
MSUD-YOLO: A Novel Multiscale Small Object Detection Model for UAV Aerial Images


Abstract
1. Introduction
- Aiming at multiscale issues in UAV aerial images, we have improved the neck network using the ASF structure. This structure achieves comprehensive fusion of different scale features and enhances detection capability by optimizing the feature pyramid and the path aggregation network. Concurrently, adding a small object prediction head P2 into the head makes the model focus more on low-level features, thereby enhancing its sensitivity to small objects.
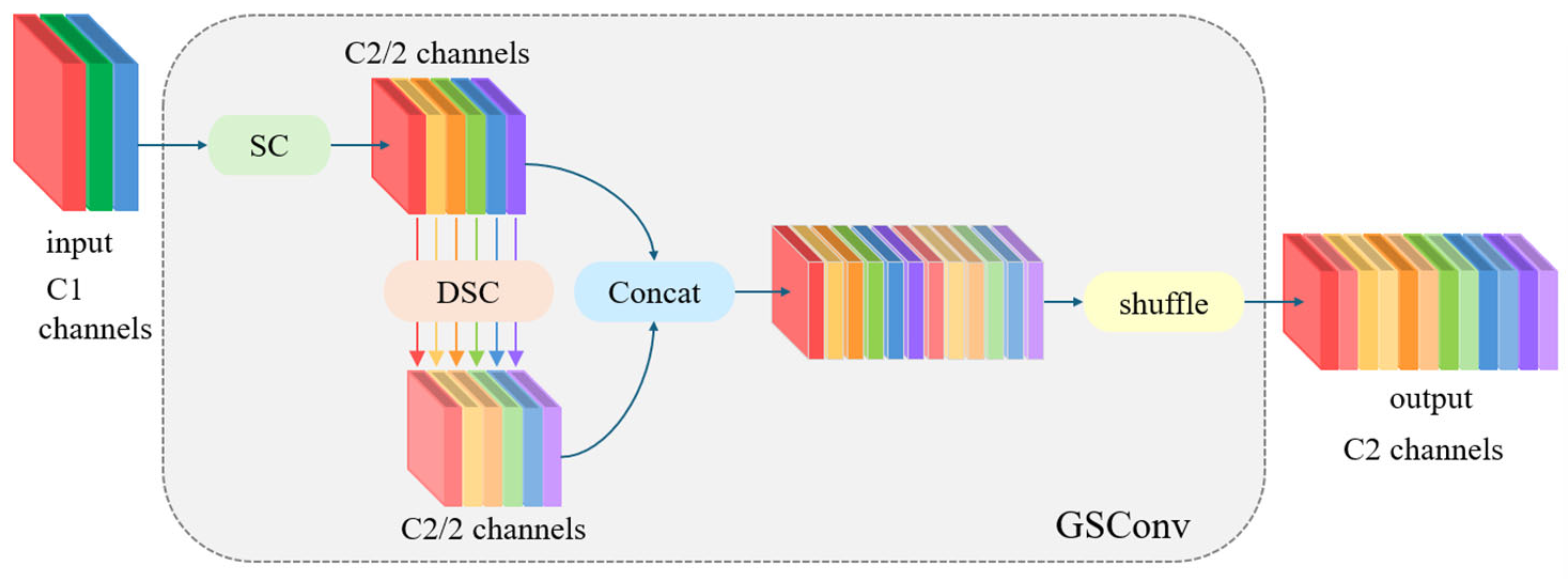
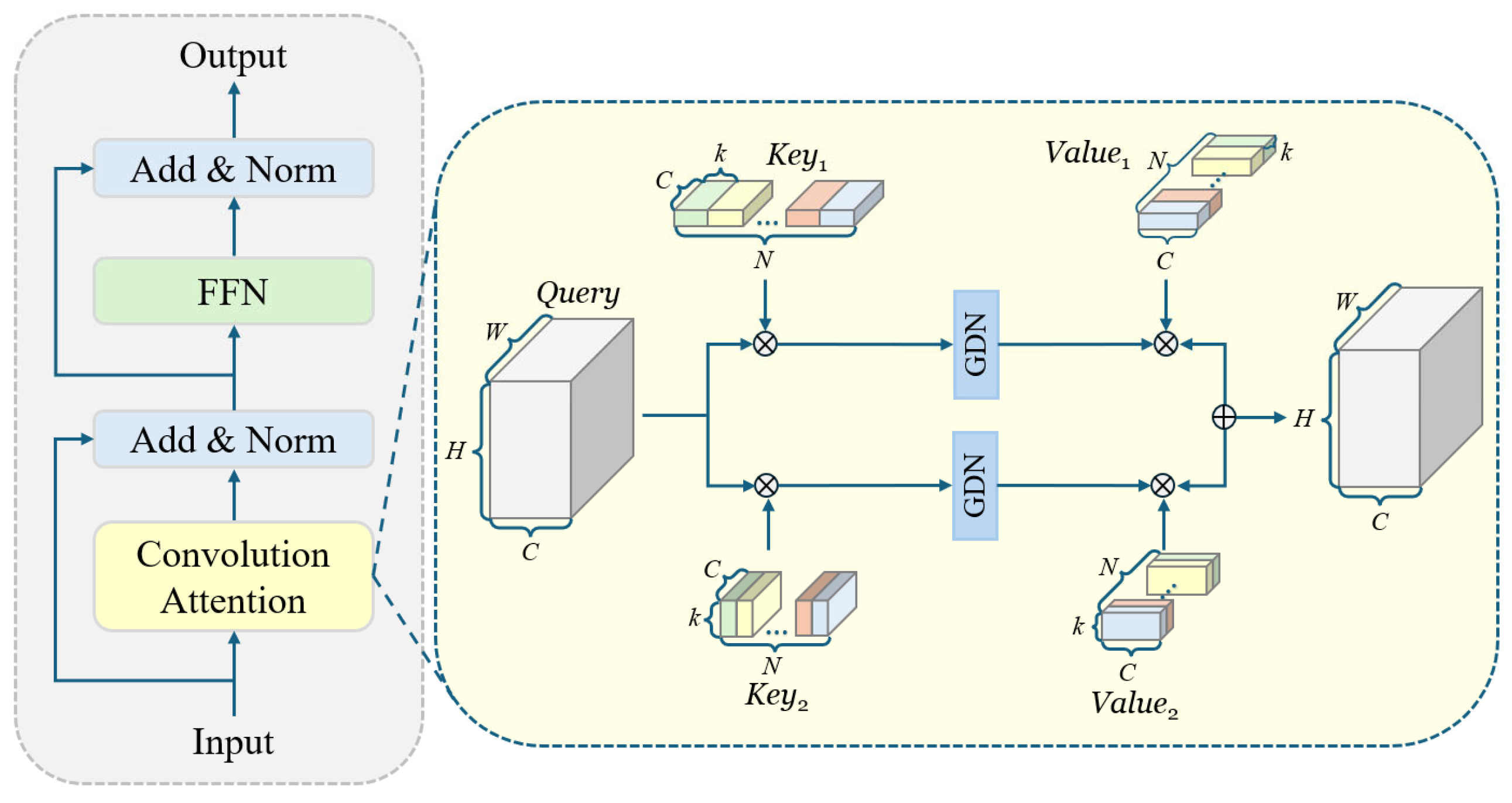
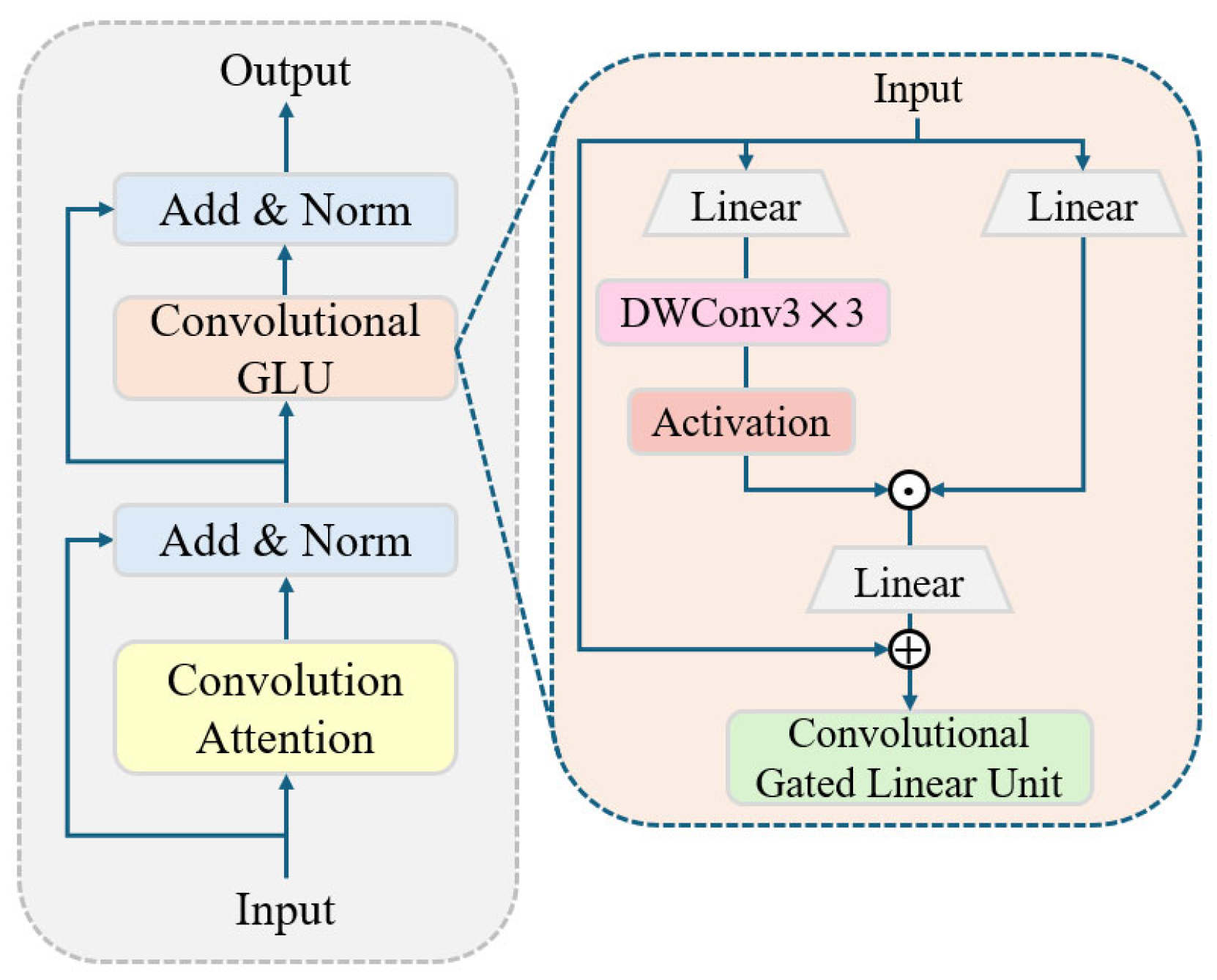
- A novel feature extraction module CFormerCGLU is designed to balance the model’s detection speed and precision. The design of this module not only boosts the model’s feature extraction ability but also solves the problem of large memory usage and high computational cost of the attention mechanism. In addition, GSConv is used instead of standard convolution to decrease the model’s computation.
- WIoU v3 is introduced into the boundary box regression loss, adopting a reasonable gradient gain allocation method, which can dynamically optimize the weight of high- and low-quality anchor boxes at a loss, so that the model focuses on ordinary-quality anchor boxes, thereby enhancing its generalization ability and overall performance.
- Extensive experiments conducted on the VisDrone2019 dataset have shown that MSUD-YOLO achieves the best balance between lightweight and detection accuracy. Compared with the baseline model, YOLOv10s, our model has excellent detection performance in multiscale object and small object detection. Furthermore, in terms of computational efficiency, MSUD-YOLO is also superior to several of the latest YOLO algorithms.
