
Heterogeneous Multi-Agent Deep Reinforcement Learning for Cluster-Based Spectrum Sharing in UAV Swarms


Abstract
1. Introduction
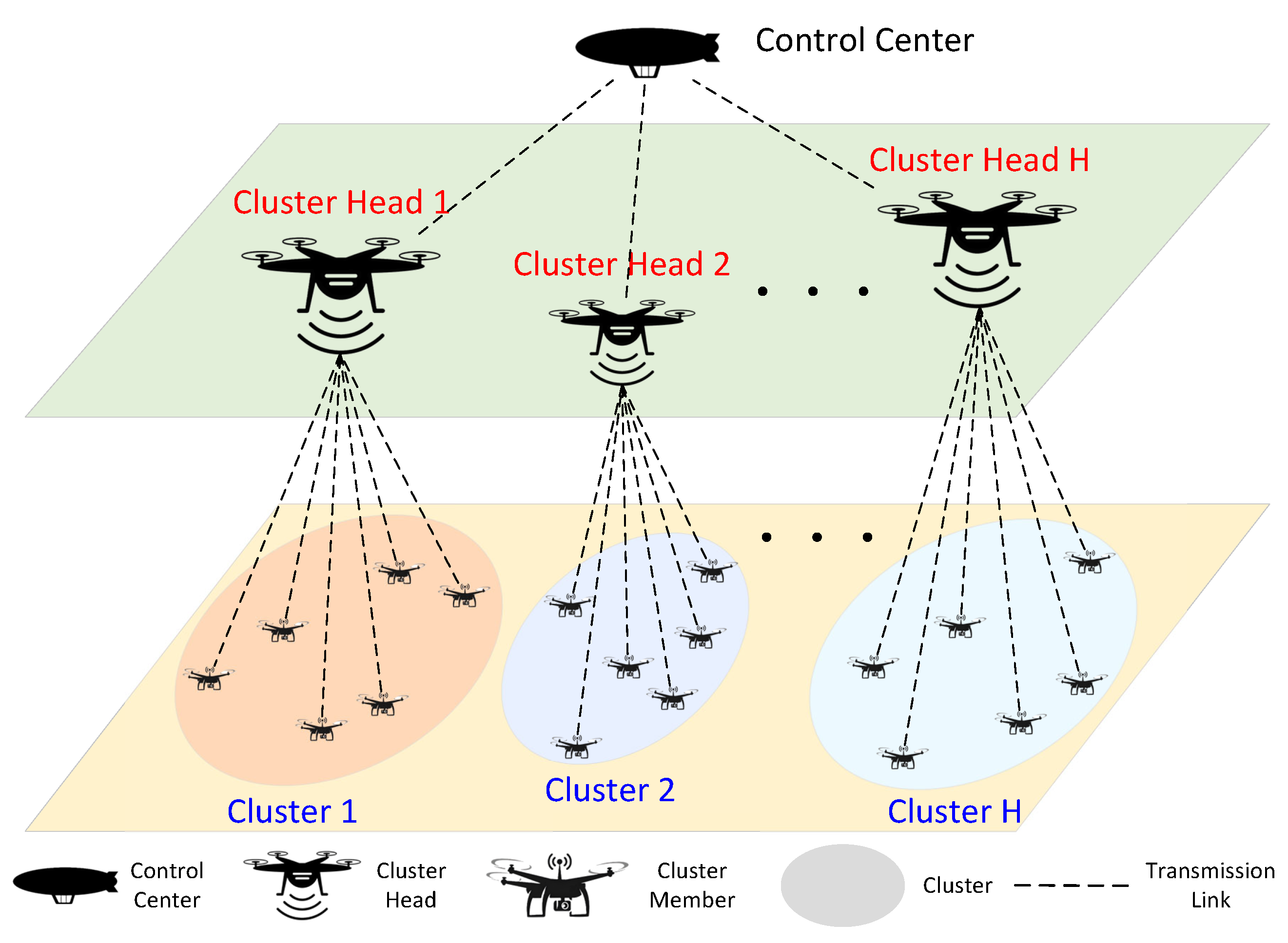
- We consider a large-scale heterogeneous UAV swarm capable of meeting various mission requirements. The UAV swarm is divided into multiple small groups, and consists of two types of UAVs: cluster head (CH) and cluster member (CM). In particular, we study a practical setup, whereby the average communication delay for CMs and throughput for CHs are jointly optimized under the assumptions of knowing the partial CDI. Moreover, the link maintenance probability is discussed for CMs with the consideration of the mobility of CMs.
