
FUR-DETR: A Lightweight Detection Model for Fixed-Wing UAV Recovery



Abstract
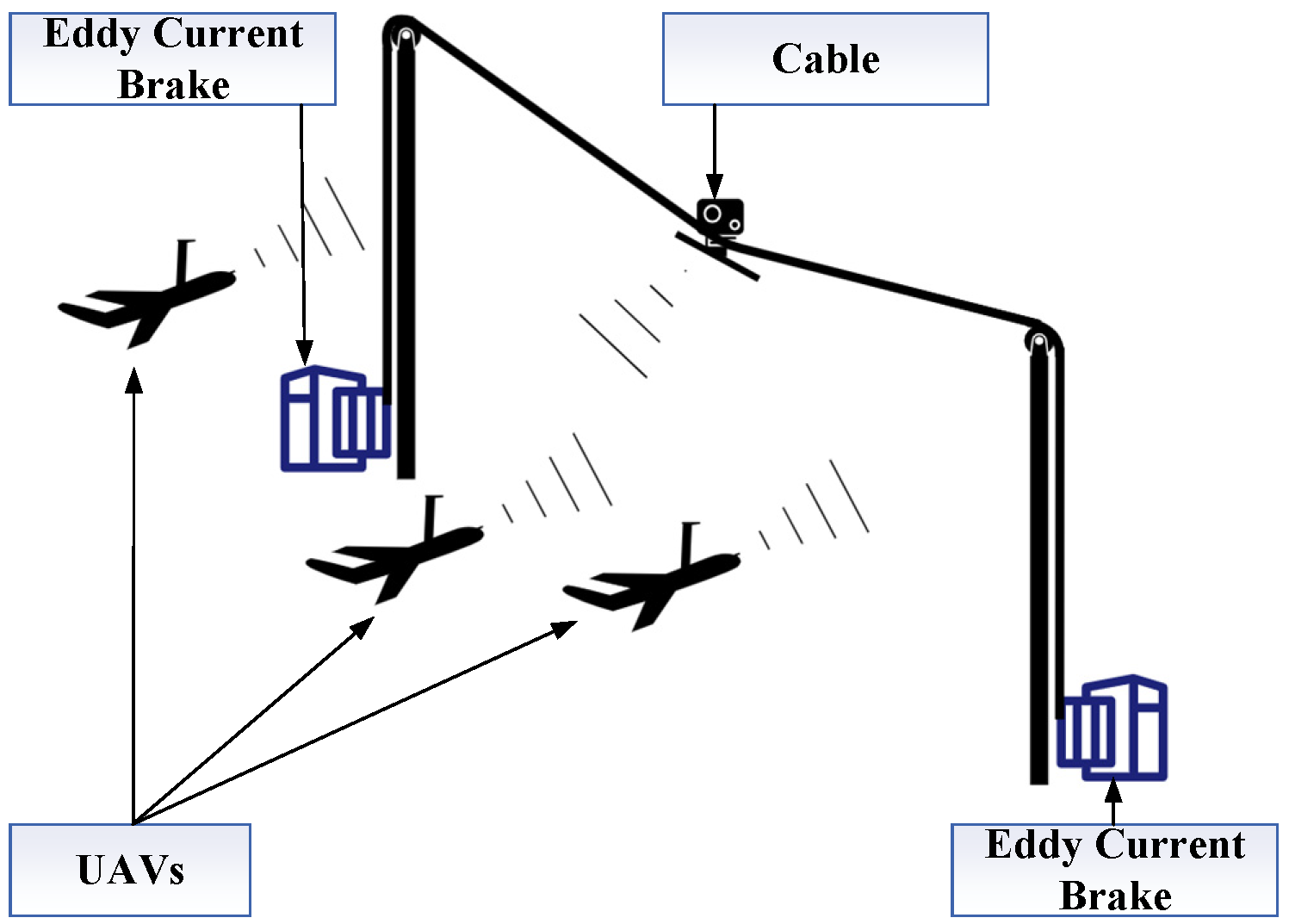
1. Introduction
2. Related Work
2.1. Transformer-Based Object Detection Algorithms
2.2. Current Research of UAV Detection Algorithms
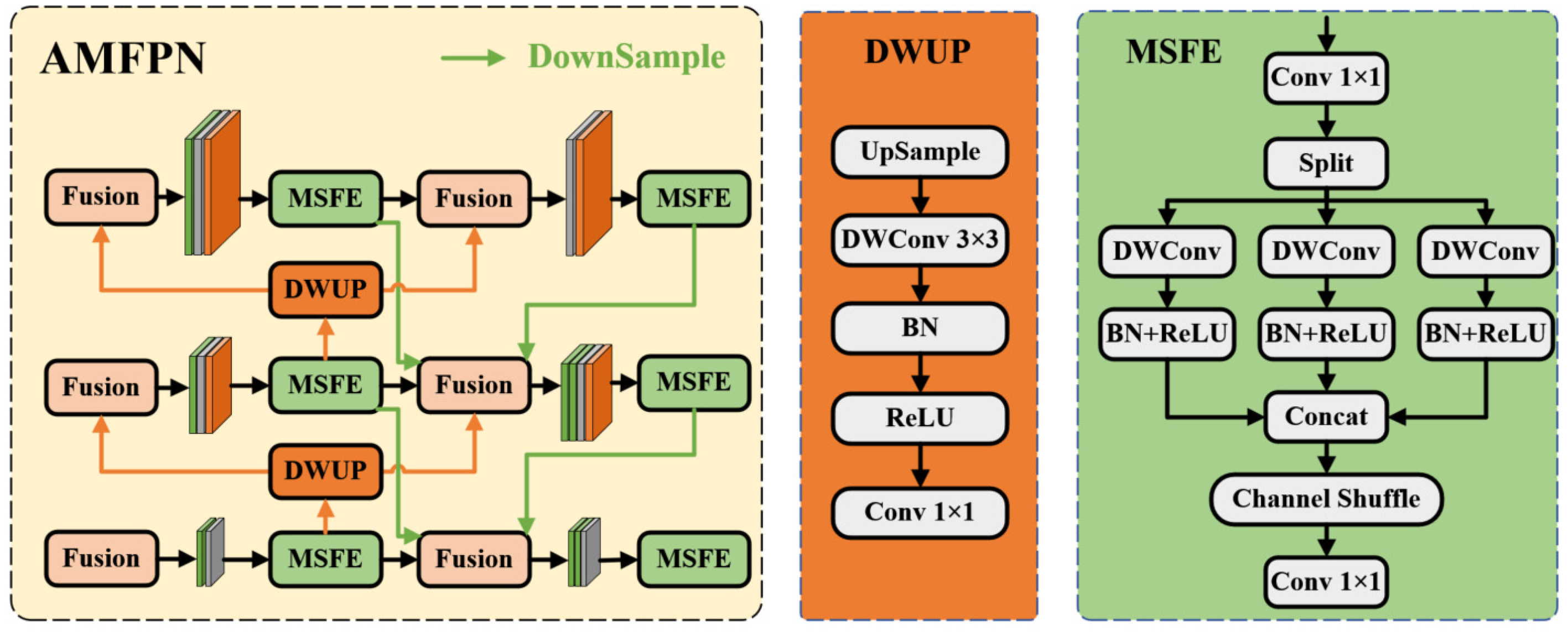
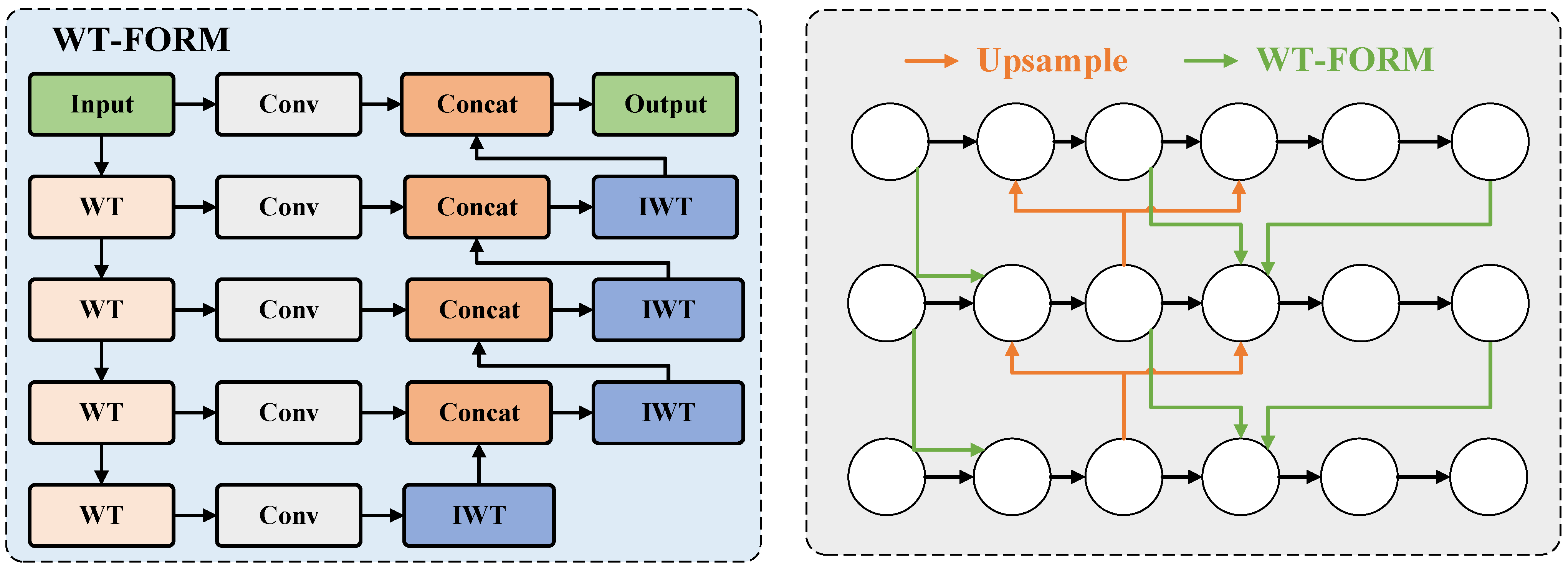
3. Methods
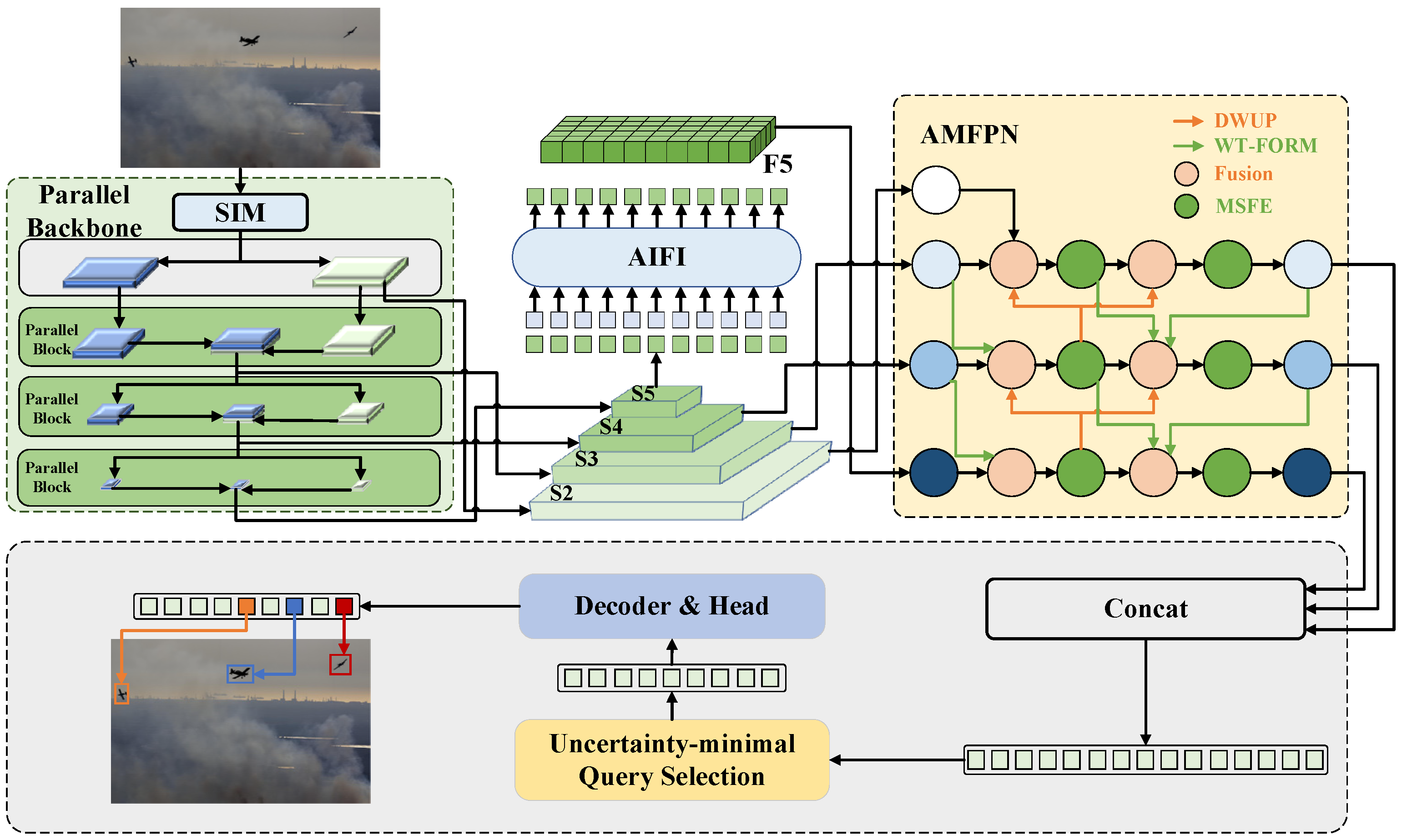
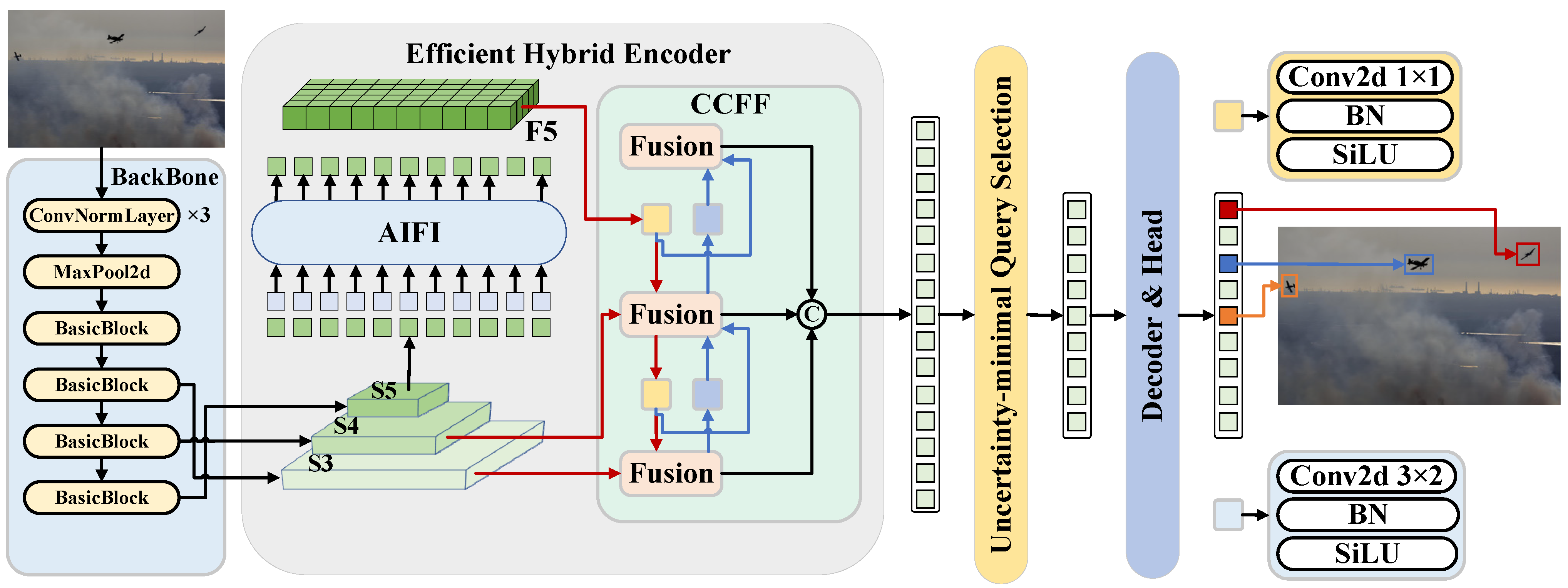
3.1. Baseline Network
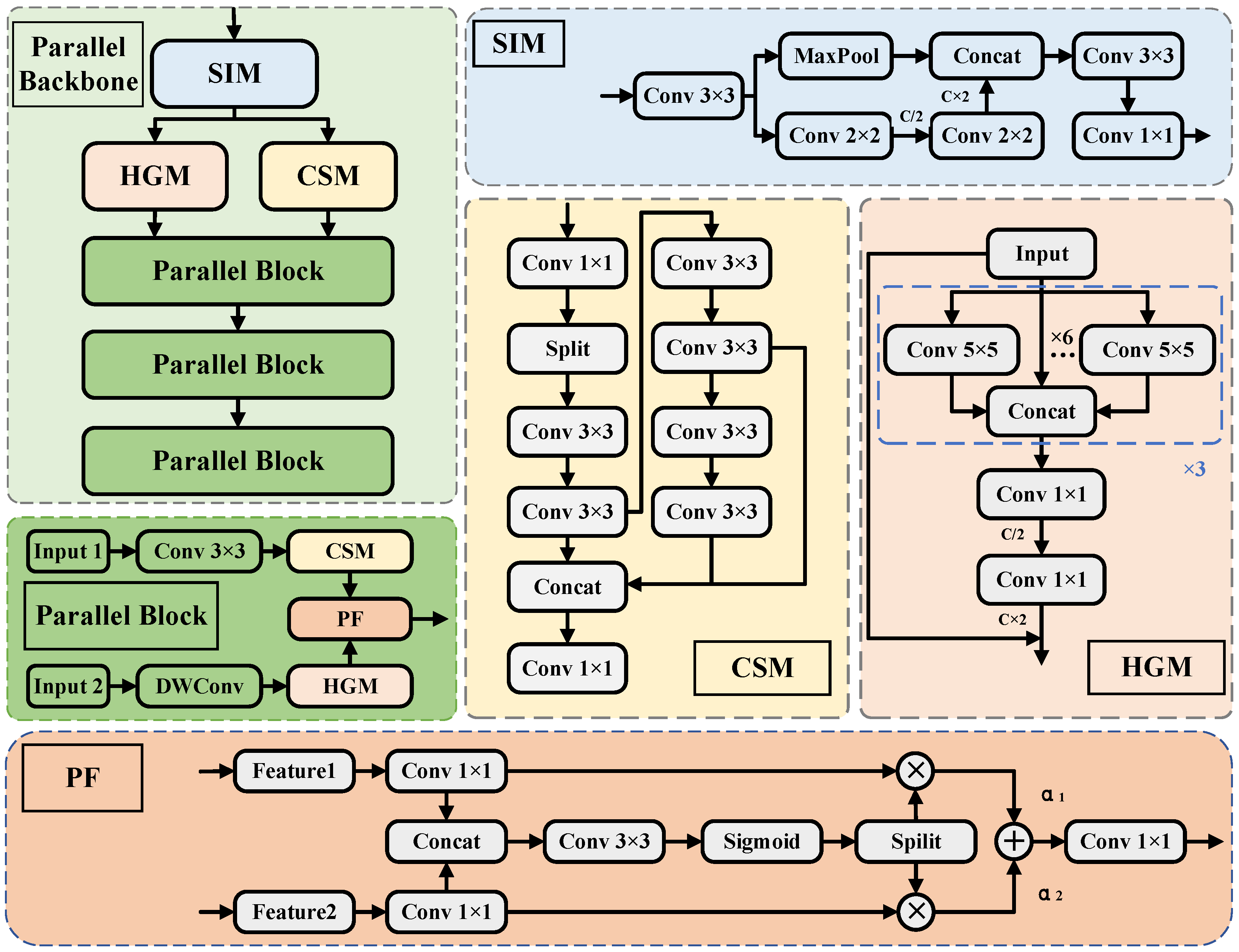
3.2. Improvement of Feature Extraction Network
3.3. Improvement of Cross-Scale Feature Fusion Network
3.4. Wavelet-Based Frequency-Optimized Reverse Fusion Mechanism
4. Results
4.1. Dataset Introduction
4.2. Evaluation Metrics
4.3. Experiment Settings
4.4. Ablation Experiment
4.5. Performance Comparison Experiments with the Deep Learning Model
4.5.1. Comparisons with Different Backbone Networks
4.5.2. Comparisons with Different FPN Networks
4.5.3. Comparisons with Different Convolutional Networks
4.5.4. Comparisons of Different Detection Models
4.5.5. Performance Comparisons on Different Datasets
4.5.6. Comparative Analysis with Established Benchmarks
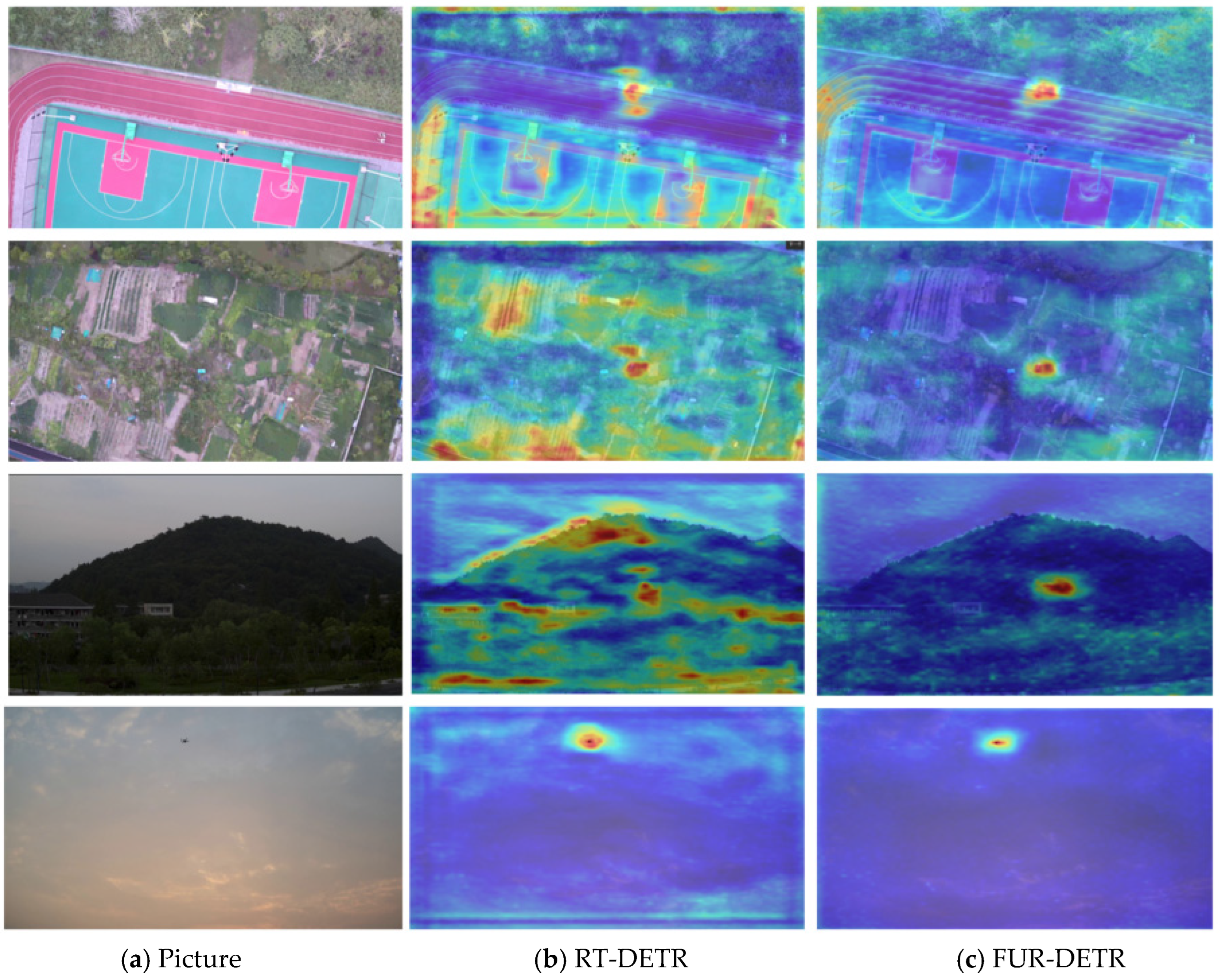
4.6. Visualization of Detections
4.7. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Farajijalal, M.; Eslamiat, H.; Avineni, V.; Hettel, E.; Lindsay, C. Safety Systems for Emergency Landing of Civilian Unmanned Aerial Vehicles—A Comprehensive Review. Drones 2025, 9, 141. [Google Scholar] [CrossRef]
- Yao, Y.; Wu, J.; Chen, H.; Xu, J.; Yin, Z. Braking Models for Short-Distance Recovery of UAV. In The Proceedings of 2024 International Conference of Electrical, Electronic and Networked Energy Systems; Jia, L., Yang, F., Cheng, X., Wang, Y., Li, Z., Huang, W., Eds.; Lecture Notes in Electrical Engineering; Springer Nature: Singapore, 2025; Volume 1316, pp. 37–47. ISBN 978-981-96-2079-1. [Google Scholar]
- Souto, A.; Alfaia, R.; Cardoso, E.; Araújo, J.; Francês, C. UAV Path Planning Optimization Strategy: Considerations of Urban Morphology, Microclimate, and Energy Efficiency Using Q-Learning Algorithm. Drones 2023, 7, 123. [Google Scholar] [CrossRef]
- Hu, Z.; Chen, H.; Lyons, E.; Solak, S.; Zink, M. Towards Sustainable UAV Operations: Balancing Economic Optimization with Environmental and Social Considerations in Path Planning. Transp. Res. Part E Logist. Transp. Rev. 2024, 181, 103314. [Google Scholar] [CrossRef]
