

Adaptive Missile Avoidance Algorithm for UAV Based on Multi-Head Attention Mechanism and Dual Population Confrontation Game

 , ,
, ,
Abstract
1. Introduction
2. Preliminary
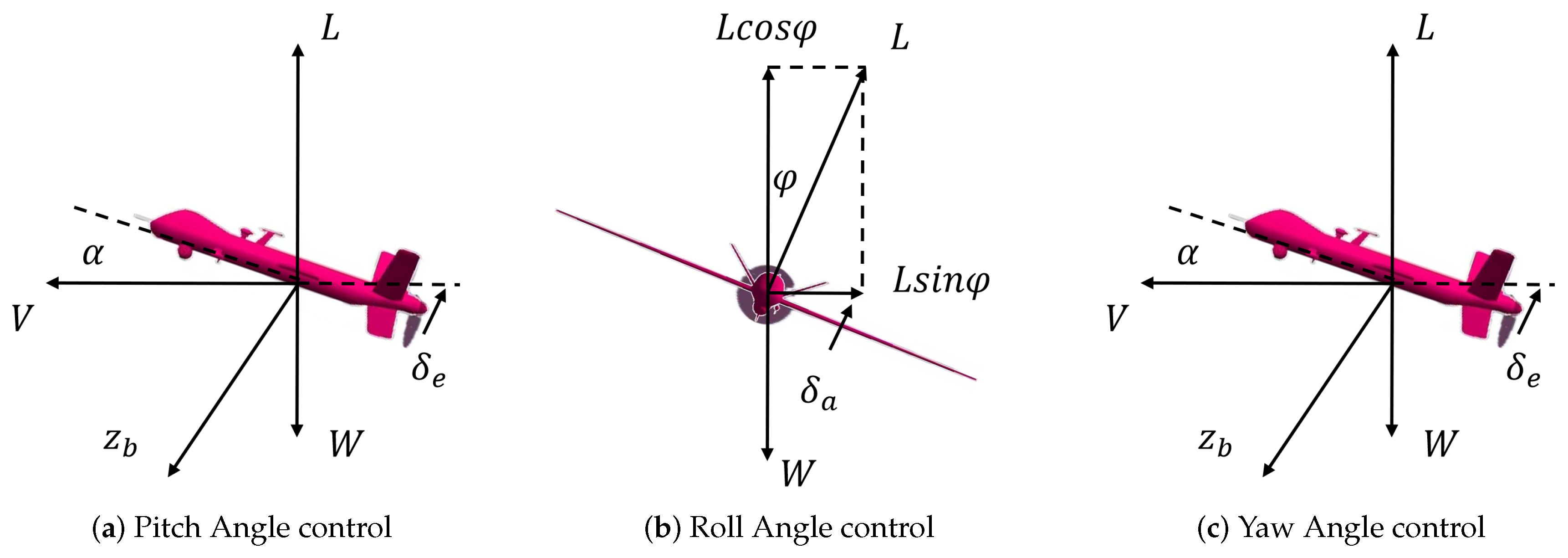
2.1. UAV Dynamic Model
2.2. Missile Motion and Dynamics Model
2.3. Decoy Motion Model
3. Method
3.1. Risk-Sensitive PPO
| Algorithm 1 Risk-sensitivePPO(RPPO) |
| Input: initial actor network parameter and critic network parameter , replay buffer D, update epochs K for do Collect trajectories by running policy until the replay buffer is filled. Compute -variant returns according to Equation (19) Compute advantages according to Equation (20) for do Update the by maximizing the surrogate function with via Adam algorithms. Update the by minimizing the mean-squared error with via Adam algorithms. end for end for |
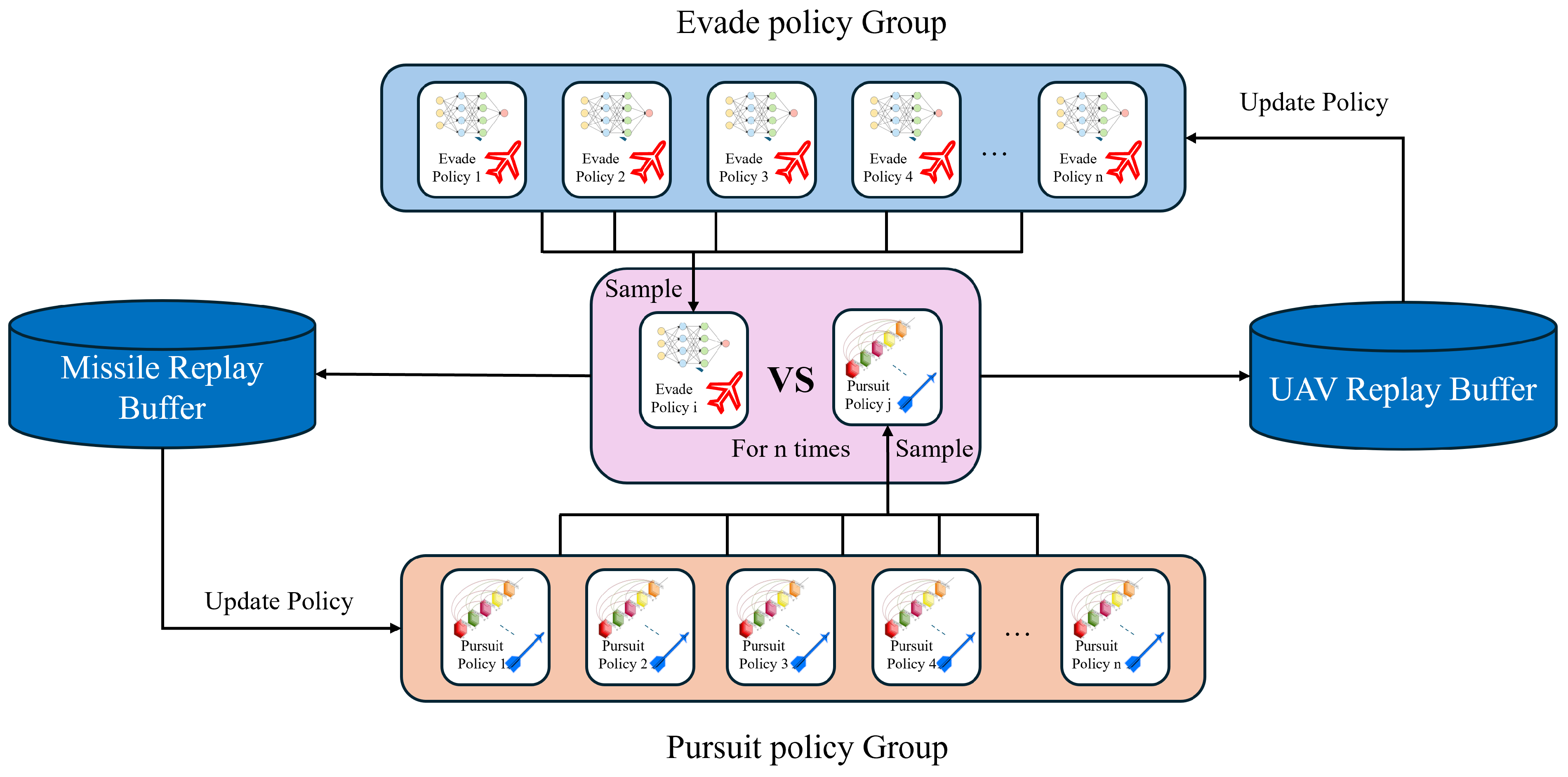
3.2. Cyclic Group Game
3.3. Markov Decision Model
3.3.1. State Space
3.3.2. Action Space
3.3.3. Reward Function
3.3.4. Reward Function
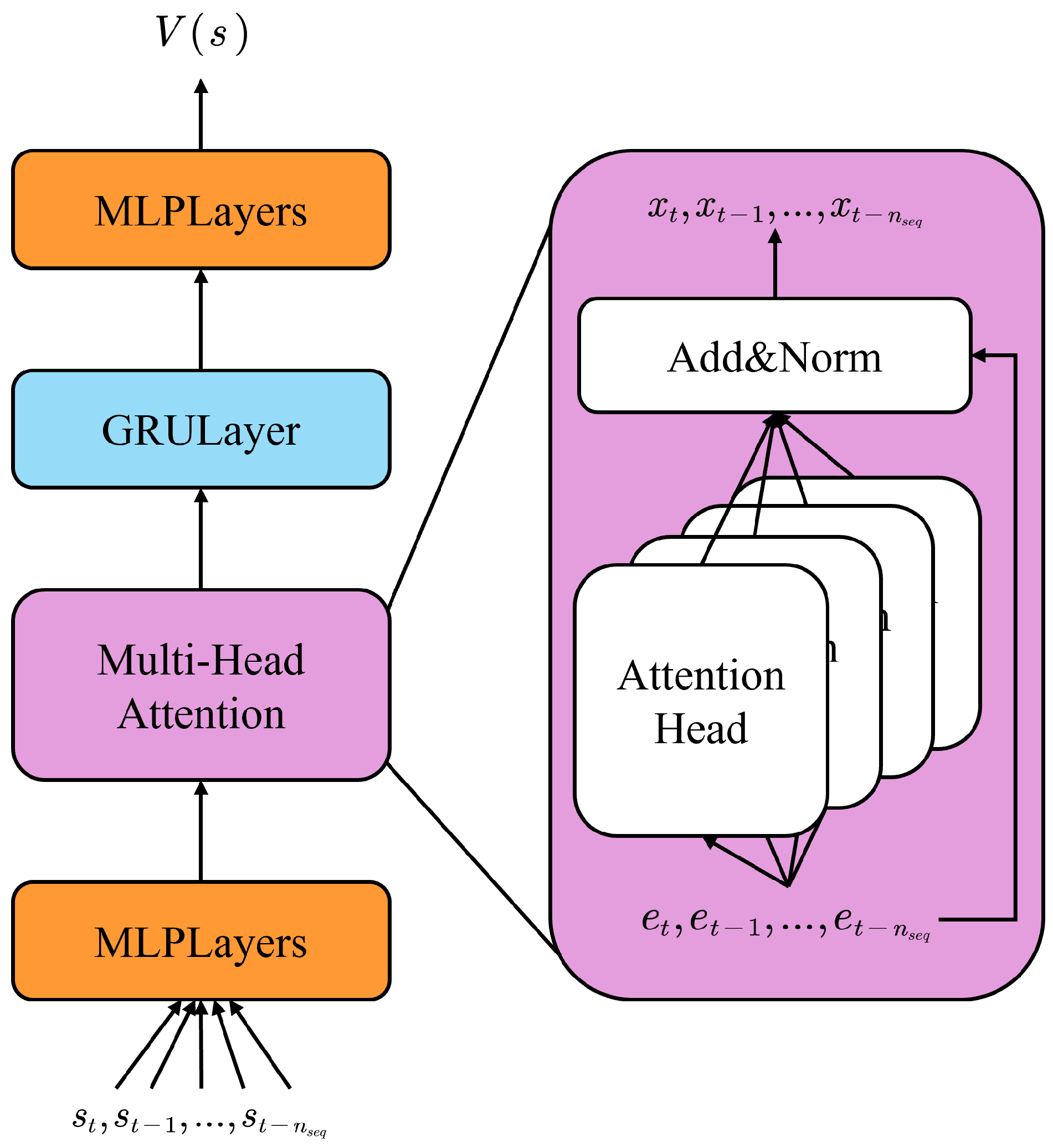
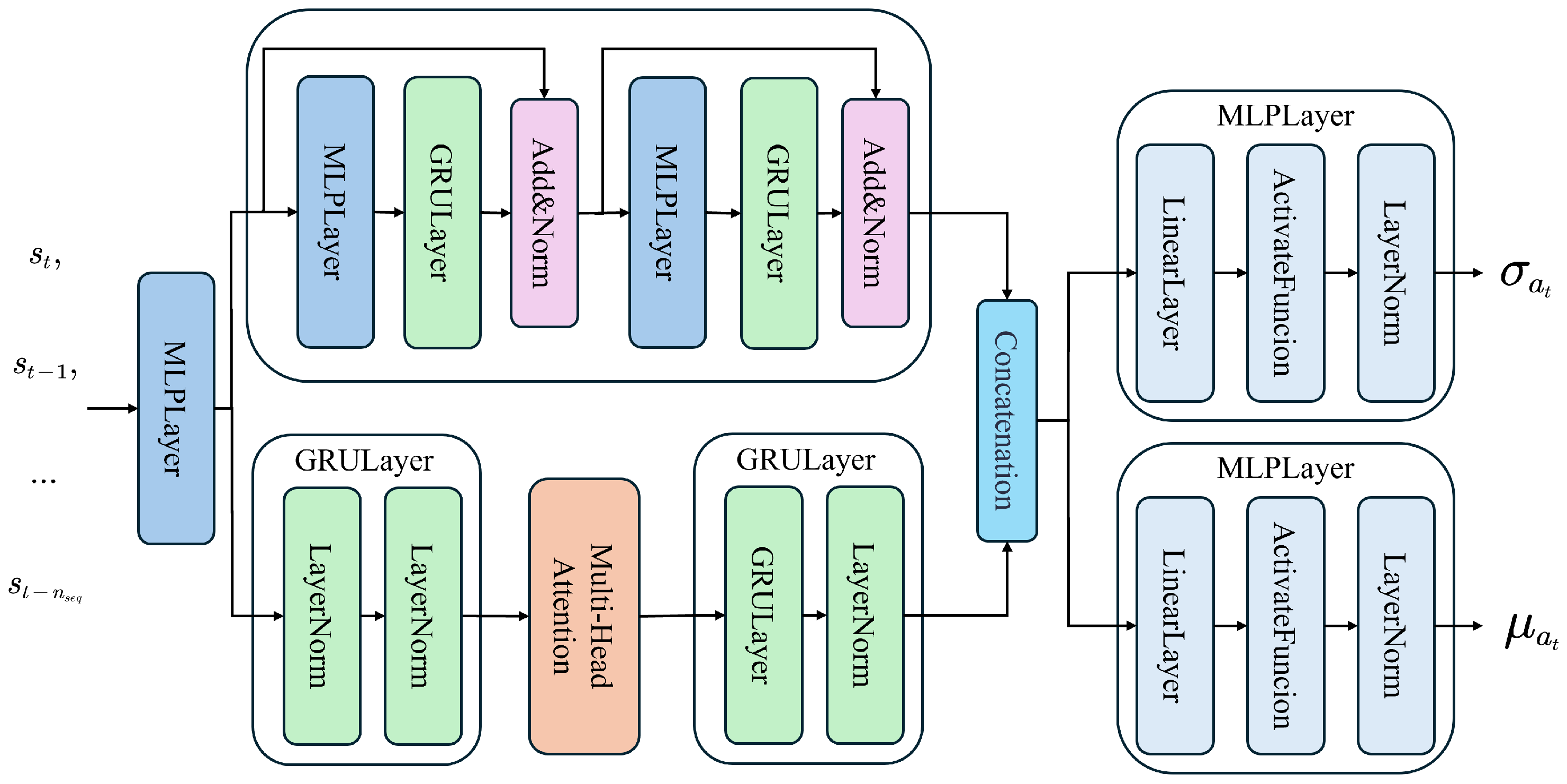
3.4. Policy and Value Network Structure
4. Experiments
4.1. Experiment Configuration
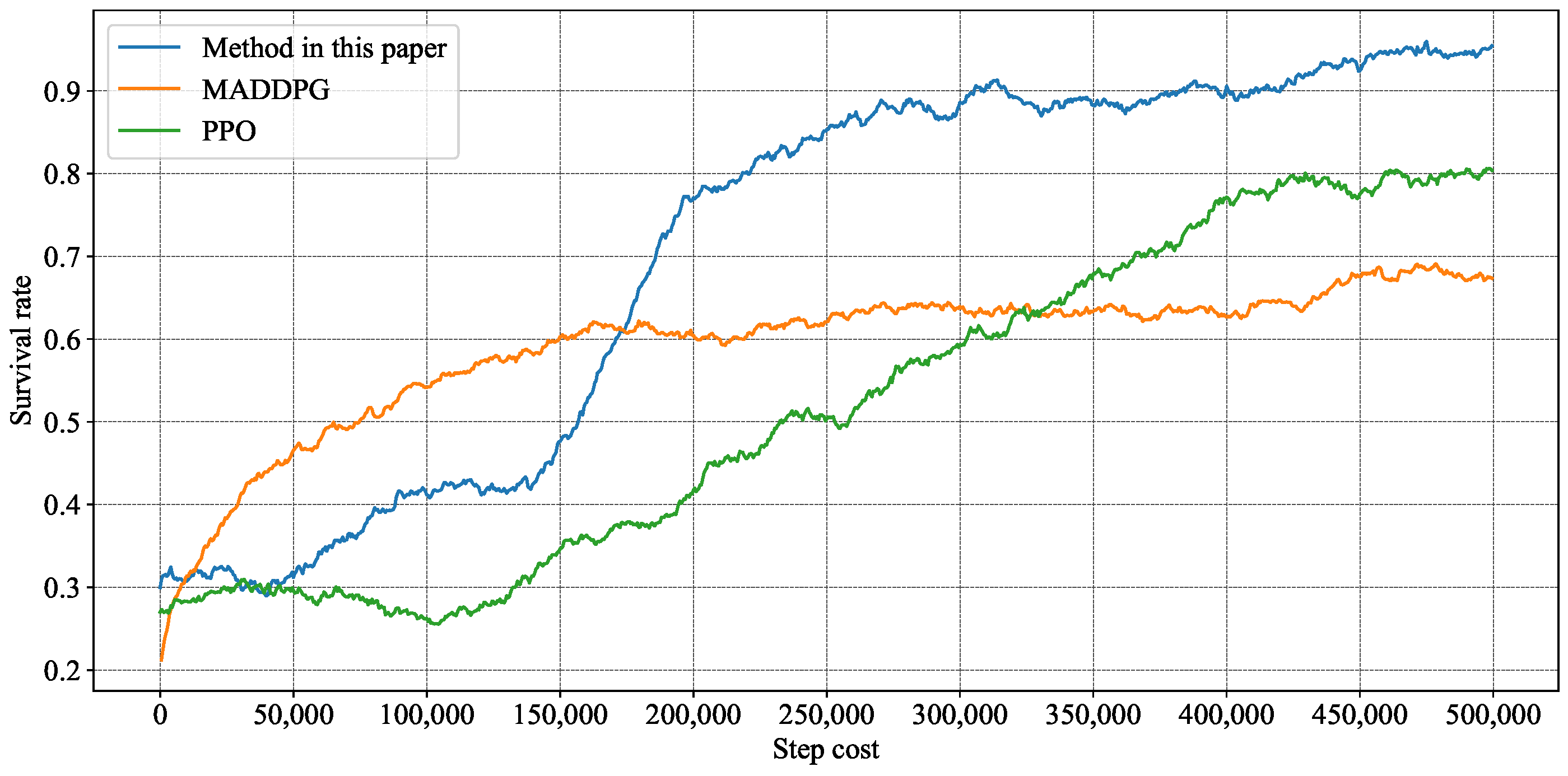
