
Autonomous UAV Detection of Ochotona curzoniae Burrows with Enhanced YOLOv11


Abstract
1. Introduction
- Performance evaluation of the improved model: the performance of the enhanced YOLOv11 model is systematically evaluated under complex background conditions for detecting small plateau pika burrows, with a focus on key metrics such as precision, recall, mean average precision (mAP), and computational efficiency.
- The improved YOLOv11 model is compared with state-of-the-art object detection models, including various versions of the YOLO series—YOLOv5, YOLOv8, YOLOv9, YOLOv11, and the newly released YOLOv12. In addition to comparisons with different YOLO series versions, the model is also evaluated against Retina Net and Faster R-CNN to assess its superiority and applicability in plateau pika burrow detection tasks.
2. Materials and Methods
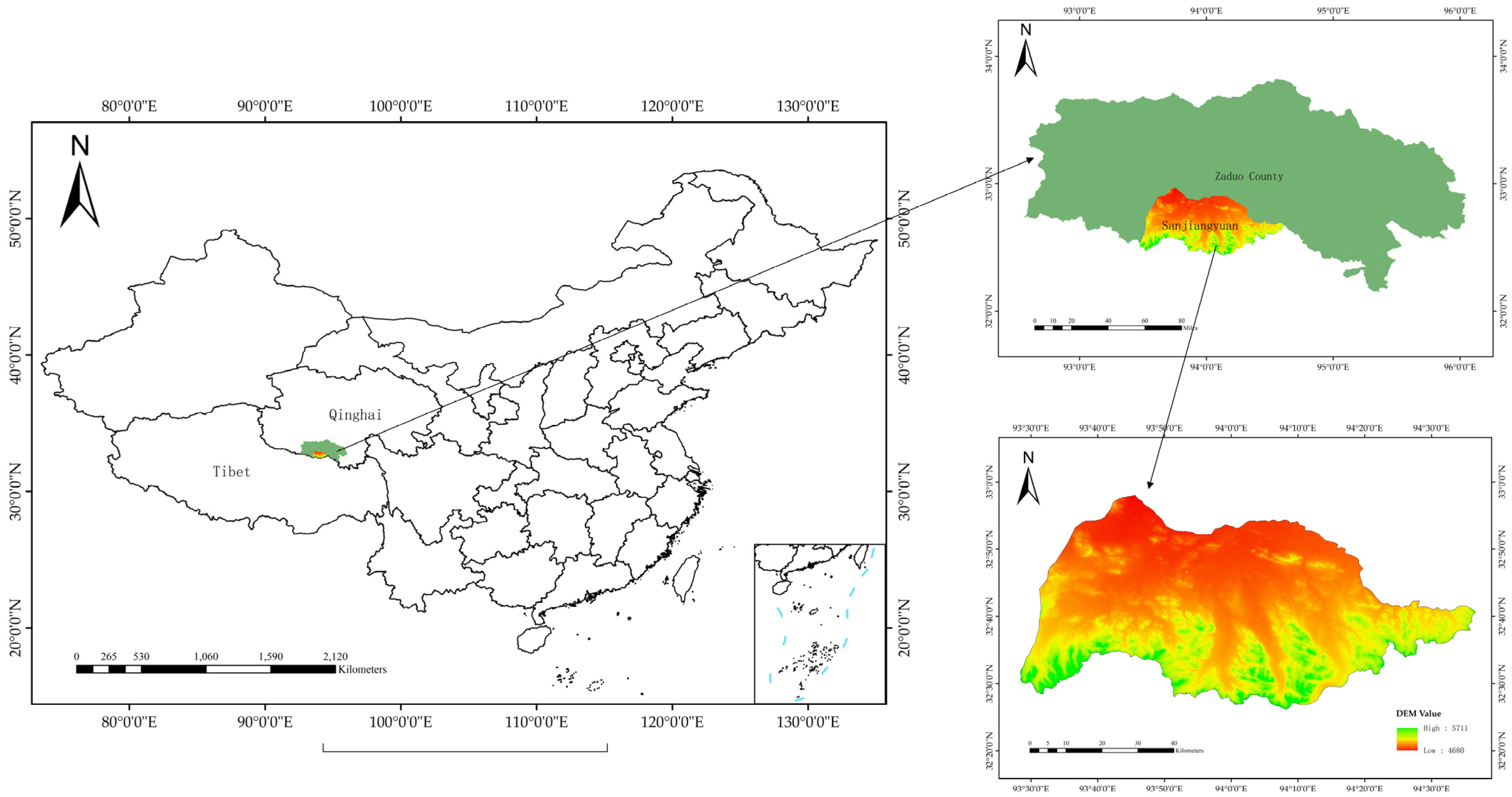
2.1. Study Area
2.2. Data Collection and Dataset Construction
2.3. YOLOv11 Algorithm
- The C3k2 mechanism is proposed, where the parameter of C3k2 is denoted as c3k. In the shallow layers of the network, c3k is set to False, optimizing the model’s feature extraction capability, particularly excelling in handling complex backgrounds and small targets.
- C2PSA mechanism: The C2PSA mechanism was proposed, which embeds a multi-head attention mechanism within the C2 mechanism (the predecessor of C2f). This mechanism enhances the model’s ability to focus on different features through multi-head attention, thereby improving the model’s detection accuracy and robustness.
