1. Introduction
Multimodal large language models (MLLMs) powered by transformer architectures represent a breakthrough in artificial intelligence, fundamentally differing from ordinary AI optimization algorithms such as traditional machine learning models or heuristic optimization techniques. While conventional AI models typically process single-modality data with limited computational complexity, MLLMs integrate diverse data modalities for advanced pattern recognition and contextually rich output generation. However, this advanced functionality comes at the cost of massive computational requirements, often billions of parameters, making their deployment particularly challenging. The prevalent cloud-based deployment model introduces critical bottlenecks: prohibitive latency for real-time applications and excessive bandwidth consumption for multimodal data transmission [
1]. These limitations are particularly acute in IoT environments where edge devices possess minimal computational capacity, creating an urgent need for distributed computing solutions specifically designed for MLLMs.
Mobile edge computing (MEC) emerged as a promising solution by bringing computational resources closer to data sources [
2,
3,
4]. However, as IoT applications expand into remote terrestrial and maritime environments, areas crucial for applications like offshore monitoring and disaster response, traditional cellular-based MEC faces fundamental coverage limitations [
5]. The prohibitive costs of infrastructure deployment in these regions demand alternative approaches. This gap has catalyzed the development of satellite edge computing (SEC), which leverages low Earth orbit (LEO) satellites augmented by unmanned aerial vehicles (UAVs) to create a ubiquitous computational layer [
6,
7]. UAVs serve as dynamic computing nodes that can process tasks locally, adapting their positions to optimize coverage and minimize latency, capabilities essential for supporting MLLM-based services in connectivity-challenged environments [
8].
The integration of MLLMs into SEC networks unlocks unprecedented possibilities for intelligent edge applications. By enabling complex multimodal reasoning at the network edge, this paradigm supports autonomous decision-making while preserving data privacy. The key to realizing this potential lies in intelligent task distribution: determining optimal processing locations based on task characteristics, network conditions, and available resources. This requires sophisticated algorithms for task offloading and resource allocation that can navigate the trade-offs between computational capacity, communication latency, and energy constraints across heterogeneous computing nodes [
9].
However, MLLM task offloading and resource allocation in SEC networks present unique challenges that far exceed traditional edge computing scenarios [
10]. The massive parameter scale of MLLMs, often billions of parameters, creates extraordinary computational demands that strain the limited resources of satellite and UAV platforms [
11]. Compounding this challenge, the inherent dynamics of SEC networks introduce additional complexity: LEO satellites’ rapid orbital motion causes frequent topology changes, time-varying channel conditions create unpredictable communication links, and the heterogeneous nature of computing nodes, including LEO satellites and UAVs, requires coordinated resource management [
12]. These factors render static optimization approaches obsolete, as they cannot adapt to the continuously evolving network state [
13].
The complexity and scale of this optimization problem exceed the capabilities of conventional approaches. While dynamic programming suffers from the curse of dimensionality, heuristic methods lack performance guarantees in highly dynamic environments. Deep reinforcement learning (DRL) offers a compelling alternative, learning adaptive policies through interaction with the environment [
14,
15,
16]. However, the SEC task offloading problem presents a particularly challenging scenario: the action space combines discrete decisions (task offloading choices) with continuous variables (power allocation, UAV trajectories) [
17]. Traditional DRL methods either discretize the entire action space, sacrificing precision and creating computational bottlenecks, or struggle to handle hybrid action spaces effectively.
Given the aforementioned challenges, this work addresses three key research questions. How can MLLMs be efficiently deployed in UAV-assisted SEC networks to provide ubiquitous services to IoT devices in remote areas? How can we jointly optimize discrete offloading decisions and continuous resource allocation variables to minimize system latency and energy consumption while ensuring MLLM service quality in dynamic SEC environments? How can we develop a DRL that effectively handles the hybrid discrete–continuous action space inherent in SEC task offloading problems?
To address these research questions, this paper aims to achieve comprehensive performance optimization for MLLM inference in UAV-assisted SEC networks through intelligent MLLM task offloading, bandwidth allocation, and UAV trajectory. The primary objective is to develop a framework that minimizes system-wide latency and energy consumption while ensuring reliable MLLM service delivery to remote IoTDs. This involves formulating the joint optimization problem as a mixed-integer nonlinear programming (MINLP) problem that simultaneously handles discrete offloading decisions and continuous resource allocation variables. To solve this challenging optimization problem, we propose an action-decoupled soft actor–critic (AD-SAC) algorithm specifically designed for hybrid discrete–continuous action spaces. This approach maintains the precision of continuous control while efficiently handling discrete decisions, enabling real-time adaptation to dynamic SEC environments. The framework aims to minimize system-wide latency and energy consumption while ensuring sustainable MLLM service delivery to IoTDs in remote environments. The main contributions of this work are summarized as follows.
We develop a novel MLLM inference framework that jointly optimizes task offloading and resource allocation in UAV-assisted SEC networks, enabling ubiquitous MLLM services for IoT devices in remote environments through coordinated utilization of UAVs and LEO satellites.
We formulate the joint optimization problem as an MINLP problem that minimizes the weighted sum of MLLM offloading latency and energy consumption. The formulation simultaneously optimizes discrete offloading decisions and continuous variables, including power allocation and UAV trajectories, while satisfying accuracy requirements and accounting for dynamic LEO satellite coverage.
We propose an AD-SAC algorithm to solve the MINLP problem with hybrid discrete–continuous action spaces. By delegating discrete and continuous actions to specialized agents within a cooperative training framework, AD-SAC effectively leverages off-policy data to develop robust hybrid policies for real-time adaptation.
Extensive simulation results demonstrate that our proposed method achieves a more effectively converged policy and exhibits enhanced performance in MLLM inference when compared to prevalent DRL baseline algorithms.
The organization of this manuscript is structured as follows.
Section 2 reviews the related work. The system model and problem formulation are delineated in
Section 3. A comprehensive description of the hybrid space SAC algorithm is provided in
Section 4. The performance evaluation of the proposed algorithm is presented in
Section 5, and the study is summarized in
Section 6.
3. System Model
This section presents the system model for MLLM inference in UAV-assisted SEC networks. We first describe the network architecture and then introduce the task model, followed by the wireless transmission, latency, and energy consumption models.