- Hansen, J.M.; Johansen, T.A.; Sokolova, N.; Fossen, T.I. Nonlinear Observer for Tightly Coupled Integrated Inertial Navigation Aided by RTK-GNSS Measurements. IEEE Trans. Control Syst. Technol. 2019, 27, 1084–1099. [Google Scholar] [CrossRef]
- Cheng, C.; Li, X.; Xie, L.; Li, L. Autonomous Dynamic Docking of UAV Based on UWB-Vision in GPS-Denied Environment. J. Franklin Inst. 2022, 359, 2788–2809. [Google Scholar] [CrossRef]
- Skulstad, R.; Syversen, C.; Merz, M.; Sokolova, N.; Fossen, T.; Johansen, T. Autonomous Net Recovery of Fixed-Wing UAV with Single-Frequency Carrier-Phase Differential GNSS. IEEE Aerosp. Electron. Syst. Mag. 2015, 30, 18–27. [Google Scholar] [CrossRef]
- Kassab, M.; Zitar, R.A.; Barbaresco, F.; Seghrouchni, A.E.F. Drone Detection with Improved Precision in Traditional Machine Learning and Less Complexity in Single Shot Detectors. IEEE Trans. Aerosp. Electron. Syst. 2024, 60, 3847–3859. [Google Scholar] [CrossRef]
- Muzammul, M.; Li, X. Comprehensive Review of Deep Learning-Based Tiny Object Detection: Challenges, Strategies, and Future Directions. Knowl. Inf. Syst. 2025, 67, 3825–3913. [Google Scholar] [CrossRef]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs Beat Yolos on Real-Time Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Jocher, G.; Qiu, J.; Chaurasia, A. Ultralytics YOLO, version 8.0.0; Ultralytics: Frederick, MD, USA, 2023. Available online: https://ultralytics.com (accessed on 12 March 2025).
- Wang, C.-Y.; Yeh, I.-H.; Mark Liao, H.-Y. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. In Proceedings of the European Conference on Computer Vision (ECCV), Milan, Italy, 29 September–4 October 2024; Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G., Eds.; Springer Nature: Cham, Switzerland, 2024; pp. 1–21. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2020; Volume 12346, pp. 213–229. ISBN 978-3-030-58451-1. [Google Scholar]
- Shehzadi, T.; Hashmi, K.A.; Stricker, D.; Afzal, M.Z. Object Detection with Transformers: A Review. arXiv 2023, arXiv:2306.04670. [Google Scholar]
- Li, F.; Zhang, H.; Liu, S.; Guo, J.; Ni, L.M.; Zhang, L. Dn-Detr: Accelerate Detr Training by Introducing Query Denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 13619–13627. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.-Y. DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- Chen, Q.; Chen, X.; Wang, J.; Zhang, S.; Yao, K.; Feng, H.; Han, J.; Ding, E.; Zeng, G.; Wang, J. Group Detr: Fast Detr Training with Group-Wise One-to-Many Assignment. In Proceedings of the IEEE/CVPR International Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6633–6642. [Google Scholar]