- Decoupled head improvement: Two depth-wise separable convolutions (DWConvs) were added to the classification detection head in the original decoupled head. This improvement not only enhances the model’s feature extraction capability but also reduces its computational complexity, making the model more lightweight and efficient while maintaining high accuracy [16].
2.4. Improved YOLOv11 Algorithm
2.4.1. Improved YOLOv11 Network Structure
- Backbone replacement: the original backbone network is replaced with EfficientViT, a robust vision transformer architecture, to enhance fine-grained feature extraction in remote sensing imagery, specifically targeting plateau pika burrows with average pixel occupancy <0.1% [16].
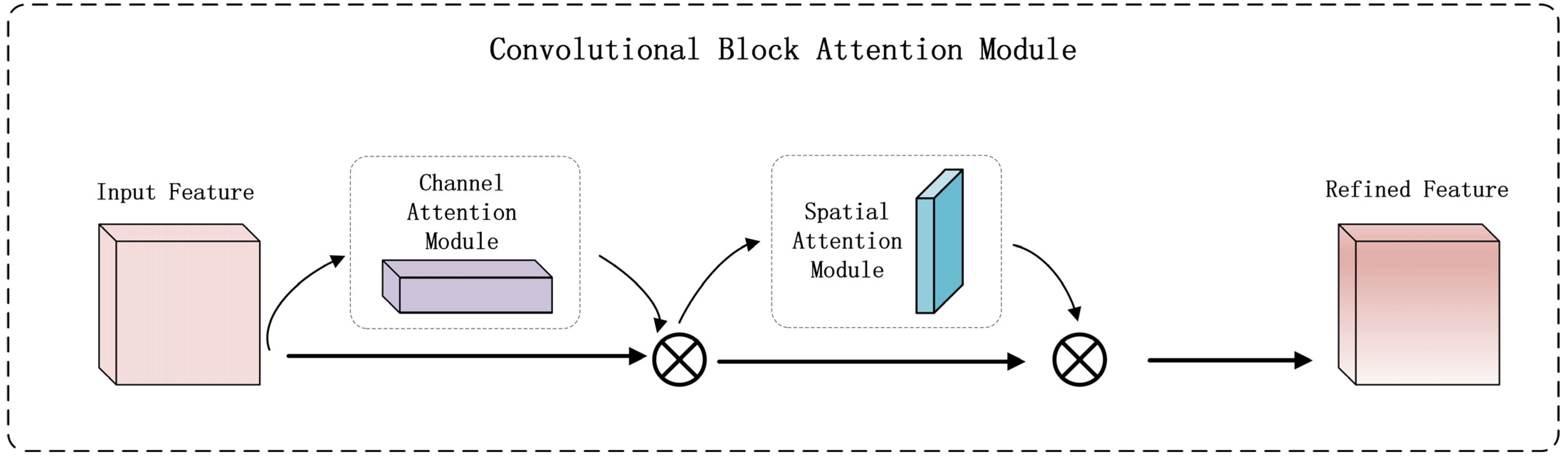
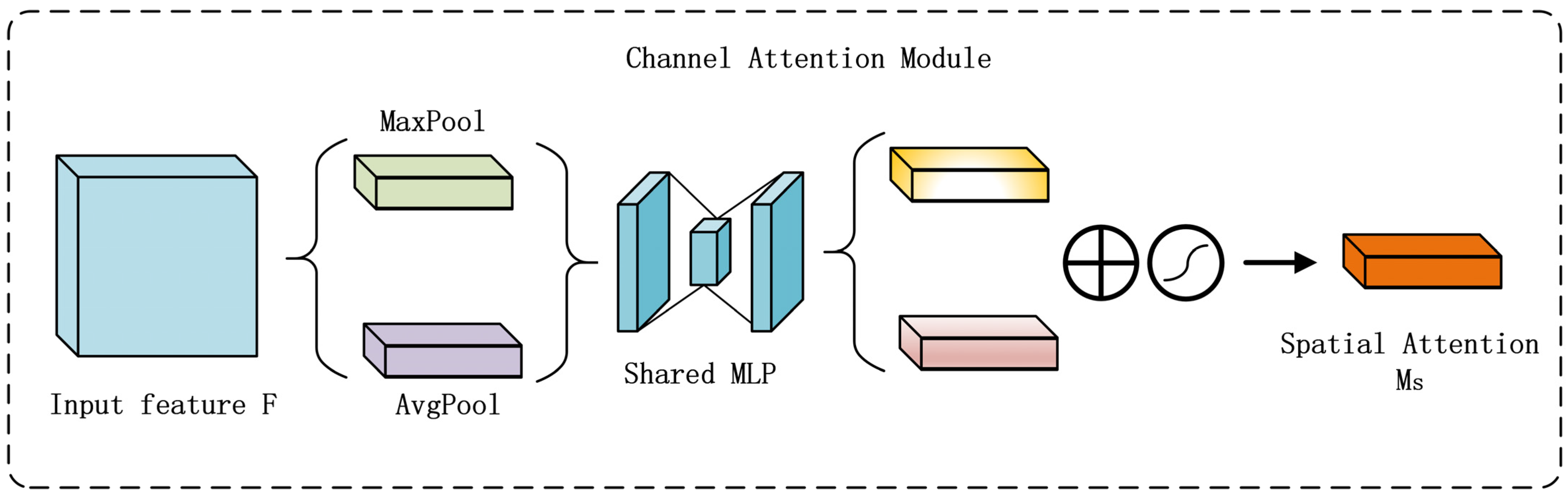
- Neck enhancement: a Convolutional Block Attention Module (CBAM) is integrated into the neck network, establishing dual-dimensional feature optimization pathways to refine feature map fusion [17].