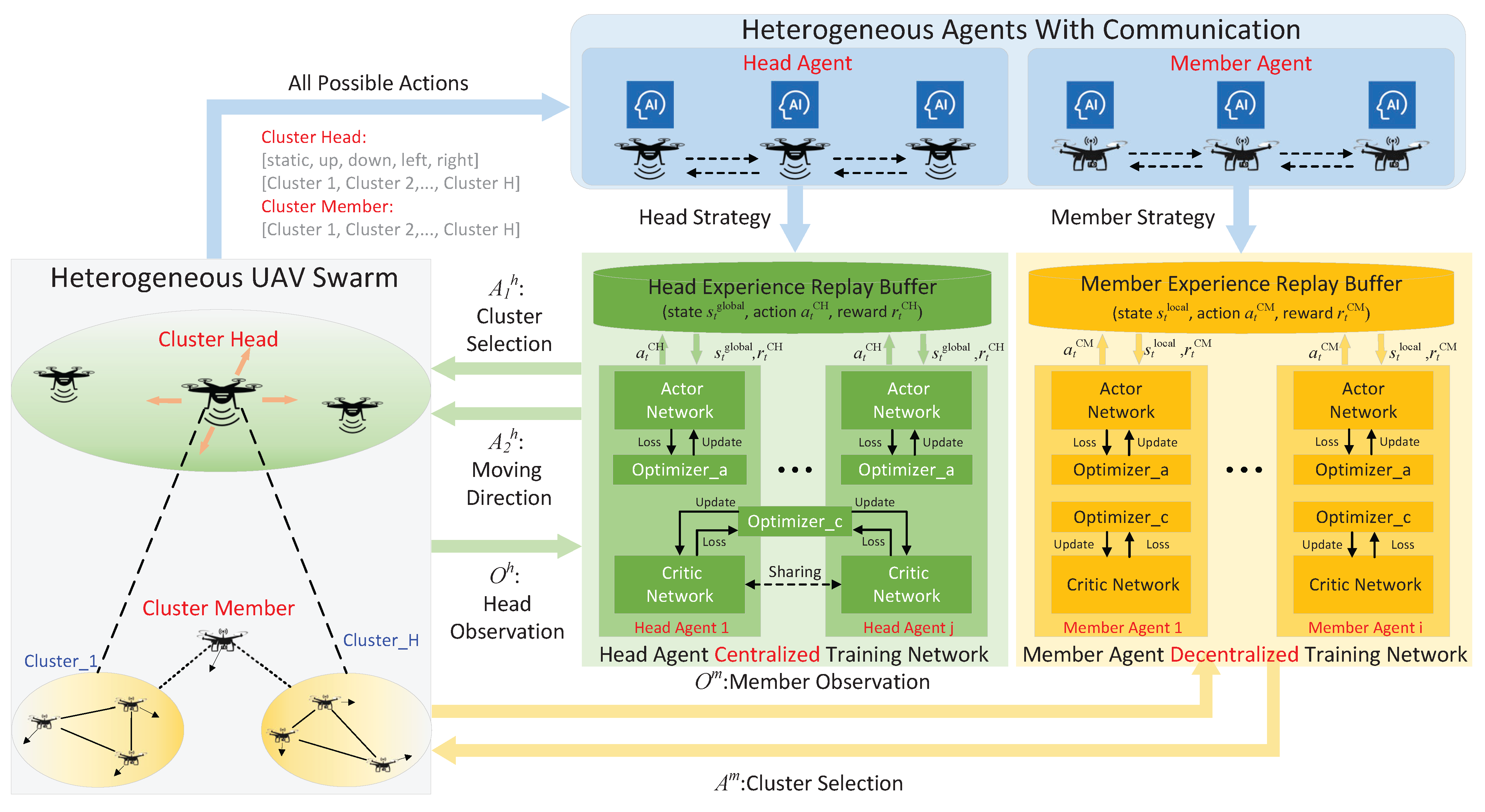
- We propose a novel distributed HMDRL-UC algorithm for heterogeneous UAV swarms, where each UAV acts as an intelligent agent. In detail, the HMDRL-UC is composed of two subalgorithms: the multi-agent PPO for CHs (MAPPO-H) and the independent PPO for CMs (IPPO-M). MAPPO-H is responsible for controlling the cluster selection and movement of CHs, while the IPPO-M is used to decide the cluster selection of CMs.
