



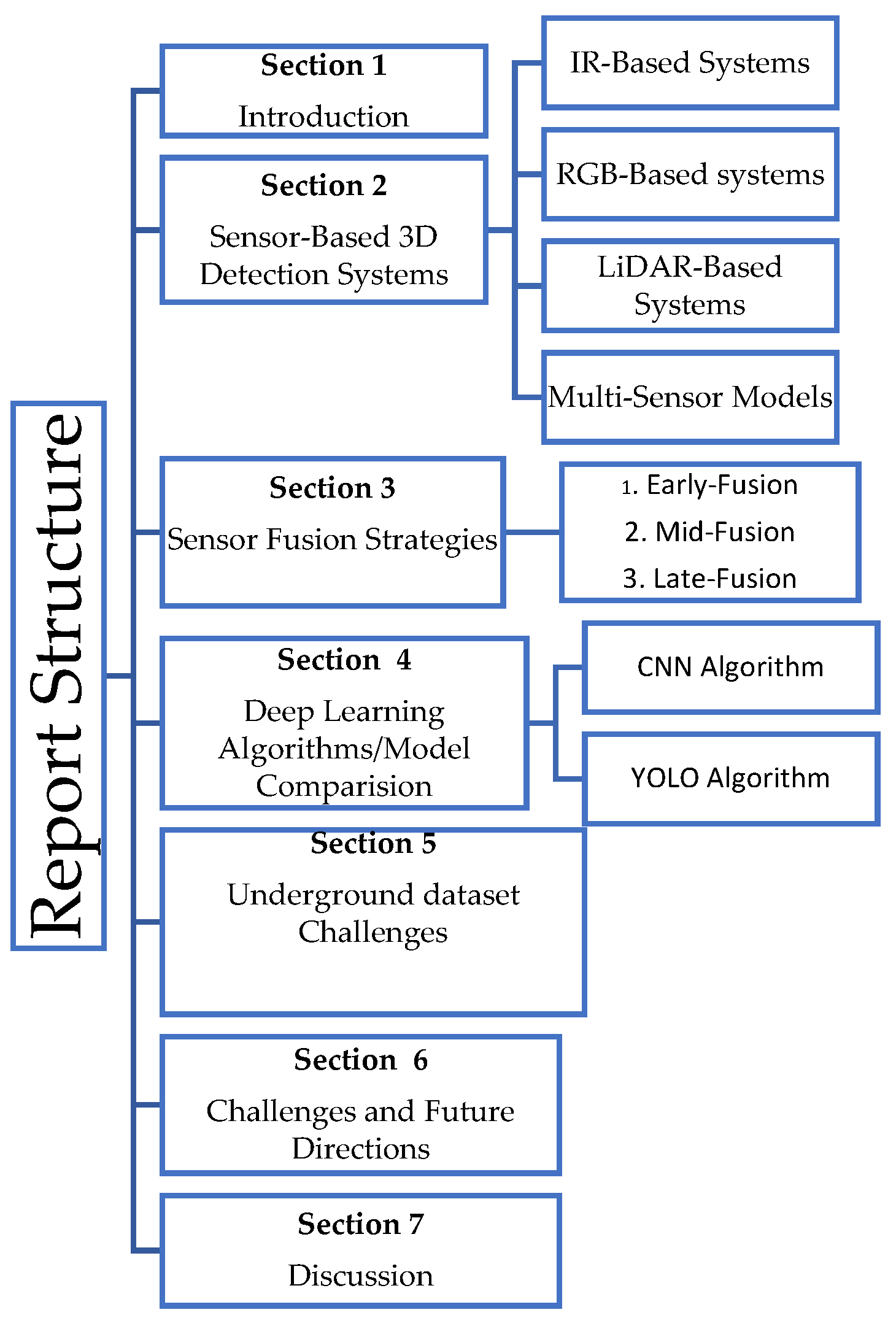
Enhancing Autonomous Truck Navigation in Underground Mines: A Review of 3D Object Detection Systems, Challenges, and Future Trends



Abstract
1. Introduction
- To categorize and evaluate the various sensor modalities employed in underground autonomous haulage 3D detection systems.
- To explore multi-sensor fusion approaches, their performance, and trade-offs.
- To analyze and synthesize the deep learning architectures used in object detection models, particularly YOLO variants and CNNs.
- To identify key underground dataset limitations for object detection models.
- To identify significant challenges in underground autonomous truck object detection deployment and propose future directions for developing scalable and reliable detection systems.
2. Overview of Sensor Modalities for 3D Object Detection in Underground Autonomous Haulage Trucks
2.1. Infrared (IR) Thermal Systems
- Pedestrian or worker detection by identifying humans’ heat signatures.
- Collision avoidance in situations where RGB cameras and LiDAR sensors struggle.
- Effective in Low- or No-Light Conditions: IR systems rely on detecting heat signatures rather than visible light, making them highly effective in poorly lit or completely dark environments in underground mines.
- Thermal Object Detection: These sensors distinguish objects based on their heat signatures to identify equipment, vehicles, and workers, even in smoke, fog, or dust.
- Long-Range Detection Capabilities: Certain IR sensors, like long-wave infrared (LWIR), can detect objects over significant distances, enabling the early identification of hazards or obstacles.
- Insensitive to Ambient Light Variations: Unlike RGB cameras, IR systems are unaffected by ambient light changes, ensuring consistent performance in dynamic lighting conditions.
- Compact and Durable Designs: IR sensors are lightweight, built to endure the harsh mining environment, and can withstand hot temperatures, vibrations, and dust.
- Resistance to Ambient Light Variations: Unlike RGB cameras, IR sensors are not affected by changes in ambient light, offering consistent performance both day and night.
- Limited spatial resolution often affects fine-grained object classification;
- High purchase cost of IR sensors such as long-wave IR (LWIR) are often costly;
- Inference from reflective equipment or heat surfaces with similar thermal profiles degrades their performance.
2.2. RGB-Based 3D Detection Systems
- The monocular cameras, which are lightweight and cost-effective, do not have depth perception.
- Stereo cameras estimate depth by triangulating differences between two lenses.
- Depth cameras incorporate active sensors for near-field 3D imaging.
- High-Resolution Imaging. RGB cameras can capture rich and detailed visual information, providing the necessary resolution to identify and classify objects based on color and texture.
- Cost-Effectiveness. They are relatively inexpensive compared to other sensors, such as LiDAR sensors, making them a known choice for cost-effective object detection models. Their affordability enables widespread applicability in autonomous vehicles.
- Color-Based Object Recognition. An additional layer of information is provided by the ability of RGB cameras to perceive colors, to distinguish between similar-shaped objects, and to identify warning signals.
- Lightweight Design. RBG cameras are compact and easy to integrate into autonomous vehicle platforms, enabling more sensor placement, system design, and integration flexibility.
- High reliance on lighting makes them unsuitable for low-light environments.
- Affected by visual occlusions from debris and dust, which reduce detection accuracy.
- Lack of depth perception unless integrated with a stereo or LiDAR sensor.
- High computational load for processing high-resolution image frames in real time.
2.3. LiDAR (Light Detection and Ranging) System
- High-Precision Depth Measurement: LiDAR sensors’ time-of-flight range ensures the precise localization of objects: This makes it particularly useful in underground mining, where exact spatial awareness is critical for safety and overall operational efficiency.
- Resilience to Environmental Interference: LiDAR is highly resistant to environmental interferences, such as vibration and glare. Advanced multi-echo and solid-state have built-in glare filters, enabling reliable performance in some of the underground mining environments.
- Wide Field of View and Real-Time Mapping: Several LiDAR sensors offer a full 360° coverage view. This ensures comprehensive detection of objects, obstacles, and workers around mining vehicles, enhancing situational awareness.
- Efficient and Reliable Performance: LiDAR sensors are unaffected by an object’s color or texture, allowing consistent detection regardless of the visual appearance of objects. Unlike RGB cameras, LiDAR systems are effective in low-light conditions as they solely rely on active laser emissions rather than ambient light.
- Compatibility with SLAM systems: LiDAR systems support simultaneous localization and mapping (SLAM), enabling autonomous haulage trucks to track their positions while dynamically building maps of the environment.
