Abstract
The increasing complexity of Internet of Drones (IoD) platforms demands more accessible ways for users to interact with unmanned aerial vehicle (UAV) data systems. Traditional methods requiring technical API knowledge create barriers for non-specialist users in dynamic operational environments. To address this challenge, we propose a retrieval-augmented generation (RAG) architecture that enables natural language querying over UAV telemetry, mission, and detection data. Our approach builds a semantic retrieval index from structured application programming interface (API) documentation and uses lightweight large language models to map user queries into executable API calls validated against platform schemas. This design minimizes fine-tuning needs, adapts to evolving APIs, and ensures schema conformity for operational safety. Evaluations conducted on a curated IoD dataset show 91.3% endpoint accuracy, 87.6% parameter match rate, and 95.2% schema conformity, confirming the system’s robustness and scalability. The results demonstrate that combining retrieval-augmented semantic grounding with structured validation bridges the gap between human intent and complex UAV data access, improving usability while maintaining a practical level of operational reliability.
1. Introduction
Applications of unmanned aerial vehicles have spread across various domains, including environmental monitoring, precision agriculture, logistics, infrastructure inspection, and public safety missions. As fleet sizes and mission complexities grow, effective management of such distributed systems has emerged as a significant concern. This necessity has propelled the creation of Internet of Drones platforms that facilitate centralized monitoring, coordination, and control of UAV missions by consolidating mission information, telemetry data, object detection logs, and status reports into unified systems.
In spite of such technological evolution, the interaction with Internet of Drones systems remains largely technical in nature. End users typically must possess in-depth system-specific application programming interface expertise, sift through a huge amount of documentation, and manually craft complex queries to retrieve or interact with UAV-generated data. This technical barrier inhibits the broader adoption of IoD platforms, rendering them accessible to field specialists alone and disenfranchising non-technical stakeholders who may significantly benefit from real-time UAV data.
In dynamic operational settings such as disaster relief, environmental monitoring, and military logistics, the decision-makers must be provided with real-time access to drone-provided information without the overhead of technical queries. Large language models (LLMs) have shown tremendous promise in bridging this limitation by enabling users to query complex data systems using natural language instructions. The ability to convert human conversation into data querying in a structured format has therefore emerged as a critical requirement for future Internet of Drones systems.
Nonetheless, drone data ecosystems present certain unique challenges for information retrieval systems. UAVs generate continuous real-time telemetry data, sensor readings, and detection events, which need time-sensitive filtering and quick access structures. In addition, an IoD platform integrates heterogeneous multi-modal data types, including numeric telemetry streams, image-based detections, mission metadata, and environmental sensor recordings. The user might require elaborate, multi-part queries with several filters spanning multiple data tables. In addition, UAV systems comprise different mission types and payloads, and consequently, different data schemas are incorporated into the same platform. Access control security makes it even more complex to build queries and retrieve data.
Traditional API-based systems attempt to address these needs using highly parameterized endpoints. Yet, constructing correct API requests demands significant familiarity with the platform’s structure, query parameters, and expected response formats, creating a critical usability bottleneck.
While large language model interfaces have seen notable progress in static relational database environments, their application to dynamic, real-time, multi-modal drone data remains underexplored. Existing systems often assume static and homogeneous data schemas, whereas IoD environments involve evolving, mission-specific, and context-sensitive information. Time-stamped and spatially contextual drone data require interpretation that accurately captures temporal, spatial, and event-based references.
Current solutions inadequately support UAV operational vocabularies, dynamic API orchestration for mission-specific queries, or retrieval-augmented architectures capable of efficiently mapping large language model inputs to structured API calls with minimal training data. Furthermore, they often fail to utilize the rich semantics encoded within API documentation (e.g., Swagger/OpenAPI specifications), missing an opportunity to systematically align user intents with available system functionalities.
In critical field operations such as disaster relief, wildfire response, or search-and-rescue missions, the ability to rapidly query UAV systems becomes a time-sensitive and potentially life-saving function. However, frontline operators often lack the technical training required to construct valid API calls or navigate complex documentation under stress. This creates a usability gap between those who control UAVs and those who rely on their data. Furthermore, latency in accessing mission telemetry or object detections—caused by manual query bottlenecks—can delay coordination, reduce situational awareness, and ultimately compromise mission outcomes. Therefore, empowering operators with natural language interfaces that eliminate technical barriers is not merely a convenience but a necessity for modern IoD deployments in field-critical applications.
To address these gaps, this paper proposes an architecture that combines a retrieval-augmented generation framework with structured API documentation to enable dynamic, large language model-driven access to IoD data. Our approach systematically extracts and annotates natural language query examples mapped to specific API endpoints and parameter configurations directly from the IoD platform’s API documentation. These annotated examples are embedded using semantic models to construct a vector-based retrieval database. Incoming user queries are matched against this database to find the most relevant examples, which are then refined through a lightweight language model to generate the appropriate API call.
This architecture minimizes the need for extensive fine-tuning, leverages existing documentation artifacts, and remains adaptable to evolving IoD system configurations. It enables end users to perform complex operational queries on UAV data using simple large language model inputs, enhancing usability, accessibility, and operational efficiency in IoD environments.
The contributions of this paper are as follows: (1) a semantic query interface is designed and implemented that allows users to interact with UAV telemetry, detection, and mission data using unconstrained natural language, eliminating the need for manual API reference or endpoint knowledge; (2) a retrieval-augmented generation pipeline is constructed by embedding 520 annotated query–endpoint–parameter triples using a transformer-based sentence encoder (all-MiniLM-L6-v2), and indexing them using Facebook AI Similarity Search (FAISS) for real-time similarity search. At query time, semantically close examples are retrieved and composed into structured few-shot prompts to contextualize the LLM’s inference; (3) the LLM (LLaMA 3.1 8B Instruct) interprets these prompts to produce schema-compliant API call structures, including endpoint resolution and parameter inference. The output is then subjected to strict validation against OpenAPI definitions to ensure structural correctness, type safety, and semantic alignment with the IoD backend; (4) the complete system is deployed in a microservice-based architecture, composed of containerized modules for embedding, retrieval, prompt construction, inference, validation, and API execution. This enables scalable deployment on IoD platforms, with support for runtime monitoring, error handling, and schema evolution.
The remainder of this paper is organized as follows. Section 2 reviews related work in large language model querying, API mapping, and drone data management. Section 3 details the proposed methodology, including dataset construction, system architecture, and implementation details. Section 4 presents the experimental setup and evaluation results. Section 5 provides the conclusion of this study, summarizing key findings and highlighting the significance of the proposed approach. Section 6 outlines directions for future research, focusing on opportunities to expand the system’s capabilities, enhance scalability, and explore additional application domains.
Unlike our previous study [1], which emphasized autonomous decision-making based on telemetry logs, the current work introduces a natural language interface for interacting with IoD APIs using structured semantic queries. A detailed comparison of the two approaches is provided in Table 1.

Table 1.
Key differences between the previous study and the current work.
2. Related Work
2.1. Cross-Domain Knowledge Integration for Table QA and SQL Generation
Recent advancements in cross-domain Table QA and text-to-SQL systems focus on adaptive knowledge integration, modular designs, and training innovations to address domain shifts, query complexity, and sparsity of labeled data. Representative methods, ranging from confidence-based fusion to LLM-based solutions, are integrated to expose evolving methodologies in the field.