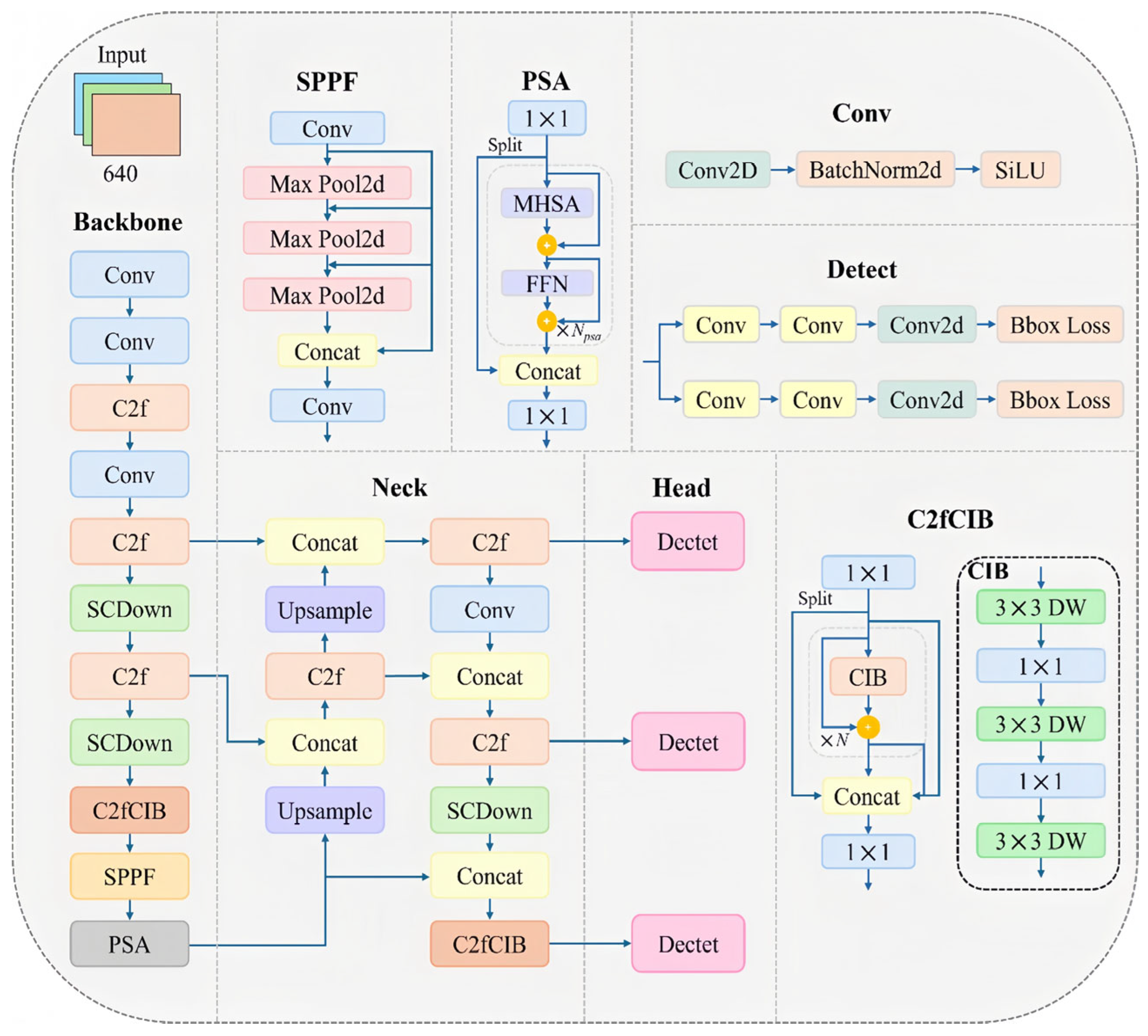
2. YOLOv10s Algorithm
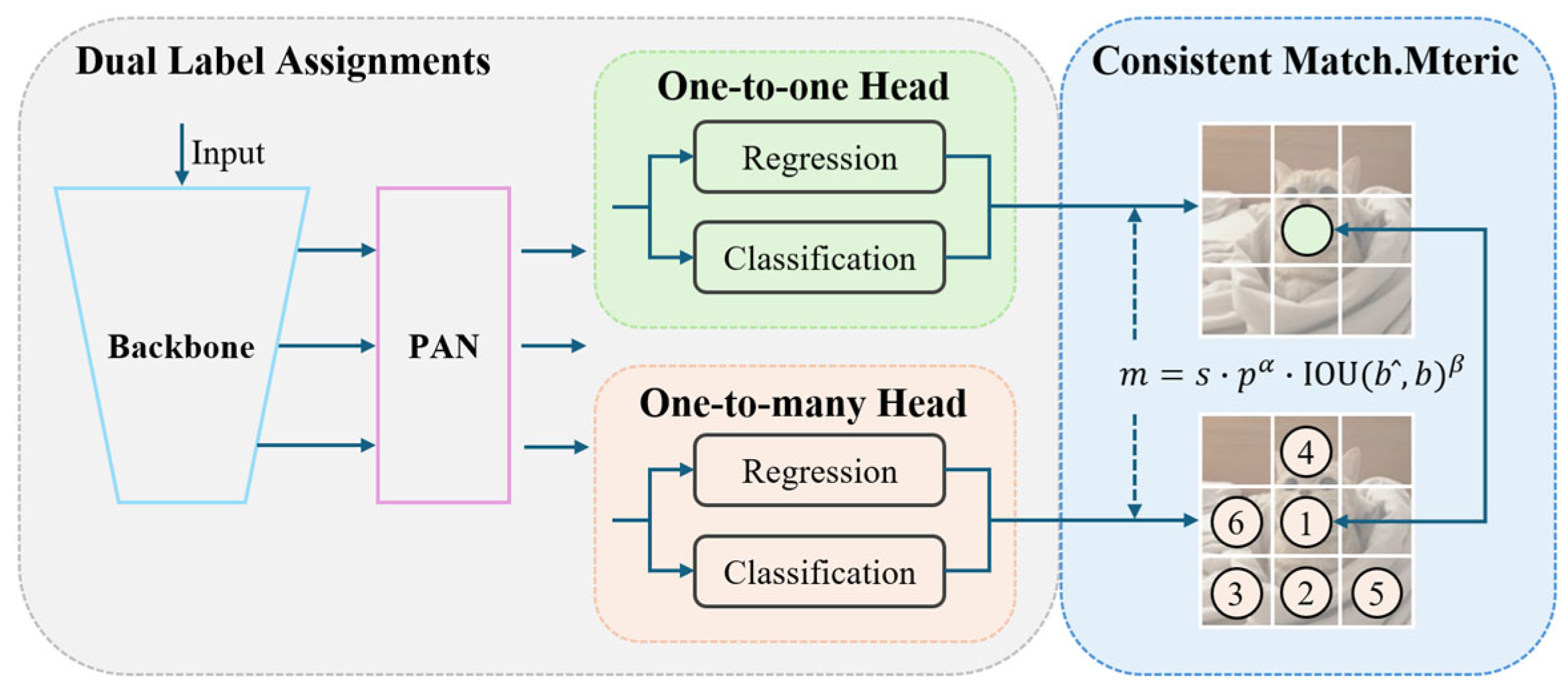
2.1. Consistent Dual Assignments for NMS-Free Training
2.1.1. Dual Label Assignments
2.1.2. Consistent Matching Metric
2.2. Efficiency and Accuracy Model Design
2.2.1. SCDown
2.2.2. C2fCIB
2.2.3. Partial Self-Attention (PSA)
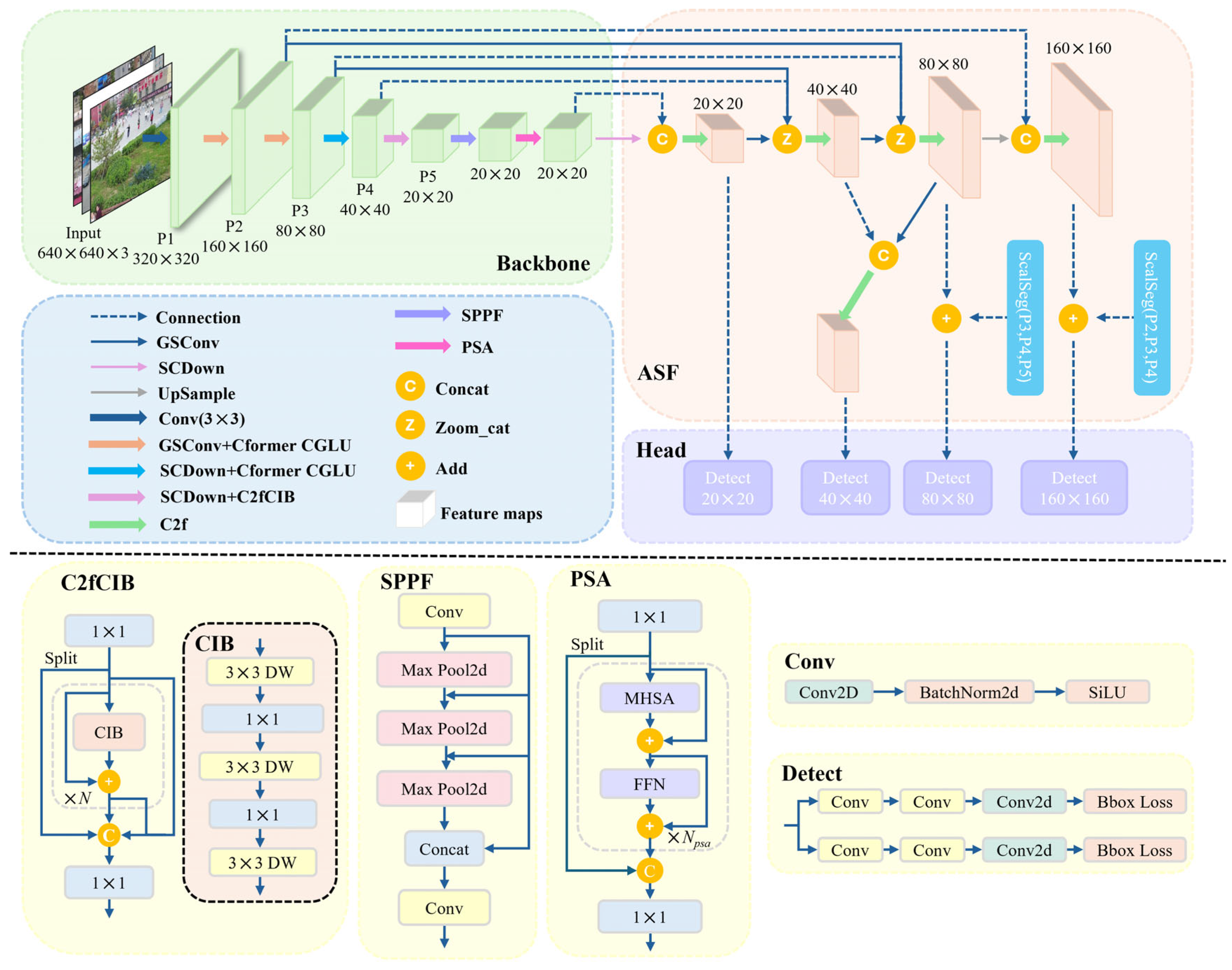
3. Proposed MSUD-YOLO
3.1. Overall Framework
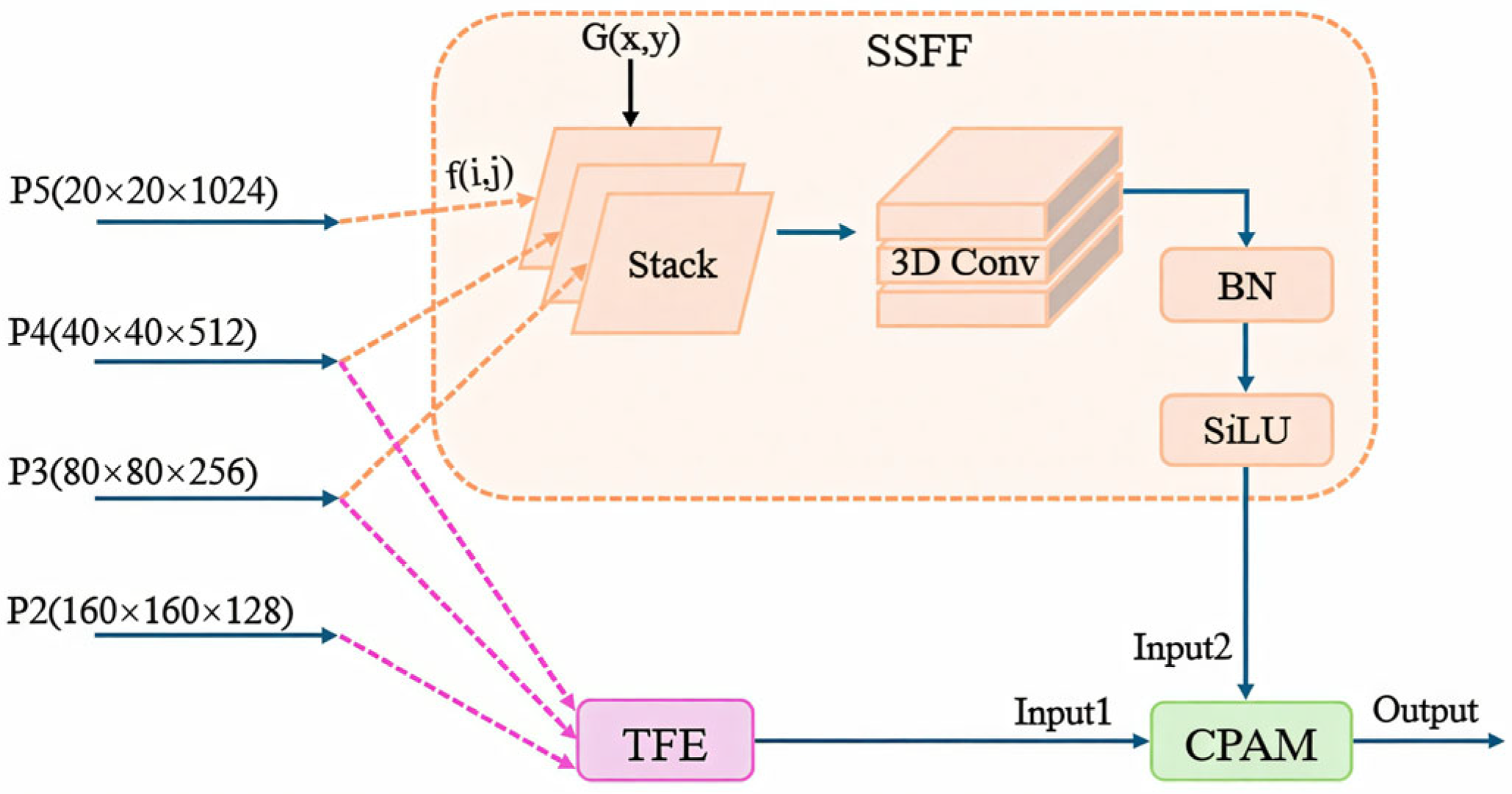
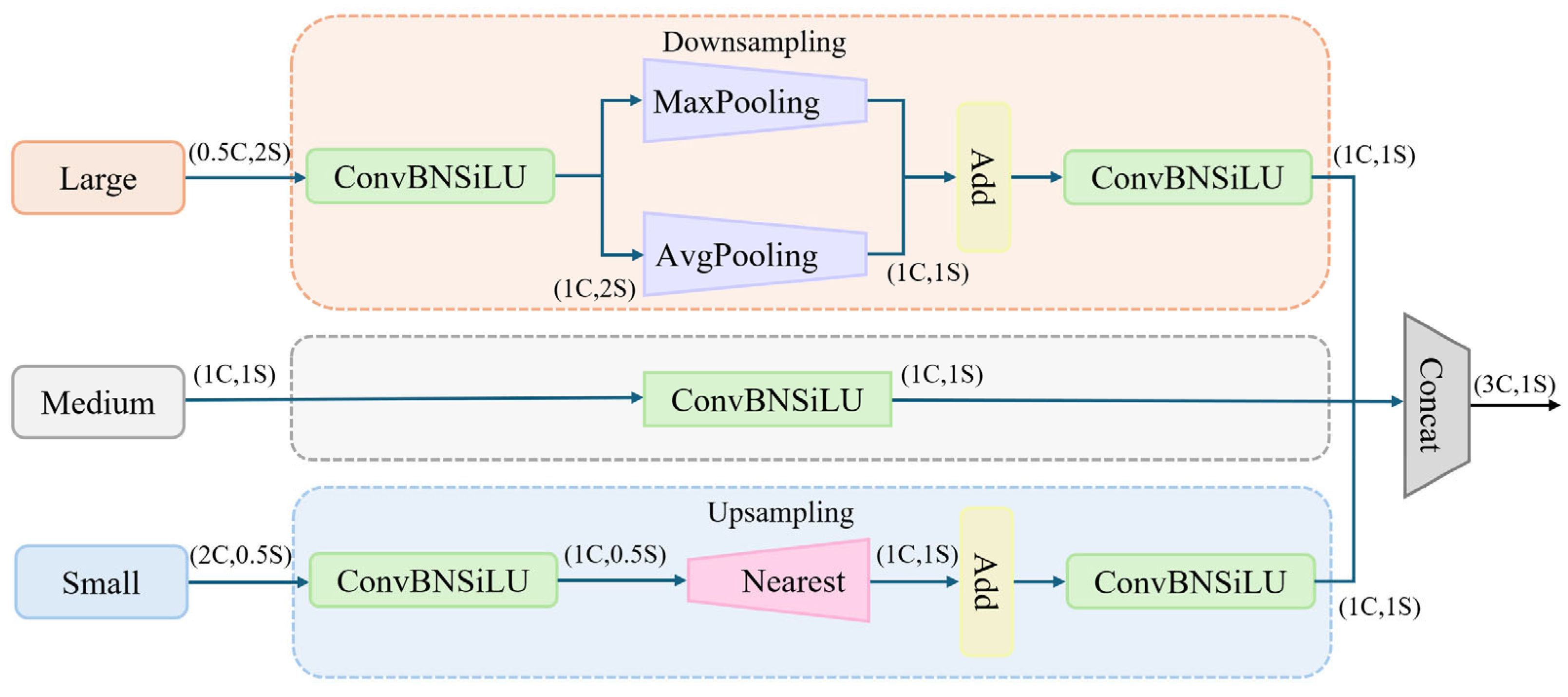
3.2. ASF Neck Structure
3.2.1. Scale Sequence Feature Fusion (SSFF) Module
3.2.2. Triple Feature Encoding (TFE) Module
3.2.3. Channel and Position Attention Mechanism (CPAM)
3.3. Tiny Prediction Head-P2
3.4. GSConv Module
3.5. CFormerCGLU Module
3.6. WIoU v3
4. Experiment
4.1. Dataset
4.2. Experimental Environment and Experimental Parameters
4.3. Assessment Indicators
4.4. Ablation Experiment
4.5. Compare Experiment
4.6. Visual Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, Q.; Zhan, Y.; Zou, Y. UAV recognition algorithm for ground military targets based on improved Yolov5n. Comput. Meas. Control 2024, 32, 189–197. [Google Scholar]
- Rao, J.; Xiang, C.; Xi, J.; Chen, J.; Lei, J.; Giernacki, W.; Liu, M. Path planning for dual UAVs cooperative suspension transport based on artificial potential field-A* algorithm. Knowl.-Based Syst. 2023, 277, 110797. [Google Scholar] [CrossRef]
- Bhadra, S.; Sagan, V.; Sarkar, S.; Braud, M.; Mockler, T.C.; Eveland, A.L. PROSAIL-Net: A transfer learning-based dual stream neural network to estimate leaf chlorophyll and leaf angle of crops from UAV hyperspectral images. ISPRS J. Photogramm. Remote Sens. 2024, 210, 1–24. [Google Scholar] [CrossRef]
- Duo, C.; Li, Y.; Gong, W.; Li, B.; Qi, G.; Zhang, J. UAV-aided distribution line inspection using double-layer offloading mechanism. IET Gener. Transm Distrib. 2024, 18, 2353–2372. [Google Scholar] [CrossRef]
- Hang, R.; Xu, S.; Yuan, P.; Liu, Q. AANet: An ambiguity-aware network for remote-sensing image change detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5612911. [Google Scholar] [CrossRef]