2.3.1. Traditional Methods
2.3.2. Deep Learning-Based Methods
- Voxel-Based Methods: Voxel-based models transform raw and irregular 3D point clouds into structured grids known as voxels for processing using 3D convolutional neural [65,66,67,68]. This generates simplified data, allowing the use of mature CNN architectures for object detection. Popular techniques include the following:
- ○
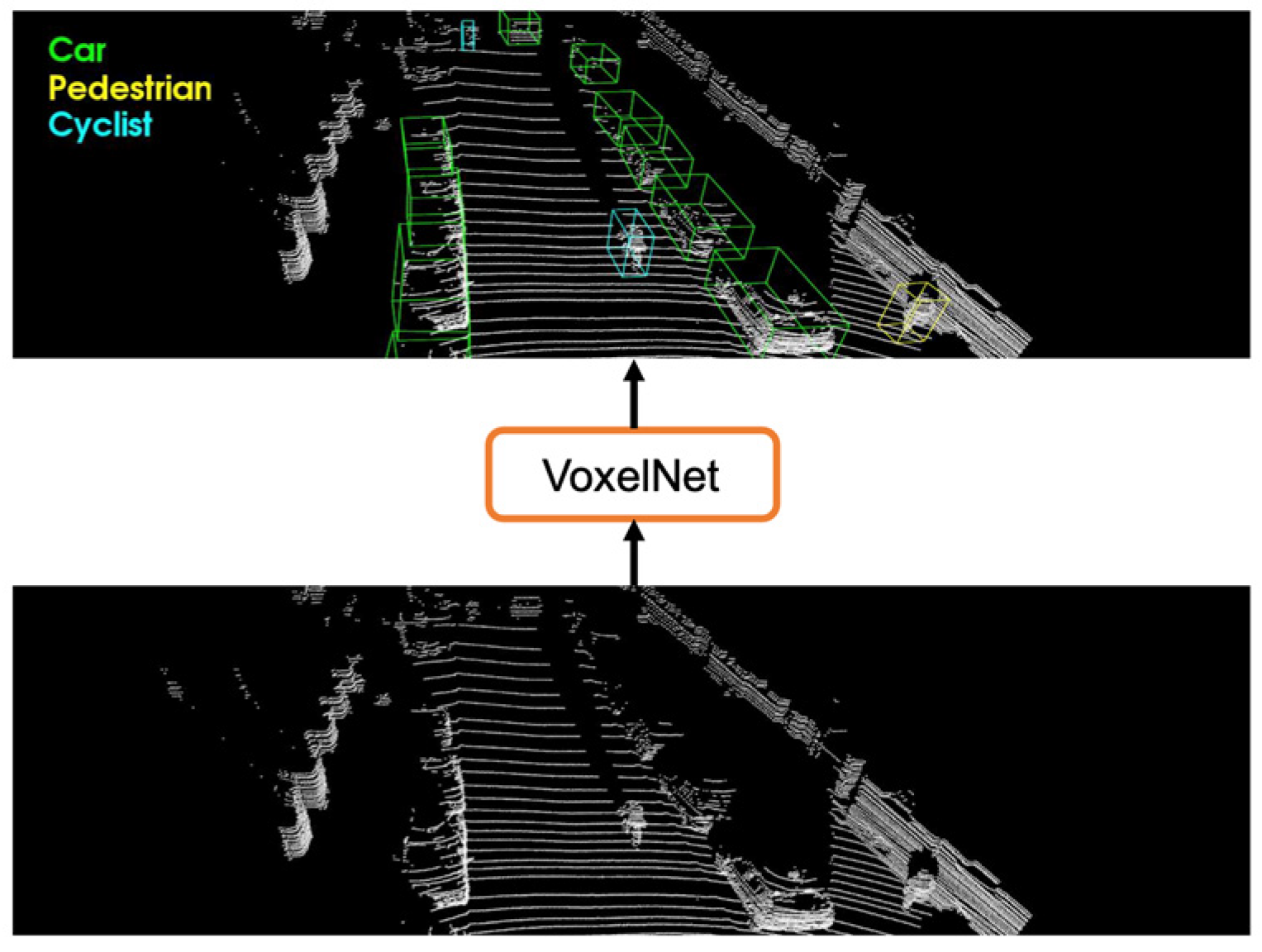
- VoxelNet [67]: This end-to-end framework partitions LiDAR point clouds into voxel grids and encodes object features using stacked voxel feature encoding (VFE) layers. This process is followed by 3D convolution to extract geometric and spatial features. The method streamlines the detection pipeline by eliminating separate feature extraction stages. Figure 8 shows the application of voxelization for autonomous truck navigation and detection, aiming to improve safety and operational efficiency
- ○
- 2.
- Point-Based Methods. Point-based methods directly process raw LiDAR point clouds without converting them into voxel grids (voxelization) to 2D projections. This method preserves fine-grained geometric details of the environment by operating on ordered 3D points. This makes them highly effective in detecting partially occluded or irregularly shaped objects. The key pioneering family of point-based methods is PointNet [69]. This uses symmetric functions to learn object global shape features from unordered point sets. PointNett++ [70] extends this by using hierarchical feature learning to capture local context in clustered regions. PointPillars [71] shown in Figure 9 are a widely adopted method in autonomous driving. The method partitions point clouds into vertical columns known as “pillars” to offer a balance between detail preservation and computational efficiency. It converts spatial features into a pseudo-image format, which enables fast detection through 2D convolution while retaining meaningful 3D structures.
- 3.
- Hybrid-Based Methods: Hybrid approaches integrate the strengths of voxel-based and point-based techniques to enhance the accuracy and efficiency of 3D object detection. These methods utilize voxelization for structured data representation while leveraging fine local feature extraction of point-based models. A hybrid model typically starts by extracting local geometric object features from raw point clouds using point-based encoders. The features are then embedded into voxel grids, where the voxel-based backbone utilizes convolutions to learn global context and make predictions. This design helps the hybrid model to balance robustness, precision, and processing speed, making it suitable for cluttered and complex underground environments.
- Lack of Object Identification: LiDAR systems can detect the presence and position of objects, but do not provide detailed information about object types or characteristics, which is essential for some mining applications.
- Computational Demand: This includes the processing of dense and sparse point clouds.
- Environmental Sensitivity: Accuracy is impacted by environmental conditions, such as dust, fog, water vapor, and snow. These factors degrade signal quality and require additional hardware and software processing to mitigate detection failures.
- Sensor Surface Contamination Challenges: Dust and debris accumulating on the sensor surface impair detection functionality, necessitating regular cleaning or protective mechanisms to maintain reliability.
- High Costs and High Resolution: These LiDAR units are expensive, which often hinders their large-scale deployment in budget-sensitive underground operations
- Range and Field of View Limitations: The typical range of LiDAR sensors is limited to around 50 m [28], restricting their effectiveness in larger underground mining operations. Furthermore, planar scanning systems may miss obstacles above or below the scanning plane, posing safety risks.
- Energy Consumption and Infrastructure Requirements: LiDAR systems consume more energy than other sensors and demand robust infrastructure for effective operation, complicating deployment in confined underground mining spaces.
2.4. Multi-Sensor Fusion in Underground Mining: Perception Enhancement Through Integration
- Enhanced Detection Accuracy: Combining the complementary strengths of different sensors, like LiDAR’s depth information with RGB camera’s texture data and thermal imaging’s heat signatures, will improve overall object detection performance.
- Robustness in Harsh Conditions: Multi-sensor models maintain improved detection capabilities in challenging underground conditions where individual sensors may fail.
- Redundancy for Safety: These models provide multiple sources of information, allowing the system to continue functioning safely if one sensor fails or becomes unreliable.
- Improved Localization and Mapping: Fusing vision (RGB cameras) with depth measurements (LiDAR) strengthens localization precision and supports robust mapping in GPS-denied underground environments.
- Adaptability to Dynamic Conditions: Adaptability provides dynamic sensor prioritization, where the system can rely more heavily on the most reliable sensors depending on environmental changes, like thermal sensors in low-visibility conditions and LiDAR for depth information.
- High Computational Demand: Processing large volumes of synchronized data from different sensors in real time requires powerful and often costly computational hardware.
