Abstract
Multi-object tracking (MOT) is a key intermediate task in many practical applications and theoretical fields, facing significant challenges due to complex scenarios, particularly in the context of drone-based air-to-ground military operations. During drone flight, factors such as high-altitude environments, small target proportions, irregular target movement, and frequent occlusions complicate the multi-object tracking task. This paper proposes a cross-scene multi-object tracking (CST) method to address these challenges. Firstly, a lightweight object detection framework is proposed to optimize key sub-tasks by integrating multi-dimensional temporal and spatial information. Secondly, trajectory prediction is achieved through the implementation of Model-Agnostic Meta-Learning, enhancing adaptability to dynamic environments. Thirdly, re-identification is facilitated using Dempster–Shafer Theory, which effectively manages uncertainties in target recognition by incorporating aircraft state information. Finally, a novel dataset, termed the Multi-Information Drone Detection and Tracking Dataset (MIDDTD), is introduced, containing rich drone-related information and diverse scenes, thereby providing a solid foundation for the validation of cross-scene multi-object tracking algorithms. Experimental results demonstrate that the proposed method improves the IDF1 tracking metric by 1.92% compared to existing state-of-the-art methods, showcasing strong cross-scene adaptability and offering an effective solution for multi-object tracking from a drone’s perspective, thereby advancing theoretical and technical support for related fields.
1. Introduction
With the rapid development of drone technology and its wide application in transportation, security, environmental protection and other fields, such as traffic tracking, inspection, wildlife tracking and other tasks, the demand for efficient and accurate air-to-ground multi-object tracking technology (MOT) is growing. These application scenarios require the support of image target tracking as an intermediate technology to achieve effective recognition and tracking of ground targets. Multi-target tracking technology plays a key role in achieving target positioning and tracking. Therefore, air-to-ground multi-target tracking and re-identification technology that assists drones in their role has become a key research direction.
However, from the perspective of drones, it is necessary to deal with problems such as small target size and weak imaging features due to high-altitude flight, irregular target movement, easy occlusion of the target, and frequent entry and exit of the target in the field of view due to drone shaking. The existence of these problems significantly increases the complexity and difficulty of the MOT task and limits its effectiveness in practical applications [1].
Traditional multi-target tracking methods mainly focus on relatively stable environments such as urban or road scenes, and adopt detection-based multi-target tracking methods. These methods first use target detection algorithms to detect all potential targets in each frame of the image, and then use tracking algorithms such as DeepSORT to associate and track these detection results to complete the tracking task. However, in the context of UAVs, the weak imaging features, nonlinear motion patterns, and discontinuous trajectories of the target make it difficult for traditional methods to adapt effectively, especially when processing large-size images, which further affects tracking accuracy and robustness. Moreover, traditional methods merely approach multi-target tracking from the perspective of image features, without leveraging the state information of the aircraft and payload to quantify the dynamic changes in the images.
In order to solve these problems, this paper studies the target detection, trajectory prediction and re-identification methods for multi-target tracking. A lightweight target detection method based on layer decoupling fusion of convolutional attention and global context enhancement, a nonlinear trajectory prediction method based on an adaptive bidirectional long short-term memory network, and a re-identification method based on world coordinate data and knowledge fusion are proposed. In addition, the existing UAV-based tracking datasets are mostly concentrated on pedestrians or vehicle targets in limited environments such as cities or roads, lacking consideration of the relevant parameter information of the drone’s perspective and optoelectronic pod, making it difficult to meet the verification requirements of air-to-ground multi-target tracking algorithms. In response to the above problems, this paper also constructs a drone detection and tracking dataset (MIDDTD) containing drone and optoelectronic pod parameter information, which provides a solid foundation for the effective verification of the algorithm. A typical example of each environment background of the dataset is shown in Figure 1, below.

Figure 1.
MIDDTD example display.
The technical route and main innovations of this article are as follows:
- The Model-Agnostic Meta-Learning (MAML) method is employed to enhance trajectory prediction capabilities. By leveraging the adaptability of MAML in quickly adjusting learned parameters to new tasks, more robust and generalized predictions for dynamic object movements are achieved, significantly improving performance in multi-target tracking scenarios.
- A novel approach for trajectory re-identification is introduced, utilizing Dempster-Shafer (DS) theory to effectively manage and combine uncertain information from multiple sources. This method enhances the accuracy of identifying reappearing targets in complex environments, thereby increasing the reliability of the tracking system.
- The MIDDTD is constructed as a comprehensive dataset specifically designed for air-to-ground multi-target tracking. This dataset integrates diverse scenes and detailed drone-specific parameters, including GPS and IMU data, which support the validation of advanced tracking algorithms and address the limitations of existing datasets focused primarily on pedestrian or vehicle targets.
The structure of this paper is as follows: In Section 2, a comprehensive review of related works is presented, highlighting advancements in multi-object tracking and trajectory prediction methodologies. Section 3 details the proposed methodology, including the implementation of the MAML method for trajectory prediction and the application of Dempster-Shafer theory for trajectory re-identification. Section 4 discusses the construction of the MIDDTD as well as the experimental results, showcasing the performance of the proposed approaches. Finally, Section 5 concludes the paper with a discussion of the findings and potential future research directions.
2. Related Work
With the development of deep learning-based object detection tasks, many detection-based MOT methods have been proposed in recent years. The simple online real-time tracking algorithm SORT, proposed by Bewley et al. [2], is one of the earliest MOT algorithms to utilize convolutional neural networks for object detection. This algorithm focuses on inter-frame prediction and association, using a linear velocity model Kalman filter to predict object motion, then measuring the Intersection over Union (IoU) between the detection boxes and tracking boxes, and finally associating the detection results using the Hungarian algorithm. However, the SORT algorithm does not address the problem of frequent target ID changes due to occlusions during long-term tracking. Later, Wojke et al. [3] proposed the DeepSORT algorithm, which improves upon SORT by introducing re-identification features for extracting deep appearance features in the data association part. This allows partially occluded objects to be re-identified. They also introduced a cascade matching strategy to improve the accuracy of target matching. Chen et al. [4] proposed the MOTDT algorithm, which designed a new multi-object tracking framework that integrates deep appearance information with spatial information. They also proposed a hierarchical data association strategy, associating predicted targets with multiple detected targets hierarchically. A soft assignment strategy with a trajectory scoring mechanism was used to associate targets, making full use of re-identification features and spatial information to improve tracking performance. Zhang et al. [5] proposed the ByteTrack method, which associates almost all detection boxes, not just the high-scoring ones. For low-scoring detection boxes, the method utilizes their similarity with tracking fragments to recover true targets and filters out background detections, improving tracking accuracy to some extent. Aharon et al. [6] proposed the BoTSORT method, which introduces global motion compensation technology to estimate background motion and generate more accurate object motion predictions. They also proposed a simple and effective fusion method combining IoU and re-identification cosine distance, establishing a stronger association between detections and trajectories. Du et al. [7] proposed the StrongSORT method, which constructs a connection model without appearance information, achieving a good balance between speed and accuracy through global association that does not rely on appearance information. The Gaussian smoothing interpolation method using Gaussian process regression was employed to mitigate the issue of missed detections. Cao et al. [8] proposed the OcSORT method, which uses target detection observations to correct error accumulation during occlusion. By using an observation center method, they replaced the traditional linear state estimation method, enabling error correction during occlusions and complex motion processes. Maggiolino et al. [9] proposed the DeepOcSORT method, which builds upon OcSORT by adding appearance feature information, improving the performance of the tracking system in dynamic environments.