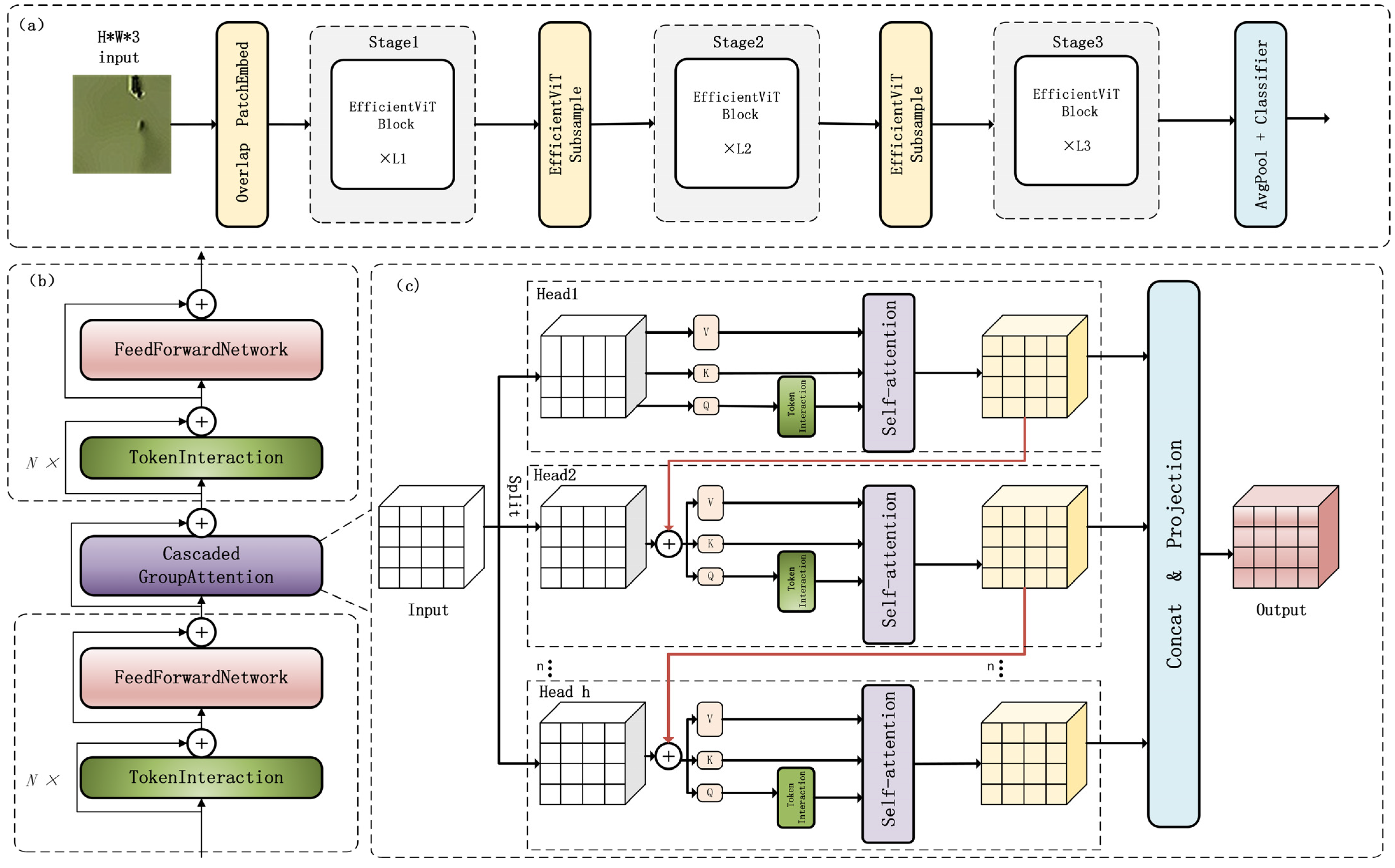
- Backbone architecture redesign: The original convolutional neural network (CNN) backbone is innovatively replaced with EfficientViT modules. This advanced architecture synergizes the local feature extraction precision of convolutional operations with the global contextual modeling capabilities of vision transformers. Leveraging self-attention mechanisms, it effectively captures long-range dependencies inherent in micro-targets like pika burrows. Benefiting from a lightweight design philosophy, the revamped backbone significantly enhances feature representation for small targets in complex backgrounds with 416 × 416-pixel input images, while substantially reducing computational overhead, establishing a robust semantic foundation for downstream detection tasks.