- Wan, M.; Gu, G.; Qian, W.; Ren, K.; Maldague, X.; Chen, Q. Unmanned aerial vehicle video-based target tracking algorithm using sparse representation. IEEE Internet Things J. 2019, 6, 9689–9706. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Weber, J.; Lefevre, S. A multivariate hit-or-miss transform for conjoint spatial and spectral template matching. In Proceedings of the 3rd International Conference, Image and Signal Processing, Cherbourg-Octeville, France, 1–3 July 2008; pp. 226–235. [Google Scholar]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of online learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Song, X.; Fang, X.; Meng, X.; Fang, X.; Lv, M.; Zhuo, Y. Real-time semantic segmentation network with an enhanced backbone based on Atrous spatial pyramid pooling module. Eng. Appl. Artif. Intel. 2024, 133, 107988. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Terven, J.; Cordova-Esparza, D. A comprehensive review of YOLO: From YOLOv1 and beyond. Compu. Vis. Pattern Recognit. 2023, arXiv:2304.00501. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767, 1–6. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934, 10934. [Google Scholar]
- Wang, C.; Liao, H.; Wu, Y.; Chen, P.; Hsieh, J.; Yeh, I. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the 2018, IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Jocher, G.; Liu, C.; Hogan, A.; Yu, L.; Rai, P.; Sullivan, T. Ultralytics/YOLOv5: Initial Release; Zenodo: Geneva, Switzerland, 2020. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Wang, C.; Bochkovskiy, A.; Liao, H. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Gallagher, J. How to Train an Ultralytics YOLOv8 Oriented Bounding Box (OBB) Model; Roboflow: Des Moines, IA, USA, 2024. [Google Scholar]
- Wang, C.; Yeh, I.; Liao, H. YOLOV9: Learning What You Want to Learn Using Programmable Gradient Information. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2024; pp. 1–21. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J. YOLOV10: Real-Time End-to-End Object Detection. Comput. Vis. Pattern Recognit. 2025, 37, 107984–108011. [Google Scholar]