With the development of the MOT field, many joint detection-based MOT methods have been proposed. Wang et al. [10] proposed the JDE algorithm, which integrates a one-stage object detection network and a pedestrian re-identification (ReID) network, considering the model inference speed. This allows the network to output both detection and re-identification information simultaneously, accelerating the inference speed. Zhang et al. [11] proposed the FairMOT algorithm, where the detection branch uses the anchor-free object detection algorithm CenterNet. At the same time, a parallel branch directly outputs ReID features to distinguish different targets, effectively unifying object detection and re-identification networks. Zhou et al. [12] proposed the CenterTrack algorithm, which enables the simultaneous extraction of detection and target deep features. By performing parallel inference for all targets, the algorithm quickly recovers targets that are missed due to occlusion, enhancing the robustness of the method to overlapping occlusion issues. Yan et al. [13] proposed the Co-MOT algorithm, which addresses the imbalance caused by the label assignment strategy used during training. They introduced a new cooperative–competitive label assignment strategy and the shadow concept. During training, tracked targets are added to the detection query’s matched targets, making the label assignment process more balanced. For query initialization, each query is expanded by a set of shadow copies. This helps maintain the accuracy and stability of the tracking.
Li et al. [14] proposed a residual-aware correlation filter method to address the problem of tracking accuracy degradation due to target scale variation, which affects the quality of appearance models. The method models the residuals between two adjacent frames based on spatial and temporal regularization, and introduces a scale refinement strategy. This algorithm enhances the accuracy of scale estimation and improves tracking precision, but it still suffers from sensitivity to occlusion. Zhang et al. [15] designed a dual-regression correlation filter method to address the issue of tracking drift or failure caused by target appearance changes, background clutter, and similar targets in complex scenes. The method uses a target filter and a global filter, adopting a dual-regression strategy, which enhances the feature-learning ability of the target. However, this increases computational cost, reducing the system’s real-time performance. He et al. [16] aimed to improve the discriminative ability of the tracker by integrating context attention, dimension attention, and spatiotemporal attention into the training and detection stages based on correlation filters. The algorithm uses context attention to consider the relationship between the target and surrounding targets, dimension attention to select feature dimensions relevant to target tracking, and spatiotemporal attention to capture the target’s motion trajectory, enhancing the robustness of the tracking system. However, it still faces the problem of not being able to handle significant target scale variations. Benaly et al. [17] proposed a multi-object tracking algorithm based on a hash set matching approach to improve real-time tracking performance. This algorithm combines HOG and optical flow features for target tracking, further improving real-time processing speed, but still faces the issue of low tracking accuracy. Lusardi et al. [18] designed a re-identification network based on a graph neural network to improve feature extraction capabilities. This network uses center point appearance features to strengthen overall feature extraction ability and incorporates a class-based triplet loss during training to improve the discriminative ability of center point appearance features. The algorithm enhances target re-identification performance but still suffers from poor tracking performance at the edges of the field of view. Batorli et al. [19] designed a novel similarity metric that combines position, appearance, and size information, proposing the PAS-Tracker algorithm, which uses a camera motion compensation model to align tracking positions across frames. While both of the above algorithms exhibit strong robustness in complex environments, they still face challenges with complex dynamic weight strategy designs and the lack of generality in weight designs.
Despite some significant progress in air-to-ground visual target tracking, many challenges remain. For example, the SORT algorithm, which uses convolutional neural networks for object detection and Kalman filters to predict object motion, frequently encounters target ID changes during long-term tracking, particularly performing poorly in occlusion scenarios [20]. DeepSORT improves on this issue by introducing re-identification features and cascade matching strategies, but it still cannot completely avoid ID switching problems. Other methods such as MOTDT, ByteTrack, and BoTSORT show improvements in specific scenarios, but they still fall short in handling weak small-target detection, non-linear trajectory prediction, and trajectory continuity. Additionally, many joint detection MOT methods like JDE, FairMOT, and CenterTrack improve inference speed, but they still face challenges in accuracy and robustness when dealing with target scale variations, occlusions, and complex background interference. In summary, current methods have significant room for improvement in weak small-target detection, non-linear trajectory prediction, and trajectory continuity. The proposed method in this paper effectively addresses these issues by combining convolutional attention modules, global context enhancement, and adaptive, bidirectional, long short-term memory networks, significantly improving the precision and robustness of multi-target tracking; the algorithm structure is shown in Figure 2. Compared to the aforementioned classical methods, the proposed approach achieves an improvement of over 3% in the MOTA metric, particularly demonstrating a 20% reduction in ID switches under scenarios involving occlusion and small/weak targets.
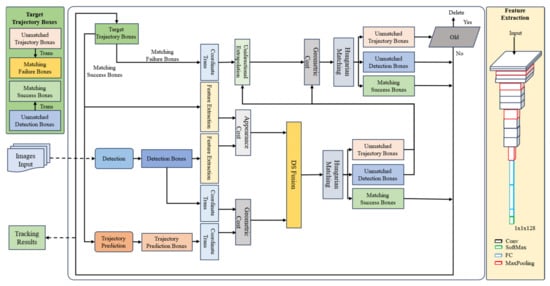
Figure 2.
Framework of CST.
3. Method
3.1. Detection
The detection method used in this paper is based on the YOLO network architecture, with ResNet34 [21] as the backbone. Additionally, a Convolutional Block Attention Module (CBAM) [22] is introduced into the backbone network to enhance the model’s focus on the target and improve feature extraction accuracy. The Neck section follows the original structure of YOLOv8 [23], with modules sourced from YOLOv8, offering efficient feature fusion and multi-scale feature expression capabilities. The detection head uses a novel global context-enhanced adaptive sparse convolutional network (CEASC) [24] detection head to improve the model’s ability to detect weak targets. The overall structure is shown in Figure 3.
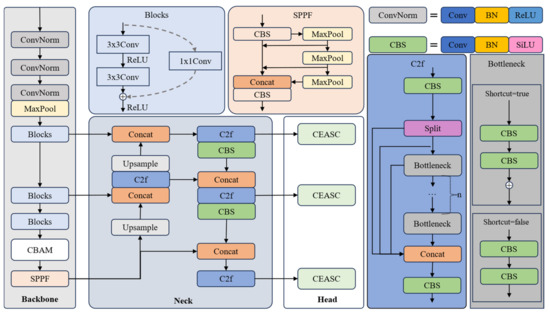
Figure 3.
Framework of detection.
In the figure, Conv represents the convolution operation, SPPF is the fast Spatial Pyramid Pooling module used for multi-scale feature fusion, BN is Batch Normalization, and ReLU and SiLU are activation functions. SiLU is smoother compared to ReLU. ConvNorm is a module composed of Conv, BN, and ReLU, while CBS is a module composed of Conv, BN, and SiLU. Upsample is the upsampling operation used to increase the size of the feature map, and MaxPool is the max pooling operation, which reduces computational load while preserving prominent features. The Split operation divides a tensor along a certain dimension into multiple sub-tensors. CBAM is the Convolutional Block Attention Module, and CEASE is the Context Enhancement and Detection Head. The detailed structures of CBAM and CEASE are described below.