- Wang, S.; Jiang, H.; Li, Z.; Yang, J.; Ma, X.; Chen, J.; Tang, X. Phsi-Rtdetr: A Lightweight Infrared Small Target Detection Algorithm Based on UAV Aerial Photography. Drones 2024, 8, 240. [Google Scholar] [CrossRef]
- Titu, M.F.S.; Pavel, M.A.; Michael, G.K.O.; Babar, H.; Aman, U.; Khan, R. Real-Time Fire Detection: Integrating Lightweight Deep Learning Models on Drones with Edge Computing. Drones 2024, 8, 483. [Google Scholar] [CrossRef]
- Qin, D.; Leichner, C.; Delakis, M.; Fornoni, M.; Luo, S.; Yang, F.; Wang, W.; Banbury, C.; Ye, C.; Akin, B.; et al. MobileNetV4: Universal Models for the Mobile Ecosystem. In Computer Vision—ECCV 2024; Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G., Eds.; Lecture Notes in Computer Science; Springer Nature: Cham, Switzerland, 2025; Volume 15098, pp. 78–96. ISBN 978-3-031-73660-5. [Google Scholar]
- Wang, A.; Chen, H.; Lin, Z.; Han, J.; Ding, G. Repvit: Revisiting Mobile Cnn from Vit Perspective. In Proceedings of the IEEE/CVPR Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 15909–15920. [Google Scholar]
- Li, Y.; Li, X.; Dai, Y.; Hou, Q.; Liu, L.; Liu, Y.; Cheng, M.-M.; Yang, J. LSKNet: A Foundation Lightweight Backbone for Remote Sensing. Int. J. Comput. Vision 2025, 133, 1410–1431. [Google Scholar] [CrossRef]
- Ashraf, M.W.; Sultani, W.; Shah, M. Dogfight: Detecting Drones from Drones Videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7067–7076. [Google Scholar]
- Zhao, Y.; Ju, Z.; Sun, T.; Dong, F.; Li, J.; Yang, R.; Fu, Q.; Lian, C.; Shan, P. Tgc-Yolov5: An Enhanced Yolov5 Drone Detection Model Based on Transformer, Gam & ca Attention Mechanism. Drones 2023, 7, 446. [Google Scholar] [CrossRef]
- Sangam, T.; Dave, I.R.; Sultani, W.; Shah, M. Transvisdrone: Spatio-Temporal Transformer for Vision-Based Drone-to-Drone Detection in Aerial Videos. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–02 June 2023; IEEE: London, UK, 2023; pp. 6006–6013. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Ni, Z.; Chen, X.; Zhai, Y.; Tang, Y.; Wang, Y. Context-Guided Spatial Feature Reconstruction for Efficient Semantic Segmentation. In Computer Vision—ECCV 2024; Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G., Eds.; Lecture Notes in Computer Science; Springer Nature: Cham, Switzerland, 2025; Volume 15110, pp. 239–255. ISBN 978-3-031-72942-3. [Google Scholar]