4.2. Training Results
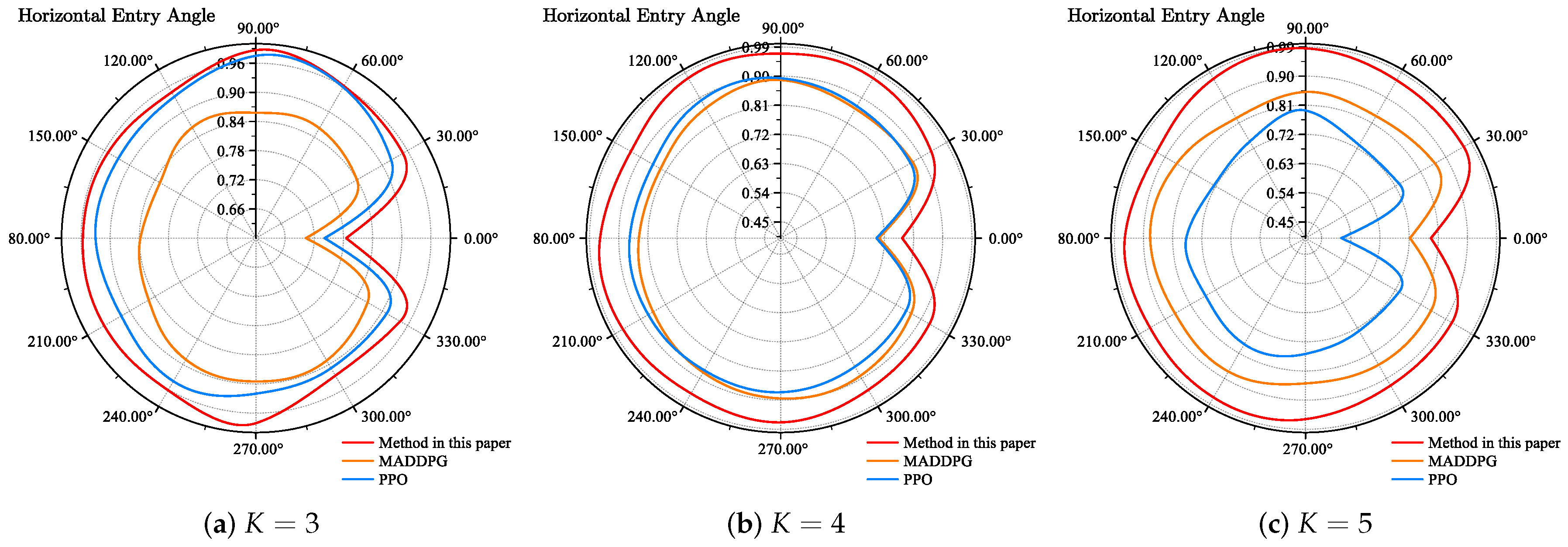
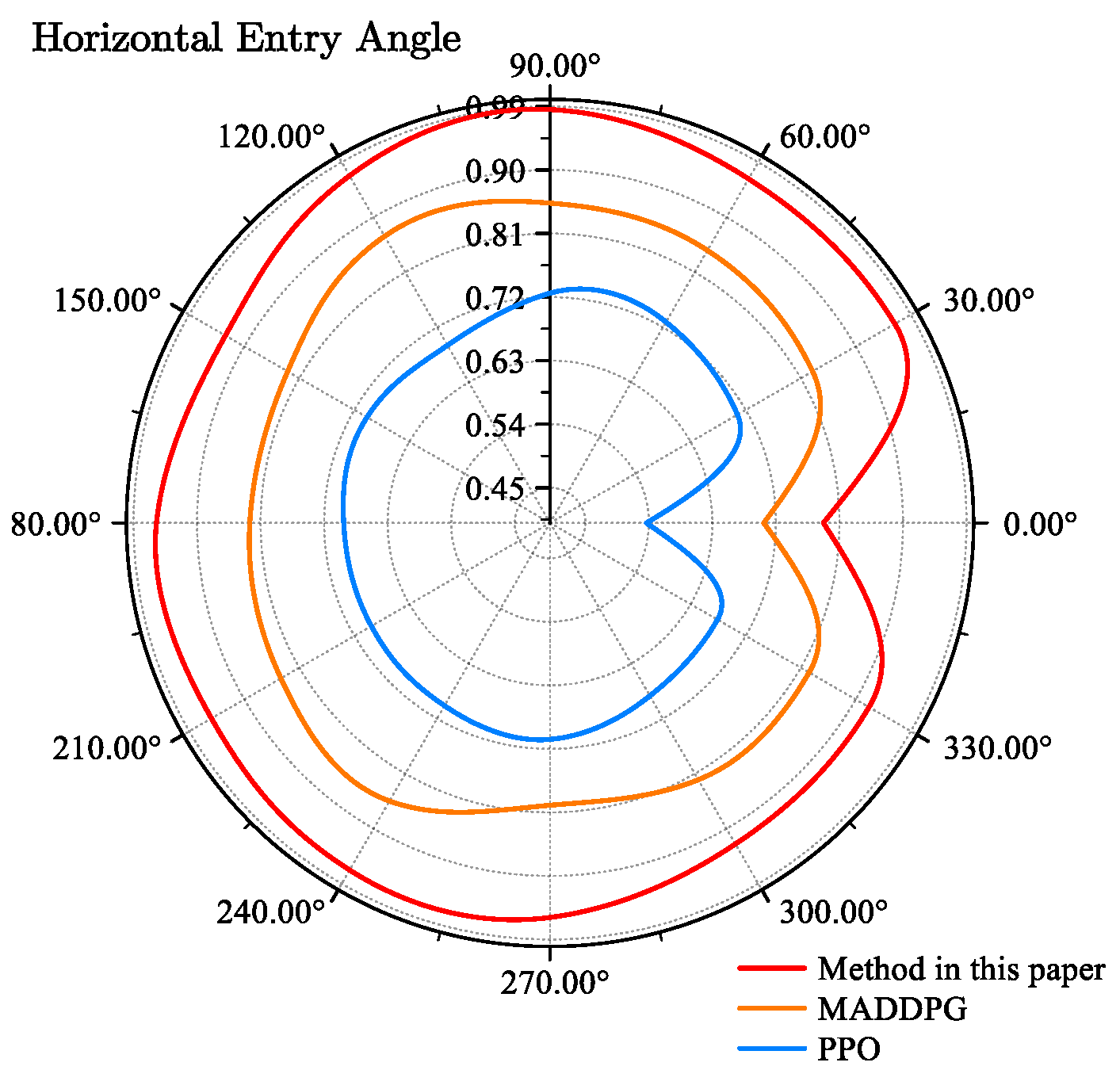
4.3. Survival Rate Statistics
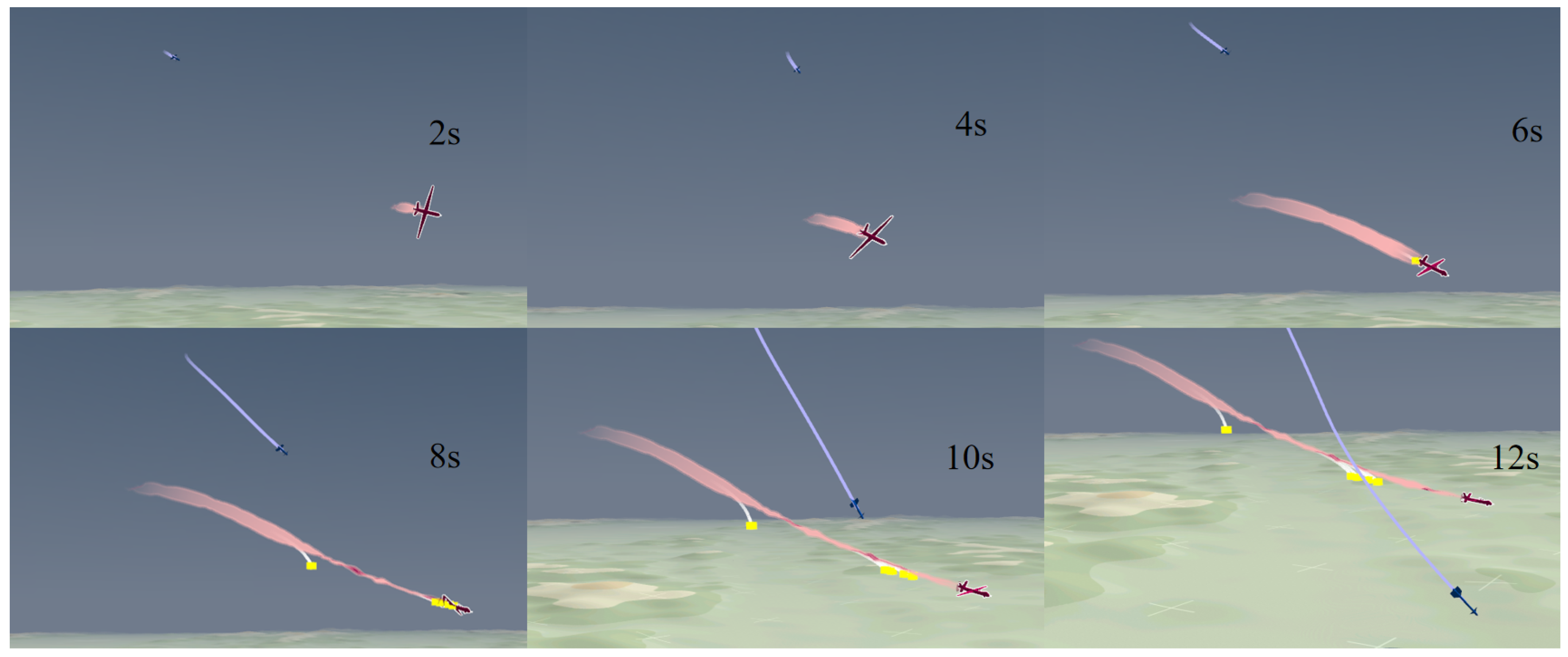
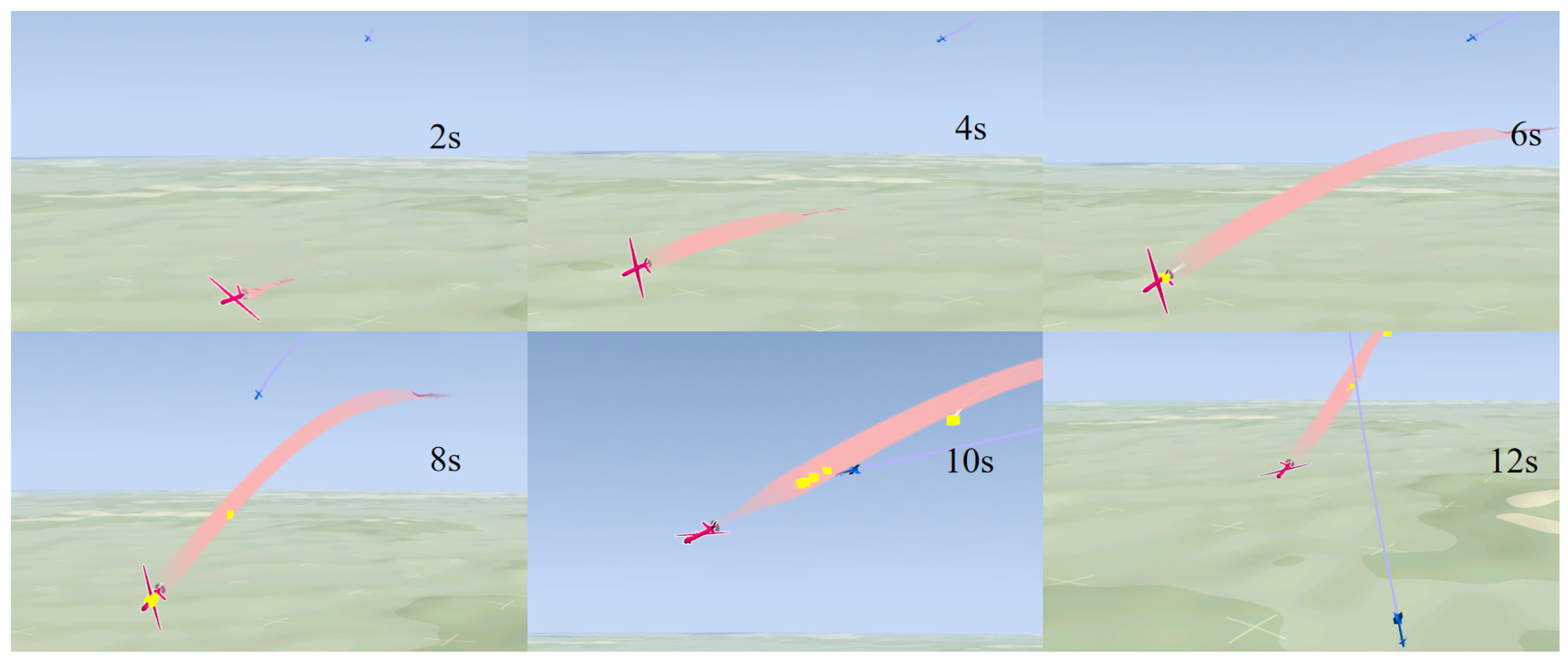
4.4. Simulation Sample
5. Conclusions
Author Contributions
Funding
Data Availability Statement
DURC Statement
Conflicts of Interest
References
- Shima, T. Optimal cooperative pursuit and evasion strategies against a homing missile. J. Guid. Control. Dyn. 2011, 34, 414–425. [Google Scholar] [CrossRef]
- Tian, Z.; Danino, M.; Bar-Shalom, Y.; Milgrom, B. Missile Threat Detection and Evasion Maneuvers With Countermeasures for a Low-Altitude Aircraft. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 7352–7362. [Google Scholar] [CrossRef]
- Turetsky, V.; Shima, T. Hybrid evasion strategy against a missile with guidance law of variable structure. In Proceedings of the 2016 American Control Conference (ACC), Boston, MA, USA, 6–8 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 3132–3137. [Google Scholar]
- Li, A.; Hu, X.; Ran, J.; Wei, P.; Yuan, X. Receding Horizon Control Based Real-time Strategy for Missile Pursuit-evasion Game. In Proceedings of the 2024 IEEE 25th China Conference on System Simulation Technology and its Application (CCSSTA), Tianjin, China, 21–23 July 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 408–415. [Google Scholar]