- Complex Synchronization and Calibration: Multi-sensor fusion requires precise calibration and alignment across different sensors, which is technically challenging, especially in underground settings with vibrations and environmental noise.
- Scarcity of Datasets for Training: There is a lack of large, annotated, multi-sensor datasets that specifically capture underground environment conditions, limiting the ability to train robust deep learning models
- Increased System Weight: Adding multiple high-end sensors such as LiDAR, thermal, and RGB cameras raises the overall cost and maintenance complexity and may impact autonomous truck payload or energy efficiency.
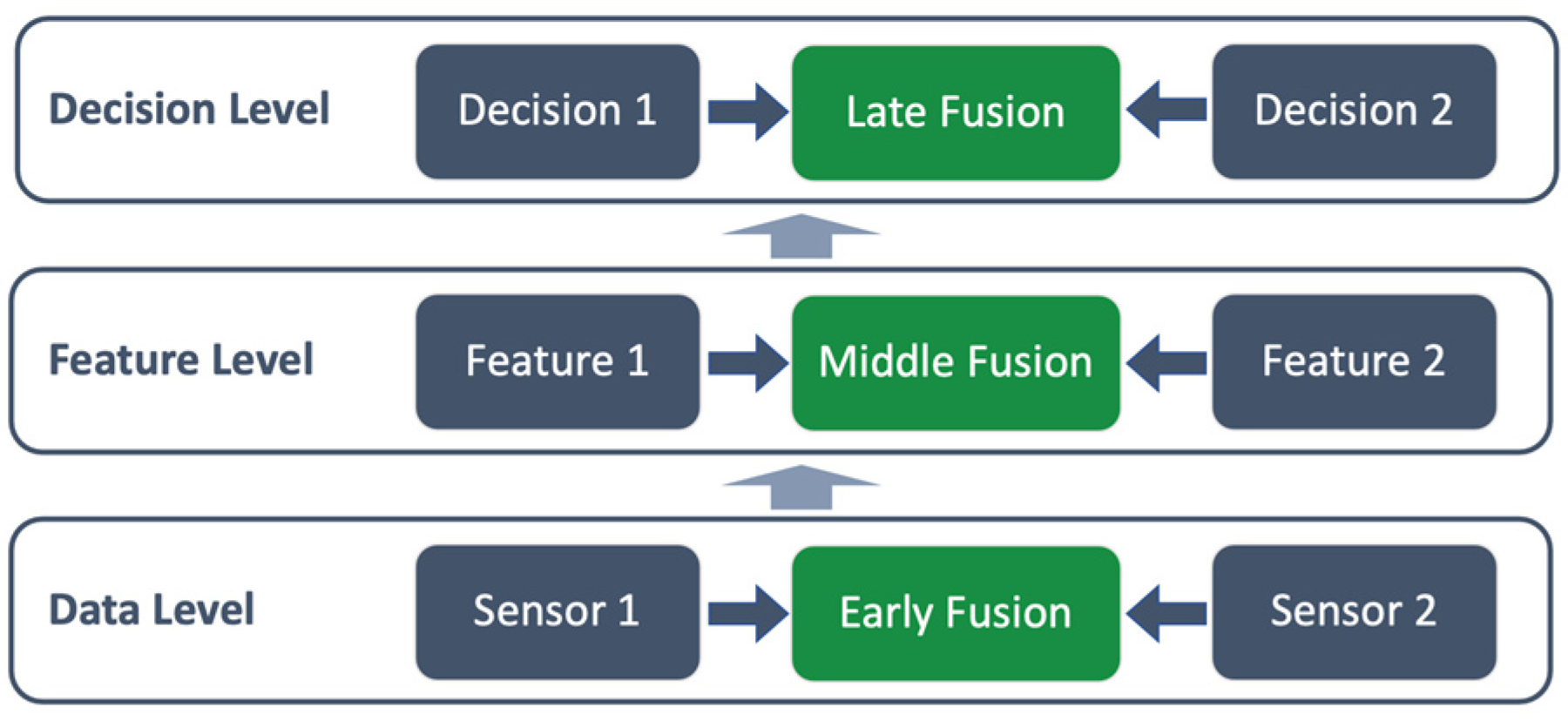
3. Sensor Data Fusion Methods
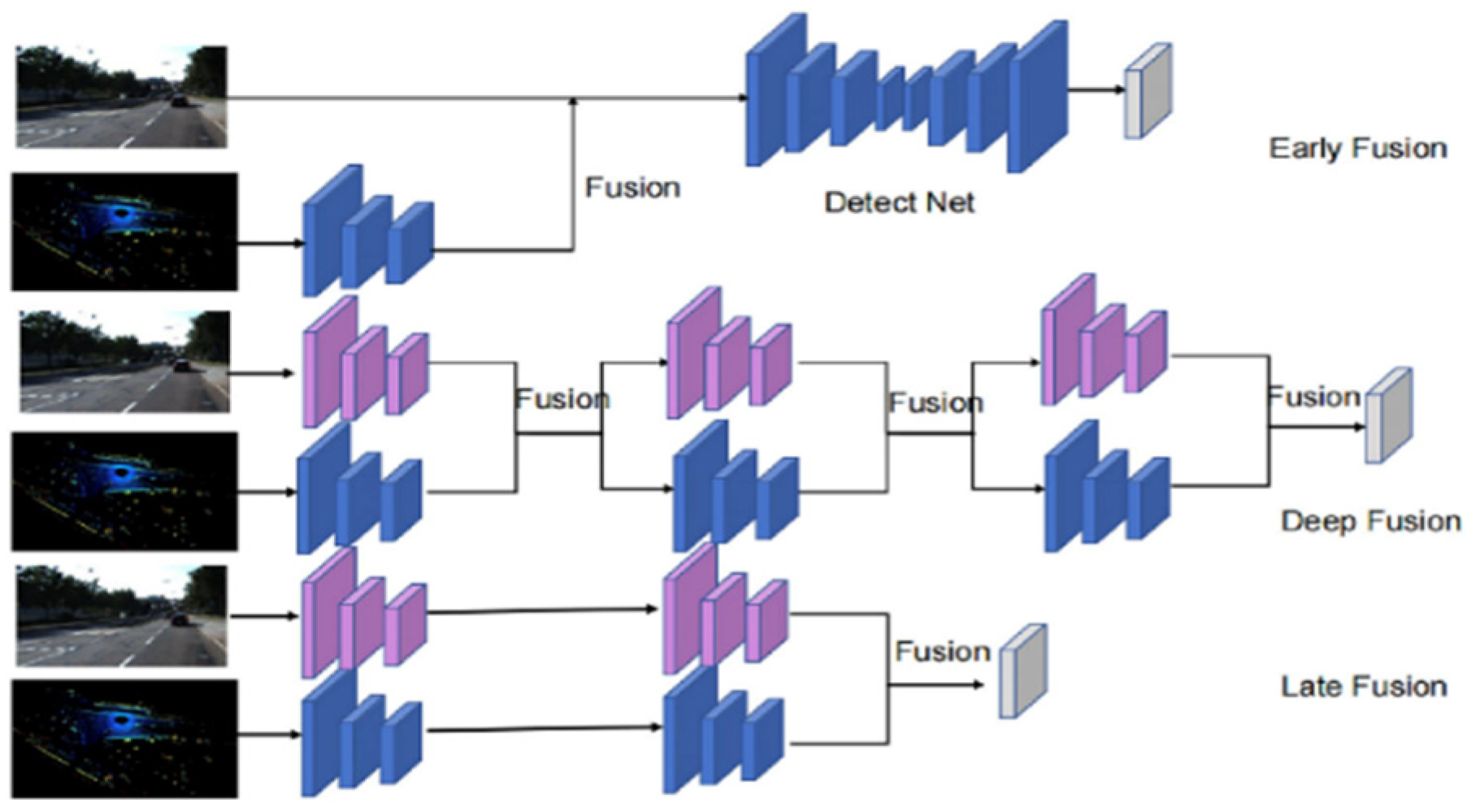
3.1. Multi-Fusion-Level Methods
3.1.1. Early-Stage Fusion
3.1.2. Mid-Level Fusion
3.1.3. Late-Stage Fusion
3.2. Sensor Fusion Advantages and Limitations
3.2.1. Advantages of Sensor Fusion in the Underground Mine Environment
- Resilience in Harsh Conditions: Sensor fusion compensates for individual sensor weaknesses. For example, LiDAR often degrades in dense particulate environments, cameras struggle in low light, and thermal sensors may lose range in open spaces. The fusion of these sensors provides a more consistent and robust perception across such extreme conditions [87].
- Enhanced Object Detection and Classification: Multi-modal sensor integration improves object detection precision. Combining LiDAR and thermal or camera data enhances the recognition of equipment, workers, and structural features, especially in low-visibility or occluded scenes [81].
- Improved Operational Safety: Integrating multiple sensors increases system reliability and robustness, providing better object identification and more reliable obstacle avoidance. This ensures workers’ and equipment safety in confined underground settings [72].
- Real-Time Decision-Making: Fusion systems enable faster and more informed decision-making, allowing real-time analysis of extreme environmental conditions. This enables autonomous trucks to respond promptly to dynamic changes in the environment [90].
- Model reliability and Redundancy: Fusion systems enhance fault tolerance and robustness by ensuring that the failure of one sensor modality does not compromise the entire perception system.
3.2.2. Challenges in Sensor Data Fusion
- Sensor Signal Reliability and Noise: Underground environmental conditions, such as noise, vibrations, dust, and electromagnetic interference, can significantly introduce noise into sensor outputs, degrading performance. LiDAR sensors may produce inaccurate point clouds due to reflective surfaces, while RGB cameras may struggle in low-light conditions. Filtering this noise without losing essential features requires advanced adaptive filtering and denoising techniques [91].
- Heterogeneous Sensor Integration: Each sensor type, such as LiDAR, cameras, radar, and IR, produces data in distinct resolutions, formats, and operational ranges. Integrating this heterogeneous input data requires overcoming challenges associated with data pre-processing, feature extraction, and data representation. For instance, fusing LiDAR point cloud data with pixel-based data from cameras involves significant computational effort and advanced algorithms to ensure meaningful integration and representation [2].
- Data Synchronization and Latency Management: Precise synchronization of data streams from various sensors is crucial for real-time sensor fusion performance. Differences in signal delays, sampling rates, and processing times can lead to temporal data mismatches, resulting in inaccurate fusion outputs. For example, data from a camera capturing images at 30 frames per second (fps) must be aligned with LiDAR data that operates at a different frequency (e.g., 15 Hz). Sophisticated temporal alignment algorithms or interpolation methods are required to ensure all sensor inputs contribute meaningful data to the fused output [2,37,91].
- Computational Complexity. The large volume of high-dimensional data that multiple sensors generate presents significant computational challenges. Real-time processing, critical for applications such as autonomous truck navigation, demands high-performance hardware and optimized algorithms. Resource constraints, including limited processing power and energy availability in mining vehicles, further complicate this task. Efficient techniques that balance computational load with fusion accuracy are crucial for deployment in such environments. Refs. [83,91] discuss the computational challenges in sensor fusion, emphasizing the need for efficient distributed processing strategies and the use of techniques like data compression and dimensionality reduction to manage computational and resource requirements.
- Environmental Factors: Underground conditions pose severe challenges to sensor performance. Poor lighting, dust, smoke, noise, and fog can obscure camera, radar, and LiDAR data, while extreme temperatures can impact sensor calibration and accuracy. Additionally, confined spaces and irregular terrains can cause occlusions or reflections that lead to distorted sensor readings. Designing fusion algorithms that can compensate for these environmental factors is a critical area of research. Addressing these challenges requires interdisciplinary solutions drawn from signal processing and machine learning.
