Search and Rescue applications for civil applications. A key goal was maintaining an inference rate of at least one to two frames per second, a threshold deemed sufficient given the nature of UAV motion in Search and Rescue contexts, which typically involves hovering or slow aerial scanning.
The architecture was implemented with multithreading to prevent system bottlenecks, where video streaming and inference were handled on separate execution threads. Multithreading ensured that the streaming process remained uninterrupted by the time-consuming operations associated with model inference.
Finally, to reduce redundant computations, the system supported on-demand inference triggering. In cases where continuous detection was not required, the operator could request person detection only when necessary, such as after identifying a potential target in the live video feed. This feature was handy in static or low-activity scenes, where continuous inference would waste computational resources without significantly improving mission outcomes.
2.5. Evaluation Metrics
The training followed a two-step transfer learning process: first, training on VisDrone for general small-object recognition from aerial images, then fine-tuning on Heridal to adapt to Search and Rescue-specific features. This approach provided a 7.82% boost in mAP@50 compared to training on Heridal from scratch.
The mean Average Precision (mAP) is the area under the precision–recall curve. A true positive is considered if a target is detected with an intersection over union (IoU) of at least 0.5, and a detection is considered positive if the predicted bounding box overlaps with the ground truth by at least IoU = 0.5. When evaluated with an IoU threshold of 0.5, it is referred to as mAP@50. This means that a detection is considered correct if the predicted bounding box overlaps with the ground truth by at least 50%.
The mAP@50:95 is computed as the average of mAP values at different IoU thresholds ranging from 0.5 to 0.95 in increments of 0.05 (i.e., IoU thresholds of 0.50, 0.55, 0.60,…, 0.95). This stricter metric provides a more comprehensive evaluation of the model’s localization accuracy, as it penalizes predictions that only roughly overlap with the ground truth.
Results are reported in
Section 3. The training strategy using VisDrone pretraining followed by Heridal fine-tuning led to consistently higher performance in both precision and recall. Results from experiments involving different fusion layers and attention mechanisms are compared and analyzed in
Section 3.
3. Results
This section presents the experimental results obtained by training and evaluating various configurations of YOLOv5 and YOLOv8 for person detection in aerial imagery, specifically targeting Search and Rescue applications. The performance was assessed using metrics including mAP@50, mAP@50:95, precision, recall, parameter count, and computational cost in GFlops. All results are contextualized concerning deployment feasibility on embedded systems such as the NVIDIA Jetson Nano.
Initial experiments focused on evaluating the impact of different dataset combinations on model performance (
Table 3).
Training the baseline YOLOv5s model on the Heridal dataset alone resulted in a mAP@50 of 0.665. Pretraining the same model on VisDrone before fine-tuning Heridal substantially improved it, reaching a mAP@50 of 0.738. A similar strategy using the Stanford Drone Dataset (S + H) achieved 0.700, while the combined use of VisDrone, Stanford, and Heridal (V + S + H) slightly underperformed, yielding 0.679. These results confirm the effectiveness of VisDrone pretraining and highlight potential overfitting or domain shift when too many heterogeneous sources are combined.
The second set of experiments examined the effect of different feature fusion strategies in the neck of the YOLOv5s model (
Table 4).
Replacing the default PANet with FPN improved the mAP@50 to 0.783, while BiFPN reached 0.750. The best result was obtained with the PB-FPN configuration, which achieved 0.801 mAP@50 and 0.386 mAP@50:95, with fewer parameters (5.493 M) and comparable computational cost. This suggests that lightweight fusion structures with strong top-down pathways are particularly beneficial for small-object detection in cluttered aerial scenes.
Additional improvements were tested by modifying the detection head structure (
Table 5).
Adding a detection head at the P2 scale (YOLOv5s-P2) resulted in a mAP@50 of 0.781, indicating that enhancing the model’s sensitivity to higher-resolution features is advantageous when detecting small targets. Combining P2 with FPN or PB-FPN maintained high performance, with YOLOv5s-PBFPNP2 reaching 0.783 mAP@50 and 0.373 mAP@50:95. Conversely, placing detection heads too early (P1) degraded performance significantly (mAP@50 = 0.641), confirming that extremely shallow layers lack sufficient semantic context.
We evaluated various modular additions to the best-performing models to further explore architectural enhancements. TPH-YOLOv5, which includes transformer-based heads and CBAM modules, resulted in 0.735 mAP@50. However, applying these components separately proved more effective. In particular, YOLOv5s-P2-Deconvolution achieved 0.779 mAP@50, while the addition of PB-FPN and deconvolution layers (YOLOv5s-PBfpn-Deconvolution) reached the best overall result in this group: 0.802 mAP@50 and 0.388 mAP@50:95. Models combining PB-FPN, CBAM, and deconvolution also performed well, slightly sacrificing recall for precision. These findings underline the critical balance between architectural complexity and small-object detection capability. The results are shown in
Table 6.