- A comprehensive performance analysis is carried out for the proposed HMDRL-UC algorithm, as well as a comparison with those of existing algorithms. The proposed HMDRL-UC algorithm demonstrates significant advantages in terms of average throughput, intra-cluster communication delay, and minimum signal-to-noise ratio (SNR). Moreover, it can optimize clustering for dynamic UAV swarm scenarios. Therefore, the HMDRL-UC algorithm is a highly promising clustering-based spectrum sharing candidate for multi-mission large-scale UAV swarm scenarios.
2. System Model and Problem Formulation
2.1. Link Maintenance Probability Prediction of CMs
2.2. Channel Model
2.3. Problem Formulation
3. Proposed Heterogeneous Multi-Agent Deep Reinforcement Learning Algorithm for UAV Clustering (HMDRL-UC)
3.1. The Framework of HMDRL-UC
3.2. The Design of IPPO-M
3.2.1. Observation Set
3.2.2. Action Set
3.2.3. Reward
3.3. The Design of MAPPO-H
3.3.1. Observation Set
3.3.2. Action Set
3.3.3. Reward
3.4. Training Procedure
| Algorithm 1 Network Training Stage of HMDRL-UC Algorithm |
|
3.5. Complexity Analysis
4. Simulation and Analysis
4.1. Experiment Setting
4.2. Training Efficiency and Resource Consumption Analysis
4.3. Comparison
4.4. Effects of Different Numbers of CMs
4.5. Effects of Different Speeds of CH
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Javed, S.; Hassan, A.; Ahmad, R.; Ahmed, W.; Ahmed, R.; Saadat, A.; Guizani, M. State-of-the-Art and Future Research Challenges in UAV Swarms. IEEE Internet Things J. 2024, 11, 19023–19045. [Google Scholar] [CrossRef]
- Zhang, J.; Lu, Y.; Wu, Y.; Wang, C.; Zang, D.; Abusorrah, A.; Zhou, M. PSO-Based Sparse Source Location in Large-Scale Environments with a UAV Swarm. IEEE Trans. Intell. Transp. Syst. 2023, 24, 5249–5258. [Google Scholar] [CrossRef]
- Liu, C.; Feng, W.; Chen, Y.; Wang, C.X.; Ge, N. Cell-Free Satellite-UAV Networks for 6G Wide-Area Internet of Things. IEEE J. Sel. Areas Commun. 2021, 39, 1116–1131. [Google Scholar] [CrossRef]
- Wang, Y.; Ren, B. Quadrotor-Enabled Autonomous Parking Occupancy Detection. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24–30 October 2020; pp. 8287–8292. [Google Scholar] [CrossRef]
- Fan, B.; Li, Y.; Zhang, R.; Fu, Q. Review on the Technological Development and Application of UAV Systems. Chin. J. Electron. 2020, 29, 199–207. [Google Scholar] [CrossRef]
- Wang, Z.; Yao, H.; Mai, T.; Xiong, Z.; Wu, X.; Wu, D.; Guo, S. Learning to Routing in UAV Swarm Network: A Multi-Agent Reinforcement Learning Approach. IEEE Trans. Veh. Technol. 2023, 72, 6611–6624. [Google Scholar] [CrossRef]
- Li, S.; Li, J.; Xiang, C.; Xu, W.; Peng, J.; Wang, Z.; Liang, W.; Yao, X.; Jia, X.; Das, S.K. Maximizing Network Throughput in Heterogeneous UAV Networks. IEEE/ACM Trans. Netw. 2024, 32, 2128–2142. [Google Scholar] [CrossRef]
- Sun, Z.; Qi, F.; Liu, L.; Xing, Y.; Xie, W. Energy-Efficient Spectrum Sharing for 6G Ubiquitous IoT Networks Through Blockchain. IEEE Internet Things J. 2023, 10, 9342–9352. [Google Scholar] [CrossRef]
- Wang, H.; Wang, J.; Ding, G.; Xue, Z.; Zhang, L.; Xu, Y. Robust Spectrum Sharing in Air-Ground Integrated Networks: Opportunities and Challenges. IEEE Wirel. Commun. 2020, 27, 148–155. [Google Scholar] [CrossRef]