Study [2] suggests a confidence-based solution to Table QA, with dynamic external knowledge (e.g., Wikidata) selection using relevance scores and hierarchical composition with table data. This reduces domain dependency by 12% on benchmarks such as WikiTableQuestions. A complementary study [3] democratizes database access using an NLP-based SQL generator, translating natural language to SQL without schema information. By fine-tuning BERT on cross-domain queries, it achieves 78% execution accuracy on Spider, a 22% improvement compared with rule-based systems. Both methods highlight the importance of semantic alignment but suffer from rare schema elements.
For easing SQL generation, study [4] divides query structuring into two phases: skeleton prediction (e.g., SELECT/WHERE clauses) and detail completion (e.g., column names). The modular approach improves Spider accuracy by 15%, particularly for nested queries. Meanwhile, study [5] reinforces semantic correctness via reinforcement learning (RL), which promotes execution accuracy (e.g., correct outputs) along with syntactic accuracy. Hybrid RL-supervised training improves Spider execution accuracy to 82% while reducing logical errors by 30%. Building on this, study [6] (ExSPIN) removes human feedback by iteratively refining queries via self-play. Running synthetic queries and iterating over errors (e.g., syntax errors) achieves a 14% improvement in Bird benchmark accuracy, demonstrating scalable supervision.
LLMs enhance text-to-SQL robustness through retrieval-augmented generation (RAG). Study [7] grounds LLMs within a schema context by retrieving relevant table relationships during generation, achieving 85% accuracy on complex real-world queries. However, retrieval latency remains a bottleneck. To balance efficiency, study [8] employs intelligent agents that route queries between fine-tuned and few-shot LLMs based on complexity. This hybrid approach reduces inference time by 40% on ClassicModels while maintaining 88% accuracy.
Beyond technical systems, study [9] addresses education with an LLM-powered SQL autograder, providing granular feedback (e.g., missing GROUP BY hints) and achieving 95% grader agreement. For big data environments, study [10] (XL-HQL) tailors SQL generation to Hive Query Language (HQL), using XLNet and column attention to handle nested JSON structures. It achieves 91% HQL accuracy, outperforming general models by 12%.
2.2. LLM-Driven Autonomous Systems and IoT Applications
To frame the importance of large language models into perspective in mission-critical IoT systems, the next section briefly surveys representative applications by domain. These examples serve to demonstrate the broad applicability of LLMs and put into context our emphasis on UAVs.
In robotics, LLMs enhance flexibility and precision. Study [11] introduces agentic workflows, enabling robots to decompose high-level objectives into environment-aware actions. Through the composition of object attributes and spatial contexts, the method achieves a 25% higher task success rate than standard prompting. Taking this further, study [12] translates natural language instructions into executable Python code, bridging the gap between high-level planning and actuator-level control.
In UAV systems, study [1] contrasts LLM-enhanced agents in dynamic missions, such as payload delivery during adverse weather, yielding a 20% gain in mission completion. Study [13] fuses federated multi-armed bandits and a Multipath Transmission Control Protocol (TCP) for enhanced IoD network reliability and reduced video transmission latency. Study [14] proposes a smart home LLM framework in which autonomous agents manage devices with privacy and latency improvements. While not UAV-specific, this distributed agent rationale informs edge-based autonomy frameworks.
Extending to swarm coordination of drones, study [15] offers a management paradigm connected with urban transportation systems, discussing trajectory planning in smart cities. Study [16] describes LLM–IoT fusion architectures and accounts for enhanced automation in edge–cloud collaboration. Study [17] reviews the use of LLMs in IoT for anomaly detection and natural language-based orchestration, which is applicable to autonomous drone coordination.
For UAV applications, study [18] suggests a retrieval-augmented generation system that converts natural queries to API calls with 92% accuracy, fine-tuned over drone telemetry data. Study [19] explores agentic UAV mobility where drones re-plan routes adaptively based on real-world conditions, highlighting challenges such as energy consumption and explainability. Study [20] integrates wearable IoT and LLMs for health monitoring, and study [21] leverages scene graphs for traffic knowledge. Finally, study [22] deals with remote sensing infrastructure mapping, and through non-LLM-based methods, it contributes to aerial perception tasks relevant to UAV intelligence.
2.3. Retrieval-Augmented Generation and Dynamic Knowledge Fusion
The realization of retrieval-augmented generation through dynamic knowledge fusion has taken a big leap forward in applications needing contextual sensitivity, ranging from conversational systems to code generation. Improvements in adaptive retrieval approaches, schema-aware modeling, and multi-context fusion are driving accuracy, efficiency, and user experience forward across these applications, demonstrating progress in achieving a balance between real-time adaptability and domain-specific precision.
One of the foundations of modern RAG systems is their ability to dynamically retrieve contextually relevant information. Study [23] introduces a system of dialogue systems where natural language queries are generated in real-time based on conversation context. As an example, if the conversation is about climate change, the model would retrieve the latest IPCC reports and use them as a basis for its response. This method attains a 15% gain in response informativeness compared with static retrieval models on the CMU-DoG dataset. Likewise, study [24] consolidates retrieval decision-making, query generation, and response generation phases into one model. By jointly optimizing all these stages, UniRQR lowers inference latency by 30% and enhances the relevance of responses by 22% on the KdConv benchmark. These techniques underscore the value of end-to-end optimization for retrieval-augmented systems.
To surmount computational overhead, study [25] modifies RAG for autonomous systems with Low-Rank Adaptation (LoRA). LoRA-based fine-tuning of a BERT-based retriever reduces trainable parameters by 13.6% and improves retrieval accuracy of traffic rules by 18%. Multi-stage filtering using maximal marginal relevance (MMR) guarantees that retrieved clauses (e.g., “right-of-way rules”) are relevant to driving scenarios, leading to a 9% improvement in BLEU scores of responses. For database documentation, study [26] evaluates LLMs on the translation of ER schemas to natural language. While models such as ChatGPT-4 achieve 85% F1 scores on simple schemas, complicated abstractions such as ternary relationships require schema hints with more context (e.g., adding cardinality constraints), improving accuracy by 12%. This reiterates the need for domain-specific adaptations in knowledge-intensive applications. Study [27] explores the synergy of blockchain and IoD, emphasizing decentralized architectures for secure knowledge retrieval and transmission in mission-critical drone operations.
In addition to fact retrieval, study [28] incorporates emotion-sensitive embeddings into LLMs to increase response sensitivity. By combining task-specific embeddings with emotional context (e.g., identifying frustration in user queries), the approach increases emotional alignment by 25% on the EmoResponse dataset. For example, when a user is anxious about deadlines, the model gives priority to reassuring language. In contrast, study [29] addresses pseudocode generation by integrating retrieval-based similarity search with transformer models. Extracting semantically similar code snippets (e.g., sorting functions) enables the model to handle out-of-vocabulary tokens, with BLEU scores of 61.96 on the Django dataset—a 10% gain compared with vanilla transformers.