- Chen, Y.; Zhang, C.; Chen, B.; Huang, Y.; Sun, Y.; Wang, C.; Fu, X.; Dai, Y.; Qin, F.; Peng, Y. Accurate Leukocyte Detection Based on Deformable-DETR and Multi-Level Feature Fusion for Aiding Diagnosis of Blood Diseases. Comput. Biol. Med. 2024, 170, 107917. [Google Scholar] [CrossRef] [PubMed]
- Yang, R.; Shan, P.; He, Y.; Xiao, H.; Zhang, L.; Zhao, Y.; Fu, Q. A Lightweight Bionic Flapping Wing Drone Recognition Network Based on Data Enhancement. Measurement 2025, 239, 115476. [Google Scholar] [CrossRef]
- Zhang, X.; Song, Y.; Song, T.; Yang, D.; Ye, Y.; Zhou, J.; Zhang, L. LDConv: Linear Deformable Convolution for Improving Convolutional Neural Networks. Image Vis. Comput. 2024, 149, 105190. [Google Scholar] [CrossRef]
- Lu, W.; Chen, S.-B.; Tang, J.; Ding, C.H.; Luo, B. A Robust Feature Downsampling Module for Remote-Sensing Visual Tasks. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–12. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A New Backbone That Can Enhance Learning Capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 390–391. [Google Scholar]
- Cai, H.; Zhang, J.; Xu, J. ALDNet: A Lightweight and Efficient Drone Detection Network. Meas. Sci. Technol. 2025, 36, 025402. [Google Scholar] [CrossRef]
- Finder, S.E.; Amoyal, R.; Treister, E.; Freifeld, O. Wavelet Convolutions for Large Receptive Fields. In Computer Vision—ECCV 2024; Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G., Eds.; Lecture Notes in Computer Science; Springer Nature: Cham, Switzerland, 2025; Volume 15112, pp. 363–380. ISBN 978-3-031-72948-5. [Google Scholar]
- Zheng, Y.; Chen, Z.; Lv, D.; Li, Z.; Lan, Z.; Zhao, S. Air-to-Air Visual Detection of Micro-Uavs: An Experimental Evaluation of Deep Learning. IEEE Robot. Autom. Lett. 2021, 6, 1020–1027. [Google Scholar] [CrossRef]
- Zhao, J.; Zhang, J.; Li, D.; Wang, D. Vision-Based Anti-UAV Detection and Tracking. IEEE Trans. Intell. Transp. Syst. 2022, 23, 25323–25334. [Google Scholar] [CrossRef]
- Sun, H.; Yang, J.; Shen, J.; Liang, D.; Ning-Zhong, L.; Zhou, H. TIB-Net: Drone Detection Network with Tiny Iterative Backbone. IEEE Access 2020, 8, 130697–130707. [Google Scholar] [CrossRef]
- Zhou, X.; Han, B.; Li, L.; Chen, J.; Chen, B.M. DRNet: A Miniature and Resource- Efficient MAV Detector. IEEE Trans. Instrum. Meas. 2025, 74, 1–14. [Google Scholar] [CrossRef]