3.1.1. CBAM
The Convolutional Block Attention Module (CBAM) can dynamically adjust the important regions within feature maps, allowing the network to focus more on the key target areas and reduce attention to irrelevant background or interfering objects, thereby significantly improving the detection accuracy of small targets from an air-to-ground perspective.
In previous studies, CBAM is typically added to the Neck module to generate feature pyramids. However, when applying CBAM in the Neck module, the attention mechanism weights and filters the features based on already down-sampled feature maps, which may result in CBAM failing to fully utilize the original high-resolution features, leading to the loss of some fine-grained target information, especially for small targets or weak features. This method integrates CBAM directly into the Backbone network, allowing it to enhance attention to key features during the feature extraction process, rather than relying on the Neck to generate feature pyramids [25]. This strategy has two main advantages: first, it reduces the complexity of the Neck module; second, it enables adaptive optimization of features at an early stage of feature extraction. By enhancing the lower-level features, this method effectively improves the detection capability of small targets while reducing false positives and missed detections due to feature detail loss, providing stronger support for overall detection performance.
CBAM is an effective model based on the attention mechanism, consisting of two modules: the channel attention module and the spatial attention module, as shown in Figure 4. These two modules generate a channel attention map and a spatial attention map, respectively, which are then multiplied with the input feature map to refine the features adaptively. In this way, meaningful features along the channel and spatial axes are emphasized, while redundant features are suppressed, as shown in the following formula.
Here, represents element-wise multiplication, is the input feature map, is one-dimensional channel attention diagram, and is the two-dimensional space attention diagram.
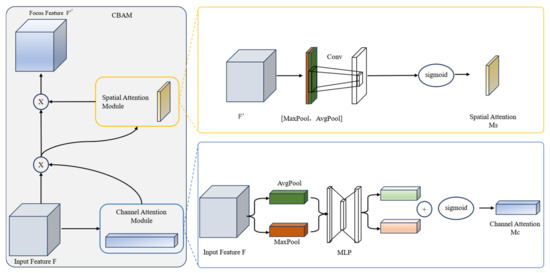
Figure 4.
Framework of CBAM.
The channel attention module [26] first performs global max pooling and average pooling operations on the feature maps of different channels, followed by element-wise summation and Sigmoid activation. The formula is as follows:
where is the Sigmoid activation function, denotes the output of the channel attention mechanism, and represents the input feature map. is the average pooling operation, and is the max pooling operation. is the output after the average pooling operation on , is the output after the max pooling operation on , the weights and of the multilayer perceptron (MLP) are shared between the two inputs, and ReLU activation is applied after .
The spatial attention module first performs global max pooling and average pooling operations on the pixel values at the same positions across different feature maps [27]. The two pooling results are then concatenated, followed by a 2D convolution operation and Sigmoid activation. The formula is as follows:
where conv represents the convolution operation.
In this way, CBAM can effectively and automatically adjust the key regions in the feature map, allowing even smaller target areas to be given more attention by the network. This enables the network to focus more on meaningful information during feature extraction, thereby significantly improving the detection accuracy of small targets.
3.1.2. CEASC
The algorithm structure of CEASC is shown in Figure 5, below. In each FPN layer, context enhancement is performed by generating mask features Hi and global features Gi. The detection head is replaced with Context-Enhanced Sparse Convolution (CESC), where SC represents the sparse convolution operation. The ratio of the mask Hi is automatically optimized through the Adaptive Multi-Layer Mask (AMM) scheme. The AMM module enables the model to adaptively generate masks with an appropriate masking ratio, achieving a better balance between accuracy and efficiency.
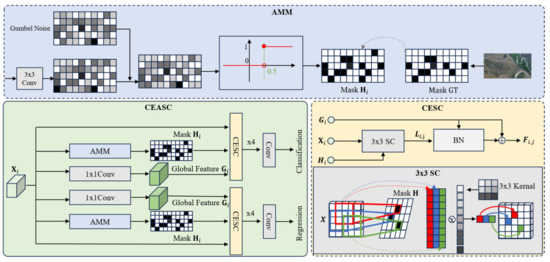
Figure 5.
Framework of CEASC.
Sparse convolution dynamically generates sparse masks and performs convolution operations only on the regions of the feature map related to foreground targets, significantly reducing the computation on background regions and focusing on target areas [28]. In blurry images, sparse convolution limits computations to the target region, effectively reducing background interference and improving detection efficiency and accuracy.
Specifically, given the feature map from the -th layer of the Neck, SC uses a mask network composed of the shared kernel , where , and represent batch size, channel size, height, and width, respectively. The convolution of with generates a soft feature map , which is then converted into a mask matrix through the Gumbel–Softmax technique [29]. The formula is as follows:
where represent two random Gumbel noises, is the Sigmoid function, and is the temperature parameter in the Gumbel–Softmax, set to 1 in the experiments.
According to the formula, during inference, only the regions where the mask value is 1 are involved in convolution, thereby reducing the overall computational cost. The sparsity of is controlled by the mask ratio . In existing studies, the manually set mask ratio is typically greater than 0.9. Since the detection framework of the base detector includes a classification head and a regression head, which typically focus on different areas, we introduce a separate mask network for each detection head. Each detection head uses four context-enhanced layers and one convolute layer for prediction.
As mentioned in [30], background information, such as the surrounding background of an object, is helpful for object detection. However, sparse convolution, by focusing convolution on the foreground, may sometimes neglect background areas that contain useful information, potentially reducing overall accuracy, especially when small objects dominate. To address this, the authors of [31] attempted to recover surrounding context information through interpolation, but due to the significant difference between the focal region and the background, this method is not reliable. In this section, we construct a global context enhancement module that jointly utilizes focal information and global context to enhance the missing edge information and fine-grained features in blurry images, while simultaneously improving the stability of subsequent computations.
As shown in Figure 5, we apply point convolution to the feature map to generate the global context feature . Since only a small number of elements are processed in sparse convolution, after several rounds of stabilizes and does not incur significant additional computational overhead.
As an important part of sparse convolution, global context information is embedded into the context-enhanced layer. This layer takes , and as input, where represents the context-enhanced layer at the -th level. Unlike traditional SC, which uses activation elements to compute the statistics for group normalization (GN), we use the mean and standard deviation of for normalization, aiming to compensate for the missing context information. Let be the output feature map after applying SC to , then the enhanced feature is obtained by context-enhanced normalization (CE-GN), as shown in the following equation:
where mean[.] and std[.] represent the mean and standard deviation, respectively, and w and b are learnable parameters. To further alleviate information loss in sparse convolution and stabilize the training process, we maintain standard dense convolution during training to generate a feature map obtained by convolution over the complete input feature map. Then, by optimizing the mean squared error loss, is used to enhance the sparse feature map , with the optimization objective as follows:
where is the number of layers in the Neck.
Finally, a residual structure is applied before the activation layer, adding to , i.e., , to enhance the retention of context information. The full architecture of the context-enhanced sparse convolution module and context-enhanced normalization layer is shown in Figure 5.