2.4. Security and Reliability in Distributed Systems
While this work does not experimentally evaluate security mechanisms, we find it important to outline conceptual considerations and architectural directions that may inform future extensions toward secure deployments. These reflections are intended to contextualize potential threat surfaces and system-level resilience rather than present validated security claims.
The growing complexity of distributed systems, particularly in IoT and fog computing environments, demands robust solutions for threat detection, secure data management, and system reliability. Advancements in cybersecurity, architectural analysis, and fault prediction are addressing these challenges, playing a critical role in safeguarding interconnected systems through improved threat detection frameworks, secure data protocols, and predictive reliability models.
Modern cybersecurity frameworks prioritize dynamic defense mechanisms. Study [30] introduces a method to identify machine code architectures (e.g., ARM and MIPS) in smart home devices by analyzing binary files. Using feature extraction and classifiers such as Random Forest, the model achieves 98% accuracy in detecting processor types, enabling targeted vulnerability assessments. For instance, identifying an ARM-based device allows security teams to prioritize patches for known ARM-specific exploits. Complementing this, study [31] employs LLM-driven honeypots to deceive attackers. Building on LLM-driven deception, study [32] introduces a cross-layer convolutional attention IDS tailored for drone-to-drone and drone-to-base communications, achieving 98.4% accuracy on real-world IoD datasets. Unlike static honeypots, DecoyPot generates contextually coherent API responses (e.g., mimicking a vulnerable login endpoint) to prolong attacker engagement. In tests, it increased interaction duration by 70%, collecting 50% more threat intelligence compared with traditional systems. These approaches highlight the shift from reactive to adaptive security strategies. Study [33] proposes a deep-autoencoder-based IDS framework that leverages crystal structure optimization to enhance intrusion detection in IoD environments, demonstrating improved detection accuracy over conventional methods.
Ensuring system reliability in distributed environments requires efficient fault prediction. Study [34] presents a Q-learning-based cooperative IDS system for IoD that combines intelligent voting and auditing layers, significantly reducing false positive rates and extending the system lifespan. Study [35] enhances Monte Carlo reliability analysis by integrating a BP neural network. Traditional Monte Carlo methods suffer from high computational costs when simulating rare failures (e.g., 1-in-106 events). By training the BP network to predict failure probabilities from partial simulations, the hybrid approach reduces computation time by 65% while maintaining 92% accuracy. A case study on power grids demonstrates its effectiveness in identifying cascading failures, enabling preemptive maintenance.
Fog computing introduces unique security challenges because of its distributed nature. Study [36] (SURETY-Fog) addresses these with a framework combining searchable encryption and secure indexing. For example, medical IoT devices encrypt patient data locally using AES-256 before transmitting it to fog nodes. Authorized users can query encrypted records (e.g., “retrieve blood pressure readings > 140”) without decrypting the entire dataset, ensuring confidentiality. SURETY-Fog also enforces role-based access control, reducing unauthorized access by 80% in trials. However, latency increases by 15%, necessitating trade-offs between security and real-time performance.
2.5. Efficient Model Optimization for Edge and Real-Time Applications
The deployment of AI models in resource-constrained environments requires balancing accuracy, latency, and computational efficiency. Advancements in lightweight model architectures, hybrid pipelines, and cost-effective frameworks—specifically tailored for edge devices and real-time applications—are enabling more efficient deployment while maintaining performance, addressing the trade-offs inherent in low-resource settings.
Edge AI demands optimized models to handle hardware limitations. Study [37] reviews techniques such as pruning, quantization, and knowledge distillation to compress CNNs and LLMs for edge devices. For instance, quantizing a ResNet-50 model to 8-bit precision reduces its size by 75% with only a 3% accuracy drop. This study also highlights hardware innovations, such as neural processing units (NPUs), which accelerate inference for real-time tasks such as facial recognition. Complementing this, study [38] (ASKSQL) adopts lightweight machine learning models for natural language-to-SQL conversion, avoiding the computational overhead of large LLMs. By using template-based approaches and modular integration, ASKSQL achieves 89% accuracy on Spider benchmarks while reducing latency by 40% compared with GPT-3.5.
In healthcare, hybrid models enhance efficiency without sacrificing performance. Study [39] proposes a pipeline combining CNNs with ensemble classifiers for adenoma detection in MRI. Features extracted via pre-trained CNNs (e.g., EfficientNet) are fed into Random Forest and SVM classifiers, achieving 94% accuracy, which is 12% higher than standalone CNNs. This hybrid approach reduces inference time by 30%, as traditional ML classifiers are less compute-intensive than end-to-end deep learning. The system’s robustness is validated on multi-center datasets, demonstrating its suitability for real-time diagnostics in edge settings. This cross-domain example illustrates a broader principle: the adaptation of pre-trained models for efficient inference in constrained environments, highlighting optimization strategies that are transferable across domains.
For database systems, study [40] enables real-time Cypher query generation for graph databases using LLMs. By designing dynamic few-shot prompts (e.g., schema-aware examples), the model translates natural language queries into Cypher commands with 92% accuracy and <200 ms latency. A custom benchmark shows superior performance compared with rule-based systems, particularly for complex traversals such as multi-hop relationships. Similarly, study [41] optimizes service mashup development via a data-driven API recommendation system. By analyzing historical usage patterns and API features (e.g., compatibility and latency), the framework recommends optimal API combinations with 85% precision, reducing development time by 50% in service-oriented environments.
3. Methodology
In this work, we propose an end-to-end system that integrates autonomous query understanding, schema-aware validation, and UAV-specific API interactions. The framework is designed to convert user-defined queries in natural language to structured API calls for fetching UAV-related information precisely. The method involves three main stages: data preparation, retrieval-augmented inference, and system integration.
3.1. Data Preparation and Embedding Index Construction
To enable accurate query interpretation, we began by constructing a comprehensive dataset derived from the IoD platform’s API documentation. This dataset consisted of example queries, associated API endpoints, required parameters, and response schemas. For each API route, we generated multiple semantically diverse query variants that a user might naturally express. These were manually annotated with their corresponding endpoint and parameter mappings, resulting in a corpus of 520 annotated samples.
Each query was embedded using the all-MiniLM-L6-v2 sentence transformer, producing high-dimensional vectors that encode semantic similarity. These embeddings were stored in a FAISS vector index to support efficient similarity-based retrieval during runtime.
The dataset consists of 520 natural language queries, semi-automatically created and manually curated to reflect realistic operator requests from UAV mission logs, telemetry messages, and object detection reports. Query templates were crafted from commonly used access patterns in the IoD platform and then diversified further by paraphrasing and contextual enrichment. Every sample was annotated with the corresponding API endpoint, required parameters, and desired response format.
For indexing, we employed FAISS with a Hierarchical Navigable Small World (HNSW) index. The dimensionality of the vectors was 384, the dimensionality of the output of the all-MiniLM-L6-v2 model. The HNSW index parameters were configured as follows: M = 32 (maximum number of outgoing links), efConstruction = 100, and efSearch = 50. These parameters were chosen as a trade-off between retrieval accuracy and runtime performance in real-time inference settings. All embeddings were L2 normalized prior to indexing to guarantee metric consistency.