3.1. Network Model
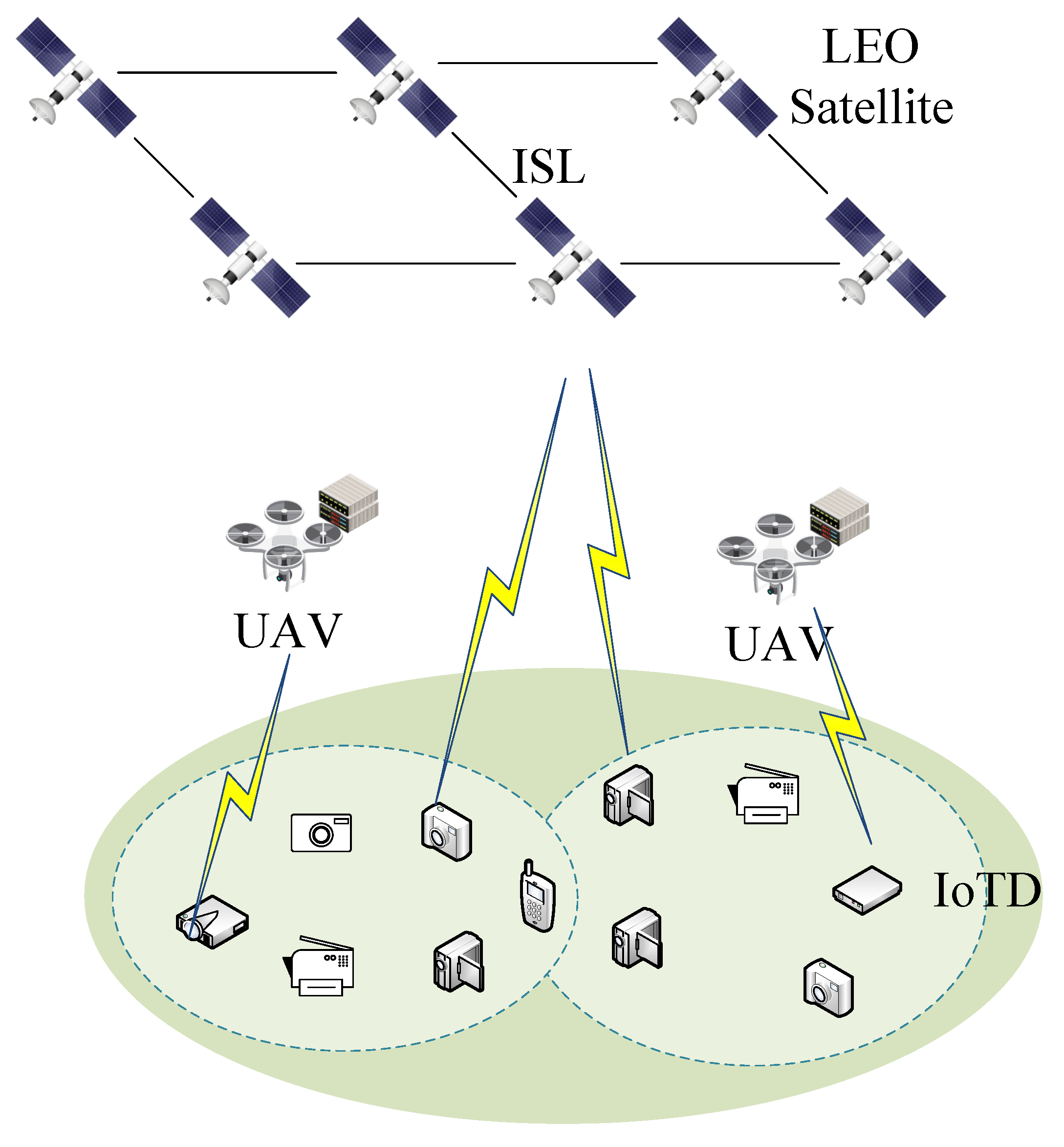
We consider a three-tier SEC network architecture as illustrated in
Figure 1, comprising
K IoTDs,
M UAVs, and
N LEO satellites, denoted by the sets
,
, and
, respectively. In this MLLM-enabled SEC framework, resource-constrained IoTDs are not capable of processing the MLLM task locally; thus, the MLLM task requests are offloaded to UAVs and LEO satellites. UAVs deploy smaller MLLMs, offering accuracy
, for processing tasks, while LEO satellites, equipped with high-performance computing capability, run larger MLLMs, achieving a higher inference accuracy
. For clarity, MLLMs deployed on UAVs will be referred to as MLMM
m, while those deployed on LEO satellites will be referred to as MLMM
n.
The system time is discrete into T time slots; within each time slot t, IoTDs can offload MLLM inference tasks to either UAVs through direct wireless links or to LEO satellites via ground-to-satellite communication. This hierarchical architecture enables flexible task distribution based on accuracy requirements, latency constraints, and resource availability.
While some IoTDs may have the ability to perform partial processing of smaller MLLM tasks, this work assumes that all MLLM tasks are offloaded to UAVs or LEO satellites. This assumption is grounded in the resource constraints of typical IoTDs with limited computational power, memory, and energy, which make local processing of large-scale MLLM or quantized MLLM tasks impractical, especially in remote or challenging environments like offshore monitoring or disaster response. By assuming full offloading, we simplify the system model and focus on optimizing task allocation across UAVs and LEO satellites, though extending the framework to include partial local processing remains an interesting avenue for future work.
3.2. Task Model
At each discrete time slot t, IoTD generates an MLLM service request characterized by the tuple , where denotes the multimodal input data size (bits), encompassing text, image, and video content, represents the discrete output length level, determined by the service type and input characteristics, specifies the maximum tolerable latency from task initiation to result reception, and indicates the minimum acceptable inference accuracy.
The output length , selected from the discrete set , is determined by the specific MLLM application and the characteristics of the input data . For example, in translation tasks, is typically proportional to the input size , reflecting the length of the translated text. In contrast, video summarization yields a fixed-length summary (e.g., a paragraph), while visual question answering produces a short fixed output (e.g., a few words). The discrete levels are predefined based on the expected output sizes for different application types, allowing the system to accommodate varying computational and bandwidth demands.
Given the computational limitations of IoTDs, all MLLM tasks need to be offloaded to UAVs or LEO satellites. Upon task completion, the server node transmits the processed outcomes back to the IoTD. Formally, let
denote a binary variable for IoTD
k, capturing the task offloading choice at time slot
t. Here,
signifies that IoTD
k assigns the task to UAV
m, whereas
indicates that the task is offloaded to LEO satellite
n, with
otherwise. A key constraint ensures that, within each time slot, an IoTD’s task is allocated to precisely one execution node. The subsequent constraints governing task offloading are as follows:
Additionally, accuracy constraints must be satisfied based on the selected computing node:
While IoTD locations and wireless channels remain stable within each time slot, inter-slot variations arise from device mobility and environmental dynamics, necessitating adaptive resource allocation strategies.
3.3. Service Coverage Model
The heterogeneous nature of the SEC network necessitates distinct coverage models for UAVs and LEO satellites, reflecting their different mobility patterns and communication characteristics.
3.3.1. UAV Service Coverage
Each UAV
maintains a circular service coverage area with radius
, within which IoTDs can establish communication links for task offloading. At time slot
t, UAV
m operates at position
, where
denote the horizontal coordinates, and
represents the fixed flight altitude. For IoTD
k located at
to successfully offload tasks to UAV
m, the following coverage constraint must be satisfied:
This constraint ensures that only IoTDs within the UAV’s coverage can access its computational resources, directly impacting the feasibility of offloading decisions.
3.3.2. LEO Satellite Service Coverage
Unlike stationary UAVs, LEO satellites exhibit continuous orbital motion, creating time-varying coverage windows for ground IoTDs. The visibility duration
during which IoTD
k can communicate with satellite
is determined by
where
represents the linear velocity of the accessible LEO satellite
n for IoTD
k. Let
denote the arc length of the ground-to-satellite communication link between IoTD
k and its accessible LEO satellite
n, where
is the coverage angle of the accessible LEO satellite
n, calculated as follows:
where
signifies the altitude of the accessible LEO satellite
n from the ground for IoTD
k,
denotes the Earth’s radius, and
represents the elevation angle between IoTD
k and its accessible LEO satellite
n.
3.4. Communication Model
The wireless channels in the UAV-assisted SEC network exhibit distinct characteristics for UAV and satellite links. In this paper, we consider radio frequency (RF) wireless communication channels for both ground-to-UAV and ground-to-satellite links [
28], rather than free space optical (FSO) channels [
29]. The choice of RF communication is motivated by its robustness to weather conditions and lower pointing requirements compared to FSO, which is particularly important for mobile UAVs and fast-moving LEO satellites.
3.4.1. Ground-to-UAV Communication
Similar to the existing works [
30], the channel between IoTD
k and UAV
m follows a Rician fading model, capturing both line-of-sight (LoS) and non-line-of-sight (NLoS) components. The channel coefficient is expressed as
where
represents the reference channel gain at unit distance, and
is the path-loss exponent (typically
for UAV communications). Then, the
denotes the small-scale fading component:
where
is the Rician factor,
represents the LoS component, and
denotes the NLoS component.
When the MLLM tasks are offloaded to the UAVs, the uplink transmission rate
from the IoTD
k to the UAV
m is expressed as
where
denotes the uplink transmit power of the IoTD
k,
signifies the channel bandwidth of the UAV
m, and
signifies the power spectral density of the AWGN. Correspondingly, the downlink transmission rate
is given as
3.4.2. Ground-to-Satellite Communication
Satellite links experience more severe propagation conditions, modeled using the Rician-Shadowed fading distribution to capture atmospheric effects and shadowing. The uplink rate from IoTD
k to satellite
n is
where
represents the channel power gain between the IoTD
k and the LEO satellite
n following the Racian-Shadowed fading model [
31], and
indicates the channel bandwidth of LEO satellite
n. For the downlink, the large propagation distance typically eliminates inter-satellite interference at the IoTD. Then, the downlink transmission rate
can be calculated as
3.5. Computing Model
The MLLM inference process involves three sequential phases: uplink transmission of multimodal input data, inference computation, and downlink transmission of generated results. This section models the latency and energy consumption for both UAV and LEO satellite computing.