4. Algorithms for 3D Object Detection in Autonomous Trucks
4.1. Convolutional Neural Networks (CNNs)
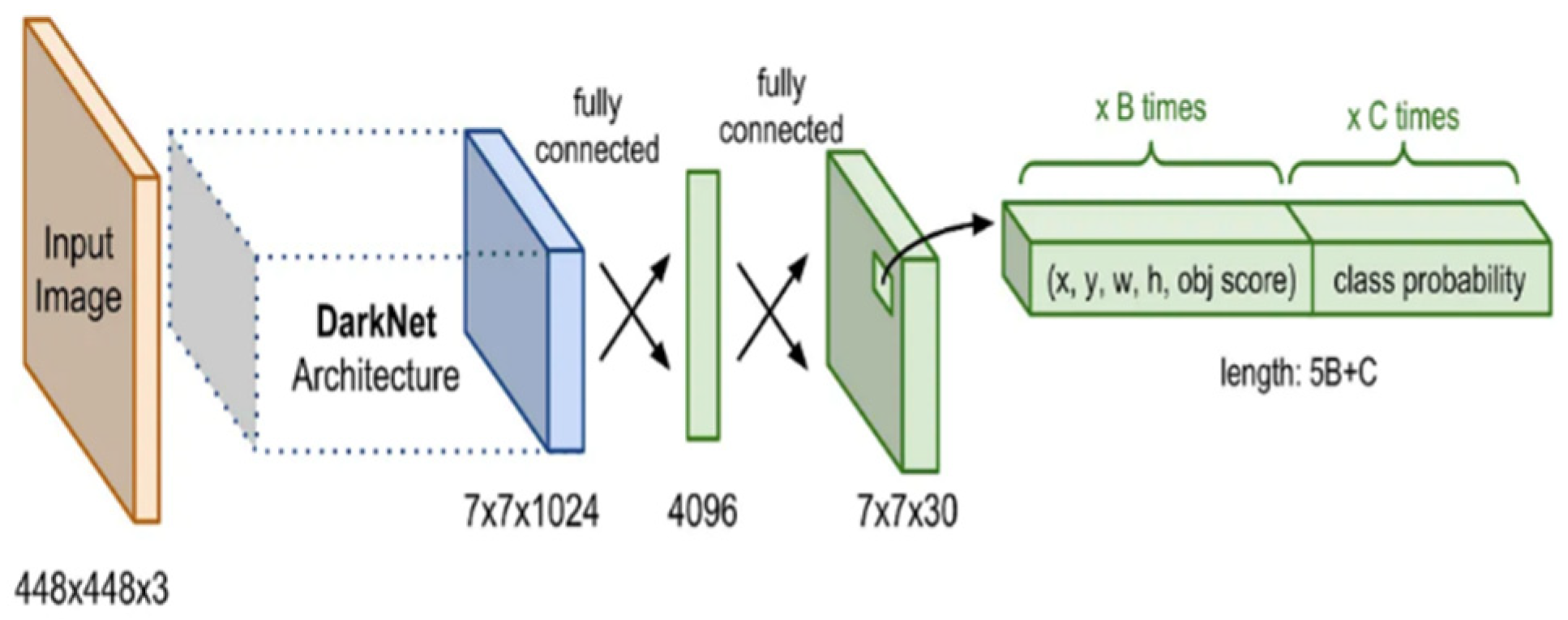
4.2. YOLO (You Only Look Once) Series Algorithm
4.3. Detection Model Comparison for Underground Autonomous Haulage Systems
4.4. Real World Case Scenarios of 3D Object Detection Systems in Underground Autonomous Truck Navigation
5. Dataset Analysis, Challenges, and Proposed Strategies
5.1. Dataset Challenges in the Underground Environment
- Environmental Complexity: Underground environmental conditions pose significant challenges, which hinder effective dataset collection for detection models. Such challenges include poor lighting conditions, as these settings lack natural light. This leads to images with low contrast and clarity, making it difficult for optical sensors such as cameras to capture objects accurately. Additionally, dust and smoke from drilling, blasting, and transportation activities often scatter light and obscure sensors, limiting data quality. Furthermore, uneven terrain, cluttered backgrounds, and waste materials make distinguishing between detection objects and irrelevant objects challenging for safe detection.
- Data Annotation Challenges: Annotating 3D data like LiDAR point clouds for detection models is particularly challenging as it is labor-intensive and needs expert knowledge of mining scenarios. Unlike 2D image annotation, identifying objects in 3D, especially in scenarios involving overlapping objects or partial occlusions, demands significant effort. The annotating process is prone to human errors and can significantly impact model performance [2,37].
- Suboptimal Dataset Representation: Mining datasets are often characterized by issues related to overrepresenting common objects, such as trucks, and under-representing critical but rare classes, such as pedestrians. Frequently encountered objects dominate the dataset, while less common but critical elements, such as workers, are under-represented in the data. This imbalance causes biases that prioritize common classes at the expense of rarer but safety-critical objects to be detected. This degrades model performance and limits generalizability.
- Inefficient Model Generalization: A significant challenge in underground mining is the variability in mine layout and equipment types across different mines. This makes models trained in one mine less effective in another. The dynamic nature of mining operations necessitates continuous model updates that can adapt to variable scenarios.
- High Computational Complexity and Real-Time Constraints: High-resolution sensors generate terabytes of data daily, which require massive infrastructure for storage, robust computational efficiency, and real-time processing. Managing such large datasets while maintaining efficiency is a persistent issue [74]. Latency in data processing can potentially compromise the system’s effectiveness and lead to unsafe critical decisions [82,87].
- Temporal Synchronization in Multi-sensor Models: Temporal synchronization is a significant challenge in multi-sensor 3D object detection models. Variability in sampling rates, operating modes, and data speed from different sensors causes a misaligned data stream and impairs fusion quality and detection accuracy. Delays in transmission and hardware limitations worsen synchronization challenges. The study by [113] highlights the critical issue of temporal misalignment in sensor fusion, particularly in 3D object detection scenarios. Their study demonstrates that even minor synchronization errors between sensors, such as LiDAR and cameras, can result in significant inaccuracies in object detection, underscoring the need for robust synchronization mechanisms.
5.2. Proposed Strategies for Dataset Optimization and Model Robustness in Underground
- Enhance Sensor Capabilities: Deploy robust sensors that withstand uneven terrain, dust, extreme vibrations, and temperature fluctuations to ensure consistent detection system performance. Integrate multi-sensor configurations by combining complementary sensing modalities. This will provide a robust and reliable detection system to enhance safety in underground mining operations.
- Advanced Data Preprocessing and Augmentation Techniques: Effective preprocessing and data augmentation techniques should be employed to significantly simulate dust, noise, occlusion, and variabilities in lightning [7,9,75]. Synthetic dust clouds, altering textures, and adjusting brightness can help the system adapt to variable surface types or equipment, ensuring robust object detection models for challenging underground conditions.
- Improved Data Synchronization: Solving temporal synchronization issues in multi-modal 3D object detection demands a combination of advanced computational methods and real-time data management strategies. Use software-based interpolation, a Kalman filter, or a deep learning-driven alignment framework to offer more flexible solutions for proper data synchronization. Catching strategies can also compensate for data transmission delays.
- Effective Data Annotation: Leverage data annotation tools such as semi-automated tools, active learning, and pre-trained models [83]. This will reduce manual annotation effort and improve labeling accuracy by minimizing human error and maximizing efficiency. Additionally, domain-specific annotation guidelines can ensure consistency.
- Optimize Dataset Representation: Accurate object detection requires balanced datasets. Applying class weighting, oversampling, and Generative Adversarial Network (GAN)-based synthetic data generation will balance rare and common object instances in datasets. This approach ensures that objects like pedestrians and/or rare but critical events receive more attention during training. This improves model robustness in accurately detecting safety-critical objects in real-world scenarios.
- Improvement in Model Generalization: Employ domain adaptation techniques such as transfer learning and adversarial training to improve models’ generalizability in cross-site applications. Consistent and continuous fine-tuning based on environmental feedback and characteristics enhances model adaptation.
- Edge Processing and Optimized Data Handling: Efficient data handling is crucial in managing large data volumes. Use efficient compression techniques to reduce the size of datasets without sacrificing critical features and integrity. Employing edge computing to optimize data will enable real-time and on-site data preprocessing. This reduces latency and bandwidth usage, enhancing the system’s ability to operate in real time. It will reduce data transmission time and minimize the load on central systems, allowing for quicker decision-making.
6. Key Challenges and Future Directions in 3D Detection Systems for Underground Mines
6.1. Challenges in the Underground Environment
- Environmental Challenges. Underground environments present near-zero natural light, which requires reliance on artificial illumination. This condition introduces variable lighting, low-light noise, shadows, and glare, adversely impacting vision-based systems. The prevalence of low-light imaging noise and incomplete data under artificial lighting conditions affects the performance of object detectors. IR modalities improve visibility but are limited in range and resolution. Dust, airborne particulates, and smoke generated by drilling, blasting, and other unit mining operational activities interfere with sensor signals [4]. These conditions degrade the quality of LiDAR point cloud data, leading to degraded object detection. Although radar sensors are less affected by these environmental factors, they lack resolution, necessitating multi-sensor fusion techniques to ensure robust detection. Creating fail-safes, redundancy in sensor data, and methods for ensuring detection capabilities and reliability are essential for reliable performance.
- Dynamic and Irregular Obstacles. Continuous machinery and other object movements of other objects create a dynamic and unpredictable detection environment. Debris, uneven terrain, and narrow layouts can lead to misclassifications due to their resemblance to natural geological features in sensor data. Advanced semantic segmentation and computationally efficient ML-based classifiers are needed to address these challenges.
- Equipment Blind Spots and Sensor Occlusion. Large mining trucks have extensive blind spots, particularly around corners and confined spaces, and occlusions from structures or materials often obscure key objects. This increases the risk of undetected obstacles, raising the likelihood of collisions causing fatalities. Multi-view and re-identification methods for occluded objects have shown improved continuity in detection. However, these solutions often introduce significant computational overheads, limiting real-time performance implementation in underground environments.
- Sensor Data Integration and Overload. High-resolution LiDAR generates millions of data points per second, requiring advanced data fusion algorithms to integrate and process information from multiple sensors efficiently. Real-time data fusion across LiDAR, IR, and camera presents a substantial computational load. Managing data overload is critical to ensuring timely and accurate object detection.
- Real-Time Latency Challenges. The maximum need for split-second decision-making in autonomous trucks operating in high-risk environments means delays are unacceptable. Edge computing systems, which process data locally to reduce latency, have demonstrated effectiveness in mitigating this issue. However, challenges remain in the trade-offs between model complexity and detection accuracy. While YOLO algorithms have shown potential enhancement in 3D object detection, they are often affected by low-light, cluttered, small objects, and dynamic underground mine settings.
- Efficiency vs. Accuracy Trade-Offs. Large models give high accuracy but are computationally intensive and unsuitable for resource-constrained environments. Lightweight models such as YOLO-Nano have high speed but may lack robustness for detecting small or partially occluded objects [114].
- Generalization Across Mining Sites. Every underground mining environment has unique variability in tunnel geometry, layout, infrastructure, machinery, and operational processes. Detection models trained in one site may not be scalable in another, which poses a significant obstacle to generalizing 3D object detection systems. Due to these variations, domain shifts cause models to fail to perform effectively on another site.