- Du, Q.; Hu, Y.; Jing, W.; Gao, C. Three-dimensional target evasion strategy without missile guidance information. Aerosp. Sci. Technol. 2025, 157, 109857. [Google Scholar] [CrossRef]
- Chen, N.; Li, L.; Mao, W. Equilibrium Strategy of the Pursuit-Evasion Game in Three-Dimensional Space. IEEE/CAA J. Autom. Sin. 2024, 11, 446–458. [Google Scholar] [CrossRef]
- Yan, M.; Yang, R.; Zhang, Y.; Yue, L.; Hu, D. A hierarchical reinforcement learning method for missile evasion and guidance. Sci. Rep. 2022, 12, 18888. [Google Scholar] [CrossRef] [PubMed]
- Gong, X.; Chen, W.; Chen, Z. Intelligent game strategies in target-missile-defender engagement using curriculum-based deep reinforcement learning. Aerospace 2023, 10, 133. [Google Scholar] [CrossRef]
- Wang, Y.; Zhao, K.; Guirao, J.L.; Pan, K.; Chen, H. Online intelligent maneuvering penetration methods of missile with respect to unknown intercepting strategies based on reinforcement learning. Electron. Res. Arch. 2022, 30, 4366–4381. [Google Scholar] [CrossRef]
- Jain, G.; Kumar, A.; Bhat, S.A. Recent developments of game theory and reinforcement learning approaches: A systematic review. IEEE Access 2024, 12, 9999–10011. [Google Scholar] [CrossRef]
- Sharma, R.; Gopal, M. Synergizing reinforcement learning and game theory—A new direction for control. Appl. Soft Comput. 2010, 10, 675–688. [Google Scholar] [CrossRef]
- Nowé, A.; Vrancx, P.; De Hauwere, Y.M. Game theory and multi-agent reinforcement learning. In Reinforcement Learning: State-of-the-Art; Springer: Berlin/Heidelberg, Germany, 2012; pp. 441–470. [Google Scholar]
- Dolinger, G.; Stringer, A.; Sharp, T.; Karch, J.; Metcalf, J.G.; Bowersox, A. Collaborative Game Theory and Reinforcement Learning Improvements for Radar Tracking. In Proceedings of the 2023 IEEE International Radar Conference (RADAR), Sydney, Australia, 6–10 November 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–6. [Google Scholar]
- Cao, Y.; Tao, C. Reinforcement learning and game theory based cyber–physical security framework for the humans interacting over societal control systems. Front. Energy Res. 2024, 12, 1413576. [Google Scholar] [CrossRef]