Without additional constraints, sparse detectors tend to generate masks with large activation ratios or small mask ratios to improve accuracy, thereby increasing overall computational cost. To solve this issue, most existing approaches use a fixed activation ratio. However, due to the significant fluctuations of foreground regions in air-to-ground images, a fixed ratio often leads to a significant increase in computation or reduces accuracy due to insufficient foreground coverage. To balance accuracy and efficiency, we use an adaptive multi-layer mask scheme (AMM) that can adaptively control the activation ratio.
Specifically, AMM first estimates an optimal mask ratio based on the ground truth labels. By utilizing label assignment techniques, for the -th Neck layer, we obtain the ground truth classification result , where represents the number of classes (including background), and and represent the height and width of the feature map. The estimation formula for the optimal activation ratio in the -th Neck layer is as follows:
where and represent the number of positive sample pixels and the total number of pixels, respectively.
To guide the network to generate masks with appropriate mask ratios adaptively, the following loss function is used:
where represents the activation ratio of the mask . By minimizing is forced to follow the same activation ratio as the ground truth foreground ratio , thus promoting the generation of an appropriate mask ratio.
By adding the traditional detection loss , the overall training loss is formulated as follows:
where and are hyperparameters used to balance the importance of and set to 1 and 10 in the experiments.
3.2. Trajectory Prediction
The adaptive bidirectional long short-term memory (LSTM) network combined with meta-learning built in this paper can effectively improve the model’s performance. Meta-learning learns a universal model initialization across multiple tasks, enabling the model to quickly adapt when facing new tasks. This is particularly significant for trajectory prediction in multi-object tracking tasks, especially in cross-scene or dynamically changing scenes. This method can quickly optimize model parameters using a small amount of historical target trajectory data, reducing adaptation time across scenes and tasks. By teaching the model how to quickly extract useful information from a small amount of data, it enhances the model’s adaptability; the structure is shown in Figure 6.
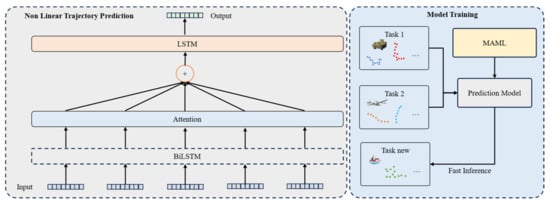
Figure 6.
Framework of trajectory prediction.
In meta-learning, the basic unit of training is a task, and the objectives of each task are different. For example, in a trajectory prediction meta-learning task, Task 1 may involve car trajectory prediction, while Task 2 involves aircraft and tank trajectory prediction. The learning data consist of a training task set and a test task set, and each task as a basic unit includes its own training and testing data. To facilitate understanding and distinction, the training set within a task is referred to as the support dataset, and the test set is referred to as the query dataset.
This section is based on MAML (Model-Agnostic Meta-Learning), where the MAML algorithm first randomly initializes the model weights during the model training process. Then, a loop is used to enter each training round. In each training round, a batch of tasks is sampled from the task distribution. Next, for each task, the trajectories and labels are obtained from the support set, and for each trajectory, forward propagation is performed, followed by gradient calculation. The task-specific model weights are updated using the learning rate through backpropagation. Then, the corresponding task is taken from the query set, and forward propagation is performed without updating the model parameters. Finally, the losses calculated from are summed, and the gradient is computed to update the global model weights using the meta-learning rate . The specific process flow is shown in Figure 7. The mathematical expression for updating model parameters during the training process is as follows:
where represents the initial weights learned from meta-learning, which are the initialization parameters for all training tasks. is the loss for the support set task, and is the gradient of the loss. represents the learning rate for the task and is independent of the meta-learning rate . The gradient parameter update for meta-learning is expressed as follows:
where is the meta-learning rate, determining the step size for each gradient update.
where represents the model parameters learned from the -th task, depending on the initial weights is the number of tasks, and is the loss function value for the -th task. The gradient computation is as follows:
The above formula shows the calculation process of . The MAML method does not make assumptions about the form of the model, such as Bidirectional Long Short-Term Memory (BiLSTM) networks, which are commonly used for sequence prediction tasks. This flexibility is why it is referred to as the model-agnostic meta-learning method. Additionally, the MAML method does not introduce extra parameters for meta-learning, and the training method is based on traditional gradient descent, making it simple and efficient. However, since the goal of this method is to train a set of generalized initial weights, it cannot alter the structural parameters of the model. Therefore, the MAML method can only be applied when the model structure is already determined. The operational steps for the MAML-based trajectory prediction model are shown in Algorithms 1 and Figure 8.
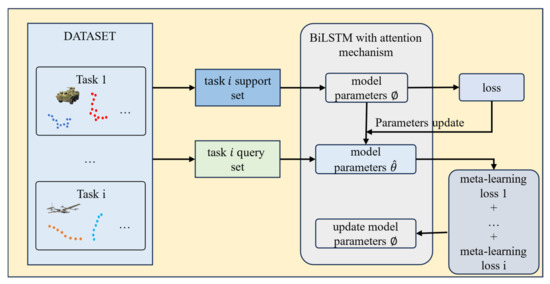
Figure 7.
Adaptive trajectory prediction flow chart combined with MAML.
| Algorithms 1. The operational steps for the MAML-based trajectory prediction model. | |
| Initialize the weights of the Bidirectional Long Short-Term Memory (BiLSTM) network as , the attention mechanism parameters as , and the meta-learning optimization parameters (learning rates and ). | |
| 1. | Select a task from the task set . |
| 2. | Update the task-specific parameters from the support set : |
| 3. | Update the general parameters based on the query set : |
| 4. | On new task data , use the meta-learned parameters to quickly adjust with a small amount of data: |
| 5. | Input historical trajectory data: |
| 6. | Extract time-series features: |
| 7. | Calculate the time-step weights: |
| 8. | Sum the weighted hidden states: |
| 9. | Use a fully connected layer to generate future trajectory points: |
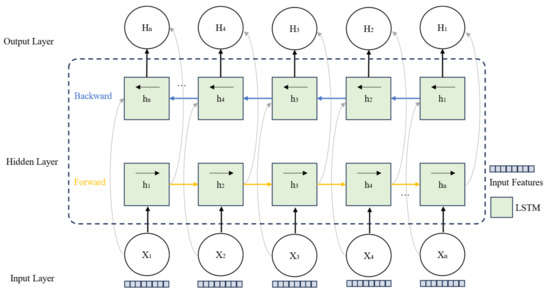
Figure 8.
BiLSTM structure diagram.
3.3. Re-Identification
The method developed in this section integrates the geometric position and appearance information of the targets, combined with the parameter information provided by the drone, to convert the target position from image coordinates to world coordinates, thereby enabling accurate cross-frame association of targets. By utilizing the target trajectory memory map in the world coordinate system and integrating multi-source information with Dempster–Shafer (DS) theory, the method is designed to enhance the accuracy of target re-identification and the stability of multi-object tracking in complex scenarios such as occlusion or targets leaving and re-entering the field of view.
3.3.1. Unidirectional Extrapolation and World Coordinate Transformation
By utilizing the rich metadata provided by the drone, including longitude, latitude, altitude, pitch angle, and yaw angle, we can construct a camera model and build the world coordinates based on 3D geometry, as shown in Figure 9.