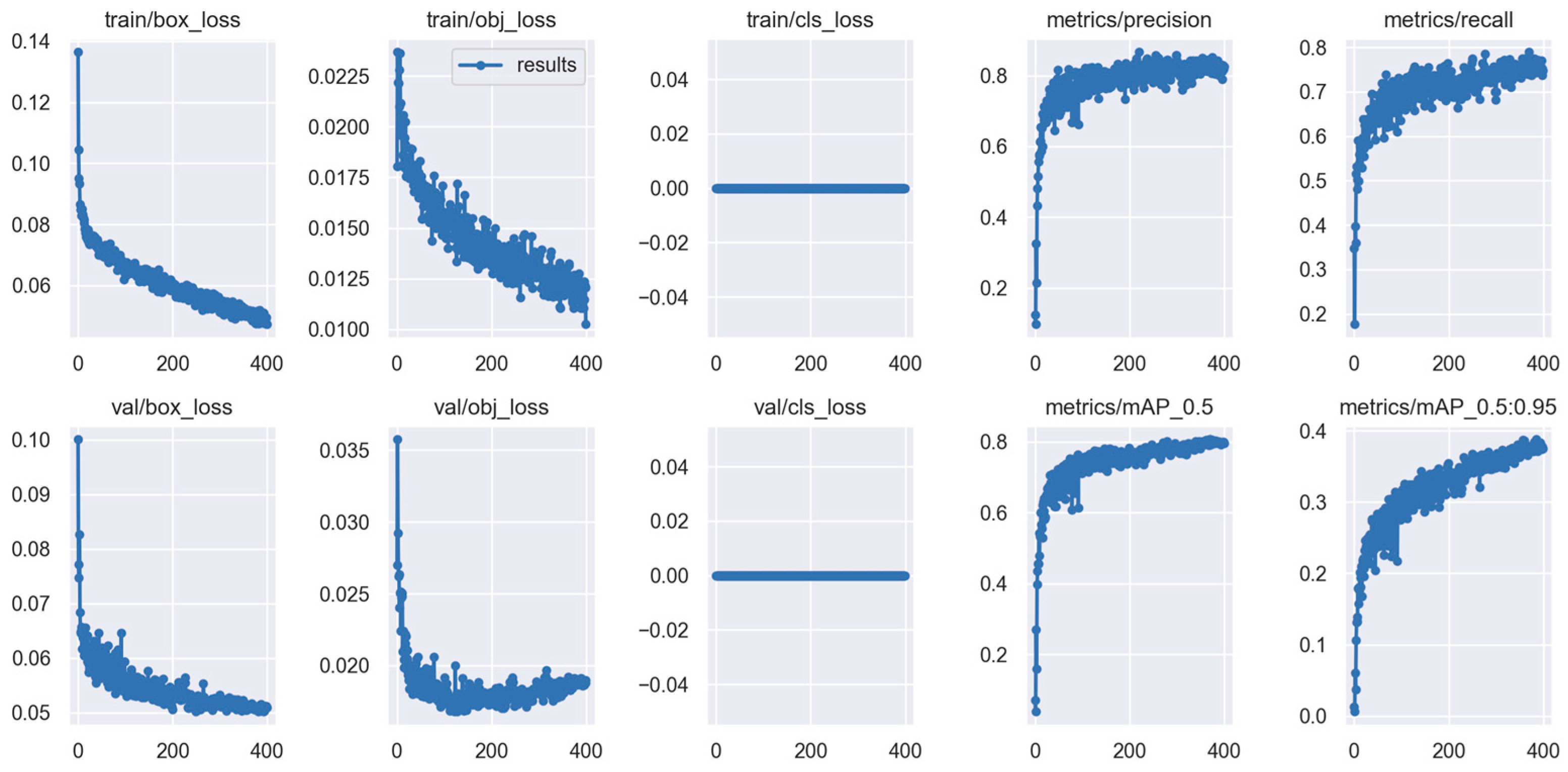
A visual representation of the training performance for the best configuration (YOLOv5s-PBfpn-Deconvolution) is provided in the training curve graphs (
Figure 7), which illustrate rapid convergence and stable validation metrics over epochs.
Moreover,
Figure 8 shows an example of prediction conducted by the trained model YOLOv5s-PBFPN-Deconvolution.