6.2. Future Research Directions
- Multi-Sensor Fusion and Edge Computing: Integrating data from sensors like LiDAR, IR, and cameras with edge computing is needed to reduce latency and improve real-time processing. Enhanced fusion techniques that combine high-resolution LiDAR data with camera visual information could provide more detailed and accurate object detection. Additionally, by processing data locally, autonomous trucks can make real-time decisions without relying on external servers, improving response times and operational efficiency.
- Collaborative Detection Systems: Future autonomous trucks may not operate in isolation but as part of a larger network of autonomous systems, including other trucks, drones, and support equipment. Collaboration between these systems to share detection data and build shared scene understanding can improve object detection. Multi-agent communication and coordination could improve detection capabilities, object tracking, awareness, and cooperative navigation.
- Design Lightweight and Real-time DL Models: Research into the development of optimized lightweight models for embedded GPUs in autonomous trucks. Advancements in pruning and quantization can minimize model size without significantly compromising detection accuracy.
- Real-Time Object Classification and Localization: Improvements should be made in detection, real-time object classification, and 3D localization. Improved situational awareness enhances safe navigation and operational efficiency in underground mining operations.
- Development of Standardized, open-access datasets: More effort is needed to develop large-scale, labeled datasets that are open-access and reflect underground mining conditions, which will improve research into more robust models for autonomous truck safe navigation. Simulation data combined with real underground mining footage will provide efficient training benchmarks.
- Advanced AI and ML Models: Leveraging cutting-edge AI techniques, such as transfer learning, reinforcement learning, or deep reinforcement learning, could significantly enhance the adaptability and robustness of 3D object detection systems. These models could enable them to learn from diverse datasets and improve their detection capabilities, even in challenging environments like the underground mine. More sophisticated and newer versions of YOLO, like YOLOv8, can be integrated to improve detection speed and accuracy for maximum system performance. Developing domain-adaptive and site-specific fine-tuning models capable of learning and generalizing across different environments needs much research focus.
- Field Validation of Object Detection Systems: Validation of detection systems in operational underground sites to evaluate the model’s real-world performance. Additionally, safety-critical metrics should be incorporated into the evaluation process to assess the developed models’ real-world capabilities and safety impact.
- Regulatory and Ethical Compliance: As autonomous trucks become more recognized in the mining industry, ensuring that object detection systems meet safety standards and regulatory requirements will be essential. Developing frameworks that align detection systems with safety regulations and ethical standards is crucial. This will ensure transparency in model design and performance benchmarking, which is key to operational and public trust.
- Long-Term Robustness and Reliability: Long-term deployment of autonomous trucks in underground mines will require systems that can withstand harsh conditions, such as exposure to dust, vibration, and moisture. Ensure long-term stability of systems through real-time health monitoring, regular sensor updates, and robustness against sensor drift and wear. This will be essential to ensure continued safety and model performance.
7. Discussions
- Accuracy vs. Speed: It was noticed that high-accuracy models like YOLOv8 often demonstrate slower inference times. This can be problematic for real-time underground navigation.
- Sensor Cost vs. Redundancy: Multi-sensor models improve robustness. However, they also increase hardware costs and integration complexity.
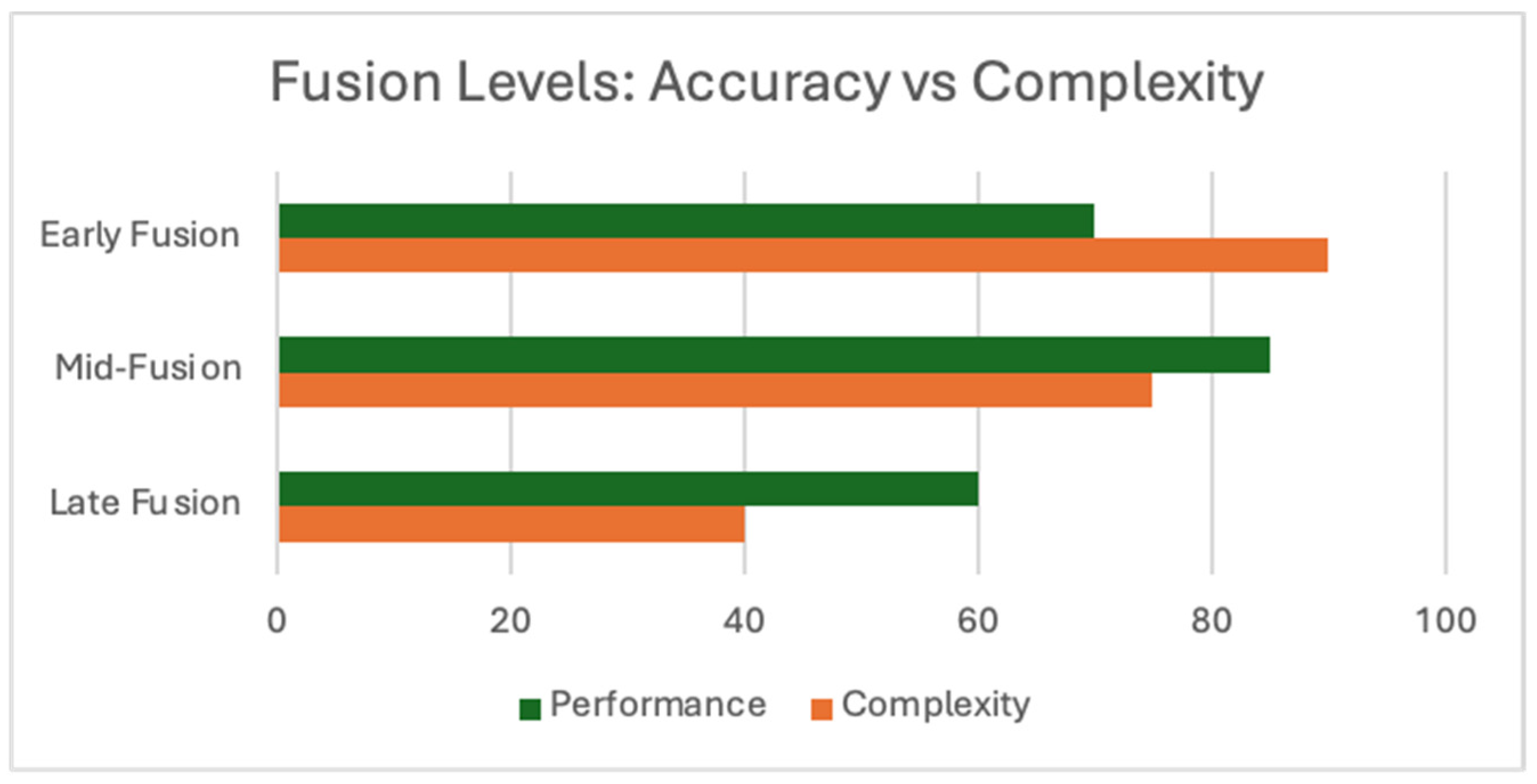
- Fusion Complexity vs. Benefit: The early fusion approach provides detailed insights and features but is highly computationally expensive. Late fusion is computationally efficient but is less accurate.
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mao, J.; Shi, S.; Wang, X.; Li, H. 3D Object Detection for Autonomous Driving: A Comprehensive Survey. arXiv 2022, arXiv:2206.09474. [Google Scholar] [CrossRef]
- Tang, L.; Bi, J.; Zhang, X.; Li, J.; Wang, L.; Yang, L.; Song, Z.; Wei, H.; Zhang, G.; Zhao, L.; et al. Multi-Modal 3D Object Detection in Autonomous Driving: A Survey and Taxonomy. IEEE Trans. Intell. Veh. 2023, 8, 3781–3798. [Google Scholar] [CrossRef]
- Yuan, Q.; Chen, X.; Liu, P.; Wang, H. A review of 3D object detection based on autonomous driving. Vis. Comput. 2024, 41, 1757–1775. [Google Scholar] [CrossRef]
- Xu, T.; Tian, B.; Wang, G.; Wu, J. 3D Vehicle Detection with RSU LiDAR for Autonomous Mine. IEEE Trans. Veh. Technol. 2021, 70, 344–355. [Google Scholar] [CrossRef]
- Yu, G.; Chen, P.; Zhou, B.; Zhao, F.; Wang, Z.; Li, H.; Gong, Z. 3DSG: A 3D LiDAR-Based Object Detection Method for Autonomous Mining Trucks Fusing Semantic and Geometric Features. Appl. Sci. 2022, 12, 12444. [Google Scholar] [CrossRef]
- Peng, P.; Pan, J.; Xi, M.; Chen, L.; Zhao, Z. A Novel Obstacle Detection Method in Underground Mines Based on 3D LiDAR. IEEE Access 2024, 12, 106685–106694. [Google Scholar] [CrossRef]
- Garg, S.; Rajaram, G.; Sundar, R.; Murugan, P.; Dakshinamoorthy, P.; Manimaran, A. Artificial Intelligence Algorithms for Object Detection and Recognition In video and Images. Multimed. Tools Appl. 2025, 83, 1–18. [Google Scholar] [CrossRef]
- Lee, K.; Dai, Y.; Kim, D. An Advanced Approach to Object Detection and Tracking in Robotics and Autonomous Vehicles Using YOLOv8 and LiDAR Data Fusion. Electronics 2024, 13, 2250. [Google Scholar] [CrossRef]
- Roghanchi, P.; Shahmoradi, J.; Talebi, E.; Hassanalian, M. A comprehensive review of applications of drone technology in the mining industry. Drones 2020, 4, 34. [Google Scholar] [CrossRef]
- Awuah-Offei, K.; Nadendla, V.S.S.; Addy, C. YOLO-Based Miner Detection Using Thermal Images in Underground Mines. Min. Met. Explor. 2025, 1–18. [Google Scholar] [CrossRef]
- Somua-Gyimah, G.; Somua-Gyimah, G.; Frimpong, S.; Gbadam, E. A Computer Vision System for Terrain Recognition and Object Detection Tasks in Mining and Construction Environments. 2018. Available online: https://www.researchgate.net/publication/330130008 (accessed on 15 December 2024).