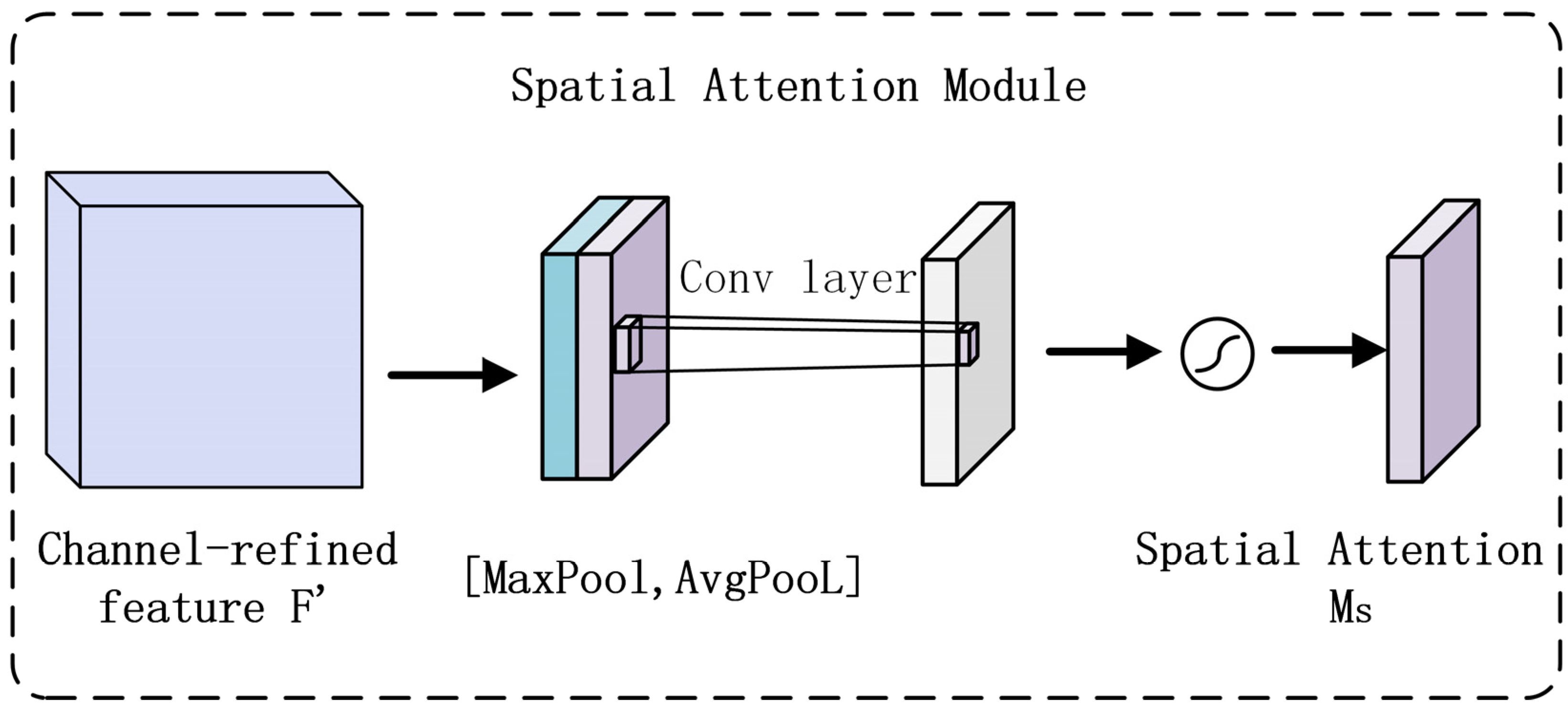
- Hybrid attention integration: A Convolutional Block Attention Module (CBAM) is introduced into the feature fusion neck architecture to achieve in-depth mining and precise focusing of critical information. CBAM employs a phased attention strategy: channel attention filters feature channels to amplify discriminative features; spatial attention pinpoints target regions to refine spatial localization.
2.4.2. EfficientViT Model
2.4.3. CBAM Module
2.5. Accuracy Evaluation
3. Results
3.1. Experimental Environment
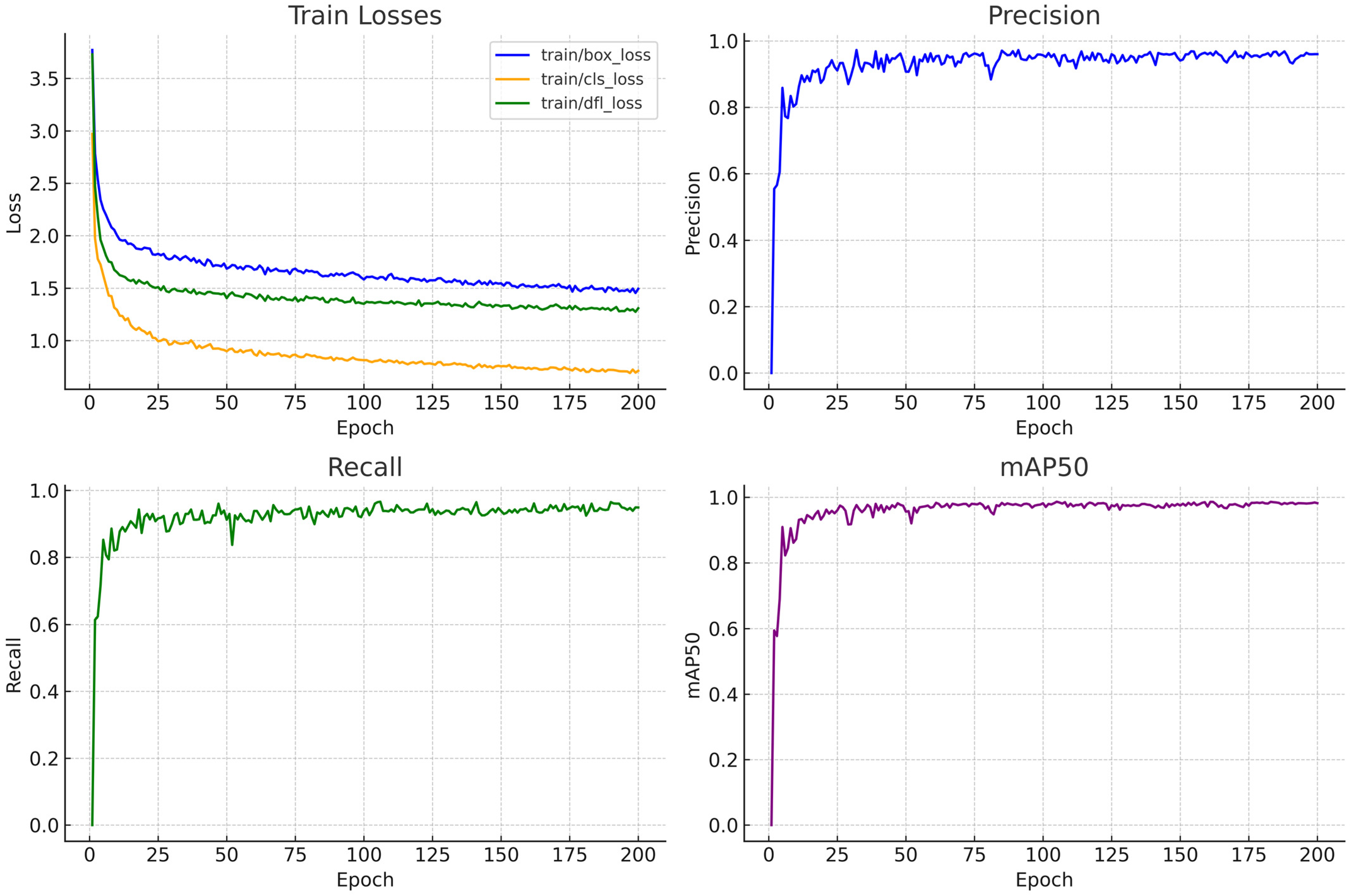
3.2. Ablation Experiment
3.2.1. Lightweight Backbone Networks
3.2.2. EfficientViT Variants
3.2.3. Attention Mechanisms
3.2.4. Ablation Experiment Results
- Solely introducing EfficientViT (A1) increases mAP50 by 2.1% (95.1% → 97.2%), validating its effectiveness in enhancing cross-scale feature extraction. However, mAP50-95 decreases by 0.9% (53.9% → 53.0%), indicating that merely increasing feature diversity may weaken high-IoU localization capability.
- The position of the attention mechanism significantly affects performance. Post-CBAM placement after C3K2 (A3) improves mAP50 by 0.7% (95.8% → 96.5%) compared to pre-CBAM (A2), demonstrating that applying spatial attention after feature fusion better captures burrow edge characteristics.
- Synergistic module effects are prominent. The combination of EfficientViT with post-CBAM (A5) achieves maximum gains: mAP50 reaches 98.6% (+3.5% improvement) and recall increases by 7.2% (88.9% → 96.1%), illustrating complementary effects between global modeling from visual transformers and local enhancement from attention mechanisms.
- For mAP50-95, only A4/A5 surpasses the baseline model, with A5 in particular reaching 55.3% (+1.4%), proving that dual improvement strategies simultaneously enhance detection sensitivity and localization accuracy while mitigating boundary regression errors caused by irregular burrow shapes. These results demonstrate that coordinated optimization of feature extraction networks and attention mechanisms is critical for achieving high-precision detection of plateau pika burrows.
3.3. Detection Performance: Missed Detections and Burrow Size
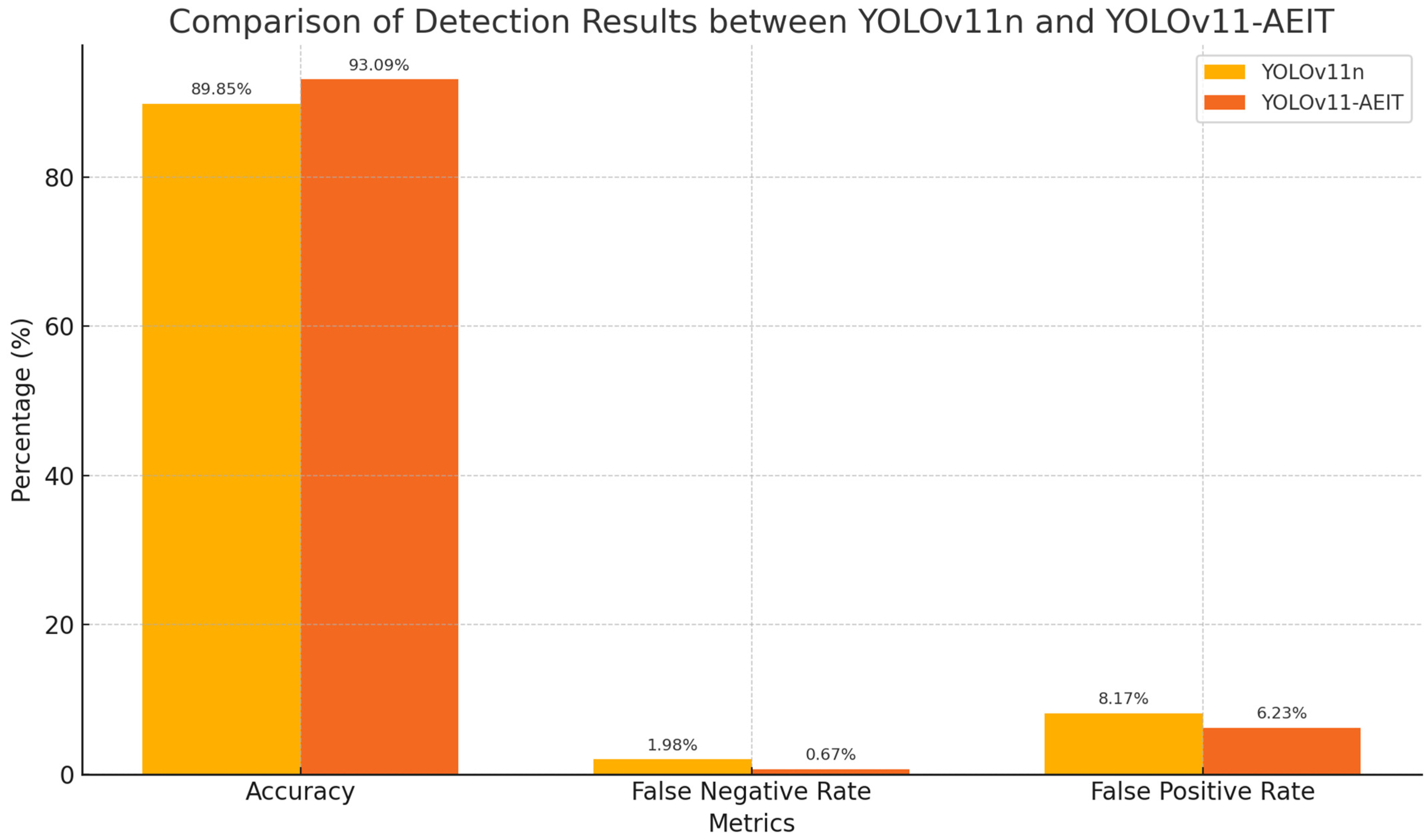
3.4. Comparative Analysis of Various Deep Learning Networks
4. Discussion
4.1. Theoretical Mechanisms of Performance Enhancement and Comparative Advantages
4.2. Performance Across Burrow Sizes and Environmental Conditions
4.3. Practical Applications, Limitations, and Future Directions
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| YOLOv11 | You Only Look Once version 11 |