3.5.1. UAV Computing Latency
When IoTDs choose to offload their MLLM tasks to UAVs through wireless connections, the communication latency model encompasses both the upload transmission latency and the latency associated with returning the results. In this context, the term
represents the total UAV computing latency, which includes the latency needed to upload multimodal data from IoTD
k to UAV
m, the inference processing latency at UAV
m, and the transmission of the resulting data back to IoTD
k. For a specified volume of multimodal input data
, the upload transmission latency can be calculated by
Hence, the energy consumption of upload transmission from IoTD
k to UAV
m is
Upon acquiring multimodal data, UAV
m is able to handle the MLLM inference request for IoTD
k. The inference execution duration, denoted as
, is influenced by the maximum floating-point operations per second (FLOPS) capacity of the onboard computing capability of UAV
m, in addition to the total computational resources required for the inference process. Consequently, the computational latency for the MLLM on UAV
m to generate content for IoTD
k can be expressed as
where
denotes the number of FLOPS used by one inference step of MLLM on UAV
m per output word, and
is the FLOPS capability of UAV
m.
The energy consumption associated with the inference task of IoTD
k on UAV
m is expressed as
where
denotes the power consumption of UAV
m’s processing unit.
During the result return phase, the output of the MLLM task for IoTD
k is determined by multiplying the average data size per output word, denoted as
(in bits per word), by the total number of output words. Consequently, the downlink transmission latency is defined as
where
represents the downlink transmission rate between IoTD
k and UAV
m.
The energy consumption associated with the downlink transmission from UAV
m to IoTD
k is computed as
where
represents the transmission power of UAV
m.
In summary, the total UAV computing latency for IoTD
k on UAV
m at time slot
t is expressed as
Thus, the total energy consumption for the MLLM task of IoTD
k processed on UAV
m is calculated as follows.
3.5.2. LEO Satellite Computing Latency
Analogous to the UAV computing latency, when IoTD k offloads its MLLM request to a LEO satellite, the process involves IoTD k initially transmitting multimodal data to the LEO satellite n through a ground-to-satellite link.
If an MLLM task is transmitted from accessible satellite
n to satellite
via a multi-hop path through inter-satellite links (ISL), the transmission latency of ISL needs to be considered. Let the path be a sequence of satellites
, where
and
. Then, the upload transmission latency from IoTD
k to the satellite
via accessible satellite
n can be expressed as
where
c is the speed of light for propagation latency,
is the distance between satellites
and
,
is the number of routing hops, and
is the transmission rate of the ISL. Here,
is the indicator function of whether or not the accessible satellite
n and offloaded satellite
are the same, which is defined as
Consequently, the energy consumption for the upload transmission from IoTD
k to LEO satellite
via accessible satellite
n is expressed as
where
is the transmission power of the ISL.
When the MLLM task is executed on the LEO satellite, the inference latency for IoTD
k at LEO satellite
n is calculated as
where
represents the number of FLOPs used by one inference step of MLLM on LEO satellite
n per output word, and
is the FLOPS of LEO satellite
n.
The inference energy consumption for IoTD
k’s task executed on LEO satellite
n is
where
represents the device power of LEO satellite
n.
The latency associated with transmitting the token results from LEO satellite
to IoTD
k through accessible satellite
n is expressed as
where
represents the downlink transmission rate of the ground-to-satellite link.
The energy consumption for the resulting transmission from LEO satellite
to IoTD
k through accessible satellite
n is given by
In summary, the LEO satellite computing latency for the MLLM task of IoTD
k is calculated as
The energy consumption for LEO satellite computing associated with the MLLM task of IoTD
k is expressed as
The total latency for the MLLM service request of IoTD
k is
The total energy consumption for the MLLM task of IoTD
k across all server nodes is given by
3.6. Problem Formulation
This section formulates the MLLM task offloading and resource allocation problem as an MINLP problem. The objective is to minimize the weighted sum of the system latency and energy consumption for MLLM task requests from IoTDs within UAV-assisted SEC networks. The optimization simultaneously optimizes the offloading decisions, transmission power allocation of IoTDs, and UAV trajectory while satisfying the accuracy requirements of the IoTDs. The optimization problem is structured as follows:
where
represents the offloading decisions of IoTDs,
indicates the transmitted power allocation of IoTDs, and
denotes the locations of IoTDs. Constraint (
31a) delineates the offloading decision for the MLLM task associated with IoTD
k. Constraint (
31b) signifies that the offloaded server node fulfills the minimum accuracy threshold specified by IoTD
k. Constraint (
31c) establishes the upper bound on acceptable latency for each MLLM task. Constraint (
31d) enforces that the maximum transmission power of IoTD
k.
In the objective function, the terms and have distinct physical units and cannot be summed directly. To resolve this, we employ weight factors and to form the weighted sum . These factors serve dual purposes: (1) they ensure dimensional consistency by making the terms dimensionless or commensurable, and (2) they normalize the contributions of delay and energy, enabling a fair comparison in the optimization process. The values of and can be adjusted based on system requirements, such as typical latency and energy scales or the relative importance of each objective, allowing the framework to effectively balance real-time performance and energy efficiency.
4. Hybrid Action Space SAC-Based MLLM Task Offloading and Resource Allocation Scheme
In this section, we address the challenges of optimizing task offloading and resource allocation for MLLMs in the SEC environment. Specifically, we consider MLLM tasks that involve processing inputs from the MMMU dataset [
32], which includes multimodal inputs consisting of text sequences of varying lengths and images. The MLLMs deployed on the servers include VILA1.5 (3B, 8B, 13B parameters) [
33], Obsidian 3B [
34], and Llava1.6 (7B, 13B parameters) [
35]. To accommodate different computational constraints and accuracy requirements, these models are deployed with various quantization levels ranging from 4-bit to semi-precision, enabling flexible trade-offs between inference speed and model accuracy.
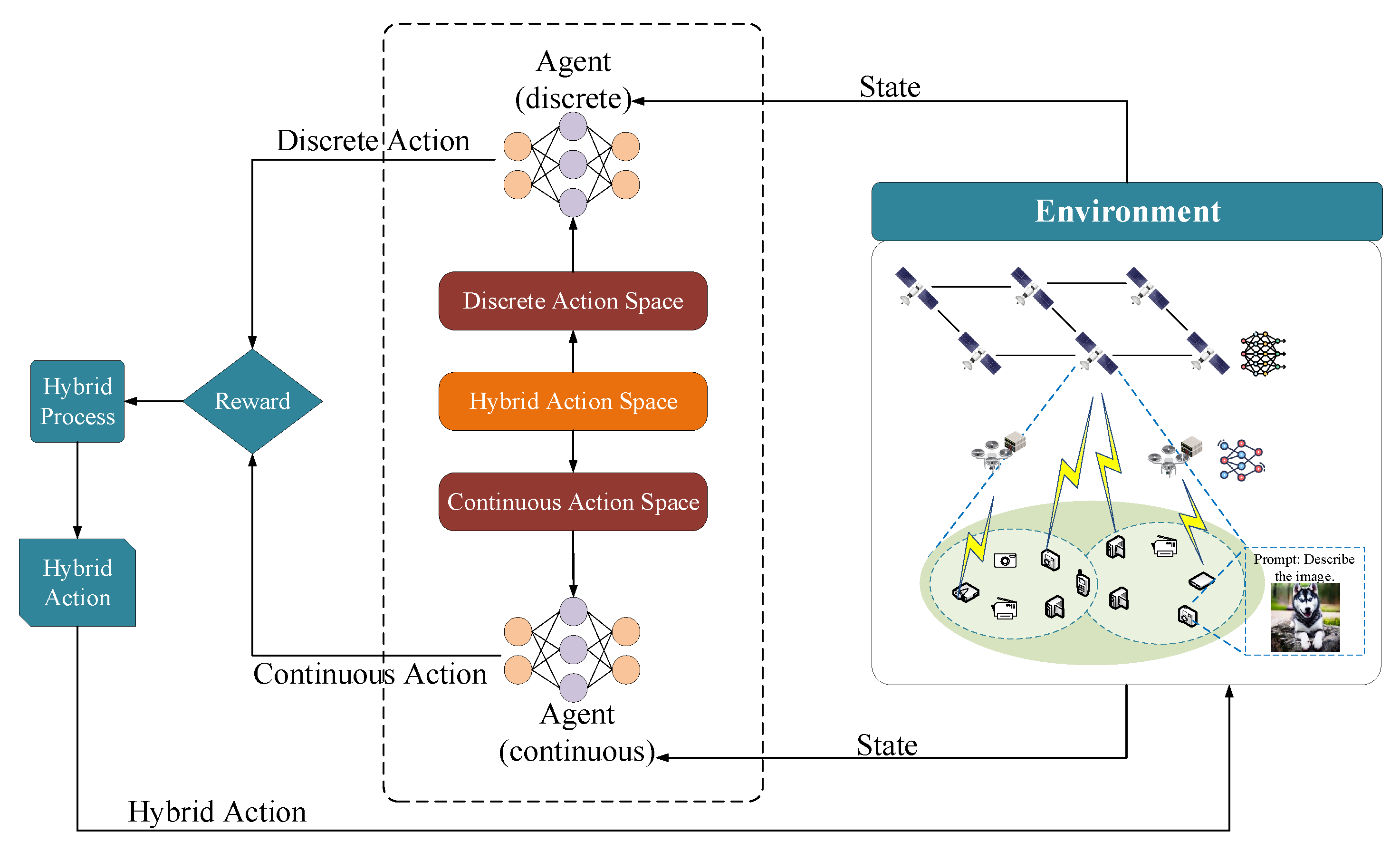
DRL is particularly effective for tackling the long-term optimization objectives of the identified challenges, despite the complications arising from complex hybrid discrete–continuous action spaces. Traditional methods, such as discretizing continuous actions or converting discrete actions to a continuous format, often result in excessively large action spaces or significant exploration demands. To address these challenges, we propose a hybrid action space framework that decouples actions and allocates them to separate agents for collaborative learning, thereby effectively integrating discrete and continuous policies.