The dataset contains natural language requests and corresponding API endpoints and parameters from IoD structured documentation. Annotation was performed by a team of three domain experts with prior knowledge of UAV operations and API design. Annotators followed a predefined set of guidelines in interpreting user intent, matching this with API actions, and formatting the expected responses to ensure consistency.
The original questions were generated from Swagger/OpenAPI v3.0 specifications by transforming formal text into its natural language counterpart. The base questions were then modified by systematic paraphrasing, tense changes, entity replacement, and query enrichment (e.g., “drone 5 battery level” was transformed to “how much battery does drone 5 have?”).
3.2. Retrieval-Augmented Inference Pipeline
At query time, a user submits a single natural language query to a unified/api/query endpoint. The input is embedded and matched against the pre-computed vector index to retrieve the top-k most similar examples. These examples are assembled into a few-shot prompt, which is forwarded to a lightweight large language model, specifically LLaMA 3.1 8B Instruct. The LLM infers the intended API endpoint and parameter configuration, producing a structured JSON object. The key components of a typical output are summarized in Table 2.
Table 2.
Structured fields of the generated API request.
The system validates the LLM’s output against the API specification to ensure conformity with parameter types, required fields, and value formats. This guards against erroneous or hallucinated queries.
Unlike supervised fine-tuning approaches, we expressly employed retrieval-augmented few-shot prompting solely for inference. The architecture was selected to support flexibility, modularity, and low-latency performance in real-time IoD environments. Fine-tuning would require considerable computational overhead and repeated retraining for adjustment to API evolution and, thus, was less suitable for rapidly changing deployment environments. In contrast, our few-shot approach enables the seamless addition of new examples by simply updating the FAISS index without any alteration to the model itself. Fine-tuning can yield incremental task-specific improvements but at the expense of our approach’s emphasis on adaptability, maintainability, and lean deployment—supreme requirements for edge-oriented UAV systems.
3.3. System Design and Integration
The final API request, once validated, is sent to the IoD backend via Representational State Transfer (REST). The results are returned and wrapped in a top-level response that includes both interpreted query metadata and actual retrieved data. This allows for enhanced transparency and traceability in dynamic query execution.
The architecture comprises stateless components, including:
- A unified gateway layer for handling incoming queries;
- A dedicated service for embedding, retrieval, and vector-based search;
- A large language model inference engine;
- A schema-aware validator and dynamic API execution layer.
These components operate in coordination to process natural language queries. The gateway receives requests and forwards them to the retrieval service, which locates semantically similar examples from a pre-indexed vector database. These examples, along with the original query, are passed to the LLM engine to determine the correct API call. The schema validator ensures the generated API request adheres to platform specifications before it is executed. This pipeline ensures accurate, explainable, and secure access to complex UAV data through a single, dynamic interface.
All components communicate via REST and are containerized for scalable deployment. Swagger files are periodically parsed and transformed into structured schemas to update the retrieval corpus and validation layer.
To better illustrate the operational flow, the system architecture can be visualized across four main layers: user interaction, semantic retrieval, inference and validation, and execution and response. This layered structure is depicted in Figure 1.
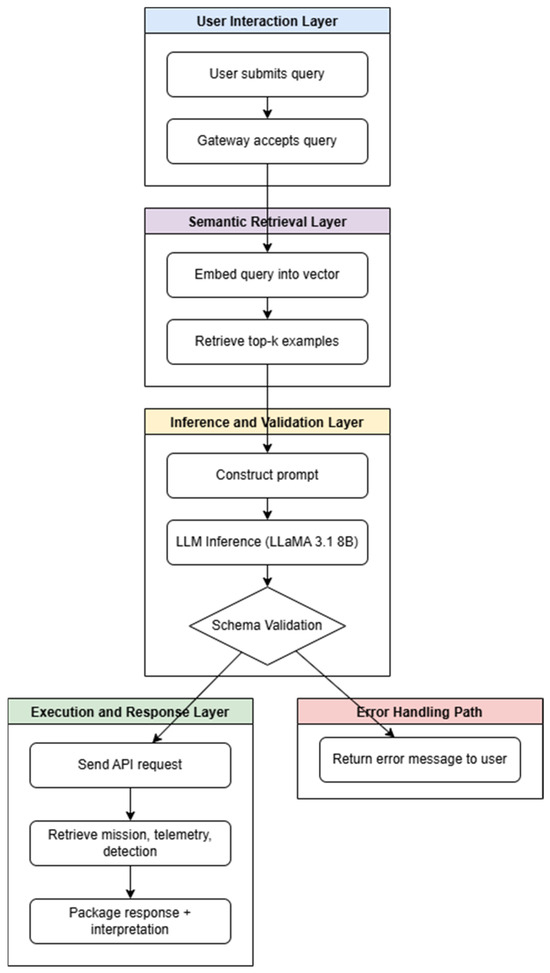
Figure 1.
Layered architecture of the system.
The first stage, referred to as the user interaction layer, captures the entry point of the user query. When a user submits a natural language question, it is initially received by the gateway. The gateway acts as the centralized access point that routes incoming requests to the appropriate processing modules in the pipeline. It also handles tasks such as basic authentication, logging, and formatting, providing a uniform interface for the end user.
At the semantic retrieval layer, the user’s query is converted to a vector representation using a transformer-based embedding model. This embedding effectively encodes the semantic intent of the user’s input, enabling comparison with past queries in a meaningful way. The top-k queries with the most similar semantic meaning are then retrieved from the pre-computed dataset using the FAISS index by the system. This retrieval grounds the user’s request in previously discovered instances, enhancing contextual relevance.
Upon retrieval, the inference and validation layer produces the inputs. The retrieved instances and the original user query are combined to formulate a structured prompt. This is fed through the LLaMA 3.1 8B Instruct model, which comprehends the action wanted and generates an API call suggestion in the form of a JSON message. Then, the output is compared meticulously against the API schema to verify the existence of valid parameter types, adherence to structural necessities, and conformance with predetermined endpoints.
Upon validation, the execution and response layer is invoked. The suggested API call is invoked against the IoD backend. The backend retrieves the requested information, which could be mission records, telemetry logs, object detections, or live metrics. The information is then combined with the interpreted query metadata in a structured form of response. The final output is rendered to the user via the gateway, thereby completing the interaction cycle with clear and traceable data.
For poorly formatted inputs, unforeseen query formats, or validation errors due to missing or incorrectly typed parameters, an error handling path is invoked to maintain system reliability and user confidence. This functionality guarantees that the user is presented with a correct, context-dependent error message specifying the issue—be it schema mismatch, missing parameters, or unrecognized endpoints. By trapping invalid outputs early in the processing pipeline, the system effectively blocks the transmission of defective or unwanted API calls to the backend, thereby ensuring both data integrity and system safety.
The error handling mechanism is also proficient in documenting erroneous queries for subsequent examination, facilitating ongoing enhancements in both the performance of retrieval and the construction of prompts. Furthermore, alternative prompts can be employed in situations of significant failure to suggest restructured queries or direct users toward acceptable input formats. This degree of resilience contributes to the overall robustness of the system.
Overall, this stratified and modular architecture improves the natural language to API format conversion while supporting transparency, scalability, and real-time responsiveness simultaneously, thus ensuring dependable performance and secure operation in mission-critical drone operation scenarios.