- Chen, J.; Wu, Q.; Xu, Y.; Qi, N.; Fang, T.; Liu, D. Spectrum Allocation for Task-Driven UAV Communication Networks Exploiting Game Theory. IEEE Wirel. Commun. 2021, 28, 174–181. [Google Scholar] [CrossRef]
- You, W.; Dong, C.; Cheng, X.; Zhu, X.; Wu, Q.; Chen, G. Joint Optimization of Area Coverage and Mobile-Edge Computing with Clustering for FANETs. IEEE Internet Things J. 2021, 8, 695–707. [Google Scholar] [CrossRef]
- Wang, Y.; Feng, W.; Wang, J.; Zhou, S.; Wang, C.X. Fine-Over-Coarse Spectrum Sharing with Shaped Virtual Cells for Hybrid Satellite-UAV-Terrestrial Maritime Networks. IEEE Trans. Wirel. Commun. 2024, 23, 17478–17492. [Google Scholar] [CrossRef]
- Wu, S.H.; Ko, C.H.; Chao, H.L. On-Demand Coordinated Spectrum and Resource Provisioning Under an Open C-RAN Architecture for Dense Small Cell Networks. IEEE Trans. Mob. Comput. 2024, 23, 673–688. [Google Scholar] [CrossRef]
- Bonati, L.; Polese, M.; D’Oro, S.; Basagni, S.; Melodia, T. NeutRAN: An Open RAN Neutral Host Architecture for Zero-Touch RAN and Spectrum Sharing. IEEE Trans. Mob. Comput. 2024, 23, 5786–5798. [Google Scholar] [CrossRef]
- Xie, N.; Ou-Yang, L.; Liu, A.X. Spectrum Sharing in mmWave Cellular Networks Using Clustering Algorithms. IEEE/ACM Trans. Netw. 2020, 28, 1378–1390. [Google Scholar] [CrossRef]
- Alhussien, N.; Gulliver, T.A. Joint Resource and Power Allocation for Clustered Cognitive M2M Communications Underlaying Cellular Networks. IEEE Trans. Veh. Technol. 2022, 71, 8548–8560. [Google Scholar] [CrossRef]
- Zeng, M.; Luo, Y.; Jiang, H.; Wang, Y. A Joint Cluster Formation Scheme with Multilayer Awareness for Energy-Harvesting Supported D2D Multicast Communication. IEEE Trans. Wirel. Commun. 2022, 21, 7595–7608. [Google Scholar] [CrossRef]
- Zhang, G.; Ke, F.; Zhang, H.; Cai, F.; Long, G.; Wang, Z. User Access and Resource Allocation in Full-Duplex User-Centric Ultra-Dense Networks. IEEE Trans. Veh. Technol. 2020, 69, 12015–12030. [Google Scholar] [CrossRef]
- Karmakar, R.; Kaddoum, G.; Akhrif, O. A Blockchain-Based Distributed and Intelligent Clustering-Enabled Authentication Protocol for UAV Swarms. IEEE Trans. Mob. Comput. 2024, 23, 6178–6195. [Google Scholar] [CrossRef]
- Dai, X.; Lu, Z.; Chen, X.; Xu, X.; Tang, F. Multiagent RL-Based Joint Trajectory Scheduling and Resource Allocation in NOMA-Assisted UAV Swarm Network. IEEE Internet Things J. 2024, 11, 14153–14167. [Google Scholar] [CrossRef]
- Asim, M.; ELAffendi, M.; El-Latif, A.A.A. Multi-IRS and Multi-UAV-Assisted MEC System for 5G/6G Networks: Efficient Joint Trajectory Optimization and Passive Beamforming Framework. IEEE Trans. Intell. Transp. Syst. 2023, 24, 4553–4564. [Google Scholar] [CrossRef]
- Sun, G.; Qin, D.; Lan, T.; Ma, L. Research on Clustering Routing Protocol Based on Improved PSO in FANET. IEEE Sens. J. 2021, 21, 27168–27185. [Google Scholar] [CrossRef]
- Xu, W.; Ke, Y.; Lee, C.H.; Gao, H.; Feng, Z.; Zhang, P. Data-Driven Beam Management with Angular Domain Information for mmWave UAV Networks. IEEE Trans. Wirel. Commun. 2021, 20, 7040–7056. [Google Scholar] [CrossRef]
- Zhu, G.; Yao, H.; Mai, T.; Wang, Z.; Wu, D.; Guo, S. Fission Spectral Clustering Strategy for UAV Swarm Networks. IEEE Trans. Serv. Comput. 2024, 17, 537–548. [Google Scholar] [CrossRef]