4.1. Markov Decision Process
Prior to implementing DRL algorithms, it is essential to formulate each problem as an MDP. An MDP is characterized by three fundamental components: state, action, and reward.
4.1.1. State Space
The system state at any given time slot
t is conceptualized as encompassing several distinct elements, which can be expressed as
where
describes the input data size of IoTDs’ MLLM request,
represents the length of the generated text output of the
k-th MLLM request,
indicates the required accuracy for the
k-th MLLM request, and
denotes the maximum tolerable latency.
signifies the channel gains between IoTDs and UAVs and between IoTDs and LEO satellites.
represents the locations of IoTDs at each time slot
t.
indicates the visibility window of the accessible LEO satellite.
4.1.2. Action Space
After observing the state
at a specific time slot
t, the agent undertakes an action
, which is defined as
where
is the offloading decision,
represents the power allocation strategies, and
indicates the trajectory decisions of UAVs.
4.1.3. Reward Function
To align the DRL objective with the aim of minimizing the total energy consumption, which contrasts with the conventional goal of maximizing cumulative rewards, we define the reward function as the inverse of the weighted sum of system latency and energy consumption for MLLM task requests. The reward function can be defined as
where
is the adjustable coefficient.
4.2. SAC Framework
To optimize the decision variables in alignment with the MDP defined for Equation (
34), we utilize the SAC algorithm to identify effective solutions. The SAC algorithm, an actor–critic method, integrates policy-based and value-based strategies, employing four neural networks: a value function network parameterized by
, a soft Q-function network parameterized by
, a policy network parameterized by
, and a target value function network denoted by
. Then, we clarify the roles of different Q-function networks:
: the state value function network that estimates the expected return from state under the entropy-regularized policy.
: the soft Q-function network that evaluates state-action pairs, incorporating entropy bonuses in the value estimation.
: the target value function network, updated slowly for training stability.
: the target Q-value computed using the Bellman equation: .
In practice, these networks require training to implement the SAC algorithm. The update rule for the value function is given as
where the Q-value associated with a given network is denoted by
, the expectation operator by
, and the sample distribution by
. The SAC algorithm minimizes the loss by leveraging the squared residual error for the value function. The gradient of the value function loss, as derived from Equation (
35), is expressed as
Additionally, the loss function for updating the soft Q-network
is formulated as
where the target Q-value
is defined as
with
representing the discount factor and
denoting the state transition probability.
The corresponding gradient for the Q-network update is given by
Furthermore, the policy network is reformulated through a neural network transformation defined as
, where
represents a noise term adhering to a Gaussian distribution. The loss function for updating the policy network
is computed as
where
signifies the normal distribution. The corresponding gradient is calculated by
with the Q-value updated as
where
denotes the discount factor, and
represents the state transition probability.
4.3. Continuous–Discrete Action Space-Based SAC Algorithm
In the optimization challenges delineated in problem
, the decision-making process involves a combination of discrete and continuous actions, presenting a substantial obstacle for traditional DRL algorithms [
36]. Conventional techniques frequently address this issue by converting the continuous action space into a discrete form, which significantly expands the size of the action space. Alternatively, some methods attempt to reframe discrete actions as continuous, a strategy that increases complexity and obstructs the training process’s ability to converge effectively. To mitigate these difficulties, we propose the integration of an action decoupling algorithm within the SAC framework through decomposing the Q-functions into discrete and continuous components:
Discrete agent networks: , , handle discrete actions (offloading decisions), where subscript denotes discrete components.
Continuous agent networks: , , handle continuous actions (power allocation and UAV trajectories), where subscript denotes continuous components.
This approach entails a redefinition of both the action and the policy, enabling more efficient management of the hybrid action space. The policy function and action can be redefined as
where,
represents discrete actions, and
denotes continuous actions. Here,
represents the joint policy function obtained by combining the discrete and continuous policy components. This factorization enables independent learning of discrete and continuous action policies while maintaining their interdependence through the joint Q-value estimation.
Accordingly, we develop two independent agents, each utilizing a distinct SAC framework to optimize the discrete or continuous variables of problem
. Consequently, the cost functions for the value networks of the discrete and continuous agents are expressed as
Then, the cost functions for the soft Q-networks associated with discrete and continuous agents are defined as
Additionally, the cost functions for the policy networks of the discrete and continuous agents are given by
To optimize the decoupled policies, we adopt the maximum a posteriori policy optimization algorithm, as described in [
37]. For the hybrid action space within the SAC framework, we introduce a new policy
ℓ to maximize expected Q-values while satisfying Kullback–Leibler (KL) divergence constraints to ensure stable policy updates:
where
represents the Q-function derived from the replay buffer
[
38]. To maintain stability, it is imperative to constrain the divergence between the new policy and the existing one. This is achieved through the following condition:
where
denotes the Kullback–Leibler divergence,
represents the current hybrid policy, and
is the stability threshold.
The updated policy is determined by optimizing the following objective:
subject to the constraints:
where
and
represent the stability thresholds for the discrete and continuous agents, respectively, and
denotes the number of discrete choices. The structure of the hybrid action space AD-SAC algorithm is illustrated in
Figure 2.
The proposed algorithm decomposes the hybrid action space into discrete and continuous components, allocating each to a distinct agent trained within its own SAC framework. Subsequently, the maximum a posteriori policy optimization algorithm [
37] is utilized to integrate the decoupled policies from all agents. This approach effectively tackles the complexities associated with hybrid action spaces in the addressed problems, offering a robust and adaptable framework for hybrid action selection. Algorithm 1 provides a comprehensive overview of the AD-SAC algorithm.
| Algorithm 1 AD-SAC Algorithm for MLLM Task Offloading and Resource Allocation |
- 1:
Initialize all the networks, , , , , , , , and ℓ. - 2:
repeat - 3:
for each time slot do - 4:
Obtain , , based on the policy ℓ and current state . - 5:
Save the sample to replay . - 6:
Generate samples for unavailable actions and save them to replay . - 7:
end for - 8:
for each training epoch do - 9:
Update based on (45), based on (47), based on (49). - 10:
Update based on (46), based on (48), based on (50). - 11:
;Soft update and . - 12:
Update ℓ based on (51), (52) and (53). - 13:
end for - 14:
until convergence.
|
4.4. Complexity Analysis of AD-SAC
4.4.1. Time Complexity
The proposed AD-SAC algorithm employs two independent agents, each utilizing four neural networks (value network, soft Q-network, policy network, and target value network). Assuming each network consists of L fully-connected layers with hidden dimension H, the computational complexity for a single forward pass is . During each training iteration with batch size B, the algorithm performs forward and backward propagation across all eight networks, resulting in a time complexity of per iteration. Additionally, the policy integration step using maximum a posteriori optimization introduces a computational overhead of , where and represent the discrete and continuous action dimensions, respectively. Therefore, the overall time complexity per training epoch is , which scales linearly with the batch size and quadratically with the hidden layer dimension.