- Zhao, X.; Hu, S.; Cho, J.H.; Chen, F. Uncertainty-based decision making using deep reinforcement learning. In Proceedings of the 2019 22th International Conference on Information Fusion (FUSION), Ottawa, ON, Canada, 2–5 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–8. [Google Scholar]
- Fonod, R.; Shima, T. Multiple model adaptive evasion against a homing missile. J. Guid. Control. Dyn. 2016, 39, 1578–1592. [Google Scholar] [CrossRef]
- Yan, T.; Jiang, Z.; Li, T.; Gao, M.; Liu, C. Intelligent maneuver strategy for hypersonic vehicles in three-player pursuit-evasion games via deep reinforcement learning. Front. Neurosci. 2024, 18, 1362303. [Google Scholar] [CrossRef] [PubMed]
- Jia, Y.; Dong, Y. Optimal Capture Strategy Design Based on Reinforcement Learning in the Pursuit-Evasion Game with Unknown Dynamics. In Proceedings of the 2024 American Control Conference (ACC), Toronto, ON, Canada, 10–12 July 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 2685–2690. [Google Scholar]
- Ho, J.; Wang, C.M.; King, C.T.; You, Y.H.; Feng, C.W.; Chen, Y.M.; Kuo, B.Y. Learning Adaptation and Generalization from Human-Inspired Meta-Reinforcement Learning Using Bayesian Knowledge and Analysis. In Proceedings of the 2023 IEEE Sixth International Conference on Artificial Intelligence and Knowledge Engineering (AIKE), Laguna Hills, CA, USA, 25–27 September 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 9–16. [Google Scholar]