- Jawaharlalnehru, A.; Sambandham, T.; Sekar, V.; Ravikumar, D.; Loganathan, V.; Kannadasan, R.; Khan, A.; Wechtaisong, C.; Haq, M.; Alhussen, A.; et al. Target object detection from unmanned aerial vehicle (UAV) images based on improved YOLO algorithm. Electronics. 2022, 11, 2343. [Google Scholar] [CrossRef]
- Sahin, O.; Ozer, S. YOLODrone: Improved YOLO architecture for object detection in drone images. In Proceedings of the 2021 44th International Conference on Telecommunications and Signal Processing (TSP), Brno, Czech Republic, 26–28 July 2021; pp. 361–365. [Google Scholar]
- Koay, H.; Chuah, J.; Chow, C.; Chang, Y.; Yong, K. YOLO-RTUAV: Towards real-time vehicle detection through aerial images with low-cost edge devices. Remote Sens. 2021, 13, 4196. [Google Scholar] [CrossRef]
- Cao, J.; Bao, W.; Shang, H.; Yuan, M.; Cheng, Q. GCL-YOLO: A ghostconv-based lightweight YOLO network for UAV small object detection. Remote Sens. 2023, 15, 4932. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, F.; Zhang, Y.; Liu, Y.; Cheng, T. Lightweight object detection algorithm for UAV aerial imagery. Sensors 2023, 23, 5786. [Google Scholar] [CrossRef]
- Hui, Y.; Wang, J.; Li, B. DSAA-YOLO: UAV remote sensing small target recognition algorithm for YOLOv7 based on dense residual super-resolution and anchor frame adaptive regression strategy. J. King Saud Univ. Comput. Inf. Sci. 2024, 36, 101863. [Google Scholar] [CrossRef]
- Wang, G.; Chen, Y.; An, P.; Hong, H.; Hu, J.; Huang, T. UAV-YOLOv8: A Small Object-Detection Model Based on improved YOLOv8 for UAV Aerial Photography Scenarios. Sensors 2023, 23, 7190. [Google Scholar] [CrossRef] [PubMed]
- Fan, Q.; Li, Y.; Deveci, M.; Zhong, K.; Kadry, S. LUD-YOLO: A novel lightweight object detection network for unmanned aerial vehicle. Inf. Sci. 2025, 686, 121366. [Google Scholar] [CrossRef]
- Qi, S.; Song, X.; Shang, T.; Hu, X.; Han, K. MSFE-YOLO: An Improved YOLOv8 Network for Object Detection on Drone View. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Zhang, Y.; Ye, M.; Zhu, G.; Liu, Y.; Guo, P.; Yan, J. FFCA-YOLO for Small Object Detection in Remote Sensing Images. IEEE Tran. Geosci. Remote Sens. 2024, 62, 1–15. [Google Scholar] [CrossRef]