The extensible and modular architecture guarantees robustness along with simplicity in maintenance, while the use of retrieval-augmented generation enables the interpretation of sophisticated UAV queries in real-time within operational settings.
4. Experimental Setup and Evaluation
The experimental setup and evaluation procedures for the proposed dynamic query interpretation system in the context of the Internet of Drones are described in this section. The testing environment, datasets, evaluation metrics, and analysis methodologies are detailed to assess the performance of the retrieval-augmented generation (RAG) architecture integrated with a large language model. Furthermore, comparative assessments across different system configurations are conducted to analyze the individual contributions of each component within the overall pipeline.
4.1. Experimental Setup
To simulate a realistic environment, we developed a testing framework aligned with the operational characteristics of an Internet of Drones system. The evaluation setup incorporated the platform’s API documentation, which defines available endpoints, request structures, and validation rules. This documentation was parsed and utilized to support structured prompt construction and ensure the accuracy of schema-based query validation.
The dataset used in this evaluation consists of 520 natural language query samples constructed from UAV telemetry, mission logs, and detection data originating from previously logged operations within an IoD platform. Each query was manually annotated with its corresponding API endpoint and structured parameters. To ensure diversity, the queries were generated in varying sentence structures, levels of specificity, and types of operations (e.g., detection queries, telemetry access, mission history, and anomaly reports).
For testing purposes, the dataset was split into 80% training examples used for retrieval corpus indexing and 20% held out as unseen queries. The model did not have direct access to test queries during inference; instead, it leveraged semantically similar examples retrieved via vector search to perform few-shot prompting.
We employed the all-MiniLM-L6-v2 model to embed each query into a 384 dimensional vector, which was then indexed using Facebook AI Similarity Search (FAISS) with an HNSW configuration to support fast top-k retrieval. At runtime, for each test query, the top five closest examples were retrieved and used to construct a prompt for the LLaMA 3.1 8B Instruct model.
The final evaluation pipeline begins by embedding the incoming user query into a vector space using the same transformer model that was used during index construction. This ensures consistency in semantic representation.
Next, the system retrieves the top-k most similar queries from the indexed training corpus. These examples serve as context to help the language model understand the intent and structure expected for similar inputs.
Once the relevant examples are identified, a structured prompt is constructed. This prompt includes both the retrieved examples and the current user query, formatted in a way that the LLM can parse and learn from the context. The structured prompt is then submitted to the LLM, which returns a predicted API call, including the target endpoint and associated parameters. After inference, the system parses the output and performs validation. The predicted endpoint and parameters are checked against the API schema to ensure conformity in data types, parameter formats, and required fields. If the output passes validation, the system simulates an API call using the predicted values. The result of this simulated call is compared against the annotated ground truth to evaluate correctness and system reliability.
The experimental environment was established with a simulated Internet of Drones dashboard, which interacted with a backend API server. A specific frontend interface allowed evaluators to provide queries formulated in natural language through a web form, which were fed into the retrieval and inference pipeline. The API requests generated as structured requests were then formulated in JSON format, along with the result of their execution. The interaction also provided feedback regarding adherence to the schema. This configuration supported an integrative cycle with the inquiry process, data gathering, and presenting outcomes. One instance of this interface is represented in Figure 2.
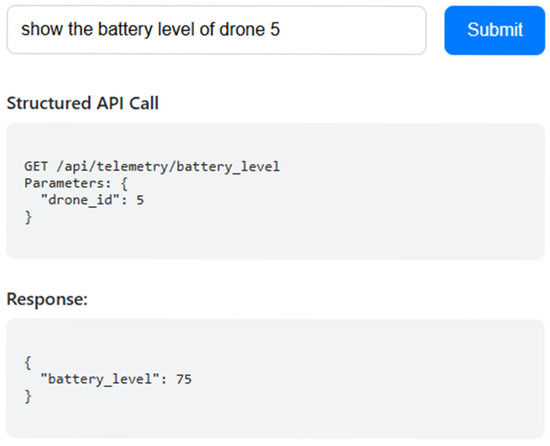
Figure 2.
Screenshot of the IoD interaction interface.
4.2. Evaluation Metrics
To assess the performance of the system, we employ multiple evaluation metrics designed to capture different aspects of query interpretation quality and overall system robustness.
Endpoint accuracy (EA): Endpoint accuracy measures the proportion of queries where the system correctly predicts the intended API endpoint. It quantifies the system’s ability to map natural language queries to their corresponding API routes, as formalized in Equation (1).
Parameter match rate (PMR): Parameter match rate evaluates the extent to which the predicted parameters (both names and values) match ground truth annotations. This metric assesses the precision of the generated API call arguments, as described in Equation (2).
Schema conformity (SC): Schema conformity indicates the degree to which the LLM-generated API calls adhere to the predefined API schema, ensuring structural and type correctness. As shown in Equation (3), this metric reflects schema validation success.
Retrieval precision at top-k (RP@k): Retrieval precision at top-k measures the fraction of retrieved examples within the top-k candidates that are semantically relevant to the input query. This is expressed formally in Equation (4).
These formulations are adapted from standard evaluation methodologies for information retrieval and structured prediction tasks.
4.3. Results and Discussion
We evaluated our system using 104 held-out test queries. The following results summarize the average performance across the test set:
- Endpoint accuracy (EA): 91.3%
- Parameter match rate (PMR): 87.6%
- Schema conformity (SC): 95.2%
- Retrieval precision (RP@5): 89.7%
These results indicate that the system can correctly interpret a wide range of user queries and produce executable API calls with high reliability. As illustrated in Figure 3, the system achieves 91.3% endpoint accuracy, 87.6% parameter match rate, and 95.2% schema conformity. These results confirm that the proposed pipeline is capable of producing both semantically correct and structurally valid API queries, ensuring robust communication with the IoD backend.
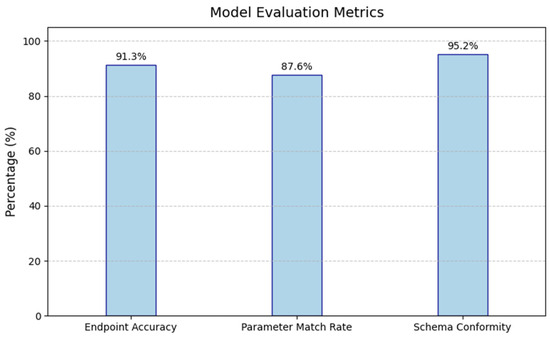
Figure 3.
Core performance metrics.
The relatively high endpoint accuracy demonstrates the effectiveness of the prompt structure and retrieval examples. In contrast, the parameter match rate was slightly lower, often because of ambiguous or underspecified user queries (e.g., missing time windows or vague object references). In such cases, the system either inserted defaults based on similar examples or flagged the issue via the validator. Although 91% endpoint accuracy seems hopeful, it by no means eliminates the possibility of intermittent misinterpretation or breakdown in high-stakes situations. Hence, we accept this as a successful outcome for semi-automated functions and recognize that additional verification—especially in mission-critical environments—is necessary before announcing high-reliability deployment.