- Petrlik, M.; Baca, T.; Hert, D.; Vrba, M.; Krajnik, T.; Saska, M. A Robust UAV System for Operations in a Constrained Environment. IEEE Robot. Autom. Lett. 2020, 5, 2169–2176. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, Y.; Ren, B. Energy Saving Quadrotor Control for Field Inspections. IEEE Trans. Syst. Man, Cybern. Syst. 2022, 52, 1768–1777. [Google Scholar] [CrossRef]
- Xing, N.; Zong, Q.; Dou, L.; Tian, B.; Wang, Q. A Game Theoretic Approach for Mobility Prediction Clustering in Unmanned Aerial Vehicle Networks. IEEE Trans. Veh. Technol. 2019, 68, 9963–9973. [Google Scholar] [CrossRef]
- Chen, J.; Wu, Q.; Xu, Y.; Qi, N.; Guan, X.; Zhang, Y.; Xue, Z. Joint Task Assignment and Spectrum Allocation in Heterogeneous UAV Communication Networks: A Coalition Formation Game-Theoretic Approach. IEEE Trans. Wirel. Commun. 2021, 20, 440–452. [Google Scholar] [CrossRef]
- Ruan, L.; Li, G.; Dai, W.; Tian, S.; Fan, G.; Wang, J.; Dai, X. Cooperative Relative Localization for UAV Swarm in GNSS-Denied Environment: A Coalition Formation Game Approach. IEEE Internet Things J. 2022, 9, 11560–11577. [Google Scholar] [CrossRef]
- Huang, Y.; Qi, N.; Huang, Z.; Jia, L.; Wu, Q.; Yao, R.; Wang, W. Connectivity Guarantee Within UAV Cluster: A Graph Coalition Formation Game Approach. IEEE Open J. Commun. Soc. 2023, 4, 79–90. [Google Scholar] [CrossRef]
- Halder, S.; Ghosal, A.; Conti, M. Dynamic Super Round-Based Distributed Task Scheduling for UAV Networks. IEEE Trans. Wirel. Commun. 2023, 22, 1014–1028. [Google Scholar] [CrossRef]
- Halli Sudhakara, S.; Haghnegahdar, L. Security Enhancement in AAV Swarms: A Case Study Using Federated Learning and SHAP Analysis. IEEE Open J. Intell. Transp. Syst. 2025, 6, 335–345. [Google Scholar] [CrossRef]
- Hassan, M.Z.; Kaddoum, G.; Akhrif, O. Resource Allocation for Joint Interference Management and Security Enhancement in Cellular-Connected Internet-of-Drones Networks. IEEE Trans. Veh. Technol. 2022, 71, 12869–12884. [Google Scholar] [CrossRef]
- Guo, J.; Gao, H.; Liu, Z.; Huang, F.; Zhang, J.; Li, X.; Ma, J. ICRA: An Intelligent Clustering Routing Approach for UAV Ad Hoc Networks. IEEE Trans. Intell. Transp. Syst. 2023, 24, 2447–2460. [Google Scholar] [CrossRef]
- He, W.; Yao, H.; Mai, T.; Wang, F.; Guizani, M. Three-Stage Stackelberg Game Enabled Clustered Federated Learning in Heterogeneous UAV Swarms. IEEE Trans. Veh. Technol. 2023, 72, 9366–9380. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Bai, Z.; Lin, Y.; Cao, Y.; Wang, W. Delay-Aware Cooperative Task Offloading for Multi-UAV Enabled Edge-Cloud Computing. IEEE Trans. Mob. Comput. 2022, 23, 1034–1049. [Google Scholar] [CrossRef]
- Han, Z.; Zhou, T.; Xu, T.; Hu, H. Joint User Association and Deployment Optimization for Delay-Minimized UAV-Aided MEC Networks. IEEE Wirel. Commun. Lett. 2023, 12, 1791–1795. [Google Scholar] [CrossRef]
- Ni, M.; Zhong, Z.; Zhao, D. MPBC: A Mobility Prediction-Based Clustering Scheme for Ad Hoc Networks. IEEE Trans. Veh. Technol. 2011, 60, 4549–4559. [Google Scholar] [CrossRef]
- Vo, V.N.; Nguyen, L.M.D.; Tran, H.; Dang, V.H.; Niyato, D.; Cuong, D.N.; Luong, N.C.; So-In, C. Outage Probability Minimization in Secure NOMA Cognitive Radio Systems with UAV Relay: A Machine Learning Approach. IEEE Trans. Cogn. Commun. Netw. 2023, 9, 435–451. [Google Scholar] [CrossRef]