- Luo, X.; Zhu, X. YOLO-SMUG: An Efficient and Lightweight Infrared Object Detection Model for Unmanned Aerial Vehicles. Drones 2025, 9, 245. [Google Scholar] [CrossRef]
- Liu, L.; Huang, K.; Li, Y.; Zhang, C.; Zhang, S.; Hu, Z. Real-time pedestrian recognition model on edge device using infrared vision system. J. Real-Time Image Process. 2025, 22, 1–11. [Google Scholar] [CrossRef]
- Kang, M.; Ting, C.; Ting, F.; Raphael, C. ASF-YOLO: A novel yolo model with attentional scale sequence fusion for cell instance segmentation. Image Vis. Comput. 2024, 147, 105057. [Google Scholar] [CrossRef]
- Lindeberg, T. Scale-Space Theory in Computer Vision; Springer: Cham, Switzerland, 1994; pp. 10–11. [Google Scholar]
- Lowe, D.J. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3D convolutional networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Lin, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-neck by GSConv: A lightweight-design for real-time detector architectures. Comput. Vis. Pattern Recognit. 2024, 21, 62. [Google Scholar]
- Peng, Z.; Huang, W.; Gu, S.; Xie, L.; Wang, Y.; Jiao, J.; Ye, Q. Conformer: Local Features Coupling Global Representations for Visual Recognition. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 367–376. [Google Scholar]
- Shi, D. TransNeXt: Robust Foveal Visual Perception for Vision Transformers. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024. arXiv:2311.17132. [Google Scholar]
- Zhang, Y.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Gevorgyan, Z. SIoU Loss: More Powerful Learning for Bounding Box Regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Du, D.; Zhu, P.; Wen, L.; Bian, X.; Lin, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y.; et al. VisDrone-DET2019: The vision meets drone object detection in image challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019; pp. 213–226. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Xu, S.; Song, L.; Yin, J.; Chen, Q.; Zhan, T.; Huang, W. MFFCI–YOLOv8: A Lightweight Remote Sensing Object Detection Network Based on Multiscale Features Fusion and Context Information. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 19743–19755. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Number | Tags Number | |