- Wu, T.; Tang, S.; Zhang, R.; Cao, J.; Zhang, Y. Cgnet: A Light-Weight Context Guided Network for Semantic Segmentation. IEEE Trans. Image Process. 2020, 30, 1169–1179. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Kao, S.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Lyu, C.; Zhang, W.; Huang, H.; Zhou, Y.; Wang, Y.; Liu, Y.; Zhang, S.; Chen, K. RTMDet: An empirical study of designing real-time object detectors. arXiv 2022, arXiv:2212.07784. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, L.; Mei, S.; Wang, Y.; Lian, J.; Han, Z.; Chen, X. Few-Shot Object Detection with Multilevel Information Interaction for Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–14. [Google Scholar] [CrossRef]
- Zhu, L.; Lee, F.; Cai, J.; Yu, H.; Chen, Q. An Improved Feature Pyramid Network for Object Detection. Neurocomputing 2022, 483, 127–139. [Google Scholar] [CrossRef]
- Hendrycks, D.; Dietterich, T. Benchmarking Neural Network Robustness to Common Corruptions and Perturbations. arXiv 2019, arXiv:1903.12261. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Research Direction | Representative Methods | Main Advantages |
|---|---|---|
| Transformer-based Detection | YOLO series [11,12,13] | Single-stage detection, balanced speed and accuracy |
| DETR [14] | End-to-end architecture, simplified process | |
| DN-DETR [16] | Mitigating matching instability, faster convergence | |
| DINO [17] | Enhanced detection performance and training efficiency | |
| Group DETR [18] | Accelerated convergence, reduced redundancy | |
| RT-DETR [10] | Reduced resource requirements, real-time detection | |
| Architecture Optimization | PHSI-RTDETR [19] | Balance of detection accuracy and real-time performance |
| MobileNetV4 [21] | Efficiency–accuracy balance on mobile platforms | |
| RepViT [22] | Enhanced performance on mobile devices | |
| LSKNet [23] | Adaptation to scale changes and complex backgrounds | |
| Multiscale Feature Fusion | Dogfight [24] | Improved small UAV detection in complex environments |
| TGC-YOLOv5 [25] | Better detection in low-visibility conditions | |
| TransVisDrone [26] | Good performance across datasets, complex background adaptation | |
| BiFPN [27] | Lower computational complexity and parameters | |
| CGRSeg [28] | Enhanced feature representation capability | |
| HSFPN [29] | Enhanced feature expression capabilities | |
| Convolution Optimization | MLWConv [30] | Efficient multiscale information acquisition |
| LDConv [31] | Improved sampling effect with fewer parameters | |
| RFD [32] | Reduced information loss during downsampling |
| Parameter | Setup |
|---|---|
| Image Size | 640 × 640 |
| Epochs | 500 |
| Patience | 80 |
| Number of GPUs | 1 |
| GPU type | RTX 4090D |