- Vu, T.H.; Nguyen, T.V.; Kim, S. Wireless Powered Cognitive NOMA-Based IoT Relay Networks: Performance Analysis and Deep Learning Evaluation. IEEE Internet Things J. 2022, 9, 3913–3929. [Google Scholar] [CrossRef]
- Arafat, M.Y.; Moh, S. Localization and Clustering Based on Swarm Intelligence in UAV Networks for Emergency Communications. IEEE Internet Things J. 2019, 6, 8958–8976. [Google Scholar] [CrossRef]
- Hong, L.; Guo, H.; Liu, J.; Zhang, Y. Toward Swarm Coordination: Topology-Aware Inter-UAV Routing Optimization. IEEE Trans. Veh. Technol. 2020, 69, 10177–10187. [Google Scholar] [CrossRef]
- Liu, Y.; Yan, J.; Zhao, X. Deep Reinforcement Learning Based Latency Minimization for Mobile Edge Computing with Virtualization in Maritime UAV Communication Network. IEEE Trans. Veh. Technol. 2022, 71, 4225–4236. [Google Scholar] [CrossRef]
- Hu, Z.; Liu, S.; Zhou, D.; Xu, F.; Ma, J.; Ning, X. Deep Reinforcement Learning for Task Offloading and Resource Allocation in UAV Cluster-Assisted Mobile Edge Computing. IEEE J. Miniaturization Air Space Syst. 2024. early access. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario | Training Time (CPU) | Training Time (GPU) | GPU Memory (GB) | CPU Utilization | Energy (Wh) | FLOPs (G) |
|---|---|---|---|---|---|---|
| 2 CHs + 20 CMs | 2.1 h | 0.8 h | 8–10 | % (64 threads) | 420 (CPU) 240 (GPU) | 0.8 |
| 4 CHs + 40 CMs | 5.3 h | 1.9 h | 10–12 | % (64 threads) | 1060 (CPU) 570 (GPU) | 2.1 |
| 6 CHs + 60 CMs | 12.6 h | 4.5 h | 12–14 | % (64 threads) | 2520 (CPU) 1350 (GPU) | 5.3 |
| 9 CHs + 90 CMs | 19.8 h | 6.7 h | 15–17 | % (64 threads) | 3960 (CPU) 2010 (GPU) | 10.5 |
| Algorithm | Average Throughput (Mbps) | Average Intra-Cluster Delay (ms) | Minimum SNR (dB) | Dynamic Adaptation | Required Channel Information | Complexity |
|---|---|---|---|---|---|---|
| HMDRL-UC | 11.9 | 3.2 | 0.88 | Yes | Partial CDI | High |
| DDPG D [45] | 11.5 | 3.4 | 0.85 | Yes | Full CSI | High |
| CECA [11] | 7.8 | 3.9 | 0.35 | No | Full CSI | Moderate |
| CFG [29] | 8.5 | 4.0 | 0.33 | No | Partial CDI | Moderate |
| SIC-PSO [42] | 9.7 | 3.8 | 0.42 | Yes | Full CSI | Moderate |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, X.; Wang, Y.; Han, Y.; Li, Y.; Lin, C.; Zhu, X. Heterogeneous Multi-Agent Deep Reinforcement Learning for Cluster-Based Spectrum Sharing in UAV Swarms. Drones 2025, 9, 377. https://doi.org/10.3390/drones9050377
Liao X, Wang Y, Han Y, Li Y, Lin C, Zhu X. Heterogeneous Multi-Agent Deep Reinforcement Learning for Cluster-Based Spectrum Sharing in UAV Swarms. Drones. 2025; 9(5):377. https://doi.org/10.3390/drones9050377
Chicago/Turabian StyleLiao, Xiaomin, Yulai Wang, Yang Han, You Li, Chushan Lin, and Xuan Zhu. 2025. "Heterogeneous Multi-Agent Deep Reinforcement Learning for Cluster-Based Spectrum Sharing in UAV Swarms" Drones 9, no. 5: 377. https://doi.org/10.3390/drones9050377
APA StyleLiao, X., Wang, Y., Han, Y., Li, Y., Lin, C., & Zhu, X. (2025). Heterogeneous Multi-Agent Deep Reinforcement Learning for Cluster-Based Spectrum Sharing in UAV Swarms. Drones, 9(5), 377. https://doi.org/10.3390/drones9050377