4.4.2. Space Complexity
The memory requirements of AD-SAC are primarily determined by the storage of network parameters and the experience replay buffer. Each neural network with L layers and hidden dimension H requires approximately parameters, where denotes the state dimension, and represents the corresponding action dimension. With eight networks in total, the parameter storage requires memory. The experience replay buffer stores tuples of states, actions, and rewards, consuming memory, where is the buffer capacity. Consequently, the total space complexity is , demonstrating that the algorithm maintains reasonable memory requirements even for large-scale MLLM task offloading scenarios.
5. Performance Evaluation
In this section, we initially outline the experimental framework and configuration for the MLLM-based SEC environment. Subsequently, we assess the performance of our algorithm in comparison to established benchmark algorithms across various conditions.
5.1. Parameter Settings
In the UAV-assisted SEC environment, we consider that multiple IoTDs are arbitrarily dispersed within a 500 m × 500 m region, where UAVs and LEO satellites, equipped with ESs, are capable of offering computational support to these IoTDs. Each IoTD generates an MLLM task request that necessitates processing, either via task offloading to UAVs or LEO satellites. We set the number of IoTDs
, the number of UAVs
, and the number of LEO satellites
, wherein UAVs fly at an altitude of
m and LEO satellites at an altitude of 500 km. In this simulation, each UAV is assumed to be equipped with NVIDIA Jetson Orin NX with 1.88 TFLOPS and 16 GB memory, and the LEO satellite is equipped with NVIDIA Jetson AGX Orin with 3.33 TFLOPS and 32 GB memory [
39].
We implement the proposed algorithm based on the HuggingFace [
40]. To evaluate the inference performance of our algorithm, we implement a text generation benchmark. Utilizing the MMMU dataset provided by HuggingFace, we randomly selected a specific subset where each input sequence contains
tokens and a picture; then, the server generated
tokens based on these inputs. The duration of each time slot was set as 3 s. The MDs’ request arrivals were characterized by a Poisson distribution, with the rate parameter ranging from 1 to 1.5 requests at each time slot. The actor and critic learning rates were
and
, respectively. The buffer size
10,000, the soft update coefficient
was
, and the batch size is 128. The other simulation parameters are presented in
Table 1. Similar experimental configurations were adopted in [
18,
41]. The hyperparameters of the AD-SAC algorithm are listed in
Table 2. The simulations were conducted on a platform featuring an Intel(R) Xeon(R) Platinum 8370C CPU 2.80 GHz and an NVIDIA GeForce GTX 4090 graphics.
Benchmark: In our study, we evaluated the efficacy of our enhanced AD-SAC algorithm compared to four benchmarking schemes:
Random: This method selects actions uniformly at random, serving as a baseline to assess the effectiveness of learning-based approaches.
Proximal Policy Optimization (PPO): PPO is a policy optimization DRL technique that iteratively refines the policy to maximize expected cumulative rewards.
Dueling Double Deep Q-Network (D3QN): D3QN builds upon the Deep Q-Network framework by incorporating a dueling architecture to estimate state values and action advantages separately.
Deep Deterministic Policy Gradient (DDPG): DDPG is a policy gradient algorithm that learns a deterministic policy alongside a value function for optimization.
Hybrid Proximal Policy Optimization (Hybrid-PPO): Hybrid-PPO introduces a parameterized PPO method based on the hybrid action space to solve the collaborative partial task offloading problem at the edge [
42].
5.2. Numerical Results
First, we analyze the convergence of the proposed AD-SAC algorithm and the comparative DRL algorithms.
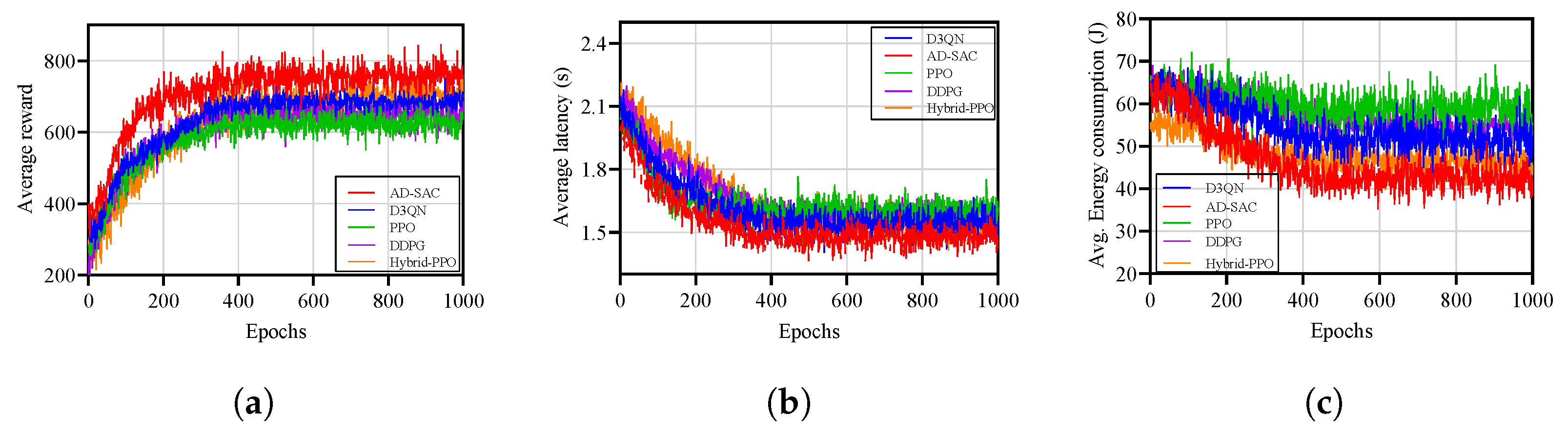
Figure 3 illustrates the learning curves for the AD-SAC, PPO, D3QN, DDPG, and Hybrid-PPO algorithms across 1000 epochs. AD-SAC demonstrates superior convergence speed and performance, outperforming the benchmark algorithms. Specifically, AD-SAC reaches a significantly higher final average reward, while Hybrid-PPO, DDPG, D3QN, and PPO obtain approximately 5.7–13.4% lower reward compared to the AD-SAC algorithm. This indicates that AD-SAC not only converges faster but also maintains better stability throughout training. While Hybrid-PPO exhibits a relatively stable learning curve and a higher final reward than DDPG, D3QN, and PPO, its performance is still notably lower than that of the AD-SAC algorithm. PPO and D3QN, on the other hand, exhibit greater reward fluctuations and slower convergence rates, ultimately stabilizing at lower reward levels. This analysis emphasizes AD-SAC’s superior stability, faster convergence, and overall effectiveness compared to the other algorithms.