| YOLOv11-AEIT | You Only Look Once version 11–Attention-Enhanced Intelligent Transformer |
| EfficientViT | Efficient Vision Transformer |
| CBAM | Convolutional Block Attention Module |
| PPCave2025 | A custom dataset for detecting plateau pika burrows (used in this study) |
| mAP | Mean Average Precision |
| FPS | Frames Per Second |
| CNN | Convolutional Neural Network |
| RTK-GNSS | Real-Time Kinematic Global Navigation Satellite System |
| GCP | Ground Control Point |
| UAV | Unmanned Aerial Vehicle |
| SAM | Spatial Attention Module |
| CAM | Channel Attention Module |
| MSA | Multi-Scale Attention |
| MLP | Multilayer Perceptron |
| SGD | Stochastic Gradient Descent |
| GAN | Generative Adversarial Network |
| GFLOPS | Giga Floating Point Operations Per Second |
| ML | Machine Learning |
| CV | Computer Vision |
| API | Application Programming Interface |
References
- Andrew Smith, M.F. The plateau pika (Ochotona curzoniae) is a keystone species for biodiversity on the Tibetan plateau. Anim. Conserv. 1999, 2, 235–240. [Google Scholar] [CrossRef]
- Li, J.; Qi, H.H.; Duan, Y.Y.; Guo, Z.G. Effects of Plateau Pika Disturbance on the Spatial Heterogeneity of Vegetation in Alpine Meadows. Front. Plant Sci. 2021, 12, 771058. [Google Scholar] [CrossRef] [PubMed]
- Tang, Z.; Zhang, Y.; Cong, N.; Wimberly, M.; Wang, L.; Huang, K.; Li, J.; Zu, J.; Zhu, Y.; Chen, N. Spatial pattern of pika holes and their effects on vegetation coverage on the Tibetan Plateau: An analysis using unmanned aerial vehicle imagery. Ecol. Indic. 2019, 107, 105551. [Google Scholar] [CrossRef]
- Anderson, K.; Gaston, K.J. Lightweight unmanned aerial vehicles will revolutionize spatial ecology. Front. Ecol. Environ. 2013, 11, 138–146. [Google Scholar] [CrossRef]
- Wei, W.; Zhang, W. Architecture Characteristics of Burrow System of Plateau Pika, Ochotona curzoniae. Pak. J. Zool. 2018, 50, 311–316. [Google Scholar] [CrossRef]
- Chen, Y.Y.; Yang, H.; Bao, G.S.; Pang, X.P.; Guo, Z.G. Effect of the presence of plateau pikas on the ecosystem services of alpine meadows. Biogeosciences 2022, 19, 4521–4532. [Google Scholar] [CrossRef]
- Qiu, J.; Ma, C.; Jia, Y.-H.; Wang, J.-Z.; Cao, S.-K.; Li, F.-F. The distribution and behavioral characteristics of plateau pikas (Ochotona curzoniae). ZooKeys 2021, 1059, 157–171. [Google Scholar] [CrossRef]
- Wei, J.; Wang, R.; Wei, S.; Wang, X.; Xu, S. Recognition of Maize Tassels Based on Improved YOLOv8 and Unmanned Aerial Vehicles RGB Images. Drones 2024, 8, 691. [Google Scholar] [CrossRef]