|---|---|---|
| All | 8629 | 457,063 |
| Train set | 6471 | 343,205 |
| Val set | 548 | 38,756 |
| Test set | 1610 | 75,102 |
| Environment | Parameters |
|---|---|
| GPU | Intel(R) Xeon(R) Platinum 8488C |
| CPU | NVIDIA A100 |
| GPU memory size | 80 G |
| Operating system | Win 10 |
| Language | Python 3.8.20 |
| Frame | Pytorch 2.4.1 |
| CUDA version | Cuda 12.1 |
| Parameters | Setup |
|---|---|
| Epochs | 300 |
| Input image size | 640 × 640 |
| Batch size | 16 |
| Optimizer | SGD |
| Initial learning rate | 0.01 |
| Final learning rate | 0.0001 |
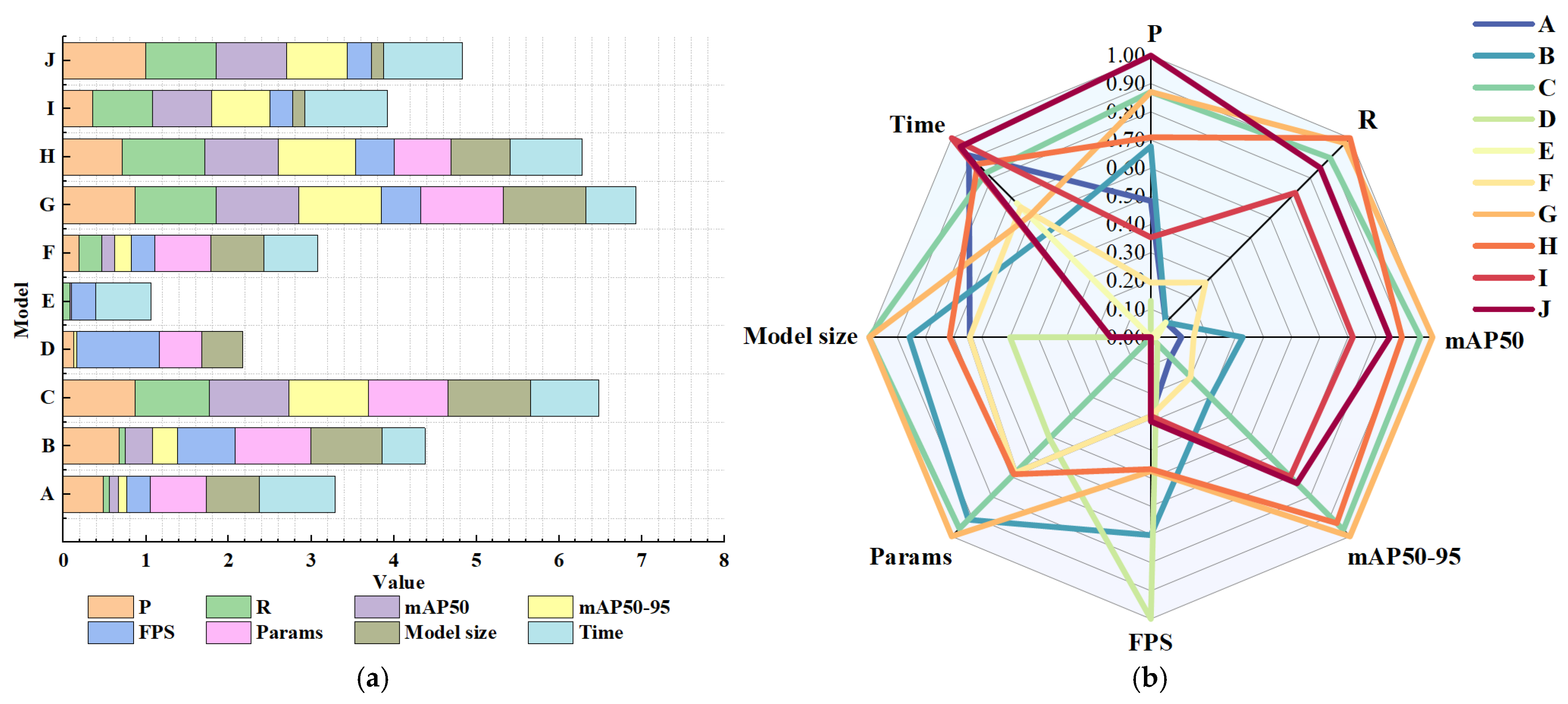
| ASF | P2 | GSConv | CFormer-CGLU | WIoU v3 | P (%) | R (%) | mAP50 (%) | mAP50-95 (%) | FPS | Params /Million | Model Size /MB | Time (ms/Frame) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 51.4 | 38.9 | 40.0 | 23.7 | 131.5 | 7.222 | 15.8 | 11.1 | |||||
| √ | 52.0 | 38.9 | 41.0 | 24.3 | 188.9 | 7.379 | 16.1 | 9.3 | ||||
| √ | 52.6 | 42.2 | 43.9 | 26.3 | 93.3 | 7.409 | 16.3 | 10.7 | ||||
| √ | 50.3 | 38.6 | 39.5 | 23.5 | 229.4 | 7.106 | 15.6 | 6.9 | ||||
| √ | 49.9 | 38.9 | 39.6 | 23.4 | 132.7 | 6.768 | 14.9 | 10.0 | ||||
| √ | 50.5 | 39.7 | 40.2 | 24.0 | 131.5 | 7.222 | 15.8 | 9.9 | ||||
| √ | √ | 52.6 | 42.5 | 44.1 | 26.4 | 158.0 | 7.435 | 16.3 | 9.7 | |||
| √ | √ | √ | 52.1 | 42.6 | 43.6 | 26.2 | 157.0 | 7.226 | 15.9 | 10.9 | ||
| √ | √ | √ | √ | 51.0 | 41.5 | 42.8 | 25.5 | 131.4 | 6.766 | 15.1 | 11.5 | |
| √ | √ | √ | √ | √ | 53.0 | 42.0 | 43.4 | 25.6 | 134 | 6.766 | 15.1 | 11.3 |
| Model | P (%) | R (%) | mAP50 (%) | mAP50-95 (%) | Params/Million |
|---|---|---|---|---|---|
| ASF w/o TEF and CPAM | 51.0 | 38.8 | 40.2 | 23.7 | 7.337 |
| ASF w/o SSFF and CPAM | 51.3 | 39.2 | 40.7 | 24.0 | 7.263 |
| ASF w/o CPAM | 51.6 | 38.7 | 40.8 | 24.2 | 7.365 |
| ASF | 52.0 | 38.9 | 41.0 | 24.3 | 7.379 |
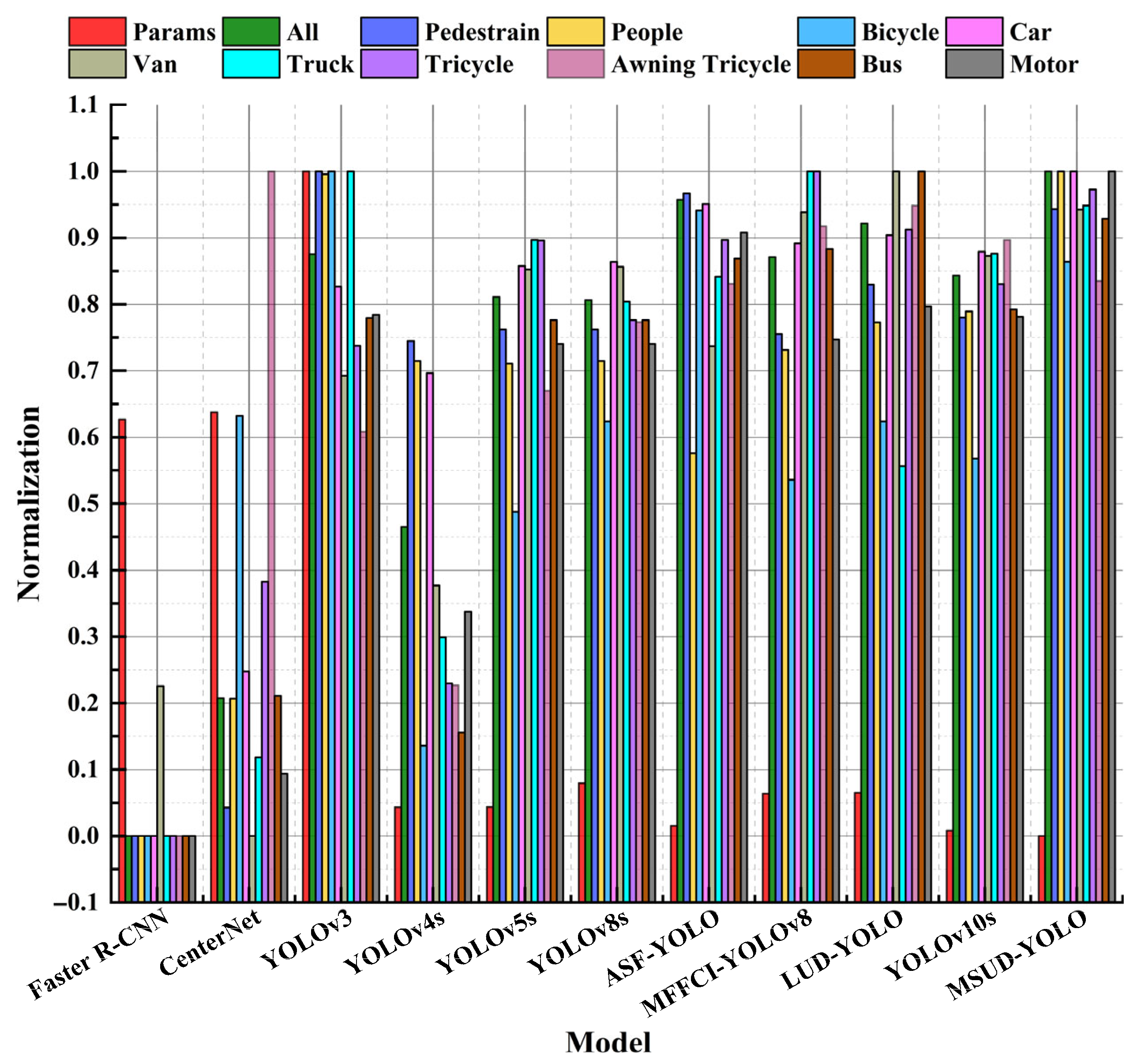