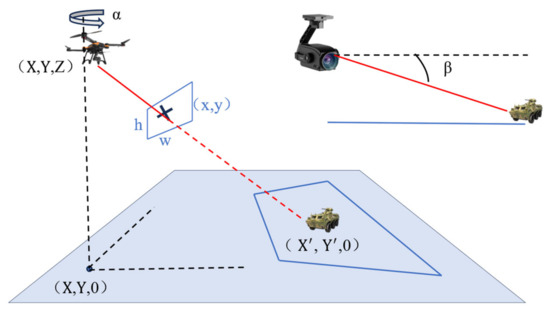
Figure 9.
Framework of coordinate transformation.
The intrinsic parameters of the camera can be obtained from the field of view, and the process for calculating coordinate transformation is as follows [32]:
where and are the image width and height, and is the diagonal field of view angle of the camera.
where is the sensor diagonal size and is the focal length of the lens. Using the data provided by the drone, a rotation matrix between the camera coordinates and the world coordinates can be established for each frame:
where and are the yaw and pitch angles of the drone’s payload. Specifically, the yaw angle of the payload, and is the pitch angle, with both angles given by the world information data. Combining and , any detected object and its corresponding image coordinates can be projected onto the world coordinates using the 3D direction vector:
Finally, using the altitude information , we compute the intersection of the ray with the ground, assuming the ground is the plane :
represents the 3D coordinates of the object in the world coordinate system, represents the 3D coordinates of the drone in the world coordinate system, represents the height of the drone above the horizontal plane, and is the direction vector of the target ray, indicating the spatial direction of the target relative to the camera. is the value in that represents the vertical direction. is the proportion of the vertical distance between the camera and the target, used to calculate the specific 3D intersection point along the ray . The basis of this formula lies in the pinhole camera model and the calculation process of the intersection between a ray and a plane.
For cases where the drone or payload experiences vibration but the target has not left the window, the key is to effectively associate the target that has not left the image, preventing track fragmentation. This typically occurs within a short time window. Given the limited time, we use a direct calculation method based on world coordinates. This approach allows for more efficient tracking and enhances the ability to maintain continuous target tracking under dynamic and challenging conditions.
For each detection at frame , the world coordinates are computed using the drone data (GPS, altitude, payload orientation) and the projection , as follows:
where represents the center of the bounding box . The bounding box represents the target frame of the object outlined in the image.
For targets that are occluded or leave and re-enter the field of view, we need to closely monitor their potential movement outside the image view. This section introduces the key part of the unidirectional motion extrapolation method. The bidirectional motion extrapolation method is a simple technique that can extrapolate the world coordinates of trajectories leaving the image. Given some trajectories , which enter and leave the image between frames and , the world coordinates of at time can be forward-extrapolated as follows:
where , and the velocity of the trajectory as it leaves the field of view is estimated as the following:
where is the window size, a constant. It is assumed that no further inference will be made after a certain time because the world coordinates after this time tend to become unreliable and may be confused with new trajectories.
3.3.2. Information Fusion Association Based on DS Theory
Through the constructions in previous chapters, the information available during the information fusion association phase includes three sets of boxes: the trajectory boxes of the tracked targets from previous sequences, the detection boxes from the current frame, and the predicted boxes for the current frame based on previous trajectory boxes.
The detection boxes and predicted boxes are converted to world coordinates using the world coordinate mapping relationship mentioned earlier. Then, the geometric distance cost between the detection and predicted boxes is calculated as follows:
where is the world coordinate of the trajectory box, and is the world coordinate of the detection box. If the error in world coordinates is small, it indicates that the detection box and trajectory box are likely to belong to the same target.
The detection box and trajectory box utilize a convolutional neural network to extract features from the target regions of the boxes, and then the appearance cost between the detection box and trajectory box is computed using the cosine distance, as follows:
where is the trajectory box, is the detection box, and if the feature similarity is high, it suggests that they may belong to the same target. The function “Feature” represents the feature extraction function of the CNN, and VGG16 is used as the feature extraction network, with an output of 128 dimensional features.
After obtaining this information, how to use it for association matching is the key. During association matching, the reliability of different information sources needs to be considered. First, due to factors such as occlusion and target scale variation, relying solely on one information source may not be reliable. Additionally, different information sources may lead to contradictory association conclusions, for example, a small geometric distance but mismatched appearance features. Moreover, the weight of different information sources may vary depending on the scene. For instance, in occlusion scenarios, appearance features are more reliable, while in fast-moving scenarios, geometric information becomes more important.
DS theory, through belief assignment and evidence fusion, effectively handles the uncertainty and conflicts of information and provides a flexible mathematical framework for multi-source information fusion. First, by separating confidence and plausibility, DS theory can explicitly express the range of uncertainty of information. Second, the evidence fusion rule in DS theory can reasonably combine information from different sources to generate a global fusion result. Furthermore, DS theory increases the robustness of the fusion result by appropriately allocating the influence of conflicting evidence.
DS theory is a mathematical framework based on set theory, primarily used for uncertainty reasoning and decision-making. Its core includes the following:
- (1)
- Hypothesis Space: Define a hypothesis space that contains all possible target matching results.This represents whether two boxes belong to the same target.
- (2)
- Basic Belief Assignment (BBA): The belief assignment represents the degree of support for hypothesis , satisfying the following:
- (3)
- Belief (Bel): The belief represents the minimum degree of support for hypothesis , i.e., the total belief in and all of its subsets:
- (4)
- Plausibility (PI): The plausibility represents the possibility that is true, including all sets that support and those that overlap with other hypotheses:
- (5)
- Uncertainty: The difference between belief and plausibility reflects the uncertainty of the evidence:
For two independent information sources and , the DS theory evidence fusion rule is as follows:
where are subsets of the hypothesis space. The numerator calculates the joint evidence supporting , and the denominator excludes the influence of conflicting evidence.
In multi-object tracking, the two information sources are the appearance cost and the geometric distance cost . For each information source, the basic belief assignment (BBA) is constructed:
For appearance cost:
For geometric cost:
Using the DS theory evidence fusion rule, the appearance and geometric information are fused as follows:
where “Same”,”Different”.
Finally, the fused matching cost is calculated through confidence:
The fused matching cost matrix is constructed, where the elements represent the matching cost between trajectory box and detection box :
This cost matrix is used for the Hungarian algorithm to perform matching and find the optimal match, thereby updating the tracking trajectory.
4. Experiments
We evaluate the effectiveness of the proposed method by comparing it with existing multi-object tracking approaches and conducting comprehensive ablation studies.
4.1. Datasets
Most existing datasets mainly focus on pedestrian or vehicle targets in limited environments, such as urban areas or roads, with little consideration of drone perspectives and electro-optical payload parameters. Therefore, constructing a dedicated dataset with diverse scenes and integrating drone flight parameters has become key to improving the performance of air-to-ground multi-target tracking systems. To meet the algorithm validation needs of this paper, we have constructed a large-scale and challenging drone detection and tracking dataset, the MIDDTD. The MIDDTD dataset covers multiple representative scenes, including mountains, urban areas, deserts, villages, and fields, each with distinct geographical environments and background characteristics. This allows for effective testing of multi-target tracking algorithms in complex environments. The dataset design includes three essential tasks: object detection, single-target tracking (SOT), and multi-target tracking, with rich drone-related information annotated in each frame, including GPS data, flight altitude, and electro-optical payload information. Through the design of the dataset, scene division, and the integration of multi-source information, the dataset not only enhances its comprehensiveness and complexity but also provides strong support for the validation of drone-based multi-target tracking and detection algorithms.