- Rao, T.; Xu, H.; Pan, T. Pedestrian Detection Model in Underground Coal Mine Based on Active and Semi-supervised Learning. In Proceedings of the 2023 8th International Conference on Signal and Image Processing (ICSIP), Wuxi, China, 8–10 July 2023; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA; pp. 104–108. [Google Scholar]
- Yu, Z.; Li, Z.; Sana, M.U.; Bashir, R.; Hanif, M.W.; Farooq, S.A. A new network model for multiple object detection for autonomous vehicle detection in mining environment. IET Image Process. 2024, 18, 3277–3287. [Google Scholar] [CrossRef]
- Benz, P.; Montenegro, S.; Gageik, N. Obstacle detection and collision avoidance for a UAV with complementary low-cost sensors. IEEE Access 2015, 3, 599–609. [Google Scholar] [CrossRef]
- Pobar, M.; Ivasic-Kos, M.; Kristo, M. Thermal Object Detection in Difficult Weather Conditions Using YOLO. IEEE Access 2020, 8, 125459–125476. [Google Scholar] [CrossRef]
- Tang, K.H.D. Artificial Intelligence in Occupational Health and Safety Risk Management of Construction, Mining, and Oil and Gas Sectors: Advances and Prospects. J. Eng. Res. Rep. 2024, 26, 241–253. [Google Scholar] [CrossRef]
- Tripathy, D.P.; Ala, C.K. Identification of safety hazards in Indian underground coal mines. J. Sustain. Min. 2018, 17, 175–183. [Google Scholar] [CrossRef]
- Imam, M.; Baïna, K.; Tabii, Y.; Ressami, E.M.; Adlaoui, Y.; Benzakour, I.; Abdelwahed, E.H. The Future of Mine Safety: A Comprehensive Review of Anti-Collision Systems Based on Computer Vision in Underground Mines. Sensors 2023, 23, 4294. [Google Scholar] [CrossRef]
- Li, C.; Wang, H.; Li, J.; Yao, L.; Zhang, Z.; Tao, L. LDSI-YOLOv8: Real-time detection method for multiple targets in coal mine excavation scenes. IEEE Access 2024, 12, 132592–132604. [Google Scholar] [CrossRef]
- Li, P.; Li, C.; Yao, G.; Long, T.; Yuan, X. A Novel Method for 3D Object Detection in Open-Pit Mine Based on Hybrid Solid-State LiDAR Point Cloud. J. Sens. 2024, 2024, 5854745. [Google Scholar] [CrossRef]
- Velastin, S.A.; Salmane, P.H.; Velázquez, J.M.R.; Khoudour, L.; Mai, N.A.M.; Duthon, P.; Crouzil, A.; Pierre, G.S. 3D Object Detection for Self-Driving Cars Using Video and LiDAR: An Ablation Study. Sensors 2023, 23, 3223. [Google Scholar] [CrossRef]
- Zhang, P.; He, L.; Lin, X. A New Literature Review of 3D Object Detection on Autonomous Driving. J. Artif. Intell. Res. 2025, 82, 973–1015. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, S.; Li, Y.; Liu, M. A Comprehensive Review of 3D Object Detection in Autonomous Driving: Technological Advances and Future Directions. arXiv 2024, arXiv:2408.16530. [Google Scholar]
- Jiang, P.; Wang, J.; Song, L.; Li, J.; Xu, X.; Dong, S.; Ding, L.; Xu, T. FusionRCNN: LiDAR-Camera Fusion for Two-Stage 3D Object Detection. Remote. Sens. 2023, 15, 1839. [Google Scholar] [CrossRef]
- Fu, Z.; Ling, J.; Yuan, X.; Li, H.; Li, H.; Li, Y. Yolov8n-FADS: A Study for Enhancing Miners’ Helmet Detection Accuracy in Complex Underground Environments. Sensors 2024, 24, 3767. [Google Scholar] [CrossRef] [PubMed]
- Agrawal, P.; Das, B. Object Detection for Self-Driving Car in Complex Traffic Scenarios. MATEC Web Conf. 2024, 393, 04002. [Google Scholar] [CrossRef]
- Ogunrinde, I.; Bernadin, S. Deep Camera–Radar Fusion with an Attention Framework for Autonomous Vehicle Vision in Foggy Weather Conditions. Sensors 2023, 23, 6255. [Google Scholar] [CrossRef]
- Ren, Z. Enhanced YOLOv8 Infrared Image Object Detection Method with SPD Module. 2024. Available online: https://woodyinternational.com/index.php/jtpet/article/view/21 (accessed on 29 March 2025).
- Ruiz-Del-Solar, J.; Parra-Tsunekawa, I.; Inostroza, F. Robust Localization for Underground Mining Vehicles: An Application in a Room and Pillar Mine. Sensors 2023, 23, 8059. [Google Scholar] [CrossRef]
- Chahal, M.; Poddar, N.; Rajpurkar, A.; Joshi, G.P.; Kumar, N.; Cho, W.; Parekh, D. A Review on Autonomous Vehicles: Progress, Methods and Challenges. Electronics 2022, 11, 2162. [Google Scholar] [CrossRef]
- Liu, Q.; Cui, Y.; Liu, S. Navigation and positioning technology in underground coal mines and tunnels: A review. J. South Afr. Inst. Min. Met. 2021, 121, 295–303. [Google Scholar] [CrossRef]
- Pira, E.; Sorlini, A.; Patrucco, M.; Pentimalli, S.; Nebbia, R. Anti-collision systems in tunneling to improve effectiveness and safety in a system-quality approach: A review of the state of the art. Infrastructures 2021, 6, 42. [Google Scholar] [CrossRef]
- Bao, J.; Yin, Y.; Wang, M.; Yuan, X.; Khalid, S. Research Status and Development Trend of Unmanned Driving Technology in Coal Mine Transportation. Energies 2022, 15, 9133. [Google Scholar] [CrossRef]
- Liang, L.; Du, Y.; Zhang, H.; Song, B.; Zhang, J. Applications of Machine Vision in Coal Mine Fully Mechanized Tunneling Faces: A Review. IEEE Access 2023, 11, 102871–102898. [Google Scholar] [CrossRef]
- Wang, K.; Ren, F.; Zhou, T.; Li, X. Performance and Challenges of 3D Object Detection Methods in Complex Scenes for Autonomous Driving. IEEE Trans. Intell. Veh. 2022, 8, 1699–1716. [Google Scholar] [CrossRef]
- Banerjee, A.; Contreras, M.; Jain, A.; Bhatt, N.P.; Hashemi, E. A survey on 3D object detection in real time for autonomous driving. Front. Robot. AI 2024, 11, 1212070. [Google Scholar] [CrossRef]
- Mao, Z.; Tang, Y.; Wang, H.; Wang, Y.; He, H. Multi-modality 3D object detection in autonomous driving: A review. Neurocomputing 2023, 553, 126587. [Google Scholar] [CrossRef]
- Hao, G.; Zhang, K.; Li, Z.; Zhang, R. Unmanned aerial vehicle navigation in underground structure inspection: A review. Geol. J. 2023, 58, 2454–2472. [Google Scholar] [CrossRef]
- Jiao, W.; Li, L.; Xu, X.; Zhang, Q. Challenges of Autonomous Navigation and Perception Technology for Unmanned Special Vehicles in Underground Mine. In Proceedings of the 2023 6th International Symposium on Autonomous Systems (ISAS), Nanjing, China, 23–25 June 2023; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA; pp. 1–6. [Google Scholar]
- Tau 2|Teledyne FLIR. Available online: https://www.flir.fr/products/tau-2/ (accessed on 26 April 2025).
- IEEE Xplore Full-Text PDF. Available online: https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=6072167 (accessed on 4 May 2025).