| Works | 8 |
| Batchsize | 8 |
| Optimizer | AdmW |
| Initial learning rate | 0.0001 |
| Final learning rate | 0.0001 |
| Methods | Parallel Backbone | AM FPN | WT-FORM | Param | GFLOPS | AP 50-95 | AP 50 | AP 75 | APs | APm | APl |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1-Base | - | - | - | 19.9 M | 56.9 | 0.667 | 0.968 | 0.788 | 0.428 | 0.668 | 0.742 |
| 2-A | √ | 14.0 M | 34.0 | 0.658 | 0.965 | 0.766 | 0.423 | 0.654 | 0.740 | ||
| 3-B | √ | 17.9 M | 48.6 | 0.668 | 0.967 | 0.788 | 0.439 | 0.668 | 0.742 | ||
| 4-C | √ | 18.8 M | 54.8 | 0.670 | 0.967 | 0.791 | 0.447 | 0.668 | 0.746 | ||
| 5-A+B | √ | √ | 12.0 M | 25.4 | 0.662 | 0.965 | 0.772 | 0.441 | 0.662 | 0.731 | |
| 6-A+C | √ | √ | 12.9 M | 31.8 | 0.660 | 0.961 | 0.775 | 0.437 | 0.662 | 0.733 | |
| 7-B+C | √ | √ | 17.2 M | 47.2 | 0.672 | 0.965 | 0.792 | 0.451 | 0.673 | 0.744 | |
| 8-Ours | √ | √ | √ | 11.3 M | 23.9 | 0.662 | 0.966 | 0.780 | 0.446 | 0.663 | 0.731 |
| Model | Param | GFLOPS | AP50-95 | AP50 | AP75 | APs | APm | APl |
|---|---|---|---|---|---|---|---|---|
| RT-DETR(Base) [10] | 19.9 M | 56.9 | 0.667 | 0.968 | 0.788 | 0.428 | 0.668 | 0.742 |
| RT-DETR+MobileNetV4-Conv-S [21] | 11.3 M | 39.5 | 0.655 | 0.964 | 0.763 | 0.427 | 0.655 | 0.732 |
| RT-DETR+RepViT-M-09 [22] | 13.3 M | 36.3 | 0.643 | 0.956 | 0.747 | 0.391 | 0.639 | 0.730 |
| RT-DETR+LSKNet-T [23] | 12.6 M | 37.5 | 0.643 | 0.963 | 0.746 | 0.400 | 0.639 | 0.731 |
| RT-DETR+Parallel Backbone | 14.0 M | 34.0 | 0.658 | 0.965 | 0.766 | 0.423 | 0.654 | 0.740 |
| Model | Param | GFLOPS | AP50-95 | AP50 | AP75 | APs | APm | APl |
|---|---|---|---|---|---|---|---|---|
| RT-DETR (Base) [10] | 19.9 M | 56.9 | 0.667 | 0.968 | 0.788 | 0.428 | 0.668 | 0.742 |
| RT-DETR+BIFPN [27] | 20.3 M | 64.3 | 0.672 | 0.969 | 0.794 | 0.467 | 0.672 | 0.74 |
| RT-DETR+CGRFPN [28] | 19.2 M | 48.2 | 0.665 | 0.967 | 0.779 | 0.429 | 0.668 | 0.739 |
| RT-DETR+HSFPN [29] | 18.1 M | 53.3 | 0.673 | 0.968 | 0.791 | 0.442 | 0.675 | 0.749 |
| RT-DETR+AMFPN | 17.9 M | 48.6 | 0.668 | 0.967 | 0.788 | 0.439 | 0.668 | 0.742 |
| Model | Param | GFLOPS | AP50-95 | AP50 | AP75 | APs | APm | APl |
|---|---|---|---|---|---|---|---|---|
| RT-DETR (Base) [10] | 19.9 M | 56.9 | 0.667 | 0.968 | 0.788 | 0.428 | 0.668 | 0.742 |
| RT-DETR+LDConv [31] | 19.6 M | 57.9 | 0.673 | 0.968 | 0.789 | 0.451 | 0.672 | 0.753 |
| RT-DETR+ContextGuidedDown [40] | 22.3 M | 61.7 | 0.667 | 0.969 | 0.791 | 0.433 | 0.668 | 0.743 |
| RT-DETR+SRFD [32] | 19.6 M | 55.0 | 0.657 | 0.965 | 0.758 | 0.422 | 0.657 | 0.734 |