Detailed Data Acquisition Process
During data collection, a DJI M210 drone was used for flight acquisition, equipped with a Syuwei ZT6 electro-optical payload. The drone’s corresponding height and GPS information were obtained in real time through the DJI SDK via a Jetson Xavier NX. Additionally, the Jetson Xavier NX communicated with the electro-optical payload via serial port, and real-time attitude data of the payload were retrieved using SDK commands. The camera’s focal length was 20 mm, and its diagonal field of view () was 93°. The filming process focused on areas such as the urban district of Xi’an, surrounding mountainous fields, and desert regions near Wuhai. The data acquisition process is shown in Figure 10, below. Over the course of one week, 114 raw video segments were captured, each ranging from 30 s to 5 min in length, with a frame rate of 30 frames per second and a resolution of 1920 × 1080 pixels. After post-processing, including video screening and trimming, 110 video sequences were retained, totaling approximately 99,000 frames. Each video sequence contains between 294 and 2684 frames.
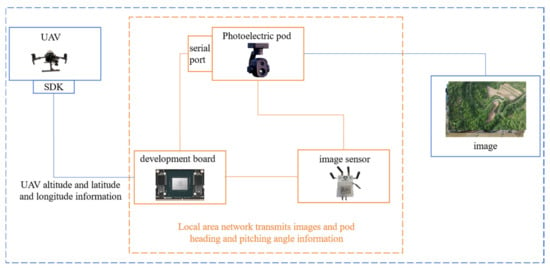
Figure 10.
Data acquisition flow chart.
For data annotation, the DarkLabel open-source labeling tool was used. After labeling, the data underwent five rounds of re-checking to ensure accuracy. The final annotations are summarized as follows: the dataset contains 110 video sequences with 99,000 frames, marking approximately 2100 pedestrian and vehicle targets, with around 750,000 bounding boxes. Additionally, each frame includes annotated information on the drone’s altitude, latitude and longitude, as well as the electro-optical payload’s heading and pitch angles.
The dataset defines several different scenes, including mountain, field, desert, urban, and village environments. The filming altitude ranged from 50 m to 600 m, with video durations ranging from 10 to 90 s. The primary target category is vehicles, with a small number of personnel targets. Based on different filming altitudes, the dataset is categorized into low altitude (50–200 m), mid altitude (200–400 m), and high altitude (>400 m). Based on video duration, the dataset is classified into short-duration (10–60 s) and long-duration (60–90 s). Additionally, based on the Sobel gradient mean size of the images, the dataset is divided into clear (gradient mean >= 15) and blurred (gradient mean < 15). For each video, 10 random frames are sampled, and if more than four of them are blurred, the video is classified as blurred; the specific distribution is shown in Figure 11, below.
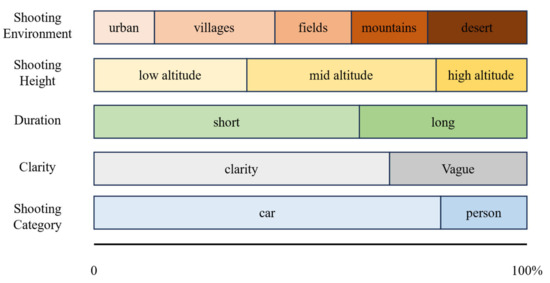
Figure 11.
MIDDTD attribute distribution map.
Compared to existing datasets, the dataset constructed in this section may not have the largest number of frames or detection target boxes, but it includes valuable drone and electro-optical payload parameter information for complex ground scenes, which are not found in other datasets.
4.2. Implementation Details
4.2.1. Detection Experiment
We built the code framework in PyTorch 1.10, and the entire training process was conducted on a computer equipped with a single NVIDIA GeForce RTX 4090 GPU. Testing was performed on an Nvidia Jetson Xavier NX edge device.
To ensure the relative feature integrity of small targets, the image size was kept at the original resolution of 1920 × 1080. During network training, the Adam optimizer was used with an initial learning rate of 0.0001, and the learning rate was adjusted using a cosine annealing strategy.
4.2.2. Trajectory Prediction Experiment
To conduct a comprehensive evaluation of the method, the model parameters were first initialized in the experimental implementation. The hidden layer dimension of the bidirectional long short-term memory (BiLSTM) network was set to 128, and the parameters of the temporal attention mechanism were also initialized simultaneously. The learning rates were set as for inner optimization and for outer optimization.
In the data processing phase, the input trajectory data were normalized, and the trajectories were divided into historical and future trajectories. The length of the historical trajectory was set to 5, while the length of the predicted trajectory was set to 1. If there was no historical trajectory or the historical trajectory length was small at the initial frame, the previous frame was repeated for prediction. Subsequently, a sliding window approach was used to utilize historical trajectory information. Additionally, a batch size of 32 was set to improve training efficiency.
During the meta-training phase, the model was optimized using data from multiple tasks. For each task, the task-specific parameters were adjusted through inner optimization, and then the model’s general parameters were updated via outer optimization, enabling it to quickly adapt to new tasks.
In the new task adaptation phase, a small amount of historical trajectory data were used to update the model parameters through fast gradient descent, achieving rapid adaptation to new scenes.
In the trajectory prediction phase, based on the adapted model, the temporal attention mechanism was used to weight the trajectory features, and future target trajectories were output through a fully connected layer.
The performance of different algorithms on test data is evaluated in detail. The contrast effect is shown in Figure 12, below. The figure below shows the experimental performance of our proposed trajectory prediction method on different trajectory datasets, along with a performance comparison with other methods. Here, X and Y represent the coordinate positions of the target on the image plane, and T represents the frame number of the image sequence where the target is located. The points in the figure indicate trajectory points.
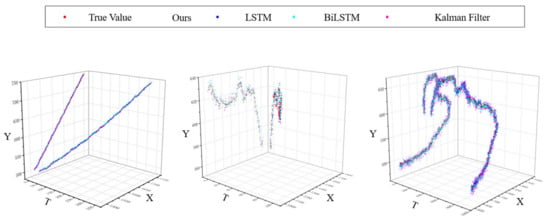
Figure 12.
Demonstration of prediction effect of different trajectory prediction algorithms.
4.2.3. Re-Identification Experiment
The re-identification module maps the 2D image coordinates of the detection boxes to 3D world coordinates using the camera’s intrinsic and extrinsic parameter matrices. The intrinsic matrix is calculated using a field of view angle of and an image size of . The window size used in the unidirectional extrapolation process is set to 5. The target’s lifespan is set to 30. Based on experimental comparison, the matching threshold parameter is set to 0.7. Due to computational constraints and deployment considerations on UAV edge-devices, we did not directly include computationally intensive Transformer-based methods such as MOTR in our current experimental comparisons [33]. Future work will involve extending our evaluations to include such advanced approaches. Table 1 below shows the performance comparison of MIDDTD dataset on our algorithm and several mainstream tracking algorithms.