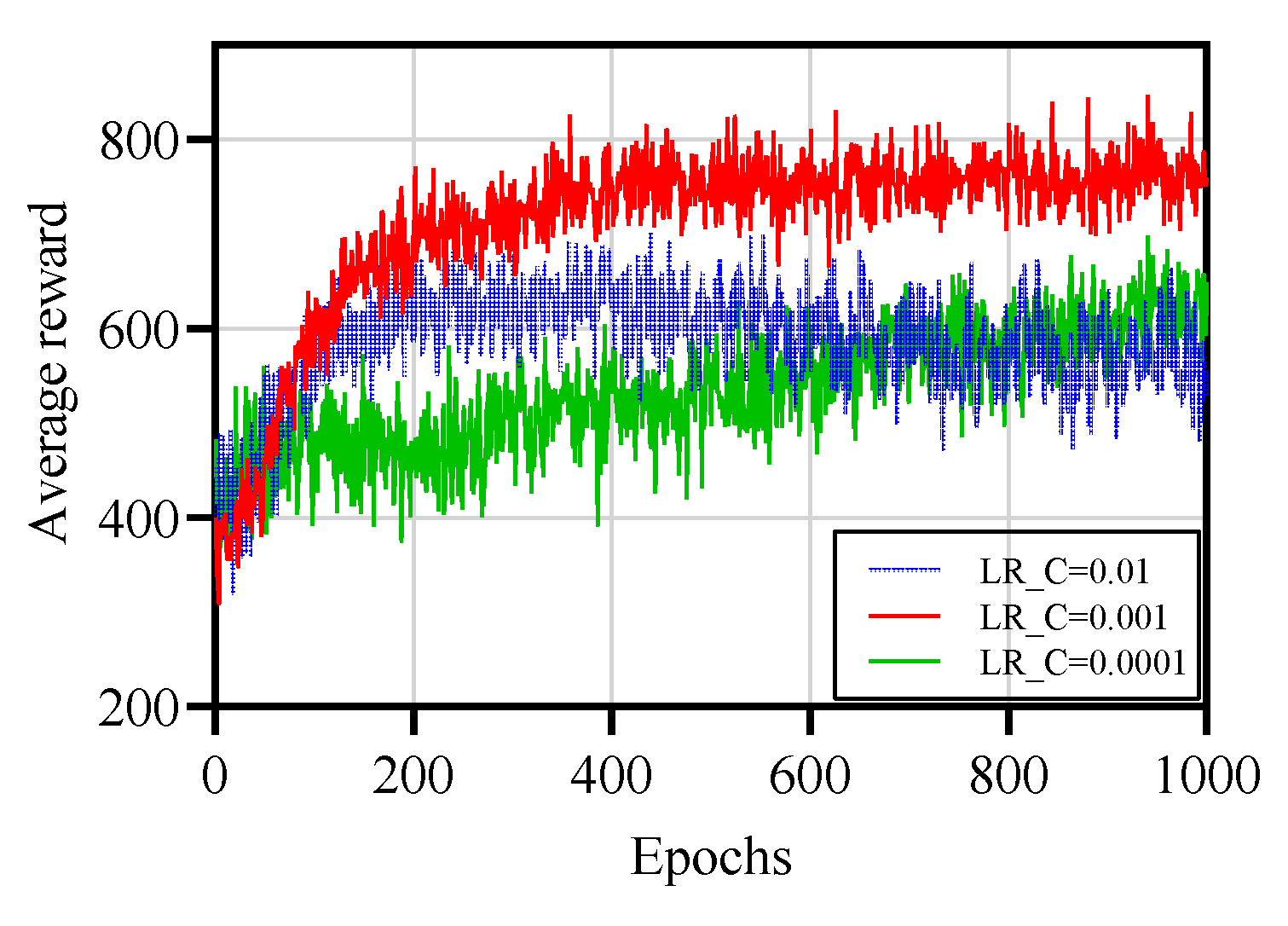
Figure 4 demonstrates the impact of varying the critic learning rate on the convergence behavior of the AD-SAC algorithm for MLLM task offloading in UAV-assisted SEC networks. The figure illustrates that a moderate critic learning rate facilitates rapid and stable convergence, with the average reward per episode increasing swiftly to a high plateau, indicating efficient minimization of the weighted sum of latency and energy consumption. In contrast, the lower critic learning rate with 0.0001 results in slower convergence, requiring more training episodes to achieve comparable performance, while the critic learning rate with 0.01 leads to oscillatory behavior and failure to stabilize, reflecting instability in the training process. These findings highlight the critical role of carefully tuning the critic learning rate to balance the learning speed and stability within the hybrid action space DRL framework, ensuring effective task allocation and resource management in the resource-constrained SEC environment. Therefore, in the subsequent experiments, we set the critic learning rate to 0.001 to ensure the efficiency and robustness of the AD-SAC algorithm.
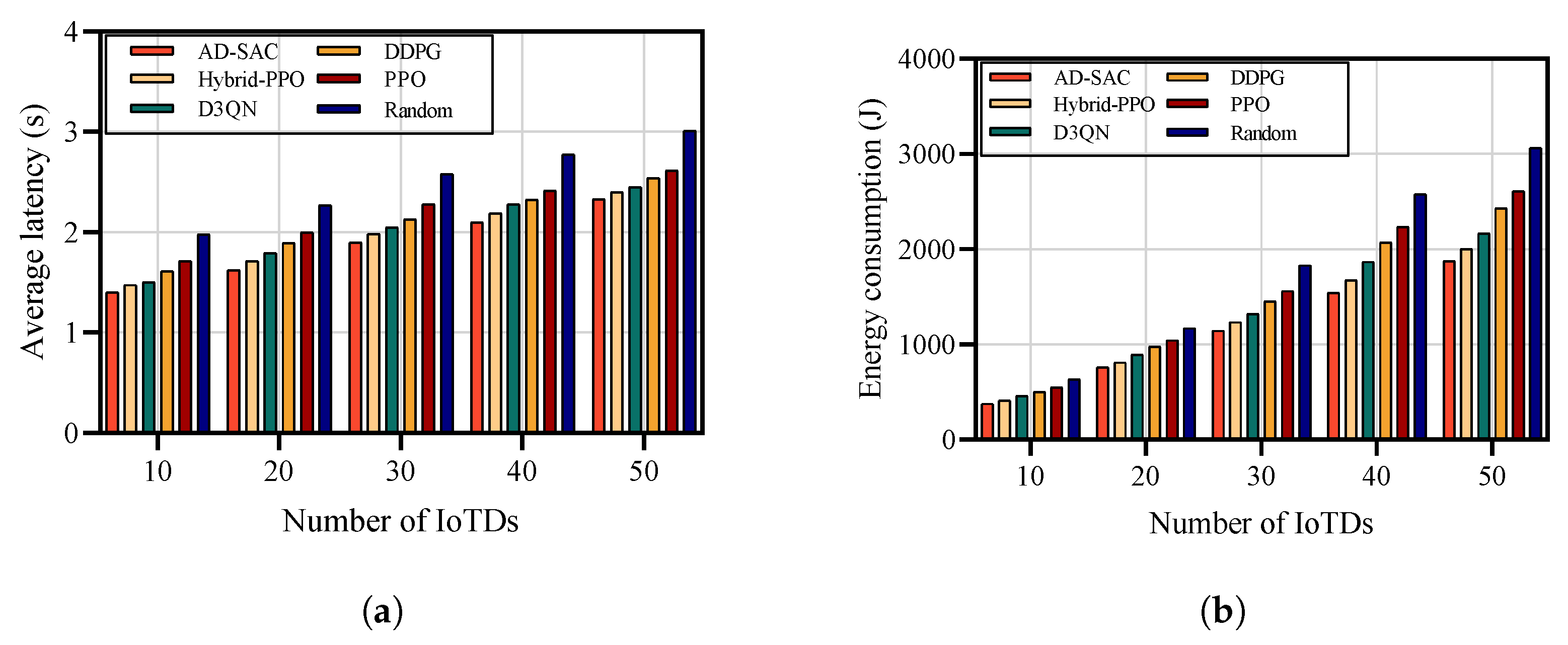
To investigate the impact of the number of IoTDs on the efficiency of the proposed algorithm, we conducted a series of comparative analyses involving five distinct algorithms, including AD-SAC, PPO, D3QN, DDPG, Hybrid-PPO, and Random. As illustrated in
Figure 5, the increase in the number of IoTDs leads to higher service latency and energy consumption across all evaluated algorithms. This performance can be attributed to the diminishing resource availability of nearby UAVs, as the number of IoTDs increases, which necessitates offloading MLLM tasks to more distant LEO satellites, ultimately resulting in increased service latency and transmission energy consumption. Additionally, as the number of IoTDs rises, the AD-SAC algorithm consistently achieves the lowest service latency and energy consumption, showcasing a strong adaptability to varying environmental conditions. This is because our proposed AD-SAC algorithm stems from its integration of a hybrid action space to approximate optimal decisions on offloading and resource allocation, thereby optimizing convergence efficiency and reducing latency and energy consumption.