- Vogt, P.; Riitters, K.H.; Estreguil, C.; Kozak, J.; Wade, T.G.; Wickham, J.D. Mapping Spatial Patterns with Morphological Image Processing. Landsc. Ecol. 2006, 22, 171–177. [Google Scholar] [CrossRef]
- Yao, H.; Liu, L.; Wei, Y.; Chen, D.; Tong, M. Infrared Small-Target Detection Using Multidirectional Local Difference Measure Weighted by Entropy. Sustainability 2023, 15, 1902. [Google Scholar] [CrossRef]
- Cusick, A.; Fudala, K.; Storożenko, P.P.; Świeżewski, J.; Kaleta, J.; Oosthuizen, W.C.; Pfeifer, C.; Bialik, R.J. Using machine learning to count Antarctic shag (Leucocarbo bransfieldensis) nests on images captured by remotely piloted aircraft systems. Ecol. Inform. 2024, 82, 102707. [Google Scholar] [CrossRef]
- Jiang, L.; Wu, L. Enhanced Yolov8 network with Extended Kalman Filter for wildlife detection and tracking in complex environments. Ecol. Inform. 2024, 84, 102856. [Google Scholar] [CrossRef]
- Hinke, J.T.; Giuseffi, L.M.; Hermanson, V.R.; Woodman, S.M.; Krause, D.J. Evaluating Thermal and Color Sensors for Automating Detection of Penguins and Pinnipeds in Images Collected with an Unoccupied Aerial System. Drones 2022, 6, 255. [Google Scholar] [CrossRef]
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y.; Xu, H.; Tan, W.; Yang, Q.; Wang, J.; et al. Deep learning in environmental remote sensing: Achievements and challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- Khanam, R.; Hussain, M. YOLOv11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Guo, Z.; Xiao, Y.; Liao, W.; Veelaert, P.; Philips, W. FLOPs-efficient filter pruning via transfer scale for neural network acceleration. J. Comput. Sci. 2021, 55, 101459. [Google Scholar] [CrossRef]
- Liu, X.; Peng, H.; Zheng, N.; Yang, Y.; Hu, H.; Yuan, Y. EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 14420–14430. [Google Scholar]
- Cai, H.; Li, J.; Hu, M.Y.; Gan, C.; Han, S. EfficientViT: Lightweight multi-scale attention for high-resolution dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 17302–17313. [Google Scholar]
- Tang, H.; Liang, S.; Yao, D.; Qiao, Y. A visual defect detection for optics lens based on the YOLOv5-C3CA-SPPF network model. Opt. Express 2023, 31, 2628–2643. [Google Scholar] [CrossRef]
- Ferchichi, A.; Ferchichi, A.; Hendaoui, F.; Chihaoui, M.; Toujani, R. Deep learning-based uncertainty quantification for spatio-temporal environmental remote sensing: A systematic literature review. Neurocomputing 2025, 639, 130242. [Google Scholar] [CrossRef]
- Chen, C.; Zheng, Z.; Xu, T.; Guo, S.; Feng, S.; Yao, W.; Lan, Y. YOLO-Based UAV Technology: A Review of the Research and Its Applications. Drones 2023, 7, 190. [Google Scholar] [CrossRef]