| RT-DETR+WT-FORM | 18.8 M | 54.8 | 0.670 | 0.967 | 0.791 | 0.447 | 0.668 | 0.746 |
| Model | Param | GFLOPS | AP50-95 | AP50 | AP75 | APs | APm | APl |
|---|---|---|---|---|---|---|---|---|
| RT-DETR(Base) [10] | 19.9 M | 56.9 | 0.667 | 0.968 | 0.788 | 0.428 | 0.668 | 0.742 |
| YOLO v8m [11] | 25.8 M | 78.7 | 0.578 | 0.886 | 0.667 | 0.149 | 0.571 | 0.740 |
| YOLO v9m [12] | 20.0 M | 76.5 | 0.583 | 0.888 | 0.676 | 0.160 | 0.574 | 0.744 |
| YOLO v10m [13] | 16.5 M | 63.4 | 0.578 | 0.888 | 0.657 | 0.157 | 0.566 | 0.738 |
| YOLO v11m [11] | 20.0 M | 67.6 | 0.584 | 0.883 | 0.680 | 0.159 | 0.577 | 0.744 |
| MobileNetV4+Base [21] | 11.3 M | 39.5 | 0.655 | 0.964 | 0.763 | 0.427 | 0.655 | 0.732 |
| FasterNet+Base [41] | 10.8 M | 28.5 | 0.635 | 0.959 | 0.740 | 0.377 | 0.632 | 0.724 |
| RTMDet [42] | 27.5 M | 54.2 | 0.554 | 0.876 | 0.622 | 0.124 | 0.532 | 0.733 |
| FUR-DETR (Ours) | 11.3 M | 23.9 | 0.662 | 0.966 | 0.780 | 0.446 | 0.663 | 0.731 |
| Model | Param | GFLOPS | AP50-95 | AP50 | AP75 | APs | APm | APl |
|---|---|---|---|---|---|---|---|---|
| RT-DETR(Base) [10] | 19.9 M | 56.9 | 0.706 | 0.960 | 0.801 | 0.636 | 0.742 | 0.775 |
| YOLO v8m [11] | 25.8 M | 78.7 | 0.663 | 0.932 | 0.755 | 0.521 | 0.722 | 0.788 |
| YOLO v9m [12] | 20.0 M | 76.5 | 0.673 | 0.931 | 0.755 | 0.527 | 0.737 | 0.796 |
| YOLO v10m [13] | 16.5 M | 63.4 | 0.660 | 0.928 | 0.742 | 0.519 | 0.721 | 0.779 |
| YOLO v11m [11] | 20.0 M | 67.6 | 0.667 | 0.932 | 0.756 | 0.531 | 0.728 | 0.778 |
| MobileNetV4+Base [21] | 11.3 M | 39.5 | 0.671 | 0.953 | 0.763 | 0.595 | 0.713 | 0.745 |
| FasterNet+Base [41] | 10.8 M | 28.5 | 0.688 | 0.959 | 0.783 | 0.604 | 0.725 | 0.772 |
| RTMDet [42] | 27.5 M | 54.2 | 0.623 | 0.900 | 0.703 | 0.455 | 0.681 | 0.766 |
| FUR-DETR (Ours) | 11.3 M | 23.9 | 0.698 | 0.959 | 0.792 | 0.614 | 0.733 | 0.773 |
| Model | Param | GFLOPS | AP50-95 | AP50 | AP75 | APs | APm | APl |
|---|---|---|---|---|---|---|---|---|
| RT-DETR(Base) [10] | 19.9 M | 56.9 | 0.393 | 0.926 | 0.227 | 0.349 | 0.453 | 0.560 |
| YOLO v8m [11] | 25.8 M | 78.7 | 0.342 | 0.844 | 0.171 | 0.268 | 0.438 | 0.545 |
| YOLO v9m [12] | 20.0 M | 76.5 | 0.346 | 0.859 | 0.183 | 0.266 | 0.449 | 0.625 |
| YOLO v10m [13] | 16.5 M | 63.4 | 0.349 | 0.843 | 0.188 | 0.265 | 0.454 | 0.325 |
| YOLO v11m [11] | 20.0 M | 67.6 | 0.336 | 0.833 | 0.179 | 0.242 | 0.465 | 0.500 |
| MobileNetV4+Base [21] | 11.3 M | 39.5 | 0.368 | 0.904 | 0.209 | 0.328 | 0.430 | 0.502 |