The study was then extended to the newer YOLOv8 architecture, which integrates an anchor-free design and a more refined backbone. The results are shown in
Table 7.
The baseline YOLOv8s achieved 0.781 mAP@50 and 0.387 mAP@50:95. Adding a P2 detection head slightly improved the performance to 0.788 and 0.393, respectively. PB-FPN integration yielded 0.807 mAP@50 and 0.421 mAP@50:95, the best results among all tested configurations. However, the variant combining both PB-FPN and P2 (YOLOv8s-PBfpnP2), while slightly less accurate (0.792 mAP@50), suffered from a significant increase in model size and complexity, reaching over 25 million parameters and 236.8 GFlops. Such a model exceeds the capabilities of current embedded systems like the Jetson Nano and is thus better suited for offline or cloud-based analysis.
Using UAV-acquired imagery, a complementary experiment evaluated the model’s inference performance at different flight altitudes, specifically at 10 m, 20 m, and 50 m. Interestingly, the results revealed a counterintuitive trend: detection accuracy improved with increasing altitude. This behavior can be explained by the fact that the Heridal dataset itself was collected at similar altitudes, meaning the model was implicitly optimized to detect targets under these specific acquisition conditions; YOLOv5 (and v8) uses k-means algorithm to compute the best anchor boxes relative to the dataset, so if the dataset contains only very small objects, the model will learn to detect only very small objects. Performance naturally improved as the test images aligned closely with the training distribution in terms of perspective, object scale, and visual context. Moreover, the broader field of view at higher altitudes may have enhanced the model’s ability to capture contextual cues that help recognize small objects, such as human figures.
Figure 9 illustrates detection outputs at 50 m tested altitude, confirming that the feature fusion technique (e.g., PB-FPN) contributed to robust detection across this range of image scales.
More tests have been conducted using YOLOv8s-PBFPN to highlight its detection abilities in scenarios where missing people must be found. The same background as the collected video was used. However, it has been possible to create different humanoid figures with different clothes, positions, gender, and skin color using “MakeHuman” open-source software v1.3.0.
Figure 10 shows the figures used with the respective detections: an exhausted woman sitting on the ground, a runner lying on the ground after a heart attack, a man wearing a casual white shirt and jeans walking, and another man running away from hazardous zones are the four virtual mannequins implemented for this test.
Overall, the results demonstrate that careful adaptation of the detection model through feature fusion, head placement, and modular enhancements can significantly improve the detection of small objects like missing persons in aerial Search and Rescue imagery. The optimal configurations achieve a strong balance between accuracy and efficiency, making them viable for real-time deployment on edge devices embedded in UAV systems.
To evaluate the interpretability and robustness of the proposed detection system, we conducted an explainability analysis using EigenCAM [
39], a gradient-based class activation mapping method that highlights the regions of the input image most influential in the model’s prediction. This technique is beneficial for understanding the internal mechanisms of convolutional neural networks (CNNs) when applied to aerial imagery, where object size and background context play a critical role.
These visual explanations confirmed that the improved architectures focused on relevant regions of the input image. An example image (
Figure 11) illustrates how the model’s attention aligns with true positive detections, further validating the system’s reliability in operational contexts.
Finally, to assess the feasibility of deploying the proposed model on embedded hardware, inference experiments were conducted on the NVIDIA Jetson Nano platform. The model was evaluated using representative video sequences containing aerial imagery with small objects to simulate operational conditions.
The evaluation focused on measuring inference latency and confirming that the model could maintain acceptable detection performance on resource-constrained hardware. No additional optimizations, such as INT8 quantization or TensorRT acceleration, were applied at this stage.
The average inference time per frame at 640 × 640 input resolution was approximately 450 ms, corresponding to an effective processing speed of about 2 frames per second. This latency includes image preprocessing, model inference, and output post-processing. While not yet optimized for real-time operation, these results demonstrate that the model is functional on the Jetson Nano and provides a baseline for future improvements.
Visual inspections confirmed that the model was able to detect persons across different scales, poses, and backgrounds, consistent with the results obtained during desktop evaluation. However, a quantitative measurement of the detection rate under field conditions remains to be conducted.
4. Discussion
This study aimed to develop and optimize real-time object detection models for aerial Search and Rescue civil missions, focusing on improving the accuracy of small-object detection under resource-constrained conditions typical of UAV-based deployments by civil protection agencies. The experimental results provided a comprehensive understanding of how different architectural choices, training strategies, and environmental factors impact model performance, interpretability, and deployability.