We observed that the inclusion of top-k examples in the prompt significantly enhanced the performance of the large language model. Without the retrieval of similar examples, the model’s endpoint accuracy dropped to 74.1%, and the hallucination rate nearly doubled, highlighting the critical role of semantic retrieval as a grounding mechanism in structured reasoning tasks.
To further evaluate the contribution of each architectural component, an ablation study was conducted by selectively disabling major subsystems and analyzing their impact on performance. The comparative results are summarized in Table 3.
Table 3.
Impact of architectural components on system performance.
The results confirm that both the retrieval component and the schema validator are essential for high performance and reliability. Figure 4 provides a comparative view of system performance across different architectural configurations. The full system achieves the highest scores in all metrics while disabling retrieval or schema validation leads to significant performance degradation. Notably, removing validation causes a sharp drop in schema conformity, indicating that LLMs alone are prone to producing structurally incorrect outputs without external constraints.
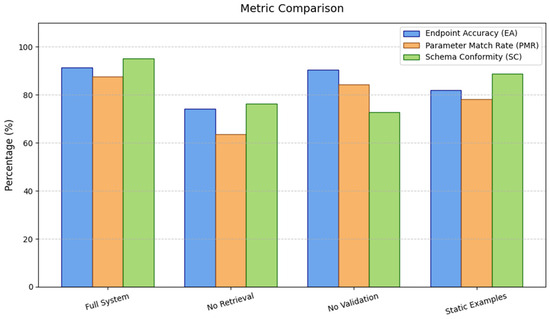
Figure 4.
Comparison of system variants.
The other significant strength of our analysis is the high schema conformity rate of 95.2% achieved by the system across various types of queries. The metric not only indicates semantic equivalence between natural language intention and API structure but also structural validity confirmed by OpenAPI specifications. High schema compliance is an essential component for enhancing system reliability by reducing the number of erroneous or non-executable requests, thereby preventing API failure and guaranteeing type-safe parameter generation. In safety-critical UAV settings, where reliability and automation take precedence, this method of validation acts as insurance against errors of inference and enables effortless integration into the operational backend.
4.4. Qualitative Evaluation Cases
One of the key goals of this system is to bridge the gap between natural language expressions and structured API calls. To evaluate the semantic precision and practical value of the proposed approach, we present a series of representative user queries and their corresponding interpretations by the LLM–RAG pipeline. These examples illustrate how well the system can infer intent, resolve ambiguous phrasing, and generate valid and executable API structures in diverse contexts.
The selected queries cover a range of operations frequently encountered in Internet of Drones (IoD) platforms, such as retrieving telemetry data, listing object detections, and filtering events by mission or time interval. Each case demonstrates how the system integrates retrieval-augmented context with prompt-based inference to derive API endpoint mappings and parameter configurations. The outputs shown were schema-validated and would be directly executable within the backend infrastructure.
Notably, the system demonstrates strong generalization for semantically similar inputs, even when user phrasing varies significantly. In contrast, cases with vague intent or missing constraints still result in acceptable outputs because of the influence of relevant examples retrieved during the prompt construction phase. Table 4 summarizes a selection of query-to-API transformations as observed in the evaluation phase.
Table 4.
Mapping of user queries to structured API outputs based on retrieval-augmented inference.
These qualitative results provide insight into how the system generalizes across varied natural language queries and maintains structural consistency in its outputs. The presented queries differ in phrasing complexity, intent specificity, and temporal or spatial references. Despite this diversity, the system consistently produces semantically aligned and schema-valid API calls, demonstrating both linguistic flexibility and adherence to backend constraints. This confirms the strength of the retrieval-augmented prompt in guiding the large language model toward the correct endpoint and parameter configuration.
The examples further show the system’s capacity to handle implicit constraints and linguistic ambiguity. Queries involving relative time expressions (e.g., “yesterday afternoon” or “latest telemetry”) are accurately grounded using example-based inference and prior schema knowledge. The presence of diverse operators, such as filtering by region, altitude, or mission scope, also illustrates the model’s adaptability in multi-dimensional query interpretation. These cases validate the system’s robustness in real-world scenarios where user input may be underspecified, informal, or context dependent.
5. Conclusions
5.1. Overview of Findings
This paper proposes a retrieval-augmented generation system based on a large language model to dynamically decode natural language queries for the Internet of Drones. The system allows users to query structured UAV telemetry and mission data using natural language-based input, lowering the technical barrier for data querying and command generation in sophisticated drone missions. A semantic interface is presented to facilitate natural language access to structured IoD data through the incorporation of a light large language model and structured API documentation. Unlike our previous work, which dealt with decision-making logic mined from telemetry logs and mission scenarios, this project deals with real-time data accessibility and schema-compliant query generation. With API documentation indexing and output structure verification, the system presented herein paves a new way for intelligent and secure interaction with UAV platforms. This work, therefore, opens up the usage realm of LLMs in autonomous systems, from mission reliability to dynamic and natural data inquiry.
To demonstrate the real-world applicability of our system, we present a representative example taken from post-disaster field deployments. Consider an earthquake relief operation in which drones are deployed to scan impacted zones and locate survivors through onboard thermal imaging cameras. A field operator—a non-technical API expert—needs to fetch all human detections made by drones in “District 12” within the last hour. Instead of coding a formal API request manually, the operator simply states:
List all human sightings near Zone 12 in the past 60 min.
The system accepts this natural language input via the proposed semantic retrieval pipeline and translates it into a schema-compliant API call. Table 5 presents the composition of the generated request, ranging from the endpoint to the parameters required. Such an immediate response allows command centers to allocate rescue resources more effectively and without delay due to technical constraints in support of the platform’s usability in time-critical environments.
Table 5.
Schema-compliant API call generated from natural language query in a disaster response scenario.
In addition to demonstrating schema-conformant generation, this research shows how structured retrieval and consistent, prompt formatting can significantly mitigate hallucination risk in practical applications. Semantic variation in the example set was found to promote robustness to varied input expressions. In the absence of decoding constraints being actually applied, schema validation proved an effective guard against malformed outputs.
We validated the efficacy of our method through extensive experimentation across a range of evaluation metrics. The system performed well in endpoint accuracy, schema validity, and parameter prediction accuracy, with a dramatic boost when utilizing semantically close retrieval examples. Comparative findings on various system settings verified the indispensable role of both the semantic retrieval layer and the schema validation component in producing correct and executable API responses.
Our results highlight the importance of augmenting lightweight transformer-based retrieval with guided prompting for enhancing structured prediction in LLMs. In addition, the modularity and containerization of the architecture provide maintainability and scalability in production environments.
As the variety of drones and missions increases, the RAG pipeline’s efficiency can be improved by a semantically more diverse example corpus. The addition of mission logs from various drone types (e.g., fixed-wing vs. multirotor) or task domains (e.g., mapping, surveillance, and delivery) improves retrieval accuracy if the input differs. Schema validation, however, depends on OpenAPI specification accuracy and coverage. If unregistered endpoints are introduced during missions, validation failure acts as a defense mechanism rather than a system fault.