Table 1.
Results on MIDDTD.
MOTP is a metric designed to assess the precision of object tracking algorithms, primarily measuring a tracker’s accuracy in localizing target positions while disregarding its identification capability and trajectory consistency. As MOTP solely provides information about localization accuracy, it is typically used in conjunction with MOTA, which focuses on evaluating trajectory consistency and matching performance of targets.
MOTA serves as a core evaluation metric in multi-object tracking tasks, specifically measuring a tracker’s capability in target detection and trajectory prediction without considering positional accuracy.
IDF1 is a crucial metric for evaluating multi-object tracking system performance, emphasizing whether a tracker can maintain identity consistency of targets throughout the tracking process. IDF1 comprehensively integrates identity precision (IDP) and identity recall (IDR), providing a unified score that reflects the tracker’s holistic performance in target identity association.
HOTA offers a singular composite score encompassing all elements of multi-object tracking evaluation, while maintaining the capability to be decomposed into sub-metrics for detailed analysis of specific aspects in tracking system performance.
Experimental results show that DeepSORT improves IDF1 through appearance features but underutilizes geometric information in dynamic scenes, resulting in lower MOTA and HOTA [34]. DeepOCSORT, combining motion consistency optimization, shows some improvement in IDF1 and HOTA, but its adaptability to dense scenes remains limited. StrongSORT enhances appearance feature extraction and performs excellently in HOTA, but the lack of geometric information limits overall performance. OcSORT focuses on motion consistency and is suitable for short-term matching, but it lacks appearance feature assistance, resulting in suboptimal IDF1. BoTSORT balances appearance and motion information, reducing ID switches, but its association strategy is somewhat lacking in complex dynamic scenes. ByteTrack significantly improves MOTA by optimizing the use of detections with different confidences. Its efficient cost-matching strategy allows faster operation, but the lack of appearance information for matching detections with different confidences leads to poorer performance in some dynamic scenes. Examples of the model tracking effect and bytetrack tracking effect in this paper are shown in the following Figure 13, Figure 14, Figure 15, Figure 16 and Figure 17.

Figure 13.
Graphical representation of multi-target tracking effect in an urban scene.

Figure 14.
Graphical representation of multi-target tracking effect in a village scene.

Figure 15.
Graphical representation of multi-target tracking effect in a desert scene.

Figure 16.
Graphical representation of multi-target tracking effect in a mountain scene.

Figure 17.
Graphical representation of multi-target tracking effect in a fields scene.
The proposed method shows relatively balanced performance in multi-object tracking tasks. Compared to existing mainstream methods, it outperforms in several key metrics, especially achieving optimal levels in the core metrics MOTA and HOTA, demonstrating a high balance between detection quality and trajectory association performance. By introducing a geometric and appearance information fusion strategy based on DS theory, the method significantly improves the accuracy of target association, with MOTP increased to 0.8542, further enhancing precise target location prediction. Combining the trajectory prediction model with the unidirectional extrapolation strategy effectively addresses the uncertainty of target motion in complex dynamic scenes. Using a world coordinate-based target location memory map reduces the number of ID switches caused by occlusion or target re-entry, with only 907 ID switches, significantly outperforming other methods. Although the fusion strategy’s computational complexity results in a slightly lower FPS than ByteTrack, it still remains at a high level. Overall, the proposed method significantly surpasses existing mainstream methods in terms of accuracy, stability, and robustness, providing a more efficient and reliable solution for multi-object tracking tasks.
4.3. Ablation Study
In this section, an ablation experiment is designed to validate the impact of introducing world coordinate transformation on the tracking performance of different algorithms. Specifically, after converting the position information in the original method to world coordinates, the cost calculation and matching decision are performed for different algorithms in the world coordinate system. The experimental results are shown in Table 2.
Table 2.
Ablation study results on MIDDTD.
The above experimental results show that the introduction of world coordinates significantly improves the performance of multi-object tracking algorithms, particularly in terms of MOTA and ID switches. By converting position information into world coordinates, the geometric association performance of each algorithm is notably enhanced, effectively reducing mismatches and ID switches caused by target occlusion, leaving the field of view, or changes in perspective. For example, DeepSORT’s ID switches decreased from 1304 to 1205, and BoTSORT’s from 1219 to 1003. ByteTrack and BoTSORT showed the most balanced performance after incorporating world coordinates, with MOTA increasing to 0.7152 and 0.6791, respectively, demonstrating a good combination of geometric information and their own high-confidence association strategies. At the same time, improvements in HOTA and MOTP reflect synchronized optimization of object detection and association accuracy. However, for algorithms like StrongSORT that heavily rely on appearance features, the enhancement effect of world coordinates is relatively limited. In terms of efficiency, the introduction of world coordinate information did not significantly increase the computational overhead. Overall, the experimental results fully validate the key role of world coordinates in improving the accuracy and robustness of multi-object tracking tasks.
In this section, the construction method is used to carry out experimental analysis for different scenarios, and the analysis results are shown in Figure 18, below.
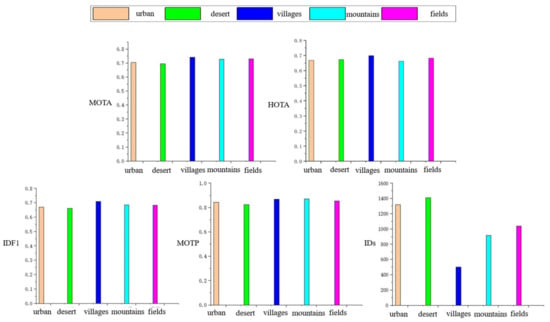
Figure 18.
Analysis of multi-target tracking indicators in different scenes.
5. Conclusions
Overall, this paper focuses on multi-object tracking from an air-to-ground perspective.
- A multi-object tracking dataset from the air-to-ground perspective was constructed, containing multiple scenes and annotated with drone GPS coordinates, altitude, and payload attitude parameters. This provides an important foundation for the experiments in subsequent sections and sets evaluation benchmarks for experimental validation.
- A lightweight object detection method based on global context enhancement and layer-decoupling fusion was developed. As the core component of the multi-object tracking method in this paper, this approach improves the performance ceiling for subsequent multi-object tracking.
- A nonlinear trajectory prediction method based on an adaptive BiLSTM network was constructed, further optimizing multi-object tracking performance from the motion feature perspective.
- A target re-identification method based on coordinate data and knowledge fusion was developed. From the perspective of optimization problem solving, it converted and fused the target’s position and feature information, further enhancing the overall performance of multi-object tracking. These four approaches progressively build upon and complement each other, collectively improving the stability of the multi-object tracking system.
Although the target re-identification method based on coordinate data and knowledge fusion proposed in this paper partially addresses the issue of discontinuous target trajectories, it remains somewhat limited in scenarios that require maintaining the continuity of multiple target tracks. Multi-camera, multi-object tracking, which involves multiple drones collaboratively tracking the same scene, is a more complex task. It requires accurate alignment of the world coordinate system and maintaining information sharing and collaboration between multiple drones. On this basis, more spatial information must be obtained to improve the accuracy and stability of target tracking. In future research, we will explore this collaborative scenario in greater depth.