- Yang, Z.; Ren, K.; Luo, X.; Liu, M.; Liu, W.; Bian, J.; Zhang, W.; Li, D. Towards applicable reinforcement learning: Improving the generalization and sample efficiency with policy ensemble. arXiv 2022, arXiv:2205.09284. [Google Scholar]
- McClellan, J.; Haghani, N.; Winder, J.; Huang, F.; Tokekar, P. Boosting sample efficiency and generalization in multi-agent reinforcement learning via equivariance. arXiv 2024, arXiv:2410.02581. [Google Scholar]
- Prajapati, R.; El-Wakeel, A.S. Cloud-based Federated Learning Framework for MRI Segmentation. arXiv 2024, arXiv:2403.00254. [Google Scholar]
- Hu, Q.; Li, R.; Deng, Q.; Zhao, Y.; Li, R. Enhancing Network by Reinforcement Learning and Neural Confined Local Search. In Proceedings of the IJCAI, Macao, China, 19–25 August 2023; pp. 2122–2132. [Google Scholar]
- Heinrich, J.; Lanctot, M.; Silver, D. Fictitious self-play in extensive-form games. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; PMLR: Birmingham, UK, 2015; pp. 805–813. [Google Scholar]
- Jaderberg, M.; Czarnecki, W.M.; Dunning, I.; Marris, L.; Lever, G.; Castaneda, A.G.; Beattie, C.; Rabinowitz, N.C.; Morcos, A.S.; Ruderman, A.; et al. Human-level performance in 3D multiplayer games with population-based reinforcement learning. Science 2019, 364, 859–865. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Xu, Y.; Song, J.; Zhou, Q.; Rasol, J.; Ma, L. Planet craters detection based on unsupervised domain adaptation. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 7140–7152. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Actor network learning rate | |
| Critic network learning rate | |
| Replay buffer size | |
| Population size | 30 |
| Maximum number of steps | 30 |
| Parameter update steps | 100 |
| Parameter | Value |
|---|---|
| Missile’s initial velocity | 800 m/s |
| UAV’s initial velocity | 350 m/s |
| Initial line-of-sight deflection angle | |
| Initial line-of-sight inclination angle | |
| Max number of decoy | 30 |
| Software Item | Version | Hardware Item | Model |
|---|---|---|---|
| Operating system | Window 11 10.0.22631 | CPU | Intel(R) Core(TM) i9-10900K @ 3.70 GHz |
| Python | 3.12.3 v.1938 64 bit | GPU | NVIDIA GeForce RTX 4090 *8 |
| PyTorch | 2.4.1 | Internal memory | Kingston FURY DDR4 3600 16G × 2 |