Though our system purposely avoids fine-tuning in favor of few-shot prompting and schema validation, future work can explore domain-specific LLM training for UAV systems. One direction is integrating time-series telemetry, object detection outputs, and spatial features into multi-modal training pipelines to improve contextual grounding. Further, synthetically created questions—extracted from actual mission scenarios or simulated logs—have the potential to reduce annotation effort while improving coverage.
Our effort aids in the development of intelligent, human-in-the-loop drone platforms through the incorporation of natural language interfaces and structured control systems via explainable and trustworthy AI techniques.
5.2. Limitations
Although the system suggested herein is very good at converting natural language queries to executable API calls, it does have some limitations. First, the model depends to a large extent on retrieving semantically close examples to steer inference. In situations where such examples do not exist or are mismatched, performance can break down, particularly for out-of-distribution queries. Second, the framework presupposes the existence of a carefully designed API specification; endpoint definition or parameter format changes may need manual involvement in prompt construction and validation schema changes. Third, while schema validation helps reduce hallucinations during deployment by enforcing structural consistency and endpoint compliance, it does not fully eliminate the risk of hallucinating outputs. The present version only takes English queries and presumes a certain background knowledge of the API ecosystem, restricting its utilization for general or multilingual purposes.
6. Future Work
While the current system provides satisfactory performance in natural language query understanding and processing in IoD environments, there are still some research and development possibilities left for the future.
One such promising direction is the integration of multi-modal data sources, i.e., visual data or sensor data from the world, into the query understanding process. This would enable users to pose queries that combine textual as well as visual data, making the system more expressive.
Another area of interest relates to temporal reasoning and contextual grounding. Enhancing the model’s capacity to decipher vague temporal expressions and preserve dialogue context within multi-turn conversations has the potential to greatly improve both usability and accuracy.
Continual learning techniques can also be investigated, where user feedback is leveraged to update the retrieval and inference models incrementally over time. This would facilitate system adaptability and personalization in evolving mission contexts.
The presence of proactive features such as real-time notifications, anomaly detection, and automatic recommendation generation would make the platform more of a decision-support entity. Then, leveraging the system to run efficiently in resource-scarce settings, such as edge-deployed UAVs, can expand the usability of the system to distributed, low-latency environments required for field operations.
In addition to the aforementioned directions, future work will also explore schema versioning strategies, incremental registration of newly introduced endpoints, and enabling multi-agent query orchestration for large-scale deployments. Moreover, adaptive prompting based on validation feedback and benchmark comparisons between fine-tuned and prompted models may offer insights into trade-offs regarding speed, memory, and quality, especially in edge-constrained UAV environments.
Funding
This research received no external funding.
Data Availability Statement
Data presented in this study are available on request from the corresponding author. These data were collected from flights conducted on the Internet of Drones platform, developed by Hypersense, an academic spinoff startup. The platform is dedicated to research and development activities rather than commercial applications and serves as the primary source for data used in this research.
Acknowledgments
We would like to express our sincere gratitude to Siemens A.S. for their valuable collaboration throughout the completion of this study. This work also benefited from the use of the Hypersense platform and its dataset, which were instrumental in the development and evaluation of the proposed system.
Conflicts of Interest
The author Anıl Sezgin is employed by Research and Development, Siemens A.S. The author declared that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| API | Application Programming Interface |
| IoD | Internet of Drones |
| IoT | Internet of Things |
| JSON | JavaScript Object Notation |
| LLM | Large Language Model |
| NLP | Natural Language Processing |
| RAG | Retrieval-Augmented Generation |
| REST | Representational State Transfer |
| TCP | Transmission Control Protocol |
| UAV | Unmanned Aerial Vehicle |
References
- Sezgin, A. Scenario-Driven Evaluation of Autonomous Agents: Integrating Large Language Model for UAV Mission Reliability. Drones 2025, 9, 213. [Google Scholar] [CrossRef]
- Fan, Y.; Ren, T.; Huang, C.; Zheng, B.; Jing, Y.; He, Z.; Li, J.; Li, J. A confidence-based knowledge integration framework for cross-domain table question answering. Knowl.-Based Syst. 2024, 306, 112718. [Google Scholar] [CrossRef]
- Naik, B.B.; Reddy, T.J.V.R.; Karthik, K.R.V.; Kuila, R. An SQL query generator for cross-domain human language based questions based on NLP model. Multimed. Tools Appl. 2024, 83, 11861–11884. [Google Scholar] [CrossRef]
- Yi, J.; Chen, G.; Zhou, X. Decoupling SQL query hardness parsing for text-to-SQL. Neurocomputing 2025, 612, 129293. [Google Scholar] [CrossRef]
- Nguyen, X.; Phan, X.; Piccardi, M. Fine-tuning text-to-SQL models with reinforcement-learning training objectives. Nat. Lang. Process. J. 2025, 10, 100135. [Google Scholar] [CrossRef]
- Yan, L.; Su, J.; Liu, C.; Duan, S.; Zhang, Y.; Li, J.; Han, P.; Liu, Y. ExSPIN: Explicit Feedback-Based Self-Play Fine-Tuning for Text-to-SQL Parsing. Entropy 2025, 27, 235. [Google Scholar] [CrossRef]
- Nascimento, E.R.; Garcia, G.; Izquierdo, Y.T.; Feijó, L.; Coelho, G.M.; de Oliveira, A.R.; Lemos, M.; Garcia, R.L.S.; Leme, L.A.P.P.; Casanova, M.A. LLM based text to SQL for real-world databases. SN Comput. Sci. 2025, 6, 130. [Google Scholar] [CrossRef]
- Ojuri, S.; Han, T.A.; Chiong, R.; Di Stefano, A.D. Optimizing text-to-SQL conversion techniques through the integration of intelligent agents and large language models. Inf. Process. Manag. 2025, 62, 104136. [Google Scholar] [CrossRef]
- Manikani, K.; Chapaneri, R.; Shetty, D.; Shah, D. SQL Autograder: Web-based LLM-powered autograder for assessment of SQL queries. Int. J. Artif. Intell. Educ. 2025, 1–31. [Google Scholar] [CrossRef]