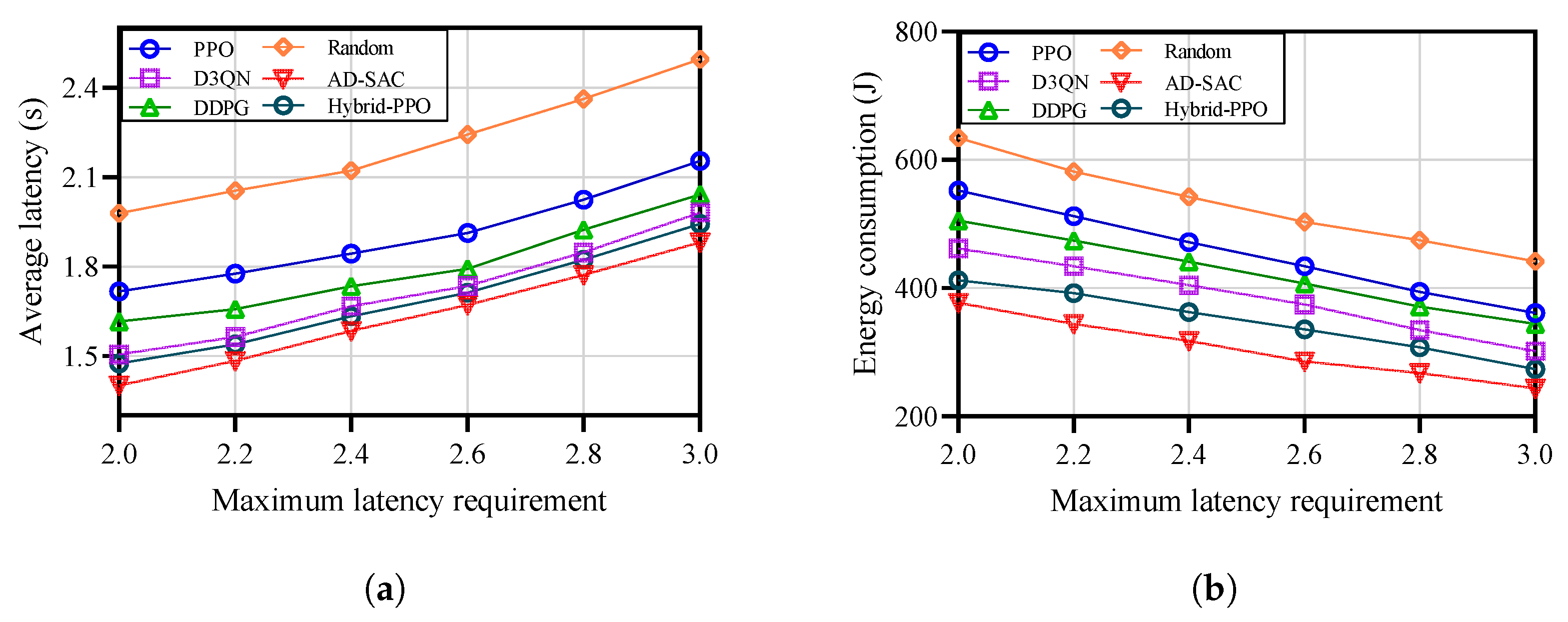
Figure 6 demonstrates the impact of maximum latency constraints
on the performance of five distinct task offloading algorithms. It is intuitive that
Figure 6a reveals a direct correlation between increasing
and heightened service latency across all assessed algorithms. This trend can be attributed to the algorithms’ propensity to offload a greater number of tasks to LEO satellite infrastructure when latency constraints are more loose. While this scheme results in higher latency, it simultaneously enhances service reliability. Notably, the proposed AD-SAC algorithm consistently achieves the lowest service latency as
increases. This outstanding performance is attributed to AD-SAC’s preference for offloading tasks to nearby UAVs and LEO satellites, effectively reducing communication latency.
Figure 6b further emphasizes that the AD-SAC algorithm also shows the lowest energy consumption. This efficiency primarily arises from its inclination to offload tasks to proximate servers, unlike other algorithms that often rely on more distant LEO satellites, resulting in higher communication energy costs. Additionally, as the maximum service delay threshold expands, a marked reduction in energy consumption is observed across all algorithms. This decline is driven by the increased task offloading to LEO satellites, which utilize their advanced computational efficiency to lower overall energy demands.
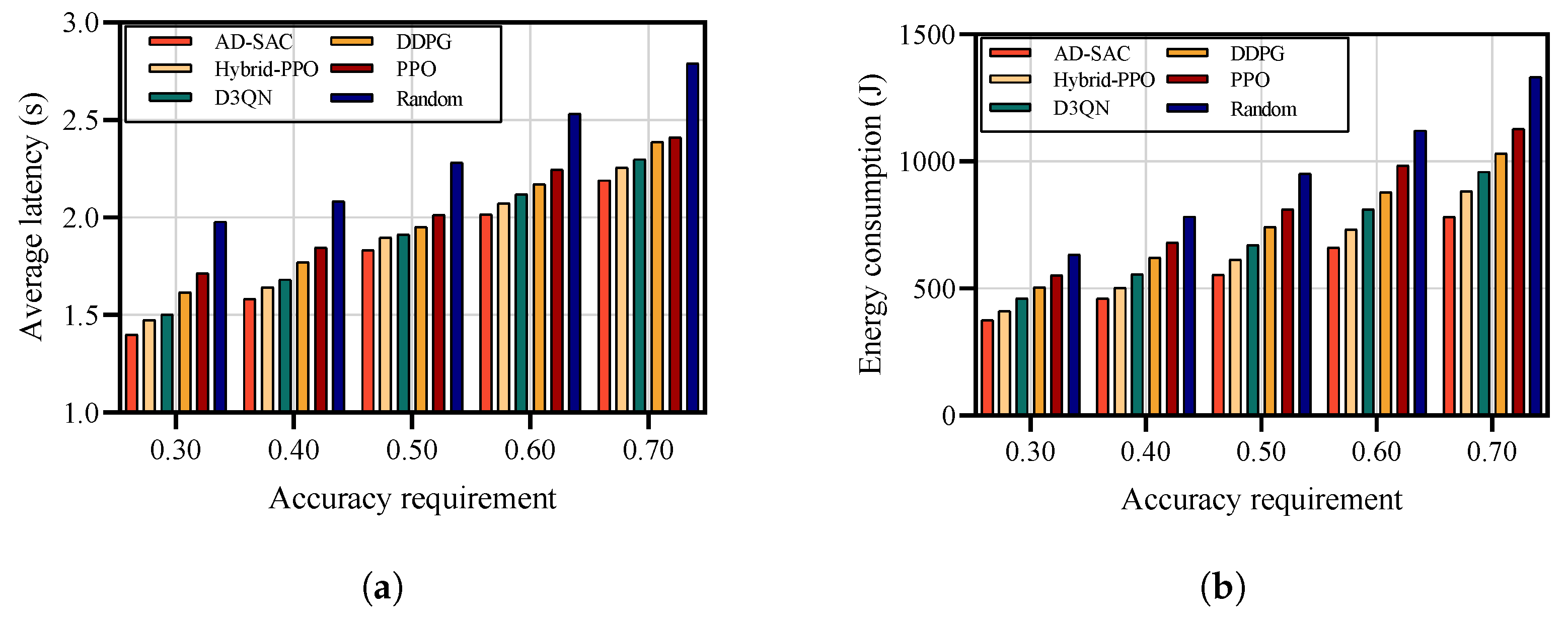
We evaluated the impact of varying MMMU accuracy requirements on system performance by conducting experiments with accuracy thresholds ranging from 0.3 to 0.7.
Figure 7 illustrates the relationship between accuracy requirements and system metrics. The experimental results demonstrate an increase in both latency and energy consumption as accuracy requirements become more stringent. Specifically, when the accuracy requirement increases from 0.3 to 0.7, the average system latency rises from 1.41 s to 2.19 s, representing a 55.3% increase. Similarly, energy consumption exhibits a substantial growth from 377J per time slot to 782J per time slot, marking a 107.4% increase. The most significant performance degradation occurs in the transition from accuracy requirement 0.5 to 0.6, where we observe a sharp increase in latency and energy consumption. This indicates a critical threshold where the SEC system shifts from predominantly UAV-based processing to satellite-based processing. It can be observed that our proposed AD-SAC algorithm with a hybrid action space demonstrates significant advantages compared to D3QN, PPO, DDPG, Hybrid-PPO, and Random methods. The superiority of AD-SAC stems from its ability to effectively handle the mixed discrete–continuous action space inherent in our problem. In contrast, Hybrid-PPO addresses the discrete–continuous action space by parameterization, because the single network needs to learn two different types of action mappings simultaneously, which is prone to achieving suboptimal performance. In addition, while D3QN struggles with the continuous power allocation and UAV trajectory optimization, and DDPG faces challenges in discrete offloading decisions, our decoupled approach allows specialized agents to optimize each action type. The discrete agent efficiently learns offloading patterns based on accuracy requirements, while the continuous agent finetunes power allocation and UAV positioning to minimize interference and reduce transmission latency.