- Worsa-Kozak, M.; Szrek, J.; Wodecki, J.; Zimroz, R.; Góralczyk, M.; Michalak, A. Application of the infrared thermography and unmanned ground vehicle for rescue action support in underground mine—The AMICOS project. Rem. Sens. 2020, 13, 69. [Google Scholar] [CrossRef]
- Wei, X.; Yuan, X.; Dai, X. TIRNet: Object detection in thermal infrared images for autonomous driving. Appl. Intell. 2020, 51, 1244–1261. [Google Scholar] [CrossRef]
- Parasar, D.; Kazi, N. Human identification using thermal sensing inside mines. In Proceedings of the 2021 5th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 6–8 May 2021; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA; pp. 608–615. [Google Scholar]
- Green, J.J.; Dickens, J.S.; van Wyk, M.A. Pedestrian detection for underground mine vehicles using thermal images. In Proceedings of the IEEE AFRICON Conference, Livingstone, Zambia 13–15 September 2011; pp. 1–6. [Google Scholar]
- Papachristos, C.; Khattak, S.; Mascarich, F. Autonomous Navigation and Mapping in Underground Mines Using Aerial Robots; IEEE: Piscateway, NJ, USA, 2019. [Google Scholar]
- Wang, S.; Liu, Q.; Ye, H.; Xu, Z. YOLOv8-CB: Dense Pedestrian Detection Algorithm Based on In-Vehicle Camera. Electronics 2024, 13, 236. [Google Scholar] [CrossRef]
- Apoorva, M.; Shanbhogue, N.M.; Hegde, S.S.; Rao, Y.P.; Chaitanya, L. RGB Camera Based Object Detection and Object Co-ordinate Extraction. In Proceedings of the 2022 IEEE 7th International Conference for Convergence in Technology (I2CT), Mumbai, India, 7–9 April 2022; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA; pp. 1–5. [Google Scholar]
- Rahul; Nair, B.B. Camera-based object detection, identification and distance estimation. In Proceedings of the 2018 2nd International Conference on Micro-Electronics and Telecommunication Engineering (ICMETE), Ghaziabad, India, 20–21 September 2018; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA; pp. 203–205. [Google Scholar]
- Gu, J.; Guo, J.; Liu, H.; Lou, H.; Duan, X.; Bi, L.; Chen, H. DC-YOLOv8: Small-Size Object Detection Algorithm Based on Camera Sensor. Electronics 2023, 12, 2323. [Google Scholar] [CrossRef]
- Baïna, K.; Imam, M.; Tabii, Y.; Benzakour, I.; Adlaoui, Y.; Ressami, E.M.; Abdelwahed, E.H. Anti-Collision System for Accident Prevention in Underground Mines using Computer Vision. In Proceedings of the ICAAI 2022: 2022 The 6th International Conference on Advances in Artificial Intelligence, Birmingham, UK, 21–23 October 2022; Association for Computing Machinery: New York, NY, USA; pp. 94–101. [Google Scholar]
- Fidler, S.; Philion, J. Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D. arXiv 2020, arXiv:2008.05711. [Google Scholar]
- Huang, K.; Zhou, R.; Cai, F.; Li, S. Detection of Large Foreign Objects on Coal Mine Belt Conveyor Based on Improved. Processes 2023, 11, 2469. [Google Scholar] [CrossRef]
- Baltes, R.; Clausen, E.; Uth, F.; Polnik, B.; Kurpiel, W.; Kriegsch, P. An innovative person detection system based on thermal imaging cameras dedicate for underground belt conveyors. Min. Scince 2019, 26, 263–276. [Google Scholar] [CrossRef]
- Yin, G.; Geng, K.; Wang, Z.; Li, S.; Qian, M. MVMM: Multiview Multimodal 3-D Object Detection for Autonomous Driving. IEEE Trans. Ind. Inform. 2023, 20, 845–853. [Google Scholar] [CrossRef]
- Chung, M.; Seo, S.; Ko, Y. Evaluation of Field Applicability of High-Speed 3D Digital Image Correlation for Shock Vibration Measurement in Underground Mining. Rem. Sens. 2022, 14, 3133. [Google Scholar] [CrossRef]
- Zhou, Z.; Geng, Z.; Xu, P. Safety monitoring method of moving target in underground coal mine based on computer vision processing. Sci. Rep. 2022, 12, 17899. [Google Scholar]
- Mitsunaga, T.; Nayar, S. High Dynamic Range Imaging: Spatially Varying Pixel Exposures. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2000, Hilton Head, SC, USA, 15 June 2000; pp. 472–479. [Google Scholar]
- Wang, X.; Pan, H.; Guo, K.; Yang, X.; Luo, S. The evolution of LiDAR and its application in high precision measurement. IOP Conf. Ser. Earth Environ. Sci. 2020, 502, 012008. [Google Scholar] [CrossRef]
- Jia, J.; Shen, X.; Yang, Z.; Sun, Y.; Liu, S. STD: Sparse-to-Dense 3D Object Detector for Point Cloud. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October 2019–2 November 2019; pp. 1951–1960. [Google Scholar]
- Nguyen, H.T.; Lee, E.-H.; Bae, C.H.; Lee, S. Multiple object detection based on clustering and deep learning methods. Sensors 2020, 20, 4424. [Google Scholar] [CrossRef]
- An, S.; Lee, S.E.; Oh, J.; Lee, S.; Kim, R. Point Cloud Clustering System with DBSCAN Algorithm for Low-Resolution LiDAR. In Proceedings of the 2024 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 6–8 January 2024; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA; pp. 1–2. [Google Scholar]
- Abudayyeh, O.; Awedat, K.; Chabaan, R.C.; Abdel-Qader, I.; El Yabroudi, M. Adaptive DBSCAN LiDAR Point Cloud Clustering For Autonomous Driving Applications. In Proceedings of the 2022 IEEE International Conference on Electro Information Technology (eIT), Mankato, MN, USA, 19–21 May 2022; pp. 221–224. [Google Scholar]
- Zhu, M.; Tian, C.; Gong, Y.; Zhu, Z. A Systematic Survey of Transformer-Based 3D Object Detection for Autonomous Driving: Methods, Challenges and Trends. Drones 2024, 8, 412. [Google Scholar] [CrossRef]
- Urtasun, R.; Luo, W.; Yang, B. PIXOR: Real-time 3D Object Detection from Point Clouds. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7652–7660. [Google Scholar]
- Li, B.; Mao, Y.; Yan, Y. SECOND: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4490–4499. [Google Scholar]
- Moon, J.; Park, G.; Koh, J.; Kim, J.; Choi, J.W. LiDAR-Based 3D Temporal Object Detection via Motion-Aware LiDAR Feature Fusion. Sensors 2024, 24, 4667. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Li, C.R.Q.; Hao, Y.; Leonidas, S.; Guibas, J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Yang, J.; Lang, A.H.; Zhou, L.; Beijbom, O.; Caesar, H.; Vora, S. PointPillars: Fast Encoders for Object Detection from Point Clouds. 2019. Available online: https://github.com/nutonomy/second.pytorch (accessed on 8 March 2025).
- Yuan, X.; Liu, H.; Hu, Y.; Li, C.; Pan, W.; Long, T. A Detection and Tracking Method Based on Heterogeneous Multi-Sensor Fusion for Unmanned Mining Trucks. Sensors 2022, 22, 5989. [Google Scholar] [CrossRef] [PubMed]
- Wei, P.; Cagle, L.; Reza, T.; Ball, J.; Gafford, J. LiDAR and camera detection fusion in a real-time industrial multi-sensor collision avoidance system. Electronics 2018, 7, 84. [Google Scholar] [CrossRef]
- Remondino, F.; Zimroz, R.; Szrek, J.; Wodecki, J.; Blachowski, J.; Kujawa, P.; Trybała, P. MIN3D Dataset: MultI-seNsor 3D Mapping with an Unmanned Ground Vehicle. PFG-J. Photogramm. Rem. Sens. Geoinf. Sci. 2023, 91, 425–442. [Google Scholar] [CrossRef]
- Yang, W.; You, K.; Kim, Y.-I.; Li, W.; Xu, Z. Vehicle autonomous localization in local area of coal mine tunnel based on vision sensors and ultrasonic sensors. PLoS ONE 2017, 12, e0171012. [Google Scholar] [CrossRef]
- Li, X.; Sun, Y.; Zhang, L.; Liu, J.; Xu, Y. Research on Positioning and Tracking Method of Intelligent Mine Car in Underground Mine Based on YOLOv5 Algorithm and Laser Sensor Fusion. Sustainability 2025, 17, 542. [Google Scholar] [CrossRef]
- Nabati, M.R. Sensor Fusion for Object Detection and Tracking in Autonomous Sensor Fusion for Object Detection and Tracking in Autonomous Vehicles Vehicles. Available online: https://trace.tennessee.edu/utk_graddiss (accessed on 8 March 2025).
- Glowacz, A.; Haris, M. Navigating an Automated Driving Vehicle via the Early Fusion of Multi-Modality. Sensors 2022, 22, 1425. [Google Scholar] [CrossRef]
- Li, K.; Chehri, A.; Wang, X. Multi-Sensor Fusion Technology for 3D Object Detection in Autonomous Driving: A Review. IEEE Trans. Intell. Transp. Syst. 2023, 25, 1148–1165. [Google Scholar] [CrossRef]
- Xu, Y.; Chen, Q.; Dai, Z.; Guan, Z.; Sun, F. Enhanced Object Detection in Autonomous Vehicles through LiDAR—Camera Sensor Fusion. World Electr. Veh. J. 2024, 15, 297. [Google Scholar] [CrossRef]
- Lang, A.H.; Helou, B.; Beijbom, O.; Vora, S. Point painting: Sequential fusion for 3D object detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4603–4611. [Google Scholar]
- Tian, B.; Liu, B.; Qiao, J. Mine track obstacle detection method based on information fusion. J. Phys. Conf. Ser. 2022, 2229, 012023. [Google Scholar] [CrossRef]
- Barry, J.; Yeong, D.J.; Velasco-Hernandez, G.; Walsh, J. Sensor and sensor fusion technology in autonomous vehicles: A review. Sensors 2021, 21, 2140. [Google Scholar] [CrossRef]
- Jahromi, B.S.; Tulabandhula, T.; Cetin, S. Real-time hybrid multi-sensor fusion framework for perception in autonomous vehicles. Sensors 2019, 19, 4357. [Google Scholar] [CrossRef]
- Zhou, R.; Li, X.; Jiang, W. SCANet: A Spatial and Channel Attention based Network for Partial-to-Partial Point Cloud Registration. In Proceedings of the ICASSP: 2018 IEEE International Conference on Acoustics, Speech and Signal Processing, Calgary Telus Convention Center, Calgary, AB, Canada, 15–20 April 2018; Institute of Electrical and Electronics Engineers: New York, NY, USA, 2018. [Google Scholar]
- Navab, N.; Wachinger, C.; Roy, A.G. Concurrent Spatial and Channel Squeeze & Excitation in Fully Convolutional Networks. arXiv 2018, arXiv:1803.02579. [Google Scholar]
- Qiu, Z.; Martínez-Sánchez, J.; Arias-Sánchez, P.; Rashdi, R. External multi-modal imaging sensor calibration for sensor fusion: A review. Inf. Fusion 2023, 97, 101806. [Google Scholar] [CrossRef]
- Tao, F.; Fu, Z.; Wang, J.; Han, L.; Li, C. A Novel Multi-Object Tracking Framework Based on Multis-ensor Data Fusion for Autonomous Driving in Adverse Weather Environments. IEEE Sens. J. 2025, 25, 16068–16079. [Google Scholar] [CrossRef]
- Ou, Y.; Qin, T.; Cai, Y.; Wei, R. Intelligent Systems in Motion. Int. J. Semantic Web Inf. Syst. 2023, 19, 1–35. [Google Scholar] [CrossRef]
- Zhao, G.; Yang, J.; Huang, Q.; Ge, S.; Gui, T.; Zhang, Y. Enhancement Technology for Perception in Smart Mining Vehicles: 4D Millimeter-Wave Radar and Multi-Sensor Fusion. IEEE Trans. Intell. Veh. 2024, 9, 5009–5013. [Google Scholar] [CrossRef]
- Raja, P.; Kumar, R.K.; Kumar, A. An Overview of Sensor Fusion and Data Analytics in WSNs. Available online: www.ijfmr.com (accessed on 5 June 2025).