- Wang, R.; Hou, Y.; Tian, Y.; Cui, Z.; Jiang, S. XL-HQL: A HQL query generation method via XLNet and column attention. Inf. Softw. Technol. 2025, 180, 107674. [Google Scholar] [CrossRef]
- Moncada-Ramirez, J.; Matez-Bandera, J.; Gonzalez-Jimenez, J.; Ruiz-Sarmiento, J. Agentic workflows for improving large language model reasoning in robotic object-centered planning. Robotics 2025, 14, 24. [Google Scholar] [CrossRef]
- Singh, I.; Blukis, V.; Mousavian, A.; Goyal, A.; Xu, D.; Tremblay, J.; Fox, D.; Thomason, J.; Garg, A. PROGPROMPT: Program generation for situated robot task planning using large language models. Auton. Robots 2023, 47, 999–1012. [Google Scholar] [CrossRef]
- Pokhrel, S.R.; Mandjes, M. Internet of Drones: Improving Multipath TCP over WiFi with Federated Multi-Armed Bandits for Limitless Connectivity. Drones 2023, 7, 30. [Google Scholar] [CrossRef]
- Rivkin, D.; Hogan, F.; Feriani, A.; Konar, A.; Sigal, A.; Liu, X.; Dudek, G. AIoT Smart Home via Autonomous LLM Agents. IEEE Internet Things J. 2025, 12, 2458–2472. [Google Scholar] [CrossRef]
- Nguyen, D.; Dang, Q. Development of an Intelligent Drone Management System for Integration into Smart City Transportation Networks. Drones 2024, 8, 512. [Google Scholar] [CrossRef]
- Zong, M.; Hekmati, A.; Guastalla, M.; Li, Y.; Krishnamachari, B. Integrating large language models with internet of things: Applications. Discov. Internet Things 2025, 5, 2. [Google Scholar] [CrossRef]
- De Vito, G.; Palomba, F.; Ferrucci, F. The role of large language models in addressing IoT challenges: A systematic literature review. Future Gener. Comput. Syst. 2025, 171, 107829. [Google Scholar] [CrossRef]
- Sezgin, A.; Boyacı, A. Real-Time Drone Command Processing: A Large Language Model Approach for IoD Systems. Turk. J. Sci. Technol. 2025, 20, 281–297. [Google Scholar] [CrossRef]
- Tian, Y.; Lin, F.; Li, Y.; Zhang, T.; Zhang, Q.; Fu, X.; Huang, J.; Dai, X.; Wang, Y.; Tian, C.; et al. UAVs meet LLMs: Overviews and perspectives towards agentic low-altitude mobility. Inf. Fusion 2025, 122, 103158. [Google Scholar] [CrossRef]
- Kajornkasirat, S.; Sawangwong, C.; Puangsuwan, K.; Chanapai, N.; Phutthamongkhon, W.; Puttinaovarat, S. Integrating AI-driven predictive analytics in wearable IoT for real-time health monitoring in smart healthcare systems. Appl. Sci. 2025, 15, 4400. [Google Scholar] [CrossRef]
- Tian, Y.; Carballo, A.; Li, R.; Thompson, S.; Takeda, K. Query by example: Semantic traffic scene retrieval using LLM-based scene graph representation. Sensors 2025, 25, 2546. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Duan, Y.; Zhang, X.; Zhang, W.; Wang, C. FEPA-Net: A building extraction network based on fusing the feature extraction and position attention module. Appl. Sci. 2025, 15, 4432. [Google Scholar] [CrossRef]
- Hu, Z.; Wang, L.; Chen, Y.; Liu, Y.; Li, R.; Zhao, M.; Lu, X.; Jiang, Z. Dynamically retrieving knowledge via query generation for informative dialogue generation. Neurocomputing 2024, 569, 127036. [Google Scholar] [CrossRef]
- Hu, Z.; Chen, Y.; Zhao, M.; Li, R.; Wang, L. UniRQR: A unified model for retrieval decision, query, and response generation in internet-based knowledge dialogue systems. Expert Syst. Appl. 2025, 270, 126494. [Google Scholar] [CrossRef]
- Choi, Y.; Kim, S.; Bassole, Y.C.F.; Sung, Y. Enhanced retrieval-augmented generation using low-rank adaptation. Appl. Sci. 2025, 15, 4425. [Google Scholar] [CrossRef]
- Avignone, A.; Tierno, A.; Fiori, A.; Chuisano, S. Exploring large language models’ ability to describe entity-relationship schema-based conceptual data models. Information 2025, 16, 368. [Google Scholar] [CrossRef]
- Tychola, K.A.; Voulgaridis, K.; Lagkas, T. Beyond Flight: Enhancing the Internet of Drones with Blockchain Technologies. Drones 2024, 8, 219. [Google Scholar] [CrossRef]
- Rasool, A.; Shahzad, M.I.; Aslam, H.; Chan, V.; Arshad, M.A. Emotion-aware embedding fusion in large language models (Flan-T5, Llama 2, DeepSeek-R1, and ChatGPT 4) for intelligent response generation. AI 2025, 6, 56. [Google Scholar] [CrossRef]
- Alokla, A.; Gad, W.; Nazih, W.; Aref, M.; Salem, A. Retrieval-based transformer pseudocode generation. Mathematics 2022, 10, 604. [Google Scholar] [CrossRef]
- Kotenko, I.; Izrailov, K.; Buinevich, M. Analytical modeling for identification of the machine code architecture of cyberphysical devices in smart homes. Sensors 2022, 22, 1017. [Google Scholar] [CrossRef]
- Sezgin, A.; Boyacı, A. DecoyPot: A large language model-driven web API honeypot for realistic attacker engagement. Comput. Secur. 2025, 154, 104458. [Google Scholar] [CrossRef]
- Aldossary, M.; Alzamil, I.; Almutairi, J. Enhanced Intrusion Detection in Drone Networks: A Cross-Layer Convolutional Attention Approach for Drone-to-Drone and Drone-to-Base Station Communications. Drones 2025, 9, 46. [Google Scholar] [CrossRef]
- Alissa, K.A.; Alotaibi, S.S.; Alrayes, F.S.; Aljebreen, M.; Alazwari, S.; Alshahrani, H.; Elfaki, M.A.; Othman, M.; Motwakel, A. Crystal Structure Optimization with Deep-Autoencoder-Based Intrusion Detection for Secure Internet of Drones Environment. Drones 2022, 6, 297. [Google Scholar] [CrossRef]
- Zaidi, S.; Attalah, M.A.; Khamer, L.; Calafate, C.T. Task Offloading Optimization Using PSO in Fog Computing for the Internet of Drones. Drone 2025, 9, 23. [Google Scholar] [CrossRef]
- Song, X.; Zou, L.; Tang, M. An improved Monte Carlo reliability analysis method based on BP neural network. Appl. Sci. 2025, 15, 4438. [Google Scholar] [CrossRef]
- Sharma, P.; Saini, H.; Kalia, A. SURETY-Fog: Secure data query and storage processing in fog driven IoT environment. Sustain. Comput. Inform. Syst. 2025, 46, 101113. [Google Scholar] [CrossRef]
- Sun, K.; Wang, X.; Miao, X.; Zhao, Q. A review of AI edge devices and lightweight CNN and LLM deployment. Neurocomputing 2025, 614, 128791. [Google Scholar] [CrossRef]
- Bajgoti, A.; Gupta, R.; Dwivedi, R. ASKSQL: Enabling cost-effective natural language to SQL conversion for enhanced analytics and search. Mach. Learn. Appl. 2025, 20, 100641. [Google Scholar] [CrossRef]
- Gonçalves, B.; Saldanha, G.; Ramalho, M.; Vieira, L.; Vieira, P. A machine learning pipeline for adenoma detection in MRI: Integrating deep learning and ensemble classification. Appl. Sci. 2025, 15, 4100. [Google Scholar] [CrossRef]
- Hornsteiner, M.; Kreussel, M.; Steindl, C.; Ebner, F.; Empl, P.; Schönig, S. Real-time text-to-Cypher query generation with large language models for graph databases. Future Internet 2024, 16, 438. [Google Scholar] [CrossRef]
- Alam, K.A.; Haroon, M.; Ain, Q.; Inayat, I. A data-driven API recommendation approach for service mashup composition. Int. J. Syst. Assur. Eng. Manag. 2025, 1–22. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).