- Rabbi, J.; Ray, N.; Schubert, M.; Chowdhury, S.; Chao, D. Small-Object Detection in Remote Sensing Images with End-to-End Edge-Enhanced GAN and Object Detector Network. Remote Sens. 2020, 12, 1432. [Google Scholar] [CrossRef]
- Cheng, S.; Han, Y.; Wang, Z.; Liu, S.; Yang, B.; Li, J. An Underwater Object Recognition System Based on Improved YOLOv11. Electronics 2025, 14, 190. [Google Scholar] [CrossRef]
- Sun, F.; Chen, W.; Liu, L.; Liu, W.; Lu, C.; Smith, P. The density of active burrows of plateau pika in relation to biomass allocation in the alpine meadow ecosystems of the Tibetan Plateau. Biochem. Syst. Ecol. 2015, 58, 257–264. [Google Scholar] [CrossRef]
- Li, Z.; Dong, Y.; Shen, L.; Liu, Y.; Pei, Y.; Yang, H.; Zheng, L.; Ma, J. Development and challenges of object detection: A survey. Neurocomputing 2024, 598, 128102. [Google Scholar] [CrossRef]
- Sheikholeslami, S.; Meister, M.; Wang, T.; Payberah, A.H.; Vlassov, V.; Dowling, J. AutoAblation. In Proceedings of the 1st Workshop on Machine Learning and Systems, Edinburgh, UK, 26 April 2021; pp. 55–61. [Google Scholar]
- Liu, X.; Qin, Y.; Sun, Y.; Yi, S. Monitoring Plateau Pika and Revealing the Associated Influencing Mechanisms in the Alpine Grasslands Using Unmanned Aerial Vehicles. Drones 2025, 9, 298. [Google Scholar] [CrossRef]
- Assmann, J.J.; Kerby, J.T.; Cunliffe, A.M.; Myers-Smith, I.H. Vegetation monitoring using multispectral sensors—Best practices and lessons learned from high latitudes. J. Unmanned Veh. Syst. 2019, 7, 54–75. [Google Scholar] [CrossRef]
- Lin, G.; Jiang, D.; Fu, J.; Zhao, Y. A Review on the Overall Optimization of Production–Living–Ecological Space: Theoretical Basis and Conceptual Framework. Land 2022, 11, 345. [Google Scholar] [CrossRef]
- Tai, C.-Y.; Wang, W.-J.; Huang, Y.-M. Using Time-Series Generative Adversarial Networks to Synthesize Sensing Data for Pest Incidence Forecasting on Sustainable Agriculture. Sustainability 2023, 15, 7834. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Parameters and Versions |
|---|---|
| Central Processing Unit (CPU) | 13th Gen Intel(R) Core (TM) i5-13500H |
| Random Access Memory (RAM) | 16 GB |
| Hard Disk Drive (SSD) | YMTC PC300-1TB-B |
| Graphic Card (GPU) | NVIDIA GeForce RTX 4060 Laptop GPU |
| Operating System (OS) | Microsoft Windows 11 Professional |
| Programming Environment (ENVS) | Python 3.10.16+ Pytorch2.0.0 + cu118 |
| Backbone Network | mAP@0.5 (%) | Params (M) | GFLOPS | FPS | Edge Device Memory (MB) |
|---|---|---|---|---|---|
| EfficientViT-M0 | 98.6 | 2.3 | 3.8 | 49.5 | 126 |