| Model | Params /Million | mAP50 (%) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pedestrain | People | Bicycle | Car | Van | Truck | Tricycle | ATricycle | Bus | Motor | All | ||
| Faster R-CNN | 41.100 | 21.4 | 15.6 | 6.7 | 51.7 | 29.5 | 19.0 | 13.1 | 7.7 | 31.4 | 20.7 | 21.7 |
| CenterNet | 41.700 | 22.6 | 20.6 | 14.6 | 59.7 | 24.0 | 21.3 | 20.1 | 17.4 | 37.9 | 23.7 | 26.2 |
| YOLOv3 | 61.546 | 49.6 | 39.7 | 19.2 | 78.4 | 40.9 | 38.4 | 26.6 | 13.6 | 55.4 | 45.8 | 40.7 |
| YOLOv4s | 9.135 | 42.4 | 32.9 | 8.4 | 74.2 | 33.2 | 24.8 | 17.3 | 9.9 | 36.2 | 31.5 | 31.8 |
| YOLOv5s | 9.153 | 42.9 | 32.8 | 12.8 | 79.4 | 44.8 | 36.4 | 29.5 | 14.2 | 55.3 | 44.4 | 39.3 |
| YOLOv8s | 11.129 | 42.9 | 32.9 | 14.5 | 79.6 | 44.9 | 34.6 | 27.3 | 15.2 | 55.3 | 44.4 | 39.2 |
| MFFCI-YOLOv8 | 10.260 | 42.7 | 33.3 | 13.4 | 80.5 | 46.9 | 38.4 | 31.4 | 16.6 | 58.6 | 44.6 | 40.6 |
| ASF-YOLO | 7.600 | 48.4 | 39.0 | 13.9 | 82.1 | 47.2 | 33.3 | 28.5 | 16.4 | 57.0 | 48.5 | 41.4 |
| LUD-YOLO | 10.340 | 44.8 | 34.3 | 14.5 | 80.9 | 48.4 | 29.8 | 29.8 | 16.9 | 62.2 | 46.2 | 41.7 |
| YOLOv10s | 7.222 | 43.4 | 34.7 | 13.8 | 80.1 | 45.3 | 36.0 | 28.3 | 16.4 | 55.8 | 45.7 | 40.0 |
| MSUD-YOLO | 6.766 | 48.0 | 39.8 | 17.5 | 84.0 | 47.0 | 37.4 | 30.9 | 15.8 | 60.0 | 52.7 | 43.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, X.; Zhang, H.; Zhang, W.; Ma, J.; Li, C.; Ding, Y.; Zhang, Z. MSUD-YOLO: A Novel Multiscale Small Object Detection Model for UAV Aerial Images. Drones 2025, 9, 429. https://doi.org/10.3390/drones9060429
Zhao X, Zhang H, Zhang W, Ma J, Li C, Ding Y, Zhang Z. MSUD-YOLO: A Novel Multiscale Small Object Detection Model for UAV Aerial Images. Drones. 2025; 9(6):429. https://doi.org/10.3390/drones9060429
Chicago/Turabian StyleZhao, Xiaofeng, Hui Zhang, Wenwen Zhang, Junyi Ma, Chenxiao Li, Yao Ding, and Zhili Zhang. 2025. "MSUD-YOLO: A Novel Multiscale Small Object Detection Model for UAV Aerial Images" Drones 9, no. 6: 429. https://doi.org/10.3390/drones9060429
APA StyleZhao, X., Zhang, H., Zhang, W., Ma, J., Li, C., Ding, Y., & Zhang, Z. (2025). MSUD-YOLO: A Novel Multiscale Small Object Detection Model for UAV Aerial Images. Drones, 9(6), 429. https://doi.org/10.3390/drones9060429