| FasterNet+Base [41] | 10.8 M | 28.5 | 0.368 | 0.900 | 0.202 | 0.314 | 0.439 | 0.600 |
| RTMDet [42] | 27.5 M | 54.2 | 0.277 | 0.714 | 0.138 | 0.181 | 0.419 | 0.650 |
| FUR-DETR (Ours) | 11.3 M | 23.9 | 0.375 | 0.915 | 0.216 | 0.331 | 0.438 | 0.500 |
| Model | Backbone | AP50 |
|---|---|---|
| Cascade R-CNN [36] | ResNet50 | 0.794 |
| FPN [36] | ResNet50 | 0.787 |
| Faster R-CNN [36] | ResNet50 | 0.705 |
| Grid R-CNN [36] | ResNet50 | 0.824 |
| RetinaNet [36] | ResNet50 | 0.779 |
| RefineDet [36] | ResNet50 | 0.695 |
| SSD512 [36] | ResNet50 | 0.787 |
| YOLOv3 [36] | DarkNet53 | 0.723 |
| FUR-DETR | Parallel Backbone | 0.966 |
| Model | Backbone | AP50-95 |
|---|---|---|
| Faster-RCNN [37] | ResNet50 | 0.653 |
| Faster-RCNN [37] | ResNet18 | 0.605 |
| Faster-RCNN [37] | VGG16 | 0.633 |
| Cascade-RCNN [37] | ResNet50 | 0.683 |
| Cascade-RCNN [37] | ResNet18 | 0.652 |
| Cascade-RCNN [37] | VGG16 | 0.667 |
| ATSS [37] | ResNet50 | 0.642 |
| ATSS [37] | ResNet18 | 0.610 |
| ATSS [37] | VGG16 | 0.641 |
| YOLOX [37] | ResNet50 | 0.427 |
| YOLOX [37] | ResNet18 | 0.400 |
| YOLOX [37] | VGG16 | 0.551 |
| YOLOX [37] | DarkNet | 0.552 |
| SSD [37] | VGG16 | 0.632 |
| FUR-DETR | Parallel Backbone | 0.698 |
| Model | Backbone | AP50 |
|---|---|---|
| Faster RCNN [38] | ResNet50 | 0.872 |
| Faster RCNN [38] | MobileNet | 0.675 |
| Cascade RCNN [38] | ResNet50 | 0.901 |
| Cascade RCNN [38] | MobileNet | 0.780 |
| YOLOv3 [38] | DarkNet53 | 0.849 |
| YOLOv4 [38] | CSPDarkNet53 | 0.860 |
| YOLOv5 [38] | YOLOv5-s | 0.862 |
| EXTD [38] | MobileFaceNet | 0.851 |
| TIB-Net [38] | TIB-Net | 0.892 |
| FUR-DETR | Parallel Backbone | 0.915 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, Y.; Wu, J.; Hao, Y.; Huang, Z.; Yin, Z.; Xu, J.; Chen, H.; Pi, J. FUR-DETR: A Lightweight Detection Model for Fixed-Wing UAV Recovery. Drones 2025, 9, 365. https://doi.org/10.3390/drones9050365
Yao Y, Wu J, Hao Y, Huang Z, Yin Z, Xu J, Chen H, Pi J. FUR-DETR: A Lightweight Detection Model for Fixed-Wing UAV Recovery. Drones. 2025; 9(5):365. https://doi.org/10.3390/drones9050365
Chicago/Turabian StyleYao, Yu, Jun Wu, Yisheng Hao, Zhen Huang, Zixuan Yin, Jiajing Xu, Honglin Chen, and Jiahua Pi. 2025. "FUR-DETR: A Lightweight Detection Model for Fixed-Wing UAV Recovery" Drones 9, no. 5: 365. https://doi.org/10.3390/drones9050365
APA StyleYao, Y., Wu, J., Hao, Y., Huang, Z., Yin, Z., Xu, J., Chen, H., & Pi, J. (2025). FUR-DETR: A Lightweight Detection Model for Fixed-Wing UAV Recovery. Drones, 9(5), 365. https://doi.org/10.3390/drones9050365