| MobileNetv3-Large | 95.2 | 5.47 | 4.7 | 52.3 | 158 |
| ShuffleNetv2-1.5x | 93.8 | 3.4 | 4.1 | 55.1 | 142 |
| YOLOv11n | 95.1 | 2.6 | 4.5 | 51.2 | 135 |
| Version | Attention Mechanism Configuration | mAP@0.5 (%) | GFLOPS | Inference Latency (ms) |
|---|---|---|---|---|
| M0 | Local Window (4 × 4) + Dilated Global (d = 2) | 98.6 | 3.8 | 20.2 |
| M1 | Local Window (8 × 8) + Dense Global | 97.3 | 5.1 | 27.5 |
| M2 | Dense Global + Cross-Scale Dynamic Conv | 96.8 | 6.7 | 34.1 |
| Attention Module | mAP@0.5 | AP_small | FPS | Params (M) | IoU |
|---|---|---|---|---|---|
| No attention (baseline) | 90.8 | 62.5% | 45 | 1.8 | 68.3 |
| SE | 91.1 | 65.3% | 44 | 1.84 (+0.4%) | 69.1 |
| ECA | 92.8 | 64.8% | 44 | 1.82 (+0.2%) | 70.5 |
| Non-local | 91.6 | 70.1% | 29 | 2.08 (+2.8%) | 71.8 |
| CBAM | 93.5 | 75.3% | 41 | 2.06 (+0.8%) | 80.9 |
| Method | Model Number | EfficientViT -M0 | Attention Mechanism | Precision (%) | Recall (%) | mAP50 (%) | mAP50-95 (%) | |
|---|---|---|---|---|---|---|---|---|
| CBAM (before C3K2) | CBAM (after C3K2) | |||||||
| YOLOv11n | - | - | - | 90.8 | 88.9 | 95.1 | 53.9 | |
| YOLOv11-AEIT | A1 | √ | - | - | 94.0 | 93.4 | 97.2 | 53.0 |
| A2 | - | √ | - | 92.5 | 91.5 | 95.8 | 51.8 | |
| A3 | - | - | √ | 93.5 | 92.8 | 96.5 | 52.5 | |
| A4 | √ | √ | - | 94.0 | 95.0 | 97.5 | 54.5 | |
| A5 | √ | - | √ | 95.6 | 96.1 | 98.6 | 55.3 | |
| Model | mAP@0.5 (%) | mAP@0.5:0.95 (%) | Recall (%) | Inference Speed (FPS) |
|---|---|---|---|---|
| YOLOv5 | 92.5 | 51.8 | 88.9 | 55.3 |
| YOLOv8 | 96.0 | 53.0 | 91.5 | 50.1 |
| YOLOv9 | 96.5 | 52.5 | 92.0 | 48.8 |
| YOLOv11 | 95.1 | 53.9 | 95.7 | 51.2 |
| YOLOv11-AEIT | 98.6 | 55.3 | 96.1 | 49.5 |
| YOLOv12 | 97.3 | 52.5 | 94.5 | 52.5 |
| Faster R-CNN | 85.2 | 44.0 | 78.4 | 8.1 |
| Retina Net | 89.5 | 50.0 | 83.6 | 14.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, H.; Jia, L.; Wang, Y.; Yan, F. Autonomous UAV Detection of Ochotona curzoniae Burrows with Enhanced YOLOv11. Drones 2025, 9, 340. https://doi.org/10.3390/drones9050340
Zhao H, Jia L, Wang Y, Yan F. Autonomous UAV Detection of Ochotona curzoniae Burrows with Enhanced YOLOv11. Drones. 2025; 9(5):340. https://doi.org/10.3390/drones9050340
Chicago/Turabian StyleZhao, Huimin, Linqi Jia, Yuankai Wang, and Fei Yan. 2025. "Autonomous UAV Detection of Ochotona curzoniae Burrows with Enhanced YOLOv11" Drones 9, no. 5: 340. https://doi.org/10.3390/drones9050340
APA StyleZhao, H., Jia, L., Wang, Y., & Yan, F. (2025). Autonomous UAV Detection of Ochotona curzoniae Burrows with Enhanced YOLOv11. Drones, 9(5), 340. https://doi.org/10.3390/drones9050340