| CUDA Toolkit | 11.8 | Hard disk | ZhiTai PCIe 4.0 1TB SSD |
| Tacview | 1.9.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Song, J.; Tao, C.; Su, Z.; Xu, Z.; Feng, W.; Zhang, Z.; Xu, Y. Adaptive Missile Avoidance Algorithm for UAV Based on Multi-Head Attention Mechanism and Dual Population Confrontation Game. Drones 2025, 9, 382. https://doi.org/10.3390/drones9050382
Zhang C, Song J, Tao C, Su Z, Xu Z, Feng W, Zhang Z, Xu Y. Adaptive Missile Avoidance Algorithm for UAV Based on Multi-Head Attention Mechanism and Dual Population Confrontation Game. Drones. 2025; 9(5):382. https://doi.org/10.3390/drones9050382
Chicago/Turabian StyleZhang, Cheng, Junhao Song, Chengyang Tao, Zitao Su, Zhiqiang Xu, Weijia Feng, Zhaoxiang Zhang, and Yuelei Xu. 2025. "Adaptive Missile Avoidance Algorithm for UAV Based on Multi-Head Attention Mechanism and Dual Population Confrontation Game" Drones 9, no. 5: 382. https://doi.org/10.3390/drones9050382
APA StyleZhang, C., Song, J., Tao, C., Su, Z., Xu, Z., Feng, W., Zhang, Z., & Xu, Y. (2025). Adaptive Missile Avoidance Algorithm for UAV Based on Multi-Head Attention Mechanism and Dual Population Confrontation Game. Drones, 9(5), 382. https://doi.org/10.3390/drones9050382