The first set of experiments highlighted the importance of dataset composition in training robust detection models. Models trained exclusively on the Heridal dataset exhibited decent performance, but pretraining on VisDrone, followed by fine-tuning on Heridal, yielded a significant boost in detection accuracy, particularly in mAP@50 and precision. This suggests that cross-domain transfer learning from general aerial imagery enhances feature generalization, even when the target dataset contains more specific Search and Rescue scenarios. On the other hand, pretraining on the Stanford Drone Dataset produced more modest gains, possibly due to differences in perspective, scene complexity, and person distribution. Notably, the combination of all three datasets (VisDrone + Stanford Drone Dataset + Heridal) decreased performance, which may be attributed to domain drift and increased intra-dataset variance, reinforcing the idea that more data is not always better without proper domain alignment.
The study of different feature fusion strategies provided additional insight into the backbone-neural encoding capabilities of the models. Replacing the default PANet neck in YOLOv5s with alternative structures such as FPN, BiFPN, and PB-FPN demonstrated that top-down fusion methods with high-resolution preservation are particularly beneficial for small-object detection. Among them, PB-FPN consistently achieved the best performance, suggesting that lightweight, information-rich, and semantically aware feature aggregation can substantially enhance localization precision without increasing model complexity.
In terms of detection head configuration, adding a prediction layer at the P2 scale significantly improved detection metrics across the board. The P2 layer allows the model to utilize high-resolution, shallow features that are particularly informative for detecting small instances, such as humans, in aerial scenes. However, detection heads placed at very early layers (P1) led to underwhelming results, confirming that a minimal semantic representation is required, even when leveraging high spatial resolution.
The evaluation of modular enhancements revealed nuanced trade-offs between architectural complexity and detection efficacy. The integration of Transformer-based modules provided a moderate improvement in recall, likely due to their ability to capture long-range dependencies and contextual relationships. The addition of CBAM increased precision in most configurations by guiding the model’s attention toward salient spatial and channel-wise features. Among all tested modules, deconvolution layers offered the most consistent gains in both mAP and precision, particularly when combined with PB-FPN and P2 heads. These findings support the hypothesis that enhancing the spatial resolution in the later stages of the model pipeline is a key factor for improving small-object detection in low-resolution UAV imagery.
The training curves for the best-performing configurations showed smooth convergence and limited overfitting, even in scenarios with deep feature hierarchies. Using well-structured pretraining and careful dataset balancing contributed to stable generalization across epochs. Models that incorporated multiple architectural innovations (e.g., PB-FPN + P2 + deconvolution) reached higher validation accuracy without exhibiting divergence or performance decay, confirming the robustness of the proposed training pipeline.
A comparative analysis between YOLOv5 and YOLOv8 revealed the inherent trade-off between detection performance and computational feasibility. YOLOv8s and its variants achieved higher mAP@50:95 scores than YOLOv5-based models, benefiting from an anchor-free architecture and a more efficient backbone. However, this gain came at the cost of increased parameter count and GFlops, making several YOLOv8 configurations impractical for real-time inference on edge devices such as the Jetson Nano. Notably, YOLOv5s models with optimized architecture and lightweight modules achieved comparable accuracy at a fraction of the computational cost, reinforcing the suitability of YOLOv5 for embedded Search and Rescue applications in civil scenarios.
An additional set of experiments evaluated the model’s performance at different flight altitudes (10 m, 20 m, 50 m). Contrary to common expectations, detection accuracy increased with altitude. This effect can be attributed to the Heridal dataset being collected within the same altitude range, resulting in training data that closely matched the test conditions. Moreover, the higher altitude provides a broader contextual view, which may help the model distinguish humans from background clutter better. This highlights the importance of dataset alignment with deployment conditions and suggests that models trained on a specific altitude distribution may struggle to generalize outside that range.
The practical implications for UAV deployment were explored through a Jetson Nano-based embedded system, where person detection models were executed onboard with real-time transmission of inference results to a ground station. The system was tested under laboratory and field conditions, confirming that the best-performing YOLOv5s configuration achieved a stable inference rate of 1–2 FPS, which is acceptable for UAVs performing stationary or low-speed search operations. Modular, multithreaded communication protocols (TCP/UDP) and a task-specific HMI interface enhanced system reliability and usability, allowing civil protection agencies to use them.
Explainability analyses using EigenCAM added a crucial layer of transparency to the system. One observation was that the model consistently activated more strongly around individuals lying down than those standing upright. This difference may be partially explained by the vertical aspect ratio and the limited footprint of a standing person in top-down views, which leads to weaker gradient signals during training and reduced visual prominence in activation maps. It is important to note that this does not necessarily imply a detection failure but rather a reduced interpretability signal in CAM outputs, a limitation known in the literature for narrow or low-contrast targets.