- Zimmer, W.; Ercelik, E.; Zhou, X.; Ortiz, X.J.D.; Knoll, A. A Survey of Robust 3D Object Detection Methods in Point Clouds. arXiv 2022, arXiv:2204.00106. [Google Scholar]
- Hussain, M. YOLO-v1 to YOLO-v8, the Rise of YOLO and Its Complementary Nature toward Digital Manufacturing and Industrial Defect Detection. Machines 2023, 11, 677. [Google Scholar] [CrossRef]
- Stemmer, M.R.; Schneider, D.G. CNN-Based Multi-Object Detection and Segmentation in 3D LiDAR Data for Dynamic Industrial Environments. Robotics 2024, 13, 174. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J.; Mercan, E. R-CNN for Object Detection Outline 1. Problem Statement: Object Detection (and Segmentation) 2. Background: DPM, Selective Search, Regionlets 3. Method overview 4. Evaluation 5. Exten-sions to DPM and RGB-D 6. Discussion, 20214.Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar] [CrossRef]
- Lu, D.; Xie, Q.; Wei, M.; Gao, K.; Xu, L.; Li, J. Transformers in 3D Point Clouds: A Survey. arXiv 2023, arXiv:2205.07417. [Google Scholar]
- Ni, Y.; Huo, J.; Hou, Y.; Wang, J.; Guo, P. Detection of Underground Dangerous Area Based on Improving YOLOV8. Electronics 2024, 13, 623. [Google Scholar] [CrossRef]
- Ouyang, Y.; Li, Y.; Gao, X.; Zhao, Z.; Zhang, X.; Zheng, Z.; Deng, X.; Ye, T. An adaptive focused target feature fusion network for detection of foreign bodies in coal flow. Int. J. Mach. Learn. Cybern. 2023, 14, 2777–2791. [Google Scholar] [CrossRef]
- Song, Z.; Zhou, M.; Men, Y.; Qing, X. Mine underground object detection algorithm based on TTFNet and anchor-free. Open Comput. Sci. 2024, 14. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhou, Y.; Zhang, Y. YOLOv5 Based Pedestrian Safety Detection in Underground Coal Mines. In Proceedings of the 2021 IEEE International Conference on Robotics and Biomimetics (ROBIO), Sanya, China, 27–31 December 2021; pp. 1700–1705. [Google Scholar]
- Zhao, D.; Wang, P.; Chen, W.; Cheng, G.; Yang, Y.; Su, G. Research on real-time perception method of key targets in the comprehensive excavation working face of coal mine. Meas. Sci. Technol. 2023, 35, 015410. [Google Scholar] [CrossRef]
- Li, Y.; Yan, H.; Li, D.; Wang, H. Robust Miner Detection in Challenging Underground Environments: An Improved YOLOv11 Approach. Appl. Sci. 2024, 14, 11700. [Google Scholar] [CrossRef]
- Wang, Z.; Guan, Y.; Liu, J.; Xu, T.; Chen, W.; Mu, H. Slim-YOLO-PR_KD: An efficient pose-varied object detection method for underground coal mine. J. Real-Time Image Process. 2024, 21, 160. [Google Scholar] [CrossRef]
- Cat® MineStarTM Command for Hauling Manages the Autonomous Ecosystem|Cat|Caterpillar. Available online: https://www.cat.com/en_US/news/machine-press-releases/cat-minestar-command-for-hauling-manages-the-autonomous-ecosystem.html (accessed on 5 June 2025).
- Autonomous Haulage System|Komatsu. Available online: https://www.komatsu.com/en-us/technology/smart-mining/loading-and-haulage/autonomous-haulage-system (accessed on 5 June 2025).
- Mining Fleet Management|Fleet Management System (FMS)|Production Monitoring and Control|Wenco Mining Sys-tems. Available online: https://www.wencomine.com/our-solutions/mining-fleet-management (accessed on 5 June 2025).
- Autonomous Haulage System (AHS—Hitachi) Construction Machinery. Available online: https://www.hitachicm.com/global/en/solutions/solution-linkage/ahs/ (accessed on 5 June 2025).
- Lin, C.-C.; Chen, J.-J.; Von Der Bruggen, G.; Gunzel, M.; Teper, H.; Kuhse, D.; Holscher, N. Sync or Sink? The Robustness of Sensor Fusion against Temporal Misalignment. In Proceedings of the 2024 IEEE 30th Real-Time and Embedded Technology and Applications Symposium (RTAS), Hong Kong, 13–16 May 2024; pp. 122–134. [Google Scholar]
- Jegham, N.; Koh, C.Y.; Abdelatti, M.; Hendawi, A. YOLO Evolution: A Comprehensive Benchmark and Architectural Review of YOLOv12, YOLO11, and Their Previous Versions. arXiv 2024, arXiv:2411.00201. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Review Paper | Focus Area | Limitations | Key Contributions in This Study |
|---|---|---|---|
| Imam et al. [18] | General object detection systems in underground mining | Focuses only on anti-collision frameworks | DL-based perception, systems, and underground-specific design limitations |
| Cui et al. [31] | Underground mine positioning systems and algorithms | Limited discussion on fusion architecture comparison and underground constraints | Provide comparative analysis across fusion levels with underground mining focus |
| Patrucco et al. [32] | Anti-collision technologies and safety protocols in tunneling and underground construction | No discussion on dataset limitations or challenges in confined spaces | Highlights dataset gaps and 3D perception limitations in underground scenarios |
| Shahmoradi et al. [9] | Applications of drones across surface and underground mining operations | Not focused on object detection challenges or underground autonomous truck navigation | Narrows down to AHS and object perception in underground environments |
| Zhang et al. [38] | UAV-based navigation and mapping in underground mining inspections | Only on UAVs for mapping and inspection | Addresses underground AHS detection models and dataset challenges |
| Xu et al. [39] | Sensing and navigation technologies for underground vehicle navigation | Does not delve into DL-based object detection | Discusses integration of DL-based 3D object detection and fusion strategies for underground autonomous trucks |
| Fusion Approach | Level | Advantages | Limitations |
|---|---|---|---|
| Early-Level Fusion | Raw data |
|
|
| Mid-Level Fusion | Feature Level |
|
|
| Late-Stage Fusion | Decision Level |
|
|
| DL-Approach | Advantages | Limitation |
|---|---|---|
| CNN |
|
|
| YOLO Series |
|
|
| Model/Framework | Detection Algorithm | Sensor Modalities | mAP (%) | FPS | Limitations |
|---|---|---|---|---|---|
| LDSI-YOLOv8 [19] | YOLOv8n | RGB Camera | 91.4 | 82.2 | It has limited scalability in other mining environments. |
| YOLOv8 for Hazard Detection [100] | YOLOv8-based | RGB Camera | 99.5 | 45 | Limited robustness and generalization due to reliance on a small, self-constructed dataset |
| YOLO-UCM [105] | YOLOv5 | RGB Camera | 93.5 | 15 | Model trained on a simulated dataset |
| DDEB-YOLOv5s + StrongSORT [106] | YOLOv5s with StrongSORT | RGB Camera | 91.7 | 98 | High model complexity
|
| YOLOv11-based Model [107] | YOLOv11 | RGB Camera | 95.8 | 59.6 | Focuses mainly on personnel detection |
| Pedestrian Detection Model [51] | YOLOv5 (Deep Learning) | RGB Camera | 71.6 | x | Challenges with occlusion and detection in crowded scenes |
| Slim-YOLO-PR_KD [108] | YOLOv8s | RGB Camera | 92.4 | 67 | Scope limited to pedestrian detection |
| Dataset Name | Sensor Type (s) | Objects Annotated | Environment | Limitations |
|---|---|---|---|---|
| LDSI-YOLOv8 Excavation Scenes [19] | RGB Camera | Pedestrian | Underground coal mine | Limited scalability across diverse mining environments Scene specific |
| Thermal image set [54] | Thermal IR | Workers, conveyor loads | Real coal mine | Lacks scalability |
| YOLO-UCM [105] | RGB Camera | Pedestrians | Underground mines | Model trained on a simulated dataset; real underground variability may affect model performance |
| Real-time perception excavation dataset [106] | RGB Camera | Miners, Equipment | Excavation working faces in coal mines | Generalization to highly dynamic or new tunnel layouts is untested |
| MANAGEM Pedestrian Detection Model [51] | RGB Camera | Pedestrians | Underground coal mines | Sensitive to occlusion and crowded scenes |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Essien, E.; Frimpong, S. Enhancing Autonomous Truck Navigation in Underground Mines: A Review of 3D Object Detection Systems, Challenges, and Future Trends. Drones 2025, 9, 433. https://doi.org/10.3390/drones9060433
Essien E, Frimpong S. Enhancing Autonomous Truck Navigation in Underground Mines: A Review of 3D Object Detection Systems, Challenges, and Future Trends. Drones. 2025; 9(6):433. https://doi.org/10.3390/drones9060433
Chicago/Turabian StyleEssien, Ellen, and Samuel Frimpong. 2025. "Enhancing Autonomous Truck Navigation in Underground Mines: A Review of 3D Object Detection Systems, Challenges, and Future Trends" Drones 9, no. 6: 433. https://doi.org/10.3390/drones9060433
APA StyleEssien, E., & Frimpong, S. (2025). Enhancing Autonomous Truck Navigation in Underground Mines: A Review of 3D Object Detection Systems, Challenges, and Future Trends. Drones, 9(6), 433. https://doi.org/10.3390/drones9060433