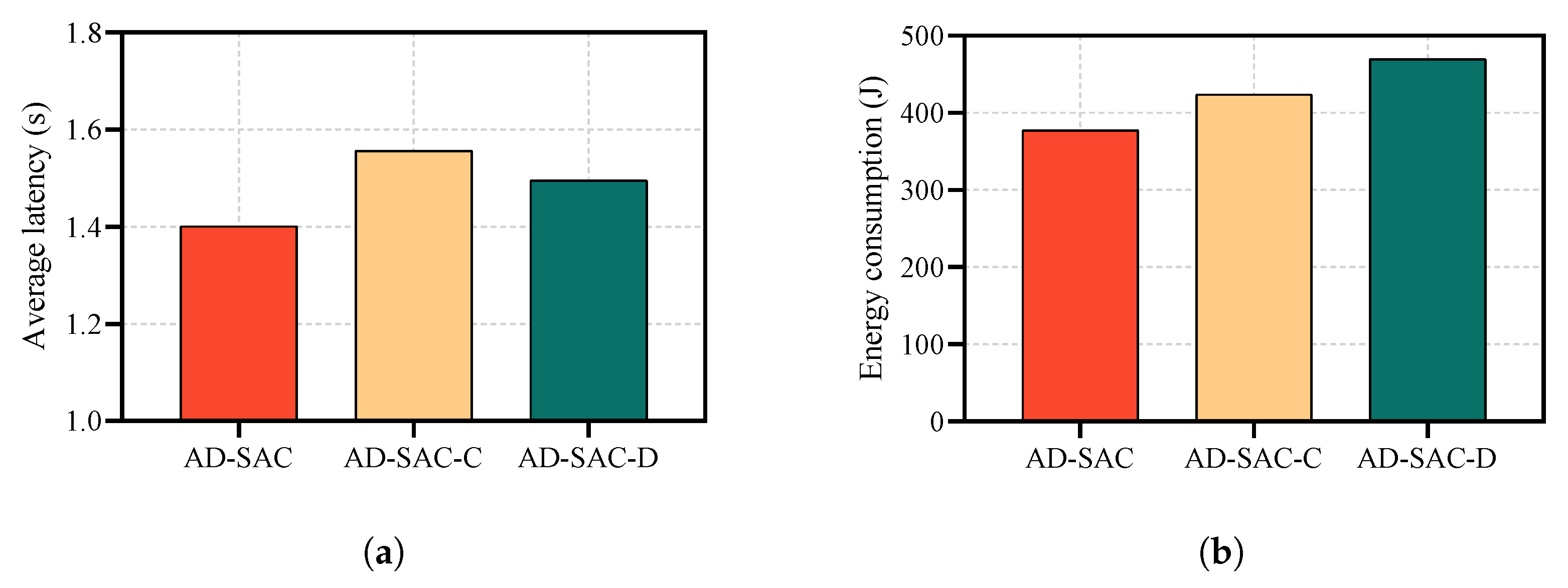
To validate the effectiveness of our hybrid action space decoupling approach,
Figure 8 ablation studies comparing our proposed AD-SAC, AD-SAC-D (discrete agent with continuous actions mapped to discrete space), and AD-SAC-C (continuous agent with discrete actions mapped to continuous space). The results demonstrate that the proposed AD-SAC achieves optimal performance in terms of latency and energy consumption. AD-SAC-D shows a 7.4% latency increase and 24.3% energy increase due to discretization loss in power allocation and trajectory, while AD-SAC-C exhibits the worst latency performance 11.7% increase but better energy efficiency 13.5% increase due to the continuous representation of discrete offloading decisions. This cross-advantage phenomenon validates our theoretical analysis that latency is primarily dominated by offloading decisions, while energy is dominated by power allocation and trajectory. The results conclusively demonstrate that forcing action space conversions leads to significant performance degradation, proving the necessity of our decoupling design that preserves the native characteristics of both discrete and continuous actions.
5.3. Discussion
In our study, deployment feasibility is a core consideration, particularly in addressing the inherent challenges of intermittent connectivity in low Earth orbit (LEO) satellite networks. To this end, we explicitly introduce the visibility time window into the MDP state space. This parameter represents the dynamic communication window between an IoTD k and satellite n at time t. This design captures the time-varying availability characteristics of LEO satellites due to their orbital motion.
By incorporating into the MDP state space, our framework can adaptively respond to the dynamic changes in satellite connectivity. For instance, during task offloading and resource allocation, the algorithm makes optimized decisions based on the real-time visibility window of the satellite, choosing to offload tasks to the satellite only when the communication window is sufficient to support computation and data transmission. This mechanism effectively mitigates the impact of intermittent satellite connectivity on service reliability, thereby enhancing the system’s robustness.
While our proposed framework for MLLM inference in UAV-assisted SEC networks achieves significant performance improvements in terms of latency and energy efficiency, certain simplifying assumptions in the system model warrant further exploration to enhance its applicability to real-world scenarios. Below, we discuss key limitations and potential avenues for future research.
In this work, we assume that IoTD locations remain static within each time slot to simplify the optimization problem and focus on the joint task offloading and resource allocation challenge. This assumption facilitates the development and evaluation of our AD-SAC algorithm by reducing the complexity of the dynamic environment. However, in practical IoT deployments, such as disaster response or maritime monitoring, IoTDs may exhibit mobility, leading to variations in network topology, channel conditions, and UAV coverage requirements. While our model accounts for inter-slot variations due to device mobility (as noted in
Section 3.2), explicitly incorporating intra-slot IoTD mobility could improve the framework’s robustness. Future work could extend our approach by integrating mobility models for IoTDs, such as random waypoint or trajectory-based patterns, and developing adaptive algorithms that dynamically adjust offloading decisions and UAV trajectories in response to these changes.
Another limitation of our current model is the absence of explicit energy constraints or depletion models for UAVs and LEO satellites. We opted not to include these factors to maintain focus on optimizing MLLM task offloading and resource allocation, rather than energy management of the computing nodes. In our formulation, energy consumption is minimized from a system-wide perspective (e.g., transmission and inference energy), but the battery life and recharge cycles of UAVs and satellites are not directly modeled. In real-world deployments, especially in remote areas where recharging infrastructure is scarce, energy constraints are critical for ensuring the sustained operation of these mobile nodes. For instance, UAVs may need to return to base for recharging, and satellites may rely on solar energy with limited storage capacity. Future research could enhance our framework by incorporating energy-aware mechanisms, such as battery depletion models, recharge scheduling, or energy harvesting strategies (e.g., solar panels for UAVs and satellites). This would enable a more holistic optimization that balances computational performance with operational longevity.
6. Conclusions and Future Work
In this paper, we investigate the challenging problem of MLLM task offloading and resource allocation in UAV-assisted SEC networks. We formulate an MINLP problem to minimize the weighted sum of system latency and energy consumption while satisfying accuracy requirements for diverse MLLM services. The problem poses significant challenges due to the hybrid discrete–continuous action space, involving discrete offloading decisions and continuous power allocation and UAV trajectory optimization. To address these challenges, we proposed a novel AD-SAC algorithm that effectively handles the hybrid action space by employing separate agents for discrete and continuous actions. Our approach leverages the maximum a posteriori policy optimization to integrate the decoupled policies, ensuring stable learning and efficient exploration. The AD-SAC framework enables intelligent decision-making that considers the trade-offs between UAV-based edge computing with lower latency but limited accuracy and satellite-based computing with higher accuracy but increased communication overhead. Extensive experiments demonstrate the superiority of our proposed AD-SAC algorithm over state-of-the-art baselines.
While our work demonstrates the advantages of SEC-based MLLM deployment, a limitation of this study is the lack of a comprehensive quantitative comparison with cloud-based deployment scenarios. In future work, we will expand the research scope to include cloud computing deployment scenarios for MLLM services and provide concrete real-world examples and quantitative data, such as latency metrics from actual IoT deployments, bandwidth consumption patterns for multimodal data transmission, and comparative analysis between cloud, UAV, and SEC paradigms. This expanded investigation will offer comprehensive empirical evidence to justify the bottlenecks in different IoT environments.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}