More intriguingly, the activation maps showed a clear bias in spatial attention toward areas containing vegetation instead of regions with cultivated soil or artificial textures. This was evident in multiple Heridal test images, where the right-hand side (vegetation) triggered significantly stronger activations, even without ground-truth objects, than the left-hand side (open field). This suggests that the model may have implicitly learned to associate natural textures with the presence of humans, potentially due to an unbalanced distribution in the training dataset.
The Heridal dataset includes numerous scenes where persons are embedded within vegetated environments, such as forests or overgrown rural paths. As a result, the network may have developed a spurious correlation, effectively learning that “vegetation implies a higher probability of a person being present.” While such a heuristic might be effective within distribution, it introduces the risk of background-induced false positives or blind spots in non-vegetated regions during inference in unseen environments.
From a broader XAI perspective, this phenomenon aligns with concerns regarding background context bias in deep learning models. CNN-based detectors can latch onto dominant low-level features (e.g., color, texture, edge density) that co-occur with positive samples, even when these features are not causally linked to the target object. Although these patterns may improve local accuracy during training, they compromise generalization and interpretability, particularly in safety-critical scenarios like Search and Rescue missions, where people must be detected in environmental crises or accidents.
To validate whether this behavior stems from genuine spatial correlation or is an artifact of explainability methods like EigenCAM, future work should include feature ablation studies and counterfactual visual explanations (e.g., by systematically masking background textures or altering terrain types). Such techniques would clarify whether attention is semantically grounded or driven by texture bias.
These findings underscore the importance of dataset curation and bias analysis in critical applications such as the typical Search and Rescue operations occurring after accidents, disasters, or medical emergencies.
Nonetheless, the study has some limitations. All experiments were conducted using RGB imagery without incorporating other sensor modalities such as thermal or multispectral data, which could be advantageous in low-visibility conditions. Additionally, while the inference system was validated on the Jetson Nano, future work should explore deployment on other embedded platforms (e.g., Coral Dev Board, Jetson Orin Nano) to assess energy efficiency and throughput across different hardware configurations. The performance of the detection models should also be evaluated under more diverse environmental conditions, such as urban areas, maritime settings, or nighttime operations.
5. Conclusions
This study proposed and validated a complete methodology for real-time aerial detection of missing persons using optimized YOLO-based architectures deployed on embedded UAV platforms. The system has been developed to support civil protection activities, such as the detection of people lost or disoriented, blocked by flooding, escaping wildfires, or disabled by health issues. By systematically evaluating a wide range of architectural modifications, including enhanced feature fusion strategies, lightweight detection heads, and modular attention mechanisms, we demonstrated that substantial gains in detection accuracy for small objects can be achieved without compromising computational efficiency. Among the tested configurations, the integration of PB-FPN with a P2 detection head and a lightweight deconvolution module yielded the best trade-off between performance and resource usage, making it well suited for real-time deployment on low-power hardware such as the Jetson Nano.
Through extensive training on Search and Rescue-relevant datasets (Heridal) combined with a multi-step transfer learning strategy, the proposed models consistently increased mAP and recall metrics, even in scenarios with cluttered backgrounds and low-resolution targets. Our results also revealed that detection performance can be sensitive to the flight altitude of the UAV, suggesting the need for altitude-aware training or augmentation when targeting broader operational ranges.
Furthermore, the incorporation of explainability methods, specifically EigenCAM, enabled a deeper understanding of the model’s internal decision-making processes. This interpretability analysis uncovered strengths (e.g., attention on partially occluded persons) and biases (e.g., over-reliance on vegetated regions), underscoring the need for dataset diversity and careful validation when deploying AI in safety-critical contexts like Search and Rescue.
The embedded deployment tests confirmed the feasibility of running the detection pipeline onboard in near real time, demonstrating the system’s applicability in field scenarios where wireless bandwidth, processing power, and operator attention are constrained.
In future work, we plan to extend the system to support multimodal detection (e.g., thermal, IR), increase its robustness to diverse terrains and lighting conditions, and integrate higher-level reasoning modules to support mission-level decision-making, integrating also procedures developed by civil protection authorities. Additionally, we intend to evaluate and compare newer YOLO versions (e.g., YOLOv8, YOLOv10, YOLOv11, YOLOv12) to assess their suitability for embedded deployment and potential accuracy improvements in Search and Rescue civil scenarios. Ultimately, the methodology outlined in this work lays the foundation for building reliable, interpretable, and efficient UAV-based perception systems tailored for real-world Search and Rescue operations managed by civil protection authorities.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}