Author Contributions
Conceptualization, C.W.; Methodology, C.W.; Software, C.W. and Y.X.; Validation, Y.X.; Formal analysis, C.W.; Investigation, C.W. and Z.Z.; Resources, C.T.; Data curation, X.S.; Writing—original draft, C.W. and X.S.; Visualization, Z.Z.; Supervision, C.T. All authors have read and agreed to the published version of the manuscript.
Funding
This work has been funded by the Young Scientists Fund of the National Natural Science Foundation of China, grant no. 52302506.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Moon, S.; Youn, W.; Bang, H. Novel deep-learning-aided multimodal target tracking. IEEE Sens. J. 2021, 21, 20730–20739. [Google Scholar] [CrossRef]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple Online and RealtimeTracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Chen, L.; Ai, H.; Zhuang, Z.; Shang, C. RealTime Multiple People Tracking with Deeply Learned Candidate Selection and Per-son Re-Identification. arXiv 2018, arXiv:1809.04427. [Google Scholar]
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Weng, F.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. ByteTrack: Multi-object tracking by associating e-very detection box. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 1–21. [Google Scholar]
- Aharon, N.; Orfaig, R.; Bobrovsky, B.Z. BoT-SORT: Robust associations multi-ped-estrian tracking. arXiv 2022, arXiv:2206.14651. [Google Scholar]
- Du, Y.; Zhao, Z.; Song, Y.; Zhao, Y.; Su, F.; Gong, T.; Meng, H. Strongsort: Make deepsort great again. IEEE Trans. Multimed. 2023, 25, 8725–8737. [Google Scholar] [CrossRef]
- Cao, J.; Pang, J.; Weng, X.; Khirodkar, R.; Kitani, K. Observation-centric sort: Rethinking sort for robust multi-object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 9686–9696. [Google Scholar]
- Maggiolino, G.; Ahmad, A.; Cao, J.; Kitani, K. Deep oc-sort: Multi-pedestrian tracking by adaptive re-identification. In Proceedings of the 2023 IEEE International Conference on Image Processing (ICIP), Kuala Lumpur, Malaysia, 8–11 October 2023; IEEE: New York, NY, USA, 2023; pp. 3025–3029. [Google Scholar]
- Wang, Z.; Zheng, L.; Liu, Y.; Li, Y.; Wang, S. Towards Real-Time Multi-Object Tracking. arXiv 2019, arXiv:1909.12605. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. FairMOT: On the Fairness of Detection and Re-identification in Multiple Object Tracking. Int. J. Comput. Vis. 2021, 129, 3069–3087. [Google Scholar] [CrossRef]
- Zhou, X.; Koltun, V.; Krahenbuhl, P. Tracking Objects as Points. In Proceedings of the Computer Vision—ECCV 2020 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Yan, F.; Luo, W.; Zhong, Y.; Gan, Y.; Ma, L. Bridging the gap between end-to-end and non end to end multi-object tracking. arXiv 2023, arXiv:2305.12724. [Google Scholar]
- Li, S.; Liu, Y.; Zhao, Q.; Feng, Z. Learning residue-aware correlation filters and refining scale for real-time UAV tracking. Pattern Recognit. 2022, 127, 108614. [Google Scholar] [CrossRef]
- Zhang, F.; Ma, S.; Qiu, Z.; Qi, T. Learning target-aware background-suppressed correlation filters with dual regression for real-time UAV tracking. Signal Process. 2022, 191, 108352. [Google Scholar] [CrossRef]
- He, Y.; Fu, C.; Lin, F.; Li, Y.; Lu, P. Towards robust visual tracking for unmanned aerial vehicle with tri-attentional correlation filters. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 1575–1582. [Google Scholar]
- Mohamed, B.; Noura, J.; Lamaari, H.; Abdelkader, M. Strengthen aircraft real-time multiple object tracking with optical flow and histogram of oriented gradient provided HSMA implemented in low-cost energy VPU for UAV. In Proceedings of the 2023 3rd International Conference on Innovative Research in Applied Science, Engineering and Technology (IRASET), Mohammedia, Morocco, 18–19 May 2023; pp. 1–5. [Google Scholar]
- Lusardi, C.; Taufique, A.M.N.; Savakis, A. Robust multi-object tracking using re-identification features and graph convolutional networks. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 3868–3877. [Google Scholar]
- Bartoli, A.; Fusiello, A. PAS Tracker: Position, appearance- and size- aware multi-object tracking in drone videos. In Proceedings of the 2021 16th European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2021; pp. 604–620. [Google Scholar]
- Zhang, Z.; Xu, Y.; Song, J.; Zhou, Q.; Rasol, J.; Ma, L. Planet craters detection based on unsupervised domain adaptation. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 7140–7152. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Sohan, M.; Sai Ram, T.; Reddy, R.; Venkata, C. A review on yolov8 and its advancements. In Proceedings of the International Conference on Data Intelligence and Cognitive Informatics, Tirunelveli, India, 18–20 November 2024; pp. 529–545. [Google Scholar]
- Du, B.; Huang, Y.; Chen, J.; Huang, D. Adaptive sparse convolutional networks with global context enhancement for faster object detection on drone images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 13435–13444. [Google Scholar]
- Wang, W.; Tan, X.; Zhang, P.; Wang, X. A CBAM based multiscale transformer fusion approach for remote sensing image change detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 6817–6825. [Google Scholar] [CrossRef]
- Bastidas, A.A.; Tang, H. Channel attention networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Zhu, X.; Cheng, D.; Zhang, Z.; Lin, S.; Dai, J. An empirical study of spatial attention mechanisms in deep networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6688–6697. [Google Scholar]
- Liu, B.; Wang, M.; Foroosh, H.; Tappen, M.; Pensky, M. Sparse convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 806–814. [Google Scholar]
- Verelst, T.; Tuytelaars, T. Dynamic convolutions: Exploiting spatial sparsity for faster inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2320–2329. [Google Scholar]
- Yang, Z.; Li, Z.; Jiang, X.; Gong, Y.; Yuan, Z.; Zhao, D.; Yuan, C. Focal and global knowledge distillation for detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4643–4652. [Google Scholar]
- Xie, Z.; Zhang, Z.; Zhu, X.; Huang, G.; Lin, S. Spatially adaptive inference with stochastic feature sampling and interpolation. In Proceedings of the Computer Vision–ECCV 2020 16th European Conference Part I, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 531–548. [Google Scholar]
- Hartley, R. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Meireles, L.; Guterres, B.; Sbrissa, K.; Mendes, A.; Vermeulen, F.; Lain, L.; Smith, M.; Martinez, J.; Drews, P.; Filho, N.D. The not-so-easy task of taking heavy-lift ML models to the edge: A performance-watt perspective. In Proceedings of the SAC ‘23: 38th ACM/SIGAPP Symposium on Applied Computing, New York, NY, USA, 27–31 March 2023. [Google Scholar]
- Bernardin, K.; Stiefelhagen, R. Evaluating multiple object tracking performance: The clear mot metrics. EURASIP J. Image Video Process. 2008, 2008, 1–10. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).